
Abstract
In this paper, we propose the descent method with new inexact line-search for unconstrained optimization problems on Riemannian manifolds. The global convergence of the proposed method is established under some appropriate assumptions. We further analyze some convergence rates, namely R-linear convergence rate, superlinear convergence rate and quadratic convergence rate, of the proposed descent method.
Similar content being viewed by others
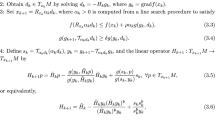


Avoid common mistakes on your manuscript.
1 Introduction
Since the non-convex problems can be translated into convex problems with appropriate Riemannian metrics, and constrained optimization problems can be written as unconstrained optimization problems from the Riemannian geometry viewpoint, in recent years, many concepts, techniques, as well as methods of optimization theory have been extended from Euclidean space to Riemannian manifolds; see, for instance, [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]. It is an emerging area of research in convex analysis, optimization theory, game theory, etc; see, for example, [12, 14] and the references therein.
The descent method is one of the oldest and widely known methods for solving minimization problems. Many convergence results for descent method have been established in the setting of Euclidean space. For instance, some line-search techniques for the general descent method in \(\mathbb {R}^{n}\) are proposed by Nocedal and Wright [16]. They proved the global convergence and studied convergence rate of steepest descent method, Newton’s method and coordinate descent method. Shi and Shen [17] also proved the global convergence and local convergence rate of descent method with new inexact line-search in \(\mathbb {R}^{n}\). The new inexact line-search in [17] has many advantages comparing with some other similar line-searches, such as Armijo line-search and Wolfe line-search; see [18, 19]. Based on the results in [17], a new inexact line-search for quasi-Newton method is proposed and some global convergence results are established by Shi [20]. Recently, some authors focused on extending the convergence results for descent methods from Euclidean space to Riemannian manifolds. In particular, the steepest descent method and the Newton method to solve convex optimization problems on Riemannian manifolds have been studied by Udrişte [14], in which the linear convergence result for the steepest descent method is obtained under the assumption of exact line-search. Smith [21] considered the steepest descent, Newton method and conjugate gradient method on Riemannian manifolds and analyzed their convergence properties by employing the Riemannian structure of the manifold. The full convergence result for the steepest descent method with the Armijo line-search on Riemannian manifolds has been studied by da Cruz Neto et al. [4, 5]. A combination of generalized Armijo method and generalized Newton method in the setting of Riemannian manifolds is investigated by Yang [15]. The global convergence results for these methods with less restrictions are obtained. Estimations of linear/quadratic convergence rate for the generalized Armijo–Newton algorithms are also derived in [15]. Moreover, the global and local convergence analysis of the exact and approximate line-search such as the Newton’s method, the gradient descent method and the trust-region method on Riemannian manifolds is studied in [22,23,24,25,26,27].
Motivated by the results described above, in this paper, we propose a new inexact line-search for the descent method on Riemannian manifolds and establish its convergence results. Since the computation of the exponential mapping and parallel transport can be quite expensive in the setting of manifolds, and many convergence results show that the nice properties of some algorithms hold for all suitably defined retractions and isometric vector transports on Riemannian manifolds (see, for example, [6, 13, 28]), we replace the geodesic by retraction and parallel transport by isometric vector transport, respectively. As a result, the global convergence result of the descent method, with new inexact line-search for unconstrained optimization problems on Riemannian manifolds, is proved under some appropriate assumptions. Moreover, we analyze the convergence rate, such as R-linear convergence rate, superlinear convergence rate and quadratic convergence rate, of the descent method on Riemannian manifolds. To the best of our knowledge, these results have not been studied before, and it is very interesting to explore the convergence results for a new inexact line-search algorithm on manifolds by utilizing Riemannian techniques.
The present paper is organized as follows: In Sect. 2, we recall some notions and known results from Riemannian geometry, which will be used throughout the paper. We propose the descent method with new inexact line-search for unconstrained optimization problems on Riemannian manifolds. In Sect. 3, the global convergence result for the descent method on Riemannian manifolds is proved. Section 4 is devoted to analyze the convergence rate of the descent method with new inexact line-search.
2 Preliminaries
In this section, we recall some standard notations, definitions and results from Riemannian manifolds, which can be found in any introductory book on Riemannian geometry; see, for example, [2, 3, 7].
Let M be a finite-dimensional differentiable manifold and \(x\in M\). The tangent space of M at x is denoted by \(T_{x}M\) and the tangent bundle of M by \(TM=\bigcup _{x\in M}T_{x}M\), which is naturally a manifold. We denote by \(g_{x}(.,.)\) the inner product on \(T_{x}M\) with the associated norm \(\Vert \cdot \Vert _{x}\). If there is no confusion, then we omit the subscript x. If M is endowed with a Riemannian metric g, then M is a Riemannian manifold. Throughout the paper, unless otherwise specified, we assume that M is a Riemannian manifold. Given a piecewise smooth curve \(\gamma : [t_{0}, t_{1}]\rightarrow M\) joining x to y, that is, \(\gamma (t_{0})=x\) and \(\gamma (t_{1})=y\), we can define the length of \(\gamma \) by \(l(\gamma )=\int _{a}^{b}\Vert \gamma '(t)\Vert \hbox {d}t\). Minimizing this length functional over the set of all curves, we obtain a Riemannian distance d(x, y) which induces the original topology on M.
Let \(\nabla \) be the Levi-Civita connection associated with M. A vector field \(V: M\rightarrow TM\) along \(\gamma \) is said to be parallel if \(\nabla _{\gamma '} V = 0\). We say that \(\gamma \) is a geodesic when \(\nabla _{\gamma '} \gamma ' = 0\); in the case \(\Vert \gamma '\Vert =1\), \(\gamma \) is said to be normalized. Let \(\gamma : \mathbb {R}\rightarrow M\) be a geodesic and \(P_{\gamma [.,.]}\) denote the parallel transport along \(\gamma \), which is defined by \(P_{\gamma [\gamma (a),\gamma (b)]}(v)=V(\gamma (b))\) for all \(a, b\in \mathbb {R}\) and \(v\in T_{\gamma (a)}M\), where V is the unique \(C^{\infty }\) vector field such that \(\nabla _{\gamma '(t)}V=0\) and \(V(\gamma (a))=v\).
A Riemannian manifold is complete if, for any \(x\in M\), all geodesic emanating from x are defined for all \(t \in \mathbb {R}\). By Hopf–Rinow theorem [29], any pair of points \(x,y\in M\) can be joined by a minimal geodesic. The exponential mapping \(\exp _{x}: T_{x}M\rightarrow M\) is defined by \(\exp _{x}v=\gamma _{v}(1, x)\) for each \(v\in T_{x}M\), where \(\gamma (\cdot )=\gamma _{v}(\cdot , x)\) is the geodesic starting from x with velocity v, that is, \(\gamma (0)=x\) and \(\gamma '(0)=v\). It is easy to see that \(\exp _{x}tv=\gamma _{v}(t, x)\) for each real number t.
The exponential mapping \(\exp _{x}\) provides a local parametrization of M via \(T_{x}M\). However, the systematic use of the exponential mapping may not be desirable in all cases. Some local mappings to \(T_{x}M\) may reduce the computational cost while preserving the useful convergence properties of the considered method. In this paper, we relax the exponential mapping by a class of mappings called retractions, a concept that can be seen in [1, 6, 13, 30, 31].
Definition 2.1
Given \(x\in M\), a retraction is a smooth mapping \(R_{x}: T_{x}M\rightarrow M\) such that
-
(i)
\(R_{x}(0_{x})=x\) for all \(x\in M\), where \(0_{x}\) denotes the zero element of \(T_{x}M\);
-
(ii)
\(DR_{x}(0_{x})=\mathrm {id}_{T_{x}M}\), where \(DR_{x}\) denotes the derivative of \(R_{x}\) and id denotes the identity mapping.
As we know, the exponential mapping is a special retraction, and some retractions can be seen as an approximation of the exponential mapping.
The parallel transport is often too expensive to use in a practical method, so we can consider a more general vector transport (see, for example, [6, 13, 22]), which is built upon the retraction \(R_{x}\). A vector transport \(\mathscr {\mathscr {\mathscr {T}}}:TM\bigoplus TM\rightarrow TM\), \((\eta _{x},\xi _{x})\mapsto \mathscr {T}_{\eta _{x}}\xi _{x}\) with the associated retraction \(R_{x}\) is a smooth mapping such that, for all \(\eta _{x}\) in the domain of \(R_{x}\) and all \(\xi _{x},\zeta _{x}\in T_{x}M\), (i) \(\mathscr {T}_{\eta _{x}}\xi _{x}\in T_{R_{x}(\eta _{x})}M\); (ii) \(\mathscr {T}_{0_{x}}\xi _{x}=\xi _{x}\); (iii) \(\mathscr {T}_{\eta _{x}}\) is a linear mapping. Let \(\mathscr {T}_{S}\) denote the isometric vector transport (see, for example, [13, 22, 31]) with \(R_{x}\) as the associated retraction. Then it satisfies (i), (ii), (iii) and the following condition (iv):
In most of the practical cases, \(\mathscr {T}_{S(\eta _{x})}\) exists for all \(\eta _{x}\in T_{x}M\), and thus, we make this assumption throughout the paper. Furthermore, let \(\mathscr {T}_{R_{x}}\) denote the derivative of the retraction, that is,
Let L(TM, TM) denote the fiber bundle with the base space \(M\times M\) such that the fiber bundle over \((x,y)\in M\times M\) is \(L(T_{x}M,T_{y}M)\), the set of all linear mappings from \(T_{x}M\) to \(T_{y}M\). We recall, from Section 4 in [6], that a transporter \(\mathscr {L}\) on M to be a smooth section of the bundle L(TM, TM), that is, for all \(x,y\in M\), \(\mathscr {L}(x,y)\in L(T_{x}M,T_{y}M)\) and \(\mathscr {L}(x,x)=\mathrm {id}\), where \(\mathrm {id}\) means the identity mapping. Furthermore, \(\mathscr {L}(x,y)\) is isometric from \(T_{x}M\) to \(T_{y}M\), \(\mathscr {L}^{-1}(x,y)=\mathscr {L}(y,x)\) and \(\mathscr {L}(x,z)=\mathscr {L}(y,z)\mathscr {L}(x,y)\). Given a retraction \(R_{x}\), for any \(\eta _{x}, \xi _{x}\in T_{x}M\), the isometric vector transport \(\mathscr {T}_{S}\) can be defined by
In this paper, we require
In some manifolds, there exist retractions such that the above equality holds, e.g., the Stiefel manifold and the Grassmann manifold [31]. Furthermore, from the above equality and (1), we have
In this paper, we consider the following unconstrained minimization problem
where \(f: M\rightarrow \mathbb {R}\) is a continuously differentiable function with a lower bound and M is a complete Riemannian manifold.
Now, we describe the descent method with new inexact line-search on Riemannian manifolds for finding the solution of the minimization problem (3).
3 New Inexact Line-Search on Riemannian Manifolds
Given \(\beta \in \, ]0,1[\) and \(\sigma \in \, ]0,1[\), the Hessian approximation \(B_{k}\) is symmetric positive definite with respect to the metric g, and \(s_{k} = \frac{-g(\mathrm {grad}f(x_{k}),d_{k})}{g(B_{k}[d_{k}],d_{k})}\), where \(d_{k}\in T_{x_{k}}M\) is a descent direction with \(g(\mathrm {grad}f(x_{k}), d_{k})<0\). The step size \(\alpha _{k}\) is the largest one in \(\{s_{k}, s_{k}\beta , s_{k}\beta ^{2},\ldots \}\) such that
In comparison with the original Armijo line-search on Riemannian manifolds [4, 5], there are some advantages of the new inexact line-search. For example, let \(\alpha _{k}\) denote the step size defined by the original Armijo line-search and \(\alpha '_{k}\) denote the step size defined by the new inexact line-search; then, it is easy to see that \(\alpha _{k}<\alpha '_{k}\).
Now we present a related descent method with the new inexact line-search on Riemannian manifolds for the minimization problem (3) as follows.
Algorithm 2.1
(Descent Method with New Inexact Line-search)
- Step 1. :
-
Given \(x_{0}\in M\), initial Hessian approximation \(B_{0}\), which is symmetric positive definite with respect to the metric g, \(k:=0\);
- Step 2. :
-
If \(\Vert \mathrm {grad}f(x_{k})\Vert =0\), then stop. Else go to step 3;
- Step 3. :
-
Set \(x_{k+1}=R_{x_{k}}(\alpha _{k}d_{k})\), where \(d_{k}\) is a descent direction with \(g(\mathrm {grad}f(x_{k}), d_{k})<0\), \(\alpha _{k}\) is defined by the new inexact line-search on Riemannian manifolds;
- Step 4. :
-
Define \(p_{k}=\mathrm {grad}f(x_{k+1})-\mathscr {L}(x_{k}, x_{k+1})\mathrm {grad}f(x_{k})\) and modify \(B_{k}\) as \(B_{k+1}\) by using BFGS quasi-Newton algorithm or other quasi-Newton algorithms (see, for example, [6, 13]);
- Step 5. :
-
Set \(k: =k+1\) and go to step 2.
Remark 2.1
If M is a Riemannian manifold with nonnegative curvature, then by Proposition 5.4.1 in [22], the exponential mapping on M induced by \(\nabla \) is a retraction R, and the parallel transport is isometric vector transport. Furthermore, if \(d_{k}=-\mathrm {grad}f(x_{k})\) and \(B_{k}=I\) (I denotes the unit matrix), then from (4), we get
In this case, the descent method with new inexact line-search on Riemannian manifolds is a generalization of the steepest descent method with Armijo line-search in [4].
From Lemma 5.2.1 and Lemma 5.2.2 in [31], and the definition of \(\mathscr {L}(.,.)\), we obtain the following result.
Lemma 2.1
Suppose that the function \(f:M\rightarrow \mathbb {R}\) is twice continuously differentiable on a set \(S\subset M\). Then, there exists a constant \(L_{0}>0\) such that, for all \(x, y\in S\),
4 Global Convergence
In this section, we study the global convergence property of the descent method with new inexact line-search on Riemannian manifolds under some appropriate assumptions.
Definition 3.1
The matrix \(B_{k}\) is said to be uniformly positive definite, iff there exist constants \(m'\) and \(\overline{m}\) such that \(0<m'\le \overline{m}\) and for any \(k\in \mathbb {N}\),
Proposition 3.1
Assume that f is twice continuously differentiable on M, \(B_{k}\) is uniformly positive definite, \(d_{k}\) is a descent direction, and \(\{x_{k}\}\) is the sequence generated by Algorithm 2.1. Then, there exists \(\tau >0\) such that
Proof
Let \(K_{1} = \{ k \in \mathbb {N} : \alpha _{k}=s_{k}\}\) and \(K_{2} = \{ k \in \mathbb {N} : \alpha _{k}<s_{k}\}\). The proof is divided into two parts.
Part 1. If \(k\in K_{1}\), then by (4) and (6), we have
Thus,
Part 2. If \(k\in K_{2}\), then \(\alpha _{k}\beta ^{-1}\in \{s_{k}, s_{k}\beta , s_{k}\beta ^{2},\ldots \}\). This implies that (4) does not hold, and so,
Define \(m(t)=f(R_{x_{k}}(td_{k}))\). By using mean value theorem on the left-hand side of the above inequality, there exists \(\theta _{k} \in \, ]0,1[\) such that
This shows that
Noting that
it follows from Lemma 2.1 that there exists \(L_{0}>0\) such that
This together with (10) implies that
Thus, we obtain
Let
Then,
Now, from (4) and (11), one has
Thus,
Let
This completes the proof. \(\square \)
Corollary 3.1
Suppose that all the assumptions of Proposition 3.1 are satisfied and \(d_{k}\) satisfies
where \(0<\mu \le 1\) is a constant and \(\theta _{k}\) denotes the angle between \(-\mathrm {grad}f(x_{k})\) and \(d_{k}\). Then,
Proof
It follows from (13) that
This together with (7) implies that
This completes the proof. \(\square \)
Theorem 3.1
Suppose that all the assumptions of Corollary 3.1 are satisfied. Then,
and thus,
Proof
Since f has a lower bound on M, by Corollary 3.1, the result follows. \(\square \)
Remark 3.1
Theorem 3.1 shows that all accumulation points of the sequence \(\{x_{k}\}\) generated by Algorithm 2.1 are stationary points. Moreover, if we consider \(M = \mathbb {R}^{n}\) and \(R_{x}(\eta ) = x+\eta \), then Theorem 3.1 reduces to Corollary 3.4 in [17].
5 Convergence Rate
In this section, we analyze the convergence rate, such as R-linear convergence rate, superlinear convergence rate and quadratic convergence rate, of the descent method with new inexact line-search on Riemannian manifolds.
Definition 4.1
Let \(\{x_{k}\}\) be a sequence converging to \(x^*\). The convergence is said to be
-
(a)
R-linear, iff there exist a constant \(0\le \theta <1\) and a positive integer N such that
$$\begin{aligned}{}[d(x_{k},x^*)]^{\frac{1}{k}}\le \theta , \quad \forall k>N; \end{aligned}$$ -
(b)
superlinear, iff there exist a sequence \(\{\alpha _{k}\}\) converging to 0 and a positive integer N such that
$$\begin{aligned} d(x_{k+1}, x^*)\le \alpha _{k} d(x_{k},x^*), \quad \forall k>N; \end{aligned}$$ -
(c)
quadratic, iff there exist a constant \(\theta \ge 0\) and a positive integer N such that
$$\begin{aligned} d(x_{k+1}, x^*)\le \theta d^{2}(x_{k},x^*), \quad \forall k>N. \end{aligned}$$
The convergence rate depends on the property of uniformly retraction-convexity, which is defined as follows.
Definition 4.2
For a function \(f:M\rightarrow \mathbb {R}\) on the Riemannian manifold M with the retraction R, define the function \(m_{x,\eta }(t)=f(R_{x}(t\eta ))\) for \(x\in M\) and \(\eta \in T_{x}M\). The function f is said to be uniformly retraction-convex on \(S\subset M\), iff \(m_{x,\eta }(t)\) is uniformly convex, i.e., there exists a constant \(c>0\) such that
for all \(x\in S\), \(\eta \in T_{x}M\) with \(\Vert \eta \Vert =1\), \(\alpha \in \, ]0,1[\) and \(t_{1}, t_{2}\ge 0\) such that \(R_{x}(\varsigma \eta )\in S\) for all \(\varsigma \in [0, \max (t_{1}, t_{2})]\).
Remark 4.1
From Section 3.4 in [32], if there exists a constant \(c>0\) such that \(\frac{\mathrm {d}^{2}m_{x,\eta }(t)}{\mathrm {d}t^{2}}\ge c\), then \(m_{x,\eta }(t)\) is uniformly convex, and so f is uniformly retraction-convex. Next, we provide a sufficient condition to ensure the uniformly retraction-convexity of f. Assume that \(x^*\) is a stationary point of f and the Hessian matrix of f at \(x^{*}\), denoted by \(\mathrm {Hess}f(x^{*})\), is positive definite. Then, from Lemma 3.1 in [6], there exist \(c_{1}, c_{2}>0\), \(\overline{t}>0\) and a neighborhood N of \(x^{*}\) such that \(c_{1}\le \frac{\mathrm {d}^{2}m_{x,\eta }(t)}{\mathrm {d}t^{2}}\le c_{2}\) for all \(x\in N\) and \(t\le \overline{t}\). Thus, f is uniformly retraction-convex on a neighborhood of \(x^{*}\).
Lemma 4.1
Assume that f is twice continuously differentiable and uniformly retraction-convex on M, and \(x^*\) is a stationary point of f. Moreover, assume that
where \(\mathrm {D}/\mathrm {d}t\) denotes the covariant derivative along the curve \(t\mapsto R_{x}(t\eta )\) (see Chapter 2 in [33]). Then, there exist constants \(m'\) and \(\overline{m}\) such that \(0<m'\le \overline{m}\) and
and thus,
Proof
Define \(m_{x,\eta }(t)=f(R_{x}(t\eta ))\), for all \(x\in M, \eta \in T_{x}M\) with \(\Vert \eta \Vert =1\) and \(t\ge 0\). Let \(y=R_{x}(t\eta )\). Then, it is easy to see that \(t\eta =R^{-1}_{x}y\). Since f is uniformly retraction-convex on M, there exists a constant \(c>0\) such that
This implies that
By the similar argument, we also have
Combining (20) and (21), we get
Hence,
Clearly,
and
Then, it follows from (23) that
Since \(\frac{\mathrm {D}}{\mathrm {d}t}\mathrm {D}R_{x}(t\eta )[\eta ]=0\), we have
Thus, by (22), (23), (24) and (25), we have
Since f is twice continuously differentiable on M, from Lemma 2.1, for \(t>0\), we obtain
Taking \(2c=m'\) and \(L_{0}=\overline{m}\), then, it follows from (26) and (27) that
Thus, (16) holds.
For any \(x\in M\) and \(x\ne x^*\), let \(z=\Vert R^{-1}_{x^*}x\Vert \) and \(p=\frac{R^{-1}_{x^*}x}{z}\). Define
From Taylor theorem, we have
Noting that
then, it follows from (29) that
By combining (28) and (30), we obtain
Hence, (17) holds.
For any \(x,y\in M\) and \(x\ne y\), let \(\widetilde{z}=\Vert R^{-1}_{x}y\Vert \) and \(\widetilde{p}=\frac{R^{-1}_{x}y}{\widetilde{z}}\). Define \(m_{x,p}(t)=f(R_{x}(t\widetilde{p}))\). Then, we have
Therefore,
since
From (32) and the above inequality, we have
Then, inequality (18) holds. Furthermore, we obtain
In particular, when \(y=x\) and \(x=x^*\), one has
This completes the proof. \(\square \)
Remark 4.2
If the retraction \(R_{x}\) is an exponential mapping, then from [22], assumption (15) holds. We further illustrate assumption (15) by the following example.
We consider the sphere \(\mathbb {S}^{n-1} := \{ x \in \mathbb {R}^{n} : x^{\top } x = 1\}\) with its structure of Riemannian submanifold of the Euclidean space \(\mathbb {R}^{n}\). The projection retraction \(R_{x}\) is defined by
The chosen isomeric vector transport \(\mathscr {T}\) on \(\mathbb {S}^{n-1}\) is
where \(y=R_{x}(\eta )\). For further details, see, for example [22, 31]. From Section 8.1 in [22] and Section 5 in [34], we obtain
Thus, assumption (15) holds on \(\mathbb {S}^{n-1}\) for the projection retraction.
Lemma 4.2
[13] Let \(S\subset M\) be an open set, \(x\in S\) and the retraction \(R_{x}:T_{x}M\rightarrow M\) has equicontinuous derivatives at x in the sense that
Then, for any \(\epsilon >0\), there exists \(\epsilon '>0\) such that, for all \(x\in S\) and \(v,w\in T_{x}M\) with \(\Vert v\Vert ,\Vert w\Vert <\epsilon '\),
Theorem 4.1
Suppose that all the assumptions of Lemma 4.1 are satisfied, \(B_{k}\) is uniformly positive definite, and \(d_{k}\) satisfies (13). Furthermore, assume that \(\mathrm {D}R_{x_{k}}\) is equicontinuous on a neighborhood U of the stationary point \(x^*\). Then, the sequence \(\{x_{k}\}\) generated by Algorithm 2.1 converges R-linearly to \(x^*\).
Proof
It follows from Corollary 3.1, (17) and (19) that
Set \(\theta =\sqrt{2\frac{\tau \mu ^{2}m'^{2}}{\overline{m}}} = m'\sqrt{2\frac{\tau \mu ^{2}}{\overline{m}}}\). Then,
We can prove that \(\theta <1\). Indeed, since f is twice continuously differentiable on M, it follows from Lemma 2.1 that there exists a constant \(L_{0}>0\) such that
Then,
Taking \(L_{0}= \overline{m}\), then by the definition of \(\tau \) in the proof of Proposition 3.1, we obtain
Set \(\omega =\sqrt{1-\theta ^{2}}\). Then, \(\omega <1\), and from (33), we obtain
From (17), we have
It follows from Lemma 4.2 that, for k sufficiently large,
By (34), we get
Thus, \(x_{k}\) converges R-linearly to \(x^*\). This completes the proof. \(\square \)
In the following, we assume that
-
(H)
\(B_{k}\) and \(d_{k}\) generated by Algorithm 2.1 satisfy the following condition
$$\begin{aligned} \lim _{k\rightarrow +\infty }\frac{\Vert B_{k}[d_{k}]-\mathscr {L}(x^*,x_{k}) (\mathrm {Hess}f(x^*)[\mathscr {L}(x_{k},x^*)d_{k}])\Vert }{\Vert d_{k}\Vert }=0. \end{aligned}$$
Lemma 4.3
Suppose that all the assumptions of Lemma 4.1 are satisfied, \(B_{k}\) is uniformly positive definite, \(d_{k}=-B_{k}^{-1}\mathrm {grad}f(x_{k})\) and the assumption (H) holds. Then, there exists \(k'\in \mathbb {N}\) such that
Proof
Since \(B_{k}\) is uniformly positive definite, there exists a constant \(q>0\) such that
Then, from (14) and the above inequality, we obtain
and thus,
Assumption (H) implies that
and thus,
Clearly,
This together with (37) implies that, for k sufficiently large,
Define \(m(t)=f(R_{x_{k}}(td_{k}))\). By using Taylor theorem, (38) and the above equality, we obtain for k sufficiently large,
Thus, for k sufficiently large, we obtain
This implies that there exists \(k'>0\) such that
This completes the proof. \(\square \)
Theorem 4.2
Suppose that all the assumptions of Lemma 4.3 are satisfied, and \(\mathrm {D}R_{x_{k}}\) is equicontinuous on a neighborhood U of the stationary point \(x^*\). Then, the sequence \(\{x_{k}\}\) generated by Algorithm 2.1 converges superlinearly to \(x^*\).
Proof
From Lemma 4.3, we obtain that there exists \(k'>0\) such that
where \(d_{k}=-B^{-1}_{k}\mathrm {grad}f(x_{k})\). Let \(\gamma \) be the curve defined by \(\gamma (t)=R_{x_{k}}(td_{k})\). Then, we have
It follows from (35) and (37) that, for k sufficiently large,
Noting that
Since \(d_{k}=-B_{k}^{-1}\mathrm {grad}f(x_{k})\), we have \(\mathrm {grad}f(x_{k})=-B_{k}d_{k}\) and
Consequently, for k sufficiently large, it follows from (39) that
By assumption (H), we have
From Lemma 4.2, we obtain for k sufficiently large,
and
This together with (19) implies that
Consequently, from (40), we obtain
which implies that \(\{x_{k}\}\) converges superlinearly to \(x^*\) . This completes the proof. \(\square \)
Theorem 4.3
Suppose that all the assumptions of Lemma 4.3 are satisfied, \(B_{k}=\mathrm {Hess}f(x_{k})\) for k sufficiently large, and \(DR_{x_{k}}\) is equicontinuous on a neighborhood U of the stationary point \(x^*\). Moreover, assume there exists a constant \(\widetilde{L}>0\) such that
Then, the sequence \(\{x_{k}\}\) generated by Algorithm 2.1 converges quadratically to \(x^*\) .
Proof
From Lemma 4.3, there exists \(k'>0\) such that
where \(d_{k}=-(\mathrm {Hess}f(x_{k}))^{-1}\mathrm {grad}f(x_{k})\). Let \(\gamma \) be the curve defined by \(\gamma (t)=R_{x_{k}}(tR^{-1}_{x_{k}}x^*)\). Then, it follows from Lemma 4.2 that, for k sufficiently large,
Since f is uniformly retraction-convex on M, from (16), there exists \(m'>0\) such that
Furthermore, it follows from Lemma 4.2 that, for k sufficiently large,
and
By (41), (42), (43) and (44), we obtain
Thus,
which implies that \(\{x_{k}\}\) converges quadratically to \(x^*\). This completes the proof. \(\square \)
Remark 4.3
Smith [21, Theorem 4.4] presented Newton’s method on Riemannian manifolds and proved that its convergence is quadratic. If the retraction \(R_{x}\) is the exponential mapping, and the isometric vector transport is the parallel transport, then Theorem 4.3 can be seen as a generalization of Theorem 4.4 in [21]. If \(M=\mathbb {R}^{n}\) and \(R_{x}(\eta )=x+\eta \), then Theorems 4.1, 4.2 and 4.3 reduce to Theorems 4.1, 5.1 and 5.3 in [17].
Example 4.1
Let \(\mathrm {St}(p,n) \, (p\le n)\) denote the set of all \(n\times p\) orthonormal matrices, that is,
where \(I_{p}\) denotes the \(p\times p\) identity matrix. The set \(\mathrm {St}(p,n)\) is called Stiefel manifold. The tangent space of \(\mathrm {St}(p,n)\) is given by
where \(X_{\bot }\) is any \(n\times (n-p)\) orthonormal matrix such that \((X ~X_{\bot })\) is an orthogonal matrix. The canonical inner product is given by
As in [6], the isometric vector transport from \(T_{X_{1}}\mathrm {St}(p,n)\) to \(T_{X_{2}}\mathrm {St}(p,n)\) is given by
where \(a^{\flat }\) denotes the flat of \(a\in T_{X}\mathrm {St}(p,n)\), i.e., \(a^{\flat }:T_{X}\mathrm {St}(p,n)\rightarrow \mathbb {R}:v\rightarrow g(a,v)\). Moreover, a smooth function \(\mathscr {B}:U\rightarrow \mathbb {R}^{np\times (\frac{np-p(p+1)}{2})}:X\mapsto \mathscr {B}_{X}\) is defined on an open set U of \(\mathrm {St}(p,n)\), and the columns of \(\mathscr {B}_{X}\) form an orthonormal basis of \(T_{X}\mathrm {St}(p,n)\). Let \(X\in \mathrm {St}(p,n)\). Then, from [6, 31], we obtain
where \(\varOmega =X^{\mathrm {\top }}\eta \) and \(K=X_{\bot }^{\top }\eta \). The function \(Y=R_{X}(\eta )\) is the desired retraction by the isometric vector transport \(\mathscr {L}(\cdot ,\cdot )\). Consider the cost function
where \(A=\mathrm {diag}(\mu _{1},\ldots ,\mu _{p})\) with \(0<\mu _{1}<\cdots <\mu _{p}\). From Chapter 11 in [31], the gradient of f is
where \(\mathrm {sym}(Q)=\frac{Q+Q^{\mathrm {\top }}}{2}\) and \(P_{X}(V)=X\mathrm {sym}(X^{\mathrm {\top }}V)\). Moreover, the Hessian of f on \(\eta \in T_{X}\mathrm {St}(p,n)\) is given by
Let \(\beta , \sigma \in \, ]0,1[\), \(B_{k}=\mathrm {Hess}f(x_{k})\) and \(d_{k}=-B_{k}^{-1}\mathrm {grad}f(x_{k})\) for all \(k\in \mathbb {N}\). Define \(m_{X,\eta }(t)=f(R_{X}(t\eta ))\) for all \(X\in \mathrm {St}(p,n)\) and \(\eta \in T_{X}\mathrm {St}(p,n)\). From the above equality, it is easy to check that \(\frac{\mathrm {d}^{2}m_{X,\eta }(t)}{\mathrm {d}t^{2}}>0\). Thus, by Remark 4.1, f is uniformly retraction-convex. Furthermore, the vector transport \(\mathscr {L}(\cdot ,\cdot )\) is parallel translation. From Section 8.1 in [22] and Section 5 in [34], it follows that assumption (15) holds. Thus, all the assumptions of Theorem 4.1 are satisfied. Assume that \(X^*\) is a stationary point of f. Then, the sequence \(\{X_{k}\}\) generated by Algorithm 2.1 converges R-linearly to the stationary point \(X^*\).
Example 4.2
Let \(M=\mathbb {H}:=\{(x_{1}, x_{2})\in \mathbb {R}^{2} : x_{2}>0\}\) be the Poincaré plane endowed with the Riemannian metric given by
Then, \(\mathbb {H}\) is a Hadamard manifold with the constant sectional curvature \(-\,1\) (see [14]). The geodesics in \(\mathbb {H}\) are vertical semilines
and semicircles
For fixed \((x_{0},y_{0}) \in \mathbb {H}\) and for the vector \(p=(p_{1}, p_{2}) \in T_{(x_{0},y_{0})}\mathbb {H}\), we have
where \(\Vert p\Vert ^2=\Vert p_{1}\Vert ^2+\Vert p_{2}\Vert ^2\). For further details, see Chapter 1 in [14]. Let \(f: \mathbb {H}\rightarrow \mathbb {R}\) be a twice continuously differentiable function. Then, as in [14], the gradient of f and the Hessian of f are given by
and
respectively. Let \(C\subseteq H\) be defined by
Then, C is geodesic convex in \(\mathbb {H}\) (see, [14]). Consider the cost function
Then, we obtain
It is easy to check f is uniformly retraction-convex on C. However, f is not uniformly convex on C in Euclidean sense. Suppose that the isometric vector transport is parallel transport. Let \(\beta , \sigma \in \, ]0,1[\), \(B_{k}=\mathrm {Hess}f(x_{k})\) and \(d_{k}=-B_{k}^{-1}\mathrm {grad}f(x_{k})\) for all \(k\in \mathbb {N}\). Then, all the assumptions of Theorems 4.1, 4.2 and 4.3 are satisfied. Hence, the sequence \(\{x_{k}\}\) generated by Algorithm 2.1 converges R-linearly / superlinearly/quadratically to the stationary point \(x^*\).
6 Conclusions
We proposed a descent method with new inexact line-search for unconstrained optimization problems on Riemannian manifolds. By using the retraction and isometric vector transport, the global convergence of the descent method with new inexact line-search on Riemannian manifolds is obtained, under some appropriate assumptions. Moreover, the R-linear / superlinear / quadratic convergence rate of the descent method, with new inexact line-search, is extended from linear spaces to Riemannian manifolds. In the future, we shall explore some other efficiently computable retractions and vector transport, which can be adjusted in the given problems. Moreover, it is interesting to do some numerical experiments and comparisons with other line-search algorithms for practical problems on Riemannian manifolds.
References
Absil, P.A., Baker, C.G., Gallivan, K.A.: Trust-region methods on Riemannian manifolds. Found. Comput. Math. 7, 303–330 (2007)
Burago, D., Burago, Y., Ivanov, S.: A Course in Metric Geometry. Graduate Studies in Math., vol. 33. Amer. Math. Soc, Providence (2001)
Chavel, I.: Riemannian Geometry—A Modern Introduction. Cambridge University Press, London (1993)
da Cruz Neto, J.X., de Lima, L.L., Oliveira, P.R.: Geodesic algorithms in Riemannian geometry. Balkan J. Geom. Appl. 3(2), 89–100 (1998)
da Cruz Neto, J.X., Ferreira, O.P., Lucambio Perez, L.R.: A proximal regularization of the steepest descent method in Riemannian manifolds. Balkan J. Geom. Appl. 4(2), 1–8 (1999)
Huang, W., Gallivan, K.A., Absil, P.A.: A Broyden class of quasi-newton methods for Riemannian optimization. SIAM J. Optim. 25, 1660–1685 (2015)
Klingenberg, W.: A Course in Differential Geometry. Springer, Berlin (1978)
Li, S.L., Li, C., Liou, Y.C., Yao, J.C.: Existence of solutions for variational inequalities on Riemannian manifolds. Nonlinear Anal. 71, 5695–5706 (2009)
Li, C., Mordukhovich, B.S., Wang, J.H., Yao, J.C.: Weak sharp minima on Riemannian manifolds. SIAM J. Optim. 21, 1523–1560 (2011)
Li, C., Yao, J.C.: Variational inequalities for set-valued vector fields on Riemannian manifolds: convexity of the solution set and the proximal point algorithm. SIAM J. Control Optim. 50, 2486–2514 (2012)
Li, X.B., Zhou, L.W., Huang, N.J.: Gap functions and global error bounds for generalized mixed variational inequalities on Hadamard manifolds. J. Optim. Theory Appl. 168(3), 830–849 (2016)
Rapcsák, T.: Smooth Nonlinear Optimization in \({\mathbb{R}}^{n}\). Kluwer Academic Publishers, Dordrecht (1997)
Ring, W., Wirth, B.: Optimization methods on Riemannian manifolds and their application to shape space. SIAM J. Optim. 22(2), 596–627 (2012)
Udrişte, C.: Convex Functions and Optimization Methods on Riemannian Manifolds. Kluwer Academic Publishers, Dordrecht (1994)
Yang, Y.: Globally convergent optimization algorithms on Riemannian manifolds: uniform framework for unconstrained and constrained optimization. J. Optim. Theory Appl. 132, 245–265 (2007)
Nocedal, J., Wright, S.J.: Numerical Optimization. Springer Series in Operations Research. Springer, New York (1999)
Shi, Z.J., Shen, J.: Convergence of descent method with new line search. J. Appl. Math. Comput. 20, 239–254 (2006)
Armijo, L.: Minimization of functions having Lipschitz continuous first partial derivatives. Pac. J. Math. 16, 1–3 (1966)
Wolfe, P.: Convergence conditions for ascent methods. SIAM Rev. 11, 226–235 (1969)
Shi, Z.J.: Convergence of quasi-Newton method with new inexact line search. J. Math. Anal. Appl. 315, 120–131 (2006)
Smith, S.T.: Optimization techniques on Riemannian manifolds: hamiltonian and gradient flows. Algorithm Control 3, 113–136 (1994)
Absil, P.A., Mahony, R., Sepulchre, R.: Optimization Algorithms on Matrix Manifolds. Princeton University Press, Princeton (2008)
Ferreira, O.P., Svaiter, B.F.: Kantorovich’s theorem on Newton’s method in Riemannian manifolds. J. Complex. 18, 304–329 (2002)
Adler, R.L., Dedieu, J.P., Malajovich, J.Y., Martens, M., Shub, M.: Newton’s method on Riemannian manifolds and a geodesic model for the human spine. IMA J. Numer. Anal. 22, 359–390 (2002)
Dedieu, J.P., Priouret, P., Malajovich, G.: Newton’s method on Riemannian manifolds: covariant alpha theory. IMA J. Numer. Anal. 23, 395–419 (2003)
Li, C., Wang, J.H.: Newton’s method for sections on Riemannian manifolds: generalized covariant \(\alpha \)-theory. J. Complex. 24, 423–451 (2008)
Li, C., Wang, J.H.: Convergence of the Newton method and uniqueness of zeros of vector fields on Riemannian manifolds. Sci. China Math. 48, 1465–1479 (2005)
Brace, I., Manton, J.H.: An improved BFGS-on-manifold algorithm for computing weighted low rank approximations. In: Proceeding of the 17th International Symposium on Mathematical Theory of Networks and Systems, pp. 1735–1738 (2006)
Sakai, T.: Riemannian Geometry, Translations of Mathematical Monographs. American Mathematical Society, Providence (1996)
Shub, M.: Some remarks on dynamical systems and numerical analysis. In: Lara-Carrero, L., Lwowicz, J. (eds.) Dynamical Systems and Partial Differential Equations: Proceedings of VII ELAM Caracas, pp. 69–92. Equinoccio Universidad Simon Bolivar (1986)
Huang, W.: Optimization algorithms on Riemannian manifolds with applications. Ph.D. Thesis, Department of Mathematics, Florida State University, Tallahassee, FL (2013)
Ortega, J.W., Rheinboldt, W.C.: Iterative Solution of Nonlinear Equations in Several Variables. Academic Press, New York (2003)
do Carmo, M.P.: Riemannian Geometry, Mathematics: Theory Applications. Birkhäuser, Boston (1992)
Huang, W., Absil, P.A., Gallivan, K.A.: A Riemanian symmetric rank-one trust-region method. Math. Program. 150, 179–216 (2015)
Acknowledgements
Authors are grateful to the referees for their valuable suggestions and comments to improve this paper. In this paper, the second author was supported by the National Natural Science Foundation of China (11671282), the third author was supported by a research Grant of DST-SERB No. EMR/2016/005124 and the fourth author was partially supported by the Grant MOST 105-2115-M-039-002-MY3.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Sándor Zoltán Németh.
Rights and permissions
About this article

Cite this article
Li, Xb., Huang, Nj., Ansari, Q.H. et al. Convergence Rate of Descent Method with New Inexact Line-Search on Riemannian Manifolds. J Optim Theory Appl 180, 830–854 (2019). https://doi.org/10.1007/s10957-018-1390-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-018-1390-6