
Abstract
This article proposes an improved learning based super resolution scheme using manifold learning for texture images. Pseudo Zernike moment (PZM) has been employed to extract features from the texture images. In order to efficiently retrieve similar patches from the training patches, feature similarity index matrix (FSIM) has been used. Subsequently, for reconstruction of the high resolution (HR) patch, a collaborative optimal weight is generated from the least square (LS) and non-negative matrix factorization (NMF) methods. The proposed method is tested on some color texture, gray texture, and some standard images. Results of the proposed method on texture images advocate its superior performance over established state-of-the-art methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Image analysis is a universal need in image processing and computer vision. However, lack of high-frequency details in an image leads to incorrect image analysis. To overcome such issues, super resolution (SR) technique has been used to generate a high resolution (HR) image from the given low resolution (LR) image(s) observations [23]. Prior to SR algorithm, another possible approach was adopted to increase the number of pixels per unit area to combat the loss of high-frequency details. Such process considers the decrease in pixel size and increases the number of sensors [36,37,38]. However, due to diffraction effect decreasing the pixel size prompts to high capacitance which in turn slows down the system performance and results in increase of noise. SR algorithm is devoid of such limitations and found to be suitable in applications like satellite and areal imaging, medical image processing, textured recognition, face recognition, video surveillance, etc.
Various research articles have been reported on SR techniques over the past two decades. Generally, the SR can be achieved on both frequency as well as spatial domain [2, 18, 30, 35, 45]. Furthermore, the SR methods can be broadly categorized into two types such as (i) Multi frame SR and (ii) Single frame SR based on the number of LR reference images considered. Various multi image based SR approaches [21, 28, 38, 41] require accurate registration among images which lead to ringing effects and artifacts in the reconstructed image. In addition, they do not work well for unprocessed data. On the other hand, single image LR image based SR methods do not suffer from these problems. Further, existing single image based SR approaches can be classified into three general classes, i.e., interpolation based, reconstruction based and learning based. In the interpolation based methods [29, 51], it is hard to restore the high-frequency details. Therefore, blurred edge and complex texture are found in interpolation method. In reconstruction based method [30, 54], prior knowledge like edge, gradient, etc. are required to reconstruct the HR image. This method can suppress the aliasing artifacts and preserve sharper edges. However, it cannot generate fine details in larger magnification. To tackle this problem, learning based SR methods [5, 7, 9, 20, 52] have been introduced by inferring the mapping relationship between LR-HR image pairs.
Learning based SR approach can be further categorized into three categories such as belief network [3, 19, 20], manifold learning [6, 7, 9, 13] and compressive sensing [46, 47, 50]. Freeman et al. [19] are the forerunners who introduced learning based single image super resolution scheme in 1999. Later on, they have used Markov random field (MRF) model and loopy belief propagation to find the relationship between LR-HR image patch pairs. However, boundary effect and incompatibility between reconstructed HR patches and its surrounding patches have been seen in texture images [19, 20]. Based on these works, Sun et al. [40] proposed primal sketch apriori to overcome the blur present in edges, ridges and corners. To overcome the incompatibility between HR patches and its neighboring patches, manifold learning based super resolution techniques have been introduced in [4, 5, 7, 9]. Chang et al. [9] introduced single image SR using manifold learning where local geometry based features are extended from LR-HR patch pairs inferred to reconstruct the expected HR patches using optimal reconstruction weight. Thereafter, a novel feature selection scheme for neighbor embedding SR has been proposed by Chan et al. [7]. Guo et al. [24] have used maximum a posteriori (MAP) estimation to combine the global parametric constraint with a patch-based local non-parametric constraint. In another work, Gao et al. [22] have proposed a method to project the original HR and LR patch onto the jointly learning unified feature subspace. Later on, compressive sensing techniques have drawn attention from many researchers for single image super resolution [16, 26]. Mishra et al. [33] have introduced a robust scheme to generate a HR image from the registered LR image. In this work,they remove the outlier generated during registration using robust locally linear embedding (RLLE). Further, they used Zernike moment as feature selection for neighborhood preservation during HR image reconstruction [34].
In addition to these, few other studies have also proposed for the enhancement of texture image. Wei et al. [44] have discussed the extensions and applications of texture synthesis. HaCohen et al. [25] introduced consistent fine-scale detail to textured regions and produced edges with proper sharpness. To enhance the quality of complicated texture structure in the image, an example based SR using clustering and partially supervised neighbor embedding has been proposed by Zhang et al. [52]. Due to overlapping in the frequency range with that of the noise in the texture images, de-noising or in-painting is used for single image super resolution [49]. Yoo et al. [48] proposed a novel texture enhancement strategy to improve the single image super resolution performance. In recent years, many neural network (NN) based approaches has addressed for single image super resolution with excellent performance. Ahn et al. [1] proposed a texture enhancement framework by the combining interpolation technique and customized style transfer technique. Here they used repetitive tiling concept for the style transfer technique. Sajjadi et al. [39] introduced an automated texture synthesis technique by using feed forward fully convolutional neural networks. This method gives an efficient result due to the feed-forward architecture which inference time since the LR image only needs to be passed through the network once to get the result. Liu et al. [31] used total variation (TV) regularization approach for SR image reconstruction for synthetic aperture radar (SAR) image. In this work, they used gradient profile prior or other texture image prior in the maximum a posteriori framework. Cruz et al. [15] used Wiener filter in similarity domain to generate a super resolution image from a single reference image. Here they introduced filtering of the patches in 1D similarity domain and coupled it with the iterative back propagation (IBP) frame work. Chang et al. [11] presented a bi-level semantic representation analysing framework for image/ video which is work for weight learning approach for multimedia representation. Later, they introduced a semi supervised feature selection technique. For maintain the correlation between various feature in the training data they adopted manifold learning to labeled and unlabelled training data [8]. In addition, to maintain the correlation between the linear effect and the nonlinear effect for embedding feature interaction, an optimization algorithm has been proposed by them [10]. An isotonic regularizer that is able to exploit the constructed semantic ordering information has introduced by Chang et al. [12] for the video shots.
The literature review reveals that most of the existing schemes fail to reproduce the fine details during image reconstruction. Different applications on SR need suitable algorithms in order to achieve an optimal reconstruction image. Enhancement in texture images still points as an outstanding problem. In this work, we propose an improved learning based SR algorithm for texture image to generate a HR image from a single LR image. The scheme utilizes neighbor embedding technique (manifold learning) and is suitably named as single image super resolution using manifold learning (SSRM). In this approach, HR patches are reconstructed from the input test LR patches by the prior information that fetched from the training LR-HR pairs. The major contribution of this paper includes
- 1.
Feature representation using pseudo Zernike moments (PZM) to classify the patches
- 2.
Finding the k most similar patches from the test patch using similarity measure, i.e. Feature similarity index (FSIM)
- 3.
Computation of optimal reconstruction weight using least square (LS) and non-negative matrix factorization (NMF) for HR patch reconstruction
Experimental results and comparisons on textural images show that proposed method offers better performance than other existing methods. Additionally, the proposed scheme works well on standard images.
The rest of the paper is organized as follows. Section 2 discusses the proposed algorithm. The experimental results and discussion are presented in Section 3. Finally, Section 4 deals with the concluding remarks and the scope for future work.
2 Proposed SSRM algorithm
In this work, an improved single image SR using manifold learning is proposed. The scheme follows three main steps
- (i)
feature extraction using pseudo Zernike moments (PZM)
- (ii)
finding k-nearest neighbor using similarity measure FSIM
- (iii)
optimal reconstruction weight computation using collaborative method
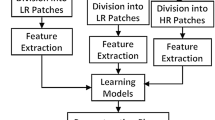
Features are extracted from each LR-HR patch separately by considering the phase and magnitude values of PZM. In addition, FSIM has been used as a similarity measure for searching the nearest neighbor patches for HR patch reconstruction. Thereafter, a collaborative technique is used to find out the optimal reconstruction weight to generate the HR patch from a given LR input patch. Figure 1 shows the overall frame work of the proposed scheme.

Overall block diagram of proposed scheme
The overall steps to generate the reconstructed HR image is listed in Algorithm 1.

2.1 Patch generation
In this approach, each image is first converted from RGB to YCbCr color model and only the luminance component of the image is considered. Each LR image is decomposed into a set of t × t patches with two overlapping pixels. The corresponding HR image patch size is γt × γt with 2γ overlapping pixels, where γ is the magnification factor. Let the training LR image, HR image and testing LR image are denoted by \(L_{r}=\left \{{l_{r}^{p}} \right \}_{p = 1}^{a}, H_{r}=\left \{{h_{r}^{p}} \right \}_{p = 1}^{a}\), and \(L_{t}= \left \{{l_{t}^{q}} \right \}_{q = 1}^{b}\), respectively. The number of patches for the LR image of size t × t is t × t × [(row − stepsize) × (col − stepsize)], where stepsize = patchsize − overlappingpixels. The number of patches for the HR image of size γt × γt is γt × γt × [(row − stepsize) × (col − stepsize)], where stepsize = γ × patchsize − γ × overlappingpixels.
2.2 Feature selection by PZM
In this work, we use pseudo Zernike moment (PZM) for feature selection. It has higher description ability for same order as compared to Zernike moment. Moreover, it provides meaningful information for image reconstruction. It is a widely used orthogonal moment. It has several applications in various areas of image processing and pattern recognition. Because of its orthogonality and invariance properties, it is robust to noise and have better ability for image representation [14]. Figure 2 shows the linear transformation on a single patch through normalization.

Normalization of the patch in unit circle
The PZM of a continous image intensity f(x, y) is defined as
where n, m is the order and repetition respectively. Here, \(n = 0,1,2,...,\infty \) and |m|≤ n such that n −|m| = even. The discrete form of PZM for digital image intensity f(xq,yp) is represented as
where \({x_{q}}=-\frac {\sqrt {2}}{2}+\frac {\sqrt {2}}{N-1}q, q = 0,1,..,(N-1)\) and \({y_{p}}=\frac {\sqrt {2}}{2}-\frac {\sqrt {2}}{N-1}p, p = 0,1,..,(N-1)\). Here \(\frac {{n + 1}}{\pi }\) is a normalization factor, \(\lambda (N)=\frac {N^{2}}{2}\). Vn, m is the complex polynomial and Vn, m∗ is the complex conjugate of Vn, m.
The pseudo Zernike polynomials is represented as
where radial polynomials \(R_{n,m} \left (r \right )\) is defined as
here the PZM are defined in terms of polar coordinates (r, 𝜃) with \(0 \le \left | m \right |\le n \) and \(\left | r \right | \le 1\).
It is reported that PZM is unsuitable to extract the global information from the whole image. Hence, in this scheme, we compute the feature vector for each patch with respect to magnitude and phase of PZM [27].
2.2.1 Generation of feature vector considering the magnitude of the PZM
Generally, the 2-D PZM feature is represented by a complex value, which is the combination of magnitude and phase coefficients. The magnitude based PZM feature vector of order n = 0to nmax, with m ≥ 0 is represented in Table 1. For nmax = 5, the total number of feature vector is 21. Since, PZM with higher order moment is sensitive to noise and distortion, we consider 5 as the maximum order. So the feature vector for each patch f(xq,yp)is defined as
where |PZMu, v(f(xq,yq))| is the magnitude of PZMn, m(f(xq,yp)).
2.2.2 Generation of feature vector considering the phase of the PZM
The wide range of edges are represented by high phase values. The gradient based edge detection technique are sensitive to blurring and magnification. Hence, in this work, PZM is used to preserve the high-frequency details during image reconstruction. By using various heuristic criteria, the patch with edge and without edge can be calculated from the training patches. Hence, for a input test patches, it will be easy to classify the nearest neighbor patches from the whole training patch. Then each patch having edge is counted according to Table 2. It will speed-up the searching process. In order to compute the phase feature, rotation invariant PZM is defined as
where \(PZM^{R}_{n,m}(f({x_{q}},{y_{p}}))\) is the rotated version of PZM with the rotation angle 𝜃. To remove the rotational effect on phase, a complex valued rotation invariant is created by combining phase coefficients of different orders with repetitions. This is represented as

where \(\varphi ^{R}_{n,m}=\varphi _{n,m}-m\theta \). Here, φn, m the phase coefficient and \(\varphi ^{R}_{n,m}\) is the phase value of rotated image. When we set n0 = 1 the modified phase angle of PZM is

where φ1,1 = 0. Therefore, the phase feature vector of each patch f(xq,yp) is represented as

After the phase feature vector generation, several heuristic criteria have been used for identify the patches with edge and without edge. If ϕ < 𝜃, then its corresponding patch is labelled as non edge else labelled the patch as edged. This makes the searching of the patches having more information faster.
2.3 Patch classification
The similar patches of an input patch are directly searched from the training database. However, this scheme is inefficient and similar optimal patches may not be obtained. Hence, to find out the similar optimal patches, we use feature similarity index (FSIM) [53] instead of the Euclidean distance, since it fails to search the appropriate nearest neighbor patches in the manifold. FSIM is computed by phase congruency (SPC(x)) and gradient (SG(x)) based similarity.
Feature similarity index is computed by combining SPC(x) and SG(x)as
where α and β are parameters for adjusting relative importance of both the features. Range of the FSIM is 0 to 1. The FSIM of two similar patches is nearer to 1. The value of FSIM between two patches lies between 0 to 1 and higher the value of FSIM, the similar the patches are. Thus, optimal patches are computed by top k-nearest neighbor patches with respect to FSIM.
2.4 Collaborative optimal weight reconstruction
In this section, a collaborative weight reconstruction is used during the HR patch generation. Firstly, the weight is computed using least squarer technique. Further, another weight vector is generated using non-negative matrix factorization method. Thereafter, final weight vector is collaboratively constructed using LS and NMF technique.
2.4.1 Weight vector generated by LS method
After generating the patches from images, each testing patch is taken into account to generate an expected HR patch. For each input patch \({l_{t}^{q}}\) of \(L_{t}= \left \{{l_{t}^{q}}, q = 1,2,3,...m\right \}, k\)-nearest neighbor training patches are searched. Through least square (LS) method the weights related to k-nearest neighbor training patches are found by minimizing the local reconstruction error as
where ℵq is the neighbor of \({l_{t}^{q}}\) in training set Lr and element wqp of Wq is the weight for \({l_{r}^{p}}\), subject to two constraints \(\sum \nolimits _{{l_{r}^{p}} \in {\aleph _{q}}} {{w_{qp}}} = 1\) and wqp = 0 for any \({l_{r}^{p}} \notin {\aleph _{q}}\).
Let us define a local Gram matrix Gqfor ltq as
where 1 is a column vector of ones and L is a D × K matrix with its columns being the neighbors of \({x_{t}^{q}}\). To form a K-dimensional weight vector Wq, each weight wqpis reordered by the subscript p.
To solve an eigenvalue problem using the Lagrange theorem, the formulation is given by
where
and
When G is singular, the result of the least squares problem for finding wq does not have the unique solution. The constrained least squares problem has the following closed-form solution as:
Hence, the least square optimal weight vector is represented by wl where wq is the element.
2.4.2 Weight vector generated by NMF method
Apart from that another weight vector is generated by non-negative matrix factorization (NMF). According to non-negative matrix factorization the weight is generated by
The iterative solution for (17) is proved to converge to a local minimum of the Euclidean distance \( {\left \| {X - F{w_{n}}T} \right \|^{2}}\). The iterative solution consists of two multiplicative update rules, both for F and wij. In this case matrix F, formed by the actual LR patches in the dictionary, is fixed and no update rule is needed for it. But the weight of each patch can be updated by
The final weight vector is represented as wn, where wijis the element.
Thus, a collaborative algorithm is developed by combine weight generated by LS and the NMF to compute the optimal weight vector. The collaborative optimal reconstruction weight for the HR patch reconstruction is defined as
where wqlis the element of final optimal weight vector W.
2.5 HR image reconstruction
As the manifold between LR-HR space is similar, the high-resolution output image patch htq is computed as follows
where \(\overline {{h_{r}^{p}}}\) is the mean of the luminance and wqlis the final reconstruction weight. The HR patch generation is shown in Fig. 3. To generate the output image, the overlapping patches \(H_{t}=\left \{{h_{t}^{q}} \right \}_{q = 1}^{n}\) is merged. The major factor that improves the performance of the reconstruction image are neighborhood preservation between patches and optimal reconstruction weight. Hence, this paper mainly focuses on the feature selection, neighborhood patch search by similarity measures and the collaborative reconstruction weight. Finally, the reconstructed image in luminance channel has been combined with the interpolated chromatic channel. Thereafter, the YCbCr image is converted to RGB channel for final HR image reconstruction.

HR patch generation
3 Experimental results
3.1 Experimental set up
In this paper, we validate our algorithm with various texture images collected from https://www.robots.ox.ac.uk/vgg/data/dtd/ and http://sipi.usc.edu/database/database.php?volume=textures [43]. In addition, some standard images used in Matlab tool have been considered for the experiment. To conduct the experiment, LR image is produced from the original HR image by 5 × 5Gaussian blur with a down-sampling factor 3. Both color and gray texture images are taken into account as shown in Figs. 4 and 5, respectively. Further, the scheme is validated on standard images as shown in Fig. 6. As human eyes has different sensitivity to change in illumination rather than chromatic component, the color image for the experiment is transformed from RGB to YCbCr channel. Moreover, RGB component is not very compatible for image representation. Hence, the proposed algorithm executed on the Y component of the YCbCr channel. The performance of the proposed scheme has been evaluated and a comparison has been made with different existing schemes. The existing competent schemes are Bicubic, EBSR [20], SRNE [9], NEVPM [17], NeedFS [7] and SCSR [46]. To access the quality of the image, two commonly used performance measures are employed i.e., Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) [42] to evaluate the sensitivity of the noise and structural similarity between the reconstructed image and ground truth image respectively.

Testing color texture images

Testing gray texture images

Testing standard images
3.2 Experimental results and discussion
3.2.1 Performance evaluation with varying magnification factor (γ)
In this section, we validate the proposed approach with respect to various magnification factor. In this approach, magnification factors are 2,3 and 4. Figures 7 and 8 show PSNR evaluation and SSIM evaluation with various magnification factor. From the given graph, it is observed that the quality is gradually decreasing according to the increase in magnification size. Hence, we consider 3 as the suitable factor for the experiment.

PSNR evaluation with respect to various magnification factor (γ)

SSIM evaluation with respect to various magnification factor (γ)
3.2.2 Performance evaluation with varying patch size (t)
The performance measures are computed with different patch sizes i.e., 5, 7, and 9. Tables 3 and 4 list the PSNR values of color and gray texture images respectively, whereas Tables 5 and 6 record the SSIM values for the color and gray respectively. Tables 7 and 8 show the PSNR and SSIM results for few standard images. It observed that the proposed method performs better than other existing methods on color texture, gray texture images and standard images. Further, it may be noticed that the larger the patch size, the better is the PSNR and SSIM values.
3.2.3 Performance evaluation by neighborhood preservation rate
In this section, neighborhood preservation rate is considered as another criterion to evaluate the efficacy of the proposed feature selection. Firstly, a group of LR patches have been selected randomly from the testing patch set. Then for each LR patch, the k-nearest neighbor patches have been considered from the test set. Prior to this, the corresponding k-nearest neighbor HR patches are identified from the HR patches. Comparing the number of corresponding HR patches of the k-nearest neighbor of LR patches, the neighborhood preservation rate is obtained.
In this section, we have performed the comparison between LR and HR patch with different features used in the state-of-the-art schemes. In SRNE [9] method, first gradient and second gradient are used as features, whereas in NeedFS [7] a combination of first-order gradient and norm luminance are considered. NESRRL [32] considered first gradient and residual luminance as the feature vector to generate the expected HR image. Moreover, to verify the advantage of PZM over ZM, we have validated with [34]. In this work, we have used PZM for feature generation. Here, we randomly consider 1800 LR patches, and out of which 300 patches are used as testing LR patches. Then, we have evaluated the neighborhood preservation for 3 magnification with different neighborhood size.
The neighborhood preservation rate obtained by the existing schemes with respect to different neighborhood size are shown in Fig. 9. It can be observed that the proposed scheme achieves better results as compared to the existing schemes by means of neighborhood preservation rate due to better feature vector.

Neighborhood preservation of test image
3.2.4 Performance evaluation varying with neighborhood size (k)
It has been observed that the neighborhood size has significant impact on the performance of the model. Hence, in this experiment the neighborhood size is varied between 1 to 15 and the corresponding PSNR and SSIM results for color, gray texture images and standard images are shown in Figs. 10 and 11 respectively. It may be seen that the proposed scheme achieves better PSNR and SSIM results for neighborhood size between 5 to 8. Further, the visual performance comparisons for three different category of images are shown in Figs. 12, 13, 14, 15, 16 and 17. From these figures, it may be observed that the propose scheme yields better visualization results than other state-of-the-art schemes.

PSNR evaluation with respect to various neighborhood size (k)

SSIM evaluation with respect to various neighborhood size (k)

Comparison of SR results with (3 ×) magnification for c1image

Comparison of SR results with (3 ×) magnification for c3image

Comparison of SR results with (3 ×) magnification for g1image

Comparison of SR results with (3 ×) magnification for g2image

Comparison of SR results with (3 ×) magnification for bird image

Comparison of SR results with (3 ×) magnification for butterfly image
4 Conclusion
In this paper, a new framework for learning based super resolution has been proposed for texture image. Pseudo Zernike moments are utilized for the feature selection. Moreover, FSIM is used for patch classification during neighbor embedding. Subsequently, a collaborative optimal reconstruction weight is computed to HR patch generation. Optimal reconstruction weight is defined by the combination of least square error and non-negative factorization matrix. The experimental results on texture and standard images demonstrate that the proposed scheme achieves better results than other competent schemes. In future, we intent to explore our method on different images like areal image, medical image, video surveillance, etc. In addition, other feature generation schemes could be investigated as the potential alternatives to PZM.
References
Ahn IJ, Nam WH (2016) Texture enhancement via high-resolution style transfer for single-image super-resolution. arXiv:1612.00085
Baker S, Kanade T (2002) Limits on super-resolution and how to break them. IEEE Trans Pattern Anal Mach Intell 24(9):1167–1183. https://doi.org/10.1109/TPAMI.2002.1033210
Begin I, Ferrie FP (2004) Blind super-resolution using a learning-based approach. In: 2004 International conference on pattern recognition, pp 85–89. https://doi.org/10.1109/ICPR.2004.1334046
Bevilacqua M, Roumy A, Guillemot C, Morel MLA (2013) Super-resolution using neighbor embedding of back-projection residuals. In: 18th International conference on digital signal processing, pp 1–8. https://doi.org/10.1109/ICDSP.2013.6622796
Cao M, Gan Z, Zhu X (2012) Super-resolution algorithm through neighbor embedding with new feature selection and example training. In: 2012 IEEE International conference on signal processing, vol 2, pp 825–828. https://doi.org/10.1109/ICoSP.2012.6491708
Chan TM, Zhang J (2006) An improved super-resolution with manifold learning and histogram matching. In: 2006 International conference on advances in biometrics, pp 756–762. https://doi.org/10.1007/11608288_101
Chan TM, Zhang J, Pu J, Huang H (2009) Neighbor embedding based super-resolution algorithm through edge detection and feature selection. Pattern Recogn Lett 30(5):494–502. https://doi.org/10.1016/j.patrec.2008.11.008
Chang X, Yang Y (2017) Semisupervised feature analysis by mining correlations among multiple tasks. IEEE Transactions on Neural Networks and Learning Systems 28(10):2294–2305. https://doi.org/10.1109/TNNLS.2016.2582746
Chang H, Yeung DY, Xiong Y (2004) Super-resolution through neighbor embedding. In: 2004 IEEE Computer society conference on computer vision and pattern recognition, vol 1, pp 275–28. https://doi.org/10.1109/CVPR.2004.1315043
Chang X, Ma Z, Lin M, Yang Y, Hauptmann A (2017) Feature interaction augmented sparse learning for fast kinect motion detection. IEEE Trans Image Process 26 (8):3911–3920. https://doi.org/10.1109/TIP.2017.2708506
Chang X, Ma Z, Yang Y, Zeng Z, Hauptmann A G (2017) Bi-level semantic representation analysis for multimedia event detection. IEEE Trans Cybern 47(5):1180–1197. https://doi.org/10.1109/TCYB.2016.2539546
Chang X, Yu YL, Yang Y, Xing EP (2017) Semantic pooling for complex event analysis in untrimmed videos. IEEE Trans Pattern Anal Mach Intell 39 (8):1617–1632. https://doi.org/10.1109/TPAMI.2016.2608901
Chen X, Qi C (2014) Nonlinear neighbor embedding for single image super-resolution via kernel mapping. Signal Process 94:6–22. https://doi.org/10.1016/j.sigpro.2013.06.016
Chong CW, Raveendran P, Mukundan R (2003) The scale invariants of pseudo-Zernike moments. Pattern Anal Appl 6(3):176–184. https://doi.org/10.1007/s10044-002-0183-5
Cruz C, Mehta R, Katkovnik V, Egiazarian K (2017) Single image super-resolution based on Wiener filter in similarity domain. arXiv:1704.04126
Dong W, Zhang L, Shi G, Li X (2013) Nonlocally centralized sparse representation for image restoration. IEEE Trans Image Process 22(4):1620–1630. https://doi.org/10.1109/TIP.2012.2235847
Fan W, Yeung DY (2007) Image hallucination using neighbor embedding over visual primitive manifolds. In: 2007 IEEE Conference on computer vision and pattern recognition, pp 1–7. https://doi.org/10.1109/CVPR.2007.383001
Farsiu S, Robinson D, Elad M, Milanfar P (2004) Advances and challenges in super-resolution. Int J Imaging Syst Technol 14(2):47–57. https://doi.org/10.1002/ima.20007
Freeman WT, Pasztor EC, Carmichael OT (2000) Learning low-level vision. Int J Comput Vis 40(1):25–47. https://doi.org/10.1023/A:1026501619075
Freeman WT, Jones TR, Pasztor EC (2002) Example-based super-resolution. IEEE Comput Graph Appl 22(2):56–65. https://doi.org/10.1109/38.988747
Gao X, Wang Q, Li X, Tao D, Zhang K (2011) Zernike-moment-based image super resolution. IEEE Trans Image Process 20 (10):2738–2747. https://doi.org/10.1109/TIP.2011.2134859
Gao X, Zhang K, Tao D, Li X (2012) Joint learning for single-image super-resolution via a coupled constraint. IEEE Trans Image Process 21(2):469–480. https://doi.org/10.1109/TIP.2011.2161482
Gerchberg R (1974) Super-resolution through error energy reduction. Optica Acta: Int J Opt 21(9):709–720. https://doi.org/10.1080/713818946
Guo K, Yang X, Lin W, Zhang R, Yu S (2012) Learning-based super-resolution method with a combining of both global and local constraints. IET Image Process 6(4):337–344. 10.1049/iet-ipr.2010.0430
HaCohen Y, Fattal R, Lischinski D (2010) Image upsampling via texture hallucination. In: 2010 IEEE International conference on computational photography, pp 1–8. https://doi.org/10.1109/ICCPHOT.2010.5585097
Jiang J, Ma X, Cai Z, Hu R (2015) Sparse support regression for image super-resolution. IEEE Photon J 7(5):1–11. https://doi.org/10.1109/JPHOT.2015.2484287
Kanan HR, Salkhordeh S (2016) Rotation invariant multi-frame image super resolution reconstruction using pseudo Zernike moments. Signal Process 118:103–114. https://doi.org/10.1016/j.sigpro.2015.05.015
Kim SP, Bose NK, Valenzuela HM (1990) Recursive reconstruction of high resolution image from noisy undersampled multiframes. IEEE Trans Acoust Speech Signal Process 38(6):1013–1027. https://doi.org/10.1109/29.56062
Li X, Orchard MT (2001) New edge-directed interpolation. IEEE Trans Image Process 10(10):1521–1527. https://doi.org/10.1109/83.951537
Lin Z, Shum HY (2004) Fundamental limits of reconstruction-based superresolution algorithms under local translation. IEEE Trans Pattern Anal Mach Intell 26(1):83–97. https://doi.org/10.1109/TPAMI.2004.1261081
Liu L, Huang W, Wang C (2017) Texture image prior for SAR image super resolution based on total variation regularization using split bregman iteration. Int J Remote Sens 38(20):5673–5687. https://doi.org/10.1080/01431161.2017.1346325
Mishra D, Majhi B, Sa PK (2014) Neighbor embedding based super-resolution using residual luminance. In: 2014 Annual IEEE India conference (INDICON), pp 1–6. https://doi.org/10.1109/INDICON.2014.7030659
Mishra D, Majhi B, Sa PK, Dash R (2016) Development of robust neighbor embedding based super-resolution scheme. Neurocomputing 202:49–66. https://doi.org/10.1016/j.neucom.2016.04.013
Mishra D, Majhi B, Sa PK (2017) Improved feature selection for neighbor embedding super-resolution using Zernike moments. In: Proceedings of international conference on computer vision and image processing, pp 13–24. https://doi.org/10.1007/978-981-10-2107-7_2
Nasrollahi K, Moeslund TB (2014) Super-resolution: a comprehensive survey. Mach Vis Appl 25(6):1423–1468. https://doi.org/10.1007/s00138-014-0623-4
Park SC, Park MK, Kang MG (2003) Super-resolution image reconstruction: a technical overview. IEEE Signal Process Mag 20(3):21–36. https://doi.org/10.1109/MSP.2003.1203207
Patanavijit V (2009) Super-resolution reconstruction and its future research direction. AU J Technol 12(3):149–163
Rajan D, Chaudhuri S, Joshi MV (2003) Multi-objective super resolution: concepts and examples. IEEE Signal Process Mag 20(3):49–61. https://doi.org/10.1109/MSP.2003.1203209
Sajjadi MS, Schölkopf B, Hirsch M (2016) Enhancenet: single image super-resolution through automated texture synthesis. arXiv:1612.07919
Sun J, Zheng NN, Tao H, Shum HY (2003) Image hallucination with primal sketch priors. In: 2003 IEEE Computer society conference on computer vision and pattern recognition, vol 2, pp 29–36. https://doi.org/10.1109/CVPR.2003.1211539
Tsai RY, Huang TS (1984) Multiframe image restoration and registration. Adv Comput Vis Image Process 1(2):317–339
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4):600–612. https://doi.org/10.1109/TIP.2003.819861
Weber AG (1997) The USC-SIPI image database. http://sipi.usc.edu/database/database.php?volume=textures
Wei LY, Lefebvre S, Kwatra V, Turk G (2009) State of the art in example-based texture synthesis. In: Eurographics 2009, State of the Art Report, EG-STAR
Yang J, Huang T (2010) Image super-resolution: historical overview and future challenges. In: Milanfar P (ed) Super-Resolution imaging, chap. 1. ISBN: 9781439819302. CRC Press, pp 1–24
Yang J, Wright J, Huang TS, Ma Y (2010) Image super-resolution via sparse representation. IEEE Trans Image Process 19(11):2861–2873. https://doi.org/10.1109/TIP.2010.2050625
Yang S, Wang Z, Zhang L, Wang M (2014) Dual-geometric neighbor embedding for image super resolution with sparse tensor. IEEE Trans Image Process 23 (7):2793–2803. https://doi.org/10.1109/TIP.2014.2319742
Yoo SB, Choi K, Jeon YW, Ra JB (2016) Texture enhancement for improving single-image super-resolution performance. Signal Process Image Commun 46:29–39. https://doi.org/10.1016/j.image.2016.04.007
Zachevsky I, Zeevi YY (2014) Single-image superresolution of natural stochastic textures based on fractional brownian motion. IEEE Trans Image Process 23 (5):2096–2108. https://doi.org/10.1109/TIP.2014.2312284
Zeyde R, Elad M, Protter M (2010) On single image scale-up using sparse-representations. In: Proceedings of the 7th international conference on curves and surfaces, vol 6920, pp 711–730. https://doi.org/10.1007/978-3-642-27413-8_47
Zhang L, Wu X (2006) An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans Image Process 15(8):2226–2238. https://doi.org/10.1109/TIP.2006.877407
Zhang K, Gao X, Li X, Tao D (2011) Partially supervised neighbor embedding for example-based image super-resolution. IEEE J Selected Topics Signal Process 5(2):230–239. https://doi.org/10.1109/JSTSP.2010.2048606
Zhang L, Zhang D, Mou X, Zhang D (2011) FSIM: a feature similarity index for image quality assessment. IEEE Trans Image Process 20(8):2378–2386. https://doi.org/10.1109/TIP.2011.2109730
Zhang K, Gao X, Tao D, Li X (2012) Single image super-resolution with non-local means and steering kernel regression. IEEE Trans Image Process 21 (11):4544–4556. https://doi.org/10.1109/TIP.2012.2208977
Acknowledgments
This research is partially supported by the following project: Grant No. ETI/359/2014 by Fund for Improvement of S&T Infrastructure in Universities and Higher Educational Institutions (FIST) Program 2016, Department of Science and Technology, Government of India.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Mishra, D., Majhi, B., Bakshi, S. et al. Single image super resolution for texture images through neighbor embedding. Multimed Tools Appl 79, 8337–8366 (2020). https://doi.org/10.1007/s11042-017-5367-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-5367-5