
Abstract
This paper presents an audio watermarking technique based on singular value decomposition (SVD) and fractional Fourier transform (FRT). The basic idea of this technique is to implement SVD watermarking on the audio signals in the FRT domain due to its recommended degree of security resulting from using a rotation angle in addition to the frequency-domain transformation. The SVD has an invariance to changes in the signal after watermark embedding. Hence, the proposed technique has a large degree of security and resistance to attacks. This technique is based on embedding an image watermark in either the audio signal or a transformed version of this signal. Experimental results show that watermark embedding in the FRT of an audio signal achieves less distortion of the audio signal in the absence of attacks. In the presence of attacks, it is recommended that the embedding is performed in the FRT of the audio signal to maintain a high detection correlation coefficient between the original watermark and the obtained watermark. A segment-based implementation of the proposed audio watermarking technique is also presented. This implementation succeeds in obtaining a high detection correlation coefficient in the presence of severe attacks. It is noticed from the results that in the presence of attacks, the SVD watermarking in the FRT domain with a phase angle of 5π/4 is better for watermark detection than watermarking using other angles in the FRT domain.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Watermarking is a digital signal processing branch, which attracts much of the researchers' interests. There are several types of watermarking schemes such as audio watermarking, image watermarking and video watermarking [29, 46]. So many approaches have been proposed for image and video watermarking. Audio watermarking is the process of information embedding in audio signals for identification of the source of information, authentication of the owner, copyright protection, and copy control [11, 17, 21, 31, 32]. Therefore, digital audio watermarking can also be classified as the process in which some digital data is embedded into the audio file in such a way that the audibility of the audio file is not affected. The least significant bit (LSB) was the first research proposal in digital watermarking.
The basic idea of audio watermarking depends on processing of audio signals in the time or transform domains [29]. The Fourier transform and its versions can be used for audio watermarking. The Fourier transform transforms a time-domain signal into a frequency-domain signal. On the other hand, the inverse Fourier transform is a transform of a frequency-domain signal into a time-domain signal. However, the FRT [29, 32] transforms a signal (either in the time domain or frequency domain) into an intermediate domain between time and frequency. It is some sort of rotation in the time-frequency domain.
In [1], the mathematical SVD technique has been utilized for audio watermarking in time and transform domains. Firstly, the audio signal in time or an appropriate transform domain is transformed to a 2-D format. The SVD algorithm is applied on this 2-D matrix, and an image watermark is added to the matrix of singular values (SVs) with a small weight to guarantee the possible extraction of the watermark without introducing harmful distortions to the audio signal. The transformation of the audio signal between the 1-D and 2-D formats is performed with the well-known lexicographic ordering method used in image processing. A comparison study was presented in this paper between the time and transform domains as possible hosting media for watermark embedding. Experimental results are in favor of watermark embedding in the time domain if the distortion level in the audio signal is to be kept as low as possible with a high detection probability. This presented algorithm was utilized also for embedding of chaotic encrypted watermarks to increase the level of security. Experimental results showed that watermarks embedded with this algorithm can survive several attacks. A segment-by-segment implementation of this algorithm was also presented to enhance the detectability of the watermark in the presence of severe attacks.
In [4], another approach for audio watermarking using the SVD technique has been presented. This approach can be used for data hiding in the audio signals transmitted over wireless networks and for multi-level security systems. This approach is based on embedding a chaotic encrypted watermark in the singular values of the audio signal after transforming it into a 2-D format. The selection of the chaotic encryption algorithm for watermark encryption is attributed to its permutation nature, which resists noise, filtering, and compression attacks. After watermark embedding, the audio signal is transformed again into a 1-D format. The transformation between the 1-D and 2-D formats is performed with the well-known lexicographic ordering method used in image processing. The presented approach can be implemented on the audio signal as a whole or on a segment-by-segment basis. The segment-by-segment implementation allows embedding the same watermark several times in the audio signal, which enhances the detectability of the watermark in the presence of severe attacks. Experimental results showed that the presented audio watermarking approach maintains the high quality of the audio signal and that the watermark extraction, and decryption are possible even in the presence of attacks.
As the security is an important issue in wireless networks, the authors of [13] discussed audio watermarking as a tool to improve the security of image communication over the IEEE 802.15.4 ZigBee network. The adopted watermarking method implements the SVD technique. This method is based on embedding a chaotic encrypted image in the SVs of the audio signal after transforming it into a 2-D format. The objective of chaotic encryption is to enhance the level of security and resist different attacks. Experimental results showed that the SVD audio watermarking method maintains the high quality of the audio signals and that the watermark extraction and decryption are possible even in the presence of attacks over the ZigBee network.
The SVD audio watermarking algorithm can be implemented on audio signals in time domain or in another appropriate transform domain and can be applied to the audio signal as a whole or on a segment-by segment basis. The authors of [2] suggested the utilization of SVD digital audio watermarking to increase the security of automatic speaker identification (ASI) systems and presented a study for the effect of watermarking on the ASI system performance. The speaker recognition system works by generating a database of speakers' features using the mel frequency cepstral coefficients (MFCCs) and polynomial shape coefficients extracted from each speaker signal after it is lexicographically ordered into a 1-D signal. A matching process is performed for any new signal to determine if it belongs to the database or not using a trained neural network. Experimental results showed that the SVD audio watermarking does not degrade the ASI system performance, severely. So, it can be used with ASI to increase security. Also, it was shown that the segment-by-segment watermarking in the time domain achieves the highest detectability of the watermark. So, we can say that it is recommended to use the segment-by-segment SVD audio watermarking with ASI systems implementing features extracted from the DCT or the DWT.
In [15], digital watermarking technology was utilized in solving the problem of copyright protection, data authentication, content identification, distribution, and duplication of the digital media due to the great developments of computers and Internet technology. In recent times, protection of digital audio signals has captured a great attention of the researchers. The authors of [15] presented an audio watermarking scheme based on discrete wavelet transform (DWT), SVD, and quantization index modulation (QIM) with a synchronization code embedded within double encrypted watermark images or logos into stereo audio signals. In this scheme, the original audio signal is split into blocks and each block is decomposed with two-level discrete wavelet transform, and then the approximate low-frequency sub-band coefficients are decomposed by the SVD giving a diagonal matrix. The prepared watermarking and synchronization code bit streams are embedded into the diagonal matrix using QIM. Then, the inverse singular value decomposition (ISVD) and inverse discrete wavelet transform (IDWT) are applied to obtain the watermarked audio signal. The watermark can be blindly extracted without knowledge of the original audio signal. Experimental results showed that the transparency and imperceptibility of the presented algorithm are satisfied, and that the robustness is strong against popular audio signal processing attacks. High watermark payload was achieved, and performance analysis was presented.
In [7], desired properties and possible applications of audio watermarking algorithms have been considered. A special attention was given to statistical methods working in the Fourier domain. The authors presented a solution that achieves robust watermarking of audio signals. Experimental results in [7] showed good robustness against MP3 compression and other common signal processing manipulations. In [5], digital audio watermarking was used for copyright owner identification. A number of audio watermarking techniques was presented. These techniques exploit different ways in order to embed a robust watermark and to maintain the original audio signal fidelity. Alsalami et al. presented a tutorial on general digital watermarking principles and focused on describing digital audio watermarking techniques [5]. These techniques are classified according to the domain, in which the watermark is embedded.
In [40], digital audio watermarking was used to hide the information signal in a digital form based on spread spectrum. The identity of the owner of the audio file becomes invisible in the audio file. In [40], various methods of audio watermarking have been discussed to protect ownership. Elimination of the watermark from the data is very difficult, which is a desired property for ownership protection.
Chen et al. presented an adaptive audio watermarking method using wavelet-based entropy (WBE) [10]. This method converts low-frequency coefficients of the DWT into the WBE domain, and this is followed by the calculation of mean values as well as the derivation of some essential properties of the WBE. A characteristic curve relating the WBE with the DWT coefficients was also presented. The quality of the watermarked audio signal is optimized in this method. In the watermark detection process, the watermark can be extracted using only values of the WBE. The performance of this watermarking method was analyzed in terms of the signal-to-noise ratio (SNR), mean opinion score and robustness. Experimental results confirmed that the embedded data resists the common attacks like re-sampling, MP3 compression, low-pass filtering, and amplitude scaling.
With the increasing usage of digital multimedia, the protection of intellectual property rights has become a very important issue. Digital watermarking is now drawing attention as a new trend for protecting multimedia content from unauthorized copying. The need for audio watermarking along with its important properties was explained in [18]. Goenka et al. brought to view the works done by various authors on digital audio watermarking.
Arnold et al. considered the desired properties and possible applications of audio watermarking algorithms [6]. Special attention was given to statistical methods working in the frequency domain. They presented a solution to guarantee robust watermarking of audio signals that reflects the security properties. Experimental results showed good robustness of their algorithm to MP3 compression and other common signal processing manipulations. Enhancements to this algorithm were also discussed in [6].
The strength of audio signal modifications allowed in audio watermarking is limited by the necessity to produce an output signal that is perceptually similar to the original one. This requirement puts some restrictions on any watermarking method [8]. The watermarking method presented in [8] does not require the use of the original signal for watermark detection. The watermark signal is generated using a key, i.e., a single number known only to the copyright owner is embedded. Watermark embedding in this method depends on the audio signal amplitude and frequency in a way that minimizes the audibility of the watermark signal. The embedded watermark is robust to common audio signal manipulations like MPEG audio coding, cropping, time shifting, filtering, resampling, and requantization.
The rest of this paper is organized as follows. In section 2, the traditional audio watermarking schemes are explained. In section 3, we introduce the proposed audio watermarking technique in detail. The steps of FRT embedding and extraction for audio signals are given in section 3. Section 4 covers the different objective quality metrics for audio signals. Experimental results are shown in section 5. The concluding remarks are presented in section 6.
2 Traditional audio watermarking schemes
Time-domain audio watermarking methods can be divided into blind and non-blind methods. In blind audio watermarking methods, no side information about the watermarking process is used in the watermark extraction or verification [9].
Huynh et al. presented a blind watermarking method based on wavelet tree quantization using an adaptive threshold [26]. On the other hand, in non-blind watermarking methods, some side information is used in the watermark detection or verification. One of the most popular non-blind audio watermarking methods is the SVD watermarking. In this method, some side information regarding the Eigen distribution of original signals is used in the detection process. This side information may appear as a redundancy, but it contributes to enhancing the detection or verification performance.
Different domains have been investigated for embedding useful information in audio signals. This useful information is represented as images. These domains include Fourier domain, wavelet domain empirical mode decomposition (EMD) domain, and discrete coine transform (DCT) domain [3].
Several attempts have been presented to embed images inside audio signals through some sort of decomposition. Some of these attempts tried to build multi-level security systems with the help of audio watermarking [20, 24, 25, 30, 37, 45, 48, 49]. In this framework, both audio watermarking, audio encryption, and speaker identification have been used in a security framework. The sensitivity of speaker identification to audio watermarking has been investigated in [2].
The FRT is one of the discrete transforms with sophisticated characteristics. It has a rotation angle to control the transform plane between time and Fourier planes. The selection of this angle with certain values may lead to better security. So, if we think to benefit from the FRT in watermark embedding, we can make use of the security aspects of this transform. That is why we investigate the process of watermark embedding in the FRT domain in this paper.
2.1 Discrete transforms for audio watermarking
In this section, the DWT, DCT, Discrete Sine Transform (DST), and Discrete Fourier Transform (DFT) are briefly summarized.
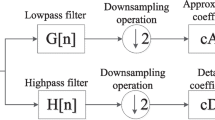
The idea of the DWT is to represent a signal as a series of approximations (low-pass version) and details (high-pass version). The signal is low-pass filtered with H0(z) to give an approximation signal and high-pass filtered with H1(z) to give a detail signal. The wavelet basis function is chosen such that a perfect reconstruction can be achieved. Figure 1 shows a single-level wavelet decomposition and reconstruction filter bank. For this filter bank, to achieve perfect reconstruction, the following two equations must be satisfied [19, 27, 28, 38, 42, 44].

The two-band decomposition-reconstruction wavelet filter bank
The approximation and detail components of the signal are then padded together to form 1-D vectors which can be used after that for watermark embedding.
The DCT expresses the samples of the audio signal in terms of a sum of cosine functions oscillating at different frequencies. The DCT is defined by the following equation [19, 27, 28, 38, 42, 44]:
where.
\( w(k)=\Big\{{\displaystyle \begin{array}{llll}\frac{1}{\sqrt{N}}& & & k=0\\ {}\sqrt{\frac{2}{N}}& & & k=1,......,N-1\end{array}} \)
The DCT has a sophisticated characteristic of energy compaction by collecting most of the signal energy in few samples leaving the other samples very small in amplitude. This characteristic can be exploited in audio watermarking to reduce the deterioration in the audio signal due to watermarking.
The Inverse Discrete Cosine Transform (IDCT) is represented by:
The DST is the same as the DCT, but it uses sine functions oscillating at different frequencies [19, 27, 28, 38, 42, 44]. The DST is defined as follows:
It has an advantage of energy compaction that is useful in audio watermarking. The Fourier transform gives a complex basis function. It can be shown that the DFT multiplexes both the DCT and the DST [20, 24, 37, 45, 48, 49]:
The Fourier transform (FT) is one of the most frequently used tools in signal analysis. A generalization of the FT is the FRT. It has been presented in [33] and has become a powerful tool for time-varying signal analysis. It has a high degree of security as it has an additional control parameter, which is the rotation angle. Both time and frequency domains are special cases of the FRT [14]. In this type of analysis, it is customary to use the time-frequency plane, with two orthogonal time and frequency axes. Because the successive two forward FT operations will result in a reflected version of the original signal, the FT can be interpreted as a rotation of the signal by an angle of π/2 in the time–frequency plane. The FRT performs a rotation of the signal in the continuous time–frequency plane to any angle. The FRT is also called a rotational FT or an angular FT in some documents.
Besides being a generalization of the FT, the FRT is related to other time-varying signal analysis tools, such as the Wigner distribution, the short-time FT, and the wavelet transforms. The applications of the FRT include solving differential equations [33], quantum mechanics, optical signal processing, time-varying filtering and multiplexing, swept-frequency filtering, pattern recognition, and time–frequency signal analysis [35]. In [36], the authors gave 6 different possible definitions of the FRT. The more intuitive way of defining the FRT is by generalizing this concept of rotation with an angle that is π/2 in the classical FT case as shown in Fig. 2. As the classical FT corresponds to a rotation in the time–frequency plane over an angle α = lπ/2, the FRT corresponds to a rotation over an arbitrary angle α = aπ/2 with a ϵ R. This FRT operator is denoted as Fα.

a The original coordinates (t, w) rotate to the coordinates (u, v) with an angle α in the time-frequency plane, b FRT of a rectangle, computed at various angles. Blue line: real part. Green line: imaginary part
The fractional order of the transform is usually denoted as “a”. Due to FRT properties, we can usually limit the discussion to the range 0 ≤ a ≤ 1. When a = 0, the FRT coincides with the identity operator, and when a = 1, it coincides with the Fourier operator. The FRT of a signal x(t) is denoted by Xα(u). The free variable “u” can be interpreted as some hybrid time/frequency variable. When a = 0, it is a time variable, and when a = 1, it is a frequency variable. As “a” takes values from 0 to 1, the interpretation of “u” changes gradually from “time” to “frequency,” reflecting temporal changes in the frequency content of the transformed signal. The FRT is defined by means of a transform kernel as:
The FRT of a function x(t), with an angle α, is defined as [16, 39]:
Fα represents rotation of a signal with coordinates (t, w) counter-clockwise to coordinates (u, v) with an angle α in the time–frequency plane as illustrated in Fig. 2.
3 Proposed audio watermarking framework
3.1 FRT watermarking based on SVD
The SVD watermarking has been previously used in image watermarking [30, 41, 50]. We try to extend the idea into audio watermarking, especially in FRT domain as shown in Fig. 3. The SVD mathematical technique extracts algebraic features from a 2-D matrix. Because of the SVD matrix stability, it is robust to attacks. When a small perturbation occurs to the original data matrix, no large variations in its SVs take place [30, 41, 50].

The embedding and extraction procedures of FRT audio watermarking
The proposed FRT-based SVD audio watermark embedding steps are summarized as follows and as shown in Fig. 4:
- 1.
The audio signal is used either in time domain or transformed to a certain transform domain.
- 2.
The A matrix is obtained by transforming the 1-D signal to a 2-D matrix.
- 3.
The SVD is performed on the A matrix.

The embedding procedure of the FRT watermarking
-
4.
The W matrix (image watermark) is added to the SVs of the original matrix.
-
5.
The SVD is performed on the D matrix (the new modified matrix).
-
6.
The Aw matrix (the watermarked image) is obtained using the Sw matrix (the modified matrix).
-
7.
The Aw matrix (2-D matrix) is transformed again to a 1-D audio signal.
The above steps are reversed to extract the corrupted watermark from the possibly distorted watermarked audio signal as shown in Fig. 5 as follows:
- 1)
The obtained signal is transformed to the \( {\mathbf{A}}_{\mathbf{w}}^{\ast} \) matrix (1-D to 2-D).
- 2)
The SVD is performed on the possibly distorted watermarked image (\( {\mathbf{A}}_{\mathbf{w}}^{\ast} \) matrix).

The watermark extraction procedure in FRT watermarking
-
3)
The matrix that includes the watermark is computed.
-
4)
The possibly corrupted encrypted watermark is obtained.
The ∗ refers to corruption due to attacks.
3.2 The proposed FRT segment-based SVD watermarking technique
The above-mentioned proposed technique is based on single watermark embedding in the audio signal as a whole. If multiple watermarks are added, it is expected that the detectability of the watermark will be enhanced and its robustness to attacks will be increased. Segmenting the audio signal and then embedding the watermark in the singular values of each segment, separately, reduces the effect of attacks and achieves higher correlation coefficients in the detection process.
3.2.1 Watermark embedding
The original audio signal is segmented into non-overlapping segments. Each segment is reshaped to a 2-D matrix, and the watermark image is embedded to the singular values (S matrix) of each segment. To get the S matrices of the segments, we carry out SVD on each of these matrices.
The steps of the embedding process can be summarized as follows:
- 1.
Segment the obtained signal into non-overlapping segments and transform each segment into a 2-D matrix.
- 2.
Carry out the SVD on the 2-D matrix of each segment (Bi matrix) to obtain the SVs (Si matrix) of each segment, where i = 1, 2, 3, . . ., N, and N is the number of segments.
-
3.
Add the watermark image (W matrix) to the S matrix of each segment.
-
4.
Carry out the SVD on each Di matrix to obtain the SVs of each Swi matrix.
-
5.
Use the SVs of each Di matrix (Swi matrix) to build the watermarked segments in the time domain.
-
6.
Transform the watermarked segments into 1-D format.
-
7.
Combine the watermarked segments back into a 1-D audio signal in time domain.
-
8.
If watermarking has been carried out in a transform domain, an inverse of this transform is performed.
3.2.2 Watermark detection
The steps mentioned below are used to extract the possibly corrupted watermark:
- 1.
Segment the possibly corrupted watermarked signal into small segments having the same size used in the embedding process and transform these segments into a 2-D format.
- 2.
Carry out SVD on the \( {\mathbf{B}}_{\mathbf{w}i}^{\ast} \)matrix to obtain the \( {\mathbf{S}}_{\mathbf{w}i}^{\ast} \) matrix.
-
3.
Obtain the matrices that contain the watermark using Uwi, Vwi,\( {\mathbf{S}}_{\mathbf{w}i}^{\ast} \), matrices.
-
4.
Extract the \( {\mathbf{W}}_i^{\ast} \)matrix from the Di matrices.
4 Objective quality metrics for audio signals
The proposed approach has two main advantages: embedding encrypted images in the audio signals and saving the quality of the signals. So, we need to measure the quality of the watermarked signals. Several approaches based on subjective and objective metrics have been adopted to measure the quality of audio signals [12, 22, 23, 34, 43, 47]. Objective metrics can be used for the evaluation of the quality of the watermarked audio signals. Objective metrics are generally divided into intrusive and non-intrusive metrics. Intrusive metrics include:
- 1-
Signal-to-noise ratio (SNR).
- 2-
Segmental signal-to-noise ratio (SNRseg).
- 3-
Linear predictive coefficients (LPCs).
- 4-
Linear reflection coefficients (LRCs).
- 5-
Log likelihood ratio (LLR).
- 6-
Cepstral distance (CD).
- 7-
Spectral distortion (SD), which is based on the comparison between the power spectra of the original and processed signals [12, 22, 23, 34, 43, 47].
4.1 Signal-to-noise ratio (SNR)
The SNR is defined as follows [12, 22, 23, 34, 43, 47]:
where x(i) is the original signal, y(i) is the processed signal, i is the sample index, and N is the total number of samples in both audio signals.
4.2 Segmental signal-to-noise ratio (SNRseg)
SNRseg is defined as an average of the SNR values of short segments. It is defined as [12, 22, 23, 34, 43, 47]:
4.3 Log likelihood ratio (LLR)
The LLR distance for an audio segment is based on the assumption that this audio segment can be represented by a pth order all-pole linear predictive coding (LPC) model of the form [35]:
where x(n) is the nth audio sample, am (for m = 1, 2, …., p) are the coefficients of an all-pole filter, Gx is the gain of the filter and u(n) is an appropriate excitation source for the filter. The audio signal is windowed to form frames of 15 to 30 ms in length. The LLR measure is then defined as: [30]:
where \( \overrightarrow{{\mathbf{a}}_{\mathbf{x}}} \) is the LPC coefficient vector (1, ax(1), ax(2), . . ., ax (p)) for the original audio signal x(n), \( \overrightarrow{{\mathbf{a}}_{\mathbf{y}}} \) is the LPC coefficient vector (1, ay(1), ay(2), . . ., ay(p)) for the watermarked audio signal y(n), and \( \overline{{\overline{\mathbf{R}}}_{\mathbf{y}}} \) is the autocorrelation matrix for the watermarked audio signal. The closer the LLR to zero, the better the quality of the watermarked audio signal.
4.4 Spectral distortion (SD)
The spectral distortion (SD) is a form of measures that are implemented in frequency domain on the frequency spectra of the original and processed signals. It is a measure calculated in dB to show how far is the spectrum of the processed signal from that of the original signal. The SD can be calculated as follows [12, 22, 23, 34, 43, 47]:
where Vx(i) is the spectrum of the original audio signal in dB for a certain segment in the time domain, Vy(i) is the spectrum of the watermarked audio signal in dB for the same segment, N is the segment length and M is the number of segments of the audio signal. The less the SD, the better the quality of the audio watermarked signal.
4.5 Correlation coefficient
The correlation coefficient (Cr) is taken between the extracted watermark (y) and the original watermark (x), and it is defined as:
where n is the sample size, ∑xy is the sum of the products of every point of the extracted watermark (y) and the original watermark (x), ∑x is the sum of the original watermark (x) points, ∑y is the sum of the extracted watermark (y) points, ∑x2 is the sum of squared original watermark (x) points and ∑y2 is the sum of squared extracted watermark (y) points.
5 Experimental results
Several experiments have been carried out to test the performance of the proposed SVD audio watermarking algorithm and to verify the embedding performance. Simulation software is Matlab R2018a. Time and transform domains have been used for watermark embedding. Both the proposed SVD and segment-based SVD watermarking techniques have been simulated. The CS image shown in Fig. 6a is used as a watermark to be embedded in the first test audio signal, shown in Fig. 6b. A second test audio signal is shown in Fig. 6c. In all experiments, the above-mentioned audio quality metrics have been used for the evaluation of the quality of the watermarked audio signal, and the correlation coefficient Cr has been used to measure the closeness of the obtained watermark to the original one.

a CS image (watermark), b First test signal (cover), and c Second test audio signal
In the first experiment, the effect of the watermark strength K used to add the watermark to the SVs of the audio signal is studied for both the SVD and the segment-based SVD techniques. The results of this experiment in the absence of attacks are shown in Figs. 8a, 9, 10, and 11. The results show that the case of FRT with phase \( \frac{5\pi }{4} \) has larger values of SNR and SNRseg, and lower values of LLR and SD compared to the other transform domains. It is clear from this experiment that in the absence of attacks, SVD watermarking in the FRT domain leads to the lowest deterioration in the audio signal. So, it is preferred to all other domains in the detection process.
It is also clear that segment-based audio watermarking causes more deterioration in the audio signal as shown in Figs. 7b, 8, 9, 10, and 11, but it achieves some success in the detection in the presence of attacks as will be shown in the next experiments. Figures 12a and b show the spectrogram of the first test audio signal and the watermarked version of this signal. It is clear that there is a little difference between the watermarked signal, and the original audio signal, which cannot be noticed without the objective quality metrics.

Variation of the SNR of the watermarked version signal of the first test signal with the watermark strength in the absence of attacks

Variation of the SNRseg of the watermarked version of the first test signal with the watermark strength in the absence of attacks

Variation of the LLR of the watermarked version of the first test signal with the watermark strength in the absence of attacks

Variation of the SD of the watermarked version of the first test signal with the watermark strength in the absence of attacks

Variation of the correlation coefficient Cr between the original and extracted watermarks for the first test signal in the absence of attacks

Spectrograms of (a) First test signal, (b) Watermarked version of the first test signal
Audio signals may be subjected to Gaussian noise. Gaussian noise is a statistical noise having a probability density function (PDF) equal to that of the normal distribution, which is also known as the Gaussian distribution. In other words, the values that the noise can take are Gaussian distributed. The PDF of a Gaussian random z is given by:
where z represents the amplitude, μ is the mean value, and σ is the standard deviation of the distribution.
In the second experiment, the robustness of both the SVD and the block-based SVD watermarking techniques is studied in the presence of a white Gaussian noise attack. Figures 13, 14, 15, 16, and 17 show the variation of the SNR, SNRseg, LLR and SD, respectively, of the watermarked signal with the watermark strength for the first audio signal in the presence of white noise attack. They show that the case of using FRT with phase \( \frac{\pi }{4} \) and SVD watermarking achieves larger values of SNR and SNRseg, and lower values of LLR and SD compared to the other cases.

Variation of the SNR of the watermarked signal with the watermark strength in the presence of white Gaussian noise attack for the first test signal

Variation of the SNRseg of the watermarked signal with the watermark strength in the presence of white Gaussian noise attack for the first test signal

Variation of the LLR of the watermarked signal with the watermark strength in the presence of white Gaussian noise attack for the first test signal

Variation of the SD of the watermarked signal with the watermark strength in the presence of white Gaussian noise attack for the first test signal

Variation of the correlation coefficient Cr between the original and watermarked signals in the presence of white Gaussian noise attack for the first test signal
In the third experiment, the robustness of both the SVD and the block-based SVD watermarking techniques is studied in the absence of attacks. Figures 18, 19, 20, and 21 show the variation of the SNR, SNRseg, LLR and SD of the watermarked version of the second test audio signal with the watermark strength in the absence of attacks. The results show that the case of FRT with phase \( \frac{5\pi }{4} \) achieves larger values of SNR and SNRseg, and smaller values of LLR and SD compared to the other cases. It is clear from this experiment that in the absence of attacks, SVD watermarking in the FRT domain achieves the lowest deterioration in the audio signals. So, the FRT is preferred to all other domains in the detection process.

Variation of the SNR of the watermarked version of the second test signal with the watermark strength in the absence of attacks

Variation of the SNRseg of the watermarked version of the second test signal with the watermark strength in the absence of attacks

Variation of the LLR of the watermarked version of the second test signal with the watermark strength in the absence of attacks

Variation of the SD of the watermarked version of the second test signal with the watermark strength in the absence of attacks
Figure 22 shows that variation of the correlation coefficient Cr between the original and watermarked versions of the second test audio signal in the absence of attacks. It is clear that the segment-based method increases the correlation coefficient of approximately all cases of transform domain watermarking. Figures 23a and b show the spectrograms before and after the watermark embedding process for the second test audio signal, which reveal that there is a little difference between the watermarked signal and the original audio signal.

Variation of the correlation coefficient Cr between the original and extracted watermarks for the second test signal in the absence of attacks

Spectrograms of the (a) Second test signal, (b) Watermarked version of the second test signal
In the fourth experiment, the robustness of both the SVD and the block-based SVD watermarking techniques is studied in the presence of white Gaussian noise attack. Figures 24, 25, 26, 27, and 28 show the variations of the SNR, SNRseg, LLR and SD, respectively, of the watermarked version of the second test audio signal with the watermark strength in the presence of white Gaussian noise attack. They show that there is a little difference in performance between both cases.

Variation of the SNR of the watermarked signal with the watermark strength in the presence of white Gaussian noise attack for the second test signal

Variation of the SNRseg of the watermarked signal with the watermark strength in the presence of white Gaussian noise attack for the second test signal

Variation of the LLR of the watermarked signal with the watermark strength in the presence of white Gaussian noise attack for the second test signal

Variation of the SD of the watermarked signal with the watermark strength in the presence of white Gaussian noise attack for the second test signal

Variation of the correlation coefficient Cr between the original and watermarked versions of the second test signals in the presence of white Gaussian noise attack
6 Conclusion
For more security and robustness, we have studied the problem of embedding image watermarks in audio signals. We have investigated the time and transform domains for watermark embedding. An SVD-based audio watermarking technique in the FRT domain has been introduced. Two implementations of this technique have been presented. We have concluded that the SVD watermarking is very suitable for data hiding in audio signals. SVD watermarking in the FRT domain with a phase of 5π/4 achieves the lowest deterioration of audio signals. It is clear from the results that in the presence of attacks, the watermarking in the FRT domain with a phase of π/4 is better for watermark detection. It is also clear that the segment-based implementation can achieve better performance, especially for correlation-based detection.
References
Abd El-Samie FE (2009) An efficient singular value decomposition algorithm for digital audio watermarking. International Journal of Speech Technology 12(1):27–45
Abd El-Samie FE, Shafik A, El-sayed HS, Elhalafawy SM, Diab SM, Sallam BM, Faragallah OS (2015) Sensitivity of automatic speaker identification to SVD digital audio watermarking. International Journal of Speech Technology 18(4):565–581
Abdallah HA, Hadhoud MM, Shaalan AA, Abd El-samie Fathi E (2011) Blind wavelet-based image watermarking. International Journal of Signal Processing, Image Processing and Pattern Recognition 4(1):15–28
Al-Nuaimy W, El-Bendary MAM, Shafik A, Shawki F, Abou-El-azm AE, El-Fishawy NA, Elhalafawy SM, Diab SM, Sallam BM, Abd El-Samie FE, Kazemian HB (2011) An SVD audio watermarking approach using chaotic encrypted images. Digital Signal Processing 21(6):764–779
Alsalami MAT, Al-akaidi MM. Digital audio watermarking: survey. School of Engineering and Technology - De Montfort University, UK
Arnold M (2002) Audio watermarking: features, applications and algorithms. IEEE International Conference on Multimedia and Expo. ICME2000. Proceedings. Latest Advances in the Fast-Changing World of Multimedia
Arnold M. Audio watermarking: features, applications and algorithms. Department for Security Technology for Graphics and Communication Systems, Fraunhofer-Institute for Computer Graphics, 64283 Darmstadt, Germany
Bassia P, Pitas I, Nikolaidis N (2001) Robust audio watermarking in the time domain. IEEE Transactions on Multimedia 3(2):232–241
Bassia P, Pitas I, Nikolaidis N, Akhaee MA, Saberian M, Feizi JS, Marvasti F (2001) Robust audio watermarking in the time domain. IEEE Transactions on Multimedia 3(2):232–241
Chen, S-T, Huang, H-N, Chen, C-J. Adaptive audio watermarking via the optimization point of view on the wavelet-based entropy. Department of Mathematics, Tunghai University, Taichung 40704, Taiwan
Chu WC (2003) DCT-based image watermarking using subsampling. IEEE Transactions on Multimedia 5(1):34–38
Crochiere RE, Tribolet JE, Rabiner LR (1980) An interpretation of the log likelihood ratio as a measure of waveform coder performance. IEEE Trans Acoust Speech Signal Process 28(3):318–323
El-Bendary MAMM, Abou El-Azm A, El-Fishawy N, Al-Hosarey FSM, Eltokhy MAR, Abd El-Samie FE, Kazemian HB (2011) SVD audio watermarking: a tool to enhance the security of image transmission over ZigBee networks. Res J Telecommun Inf Technol 4:99–107
Elshazly EH, Faragallah OS, Abbas AM, Ashour MA, El-Rabaie E-SM, Kazemian H, Alshebeili SA, Abd El-Samie FE, El-sayed HS (2015) Robust and secure fractional wavelet image watermarking. SIViP 9(1):89–98
Elshazly R, Nasr ME, Fuad MM, Abd El-Samie FE (2016) Synchronized double watermark audio watermarking scheme based on a transform domain for stereo signals. Proceedings of the Fourth International Japan-Egypt Conference on Electronics, Communications and Computers (JEC-ECC), p 52–57
Furht B, Socek D (2003) A survey of multimedia security. Technical Report
Ghouti L, Bouridane A, Ibrahim MK, Boussakta S (2006) Digital image watermarking using balanced multiwavelets. IEEE Trans Signal Process 54(4):1519–1536
Goenka KV, Patil PK (2012) Overview of audio watermarking techniques. International Journal of Emerging Technology and Advanced Engineering 2(2)
Guillemain P, Martinet RK (1996) Characterization of acoustic signals through continuous linear time-frequency representations. Proc IEEE 84(4):561–585
Huh J-H, Seo K (2018) Blockchain-based mobile fingerprint verification and automatic log-in platform for future computing. J Supercomput:1–17
Kim HS, Lee HK (2003) Invariant image watermark using Zernike moments. IEEE Transactions on Circuits and Systems for Video Technology 13(8):766–775
Kubichek R (1993) Mel-cepstral distance measure for objective speech quality assessment. In: Proc. IEEE pacific rim Conf. on Communications, Computers and Signal Processing, p 125–128
Kubichek RF (1993) Mel-cepstral distance measure for objective speech quality assessment. Proceedings of the IEEE pacific Rim Conf on Communications, Computers and Signal Processing, p 125–128
Lee S, Huh J-H (2018) An effective security measures for nuclear power plant using big data analysis approach. J Supercomput:1–28
Li S, Li C, Chen G, Bourbakis NG, Lo K-T (2008) A general quantitative cryptanalysis of permutation-only multimedia ciphers against plaintext attacks. Signal Process Image Commun 23(3):212–223
Lie W-N, Chang L-C (2006) Robust and high-quality time-domain audio watermarking based on low-frequency amplitude modification. IEEE Transactions on Multimedia 8(1):46–59
Lim JS (1990) Two-dimensional signal and image processing. Prentice Hall Inc, Cliffs Englewood, p 710
Lindley, Craig A., Wiley John & Sons, Inc. (1991) Digital image processing.
Liu Z, Inoue A (2003) Audio watermarking techniques using sinusoidal patterns based on pseudorandom sequences. IEEE Transactions on Circuits and Systems for Video Technology 13(8):801–812
Liu R, Tan T (2002) An SVD-based watermarking scheme for protecting rightful ownership. IEEE Transactions on Multimedia 4(1):121–128
Lu ZM, Xu DG, Sun SH (2005) Multipurpose image watermarking algorithm based on multistage vector quantization. IEEE Trans Image Process 14(6):822–831
Macq B, Dittmann J, Delp E (2004) Benchmarking of image watermarking algorithms for digital rights management. IEEE Transactions on Multimedia 92(6):971–984
McBride AC, Kerr FH (1987) On Namia fractional Fourier transforms. IMA J Appl Math 39:159–175
McDermott BJ, Scaglia C, Goodman DJ (1978) Perceptual and objective evaluation of speech processed by adaptive differential PCM. Proceedings of the IEEE International Conf on Acoustic, Speech and Signal Processing (ICASSP), Tulsa, p 581–585
Ozaktas HM (1995) Fractional Fourier domains. Signal Process 46:119–124
Ozaktas HM, Zalevsky Z, Kutay MA (2001) The fractional Fourier transform. Wiley, Chichester
Panaousis EA, Nazaryan L, Politis C (2009) Securing aodv against wormhole attacks in emergency manet multimedia communications. Proceedings of the 5th International ICST Mobile Multimedia Communications Conference. ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering), 34
Prochazka UJ, Rayner PJW, Kingsbury NJ (1998) Signal analysis and prediction. Birkhauser Inc
Schneier B (1996) Applied cryptography-protocols, algorithms, and source code in C, 2nd edn. Wiley, New York
Shelke RD, Nemade, Milind U (2017) Audio watermarking techniques for copyright protection: a review. IEEE Xplore
Sun X, Liu J, Sun J, Zhang Q, Ji W (2008) A robust image watermarking scheme based-on the relationship of SVD. Proceedings of the International Conference on Intelligent Information Hiding and Multimedia Signal Processing
Walker JS (2002) A primer on wavelets and their scientific applications. CRC Press LLC
Wang S, Sekey A, Gersho A (1992) An objective measure for predicting subjective quality of speech coders. IEEE Journal on selected areas in communication 10(5):819–829
Wornell GW (1996) Emerging applications of multi-rate signal processing and wavelets in digital communications. Proc IEEE 84(4):586–603
Wu L, Du X, Fu X (2014) Security threats to mobile multimedia applications: camera-based attacks on mobile phones. IEEE Commun Mag 52(3):80–87
Xiang S, Huang J (2007) Histogram-based audio watermarking against time-scale modification and cropping attacks. IEEE Transactions on Multimedia 9(7):1357–1372
Yang W, Benbouchta M, Yantorno R (1998) Performance of the modified bark spectral distortion as an objective speech quality measure. Proceedings of the IEEE International Conf on Acoustic, Speech and Signal Processing (ICASSP) 1:541–544
Zhao, H, Wu M, Wang ZJ, Liu, KJR (2003) Nonlinear collusion attacks on independent fingerprints for multimedia. Multimedia and Expo, 2003. ICME’03. Proceedings. 2003 International Conference, (1):1–613
Zhao HV, Wu M, Wang ZJ, Liu KJR (2005) Forensic analysis of nonlinear collusion attacks for multimedia fingerprinting. IEEE Trans Image Process 14(5):646–661
Zhu X, Zhao J, Xu H. A digital watermarking algorithm and implementation based on improved SVD. Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Abdelwahab, K.M., Abd El-atty, S.M., El-Shafai, W. et al. Efficient SVD-based audio watermarking technique in FRT domain. Multimed Tools Appl 79, 5617–5648 (2020). https://doi.org/10.1007/s11042-019-08023-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-019-08023-z