
Abstract
With the increasing number of the images, how to effectively manage and use these images becomes an urgent problem to be solved. The classification of the images is one of the effective ways to manage and retrieve images. In this paper, we propose a novel large-scale multimedia image data classification algorithm based on deep learning. We firstly select the image characteristics to represent the flag for retrieval, which represents the color, texture and shape characteristics respectively. A feature of color is the most basic image data, mainly including the average brightness, color histogram and dominant color, etc. What the texture refers to is the image data in the anomalous, macroscopic as well as orderly one key character that on partial has. The contour feature extraction of image data needs to rely on the edge detection, edge of the detected edge through the connection or grouping to form a meaningful image event. Secondly, we revise the convolutional neural network model based on the pooling operation optimization, the pooling is in the process of the convolution operation to extract the image characteristics of the different locations to gather statistics. Furthermore, we integrate the parallel and could storage strategy to enhance the efficiency of the proposed methodology. The performance of the algorithm is verified, compared with the other state-of-the-art approaches, the proposed one obtains the better efficiency and accuracy.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Along with the development of electronics technology and computer technology, the DIP (digital image processing) enters the high-speed period of development. Now we can gain the massive images from the image equipment and the image database or the Internet and thus carries on the effective classification and retrieval to the massive images also becomes the research subjects of many scientific researchers [25, 26, 38]. With the increasing number of the images, how to effectively manage and use these images becomes an urgent problem to be solved. The classification of the images is one of the effective ways to manage and retrieve images. However, most of the image classification is in the manual labeling stage. Because manual classification is not only time-consuming and laborious, but also prone to errors, so the automatic classification of the images has become the focus of current research [44, 46].
Starting from the previous research [5, 20, 23, 57], numerous researchers from the different angle analysis and solution labelling issue, expected that can find the good retrieval and the labelling method. And refer to the literatures of the [17, 19, 21, 28, 54], the deep learning has been a proper selection for implement some of the application scenarios. These methods analyze from the feature expression mechanism of image which can be divided into two kinds approximately.
-
1)
Firstly, the image is divided into several homogeneous regions or image sub-blocks, then the image is analyzed with the semantic annotation. This kind of method uses image segmentation algorithm, tries to be divided into certain semantic object units the image effectively, through seeking for the labelling keyword and region semantics object or the view picture image itself within the corresponding relationships realizes automatic image labelling [3, 9].
-
2)
Use images of the global visual information using the method of semantic annotation for image scene, the method to image characteristics and the label text word for the complete separation, and compare the image similarity on pure visual hierarchy which is a supervised learning method [12, 18].
Among all the methodologies, the feature selection and extraction step is the essential one that needs in-depth analysis. From the literature review, we summarize the state-of-the-art characteristics selection approaches into the following categories.
-
1)
The global feature. Image characteristics including high-level semantic feature and low-level feature. As a result of “semantic gap” existence, the high-level semantic feature is hard to gain through the computer directly, by the semantic key retrieval image was still an arduous duty. The problem of the semantic gap comes from the research of content-based retrieval, but the problem also exists in the field of text search, web search and video retrieval, for the problem of how to cross the semantic gap, the methods of the relevance feedback and automatic annotation. The former uses the interaction between the system and the user to obtain the mapping relation between the high-level semantics and the underlying characteristics of the multimedia data. The latter uses the keywords to mark the multimedia data. This technology is widely used in the image field. But using the similarity matching retrieval image of image low-level feature is another important image retrieval method, but this method relies on the validity of image characteristics.
-
2)
Color characteristics. Commonly used in the image retrieval color space HSV color space, CIELAB space and CIELUV space, because they are similar to the human eye and subjective visual. The color histogram can represent the distribution of the color space value of all the pixels in an image [32, 55]. The color moment is a simple and effective color feature. Since color distribution information is mainly concentrated in the low order moment, the first order moment, the second moment and the third moment of the color are enough to express the color distribution of the image. The advantage of this approach over color histograms is that it does not need to vectorize the characteristics, thus speeding up the processing speed [35].
-
3)
Texture feature. Scholars summarized six associated with human visual perception of the texture feature and its calculation method: roughness, contrast, directivity, line, regularity, and a rough degree of similarity. The first three characteristics play an important role in image retrieval and classification which reflects the degree of the coarse or fine image texture roughness while contrast to reflect the degree of a texture clear. If there is a rule in the direction of the directional reflection texture.
While implementing the automatic image classification system, the efficiency and the hardware effectiveness should be taken into consideration. With this target, the processing paradigm for the large-scale multimedia system should be finalized. Multimedia cloud computing platform through a number of servers to complete the transfer of large-scale data flow, data flow between servers in parallel processing, prone to resource conflict, resulting in waste of server resources and data flow scheduling lag, Under the multi-server scheduling data flow between the rational allocation of server resources that can be separated into the three aspects. (1) Control level: the management of scheduling platform of large-scale data flow hardware resources for each data flow to allocate the corresponding hardware resources, the data flow into a scheduling platform of large-scale data flow for real-time operation. (2) Data level: according to topology of management level establishment, regulates the server in large-scale data stream dispatch platform, the data of receive control level feedback, guarantees the large-scale data stream live transmission. (3) Management level: the deployment of the scheduling platform of large-scale data flow in the data-level topology, while the multimedia cloud computing environment, the allocation of hardware resources to regulate.
Scheduling platform of large-scale data flow also includes the timer which need to pass the packet to the timer, the timer in the packet arrival time after the transmission of data packets to the output module. In the Figs. 1 and 2, we show the large-scale multimedia system and the data interaction flow and the initialized code for the system. The configuration control module initializes scheduling platform of large-scale data flow and regulates the program flow resources. The packet input module collects the data in the multimedia cloud computing environment and classifies and filters the data, and then transfers the processed data to the streaming application. The packet input module receives the RTSP and IP packet data fed back by the streaming application and sends the data to the grouping operation module [36, 41, 48]. Under this paradigm, efficiency from the hardware perspective will be enhanced and the robustness will be improved. A distributed multimedia system, multimedia information is the object of system transmission and processing, network is the material basis for the transmission of information and security. Through the network transmission, multimedia information from the source site to reach the destination site, and multimedia information and the network there is a close and inevitable link between. Model to a communication channel for network abstraction, eliminates the complexity of network topology and various forms of research work to bring difficulties, while retaining the basic characteristics of the network that is to simplify the multimedia communication network is reasonable and effective which can be reflected from the Fig. 1.

The large-scale multimedia system and the data interaction flow

The initialization code block for the large-scale multimedia system
As shown in the Fig. 2, the initialization code block for the large-scale multimedia system is demonstrated. The operating system bootloader provides a set of the software environments that are required before the operating system loads. Through the execution of this program, the embedded system can initialize the mapping between the hardware device and the memory space, and finally bring the system into the appropriate hardware and software environment. After an embedded hardware device is powered up or reset, the processor typically fetches instructions from an address pre-arranged by the manufacturer.
In this paper, to provide the more efficient image classification algorithm, we conduct research on the large-scale multimedia image data classification algorithm based on the deep learning. The theoretical details will be introduced in the later sections.
2 Convolutional neural network and the optimization strategy
The depth study is new domain in a machine learning research, the depth study through combining the low level characteristics, forms the higher abstract level feature expression property category, to discover that data distributional characteristics, and its characteristics include multi-layer perceptron structure of hidden-layer that has parallelism of information processing, the distributivity of information processing and interconnection of information processing unit, the plasticity of structure, high non-linearity and with good fault tolerance, learning control, self-organization and from compatibility and other characteristics [7, 27, 31, 43, 51]. CNN is proposed as a depth learning architecture in order to minimize the data preprocessing requirements. Convolution neural network (CNN) is essentially the multi-layer perceptron which is a variety of structures that can contain multiple nerves, input layer, hidden layer, the output layer [16, 37]. The convolutional neural network is essentially a variant of multilayer perceptron, which consists of an input layer, a hidden layer and an output layer. The hidden layer can have a plurality of layers, each layer is composed of a plurality of two-dimensional planes, and each plane is composed of a plurality of independent neurons. Theoretically, the essential part of the CNN can be separate into the S and the C layers. C levels are mainly to use the convolution kernel extraction characteristics and realize carries on the effect of the filtration and strengthening to the characteristics. In each convolution level, it firstly carries on the convolution operation the characterization diagram and convolution kernel of the previous output, then through activation function and then the characterization diagram of output this level [22, 30, 56].
S mainly by the sampling C layer characteristic dimension of the each size of n in the pool for average “pool” or “pool” largest operation that can be expressed as formula 2. Where the dowm_sampling(y t − 1j + b tj ) represents the down sampling function and the y t − 1j , y tj represent the signal before and after the operation, respectively.
In the above formulas, the f represents activation function, t represents the layer numbers, the k ti,j denotes the kernel [14, 53], dowm_sampling is the sampling function. Traditional convolution neural network is by the convolution level and depth structure of sub-sampling level alternately constitution, this depth structure can reduce the computing time effectively and establishes invariability in the spatial structure. The input picture carries on the network layer upon layer maps, and ultimately obtains the various levels regarding the image different expression forms, realizes the image the depth to indicate that convolution kernel as well as sub-sampling the mapping way of way direct decision image. In the following Fig. 3, we show the architecture of the CNN.

The architecture of the CNN
In training, its forward propagation is used for feature extraction, and convolution and the down-sampling are used to obtain image characteristics. The back propagation is used for the error correction. The traditional Back Propagation mechanism is used to propagate the error layer by layer, and the chain convolution rule is used to update the convolution kernel. The output function can be demoted as the formula 3.
The zoutput represents the output function, the gL is the exchange function, the XL is the value of the prior-layer output, the wL represents the weight matrix. As shown in the Fig. 3, the convolution feature mapping phase generates a total of K feature maps, each feature map has its own automatic encoder following to the k-th feature map that corresponding to the k-th automatic encoder as an example, In this paper, an automatic encoder with only the single hidden layer is used. The hidden layer feature can be formulized as Eq. 4.
The matric of the ak and bk can be denoted as formula 5 ~ 6.
At level L, the loss function can be expressed as the follows [4, 15].
Where the parameter of the λ is the essential term we should take into consideration. Overall, at present bases on the depth CNN model to be mostly centralized in the depth exploitation, in the fitting control and practical application, during the training needed the mass data support. In the case of a small sample, its performance is even less than the traditional feature extraction method, but in other large data sets on the case of pre-training model, the effect is far more than the existing manual feature model, the current model design and most applications are based on pre-training and implementation. For this concern, the general network output issue can be formulized as the following equation.
And the optimization issue can be transferred into the formula 10.
Under the conditions of the formula 11.
In addition to its own depth structure, the maximum difference between the convolutional neural network and the general BP neural network is to reduce the network parameters by means of local receptive field and weight sharing method. The so-called localized receptive field means that each convolution kernel is connected only to a specific region in the image, that is, each convolution kernel only convolves a portion of the image, and in the subsequent layers these local convolutions feature, which is consistent with the spatial correlation of the image pixels and reduces number of convolution parameters. Accordingly, the task function can be expressed as the formula 12.
The ∂Ep/∂wji is the primary parameter we should consider. For this situation, we need the mapping optimization shown as the Fig. 4. The system input is one with the time related process, its value of exports both relies on the input function spatial polymerization, and time build-up effect close correlation that must solve this kind of problem, the traditional method needs to establish and to solve the more complex mathematical model generally. But these systems often affect factor many nonlinear systems. The main purpose of the self-organizing feature map neural network is to convert the input signal pattern of any dimension into one-dimensional or two-dimensional discrete mapping, which reflects the memory pattern of the nerve cells and excitability rules of nerve cells stimulated. The characteristics of the nervous system and this network correspond to a group of the unit neurons, rather than a neuron corresponding to a model.

The mapping optimization for the CNN
The crucial technique is the transferring matrix, after the error back propagation, the error function of each network layer is obtained, then the network weights are modified by the stochastic gradient descent method, and then the next iteration is carried out until the convergence condition is reached. Note that due to the difference between the size of the layer and the layer, in the error transfer need to be sampled before and after the two layers of the same size, and then the error transfer. In the two cross connection layer, the weight updates also uses the chain derivative rule can be expressed as follows.
When the convolution of a layer of sampling and at this time from the lower convolution layer error of the drop sampling error, we need to re-calculate the term as follows.
In the process of calculating the optimal solution of the objective function, through continuous iteration, to eventually achieve convergence error state. The universal can be expressed as the formula 15.
3 The fundamental basis for the proposed methodology
3.1 The large-scale multimedia data properties
Under the cloud of multimedia data flow has the characteristics of real-time, randomness, number, etc., and multimedia application of cloud computing environment required to support multimedia services can provide high quality service, to achieve the service quality is the key to effective process data congestion problems, and thus to seek effective mass data stream scheduling method. According to the development of the network transmission technology, large-scale streaming media system has experienced three stages as follows.
-
1)
IP multicast protocol to carry streaming media transmission, IP layer multicast due to congestion control, scalability, availability and other aspects of a series of problems, so the IP multicast-based video communications applications have not been widely used in Internet usage.
-
2)
As the one special realization mode of peer-to-peer network P2P mode of basic transmission, statement of application-layer multicast agreement, especially bases on the application-layer multicast agreement the use of the end system multicast system SIGCOMM conference, symbolizes that the streaming media broadcast plan was in the 2nd stage of development [10, 33, 58].
-
3)
In the multi-sender multi-receiver transmission mode, each node can receive the data from multiple nodes or send data to multiple nodes. The data topology between nodes forms a network structure, which greatly improves the system expansion feature.
In the Fig. 5, we show the architecture of the large-scale multimedia data processing system, as shown, the data stream content extraction module through the data import module gain high-speed multimedia data class, with degree of correlation between the multi-channel degrees of the correlation computation module computation different data circulation, the multi-channel information extraction module is responsible to the channel data stream carries on the information extraction according to the modality as well as the system, vector extraction module is responsible to the processed information carries on the feature extraction, the characteristic vector that will then extract sends in the filtration computation module.

The large-scale multimedia data processing system architecture
To maintain the satisfactory processing efficiency, we adopt the multi-channel connections architecture. Whether the data flows of different channels are federated or not is based on whether the channels are correlated. A filter rule consists of the conditional expressions and action expressions. The conditional expression consists of a general predicate and a relational operator ∧, and the action expression consists of an action unit and a relational operator ∧. Simply put, a filter rule means that if the conditional expression is true, then implementation of the action, or not the implementation of action. If the conditional expression is empty, the action is executed unconditionally, which means that all the multimedia streams are executed. If in a filtration rule includes the filtration demands between the filtration demands or the different channels of different modality, then this rule for fusion filtration rule. Suppose we have a sequence of S denoted as the formula 16.
Defines interrelatedness between the two channels to have the difference in the different practical application systems and below uses in our validation assemblies the definition example about interrelatedness.
In our verification system, the definition of “key content dictionary” and “filter content dictionary” to calculate the channel data stream in the text content relevance that can basically reflect the channel itself semantic information relevance. We consider the textual information in the channel data stream as a “word flow” and then build a temporary “word frequency table” with our “Key Content Dictionary” and the “Filter Content Dictionary”. The standard for our methodology can be defined as the formula 18.
From the above mentioned analysis, we can reach the listed conclusion.
-
(1)
The correlation content related to N.
-
(2)
The content correlation is associated with the expression of channel.
-
(3)
The content of correlation degree between the channel and sharing degree.
3.2 The image retrieval and classification paradigms
Image retrieval technology has a lot of kinds, most of which are based on the shape of the image, such as color, texture characteristics for image retrieval. The primary application of the image classification and retrieval is the automatic annotation. Automatic image annotation is to make the computer automatically able to any unsigned paintings that reflect the meaning of the image content keywords. It by using the annotated image set or other available information automatically learn the semantic concept space and the relationship between visual feature space model, and use this model with unknown semantic image, i.e., it is trying to image the high-level semantic information and to establish a mapping relationship between low-level characteristics, thus to some extent, can solve the problem of “semantic gap”.
Existing majority automatic image labelling algorithm, attempts to realize labelling of semantic keyword in the image rank directly, namely the algorithm does not need between the region and keyword of image establishes the mapping relationships of correspondences. But also some work try to solve the labelling problem from the technical angle of object recognition that is each region of image entrusts with the keyword. In the Fig. 6, we show the sample illustration of the retrieval and annotation result.

The image retrieval and annotation result demonstration
Based on the literature review, the annotation methods can be generally summarized as the following aspects. (1) Classification-based automatic image labelling algorithm. The mentality of quite direct-viewing automatic image labelling, labelling the issue regards as is the image retrieval classification issue. If regards as each semantic keyword is a category marks, then the image labelling issue transforms as the image classification issue and therefore can definitely solve the labelling problem from the angle of image classification. (2) Probability context modeling-based automatic image labelling algorithm. While the image annotation algorithm based on the probability association model is based on probabilistic statistical model, and that analyzes the symbiosis probability relation between image region feature and semantic keywords, and uses this as the annotation of the image to be annotated. Intuitively, if two images have high visual similarity, the higher the probability of the two keywords are similar. (3) Based on the learning algorithm of automatic image annotation. Graph based learning algorithm is a semi supervised learning algorithm, which is known to be involved in the learning process of the algorithm. With the traditional supervised learning and unsupervised learning, semi supervised learning can use more information in the learning stage, such as the distribution of data characteristics and it applies to a large amount of data that has been labeled a relatively small amount of data [6, 8, 34, 52].
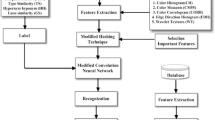
The existing potential optimization approaches for the classification can be organized as the following aspect. (1) Hash algorithm integration. Through the HASH algorithm can under the rapid localization centralized certain probability with the data of search data correlation, coordinate Hamming space similarity measure the rapidity and characteristics of index result easily further expansion that can greatly enhance the efficiency of index and retrieval, thus Hash technology is regarded as most has the similar reconnaissance method of potential. (2) Based on the Search algorithm of the automatic image annotation [1, 42, 47]. Search based annotation method avoids the complicated parameter learning process. Moreover, since the relevant image is found by retrieval, the method is not limited by the training set or the set of the annotated words. (3) In the candidate labelling information that the basic image labelling stage obtains possibly is incomplete, or contained some and image not related labelling information. This is mainly because the existing labelling algorithm analyzes each semantic keyword alone, has not considered the semantic connection between keywords. But under normal conditions, the semantic link between glossary and glossary is very close, usually among glossaries including hierarchical relation and relevant information. (4) What character description to express the semantic information of the images, what the image segmentation algorithm based on semantic that can effectively characterize the user perception of image content, is an important means to improve the performance of image automatic classification. In the Fig. 7, we show the procedures [39].

The illustration of the classification procedures
4 The proposed framework
4.1 The CNN based classification and retrieval framework
This article uses the depth study of the convolutional neural network, it is a kind of the feedforward neural networks which is mainly composed of the multiple convolution and full connection layer. The weight of some connections between neurons in the same layer of is shared. A feedforward neural network can be considered to be the combination of a series of function [2, 11]. The basic theories are introduced previously, in this section, we focus on the optimization and the modification operation [24, 40, 50]. Pooling is in the process of the convolution operation to extract the image characteristics of the different locations to gather statistics. Pooling can reduce the dimension of convolution characteristics, at the same time also can prevent data fitting, and the Fig. 8 reflects the feature.

The pooling operation and the flowchart demonstration
We formulize the pooling procedure as the Eq. 19.
Under normal conditions, the image collection of target task with pre-training image collection the category quantity or the image style have very big difference, in the retrieval duty of picture target collection, often is directly hard to achieve the optimal performance with pre-training the visual feature of CNN model extraction image. Therefore, to cause the CNN model parameter of pre-training well the feature extraction for picture target collection, to the CNN model parameter of pre-training carries on the trimming using the image of the picture target collection. The entire trimming process is as follows.
-
1)
Step One. Each image from picture target storehouse first was adjusted to the 256*256, then withdraws this chart stochastically the sub-block or its mirror image takes the input of CNN.
-
2)
Step Two. Regarding 1st to 7th, we use in the parameter that in the pre-training process obtains initializes it. In trimming process, with pre-training step two similar parameter set-ups based on the Eq. 20.
-
3)
Step Three. For the first 7 layers to set a smaller learning rate, we can ensure that the parameters obtained through the pre-training CNN model that is not destroyed during the trimming process. For the last layer to set a higher learning rate, and the whole network can be quickly converged to the new optimal point on the target image set of the general pool.
The similar measure method of traditional image has the cosine to be away from, the Euclidean distance, among the distance through characteristic vectors judges the image the similar degree. Because the distance between the sole vectors cannot accurately reflect the similar degree between images, therefore this article used manifold distance-based ranking on manifolds method to measure the similarity between images [13, 45, 49]. The ranking function can be them formulized as the Eq. 21.
Where the In represents the sample matrix and in the Fig. 9, we show the modified CNN systematic architecture [29, 56].

The modified CNN systematic architecture
As the further step, to test the effectiveness of the algorithm, we should define the function for the performance evaluation. The 22 ~ 24 defines the adopted standard. Image processing system appraisal effect main consideration accuracy and retrieval speed two aspect factors. Before the accuracy is decided in withdraws the image characteristic separating capacity and the match algorithm validity, the retrieval speed is decided by the image characteristic order of complexity and match algorithm order of complexity and the image database organization form. Refinement refers to the ratio of effective images in the returned result set, and is used to exclude the system from irrelevant images. The recall rate refers to the ratio of the number of valid images in the returned set to the number of all similar images in the database and is used to measure the ability of the system to retrieve the relevant image.
4.2 Classification referred multimedia system efficiency enhancement model
KD tree as a data structure of k-dimensional data space division, that mainly used in multi-dimensional space key data search. In order to facilitate the processing of image data, a large number of eigenvectors representing image characteristics are used to refer to the whole image data. This feature vector accords with the characteristics of the high-dimensional key-value, and is suitable for indexing by using the KD tree to speed up image retrieval process. The KD tree is each node is a binary tree of K vector. Each non-leaf node can regard as a planoid, but this planoid the multi-dimensional space division is the two sub-planes. Was divided into the left subtree at this planoid left point, the right point was divided into the right subtree.
There are many ways to determine the hyperplane of this partitioned subspace, so there are many ways to construct a KD tree, which calculates the variance of each dimension of all points in the sub-plane and also chooses the dimension with the largest variance as the perpendicular to the partitioned subspace The direction of the hyperplane is one of the most popular methods of building KD trees today. This paper chooses the following architectures as the primary characteristics and reference approach.
-
Polynuclear construction: A polynuclear construction usually is one contains two or more independent achievement to carry out the unit basically the computation chip of CPU nucleus. These CPU have the respective independent buffer and bigger shared buffer. The communication network on these nucleus usual execution different thread and data exchage between processors through shared buffer or chip.
-
The nuclear architecture: relative to the multi-core structure, there are more and more intense in the nuclear architecture components are integrated into one chip. And that among all the nuclear architecture, the GPGPU is one of the most popular architecture. Taking into account the entire hardware storage system, each SM has a separate contains thousands of registers and dozens of KB of the shared memory on the chip memory SM is shared by several SP and is not visible to the outside. Data transfer is through the slice under the global memory. Through the above design, GPGPU in the overall cost of the basic and global memory consistent with the case to support the register and shared memory register-level access speed.
5 Experiment and simulation
In this section, we conduct experimental simulation on the proposed methodology. In the Fig. 10, the databased used for testing is shown. The generated database is formed of by the listed ones: natural scene image library and NUS-WIDE image library. The detailed information descriptions of these two image storehouses are as follows: Natural scene image storehouse contains 2000 images, all these images contain following 5 labelling: deserts, mountains, sea, setting sun and trees. In addition, we also add the animal and building images for testing. Image library contains 30,000 kinds of the images as these images are marked with the boats, cars, flags, horses, sky, sun, towers, aircraft, zebra, including the 31 kinds of labels.

The databases adopted by the experiment
To test the effectiveness of the proposed methodology, we compare it with the other algorithms, the Method 1 [53], 2 [1], 3 [42], 4 [13], respectively. The method 1 is similarity function based content-based image retrieval, the method 2 is the multiclass associative classification algorithm, the method 3 is the sparse representations of morphological attribute profiles based image retrieval and the method 4 is the ABACOC algorithm.
The Tables 1, 2, 3, 4 and 5 shows the statistical data of the comparison experiment, the Fig. 11 is the visualized performance of the experiment algorithms, these are the visualized result of the Tables 1, 2 and 3, he Fig. 12 represents the time consuming test based on the different data center sizes. In the experiment, we use 700 images and the training set and another 700 as the prediction one. The effectiveness and efficiency of the proposed method is well proved compared with other state-of-the-art approaches. In our experiment, the proposed algorithm got the average advancement of 17.5% compared with the other ones, the recall rate is much higher.

The visualized performance of the experiment algorithms

The time consuming test based on different data center sizes
6 Conclusion and future work
In this paper, we propose a novel large-scale multimedia image data classification algorithm based on deep learning. This method in the label loses under the erroneous minimum significance to fill the omission label, constructs the semantic balanced neighborhood and then in the semantic uniformity of sample through the neighborhood measure study guarantee neighborhood of the multi-label information inserting, obtains some relevance between images through the sparse representation, and constructs the semantic consistent neighborhood and ensure neighborhood sample has the overall situation similarity, some relevance and semantic uniformities. To optimize the CNN, we integrate the manifold learning for systematic modification. The experiment proves the robustness of the proposed method. In the future, we will focus on the CNN structural optimization and large scale multimedia data compression for building the more efficient classification paradigm.
Change history
20 September 2022
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s11042-022-13988-5
References
Abdelhamid N et al (2012) MAC: a multiclass associative classification algorithm. J Inf Knowl Manag 11(02):1250011
Bae C et al (2014) Effective audio classification algorithm using swarm-based optimization. Int J Innov Comput Inf Control 10(1):151–167
Bian J, Gao B, Liu, TY (2014) Knowledge-powered deep learning for word embedding. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases (pp. 132–148). Springer Berlin Heidelberg.
Blake K et al (2015) Use of mobile devices and the internet for multimedia informed consent delivery and data entry in a pediatric asthma trial: Study design and rationale. Contemp Clin Trials 42:105–118
Chen B et al (2013) Deep learning with hierarchical convolutional factor analysis. IEEE Trans Pattern Anal Mach Intell 35(8):1887–1901
Chen C et al (2013) A multiresolution hierarchical classification algorithm for filtering airborne LiDAR data. ISPRS J Photogramm Remote Sens 82:1–9
Chen GW, et al. (2015) A Novel Recognition Method of Multimedia Data for Social Network. Applied Computing and Information Technology/2nd International Conference on Computational Science and Intelligence (ACIT-CSI), 2015 3rd International Conference on. IEEE
Chou YC, et al. (2014) A reversible data hiding method using inverse S-scan order and histogram shifting. Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP), 2014 Tenth International Conference on. IEEE
Cui H, Ganger GR, Gibbons PB (2015) Scalable deep learning on distributed GPUs with a GPU-specialized parameter server. CMU PDL Technical Report (CMU-PDL-15-107)
Dal Mas M. (2015) Layered ontological image for intelligent interaction to extend user capabilities on multimedia systems in a folksonomy driven environment. Intelligent Interactive Multimedia Systems and Services in Practice. Springer International Publishing, 103–122
Das R, Saha S (2015) Microarray gene expression data classification using modified differential evolution based algorithm. 2015 Annual IEEE India Conference (INDICON). IEEE
de Freitas N (2016) Learning to Learn and Compositionality with Deep Recurrent Neural Networks: Learning to Learn and Compositionality. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 3–3). ACM
De Rosa R, Orabona F, Cesa-Bianchi N (2015) The ABACOC algorithm: a novel approach for nonparametric classification of data streams. Data Mining (ICDM), 2015 I.E. International Conference on. IEEE
Dharani T, Aroquiaraj IL (2013) A survey on content based image retrieval. Pattern Recognition, Informatics and Mobile Engineering (PRIME), 2013 International Conference on. IEEE,
Fang Y, Li H, Li X (2014) Lifetime enhancement techniques for PCM-based image buffer in multimedia applications. IEEE Trans Very Large Scale Integr (VLSI) Syst 22(6):1450–1455
Gelman A, Loken E (2014) The statistical crisis in science data-dependent analysis—a “garden of forking paths”—explains why many statistically significant comparisons don’t hold up. Am Sci 102(6):460
Giesecke K, Sirignano J, Sadhwani A (2016) Deep Learning for Mortgage Risk. Working Paper, Stanford University
Hannagan T, Ziegler JC, Dufau S, Fagot J, Grainger J (2014) Deep learning of orthographic representations in baboons. PLoS ONE 9(1):e84843
Howell C, Stein F, Kordella S, Booker L, Rockower E, Motahari H, … Spohrer J (2016) Cognitive Assistance in Government and Public Sector Applications. KI-Künstliche Intelligenz 1–2
Islamoglu H, Branch RM (2013) Promoting interest, engagement, and deep learning approach in online higher education settings. In: 36 th Annual Proceedings Presented at the Annual Convention of the Association for Educational Communications and Technology (pp. 444–451)
Jean N, Burke M, Xie M, Davis WM, Lobell DB, Ermon S (2016) Combining satellite imagery and machine learning to predict poverty. Science 353(6301):790–794
Jeong Y-S et al (2015) Guest editorial: advanced technologies and services for multimedia Big data processing. Multimedia Tools Appl 74(10):3413–3418
Jiu M et al (2014) Human body part estimation from depth images via spatially-constrained deep learning. Pattern Recogn Lett 50:122–129
Krizhevsky A, Hinton GE (2011) Using very deep autoencoders for content-based image retrieval. In: ESANN
Le QV (2013) Building high-level features using large scale unsupervised learning. In: 2013 I.E. international conference on acoustics, speech and signal processing (pp. 8595–8598). IEEE
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521:436–444
Lee C-F, Chen S-T, Shen J-J (2015) Reversible dual-image data embedding on pixel differences using histogram modification shifting and cross magic matrix. 2015 International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP). IEEE
Liu Y, Sun C, Lin L, Wang X (2016) Learning Natural Language Inference using Bidirectional LSTM model and Inner-Attention. arXiv preprint arXiv:1605.09090
Madadi Y, Mohammad ESA, Madadi Y (2013) An accurate classification algorithm with genetic algorithm approach. Int J Comput Inf Technol 1(3):198–210
Miller K, Morreale P (2014) Finding the needle in the image stack: performance metrics for big data image analysis. IEEE MultiMedia 21(1):84–89
Naaman M (2012) Social multimedia: highlighting opportunities for search and mining of multimedia data in social media applications. Multimed Tools Appl 56(1):9–34
Noda K, Yamaguchi Y, Nakadai K, Okuno HG, Ogata T (2015) Audio-visual speech recognition using deep learning. Appl Intell 42(4):722–737
Norouzi B et al (2014) A novel image encryption based on hash function with only two-round diffusion process. Multimedia Systems 20(1):45–64
Nouaouria N, Boukadoum M (2014) Improved global-best particle swarm optimization algorithm with mixed-attribute data classification capability. Appl Soft Comput 21:554–567
Papernot N, McDaniel P, Jha S, Fredrikson M, Celik ZB, Swami A (2016) The limitations of deep learning in adversarial settings. In: 2016 I.E. European Symposium on Security and Privacy (EuroS&P) (pp. 372–387). IEEE
Santhanam A, Min Y, Beron P, Agazaryan N, Kupelian P, Low D (2016) SU-D-201-05: on the automatic recognition of patient safety hazards in a radiotherapy setup using a novel 3D camera system and a deep learning framework. Med Phys 43(6):3334–3335
Sarisaray-Boluk P, Akkaya K (2015) Performance comparison of data reduction techniques for wireless multimedia sensor network applications. Int J Distrib Sensor Netw 2015:160
Schmidhuber J (2015) Deep learning in neural networks: an overview. Neural Netw 61:85–117
Schmidtler MAR, Borrey R, Sarah A (2014) Data classification using machine learning techniques. U.S. Patent No. 8,719,197. 6 May
Sklan JE, Plassard AJ, Fabbri D, Landman BA (2015) Toward content based image retrieval with deep convolutional neural networks. In: SPIE Medical Imaging (pp. 94172C-94172C). International Society for Optics and Photonics
Song J, Gao L, Zou F, Yan Y, Sebe N (2016) Deep and fast: deep learning hashing with semi-supervised graph construction. Image Vis Comput
Song B et al (2014) Remotely sensed image classification using sparse representations of morphological attribute profiles. IEEE Trans Geosci Remote Sens 52(8):5122–5136
Suk HI, Wee CY, Lee SW, Shen D (2016) State-space model with deep learning for functional dynamics estimation in resting-state fMRI. NeuroImage 129:292–307
Sun Y, et al. (2014) Deep learning face representation by joint identification-verification. Adv Neural Inf Process Syst
Taneja S, et al. (2014) An enhanced k-nearest neighbor algorithm using information gain and clustering. 2014 Fourth International Conference on Advanced Computing & Communication Technologies. IEEE
Tian Y, et al. (2015) Pedestrian detection aided by deep learning semantic tasks. Proc IEEE Conf Comput Vis Pattern Recognit
Triguero I et al (2015) ROSEFW-RF: the winner algorithm for the ECBDL’14 big data competition: an extremely imbalanced big data bioinformatics problem. Knowl-Based Syst 87:69–79
Tseng PH, Paolozza A, Munoz DP, Reynolds JN, Itti L (2013) Deep learning on natural viewing behaviors to differentiate children with fetal alcohol spectrum disorder. In: International Conference on Intelligent Data Engineering and Automated Learning (pp. 178–185). Springer Berlin Heidelberg
Visco C et al (2012) Comprehensive gene expression profiling and immunohistochemical studies support application of immunophenotypic algorithm for molecular subtype classification in diffuse large B-cell lymphoma: a report from the International DLBCL Rituximab-CHOP Consortium Program Study. Leukemia 26(9):2103–2113
Wan J, Wang D, Hoi SCH, Wu P, Zhu J, Zhang Y, Li J (2014). Deep learning for content-based image retrieval: A comprehensive study. In: Proceedings of the 22nd ACM international conference on Multimedia (pp. 157–166). ACM
Wang H, Wang J (2014) An effective image representation method using kernel classification. 2014 I.E. 26th International Conference on Tools with Artificial Intelligence. IEEE
Wang J, et al. (2015) Multiple kernel multivariate performance learning using cutting plane algorithm. Systems, Man, and Cybernetics (SMC), 2015 I.E. International Conference on. IEEE
Wang J, et al. (2016) Optimizing top precision performance measure of content-based image retrieval by learning similarity function. arXiv preprint arXiv:1604.06620
Xiao SUN, Chengcheng LI, Fuji REN (2016) Sentiment analysis for chinese microblog based on deep neural networks with convolutional extension features. Neurocomputing
Yang S, Luo P, Loy CC, Tang X (2015) From facial parts responses to face detection: A deep learning approach. In: Proceedings of the IEEE International Conference on Computer Vision (pp. 3676–3684)
Yang X, Zhang T, Changsheng X (2015) Cross-domain feature learning in multimedia. IEEE Trans Multimedia 17(1):64–78
Zeng X, et al. (2014) Deep learning of scene-specific classifier for pedestrian detection. European Conference on Computer Vision. Springer International Publishing
Zhang L et al (2014) Feature correlation hypergraph: exploiting high-order potentials for multimodal recognition. IEEE Trans Cybern 44(8):1408–1419
Author information
Authors and Affiliations
Corresponding author
About this article

Cite this article
Li, J., Singh, R. & Singh, R. RETRACTED ARTICLE: A novel large-scale multimedia image data classification algorithm based on mapping assisted deep neural network. Multimed Tools Appl 76, 18687–18710 (2017). https://doi.org/10.1007/s11042-017-4364-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-017-4364-z