
Abstract
In this paper, a novel active contour model based on hybrid image fitting energy which utilizes both global and local image information is proposed. Two fitting images are constructed to approximate the original image and the square of the original image. Both global and local image information are incorporated into these two fitting images. Based on these two fitting images, a hybrid image fitting energy, which is then minimized in a variational level set framework to guide the evolving contours to the desired boundaries. The proposed approach is validated by experiments on both synthetic and real images. The experiments demonstrate that the proposed model is more efficient and robust for segmenting different kinds of images compared with several typical active contour models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Image segmentation is an important task in many image processing and computer vision applications. However, due to the presence of noise, complex backgrounds, inhomogeneous intensities and low contrast, image segmentation is still a challenging problem. In the past few decades, various approaches have been proposed for image segmentation. Among them, active contour models (ACM) have attracted considerable interest. The active contour models treat image segmentation as an energy minimization problem. It can iteratively evolve the initial contour toward object boundaries by minimizing a given energy functional. The active contour models can be classified into two categories: edge-based methods and region-based methods. Edge-based active contour models [1,2,3,4] usually design a gradient stopping function to accurately segment object boundaries. The geodesic active contour (GAC) [2] model which is one of the best-known edge based models, utilizes the edge indicator depending on image gradient to construct forces to guide the contour toward the boundaries of the specific objects. This method is particularly effective in segmenting images with sharp gradients. Generally, edge-based models are very sensitive to noise and initializations. Unlike the edge-based models, region-based models often utilize the region statistical information to guide the evolution of a contour. Thus, they are less sensitive to noise and initializations. Furthermore, region-based methods perform better than edge-based active contour models for the segmentation of images with weak and missing boundaries. The region-based models can be further divided into ACMs based on global image information, the ACMs based on local image information and hybrid active contour models. Chan and Vese [5] proposed an active contour model (C–V model) based on Mumford-Shah [6] and level set method [7]. It is one of the most famous global image information based active contour models. However, these global based models may not work well for images with intensity inhomogeneity due to merely use of global intensity information. To overcome the difficulty caused by intensity inhomogeneity, Li et al. [8] proposed the region-scalable fitting active contour model (RSF model) which draws upon spatially varying local image information as constraints and has the ability to handle intensity inhomogeneity. Similarly, Lankton et al. [9] proposed a localized region-based active contour model, which utilizes a characteristic function defined by the radius parameter to extract the local image information. Zhang et al. [10] proposed a local image fitting (LIF) energy that minimizes the difference between the original image and a local binary fitting (LBF) [11] image. That is, the LIF model aims to look for a LBF-image that best fits the original image. Based on the LIF model, Wang et al. [12] composed a square fitting image to construct a local hybrid image fitting energy. Li et al. [13] proposed an active contour model based on local image statistics and kernel mapping strategies for the segmentation of image with intensity inhomogeneities. These models seem to produce good results only in such cases where the intensity inhomogeneity is slowly varying. Wang et al. [14] defined a hybrid energy functional (LGIF) with a local intensity fitting term used in LBF model and an auxiliary global intensity fitting term used in C–V model. Xie et al. [15] proposed an improved scheme of LIF model to combine both the global and local image information. However, to some extent, these models are still sensitive to initial contours, noise and severe intensity inhomogeneity which limit their practical applications. More advanced features(e.g., structure tensors [16], texture features [17], salient information [18]) are also employed to get more robust segmentation results. Some related methods can be found in Refs. [19,20,21,22,23,24,25,26,27,28].
In this paper, two fitting images \(I^f\) and \(I^s\) are constructed to approximate the original image I and the square of the original image \(I^2\). Both global and local image information are incorporated into these two fitting images. We construct a hybrid energy functional based on the Kullback–Leibler divergence to evaluate the difference between I and \(I^2\) and two constructed fitting images \(I^{f}\) and \(I^{s}\) respectively. Minimizing this energy functional in a variational level set formulation will guide the contours toward the desired boundaries. The proposed method has been tested on both synthetic and real images and the experimental results show that the hybrid energy effectively drives the active contour to the object boundary compared to state-of-art methods.
2 Related Works
Let \(I: \Omega \rightarrow R\) be the input image. C is a closed contour represented by a level set function \(\phi (x) , x \in \Omega \), that is \(C:= \{\ x \in \Omega | \phi (x)=0\}\ \). The region inside the contour is represented as \( \Omega _{in}=\{\ x \in \Omega | \phi (x) > 0 \} \) and the region outside the contour is \(\Omega _{out}= \{ \ x \in \Omega | \phi (x) < 0 \} \). Then the energy functional of the C–V model can be reformulated by the level set [7] function:
where \(\mu ,\lambda _1 ,\lambda _2\) are fixed positive constants. The first term is the regularization term which helps to maintain the smoothness of the contour. \(u_1,u_2\) are two constants that represent the average intensities inside and outside the contour respectively. However, the C–V model cannot achieve satisfying segmentation results when the intensity of an image is inhomogeneous since the model assumes that the image domain is composed of some homogeneous parts. To overcome this problem, Li et al. [8] proposed the RSF model by embedding the local image information into the C–V model. Instead of using the global average intensities inside and outside the contour, they used a Gaussian kernel with a controllable scale to define the region fitting term in the energy functional. The energy functional is defined as:
where \(\mu ,\lambda _1 ,\lambda _2\) are the same as in the C–V model, \(u_1,u_2\) are smooth functions to approximate the local image intensities inside and outside the contour C. \(K_\sigma (x-y)\) is the Gaussian kernel function with variation \(\sigma ^2\):
The LIF model [10] was proposed by introducing the local image fitting energy to extract the local image information. A local fitted image \(I_{LFI}\) is composed to approximate the original image I.
\(I_{LFI}\) denotes the local fitted image to approximate the original image I. \(m_1\) and \(m_2\) are local intensity averages in the local region defined by a Gaussian window function \(W_k\) with standard deviation \(\sigma \) and of size \((4k+1)\times (4k+1)\), where k is the greatest integer smaller than \(\sigma \). A local image fitting energy functional by minimizing the difference between the fitted image and the original image is formulated as:
This model is able to achieve similar segmentation results as the RSF model but with less computational time. However, it may also get unprecise segmentation results when the images to be segmented are with severe intensity inhomogeneous.
3 The Proposed Model
The C–V model approximates the images with piecewise constant functions. The original image I can be approximate by \(u_1\) and \(u_2\) as:
where \(H_2=1-H_1\). The data fitting term of the C–V model can be written as:
By using the approximation (7), the data fitting term becomes:
This means that, during the minimization of the C–V energy functional, \(u_1^2H_1(\phi )+u_2^2H_2(\phi )-I^2\) is also minimized. In other words, \(I^2\) can also be approximated by \(I^2=u_1^2H_1(\phi )+u_2^2H_2(\phi ).\) Inspired by the LIF model [10] and the LGIF [14] model, we can construct the following two fitting images: \(I^f\) and \(I^s\) to incorporate both global and local image information. These two fitting images are defined as follows:
Here \(c_1\) and \(c_2\) are global intensity averages in \(\Omega _{in}\) and \(\Omega _{out}\), \(m_1\) and \(m_2\) are local intensity averages defined in 5. \(I^{f}\) and \(I^{s}\) are two fitting images to approximate images I and \(I^2\) respectively. The square image \(I^2\) usually shows higher contrast than the original image. From the definition of local fitted image in 5, we can come up with a logical idea that using the combination of the square of \(c_1\), \(c_2\) and \(m_1\), \(m_2\) to approximate the original image and the square of the original image. In this way, \(I^f\) and \(I^s\) combined both global and local image information.
We use the Kullback–Leibler [29] divergence to measure the difference between the images. The hybrid energy functional of the proposed algorithm is:
To obtain smooth contours, two regularization terms \(P(\phi )=\frac{1}{2}\int (|\nabla \phi |-1)^2dx\) and \(L(\phi )=\int |\nabla H(\phi )|dx\) defined in [8] were introduced. The total energy functional of the proposed model becomes:
where \(\mu \) and \(\nu \) are weighting parameters for the two regularization terms. By taking the first variation of the energy functional with respect to \(\phi \), we can get the updating equation of \(\phi \):
Here \(e_1\) and \(e_2\) has the following form:
4 Experiment Results
The proposed algorithm is implemented with Matlab R2011a on a PC of CPU 2.5 GHz, RAM 6.00G. In this section, we apply the proposed method to synthetic images and real images of different modalities. For the experiments in Sects. 4.1 to 4.3, we keep the parameters as follow: \(timestep=0.01\), \(\epsilon =1\), \(\omega _1=\omega _2=0.01\), \(\mu =2.8\), whereas the parameters \(\lambda _1, \lambda _2, \sigma \) and \(\nu \) should be tuned for different kinds of images.
4.1 Application on Real Images and Synthetic Images
Figure 1 shows the segmentation results of the proposed model for both synthetic and real images, which are with inhomogeneous intensities and nonuniform illumination. Three randomly chosen initial rectangular contours are shown in the first row. The \(I^f\) and \(I^s\) are shown in the last two rows respectively. From Fig. 1, both the \(I^s\) and \(I^f\) can effectively emphasize the desirable objects and the \(I^s\) can significantly reduce the adverse influence of complicated image background in image segmentation. Due to the existence of both global and local image information in \(I^f\) and \(I^s\), the proposed model can successfully capture the boundaries of the desired objects with different texture characteristics.

Segmentation results of the proposed model for both synthetic and real images displayed in different columns by changing parameter values (\(\lambda _1=0.1\), \(\lambda _2=0.6\), \(\sigma =3\) and \(\nu =90\) for the first image, \(\lambda _1=0.5\), \(\lambda _2=0.3\), \(\sigma =3\) and \(\nu =10\) for the last two images). Row 1: initial rectangle contours. Row 2: final segmentation results. The last two rows show the two fitting images \(I^f\) and \(I^s\) respectively
4.2 Application on Medical Images
Figure 2 shows the segmentation results of the proposed algorithm on clinically medical images with inhomogeneous intensities and chaotic backgrounds. The proposed algorithm successfully identifies the object boundaries in these images. Due to the usage of both global and local information in the fitting images \(I^{f}\) and \(I^{s}\), the proposed algorithm can efficiently drive the contour to the desired object boundaries with different texture characteristics and reduce the influence of chaos in backgrounds.

Segmentation results of medical images. The first and third rows: Original images with initializations (blue contours). The second and fourth rows: the segmentation results (red contours). For the first image in the first row, \(\lambda _1=1,\lambda _2=0.08,\sigma =3,\nu =4\). \(\lambda _1=0.5,\lambda _2=0.2,\sigma =3,\nu =10.8\) for the second and third images in the same row. For the first image in the third row, \(\lambda _1=0.9,\lambda _2=0.1,\sigma =3,\nu =4\). \(\lambda _1=0.45,\lambda _2=0.01,\sigma =3,\nu =2.3\) for the second image in the third row. \(\lambda _1=0.45,\lambda _2=0.01,\sigma =5,\nu =4\) for the last image in the third row

Images with different initializations are shown in the first column. In the second column, segmentation results of the proposed method are presented. The segmentation results of the C–V, RSF, LIF and LGIF models are shown in the last four columns respectively
4.3 Robustness to the Initial Contours, Intensity Inhomogeneity and Noise
We compared the proposed model with some of the famous active contour modelsFootnote 1 (i.e. the C–V model [5], the RSF model [8], the LIF model [10] and the LGIF model [14]).
In Fig. 3, we show the segmentation results of the proposed model with different initializations. Two intensity inhomogeneous images are used in this experiment. In the first column, these two intensity inhomogeneous images with three different initializations are shown. Segmentation results of the proposed algorithm are shown in the second column. The segmentation results of the C–V, RSF, LIF and LGIF models are presented in the last four columns respectively. Generally, the RSF, LIF and the LGIF models have better performance than the C–V model. But they are sensitive to initializations to some extent. The LGIF model utilizes both global and local image information. But for some of the initializations in this paper, it can not get correct segmentation results. Due to the usage of the \(I^f\) and \(I^s\) which contains the higher order of image information, the proposed model is less sensitive to initializations compared to the other four active contour models.
The proposed algorithm is also used to segment images with extremely inhomogeneous intensities. Three images are shown in the first column in Fig. 4. Initializations are blue rectangles, and the segmentation results of the proposed algorithm are shown in the third column. The segmentation results of the C–V, RSF, LIF and LGIF models are shown in the last four columns respectively. The LIF and LGIF models achieve better segmentation results than the C–V and RSF models. But for the segmentation of the last image with extremely inhomogeneous intensities, both the LIF and LGIF models missed some part of weak boundaries. In Fig. 4, we can see that, for these intensity inhomogeneous images, the proposed hybrid energy functional can guide the active contours to the correct object boundaries. This experiment shows that for the segmentation of intensity inhomogeneous images, the proposed model behave superior to the other four active contour models.

The first column: the original intensity inhomogeneous images. Second column: initial contours shown in blue rectangles. The segmentation results of the proposed model, the C–V model, the RSF model, the LIF model and the LGIF model are shown in the last five columns respectively
In Fig. 5, we show the noise robustness of the proposed algorithm. We show the segmentation results of images with the different level of Gaussian noise. The first column shows the original clean image and images with Gaussian white noise with mean 0, variances 0.01, 0.02, 0.04 and mean 0.01, variance 0.008. The second column shows the segmentation results of the proposed method, the third column shows the segmentation results of the C–V model, the fourth column shows the segmentation results of the RSF model, the fifth column shows the segmentation results of the LIF model and the last column shows the segmentation results of the LGIF model. The proposed model yields the best overall performance for the five images. The LGIF model behaves better than the C–V, RSF and LIF models. The LGIF model can also get the boundaries of the objects. However, for the segmentation of last two images, the proposed model is more accurate. This experiment shows that the proposed model is robust to some extent against Gaussian white noise in segmentation compared with the other four models.

Segmentation results of noisy images
4.4 Results on Large-Scale Image Set
To further test the effectiveness of the proposed model, we did experiments based on the MSRA dataset [30]. The MSRA dataset contains 1000 color images and the ground truths. We also quantitatively assessed the performance of these models using the Dice Similarity Coefficient (DSC) [31] defined as:
where A is the segmentation results of a given algorithm, B is the ground truth. The higher DSC is, the more accurate the segmentation result is.
Table 1 shows the Dice of the proposed algorithm and the other four methods. It can be seen that among all the tested models, the proposed model has the highest Dice. Table 2 illustrates the average executive times of the five models, and the results show that the proposed algorithm performs faster than the LGIF model but a little bit slower than RSF model, it is because the proposed model needs to generate two fitting images \(I^f\) and \(I^s\). In Fig. 6, we show some of the segmentation results of the five models from the MSRA dataset. Natural images are usually have more information and more complex backgrounds, so they are more difficult to be segmented. The C–V model mainly considers the global intensity information, the RSF and LIF models consider the intensity information in local regions. From Fig. 6 we can see that, the segmentation results of these three models contain the area of background in different extent. Due to the usage of both global and local intensity information, the LGIF performs better than the other three methods but the structures in the images cannot be completely detected. However, due to the usage of both global and local intensity information in the original image and the square image, the proposed model has the overall best performance.

The first column: the original images. The second column: the ground truths. The last five columns: the segmentation results of the C–V model, the RSF model, the LIF model, the LGIF model and the proposed method
4.5 Initialization and Parameter Selection for the MSRA Dataset
For most of the active contour models, different positions of initial contours may lead to different segmentation results. In order to achieve unprejudiced initializations for each algorithm, the initial contours are obtained by threshold the saliency map achieved by Cheng et al. [32]. The thresholding value is set to be 0.25.
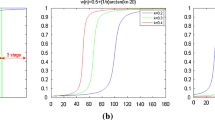
There are totally six parameters in the proposed model: \(\lambda _1, \lambda _2, \mu , \nu , \omega _1\) and \(\omega _2\). Although the proposed model shows a relatively high performance, it is not easy to achieve an optimal tradeoff among different weighting parameters. In our experiments on MSRA dataset, we empirically set \(\mu =20\) and \(\nu =0.02\times col \times row\), where \(col\times row\) denotes the size of the images to be segment. For simplicity, we set \(\omega _1 = \omega _2\). In this way, \(\lambda _1, \lambda _2\), and \(\omega \) have influence on the final segmentation results. In this experiment, we only focus on the effectiveness of \(\omega \), so \(\lambda _1\) and \(\lambda _2\) are also empirically set to 0.3 and 0.06 based on our previous experiments. The selection of \(\omega \) is based on the following experiment. It is shown that, \(\omega \) controls the influence of the global image information in the energy functional, so when the intensity inhomogeneity in the image is more severe, the parameter value \(\omega \) should be chosen smaller. 200 images from the MSRA dataset were randomly selected to calculate the mean DSC by using \(\omega \in [0.01, 0.2]\). The following figure (Fig. 7) shows the DSCs of using different \(\omega \). Based on this experiment, for the segmentation of the MSRA dataset in this paper, we set \(\omega =0.02\). It is worth mentioning that, for the segmentation of MSRA dataset, except for the \(\omega \), the other parameters are fixed. Our tests in previous sections show that if the parameters are further optimized for each single image, we could get better segmentation results.

The DSCs of using different \(\omega \)
4.6 Comparison with CNN-Based Segmentation Method

The first row: the original images. The second to sixth rows: the segmentation results of the C–V model, the RSF model, the LIF model, the LGIF model and the U-net. The segmentation results of the proposed method and the ground truths are shown in the last two rows respectively
Recently, deep convolutional networks have achieved a great success in image analysis such as classification, detection and segmentation [33,34,35,36,37]. U-net [36] is a representative convolution network for image segmentation. In this paper, we also compare the proposed algorithm with the U-net on the MSRA dataset. 200 images are randomly selected to test the performance of the U-net and the other 800 images are used to train the U-net. The DSC of the U-net and the proposed model on 200 images is \(63.9\%\) and \(68.8\%\) respectively. Usually the U-net can achieve better segmentation results when the training dataset contains sufficient images. However, the size of the current training dataset is small. 800 images are not enough for training the network. We believe that if there are more images for training, the segmentation performance of the U-net can be improved. The difference between the U-net and the proposed model is that the proposed model is an unsupervised model and the U-net is a supervised model which needs training samples and limits its application sometimes. In Fig. 8, we show some of the segmentation results of the proposed model and the C–V, the RSF, the LIF, the LGIF and the U-net models.
5 Conclusion
In this paper, a novel hybrid region-based active contour model is proposed for image segmentation. The energy functional of the proposed model is based on the quantification of the Kullback–Leibler divergence of the original image I and \(I^2\) and two constructed fitting images \(I^f\) and \(I^s\). The \(I^f\) and the \(I^s\) utilize the global and local image information in I and \(I^2\). The square operation of the original image can somehow enhance the contrast of the original image. It is supplementary of the intensity information of the original image. Experimental results show that the proposed model is capable of segmenting images with intensity inhomogeneities, robust to noise and less sensitive to initializations. Segmentation results on both synthetic and real natural images from MSRA dataset show that, compared to the-state-of-art methods, the proposed segmentation model has a relatively better performance.
In our current model, the only used information of the images is the intensity. More image information like texture, is not considered into our model. The performance of the proposed model still has space for further improvements by utilizing more image information. In our future work, we will consider texture information to enhance the segmentation results for images with clutter background. In addition, we will also try to find an automatic way to calculate the weights during evolution.
Notes
The matlab source code of the C–V, the RSF, the LIF and the LGIF algorithms can be found from http://www.engr.uconn.edu/~cmli/, http://www.kaihuazhang.net/ and https://www.unc.edu/~liwa/.
References
Kass M, Witkin A, Terzopoulos D (1991) Snake: active contours model. Int J Comput Vis 1(4):1167–1186
Caselles V, Kimmel R, Sapiro G (1998) Geodesic active contours. Int J Comput Vis 22(1):61–79
Xu C, Prince JL (1998) Snakes, shapes, and gradient vector flow. IEEE Trans Image Process 7(3):359–369
Kichenassamy S, Kumar A, Olver P, et al (1995) Gradient flows and geometric active contour models. In: Proceedings of international conference on computer vision, pp 810–815
Chan T, Vese L (2001) Active contours without edges. IEEE Trans Image Process 10(2):266–277
Mumford D, Shah J (1989) Optimal approximations of piecewise smooth functions and associated variational problems. Commun Pure Appl Math 42:577–685
Osher S, Sethian JA (1998) Fronts propagating with curvature-dependent speed: algorithms based on Hamilton–Jacobi formulations. J Comput Phys 79(1):12–49
Li C, Kao C, Gore J, Ding Z (2008) Minimization of region-scalable fitting energy for image segmentation. IEEE Trans Image Process 17:1940–1949
Lankton S, Tannenbaum A (2008) Localizing region based active contour. IEEE Trans Image Process 17(11):2029–2039
Zhang K, Song H, Zhang L (2010) Active contours driven by local image fitting energy. Pattern Recognit 43(4):1199–1206
Li C, Kao C, Gore J, Ding Z (2007) Implicit active contours driven by local binary fitting energy. In: Proceedings of IEEE conference on computer vision and pattern recognition (CVPR). IEEE Computer Society, Washington, DC, pp 1–7
Wang L, Chang Y, Wang H et al (2017) An active contour model based on local fitted images for image segmentation. Inf Sci 418:61–73
Li Y, Cao Q, Yu Q et al (2018) Fast and robust active contours model for image segmentation. Neural Process Lett 1:1–22
Wang L, Li C, Sun Q et al (2009) Active contours driven by local and global intensity fitting energy with application to brain MR image segmentation. Comput Med Imaging Graph 33(7):520–531
Xie X, Wang C et al (2013) Active contours model exploiting hybrid image information: an improved formulation and level set method. J Comput Inf Syst 9(20):8371–8379
Ge Q, Li C, Shao W et al (2015) A hybrid active contour model with structured feature for image segmentation. Signal Process 108:147–158
Dai L, Ding J, Yang J (2015) Inhomogeneity-embedded active contour for natural image segmentation. Pattern Recognit 48(8):2513–2529
Kim W, Kim C (2013) Active contours driven by the salient edge energy model. IEEE Trans Image Process 22(4):1667–1673
Piovano J, Rousson M, Papadopoulo T (2007) Efficient segmentation of piecewise smooth images. In: SSVM07, Ischia, pp 709–720
Zhang Z, Xu Y, Shao L et al (2017) Discriminative block-diagonal representation learning for image recognition. IEEE Trans Neural Netw Learn Syst 29(7):3111–3125
Li X, Li C, Fedorov A et al (2016) Segmentation of prostate from ultrasound images using level sets on active band and intensity variation across edges. Med Phys 43:3090–3103
Zhang Z, Liu L, Shen F, Shen HT, Shao L (2018) Binary multi-view clustering. IEEE Trans Pattern Anal Mach Intell 1:83
Zhang Z, Shao L, Xu Y, Liu L, Yang J (2017) Marginal representation learning with graph structure self-adaptation. IEEE Trans Neural Netw Learn Syst 23:1
Ma Q, Peng J, Kong D (2017) Image segmentation via mean curvature regularized Mumford–Shah model and thresholding. Neural Process Lett 3:1–15
Gao J, Dai X, Zhu C et al (2017) Supervoxel segmentation and bias correction of MR image with intensity inhomogeneity. Neural Process Lett 8:1–14
Zhang Z, Li F, Zhao M et al (2017) Robust neighborhood preserving projection by nuclear/L2,1-norm regularization for image feature extraction. IEEE Trans Image Process 26(4):1607–1622
Ye Q, Fu L, Zhang Z et al (2018) Lp-and Ls-norm distance based robust linear discriminant analysis. Neural Netw 105:393–404
Zhang Y, Zhang Z, Qin J et al (2018) Semi-supervised local multi-manifold Isomap by linear embedding for feature extraction. Pattern Recognit 76:662–678
Kullback S, Leibler RA (1951) On information and sufficiency. Ann Math Stat 22(1):79–86
Liu T, Sun J, Zheng N et al (2007) Learning to detect a salient object. In: Proceedings of IEEE international conference on computer vision pattern recognition, pp 1–8
Dice LR (1945) Measures of the amount of ecologic association between species. Ecology 26(3):297–302
Cheng MM, et al (2011) Global contrast based salient region detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 409–416
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: NIPS, pp 1097–1105
Szegedy C, Liu W, Jia Y, Sermanet P, Reed C, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In: IEEE conference on computer vision and pattern recognition, Boston, pp 1–9
Long J, Shelhamer E, Darrell T (2015) Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3431–3440
Ronneberger O, Fischer P, Brox T (2015) U-net: convolutional networks for biomedical image segmentation. In: International conference on medical image computing and computer-assisted intervention. Springer, Cham, pp 234–241
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Acknowledgements
The author (Hairong Liu) was supported by Natural Science Foundation of Jiangsu Province (BK20140965) and Natural Science Foundation of the Jiangsu Higher Education Institutions of China (14KJB110010). The author (Yu Xing) was supported by the Natural Science Foundation for Youths of Jiangsu Province (BK20171072), the Natural Science Foundation of the Higher Education Institutions of Jiangsu Province (17KJB110007) and the Open Project of Jiangsu Key Laboratory of Financial Engineering (NSK2015-15).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Li, X., Liu, H. & Xing, Y. A Hybride Active Contour Model Driven by Global and Local Image Information. Neural Process Lett 50, 989–1003 (2019). https://doi.org/10.1007/s11063-019-10004-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-019-10004-0