
Abstract
Landslide is a type of slope process causing a plethora of economic damage and loss of lives worldwide every year. This study aimed to analyze spatial landslide susceptibility mapping in the Khalkhal-Tarom Basin by integrating an adaptive neuro-fuzzy inference system (ANFIS) with two multi-criteria decision-making approaches, i.e., the best-worst method (BWM) and the stepwise weight assessment ratio analysis (SWARA) techniques. For this purpose, the first step was to prepare a landslide inventory map, which was then divided randomly into the ratio of 70/30% for model training and validation. Thirteen conditioning factors were selected based on the previous studies and available data. In the next step, the BWM and the SWARA methods were utilized to determine the relationships between the sub-criteria and landslides. Finally, landslide susceptibility maps were generated by implementing ANFIS-BWM and ANFIS-SWARA ensemble models, and then several quantitative indices such as positive predictive value, negative predictive value, sensitivity, specificity, accuracy, root-mean-square-error, and the ROC curve were employed to appraise the predictive accuracy of each model. The results indicated that the ANFIS-BWM ensemble model (AUC = 75%, RMSE = 0.443) has better performance than ANFIS-SWARA (AUC = 73.6%, RMSE = 0.477). At the same time, the ANFIS-BWM model had the maximum sensitivity, specificity, and accuracy with values of 87.1%, 54.3%, and 40.7%, respectively. As a result, the BWM method was more efficient in training the ANFIS. Evidently, the generated landslide susceptibility maps (LSMs) can be very efficient in managing land use and preventing the damage caused by the landslide phenomenon.
Graphical abstract

Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Causing great losses of lives and properties, landslides are dangerous processes that occur repeatedly in mountainous and hilly areas worldwide (Juliev et al. 2019; Gutiérrez et al. 2015). This mass movement occurs whenever the loading of an earth material exceeds its shear strength (Lin et al. 2017 (Ilia and Tsangaratos 2016)). Although this geological phenomenon is often triggered by earthquakes and heavy rainfalls, the expansion of anthropogenic activities in susceptible areas has always played an important factor in its occurrence (Baena et al. 2019). In recent years, the damage caused by landslides will increase due to climate change and urban development (Vakhshoori and Zare 2016). Therefore, it is essential to acquire accurate and realistic information about the spatial distribution and degrees of susceptibility to landslide-prone regions (Colkesen et al. 2016). To achieve this goal and to mitigate the destructive impacts of this phenomenon, landslide susceptibility maps can serve as an appropriate tool for increasing awareness and predicting future hazards (Feizizadeh et al. 2017). Based on previous landslides and identical physical features in similar areas, a landslide susceptibility map provides important signs regarding the locations where future landslides are likely to occur (Pradhan et al. 2017).
The Alborz Mountain has always been subjected to natural disasters such as landslides due to its being on the seismic belt of the Himalayas (Farrokhnia et al. 2011). In a study identifying high-risk regions of the world with respect to landslide hazard, Nadim et al. (2006) reported that the Alborz and Zagros Mountains of Iran were among the areas with moderate to high landslide risks. In addition, according to the National Committee on Natural Disaster Reduction of the Iranian Ministry of Interior, the annual damage caused by landslides in Iran amounts to about 500 billion Rials (Arabameri et al. 2019). Consequently, if the loss of human life is taken into account, it is evident that zoning of the study area is necessary.
In recent years, researchers have used different methods and their combinations to zone the areas susceptible to landslide in different areas worldwide that can generally classify into two quantitative and qualitative groups (Sahin 2020). The qualitative approaches, also known as knowledge-driven approaches, are the techniques of assigning weights to and rank criteria and sub-criteria based on experts’ knowledge (Achour et al. 2017). Some of these methods, which have been used in various studies and have yielded acceptable results, include the analytic hierarchy process (AHP) (Yan et al. 2019; Du et al. 2019; Bahrami et al. 2020) and hybrid methods such as MCDA and MCE (Erener et al. 2016; Kumar et al. 2017; Wang et al. 2019) and the WLC (Ahmed 2015; Gigović et al. 2019). The second group, also known as data-driven approaches, consists of techniques which are not influenced by experts’ opinions in the computational process (Kavzoglu et al. 2015). Instead, the relationship between the landslides and the effective parameters is determined by using numerical data and statistical equations (Yan et al. 2019). These methods, which have been used repeatedly in various studies on landslides, include bivariate and multivariate probability models such as frequency ratio (FR) (Hong et al. 2017; Sharma and Mahajan 2019; Berhane et al. 2020), weight of evidence (WoE) (Ding et al. 2017; Cui et al. 2017; Sifa et al. 2020), and logistic regression (LR) (Oh et al. 2018; Kalantar et al. 2018; Sun et al. 2021) as well as soft computing methods such as artificial neural network (ANN) (Bui et al. 2016; Zhu et al. 2018; Yu and Chen 2020), fuzzy logic (Ramesh and Anbazhagan 2015; Turan et al. 2020), adaptive neuro-fuzzy inference system (ANFIS) (Polykretis et al. 2019; Panahi et al. 2020; Mehrabi et al. 2020), random forest (RF) (Kim et al. 2018; Chen et al. 2020; Sahin et al. 2020), and support vector machine (SVM) (Oh et al. 2018; Al-Najjar and Pradhan 2021; Hu et al. 2020). Although mentioned models have suitable performance as predictive models, there are some drawbacks when applied individually (Youssef et al. 2015). According to the literature review, ensemble models perform more accurate results than a single method (Roy et al. 2019; Costache et al. 2020). For example, Aghdam et al. (2017) combined FR and WoE statistical methods with ANFIS algorithms to produce a landslide susceptibility map of the Zagros Mountains in Iran. Their results indicated that FR-ANFIS and WoE-ANFIS have better performance compared with FR and WofE. In another study, Roy and Saha (2019) combined WoE statistical and SVM machine learning models with different kernel functions to identify landslide hazard zones. They found that WofE and Linear-SVM ensemble model with more than 90% accuracy has an excellent performance in spatial modeling. Althuwaynee et al. (2016) indicated that the combination of CHAID and AHP methods has better results than stand-alone implementations of each model.
In limited studies, the combination of machine learning algorithms with MCDM methods has been used (Dehnavi et al. 2015; Arabameri et al. 2019; Costache et al. 2020). For instance, Arabameri et al. (2019) used the VICOR-RF-FR as an MCDM statistical machine learning ensemble method to evaluate groundwater potential. They showed the strength ensemble model to improve the results of nonlinear problems. Dehnavi et al. (2015) showed that the ensemble ANFIS-SWARA model yielded more realistic results than the SWARA.
The best-worst method is one of the latest MCDM methods introduced by Rezaei in 2015. Although this method has been used in two different landslide studies (Gigović et al. 2019; Moharrami et al. 2020), it has not yet been applied in combination with machine learning methods. Reviewing the previous studies shows that despite very good results, the combination of machine learning algorithms with MCDM methods has received less attention. The aim of the present study is to combine the BWM method with ANFIS to implement a new framework and compare it with the widely used SWARA method in order to fill this gap in the spatial modeling studies.
Two important points should be considered to achieve optimal results in the spatial modeling of landslides: (a) the quality of the input data and (b) the structure of the model used (Adineh et al. 2018). In connection with the first point, in this work, an attempt has been made to be as careful as possible in preparing the data. Regarding the second point, the difference between this study and other studies is the combination of the BWM model with ANFIS machine learning method. Moreover, in this study, the hybrid ANFIS-SWARA model has been used to compare them to determine which of these models of MCDM provides better results in combination with the ANFIS. After preparing landslide susceptibility maps, the performance of each model was estimated using the indices of sensitivity, specificity, accuracy, RMSE, and ROC curve. The results showed that the ensemble ANFIS-BWM model performed better and can be used in future studies.
1.1 Study region
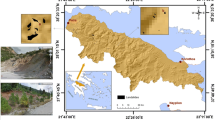
With an area of 8604 km2, the Khalkhal-Tarom Basin is located on the southern slopes of the Alborz mountain range along from 47° 42′ 44″ to 49° 10′ 34″ E and 36° 37′ 22″ to 37° 56′ 35″″ N (Fig. 1). Approximately 92% (7967 km2) of the basin consists of highlands and the remainder of plains. The highest and lowest elevations are 3314 m and 288 m, respectively. The data from the climatological stations of the Iran Meteorological Organization and Ministry of Energy were utilized to estimate temperature and rainfall. The average annual temperature in the region is about 10.5 °C, while the coldest month is February, and the warmest is August. In addition, the average annual rainfall is about 375 mm. The difference in rainfall levels in the highlands on the two sides of the main river (the Ghezel Ozan River) results from the differences in the prevailing climatic conditions in the areas adjacent to the study area. Although the study area has diverse lithology, pyroclastic rocks of Karaj Formation cover most of its surface area. Moreover, based on the unit ages,Eocene has the highest coverage of the study area (Fig.2). Various factors such as weather conditions, topography, and human activities, including land use change, have increased the occurrence of landslides in this area. To confirm this important issue, the findings of this study showed that agricultural lands have the highest risk of landslides due to human activities. Given the existence of economic infrastructures and the growing residential areas on the unstable slopes in the future, zoning of landslide-prone regions seems to be vitally important.

Location of the study area

Lithology map
1.2 Database development and data preparation
It is necessary to create a spatial database in any study using geographical information system. The landslide susceptibility mapping is no exception, and database creation including inventory map and conditioning factors is considered as the first and the most important step in this process. The landslide inventory map shows the locations and spatial distribution of landslides that happened in the past (Ding et al. 2017). Since it is crucial to pinpoint the locations of the past and present landslides in order to predict future high-risk areas, preparation of a landslide inventory map is a requisite to any study on landslides (Regmi et al. 2014). Information on the locations of past landslides and their spatial distributions was obtained from the Forest, Rangeland and Watershed Organization of Iran (Fig. 1). According to Fig. 1, the inventory map was employed to randomly select 172 (or 70%) of the 242 landslides that have occurred in the region for training the data and the 30% for model validation.
Various factors including geology, hydrology, geomorphology, climate, and topography affect slope instability. Determination of these factors is among the basic and initial steps in landslide susceptibility mapping. In this study, thirteen conditioning factors including slope angle, slope aspect, altitude, topographic wetness index (TWI), plan curvature, profile curvature, distance to roads, distance to streams, distance to faults, lithology, land use, rainfall, and normalized difference vegetation index (NDVI) were selected based on the available data and previous studies for the spatial modeling of the landslides (Table 1). According to Table 1, these thirteen factors were determined by using the information obtained from the related organizations and the reference data. Following that, ArcGIS 10.5 was employed to generate and digitalize the maps (30×30 m pixels). Raster data models of the layers were then prepared by using the selected methods.
In order to prepare the different information layers, the digital elevation model (DEM) was prepared first using ASTER satellite images. DEM is one of the most important databases in any landslide study because preparation of some important thematic maps depends on it. The slope angle, slope aspect, altitude, TWI, and plan and profile curvature layers were extracted from the DEM (Fig. 3a–f). The other considered factors (distance to roads, distance to streams, distance to faults, lithology, land use, rainfall, and the normalized difference vegetation index) were then determined (Fig. 3g–m). In addition, the conditioning factors were categorized based previous studies and available data.



Conditioning factors of the study. a Slope angle. b Slope aspect. c Altitude. d TWI. e Plan curvature. f Profile curvature. g Distance to roads. h Distance to streams. i Distance to faults. j Lithology. k Land use. l Rainfall. m NDVI
The slope degree is always considered as an essential factor in analyzing the areas susceptible to landslide (Umar et al. 2014), because it is the major cause of mass movements. Exposure to sunlight, dry winds, and increased relative humidity due to rainfall are all factors associated with slope aspect that trigger landslides (Kavzoglu et al. 2014). Therefore, slope aspect has always been considered by researchers. This factor is divided into 9 classes. Altitude is not directly involved in the occurrence of landslides; however, other factors related to it such as tectonic activity, weathering, and climate change influence the entire process (Rozos et al. 2008). The topographic wetness index is a useful tool for estimating moisture conditions at a basin scale (Grabs et al. 2009). This factor was used due to the varying humidity conditions in the study area. The values obtained from the slope curvature show the morphology of the different elevation points (Erener and Düzgün 2010). In this paper, both the profile curvature curve and the plan curvature were taken into account. The former indicates the velocity and process of sediment transport, and the second, the divergence and convergence of the flow passing through the surface (Dehnavi et al. 2015). Road construction, especially when engineering principles are ignored, reduces slope stability and consequently triggers landslides (Moosavi and Niazi 2016). Therefore, the distance from the road has always attracted the interest of researchers (Xiao et al. 2019; Bui et al. 2012). Streams decrease shear strength by eroding the materials from the toe of the slope. Consequently, the factor of distance from the stream is very important in relation to slope stability (Achour et al. 2017). Faults, especially in seismic zones, play a significant role in triggering mass movements (Shirzadi et al. 2017). They either act directly as a triggering factor for landslides or indirectly by causing fractures in slope layers that lead to the penetration of water into joints and fissures, thereby reducing the shear strength of materials constituting the slope that results in the occurrence of landslides (Dehnavi et al. 2015). Lithology as a geological factor has always played an important role in predicting landslide, because different geological units with varying degrees of permeability influence slope stability (Chalkias et al. 2014). Due to their impacts on slope instability, different types of land use have always attracted many researchers in their research on landslides (Conforti et al. 2014; Dou et al. 2014). The rainfall factor was used in this research because the amount of rainfall varies with changes in elevation and rainfall directly and indirectly influences landslide occurrence. The NDVI index was calculated to analyze the effect of vegetation on slope instability:
The NDVI benefits from the ratio of near-infrared (NIR) reflection to red (R) reflection to estimate vegetation density (Polykretis et al. 2019).
2 Methodology
2.1 Adaptive neuro-fuzzy inference system (ANFIS)
Although a fuzzy inference system (FIS) using “if-then” rules can analyze complex processes, it is unable to perform the learning process. The adaptive neuro-fuzzy inference system (ANFIS) (Jang 1993) is one of the most widely used fuzzy systems for modeling nonlinear problems. This approach, developed by combining a FIS and an artificial neural network (ANN), utilizes the advantages of both approaches to solve problems. The ANN model is able to optimize the fuzzy logic solution through the learning process (Oh and Pradhan 2011). The details of the ANFIS model structure are as follows.
The ANFIS structure was developed by using the Takagi-Sugeno fuzzy rule base (the details are presented in Eqs. 10 and 11).
Here, x and y are the system inputs, and A1, A2, B1, and B2 are fuzzy membership functions. In addition, pi, qi, and ri (∀ i = 1, 2) are the parameters of the output function (Jang 1993). In general, the ANFIS structure is made of five layers described below (Fig. 4).
-
Layer 1

The structure of the ANFIS model
This layer is responsible for the fuzzification of the variables, and the nodes in this layer are adaptive nodes.
Here, i represents the related node, x and y are its input variables, Ai and Bi are linguistic terms, and μAi (x) and μBi (y) are the membership functions of the node i.
-
Layer 2
In this section, every node is a fixed node, and each one is responsible for multiplying signals entering it. The nodes are named by the Π label, and their outputs are as follows (Oh and Pradhan 2011):
Here, Wi (the so-called firing strength of each fuzzy rule) represents each node’s output.
-
Layer 3
This layer has the task of normalizing the output of the second layer. Therefore, the nodes, which are fixed ones and named by the N label, normalize the input values (Eq. 15). The numerator of the fraction includes the firing strength of each fuzzy rule, and the denominator includes the total firing strength of each rule.
-
Layer 4
This is considered the second adaptive layer in the ANFIS structure, and each node’s output is obtained from the following equation:
In this equation, \( {\overline{W}}_i \) is the normalized firing strength of the third layer. pi, qi , and ri are the variable parameters (also referred to as the result parameters) of the node i.
-
Layer 5
The only node existing in this layer is fixed node labeled Σ. This node sums up all the input signals and calculates the resulting output (Eq. 17).
For more details on the layers and the algorithms, refer to Jang (1993).
2.2 Best-worst multi-criteria decision making (BWM) model
The best-worst method (BWM) is one of the newest and most efficient multi-criteria decision-making approaches introduced in 2015 by Rezaei to calculate the final weights of criteria in decision-making problems. As in other MCDM methods such as AHP, pair-wise comparisons are used in BWM. One of the advantages of BWM over AHP is that fewer pair-wise comparisons are used (for AHP we need n(n − 1)/2 comparisons, and for the BWM method, we need 2n − 3 comparisons) (Rezaei 2015). However, the differences in the final weight calculation in this method have made the final result much more realistic and consistent than methods such as AHP. The numbers used for pair-wise comparisons are integers ranging between 1 and 9, and there is no need for fractional numbers. It is also possible to integrate the BWM with other MCDM methods (Ahmad et al. 2017). The various steps in this method and its algorithms for problem solving are as follows (Rezaei 2015):
-
1.
Specifying the decision-making criteria for evaluation. The set of criteria is defined as {C1, C2, …, Cn}.
-
2.
Determining the best (B) and worst (W) criteria by the experts. The best criterion includes most important or the most desirable criterion, whereas the worst ones include those with the least desirability and/or lowest importance.
-
3.
Determining the priority of the best criteria compared to all the others (the numbers 1 to 9 are used for this purpose). This preference is represented in the form of the following vector:
Here, αB1 represents the preference of the best criterion (B) over the criterion j (αBB = 1) (Fig. 5).
-
4.
Determining the priority of all the criteria over the worst one (W). The preference vector for this phase is as follows:

Reference comparison for BWM model (Rezaei 2015)
Here, αjW is the preference of the j criterion over the worst one (W) (αWW=1) (Fig. 5).
-
5.
Calculating the final weights of the criteria. The following equations are used for this purpose:

The values of the final optimum weights (\( {\mathrm{W}}_1^{\ast },{\mathrm{W}}_2^{\ast },\dots .{\mathrm{W}}_{\mathrm{n}}^{\ast}\Big) \) and

are obtained by Eq. 8. In addition, the consistency ratio for each criterion can be estimated by using the consistency index table (Table 2) and the

value. The following equation states that:

It is evident that the closer the value of the consistency index is to zero, the more realistic the results will be. Refer to Rezaei (2015) for more details of this method.
2.3 Step-wise weight assessment ratio analysis (SWARA) model
This is a multi-criteria decision-making method with an ultimate objective like that of other similar approaches: assigning weights to criteria and sub-criteria. Since its introduction by Keršulien et al. in 2010, researchers have used it to analyze various areas (Mardani et al. 2017). An advantage of this method is its flexibility that allows experts to prioritize the criteria based on the existing conditions. The main feature of this approach is its capability in estimating experts’ opinions in relation to the relative importance of the criteria in order to determine their weights (Keršulien et al. 2010). This procedure consists of the following steps:
-
1.
Selecting the required criteria and ranking them according to their degrees of importance (the most important criteria take the highest position of ranking and the least important ones the lowest)
-
2.
Calculating the coefficient Kj, which is a function of the relative importance of each criterion
-
3.
Determining the initial weight of each criterion
-
4.
Calculating the final normalized weight
The final weight for each criterion is calculated through the following equations (Keršulien et al. 2010):
In this equation, j and n represent the criterion number and the number of experts, respectively. The value of Ai also indicates the suggested rating of each criterion.
Here, Kj and Qi are functions of the relative importance and initial weight of each criterion, respectively.
In this formula, j represents the criterion number, and m shows the number of criteria when Wj indicates the final weight.
The final weight (Wj) obtained for each sub-criteria in this study indicates the relationship between landslides and conditioning factors (Table 3).
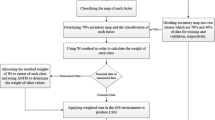
Figure 6 shows the process of the study, including the methods and type of combination used.

Flowchart of the study area that shows all steps
3 Results and validation
Table 3 shows the weights obtained from the BWM model and SWARA. As shown in Table 3, the values are between 0 and 0.5. The higher are these values, the greater is their impact. The values for the slope factor indicate that most of the landslides that occurred in the study area were of the 5–15° class with weights of 0.409 and 0.405, respectively. Aghdam et al. (2017) also reported that the highest probability of landslide occurrence is related to the slope 5–20°, and this probability decreases with an increase in degree. Among the different slope aspects, the northeast aspect, with the values of 0.249 (BWM) and 0.486 (SWARA), had the highest effect on landslide occurrence, due to increased moisture. According to Fig. 7, the main areas with high and very high degrees of susceptible are in the north to east. In line with the present study, Sahin (2020) also showed that the northeast of the study area has the highest susceptible to landslide. In relation to the altitude factor, the 1500–1700 m class had the highest impact on landslide (with values of 0.212 and 0.434 for BWM and SWARA, respectively). As shown in Table 3, the degree of susceptibility decreases with an increase in altitude. In a study, Ding et al. (2017) concluded that the highest probability of landslide occurrence is up to medium altitude and this probability decreases with increasing this altitude. The results of the BWM model for the TWI showed that the 5.65–7.31 and 7.31–9.87 classes with the weight of 0.371 had the highest impact on landslide occurrence. For the SWARA, the 7.31–9.87 class with values of 0.482 had the highest probabilities. Consistent with the present study, Roy et al. (2019) also found that low and medium TWI values (7.37–9.76) have the highest risk. For the plan curvature factor, according to Table 3, the maximum weights obtained from the BWM and SWARA were for the convex class with weights of 0.769 and 0.410, respectively. This is due to divergence and convergence water flow (Arabameri et al. 2019). The obtained results are in accordance with the findings of Chen et al. (2020). For the profile curvature factor, the highest BWM weight (0.470) was that of the concave and convex classes and for SWARA the highest value (0.489) was that of the concave class. The finding of a study by Dehnavi et al. (2015) also revealed that the class “concave” has the highest impact on the landslide occurrence. The results obtained from BWM indicated that the distance to road, distance to stream, and distance to fault in the 0–100-m, 0-100-m, and 1200–1500-m classes with weights of 0.397, 0.297, and 0.330, respectively, had the highest influence on landslide. As in the BWM method, in the SWARA, also the same classes had the highest weights with the values of 0.311, 0.404, and 0.386, respectively. Consistent with the present study, Aghdam et al. (2017) also concluded that the maximum weight for the factors of distance to road and distance to stream is related to the distance of 0–100 m, and it decreases with an increase in distance. Concerning lithology, the Jl and PlQc classes had the highest values in the BWM method (0.2), and the highest in the SWARA (0.344) was in the Jl class. For the land use factor, the agriculture class in both models had the strongest relationship with landslide occurrence with values of 0.505 and 0.270, respectively. The results of this study showed that land use change disturbs the natural balance of the slopes and increases the risk of landslide occurrence. The findings of Arabameri et al. (2019) also showed that the class “dryfarming-agriculture” has the highest risk. Landslides were more likely to occur with increases in rainfall. For the rainfall factor, 332.9–387.65 mm of rainfall had the highest weights in the BWM model and SWARA (0.352 and 0.647 and 0.352, respectively). In relation to the NDVI factor, the likelihood of landslide occurrence was greatest for the class >0.5 with the weights of 0.574 and 0.356 for the BWM method and SWARA, respectively.

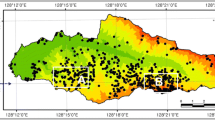
Landslide susceptibility map produced by ANFIS-BWM (a) and ANFIS-SWARA (b) models
3.1 Integration of the ANFIS with SWARA and BWM
In this study, MATLAB was employed to construct the ANFIS model and the SWARA method and BWM to feed it for training the network. For this purpose, all the data were first divided into the training and validation sets. As mentioned earlier, 70% of the data (172 landslide locations) were allocated for training and 30% (70 landslide locations) for validation, and they were assigned the value of 1. Using the training data and the SWARA model and BWM, the weights of the sub-criteria were calculated (Table 3). In the next step, 242 non-landslide points, showing the total number of data, were created in the non-landslide areas. Then, 0 was allocated to each of them. Out of these non-landslide points, 70% (172) points were selected randomly and considered for training the network. Next, 172 landslide and non-landslide points (with values of 1 and 0) were overlaid upon the conditioning factors, and the value of each one was determined. This process was carried out once for the SWARA model and once for the BWM. The values obtained from the overlaying were used as input data for ANFIS training. After ANFIS training using the BWM method and SWARA, all the pixels were entered into MATLAB, and the final value of each pixel was determined using the created network. Finally,landslide susceptibility maps were prepared for the ensemble ANFIS-BWM and ANFIS-SWARA models (Fig.7). The prepared maps were divided into five classes with susceptibility degree of very low, low, moderate, high, and very high by applying natural break method (Ilia and Tsangaratos 2016; Ding et al. 2017; Panahi et al. 2020). Figure 8 shows the percent area for each class in the ANFIS-BWM and ANFIS-SWARA ensemble models. It is quite clear that the class with very high landslide susceptibility had the lowest area in both LSMs with values of 18.65% and 16.21%, respectively (Table 4). In addition, the classes with low and high landslide susceptibility had the largest areas with the values of 20.50% and 23.01% for ANFIS-BWM and ANFIS-SWARA, respectively.

Percentages of landslide susceptibility classes
3.2 Models validation and comparison
Validation is a very important step in estimating the accuracy of a method in producing landslide susceptibility maps. In this study, validation was performed by using 30% of landslide and non-landslide locations (72 points with values of 0 and 1) in three stages. In the first stage, the mean-squared-error (MSE) and root-mean-squared-error (RMSE) were calculated to estimate the accuracy of ANFIS-trained network using SWARA and BWM methods. MSE and RMSE are defined as follows:
where, Tj is the target values and \( {\overline{T}}_j \) is the output values, and n is the total number of samples. RMSE is the square root of MSE.
The lower the MSE value is (closer to zero), the lower the amount of error in the final prediction, and hence, the more accuracy the modeling will be (Jackson et al. 2019). Figure 9c shows MSE and RMSE for the test dataset. The results showed that the MSE values for the ANFIS-BWM and ANFIS-SWARA models are 0.242 and 0.299, and RMSE values are 0.443 and 0.477, respectively (Table 4). As the results indicate, the new BWM method outperformed the SWARA model in training the ANFIS.

ANFIS-SWARA and ANFIS-BWM training and testing datasets. a MSE and RMSE value in the training phase. b Frequency errors in the training phase. c MSE and RMSE value in the testing phase. d Frequency errors in the testing phase
In the second step, indices such as positive predictive value (PPV), negative predictive value (NPV), sensitivity (SST), specificity (SPE), and accuracy (ACC) were calculated using the error matrix (Bui et al. 2016; Wang et al. 2020). The following equations were used to calculate the indices:
Here, TP indicates pixels which have correctly been classified as the landslide occurrence, TN stands for pixels which have correctly been classified as non-landslide pixels, FP represents pixels that have incorrectly been classified as landslide pixels, and FN also indicates pixels that are incorrectly classified as non-landslide pixels. As shown in Table 5, the PPV values for ANFIS-BWM and ANFIS-SWARA are 65.6% and 63.8%, the NPV values are 80.9% and 78.3%, the SST values are 87.1% and 85.7%, the SPE values are 54.3% and 51.4%, and the ACC values are 70.7% and 68.6%, respectively. The results show that the ANFIS-BWM model has a higher percentage in all indicators.
In the third stage, the LSMs were evaluated using the ROC curve. The ROC curve is a graphical representation of the balance between negative and positive error values that can quantitatively estimate the model accuracy. The area under the curve (AUC) illustrates the predicted value of the system by describing its ability in correctly estimating the occurrence of the event (landslide) and the non-occurrence of the event (non-landslide) (Yan et al. 2019). Therefore, the larger the area under the curve (AUC), the more accurate the model will be, and the lower AUC show the weak performance of the model. Further details on this curve for validating landslide susceptibility maps are provided in paper by Fan et al. (2017).
In this study, 72 landslide and non-landslide points were overlaid upon the final maps to plot the ROC curves. The values obtained for each point were then used as input data. Figure 10 shows the ROC curves for the methods. Based on the results, the areas under the curves for the ANFIS-BWM and ANFIS-SWARA ensemble models are 75% and 73.6%, respectively. The results obtained from the evaluation of the zoning suggested that both models were able to predict the landslide prone areas well; however, the ANFIS-BWM model was more accurate and, hence, yielded more reliable outputs.

Receiver operating characteristic curve for validation
4 Discussion
Landslide spatial modeling is a nonlinear and complex problem because it is affected by various parameters. Therefore, to achieve the better results, using new methods and their combination is necessary. In spatial modeling of landslide, the combination of machine learning algorithms with MCDM methods has received less attention. In this study, we produced a new ensemble ANFIS-BWM model for landslide susceptibility mapping in the Khalkhal-Tarom, Iran. The performance of this model was then compared with the ensemble ANFIS-SWARA model using confusion matrix and ROC curve. One of the important steps in spatial modeling is to compare the results with other similar studies.
To produce landslide susceptibility map, several studies have been applied MCDM and machine learning methods. For example, Gigović et al. (2019) integrated the BWM with the WLC and OWA methods for zoning regional landslides in western Serbia. They showed that the ensemble MCDM-BWM methods with more than 90% accuracy can be a powerful method for spatial modeling of landslides. In another study, Moharrami et al. (2020) applied the combination of fuzzy with BWM and AHP methods to evaluate areas that are prone to landslides. Their findings showed that FBWM ensemble method has better performance than FAHP. According to Gigović et al. (2019) and Moharrami et al. (2020), the BWM method has advantages such as (1) it requires less pairwise comparisons compared to other widely used MCDM methods like AHP, (2) its results are more reliable because it has a higher consistency ratio compared to AHP, and (3) working with this method is more accurate and easier because it does not use secondary comparisons. They also stated that the combination of BWM method with other models has better performance than stand-alone implementation. Consistent with previous studies, the results of the present study showed that the ensemble ANFIS-BWM method has a good performance and is more accurate in preparing LSM when compared to ANFIS-SWARW.
In spatial modeling, the ANFIS method has been used as a powerful method in combination with other methods (Chen et al. 2021; Costache et al. 2020; Dehnavi et al. 2015). Chen et al. (2021), for example, used the ANFIS model and its combination with two intelligent TLBO and SBO algorithms to generate a landslide susceptibility map. Their results showed that the hybrid ANFIS-SBO model outperformed the ANFIS and ANFIS-TLBO models. In addition, they stated that the advantages of the ANFIS method such as capacity, simplicity, and speed of estimation have made it to have better adaptability to other methods in order to create a hybrid model. Panahi et al. (2020) also stated that the ANFIS model has some benefits, including good learning ability, good integration by its neural network, and more flexibility in nature. In another study, Costache et al. (2020) used a combination of ANFIS with three qualitative and quantitative methods of AHP, CF, and WOE. Their findings showed that all three ensemble models with the accuracy more than 80% have excellent performance in flood susceptibility zoning. They also reported that although ANFIS is a powerful method, the type of model used in the production of input data is important and can affect the accuracy of the results. Consistent with the study, in this study, we showed that although both models used are of MCDM type, the BWM method is better than SWARA in combination with ANFIS. Since bringing the prediction closer to reality is the most important objective in complex environmental issues such as landslides, it is necessary to compare newly introduced ensemble methods with the previous ones in order to achieve more optimal results.To generate landslide susceptibility map, Dehnavi et al. (2015) integrated the SWARA multi-criteria decision-making approach with the ANFIS method. They found that the ANFIS-SWARA model with an area under the curve of 0.8 yielded a more accurate prediction than the SWARA method. In line with the study conducted, we also found that although the ensemble ANFIS-SWARA model has a good performance with more than 70% accuracy, but the ANFIS-BWM exhibited higher accuracy. There are also disadvantages to implementing ANFIS-BWM model. For a limited number of landslide points, the model does not provide a suitable output.
In brief, to improve the performance of ANFIS model, two type of MCDM methods were applied. According to the literature review, the type of model that is used to determine the correlation between conditioning factors and the landslide occurrence is effective in improving the results (Dehnavi et al. 2015; Aghdam et al. 2017; Costache et al. 2020). Based on the results shown in Table 3, although both methods are of the type of MCDM and include values between 0 and 0.5, the BWM model performs better compared to SWARA model. In other word, the results indicated that the BWM produced more realistic results than the SWARA method which trained the ANFIS model well and obtained an acceptable output from it.
As a final conclusion, based on the ROC results with more than 70% accuracy, the ensemble models used in this study have a suitable structure for use in other spatial modeling studies. It is recommended to integrate novel multi-criteria decision-making models with machine learning algorithms such as ANFIS for improve the accuracy.
5 Conclusion
Known as natural destructive ground-deforming phenomena, landslides have occurred in all historical periods. In the current study, for spatial prediction of landslide in the Khalkhal-Tarom, Iran, a new combination of MCDM method and machine learning algorithm was conducted. For this purpose, we integrated BWM method with ANFIS model. Moreover, the ANFIS-SWARA ensemble model was applied to compare with ANFIS-BWM to select more realistic LSM. The results of ROC showed that with more than 70% accuracy, although both ensemble models used in this study have a suitable structure for spatial modeling of landslide, new ensemble ANFIS-BWM model performed more accurately than ANFIS-SWARA. In addition, the results of sensitivity, specificity and accuracy proved the superiority of the ANFIS-BWM model.Final maps also indicated that the largest percentage of high and very high susceptibility zones is from north to east. Since the ANFIS-BWM model yielded better results, it is recommended for use in other similar areas because it can substantially help land use managers and planners in making essential decisions.
Data availability
All data generated or analyzed during this study are confidential.
References
Achour Y, Boumezbeur A, Hadji R, Chouabbi A, Cavaleiro V, Bendaoud EA (2017) Landslide susceptibility mapping using analytic hierarchy process and information value methods along a highway road section in Constantine, Algeria. Arab J Geosci 10:194
Adineh F, Motamedvaziri B, Ahmadi H, Moeini A (2018) Landslide susceptibility mapping using Genetic Algorithm for the Rule Set Production (GARP) model. J Mt Sci 15:2013–2026
Aghdam IN, Pradhan B, Panahi M (2017) Landslide susceptibility assessment using a novel hybrid model of statistical bivariate methods (FR and WOE) and adaptive neuro-fuzzy inference system (ANFIS) at southern Zagros Mountains in Iran. Environ Earth Sci 76:237
Ahmad WNKW, Rezaei J, Sadaghiani S, Tavasszy LA (2017) Evaluation of the external forces affecting the sustainability of oil and gas supply chain using Best Worst Method. J Clean Prod 153:242–252
Ahmed B (2015) Landslide susceptibility mapping using multi-criteria evaluation techniques in Chittagong Metropolitan Area, Bangladesh. Landslides 12:1077–1095
Al-Najjar HH, Pradhan B (2021) Spatial landslide susceptibility assessment using machine learning techniques assisted by additional data created with generative adversarial networks. Geosci Front 12(2):625–637
Althuwaynee OF, Pradhan B, Lee S (2016) A novel integrated model for assessing landslide susceptibility mapping using CHAID and AHP pair-wise comparison. Int J Remote Sens 37(5):1190–1209
Arabameri A, Pradhan B, Rezaei K, Sohrabi M, Kalantari Z (2019) GIS-based landslide susceptibility mapping using numerical risk factor bivariate model and its ensemble with linear multivariate regression and boosted regression tree algorithms. J Mt Sci 16:595–618
Baena JAP, Scifoni S, Marsella M, De Astis G, Fernández CI (2019) Landslide susceptibility mapping on the islands of Vulcano and Lipari (Aeolian Archipelago, Italy), using a multi-classification approach on conditioning factors and a modified GIS matrix method for areas lacking in a landslide inventory. Landslides 16:969–982
Bahrami Y, Hassani H, Maghsoudi A (2020) Landslide susceptibility mapping using AHP and fuzzy methods in the Gilan province, Iran. GeoJournal:1–20
Berhane G, Kebede M, Alfarrah N (2020) Landslide susceptibility mapping and rock slope stability assessment using frequency ratio and kinematic analysis in the mountains of Mgulat area, Northern Ethiopia. Bull Eng Geol Environ 80:1–17. https://doi.org/10.1007/s10064-020-01905-9
Bui DT, Pradhan B, Lofman O, Revhaug I, Dick OB (2012) Spatial prediction of landslide hazards in Hoa Binh province (Vietnam): a comparative assessment of the efficacy of evidential belief functions and fuzzy logic models. Catena 96:28–40
Bui DT, Tuan TA, Klempe H, Pradhan B, Revhaug I (2016) Spatial prediction models for shallow landslide hazards: a comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 13:361–378
Chalkias C, Ferentinou M, Polykretis C (2014) GIS-based landslide susceptibility mapping on the Peloponnese Peninsula, Greece. Geosciences 4:176–190
Chen W, Sun Z, Zhao X, Lei X, Shirzadi A, Shahabi H (2020) Performance evaluation and comparison of bivariate statistical-based artificial intelligence algorithms for spatial prediction of landslides. ISPRS Int J Geo Inf 9(12):696
Chen W, Chen X, Peng J, Panahi M, Lee S (2021) Landslide susceptibility modeling based on ANFIS with teaching-learning-based optimization and Satin bowerbird optimizer. Geosci Front 12(1):93–107
Colkesen I, Sahin EK, Kavzoglu T (2016) Susceptibility mapping of shallow landslides using kernel-based Gaussian process, support vector machines and logistic regression. J Afr Earth Sci 118:53–64
Conforti M, Pascale S, Robustelli G, Sdao F (2014) Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment (northern Calabria, Italy). Catena 113:236–250
Costache R, Țîncu R, Elkhrachy I, Pham QB, Popa MC, Diaconu DC, Avand M, Costache I, Arabameri A, Bui DT (2020) New neural fuzzy-based machine learning ensemble for enhancing the prediction accuracy of flood susceptibility mapping. Hydrol Sci J 65(16):2816–2837
Cui K, Lu D, Li W (2017) Comparison of landslide susceptibility mapping based on statistical index, certainty factors, weights of evidence and evidential belief function models. Geocarto Int 329:935–955
Dehnavi A, Aghdam IN, Pradhan B, Varzandeh MHM (2015) A new hybrid model using step-wise weight assessment ratio analysis (SWARA) technique and adaptive neuro-fuzzy inference system (ANFIS) for regional landslide hazard assessment in Iran. Catena 135:122–148
Ding Q, Chen W, Hong H (2017) Application of frequency ratio, weights of evidence and evidential belief function models in landslide susceptibility mapping. Geocarto Int 32:619–639
Dou J, Oguchi T, Hayakawa YS, Uchiyama S, Saito H, Paudel U (2014) GIS-based landslide susceptibility mapping using a certainty factor model and its validation in the Chuetsu Area, Central Japan. In Landslide science for a safer geoenvironment. p. 419–424
Du G, Zhang Y, Yang Z, Guo C, Yao X, Sun D (2019) Landslide susceptibility mapping in the region of eastern Himalayan syntaxis, Tibetan Plateau, China: a comparison between analytical hierarchy process information value and logistic regression-information value methods. Bull Eng Geol Environ 78(6):4201–4215
Erener A, Düzgün HSB (2010) Improvement of statistical landslide susceptibility mapping by using spatial and global regression methods in the case of More and Romsdal (Norway). Landslides 7:55–68
Erener A, Mutlu A, Düzgün HS (2016) A comparative study for landslide susceptibility mapping using GIS-based multi-criteria decision analysis (MCDA), logistic regression (LR) and association rule mining (ARM). Eng Geol 203:45–55
Fan W, Wei XS, Cao YB, Zheng B (2017) Landslide susceptibility assessment using the certainty factor and analytic hierarchy process. J Mt Sci 14:906–925
Farrokhnia A, Pirasteh S, Pradhan B, Pourkermani M, Arian M (2011) A recent scenario of mass wasting and its impact on the transportation in Alborz Mountains, Iran using geo-information technology. Arab J Geosci 4:1337–1349
Feizizadeh B, Roodposhti MS, Blaschke T, Aryal J (2017) Comparing GIS-based support vector machine nel functions for landslide susceptibility mapping. Arab J Geosci 10:122
Gigović L, Drobnjak S, Pamučar D (2019) The application of the hybrid GIS spatial multi-criteria decision analysis best – worst methodology for landslide susceptibility mapping. ISPRS Int J Geo-Inf 8:79
Grabs T, Seibert J, Bishop K, Laudon H (2009) Modeling spatial patterns of saturated areas: a comparison of the topographic wetness index and a dynamic distributed model. J Hydrol 373:15–23
Gutiérrez F, Linares R, Roqué C, Zarroca M, Carbonel D, Rosell J, Gutiérrez M (2015) Large landslides associated with a diapiric fold in Canelles Reservoir (Spanish Pyrenees): detailed geological geomorphological mapping, trenching and electrical resistivity imaging. Geomorphology 241:224–242
Hong H, Chen W, Xu C, Youssef AM, Pradhan B, Tien Bui D (2017) Rainfall-induced landslide susceptibility assessment at the Chongren area (China) using frequency ratio, certainty factor, and index of entropy. Geocarto Int 322:139–154
Hu Q, Zhou Y, Wang S, Wang F (2020) Machine learning and fractal theory models for landslide susceptibility mapping: case study from the Jinsha River Basin. Geomorphology 351:106975
Ilia I, Tsangaratos P (2016) Applying weight of evidence method and sensitivity analysis to produce a landslide susceptibility map. Landslides 13(2):379–397
Jackson EK, Roberts W, Nelsen B, Williams GP, Nelson EJ, Ames DP (2019) Introductory overview: error metrics for hydrologic modelling–a review of common practices and an open source library to facilitate use and adoption. Environ Model Softw 119:32–48
Jang JS (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23:665–685
Juliev M, Mergili M, Mondal I, Nurtaev B, Pulatov A, Hübl J (2019) Comparative analysis of statistical methods for landslide susceptibility mapping in the Bostanlik District, Uzbekistan. Sci Total Environ 653:801–814
Kalantar B, Pradhan B, Naghibi SA, Motevalli A, Mansor S (2018) Assessment of the effects of training data selection on the landslide susceptibility mapping: a comparison between support vector machine (SVM), logistic regression (LR) and artificial neural networks (ANN). Geomatics, Nat. Hazards Risk 9(1):49–69
Kavzoglu T, Sahin EK, Colkesen I (2014) Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides 11:425–439
Kavzoglu T, Sahin EK, Colkesen I (2015) An assessment of multivariate and bivariate approaches in landslide susceptibility mapping: a case study of Duzkoy district. Nat Hazards 76(1):471–496
Keršulienė V, Zavadskas EK, Turskis Z (2010) Selection of rational dispute resolution method by applying new step‐wise weight assessment ratio analysis (SWARA). J Bus Econ Manage 11(2):243–258. https://doi.org/10.3846/jbem.2010.12
Kim JC, Lee S, Jung HS, Lee S (2018) Landslide susceptibility mapping using random forest and boosted tree models in Pyeong-Chang, Korea. Geocarto Int 339:1000–1015
Kumar S, Srivastava PK, Snehmani (2017) GIS-based MCDA-AHP modeling for avalanche susceptibility mapping of Nubra valley region, Indian Himalaya. Geocarto Int 32:1254–1267
Lin L, Lin Q, Wang Y (2017) Landslide susceptibility mapping on a global scale using the method of logistic regression. Nat Hazards Earth Syst Sci 17:1411–1424
Mardani A, Zavadskas EK, Khalifah Z, Zakuan N, Jusoh A, Nor KM, Khoshnoudi M (2017) A review of multi-criteria decision-making applications to solve energy management problems: two decades from 1995 to 2015. Renew Sust Energ Rev 71:216–256
Mehrabi M, Pradhan B, Moayedi H, Alamri A (2020) Optimizing an adaptive neuro-fuzzy inference system for spatial prediction of landslide susceptibility using four state-of-the-art metaheuristic techniques. Sensors 20(6):1723
Moharrami M, Naboureh A, Gudiyangada Nachappa T, Ghorbanzadeh O, Guan X, Blaschke T (2020) National-scale landslide susceptibility mapping in Austria using fuzzy best-worst multi-criteria decision-making. ISPRS Int J Geo-Inf 9(6):393
Moosavi V, Niazi Y (2016) Development of hybrid wavelet packet-statistical models (WP-SM) for landslide susceptibility mapping. Landslides 13:97–114
Nadim F, Kjekstad O, Peduzzi P, Herold C, Jaedicke C (2006) Global landslide and avalanche hotspots. Landslides 3: 159–173
Oh HJ, Pradhan B (2011) Application of a neuro-fuzzy model to landslide-susceptibility mapping for shallow landslides in a tropical hilly area. Comput Geosci 37:1264–1276
Oh HJ, Kadavi PR, Lee CW, Lee S (2018) Evaluation of landslide susceptibility mapping by evidential belief function, logistic regression and support vector machine models. GEOMAT Nat Haz Risk 9:1053–1070
Panahi M, Gayen A, Pourghasemi HR, Rezaie F, Lee S (2020) Spatial prediction of landslide susceptibility using hybrid support vector regression (SVR) and the adaptive neuro-fuzzy inference system (ANFIS) with various metaheuristic algorithms. Sci Total Environ 741:139937
Polykretis C, Chalkias C, Ferentinou M (2019) Adaptive neuro-fuzzy inference system (ANFIS) modeling for landslide susceptibility assessment in a Mediterranean hilly area. B Eng Geol Environ 78:1173–1187
Pradhan B, Seeni MI, Kalantar B (2017) Performance evaluation and sensitivity analysis of expert-based, statistical, machine learning, and hybrid models for producing landslide susceptibility maps. In: Laser scanning applications in landslide assessment. Springer international publishing. Springer, Cham, pp 193–232
Ramesh V, Anbazhagan S (2015) Landslide susceptibility mapping along Kolli hills Ghat road section (India) using frequency ratio, relative effect and fuzzy logic models. Environ Earth Sci 73:8009–8021
Regmi AD, Devkota KC, Yoshida K, Pradhan B, Pourghasemi HR, Kumamoto T, Akgun A (2014) Application of frequency ratio, statistical index, and weights-of-evidence models and their comparison in landslide susceptibility mapping in Central Nepal Himalaya. Arab J Geosci 7:725–742
Rezaei J (2015) Best-worst multi-criteria decision-making method. Omega 53:49–57
Roy J, Saha S (2019) Landslide susceptibility mapping using knowledge driven statistical models in Darjeeling District, West Bengal, India. Geoenvironmental Disasters 6(1):1–18
Roy J, Saha S, Arabameri A, Blaschke T, Bui DT (2019) A novel ensemble approach for landslide susceptibility mapping (LSM) in Darjeeling and Kalimpong districts, West Bengal, India. Remote Sens 11(23):2866
Rozos D, Pyrgiotis L, Skias S, Tsagaratos P (2008) An implementation of rock engineering system for ranking the instability potential of natural slopes in Greek territory. An application in Karditsa County. Landslides 5:261–270
Sahin EK (2020) Assessing the predictive capability of ensemble tree methods for landslide susceptibility mapping using XGBoost, gradient boosting machine, and random forest. SN Appl Sci 2(7):1–17
Sahin EK, Colkesen I, Kavzoglu T (2020) A comparative assessment of canonical correlation forest, random forest, rotation forest and logistic regression methods for landslide susceptibility mapping. Geocarto Int 35(4):341–363
Sharma S, Mahajan AK (2019) A comparative assessment of information value, frequency ratio and analytical hierarchy process models for landslide susceptibility mapping of a Himalayan watershed, India. Bull Eng Geol Environ 78(4):2431–2448
Shirzadi A, Bui DT, Pham BT, Solaimani K, Chapi K, Kavian A, Shahabi H, Revhaug I (2017) Shallow landslide susceptibility assessment using a novel hybrid intelligence approach. Environ Earth Sci 76(2):60
Sifa SF, Mahmud T, Tarin MA, Haque DME (2020) Event-based landslide susceptibility mapping using weights of evidence (WoE) and modified frequency ratio (MFR) model: a case study of Rangamati district in Bangladesh. Geol Ecol Landsc 4(3):222–235
Sun D, Xu J, Wen H, Wang D (2021) Assessment of landslide susceptibility mapping based on Bayesian hyperparameter optimization: a comparison between logistic regression and random forest. Eng Geol 281:105972
Turan İD, Özkan B, Türkeş M, Dengiz O (2020) Landslide susceptibility mapping for the Black Sea Region with spatial fuzzy multi-criteria decision analysis under semi-humid and humid terrestrial ecosystems. Theor Appl Climatol 1-14
Umar Z, Pradhan B, Ahmad A, Jebur MN, Tehrany MS (2014) Earthquake induced landslide susceptibility mapping using an integrated ensemble frequency ratio and logistic regression models in West Sumatera Province, Indonesia. Catena 118:124–135
Vakhshoori V, Zare M (2016) Landslide susceptibility mapping by comparing weight of evidence, fuzzy logic, and frequency ratio methods. Geomat Nat Hazards Risk 7(5):1731–1752
Wang Y, Hong H, Chen W, Li S, Pamučar D, Gigović L, Drobnjak S, Tien Bui D, Duan H (2019) A hybrid GIS multi-criteria decision-making method for flood susceptibility mapping at Shangyou, China. Remote Sens 11(1):62
Wang Y, Feng L, Li S, Ren F, Du Q (2020) A hybrid model considering spatial heterogeneity for landslide susceptibility mapping in Zhejiang Province, China. Catena 188:104425
Xiao T, Yin K, Yao T, Liu S (2019) Spatial prediction of landslide susceptibility using GIS-based statistical and machine learning models in Wanzhou County, Three Gorges Reservoir, China. Acta Geochimica 38:654–669
Yan F, Zhang Q, Ye S, Ren B (2019) A novel hybrid approach for landslide susceptibility mapping integrating analytical hierarchy process and normalized frequency ratio methods with the cloud model. Geomorphology 327:170–187
Youssef AM, Pradhan B, Jebur MN, El-Harbi HM (2015) Landslide susceptibility mapping using ensemble bivariate and multivariate statistical models in Fayfa area, Saudi Arabia. Environ Earth Sci 73:3745–3761
Yu C, Chen J (2020) Landslide susceptibility mapping using the slope unit for Southeastern Helong City, Jilin Province, China: a comparison of ANN and SVM. Symmetry 12(6):1047
Zhu AX, Miao Y, Wang R, Zhu T, Deng Y, Liu J, Lin y, Qin CZ, Hong H (2018) A comparative study of an expert knowledge-based model and two data-driven models for landslide susceptibility mapping. Catena 166:317–327
Code availability (software application or custom code)
Not applicable.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Data collection and material preparation were performed by SP. Development and design of the methodology and creation of the models were performed by SP and AN. BP consulted for the methodology application. AN was the supervisor of the work. The first draft of the manuscript was written by SP and AN, and BP commented on the previous versions of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Paryani, S., Neshat, A. & Pradhan, B. Spatial landslide susceptibility mapping using integrating an adaptive neuro-fuzzy inference system (ANFIS) with two multi-criteria decision-making approaches. Theor Appl Climatol 146, 489–509 (2021). https://doi.org/10.1007/s00704-021-03695-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-021-03695-w