
Abstract
The bsml and multi-ml languages have been designed for programming, à laml, algorithms of the respectively bsp and multi-bsp bridging models. multi-bsp is an extension of the well-know bsp model by taking into account the different levels of networks and memories of modern hierarchical architectures. This is a rather new model, as well as multi-ml is a new language, while bsp and bsml have been used for a long time in many different domains. Intuitively, designing and programming multi-bsp algorithms seems more complex than with bsp, and one can ask whether it is beneficial to rewrite bsp algorithms using the multi-bsp model. In this paper, we thus investigate the pro and cons of the aforementioned models and languages by experimenting with them on different typical applications. For this, we use a methodology to measure the level of difficulty of writing code and we also benchmark them in order to show whether writing multi-ml code is worth the effort.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Context Our previous work aimed at designing a parallel functional language based on the bulk synchronous parallelism (bsp) bridging model called bsml [14]. bsp is a model of parallelism which offers a high level of abstraction and takes into account real communication and synchronisation cost [23]. bsp has been used successfully for a broad variety of applications such as scientific computation [6], artificial intelligence, big-data and graph frameworks (pregel [19]). To be compliant to a bridging model eases the way of writing code and ensures efficiency and portability from one architecture to another. Thanks to a cost model, it is also possible to reason on the algorithmic costs.
As modern high-performance computing (hpc) architectures are hierarchical and have multiple layers of parallelism, communication between distant nodes cannot be as fast as among the cores of a given processor. Because bsp was designed for flat architectures, we now consider the multi-bsp bridging model [26], an extension of bsp which is dedicated to hierarchical architectures. multi-ml uses a small set of ml-like primitives [3] for programming multi-bsp algorithms similarly to bsml for the bsp algorithms. As bsml, multi-ml [3] is implemented using the ml language ocaml (http://ocaml.org/).
Comparing languages Since we now have two programming languages dedicated each for two rather different bridging models, we ask ourselves whether they differ in terms of performances and written code. Both have structured models of execution. Both have an ocaml + mpi implementation. However, bsml has been designed for flat parallelism, whereas multi-ml is designed for controlled nested parallelism. To compare them, we have chosen three different cases that are in the field of symbolic, numerical, and big-data computations.
We want to compare the two languages for both performance and the ease of writing code.Footnote 1 For the performance, we have chosen speedup and/or timing for some data-sets. We also change the target architecture by modifying the number of cores, processors, and nodes of the machines. For the code, we have choose some traditional metrics which are the Halstead difficulty and the McCabe cyclomatic complexity. These metrics mainly count the number of operands and programming structures such as conditionals, loops, etc. We have adapted them to take into account the number of parallel operators. These metrics are not perfect but are easy to use. Finally, we have used one interesting ability of both bsml and multi-ml which is programming parallel algorithms in an incremental manner from sequential codes, which simplifies the development of parallel codes. As explained later, this is due to the fact that both bsml and multi-ml provide a global view of programs, i.e. their programs can be seen as sequential programs working on parallel data structures (“seq of par”), while in many hpc libraries such as mpi, programs are written in the spmd style and are understood as a parallel composition of communicating sequential programs (“par of seq”).
Outline The rest of this paper is structured as follows. First, Sect. 2 briefly presents the two aforementioned languages. Then, Sect. 3 defines our methodology of comparison of the languages and we apply it to different use cases (Sects. 3.2–3.4), hoping they are general enough to stand for a representative sample of hpc applications. For all of them, we give some benchmarks in terms of both performance and difficulty of writing the code. Finally, in Sect. 4, we discuss related work and Sect. 5 concludes the paper by giving a brief outlook of future work.
2 BSML and multi-ML: similar but different languages
2.1 Programming BSP algorithms in ML
2.1.1 The BSP bridging model

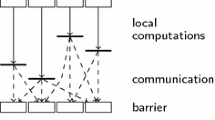
A bsp superstep
In the bspbridging model, a computer is a set of \(\mathbf {p}\)uniform pairs of processor–memory components with a communication network [6, 25]. A bsp program is executed as a sequence of supersteps (Fig. 1), each one divided into three successive disjointed phases: (1) each processor only uses its local data to perform sequential computations and to request data transfers to other nodes; (2) the network delivers the requested data; (3) a global synchronisation barrier occurs, making the transferred data available for the next superstep.
The performance of the bsp computer is characterised by 4 parameters (that we do not detail in this articleFootnote 2). To reliably estimate the execution time of a bsp program, these parameters could be easily benchmarked [6]. The execution time (cost) of a superstep is the maximal of the sum of the local processing time, the data delivery and the global synchronisation times. The total cost of a bsp program is the sum of its supersteps’s costs.
2.1.2 The BSML language
bsml [14] uses a small set of primitives and is currently implemented as a library (http://traclifo.univ-orleans.fr/bsml/) for the ml programming language ocaml. An important feature of bsml is its confluent semantics: whatever the order of execution of the processors is, the final value will be the same. Confluence is convenient for debugging since it allows to get an interactive loop, the toplevel. It also simplifies programming since the parallelisation can be done incrementally from an ocaml program.
A bsml program is built as a ml one but using a specific data structure called parallel vector. Its ml type is ’a par. A vector expresses that each of the \(\mathbf {p}\) processors embeds a value of any type ’a. Figure 2 summarises the bsml primitives. Informally, they work as follows: let\(\mathtt {\ll }\)e\(\mathtt {\gg }\) be the vector holding e everywhere (on each processor), the \(\mathtt {\ll }\,\,\mathtt {\gg }\) indicates that we enter into the scope of a (parallel) vector. Within a vector, the syntax $x$ can be used to read the vector x and get the local value it contains. The ids can be accessed with the predefined vector pid.
The proj primitive is the only way to extract local values from a vector. Given a vector, it returns a function such that, applied to the pid of a processor, returns the value of the vector at this processor. proj performs communication to make local results available globally and ends the current superstep.
The put primitive is another communication primitive. It allows any local value to be transferred to any other processor. It is also synchronous, and ends the current superstep. The parameter of put is a vector that, at each processor, holds a function returning the data to be sent to processor j when applied to j. The result of put is another vector of functions: at a processor j the function, when applied to i, yields the value received from processor i by processor j.

Summary of the bsml primitives
To illustrate the previous primitives with a small piece of code, we use the bsml toplevel and a simulation of a bsp machine with three processors. Now if we want to convert a vector into a replicated list (that is to say an identical list on each processor [14]), we write:

(where procs is a list of the processors’s ids) and we applied it to a vector which contains the processors’s ids.
2.2 Programming Multi-BSP algorithms in ML
2.2.1 The multi-BSP bridging model
multi-bsp is a bridging model [26] which is adapted to hierarchical architectures, mainly clusters of multi-cores. There exist other hierarchical models [17], but multi-bsp describes them in a simpler way. The structure and abstraction brought by multi-bsp allows to have portable programs with scalable performance predictions, without dealing with low-level details of the architectures. This model brings a tree-based view of nested components (sub-machines or siblings) of hierarchical architectures where the lowest stages (leaves symbolised by squares) are processors and every other stage (node symbolised by circles) contains memory (or a network). Figure 3 illustrates the difference between the bsp and multi-bsp models for a multi-core.

The difference between the multi-bsp and bsp models for a multi-core architecture
Every component can execute code, but they have to synchronise in favour of data exchange. Thus, multi-bsp does not allow sub-group synchronisation of any group of processors: at a stage i there is only a synchronisation of the sub-components, a synchronisation of each of the computational units that manage the stage \(i\!-\!1\). So, a node executes some code on its nested components (aka “children”), then waits for results, does the communication and synchronises the sub-machine. A multi-bsp algorithm is thus composed of several supersteps, each step is synchronised for each sub-machine. Figure 4 illustrates such an execution model where black rectangles scheme computations and dash lines between rectangles stand for communications.

Example of the multi-bsp execution model
Mainly, an instance of multi-bsp is defined by \(\mathbf {d}\), the fixed depth of the balanced and homogeneous tree architecture, and by the 4 bsp performance parameters (plus the memory size) for each stagei of the tree. Figure 5 illustrates nodes and leaves. Thus, for each \(i \in \{0,\ldots ,d\!-\!1\}\), \(p_i\) is the number of sub-components inside the \(i-1\) stage.

The multi-bsp components
The cost of a multi-bsp algorithm is the sum of the costs of the supersteps of the root node, where the cost of each of these supersteps is the maximal cost of the supersteps of the sub-components (plus communication and synchronisation); and so on.
2.2.2 The multi-ML language
multi-ml [2, 3] (https://git.lacl.fr/vallombert/Multi-ML) is based on the idea of executing bsml-like codes on every stage of a multi-bsp architecture. This approach facilitates incremental development from bsml codes to multi-ml ones. multi-ml follows the multi-bsp approach where the hierarchical architecture is composed of nodes and leaves. On nodes, it is possible to build parallel vectors, as in bsml. This parallel data structure aims to manage values that are stored on the sub-nodes: at stage i, the code letv=\(\mathtt {\ll }\)e\(\mathtt {\gg }\) evaluates the expression e on each \(i-1\) stages. Inside a parallel vector, we note \(\mathtt {\#}\)x\(\mathtt {\#}\) to copy the value x stored at stage i to the memory \(i-1\).

A multi-function code
We also introduce the concept of multi-function to recursively go through a multi-bsp architecture. A multi-function is a particular recursive function, defined by the keyword let multi, which is composed of two codes: the node and the leaf codes. The recursion is initiated by calling the multi-function (recursively) inside the scope of a parallel vector, that is to say, on the sub-nodes. The evaluation of a multi-function starts (and ends) on the root node. The code of Fig. 6 shows how a multi-function is defined. After the definition of the multi-function mf on line 1 where [args] symbolises a set of arguments, we define the node code (from line 2 to 6). The recursive call of the multi-function is done on line 5, within the scope of a parallel vector. The node code ends with a value v, which is available as a result of the recursive call from the upper node. The leaf code, from lines 7 to 9 consists of sequential computations. When a multi-function is applied to a value at the multi-bsp level, the evaluation is initiated on the root node of the architecture. In the example (Fig. 7), the multi-function mf is called inside a parallel vector (line 3) to initiate the recursion on the sub-nodes. As the evaluation of a multi-function starts from the root node, the recursion will spread from the root towards the leaves.

A multi-function
As expected, the synchronous communication primitives of bsml are also available to communicate values from/to parallel vectors. We also propose another parallel data structure called tree. A tree is a distributed structure where a value is stored in every node and leave memories. A tree can be built using a multi-tree-function, using the let multi-tree keyword. We propose three primitives to handle such a parallel data structure: (1) To easily construct a tree with a simple expression, mktreee can be used; it aims to execute the expression e on each component of the architecture, resulting in a tree; (2) the function at can be used to access the value of a tree within a component; (3) the global identifiergid is shaped as a tree of identifiers, and is useful, for example, to distribute data depending on the position in the architecture.
3 Application cases
We now compare bsml and multi-ml. To do so, we first describe our methodology for the comparison in Sect. 3.1 and then we have selected three typical cases of various domains and apply the methodology to each case: (1) state-space calculation (basis of model-checking) in Sect. 3.2; (2) implementation of the fft using algorithmic skeletons in Sect. 3.3; (3) finally, in Sect. 3.4, a classical big-data problem that is computing the similarity of millions of pairs.
It is to notice that in this paper we present non optimal implementations that cannot be compared to cutting-edge implementations: we neither use specific data structures nor domain specific tricks. For example, in the state-space algorithms, our sets of states do not use shared possibilities of the states as modern model-checkers do [9]. We use the standard ocaml ’s sets and a naive representation of the states. Here, our objective is to compare the languages and their performances. Programming the most optimised implementations is not the purpose of this work.
3.1 Methodology
bsml and multi-ml have been designed to program parallel algorithms incrementally: from a sequential ocaml code to a bsp code using bsml and finally to a multi-bsp code using multi-ml. We can thus expect better performance, but we presume that the programs will be, unfortunately, more and more complex.
To measure this difficulty we have used: (a) the Halstead effort (he) which depends on both the length and complexity of the code; the Halstead difficulty (hd) considers the amount of different operators used; (b) the McCabe cyclomatic complexity (cc) that is the number of linearly independent paths through the source; (c) the maintainability index (mi) which depends on he and cc. To do so we have adapted the ocaml metrics tool (http://forge.ocamlcore.org/projects/ocaml-metrics/) to bsml and multi-ml. We now count, as an operand, each parallel primitive; and, as a new path, each multi-function and vector. Benchmarks were performed on two architectures:
- 1.
(mirev2) 8 nodes with 2 quad-cores (amd 2376 at 2.3 Ghz) with 16 GB of memory per node and a 1 Gbit/s network;
- 2.
(mirev3) 4 nodes with 2 octa-cores with 2 hyper-threads (intelxeon\(E5-2650\) at 2.6Ghz) with 64GB of memory per node and a 10Gbit / s network.
To measure the code performance, we use the version 4.02.1 of ocaml and mpich 3.1. We measure the speedup for different sizes of data and different configurations of our architectures with a variation of the number of nodes \(\times\) processors \(\times\) cores \(\times\) threads used. We execute the codes on mirev2 and mirev3 by using different configurations. For example, \(2 \times 2 \times 8 \times 2\) means that the code is executed on an architecture made of 2 nodes with 2 multi-cores using 8 cores with 2 threads; thus, we use 64 computing units. The configurations were chosen arbitrarily, in order to compare performances with a growing number of components with both distributed and shared memories. All the sources and data are available in the multi-ml’s git repository. We note \(\infty\) when the program fails.
Thus, we aim to compare both the code difficulty and the difference, in terms of performances, between bsml and multi-ml codes.
3.2 First case: symbolic computation
Our first experiment is about model-checking (mc) which is a formal method often used to verify safety-critical systems [9]. Before verifying a logical formula, one must first compute the state-space of the systems. The parallelisation of this construction is a frequently used method in the industry [12].
The finite state-space construction problem consists of exploring all the states accessiblevia a successor function \(\mathop {\mathsf {succ}}\) (returning a set of states) from an initial state\(s_0\). This problem is computing and data intensive because realistic systems have a tremendous amount of scenarios. Usually, during this operation, all the explored states must be kept in memory in order to avoid multiple explorations of a same state. Figure 8 shows the usual sequential algorithm in ml where a set called known contains all the states that have been processed and would finally contain the state-space. It also involves a set todo that is used to hold all the states whose successors have not yet been constructed; each state t from todo is processed in turn (lines 5 to 10) and added to known (line 8), while its successors are added to todo unless they are already known—line 9.

The ocaml code for mc
The standard flat parallelisation of this problem is based on the idea that each process only computes the successors for its own states. The mc code written with bsml is given in Fig. 9. To do this incremental parallelisation, a partition function (hashing) returns, for each state, a processor id; i.e. \(\mathop {\mathsf {hash}}(s)\) returns the owner of s. Sets known and todo are still used but become local to each processor and thus provide only a partial view of the ongoing computations (lines 3–4). Initially, only state \(s_0\) is known and only its owner puts it in its todo set (line 5). Once again, processors enlarge their own local sets of states by applying the successor function on the received states; recursively to their descendants until no new states are computed (line 7). Then, a synchronous communication primitive computes and performs, for each processor, the set of received states that are not yet locally known (line 9). To ensure termination, we use the additional variable finish in which we test whether some states have been exchanged or not by the processors. If not, there is no need to continue the computation (line 6).

The bsml code for mc

The multi-ml code for mc
The main difference between the bsp and multi-bsp codes is that the multi-bsp algorithm uses a hashing function to distribute the states on the sub-trees. Figure 10 summarises the multi-ml code. Each sub-tree of the multi-bsp architecture is in charge of keeping the states it owns. Moreover, on two different sub-trees, there could be different numbers of supersteps depending of the verifying system: the synchronous communication primitive is performed on different sub-trees leading to implicit sub-group synchronisations. Due to a random strategy of walk (hashing) in the set of states, the load-balancing is mainly preserved—with specific industrial systems, different kinds of load-balancing strategies would be necessary for an industrial development. There is not only communication between the siblings but also between parents and children. Indeed, some states might not be in their right sub-trees. Thus, like in the bsp algorithm (line 18), each leaf only computes its own states. Each node manages the sub-trees of its children by performing exchanges between siblings as in the bsp algorithm (line 13) but also gathers the states that are not in the right sub-trees (line 14); it also distributes the states between the sub-trees of its children (line 11). To perform the communications, the code uses two arrays of sets, each of the size of the number of siblings of each level of the multi-bsp architecture. The reader can notice that the multi-ml code is again an incremental update of the bsml one, using the hierarchical ability of the multi-bsp model: “same” main loop and local computations.
For our experiments, we compute the state-space of the well-known cryptographic needham–schroeder public-key protocol with a standard universal dolev–yao intruder residing in the network [11]. Note that during the computation, most of the scenarios can be detected as faulty at their very beginning using a specialised mc, but this is not the subject of this article.
Figure 11 summarises the benchmarks. As intended, the multi-ml code is the more complex: by a factor of 2 compared to bsml, which is also 2 times more complex than the ocaml code.
In this example, using the hierarchical capacities is not beneficial for small architectures. But when the number of cores increases too much on nodes, for both mirev2 and mirev3, multi-ml exceeds bsml. This is not surprising since more communications append between cores without communicating through the network at every step of the algorithm. The bsp algorithm saturates the network with a large amount of communications and thus, this congestion drastically decreases the performances. On the contrary, the multi-ml program focuses on communications through local memories and communicates through the network only when necessary. Thus, the network is less saturated and the performance is better. On a configuration with many cores and physical threads, but for a small number of machines, the performance is disappointing. This is due to too much caches-misses and ram congestion. Indeed, our current algorithms take into account the different network capacities but not the memory sizes.
We have notice a strange and disappointing behaviour when using ocaml +mpi. Indeed, the ocaml ’s runtime slows down by a factor of \(\simeq 2\) when it massively allocates memory. We suspect an overhead (or incompatibility) between the ocaml garbage collector and the mpi ’s memory allocation system. Unfortunately, we do not know how to go beyond this problem, which is just technical.

Benchmarks (measures and speedup) of the mc of a security protocol
3.3 Second case: algorithmic skeletons and a numerical application
We can observe that many parallel algorithms can be characterised and classified by their adherence to a small number of generic patterns of computation. Skeletal programming proposes that such patterns can be abstracted and provided as a programmer’s toolkit with specifications [10]. Thus, they can transcend architectural variations with implementations which enhance performance.
A well-known disadvantage of skeleton languages is that the only admitted parallelism is, usually, the skeleton one, while many applications cannot be easily expressed as instances of known skeletons. Skeleton languages must be constructed to allow the integration of skeletal and ad hoc parallelism [10]. In this way, having skeletons in a more general language would combine the expression power of collective communication patterns with the clarity of the skeleton approach.
In this work, we consider the implementation of well-known data-parallel skeletons as they are simpler to use than task-parallel ones and because they encode many scientific computation problems and scale naturally. Even if this implementation is surely less efficient compared to a dedicated skeleton language, the programmer can compose skeletons when it is natural for him and uses a bsml or multi-ml programming style when new patterns are needed.
The functional semantics of the considered set of data-parallel skeletons is described in [4]. It can also be seen as a naive sequential implementation using lists. The skeletons work as follows: skeleton \(\mathbf {repl}\) creates a new list containing n times element x. The \(\mathbf {map}\) and \(\mathbf {mapidx}\) skeletons are equivalent to the classical single-program–multiple-data (spmd) style of parallel programming, where a single program f is applied to different data, in parallel. The \(\mathbf {scan}\) skeleton, like the collective operation MPI_Scan, computes the partial (prefix) sums for all list elements. A more complex data-parallel skeleton, the distributable homomorphism (\(\mathbf {dh}\)) presented in [4], is used to express divide-and-conquer algorithms, i.e. \((dh \, \oplus \, \otimes \, l)\) transforms a list \(l=[x_1,\ldots , x_n]\) of size \(n=2^m\) into a result list \(r=[y_1,\ldots , y_n]\) of the same size, whose elements are recursively computed as follows:
where \(u=\mathbf {dh} \, \oplus \, \otimes \, [x_1,\ldots ,x_{\frac{n}{2}}]\), i.e. \(\mathbf {dh}\) applied to the left half of the input list l and \(v=\mathbf {dh} \, \oplus \, \times \, [x_{\frac{n}{2}+1},\ldots ,x_n]\), i.e. \(\mathbf {dh}\) applied to the right half of l. The \(\mathbf {dh}\) skeleton provides the well-known butterfly pattern of computation which can be used to implement many computations with the appropriate \(\oplus\) and \(\otimes\) operators [4].
In this work, we choose the fast Fourier transform (fft) where a list \(x=[x_0,\ldots ,x_{n-1}]\) of length \(n=2^m\) yields a list where the ith element is defined as: \((FFT \, x)_i=\sum _{k=0}^{n-1}x_k\omega ^{ki}_n\) where \(\omega _n\) denotes the nth complex root of unity \(e^{2\pi \sqrt{-1}/n}\). The skeletal code is:
The code for asynchronous skeletons such as \(\mathbf {map}\) is trivial. Using bsml:

Each processor owns a sub-part of the list. The scan code for both bsml and multi-ml can be found in [3]: we use a logarithmic parallel reducing algorithm for bsml and a divide-and-conquer one for multi-ml.

The multi-ml code for \(\mathbf {dh}\)
The bsml code for \(\mathbf {dh}\) looks like a reducing and can be found in [2]. The one for multi-ml is in Fig. 12 and works as follows. We recursively split the list (lines 4–5) from the root node to the leaf where local_dh computes, locally, the \(\mathbf {dh}\) skeleton. Then we gather the temporary results and perform a local_dh on the data (line 7). Note that these skeletons do not change the size of the “lists” so they can be implemented using vector of arrays, that is one array per processor. It is still a divide-and-conquer strategy and, in this case, the codes for bsml and multi-ml really differ. This is mainly due to the fact that there is no sub-group synchronisation using bsml whereas it is natural using multi-ml.
We have tested our two implementations of the \(\mathbf {dh}\) skeleton (Fig. 13). To measure the difficulty, we use the implementation of the skeletons only. We test the fft for two values of m, 19 and 21, leading to \(2^m\) elements as input. We can notice an overhead with multi-ml on small architecture with a small input; and thus a speedup in favour of bsml. This is mainly due to the fact that the multi-ml\(\mathbf {dh}\) implementation needs to transfer the data between each memory level of the architecture. This issue was an expected drawback of the multi-ml algorithm. In this algorithm, the sub-synchronisation mechanism on multi-ml is under-exploited. As the architecture grows in terms of both machines and cores, multi-ml takes a small advantage on mirev3 as bsml floods the network. However, the complexity of the code is in favour of multi-ml. So there is ultimately no problem using it. The overall performance of both implementations are disappointing, but it is the best we can hope for such a toy implementation of the fft.

Benchmarks (measures and speedup) of fft using skeletons
3.4 Third case: big-data application
Given a collection of objects, the all pairs similarity search problem (apss) involves discovering all the pairs of objects whose similarity is above a given threshold. It may be used to detect redundant documents, similar users in social networks, etc. Due the huge number of objects present in real-life systems and its quadratic complexity, similarity scores are usually computed off-line.
Assuming a set of n documents of terms \(D=\{d_1, d_2, \ldots ,d_n\}\). Each document d is represented as a sparse vector containing at most m terms. d[i] denotes the number of occurrences of the ith term in the document d. The problem is to find all pairs (x, y) of documents and their exact value of similarity \(sim(x,y)=\sum _{i}^{m} x[i]*y[i]\) if the similarity is greater than a certain threshold \(\sigma\).
Different parallel algorithms have been proposed to apss [1] and some of them deal with approximation techniques. Our work focuses on exact solutions only and we use inverted indexes as it is now the most common technique [5] (our ocaml code is an implementation of this kind of algorithm). For bsp-like computing, two algorithms are mainly used [1]. The first algorithm is based on a systolic-like loop. We assume that each processor i holds a subset of documents \(D_i\). Initially, each processor i computes the similarity \(sim(D_i,D_i)\) of \(D_i\)’s documents with each other documents of \(D_i\). Then each subset is passed around from processor to processor in a sequence of \(\mathbf {p}/2\) supersteps (exploiting the symmetric similarity of two subsets): each processor receives a subset \(D_j\) and calculates \(sim(D_i,D_j)\) and then it sends \(D_j\) to its right-hand neighbour, while at the same time receiving the documents from its left-hand neighbour. If \(\mathbf {p}\) is odd, half of the processors perform an additional exchange.

The bsml code for apps
The second algorithm is based on two simple mapreduce [21] phases as illustrated in Fig. 14: (1) Indexing; for each term in the document, each processor merges the term as key, and a pair (d, d[t]) consisting of document id d and weight of the term as the value (line 3). Then the algorithm handles the grouping by key of these pairs (the shuffle, line 4); (2) Similarity; each processor emits pairs of document ids that are in the same group G as keys (line 6). There will be \(m \times (m-1)/2\) exchange pairs where \(m=|G|\) for the shuffle (line 7); then they associate with each pair the product of the corresponding term weights. Finally they reduce the sums of all the partial similarity scores for a pair to generate the final similarity scores (line 8).
The multi-bsp algorithm is again an incremental improvement of the two above bsp algorithms. It is based on the following idea (Fig. 15): Initially, on leaves, we perform a systolic-like loop to initiating the index lists and the similarities. Then, each node selects some documents (on the sub-nodes, line 4) that already have a similarity: these documents are thus a greater opportunity to be similar with other documents. These documents are passed around from sibling to sibling (line 5) and are passed down to leaves as pairs as in the mapreduce method. Now all the leaves update their similarity scores (line 7). And so on until no more documents are sending around siblings.

The multi-ml code for apps
As before, to measure the performances and the difficulty of writing the programs, we take into account the algorithm part only and not the reading of the data. We use the Twitter’s follower graph (July 2009, 24GB file with approximately 1.5 billion of followings) available at http://an.kaist.ac.kr/traces/WWW2010.html as data-set. For our experiments (Fig. 16), we take sub-parts of the original file. A pair corresponds to the same kind of following. We do not use any disc to store temporary results. There are 600M (resp. 1.5G) of pairs for 10M (resp. 17M) followings. The sequential code fails on these too large data-sets (not enough memory), so we give the execution times only. We do not use the common pruning of documents [5]: that reduces the overall computing time by reducing the number of documents to be compared and communicated but that is “independent” of using parallel algorithms. Our threshold is very low (even if it’s not realistic), thus many pairs are computed. The number of pairs quadratically increases to the size of the data-set. The fails (\(\infty\)) corresponds to “out of memory” or mpi fails when too much data are exchanged during a superstep (i.e. when less nodes take part in the computation or there are too many cores in use on a single node).

Benchmarks of the all pairs similarity search problem (apps)
As already seen in [1], for bsp computing, the systolic method is faster than the mapreduce one by an important order of magnitude. This is mainly due to a quadratic number of sending pairs. Thus, we do not give these timings.
The performances of the programs are not impressive because we use the generic data structures of ocaml which are not optimised for pairs and thus consumes too much memory. The losses are mainly due to a large use of the ram. As intended, the multi-bsp code is more complex but gives better performance. The gain is not spectacular: using a bsp systolic algorithm, only one core sends data to a another core of a machine. So there are few data exchanged in the network and there is thus not a congestion as in the mc example. This also explains why the performances are better using mirev2 than mirev3: there are too many memory accesses in the ram. However when using the multi-bsp algorithm, even if the computations and the memory uses are of the same order of magnitude as in the bsp algorithm, there is a massive use of synchronisation of sub-machines which allow a better load-balancing. Even if there is more (local) supersteps, each performs less computation leading to less congestion when accessing to the ram.
4 Related work
Hierarchical programming and multi-BSP libraries There are many papers about the gains of mixing shared and distributed memories, e.g. mpi and open-mp [7]. As intended, the programmer must manage the distribution of the data for these two different models. For example, with the mc case, the algorithm of [20] handles a specific data structure (with locks) shared by the threads on cores and distributes the states across the nodes using the hash technique. We can also cite the work of [15] in which a bsp extension of c++ runs the same code on both a cluster and on multi-cores. But it is the responsibility of the programmer to avoid harmful nested parallelism. This is thus not a dedicated language working for hierarchical architectures. We can also highlight the work of neststep [16] which is a c/java library for bsp computing, which authorises nested computations in case of a cluster of multi-cores—but without any safety.
Distributed functional languages Except in [18], there is a lack of comparisons between parallel functional languages. It is difficult to compare them since many parameters have to be taken into account: used libraries, used frameworks or architectures and what we want to measure that are efficiency, scalability, expressiveness, etc.
A data-parallel extension of haskell call nepal has been done in [8], an abstract machine is responsible for the distribution of the data over the available processors. multi-mlton [22] is a multi-core aware runtime for standard ml, which is an extension of the mlton compiler. It manages composable and asynchronous events using, in particular, safe-futures. A description of other bridging models for hierarchical architectures and other parallel languages can be found in [2]. Currently, we are not aware of any safe and efficient functional parallel language dedicated to hierarchical architectures.
5 Conclusion and future work
5.1 Conclusion
We have benchmarked different distributed applications using a flat bridging model (bsp) and its hierarchical extension (multi-bsp). We used two ml-like languages for both. We tried to compare both speedup and difficulty to write codes on rather different and typical hpc applications. Currently, we are not aware of similar works in the literature. Regarding the proposed case study, in general, the hierarchical programs are more efficient, but they are more difficult to write as a counterpart. As expected, there are also some cases where designing and programming a hierarchical algorithm does not yield much. Intuitively, to get a performance gain, you have to maximise the locality (in the lowest memories of your machine) of calculations as well as the synchronisations/communications. That is to say that we can conclude, without surprise, that to have efficient multi-bsp algorithms, we need to massively exchanges data between the fastest memories. Indeed, on standard intel or amd architectures, memories close to the physical threads (L1, L2 and L3 memories) are very fast. As a counter part, they are so small that it is a challenge to maximise their usage. As expected, we must concentrate on maximising data exchanges between computation units of the same memory locality.
Thanks to our approach, the bsp programs have been written incrementally from the sequential ones, as well as the multi-bsp programs extend the bsp ones. This seems to be an interesting point for software hpc development engineering: in a project, it is possible to work by successive additions of codes and it is not necessary to rewrite the code from scratch. However, it is still less flexible than the skeleton approach where only the patterns need to be efficiently implemented. Nevertheless, regarding an efficient multi-bsp algorithm, it is simpler to implement it using multi-ml code rather than in a skeleton framework.
5.2 Future work
The next phase will be to work on the optimisation of the previous programs. For example, how the states are kept in the memories is not optimised at all and induces many cache-misses. Using the last parameter of the multi-bsp model, that is the size of the memories, should leads to better algorithms. That should also reduce the execution time for exact apss by using a cache-conscious data layout [24]. Our methodology also suffers from the fact that we make the hypothesis that the algorithms are known. However, designing an efficient bsp algorithm is harder than a sequential one. The effort is even harder for multi-bsp even though we perform an incremental development.
In the continuity of this work, we see two interesting points:
- 1.
Doing programming experiments of our languages with students or users; this will allow to test if coding multi-bsp algorithms using multi-ml is really more difficult than coding bsp algorithms with bsml and/or sequential algorithms with ocaml; we think that designing the algorithms themselves is clearly the most difficult part;
- 2.
Comparing the experimental timings with the expected cost formulae. The second author has already done this work in the context of bsp and bsml [13]. The conclusion is that the main difficulty is finding these cost formulae.
Notes
We currently make the hypothesis that the more complicated the codes are, the more complicated the algorithmic design is. We leave the problematic of algorithmic design for future work and we focus on code writing only.
We do not show the bsp parameters nor the multi-bsp ones because we do not use them at all in this work. In fact, cost prediction is rather impossible in some of our application cases, e.g. the state-space construction where the number of computing states is unknown and no upper bound is possible in practice [9].
References
Alabduljalil MA, Tang X, Yang T (2013) Optimizing parallel algorithms for all pairs similarity search. In: Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, WSDM ’13, New York, NY, USA. ACM, pp 203–212
Allombert V (2017) Functional abstraction for programming multi-level architectures: formalisation and implementation
Allombert V, Gava F, Tesson J (2017) Multi-ML: programming multi-BSP algorithms in ML. Int J Parallel Program 45(2):20
Alt MH (2007) Using algorithmic skeletons for efficient grid computing with predictable performance. Ph.D. thesis, Münster University
Bayardo RJ, Ma Y, Srikant R (2017) Scaling up all pairs similarity search. In: Proceedings of the 16th International Conference on World Wide Web, WWW ’07, New York, NY, USA. ACM, pp 131–140
Bisseling RH (2004) Parallel scientific computation: a structured approach using BSP and MPI. Oxford University Press, Oxford
Cappello F, Etiemble D (2000) MPI versus MPI+OpenMP on IBM SP for the NAS benchmarks. In: Proceedings of the 2000 ACM/IEEE Conference on Supercomputing, SC ’00, Washington, DC, USA. IEEE Computer Society
Chakravarty MMT, Keller G, Lechtchinsky R, Pfannenstiel W (2001) Nepal-nested data parallelism in Haskell. In: Proceedings of the 7th International Euro-Par Conference Manchester on Parallel Processing, London, UK. Springer-Verlag, pp 524–534
Clarke EM, Henzinger TA, Veith H, Bloem R (2012) Handbook of model checking. Springer, Berlin
Cole M (2004) Bringing skeletons out of the closet: a pragmatic manifesto for skeletal parallel programming. Parallel Comput 30(3):389–406
Dolev D, Yao AC (1983) On the security of public key protocols. IEEE Trans Inf Theory 29(2):198–208
Garavel H, Mateescu R, Smarandache I (2001) Parallel state space construction for model-checking. Research report
Gava F (2008) BSP functional programming: examples of a cost based methodology. In: Bubak M, van Albada GD, Dongarra J, Sloot PMA (eds) Computational Science—ICCS 2008. Springer, Berlin Heidelberg, pp 375–385
Gesbert L, Gava F, Loulergue F, Dabrowski F (2010) Bulk synchronous parallel ML with exceptions. Future Gener Comput Syst 26(3):486–490
Hamidouche K, Falcou J, Etiemble D (2011) A framework for an automatic hybrid MPI+OpenMP code generation. In: Proceedings of the 19th High Performance Computing Symposia, San Diego, CA, USA. Society for Computer Simulation International, pp 48–55
Kessler CW (2000) NestStep: nested parallelism and virtual shared memory for the BSP model. J Supercomput 17(3):245–262
Li C, Hains G (2012) SGL: towards a bridging model for heterogeneous hierarchical platforms. Int J Parallel Program 7(2):139–151
Loidl H-W, Rubio F, Scaife N, Hammond K, Horiguchi S, Klusik U, Loogen R, Michaelson GJ, Peña R, Priebe S, Rebón ÁJ, Trinder PW (2003) Comparing parallel functional languages: programming and performance. High Order Symb Comput 16(3):203–251
Malewicz G, Austern MH, Bik AJ, Dehnert JC, Horn I, Leiser N, Czajkowski G (2010) Pregel: a system for large-scale graph processing. In: Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, New York, NY, USA. ACM, pp 135–146
Saad RT, Dal Zilio S, Berthomieu B (2011) Mixed shared-distributed hash tables approaches for parallel state space construction. In: International Symposium on Parallel and Distributed Computing (ISPDC 2011), Cluj-Napoca, Romania
Seo S, Yoon E, Kim J, Jin S, Kim J-S, Maeng S (2010) HAMA: an efficient matrix computation with the MapReduce framework. In: 2010 IEEE Second International Conference on Cloud Computing Technology and Science (CloudCom), pp 721–726
Sivaramakrishnan KC, Ziarek L, Jagannathan S (2014) MultiMLton: a multicore-aware runtime for standard ML. J Funct Program 24(06):613–674
Skillicorn DB, Hill JMD, McColl WF (1997) Questions and answers about BSP. Sci Program 6(3):249–274
Tang X, Alabduljalil M, Jin X, Yang T (2017) Partitioned similarity search with cache-conscious data traversal. ACM Trans Knowl Discov Data 11(3):1–34
Valiant LG (1990) A bridging model for parallel computation. Commun ACM 33(8):103–111
Valiant LG (2011) A bridging model for multi-core computing. J Comput Syst Sci 77(1):154–166
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Allombert, V., Gava, F. Programming bsp and multi-bsp algorithms in ml. J Supercomput 76, 5079–5097 (2020). https://doi.org/10.1007/s11227-019-02822-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-019-02822-9