
Abstract
We extend the classical primal-dual interior point method from the Euclidean setting to the Riemannian one. Our method, named the Riemannian interior point method, is for solving Riemannian constrained optimization problems. We establish its local superlinear and quadratic convergence under the standard assumptions. Moreover, we show its global convergence when it is combined with a classical line search. Our method is a generalization of the classical framework of primal-dual interior point methods for nonlinear nonconvex programming. Numerical experiments show the stability and efficiency of our method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In this paper, we consider the following Riemannian constrained optimization problem (RCOP):

where \(\mathcal {M}\) is a connected, complete d-dimensional Riemannian manifold and \(f :\mathcal {M}\rightarrow \mathbb {R}, h:\mathcal {M}\rightarrow \mathbb {R}^{l}\), and \(g:\mathcal {M}\rightarrow \mathbb {R}^{m}\) are smooth functions. This problem appears in many applications, for instance, matrix approximation with nonnegative constraints on a fixed-rank manifold [31] and orthogonal nonnegative matrix factorization on the Stiefel manifold [19]; for more, see [23, 27].
The body of knowledge on (RCOP) without h, g, often called simply Riemannian optimization, has grown considerably in the last 20 years. The well-known methods in the Euclidean setting, such as steepest descent, Newton, and trust region, have been extended to the Riemannian setting [1, 5, 16]. By contrast, research on (RCOP) is still in its infancy. The earliest studies go back to ones on the optimality conditions. Yang et al. [36] extended the Karush–Kuhn–Tucker (KKT) conditions to (RCOP). Bergmann and Herzog [2] considered more constraint qualifications (CQs) on manifolds. Yamakawa and Sato [34] proposed sequential optimality conditions in the Riemannian case. Liu and Boumal [23] were the first to develop practical algorithms. They extended the augmented Lagrangian method and exact penalty method to (RCOP). Schiela and Ortiz [30] and Obara et al. [27] proposed the Riemannian sequential quadratic programming method. However, to our knowledge, interior point methods have yet to be considered for (RCOP).
The advent of interior point methods in the 1980s greatly advanced the field of optimization [33, 37]. By the early 1990s, the success of these methods in linear and quadratic programming ignited interest in using them on nonlinear nonconvex cases [11, 35]. From the 1990s to the first decade of the twenty-first century, a large number of interior point methods for nonlinear programming emerged. They proved to be as successful as the linear ones. A subclass known as primal-dual interior point methods is the most efficient and practical. As described in [24], the primal-dual approach to linear programming was introduced in [25]: it was first developed as an algorithm in [20] and eventually became standard for the nonlinear case as well [11, 35].
Contribution In this paper, we extend the primal-dual interior point algorithms from the Euclidean setting, i.e., \(\mathcal {M}=\mathbb {R}^{d}\) in (RCOP), to the Riemannian setting. We call this extension the Riemannian interior point method (RIPM). Our contributions are summarized as follows:
-
1.
To our knowledge, this is the first study to apply the primal-dual interior point method to the nonconvex constrained optimization problem on Riemannian manifolds. One significant contribution is that we establish many essential foundational concepts for the general interior point method in the Riemannian context, such as the KKT vector field and its covariant derivative. In addition, we build the first framework for the Riemannian version of the interior point method. These contributions will have uses in the future, especially in developing more advanced interior point methods.
-
2.
We give a detailed theoretical analysis to ensure local and global convergence of RIPM. Considering that many practical problems involve minimizing a nonconvex function on Riemannian manifolds, the theoretical counterparts of our method are the early interior point methods for nonlinear nonconvex programming first proposed by El-Bakry et al. [11].
-
3.
Our numerical experimentsFootnote 1 demonstrate the great potential of RIPM. The method meets the challenges presented in these experiments with better stability and higher accuracy compared with the current Riemannian exact penalty, augmented Lagrangian, and sequential quadratic programming methods.
Organization The rest of this paper is organized as follows: In Sect. 2, we review the notation of Riemannian geometry and explain the Riemannian Newton method. In Sect. 3, we give a full interpretation of our RIPM and describe a prototype algorithm of RIPM. We also investigate the use of Krylov subspace methods to efficiently solve a condensed form of a perturbed Newton equation. This is particularly important for the numerical implementation of RIPM. Section 4 gives the necessary preliminaries and auxiliary results needed to prove convergence in our subsequent sections. In Sect. 5, we give the proof of local superlinear and quadratic convergence of the prototype algorithm of RIPM. Section 6 describes a globally convergent version of RIPM with a classical line search; then, Sect. 7 proves its global convergence. Section 8 is a collection of numerical experiments. Section 9 summarizes our research and presents future work.
2 Notation
2.1 Riemannian Geometry
Let us briefly review some concepts from Riemannian geometry, following the notation of [5]. \(\mathcal {M}\) denotes a finite-dimensional smooth manifold. Let \(p \in \mathcal {M}\) and \(T_p \mathcal {M}\) be the tangent space at p with \(0_{p}\) being its zero element. We use a canonical identification \( T_{p} \mathcal {E}\cong \mathcal {E}\) for a vector space \( \mathcal {E} \) and \(p \in \mathcal {E}\). A vector field is a map \(V :\mathcal {M} \rightarrow T \mathcal {M}\) with \(V(p) \in T_{p} \mathcal {M}\), where \(T \mathcal {M}:=\bigcup _{p \in \mathcal {M}} T_p \mathcal {M}\) is the tangent bundle. \(\mathfrak {X}(\mathcal {M})\) denotes the set of all smooth vector fields defined on \(\mathcal {M}\). Furthermore, \(\mathcal {M}\) is a Riemannian manifold if it is equipped with a Riemannian metric, that is, a choice of inner product \(\langle \cdot , \cdot \rangle _p :T_p \mathcal {M} \times T_p \mathcal {M} \rightarrow \mathbb {R} \) for each tangent space at p on \(\mathcal {M}\) such that for all \(V, W \in \mathfrak {X}(\mathcal {M})\), the map
is a smooth function from \(\mathcal {M}\) to \(\mathbb {R}\). Riemannian metric induces the norm \(\Vert \xi \Vert _p:=\sqrt{\langle \xi , \xi \rangle _p}\) for \(\xi \in T_p \mathcal {M}\). We often omit the subscript p if it is clear from the context. Throughout this paper, we assume that all the manifolds involved are connected and complete. Given a curve segment on \(\mathcal {M}\), \(c:[a, b] \rightarrow \mathcal {M}\), the length of c is defined as \( L(c):=\int _a^b \Vert \dot{c}(t)\Vert _{c(t)} \textrm{d} t, \) where \(\dot{c}(t) \in T_{c(t)} \mathcal {M}\) is the velocity vector of c at t. Since \(\mathcal {M}\) is connected, there exists a curve segment connecting any pair of points \(p,q \in \mathcal {M}\). Indeed, \(\mathcal {M}\) is a metric space under the Riemannian distance \(d(p, q):=\inf _{c} L(c) \) where the infimum is taken over all curve segments joining p to q [22, Thm. 2.55]. For two manifolds \(\mathcal {M}_1, \mathcal {M}_2\) and a smooth map \(F :\mathcal {M}_1 \rightarrow \mathcal {M}_2\), the differential of F at \(p \in \mathcal {M}_1\) is a linear operator denoted as \(\mathcal {D} F(p) :T_p \mathcal {M}_1 \rightarrow T_{F(p)} \mathcal {M}_2\). Let \(\mathfrak {F}(\mathcal {M})\) be the set of all smooth scalar fields (or say real-valued functions) \(f:\mathcal {M} \rightarrow \mathbb {R}\). The Riemannian gradient of f at p, \({\text {grad}}\,f(p)\), is defined as the unique element of \(T_p \mathcal {M}\) that satisfies \(\langle \xi , {\text {grad}}\, f(p)\rangle _p = \mathcal {D} f(p)[\xi ]\) for all \(\xi \in T_p \mathcal {M}\), where \(\mathcal {D} f(p) :T_p \mathcal {M} \rightarrow T_{f(p)} \mathbb {R} \cong \mathbb {R}\). Note that for any \(f \in \mathfrak {F}(\mathcal {M})\), the gradient vector field \(x \mapsto {\text {grad}}\, f(x)\) is a smooth vector field on \(\mathcal {M}\), i.e., \({\text {grad}}\,f \in \mathfrak {X}(\mathcal {M})\). A retraction \(\textrm{R} :T \mathcal {M} \rightarrow \mathcal {M}\) is a smooth map such that \(\textrm{R}_{p}\left( 0_{p}\right) =p\) and \(\mathcal {D} \textrm{R}_{p}\left( 0_{p}\right) ={\text {id}}_{T_p \mathcal {M}}\), i.e., the identity map on \(T_{p} \mathcal {M}\), where \(\textrm{R}_{p}\) is the restriction of \(\textrm{R}\) to \(T_{p} \mathcal {M}\) and \(\mathcal {D} \textrm{R}_{p}\left( 0_{p}\right) :T_{0_p} (T_p \mathcal {M}) \cong T_p \mathcal {M} \rightarrow T_{p} \mathcal {M}\) is the differential of \(\textrm{R}_{p}\) at \(0_{p}\). One theoretically perfect type of retraction is the exponential map, denoted as \({\text {Exp}}\). Since \(\mathcal {M}\) is complete, the exponential map is well-defined on the whole tangent bundle. Let \({\text {Exp}}_p:T_p \mathcal {M} \rightarrow \mathcal {M}\) be the exponential map at p; then, \(t \mapsto {\text {Exp}}_p(t \xi )\) is the unique geodesic that passes through p with velocity \(\xi \in T_p \mathcal {M}\) when \(t=0\).
2.2 Riemannian Newton Method
The Newton method is a powerful tool for finding the zeros of nonlinear functions in the Euclidean setting. The generalized Newton method has been studied in the Riemannian setting; it aims to find a singularity for the vector field \(F \in \mathfrak {X}(\mathcal {M})\), i.e., a point \(p \in \mathcal {M}\) such that,
Let \(\nabla \) be the Levi–Civita connection on \(\mathcal {M}\), i.e., the unique symmetric connection compatible with the Riemannian metric. The covariant derivative \(\nabla F\) assigns each point \(p \in \mathcal {M}\) a linear operator \(\nabla F(p):T_{p}\mathcal {M}\rightarrow T_{p}\mathcal {M}\). In particular, the Riemannian Hessian of \(f \in \mathfrak {F}(\mathcal {M})\) at p is a self-adjoint operator on \(T_{p} \mathcal {M}\), defined as \({\text {Hess}}\,f(p):=\nabla ({\text {grad}}\,f)(p).\) The Riemannian Newton method for solving (2) is performed as Algorithm 1.

Riemannian Newton Method for (2)
3 Description of Riemannian Interior Point Methods (RIPM)
In this section, we will give a comprehensive interpretation of the Riemannian interior point method. Following common usage in the interior-point literature, big letters denote the associated diagonal matrix, e.g., \(Z ={\text {diag}}(z_{1}, \ldots , z_{m})\) with \(z \in \mathbb {R}^{m}\). e denotes the all-ones vector, and 0 stands for zero vector/matrix with proper dimensions.
3.1 KKT Vector Field and Its Covariant Derivative
The Lagrangian function of (RCOP) is
where \(y \in \mathbb {R}^l\) and \(z \in \mathbb {R}^m\) are Lagrange multipliers corresponding to the equality and inequality constraints, respectively. With respect to the variable x, \(\mathcal {L}(\cdot , y, z)\) is a real-valued function defined on \(\mathcal {M}\), and its Riemannian gradient is:
where \(\{{\text {grad}}\,h_{i}(x)\}_{i=1}^{l}\) and \( \{{\text {grad}}\,g_{i}(x)\}_{i=1}^{m}\) are the gradients of the component functions of h and g. The Riemannian KKT conditions (e.g., see [23, Definition 2.3] or [36]) for (RCOP) are given by
The above conditions can be written in terms of slack variables \(\mathbb {R}^{m} \ni s:=-g(x)\), as
and \((z,s) \geqslant 0,\) where \(w:=(x, y, z,s) \in \mathcal {N}:=\mathcal {M}\times \mathbb {R}^{l} \times \mathbb {R}^{m} \times \mathbb {R}^{m}\). Here, we have generated a vector field F in (5) on the product manifold \(\mathcal {N}\), i.e., for any \(w\in \mathcal {N}\), \( F(w) \in T_{w} \mathcal {N} \cong T_{x} \mathcal {M} \times \mathbb {R}^{l} \times \mathbb {R}^{m} \times \mathbb {R}^{m}. \) We will call \(F :\mathcal {N} \rightarrow T\mathcal {N} \) in (5) above the KKT vector field for (RCOP). Note that for \(\xi =\left( \xi _x, \xi _y, \xi _z, \xi _s\right) \in T_{w} \mathcal {N} \),
is a well-defined retraction on the product manifold \(\mathcal {N}\) as long as \(\textrm{R}\) is a retraction on \(\mathcal {M}\).
Now, we aim to find a singularity of the KKT vector field F on \(\mathcal {N}\) under some nonnegative constraints \((z,s) \geqslant 0\). If the Riemannian Newton method is to be applied to (5), we must formulate the covariant derivative of F at an arbitrary \(w \in \mathcal {N}\). Before that, we need some new symbols. Fixing a point \(x \in \mathcal {M}\), we can define two linear operators \(\mathcal {H}_{x}:\mathbb {R}^{l} \rightarrow T_{x} \mathcal {M}\) and \(\mathcal {G}_{x}:\mathbb {R}^{m} \rightarrow T_{x} \mathcal {M}\) by
respectively. Then, for \(\mathcal {H}_{x}\), its adjoint operator \(\mathcal {H}_x^*:T_x \mathcal {M} \rightarrow \mathbb {R}^l\) is given by:
Also, \(\mathcal {G}_x^*:T_x \mathcal {M} \rightarrow \mathbb {R}^m\) with \(\mathcal {G}_x^* [\xi ]=\left( \left\langle {\text {grad}}\,g_1(x), \xi \right\rangle _x, \cdots ,\left\langle {\text {grad}}\,g_m(x), \xi \right\rangle _x\right) ^T\).
Now, using the solutions of Exercises 5.4 and 5.13 on covariant derivatives of vector fields on product manifolds in monograph [5], the following results can be easily derived. Given KKT vector field F in (5) and \(w \in \mathcal {N}\), the covariant derivative of F at w is the operator \(\nabla F(w):T_{w} \mathcal {N} \rightarrow T_{w} \mathcal {N}\) given by
where \(\varDelta w=(\varDelta x, \varDelta y, \varDelta z, \varDelta s) \in T_{w} \mathcal {N}\) and \({\text {Hess}}_{x} \mathcal {L}(w)\) is the Riemannian Hessian of real-valued function \(\mathcal {L}(\cdot , y, z)\). Indeed, \({\text {Hess}}_{x} \mathcal {L}(w):T_{x}\mathcal {M} \rightarrow T_{x}\mathcal {M}\) satisfies
where \(\{{\text {Hess}}\,h_{i}(x)\}_{i=1}^{l}\) and \(\{{\text {Hess}}\,g_{i}(x)\}_{i=1}^{m}\) are Hessians of the component functions of h and g.
3.2 Implication of Standard Assumptions
Next, we will discuss an important result about the covariant derivative of the KKT vector field given in (8). Let \(\mathbb {A}(x):=\left\{ i \mid g_{i}(x)=0\right\} \) denote the active set at \(x \in \mathcal {M}\). A prior study on Riemannian optimality conditions [2, 36] showed that the following assumptions are meaningful. We call them the standard Riemannian assumptions for (RCOP). Note that the \(x^{*}\) and \(w^*\) in (A2)–(A4) all refer to those in (A1).
- (A1):
-
Existence. There exists \(w^*=(x^{*}, y^{*}, z^{*}, s^{*})\) satisfying the Riemannian KKT conditions (4). Here, we introduce the slack variables \(s^{*}:=-g(x^{*})\).
- (A2):
-
Linear Independence Constraint Qualification (LICQ).
The set \(\left\{ {\text {grad}}\,h_{i}(x^{*})\right\} _{i=1}^{l} \bigcup \left\{ {\text {grad}}\,g_{i}(x^{*})\right\} _{i \in \mathbb {A}(x^{*})}\) is linearly independent in \( T_{x^{*}}\mathcal {M}\).
- (A3):
-
Strict complementarity. \((z^{*})_{i}>0\) if \(g_{i}(x^{*})=0\) for all \(i=1, \cdots ,m\).
- (A4):
-
Second-order sufficiency. \(\left\langle {\text {Hess}}_{x} \mathcal {L}(w^{*})[\xi ], \xi \right\rangle >0\) for all nonzero \(\xi \in T_{x^{*}}\mathcal {M}\)
satisfying \(\left\langle \xi , {\text {grad}}\,h_{i}(x^{*})\right\rangle =0 \) for \(i=1,\dots ,l,\) and \(\left\langle \xi , {\text {grad}}\,g_{i}(x^{*})\right\rangle =0\) for \( i \in \mathbb {A}(x^{*})\).
Recall the Riemannian Newton method discussed in Sect. 2.2. It can be shown that if \(p^*\) is a solution of equation (2) and the covariant derivative \(\nabla F\left( p^*\right) \) is nonsingular, then Algorithm 1 has the local superlinear convergence [12] and local quadratic convergence [13] under certain mild conditions on the map \(p \mapsto \nabla F(p)\). Note that the requirement of nonsingularity for the covariant derivative at the solution point is of primary importance. Therefore, the next theorem motivates us to use the Riemannian Newton method to solve (5).
Theorem 3.1
If the standard Riemannian assumptions (A1)–(A4) hold at some point \(w^{*}\), then the operator \(\nabla F(w^{*})\) in (8) is nonsingular.
Proof
This proof omits all the asterisks of the variables. Define \( \mathbb {E}:=\{1,\dots ,l\}\) and \(\mathbb {I}:=\{1,\dots ,m\} \). Take some \(w=(x, y, z, s) \in \mathcal {N} \) satisfying (A1)–(A4), then we have \( s_{i} = -g_{i}(x)\) and \(z_{i} s_{i} = 0\) for all \( i \in \mathbb {I}\). For short, let \(\mathbb {A}:=\mathbb {A}(x) \subset \mathbb {I} \). Suppose that \(\nabla {F}(w) [\varDelta w] =0\) for some \(\varDelta w = (\varDelta x, \varDelta y, \varDelta z, \varDelta s) \in T_{w} \mathcal {N} \cong T_x \mathcal {M} \times \mathbb {R}^l \times \mathbb {R}^m \times \mathbb {R}^m\). \(\varDelta y_i\) denotes the components of the vector \(\varDelta y\), as do \(\varDelta z_i\), \(\varDelta s_i\). To prove its nonsingularity, we will show that \( \varDelta w=0\). Expanding the equation \(\nabla {F}(w) [\varDelta w] =0\) gives
Strict complementarity (A3) and the last equalities above imply that \( \varDelta s_{i}=0 \) for all \( i \in \mathbb {A}\) and \( \varDelta z_{i}=0 \) for \( i \in \mathbb {I} {\setminus } \mathbb {A}\). Substituting those values into the system (10) reduces it to
and \( \varDelta s_{i}=-\left\langle {\text {grad}}\,g_{i}(x), \varDelta x\right\rangle \text{ for } \text{ all } i\in \mathbb {I} {\setminus } \mathbb {A}. \) It follows from system (11) that
Thus, from second-order sufficiency (A4), \( \varDelta x\) must be zero elements. And then \(\varDelta s_{i}=0 \text{ for } \text{ all } i\in \mathbb {I} {\setminus } \mathbb {A}.\) Next, substituting \( \varDelta x=0\) into the first equation in (11) yields \( 0=\sum _{i\in \mathbb {E}} \varDelta y_{i} {\text {grad}}\,h_{i}(x) +\sum _{i\in \mathbb {A}} \varDelta z_{i} {\text {grad}}\,g_{i}(x). \) The LICQ (A2) implies that the coefficients \(\varDelta y_{i}\) for \(i\in \mathbb {E}\) and \( \varDelta z_{i} \) for \( i\in \mathbb {A} \) must be zero. This completes the proof. \(\square \)
3.3 Prototype Algorithm of RIPM
Applying the Riemannian Newton method directly to the KKT vector field \(F: \mathcal {N} \rightarrow T \mathcal {N}\) results in the following Newton equation (see (3) without iteration count k) at each iteration:
As with the usual interior point method in the Euclidean setting, once the iterates reach the boundary of the feasible region, they are forced to stick to it [33, P6]. For the iterates to maintain a sufficient distance from the boundary, we introduce a perturbed complementary equation with some barrier parameter \(\mu >0\) and define the perturbed KKT vector field:
Notice that the perturbation term \(\hat{e}\), indeed, is a special vector field on \(\mathcal {N}\), not a constant, because \(0_x\) is essentially dependent on w and/or x. In fact, the covariant derivative of the perturbed KKT vector field is the same as that of the original. From the linearity of the connection \(\nabla \), for any \(w \in \mathcal {N}\) and any \(\mu >0\), we have
where the last equity comes from \(\nabla \hat{e}(w) [\varDelta w]=\left( 0_x, 0,0,0\right) \) for all \(\varDelta w \in T_w \mathcal {N}\). Applying the Riemannian Newton method to perturbed KKT vector field \(F_{\mu }(w)\) yields the perturbed Newton equation: \(\nabla F_{\mu }(w) [\varDelta w]+F_{\mu }(w)=0\). From (13) and (14), this equation is equivalent to
which reduces to the ordinary Newton equation (12) as \(\mu \rightarrow 0\). At this point, we can describe a prototype of the Riemannian interior point method (RIPM) in Algorithm 2.

Prototype Algorithm of RIPM for (RCOP)
In the step 2 of Algorithm 2, we just wish to compute a step size \(0<\alpha _k \leqslant 1\) to ensure new point \(w_{k+1}\) with \(\left( z_{k+1},s_{k+1}\right) >0\). There are many schemes to achieve this purpose. The scheme in (17) is simple but sufficient to guarantee the local convergence, as will be proved in Sect. 5.
3.4 Solving Perturbed Newton Equation Efficiently
The challenge of Algorithm 2 is how to solve the Newton equation (16) in an efficient manner. In this subsection, we will do this in two steps: the first step will be to turn the original full Newton equation, which is asymmetric and consists of four variables, into a condensed form, which is symmetric and consists of only two variables. In the second step, an iterative method, namely the Krylov subspace method, is used to solve the operator equations directly, avoiding the expensive computational effort of converting them into the usual matrix equations.
3.4.1 Condensed Form of Perturbed Newton Equation
Let us consider Algorithm 2 and omit the iteration count k. Given the current point \(w \in \mathcal {N}\) with \((z, s) > 0\), for the KKT vector field F(w) in (5), we denote its components by \(F_x,F_y,F_z,F_s\) in top-to-bottom order, namely \(F_x:={\text {grad}}_x \mathcal {L}(w),F_y:=h(x),F_z:=g(x)+s,F_s:=Z S e.\) By using these symbols and the formulation of \(\nabla F(w)\) in (8), the full (perturbed) Newton equation (16) defined on \(T_w \mathcal {N} \cong T_x \mathcal {M} \times \mathbb {R}^l \times \mathbb {R}^m \times \mathbb {R}^m\) is expanded as:
Not only does this equation contain four variables, but there is no symmetry on the left side of the equation, so it would be unwise to solve it just like that. By \((z, s) > 0\) and the fourth line of (18), we deduce \( \varDelta s=Z^{-1}\left( \mu e -F_s -S \varDelta z \right) . \) Substituting this \(\varDelta s\) into the third line of (18), we get \( \mathcal {G}_{x}^{*}[\varDelta x]-Z^{-1} S \varDelta z = -Z^{-1} \mu e-g(x)\) and thus \( \varDelta z=S^{-1}\left[ Z\left( \mathcal {G}_{x}^{*}[\varDelta x]+F_z\right) +\mu e -F_s\right] \). Substituting this \(\varDelta z\) further into the first line of (18) and combining it with the second line of (18) yield the following condensed Newton equation, which is defined on \(T_{x} \mathcal {M} \times \mathbb {R}^{l}\):
where
Here, c and q are constant vectors. If we defined \(\varTheta :=\mathcal {G}_x S^{-1} Z \mathcal {G}_x^*\), then \(\mathcal {A}_{w}={\text {Hess}}_{x} \mathcal {L}(w)+ \varTheta .\) Note that both \(\varTheta \) and \({\text {Hess}}_{x} \mathcal {L}(w)\) are operators from and to \(T_x \mathcal {M}.\)
From the discussion above, for any \(w \in \mathcal {N}\) with \((z, s)>0\), the operator \(\nabla F(w)\) in (8) is nonsingular if and only if the newly defined operator \(\mathcal {T}\) in (19) is nonsingular. Eventually, it is sufficient for us to solve the equation (19) containing only two variables \(\varDelta x\) and \(\varDelta y\). In fact, when we consider the case of only inequality constraints in (RCOP), then \(\varDelta y\) vanishes, and only a linear equation
on \(T_{x} \mathcal {M}\) needs to be solved. More importantly, the operator \(\mathcal {T}\) in the left side of (19) is symmetric, or say self-adjoint (although often indefinite). It is trivial to check that operators \(\varTheta \) and \(\mathcal {A}_{w}\) are self-adjoint on \(T_{x} \mathcal {M}\); and thus \(\mathcal {T}\) is self-adjoint on the product vector space \(T_{x} \mathcal {M} \times \mathbb {R}^{l}\) equipped with inner product \(\left\langle (\xi _x, \xi _y),(\eta _x, \eta _y)\right\rangle :=\left\langle \xi _x, \eta _x\right\rangle _x+ \xi _y ^T \eta _y\). We can also see that (19) is a saddle point problem defined on Hilbert spaces from its special structure.
3.4.2 Krylov Subspace Methods on Tangent Space
Next, how to solve (19) efficiently becomes critical. For simplicity, we consider the case of only inequality constraints in (RCOP), then we will solve operator equation (21) with a self-adjoint operator \(\mathcal {A}_w :T_x \mathcal {M} \rightarrow T_x \mathcal {M}\). Let \(d:={\text {dim}}\,T_x \mathcal {M}\). Unfortunately, in most cases of practical applications, the Riemannian situation leaves us with no explicit matrix form available for \(\mathcal {A}_w\). This means that we can only access \(\mathcal {A}\) (subscript w omitted) by inputting a vector v to return \(\mathcal {A}v\).
A general approach is first to find the matrix representation \(\hat{\mathcal {A}}\) for \(\mathcal {A}\) under some basis of \(T_x \mathcal {M}\). In detail, the full process of this approach is as follows:
-
(Step 1)
Obtain d random independent vectors on \(T_x \mathcal {M}\).
-
(Step 2)
Obtain an orthonormal basis \(\left\{ u_i\right\} _{i=1}^{d}\) of \(T_x \mathcal {M}\) by the modified Gram-Schmidt algorithm.
-
(Step 3)
Compute \([\hat{\mathcal {A}}]_{i j}:=\left\langle \mathcal {A} u_j, u_i\right\rangle _x\) for \(1 \leqslant i \leqslant j \leqslant d\) due to symmetry, then we obtain the matrix representation \(\hat{\mathcal {A}} \in \mathbb {R}^{d \times d}\).
-
(Step 4)
Compute \([\hat{c}]_{i}:=\left\langle c, u_i \right\rangle _x\) for \(1 \leqslant i \leqslant d\), then we obtain the vector representation \(\hat{c} \in \mathbb {R}^{d}\).
-
(Step 5)
Using arbitrary linear solver to get solution \(\varDelta \hat{x} \in \mathbb {R}^d\) from matrix equation \(\hat{\mathcal {A}} \varDelta \hat{x}=\hat{c}\).
-
(Step 6)
Recovery the tangent vector \(\varDelta x \in T_x \mathcal {M}\) by \(\varDelta x = \sum _{i=1}^{d} (\varDelta \hat{x})_i u_i\).
In Algorithm 2, at each iteration, x is updated, and thus, the tangent space \(T_x \mathcal {M}\) changes. Thus, the above six steps need to be done all over again. Obviously, this approach is so expensive that it is not feasible in practice.
An ideal approach is to use an iterative method, such as the Krylov subspace method (e.g., conjugate gradients method [5, Chapter 6.3]), on \(T_x \mathcal {M}\) directly. Such a method does not explicitly require a matrix representation \(\hat{\mathcal {A}}\) for \(\mathcal {A}\). In general, it only needs to call an abstract linear operator \(v \mapsto \mathcal {A} v\). Since \(\mathcal {A}\) in (20) is self-adjoint but indefinite, for solving operator equation (21), we will use the Conjugate Residual (CR) method (see [29, ALGORITHM 6.20]) as stated in Algorithm 3.

Conjugate Residual (CR) Method on Tangent Spaces for (21)
A significant feature is that the iterate points \(v_k\), conjugate directions \(p_k\), and residual vectors \(r_k:=\mathcal {A} v_k-c\) are all contained in \(T_x \mathcal {M}\). Usually, the initial point \(v_0\) is the zero element of \(T_x \mathcal {M}\); the iteration terminates when the relative residual \(\left\| r_k\right\| /\Vert c\Vert \leqslant \epsilon \) for some threshold \(\epsilon >0\), or some maximum number of iterates is reached.
The discussion of the above two approaches can be naturally extended to the case containing equality constraints in (RCOP), where we consider \(\mathcal {T}\) on \(T_x \mathcal {M} \times \mathbb {R}^l\) instead of \(\mathcal {A}\) on \(T_x \mathcal {M}\).
4 Preliminaries and Auxiliary Results
This section introduces the useful results that are indispensable to our subsequent discussion.
Remark 4.1
For a retraction \(\textrm{R}\) on \(\mathcal {M}\) and \(x \in \mathcal {M}\), by \(\mathcal {D} \textrm{R}_{x}\left( 0_{x}\right) =\textrm{id}_{T_{x} \mathcal {M}}\) and the inverse function theorem, there exists a neighborhood V of \(0_{x}\) in \(T_{x} \mathcal {M}\) such that \( \textrm{R}_{x} \) is a diffeomorphism on V; thus, \(\textrm{R}_{x}^{-1}(y)\) is well defined for all \( y \in \mathcal {M} \) sufficiently close to x. In this case, \(\textrm{R}_{x}(V) \subset \mathcal {M}\) is called a retractive neighborhood of x. Furthermore, the existence of a totally retractive neighborhood [38, Theorem 2] shows that for any \(\bar{x} \in \mathcal {M} \) there is a neighborhood W of \(\bar{x}\) such that \(\textrm{R}_{x}^{-1}(y)\) is well defined for all \(x, y \in W\). In what follows, we will suppose that an appropriate neighborhood has been chosen by default for the well-definedness of \(\textrm{R}_x^{-1}(y)\).
4.1 Vector Transport and Parallel Transport
Define the Whitney sum \( T \mathcal {M} \oplus T \mathcal {M}:=\left\{ (\eta , \xi ): \eta , \xi \in T_x \mathcal {M}, x \in \mathcal {M} \right\} . \) A smooth map \( \textrm{T} :T \mathcal {M} \oplus T \mathcal {M} \rightarrow T \mathcal {M}: (\eta , \xi ) \mapsto \textrm{T}_{\eta }(\xi ), \) is called a vector transport on \(\mathcal {M}\) if there exists an associated retraction \(\textrm{R}\) on \(\mathcal {M}\) such that \(\textrm{T}\) satisfies the following properties for all \(x \in \mathcal {M}\):
-
1.
Associated retraction. \(\textrm{T}_{\eta }\left( \xi \right) \in T_{\textrm{R}_{x}\left( \eta \right) } \mathcal {M}\) for all \(\eta , \xi \in T_x \mathcal {M}\).
-
2.
Consistency. \(\textrm{T}_{0_{x}}\left( \xi \right) =\xi \) for all \(\xi \in T_{x} \mathcal {M}\).
-
3.
Linearity. \(\textrm{T}_{\eta }\left( a \xi +b \zeta \right) =a \textrm{T}_{\eta }\left( \xi \right) +b \textrm{T}_{\eta }\left( \zeta \right) \) for all \(a, b \in \mathbb {R}\) and \(\eta , \xi , \zeta \in T_{x} \mathcal {M}\).
Thus, fixing any \(\eta \in T_x \mathcal {M}\), the map \( \textrm{T}_\eta :T_x \mathcal {M} \rightarrow T_{\textrm{R}_x(\eta )} \mathcal {M}: \xi \mapsto \textrm{T}_\eta (\xi ), \) is a linear operator. Additionally, \(\textrm{T}\) is isometric if \( \langle \textrm{T}_{\eta } (\xi ), \textrm{T}_{\eta } (\zeta )\rangle =\langle \xi , \zeta \rangle \) holds, for all \(x \in \mathcal {M}\) and all \(\xi , \zeta , \eta \in T_{x} \mathcal {M}\). In other words, for any \(\eta \in T_x \mathcal {M}\), the adjoint and the inverse of \(\textrm{T}_{\eta }\) coincide, i.e., \( \textrm{T}_{\eta }^{*} = \textrm{T}_{\eta }^{-1}\). There are two important classes of vector transport as follows. Let \(\textrm{R}\) be a retraction on \(\mathcal {M}\).
-
(1)
The differentiated retraction defined by
$$\begin{aligned} \textrm{T}_{\eta }(\xi ):=\mathcal {D} \textrm{R}_{x}(\eta )[\xi ], \; \eta , \xi \in T_{x} \mathcal {M}, x \in \mathcal {M}, \end{aligned}$$(22)is a valid vector transport [1, equation (8.6)].
-
(2)
Given a smooth curve \(\gamma :[0,1] \rightarrow \mathcal {M}\) and \(t_0, t_1 \in [0,1]\), the parallel transport from the tangent space at \(\gamma (t_0)\) to the tangent space at \(\gamma (t_1)\) along \(\gamma ,\) is a linear operator \( \textrm{P}_\gamma ^{t_1 \rightarrow t_0} :T_{\gamma \left( t_0\right) } \mathcal {M} \rightarrow T_{\gamma \left( t_1\right) } \mathcal {M}\) defined by \(\textrm{P}_\gamma ^{t_1 \rightarrow t_0}(\xi )=Z\left( t_1\right) \), where Z is the unique parallel vector field such that \(Z\left( t_0\right) =\xi \). Then, for any \(x \in \mathcal {M}, \eta \in T_x \mathcal {M}\), then
$$\begin{aligned} \textrm{T}_{\eta }\left( \xi \right) :=\textrm{P}_\gamma ^{1 \rightarrow 0} (\xi ) \end{aligned}$$(23)is a valid vector transport [1, equation (8.2)], where \(\textrm{P}_\gamma \) denotes the parallel transport along the curve \(t \mapsto \gamma (t):=\textrm{R}_x\left( t \eta \right) \). We often omit the superscript \(^{1 \rightarrow 0}\) if it is clear from the context. In particular, parallel transport is isometric.
4.2 Lipschitz Continuity with respect to Vector Transports
Multiple Riemannian versions of Lipschitz continuity have been defined, e.g., [5, Sect. 10.4]. Here, we consider Lipschitz continuity with respect to a vector transport. In what follows, let \(\mathcal {M}\) be a Riemannian manifold endowed with a vector transport \(\textrm{T}\) and an associated retraction \(\textrm{R}\). We first consider the Lipschitz continuous gradient of scale field f.
Definition 4.1
([17, Definition 5.2.1]) A function \(f:\mathcal {M} \rightarrow \mathbb {R}\) is Lipschitz continuously differentiable with respect to \(\textrm{T}\) in \(\mathcal {U} \subset \mathcal {M}\) if it is differentiable and there exists a constant \(\kappa >0\) such that, for all \(x, y \in \mathcal {U}\), \( \left\| {\text {grad}}\,f(y)-\textrm{T}_{\eta } [{\text {grad}}\,f(x)] \right\| \leqslant \kappa \Vert \eta \Vert , \) where \(\eta =\textrm{R}_{x}^{-1} y\).
Going one degree higher, let us now discuss the Lipschitz continuity of Hessian operators. Throughout this paper, for a linear operator \(\mathcal {A}: \mathcal {E} \rightarrow \mathcal {E}^{\prime }\) between two finite-dimensional normed vector spaces \(\mathcal {E}\) and \(\mathcal {E}^{\prime }\), the (operator) norm of \(\mathcal {A}\) is defined by \(\Vert \mathcal {A}\Vert :=\sup \left\{ \Vert \mathcal {A} v\Vert _{\mathcal {E}^{\prime }}: v \in \mathcal {E},\Vert v\Vert _{\mathcal {E}}=1\right. \), or, \(\left. \Vert v\Vert _{\mathcal {E}} \leqslant 1\right\} .\) The inverse of \(\textrm{T}_{\eta }\) is needed in the following definitions, so we can assume that vector transport \(\textrm{T}\) is isometric, e.g., parallel transport in (23). In fact, there are many ways to construct isometric vector transports; see [18, Sect. 2.3].
Definition 4.2
([18, Assumption 3]) A function \(f:\mathcal {M} \rightarrow \mathbb {R}\) is twice Lipschitz continuously differentiable with respect to \(\textrm{T}\) in \(\mathcal {U} \subset \mathcal {M}\) if it is twice differentiable and there exists a constant \(\kappa >0\) such that, for all \(x, y \in \mathcal {U}\), \( \Vert {\text {Hess}}\,f(y)-\textrm{T}_{\eta } {\text {Hess}}\,f(x) \textrm{T}_{\eta }^{-1}\Vert \leqslant \kappa d(x, y), \) where \(\eta =\textrm{R}_{x}^{-1} y\).
Lemma 4.1
([18, Lemma 4]) If \(f:\mathcal {M} \rightarrow \mathbb {R}\) is \( C^3 \), then for any \(\bar{x} \in \mathcal {M}\) and any isometric vector transport \(\textrm{T}\), there exists a neighborhood \(\mathcal {U}\) of \(\bar{x}\) such that f is twice Lipschitz continuously differentiable with respect to \(\textrm{T}\) in \(\mathcal {U}\).
If the operator, \({\text {Hess}}\,f(x)\), above is replaced by a general covariant derivative \(\nabla F (x)\), we can get the next results in a similar way. Lemma 4.2 can be proven in the same way as Lemma 4.1.
Definition 4.3
Given a vector field F on \(\mathcal {M}\). The map \(x \mapsto \nabla F(x)\) is Lipschitz continuous with respect to \(\textrm{T}\) in \(\mathcal {U} \subset \mathcal {M}\) if there exists a constant \(\kappa >0\) such that, for all \(x, y \in \mathcal {U}\), it holds that \( \Vert \nabla F(y) - \textrm{T}_{\eta } \nabla F(x) \textrm{T}_{\eta }^{-1} \Vert \leqslant \kappa d(x, y), \) where \(\eta =\textrm{R}_{x}^{-1} y\).
Lemma 4.2
If F is a \(C^{2}\) vector field, then for any \(\bar{x} \in \mathcal {M}\) and any isometric vector transport \(\textrm{T}\), there exists a neighborhood \(\mathcal {U}\) of \(\bar{x}\) such that the map \(x \mapsto \nabla F(x)\) is Lipschitz continuous with respect to \(\textrm{T}\) in \(\mathcal {U}\).
4.3 Auxiliary Lemmas
Notice that in the previous subsection on the definitions of Lipschitz continuity, we used \(\Vert \eta \Vert \) with \(\eta =\textrm{R}_x^{-1} y\) or d(x, y) to denote the upper bound on the right-hand side. The next lemma shows that the two are not essentially different. When \(\mathcal {M}=\mathbb {R}^{n}\), both reduce to \(\Vert x-y \Vert \).
Lemma 4.3
([18, Lemma 2]) Let \(\mathcal {M}\) be a Riemannian manifold with a retraction \(\textrm{R}\) and let \(\bar{x} \in \mathcal {M}\). Then,
-
(i)
there exist \(a_{0}, a_{1}, \delta _{a_{0}, a_{1}}>0\) such that for all x in a sufficiently small neighborhood of \(\bar{x}\) and all \(\xi , \eta \in T_{x} \mathcal {M}\) with \(\Vert \xi \Vert , \Vert \eta \Vert \leqslant \delta _{a_{0}, a_{1}}\), one has \( a_{0}\Vert \xi -\eta \Vert \leqslant d(\textrm{R}_{x}(\eta ), \textrm{R}_{x}(\xi )) \leqslant a_{1}\Vert \xi -\eta \Vert . \) In particular, \( a_{0}\Vert \xi \Vert \leqslant d(x, \textrm{R}_{x}(\xi )) \leqslant a_{1}\Vert \xi \Vert \) when \(\eta =0\);
-
(ii)
there exist \(a_{0},a_{1}>0\) such that for all x in a sufficiently small neighborhood of \(\bar{x}\), one has \( a_{0}\Vert \xi \Vert \leqslant d(x,\bar{x}) \leqslant a_{1}\Vert \xi \Vert \text{ where } \xi =\textrm{R}_{\bar{x}}^{-1}(x). \)
The next lemma is the fundamental theorem of calculus in the Riemannian case.
Lemma 4.4
([18, Lemma 8]) Let F be a \(C^{1}\) vector field and \(\bar{x} \in \mathcal {M}\). Then there exist a neighborhood \(\mathcal {U}\) of \(\bar{x}\) and a constant \(c_{1} \geqslant 0\) such that for all \(x, y \in \mathcal {U}\),
where \(\eta =\textrm{R}_{x}^{-1}(y)\) and \(\textrm{P}_{\gamma }\) is the parallel transport along the curve \(\gamma (t):=\textrm{R}_{x}\left( t \eta \right) \). Moreover, if \(\textrm{R}={\text {Exp}}\), then indeed \(c_1=0\) above (see [13, equation (2.4)]).
The next lemma is a Riemannian extension of some important estimates, usually used to analyze Newton methods [8, Lemma 4.1.12].
Lemma 4.5
Let F be a \( C^2 \) vector field and \(\bar{x}\in \mathcal {M}\). Then, there exist a neighborhood \(\mathcal {U}\) of \(\bar{x}\) and a constant \(c_{2}>0\) such that for all \(x \in \mathcal {U}\),
where \(\eta =\textrm{R} _{\bar{x}}^{-1} x\) and \(\textrm{P}_{\gamma }\) is the parallel transport along the curve \(\gamma (t):=\textrm{R}_{\bar{x}}(t \eta )\).
Proof
Let \(LHS:=\Vert \textrm{P}_{\gamma }^{0 \rightarrow 1} [F(x)]-F(\bar{x})-\nabla F(\bar{x}) [\eta ] \Vert .\) It follows that
Let \(\theta := \left\| \int _{0}^{1}\left( \textrm{P}_{\gamma }^{0 \rightarrow t} \nabla F(\gamma (t)) \textrm{P}_{\gamma }^{t \rightarrow 0} -\nabla F(\bar{x})\right) [\eta ] \textrm{d} t \right\| \). Note that
Combining the above results yields
where the last inequality comes from (ii) of Lemma 4.3. Letting \(c_{2}:= (c_{1}+ \frac{1}{2} c_{0} a_{1}) / a_{0}^{2} \) completes the proof. \(\square \)
We end this section with the following useful lemmas.
Lemma 4.6
([12, Lemma 3.2]) Given a vector field F on \(\mathcal {M}\). If the map \(p \mapsto \nabla F(p)\) is continuous at \(p^{*}\) and \(\nabla F(p^{*})\) is nonsingular, then there exist a neighborhood \(\mathcal {U}\) of \(p^{*}\) and a constant \(\varXi > 0\) such that, for all \(p \in \mathcal {U}\), \(\nabla F(p)\) is nonsingular and \(\left\| \nabla F(p)^{-1}\right\| \leqslant \varXi \).
Lemma 4.7
([14, Lemma 14.5]) Let F be a \(C^2\) vector field on \(\mathcal {M}\) and \(p^{*} \in \mathcal {M}\). If \( F(p^{*})=0 \) and \(\nabla F(p^{*}) \) is nonsingular, then there exist a neighborhood \(\mathcal {U}\) of \(p^{*}\) and constants \(c_{3}, c_{4} > 0\) such that, for all \(p \in \mathcal {U}\), \( c_{3} d(p, p^{*}) \leqslant \Vert F(p)\Vert \leqslant c_{4} d(p, p^{*}).\)
Lemma 4.8
([7, Lemma 3.5]) Let \(u \in T_{p} \mathcal {M}\) such that \({\text {Exp}}_{p}(u)\) exists and \(v \in T_p \mathcal {M} \cong T_p \left( T_p \mathcal {M}\right) \). Then, \(\langle \mathcal {D} {\text {Exp}}_{p}(u)[u], \mathcal {D} {\text {Exp}}_{p}(u)[v] \rangle =\langle u, v\rangle .\) In particular, \(\left\| \mathcal {D} {\text {Exp}}_{p} (\lambda u)[u]\right\| =\left\| u\right\| \) holds all \(\lambda \geqslant 0.\)
5 Local Convergence
Here, for any two nonnegative sequences \(\left\{ u_{k}\right\} \) and \(\left\{ v_{k}\right\} \), we write \(u_{k}=O(v_{k})\) if there is a constant \(M >0\) such that \(u_{k}\leqslant M v_{k}\) for all sufficiently large k, and we write \(u_{k}=o(v_{k})\) if \(v_{k}>0\) and the sequence of ratios \(\{u_{k} / v_{k}\} \) approaches zero. In this section, we will establish local convergence of our prototype Algorithm 2 of RIPM.
5.1 Perturbed Damped Riemannian Newton Method
We will rely on an application of the so-called perturbed damped Riemannian Newton method for solving the singularity problem (2), which can be stated as Algorithm 4.

Perturbed Damped Riemannian Newton Method for (2)
In contrast to the standard Riemannian Newton method described in Algorithm 1, the term “perturbed” means that we solve a Newton equation with a perturbed term \(\mu _{k} \hat{e}\), while “damped” means using \(\alpha _k\) instead of unit steps. It is well known that Algorithm 1 is locally superlinearly [12] and quadratically [13] convergent under the following Riemannian Newton assumptions:
- (B1):
-
There exists \(p^{*} \in \mathcal {M}\) such that \(F(p^{*})=0_{p^{*}}\);
- (B2):
-
The covariant derivative \(\nabla F (p^{*})\) is nonsingular;
- (B3):
-
The vector field F is \(C^2\).
As Proposition 5.1 shows, Algorithm 4 also has the same convergence properties as Algorithm 1 if we control \(\mu _{k}\) and \(\alpha _{k}\) according to the two schemes that Proposition 5.1 gives. We can see that either scheme will have \(\mu _k \rightarrow 0\) and \(\alpha _k \rightarrow 1\), which makes Algorithm 4 eventually reduce to Algorithm 1 when k is sufficiently large.
Proposition 5.1
(Local convergence of Algorithm 4) Consider the perturbed damped Riemannian Newton method described in Algorithm 4 for the singularity problem (2). Let (B1)–(B3) hold. Choose parameters \( \mu _{k}, \alpha _{k}\) as follows; then there exists a constant \(\delta >0\) such that for all \(p_{0}\in \mathcal {M}\) with \( d(p_{0}, p^{*})<\delta , \) the sequence \(\left\{ p_{k}\right\} \) is well defined. Furthermore,
-
(1)
if we choose \(\mu _{k}=o(\Vert F(p_{k})\Vert )\) and \(\alpha _{k} \rightarrow 1\), then \(p_{k} \rightarrow p^{*}\) superlinearly;
-
(2)
if we choose \(\mu _{k}=O(\Vert F(p_{k})\Vert ^{2})\) and \(1-\alpha _{k}=O(\Vert F(p_{k})\Vert )\), then \(p_{k} \rightarrow p^{*}\) quadratically.
Proof
By (B2)–(B3), Lemmas 4.2 and 4.6, we can let \(p_{k} \) be sufficiently close to \(p^{*}\) such that \(\nabla F(p_{k})\) is nonsingular, and \(\left\| \nabla F(p_{k})^{-1}\right\| \leqslant \varXi \) for some constant \(\varXi \). Then, the next iterate point,
is well defined in Algorithm 4, and it follows from \( p^{*}=\textrm{R}_{p_{k}}(\eta ) \) with \( \eta := \textrm{R}_{p_{k}}^{-1} p^{*} \) and (i) of Lemma 4.3 that
Let \(r_{k}:= \eta + \alpha _{k} \nabla F(p_{k})^{-1}(F(p_{k})-\mu _{k} \hat{e})\). Algebraic manipulations show that
where \(\textrm{P}_{\gamma }\) is the parallel transport along the curve \(\gamma (t)=\textrm{R}_{p_{k}}(t \eta )\) and \(F(p^{*})=0.\) Thus, using \(\left\| \eta \right\| \leqslant d(p_{k}, p^{*})/a_{0}\) from (ii) of Lemmas 4.3 and 4.5, we have
Combining the above with (25), we conclude that
for some positive constants \( \kappa _{1},\kappa _{2},\kappa _{3}\). On the other hand, by Lemma 4.7, we have
In what follows, we prove assertions (1) and (2).
(1) Suppose that \(\alpha _{k} \rightarrow 1\) and \(\mu _{k}=o(\Vert F(p_{k})\Vert )\), which together with (27) imply \(\mu _{k}=o(d(p_{k}, p^{*}))\). By (26), we have
We can take \(\delta \) sufficiently small and k sufficiently large, if necessary, to conclude that \( d(p_{k+1}, p^{*})<\frac{1}{2}d(p_{k}, p^{*}) <\delta . \) Thus, \(p_{k+1} \in B_{\delta }(p^{*})\), the open ball of radius \(\delta \) centered at \(p^{*}\) on \(\mathcal {M}\). By induction, it is easy to show that the sequence \(\left\{ p_{k}\right\} \) is well defined and converges to \(p^{*}\). Taking the limit of both sides of (28) proves superlinear convergence.
(2) Again, we start from (26) and rewrite it as:
Suppose that \(1-\alpha _{k}=O(\left\| F(p_{k})\right\| )\) and \(\mu _{k}=O(\left\| F(p_{k})\right\| ^{2})\). Using (27), the above reduces to \( d(p_{k+1}, p^{*}) = O(d^{2}(p_{k}, p^{*})). \) This implies that there exists a constant \(\nu \) such that \(d(p_{k+1}, p^{*}) \leqslant \nu d^{2}(p_{k}, p^{*})\), and hence, \( d(p_{k+1}, p^{*}) \leqslant \nu d^{2}(p_{k}, p^{*}) \leqslant \nu \delta ^{2}<\delta , \) if \(\delta \) is sufficiently small. Again, by induction, \(\left\{ p_{k}\right\} \) converges to \(p^{*}\) quadratically. \(\square \)
5.2 Local Convergence of Algorithm 2
Next, lemma shows the relationship between the parameter \( \gamma _{k} \) and step size \( \alpha _{k} \) in Algorithm 2.
Lemma 5.1
Consider the Algorithm 2 for solving the problem (RCOP). Let (A1) and (A3) hold at some \(w^{*}=(x^{*}, y^{*}, z^{*}, s^{*})\) and \( \alpha _{k} \) be as in (17). Define a constant,
For \(\gamma _{k} \in (0,1)\), if \( \varPi \left\| \varDelta w_{k}\right\| \leqslant \gamma _{k}, \) then \( 0 \leqslant 1-\alpha _{k} \leqslant (1-\gamma _{k})+\varPi \left\| \varDelta w_{k}\right\| . \)
Proof
Notice that the fourth line of (18) yields
which is exactly the same as in the usual interior point method in the Euclidean setting. Thus, the proof entails directly applying [35, Lemma 3 and 4] for the Euclidean case to the Riemannian case. \(\square \)
Now, let us establish the local convergence of our Algorithm 2 in a way that replicates Proposition 5.1 except for taking account of parameter \(\gamma _{k} \).
Theorem 5.1
(Local convergence of prototype Algorithm 2) Consider the Algorithm 2 for solving the problem (RCOP). Let (A1)–(A4) hold at some \(w^{*}\). Choose parameters \(\mu _k, \gamma _k\) as follows; then there exists a constant \(\delta >0\) such that, for all \( w_{0} \in \mathcal {N} \) with \(d(w_{0}, w^{*})<\delta ,\) the sequence \(\left\{ w_{k}\right\} \) is well defined. Furthermore,
-
(1)
if we choose \(\mu _{k}=o(\left\| F(w_{k})\right\| )\) and \(\gamma _{k} \rightarrow 1\), then \(w_k \rightarrow w^*\) superlinearly;
-
(2)
if we choose \(\mu _{k}=O(\left\| F(w_{k})\right\| ^{2})\) and \(1-\gamma _{k}=O(\left\| F(w_{k})\right\| )\), then \(w_k \rightarrow w^*\) quadratically.
Proof
We only prove (2) because (1) can be proven in the same way. Let \(w_{k} \) be such that \(d(w_{k}, w^{*})<\delta \) for sufficiently small \(\delta \). From Proposition 3.1, (A1)–(A4) shows that the KKT vector field F satisfies (B1)–(B3); thus, the discussion in the proof of Proposition 5.1 applies to KKT vector field F as well, simply by replacing the symbol p with w. Since we choose \(\mu _{k}=O(\Vert F(w_{k})\Vert ^{2})\), and \(\Vert F(w_{k})\Vert =O(d(w_{k}, w^{*}))\) by (27), we obtain \( \mu _{k}=O(d^{2}(w_{k}, w^{*})). \) Thus,
Since \(\delta \) is sufficiently small, from the above inequalities, the condition of Lemma 5.1 is satisfied, i.e., \( \left\| \varDelta w_{k}\right\| \leqslant \hat{\gamma } / \varPi \leqslant \gamma _k / \varPi \) for a constant \(\hat{\gamma } \in (0,1).\) Hence, by \(1-\gamma _k=O(\left\| F\left( w_k\right) \right\| )\), one has \( 1-\alpha _{k} \leqslant (1-\gamma _{k})+\varPi \left\| \varDelta w_{k}\right\| = (1-\gamma _{k})+O(d(w_{k}, w^{*})) = O(d(w_{k}, w^{*})). \) Finally, from (29), we have \( d(w_{k+1}, w^{*}) = (1-\alpha _{k}) O(d(w_{k}, w^{*}) ) +O(d^{2}(w_{k}, w^{*}) ) +O(\mu _{k}) =O(d^{2}(w_{k}, w^{*})). \) This completes the proof. \(\square \)
Algorithm 2 guaranteed the local convergence, but we are more interested in its globally convergent version (described in the next section). We still provide a simple example of Algorithm 2 online.Footnote 2 where from (2) of Theorem 5.1, in practice we set parameters \(\mu _{k+1}=\min \{\mu _{k}/1.5,0.5\left\| F(w_k)\right\| ^2\}; \) and \(\gamma _{k+1}=\max \{\hat{\gamma }, 1- \left\| F(w_k)\right\| \} \) with \(\hat{\gamma }=0.5\).
6 Global Algorithm
The globally convergent version of our RIPM uses the classical line search described in [11]. The following considerations and definitions are needed in order to describe it compactly. For simplicity, we often omit the subscript of iteration count k.
Given the current point \(w=(x, y, z, s)\) and \(\varDelta w=(\varDelta x, \varDelta y, \varDelta z, \varDelta s)\), the next iterate is obtained along a curve on product manifold \(\mathcal {N}\), i.e., \( \alpha \mapsto w(\alpha ):=\bar{\textrm{R}}_{w}(\alpha \varDelta w) \) with some step size \(\alpha >0\), see (6) for \(\bar{\textrm{R}}_{w}\). By introducing \(w(\alpha )=(x(\alpha ), y(\alpha ), z(\alpha ), s(\alpha ))\), we have \(x(\alpha )=\textrm{R}_{x}(\alpha \varDelta x)\), \(y(\alpha )=y+\alpha \varDelta y\), \(z(\alpha )=z+\alpha \varDelta z\), and \(s(\alpha )=s+\alpha \varDelta s\). For a given starting point \(w_{0} \in \mathcal {N}\) with \((z_{0}, s_{0})>0\), let us set two constants
As well, define two functions \( f^{I}(\alpha ):=\min (Z(\alpha ) S(\alpha )e)-\gamma \tau _{1} z(\alpha )^{T} s(\alpha ) / m\), and \( f^{II}(\alpha ):=z(\alpha )^{T} s(\alpha )-\gamma \tau _{2}\Vert F(w(\alpha ))\Vert , \) where \(\gamma \in (0,1)\) is a constant. For \(i=I, I I\), define
i.e., \(\alpha ^i\) are either one or the smallest positive root for the functions \(f^i(\alpha )\) in (0, 1].
Moreover, we define the merit function \(\varphi :\mathcal {N} \rightarrow \mathbb {R}\) by \(\varphi (w):=\Vert F(w)\Vert ^{2}\); accordingly, we have \({\text {grad}}\,\varphi (w)=2\nabla F(w)^{*} [F(w)],\) where symbol \(*\) means its adjoint operator. Let \(\Vert \cdot \Vert _{1}\), \(\Vert \cdot \Vert _{2}\) be \(l_{1}, l_{2}\) vector norms. Note that \(\Vert F(w)\Vert _{w}^{2}=\left\| {\text {grad}}_{x} \mathcal {L}(w)\right\| _{x}^{2}+\Vert h(x)\Vert _{2}^{2}+\Vert g(x)+s\Vert _{2}^{2}+\Vert ZSe\Vert _{2}^{2}\) by (5). Moreover, for any nonnegative \(z,s \in \mathbb {R}^{m}\), one has \( \left\| Z Se\right\| _{2} \leqslant z^{T} s = \Vert Z Se\Vert _{1}\leqslant \sqrt{m} \left\| Z Se\right\| _{2}. \) Hence,
Now, using the above definitions, the globally convergent RIPM can be stated as Algorithm 5.

Global Convergent Algorithm of RIPM for (RCOP)
Compared to the prototype Algorithm 2, the global Algorithm 5 involves a more elaborate choice of step size. Regarding the centrality condition (3a), it does not differ in any way from the Euclidean setting; thus, references [3, 9, 11] show that \(\bar{\alpha }_k\) is well-defined, thereby ensuring that \(z_k\), \(s_k\) are positive. In the following, we focus on the sufficient decrease (Armijo) condition (3b):
where \({\text {grad}}\,\varphi _k \equiv {\text {grad}}\,\varphi \left( w_k\right) \) for short. With a slight abuse of notation \(\varphi \), at the current point w and direction \(\varDelta w\), we define a real-to-real function \(\alpha \mapsto \varphi (\alpha ):=\varphi \left( \bar{\textrm{R}}_w(\alpha \varDelta w)\right) \); then, it follows from the definition of a retraction and the chain rule that
Hence, \(\varphi _{k}^{\prime }(0)=\langle {\text {grad}}\,\varphi _{k}, \varDelta w_{k}\rangle \) at the k-th iterate \(w_{k}\), and then, the Armijo condition (33) reads \( \varphi _{k}(\alpha _{k}) - \varphi _{k}(0) \leqslant \alpha _{k} \beta \varphi _{k}^{\prime }(0)\) as usual. If \( \varphi _{k}^{\prime }(0)<0 \), the backtracking loop in (3b) of Algorithm 5 will eventually stop [26, Lemma 3.1]. The next lemma shows the condition under which the Newton direction \(\varDelta w_{k}\) generated by (32) ensures the descent of the merit function.
Lemma 6.1
If the direction \(\varDelta w_{k}\) is the solution of equation (32), then
In this case, \(\varDelta w_{k}\) is a descent direction for \(\varphi (w)\) at \(w_{k}\) if and only if \( \rho _{k}<\Vert F(w_{k})\Vert ^{2} / \sigma _{k} z_{k}^{T} s_{k}. \)
Proof
The iteration count k is omitted. Let \(\varDelta w\) be given by (32). Then, we have \( \langle {\text {grad}}\,\varphi (w), \varDelta w\rangle =\left\langle 2 \nabla F(w)^{*} [F(w)], \varDelta w\right\rangle =2\langle F(w), \nabla F(w) [\varDelta w] \rangle =2\langle F(w), -F(w)+\sigma \rho \hat{e}\rangle =2(-\langle F(w), F(w)\rangle +\sigma \rho \langle F(w), \hat{e}\rangle ). \) Then, by definition of \(\hat{e}\) in (13), \( \langle F(w), \hat{e}\rangle =\langle ZSe, e\rangle = z^{T} s\) completes the proof. \(\square \)
The next proposition shows that Algorithm 5 can generate the monotonically nonincreasing sequence \(\left\{ \varphi _{k}\right\} \). Note that \(\varphi _{k+1} \equiv \varphi _k\left( \alpha _k\right) \) and \(\varphi _k \equiv \varphi _k(0) \equiv \varphi \left( w_k\right) \).
Proposition 6.1
If \(\Vert F(w_{k})\Vert \ne 0\), then the direction \(\varDelta w_{k}\) generated by Algorithm 5 is a descent direction for \(\varphi (w)\) at \(w_k\). Moreover, if the Armijo condition (33) is satisfied, then
Thus, the sequence \(\left\{ \varphi _{k}\right\} \) is monotonically nonincreasing.
Proof
The iteration count k is omitted. Suppose that \(\rho \leqslant \left\| F(w)\right\| / \sqrt{m}\) and \( \varDelta w\) is given by (32), we have
Thus, in Algorithm 5, \(\varDelta w\) is a descent direction for the merit function \(\varphi \) at w. Alternatively, by Lemma 6.1, it is sufficient to show that \( \Vert F(w)\Vert / \sqrt{m} < \Vert F(w)\Vert ^{2} /\sigma z^{T} s. \) By \(\sigma z^{T} s < z^{T} s \leqslant \sqrt{m}\Vert F(w)\Vert ;\) then, \( 1 / \sqrt{m} < \Vert F(w)\Vert /\sigma z^{T} s. \) Multiplying both sides by \(\Vert F(w)\Vert \) yields the result.
Moreover, if condition (33) is satisfied, then by (34), we have \( \varphi (\alpha ) \leqslant \varphi (0)+\alpha \beta \langle {\text {grad}}\,\varphi (w), \varDelta w\rangle \leqslant \varphi (0)+\alpha \beta (-2(1-\sigma ) \varphi (0)) =[1-2 \alpha \beta (1-\sigma )] \varphi (0). \) Note that in Algorithm 5, we set \(\beta \in (0, 1 / 2], \sigma \in (0,1)\), and \(\alpha \in (0,1]\), which imply that the sequence \(\left\{ \varphi _k\right\} \) is monotonically nonincreasing. \(\square \)
Finally, we need to make the following assumptions. For \(\epsilon \geqslant 0\), let \( \varOmega (\epsilon ):=\left\{ w\in \mathcal {N} \mid \epsilon \leqslant \varphi (w) \leqslant \varphi _{0}, \min (Z S e) /(z^{T} s / m) \geqslant \tau _{1} / 2, z^{T} s /\Vert F(w)\Vert \geqslant \tau _{2} / 2\right\} . \)
- (C1):
-
In the set \(\varOmega (0)\), f, h, and g are smooth functions; \(\left\{ {\text {grad}}\,h_{i}(x)\right\} _{i=1}^{l}\) is linearly independent for all x; and the map \(w \mapsto \nabla F (w)\) is Lipschitz continuous (with respect to parallel transport);
- (C2):
-
The sequences \(\left\{ x_{k}\right\} \) and \(\left\{ z_{k}\right\} \) are bounded [3, 10];
- (C3):
-
In any compact subset of \(\varOmega (0)\), \(\nabla F (w)\) is nonsingular.
Given the above assumptions, we can now prove the following statement.
Theorem 6.1
(Global Convergence of RIPM) Let \(\left\{ w_{k}\right\} \) be generated by Algorithm 5 with \(\textrm{R} = {\text {Exp}}\) and \(\left\{ \sigma _{k}\right\} \subset (0,1)\) be bounded away from zero and one. Let \(\varphi \) be Lipschitz continuous on \(\varOmega (0)\). If (C1)–(C3) hold, then \(\left\{ \left\| F(w_{k})\right\| \right\} \) converges to zero. Moreover, if \(w^{*}\) is a limit point of sequence \(\left\{ w_{k}\right\} \), then \(w^{*}\) satisfies Riemannian KKT conditions (4).
The proof of the above theorem will be given in the next section. Note that although the exponential map is used in the proof, the numerical experiments indicate that global convergence may hold for a general retraction \(\textrm{R}\).
7 Proof of Global Convergence
In this section, our goal is to prove the global convergence Theorem 6.1. We will follow the proof procedure in [11], which discussed Algorithm 5 when \(\mathcal {M}=\mathbb {R}^{n}\) in (RCOP), and we call the algorithm in [11] the Euclidean Interior Point Method (EIPM). In what follows, we will omit similar content because of space limitations and focus on the difficulties encountered when adapting the proof of EIPM to RIPM. In particular, we will make these difficulties as tractable as in EIPM by proving a series of propositions in Sect. 7.1.
7.1 Continuity of Some Special Scalar Fields
To show the boundedness of the sequences generated by Algorithm 5, we need the continuity of some special scalar fields on manifold \(\mathcal {M}\). The claims of this subsection are trivial if \(\mathcal {M}= \mathbb {R}^n\), but they need to be treated carefully for general \(\mathcal {M}\).
If we assign a linear operator \(\mathcal {A}_{x}:T_{x} \mathcal {M} \rightarrow T_{x} \mathcal {M}\) to each \(x \in \mathcal {M},\) then the map \( x \mapsto \left\| \mathcal {A}_{x}\right\| :=\sup \left\{ \left\| \mathcal {A}_{x}v\right\| _{x} \mid v \in T_{x} \mathcal {M},\Vert v\Vert _{x}=1, \text { or, } \Vert v\Vert _{x} \leqslant 1\right\} \) is a scalar field on \(\mathcal {M}\); but notice that the operator norm \( \Vert \cdot \Vert \) depends on x. Let \({\text {Sym}}\,(d)\) denote the set of symmetric matrices of order d, and \(\Vert \cdot \Vert _{\textrm{F}}\), \(\Vert \cdot \Vert _{2}\) denote the Frobenius norm and the spectral norm, respectively, applied to a given matrix.
Lemma 7.1
Let \(\mathcal {M}\) be an n-dimensional Riemannian manifold. Let \(x \in \mathcal {M}\) and \(\mathcal {A}_{x}\) be a linear operator on \(T_{x} \mathcal {M}\). Choose an orthonormal basis of \(T_{x} \mathcal {M}\) with respect to \(\langle \cdot ,\cdot \rangle _{x}\), and let \(\hat{\mathcal {A}}_{x}\in \mathbb {R}^{n \times n}\) denote the matrix representation of \(\mathcal {A}_{x}\) under the basis. Then, \(\Vert \hat{\mathcal {A}}_{x}\Vert _{2}\), \(\Vert \hat{\mathcal {A}}_{x}\Vert _{\textrm{F}}\) are invariant under a change of orthonormal basis; moreover, \( \left\| \mathcal {A}_{x}\right\| =\Vert \hat{\mathcal {A}}_{x}\Vert _{2} \leqslant \Vert \hat{\mathcal {A}}_{x}\Vert _{\textrm{F}}. \)
Proof
Suppose that there are two orthonormal bases \(\{E_{i}\}_{i=1}^{n},\{E^{\prime }_{i}\}_{i=1}^{n}\) on \(T_{x} \mathcal {M}\). With respect to them, let \( P \in \mathbb {R}^{n \times n}\) denote the change-of-basis matrix, i.e., \( [P]_{kj}:= \langle E^{\prime }_{j},E_{k}\rangle _{x}\), for \( 1\leqslant k,j \leqslant n \); then, P is orthogonal. Let \( \hat{\mathcal {A}}_{x}, \hat{\mathcal {A}}^{\prime }_{x} \in \mathbb {R}^{n \times n}\) denote the matrix representations of \( \mathcal {A}_{x} \) under the two bases, respectively.
We have \(\hat{\mathcal {A}}_{x}^{\prime }=P^{-1} \hat{\mathcal {A}}_{x} P.\) Then, \( \Vert \hat{\mathcal {A}}_{x}^{\prime }\Vert =\Vert P^{-1} \hat{\mathcal {A}}_{x} P\Vert =\Vert \hat{\mathcal {A}}_{x}\Vert \) holds for the Frobenius norm or the spectral norm. Therefore, the values \(\Vert \hat{\mathcal {A}}_{x}\Vert _{2}\) and \(\Vert \hat{\mathcal {A}}_{x}\Vert _{\textrm{F}}\) are invariant under a change of orthonormal basis. Now, consider an orthonormal basis \(\{E_{i}\}_{i=1}^{n}\) on \(T_{x} \mathcal {M}\). For any \( y \in T_{x} \mathcal {M}\), its vector representation \( \hat{y} \in \mathbb {R}^{n}\) is defined by \(y=\sum _{i=1}^{n} \hat{y}_{i} E_{i}\). Accordingly, we have \(\widehat{\mathcal {A}_{x} y}=\hat{\mathcal {A}}_{x} \hat{y}\), i.e., \(\mathcal {A}_{x} y=\sum _{i=1}^{n}(\hat{\mathcal {A}}_{x} \hat{y})_{i} E_{i}\), and from the orthonormal property of the basis, we have
Thus, \(\left\| \mathcal {A}_{x} y\right\| _{x}=\Vert \hat{\mathcal {A}}_{x} \hat{y}\Vert _{2}\) for any \( y \in T_{x} \mathcal {M}\). Finally, we have
It is clear that \( \Vert X \Vert _{2} \leqslant \Vert X \Vert _{\textrm{F}} \) for any matrix X. \(\square \)
Yet, we have not clarified the continuity about \(x \mapsto \left\| A_x\right\| \). The following proposition proves the continuity of an important case of \( A_x \) that appears in (RCOP).
Proposition 7.1
Consider f in (RCOP). Let \(\hat{{\text {Hess}}}\,f(x) \in {\text {Sym}}\,(d)\) denote the matrix representation of \({\text {Hess}}\,f(x)\) under an arbitrary orthonormal basis of \(T_{x} \mathcal {M}\). Then, \( x \mapsto \Vert \hat{{\text {Hess}}}\,f(x)\Vert \) is a continuous scalar field on \(\mathcal {M}\) for \(\Vert \cdot \Vert _{\textrm{F}}\) or \(\Vert \cdot \Vert _{2}\). Moreover, \(x \mapsto \Vert {\text {Hess}}\,f(x)\Vert \) is a continuous scalar field on \(\mathcal {M}\).
Proof
Lemma 7.1 shows that \(x \mapsto \Vert \hat{{\text {Hess}}}\,f(x) \Vert \) is well defined, so it suffices to prove its continuity. From Corollary 13.8 in [21], for each \( \bar{x} \in \mathcal {M} \) there is a smooth, orthonormal local frame \(\{E_{i}\}_{i=1}^{d}\) on a neighborhood \( \mathcal {U} \) of \( \bar{x} \); namely, \(\{E_{1}(x), \ldots ,E_{d}(x)\}\) forms an orthonormal basis on \( T_{x} \mathcal {M} \) for all \( x \in \mathcal {U}. \) Choose such a local frame \(\{E_{i}\}_{i=1}^{d}\) around \(\bar{x}\); then, the matrix representation of \({\text {Hess}}\,f(x)\) is given by \( [\hat{{\text {Hess}}}\,f(x)]_{kj}:= \left\langle {\text {Hess}}\,f(x)[E_{j}(x)], E_{k}(x)\right\rangle _{x} = \langle (\nabla _{E_{j}} {\text {grad}}\,f)(x), E_{k}(x)\rangle _{x} \text { for } 1\leqslant k,j \leqslant d. \) From the smoothness of the Riemannian metric (1), it follows that \( x \mapsto \hat{{\text {Hess}}}\,f(x) \) is a continuous function from \(\mathcal {U} \subset \mathcal {M}\) to \({\text {Sym}}\,(d)\). Since matrix norms are continuous, \(\Vert \hat{{\text {Hess}}}\,f(x)\Vert \) is continuous on \(\mathcal {U} \ni \bar{x}.\) This argument holds for any \( \bar{x} \in \mathcal {M} \). From Lemma 7.1, \(\Vert \hat{{\text {Hess}}}\,f(x) \Vert _{2}=\Vert {\text {Hess}}\,f(x) \Vert \) for any \(x\in \mathcal {M} \), which completes the proof. \(\square \)
The above result can be applied verbatim to the Hessian of constraint functions \(\left\{ h_{i}\right\} _{i=1}^{l}\), \(\left\{ g_{i}\right\} _{i=1}^{m}\) in (RCOP). The next proposition can be proved similarly, as in Lemma 7.1 and Proposition 7.1.
Proposition 7.2
Consider h, g in (RCOP) and the linear operators \(\mathcal {H}_{x}\), \( \mathcal {G}_{x}\) defined in (7). Then, \(x \mapsto \left\| \mathcal {H}_{x}\right\| \) and \(x \mapsto \left\| \mathcal {G}_{x}\right\| \) are continuous scalar fields on \(\mathcal {M}\).
Proposition 7.3
Given \(w=(x, y, z, s) \in \mathcal {N}\), consider the operator \(\nabla F(w)\) in (8). Let \(\{E_{i}\}_{i=1}^{d}\) be an orthonormal basis of \( T_{x} \mathcal {M} \) and \( \{e_{i}\}_{i=1}^{l} \), \( \{\dot{e}_{i}\}_{i=1}^{m} \) be the standard bases of \( \mathbb {R}^{l}, \mathbb {R}^{m}\), respectively. If we choose an orthonormal basis of \(T_{w} \mathcal {N}\) as follows:
then, the matrix representation of \(\nabla F(w)\) is given by
i.e., a matrix of order \( (d+l+2m) \) and, where
\(Q:=Q(w) \in {\text {Sym}}\,(d)\) is given by \( [Q]_{k j}:=\left\langle {\text {Hess}}_{x} \mathcal {L}(w)[E_{j}], E_{k}\right\rangle _{x}\) for \(1 \leqslant k, j \leqslant d\);
\( B:=B(x)=[\hat{{\text {grad}}}\,h_{1}(x), \cdots , \hat{{\text {grad}}}\,h_{l}(x)] \in \mathbb {R}^{d \times l};\)
\( C:=C(x)=[ \hat{{\text {grad}}}\,g_{1}(x), \cdots , \hat{{\text {grad}}}\,g_{m}(x)] \in \mathbb {R}^{d \times m}\) and the “hat” symbol above means the corresponding vector representation under the basis \(\{E_{i}\}_{i=1}^{d}\).
In this case, there is a continuous scalar field \(T:\mathcal {N} \rightarrow \mathbb {R}\) such that for any w, \( \Vert Q(w)\Vert _{\textrm{F}} \leqslant T(w)\). Moreover, \( x \mapsto \Vert B(x)\Vert _{\textrm{F}}\) and \(x \mapsto \Vert C(x)\Vert _{\textrm{F}} \) are continuous scalar fields on \(\mathcal {M}\).
Proof
The matrix \(\hat{\nabla } F(w)\) under the basis (35) is obtained through a trivial process, so we will omit its description. From relation (9), we have \( Q(w):=\hat{{\text {Hess}}}_{x} \mathcal {L}(w)= \hat{{\text {Hess}}}\,f(x) +\sum _{i=1}^{l} y_{i} \hat{{\text {Hess}}}\,h_{i}(x) +\sum _{i=1}^{m} z_{i} \hat{{\text {Hess}}}\,g_{i}(x), \) under the same basis. Thus,
From Proposition 7.1, \(\Vert \hat{{\text {Hess}}}\,f(x)\Vert _{\textrm{F}}\), \(\Vert \hat{{\text {Hess}}}\,h_{i}(x)\Vert _{\textrm{F}}\), and \(\Vert \hat{{\text {Hess}}}\,g_{i}(x)\Vert _{\textrm{F}}\) are all continuous with respect to x, thus, T is continuous. As for \( x \mapsto \Vert B(x)\Vert _{\textrm{F}}\), since the basis \(\{E_{i}\}_{i=1}^{d}\) is orthonormal,
which implies continuity by (1). The claim for \( x \mapsto \Vert C(x)\Vert _{\textrm{F}}\) can be proven similarly. \(\square \)
7.2 Global Convergence Theorem
Now, we are ready to prove the global convergence Theorem 6.1 by following the procedure in [11]. In what follows, we will omit similar content in [11] and focus on the difficulties encountered when adapting the proof of EIPM to RIPM.
Proposition 7.4
(Boundedness of the sequences) Let \(\left\{ w_{k}\right\} \) be a sequence generated by Algorithm 5 and suppose that (C1)– (C3) hold. If \(\epsilon >0\) and \(w_{k} \in \varOmega (\epsilon )\) for all k, then
-
(a)
\( \{z_{k}^{T} s_{k}\} \), \(\left\{ (z_{k})_{i}(s_{k})_{i}\right\} , i=1, \ldots , m\), are all bounded above and below away from zero;
-
(b)
\(\left\{ z_{k}\right\} \) and \(\left\{ s_{k}\right\} \) are bounded above and component-wise bounded away from zero;
-
(c)
\(\left\{ w_{k}\right\} \) is bounded;
-
(d)
\(\{ \Vert \nabla F (w_k)^{-1}\Vert \} \) is bounded;
-
(e)
\(\left\{ \varDelta w_{k}\right\} \) is bounded.
Proof
The proofs in [11, Lemma 6.1] and/or [3, Theorem 2 (a)] can be applied verbatim to (a), (b) and (e).
(c) By (b), it suffices to prove that \(\left\{ y_{k}\right\} \) is bounded. The iteration count k is omitted in what follows. By using the notation \( \mathcal {H}_{x}\) and \( \mathcal {G}_{x} \) as defined in (7), we have \( \mathcal {H}_{x}y = {\text {grad}}_{x} \mathcal {L}(w) -{\text {grad}}\,f(x) -\mathcal {G}_{x}z =:b. \) By (C1), \(\mathcal {H}_{x}\) is an injection; then, there exists a unique solution y to \(\mathcal {H}_{x}y=b\). Indeed, we have
Define \(\mathcal {C}_{x}: T_{x} \mathcal {M} \rightarrow \mathbb {R}^{l}\) as \( \mathcal {C}_{x}:= \left( \mathcal {H}_{x}^{*} \mathcal {H}_{x}\right) ^{-1} \mathcal {H}_{x}^{*}.\) Under an arbitrary orthonormal basis of \(T_{x} \mathcal {M}\) and standard basis of \(\mathbb {R}^{l}\), if \( \hat{\mathcal {H}}_{x} \) is the matrix corresponding to \( \mathcal {H}_{x} \), then \(\hat{\mathcal {C}}_{x}=(\hat{\mathcal {H}}_{x}^{T} \hat{\mathcal {H}}_{x})^{-1} \hat{\mathcal {H}}_{x}^{T}\). It is easy to show that \(\left\| \mathcal {C}_{x}\right\| =\Vert \hat{\mathcal {C}}_{x}\Vert _{2}\) for any x. We can see that for each \( \bar{x} \in \mathcal {M}\) there is a neighborhood \(\mathcal {U}\) of \( \bar{x} \) such that \( x \mapsto \hat{\mathcal {H}}_{x} \) is continuous over \(\mathcal {U}\). Then, by function composition, \(x \mapsto \hat{\mathcal {C}}_{x}\) is also continuous over \(\mathcal {U}\). This implies that \(x \mapsto \left\| \mathcal {C}_{x}\right\| =\Vert \hat{\mathcal {C}}_{x}\Vert _{2}\) is continuous at each \( \bar{x} \), and hence, on \( \mathcal {M}\). Finally, by Proposition 7.2, \( \left\| \mathcal {C}_{x}\right\| , \left\| {\text {grad}}\,f(x)\right\| ,\) and \(\left\| \mathcal {G}_{x}\right\| \) are all continuous on \( \mathcal {M} \). Because \(\{x_{k}\}\) is bounded, by (36) we have \( \left\| y_{k}\right\| \leqslant \left\| \mathcal {C}_{x_{k}} \right\| \left( \left\| {\text {grad}}_{x} \mathcal {L}(w_{k})\right\| + \left\| {\text {grad}}\,f(x_{k})\right\| + \left\| \mathcal {G}_{x_{k}}\right\| \left\| z_{k}\right\| \right) \leqslant c_{1} \left( \sqrt{\varphi _{0}}+ c_{2} + c_{3} \left\| z_{k}\right\| \right) , \) for some positive constants \( c_{1},c_{2},c_{3}.\) Then, \(\left\{ y_{k}\right\} \) is bounded because \(\left\{ z_{k}\right\} \) is bounded.
(d) For each \( w_{k} \), choose an arbitrary orthonormal basis of \(T_{w_{k}} \mathcal {N}.\) If the matrix representation \(\hat{\nabla } F(w_{k})\) corresponds to \(\nabla F(w_{k})\), then \([\hat{\nabla } F(w_{k})]^{-1}\) corresponds to \(\nabla F(w_{k})^{-1}\). By Lemma 7.1, we have \( \left\| \nabla F(w_{k})^{-1}\right\| \leqslant \Vert [\hat{\nabla } F(w_{k})]^{-1}\Vert _{\textrm{F}}; \) thus, it is sufficient to show that \(\{\Vert [\hat{\nabla } F(w_{k})]^{-1}\Vert _{\textrm{F}} \}\) is bounded. For convenience, we will choose the basis of \(T_{w_{k}} \mathcal {N}\) given in (35). Then, we have
By Proposition 7.3, there is a continuous scalar field \(T: \mathcal {N} \rightarrow \mathbb {R}\) such that \(\Vert Q(w)\Vert _{\textrm{F}} \leqslant T(w)\) for all \(w \in \mathcal {N}\); and \(\Vert B(x)\Vert _{\textrm{F}}\), \(\Vert C(x)\Vert _{\textrm{F}}\) are continuous on \(\mathcal {M}\). It follows from the boundedness of \(\left\{ x_{k}\right\} \) and \(\left\{ w_{k}\right\} \) that for all k, \( \left\| Q_{k}\right\| _{\textrm{F}} \equiv \left\| Q(w_{k})\right\| _{\textrm{F}} \leqslant T(w_{k}) \leqslant c_{4},\) \(\left\| B_{k}\right\| _{\textrm{F}} \equiv \left\| B(x_{k})\right\| _{\textrm{F}} \leqslant c_{5},\) and \(\left\| C_{k}\right\| _{\textrm{F}} \equiv \left\| C(x_{k})\right\| _{\textrm{F}} \leqslant c_{6},\) for some positive constants \( c_{4}, c_{5},\) and \(c_{6}.\)
On the other hand, whichever basis is used in the form of (35), the structure of \(\hat{\nabla } F(w_{k})\) and the properties of its block submatrices remain unchanged, e.g., symmetry of \( Q_{k} \); full rank of \(B_{k}\); identity matrix I in the third row; all zero matrices; diagonal matrices \(S_{k}, Z_{k}\); etc. This ensures that we can obtain the desired result by performing an appropriate decomposition of \(\hat{\nabla } F(w_{k})\). Up to this point, we have created all the conditions needed in the proof of the Euclidean version, namely EIPM. We can make the claim that \(\{\Vert [\hat{\nabla } F(w_{k})]^{-1}\Vert _{\textrm{F}} \}\) is bounded by applying the proofs in [11, Lemma 6.2] and/or [3, Theorem 2 (c)] directly. \(\square \)
Lemma 7.2
(\(\left\{ \bar{\alpha }_{k}\right\} \) bounded away from zero) Let \(\left\{ w_{k}\right\} \) be generated by Algorithm 5 with \(\textrm{R} = {\text {Exp}}\) and let (C1)–(C3) hold. If \(\epsilon >0\) and \(w_{k} \in \varOmega (\epsilon )\) for all k, \(\left\{ \sigma _{k}\right\} \) is bounded away from zero; then, \(\left\{ \bar{\alpha }_{k}\right\} \) is bounded away from zero.
Proof
Since \(\bar{\alpha }_{k}=\min \{\alpha _{k}^{I}, \alpha _{k}^{II}\}\), it is sufficient to show that \(\{\alpha _{k}^{I}\}\) and \(\{\alpha _{k}^{II}\}\) are bounded away from zero. For \(\alpha _{k}^{I}\), see [11, Lemma 6.3] and/or [9, Theorem 3.1]. The proofs in those references apply verbatim to the Riemannian case. On the other hand, for \(\alpha _{k}^{II}\), we need to adapt the proofs in [9, 11], since Lipschitz continuity on manifolds is more complicated, see Subsection 4.2.
Let us suppress the subscript k. Recall that \( w(\alpha )=\bar{{\text {Exp}}}_{w}(\alpha \varDelta w). \) Fix \( \alpha \varDelta w \) and let \(\textrm{P}_{\gamma }\) be the parallel transport along the geodesic \(\gamma (t)=\bar{{\text {Exp}}}_{w}\left( t \alpha \varDelta w\right) \). By Lemma 4.4 where \(c_1=0\), we obtain
Taking the norm on both sides above gives
The rest of the proof is the same as [11, Lemma 6.3] and/or [9, Theorem 3.1], so we omit it. \(\square \)
Proof of Theorem 6.1
By Proposition 6.1, we know that \(\left\{ \left\| F(w_{k})\right\| \right\} \) is monotonically nonincreasing, hence convergent. Assume that \(\left\{ \left\| F(w_{k})\right\| \right\} \) does not converge to zero. Then, there exists \(\epsilon >0\) such that \(\left\{ w_{k} \right\} \subset \varOmega (\epsilon )\) for infinitely many k. We will show that the following two cases both lead to contradictions, and thus, the hypothesis \(\left\| F(w_{k}) \right\| \nrightarrow 0\) is not valid.
Case 1. For infinitely many k, if step (3b) in Algorithm 5 is executed with \(\alpha _{k} \equiv \bar{\alpha }_{k}\), it follows from Proposition 6.1 that \( \varphi (w_{k+1}) / \varphi (w_{k}) \leqslant \lambda _{k}:= \left[ 1-2 \bar{\alpha }_{k} \beta \left( 1-\sigma _{k}\right) \right] . \) Since \(\left\{ \bar{\alpha }_{k}\right\} \) is bounded away from zero by Lemma 7.2 and \(\left\{ \sigma _{k}\right\} \) is bounded away from one, then \(\left\{ \lambda _{k}\right\} \) is bounded away from one, and hence, \(\varphi (w_{k}) \rightarrow 0\); this is a contradiction.
Case 2. On the other hand, for infinitely many k, if \(\alpha _{k}<\bar{\alpha }_{k}\), we have that \(\alpha _{k} \leqslant \theta \bar{\alpha }_{k}\). Then, condition (33) fails to hold for an \(\tilde{\alpha }_{k}\) with \(\alpha _{k}<\tilde{\alpha }_{k} \leqslant \alpha _{k} /\theta = \theta ^{t-1} \bar{\alpha }_{k}\). Notice that \( \alpha _{k} /\theta \) is the value corresponding to the last failure. Recall that the derivative of the real-valued function \(\alpha \mapsto \varphi (\alpha ):=\varphi \left( \bar{{\text {Exp}}}_{w_{k}}(\alpha \varDelta w_{k})\right) \) is
Applying the mean value theorem to \( \varphi (\alpha ) \) on the interval \( [0,\tilde{\alpha }_{k}] \) yields a number \( \xi \in (0,1)\) such that \(\tilde{\alpha }_{k} \varphi ^{\prime }(\xi \tilde{\alpha }_{k}) =\varphi (\tilde{\alpha }_{k})-\varphi (0). \) For short, let \(u:=\xi \tilde{\alpha }_{k} \varDelta w_{k}.\) Hence,
On the other hand, note that
Subtracting \(\tilde{\alpha }_{k} \left\langle {\text {grad}}\,\varphi _{k}, \varDelta w_{k}\right\rangle \) from both sides of (38) and using equalities (39) gives
Finally, we obtain \( (\beta -1) \left\langle {\text {grad}}\,\varphi _{k}, \varDelta w_{k}\right\rangle /(\kappa \xi \left\| \varDelta w_{k}\right\| ^{2}) < \tilde{\alpha }_{k}. \)
Because \( \left\langle {\text {grad}}\,\varphi _{k}, \varDelta w_{k}\right\rangle <0 \) and \(\alpha _{k}\) satisfies (33), we have
where \(\omega (\cdot )\) is an F-function (see [28, Definition 14.2.1 & 14.2.2 in P479]). Since \(\{\varphi _{k}\}\) is bounded below and \(\varphi _{k} \geqslant \varphi _{k+1}\), it follows that \(\lim _{k \rightarrow \infty }(\varphi _{k}-\varphi _{k+1})=0\). By the definition of F-functions, we obtain \( \left\langle {\text {grad}}\,\varphi _{k}, \varDelta w_{k}\right\rangle / \left\| \varDelta w_{k}\right\| \rightarrow 0. \) Since \(\{\left\| \varDelta w_{k}\right\| \}\) is bounded (Proposition 7.4), we have \( \left\langle {\text {grad}}\,\varphi _{k}, \varDelta w_{k}\right\rangle \rightarrow 0. \) Choosing \( \rho _{k} \) with \(z_{k}^{T} s_{k}/m \leqslant \rho _{k} \leqslant \left\| F(w_{k})\right\| / \sqrt{m}\) in Algorithm 5 implies that
This shows that \(\varphi (w_{k}) \rightarrow 0\), because \(\left\{ \sigma _{k}\right\} \) is bounded away from one; this is a contradiction. \(\square \)
8 Numerical Experiments
The numerical experiments compared the performance of the globally convergent RIPM (Algorithm 5) with those of other Riemannian methods in solving two problems. They were conducted in Matlab R2022a on a computer with an Intel Core i7-10700 (2.90GHz) and 16GB RAM. Algorithm 5 utilized Manopt 7.0 [6], a Riemannian optimization toolbox for MATLAB. The problems involve three manifolds:
-
fixed-rank manifold, \(\mathcal {M}_r =\left\{ X \in \mathbb {R}^{m \times n}: {\text {rank}}\,(X)=r\right\} \);
-
Stiefel manifold, \({\text {St}}\,(n, k) =\left\{ X \in \mathbb {R}^{n \times k}: X^T X=I_k\right\} \);
-
oblique manifold, \(\textrm{Ob}(n, k) =\{X \in \mathbb {R}^{n \times k}: \left( X^T X\right) _{i i}=1, \forall i=1,\dots ,k \}.\)
We only consider their embedded geometry and we apply the default retractions in Manopt, e.g., the retraction based on QR decomposition for the Stiefel manifold.
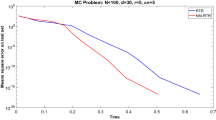
Problem I. Recently, [31] proposed the nonnegative low-rank matrix (NLRM) approximation. Formally, NLRM aims to solve

Input. We tested three cases of integer triples (m, n, r): (20, 16, 2), (30, 24, 3), and (40, 32, 4). For each (m, n, r), we generated nonnegative \(L \in \mathbb {R}^{m \times r}\), \(R \in \mathbb {R}^{r \times n}\) whose entries follow a uniform distribution in [0,1]. Then, we added the Gaussian noise with zero mean and different standard deviation \((\sigma = 0, 0.001, 0.01)\) to \( A=LR\). When there is no noise (i.e., \(\sigma = 0\)), the input data matrix A itself is exactly a solution.
Problem II. Given \(C \in \mathbb {R}^{n \times k}\), [19] computed its projection onto the nonnegative part of the Stiefel manifold. If the distance is measured in terms of \(\Vert C-X\Vert _{\textrm{F}}^2\), we can express it equivalently as

In [19], it is shown that (Model_St) can be equivalently reformulated into

where the positive integer p and \(V \in \mathbb {R}^{k \times p}\) can be arbitrary as long as \(\Vert V\Vert _{\textrm{F}}=1\) and \(V V^T\) is entry-wise positive. We examined both models. Input. We considered four cases of integer pairs (n, k): (40, 8), (50, 10), (60, 16), and (70, 14). For a general C, it is always difficult to seek nonnegative projections globally. Fortunately, Proposition 1 in [19] showed a way to construct C such that Model_St has a unique, known solution \( X^{*} \). In our experiments, we generated a feasible point B of Model_St; then, we obtained C by using codes: X1=(B>0).*(1+rand(n,k));Xstar=X1./sqrt(sum(X1.*X1));L =rand(k,k);L=L+k*eye(k);C=Xstar*L’. The initial point was computed by projecting C onto the Stiefel manifold. In addition, for Model_Ob we set p=1;V=ones(k,p);V=V/norm(V,"fro").
8.1 Implementation Details
The experimental implementation of Algorithm 5 (i.e.,RIPM) initialized \(z_0\) and \(s_0\) from a uniform distribution in [0,1] and set \(y_0=0\) if equality constraints exist. We used \(\rho _{k}=z_{k}^{T}s_{k}/m\), \(\sigma _k=\min \{0.5, \Vert F(w_{k})\Vert ^{1/2}\}\) and Algorithm 3 to solve the condensed form of Newton equation (19). Algorithm 3 stopped when the relative residual went below \(10^{-9}\), or it reached 1000 iterations. We used a backtracking line search simultaneously for the central conditions and sufficient decreasing conditions. We set \(\gamma _{-1}=0.9\), \(\gamma _{k+1}=(\gamma _{k}+0.5)/2;\) and \(\beta =10^{-4}\), \(\theta =0.5\). We compared RIPM with the following Riemannian methods:
-
RALM: Riemannian augmented Lagrangian method [23].
-
REPM\(_{\text {lqh}}\): Riemannian exact penalty method with smoothing functions of linear-quadratic and pseudo-Huber [23].
-
REPM\(_{\text {lse}}\): Riemannian exact penalty method with smoothing functions of log-sum-exp [23].
-
RSQP: Riemannian sequential quadratic programming [27].
Let \([t]_{+}:=\max (0,t)\) and \( [t]_{-}:=\min (0,t)\) for any \(t \in \mathbb {R}.\) The experimental settings followed those of [27], where they used the KKT residual defined as
to measure the deviation of an iterate from the KKT conditions. For the parameters of RALM, REPMs, and RSQP, we utilized the experimental setting and Matlab codes provided by [27].
We conducted 20 random trials of each problem and model. All the algorithms ran with the same initial point. The experiment is considered successfully terminated if it finds a solution with a KKT residual lower than \(\epsilon _{\text {kkt}}\) before triggering any of the stopping conditions. For the first-order algorithms (including RALM and the REPMs), the stopping conditions are: elapsed time exceeding \( t_{\max } \) seconds, number of outer iterations exceeding 1,000, or failure of the algorithm to update any parameters. For the second-order algorithms (including RSQP and RIPM), the stopping conditions are elapsed time exceeding \( t_{\max } \) seconds or a number of outer iterations exceeding 10,000. Here, considering that some problems might not have converged easily, the maximum number of iterations was chosen to be 1,000 (10,000), which was a sufficiently large value. The selection of \(t_{\max }\) is related to the actual time it took to run all the codes on the computer. Setting \(t_{\max }\) too large resulted in excessive time spent on poorly performing algorithms. On the other hand, \(\epsilon _{\textrm{kkt}}\) was chosen to better demonstrate that second-order algorithms could achieve more accurate solutions. Therefore, we chose the appropriate values for \( t_{\max } \) and \(\epsilon _{\text {kkt}}\) according to the problem that was to be solved.
8.2 Results and Analysis
The tables in this subsection report the success rate (Success), the average time (Time), and the average iteration number (Iter.) among the successful trials. In order to capture the combination of stability and speed, the algorithms with 0.9 or higher are first highlighted in bold in the “Success” column, and then, of those algorithms, the fastest result is highlighted in bold in the “Time” column. Here, “successful convergence in numerical experiments” means that the algorithm can generate a relatively accurate solution in a relatively reasonable amount of time. It is not exactly the same as the “theoretical convergence in any global convergence theorem”. Numerical experiments reflect the actual performance of the algorithm in the application. For example, the first-order algorithms (RALM, REPMs) also have theoretical global convergence, but under our high criterion, it is difficult for them to generate a high-precision solution within a certain period of time. The second-order algorithm (RIPM, RSQP), on the other hand, is excellent in terms of accuracy, although it takes quite a bit of time.
Problem I. Here, we set \( t_{\max } = 180\), \(\epsilon _{\text {kkt}} = 10^{-8}\). The numerical results in Table 1 show that RIPM had the best performance, except for cases (30, 40, 3) and (40, 32, 4) without noise. The time spent by RALM and the REPMs grew slowly with the problem size m and n, but their success rates dropped sharply as the noise level (standard deviation \(\sigma \)) intensified, eventually leading to non-convergence. In contrast, RSQP and RIPM were more stable and robust, while RIPM was much faster than RSQP. The cost of RSQP increased drastically with the problem size because a quadratic programming subproblem (defined over tangent space of current point) had to be solved in each iteration. Unlike RIPM, which uses Krylov subspace methods introduced in Sect. 3.4.2 to avoid expensive computations, RSQP had to transform the subproblem into a matrix representation (similar to Steps 1–6 in Sect. 3.4.2). As can be seen from Table 1, RIPM took about the same amount of time as RALM and the REPMs did.
Problem II. Here, we set \( t_{\max } = 600\), \(\epsilon _{\text {kkt}} = 10^{-6}\) for both (Model_St) and (Model_Ob). Since the true solution \(X^{*}\) is known, we added a column showing the average error \(\Vert \tilde{X} - X^{*} \Vert _{\textrm{F}}\), where \( \tilde{X} \) denotes the final iterate. The numerical results are listed in Tables 2 and 3. The error columns show that if the KKT residual is sufficiently small, then \( \tilde{X} \) does approximate the true solution. In particular, RSQP and RIPM yield a more accurate solution. (The error is less than \(10^{-7} \).) From Table 2, we can see that RALM is stable and fast for (Model_St). However, from Table 3, the success rate of RALM for (Model_Ob) decreases as the problem size becomes larger. The REPMs do not work at all on either model. RSQP also does not perform well on either model. In contrast, RIPM successfully solved all instances of both models and was only slightly slower than RALM in some cases. Overall, our RIPM was relatively fast and most stable.
9 Conclusions
In this paper, we proposed a Riemannian version of the classical interior point method and established its local and global convergence. To our knowledge, this is the first study to apply the primal-dual interior point method to the nonconvex constrained optimization problem on a Riemannian manifold. Numerical experiments showed the stability and efficiency of our method.
Recently, Hirai et al. [15] extended the self-concordance-based interior point methods to Riemannian manifolds. They aimed to minimize a geodesically convex (i.e., convex on manifolds) objective \(f :D \rightarrow \mathbb {R}\) defined on a geodesically convex subset \(D \subset \mathcal {M}\). In contrast, in (RCOP), we do not require any convexity. In practice, many convex functions (in the Euclidean sense) are not geodesically convex on some interested manifolds. For example, for any geodesically convex function defined on a connected, compact Riemannian manifold (e.g., Stiefel manifold), it must be constant [5, Corollary 11.10], which is not of interest in the field of optimization. Thus, (RCOP) has a wider applicability.
In closing, let us make a comparison with the Euclidean interior point method (EIPM) to illustrate the theoretical advantages of our RIPM and discuss two future directions of research on more advanced RIPM methods.
Comparison: Riemannian IPM (RIPM) v.s. Euclidean IPM (EIPM).
-
1.
RIPM generalizes EIPM from Euclidean space to general Riemannian manifolds. EIPM is a special case of RIPM when \(\mathcal {M} = \mathbb {R}^n\) or \(\mathbb {R}^{m \times n}\) in (RCOP).
-
2.
RIPM inherits all the advantages of Riemannian optimization. For example, we can exploit the geometric structure of \(\mathcal {M}\), which is usually regarded as a set of constraints from the Euclidean viewpoint.
-
3.
Note that in both RIPM and EIPM, we have to solve the condensed Newton equation (19) at each iteration. However, if the equality constraints can be considered to be a manifold, RIPM can solve (19) with a smaller order on \(T_x \mathcal {M} \times \mathbb {R}^l\). For example, the problem II (Model_St) can be rewritten as:
$$\begin{aligned} \min _{X \in \mathbb {R}^{n \times k}} - 2 {\text {trace}}\,(X^{T}C) \quad \text{ s.t. } X^{T} X = I_k, \; X \geqslant 0. \end{aligned}$$Here, Stiefel manifold is replaced by the equality constraints, i.e., we define \(h :\mathbb {R}^{n \times k} \rightarrow {\text {Sym}}\,(k): X \mapsto h(X):=X^T X-I_k\); and \(\mathcal {M} = \mathbb {R}^{n \times k}\), \( l = {\text {dim}}\,{\text {Sym}}\,(k) = k(k+1) / 2\) in (RCOP). Then, when we apply EIPM, it requires us to solve (19) of order \(n k + k(k+1) / 2\). On the other hand, if we apply RIPM to (Model_St), then (19) reduces to (21) since there are only inequality constraints on \(\mathcal {M} =\textrm{St}(n, k)\). In this case, we solve the equation of order \(n k-k(k+1) / 2\), i.e., the dimension of \(\textrm{St}(n, k)\). Compared to EIPM, using RIPM reduces our dimensionality by \(k(k+1)\).
-
4.
RIPM can solve some problems that EIPM cannot. For example, the problem I (NLRM) can be rewritten as:
$$\begin{aligned} \min _{X \in \mathbb {R}^{m \times n}} \Vert A-X\Vert _{\textrm{F}}^2 \quad \text{ s.t. } {\text {rank}}\,(X)=r, \; X \geqslant 0. \end{aligned}$$Since the rank function, \(X \mapsto {\text {rank}}\,(X)\), is not even continuous, we cannot apply EIPM.
Future Work I: Preconditioner for linear operator equation.
With regard to the complementary condition, \(S_{k}^{-1} Z_{k}\) values display a huge difference in magnitude as \(k\rightarrow \infty \). The operator \(\varTheta :=G_x S^{-1} Z G_x^*\) causes the system (19) to be ill-conditioned, risking failure of the iterative method without preconditioning. Matrix-decomposition-based preconditioner methods cannot be applied to a problem that does not have a matrix form. A possible alternative is to find a nonsingular \(\mathcal {P}\) such that the condition number of \(\mathcal {P}^{-1} \mathcal {T}\) is smaller.
Future Work II: Treatment of more state-of-the-art interior point methods.
While we have considered interior point methods on a manifold for the first time, our Euclidean theoretic counterpart is an early nonlinear interior point method algorithm [11]; however, the counterpart now appears to be obsolete compared with more recent interior point methods. For example, our method does not drive the iteration toward minimizers but only toward stationary points; globalization is done by monitoring only the KKT residuals; moreover, the boundedness assumption (C2) of \(\{z_{k}\}\) is too strong to hold in some simple cases (see Wächter–Biegler effect [32]). It remains an important issue to adapt more modern interior point methods to manifolds, although we may encounter various difficulties in Riemannian geometry.
Data Availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author upon reasonable request.
Notes
The code is freely available at https://doi.org/10.5281/zenodo.10612799.
See .../LocalRIPM/PrototypeRIPM.m in https://doi.org/10.5281/zenodo.10612799.
References
Absil, P.-A., Mahony, R., Sepulchre, R.: Optimization Algorithms on Matrix Manifolds. Princeton University Press, Princeton (2009)
Bergmann, R., Herzog, R.: Intrinsic formulation of KKT conditions and constraint qualifications on smooth manifolds. SIAM J. Optim. 29, 2423–2444 (2019)
Bonettini, S., Galligani, E., Ruggiero, V.: An inexact Newton method combined with Hestenes multipliers’ scheme for the solution of Karush–Kuhn–Tucker systems. Appl. Math. Comput. 168, 651–676 (2005)
Bortoloti, MAd.A., Fernandes, T.A., Ferreira, O.P., Yuan, J.: Damped Newton’s method on Riemannian manifolds. J. Glob. Optim. 77, 643–660 (2020)
Boumal, N.: An Introduction to Optimization on Smooth Manifolds. Cambridge University Press, Cambridge (2023)
Boumal, N., Mishra, B., Absil, P.-A., Sepulchre, R.: Manopt, a Matlab toolbox for optimization on manifolds. J. Mach. Learn. Res. 15, 1455–1459 (2014)
Do Carmo, M.P.: Riemannian Geometry. Birkhäuser, Boston (1992)
Dennis, J.E., Schnabel, R.B.: Numerical Methods for Unconstrained Optimization and Nonlinear Equations. SIAM (1996)
Durazzi, C.: On the Newton interior-point method for nonlinear programming problems. J. Optim. Theory Appl. 104, 73–90 (2000)
Durazzi, C., Ruggiero, V.: Global convergence of the Newton interior-point method for nonlinear programming. J. Optim. Theory Appl. 120, 199–208 (2004)
El-Bakry, A., Tapia, R.A., Tsuchiya, T., Zhang, Y.: On the formulation and theory of the Newton interior-point method for nonlinear programming. J. Optim. Theory Appl. 89, 507–541 (1996)
Fernandes, T.A., Ferreira, O.P., Yuan, J.: On the superlinear convergence of Newton’s method on Riemannian manifolds. J. Optim. Theory Appl. 173, 828–843 (2017)
Ferreira, O.P., Svaiter, B.F.: Kantorovich’s theorem on Newton’s method in Riemannian manifolds. J. Complex. 18, 304–329 (2002)
Gallivan, K.A., Qi, C., Absil, P.-A.: A Riemannian Dennis–Moré condition. In: Berry, M.W., Gallivan, K.A., Gallopoulos, E., Grama, A., Philippe, B., Saad, Y., Saied, F. (eds.) High-Performance Scientific Computing: Algorithms and Applications, pp. 281–293. Springer, London (2012)
Hirai, H., Nieuwboer, H., Walter, M.: Interior-point methods on manifolds: theory and applications, arXiv:2303.04771, (2023) to appear in FOCS (2023)
Hu, J., Liu, X., Wen, Z.W., Yuan, Y.X.: A brief introduction to manifold optimization. J. Oper. Res. Soc. China 8, 199–248 (2020)
Huang, W.: Optimization Algorithms on Riemannian Manifolds with Applications, Ph.D. thesis, Florida State University, Tallahassee, FL (2013)
Huang, W., Absil, P.-A., Gallivan, K.A.: A Riemannian symmetric rank-one trust-region method. Math. Program. 150, 179–216 (2015)
Jiang, B., Meng, X., Wen, Z.W., Chen, X.: An exact penalty approach for optimization with nonnegative orthogonality constraints. Math. Program. 1–43 (2022)
Kojima, M., Mizuno, S., Yoshise, A.: A primal-dual interior point algorithm for linear programming, in Progress in Mathematical Programming, N. Megiddo ed., Springer, pp. 29–47 (1989)
Lee, J.M.: Introduction to Smooth Manifolds, 2nd ed., Grad. Texts in Math. 218, Springer (2013)
Lee, J.M.: Introduction to Riemannian Manifolds, 2nd ed., Grad. Texts in Math. 176, Springer (2018)
Liu, C., Boumal, N.: Simple algorithms for optimization on Riemannian manifolds with constraints. Appl. Math. Optim. 82, 949–981 (2020)
Lustig, I., Marsten, R.E., Shanno, D.F.: Computational experience with a primal-dual interior point method for linear programming. Linear Algebra Appl. 152, 191–222 (1991)
Megiddo, N.: Pathways to the optimal set in linear programming, in Progress in Mathematical Programming, N. Megiddo ed., Springer, pp. 131–158 (1989)
Nocedal, J., Wright, S.J., II (eds.): Numerical Optimization. Springer, New York (2006)
Obara, M., Okuno, T., Takeda, A.: Sequential quadratic optimization for nonlinear optimization problems on Riemannian manifolds. SIAM J. Optim. 32, 822–853 (2022)
Ortega, J.M., Rheinboldt, W.C.: Iterative Solution of Nonlinear Equations in Several Variables. SIAM (2000)
Saad, Y., 2nd ed., Iterative Methods for Sparse Linear Systems, Other Titles in Applied Mathematics SIAM (2003)
Schiela, A., Ortiz, J.: An SQP method for equality constrained optimization on Hilbert manifolds. SIAM J. Optim. 31, 2255–2284 (2021)
Song, G.J., Ng, M.K.: Nonnegative low rank matrix approximation for nonnegative matrices. Appl. Math. Lett. 105, 106300 (2020)
Wächter, A., Biegler, L.T.: Failure of global convergence for a class of interior point methods for nonlinear programming. Math. Program. 88, 565–574 (2000)
Wright, S.J.: Primal-dual Interior-point Methods. SIAM (1997)
Yamakawa, Y., Sato, H.: Sequential optimality conditions for nonlinear optimization on Riemannian manifolds and a globally convergent augmented Lagrangian method. Comput. Optim. Appl. 81, 397–421 (2022)
Yamashita, H., Yabe, H.: Superlinear and quadratic convergence of some primal-dual interior point methods for constrained optimization. Math. Program. 75, 377–397 (1996)
Yang, W.H., Zhang, L.H., Song, R.: Optimality conditions for the nonlinear programming problems on Riemannian manifolds. Pacific J. Optim. 10, 415–434 (2014)
Ye, Y.: Interior Point Algorithms: Theory and Analysis. Wiley, London (1997)
Zhu, X., Sato, H.: Riemannian conjugate gradient methods with inverse retraction. Comput. Optim. Appl. 77, 779–810 (2020)
Acknowledgements
We are deeply grateful to Hiroyuki Sato of Kyoto University for his valuable comments and suggestions. This work was supported by JST SPRING, Grant Number JPMJSP2124, and JSPS KAKENHI, Grant Numbers 19H02373 and 22K18866.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Sándor Zoltán Németh.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
An earlier version of this article has been circulated under the title “Superlinear and Quadratic Convergence of Riemannian Interior Point Methods.”
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Lai, Z., Yoshise, A. Riemannian Interior Point Methods for Constrained Optimization on Manifolds. J Optim Theory Appl 201, 433–469 (2024). https://doi.org/10.1007/s10957-024-02403-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-024-02403-8