
Abstract
In this paper, we present two new relaxed inertial subgradient extragradient methods for solving variational inequality problems in a real Hilbert space. We establish the convergence of the sequence generated by these methods when the cost operator is quasimonotone and Lipschitz continuous, and when it is Lipschitz continuous without any form of monotonicity. The methods combine both the inertial and relaxation techniques in order to achieve high convergence speed, and the techniques used are quite different from the ones in most papers for solving variational inequality problems. Furthermore, we present some experimental results to illustrate the profits gained from the relaxed inertial steps.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Let \({\mathcal {C}}\) be a nonempty closed and convex subset of a real Hilbert space \({\mathcal {H}}\) with inner product \(\langle \cdot ~, \cdot \rangle \), and associated norm \(||\cdot ||\). Let \(A:{\mathcal {H}}\rightarrow {\mathcal {H}}\) be a continuous mapping. The Variational Inequality Problem (VIP) is formulated as:
The VIP is a fundamental problem in optimization and known to have numerous applications in diverse fields (see, for example [16, 17, 19, 20, 24, 26, 27] and the references therein). Its theory provides a simple, natural and unified framework for a general treatment of unrelated problems. The VIP was first considered for the purpose of modeling problems in mechanics by Stampacchia [41] (also independently by Fichera [16]).
One of the simplest methods for solving VIP (1.1) is the following gradient-projection method:
This method converges strongly to a unique solution of the VIP (1.1) if A is \(\eta \)-strongly monotone and L-Lipschitz continuous, with \(\lambda \in \left( 0,\frac{2\eta }{L^2}\right) .\) However, if A is monotone and Lipschitz continuous, the gradient-projection method may fail to converge. For instance, take \(C={\mathbb {R}}^2\) and A to be a rotation with \(\frac{\pi }{2}\) angle. Then, A is monotone and Lipschitz continuous with (0, 0) being the unique solution of (1.1). But the sequence \(\{x_n\}\) generated by (1.2) satisfies \(||x_{n+1}||>||x_n||,~\forall n\). Thus, the gradient-projection method does not always work for monotone and Lipschitz continuous operators.
In [28], Korpelevich proposed a method in finite dimensional spaces which converges to a solution of the VIP (1.1) when the operator is monotone and Lipchitz continuous. This method which is known as the extragradient method is given as:
where \(\lambda _n\in \left( 0,\frac{1}{L}\right) .\) Since the introduction of the extragradient method, many authors have studied it in infinite dimensional spaces when A is monotone (see [5, 9, 19]) and when A is pseudomonotone (see [36, 48]).
However, the major drawback of this method is that it requires two projections onto the feasible set \({\mathcal {C}}\) per iteration, which can be costly if \({\mathcal {C}}\) has complex structure. In this case, \(P_{{\mathcal {C}}}\) may not have a closed form formula, and a minimization problem has to be solved twice per iteration in implementing (1.3). Hence, the efficiency of the method may be affected.
To overcome this setback, Censor et al. [12] introduced the following subgradient extragradient method: \(x_1\in {\mathcal {H}},\)
They proved that \(\{x_n\}\) generated by (1.4) converges weakly to a solution of problem (1.1) when A is monotone and Lipschitz continuous.
Unlike (1.3), Algorithm (1.4) requires only one projection onto \({\mathcal {C}}\) per iteration since the second projection is onto a half space \(T_n\), which has an explicit formula. Hence, subgradient extragradient methods are less computationally expensive than extragradient methods. This method has also been considered by many authors for solving the VIP (1.1) in infinite dimensional spaces, when A is monotone [1, 10, 11, 25, 30] and when A is pseudomonotone [45, 51].
In recent years, algorithms with fast convergence rate have been of great interest. To accelerate the convergence of iterative methods for solving (1.1) and other related optimization problems, there exist different modifications of such iterative methods. In this paper, we consider the two very important modifications, namely; inertial and relaxation techniques. The inertial technique is based upon a discrete analogue of a second order dissipative dynamical system and is known for its efficiency in improving the convergence rate of iterative methods. The method was first considered by Polyak [38] for solving the smooth convex minimization problems. It was later made very popular by Nesterov’s acceleration gradient method [35], and was further developed by Beck and Teboulle in the case of structured convex minimization problem [6]. Since then, many authors have employed the use of inertial techniques for improving the convergence of their iterative methods (see for example [14, 15, 18, 21, 31, 32, 34, 37,38,39,40, 46, 47] and the references therein). On the other hand, the relaxation technique has proven to be an essential ingredient in the resolution of optimization problems due to the improved convergence rate that it contribute to iterative schemes. Moreover, both inertial and relaxation techniques naturally come from an explicit discretization of a dynamical system in time (see, for example [4, 49]).
Some authors have considered incorporating these two techniques into known methods in order to achieve high convergence speed of the resulting methods (see, [3, 4]). Also, in [23], the influence of inertial and relaxation techniques on the numerical performance of iterative schemes was studied.
Given the importance of these two techniques (inertial and relaxation) for solving optimization problems, our aim in this paper is to incorporate the inertial and relaxation techniques into Algorithm (1.4), when A is not necessarily pseudomonotone. That is, we design two new relaxed inertial subgradient extragradient methods, and prove that they converge weakly to a solution of VIP (1.1) when the operator A is quasimonotone and Lipschitz continuous, and when it is Lipschitz continuous without any form of monotonicity. The techniques employed in this paper are quite different from the ones used in most papers (see for example [14, 15, 22, 31, 32, 34, 37,38,39,40, 44, 46, 47]). Moreover, the assumptions on the inertial and relaxation factors in this paper, are weaker than those in many papers for solving VIPs. Finally, we provide some numerical implementations of our methods and compare them with other methods, in order to show the profits gained from the inertial and relaxation techniques.
The rest of the paper is organized as follows: Sect. 2 contains basic definitions and results needed in subsequent sections. In Sect. 3, we present and discuss the proposed methods. The convergence analysis of these methods are investigated in Sect. 4. In Sect. 5, we perform some numerical analysis of our methods in comparison with other methods in the literature. We then conclude in Sect. 6.
2 Preliminaries
In this section, we recall some concepts and results needed in subsequent sections. Henceforth, we denote the weak convergence of \(\{x_n\}\) to a point \(x^*\) by \(x_n\rightharpoonup x^*\).
Let \({\mathcal {H}}\) be a real Hilbert space and \(A:{\mathcal {H}}\rightarrow {\mathcal {H}}\) be a mapping. Then, A is said to be
-
(i)
\(L-\)Lipschitz continuous, if there exists \(L>0\) such that
$$\begin{aligned} \Vert Ax-Ay\Vert \le L\Vert x-y\Vert ,~ \forall x,y\in {\mathcal {H}}, \end{aligned}$$ -
(ii)
L-strongly monotone, if there exists \(L>0\) such that
$$\begin{aligned} \langle Ax-Ay,x-y\rangle \ge L\Vert x-y\Vert ^2,~ \forall x,y \in {\mathcal {H}}, \end{aligned}$$ -
(iii)
Monotone, if
$$\begin{aligned}\big <Ax-Ay,x-y\big >\ge 0,~ \forall x,y \in {\mathcal {H}}, \end{aligned}$$ -
(iv)
Pseudomonotone, if
$$\begin{aligned} \langle Ay, x-y \rangle \ge 0 \implies ~\langle Ax,x-y \rangle \ge 0,~\forall x,y \in {\mathcal {H}}, \end{aligned}$$ -
(v)
Quasimonotone, if
$$\begin{aligned} \langle Ay,x-y\rangle >0 \implies \langle Ax, x-y\rangle \ge 0, ~\forall x,y\in {\mathcal {H}}, \end{aligned}$$ -
(vi)
Sequentially weakly-strongly continuous, if for every sequence \(\{x_n\}\) that converges weakly to a point x, the sequence \(\{Ax_n\}\) converges strongly to Ax,
-
(vii)
Sequentially weakly continuous, if for every sequence \(\{x_n\}\) that converges weakly to a point x, the sequence \(\{Ax_n\}\) converges weakly to Ax.
Clearly, \((ii)\implies (iii)\implies (iv)\implies (v).\) But the converses are not always true.
Let \(VI({\mathcal {C}}, A)\) be the solution set of problem (1.1) and \(\Gamma \) be the solution set of the following problem:
Then, \(\Gamma \) is a closed and convex subset of \({\mathcal {C}}\), and since \({\mathcal {C}}\) is convex and A is continuous, we have the following relation
Lemma 2.1
[50] Let \({\mathcal {C}}\) be a nonempty closed and convex subset of \({\mathcal {H}}\). If either
-
(1)
A is pseudomonotone on \({\mathcal {C}}\) and \(VI({\mathcal {C}},A)\ne \emptyset ,\)
-
(ii)
A is the gradient of G, where G is a differential quasiconvex function on an open set \({\mathcal {K}}\supset {\mathcal {C}}\) and attains its global minimum on \({\mathcal {C}},\)
-
(iii)
A is quasimonotone on \(\mathcal {C,}\, \, A\, \, \ne 0\) on \({\mathcal {C}}\) and \({\mathcal {C}}\) is bounded,
-
(iv)
A is quasimonotone on \({\mathcal {C}},\, \, \)A\(\, \,\ne 0\) on \({\mathcal {C}}\) and there exists a positive number r such that, for every \(x\in {\mathcal {C}}\) with \(\Vert x\Vert \ge r,\) there exists \(y\in {\mathcal {C}}\) such that \(\Vert y\Vert \le r\) and \(\langle Ax,y-x\rangle \le 0,\)
-
(v)
A is quasimonotone on \({\mathcal {C}}, \text {int}\, \, {\mathcal {C}}\) is nonempty and there exists \(x^*\in VI({\mathcal {C}},A)\) such that \(Ax^*\ne 0.\)
Then, \(\Gamma \) is nonempty.
Recall that for a nonempty closed and convex subset \({\mathcal {C}}\) of \({\mathcal {H}}\), the metric projection denoted by \(P_{\mathcal {C}}\) (see [43]), is a map defined on \({\mathcal {H}}\) onto \({\mathcal {C}}\) which assigns to each \(x\in {\mathcal {H}}\), the unique point in \({\mathcal {C}}\), denoted by \(P_{\mathcal {C}} x\) such that
It is well known that \(P_{\mathcal {C}}\) is characterized by the inequality
Following Attouch and Cabot [3, pages 5, 10], we note that if \(x_{n+1}=x_n+\theta _n (x_n-x_{n-1})\), then for all \(n\ge 1\), we have that
which implies that
Thus, \(\{x_n\}\) converges if and only if \(x_1=x_0\) or if \(\sum \limits _{l=1}^{\infty }\prod \limits _{j=1}^l\theta _j <\infty .\)
Therefore, we assume henceforth that
Hence, we can define the sequence \(\{t_i\}\) in \({\mathbb {R}}\) by
with the convention \(\prod \limits _{j=i}^{i-1} \theta _j=1~\forall i\ge 1.\)
Remark 2.2
(See also [3]).
Assumption (2.4) ensures that the sequence \(\{t_i\}\) given by (2.5) is well-defined, and
The following proposition provides a criterion for ensuring assumption (2.4).
Proposition 2.3
[3, Proposition 3.1] Let \(\{\theta _n\}\) be a sequence such that \(\theta _n\in [0,1)\) for every \(n\ge 1.\) Assume that
for some \(c\in [0,1).\) Then,
-
(i)
Assumption (2.4) holds, and \(t_{n+1}\sim \frac{1}{(1-c)(1-\theta _n)} \) as \(n\rightarrow \infty ,\)
-
(ii)
The equivalence \(1-\theta _n \sim 1-\theta _{n+1}\) holds true as \(n\rightarrow \infty .\) Hence, \(t_{n+1}\sim t_{n+2}\) as \( n\rightarrow \infty .\)
Remark 2.4
Using Proposition 2.3, we can see that \(\theta _n=1-\frac{{\bar{\theta }}}{n},\) \({\bar{\theta }}>1\), is a typical example of a sequence satisfying assumption (2.4).
Indeed, we have that
which satisfies the assumption of Proposition 2.3. Hence by Proposition 2.3(i), assumption (2.4) holds.
It is worthy of note that the example \(\theta _n=1-\frac{{\bar{\theta }}}{n},\) \({\bar{\theta }}>1\), falls within the setting of Nesterov’s extrapolation methods. In fact, many practical choices for \(\theta _n\) satisfy assumption (2.4) (for instance, see [3, 6, 13, 35]).
The corresponding finite sum expression for \(\{t_i\}\) is defined for \(i, n\ge 1\), by
In the same manner, we have that \(\{t_{i, n}\}\) is well-defined and
The sequences \(\{t_{i}\}\) and \(\{t_{i, n}\}\) are very crucial to our convergence analysis. In fact, their effect can be seen in the following lemma which also plays a crucial role in establishing our convergence results.
Lemma 2.5
[3, page 42, Lemma B.1] Let \(\{a_n\},\{\theta _n\}\) and \(\{b_n\}\) be sequences of real numbers satisfying
Assume that \(\theta _n\ge 0\) for every \(n\ge 1.\)
-
(a)
For every \(n\ge 1,\) we have
$$\begin{aligned} \sum \limits _{i=1}^{n}a_i\le t_{1,n}a_1+\sum _{i=1}^{n-1}t_{{i+1},n}b_i, \end{aligned}$$where the double sequence \(\{t_{i,n}\}\) is defined by (2.7).
-
(b)
Under (2.4), assume that the sequence \(\{t_i\}\) defined by (2.5) satisfies \(\sum \limits _{i=1}^{\infty }t_{i+1}[b_i]_+<\infty .\) Then, the series \(\sum \limits _{i\ge 1}[a_i]_+\) is convergent, and
$$\begin{aligned} \sum \limits _{i=1}^{\infty }[a_i]_+\le t_1[a_1]_++\sum _{i=1}^{\infty }t_{i+1}[b_i]_+~, \end{aligned}$$where \([t]_+:=\max \{t,0\}\) for any \(t\in {\mathbb {R}}\).
Lemma 2.6
[3, page 7, Lemma 2.1] Let \(\{x_n\}\) be a sequence in \({\mathcal {H}}\) and \(\{\theta _n\}\) be a sequence of real numbers. Given \(z\in {\mathcal {H}}\), define the sequence \(\{\Gamma _n\}\) by \(\Gamma _n:=\frac{1}{2}\Vert x_n-z\Vert ^2.\) Then
where \(w_n=x_n+\theta _n(x_n-x_{n-1})\).
The following lemmas are well-known.
Lemma 2.7
Let \(\{x_n\}\) be any sequence in \({\mathcal {H}}\) such that \(x_n\rightharpoonup x\). Then,
Lemma 2.8
Let \(x,y\in {\mathcal {H}}\). Then,
3 Proposed Methods
In this section, we present our methods and discuss their features. We begin with the following assumptions under which we obtain our convergence results.
Assumption 3.1
Conditions on the inertial and relaxation factors:
Suppose that \(\theta _n\in [0,1)\) and \(\rho _n\in (0, 1]\) for all \(n\ge 1\) such that \(\liminf \limits _{n\rightarrow \infty } \rho _n>0\). Assume that there exists \(\epsilon \in (0,1)\) such that for n large enough,
Assumption 3.2
We further make the following assumptions:
-
(a)
\(\Gamma \ne \emptyset ,\)
-
(b)
A is Lipschitz-continuous on \({\mathcal {H}}\) with constant \(L>0,\)
-
(c)
A is sequentially weakly continuous on \({\mathcal {C}}\),
-
(d)
A is quasimonotone on \({\mathcal {H}},\)
-
(e)
The set \(\{z\in {\mathcal {C}}:Az=0\}\setminus \Gamma \) is a finite set.
We now present the proposed methods of this paper.
When the Lipschitz constant L is known, we present the following method for solving the VIP (1.1).

In situations where the Lipschitz constant L is not known, we present the following method with adaptive stepsize for solving the VIP (1.1).

Remark 3.5
In a special case when \(\rho _n=1,~\forall n\ge 1\), we have that \(x_{n+1}=z_n\). Thus, Algorithms 3.3 and 3.4 reduce to the inertial version of the subgradient extragradient method of Censor et al. [10,11,12]. In such case, we have the following simple criteria which guarantee Assumption 3.1, as well as assumption (2.4).
We give the following remarks on the difference between our proposed Algorithms 3.3 and 3.4 and [29, Algorithm 3.3] below.
Remark 3.6
The method considered in [29, Algorithm 3.3] is a subgradient extragradient method without an inertial extrapolation step and without relation parameter. Our proposed Algorithms 3.3 and 3.4 are combinations of subgradient extragradient method, inertial exttrapolation step and relaxation parameter. It can also be easily seen that [29, Algorithm 3.3] is a special case of our proposed Algorithm 3.4 when \(\theta _n=0\) and \(\rho _n=1\) in Algorithm 3.4. As pointed out in the Introduction, the aim of adding inertial extrapolation step and relaxation parameter to [29, Algorithm 3.3] (as seen in our proposed Algorithms 3.3 and 3.4) is to increase the speed of convergence of [29, Algorithm 3.3] in terms of reduction in the number of required iterations and CPU time. Consequently, we have given the numerical comparisons in terms of number of iterations and CPU time of our proposed Algorithms 3.3, 3.4 and [29, Algorithm 3.3] (kindly see Tables 3, 4, 5 and Figs. 3, 4, 5 in Section 5). This is one of the novelties of this paper.
Proposition 3.7
Assume that \(\{\theta _n\}\) is a nondecreasing sequence that satisfies \(\theta _n\in [0,1)~ \forall n\ge 1\) with \(\lim \limits _{n \rightarrow \infty }\theta _n=\theta \) such that the following condition holds:
Then, Assumptions (2.4) and 3.1 hold.
Proof
Observe that \(\theta _n\le \theta , ~~ \forall n\ge 1.\) Thus, we have that assumption (2.4) is satisfied and \(t_n\le \frac{1}{1-\theta }, ~\forall n\ge 1\) (see [3]). Now, observe that \(1-3\theta >0\) implies that \((1-\theta )>\frac{\theta (1+\theta )}{1-\theta }.\) This further implies that there exists \(\epsilon \in (0,1)\) such that
Since \(\theta _n \le \theta , ~ \forall n\ge 1,\) we obtain from (3.4) that
for some \(\epsilon \in (0,1).\)
Since \(\theta _{n-1}\le \theta _n, ~ \forall n\ge 1,\) we obtain that
Combining this with (3.5), we get that Assumption 3.1 is satisfied. \(\square \)
Proposition 3.8
Suppose that \(\theta _n \in [0,1),~\forall n\ge 1\) and there exists \(c\in [0,\frac{1}{2})\) such that
and
Then, Assumptions (2.4) and 3.1 hold.
Proof
It follows from Proposition 2.3(i) that Assumption (2.4) holds.
Now, from (3.7), we obtain that
Thus, there exists \(\epsilon \in (0,1)\) sufficiently small enough such that
This implies that
which implies that
Now, observe from (3.6) that
which implies from Proposition 2.3(ii) that
This implies that
Combining (3.10) and (3.11), we obtain that
By Proposition 2.3, we have that \(t_{n+1}\sim t_n \sim \frac{1}{(1-c)(1-\theta _{n-1})}\) as \( n\rightarrow \infty .\) Hence, (3.12) is equivalent to
which further implies Assumption 3.1. \(\square \)
When \(\rho _n\ne 1\), then we have the following proposition which provides some criteria for ensuring Assumption 3.1, as well as Assumption (2.4).
Proposition 3.9
(See for example, [3, Proposition 3.3])
Suppose that \(\theta _n \in [0,1)\) and \(\rho _n\in (0, 1)\) for all \(n\ge 1\). Assume that there exist \(c\in [0, 1)\) and \({\bar{c}}\in [c, 1)\) such that
and
where \(\gamma _n=\frac{1-\rho _n}{2\rho _n}\). Then, Assumptions (2.4) and 3.1 hold.
Remark 3.10
It is worthy of note that many practical choices for the inertial and relaxation factors \(\theta _n\) and \(\rho _n\), respectively, satisfy Assumption 3.1. In fact, similar conditions as in Propositions 3.7–3.9 have already been used in the literature to ensure the convergence of inertial and relaxation methods (see [31, 46, 47] and the references therein). Thus, Assumption 3.1, as well as assumption (2.4) are much more weaker than the assumptions in those papers.
Moreover, we shall give in Sect. 5, some typical examples of \(\theta _n\) and \(\rho _n\) which satisfy the conditions in Propositions 3.7–3.9 (therefore, satisfying assumption (2.4) and Assumption 3.1). Then, we check the sensitivity of both \(\theta _n\) and \(\rho _n\) in order to find numerically, the optimum choice of these parameters with respect to the convergence speed of our proposed methods.
4 Convergence Analysis
Lemma 4.1
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.3 such that Assumption 3.2(a)-(b) hold. Then,
where \(\gamma _n:=\frac{1-\rho _n}{2\rho _n}\) and \(\Gamma _n:=\frac{1}{2}\Vert x_n-z\Vert ^2,~\forall z\in \Gamma .\)
Proof
Let \(z\in \Gamma .\) Since \(x_{n+1}-w_n=\rho _n (z_n -w_n),\) we obtain
where the last inequality follows from \(z\in \Gamma \subseteq T_n\) and the characteristic property of \(P_{T_n}\) (see (2.3)).
Now, using (4.1) in Lemma 2.6, we obtain
where the last equality follows from Lemma 2.8.
Since \(y_n\subset {\mathcal {C}}\) and \(z\in \Gamma ,\) we get from (2.1) that \(\langle Ay_n,\, \,y_n-z\rangle \ge 0, \forall n\ge 1.\) That is \(\langle Ay_n,\, \,y_n-z_n+z_n-z\rangle \ge 0, \forall n \ge 1.\) This implies that
Substituting (4.3) into (4.2), we obtain that
where the last inequality follows from the definition of \(T_n\).
Now, from the Lipschitz continuity of A, we obtain
Substituting (4.5) into (4.4), we obtain the desired conclusion. \(\square \)
Lemma 4.2
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.3 such that Assumption (2.4) and Assumption 3.2(a)-(b) hold. Then, the following inequality holds:
where \(t_{i, n}\) is as defined in (2.7).
Proof
By Lemma 2.8, we obtain
Using (4.6) in Lemma 4.1, and noting that \(1-\lambda L> 0\), we obtain
This together with Lemma 2.5(a) imply that
Noting that \(t_{1,n}\le t_1,\) we obtain
Using \(\Gamma _n=\frac{1}{2}\Vert x_n-z\Vert ^2\ge 0,~\forall n\ge 1\) in the above inequality, we obtain the desired conclusion \(\square \)
Lemma 4.3
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.3 such that Assumptions (2.4) and 3.2(a)-(b) hold. Then, the following inequality holds:
Proof
Observe that
where the last inequality follows from \(t_{1,n}\le t_1.\)
Now, using (4.7) in Lemma 4.2, we obtain that
That is
Now, recall from (2.8) that \(t_{i,n}=1+\theta _it_{i+1,n}\) for all \(i\ge 1\) and \(n\ge i+1.\) Hence, we have
This implies that
where the last inequality follows from \(t_{i+1,n}\le t_{i+1}.\)
Now, using (4.9) in (4.8), we obtain that the desired conclusion. \(\square \)
Lemma 4.4
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.3 such that Assumptions (2.4), 3.1 and 3.2(a)-(b) hold. Then,
Proof
Without loss of generality, we may assume that inequality (3.1) holds true for all \(n\ge 1.\) That is,
where \(\gamma _n=\frac{1-\rho _n}{2\rho _n}\), for all \(n\ge 1\).
At this point, we divide our proof into two cases.
Case 1: Suppose that \(\rho _n\in (0, 1),~\forall n\ge 1\). Then, using (4.10) in Lemma 4.3, we obtain
Now, taking limit as \(n\rightarrow \infty \) in (4.11), we obtain that
Again, from (4.10), we obtain that
Using (4.13) in (4.12), we obtain
Case 2: Suppose that \(\rho _n=1,~\forall n\ge 1\). Then, \(x_{n+1}=z_n\) and \(\gamma _n=0,~\forall n\ge 1\).
Setting \(x=w_n-y_n\) and \(y=x_{n+1}-y_n\) in Lemma 2.8, and using its result in Lemma 4.1, we obtain
Now, using (4.6) in (4.14), and repeating the same line of proof as in Lemma 4.2, we get
Similar to (4.7), we have
Also, using (4.16) in (4.15), and repeating the same line of proof as in Lemma 4.3, we get
Using (4.10) in (4.17), and repeating the same line of proof as in Case 1, we obtain
which yields the desired conclusion. \(\square \)
Lemma 4.5
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.3 such that Assumption (2.4), Assumptions 3.1 and 3.2(a)-(b) hold. Then,
-
(a)
\(\lim \limits _{n\rightarrow \infty }\Vert x_n-z\Vert \) exists for all \(z\in \Gamma \), and consequently, \(\{x_n\}\) is bounded.
-
(b)
\(\lim \limits _{n\rightarrow \infty }\left[ \Vert w_n-y_n\Vert ^2+||z_n-y_n||^2\right] =0,\)
-
(c)
\(\lim \limits _{n\rightarrow \infty }\Vert x_n-w_n\Vert =0.\)
Proof
-
(a)
From Lemma 4.1, we obtain
$$\begin{aligned} \Gamma _{n+1}-\Gamma _n&\le \theta _n\Big (\Gamma _n-\Gamma _{n-1}\Big )+\frac{1}{2}\Big (\theta _n+\theta _n^2\Big )\Vert x_n-x_{n-1}\Vert ^2\nonumber \\&\quad -\frac{\rho _n}{2}\left( 1-\lambda L\right) \left[ ||w_n-y_n||^2+||z_n-y_n||^2\right] \nonumber \\&\le \theta _n\Big (\Gamma _n-\Gamma _{n-1}\Big )+\theta _n\Vert x_n-x_{n-1}\Vert ^2\nonumber \\&\quad -\frac{\rho _n}{2}\left( 1-\lambda L\right) \left[ ||w_n-y_n||^2+||z_n-y_n||^2\right] \end{aligned}$$(4.18)$$\begin{aligned}&\le \theta _n\Big (\Gamma _n-\Gamma _{n-1}\Big )+\theta _n\Vert x_n-x_{n-1}\Vert ^2, \end{aligned}$$(4.19)where the second inequality follows from \(\theta _n^2\le \theta _n\) and the third inequality follows from \(1-\lambda L>0\).
Now, applying Lemmas 2.5(b) and 4.4 in (4.19), we obtain that \(\sum \limits _{n=1}^{\infty }\Big [\Gamma _n-\Gamma _{n-1}\Big ]_+<\infty .\) Since \(\Gamma _n=\frac{1}{2}\Vert x_n-z\Vert ^2,\) we get that \(\lim \limits _{n\rightarrow \infty }\Vert x_n-z\Vert ^2\) exists. Hence, \(\{x_n\}\) is bounded.
-
(b)
By applying Lemma 2.5(a) in (4.18), we obtain that
$$\begin{aligned} \Gamma _n-\Gamma _0&=\sum _{i=1}^{n}\big (\Gamma _i-\Gamma _{i-1}\big )\\&\le t_{1,n}\Big (\Gamma _1-\Gamma _0\Big )+\sum _{i=1}^{n-1}t_{i+1,n}\Big [\theta _i\Vert x_i-x_{i-1}\Vert ^2\\&\quad -\frac{\rho _i}{2}\left( 1-\lambda L\right) \left[ ||w_i-y_i||^2+||z_i-y_i||^2\right] \Big ]\\&\le t_1\big (\Gamma _1-\Gamma _0\big )+\sum _{i=1}^{n-1}t_{i+1}\theta _i\Vert x_i-x_{i-1}\Vert ^2-\sum _{i=1}^{n-1}t_{i+1,n}\\&\quad \frac{\rho _i}{2}\left( 1-\lambda L\right) \left[ ||w_i-y_i||^2+||z_i-y_i||^2\right] \Big ], \end{aligned}$$which implies that
$$\begin{aligned}&\sum _{i=1}^{n-1}t_{i+1,n}\frac{\rho _i}{2}\left( 1-\lambda L\right) \left[ ||w_i-y_i||^2+||z_i-y_i||^2\right] \Big ]\\&\quad \le \Gamma _0-\Gamma _n+t_1(\Gamma _1-\Gamma _0)+\sum _{i=1}^{n-1}t_{i+1}\theta _i\Vert x_i-x_{i-1}\Vert ^2\\&\quad \le \Gamma _0+t_1|\Gamma _1-\Gamma _0|+\sum _{i=1}^{n-1}t_{i+1}\theta _i\Vert x_i-x_{i-1}\Vert ^2\\&\quad < \infty , \end{aligned}$$where the last inequality follows from Lemma 4.4.
Since \(t_{i+1,n}=0\) for \(i\ge n,\) letting n tend to \(\infty ,\) the monotone convergence theorem then implies that
$$\begin{aligned} \sum _{i=1}^{\infty }t_{i+1}\frac{\rho _i}{2}\left( 1-\lambda L\right) \left[ ||w_i-y_i||^2+||z_i-y_i||^2\right] \Big ]<\infty . \end{aligned}$$(4.20)Since \(\liminf \limits _{n\rightarrow \infty }\rho _n>0,\) there exists \(M>0\) such that \(\rho _n\ge M\) for n large enough. Now, replacing i with n in (4.20) and noting that \(t_n\ge 1, \forall n\ge 1,\) we obtain from (4.20) that \(\sum \limits _{n=1}^{\infty }\frac{M}{2}\left( 1-\lambda L\right) \left[ ||w_n-y_n||^2+||z_n-y_n||^2\right] <\infty ,\) which further gives that \(\lim \limits _{n\rightarrow \infty }\left[ ||w_n-y_n||^2+||z_n-y_n||^2\right] =0.\)
-
(c)
Since \(w_n=x_n+\theta _n(x_n-x_{n-1}),\) we obtain from Lemma 4.4 that
$$\begin{aligned} \sum _{n=1}^{\infty }t_{n+1}\Vert w_n-x_n\Vert ^2\le \sum _{n=1}^{\infty }\theta _nt_{n+1}\Vert x_n-x_{n-1}\Vert ^2<\infty . \end{aligned}$$Noting that \(t_n\ge 1, \forall n\ge 1,\) we conclude immediately that \(\lim \limits _{n\rightarrow \infty }\Vert w_n-x_n\Vert =0.\)
\(\square \)
Lemma 4.6
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.3 such that Assumption (2.4), Assumptions 3.1 and 3.2(a)-(d) hold. If \(x^*\) is one of the weak cluster points of \(\{x_n\},\) then we have at least one of the following: \(x^*\in \Gamma \) or \(Ax^*=0.\)
Proof
By Lemma 4.5(a), we can choose a subsequence of \(\{x_n\}\) denoted by \(\{x_{n_k}\}\) such that \(x_{n_k}\rightharpoonup x^*\in {\mathcal {H}}.\) Also, from Lemma 4.5(b),(c), we obtain that \(\lim \limits _{n\rightarrow \infty }\Vert y_n-x_n\Vert =0.\) Hence, we can choose a subsequence \(\{y_{n_k}\}\) of \(\{y_n\}\) such that \(y_{n_k}\rightharpoonup x^*.\) Note that \(x^*\in {\mathcal {C}}\) since \(\{y_{n_k}\}\subset {\mathcal {C}}.\)
We now consider two possible cases.
Case 1: Suppose that \(\limsup \limits _{k\rightarrow \infty }\Vert Ay_{n_k}\Vert =0.\) Then,\(\lim \limits _{k\rightarrow \infty }\Vert Ay_{n_k}\Vert =\liminf \limits _{k\rightarrow \infty }\Vert Ay_{n_k}\Vert =0.\) Also, by the sequentially weakly continuity of A on \({\mathcal {C}},\) we obtain that \(Ay_{n_k}\rightharpoonup Ax^*.\) Thus, by the weakly lower semicontinuity of \(\Vert \cdot \Vert ,\) we have that
which implies that \(Ax^*=0.\)
Case 2: Suppose that \(\limsup \limits _{k\rightarrow \infty }\Vert Ay_{n_k}\Vert >0.\) Then, without loss of generality, we can choose a subsequence of \(\{Ay_{n_k}\}\) still denoted by \(\{Ay_{n_k}\}\) such that \(\lim \limits _{k \rightarrow \infty }\Vert Ay_{n_k}\Vert = M>0.\) Also by the characteristics property of \(P_{{\mathcal {C}}},\) we obtain for all \(x\in {\mathcal {C}}\) that
This implies that
Thus, we obtain from Lemma 4.5(b) that
Now, note that
Moreover, since A is Lipschitz continuous on \({\mathcal {H}},\) we obtain from Lemma 4.5(b) that \(\lim \limits _{k\rightarrow \infty }\Vert Aw_{n_k}-Ay_{n_k}\Vert =0.\) Hence, we obtain from Lemmas 4.5(b), (4.23) and (4.24) that
Based on (4.25), we consider two cases under Case 2, as follows:
Case A: Suppose that \(\limsup \limits _{k\rightarrow \infty }\langle Ay_{n_k}, x-y_{n_k}\rangle >0, \forall x\in {\mathcal {C}}.\) Then, we can choose a subsequence of \(\{y_{n_k}\}\) denoted by \(\{y_{n_{k_j}}\}\) such that \(\lim \limits _{j\rightarrow \infty }\langle Ay_{n_{k_j}}, x-y_{n_{k_j}} \rangle >0\). Thus, there exists \(j_0\ge 1\) such that \(\langle Ay_{n_{k_j}},x-y_{n_{k_j}}\rangle >0, \forall j\ge j_0,\) which by the quasimonotonicity of A on \({\mathcal {H}},\) implies \(\langle Ax,x-y_{n_{k_j}}\rangle \ge 0, \forall x\in {\mathcal {C}}, j\ge j_0.\) Thus, letting \(j\rightarrow \infty ,\) we obtain that \(\langle Ax, x-x^*\rangle \ge 0, \forall x\in {\mathcal {C}}.\) Hence, \(x^*\in \Gamma .\)
Case B: Suppose that \(\limsup \limits _{k\rightarrow \infty } \langle Ay_{n_k},x-y_{n_k}\rangle =0, \forall x\in {\mathcal {C}}.\) Then, by (4.25), we obtain that
which implies that
Also, since \(\lim \limits _{k\rightarrow \infty }\Vert Ay_{n_k}\Vert =M>0,\) there exists \(k_0\ge 1\) such that \(\Vert Ay_{n_k}\Vert >\frac{M}{2}, \forall k\ge k_0.\) Therefore, we can set \(q_{n_k}=\frac{Ay_{n_k}}{\Vert Ay_{n_k}\Vert ^2}, \forall k\ge k_0.\) Thus, \(\langle Ay_{n_k}, q_{n_k}\rangle =1, \forall k\ge k_0.\) Hence, by (4.27), we obtain
which by the quasimonotonicity of A on \({\mathcal {H}},\) implies
This further implies that
for some \(M_1>0,\) where the existence of \(M_1\) follows from the boundedness of \(\{x+q_{n_k}\Big [|\langle Ay_{n_k},x-y_{n_k}\rangle |+\frac{1}{k+1}\Big ]-y_{n_k}\}.\) Note from (4.26) that \(\lim \limits _{k \rightarrow \infty }\Big (|\langle Ay_{n_k}, x-y_{n_k}\rangle |+\frac{1}{k+1}\Big )=0.\) Hence, letting \(k\rightarrow \infty \) in (4.28), we get that \(\langle Ax, x-x^*\rangle \ge 0, \forall x\in {\mathcal {C}}.\) Therefore, \(x^*\in \Gamma .\) \(\square \)
Lemma 4.7
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.3 such that Assumption (2.4), Assumption 3.1 and 3.2(a)-(d) hold. Then \(\{x_n\}\) has at most one weak cluster point in \(\Gamma .\)
Proof
Suppose on the contrary that \(\{x_n\}\) has at least two weak cluster points in \(\Gamma .\) Let \(x^*\in \Gamma \) and \({\bar{x}}\in \Gamma \) be any two weak cluster points of \(\{x_n\}\) such that \(x^*\ne {\bar{x}}.\) Also, let \(\{x_{n_j}\}\) be a subsequence of \(\{x_n\}\) such that \(x_{n_j}\rightharpoonup {\bar{x}}, \text {as}\, \,j\rightarrow \infty .\) Then, by Lemmas 4.5(a) and 2.7, we have
which is a contradiction. Therefore, \(\{x_n\}\) has at most one weak cluster point in \(\Gamma .\) \(\square \)
Using similar line of arguments as in [29, Lemma 3.5], we obtain the following weak convergence result.
Theorem 4.8
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.3 such that assumption (2.4), Assumptions 3.1 and 3.2(a)-(e) hold. Then \(\{x_n\}\) converges weakly to an element of \(VI({\mathcal {C}}, A).\)
Proof
By Assumption 3.2(e), \(\{x\in {\mathcal {C}}:Ax=0\}\setminus \Gamma \) is a finite set. Hence, by Lemma 4.6 and Lemma 4.7, we have that \(\{x_n\}\) has finite weak cluster points in \(VI({\mathcal {C}}, A).\) Let \(x^1,x^2,\cdots ,x^m\) be the weak cluster points of \(\{x_n\}\), and let \(\{x^i_{n_k}\}\) be a subsequence of \(\{x_n\}\) such that \(x^i_{n_k}\rightharpoonup x^i,\) as \(k\rightarrow \infty .\) Then, we obtain
Now, for \(j\ne i,\) set \(q=\beta ^{-1}(x^i-x^j),\) where \(\beta =\Vert x^i-x^j\Vert .\) Then,
For sufficiently large k, we obtain from (4.29) and (4.30) that
Hence, there exists \(N_1>N\) (\(N\in {\mathbb {N}}\)) such that
where
Now, from Lemma 4.5(b), we obtain that \(\lim \limits _{n\rightarrow \infty }\Vert z_{n}-w_n\Vert =0.\) Since \(x_{n+1}-w_n=\rho _n(z_n-w_n)\) and \(\{\rho _n\}\) is bounded, we obtain that \(\lim \limits _{n\rightarrow \infty }\Vert x_{n+1}-w_n\Vert =0.\) This together with Lemma 4.5(c), imply that \(\lim \limits _{n\rightarrow \infty }\Vert x_{n+1}-x_n\Vert =0.\) Hence, there exists \(N_2>N_1>N\) such that \(\Vert x_{n+1}-x_n\Vert <\epsilon _0, \forall n\ge N_2.\)
Claim: \(\{x_n\}\) has only one weak cluster point in \(VI({\mathcal {C}},A).\)
Suppose on the contrary that \(\{x_n\}\) has more than one weak cluster points in \(VI({\mathcal {C}}, A).\) Then, there exists \(N_3\ge N_2>N_1>N\) such that \(x_{N_3}\in B^i\) and \(x_{N_3+1}\in B^j,\) where
In particular, we have
Since \(x_{N_3}\in B^i\) and \(x_{N_3+1}\in B^j,\) we obtain that
and
Adding (4.35) and (4.36), and using (4.34), we obtain
which is not possible. Hence, our claim holds. That is, \(\{x_n\}\) has only one weak cluster point in \(VI({\mathcal {C}},A).\) Therefore, we conclude that \(\{x_n\}\) converges weakly to an element of \(VI({\mathcal {C}},A).\) \(\square \)
Remark 4.9
-
(i)
The conclusion of Theorem 4.8 still hold even if \(\lambda \in (0, \frac{1}{L})\) in Algorithm 3.3 is replaced with a variable stepsize \(\lambda _n\) such that \( 0<\inf _{n\ge 1}\lambda _n\le \sup _{n\ge 1} \lambda _n <\frac{1}{L}.\) However, choosing this variable stepsize still requires the knowledge of the Lipschitz constant L.
-
(ii)
When the Lipschitz constant is not known, we refer to Algorithm 3.4, where the choice of \(\lambda _n\) does not depend on its knowledge. Note from the stepsize \(\lambda _n\) in (3.2), that \(\lim \limits _{n\rightarrow \infty }\lambda _n=\lambda \) and \(\lambda \in [\min \{\frac{\mu }{L}, \lambda _1\}, \lambda _1+d]\), where \(d=\sum _{n=1}^\infty d_n\) (see also [29, Lemma 3.1]).
-
(iii)
When \(d_n=0\), then the stepsize \(\lambda _n\) generated by Algorithm 3.4 is similar to that in [52]. We recall that the stepsize in [52] is monotone non-increasing, thus, their methods may depend on the choice of the initial stepsize \(\lambda _1\). However, the stepsize given in (3.2) is non-monotonic and hence, the dependence on the initial stepsize \(\lambda _1\) is reduced.
In the light of the above remark, we analyze the convergence of Algorithm 3.4 in what follows.
Lemma 4.10
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.4 such that Assumption 3.2(a)-(b) hold. Then,
where \(\gamma _n:=\frac{1-\rho _n}{2\rho _n}\) and \(\Gamma _n:=\frac{1}{2}\Vert x_n-z\Vert ^2,~\forall z\in \Gamma .\)
Proof
By following the same line of proof used in obtaining (4.4), we have
If \(\langle Aw_n-Ay_n, z_n-y_n\rangle \le 0\), then we obtain the conclusion of Lemma 4.10 immediately from (4.38).
In the case that \(\langle Aw_n-Ay_n, z_n-y_n\rangle > 0\), we obtain from (3.2) that
Substituting (4.39) into (4.38), we obtain the desired conclusion. \(\square \)
Lemma 4.11
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.3 such that assumption (2.4) and Assumption 3.2(a)-(b) hold. Then, the following inequality holds:
where \(t_{i, n}\) is as defined in (2.7).
Proof
By following the same line of proof used in obtaining (4.6), we have
Also, by Remark 4.9(ii), we obtain that \(\lim _{n\rightarrow \infty } \lambda _n \frac{\mu }{\lambda _{n+1}}=\mu \in (0, 1)\). Thus, there exists \(n_0\ge 1\) such that \(\forall n\ge n_0\), \(0<\lambda _n \frac{\mu }{\lambda _{n+1}}<1\). Hence, we get from Lemmas 4.10 and (4.40) that
The remaining part of the proof is the same as the proof of Lemma 4.2. \(\square \)
In similar manner, we have that Lemmas 4.3 to 4.7 hold for Algorithm 3.4. Thus, we have the following theorem whose proof is the same as the proof of Theorem 4.8.
Theorem 4.12
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.4 such that Assumption (2.4), Assumptions 3.1 and 3.2(a)-(e) hold. Then \(\{x_n\}\) converges weakly to an element of \(VI({\mathcal {C}}, A).\)
Remark 4.13
From our analyses, one can see that Assumption 3.1 is mainly used to guarantee the summation:
obtained in Lemma 4.4. Thus, if we assume that (4.41) directly, then we do not need Assumption 3.1 for the convergence of our methods.
In the case where \(\rho _n=1,~\forall n\ge 1\), our methods correspond to the inertial subgradient extragradient methods. Note that if \(\theta _n \in [0, \theta ]\) for every \(n\ge 1,\) where \(\theta \in [0,1),\) then \(t_n\le \frac{1}{(1-\theta )}~~~\forall n\ge 1.\) Under these settings, (4.41) is guaranteed by the condition
Thus, instead of Assumption 3.1, we may assume directly that \(\theta _n \in [0, \theta ],~ \forall n\ge 1\) and that condition (4.42) holds. Recall that this condition has been used by numerous authors to ensure convergence of inertial methods (see, for example, [2, 15, 31, 32, 34] and the references therein).
Remark 4.14
Note that we did not make use of Assumption 3.2(c)-(e) in the proof of Lemmas 4.1–4.5. Suppose that \({\mathcal {H}}\) is a finite dimensional Hilbert space, then under Assumption 3.2(a)-(b), we get from Lemma 4.5(a) that there exists a subsequence \(\{x_{n_k}\}\) of \(\{x_n\}\) such that \(\{x_{n_k}\}\) converges to some point \(x^*\). By Lemma 4.5(b)(c), we get
and
Thus, by the definition of \(y_n\) and the continuity of A, we have
which implies that \(x^*\in VI({\mathcal {C}}, A)\).
Now, replacing z by \(x^*\) in Lemma 4.5(a), we obtain that \(\lim \limits _{n\rightarrow \infty }\Vert x_{n}-x^*\Vert ^{2}\) exists. Since \(x^*\) is a cluster point of \(\{x_n\}\), we obtain that \(\{x_n\}\) converges to \(x^*\).
In summary, in a finite dimensional Hilbert space, our methods require that \(\Gamma \ne \emptyset \) and the operator A only needs to be Lipschitz continuous without any form of monotonicity.
To achieve this (convergence without any form of monotonicity) in infinite dimensional Hilbert space, we replace Assumption 3.2(d)-(e) with the following:
-
(d)*
If \(x_n\rightharpoonup x^*\) and \(\limsup \limits _{n\rightarrow \infty }\langle Ax_n, x_n\rangle \le \langle Ax^*, {\bar{x}}\rangle \), then \(\lim \limits _{n\rightarrow \infty }\langle A x_n, x_n\rangle =\langle A x^*, x^*\rangle \).
-
(e)*
The set \(VI({\mathcal {C}}, A)\setminus \Gamma \) is a finite set.
In fact, we have the following theorem.
Theorem 4.15
Let \(\{x_n\}\) be a sequence generated by Algorithm 3.3 (or Algorithm 3.4) such that Assumptions (2.4), 3.1 and 3.2(a)-(c) and conditions (d)*-(e)* hold. Then \(\{x_n\}\) converges weakly to an element of \(VI({\mathcal {C}}, A).\)
Proof
First notice that Assumption 3.2(d) was used only after (4.25) in order to establish the conclusion of Lemma 4.6.
But from (4.25), we have that
Now, let \(\{c_k\}\) be a sequence of positive numbers such that \(\lim \limits _{k\rightarrow \infty } c_k=0\) and \(\langle Ay_{n_k}, x-y_{n_k}\rangle +c_k> 0,~\forall k\ge 0, x\in {\mathcal {C}}.\) Then,
Note that \(y_{n_k}\rightharpoonup x^*\) and \(x^*\in {\mathcal {C}}\). Thus, we have in particular,
Taking limit as \(k\rightarrow \infty \) in (4.44), and using the sequentially weakly continuity of A, we obtain that
which by condition (d)* and (4.43) implies that
This further implies that \(x^*\in VI({\mathcal {C}}, A)\).
Now, using condition (e)* and following similar line of proof as in Lemma 4.7 and Theorem 4.15, we get that \(\{x_n\}\) converges weakly to \(x^*\). \(\square \)
Remark 4.16
-
(i)
If \(x_n\rightharpoonup x^*\) and A is sequentially weakly-strongly continuous, then A satisfies condition (d)*.
-
(ii)
In the numerical experiments, we do not need to consider condition (e) (or (e)*). First note that whenever \(||y_n-w_n||<\epsilon \), Algorithms 3.3 and 3.4 terminate in a finite step of the iterations (and \(y_n\) is the solution of the VIP (1.1)). But from Lemma 4.5(b), \(\lim \limits _{n\rightarrow \infty }||y_n-w_n||=0\) and condition (e) (or (e)*) was not used in establishing it.
We now give some remarks regarding the contributions and novelties of this paper.
Remark 4.17
-
(1)
If we set the inertial factor \(\theta _n=0\) and relaxation factor \(\rho _n=1\), then our Algorithm 3.4 reduces to [29, Algorithm 3.3]. Note that these parameters (factors) play vital role in improving the convergence rate of iterative methods. In fact, their influence with regards to the numerical performance of iterative schemes was discussed in [23]. Moreover, the benefits gained from incorporating the steps of these two parameters in our algorithms, are further verified in Sect. 5. Thus, bearing in mind the importance of these two parameters in iterative algorithms, we can see that our methods significantly improve the methods in [29].
-
(2)
In the study of inertial methods for solving VIPs (even for monotone mappings), the inertia parameter is usually restricted in \([0, \frac{1}{3})\) and/or required to be nondecreasing with an upper bound (see, for example, [2, 31, 46, 47]). In many cases, to ensure convergence, authors usually require the inertial parameter to depend on the knowledge of the Lipschitz constant of the cost operator which sometimes is very difficult to estimate in practice (see, for instance, [8]). Another condition usually imposed on the inertial parameter in the literature, is condition (4.42), which rely on the sequence \(\{x_n\}\). One of the novelties of this paper is that we derived a general condition (Assumption 3.1) which is weaker than the above conditions used in the literature for ensuring the convergence of inertial methods for VIPs. As a result, we developed a different technique to ensure the convergence of our proposed Algorithms 3.3 and 3.4.
-
(3)
In addition to (2) above, bearing in mind the Nestrov’s accelerated scheme ( [35]), another novelty of this paper, is that the assumptions on the inertial and relaxation parameters in Algorithms 3.3 and 3.4 allow the case where inertial factor \(\theta _n\) converges to the limit very close to 1 (see Remark 2.4 and the choices in Experiment 1 of Sect. 5), which is very crucial in the study of inertial methods. This is actually where the relaxation effect and the parameter \(\rho _n\) come into play, as crucial ingredients of our methods. Thus, the novelty of this paper is not only in improving the convergence speed of the methods in [29] but to also provide weaker conditions on the inertial parameter in methods for solving VIPs and offer a different but unified technique in proving their convergence. Furthermore, we employed condition (Assumption 3.1) where joint adjustments of the inertial and relaxation parameters play crucial role (for instance, see Experiment 1). Indeed, this is a new perspective in the study of inertial methods for VIPs. Moreover, our study offers many possibilities for future research in this direction; like how to modify Assumption 3.1 so that inertial factor \(\theta _n\) is allowed to converge to 1.
-
(4)
The method of proof of our proposed Algorithms 3.3 and 3.4 is different from the method of proof of [29, Algorithm 3.3]. For example, we use different arguments to show that the sequence \(\{x_n\}\) is bounded in Lemma 4.5 (different from the arguments used in [29, Lemma 3.2]). We also use different arguments in Lemmas 4.1, 4.2, 4.3, and 4.4.
5 Numerical Experiments
In this section, we give some numerical examples to show the implementation of our proposed methods (Algorithms 3.3 and 3.4). We also compare our new methods with Algorithms 3.1 and 3.3 in [29], and Algorithm 2.1 in [50].
The codes are written in Matlab 2016 (b) and performed on a personal computer with an Intel(R) Core(TM) i5-2600 CPU at 2.30GHz and 8.00 Gb-RAM. In Tables 1, 2, 3, 4, 5, “Iter.” means the number of iterations while “CPU” means the CPU time in seconds.
In our computations, we define \(\hbox {TOL}_n:=||y_n-w_n||\) for Algorithms 3.3 and 3.3. While for Algorithms 3.1 and 3.3 in [29], we define \(\hbox {TOL}_n:=\Vert y_n-x_n\Vert /\hbox {min}\{\lambda _n,1\}\) and for Algorithm 2.1 in [50], we define \(\hbox {TOL}_n:=\Vert x_n-z_n\Vert =\Vert x_n-P_{\mathcal {C}}(x_n-Ax_n)\Vert \) (as done in [29] and [50], respectively). Then, we use the stopping criterion \(\hbox {TOL}_n<\varepsilon \) for the iterative processes, where \(\varepsilon \) is the predetermined error. These choices of stopping criterion for these methods are the best to be able to terminate the algorithms based on the examples we consider. As done in [29], we take \(\varepsilon =10^{-6}\) for all Algorithms.
We choose \(\mu =0.5,~ d_n=\frac{100}{(n+1)^{1.1}}\) and \(\lambda _1=1\) for Algorithm 3.4 and Algorithms 3.1 and 3.3 in [29]; \(\lambda =\frac{1}{2L}\) for Algorithm 3.3; \(\gamma =0.4\) and \(\sigma =0.99\) for Algorithm 2.1 in [50]. These choices are the same as in [29, 50] and are optimal values for these parameters.
Example 5.1
Let \({\mathcal {C}}=[-1,1]\) and
Then, A is quasimonotone and 2-Lipschitz continuous. Also, \(\Gamma =\{-1\}\) and \(VI({\mathcal {C}},A)=\{-1,0\}.\)
Example 5.2
Let \({\mathcal {C}}=\{x\in {\mathbb {R}}^2:x_1^2+x_2^2\le 1,\, \, 0\le x_1\}\) and \(A(x_1,x_2)=(-x_1e^{x_2},x_2).\) Then, A may not be quasimonotone. We can also check that \((1,0)\in \Gamma \) and \(VI({\mathcal {C}},A)=\{(1,0),(0,0)\}\) (see [29, Section 4]), which by Remark 4.14 satisfy our assumptions. This example was also tested in [29].
Example 5.3
We next consider the following problem which was also considered in [29, 33, 42].
Let \({\mathcal {C}}=[0,1]^m\) and \(Ax=(f_1x,f_2x,\cdots ,f_mx),\)
where \(f_ix=x_{i-1}^2+x_i^2+x_{i-1}x_i+x_ix_{i+1}-2x_{i-1}+4x_i+x_{i+1}-1,\, \,i=1,2,\cdots ,m,\)
\(x_0=x_{m+1}=0.\)
We test these examples under the following experiments.
Experiment 1
In this first experiment, we check the behavior of our methods by fixing the inertial parameter and varying the relaxation parameter. We do this in order to check the effects of the relaxation parameter on our methods.
For Example 1: We take \(\theta _n=\frac{3n+1}{10n+5}\) with \(\rho _n=1\) (which by Proposition 3.7, satisfies Assumptions (2.4) and 3.1), and \(\theta _n=\frac{19}{20}-\frac{1}{(n+1)^\frac{1}{2}}\) with \(\rho _n\in \{\frac{1}{20}+\frac{1}{(n+1)^2},~\frac{1}{20}+\frac{2}{(n+1)^3}, ~\frac{1}{20}+\frac{3}{(n+1)^4},\frac{1}{20}+\frac{5}{(n+1)^4}\}\) (which also satisfies Assumptions (2.4) and 3.1 by Proposition 3.9).
Also, we take \(x_1=1\) and \(x_0=0.5\) for this example. Since the Lipshitz constant is known for this example, we use Algorithms 3.3 and 3.4 for the experiment and obtain the numerical results listed in Table 1 and Fig. 1. From the table and graph, we can see that \(\rho _n=1\) performs better than other choices made for Algorithms 3.3 and 3.4.
For Example 2 and Example 3: We take \(\theta _n=\frac{9.9}{10}-\frac{1}{n+1}\) with \(\rho _n=1\) (which by Proposition 3.8 (see also Remark 2.4), satisfies Assumption (2.4) and 3.1), and \(\theta _n=\frac{9}{10}-\frac{1}{(n+1)^\frac{1}{3}}\) with \(\rho _n\in \{\frac{1}{10}+\frac{1}{n+1},~\frac{1}{11}+\frac{1}{n+1}, ~\frac{1}{12}+\frac{1}{n+1},\frac{1}{13}+\frac{1}{n+1}\}\). Also, we take \(x_1=(0.1, 0.5)\) and \(x_0=(0.2, 0.1)\) for Example 2 while for Example 3, we choose \(x_1\) and \(x_0\) randomly with \(m=50\). For these examples, we use Algorithm 3.4 for the experiment and obtain the numerical results listed in Table 2 and Fig. 2. From the table and graph, we can see that the \(\rho _n=\frac{1}{11}+\frac{1}{n+1}\) performs better than other choices made for Example 2 while \(\rho _n=\frac{1}{10}+\frac{1}{n+1}\) performs better for Example 3, which validates the benefits sometimes brought by the relaxation parameter.
Experiment 2
In this experiment, we compare our methods with Algorithms 3.1 and 3.3 in [29], and Algorithm 2.1 in [50]. Here, we randomly choose the \(\theta _n\) and \(\rho _n\) from Experiment 1, and then, consider the following cases for the starting points in each example.
For Example 1: Case I: \(x_1=0.2\), \(x_0=0.1\) and Case II: \(x_1=0.6\), \(x_0=0.2\).
For Example 2: Case I: \(x_1=(1, 0.5)\), \(x_0=(0.2, 0.1)\) and Case II: \(x_1=(0.1, 0.2)\), \(x_0=(0.3, 0.5)\).
For Example 3: Case I: \(m=100\) and Case II: \(m=150\) (\(x_1\) and \(x_0\) are randomly taken).
We use Algorithms 3.1 and 3.4 for the comparison in Example 1 while we use only Algorithm 3.4 for the comparison in Example 2 and Example 3. The numerical results are given in Tables 3, 4, 5 and Figs. 3, 4, 5. The results show that our methods perform better than Algorithms 3.1 and 3.3 in [29], and Algorithm 2.1 in [50].


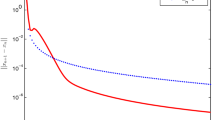
The behavior of Algorithm 3.4 for Examples 2 and 3 (Experiment 1)

The behavior of \(\hbox {TOL}_n\) for Example 1 (Experiment 2): Left: Case I; Right: Case II

The behavior of \(\hbox {TOL}_n\) for Example 2 (Experiment 2): Left: Case I; Right: Case II

The behavior of \(\hbox {TOL}_n\) for Example 3 (Experiment 2): Left: Case I; Right: Case II
Remark 5.4
From Tables 3, 4, 5 and Figs. 3, 4, 5, one can see that our proposed Algorithms 3.3 and 3.4 are more efficient than [29, Algorithm 3.3] and outperform [29, Algorithm 3.3] in terms of number of iterations and CPU time based on our test problems due to the presence of inertial extrapolation step in Algorithms 3.3 and 3.4.
6 Conclusion
We propose and study two new subgradient extragradient methods with relaxed inertial steps for solving the variational inequality problems in real Hilbert spaces when the cost operator is not necessarily pseudomonotone. The first method is proposed when the Lipschitz constant of the cost operator is known while the second method which involves adaptive stepsize strategy, is proposed when the Lipschitz constant of the operator is not available. The techniques employed in this paper are quite different from the ones used in most papers, and the assumptions on the inertial and relaxation factors, are weaker than those in many papers for solving variational inequality problems. The benefits brought from the relaxation are further verified in Experiment 1, and as seen in Experiment 2, our methods performs better when compared with other methods for solving the non-pseudomonotone variational inequality problems.
References
Alakoya, T.O., Jolaoso, L.O., Mewomo, O.T.: Modified inertia subgradient extragradient method with self adaptive stepsize for solving monotone variational inequality and fixed point problems. Optimization (2020). https://doi.org/10.1080/02331934.2020.1723586
Alvarez, F., Attouch, H.: An inertial proximal method for maximal monotone operators via discretization of a nonlinear oscillator with damping. Set-Valued Anal. 9, 3–11 (2001)
Attouch, H., Cabot, A.: Convergence of a relaxed inertial proximal algorithm for maximally monotone operators. Math. Program. (2019). https://doi.org/10.1007/s10107-019-01412-0
Attouch, H., Cabot, A.: Convergence of a relaxed inertial forward-backward algorithm for structured monotone inclusions. Appl. Math. Optim. 80(3), 547–598 (2019)
Apostol, R.Y., Grynenko, A.A., Semenov, V.V.: Iterative algorithms for monotone bilevel variational inequalities. J. Comput. Appl Math. 107, 3–14 (2012)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2(1), 183–202 (2009)
Bot, R.I., Csetnek, E.R., Hendrich, C.: Inertial Douglas–Rachford splitting for monotone inclusion. Appl. Math. Comput. 256, 472–487 (2015)
Dong, Q.L., Lu, Y.Y., Yang, J.: The extragradient algorithm with inertial effects for solving the variational inequality. Optimization 65, 2217–2226 (2016)
Ceng, L.C., Hadjisavvas, N., Wong, N.-C.: Strong convergence theorem by a hybrid extragradient-like approximation method for variational inequalities and fixed point problems. J. Glob. Optim. 46, 635–646 (2010)
Censor, Y., Gibali, A., Reich, S.: The subgradient extragradient method for solving variational inequalities in Hilbert space. J. Optim. Theory Appl. 148, 318–335 (2011)
Censor, Y., Gibali, A., Reich, S.: Strong convergence of subgradient extragradient methods for the variational inequality problem in Hilbert space. Optim. Meth Softw. 26, 827–845 (2011)
Censor, Y., Gibali, A., Reich, S.: Extensions of Korpelevich’s extragradient method for the variational inequality problem in Euclidean space. Optimization 61, 1119–1132 (2011)
Chambolle, A., Dossal, Ch.: On the convergence of the iterates of the fast iterative shrinkage/thresholding algorithm. J. Optim. Theory Appl. 166, 968–982 (2015)
Cholamjiak, W., Cholamjiak, P., Suantai, S.: An inertial forward-backward splitting method for solving inclusion problems in Hilbert spaces. J. Fixed Point Theory Appl. (2018). https://doi.org/10.1007/s11784-018-0526-5
Chuang, C.S.: Hybrid inertial proximal algorithm for the split variational inclusion problem in Hilbert spaces with applications. Optimization 66(5), 777–792 (2017)
Fichera, G.: Sul pproblem elastostatico di signorini con ambigue condizioni al contorno. Atti Accad. Naz. Lincei Rend. Cl. Sci. Fis. Mat. Natur. 34 (1963), 138-142
Gibali, A., Jolaoso, L.O., Mewomo, O.T., Taiwo, A.: Fast and simple Bregman projection methods for solving variational inequalities and related problems in Banach spaces. Results Math., 75 (2020), Art. No. 179, 36 pp
Godwin, E.C., Izuchukwu, C., Mewomo, O.T.: An inertial extrapolation method for solving generalized split feasibility problems in real Hilbert spaces. Boll. Unione Mat. Ital. (2020). https://doi.org/10.1007/s40574-020-00
He, B.-S., Yang, Z.-H., Yuan, X.-M.: An approximate proximal-extragradient type method for monotone variational inequalities. J. Math. Anal. Appl. 300, 362–374 (2004)
Izuchukwu, C., Mebawondu, A.A., Mewomo, O.T.: A new method for solving split variational inequality problems without co-coerciveness. J. Fixed Point Theory Appl.,22 (4), (2020), Art. No. 98, 23 pp
Izuchukwu, C., Ogwo, G.N., Mewomo, O.T.: An inertial method for solving generalized split feasibility problems over the solution set of monotone variational inclusions. Optimization (2020). https://doi.org/10.1080/02331934.2020.1808648
Izuchukwu, C., Okeke, C.C., Mewomo, O.T.: Systems of Variational Inequalities and multiple-set split equality fixed point problems for countable families of multivalued type-one demicontractive-type mappings. Ukraïn. Mat. Zh. 71(11), 1480–1501 (2019)
Iutzeler, F., Hendrickx, J.M.: A generic online acceleration scheme for optimization algorithms via relaxation and inertia. Optim. Methods Softw. 34(2), 383–405 (2019)
Jolaoso, L.O., Taiwo, A., Alakoya, T.O., Mewomo, O.T.: Strong convergence theorem for solving pseudo-monotone variational inequality problem using projection method in a reflexive Banach space. J. Optim. Theory Appl. 185(3), 744–766 (2020)
Khan, S.H., Alakoya, T.O., Mewomo, O.T.: Relaxed projection methods with self-adaptive step size for solving variational inequality and fixed point problems for an infinite family of multivalued relatively nonexpansive mappings in Banach Spaces. Math. Comput. Appl.,25 (2020), Art. 54, 25 pp
Khobotov, E.N.: Modification of the extragradient method for solving variational inequalities and certain optimization problems. USSR Comput. Math. Math. Phys. 27, 120–127 (1989)
Kinderlehrer, D., Stampacchia, G.: An introduction to variational inequalities and their applications. Academic Press, New York (1980)
Korpelevich, G.M.: An extragradient method for finding sadlle points and for other problems. Ekon. Mat. Metody 12, 747–756 (1976)
Liu anad, H., Yang, J.: Weak convergence of iterative methods for solving quasimonotone variational inequalities. Comput. Optim. Appl., 77 (2), (2020) 491-508
Kraikaew, R., Saejung, S.: Strong convergence of the Halpern subgradient extragradient method for solving variational inequalities in Hilbert spaces. J. Optim. Theory Appl. 163(2), 399–412 (2014)
Lorenz, D.A., Pock, T.: An inertial forward-backward algorithm for monotone inclusions. J. Math. Imaging Vis. 51, 311–325 (2015)
Mainge, P.E.: Convergence theorems for inertial KM-type algorithms. J. Comput. Appl. Math. 219(1), 223–236 (2008)
Malitsky, Y.: Projected reflected gradient methods for monotone variational inequalities. SIAM J. Optim. 25(1), 502–520 (2015)
Moudafi, A., Oliny, M.: Convergence of a splitting inertial proximal method for monotone operators. J. Comput. Appl. Math. 155, 447–454 (2003)
Nesterov, Y.: A method of solving a convex programming problem with convergence rate O(\(1/k^2\)). Soviet Math. Doklady 27, 372–376 (1983)
Noor, M.: Extragradient Methods for pseudomonotone variational inequalities. J. Optim. Theory Appl. 117, 475–488 (2003)
Ochs, P., Brox, T., Pock, T.: iPiasco: inertial proximal algorithm for strongly convex optimization. J. Math. Imaging Vis 53, 171–181 (2015)
Polyak, B.T.: Some methods of speeding up the convergence of iterates methods. U.S.S.R Comput. Math. Phys.,4 (5) (1964), 1-17
Shehu, Y., Li, X.H., Dong, Q.L.: An efficient projection-type method for monotone variational inequalities in Hilbert spaces. Numer. Algorithms 84, 365–388 (2020)
Shehu, Y., Vuong, P.T., Zemkoho, A.: An inertial extrapolation method for convex simple bilevel optimization. Optim Methods. Softw. (2019). https://doi.org/10.1080/10556788.2019.1619729
Stampacchia, G.: Variational inequalities. In: Theory and Applications of Monotone Operators,Proceedings of the NATO Advanced Study Institute, Venice, Italy (Edizioni Odersi, Gubbio, Italy, 1968), 102–192
Sun, D.: A new step-size skill for solving a class of nonlinear projection equations. J. Comput. Math. 13, 357–368 (1995)
Taiwo, A., Alakoya, T.O., Mewomo, O.T.: Halpern-type iterative process for solving split common fixed point and monotone variational inclusion problem between Banach spaces. Numer. Algorithms (2020). https://doi.org/10.1007/s11075-020-00937-2
Taiwo, A., Owolabi, A.O.-E., Jolaoso, L.O., Mewomo, O.T., Gibali, A.: A new approximation scheme for solving various split inverse problems. Afr. Mat. (2020). https://doi.org/10.1007/s13370-020-00832-y
Thong, D.V., Hieu, D.V.: A strong convergence of modified subgradient extragradient method for solving bilevel pseudomonotone variational inequality problems. Optimization 69, 1313–1334 (2019)
Thong, D.V., Hieu, D.V.: Inertial subgradient extragradient algorithms with line-search process for solving variational inequality problems and fixed point problems. Numer. Algorithms 80, 1283–1307 (2019)
Thong, D.V., Hieu, D.V.: An inertial method for solving split common fixed point problems. J. Fixed Point Theory Appl. 19(4), 3029–3051 (2017)
Vuong, P.T.: On the weak convergence of the extragradient method for solving pseudomonotone variational inequalities. J. Optim. Theory Appl. 176, 399–409 (2018)
Xia, Y., Wang, J.: A general methodology for designing globally convergent optimization neural networks. IEEE Trans. Neural Netw. 9(6), 1331–1343 (1998)
Ye, M., He, Y.: A double projection method for solving variational inequalities without monotonicity. Comput. Optim. Appl. 60(1), 141–150 (2015)
Yang, J.: Self-adaptive inertial subgradient extragradient algorithm for solving pseudomonotone variational inequalities. Appl. Anal. (2019). https://doi.org/10.1080/00036811.2019.1634257
Yang, J., Liu, H., Zexian, L.: Modified subgradient extragradient algorithms for solving monotone variational inequalities. Optimization 67, 2247–2258 (2018)
Acknowledgements
The authors are grateful to the anonymous referees and the handling Editor for their insightful comments which have improved the earlier version of the manuscript greatly. The first author acknowledges with thanks the scholarship and financial support from the University of KwaZulu-Natal (UKZN) Doctoral Scholarship. The research of the second author is wholly supported by the National Research Foundation (NRF) South Africa (S& F-DSI/NRF Free Standing Postdoctoral Fellowship; Grant Number: 120784). The second author also acknowledges the financial support from DSI/NRF, South Africa Center of Excellence in Mathematical and Statistical Sciences (CoE-MaSS) Postdoctoral Fellowship. The fourth author is supported by the National Research Foundation (NRF) of South Africa Incentive Funding for Rated Researchers (Grant Number 119903). Opinions expressed and conclusions arrived are those of the authors and are not necessarily to be attributed to the CoE-MaSS and NRF. This paper is dedicated to the loving memory of late Professor Charles Ejike Chidume (1947–2021).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Declaration
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ogwo, G.N., Izuchukwu, C., Shehu, Y. et al. Convergence of Relaxed Inertial Subgradient Extragradient Methods for Quasimonotone Variational Inequality Problems. J Sci Comput 90, 10 (2022). https://doi.org/10.1007/s10915-021-01670-1
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-021-01670-1
Keywords
- Variational inequality problems
- Quasimonotone
- Relaxation technique
- relaxed inertial
- Subgradient extragradient method
- Extragradient method