
Abstract
In this paper, we develop an interactive algorithm to support a decision maker to find a most preferred lightly robust efficient solution when solving uncertain multiobjective optimization problems. It extends the interactive NIMBUS method. The main idea underlying the designed algorithm, called LR-NIMBUS, is to ask the decision maker for a most acceptable (typical) scenario, find an efficient solution for this scenario satisfying the decision maker, and then apply the derived efficient solution to generate a lightly robust efficient solution. The preferences of the decision maker are incorporated through classifying the objective functions. A lightly robust efficient solution is generated by solving an augmented weighted achievement scalarizing function. We establish the tractability of the algorithm for important classes of objective functions and uncertainty sets. As an illustrative example, we model and solve a robust optimization problem in stock investment (portfolio selection).
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
There are many real-world optimization problems in which we need to maximize/minimize more than one objective function, simultaneously. Usually these objective functions are in conflict. This kind of problems are called Multiobjective Optimization Problems (MOPs). One cannot define the optimal solution (in the classic sense) for them, because of the conflict of the objective functions. Various solution concepts for MOPs have been introduced and different approaches for solving them have been provided [21, 36]. Optimality can be defined with the concept of efficiency. Efficient solutions are feasible points in which improvement of some objective function without deterioration of at least one other objective function is impossible [12, 27].
Solving MOPs usually requires the participation of a Decision Maker (DM) who is supposed to have insight into the problem and can express preference relations between alternative solutions and/or objective functions [27, 31]. The methods addressed in the literature for solving MOPs can be divided into four classes according to the role of the DM in the solution process [21, 27]. If the DM is not involved, the procedure is called a no-preference one [40, 42, 43]. If the DM expresses preference information after (resp. before) the solution process, we have a posteriori (resp. a priori) methods [15, 23, 38, 43]. The most extensive and practical class of algorithms is that of interactive methods, in which the DM specifies preference information progressively during the solution process.
A general interactive method works as an iterative procedure starting from an initial solution given by the solver. This solution is presented to the DM. If (s)he is satisfied with (the objective values at) the solution, it is considered as the best (most preferred) solution and the procedure is terminated. Otherwise, the DM expresses her/his preferences. Then the solver finds a solution or few solutions taking the preferences into account, and presents it or them to the DM. Again, if the DM is satisfied with the solution, then the procedure stops and the current solution is the final (most preferred) one. Otherwise, the process is repeated, following a similar manner, until satisfying the DM.
In addition to the interactive tools, other important issues in our work are uncertainty and robustness. There are many real-world optimization problems involving uncertainty in which the optimal/efficient solution depends on different possible realizations of parameters, called scenarios. These scenarios are the elements of a deterministic set, called uncertainty set [4, 6, 17]. The set of optimal/efficient solutions may change when the scenario changes. For example, in transportation problem, the optimal path may change when the fuel price changes. As another example, efficient agricultural activities may depend on the climate (weather) situation. There are several ways for dealing with uncertainty in the literature, including robust optimization, sensitivity analysis, and stochastic programming; see, e.g., [4, 6, 19, 22]. In the present work, we assume uncertainty in the objective functions, and concentrate on the robustness. We assume no distributions on uncertainty are available.
Various robust solution notions have been introduced in the literature, including set-based minmax robust efficient solution [13], highly robust efficient solution [24], flimsily robust efficient solution [24], and lightly robust efficient solution [22]. Each of these concepts has its strengths and weaknesses, however there are some interesting connections between them [22]. In the present study, assuming uncertainty in the objective functions, we work with lightly robust efficient solutions. These solutions have been introduced by Fischetti and Monaci [16] for the single-objective case, and then have been extended to multiobjective problems by Ide and Schöbel [22].
In the current paper, we sketch an interactive method which is able to find a lightly robust efficient solution of an uncertain multiobjective optimization problem satisfying the DM. This method, which is called LR-NIMBUS, is built by extending the NIMBUS method (developed for deterministic problems) [20, 27, 28, 35], especially particular versions of this method, called synchronous NIMBUS [28] and MuRO-NIMBUS [45]. The MuRO-NIMBUS method, developed by Zhou-Kangas, Miettinen and Sindhya [45], works utilizing an achievement scalarizing function, and generates a set-based minmax robust efficient solution incorporating the DM’s preferences. Minmax robust efficient solutions, which are obtained by optimizing the objective functions in the worst case over all scenarios, could be highly conservative [6, 7]. Due to the conservatism of minmax robustness, the objective function at a minmax robust efficient solution may not be that good in other scenarios. Furthermore, minmax robust efficient solutions are not always easy to compute [44].
Our method, called LR-NIMBUS, supports the DM by finding a most preferred lightly robust efficient solution. A lightly robust efficient solution is produced by using a tolerance parameter which controls the closeness of the value of the objective function at the generated robust efficient solution to the objective function values in the nominal scenario [16, 22]. Indeed, light robust efficiency leads to a robust efficient solution with tolerable degradation in the objective function values in the nominal scenario; see [16, 22, 44]. On the other hand, in LR-NIMBUS, the DM takes part in the whole method and her/his preferences are applied from beginning, while MuRO-NIMBUS performs two stages, the pre-decision making and the decision making, and the DM intervenes only in the second stage.
The main idea underlying LR-NIMBUS, as an extension of the NIMBUS method, is to ask the DM for most acceptable (typical) scenario, called nominal scenario. Then the procedure finds an efficient solution for the nominal scenario, satisfying the DM. The mentioned efficient solution is applied to generate a lightly robust efficient solution, taking the DM’s preferences into account. If the DM is satisfied with the generated lightly robust efficient solution, then the procedure is terminated; otherwise (s)he provides new preferences through classifying the objective functions. A new lightly robust efficient solution, w.r.t. the new preferences, is generated and the algorithm iterated following a similar manner. In LR-NIMBUS, lightly robust efficient solutions are computed invoking an augmented weighted achievement scalarizing function which involves a reference point and a classification of the objective functions specified by the DM.
In addition to designing and analyzing the LR-NIMBUS algorithm and highlighting the above-mentioned general issues, we prove some important theoretical results to answer the following crucial question: For which forms of uncertainty sets and objective functions, is generation of robust efficient solutions by LR-NIMBUS operational? We answer this question for linear and quadratic objective functions as well as box, norm, and polyhedral uncertainty sets. These theoretical outcomes reveal the tractability of LR-NIMBUS. In addition to presenting theoretical results and sketching the algorithm, we address an application of the LR-NIMBUS method in stock investing (portfolio selection) under uncertainty by implementing it on a data set of S&P 500 stocks extracted from Yahoo Finance.
The rest of the paper is organized as follows. In Sect. 2, some basic definitions and preliminaries are given. Section 3 is devoted to designing and analyzing the algorithm accompanying the theoretical results. Section 4 contains an application, followed by conclusions in Sect. 5.
2 Preliminaries
In this section, we provide some basic definitions and preliminaries that will be used in the rest of the paper.
2.1 Basic definitions and notations
For a vector \(d\in {R}^n\), \(d^T\) stands for the transpose of d. For \(x, y \in {R}^n\) with \(n 2\), the vector inequality \(x< y\) means \(x_i < y_i\) for all \(i =1, 2,\ldots , n.\) Furthermore, \(x y\) denotes \(x_i y_i\) for all \(i =1, 2,\ldots , n\). Moreover, \(x y\) stands for \(x y\) with \(x\ne y.\) Corresponding to these vector inequalities, we define
Consider the following deterministic multiobjective optimization problem:
where X is a nonempty set in \( {R}^n\) and \(f_i~(i\in I:=\{1,2,\ldots ,p\})\) are real-valued functions from X to \( {R}\). Here, X is the set of feasible solutions. We denote the image of X by \(Y:=f(X).\)
Definition 2.1
A feasible point \(\bar{x}\in X\) is called an efficient solution of (1) if there is no other \(x\in X\) such that \(f(x) f(\bar{x})\). In this case, \(f(\bar{x})\) is called a nondominated point of (1).
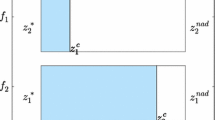
We denote the sets of all efficient solutions and nondominated points of (1) by \(X_E\) and \(Y_N,\) respectively. Indeed, \(Y_N=f(X_E)\). The nadir point \(z^N = (z^N_1,\ldots ,z^N_p)\) (resp. ideal point \(z^I = (z^I_1,\ldots ,z^I_p)\)) is the vector composed with the worst (resp. best) objective values over the efficient set. Mathematically, the components of a nadir (resp. ideal) point are defined as \(z_i^N:= \max _{x\in X_E} f_i(x)\) (resp. \(z_i^I:= \min _{x\in X} f_i(x)\)). A vector \(z^U\) with \(z^U<z^I\) is called a utopian point.
2.2 NIMBUS method
As mentioned in the preceding section, NIMBUS is an interactive method for solving multiobjective optimization problems. In this method, a DM expresses preferences at the current solution to indicate how to get a more preferred solution in each iteration by classifying objective functions to five classes as follows [27, 28]:
-
\(I^<:=\{i:~f_i~ {should be decreased}\},\)
-
\(I^{ }:=\{i:~f_i~ {should be decreased till an aspiration level}\},\)
-
\(I^=:=\{i:~ f_i~ {is satisfactory at the moment}\},\)
-
\(I^{ }:=\{i:~ f_i~ {is allowed to increase till an upper bound}\},\)
-
\(I^{\diamond }:=\{i:~ f_i~ {is allowed to change freely}\}.\)
According to the definition of efficient solutions, a classification is feasible only if \(I^< \cup I^{ } \ne \emptyset , ~I^{ }\cup I^{\diamond }\ne \emptyset ,\) and the DM has to classify all the objective functions, that is, \(I^< \cup I^{ } \cup I^= \cup I^{ } \cup I^{\diamond }=\{1,2,\dots ,p\}\). The following theorem plays a crucial role in the NIMBUS method. The proof of this theorem can be found in [28]. Indeed, in each iteration of the NIMBUS method, problem (2) below is constructed and solved. In this problem, \(x^h \in X\) is the current solution derived from the preceding iteration. Recall that, \(z^I\) is the ideal point. Whenever we use this point, we assume its existence implicitly.
Theorem 2.1
[28] Let \(w=(w_1,\ldots ,w_p)\in {R}_>^p\) be a vector of given positive weights and \(\rho \) be a sufficiently small positive scalar. Assume that \(x^h\in X\) is the current solution, \(\hat{z}_j,~ j\in I^{ },\) are aspiration levels, and \(\epsilon _i, ~i\in I^{ },\) are the upper bounds. Consider the following single-objective optimization problem:
Each optimal solution of (2) is an efficient solution for (1).
Now, we sketch Algorithm 1 invoking Theorem 2.1. Indeed, this algorithm addresses the NIMBUS method. In practice, in (2), we usually set \(w_i= \dfrac{1}{z_i^N -z_i^U}\) for \(i\in I\). In Step 0 of the algorithm, an intial efficient solution can be generated by the Achievement Scalarizing Function (ASF) [39]. See Appendix A for a brief introduction of the ASF. Throughout the present paper, we assume that the considered (single) multiobjective optimization problems are well behaved and admit at least one (optimal) efficient solution.

Actually, the method presented in [28] has other scalarizing functions besides (2) so that up to four efficient solutions can be generated and presented to the DM at each iteration. The method also has an option of generating intermediate solutions between any two efficient solutions. For details, see [28].
2.3 Robustness
In optimization under uncertainty, the optimal/efficient solution depends on different possible realizations of parameters, called scenarios. The most typical or expected scenario is called the nominal scenario [4, 6]. Robust optimization, as one of the leading tools for dealing with uncertainty, has been the subject of many publications in recent decades, e.g., [4,5,6, 13].
Suppose that \(U_i \subset {R}^{s_i},~i=1,\ldots ,p,\) are nonempty given uncertainty sets. Here, \(s_i\in {N}\) is the dimension of the uncertainty set \(U_i\). We define,
Now, associated with \(\xi \in U\), we consider the parametric problem
in which \(X\subset {R}^n\) is the (nonempty) feasible set; and \(f_i(\cdot ,\cdot ):X\times {R}^{s_i}\longrightarrow {R},~i\in I,\) are real-valued functions. Here, \(\xi \in U\) is composed by p vectors \(\xi _i \in U_i, i=1,\ldots , p\). Indeed, U is the uncertainty set in which \(\xi \) varies. We set
This set is a family of parameterized multiobjective optimization problems.
As mentioned in the introduction, there are several robustness notions in the literature of multiobjective optimization. In the following, we address two of them which are relevant to our study: set-based minmax robustness and light robustness. The main part of our work concentrates on light robustness, though we need set-based minmax robustness to define the light one.
We start with set-based minmax robustness introduced in [13].
Definition 2.2
[13] The feasible solution \(\bar{x}\in X\) is said to be a set-based minmax robust efficient solution for P(U), if there is no other feasible solution \(x{ } \in X\) such that
where \(f_U(x)=\{ f(x,\xi ),~\xi \in U\}=\{ \big ({f}_1(x,\xi _1),\ldots ,{f}_p(x,\xi _p)\big ):~~\xi _i \in U_i,~i\in I\}\).
Light robustness was first introduced in [16] for single-objective optimization problems and was extended to multiobjective cases in [22]. This robustness notion is looking for set-based minmax robust efficient solutions which are not unreasonably far from efficient solutions associated with a nominal scenario. This reasonability is controlled by a \(\delta \) parameter.
Let \(\hat{\xi }=\{\hat{\xi }_1,\ldots , \hat{\xi }_p\}\in U\) be the nominal scenario. We consider the following deterministic problem:
We denote the set of efficient solutions of \(P(\hat{\xi })\) by \(X^*(\hat{\xi })\). Suppose \(\delta \in {R}^p_{ }\) and \(\hat{x}\in X^*(\hat{\xi })\) are given. Consider the uncertain problem
and set
Definition 2.3
[22] Suppose that the nominal scenario \(\hat{\xi }\in U\) and a vector \(\delta \in {R}^p_{ }\) are given. A feasible solution \(\bar{x}\in X\) is called a lightly robust efficient solution for P(U) w.r.t. \(\delta \), if it is a set-based minmax robust efficient solution for \(P(\hat{x},\delta ,U)\) for some \(\hat{x}\in X^*(\hat{\xi })\).
3 Main results
This section is devoted to introducing and investigation of the LR-NIMBUS algorithm. In the first subsection we provide the main idea, and in the second subsection we establish the tractability of the algorithm for special cases of the uncertainty set.
3.1 LR-NIMBUS
In this subsection, we provide the main idea of the interactive LR-NIMBUS method. LR-NIMBUS is able to find a lightly robust efficient solution such that the DM plays role throughout the solution process.
MuRO-NIMBUS [45] is one of the successful interactive algorithms existing in the literature which is looking for robust solutions. MuRO-NIMBUS looks for a set-based minmax robust efficient solution, while our algorithm finds a lightly robust efficient solution. Notice that lightly robust efficient solutions are less conservative than set-based minmax ones, because the objective values at lightly robust efficient solutions do not highly differ from the objective values at efficient solutions for the nominal scenario. As mentioned in [22, p. 250], a pitfall of minmax robustness is its overconservatism. Indeed, “hedging against all scenarios from the uncertainty set usually comes with a high price, namely the quality in the nominal scenario often drastically decreases. For example, if one wants to hedge against all delays in timetabling, one would need so much buffer that the timetable becomes unattractive to the passengers. These high costs motivate the definition of light robustness, in which a certain nominal quality of the solution is required." [22]. In light robust solutions, the objective value should not differ too much from an efficient solution corresponding to the nominal scenario. To this end, an additional constraint is imposed to the problem, to produce a solution which is good enough for the nominal case.
Assume the nominal scenario \(\hat{\xi }\in U\) is given. For starting the algorithm, we find an efficient solution of the deterministic problem (4). It is done by applying the NIMBUS method; and an efficient solution satisfying DM is foundFootnote 1. To this end, according to Theorem 2.1 in each iteration of the NIMBUS method, one should solve
where \(z_i^I\) is the i-th component of the ideal point corresponding to \(f_i(\cdot ,\hat{\xi })\). Furthermore, \(x^h\) is the current solution of \(P(\hat{\xi })\), scalars \(\hat{z}_j, j\in I^{ },\) are aspiration levels for \(f_j(\cdot ,{\hat{\xi }})\), and \(\epsilon _i, i\in I^{ },\) are the upper bounds.
Theorem 3.1
Let \(w=(w_1,\ldots ,w_p)\in {R}^p_>\) be a given vector of positive weights and \(\rho \) be a sufficiently small positive scalar. Each optimal solution of (6) is an efficient solution for (4).
Proof
As problem (4) is deterministic, the claim follows from Theorem 2.1.
Theorem 3.2 introduces a single-objective optimization problem which gives a lightly robust efficient solution for P(U). Let \(\delta \in {R}^p_{ }\) and \(x^*\in X^*(\hat{\xi })\) be given. The main idea behind this result goes back to the deterministic multiobjective optimization problem
This problem provides a counterpart for robust optimization problems whose objective functions depend on some scenarios. In fact, in this problem the worst case of the objective functions \(f_i\) is optimized.
In Theorem 3.2, the parameters \(w,~{\hat{z}},~\rho ,\) and \(\epsilon \) are as described above.
Theorem 3.2
Let \(\delta \in {R}_{ }^p\) and \(x^*\in X^*(\hat{\xi })\) be given. Each optimal solution of the following single-objective optimization problem is a lightly robust efficient solution of P(U) (for uncertain multiobjective optimization problem (3) w.r.t. \(\delta \):
where \(z_i^I\) is the i-th components of the ideal point of problem (7).
Proof
Let \(\bar{x}\) be an optimal solution of problem (8). According to [28, Theorem 3.1], \(\bar{x}\) is an efficient solution of multiobjective problem (7).
To prove the theorem, it is sufficient to show that \(\bar{x}\) is a set-based minmax robust efficient solution of
in which \(\xi =\{\xi _1,\xi _2,\cdots ,\xi _p\}\) varies in U.
Let us assume that there exists a vector \(x{ }\) which is feasible for (9) and
So, for every \(\{\zeta _1,\ldots ,\zeta _p \} \in U\), there exists some \(\{\eta _1,\ldots ,\eta _p\} \in U\) such that \(f_i(x{ },\zeta _i) f_i(\bar{x},\eta _i)\) for all \(i=1,\ldots ,p\) and \(f_j(x{ },\zeta _j)< f_j(\bar{x},\eta _j)\) for at least one j. Therefore,
This contradicts the efficiency of \({\bar{x}}\) for (7) and the proof is complete.
Now, we are ready to sketch the LR-NIMBUS algorithm (Algorithm 2). A brief explanation of Algorithm 2 is as follows. In the initial step, as in the original NIMBUS method, we find a neutral compromise solution by ASF (See Appendix A), as an initial efficient solution. Then, by applying the NIMBUS method for (4) (repeatedly), taking the DM’s preferences into account, we solve (6) to get solutions that satisfy the DM (Steps 0-3). In these four steps, we find an efficient solution for the nominal scenario, denoted by \(x^*\).
Using \(x^*\), we find an initial efficient solution for (7). If the DM is satisfied with the objective values at \(x^*\), then the algorithm stops. The derived efficient solution of (7) is a lightly robust efficient solution of P(U). Otherwise, the DM is asked to classify the objective functions of (7). Then, by applying the NIMBUS method, we solve (8) repeatedly to get a solution satisfying the DM (Steps 4-8). The output of the algorithm is a lightly robust efficient solution.

Although the LR-NIMBUS algorithm works well theoretically, there is an operational difficulty in implementing it. This is related to the tractability of problems (7) and (8), because of the presence of the \(\displaystyle \max _{\xi _i\in U_i}f_i(x,\xi _i)\) term in objective functions of these problems. Notice that this maximum depends on x. This term may make the afore-mentioned problems intractable for general uncertainty sets \(U_i\). However, in the next subsection we prove tractability of problems (7) and (8) (and thus applicability of LR-NIMBUS) under special forms of objective functions and uncertainty sets.
3.2 Tractability
In this section, we establish the tractability of problem (8) for various classes of objective functions and uncertainty sets. The considered classes are popular and important in the literature [6, 18]. The results of the present subsection lead to applicability of LR-NIMBUS under the considered cases. As the problematic \(\max \)-term in both (7) and (8) is the same, we present the results only for (8). Analogous results can be developed for (7).
3.3 Linear functions and box uncertainty set
Suppose that the functions \(f_i(x,\xi _i),~i\in I,\) are affine in \(\xi _i\), while their coefficients depend on x. In addition, assume that the uncertainty set has a box form. In general, we assume
where \(\bar{f}_i: {R}^n \longrightarrow {R}^{s_i},~i\in I,\) are deterministic functions, \(\underline{\xi }_i, \bar{\xi }_i \in {R}^{s_i}\) and \(\underline{\xi }_i \bar{\xi }_i\). Here, \(U_i=[\underline{\xi }_i,\bar{\xi }_i]=\{\xi \in {R}^{s_i}: \underline{\xi }_i \xi \bar{\xi }_i\}\).
Denote the set of extreme points of \(U_i=[\underline{\xi }_i,\bar{\xi }_i],~i\in I,\) by \(E_i=\{\tilde{\xi }^{(1)},\ldots , \tilde{\xi }^{(2^{s_i})}\}\). According to this notation, the extreme points of U have the form \(\{\tilde{\xi }^{(r_1)},\ldots ,\tilde{\xi }^{(r_p)}\}\) with \(\tilde{\xi }^{(r_i)}\in E_i,~ i\in I\).
Theorem 3.3
Consider problem (8) with \(f_i(\cdot ,\cdot )\)’s and U as in (10). The following problem is equivalent to problem (8), in the sense that, \(x\in {R}^n\) is a feasible (resp. optimal) solution of problem (8), if there are \(\alpha \in {R}\) and \(\gamma =(\gamma _1,\ldots ,\gamma _p)\in {R}^p\) such that \((x,\alpha ,\gamma )\) is a feasible (resp. optimal) solution of the following problem and vice versa:
Proof
As each linear function attains its maximum over a polytope in at least one extreme point of the polytope, we have
Hence, problem (8) can be rewritten as

Now, by setting

with a little algebra, the proof is completed.
3.4 Linear functions and norm uncertainty set
Assume again the functions \(f_i(x,\xi _i),~i\in I,\) are affine in \(\xi _i\), while their coefficients depend on x. Assuming \(l>1\) given, we consider the norm uncertainty set as
where \(\bar{\xi }_i \in {R}^{s_i},\) \(\gamma _i >0\) and \(A_i\in {R}^{s_i \times s_i}\) is an invertible symmetric matrix.
Here, \(||\cdot ||_l\) is the l-norm, defined by \(||y||_l=(\displaystyle \sum _i|y_i|^l)^{\frac{1}{l}}\). In the following theorem, \(||\cdot ||^*_l\) stands for the dual norm of the l-norm, defined as
It is known that \(||y||^*_l=||y||_{\frac{l}{l-1}}\); see [9].
Theorem 3.4
Consider problem (8) with \(f_i(\cdot ,\cdot )\) functions described in (10) and uncertainty set given in (15). Then the following problem is equivalent to problem (8):
where \(R_i(x):= {\bar{\xi }}_i^T \bar{f}_i(x)+ \gamma _i \parallel A_i^{-1}\bar{f}_i(x)\parallel _{\frac{l}{l-1}}\).
Proof
According to the assumptions, we get
By setting \(z:=A_i\xi _i\), we have
Now, by replacing \(\displaystyle \max _{\xi _i\in U_i}f_i(x,\xi _i)\) with \(R_i(x):= {\bar{\xi }}_i^T \bar{f}_i(x)+ \gamma _i \parallel A_i^{-1}\bar{f}_i(x)\parallel _{\frac{l}{l-1}}\) in (8), the proof is completed.
3.5 Linear functions and polyhedral uncertainty set
Let us assume again that the functions \(f_i(x,\xi _i),~i\in I,\) are affine in \(\xi _i\), while their coefficients depend on x. In addition, we suppose that the uncertainty set is a polyhedral set as
where \(H_i\), for \(i\in I\), is an \(m_i\times s_i\) matrix. Furthermore, \(h_i\in {R}^{m_i}\), for \(i\in I\).
Theorem 3.5
Consider problem (8) with \(f_i(\cdot ,\cdot )\) functions described in (10) and uncertainty set given in (16). Assume \(I^\diamond = \emptyset \). If there exist \({\bar{x}}\in {R}^n\), \(\bar{\gamma }_i, ( i\in I^{<} \cup I^{ } \cup I^{=} \cup I^{ }),\) such that \((\bar{x}, \bar{\gamma })\) is an optimal solution for
then \(\bar{x}\) is an optimal solution for (8).
Proof
By setting
for \( i\in I,\) one can rewrite problem (8) as follows
Now, by duality theory in linear programming, we have
So, problem (19) (equivalently (8)) is rewritten as
Now, assume that \((\bar{x}, \bar{\gamma })\) is a feasible solution of (17). Due to the constraints of (17), by invoking weak duality in linear programming theory, we have
These imply that \((\bar{x}, \bar{\gamma })\) is a feasible solution of (21) which is equivalent to (8). This completes the proof because the objective functions of (17) and (21) are the same.
3.6 Quadratic functions and polyhedral uncertainty set
Let us assume that \(f_i(x,\xi _i),~i\in I,\) is a quadratic function in terms of \(\xi _i\), and coefficients of these function depend on x. We suppose
where \(\bar{F}_i(x)\) and \({\bar{f}}_i(x)\) for \(i\in I\) are an \(s_i\times s_i\) positive definite matrix and an \(s_i\)-vector, respectively. Furthermore, we assume that the uncertainty set is a polyhedral set as
Here, \(H_i\) is an \(m_i\times s_i\) matrix and \(h_i\) is an \(m_i\)-vector.
Theorem 3.6
Consider problem (8) with functions \(f_i(\cdot ,\cdot ), (i\in I),\) as described in (22) and \(U_i,~i\in I,\) is a polyhedral set as given in (23). Assume \(I^\diamond = \emptyset \). The vector \(\bar{x}\) is an optimal solution of (8) if there exist \(\bar{\gamma }_i, ( i\in I^{<} \cup I^{ } \cup I^{=} \cup I^{ }),\) such that \((\bar{x}, \bar{\gamma })\) is an optimal solution of the following problem:
where \(S_i(x,\gamma _i):= \dfrac{1}{2} \gamma _i^T D_i(x)\gamma _i + \gamma _i^T c_i(x)- \dfrac{1}{2} \bar{f}_i(x)^T \bar{F}_i(x)^{-1}\bar{f}_i(x) .\)
Proof
The main part of the proof of this theorem is similar to that of Theorem 3.5 and is hence omitted. The only point worth mentioning is the duality of quadratic programming problems. The dual of the quadratic problem
can be written as [1]
where
4 Numerical example in portfolio selection
Portfolio selection is an important, widely studied and challenging problem in applied mathematics and finance. The traditional aim is concerning how to find optimal ways for assembling a portfolio of assets such that the expected return is maximized while the investment risk is minimized. Presented in the pioneering works [25, 26], the financial risk in terms of the variance of the random variable is associated with the return of the portfolio. An efficient portfolio is defined as a feasible portfolio with the highest expected return for a given amount of risk. In multiobjective optimization terms, for an efficient portfolio it is not possible to get a higher return without accepting more risk and vice versa.
Several theoretical and practical developments have been done, e.g., in [32, 33, 37, 41] among others. In this section, we formulate a multiobjective portfolio selection problem with uncertainty in return. We solve the problem to demonstrate the ability of the LR-NIMBUS method in incorporating the DM’s preferences and generating a satisfactory lightly robust efficient solution.
The objective functions of our model are
-
Maximization of the return;
-
Minimization of the risk;
-
Maximization of the sustainability index;
-
And maximization of the liquidity index.
We do not have certain information about return and risk in the future. It means these two factors are uncertain in their essence and the DM does not exactly know about the return and risk associated with each asset. However, the intervals in which these two factors may change could be estimated using the historical data in a time window. Here, we consider the data of 7 assets in S&P 500 stocks for one year (as a time window). The data is extracted from Yahoo Finance, https://finance.yahoo.com/.
Consider a financial market with n risky assets. Let \(r_i,~i=1,2,\ldots ,n,\) be the parameter corresponding to the rate of return of asset i. We do not know the exact value of \(r_i\), though we suppose it varies within the interval \([\underline{r}_i,\bar{r}_i]\) where \(\underline{r}_i = \min _j r(i,j)\) and \(\bar{r}_i = \max _j r(i,j)\), in which r(i, j) is the rate of return of investment in asset i in jth day. Indeed, r(i, j) is equal to
Assume the decision variable \(x_i,~i=1,2,\ldots ,n,\) represents the fraction of the initial wealth invested in asset i. So, the objective function corresponding to the return is maximization of \(\sum _{i=1}^{n} r_i x_i\). Here, we assume short-selling is not allowed, and hence the decision variables are nonnegative. Evidently, we have \(\sum _{i=1}^{n} x_i=1\) as a constraint.
There are various ways for defining risk in portfolio selection literature [8, 34]. In this paper, we use the risk measure defined as \(|1- \sum _{i=1}^{n}\dfrac{r_i}{\tilde{r}}x_i|\) in [14]. In this formula, \(r_i,~i=1,2,\ldots ,n,\) are uncertain parameters. Furthermore, \(\tilde{r}\) represents the market rate of return which is calculated based upon the information of the whole market [34]. So, we have the following uncertain multiobjective programming problem. Here, \(r:=(r_1,r_2,\ldots ,r_n).\)
The third objective function of the problem is associated with sustainability. There is no uncertain parameter in this objective function. Here, \(s_i,~i=1,2,\ldots ,n,\) represents the sustainability index of the asset i. Recent studies show that many of investors in developed societies are interested in investing in companies which care about sustainability. Sustainability index is calculated with respect to three main scores: environmental, social, and governance. There are various ways for calculating the sustainability index of companies, and usually the sustainability score is a number between 1 and 100.
The fourth objective function of the above problem is the liquidity index. In this function, \(l_i,~i=1,2,\ldots ,n,\) represents the liquidity ratio of the asset i, which has been defined in various ways in the literature. One of these ratios is the so-called “ Current Liquidity Ratio", which measures company’s ability to pay off its current liabilities (payable within one year) with its current assets such as cash, receivable accounts and inventories. The higher ratio, the better the company’s liquidity position. The current liquidity ratio can be calculated as follows:
Now, we want to apply LR-NIMBUS to find a lightly robust portfolio for problem (28) taking the DM’s preferences into account. Here, the uncertainty set is a bounded box. The first objective function, \(f_1(x,\cdot )\) is linear with respect to the uncertain parameter, r. The third and fourth objective functions are deterministic ones. The second objective function is not linear, but it does not destroy the tractability of the method. It is a convex function with respect to the uncertain parameter r, and hence it takes its maximum over the uncertainty box at some extreme point of the box. Therefore, the theory presented in Subsection 3.2 (Theorem 3.3) works here. So, LR-NIMBUS can be implemented operationally. We need a nominal scenario for starting the algorithm. Assume the DM considers the scenario corresponding to maximum rates of return, i.e. \({\bar{r}}=(\bar{r}_1,{\bar{r}}_2,\ldots ,{\bar{r}}_n)\), as a nominal scenario.
We extracted information of 7 companies (assets) from the Yahoo finance website https://finance.yahoo.com/. This includes the opening prices on February 22, 2018 and the closing prices of all days during February 22, 2018 until February 22, 2019 (except holidays). We considered the opening and closing prices as purchase and selling prices, respectively. The sustainability scores of the considered companies, for 2018, were extracted from the Yahoo finance website directly. This is available in the aforementioned website since 2018. Also, we extracted the current assets and current liabilities of these companies, for four years 2015, 2016, 2017 and 2018, from the Yahoo finance website. Then, we calculated the current liquidity ratio for these four years and estimated it for 2019 using extrapolation.
After extracting the required information from the above-mentioned website, we started the process of finding a most preferred lightly robust portfolio (solution) by Algorithm 2. We considered one of our colleagues as a DM and asked him to choose a favorable scenario among the existing ones as a nominal scenario. His choice was
By considering a reference point
and applying the ASF method, we derived an initial efficient solution
in which the vector of the objective function values is
Our implementation, including solving the single-objective problems, has been done in MATLAB.
Remark 1
The reference point \(z^0\) has been chosen taking an interval, in which the desired values are reasonable and consistent with reality, into account. This interval is corresponding to the lower bounds (ideal point) and upper bounds (nadir point) of the objective functions, as follows:
Notice that, these two vectors are corresponding to the nominal scenario. There is not any efficient tool for calculation of the nadir point. Here, we considered an estimation of this point by a pay-off table approach [3].
Remark 2
We have converted all objectives to be minimized, that is, considered the first objective function as minimization of the negative of the return. So, in the vector \(z^0\), the return associated with portfolio \(x^0\) is 0.1007 (i.e., the first component of \(z^0\) should be multiplied by \((-1)\)). A similar clarification in needed for sustainability and liquidity as well.
The DM was not satisfied with the objective values at \(x^0\) (Step 1). We should get preference information, as a classification of the objective functions, from the DM (Step 2). He preferred to improve the first function (return) as much as possible and the liquidity to an aspiration level 2 (so, for the fourth function, we have \(\bar{z}_4=-2\)). On the other hand, the value of the second function (risk) is close to the ideal situation. So, he allowed to impair this function up to an upper bound \(\epsilon _2 =0.3\). Indeed, the DM preferred to sacrifice the second objective function (increase the risk) within an acceptable tolerance in order to improve other objective functions. The DM was satisfied with the value of the third function (sustainability) and preferred to keep its current value. The solution obtained from the NIMBUS problem (6), imposing the mentioned preferences of the DM (Step 3), is
The vector of the objective values at this point is
The DM was satisfied with the value of the first objective function. However, he preferred to continue the improvement of the fourth objective function as much as possible and the third function to an aspiration level 0.18 (i.e., \({\bar{z}}_3=-0.18)\), allowing the second function to be increased until the upper bound \(\epsilon _2 =0.4\). This led to the efficient solution
whose corresponding objective vector is
Here, the DM was satisfied with the solution derived for the nominal scenario. So, we started the second phase of the process of finding a most preferred lightly robust efficient solution (Step 4). Throughout the second phase, \(x^2\) was utilized as an efficient solution for the nominal scenario. To choose a reference point properly, we computed lower and upper bounds for the objective functions as follows. These two vectors are respectively the ideal and estimated nadir points for the worst-case (wc) problem, denoted by \(z^I_{wc}\) and \(z^N_{wc}\):
Due to two vectors \(z^I_{wc}\) and \(z^N_{wc}\), for the worst-case scenario, the return belongs to \([-0.3469,-0.0851]\). The negativity of these return values is natural, because of considering the worst-case scenario. Invoking the above two vectors, we considered a reference point as \({\bar{z}}= (0.2, 4, -0.15,-1.9).\) We need it to perform ths ASF method.
As we were looking for a lightly robust efficient solution, we asked the DM to choose a tolerance for the objective functions in the nominal case. This tolerance means how much the image point corresponding to the robust solution can be far from the image point associated with the efficient solution obtained for the nominal case. The DM’s answer was
The initial lightly robust efficient solution obtained from the ASF method was equal to
and the objective function vector at this point was
Notice that, here the return value is negative.
The DM was not satisfied with the objective values at \(x^3\) (Step 5). We should get preference information, as a classification of the objective functions, from the DM (Step 6). He preferred to improve the first function as much as possible and the fourth function to an aspiration level 2.2120 (so, \({\bar{z}}_4=-2.2120\)). On the other hand, the value of the second function satisfied the DM. Moreover, he agreed to decrease sustainability to a lower bound 0.1383 (Step 6). The solution obtained from problem (8), imposing the mentioned preferences of the DM (Step 7), is
The vector of the objective values at this point is
In this stage, since the value of the third function was very bad, the DM preferred to improve it as much as possible. To do this, he agreed to sacrifice the fourth function up to 1.9 (i.e., \(\epsilon _4 =-1.9\)). Also, he preferred to improve the second function to an aspiration level 2.0636 and keep the first function in its current value. The derived solution and its objective vector were
respectively.
The solution \(x^5\) also did not satisfy the DM and he wants to improve the return, no matter what it takes. So he decided to impair the second, third and fourth functions, simultaneously. The upper bounds for increasing these functions were \(\epsilon _2 =3.5000,\) \(\epsilon _3 =-0.1420,\) and \(\epsilon _4 =-1.8900\), respectively. This led to a new solution
whose corresponding objective vector is
The solution \(x^6\) satisfied the DM, as all objective function values were in a satisfactory status (taking \(z_{wc}^I\) and \(z_{wc}^N\) into account).
Computing \(z^j_{nom}\), as the vector of the objective function values (in nominal case) at \(x^j\), we have \((z^j_{nom})_i- z_i^2 \delta _i\) for each \(i=1,2,3\) and each \(j=3,4,5,6.\) Here, we have not reported the \(z^j\) vectors.
Finally, the DM was satisfied with the last lightly robust efficient solution as the final point (Step 8). The efficient portfolio derived from the LR-NIMBUS method is corresponding to investment in fourth, fifth, sixth and seventh companies with 0.0932, 0.4482, 0.2260, and 0.2326 as fractions of the capital, respectively.
As demonstrated by the example, some of the strengths of our algorithm are the participation of the DM in the solution process, taking the uncertainty in the problem into account, and the proximity of the final solution to the solution obtained for the most preferred scenario. The algorithm allows the DM to control this proximity. The participation of the DM resulted with a portfolio with characteristics (risk, return, liquidity, and sustainability) following the DM’s preferences as well as possible. Furthermore, the lightly robustness notion helped us to generate a solution which was reasonably close to the solution corresponding to the most preferred scenario. Although, return is uncertain in its essence, it is usually considered as deterministic in the models in the literature. We overcame this contradiction by incorporating an uncertainty set in the model. This includes all possible scenarios and increases the trust in the results derived from the historical data.
5 Conclusions
We have proposed an interactive method called LR-NIMBUS for solving multiobjective optimization under uncertainty. Uncertainty is assumed to be in the objective functions and the method supports a decision maker in finding a most preferred lightly robust solution.
We have proven several theorems devoted to problem types in which the proposed method is tractable. We also demonstrated the applicability of the method with a portfolio optimization problem involving four objective functions.
Notes
Two measures “price to be paid for robustness" and “gain in robustness" developed by Zhou-Kangas and Miettinen [44] could be helpful here to support the DM in controlling the trade-offs between robustness and the objective function values in the nominal scenario. See also [2, 30] and the references therein for some tools to recognize if a DM is learned and satisfied.
References
Bazaraa, M.S., Sherali, H.D., Shetty, C.M.: Nonlinear Programming: Theory and Algorithms. Wiley, New York (2006)
Belton, V., Branke, J., Eskelinen, P., Greco, S., Molina, J., Ruiz, F., Slowiński, R.: Interactive multiobjective optimization from a learning perspective. In: Branke, J., Deb, K., Miettinen, K., Slowiński, R. (eds.) Multiobjective Optimization: Interactive and Evolutionary Approaches, pp. 405–433. Springer, Berlin (2008)
Benayoun, R., de Montgolfier, J., Tergny, J., Laritchev, O.: Linear programming with multiple objective functions: Step method (STEM). Math. Prog. 1, 366–375 (1971)
Ben-Tal, A., Ghaoui, L., Nemirovski, A.: Robust Optimization. Princeton University Press, Princeton (2009)
Ben-Tal, A., Nemirovski, A.: Robust optimization methodology and applications. Math. Prog. 92, 453–480 (2002)
Bertsimas, D., Brown, D.B., Caramanis, C.: Theory and applications of robust optimization. SIAM Rev. 53, 464–501 (2011)
Bertsimas, D., Sim, M.: The price of robustness. Oper. Res. 52, 35–53 (2004)
Biglova, A., Ortobelli, S., Rachev, S.T., Stoyanov, S.: Different approaches to risk estimation in portfolio theory. J. Portfolio Manag. 31, 103–112 (2004)
Boyd, S., Vandenberghe, L.: Convex Optimization. Cambridge University Press, Cambridge (2004)
Branke, J., Deb, K., Miettinen, K., Slowinski, R. (eds.): Multiobjective Optimization: Interactive and Evolutionary Approaches. Springer, Berlin (2008)
Deb, K.: Multiobjective optimization. In: E.K. Burke, G. Kendall (Eds.), Search Methodologies. Springer, pp. 403–449 (2014)
Ehrgott, M.: Multicriteria Optimization. Springer, Berlin (2005)
Ehrgott, M., Ide, J., Schöbel, A.: Minmax robustness for multiobjective optimization problems. Eur. J. Oper. Res. 239, 17–31 (2014)
Elton, E.J., Gruber, M.J., Blake, C.R.: Common factors in active and passive portfolios. Eur. Finance Rev. 3, 53–78 (1999)
Fishburn, P.C.: Lexicographic orders, utilities and decision rules: a survey. Manag. Sci. 20, 1442–1471 (1974)
Fischetti, M., Monaci, M.: Light robustness. In: R.K. Ahuja, R. Moehring, C. Zaroliagis (Eds.), Robust and Online Large-Scale Optimization. Springer, pp. 61–84 (2009)
Fliege, J., Werner, R.: Robust multiobjective optimization applications in portfolio optimization. Eur. J. Oper. Res. 234, 422–433 (2014)
Goberna, M.A., Jeyakumar, V., Li, G., Vicente-Perez, J.: Robust solutions to multiobjective linear programs with uncertain data. Eur. J. Oper. Res. 242, 730–743 (2014)
Gutjahr, W.J., Pichler, A.: Stochastic multiobjective optimization: a survey on non-scalarizing methods. Ann. Oper. Res. 236, 475–499 (2016)
Hartikainen, M., Ojalehto, V., Sahlstedt, K.: Applying approximation method PAINT and interactive method NIMBUS to multiobjective optimization of operating a wastewater treatment plant. Eng Optim. 47, 328–346 (2015)
Hwang, C.L., Masud, A.S.M.: Multiple Objective Decision Making Methods and Applications. Springer, Berlin (1979)
Ide, J., Schöbel, A.: Robustness for uncertain multiobjective optimization: a survey and analysis of different concepts. OR Spectr. 38, 235–271 (2016)
Keeney, R.L., Raiffa, H.: Decisions with Multiple Objectives: Preferences and Value Tradeoffs. Wiley, Chichester (1976)
Kuhn, K., Raith, A., Schmidt, M., Schöbel, A.: Bicriteria robust optimization. Eur. J. Oper. Res. 252, 418–431 (2016)
Markowitz, H.M.: Portfolio Selection: Efficient Diversification of Investments. Wiley, New York (1959)
Markowitz, H.M.: Portfolio selection. J. Finan. 7, 77–91 (1952)
Miettinen, K.: Nonlinear Multiobjective Optimization. Kluwer Academic Publishers, Boston (1999)
Miettinen, K., Mäkelä, M.M.: Synchronous approach in interactive multiobjective optimization. Eur. J. Oper. Res. 170, 909–922 (2006)
Miettinen, K., Mustajoki, J., Stewart, T.J.: Interactive multiobjective optimization with NIMBUS for decision making under uncertainty. OR Spectrum 36(1), 39–56 (2014)
Miettinen, K., Ruiz, F., Wierzbicki, A.P.: Introduction to multiobjective optimization: interactive approaches. In: Branke, J., Deb, K., Miettinen, K., Slowiński, R. (eds.) Multiobjective Optimization: Interactive and Evolutionary Approaches, pp. 27–57. Springer, Berlin (2008)
Miettinen, K.: Some Methods for nonlinear multiobjective optimization. In: E. Zitzler, L. Thiele, K. Deb, C. A. Coello Coello, D. Corne (Eds.), Evolutionary Multicriterion Optimization; EMO 2001. Springer, Berlin, Heidelberg (2001)
Ogryczak, W., Slowiński, T.: On solving the dual for portfolio selection by optimizing conditional value at risk. Comput. Optim. Appl. 50, 591–595 (2011)
Pogue, G.: An extension of the Markowitz portfolio selection model to include variable transaction cost, short sales, leverage policies and taxes. J. Financ. 25, 1005–1027 (1970)
Reilly, F.K., Brown, K.C.: Investment Analysis and Portfolio Management. Cengage Learning, South Western (2011)
Ruotsalainen, H., Miettinen, K., Palmgren, J.E.: Interactive multiobjective optimization for 3D HDR brachytherapy applying IND-NIMBUS. In: Jones, D., Tamiz, M., Ries, J. (eds.) New Developments in Multiple Objective and Goal Programming. Springer, Berlin (2010)
Sawaragi, Y., Nakayama, H., Tanino, T.: Theory of Multiobjective Optimization. Academic Press, Orlando (1985)
Sharpe, W.F.: A linear programming algorithm for mutual fund portfolio selection. Management Science 13, 499–510 (1967)
Steuer, R.E.: Multiple Criteria Optimization: Theory, Computation, and Application. Wiley, New York (1986)
Wierzbicki, A.P.: On the completeness and constructiveness of parametric characterizations to vector optimization problems. OR Spectr. 8, 73–87 (1986)
Wierzbicki, A.P.: Reference point approaches. In: T. Gal, T. J. Stewart, T. Hanne (Eds.), Multicriteria Decision Making: Advances in MCDM Models, Algorithms, Theory, and Applications. Springer, Boston (1999)
Xidonas, P., Mavrotas, G., Psarras, J.: Portfolio construction on the Athens stock exchange: a multiobjective optimization approach. Optimization 59, 1211–1229 (2010)
Yu, P.L.: A class of solutions for group decision problems. Manag Sci 19, 936–946 (1973)
Zeleny, M.: Compromise programming. In: Cochrane, J.L., Zeleny, M. (eds.) Multiplecriteria Decision Making, pp. 262–301. University of South Carolina, Columbia (1973)
Zhou-Kangas, Y., Miettinen, K.: Decision making in multiobjective optimization problems under uncertainty: balancing between robustness and quality. OR Spectr. 41, 391–413 (2019)
Zhou-Kangas, Y., Miettinen, K., Sindhya, K.: Interactive multiobjective robust optimization with NIMBUS. In: M. Baum, G. Brenner, J. Grabowski, T. Hanschke, S. Hartmann, A. Schöbel (Eds.), Simulation Science; SimScience 2017. Springer, 60-76 (2018)
Acknowledgements
This research is related to the thematic research area Decision Analytics utilizing Causal Models and Multiobjective Optimization (DEMO, jyu.fi/demo) at the University of Jyvaskyla.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: ASF method
Appendix A: ASF method
The Achievement Scalarizing Function (ASF), used for generating initial efficient solutions is the objective function of the following problem corresponding to MOP (1):
Here, \(w_i= \dfrac{1}{z_i^N -z_i^U}\) for \(i=1,2,\ldots ,p\) are the weights assigned to the objective functions. The vector \(\bar{z}= (\bar{z}_1,\bar{z}_2,\ldots ,\bar{z}_p)\) is a reference point, which here is the average of nadir and ideal points, and \(\rho >0\) is a sufficiently small scalar to prevent generating weakly efficient solutions [39].
Rights and permissions
About this article

Cite this article
Koushki, J., Miettinen, K. & Soleimani-damaneh, M. LR-NIMBUS: an interactive algorithm for uncertain multiobjective optimization with lightly robust efficient solutions. J Glob Optim 83, 843–863 (2022). https://doi.org/10.1007/s10898-021-01118-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-021-01118-8