
Abstract
The synchronization problem for a class of nonlinear multi-agent systems only using sampled-data information is investigated in this paper. The multi-agent system has a leader–follower architecture, and the desired synchronization state is the leader’s state, which is available to only a subset of the follower agents. First, by integrating the graph theory and Lyapunov design methods together, a sampled-data control law is designed. Then, the explicit formula for the maximum allowable sampling period is computed to guarantee states synchronization for all agents. An example is given to verify the efficiency of the proposed method.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Recently, the synchronization/consensus theory and applications for multi-agent systems have been attracting great interest from many areas [1]. This is due to its many important applications, such as network synchronization [2, 3], formation control [4, 5], attitude alignment [6, 7], cooperative attack of multiple missiles [8], flocking [9, 10]. The synchronization of multi-agent systems means that all the agents’ states converge to a same state. To guarantee that the final synchronization state is the reference state, the method of adding a virtual leader is usually employed. In this case, the system is called leader-following multi-agent systems.
As for the leader-following multi-agent systems, the leader can be divided into two cases: One is stationary leader, and the other one is dynamic leader. In the case when the leader is stationary, in [11], the consensus problem under switching topologies was studied for double-integrator systems. To guarantee all the follower can track a dynamic leader, the consensus control algorithms were designed for single and double-integrator multi-agent systems in [12–17], respectively. For the second-order nonlinear leader-following multi-agent systems, the corresponding consensus control algorithms were discussed in [18–20].
Nevertheless, the aforementioned results on consensus results are based on continuous-time state feedback. In practice, since more and more sensors and controllers are being implemented through digital computers, how to design a consensus algorithm only using sampled-data information becomes imperative. To this end, in [21], the consensus problem via sampled-data control for the multi-agent systems with double-integrator dynamics was discussed. When the communication topology is time-varying, the corresponding sampled-data control-based consensus algorithm was proposed in [22]. When only the position information is available at the sampling instants, the consensus algorithm was given in [23]. Under the consideration of communication delay between agents, the corresponding delayed consensus algorithm via sampled-data control was proposed in [24]. In [25], some necessary and sufficient conditions were derived to guarantee states consensus via pinning control. When the sampling is aperiodic, the consensus problem was also proposed in [26].
Note that the previous listed consensus control algorithms via sampled-data information are mainly applicable to first-order or second-order multi-agent systems. This paper considers a more general case, i.e., a class of high-order nonlinear multi-agent systems. Nevertheless, because of the presence of the unknown nonlinearities, we cannot directly obtain the exact discrete-time model for the nonlinear multi-agent systems under sampled-data control. To this end, a continuous-time consensus controller is first designed to achieve states consensus. Then the controller is discretized and implemented digitally where the key issue is to compute the maximum allowable sampling period (MASP) that guarantees the closed-loop system’s stability. Under the proposed sampled-data controller and some assumptions, it is shown that the consensus for the considered second-order nonlinear multi-agent systems can be achieved by choosing appropriate gains and sampling period. The main contribution of this paper lies in two aspects: (i) A distributed sampled-data controller is constructed step by step to solve the synchronization problem for a class of high-order nonlinear multi-agent systems whose nonlinearities are allowable to be unknown and (ii) the explicit formula for the maximum allowable sampling period (MASP) is given.
2 Preliminaries and problem formulation
2.1 Problem formulation
This paper investigates the problem of synchronization via sampled-data control for a class of high-order nonlinear multi-agent systems described by:
where \((x_{i,1},\ldots ,x_{i,n})\in R^n\) is the i-th agent’s state, \(u_i\) is the control input to be designed, \(f(\cdot )\) is a unknown nonlinear continuous function. Considering in practice, many agents only send and receive information at sampling instant points, and the controller is usually digitally implemented, e.g., the most popular zero-order hold device
where the time instants \(t_k,t_{k+1}\) are the sampling points, and T is the sampling period. Motivated by this reason, the objective of this paper is to design a distributed sampled-data controller \(u(t_k)\) which is only based on the itself and neighbors’ sampled-data information such that the states of all agents reach synchronization. And the final synchronization state is a referenced state, which is represented by a virtual leader described by
From a mathematical viewpoint, the synchronization means that for all \(i\in \varGamma ,\)
where \(\Vert \cdot \Vert \) denotes the Euclidean norm, i.e., \(\Vert x\Vert =\sqrt{x^Tx}\) for a vector x.
2.2 Graph theory
For the considered multi-agent systems, i.e., leader–follower multi-agent systems (1)–(2), assume that each agent is a node and the information exchange of n follower agents is denoted by an undirected graph \(G=\{V,E,A\}\). \(V=\{v_i,i=1,\ldots ,n\}\) is the set of vertices, \(E\subseteq V\times V\) is the set of edges, and \(A=[a_{ij}]\in R^{n\times n}\) is the weighted adjacency matrix of the graph G. The node indexes belong to a finite index set \(\varGamma =\{1,\ldots ,n\}\). If there is an edge between agent i and j, i.e., \((v_i,v_j)\in E\), then \(a_{ij}=a_{ji}>0\). If there is not any edge between agent i and j, then \(a_{ij}=a_{ji}=0\). Moreover, we assume that \(a_{ii}=0\) for all \(i\in \varGamma \). The set of neighbors of node \(v_i\) is denoted by \(N_i=\{j:(v_i,v_j)\in E\}\). The out-degree of node \(v_i\) is defined as \(\mathrm{deg}_{\mathrm{out}}(v_i)=d_i=\sum _{j=1}^{n}a_{ij}=\sum _{j\in N_i}a_{ij}\). Then the degree matrix of digraph G is \(D=\mathrm{diag}\{ d_1,\ldots ,d_n\}\), and the Laplacian matrix of digraph G is \(L=D-A\). A path in the graph G from \(v_i\) to \(v_j\) is a sequence of distinct vertices starting with \(v_i\) and ending with \(v_j\) such that consecutive vertices are adjacent. The graph G is connected if there is a path between any two vertices.
Assume that the leader (labeled by 0) is represented by the vertex \(v_0\). If the i-th follower is connected to the leader, i.e., this follower can directly obtain the information of the leader, then \(b_i>0\), otherwise, \(b_i=0\). Define the matrix \(B=\mathrm{diag}\{b_1,\ldots ,b_n\}\).
2.3 Some assumptions
Firstly, as that in [18, 19], it is assumed that the unknown nonlinear function \(f(\cdot )\) satisfies the Lipschitz condition.
Assumption 1
There is a known positive constant \(\rho \) such that

Secondly, as that in [14, 17], an assumption on communication topology is presented.
Assumption 2
For the leader–follower multi-agent systems (1) and (2), the graph G for the followers is connected and there is at least one follower connected to the leader, i.e., \(B\ne 0\).
2.4 Useful lemma
Lemma 1
([12]). For the leader–follower multi-agent systems (1) and (2), if Assumption 2 holds, then \(L+B>0\), i.e., the matrix \(L+B\) is positive definite.
3 Main results
In this section, it is shown that the synchronization problem of high-order nonlinear multi-agent systems (1)–(2) only using sampled-data information is solvable under Assumptions 1–2. To achieve this control objective, at the first step, a consensus controller based on continuous-time state feedback is proposed. Then, by discretizing the continuous-time controller, it is shown that there is a maximum allowable sampling period (MASP) \(T^*>0\) (\(\sup _{k\in N} \) \(\{t_{k+1}-t_k\}\le T^*\)) such that the sampled-data control system is globally asymptotically stable.
Theorem 1
For the high-order nonlinear multi-agent systems (1)–(2), if Assumptions 1–2 are satisfied and \(u_i\) is designed as
then the states synchronization can be achieved provided that the control gains and the sampling period T satisfy

where \(\lambda _{\mathrm{max}}(L+B)\), \(\lambda _{\mathrm{min}}(L+B)\) are the maximum and minimum eigenvalues of matrix \(L+B\),
with

Proof
Denote the tracking error between the followers and the leader as:
It follows from (1) and (2) that the tracking error dynamic equation is:

Next, by integrating the graph theory and Lyapunov design method together, a sampled-data controller is first designed.
A: Design of a sampled-data controller
An inductive argument is employed.
Step 1 For the Lyapunov function
the derivative of \(V_1\) along system (9) is
where \({\overline{x}_{i,2}^*}\) is a virtual control law. Design a virtual controller \(\overline{x}_{i,2}^*\) as
which results in
Inductive Step Assume that at step \(j-1\), under the virtual controller
we have the following inequality
where
and
Next, it is shown that (15) also holds at step j. To this end, define
where \(\xi _{i,j}=\overline{x}_{i,j}-\overline{x}_{i,j}^*\).
The derivative of \(V_j\) along system (9) is
According to the definition of \(\overline{x}_{i,j}^*\), it can be obtained that
Based on this relation, completing the square for each individual cross-term leads to
where \(\beta _{j-1}\) is a function defined in (7). Based on (20), it follows from (19) that
Since \(c_j=[\beta _{j-1}(\cdot )+n-j+1]\) as chosen in (6), the virtual controller
yields
This completes the inductive proof. \(\square \)
Following the inductive procedure between (14)–(23), the following inequality is obtained for the step n
where
and
Under Assumption 1, it can be obtained that
As a result, this together with (24) leads to
In the literature, for nonlinear systems, there are usually two approaches to design a sampled-data controller. One approach is to design a discrete-time controller based on the discrete-time model of the nonlinear plant [27]. The other approach, which is called the emulation method, is to design a continuous-time controller at the first step and then discretize it [28]. Considering there are unknown nonlinear terms in the system (1), it is almost impossible to get an accurate discrete-time model of the nonlinear plant. So we employ the second approach to design a sampled-data controller.
With the relation (28) in mind, a continuous-time state feedback controller is designed as follows:
Define
By the definition of \(L+B\), \(u^*\) can be rewritten as
With (30) in mind, it follows from (28) that
By discretizing the continuous-time controller (30), the sampled-data controller can be obtained as follows:
which is equivalent to (4). Substituting the sampled-data control law (32) into (31) leads to
Chose the gain \(c_n\) such that \(c_n\ge \frac{\beta _{n-1}(\cdot )+{\gamma }_{1}+\frac{1}{2}}{\lambda _{\mathrm{min}}(L+B)}\), then
which means that the global states’ synchronization can be achieved if the sampling period \(T=0\). The key issue for emulation method is to find the maximum allowable sampling period. Next, we will show that there exists a maximum allowable sampling period (MASP) \(T^*>0\) (\(\sup _{k\in N} \) \(\{t_{k+1}-t_k\}\le T^*\)) such that the states’ synchronization is globally reached.
Step 2: Selection of a sampling period
To handle the term of \(\xi _n(t)-\xi _n(t_k)\) in (34), without loss of generality, we estimate the i-th element of \(\xi _n(t)-\xi _n(t_k)\) as follows:
Since
then it follows from (9) that
where \({\gamma }_{2}=[\rho +(c_{n-1}\cdots c_1)](c_1+\cdots +c_{n-1})+\rho +(c_{n-1}\ldots c_1)\). By the control law (32), we get
which results in
where \(V_{\mathrm{max}}(t)=\max _{\forall \tau \in [t_k,t]} V(\tau ),{\gamma }_{3}={\gamma }_{2}\sqrt{2n} + \sqrt{2}c_n\Vert L+B\Vert \). With this in mind, it follows from (35) that
Substituting (40) into (34) leads to that for any \(t\in [t_k,t_{k+1})\), the following inequality holds:
The sampling time T is chosen to satisfy the following condition:
In the sequel, based on the relation (41) and the sampling period condition (42), it is shown that
Otherwise, assume that there exists a time instant \(t'\in [t_k,t_{k+1}]\) such that \(V(t')>V(t_k)\). Firstly, it follows from (41) that for \(V(t_k) \not =0\), \(\dot{V}(t_k)<0\). That is to say that V(t) will decrease in a short time starting from \(t_k\). As a result, there is a time instant \(t{''} \in [t_k,t']\) such that
With this relations in mind, it follows from (41) that
which contradicts to the assumption \(\dot{V}(t{''})>0\). Thus,
Based on this fact, by (41), we further get
For the sake of brevity, denote \(\mu (t)=\sqrt{\frac{{V}(t)}{V(t_k)}}\), which results in
By the fact \(\mu (t_k)=1\), it follows (47) that
That is to say that
On the other hand, using the condition (42) leads to that the constant \(\Delta <1\). Therefore, \(V(t_k)\) will converge zero as k tends to infinity. Hence, it can be concluded that the closed-loop system (9) with (4) is globally asymptotically stable, i.e., \(x_i\rightarrow x_d\), \(v_i\rightarrow v_d\) as \(t\rightarrow \infty \). That is to say the consensus for systems (1)-(2) is achieved. The proof is completed. \(\square \)

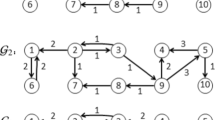
The information exchange among agents

Response curves of agents positions

Response curves of agents velocities

Response curves of agents control signals
Remark 1
Note that for each follower agent, the proposed sampled-data controller (4) only use neighbors’ and itself’s sampling-data information. And only part of followers can have access to the leader’s state. That is to say that the proposed control in this paper is a distributed control law. The distributed control has many advantages such as greater efficiency, higher robustness, and fewer communication requirements, etc.
Remark 2
Our design procedure of distributed sampled-data controller for the nonlinear multi-agent systems (1)–(2) can be divided into three steps:
4 Numerical examples and simulations
As that in [19], consider multiple coupled forced pendulums with four follower agents and one leader agent. Each agent’s dynamic is governed by:
from which it can be found that the nonlinear term \(f(t,x_i,v_i)=-\sin (x_i)-0.25v_i+1.5\cos (2.5t)\) satisfies Assumption 1 with a Lipschitz constant \(\rho =1\).
The information exchange among agents is shown in Fig. 1 with \(a_{12}=a_{21}=a_{13}=a_{31}=a_{34}=a_{43}=b_1=1\). The initial conditions of the four followers are selected as follows: \(x(0)=[0,1,3,1.5]^T,\) \(v(0)=[-1,0,1,2]^T.\) And the initial condition for leader is \(x_d(0)=-1,v_d(0)=2.\)
According to Theorem 1, we can design a consensus control algorithm (4) only using sampled-data information to achieve global states consensus with appropriate gain and sampling period. The control gain is chosen as \(k_1=k_2=10\), and the sampling period is chosen as \(T=0.05\, \mathrm{s}\). The response curves are shown in Figs. 2, 3 and 4. Clearly, all the agents’ states can reach consensus.
5 Conclusion
In this paper, we have discussed the states consensus problem for a class of high-order nonlinear multi-agent systems with unknown nonlinearities. By utilizing graph theory and feedback domination method, a distributed sampled-data controller has been proposed. An explicit formula for the MASP is computed to guarantee global stability of closed-loop systems under the proposed sampled-data controller with appropriate gains.
References
Ren, W., Beard, R.W.: Distributed Consensus in Multivehicle Cooperative Control: Theory and Applications. Springer, London (2007)
Yu, W., Chen, G., Lu, J.: On pinning synchronization of complex dynamical networks. Automatica 45(2), 429–435 (2009)
Yang, X., Wu, Z., Cao, J.: Finite-time synchronization of complex networks with nonidentical discontinuous nodes. Nonlinear Dyn. 73(4), 2313–2327 (2013)
Fax, A., Murray, R.: Information flow and cooperative control of vehicle formations. IEEE Trans. Autom. Control 49(9), 1453–1464 (2004)
Li, S., Wang, X.: Finite-time consensus and collision avoidance control algorithms for multiple AUVs. Automatica 49(11), 3359–3367 (2013)
Dimarogonas, D., Tsiotras, P., Kyriakopoulos, K.: Leader-follower cooperative attitude control of multiple rigid bodies. Syst. Control Lett. 58(6), 429–435 (2009)
Du, H., Li, S.: Attitude synchronization control for a group of flexible spacecraft. Automatica 50(2), 646–651 (2014)
Jeon, I., Lee, J.: Homing guidance law for cooperative attack of multiple missiles. J. Guid. Control Dyn. 33(1), 275–280 (2010)
Olfati-Saber, R.: Flocking for multi-agent dynamic systems: algorithms and theory. IEEE Trans. Autom. Control 51(3), 410–420 (2006)
Zhu, J., Lu, J., Yu, X.: Flocking of multi-agent non-holonomic systems with proximity graphs. IEEE Trans. Circuits Syst. I Regul. Pap. 60(1), 199–210 (2013)
Hong, Y., Gao, L., Cheng, D., Hu, J.: Lyapunov-based approach to multiagent systems with switching jointly connected interconnection. IEEE Trans. Autom. Control 52(5), 943–948 (2007)
Hong, Y., Hu, J., Gao, L.: Tracking control for multi-agent consensus with an active leader and variable topology. Automatica 42(7), 1177–1182 (2006)
Ren, W.: Multi-vehicle consensus with a time-varying reference state. Syst. Control Lett. 56(7–8), 474–483 (2007)
Hong, Y., Chen, G., Bushnell, L.: Distributed observers design for leader-following control of multi-agent networks. Automatica 44(2), 846–850 (2008)
Ren, W.: On consensus algorithms for double-integrator dynamics. IEEE Trans. Autom. Control 53(6), 1503–1509 (2008)
Meng, Z., Ren, W., Cao, Y., You, Z.: Leaderless and leader-following consensus with communication and input delays under a directed network topology. IEEE Trans. Syst. Man Cybern. Part B Cybern. 41(1), 75–88 (2011)
Li, S., Du, H., Lin, X.: Finite-time consensus algorithm for multi-agent systems with double-integrator dynamics. Automatica 47(8), 1706–1712 (2011)
Yu, W., Chen, G., Cao, M., Kurths, J.: Second-order consensus for multiagent systems with directed topologies and nonlinear dynamics. IEEE Trans. Syst. Man Cybern. Part B Cybern. 40(3), 881–891 (2010)
Song, Q., Cao, J., Yu, W.: Second-order leader-following consensus of nonlinear multi-agent systems via pinning control. Syst. Control Lett. 59(9), 553–562 (2010)
Qian, Y., Wu, X., Lu, J., Lu, J.: Consensus of second-order multi-agent systems with nonlinear dynamics and time delay. Nonlinear Dyn. 78(1), 495–503 (2014)
Cao, Y., Ren, W.: Multi-vehicle coordination for double-integrator dynamics under fixed undirected/directed interaction in a sampled-data setting. Int. J. Robust Nonlinear Control 20(9), 981–1000 (2010)
Gao, Y., Wang, L.: Sampled-data based consensus of continuous-time multi-agent systems with time-varying topology. IEEE Trans. Autom. Control 56(5), 1226–1231 (2011)
Yu, W., Zheng, W., Chen, G., Ren, W., Cao, J.: Second-order consensus in multi-agent dynamical systems with sampled position data. Automatica 47(7), 1496C–1503C (2011)
Yu, W., Zhou, L., Yu, X., Lu, J., Lu, R.: Consensus in multi-agent systems with second-order dynamics and sampled data. IEEE Trans. Ind. Inf. 9(4), 2137–2146 (2014)
Zhou, B., Liao, X.: Leader-following second-order consensus in multi-agent systems with sampled data via pinning control. Nonlinear Dyn. 78(1), 555–569 (2014)
Wen, G., Yu, W., Chen, M.Z.Q., Yu, X., Chen, G.: H-infinity pinning synchronization of directed networks with aperiodic sampled-data communications. IEEE Trans. Circuits Syst. I Regul. Pap. 61(11), 3245–3255 (2014)
Nes̆ić, D., Teel, A.R., Kokotović, P.V.: Sufficient conditions for stabilization of sampled-data nonlinear systems via discrete-time approximations. Syst. Control Lett. 38(4–5), 259–270 (1999)
Nes̆ić, D., Teel, A.R., Carnevale, D.: Explicit computation of the sampling period in emulation of controllers for nonlinear sampled-data systems. IEEE Trans. Autom. Control 54(3), 619–624 (2009)
Acknowledgments
This work is supported by the Natural Science Foundation of China (61304007), China Postdoctoral Science Foundation Funded Project (2014T70584), and Ph.D. Programs Foundation of Ministry of Education of China (20130111120007).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Du, H., Jia, R. Synchronization of a class of nonlinear multi-agent systems with sampled-data information. Nonlinear Dyn 82, 1483–1492 (2015). https://doi.org/10.1007/s11071-015-2255-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-015-2255-2