
Abstract
Let \(X=(X_t)_{t\ge 0}\) be a known process and T an unknown random time independent of X. Our goal is to derive the distribution of T based on an iid sample of \(X_T\). Belomestny and Schoenmakers (Stoch Process Appl 126(7):2092–2122, 2015) propose a solution based the Mellin transform in case where X is a Brownian motion. Applying their technique we construct a non-parametric estimator for the density of T for a self-similar one-dimensional process X. We calculate the minimax convergence rate of our estimator in some examples with a particular focus on Bessel processes where we also show asymptotic normality.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Belomestny and Schoenmakers (2015) considered the problem of recovering the distribution of an independent random time T based on iid samples from a one-dimensional Brownian motion B at time T. Comte and Genon-Catalot (2015) already considered this problem for Poisson processes. Here we use the method of Belomestny and Schoenmakers (2015) and derive corresponding results for self-similar processes. We particularly focus on Bessel processes. As a consequence, we extend results from Belomestny and Schoenmakers (2015) to multi-dimensional Brownian motion. This is accomplished by considering the two-norm of the multi-dimensional Brownian motion, thus reducing the problem to the case of a Bessel process which is a one-dimensional process and can be treated similarly to the case of one-dimensional Brownian motion. More specifically, we give a non-parametric estimator for the density \(f_T\) of T. We show consistency of this estimator with respect to the \(L^2\) risk and derive a polynomial convergence rate for sufficiently smooth densities \(f_T\). Moreover, we show that this rate is optimal in the minimax sense. The constructed estimator is also shown to be asymptotically normal.
The paper is organized as follows: In Sect. 2 we recapitulate the Mellin transform which is our main tool throughout this paper. Using this transform we construct our estimator in Sect. 3 by solving a multiplicative deconvolution problem which is related to the original problem through self-similarity of the underlying process. The use of the Mellin transform in multiplicative deconvolution problems proposed by Belomestny and Schoenmakers (2015) is different to the standard approach which consists in applying a log-transformation and thus reducing the problem to an additive deconvolution problem which is usually addressed by the kernel density deconvolution technique. In Sect. 4 we give bounds on bias and variance of the estimator in the general self-similar case. In the following two sections we lay our focus on Bessel processes and give the convergence rates of our estimator for this case (Sect. 5) and show its asymptotic normality (Sect. 6). Section 7 is devoted to two further examples of self-similar processes where our method yields consistent estimators. Their convergence rates are provided there. In the following Sect. 8 we show optimality in the minimax sense of all previously obtained rates. Some numerical examples are given in Sect. 9. Finally, we collect some of the longer proofs in Sect. 10.
2 Mellin transform
In this section we recapitulate some properties of the Mellin transform from Butzer and Jansche (1997). This integral transform will be our main tool in estimation procedures of the next sections. For an interval I define the space
If f is the density function of an \({\mathbb {R}}_+\)-valued random variable, then we have at least \(f\in {\mathfrak {M}}_{[1,1]}\). Moreover, if \(f:\mathbb {R_+}\rightarrow {\mathbb {R}}\) is locally integrable on \({\mathbb {R}}_+\) with
then \(f\in {\mathfrak {M}}_{(a,b)}\) holds.
Definition 1
For a densitiy function \(f\in {\mathfrak {M}}_{(a,b)}\) of a random variable X define
as the Mellin transform of f (or of X) in \(s\in {\mathbb {C}}\) with \({\text {Re}}(s)\in (a,b)\).
If \(f\in {\mathfrak {M}}_{(a,b)}\) holds, then \({\mathcal {M}}[f](s)\) is well defined and holomorphic on the strip \({\{s\in {\mathbb {C}}|{\text {Re}}(s)\in (a,b) \}}\) according to Butzer and Jansche (1997).
Example 2
-
(i)
Consider gamma densities
$$\begin{aligned} f(x)=\frac{r^{\sigma }}{\varGamma (\sigma )}x^{\sigma -1}e^{-rx} \end{aligned}$$(1)for \(x,\sigma ,r>0\). For all \(s\in {\mathbb {C}}\) with \({\text {Re}}(s-\sigma +1)> 0\) we have
$$\begin{aligned} {\mathcal {M}}[f](s)=\frac{r^{1-s}}{\varGamma (\sigma )}\varGamma (s+\sigma -1). \end{aligned}$$ -
(ii)
Consider for \(t>0\), \(d\ge 1\) the densities
$$\begin{aligned} f_t(x) = \frac{2^{1-\frac{d}{2}}t^{-\frac{d}{2}}}{\varGamma \left( {d}/{2}\right) } x^{d-1} e^{-\frac{x^2}{2t}} ,\quad x> 0. \end{aligned}$$(2)For \({\text {Re}}({s})> 1-d\) elementary calculus shows that
$$\begin{aligned} {\mathcal {M}}[f_1](s) = \frac{1}{\varGamma \left( {d}/{2}\right) }\varGamma \left( \frac{s+d-1}{2}\right) 2^{\frac{s-1}{2}}. \end{aligned}$$(3)
Similar to the well-known relation of the classical Fourier transform to sums of independent random variables, the Mellin transform behaves multiplicatively with respect to products of independent random variables:
Theorem 3
Let X and Y be independent \({\mathbb {R}}_+\)-valued random variables with densities \(f_X\in {\mathfrak {M}}_{(a,b)}\) and \(f_Y\in {\mathfrak {M}}_{(c,d)}\), and Mellin transforms \({\mathcal {M}}[X]\) and \({\mathcal {M}}[Y]\) for \(a<b,~c<d,~(a,b)\cap (c,d)\ne \emptyset \). Then XY has a density \(f_{XY}\in {\mathfrak {M}}_{(a,b)\cap (c,d)}\), and
for all \({s \in {\mathbb {C}}}\) with \({\text {Re}}(s)\in (a,b)\cap (c,d)\).
In the setting of Theorem 3 it is easy to see that \(f_{XY}\) is identical to
for all \({s \in {\mathbb {C}}}\) with \({\text {Re}}(s)\in (a,b)\cap (c,d)\). The function \(f_X \odot f_Y\) is called Mellin convolution of \(f_X\) and \(f_Y\).
For \(a<b\) denote the space of holomorphic functions on \(\{s\in {\mathbb {C}}|{\text {Re}}(s)\in (a,b) \}\) by \({\mathcal {H}} (a,b)\). The mapping \({\mathcal {M}}:{\mathfrak {M}}_{(a,b)}\rightarrow {\mathcal {H}} (a,b)\), \(f\mapsto {\mathcal {M}}[f]\) is injective. Given the Mellin transform of a function f we can reconstruct f:
Theorem 4
For \(a<\gamma <b\) let \(f\in {\mathfrak {M}}_{(a,b)}\). If
then the inversion formula
holds almost everywhere for \(x\in {\mathbb {R}}_+\).
Another important result in the theory of Mellin transforms is the Parseval formula for Mellin tranforms (see (Bleistein and Handelsman 1986, page 108) for the proof):
Theorem 5
Let \(f,g:{\mathbb {R}}_+\rightarrow {\mathbb {R}}\) be measurable functions such that
exists. Suppose that \({\mathcal {M}}[f](1-\cdot )\) and \({\mathcal {M}}[g](\cdot )\) are holomorphic on some vertical strip \({\mathcal {S}}:=\{z\in {\mathbb {C}}|a<{\text {Re}}(z)<b\}\) for \(a,b\in {\mathbb {R}}\). If there is a \(\gamma \in (a,b)\) with
then
3 Construction of the estimator
We consider a real-valued stochastic process \((Y_t)_{t\ge 0}\) with càdlàg paths which is self-similar with scaling parameter H (for short, H-ss), that is
Here, \({\mathop {=}\limits ^{d}}\) denotes identity of all finite dimensional distributions. Let \(T\ge 0\) be a stopping time with density \(f_T\) independent of Y. Let \(X_1,\dots ,X_n\) be iid samples of \(Y_T\). In order to construct a non-parametric estimator for \(f_T\) we use the simple consequence of (5) that
We take the absolute value on both sides and assume that \(f_T\in {\mathfrak {M}}_{(a,b)}\) with \({0\le a<b}\) and that the density of \(Y_1\) is in \({\mathfrak {M}}_{(0,\infty )}\), so we can apply the Mellin transform on both sides of (6) and obtain
for \({\max \{0,\frac{a+H-1}{H}\}< {\text {Re}}(s) < \frac{b+H-1}{H}}\). Setting \(z:=Hs-H+1\) we conclude that
If the Mellin inversion formula (Lemma 4) is applicable to T, we may write
for \(a< \gamma < b\). Combining (7) and (8) we obtain the representation
for \(\max \{1-H,a\}< \gamma < b\). In order to obtain an estimator of \(f_T\) based on (9) we would like to replace \({\mathcal {M}}[|Y_T|]\) by its empirical counterpart
However, this substitution may prevent the integral in (9) from converging. Thus, we introduce a sequence \((g_n)_{n\in {\mathbb {N}}}\) with \(g_n\rightarrow \infty \) (chosen later) in order to regularize our estimator. In view of (9) define
for \(x>0\) and \(\max \{1-H,a\}< \gamma < b\) as an estimator for \(f_T\).
4 Convergence analysis
For the sake of brevity we introduce the notation \(f(x)\lesssim g(x)\) for \(x\rightarrow a\), if \(f={\mathcal {O}}(g)\) in the Landau notation. We write \(f(x)\sim g(x)\) for \(x\rightarrow a\), if \(f(x)\lesssim g(x)\) and \(g(x)\lesssim f(x)\) for \(x\rightarrow a\). For \(0\le a<b\) and \(\beta \in (0,\pi )\) consider the class of densities
where
For the bias of the estimator (10) we have:
Theorem 6
Let \((Y_t)_{t\ge 0}\) be H-ss with càdlàg paths. Let \(T\ge 0\) be a stopping time independent of Y with density \(f_T\). If \(f_T\in {\mathcal {C}}(\beta ,a,b)\) with \(\beta \in (0,\pi )\) and \(0\le a<b\), then
for all \(x>0\), \(\gamma \in (\max \{a,1-H\},b)\).
Proof
Let \(x> 0\). By Fubini’s theorem and (7),
We combine Theorem 4 with (12) to get
Since \(f_T\in {\mathcal {C}}(\beta ,a,b)\) implies \(|{\mathcal {M}}[T](\gamma +iv)| \lesssim e^{-\beta |v|}\) for \(v\rightarrow \pm \infty \), \(\gamma \in (a,b)\) (see Proposition 5 in Flajolet et al. (1995)), we have
Moreover, (13) gives
for all \(x>0\), which is our claim. \(\square \)
Having established an upper bound on the bias of \({\hat{f}}_n\), we now shall do the same for the variance of our estimator.
Theorem 7
Let \((Y_t)_{t\ge 0}\) be H-ss with càdlàg paths. Let \(T\ge 0\) be a stopping time independent of Y with density \(f_T\). If \(f_T\in {\mathfrak {M}}_{(a,b)}\) with \({0\le a< b}\) and the density of \(|Y_1|\) is in \({\mathfrak {M}}_{(0,\infty )}\), then
for all \(n\in {\mathbb {N}}\) and all \(x>0\).
Proof
Let \(x> 0\), \(n\in {\mathbb {N}}\). As
for any bounded random function \(f_v\) (continuous in v), we obtain
In order to get a bound on \({\text {Var}}[|Y_T|^\frac{\gamma -1+iv}{H}]\) we use the self-similarity of Y to get
which (together with (15)) gives the desired bound on \({\text {Var}}[\hat{f_n}(x)]\). \(\square \)
5 Application to Bessel processes
In this section we choose Y to be a Bessel process \(BES=(BES_t)_{t\ge 0}\) starting in 0 with dimension \(d\in [1,\infty )\). Note that the case \(d=1\) leads to the absolute value of the one-dimensional Brownian motion and was already considered in Belomestny and Schoenmakers (2015). We refer to Revuz and Yor (1999) for detailed information about Bessel processes. It is well-known, that Bessel processes are \(\frac{1}{2}\)-ss and have continuous paths. Marginal densities are given by:
In Example 2(ii) we calculated \({\mathcal {M}}[BES_1](s) = \frac{1}{\varGamma \left( {d}/{2}\right) }\varGamma \left( \frac{s+d-1}{2}\right) 2^{\frac{s-1}{2}}\). Looking at (10) we obtain
as an estimator for the density \(f_T(x)\) of a stopping time \(T\ge 0\) for \(x>0\) and \(\max \{1/2,a\}< \gamma < b\), where a, b are such that \(f_T\in {\mathfrak {M}}_{(a,b)}\) and \(X_1, \ldots ,X_n\) are independent samples of \(BES_T\). With our major result Theorem 8 we shall derive the convergence rates for (16).
Theorem 8
If \(f_T\in {\mathcal {C}}(\beta ,a,b)\) for some \(0\le a<b\), \(\beta \in (0,\pi )\) and if there is a \(\gamma \in (a,b)\) with \(2\gamma -1\in (a,b)\) and \(\gamma > (4-d)/4\), then
for some \(C_{L,d,\gamma }>0\) depending only on \(L,\gamma ,d\) as well as T. Moreover, taking
in (17), one has for all \(x>0\) the polynomial convergence rate
Proof
Let \(x> 0\). We use the upper bound on variance obtained in Lemma 7 with \(H=1/2\) to get
for some \(C_0(\gamma ,d)>0\). By Example 2(ii) and Lemma 21(ii) we have
for some constants \(C_1(d,\gamma )\) and \(C_2\). Adding (21) and (11) gives
for some \(C_{L,d,\gamma }>0\). The choice (18) yields the rate (19). \(\square \)
The class \({\mathcal {C}}(\beta ,a,b)\) is fairly large. In particular, \({\mathcal {C}}(\beta ,0,\infty )\) includes for all \(\beta \in (0,\pi /2)\) such well-known families of distributions as Gamma, Weibull, Beta, log-normal and inverse Gaussian. So, if T belongs to one of those families, Theorem 8 is true for any \(\gamma >\max \{1/2,(4-d)/4 \}\). If \(d\ge 2\), then we only require \(\gamma >1/2\).
6 Asymptotic normality for Bessel processes
Note that the estimator (16) can be written as
with
Since \(\hat{f_n}\) is a sum of iid variables, we can show that (under mild assumptions on \(f_T\)) \(\hat{f_n}\) is asymptotically normal. In fact, we have:
Theorem 9
Let \(f_T\in {\mathfrak {M}}_{(a,b)}\) for some \(0\le a<b\). Suppose there is a \(\gamma \in (a,b)\) such that \(2\gamma -1\in (a,b)\), \(\gamma >(4-d)/4\) and \((\delta +2)\gamma -\delta -1\in (a,b)\) for some \(\delta >0\) and
If we choose \(g_n \sim \log (n)\) in (16) then we have
for all \(x>0\), where
with some \(c>0\) given by (47).
We present the proof in Sect. 10.1. As we mentioned in the end of Sect. 5, we can often assume \((a,b)=(0,\infty )\), so that the choice of \(\gamma \) is only restricted by \(\gamma >\max \{1/2,(4-d)/4 \}\). In this case a suitable \(\delta \) can always be found: For \(\gamma \in (1/2,1)\) choose \(\delta <(1-2\gamma )/(1-\gamma )\), for \(\gamma >1\) choose \(\delta >(1-2\gamma )/(1-\gamma )\) and for \(\gamma =1\) any \(\delta >0\). If in addition to \((a,b)=(0,\infty )\) we have \(d\ge 2\), then the statement is true for all \(\gamma >1/2\).
It is possible to give a Berry-Esseen type error estimate for the convergence in (26). This is a new result even for dimension \(d=1\).
Theorem 10
Let \(f_T\in {\mathfrak {M}}_{(a,b)}\) for some \(0\le a<b\). Suppose there is a \(\gamma \in (a,b)\) such that \(2\gamma -1\in (a,b)\), \(\gamma >(4-d)/4\), \(3\gamma -2\in (a,b)\) and (25) holds. Fix some \(x>0\). Denote by \(F_n\) the distribution function of
(where \(\hat{f}_n(x)\) is defined by (16) and \(\nu _n=n{\text {Var}}[\hat{f}_n(x)]\) is given by (27)) and by \(\varPhi \) the distribution function of the standard normal distribution. If we choose \(g_n \sim \log (n)\) in (16) then we have
for \(n\rightarrow \infty \).
Proof
Let \(x>0\) and \(n\in {\mathbb {N}}\). Consider the representation (23) of \({{\hat{f}}}_n(x)\). Berry-Esseen Theorem (see Gänssler and Stute 1977) states
We choose \(j=3\) in Lemma 11 to get
for \(n\rightarrow \infty \). By Theorem 9 we have (27). Choose \({g_n\sim \log (n)}\). Plugging (30) and (27) into (29) concludes the proof. \(\square \)
Note that the signs of the powers \({4\gamma -d+3}\) and \({3(2\gamma -d+3)/2}\) in (28) are ambiguous and depend on the relative positions of \(\gamma \) and d. However, if \(d\ge 2\) then we only have the case \(\gamma +d/2-3/2\ge 0\) and the power of the logarithm is positive.
The following observation about the absolute moments of \(Z_{n,1}\) is useful in the proof of Theorem 9 but also holds some insights in itself.
Lemma 11
Let \(f_T\in {\mathfrak {M}}_{(a,b)}\) for some \(0\le a<b\) and \((g_n)_{n\in {\mathbb {N}}}\subset {\mathbb {R}}_+\) with \(g_n\rightarrow \infty \) as \(n\rightarrow \infty \). If there is a \(\gamma \in (a,b)\) such that \(2\gamma -1\in (a,b)\), \(\gamma >(4-d)/4\) and \((\gamma -1)j+1\in (a,b)\), then
as \(n\rightarrow \infty \) for all \(j\in {\mathbb {R}}_+\). In particular, all absolute moments of \(Z_{n,1}\) exist for all \(n\in {\mathbb {N}}\) greater than some \(n_0\in {\mathbb {N}}\).
Proof
Case \(\gamma +d/2-3/2 \ge 0\): By Jensen inequality, Lemma 21(ii) and (7) (with \(H=1/2,~Y=BES\) there) we have
where \(c:=\varGamma \left( \frac{d}{2}\right) ^{j}(2^\gamma \pi x^\gamma )^{-j} \) and \(C_{\gamma ,d,j},C_j>0\). The case \(\gamma +d/2-3/2 < 0\) follows similarly applying Lemma 21(i) instead of (ii). \(\square \)
For the special case \((a,b)=(0,1)\) and \(d=j=1\) this result is mentioned in Belomestny and Schoenmakers (2015) but without an extensive proof which we provide here. Note that for \(d\ge 2\) the assumption \(\gamma >(4-d)/4\) is redundant. Moreover, we always have the smaller bound of the second case in (31).
7 Some other self-similar processes
7.1 Normally distributed processes
Let \(Y=(Y_t)_{t\ge 0}\) be H-ss with càdlàg paths and \(Y_1\) standard normally distributed. As example consider a fractional Brownian motion. This setting is easily generalized to the case where \(Y_1\sim {\mathcal {N}}(0,\sigma ^2)\) with \(\sigma ^2>0\) by considering the process \(({{\tilde{Y}}}_t)_{t\ge 0} := (Y_t/\sigma )_{t\ge 0}\) and modifying our observations to \(\tilde{X}_i :=X_i/\sigma \). Taking \(d=1\) in Example 2(ii) we see that estimator (10) assumes the form
for \(x>0\) and \(\max \{1-H,a\}< \gamma < b\). We can prove a convergence result for this estimator, similar to Theorem 8.
Theorem 12
Let \(0\le a<b\). Suppose \(f_T\in {\mathcal {C}}(\beta ,a,b)\) for some \(\beta \in (0,\pi )\). If there is some \(\gamma \in (\max \{a,1-H,3/4\},b)\), then
for \(n\rightarrow \infty \) and all \(x>0\). Taking
we obtain for all \(x>0\) the polynomial convergence rate
for \(n\rightarrow \infty \).
Proof
The proof is analogous to the one of Theorem 8 except for the upper bound on variance which is in this case
for some \(C_0(\gamma ,H)>0\). Combining this with the bound on the bias from Lemma 6(i) we obtain (33). Plugging (34) into (33) gives the rate (35). \(\square \)
Taking \(H=1/2\) in Theorem 12 we obtain the same rates as for Bessel processes (see Theorem 8). For smaller H the rate is worse and for greater H it is better. Note that we work with observations of \(|Y_T|\) rather than \(Y_T\).
7.2 Gamma distributed processes
Let \(Y=(Y_t)_{t\ge 0}\) be H-ss with càdlàg paths such that \(Y_1\) has Gamma density (1) with \(r=1\). We can easily generalize to the case \(r>0\), by considering the process \({({{\tilde{Y}}}_t)_{t\ge 0} := (r Y_t)_{t\ge 0}}\) and modifying our observations to \({{\tilde{X}}}_i :=r X_i\). As an example consider the so-called square of a Bessel process with dimension d starting at 0 (see Revuz and Yor 1999, Chapter XI, §1). Considering Example 2(i) estimator (10) takes the form
for \(x>0\) and \(\max \{1-\sigma H ,a\}< \gamma < b\). We can prove a convergence result for this estimator, that is similar to Theorems 8 and 12.
Theorem 13
Let \(0\le a<b\). Suppose \(f_T\in {\mathcal {C}}(\beta ,a,b)\) for some \(\beta \in (0,\pi )\). If there is some \(\gamma \in (\max \{a,1-\sigma H, 1-\sigma /4 \},b)\) with \(2\gamma -1\in (a,b)\), then
for \(n\rightarrow \infty \) and all \(x > 0\). If
then for all \(x>0\) we have
for \(n\rightarrow \infty \), where \(k=\frac{\beta }{\frac{\pi }{H}+2\beta } \left( \frac{2(\gamma +\sigma H-1)}{H}-1\right) \).
Proof
In this case he upper bound on variance becomes
Rest is again analogue to the proof of Theorem 8. \(\square \)
8 Optimality
The rates from Theorems 8, 12 and 13 are optimal in the minimax sense.
Theorem 14
For all \(\beta \in (0,\pi )\) and \(0<a<b<\pi /\beta \) there is \(x>0\) such that
for some \(c>0\), where infimum is over all estimators based on samples of \(Y_T\) with
-
(i)
a Bessel process Y with dimension \(d\in [1,\infty )\) and \(\psi _n=n^{-\frac{\beta }{\pi +2\beta }}\);
-
(ii)
a H-ss. Gaussian process Y (\(H\in (0,2)\)) and \(\psi _n=n^{-\frac{\beta }{\frac{\pi }{2H}+2\beta }}\);
-
(iii)
a H-ss. Gamma distributed process Y (\(H\in (0,2)\)) and \(\psi _n=n^{-\frac{\beta }{\frac{\pi }{H}+2\beta }}\).
See Sect. 10.2 for the proof of this theorem. A similar optimality result was obtained in Belomestny and Schoenmakers (2015) for the case where the absolute value of a one-dimensional Brownian motion is observed. (40) means that for each estimator \({{\hat{f}}}_n\), that we may construct with our observations, there is a true density \(f\in {\mathcal {C}}(\beta ,a,b)\) such that
for some \(x>0\), i.e. it is impossible to construct an estimator with a convergence rate (w.r.t. \(L^2\)-distance) faster than \(\psi _n\) for all \(f\in {\mathcal {C}}(\beta ,a,b)\) and all \(x>0\).
9 Simulation study
In this Section we test our estimator (16) with some simulated data. Consider a Bessel process with dimension \(d=5\) and a Gamma(2, 1) distributed stopping time T, i.e. T has the density
In order to evaluate the estimator (16) we choose \(\gamma =0.7\). Take the cut-off parameter \(g_n=\frac{\log (n)}{(\pi +2\beta )}\) (in accordance with (18)) and \(\beta =0\). To choose \(\beta \) small appears counterintuitive at first because we showed in Theorem 8 that the convergence rate is better for large \(\beta \). However, in our examples the choice \(\beta =0\) delivers the best results. This can be explained as follows: Our bound on the bias of estimator \({{\hat{f}}}_n\) contains the constant L (see (14)) as a factor. This constant is growing in \(\beta \) and seems to make a crucial contribution to the overall error. We refer to Belomestny and Schoenmakers (2015) and Schulmann (2019) for an alternative choice of \(g_n\) based purely on the data.
In order to test the performance of \({{\hat{f}}}_n\) we compute it based on 100 independent samples of \(BES_T\) of size \(n\in \{1000,5000,10{,}000,50{,}000\}\). In Fig. 1 we see the resulting box-plots of the loss.
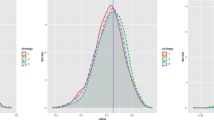
Let us demonstrate the performance of our estimator for different distributions of T. As examples we consider Exponential, Gamma, Inverse-Gaussian and Weibull distributions. To construct the estimate (16) we choose \(d=5\), \(\gamma =0.8\), \(n=1000\) and \(g_n\) as before. Figure 2 shows the densities of the four distributions and their 50 respective estimates based on 50 independent samples of \(BES_T\).
We can see that the error is particularly large in the neighborhood of 0. That is because our estimator is not defined in 0 and \(\lim \limits _{x\rightarrow 0} {\hat{f}}_n(x)\) does not exist for fixed n. Note also that the variance of our estimator is large for small x (see (27)). Conversely, we obtain better results for large x.

Box plot of the loss \(\sup _{x\in [0,10]} \{|\hat{f}_n(x)-f_T(x)| \}\) for different sample sizes

Estimated densities (red) and their 50 respective estimates (grey). (Color figure online)
10 Proofs
10.1 Proof of Theorem 9
We roughly imitate the proof of an analogous result for the special case \({d=1}\), \((a,b)=(0,1)\) found in Belomestny and Schoenmakers (2015). In distinction from Belomestny and Schoenmakers (2015) we do not restrict ourselves to the case \(x=1\) in the proof and provide the specific form of \(\nu _n\) for all \(x>0\).
Let \(x>0\). It suffices to show the Lyapunov condition, i.e. for a \(\delta >0\):
The claim (26) follows from (41) with \(\nu _n={\text {Var}}[Z_{n,1}]\). Note that \({\text {E}}[Z_{n,1}]\rightarrow f_T(x)\) for \(n\rightarrow \infty \) by monotone convergence and (9) (if we choose \(Y=BES\) there). So, (41) holds if we can prove, that \({\text {Var}}[Z_{n,1}]\rightarrow \infty \) and
In any case of Lemma 11 (for \(j=\delta +2\)) we have
for all \(\delta \in {\mathbb {R}}_+\) and some \(c>0\). Now we investigate the asymptotic behavior of \({\text {Var}}[Z_{n,1}]\). Looking at (24) we use Fubini’s theorem to obtain
By Example 2(ii) we can estimate
for some \(C>0\) and further
Our strategy now is to decompose the double integral defining \(R_1\) into pieces that are easy to estimate. To that end let \(\rho _n:=g_n^{\alpha }\), where \(0<\alpha <1/2\) and define
By Lemma 20 there are \(C_1,C_2>0\) such that
and \(K_1,K_2>0\) such that
With the help of these inequalities we deduce
Similarly,
and
for some \(l\ge 0\). Combine (44) and (45) to obtain
Next, we examine the asymptotic behavior of the integral \(I^3_{n}\). To this end, we take advantage of Stirling’s formula (Lemma 19)
for \(v\rightarrow \infty \). Consider the integrand of \(I^3_{n}\). In the denominator it holds by means of the identity \({\log (iv)=\log (v)+\frac{i\pi }{2}}\) that
for \(u,v\rightarrow \infty \). On the set
we define \(u=g_n -r\), \(v=g_n -s\) with \(0<r,s<\rho _n\), \(|r-s|<\rho _n\) to obtain
Note that due to the choice of \(\rho _n\), we have \(\rho _n g_n^{-1}\rightarrow 0\) and \(\rho ^2_n g_n^{-1}\rightarrow 0\). We use the asymptotic decomposition
to obtain
Analogously, on the set
we define \(u=-g_n +r\), \(v=-g_n +s\) with \(0<r,s<\rho _n\), \(|r-s|<\rho _n\) to obtain
Hence, \(I^3_{n}\) can be decomposed as follows:
where
with
The integral in (46) allows a series representation via Lemma 22. In fact,
uniformly in v. Thus,
holds with
Summing up the auxiliary quantities introduced above we get
and thus (27). If \(g_n\sim \log (n)\), then (27) and (43) imply (42) and hence the claim.
10.2 Proof of Theorem 14
The basic construction used in this proof is due to Belomestny and Schoenmakers (2016), where it is used in the context of an observed Brownian motion. Define the \(\chi ^2\)-divergence
between two probability measures \(P_0\) and \(P_1\) with densities \(q_0\) and \(q_1\). The following general result forms the basis for the subsequent steps (see Tsybakov 2008 for a proof).
Theorem 15
Let \(\{P_f|f\in \varTheta \}\) be family of probability measures indexed by a non-parametrical class of densities \(\varTheta \). Suppose that \(X_1, \ldots ,X_n\) are iid observations in model n with \({\mathcal {L}}(X_1)\in \{P_f|f\in \varTheta \}\). If there are \(f_{n,0},f_{n,1}\in \varTheta \) such that
and if
holds for some \(\alpha >0\) independent of n, then
holds for some \(c>0\), where the infimum is over all estimators.
Let \(\beta \in (0,\pi )\) and \(0<a<b<\pi /\beta \). Define for \(M>0\)
The following lemma provides some properties of the functions q and \(\rho _M\).
Lemma 16
The function q is a probability density on \({\mathbb {R}}_+\) with Mellin transform
The Mellin transform of the function \(\rho _M\) is given by
Proof
Formula (52) can be found in Oberhettinger (2012) and (53) is shown in (Belomestny and Schoenmakers 2016, Lemma 6.2). \(\square \)
Set now for any \(M >0\) and some \(\delta >0\),
for \(x\ge 0\), where \(q\odot \rho _M\) is defined by (4). The following lemma will help us verify condition (49).
Lemma 17
For any \(M>0\) and some \(\delta >0\) not depending on M the function \(f_{1,M}\) is a probability density satisfying
Moreover, \(f_{0,M}\) and \(f_{1,M}\) are in \({\mathcal {C}}(\beta ,a,b)\) for all \(\beta \in (0,\pi )\) and \(0<a<b<\pi /\beta \).
Proof
For (55) see (Belomestny and Schoenmakers 2016, Lemma 6.3) where it is also shown that for \(\delta \) small enough:
It is easy to see that \(f_{0,M}\in {\mathcal {C}}(\beta ,a,b)\) for all \(\beta \in (0,\pi ),~0<a<b<\pi /\beta \) and (56) implies the same for \(f_{1,M}\). \(\square \)
Looking further towards applying Theorem 15 let us consider the densities \(p_{M,0}\) and \(p_{M,1}\) of an observation associated with the hypotheses \(f_{0,M}\) and \(f_{1,M}\), respectively. At this point we have to differentiate between the models we discussed so far. We will only present the proof for the Bessel case, parts (ii) and (iii) of Theorem 14 can be showed along the same lines.
Let \(T_{0,M}\) and \(T_{1,M}\) be two random variables with respective densities \(f_{0,M}\) and \(f_{1,M}\). The density of the random variable \(BES_{T_{i,M}}\), \(i=0,1\) is obtained via (4):
For the Mellin transform of \(p_{i,M}\) we use self-similarity of BES and (3) to get
for \({\text {Re}}(s)>1-d\) and \({\text {Re}}(s)\in (-1,\frac{2\pi }{\beta }+1)\).
Lemma 18
For all \(d\ge 1\) and \(\beta \in (0,\pi )\) we have
Proof
Define \(c_{\beta ,d}:=\frac{2^{1-\frac{d}{2}}}{\varGamma \left( {d}/{2}\right) }\frac{ \sin (\beta )}{\beta }\). By the change of variables \(y=\frac{1}{\lambda }\),
with
For the next step let \(a\in \{0,(2\pi /\beta )-1\}\). We apply Theorem 5 and the rule \({\mathcal {M}}[(\cdot )^a f(\cdot )](z)={\mathcal {M}}[f(\cdot )](z+a)\) and obtain
for suitable \(\gamma \), where \({\mathcal {M}}[q\odot \rho _M]={\mathcal {M}}[q] {\mathcal {M}}[\rho _M]\). Due to (53), we can estimate
with \(\varphi (v)=e^{-\frac{v^2}{2}}\). Next, we use Lemma 20 in (59) to estimate the gamma terms, then plug in (60) and \(|{\mathcal {M}}[q](u+iv)| \le ce^{-\beta |v|}\) for some \(c>0\) to obtain
for \(a\in \{0,(2\pi /\beta )-1\}\). By (58) and (61),
where \(M^{(\pi /\beta )+d-2} e^{-M(\pi +2\beta )}\) is the dominating term. This proves the lemma. \(\square \)
Lemma 18 implies (50). With the choice
Lemma 17 implies (49). Claim of Theorem 14(i) follows with Theorem 15.
References
Andrews G, Askey R, Roy R (1999) Special functions. Encyclopedia of mathematics and its applications. Cambridge University Press, Cambridge
Belomestny D, Schoenmakers J (2015) Statistical Skorohod embedding problem: optimality and asymptotic normality. Stat Probab Lett 104:169–180
Belomestny D, Schoenmakers J (2016) Statistical inference for time-changed Lévy processes via Mellin transform approach. Stoch Process Appl 126(7):2092–2122
Bleistein N, Handelsman R (1986) Asymptotic expansions of integrals. Dover Publications, New York
Butzer P, Jansche S (1997) A direct approach to the Mellin transform. J Fourier Anal Appl 3(4):325–376
Comte F, Genon-Catalot V (2015) Adaptive laguerre density estimation for mixed poisson models. Electron J Stat 9:1113–1149
Erdélyi A (1956) Asymptotic expansions. Dover books on mathematics. Dover Publications, New York
Flajolet P, Gourdon X, Dumas P, Knuth DTD, Bruijn NGD, Mellin H (1995) Mellin transforms and asymptotics: harmonic sums. Theor Comput Sci 144:3–58
Gänssler P, Stute W (1977) Wahrscheinlichkeitstheorie. Hochschultext. Springer, Berlin
Oberhettinger F (2012) Tables of Mellin transforms. Springer, Berlin
Revuz D, Yor M (1999) Continuous martingales and Brownian motion. Springer, Berlin
Schulmann V (2019) Estimation of stopping times for some stopped random processes. TU Dortmund, dissertation
Tsybakov AB (2008) Introduction to nonparametric estimation. Springer, Berlin
Acknowledgements
The author was supported by the Deutsche Forschungsgemeinschaft (DFG) via RTG 2131 High-dimensional Phenomena in Probability – Fluctuations and Discontinuity.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that he has no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
For proof of Lemmas 19 and 20 we refer to Andrews et al. (1999).
Lemma 19
For \(|\arg (s)|\le \pi \) we have \( \varGamma (s) \sim \sqrt{2\pi }s^{s-1/2}e^{-s}\) for \(|s|\rightarrow \infty .\)
Lemma 20
For all \(\alpha \in {\mathbb {R}}\) there are \(C_1,C_2\ge 0\) such that
Corollary 21
-
(i)
For all \(\alpha \in (0,1/2), \delta >0\) and \(U>2\) there is a \(C(\alpha ,\delta )>0\) such that
$$\begin{aligned}\int _{-U}^U \frac{1}{|\varGamma (\alpha +i v)|^\delta }dv \le C(\alpha ,\delta ) U^{(1/2-\alpha )\delta }e^{U\pi \delta /2}. \end{aligned}$$ -
(ii)
For all \(\alpha \ge 1/2,~\delta >0\) and \(U>2\) there are \(C_1(\alpha ,\delta )\) and \(C_2(\alpha ,\delta )>0\) with
$$\begin{aligned} \int _{-U}^U \frac{1}{|\varGamma (\alpha +i v)|^\delta }dv \le C_1(\alpha ,\delta ) + C_2(\alpha ,\delta ) e^{U\pi \delta /2}. \end{aligned}$$
Proof
Define \(C:=\int _{-2}^{2} \frac{1}{|\varGamma (\alpha +i v)|^\delta }dv \). For \(\alpha \in (0,1/2)\) Lemma 20 gives a \(C_1 >0\) such that
which implies the claim with \(C(\alpha ,\delta ):=\max \{2C, 8C_1 (\pi \delta )^{-1}\}\). The case \(\alpha \ge \frac{1}{2}\) follows similarly with \(C_1(\alpha ,\delta ):=C\) and \(C_2(\alpha ,\delta ):= 4 C_1 (\pi \delta )^{-1}\). \(\square \)
Lemma 22
Let \(\alpha <\beta \). If \(f:(\alpha ,\beta )\rightarrow {\mathbb {C}}\) is N times continuously differentiable (\(N\in {\mathbb {N}}\)), then we have the expansion
Proof
See Erdélyi (1956, page 47). \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Schulmann, V. Estimation of stopping times for stopped self-similar random processes. Stat Inference Stoch Process 24, 477–498 (2021). https://doi.org/10.1007/s11203-020-09234-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11203-020-09234-0
Keywords
- Estimation of stopping times
- Multiplicative deconvolution
- Mellin transform
- Self-similar process
- Bessel process