
Abstract
Many landslides occur in the Karun watershed in the Zagros Mountains. In the present study, we employed a novel comparative approach for spatial modeling of landslides given the high potential of landslides in the region. The aim of the study was to combine adaptive neuro-fuzzy inference system (ANFIS) with grey wolf optimizer (GWO) and particle swarm optimizer (PSO) algorithms using the outputs of qualitative stepwise weight assessment ratio analysis (SWARA) and quantitative certainty factor (CF) models. To this end, 264 landslide positions and twelve conditioning factors including slope, aspect, altitude, distance to faults, distance to rivers, distance to roads, land use, lithology, rainfall, plan and profile curvature and TWI were then extracted considering regional characteristics, literature review and available data. In the next step, the multi-criteria SWARA decision-making model and CF probability model were used to evaluate a correlation between landslide distribution and conditioning factors. Ultimately, landslide susceptibility maps were generated by ANFIS-GWO and ANFIS-PSO hybrid models and the accuracy of models was assessed by ROC curve. According to the results, the area under the curve (AUC) for the hybrid models \({\text{ANFIS - GWO}}_{{\text{SWARA}}}\), \({\text{ANFIS - PSO}}_{{\text{SWARA}}}\), \({\text{ANFIS - GWO}}_{{\text{CF}}}\) and \({\text{ANFIS - PSO}}_{{\text{CF}}}\) was 0.789, 0.838, 0.850 and 0.879, respectively. The hybrid models \({\text{ANFIS - PSO}}_{{\text{CF}}}\) and \({\text{ANFIS - GWO}}_{{\text{SWARA}}}\) showed the highest and lowest prediction rate, respectively. Moreover, CF outperformed the SWARA method in terms of evaluating correlation between conditioning factors and landslides. The map produced in this study can be used by regional authorities to manage landslide risk.
Graphic abstract

Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Landslides occur on steep slopes of hills and mountainous areas causing mortality, economic losses, damage to water and soil resources (Schlögel et al. 2015; Raja et al. 2017). This mass movement occurs whenever the loading of an earth material exceeds its shear strength (Lin and Lin 2017). Although landslides have always occurred over time, factors such as changes in climate patterns, constant deforestation of mountainous regions and increased urbanization and its development in susceptible areas have increased landslides around the world in recent years (Goetz et al. 2011). According to a report by the Centre for Research on Epidemiology of Natural Disasters (CRED), landslides are responsible for at least 17% of losses caused by natural disasters in the world (Chen et al. 2019a, b). According to Nadim et al. (2006), the South America, the northern parts of USA and Canada, Iran, Turkey, the Himalayas, the Philippines, Indonesia, Japan and New Zealand are the most landslide vulnerable areas in the world. Therefore, landslides are of great importance as a global problem. Landslide-induced mortality risk and economic losses exceed actual reported numbers in most countries, so that in some cases damages exceed those of other natural disasters (Kjekstad and Highland 2009). In addition, environmental impacts of mass movements such as damages to forests and rangelands and increased sediment load of rivers and its transport to dams should not be ignored. Hence, research on landslides has recently received much attention by policymakers due to the consequences of this destructive phenomenon (Mohammady et al. 2012). Iran is highly susceptible to landslides due to mountainous topography caused by the Alborz and Zagros Mountains, physiography, seismicity and diverse climate and geological conditions. According to the statistics recorded in Iran, there were 4900 landslides until September 2007 that resulted in 187 casualties and about USD 12,700 million in financial losses (Pourghasemi et al. 2012a). The study area, located on the Zagros Mountains, is highly susceptible to landslides. This sensitivity is due to several factors, including the increase in rural settlements, changes in land use, adding the river tributaries and irrigation canals for agricultural use, as well as the construction of Karun 3 and 4 dams. Therefore, this region is of great importance in terms of human, economic, environmental and energy supply resources. So spatial modeling of landslides in this region seems necessary.
Landslide modeling includes using available data for landslide susceptibility mapping (LSM) by selecting an appropriate model. LSMs are in fact tools capable of dividing the ground surface into zones of various stability degrees by evaluating the effect of various factors on slope instability (Youssef et al. 2015a). Therefore, the development of landslide zoning studies and the preparation of susceptibility maps lead to better management and planning of land use and thus reduce the destructive risks arising from it (Baena et al. 2019).
In recent years, many researchers have tried to develop landslide susceptibility maps through using new methods and GIS as a powerful tool (Lorentz et al. 2016; Kadavi et al. 2018; Sameen et al. 2020). Various qualitative and quantitative methods have been used for different areas. However, quantitative (data-driven) approaches have received much attention and are often used in the related studies (Pradhan 2013; Ciurleo et al. 2017; Juliev et al. 2019). Generally, quantitative approaches are categorized into statistical and soft computing methods. Bivariate and multivariate probability models (Pradhan and Lee 2010; Erener et al. 2016; Nicu 2018; Chen et al. 2019a; Zhao et al. 2019) and their combinations (Althuwaynee et al. 2014; Youssef et al. 2015b) are among widely used statistical methods for prepare LSM. Soft computing methods including various machine learning methods such as ANN (Moayedi et al. 2018; Can et al. 2019; Harmouzi et al. 2019), SVM (Zhang et al. 2010), ANFIS (Mehrabi et al. 2020), random forest (Đurić et al. 2019), boosted regression tree and meta-heuristic algorithms (Kavzoglu et al. 2015) have also been used for this purpose. Unlike quantitative methods in which the relationships between landslide controlling factors are numerically expressed, qualitative (knowledge-driven) approaches such as multi-criteria decision analysis methods (Feizizadeh et al. 2014; Yan et al. 2019; Ozioko and Igwe 2020) consider these factors inferentially and their results depend on experts’ views. It should be noted that these methods vary in computational process and efficiency. Hence, analyzing the previous and new methods is a significant step which leads to more realistic results. There is no agreement that determines what type of method should be used for an area. Although the use of new methods is essential for making progress in landslide studies, the use of new combinations as a complementary solution can provide more optimal results. It should also be noted that the quality of the input data also affects the output. In other words, in the same conditions and simultaneous use of the same method, data with better have a more accurate output compared to lower-quality data. The above statements confirm the complexity of this issue and show that the preparation of a landslide susceptibility map depends on various factors, and all aspects must be carefully considered in order to obtain a realistic result. This study aimed at combining ANFIS with GWO and PSO algorithms using the outputs of qualitative SWARA and quantitative CF methods. The results obtained from these methods were also compared to produce the best LSM for the Karun watershed.
As the first innovative aspect, this study compared the ability of meta-heuristic GWO and PSO algorithms in preparation of ANFIS model. Furthermore, for the first time, instead of a single model, the outputs of qualitative SWARA and quantitative CF models are used as input data for training ANFIS-GWO and ANFIS-PSO hybrid models. Ultimately, the LSMs’ performance was evaluated by ROC curve, and then, they were compared.
2 Study area
The study area, as part of the Karun watershed with an approximate area of 7380 km2, lies between longitudes 49° 46′ to 51° and latitudes 31° 27′ to 32° 33′ (Fig. 1). This region is specified in the Zagros Mountains having a height of 503–3970 m above the sea level. The main river flowing in the region is the Karun River originated from Zard-Kuh in Koohrang. This watershed is of great economic and environmental importance given its large contribution in hydropower generation as well as 13% of agricultural products in the region. The climatic data of the region were obtained from the Meteorological Organization and the Ministry of Energy. The lowest average temperature is recorded in February, whereas August is reported as the warmest month (− 1.5 and 19.3 °C, respectively). According to data collected from rain-gauge stations, the mean annual precipitation rate equals 950 mm leading to the creation of many surface runoffs in this mountainous region. The surface runoffs in turn induce many landslides by slope un-stabilization in the region. Human factors such as road construction and settlements as well as agricultural activities exacerbate this natural disaster. The diverse regional lithology also causes landslides. There are many reasons why the study area is important for finding the potential for landslides. One of the reasons that are economically and humanly important is the issue of farming areas and settlements. According to the land use maps, 20.6% of the study area is covered by agricultural and orchard lands. Some of these regions and settlements are located on low slope hillsides or foothills, which are prone to landslides. Therefore, the collapse of unstable slopes will destroy agricultural regions and human casualties. Another reason that is environmentally important is the issue of the sediment accumulation in rivers and their transfer to the back of dams. Two important dams of southwest of Iran, namely Karun 3 and 4, are located in this area (Fig. 1). Therefore, considering an increase in landslides occurred in this area and the conditions mentioned above, it is necessary to spatial modeling of landslides.

Location map and landslide inventory map of the study area
3 Data preparation
3.1 Inventory map
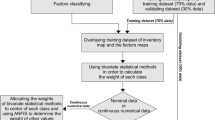
Locating the landslide points is the basis in finding the correlation between the geographical distribution of landslides and the conditioning factors (Lee et al. 2013). In this paper, the landslide locations were obtained from Forest Range and Watershed Management Organization (Fig. 1). According to estimates made, most of the landslides occurred in the region are rotational and translational slides, complex, and a small number of them are of debris flows. There was no definite approach for dividing landslide points. According to the literature (Choi et al. 2012; Juliev et al. 2019), 70% of the identified landslides (185 landslide pixels) were applied for training phase, while the remaining 30% (79 landslide pixels) were used for validation.
3.2 Preparation of factor maps
Selection of effectual factors as input variables is considered an important step in spatial modeling of landslides for evaluating the potential of susceptible areas (Trigila et al. 2015). According to the regional properties and available data, a total of 12 conditioning factors including slope, aspect, altitude, distance to faults, distance to rivers, distance to roads, land use, lithology, rainfall, plan curvature, profile curvature and TWI were selected. These factors were obtained from different resources and used for calculating the landslide susceptibility index after digitalization (spatial resolution 30 m) (Table 1). All preparation stages and display of data layers were carried out using ArcGIS 10.5.
Slope gradient is considered the main slope stability parameter due to its direct relationship with landslides (Pourghasemi et al. 2012b). Therefore, it is considered one of the factors affecting landslides (Fig. 2a). Due to the effect of rainfall and solar radiation on different directions of slopes, slope direction has always been considered as an important factor in the literature (Basharat et al. 2016). For spatial modeling of landslides, this factor was classified into flat, north, northeast, east, southeast, south, southwest, west and northwest classes (Fig. 2b). Altitude is another important conditioning factor in assessing because of its significant impact on soil properties (Gomez and Kavzoglu 2005). This factor, also known as DEM, was categorized into eight classes (Fig. 2c). Water diffusion into the porosities of slope-forming materials causes water pressure to the pores leading to reduced strength of the soil. Increased moisture leads to slope instability and landslide risk. In addition to flow accumulation, TWI shows the trend of the water flow to go downslope (Tehrany et al. 2015) (Fig. 2d).



Produced causative factors of the study: a slope, b aspect, c altitude, d TWI, e plan curvature, f profile curvature, g rainfall, h distance to rivers, i distance to roads, j distance to faults, k land use and l lithology
Plan curvature is defined as the curvature of stereometric created by the cross section of horizontal plane and the surface (Pradhan and Sameen 2017) (Fig. 2e). Profile curvature represents the curvature of the ground surface along the gradual slope relative to the vertical level of flow. This parameter controls the water velocity and erosion rate (Sujatha et al. 2013) (Fig. 2f).
Saturation degree is increased with an increase in the mean precipitation rate causing a decrease in the shear strength of slopes and increased mass movements. Therefore, rainfall intensity affects slope fractures and landslide occurrence (Su et al. 2015) (Fig. 2g). Surface runoffs adversely affect slope stability by eroding toe slope or saturating materials forming the slopes (Conforti et al. 2014). Distance to river was categorized into eight classes with a distance of 100 m using the Euclidean distance method (Fig. 2h). Road construction in mountainous areas negatively affects slope stability, and it is thus known as a destructive human activity in the literature (Regmi et al. 2014; Althuwaynee et al. 2016). The distance to roads was also classified into 8 classes with a distance of 200 m using the Euclidean distance method (Fig. 2i). The movement of tectonic plates also causes failure of unstable slopes.
Faults are known as the main stimulating factor, especially in earthquake-prone regions. Distance to active faults in the region was also placed in 8 classes with a distance of 500 m by the Euclidean distance method (Fig. 2j). The land use map is considered a key factor in the study of landslides (Persichillo et al. 2017). Land use was categorized into 12 classes (Fig. 2k). Given the role of different lithological units in landslide susceptibility, it has always been received much attention by scholars (Rozos et al. 2011) (Fig. 2l). Tables 2 and 3 show the details on the classification of conditioning factors (Fig. 3).

Flowchart of the study showing all steps to produce landslide susceptibility maps
4 Methodology
4.1 Stepwise weight assessment ratio analysis (SWARA)
Stepwise weight assessment ratio analysis (SWARA), introduced by Keršulienė and Turskis (2011), is a multi-criteria decision-making method (MCDM) aimed at ranking and calculating weights of criteria and sub-criteria. Similar to other MCDM methods, experts’ views play a key role in evaluating and calculating weights in SWARA so that each expert is able to rank criteria based on personal knowledge, information and experience and assign a weight to each criterion based on its significance (Hashemkhani Zolfani and Bahrami 2014). The main feature of this method was its ability in evaluating experts’ views on the relative significance of criteria to determine their weights (Keršulienė and Turskis 2011). The method for calculating the final weight of criteria is discussed below:
-
1.
The first step is to identify criteria and sub-criteria.
-
2.
Here, experts are provided with final criteria to rank them based on their relative significance. Accordingly, the top rank is assigned to the most significant criterion placed in the first row. The bottom rank is assigned to the less significant criterion in the last row.
-
3.
After determining the relative significance of each criterion (Sj) relative to previous criteria, the normalized weight of criteria is calculated from the following equations:
$$S_{j} = \frac{{\mathop \sum \nolimits_{i}^{n} A_{i} }}{n}$$(1)where j is the criteria index, n is the number of experts and Ai is the ranks suggested for each criterion. Kj is a function of relative significance of each criterion, and the initial weight, Qj, is determined from the following equations:
$$K_{j} = \left\{ {\begin{array}{*{20}l} 1 \hfill & {j = 1} \hfill \\ {S_{j} + 1} \hfill & {j > 1} \hfill \\ \end{array} } \right.$$(2)$$Q_{j} = \frac{{S_{j} - 1}}{{K_{j} }}$$(3)
The final normalized weight is obtained from Eq. 4:
where j and m are, respectively, the criterion index and the total number of criteria (Keršulienė and Turskis 2011).
Figure 4 (Keršulienė and Turskis 2011) shows the procedure detail of SWARA model.

Diagram of the process the SWARA model
4.2 Certainty factor (CF)
The certainty factor (CF) model was first proposed by Buchanan and Shortliffe (1984) as a function to deal with problems arising from a combination of various data layers and unreliability of input data (Devkota et al. 2013). The model was originally designed for medical diagnostic systems, but then was modified by Heckerman (1985). This model is in the category of bivariate probabilistic methods, which has been extensively used in different fields, including landslide studies (Fan et al. 2017; Chen et al. 2019a). To calculate the certainty factor, the inventory map was intersected with the maps for conditioning factors to determine the number of landslides that occurred in each class of conditioning factors. According to the following equation:
where PPa is the ratio of landslide pixels in a class to the number of all classes (the conditional likelihood of landslides occurring in the class a) and PPs is all landslide pixels ratios to all pixels in the region (is the prior probability of all landslides occurred). Larger positive values indicate higher certainty and thus an increase in the probability of landslides. In contrast, negative values indicate a lower certainty and thereby a lower probability of landslides. One cannot comment on the certainty of landslides for values close to zero (Devkota et al. 2013; Fan et al. 2017).
4.3 Combined adaptive neuro-fuzzy inference system (ANFIS)
Introduced in 1993, the ANFIS method is a combination of artificial neural network (ANN) and fuzzy, in order to solve complicated nonlinear problems. The ANFIS structure is composed of the conventional components of the fuzzy system, except computations, because this part is run by hidden neurons of the layer. In addition, the training capacity of the neural network is used to increase the knowledge of the system. The Sugeno and Mamdani are two common fuzzy systems which are based on Takagi–Sugeno–Kang method and Lotfi Zade’s paper, respectively. These systems work without any limitation on the black box and can also be provided in an uncertainty environment. The Takagi and Sugeno system is based on two if–then rules, which are as follows:
where x (\(A_{1} ,A_{2}\)) and y \((B_{1} ,B_{2} )\) are inputs, A1, B1 and B2 are fuzzy sets determined during the training process and pij, qij and rij (i, j = 1, 2) are parameters obtained in the training phase (Zhang et al. 2010).
Layer 1 In the first layer, the values of input variables are fuzzified, so that each node i is defined as an adaptive node with a node function. They are responsible for producing membership grades of the inputs (Oh and Pradhan 2011). The following equations are used to obtain the output of this layer:
where … and … are inputs for the node i, \(A_{i}\) and \(B_{i}\) indicate the associated linguistic labels and \(\mu_{{A_{i} }} \left( x \right)\) and \(\mu_{{B_{i} }} \left( y \right)\) are the membership functions from different forms including triangular, trapezoidal, Gaussian functions, generalized bell or other functions.
Layer 2 Here, all nodes are fixed, and they are denoted by Π to show that they play a role of a simple multiplier.
In this layer, the output of each node (\(\omega_{i}\)) represents the firing strength of a rule, which is expressed by the following equation:
Layer 3 In this section, every node is also a fixed node which is presented as N. The ith node calculates the ratio of the ith rule’s firing strength to the sum of all rules’ firing strengths, which also called normalized firing strength, and the outputs are given by the following equation (Zhang et al. 2010):
Layer 4 In this layer, an output is specified for each rule. Every node is an adaptive node, and the output of each node is simply the product of the normalized firing. The following equation can be used to obtain the outputs of this layer:
where \(\bar{\omega }_{i}\) is the output of the third layer and \((p_{i} ,q_{i} \,{\text{and}}\,r_{i} )\) are consequent parameters.
Layer 5 In this layer, the single node is considered a fixed node which is labeled as Σ. The fixed nodes calculate the entire output as the sum of all incoming signals. It can be described by the following equation:
The ultimate results for ANFIS are given by the above equation.
4.4 Gray wolf optimizer (GWO)
Gray wolf optimizer (Mirjalili et al. 2014) is a nature-inspired meta-heuristic algorithm based on two principles in the life of gray wolves, namely social hierarchy and hunting strategy. This is a population-based algorithm (number of wolves) and thus considered as a swarm intelligence (SI) algorithm.
There is no SI technique available in the literature that mimics the leadership hierarchy of gray wolves, which are well known for their pack hunting (Mirjalili et al. 2014).
Different steps of GWO algorithm are discussed below:
4.4.1 Social hierarchy
Social hierarchy is determined at this stage. To this end, gray wolf population is generated randomly. The generated population in each pack is modeled as a pyramid consisting of four groups of alpha, beta, delta and omega wolves. Alpha is the best solution while beta and delta are the second and third, respectively. In the GWO algorithm, hunting is carried out with the help of alpha, beta and delta wolves while omega wolves follow these three types to explore the best solution.
4.4.2 Encircling prey
The following relations show the encircling process of the gray wolves around the prey:
where t is the current iteration; A and C are coefficient vectors, \(\vec{X}_{P}\) is the prey position vector and X is the gray wolf position vector. The coefficient vectors (A, C) are evaluated as follows:
where r1 and r2 are random vectors ranging from 0 to 1. \(\vec{a}\) is linearly reduced from 2 to 0 through the iterations.
4.4.3 Hunting process
The hunting process is directed by alpha wolves. However, there is no idea on optimal position because hunting positions are constantly changing in the algorithm. Therefore, it is presumed that alpha, beta and delta wolves are aware of the best prey positions. The prey position of alpha (best candidate solution), beta and delta wolves is stored as the best solutions. Then, the remaining solutions (omega) are updated based on the position of the best exploration factors.
Using the following equations, the mathematical description of α, β and δ wolves tracking orientation of preys could be realized (Mirjalili et al. 2014):
4.4.4 Attacking prey (exploitation)
When the prey stops, gray wolves attack it and hunting process is terminated. Mathematically, the process is associated with a reduction in \(\vec{a}\) leading to a reduction in the range of \(\vec{A}\) fluctuations. \(\vec{A}\) is a random value in the range of [− 2a, 2a] where \(\vec{a}\) is decreased from 2 to 0 through several iterations. Moreover, the wolves are required to attack the prey when \(\left| A \right| < 1\) (Mirjalili et al. 2014).
4.4.5 Searching for prey
In this situation, prey searching (discovery) is evaluated according to the positions of alpha, beta and delta wolves. Gray wolves are separated for finding a prey and then approach each other for hunting.
The exploration capability is incorporated in the GWO algorithm when \(\vec{A}\) values lie outside the − 1 to 1 range.
When \(\left| A \right| > 1\), wolves should be separated for searching the prey. C is another exploratory component in GWO algorithm containing random values ranging from 0 to 2. This component gives random weights for emphasizing (C > 1) or not emphasizing (C < 1) the effect of prey in interval definition (Eq. 14). This helps the GWO algorithm to avoid the local optimum point (the algorithm gets rid of trapping in a local optimum point). It should be noted that unlike A, C does not decrease linearly. After the above steps, the algorithm is terminated by meeting a final criterion (Mirjalili et al. 2014). For more details on the gray wolf optimizer, the reader may refer to the original paper http://www.alimirjalili.com/GWO.html.
4.5 Particle swarm optimization (PSO) algorithm
For the first time in 1995, Eberhart and Kennedy introduced particle swarm optimization (PSO) algorithm. It is a population-based evolutionary algorithm inspired by the social behavior of bird flocks. This algorithm has been used as a powerful tool for solving nonlinear random optimization problems.
In PSO, a group of particles (optimization variables) are randomly distributed in the search space. Each particle in this space is defined by two main features, namely position and velocity. Each particle selects a movement direction considering its current position and the best position experienced by tracking information on one or multiple particles among the particles. A step of the algorithm is terminated after the movement of the particles. This process is repeated until the best location visited by all particles is presented as the solution. Given the impact of position of other particles on searching for a particle, PSO is also known as a swarm intelligence (SI) algorithm. A d-dimensional search space is assumed for a mathematical description of the above-mentioned process. The position (Xi) and velocity (Vi) vectors for the ith particle in the search space are defined as follows (Eberhart and Kennedy 1995):
The algorithm updates both the position and velocity of each particle in the iteration t + 1 according to the following equations (Eberhart and Kennedy 1995):
where t is the number of iterations, \(X_{i}^{t}\) and \(V_{i}^{t}\) are position and velocity of ith particle in the iteration t, \(P_{i}^{t}\) the best position of the ith particle, \(g_{i}^{t}\) the best position recorded among all particles and r1 and r2 are random weights generated in the range of 0–1. In addition, ω is the inertia coefficient, and C1 and C2 are cognitive and social coefficients, respectively. It is noteworthy that selecting appropriate inertia and acceleration coefficients may lead to a leveling between local and global searches (Assareh et al. 2010).
One of the first applications of PSO was a neural network (NN) training which was shown to be an efficient method for training neural networks.
5 Results and analysis
Tables 2 and 3 list the values obtained from SWARA implementation on criteria and sub-criteria. According to the results, the slope class 7.33°–14.59° presented the highest SWARA value of 0.319. The eastern and southern slope directions, respectively, showed the highest SWARA values of 0.463 and 0.244. Altitude class of 503–1189 m with a SWARA value of 0.372 indicated the highest landslide probability (SWARA weight decreases with increasing altitude). The TWI class of 8.56–22.38 showed the highest landslide probability (0.275). The flat and convex plan curvatures showed the lowest and highest SWARA values of 0.301 and 0.393, respectively. The lowest SWARA value was found for a convex profile curvature. The highest SWARA value (0.395) was found for flat profile curvature. The rainfall classes 435–586 and 954–1138, respectively, with a SWARA value of 0.296 and 0.156 showed the highest landslide probability. As shown in Table 2, the highest weights of 0.313, 0.418 and 0.356 were obtained for the distance to the stream (0–100), distance to the road (200–400) and distance to the fault (2000–2500), respectively. The highest SWARA value (0.277) was observed for the surface runoff class. The highest SWARA value (0.168) was found for pC-Ch lithology class (Table 2).
Tables 2 and 3 also show the results obtained from the CF model. A slope range of 7.33°–14.59° showed the highest CF value (0.444) indicating its high landslide potential. Similar to the results obtained from SWARA, the eastern and southern slope directions showed the highest CF values of 0.277 and 0.177, respectively. The altitude class 1574–1910 with a weight of 0.642 showed the highest landslide probability. The TWI class 8.56–22.38 showed the most significant correlation. As clearly shown in Table 2, the flat plan curvature and profile curvature showed the highest CF values of 0.197 and 0.252, respectively. The rainfall classes 435–586 and 956–1138 m with CF values of 0.937 and 0.928 showed the most significant correlation with landslide occurrence. The landslide probability decreased with increasing distance to the road. Accordingly, the 0–100 m and more than 700 m (> 700 m) classes showed the highest (0.733) and lowest CF values, respectively. In relation to distance to roads and fault, 0–400-m and 2000–2500-m classes showed the highest landslide probability. In the case of land use, surface runoff showed the highest probability of 0.892. According to the results on lithological units, the pC-Ch and MuPlai classes with CF values of 0.965 and 0.879 showed the most significant correlation with landslide probability (Table 2).
5.1 Application of ANFIS-GWO and ANFIS-PSO hybrid models
GWO and PSO intelligent algorithms were used in this study instead of classic functions for ANFIS training. The ANFIS-GWO and ANFIS-PSO hybrid models were implemented in MATLAB 2015.b. Training and validation data were required for implementing the algorithms. The algorithms were trained by training data, and accuracy was estimated by validation data. The SWARA and CF outputs were used to generate training and validation data. As mentioned earlier, 70% of 264 landslides were used for training and the rest (30%) for the validation of algorithms. In this regard, the same number of training data (185 points) was generated for non-landslide points. The points were generated in the landslide-free areas randomly. Thereafter, a value of 1 was allocated to 185 landslide and 0 was assigned to 185 non-landslide points, respectively. These points were then intersected with conditioning factors to obtain the value of each point. The values of points were used as input data in MATLAB for training the algorithms. The mean square error (MSE) and root mean square error (RMSE) were used for validating the training dataset (Figs. 5, 6a). MSE and RMSE are defined as follows:

Comparative results between ANFIS-GWO and ANFIS-PSO training and validation datasets used SWARA model (scenario 1): a MSE and RMSE value in the training phase; b frequency errors in the training phase; c MSE and RMSE value in the testing phase and d frequency errors in the testing phase

Comparative results between ANFIS-GWO and ANFIS-PSO training and validation datasets used CF model (scenario 2): a MSE and RMSE value in the training phase, b frequency errors in the training phase, c MSE and RMSE value in the testing phase and d frequency errors in the testing phase
Here, n is the total number of samples, \(X_{i}\) is the target values, and \(\bar{X}_{i}\) is the output values. RMSE is the square root of MSE.
Similar to the training data generation process, a similar number of non-landslide points (79 points) were randomly produced for the test dataset in the landslide-free areas. Value of 1 was assigned to 185 landslide and 0 was assigned to 185 non-landslide points. After intersecting these points with conditioning factors, the resulting values were used as the test dataset in MATLAB. To determine the most efficient model, the MSE of the test dataset should be evaluated. Figures 5c and 6c, respectively, show MSE and RMSE for the test dataset. According to the results, an MSE of 0.121 and 0.110 was obtained, respectively, for ANFIS-GWO and ANFIS-PSO hybrid models in the first scenario. The corresponding values in the second scenario were 0.107 and 0.081, respectively. It is worth mentioning that the MSE of the test dataset should be consistent with the validation results of final maps. In other words, a lower MSE (closer to zero) means a higher prediction rate (AUC) of the LSM. As shown in Table 4, ANFIS-PSO algorithm in the second scenario and ANFIS-GWO in the first scenario, respectively, with the lowest and highest MSE of 0.081 and 0.121 showed the highest and lowest accuracy among algorithms.
The final value for each pixel was calculated after entering final data into the algorithms. The resulting values were exported to ArcGIS for landslide susceptibility mapping (Figs. 7, 8). A variety of classification methods was tested for zoning the produced maps. However, the geometric interval outperformed other methods in this regard. Therefore, the maps produced by the geometric interval were classified into five classes: very low, low, moderate, high and very high.

Landslide susceptibility maps using ANFIS-GWO and ANFIS-PSO models in scenario 1

Landslide susceptibility maps using ANFIS-GWO and ANFIS-PSO models in scenario 2
5.2 Validation of the landslide susceptibility maps
Validation of models used in studies is a critical step in evaluating the ability of LSMs in predicting future events (Bui et al. 2012). As mentioned previously, 70% of identified landslides were considered for model training and 30% for validation. ROC curve was used in this study to validate the ANFIS-GWO and ANFIS-PSO hybrid models.
5.2.1 Receiver operating characteristics (ROC) curve
ROC represents the quality of the system, indicating probable and definite predictions (Assareh et al. 2010). The x and y axes of the ROC curve, respectively, show false positive and true positive rates. The area under the curve shows the quality of the predictive method by characterizing the ability to accurately forecast the frequency or failure of a pre-defined event (Devkota et al. 2013). Since AUC shows the accuracy of the method quantitatively, it is necessary to estimate this value to compare model’s performance. AUC ranges from 0.5 to 1 so that the values closer to 1 and 0.5, respectively, show the reasonable and weak performance of the model. A value 0.5 is a random guess for AUC (Dehnavi et al. 2015; Pourghasemi et al. 2012b).
Figure 9 shows the ROC curve for LSMs. According to the results, the second scenario outperforms the first one. In the first scenario, ANFIS-PSO with an AUC of 83% outperformed ANFIS-GWO with an AUC of 78.9%. In the second scenario, ANFIS-PSO with an AUC of 87.9% outperformed ANFIS-GWO with an AUA of 85%. It should be noted that a lower standard error means a larger area and thus a more accurate model (Table 5). Although AUC for all four models was greater than 0.75, ANFIS-PSO in the second scenario with an AUC of 87.9% and a standard error of 0.027 gives a more accurate landslide forecast in this research.

ROC curves for the landslide susceptibility maps: a scenario 1 and b scenario 2
6 Discussion
Landslide is a complicated phenomenon due to different factors controlling its occurrence. Thus, the use of novel analysis methods to create high precision mapping is considered a crucial step in this regard. In the current study, a new hybrid ANFIS approach was used to prepare LSM at Karun watershed, Iran. To achieve this, ANFIS was first combined with PSO and GWO algorithms and then trained by SWARA and CF models. Landslide susceptibility mapping was carried out by ANFIS_GWO and ANFIS-PSO hybrid models, and their performance was evaluated by ROC curve. In recent years, researchers have combined a variety of quantitative and qualitative models with machine learning and data mining algorithms. The study of these methods and their combinations and also the comparison of their results will provide more realistic modeling in order to produce landslide susceptibility map. The results obtained from methods in other studies are reviewed below.
SWARA multi-criteria decision-making method and the CF probability model have been applied in various studies. Dehnavi et al. (2015) prepared LSM for Iran using SWARA and ANFIS methods. To this end, SWARA and its combination with ANFIS were employed. According to their results, the SWARA-ANFIS hybrid model with an AUC of 0.8 gave better forecasts than SWARA with an AUC of 0.78. To indicate a correlation between landslides and conditioning factors CF, probability model has also been able to produce reasonable results. Arabameri et al. (2019) used a new approach by ensemble geographically weighted regression (GWR) method with the CF and RF models for gully erosion zonation mapping in the Mahabia watershed of Iran. After gully erosion zonation mapping, RF model showed distance to stream, distance to road and land use have higher influence on gully formation. In addition, validation results indicated the better performance of GWR-CF-RF new ensemble model with a prediction rate of 96.7% compared with CF, RF and the CF-RF models with an AUC of 76.3%, 77.6% and 89.7%, respectively. For spatial modeling of landslides in Ziyang district in China, Fan et al. (2017) used CF model and its combination with AHP and then compared with bivariate statistical index to evaluate landslide susceptibility. According to their results, CF-AHP and LSI models showed the highest and lowest prediction rate with an AUC of 78.3% and 69.2%, respectively.
Adaptive neuro-fuzzy inference system (ANFIS) is a combination of neural networks and fuzzy logic for implementation of neural network knowledge using fuzzy logic (Oh and Pradhan 2011). In order to evaluate flood susceptibility maps, Bui et al. (2016) used ANFIS and its combination with two meta-heuristic algorithms (PSO and EG) as a new approach which was named MONF and then compared with the J48DT, RF, MLP Neural Nets and SVM models. They concluded that although J48DT, RF, MLP neural nets and SVM models have high accuracy with an AUC of 89.5%, 89.4%, 90.3%, 90.5% and 76.7%, respectively, MONF model has better performance (AUC = 91.1%). Aghdam et al. (2017) used FR and WOE statistical methods and ANFIS machine learning to identify landslide susceptible areas in southern provinces of the Zagros Mountains. After landslide susceptibility mapping by FR and WOE models, they were combined with ANFIS to overcome drawbacks of bivariate statistical methods. Validation results indicated the better performance of FR-ANFIS and WOE-ANFIS hybrid models with a prediction rate of 0.85 and 0.84, respectively, compared with FR and WOE (AUC = 0.82).
The most important advantage of the population-based random PSO algorithm over other optimization algorithms is its ability to exchange information among members. Moayedi et al. (2018) used ANN and its combination with meta-heuristic PSO algorithm for landslide susceptibility mapping of Layle Village in Kermanshah Province. Analysis of test data showed a coefficient of determination and root mean square error of 0.9733 and 0.111, respectively. The corresponding values for PSO-ANN were 0.9899 and 0.0389, respectively. After landslide susceptibility mapping and model evaluation by color intensity rating (CER), they found that PSO-ANN provides a more realistic evaluation of landslide probability than ANN. Also, in our study, PSO algorithm showed better results in combination with ANFIS. Termeh et al. (2018) combined ANFIS with ACO, GA and PSO algorithms for zoning flood risk in Jahrom, Fars Province. Pursuant to their result, the prediction accuracy of ANFIS-ACO, ANFIS-GA and ANFIS-PSO was 91.8%, 92.6% and 94.5%, respectively. A prediction accuracy of 91.4% was obtained for FR. Based on their results, ANFIS-PSO evaluated flood risk in the region more accurately. To similar with Termeh et al. (2018), our results indicated that ANFIS-PSO has slightly better performance in comparison with ANFIS-GWO hybrid model in both scenarios.
As mentioned earlier, gray wolf optimizer is a nature-inspired meta-heuristic algorithm based on social hierarchy and behavior of wolves during hunting process (Mirjalili et al. 2014). This new algorithm has provided reasonable results in the literature (Termeh et al. 2018; Yu and Lu 2018). Jaafari et al. (2019) used novel ANFIS-BBO and ANFIS-GWO data mining techniques for landslide susceptibility mapping. According to their results, ANFIS-GWO and ANFIS-BBO with a predication rate of 0.945 and 0.95, respectively, can be used as reliable methods in other studies.
According to the literature, soft computing methods such as machine learning and intelligent algorithms estimate the relationship between data more accurately. Although the use of machine learning methods such as ANN and ANFIS provides better results compared to the statistical and qualitative models, their combination with meta-heuristic algorithms results in more efficient outputs because these methods reduce their drawbacks. This is because meta-heuristic algorithms better train the learning networks through reducing the local minimum effect. The outputs obtained in this study as well as their comparison with the results of the previous studies confirm this statement. Based on the obtained values, all four models used \(\left( {{\text{ANFIS - PSO}}\,{\text{and}}\,{\text{ANFIS - GWO}}} \right)_{\text{SWARA }}\), \(\left( {{\text{ANFIS - PSO}}\,{\text{and}}\,{\text{ANFIS - GWO}}} \right)_{{\text{CF}}}\) with the accuracy more than 75% have acceptable performance in predicting a nonlinear problem. \({\text{ANFIS - PSO}}_{{\text{CF}}}\) model with an area under the curve of 87.9% and the MSE value of 0.081 and the \({\text{ANFIS - GWO}}_{{\text{CF}}}\) model with an area under the curve of 85% and the MSE value of 0.107 showed the best performance, respectively. Comparison of GWO and PSO algorithms showed that PSO outperformed GWO in both scenarios in terms of optimization and data convergence. Moreover, the results obtained from SWARA and CF models indicated the key role of the type of method used for evaluating the correlation between landslides and conditioning factors leading to performance improvement in data mining techniques because the quantitative CF model performed better than the qualitative SWARA model. Regardless of the type of method, type of combination also plays a key role in enhancing the precision of LSMs.
7 Conclusion
Failure of unstable slopes in mountainous regions is associated with destructive social and environmental consequences besides casualties and economic losses. Hence, identification of landslide susceptible areas has become an essential tool for regional authorities and policymakers (Jaafari et al. 2019). In this study, a novel comparison between two data mining techniques was used for landslide susceptibility mapping. Qualitative SWARA and quantitative CF models were first used to determine the relationship between factors (such as slope, aspect, altitude, TWI, plan curvature, profile curvature, rainfall, distance to rivers, distance to roads, distance to faults, land use and lithology) and identified landslides. For effective training, ANFIS was combined with GWO and PSO intelligent algorithms. As a result, ANFIS-GWO and ANFIS-PSO hybrid models were separately generated using SWARA and CF outputs. Finally, LSMs were generated and then assessed by the ROC curve.
Given the AUC values, the hybrid models trained by the CF probability model (\({\text{ANFIS - GWO}}_{{\text{AUC}}} = {\text{\% }}85\,{\text{and}}\,{\text{ANFIS - PSO}}_{{\text{AUC}}} = {\text{\% }}87.9\)) gave better estimates than those generated by the SWARA multi-criteria model (\({\text{ANFIS - GWO}}_{{\text{AUC}}} = \% 78.9\,{\text{and}}\,{\text{ANFIS - PSO}}_{{\text{AUC}}} = \% 83.8\)). According to the results, the PSO algorithm outperformed GWO algorithm in terms of calculating the final value of pixels in both scenarios. In addition, in comparison with SWARA, CF probability model has better performance to evaluate relationship between landslides and conditioning factors. In general, the use of data mining techniques allows more effective understanding of latent data patterns, leading to more realistic outputs. It should be noted that the use of data mining techniques does not necessarily guarantee reaching an optimal solution. As shown in the current study, the type of method used to illustrate the correlation between effective factors and landslides is important. The models used in this study are recommended for evaluating risk of landslides in other susceptible areas to help regional authorities and policymakers.
References
Aghdam IN, Pradhan B, Panahi M (2017) Landslide susceptibility assessment using a novel hybrid model of statistical bivariate methods (FR and WOE) and adaptive neuro-fuzzy inference system (ANFIS) at southern Zagros Mountains in Iran. Environ Earth Sci 76:237
Althuwaynee OF, Pradhan B, Park HJ, Lee JH (2014) A novel ensemble bivariate statistical evidential belief function with knowledge-based analytical hierarchy process and multivariate statistical logistic regression for landslide susceptibility mapping. CATENA 114:21–36
Althuwaynee OF, Pradhan B, Lee S (2016) A novel integrated model for assessing landslide susceptibility mapping using CHAID and AHP pair-wise comparison. Int J Remote Sens 37:1190–1209
Arabameri A, Pradhan B, Rezaei K (2019) Gully erosion zonation mapping using integrated geographically weighted regression with certainty factor and random forest models in GIS. J Environ Manage 232:928–942
Assareh E, Behrang MA, Assari MR, Ghanbarzadeh A (2010) Application of PSO (particle swarm optimization) and GA (genetic algorithm) techniques on demand estimation of oil in Iran. Energy 35:5223–5229
Baena JAP, Scifoni S, Marsella M, De Astis G, Fernández CI (2019) Landslide susceptibility mapping on the islands of Vulcano and Lipari (Aeolian Archipelago, Italy), using a multi-classification approach on conditioning factors and a modified GIS matrix method for areas lacking in a landslide inventory. Landslides 16:969–982
Basharat M, Shah HR, Hameed N (2016) Landslide susceptibility mapping using GIS and weighted overlay method: a case study from NW Himalayas, Pakistan. Arab J Geosci 9:292
Buchanan BG, Shortliffe EH (1984) Rule based expert systems: The MYCIN experiments of the Stanford heuristic programming project. Addison-Wesley, Reading
Bui DT, Pradhan B, Lofman O, Revhaug I, Dick OB (2012) Landslide susceptibility assessment in the Hoa Binh province of Vietnam: a comparison of the Levenberg–Marquardt and Bayesian regularized neural networks. Geomorphology 171:12–29
Bui DT, Pradhan B, Nampak H, Bui QT, Tran QA, Nguyen QP (2016) Hybrid artificial intelligence approach based on neural fuzzy inference model and metaheuristic optimization for flood susceptibility modeling in a high-frequency tropical cyclone area using GIS. J Hydrol 540:317–330
Can A, Dagdelenler G, Ercanoglu M, Sonmez H (2019) Landslide susceptibility mapping at Ovacık-Karabük (Turkey) using different artificial neural network models: comparison of training algorithms. B Eng Geol Environ 78:89–102
Chen Z, Liang S, Ke Y, Yang Z, Zhao H (2019a) Landslide susceptibility assessment using evidential belief function, certainty factor and frequency ratio model at Baxie River basin, NW China. Geocarto Int 34:348–367
Chen W, Panahi M, Tsangaratos P, Shahabi H, Ilia I, Panahi S, Li S, Jaafari A, Ahmad BB (2019b) Applying population-based evolutionary algorithms and a neuro-fuzzy system for modeling landslide susceptibility. CATENA 172:212–231
Choi J, Oh HJ, Lee HJ, Lee C, Lee S (2012) Combining landslide susceptibility maps obtained from frequency ratio, logistic regression, and artificial neural network models using ASTER images and GIS. Eng Geol 124:12–23
Ciurleo M, Cascini L, Calvello M (2017) A comparison of statistical and deterministic methods for shallow landslide susceptibility zoning in clayey soils. Eng Geol 223:71–81
Conforti M, Pascale S, Robustelli G, Sdao F (2014) Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment (northern Calabria, Italy). CATENA 113:236–250
Dehnavi A, Aghdam IN, Pradhan B, Varzandeh MHM (2015) A new hybrid model using step-wise weight assessment ratio analysis (SWARA) technique and adaptive neuro-fuzzy inference system (ANFIS) for regional landslide hazard assessment in Iran. CATENA 135:122–148
Devkota KC, Regmi AD, Pourghasemi HR, Yoshida K, Pradhan B, Ryu IC, Dhital MR, Althuwaynee OF (2013) Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in GIS and their comparison at Mugling-Narayanghat road section in Nepal Himalaya. Nat Hazards 65:135–165
Đurić U, Marjanović M, Radić Z, Abolmasov B (2019) Machine learning based landslide assessment of the Belgrade metropolitan area: pixel resolution effects and a cross-scaling concept. Eng Geol 256:23–38
Eberhart R, Kennedy J (1995) A new optimizer using particle swarm theory. In: Proceedings of the sixth international symposium on micro machine and human science IEEE, MHS’95, pp 39–43
Erener A, Mutlu A, Düzgün HS (2016) A comparative study for landslide susceptibility mapping using GIS-based multi-criteria decision analysis (MCDA), logistic regression (LR) and association rule mining (ARM). Eng Geol 203:45–55
Fan W, Wei XS, Cao YB, Zheng B (2017) Landslide susceptibility assessment using the certainty factor and analytic hierarchy process. J Mt Sci 14:906–925
Feizizadeh B, Roodposhti MS, Jankowski P, Blaschke T (2014) A GIS-based extended fuzzy multi-criteria evaluation for landslide susceptibility mapping. Comput Geosci 73:208–221
Goetz JN, Guthrie RH, Brenning A (2011) Integrating physical and empirical landslide susceptibility models using generalized additive models. Geomorphology 129:376–386
Gomez H, Kavzoglu T (2005) Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng Geol 78:11–27
Harmouzi H, Nefeslioglu HA, Rouai M, Sezer EA, Dekayir A, Gokceoglu C (2019) Landslide susceptibility mapping of the Mediterranean coastal zone of Morocco between Oued Laou and El Jebha using artificial neural networks (ANN). Arab J Geosci 12:696
Hashemkhani Zolfani S, Bahrami M (2014) Investment prioritizing in high tech industries based on SWARA-COPRAS approach. Technol Econ Dev Econ 20:534–553
Heckerman D (1985) A probabilistic interpretation for MYCIN's certainty factors. In: Proceedings of AAAI Workshop on Uncertainty and Probability in AI, Los Angeles, CA, pp. 9–20
Jaafari A, Panahi M, Pham BT, Shahabi H, Bui DT, Rezaie F, Lee S (2019) Meta optimization of an adaptive neuro-fuzzy inference system with grey wolf optimizer and biogeography-based optimization algorithms for spatial prediction of landslide susceptibility. CATENA 175:430–445
Juliev M, Mergili M, Mondal I, Nurtaev B, Pulatov A, Hübl J (2019) Comparative analysis of statistical methods for landslide susceptibility mapping in the Bostanlik District, Uzbekistan. Sci Total Environ 653:801–814
Kadavi PR, Lee CW, Lee S (2018) Application of ensemble-based machine learning models to landslide susceptibility mapping. Remote Sens 10:1252
Kavzoglu T, Sahin EK, Colkesen I (2015) Selecting optimal conditioning factors in shallow translational landslide susceptibility mapping using genetic algorithm. Eng Geol 192:101–112
Keršulienė V, Turskis Z (2011) Integrated fuzzy multiple criteria decision making model for architect selection. Technol Econ Dev Econ 17:645–666
Kjekstad O, Highland L (2009) Economic and social impacts of landslides. In: Sassa K, Canuti P (eds) Landslides–disaster risk reduction. Springer, Berlin, pp 573–587
Lee S, Hwang J, Park I (2013) Application of data-driven evidential belief functions to landslide susceptibility mapping in Jinbu, Korea. CATENA 100:15–30
Lin L, Lin Q (2017) Landslide susceptibility mapping on a global scale using the method of logistic regression. Nat Hazard Earth Syst 17(8):1411–1424
Lorentz JF, Calijuri ML, Marques EG, Baptista AC (2016) Multicriteria analysis applied to landslide susceptibility mapping. Nat Hazards 83:41–52
Mehrabi M, Pradhan B, Moayedi H, Alamri A (2020) Optimizing an adaptive neuro-fuzzy inference system for spatial prediction of landslide susceptibility using four state-of-the-art metaheuristic techniques. Sensors 20:1723
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61
Moayedi H, Mehrabi M, Mosallanezhad M, Rashid ASA, Pradhan B (2018) Modification of landslide susceptibility mapping using optimized PSO-ANN technique. Eng Comput 35:967–984
Mohammady M, Pourghasemi HR, Pradhan B (2012) Landslide susceptibility mapping at Golestan Province, Iran: a comparison between frequency ratio, Dempster-Shafer, and weights-of-evidence models. J Asian Earth Sci 61:221–236
Nadim F, Kjekstad O, Peduzzi P, Herold C, Jaedicke C (2006) Global landslide and avalanche hotspots. Landslides 3:159–173
Nicu IC (2018) Application of analytic hierarchy process, frequency ratio, and statistical index to landslide susceptibility: an approach to endangered cultural heritage. Environ Earth Sci 77:79
Oh HJ, Pradhan B (2011) Application of a neuro-fuzzy model to landslide-susceptibility mapping for shallow landslides in a tropical hilly area. Comput Geosci 37:1264–1276
Ozioko OH, Igwe O (2020) GIS-based landslide susceptibility mapping using heuristic and bivariate statistical methods for Iva Valley and environs Southeast Nigeria. Environ Monit Assess 192:1–19
Persichillo MG, Bordoni M, Meisina C (2017) The role of land use changes in the distribution of shallow landslides. Sci Total Environ 574:924–937
Pourghasemi HR, Mohammady M, Pradhan B (2012a) Landslide susceptibility mapping using index of entropy and conditional probability models in GIS: safarood Basin, Iran. CATENA 97:71–84
Pourghasemi HR, Pradhan B, Gokceoglu C (2012b) Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat Hazards 63:965–996
Pradhan B (2013) A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput Geosci 51:350–365
Pradhan B, Lee S (2010) Delineation of landslide hazard areas using frequency ratio, logistic regression and artificial neural network model at Penang Island, Malaysia. Environ Earth Sci 60:1037–1054
Pradhan B, Sameen MI (2017) Landslide susceptibility modeling: optimization and factor effect analysis. In: Pradhan B (ed) Laser scanning applications in landslide assessment. Springer, Berlin, pp 115–132
Raja NB, Çiçek I, Türkoğlu N, Aydin O, Kawasaki A (2017) Landslide susceptibility mapping of the Sera River Basin using logistic regression model. Nat Hazards 85:1323–1346
Regmi AD, Devkota KC, Yoshida K, Pradhan B, Pourghasemi HR, Kumamoto T (2014) Akgun A (2014) Application of frequency ratio, statistical index, and weights-of-evidence models and their comparison in landslide susceptibility mapping in Central Nepal Himalaya. Arab J Geosci 7:725–742
Rozos D, Bathrellos GD, Skillodimou HD (2011) Comparison of the implementation of rock engineering system and analytic hierarchy process methods, upon landslide susceptibility mapping, using GIS: a case study from the Eastern Achaia County of Peloponnesus, Greece. Environ Earth Sci 63:49–63
Sameen MI, Sarkar R, Pradhan B, Drukpa D, Alamri AM, Park HJ (2020) Landslide spatial modelling using unsupervised factor optimisation and regularised greedy forests. Comput Geosci 134:104336
Schlögel R, Doubre C, Malet JP, Masson F (2015) Landslide deformation monitoring with ALOS/PALSAR imagery: a D-InSAR geomorphological interpretation method. Geomorphology 231:314–330
Su C, Wang L, Wang X, Huang Z, Zhang X (2015) Mapping of rainfall-induced landslide susceptibility in Wencheng, China, using support vector machine. Nat Hazards 76:1759–1779
Sujatha ER, Rajamanickam V, Kumaravel P, Saranathan E (2013) Landslide susceptibility analysis using probabilistic likelihood ratio model—a geospatial-based study. Arab J Geosci 6:429–440
Tehrany MS, Pradhan B, Mansor S, Ahmad N (2015) Flood susceptibility assessment using GIS-based support vector machine model with different kernel types. CATENA 125:91–101
Termeh SVR, Kornejady A, Pourghasemi HR, Keesstra S (2018) Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci Total Environ 615:438–451
Trigila A, Iadanza C, Esposito C, Scarascia-Mugnozza G (2015) Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 249:119–136
Xi W, Li G, Moayedi H, Nguyen H (2019) A particle-based optimization of artificial neural network for earthquake-induced landslide assessment in Ludian county, China. Geomat Nat Haz Risk 10:1750–1771
Yan F, Zhang Q, Ye S, Ren B (2019) A novel hybrid approach for landslide susceptibility mapping integrating analytical hierarchy process and normalized frequency ratio methods with the cloud model. Geomorphology 327:170–187
Youssef AM, Pradhan B, Pourghasemi HR, Abdullahi S (2015a) Landslide susceptibility assessment at Wadi Jawrah Basin, Jizan region, Saudi Arabia using two bivariate models in GIS. Geosci J 19:449–469
Youssef AM, Pradhan B, Jebur MN, El-Harbi HM (2015b) Landslide susceptibility mapping using ensemble bivariate and multivariate statistical models in Fayfa area, Saudi Arabia. Environ Earth Sci 73:3745–3761
Yu S, Lu H (2018) An integrated model of water resources optimization allocation based on projection pursuit model–Grey wolf optimization method in a transboundary river basin. J Hydrol 559:156–165
Zhang L, Xiong G, Liu H, Zou H, Guo W (2010) Bearing fault diagnosis using multi-scale entropy and adaptive neuro-fuzzy inference. Expert Syst Appl 37:6077–6085
Zhao Y, Wang R, Jiang Y, Liu H, Wei Z (2019) GIS-based logistic regression for rainfall-induced landslide susceptibility mapping under different grid sizes in Yueqing. Southeastern China, Eng Geol, p 105147
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Paryani, S., Neshat, A., Javadi, S. et al. Comparative performance of new hybrid ANFIS models in landslide susceptibility mapping. Nat Hazards 103, 1961–1988 (2020). https://doi.org/10.1007/s11069-020-04067-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-020-04067-9