
Abstract
In this paper we deal with the single machine scheduling problem with one non-availability interval to minimize the maximum lateness where jobs have positive tails. Two cases are considered. In the first one, the non-availability interval is due to the machine maintenance. In the second case, the non-availability interval is related to the operator who is organizing the execution of jobs on the machine. The contribution of this paper consists in an improved fully polynomial time approximation scheme (FPTAS) for the maintenance non-availability interval case and the elaboration of the first FPTAS for the operator non-availability interval case. The two FPTASs are strongly polynomial.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In this paper we deal with the single machine scheduling problem with one non-availability interval to minimize the maximum lateness where jobs have positive tails. Two cases are considered. In the first one, the non-availability interval is due to the machine maintenance. In the second case, the non-availibility interval is related to the operator who is organizing the execution of jobs on the machine. An operator non-availability period is a time interval in which no job can start, and neither can complete. The main difference between machine non-availability (MNA) and operator non-availability (ONA) consists in the fact that a job can be processed but cannot start neither finish during the ONA period. However, the MNA interval is a completely forbidden period. Rapine et al. (2012) have described the applications of this problem in the planning of a chemical experiments as follows: Each experiment is performed by an automatic system (a robot), during a specified amount of time, but a chemist is required to control its start and completion. At the beginning, the chemist launches the process (preparation step). The completion step corresponds to the experimental analysis, which is to be done in a no-wait mode to stop chemical reactions. Here, the automatic system is available all the time, where the chemists may be unavailable due to planned vacations or activities. This induces operator (chemist) non-availability intervals when experiments (jobs) can be performed by the automatic system (machine), but cannot neither start nor complete.
The MNA case of this type of problems has been studied in the literature under various criteria [a sample of these works includes Lee (1996), Kacem (2009), Kubzin and Strusevich (2006), Qi (2007), Qi et al. (1999), Schmidt (2000), He et al. (2006)]. However, few papers studied the problem we consider in this paper. Lee (1996) explored the Jackson’s sequence JS and proved that its deviation to the optimal makespan cannot exceed the largest processing time, which is equivalent to state that JS is a 2-approximation. Recently, Yuan et al. developed an interesting PTAS (Polynomial Approximation Scheme) for the studied problem (Yuan et al. 2008). Kacem (2009) presented a first fully polynomial time approximation scheme (FPTAS) for the maximum lateness minimization. That is why this paper is a good attempt to design more efficient approximation heuristics and approximation schemes to solve the studied problem.
For the ONA case, few works have been published. Brauner et al. (2009) considered the problem of single machine scheduling with ONA periods. They analyzed this problem on a single machine with the makespan as a minimization criterion and they showed that the problem is NP-hard with one ONA period. They also considered the problem with K ONA periods such that the length of each ONA period is no more than \(\frac{1}{\lambda }\) times the total processing time of all jobs. They introduced a worst-case ratio smaller than \(1+\frac{2K}{\lambda }\) for algorithm LS (list scheduling). They presented an approximation algorithm with a worst-case ratio close to \( 2+\frac{K-1}{\lambda }\). The natural case of periods where the duration of the periods is smaller than any processing time of any job, has been considered by Rapine et al. (2012). They proved the problem can be solved in polynomial time, where there exists only one ONA period and they showed the problem is NP-hard if one has \(K\ge 2\) small non-availability periods and the worst-case ratio of LS is no more than \(\frac{K+1}{2}\) and the problem does not admit an FPTAS for \(K\ge 3\) unless P = NP.
Recently, Chen et al. (2013) considered the single machine scheduling with one ONA period to minimize the total completion time. The problem is NP-hard even if the length of the ONA period is smaller than the processing time of any job. They have also presented an algorithm with a tight worst-case ratio of \(\frac{20}{17}\). They showed that the worst-case ratio of SPT is at least \(\frac{5}{3}\).
The contribution of this paper consists in an improved FPTAS for the MNA interval case and the elaboration of the first FPTAS for the ONA interval case. The two FPTASs are strongly polynomial. These contributions can be summarized in Table 1 for the two cases. It is worthy to note that the two cases have been addressed together in this paper for two reasons. The first one is methodological. Indeed, we will show in this paper that the design of approximation schemes for the MNA case can lead to derive efficient extended schemes for the other case. The second reason is related to the common domain of applications (resource non-availability).
The paper is organized as follows. Section 2 describes the exact formulation of the MNA interval case and the improved FPTAS. Section 3 is devoted to the ONA interval case and to the presentation of the proposed FPTAS. Finally, Sect. 4 gives some concluding remarks.
2 Case under MNA interval
Here, the studied problem (\({\mathcal {P}}\)) can be formulated as follows. We have to schedule a set J of n jobs on a single machine, where every job j has a processing time \(p_{j}\) and a tail \(q_{j}\). The machine can process at most one job at a time and it is unavailable between \(T_{1}\) and \(T_{2}\) (i.e., \(\left( T_{1},T_{2}\right) \) is a forbidden interval). Preemption of jobs is not allowed (jobs have to be performed under the non-resumable scenario). All jobs are ready to be performed at time 0. With no loss of generality, we consider that all data are integers and that jobs are indexed according to Jackson’s rule (Carlier 1982) (i.e., jobs are indexed in nonincreasing order of tails). Therefore, we assume that \( q_{1}\ge q_{2}\ge \cdots \ge q_{n}\). The consideration of tails is motivated by the large set of scheduling problems such that jobs have delivery times after their processing (Dessouky and Margenthaler 1972). Let \(C_{j}\left( S\right) \) denote the completion time of job j in a feasible schedule S for the problem and let \(\mathcal {\varphi }_{S}({\mathcal {I}})\) be the maximum lateness yielded by schedule S for instance \({\mathcal {I}}\) of (\({\mathcal {P}}\)):
The aim is to find a feasible schedule S by minimizing the maximum lateness. It is well-known that the Jackson’s order is optimal for the same problem without non-availability constraint. Due to the dominance of Jackson’s order, any optimal schedule for \({\mathcal {P}}\) is composed of two sequences of jobs scheduled in nondecreasing order of their indexes.
If all the jobs can be inserted before \(T_{1}\), the instance studied (\( {\mathcal {I}}\)) has obviously a trivial optimal solution obtained by Jackson’s rule. We therefore consider only the problems in which all the jobs cannot be scheduled before \(T_{1}\). Moreover, we consider that every job can be inserted before \(T_{1}\) (i.e., \(p_{j}\le T_{1}\) for every \(j\in J\)).
In the remainder of this paper \(\mathcal {\varphi }^{*}({\mathcal {I}})\) denotes the minimal maximum lateness for instance \({\mathcal {I}}\).
2.1 New simplifications and PTAS
Now, let us describe our FPTAS. It uses a simplification technique based on merging small jobs Kacem and Kellerer (2014).
1st STEP:
First, we simplify the instance \({\mathcal {I}}\) as follows. Given an arbitrary \(\varepsilon >0\). We assume that \(1/\varepsilon \) is integer. We split the interval \([0,\max _{j\in J}\{q_{j}\}]\) in \(1/\varepsilon \) equal lenght intervals and we round up every tail \(q_{j}\) to the next multiple of \( \varepsilon q_{\max }\) (\(q_{\max }=\max _{j\in J}\{q_{j}\}\)). The new instance is denoted as \({\mathcal {I}}^{\prime }\).
Proposition 1
The obtained instance \({\mathcal {I}}^{\prime }\) can be obtained in O(n) time and it can be done with no (\(1+\varepsilon \))-loss.
Proof
The modification can be done by setting \(q_{j}:=\lceil q_{j}/\varepsilon q_{\max }\rceil \varepsilon q_{\max }\) for every \(j\in J\). Then, it can be done in O(n) time. Moreover, since \(\lceil q_{j}/\varepsilon q_{\max }\rceil \varepsilon q_{\max }\le q_{j}+\varepsilon q_{\max }\) then, \( \mathcal {\varphi }^{*}({\mathcal {I}}^{\prime })\le \mathcal {\varphi }^{*}( {\mathcal {I}})+\varepsilon q_{\max }\le (1+\varepsilon )\mathcal {\varphi }^{*}({\mathcal {I}})\) since \(q_{\max }\) is a lower bound on the optimal maximum lateness. \(\square \)
2nd STEP:
J is divided into at most \(1/\varepsilon \) subsets J(k) (\(1\le k\le 1/\varepsilon \)) where jobs in J(k) have identical tails of \( k\varepsilon q_{\max }\). The second modification consists in reducing the number of small jobs in every subset J(k). Small jobs are those having processing times \(<\varepsilon P/2\) where \(P=p_{1}+p_{2}+\cdots +p_{n}\). The others are called large jobs. The reduction is done by merging the small jobs in each J(k) so that we obtain new greater jobs having processing times between \(\varepsilon P/2\) and \(\varepsilon P\). The small jobs are taken in the order of their index in this merging procedure. At most, for every subset J(k), a single small job remains. We re-index jobs according to nondecreasing order of their tails. The new instance we obtain is denoted as \({\mathcal {I}}^{\prime \prime }\). Clearly, the number of jobs remaining in the simplified instance \({\mathcal {I}}^{\prime \prime }\) is less than \(3/\varepsilon \).
Proposition 2
This reduction in the second step cannot increase the optimal solution value of \({\mathcal {I}}^{\prime }\) by more than (\(1+\varepsilon \))-factor. It can be done in O(n) time.
Proof
The proof is based on the comparison of a lower bound lb for \(\mathcal { \varphi }^{*}({\mathcal {I}}^{\prime })\) and a feasible solution \(\sigma \) for instance \({\mathcal {I}}^{\prime \prime }\). We will demonstrate that \(\mathcal { \varphi }_{\sigma }({\mathcal {I}}^{\prime \prime })\le \left( 1+\varepsilon \right) lb\) which implies that \(\mathcal {\varphi }^{*}({\mathcal {I}} ^{\prime \prime })\le \mathcal {\varphi }_{\sigma }({\mathcal {I}} ^{\prime \prime })\le \left( 1+\varepsilon \right) lb\le \left( 1+\varepsilon \right) \mathcal {\varphi }^{*}({\mathcal {I}}^{\prime })\). The lower bound lb is the maximum lateness of the optimal solution \( \sigma _{r}\) of a special preemptive version of problem \({\mathcal {I}}^{\prime }\) where the large jobs are supposed to be assigned (before or after the non-availability interval) as in the optimal solution of \({\mathcal {I}} ^{\prime }\). The principle of this lower bound is based on the splitting idea presented in Kacem (2009). Indeed, we split the small jobs so that the obtained pieces have an identical length of 1 and they keep their tails. It can be demonstrated that the pieces associated to the small jobs must be scheduled in \(\sigma _{r}\) according to the Jackson’s order. At most, one piece of a certain job g will be preempted by the non-availability period. For more details on this lower bound, we refer to Kacem (2009). It is easy to transform such a relaxed solution \(\sigma _{r}\) to a close feasible solution \(\sigma \) for \({\mathcal {I}}^{\prime \prime }\). Indeed, we can remark that the small jobs of every subset J(k) (\(1\le k\le 1/\varepsilon \) ), except the subset k(g) containing job g, are scheduled contiguously before or after the non-availibility period. Hence, the associated merged jobs (in \({\mathcal {I}}^{\prime \prime }\)) for these small ones (in \({\mathcal {I}} ^{\prime }\)) will take the same order in sequence \(\sigma \). The large jobs are common in the two instances and they will keep the same assignments in \( \mathcal {\sigma }\). The only possible difference between \(\sigma \) and \( \sigma _{r}\) will consist in the positions of small jobs (from \({\mathcal {I}} ^{\prime }\)) belonging to subset k(g). For these small jobs, we construct the same associated merged jobs as in \({\mathcal {I}}^{\prime \prime }\) by scheduling them in \(\sigma \) as close in \(\sigma _{r}\) as possible. As a consequence, some small jobs (from \({\mathcal {I}}^{\prime }\) and belonging to subset k(g)) will be moved after the non-availability period. Thus, it is easy to deduce that \(\mathcal {\varphi }_{\sigma }({\mathcal {I}} ^{\prime \prime })\le lb+\) \(\varepsilon P\le \left( 1+\varepsilon \right) lb\). \(\square \)
Theorem 3
Problem P has a Polynomial Time Approximation Scheme (PTAS) with a time complexity of \(O(n\ln (n)\) + \(\left( 1/\varepsilon \right) 2^{O(1/\varepsilon )})\).
Proof
The proof is based on the two previous propositions. The Jackson’s order can be obtained in \(n\ln (n)\). We construct the optimal solution of \({\mathcal {I}} ^{\prime \prime }\) by an exhaustive search in \(O(\left( 1/\varepsilon \right) 2^{O(1/\varepsilon )})\). Then, we derive a feasible solution for \({\mathcal {I}}\) , which can be done in O(n). \(\square \)
Remark 4
The new PTAS has a lower time complexity compared to the one proposed by Yuan et al. (2008) for which the time complexity is \(O(n\ln (n)+n.2^{1/\varepsilon })\).
2.2 Improved FPTAS
The improved FPTAS is similar to the one proposed by Kacem (2009). It uses the same technique but exploits also the modification of the input (\( {\mathcal {I}}\rightarrow {\mathcal {I}}^{\prime \prime }\)). First, we use the Jackson’s sequence JS obtained for the modified instance \({\mathcal {I}} ^{\prime \prime }\). Then, we apply the modified dynamic programming algorithm \( APS_{\varepsilon }^{\prime }\) introduced in Kacem (2009) on instance \( {\mathcal {I}}^{\prime \prime }\).
The main idea of \(APS_{\varepsilon }^{\prime }\) is to remove a special part of the states generated by a dynamic programming algorithm. Therefore, the modified algorithm becomes faster and yields an approximate solution instead of the optimal schedule (see Appendix 1). First, we define the following parameters:
and
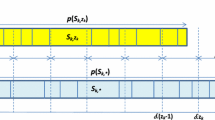
We split \(\left[ 0,\mathcal {\varphi }_{JS}\left( {\mathcal {I}}^{\prime \prime }\right) \right) \) into \(\omega _{1}\) equal subintervals \(I_{m}^{1}=\left[ (m-1)\delta _{1},m\delta _{1}\right) _{1\le m\le \omega _{1}}\). We also split \( \left[ 0,T_{1}\right) \) into \(\omega _{2}\) equal subintervals \(I_{s}^{2}= \left[ (s-1)\delta _{2},s\delta _{2}\right) _{1\le s\le \omega _{2}}\) of length \(\delta _{2}\). Moreover, we define the two singletons \( I_{\omega _{1}+1}^{1}=\left\{ \mathcal {\varphi }_{JS}\left( {\mathcal {I}} ^{\prime \prime }\right) \right\} \) and \(I_{\omega _{2}+1}^{2}=\left\{ T_{1}\right\} \). Our algorithm \(APS_{\varepsilon }^{\prime }\) generates reduced sets \({\mathcal {X}}_{j}^{\#}\) of states \(\left[ t,f\right] \) where t is the total processing time of jobs assigned before \(T_{1}\) in the associated partial schedule and f is the maximum lateness of the same partial schedule. It can be described as follows:

Theorem 5
Given an arbitrary \(\varepsilon >0\), Algorithm \(APS_{\varepsilon }^{\prime }\) yields an output \(\mathcal {\varphi }_{APS_{\varepsilon }^{\prime }}\left( {\mathcal {I}}^{\prime \prime }\right) \) such that:
Proof
The proof is similar to Kacem (2009). For self-consistency, a sketch proof is given in Appendix 1. \(\square \)
Lemma 6
Given an arbitrary \(\varepsilon >0\), algorithm \(APS_{\varepsilon }^{\prime }\) can be implemented in \(O\left( \overline{n}\log \overline{n}+\overline{n} ^{3}/\varepsilon ^{2}\right) \) time.
Proof
See Appendix 2. \(\square \)
The schedule obtained by \(APS_{\varepsilon }^{\prime }\) for instance \(\mathcal { I}^{\prime \prime }\) can be easily converted into a feasible one for instance \( {\mathcal {I}}\). This can be done in \(O\left( n\right) \) time. From the previous lemma and the proof of Lemma 13, the main result is proved and the following theorem holds.
Theorem 7
Algorithm \(APS_{\varepsilon }^{\prime }\) is an FPTAS and it can be implemented in \(O(n\log n\) + \(\min \{n,3/\varepsilon \}^{3}/\varepsilon ^{2})\) time.
3 Case under operator non-availability interval
Here, the studied problem (\(\Pi \)) can be formulated as follows. An operator has to schedule a set J of n jobs on a single machine, where every job j has a processing time \(p_{j}\) and a tail \(q_{j}\). The machine can process at most one job at a time if the operator is available at the starting time and the completion time of such a job. The operator is unavailable during \( (T_{1},T_{2})\). Preemption of jobs is not allowed (jobs have to be performed under the non-resumable scenario). All jobs are ready to be performed at time 0. With no loss of generality, we consider that all data are integers and that jobs are indexed according to Jackson’s rule and we assume that \(q_{1}\ge q_{2}\ge \cdots \ge q_{n}\). Let \(C_{j}\left( S\right) \) denote the completion time of job j in a feasible schedule S (\( C_{j}\left( S\right) \notin (T_{1},T_{2})\) and \(C_{j}\left( S\right) -p_{j}\notin (T_{1},T_{2})\)) and let \(\mathcal {\varphi }_{S}({\mathcal {I}})\) be the maximum lateness yielded by schedule S for instance \({\mathcal {I}}\) of (\( \Pi \)):
The aim is to find a feasible schedule S by minimizing the maximum lateness.
If all the jobs can be inserted before \(T_{1}\), the instance studied (\( {\mathcal {I}}\)) has obviously a trivial optimal solution obtained by Jackson’s rule. We therefore consider only the problems in which all the jobs cannot be scheduled before \(T_{1}\). Moreover, we consider that every job can be inserted before \(T_{1}\) (i.e., \(p_{j}\le T_{1}\) for every \(j\in J\)).
In the remainder of this paper \(\mathcal {\varphi }^{*}({\mathcal {I}})\) denotes the minimal maximum lateness for instance \({\mathcal {I}}\).
Proposition 8
If \(p_{j}<T_{2}-T_{1}\) for every \(j\in J\), then problem (\(\Pi \)) has an FPTAS.
Proof
In this case, it is easy to remark that Problem \(\Pi \) is equivalent to Problem \({\mathcal {P}}\) for which we can apply the FPTAS described in the previous section. \(\square \)
In the remainder, we consider the hard case where some jobs have processing times greater than \(T_{2}-T_{1}\). Let \(\mathcal {K}\) be the subset of these jobs. In this case, two scenarios are possible:
-
Scenario 1: there exists a job \(s\in \mathcal {K}\) such that in the optimal solution it starts before \(T_{1}\) and completes after \(T_{2}\) (s is called the stradling job).
-
Scenario 2: there is no stradling job in the optimal solution.
It is obvious that Scenario 2 is equivalent to Problem \({\mathcal {P}}\) for which we have an FPTAS. Thus, the last step necessary to prove the existence of an FPTAS for Problem \(\Pi \) is to construct a special scheme for Scenario 1. Without loss of generality, we assume that the stradling job s is known (indeed, it can be guessed among jobs of \(\mathcal {K}\)). The following proposition determines the time-window of the starting time of job s in the optimal solution.
Proposition 9
Let \(t_{s}^{*}\) be the starting time of s in the optimal schedule. The following relation holds: \(t_{s}^{*}\in [T_{2}-p_{s},T_{1}]\).
Proof
Obvious since the stradling job s has to cover the ONA period in the optimal schedule. \(\square \)
Proposition 10
Senario 1 has an FPTAS.
Proof
The stradling job s is assumed to be known. Given an arbitrary \( \varepsilon >0\), we divide the interval \([T_{2}-p_{s},T_{1}]\) in \(\left\lceil 1/\varepsilon \right\rceil \) equal-length sub-intervals \(\bigcup \limits _{h=1}^{\left\lceil 1/\varepsilon \right\rceil }D_{h}\) where
We consider a set of \(\left\lceil 1/\varepsilon \right\rceil +1\) instances \(\{ {\mathcal {I}}_{1},{\mathcal {I}}_{2},...,{\mathcal {I}}_{\left\lceil 1/\varepsilon \right\rceil +1}\}\) of Problem \({\mathcal {P}}\) where in \({\mathcal {I}}_{h}\) the stradling job starts at time
which is equivalent to an instance of Problem \({\mathcal {P}}\) with a set of jobs \(J-\{s\}\) and a MNA period \(\Delta _{h}\):
For every instance from \(\{{\mathcal {I}}_{1},{\mathcal {I}}_{2},\ldots ,{\mathcal {I}} _{\left\lceil 1/\varepsilon \right\rceil +1}\}\), we apply the FPTAS described in the previous section for Problem \({\mathcal {P}}\) and we select the best solution among all the \(\left\lceil 1/\varepsilon \right\rceil +1\) instances. It is easy to see that if \(t_{s}^{*}\in [t_{s}^{h},t_{s}^{h+1})\) then, delaying s and the next jobs in the optimal schedule of \({\mathcal {I}} _{h+1}\) (\(h=1,2,\ldots ,\left\lceil 1/\varepsilon \right\rceil \)) by setting \( t_{s}^{*}=t_{s}^{h+1}\) will not cost more than
Thus, the solution \(\Omega _{h+1}\) obtained by \(APS_{\varepsilon }^{\prime }\) for \({\mathcal {I}}_{h+1}\)(\(h=1,2,...,\left\lceil 1/\varepsilon \right\rceil \)) is sufficiently close to optimal schedule for Scenario 1 if s is the stradling job and \(t_{s}^{*}\in [t_{s}^{h},t_{s}^{h+1})\). As a conclusion, Scenario 1 has an FPTAS. \(\square \)
Theorem 11
Problem \(\Pi \) admits an FPTAS and this scheme can be implemented in \(O\left( n^2 /\varepsilon +n\min \{n,3/\varepsilon \}^{3}/\varepsilon ^{3}\right) \) time.
Proof
The proof is a direct deduction from all the cases mentioned in this section. \(\square \)
Remark 12
By applying the same approach, a PTAS can be elaborated for Problem \(\Pi \) and it can be implemented in \(O(n^{2}/\varepsilon +(n/\varepsilon ^{2})2^{O(1/\varepsilon )})\) time.
4 Conclusion
In this paper, we considered the non-resumable case of the single machine scheduling problem with a non-availability interval. Our aim is to minimize the maximum lateness when every job has a positive tail. Two cases are considered. In the first one, the non-availability interval is due to the machine maintenance. In the second case, the non-availibility interval is related to the operator who is organizing the execution of jobs on the machine. The contribution of this paper consists in an improved FPTAS for the MNA interval case and the elaboration of the first FPTAS for the operator non-availability interval case. The two FPTASs are strongly polynomial.
As future perspectives, we aim to consider other criteria for the single-machine problem as well as the study of multiple operator non-availablility periods.
References
Brauner N, Finke G, Kellerer H, Lebacque V, Rapine C, Potts C, Strusevich V (2009) Operator non-availability periods. 4OR 7:239–253
Carlier J (1982) The one-machine sequencing problem. Eur J Oper Res 11:42–47
Chen Y, Zhang A, Tan Z (2013) Complexity and approximation of single machine scheduling with an operator non-availability period to minimize total completion time. Inf Sci 251:150–163
Dessouky MI, Margenthaler CR (1972) The one-machine sequencing problem with early starts and due dates. AIIE Trans 4(3):214–222
Gens GV, Levner EV (1981) Fast approximation algorithms for job sequencing with deadlines. Discret Appl Math 3:313–318
He Y, Zhong W, Gu H (2006) Improved algorithms for two single machine scheduling problems. Theor Comput Sci 363:257–265
Ibarra O, Kim CE (1975) Fast approximation algorithms for the knapsack and sum of subset problems. J ACM 22:463–468
Kacem I (2009) Approximation algorithms for the makespan minimization with positive tails on a single machine with a fixed non-availability interval. J Comb Optim 17(2):117–133
Kacem I, Kellerer H (2014) Approximation algorithms for no idle time scheduling on a single machine with release times and delivery times. Discret Appl Math 164(1):154–160
Kubzin MA, Strusevich VA (2006) Planning machine maintenance in two machine shop scheduling. Oper Res 54:789–800
Lee CY (1996) Machine scheduling with an availability constraints. J Glob Optim 9:363–384
Qi X (2007) A note on worst-case performance of heuristics for maintenance scheduling problems. Discret Appl Math 155:416–422
Qi X, Chen T, Tu F (1999) Scheduling the maintenance on a single machine. J Oper Res Soc 50:1071–1078
Rapine C, Brauner N, Finke G, Lebacque V (2012) Single machine scheduling with small operator-non-availability periods. J Sched 15:127–139
Sahni S (1976) Algorithms for scheduling independent tasks. J ACM 23:116–127
Schmidt G (2000) Scheduling with limited machine availability. Eur J Oper Res 121:1–15
Yuan JJ, Shi L, Ou JW (2008) Single machine scheduling with forbidden intervals and job delivery times. Asia-Pac J Oper Res 25(3):317–325
Acknowledgments
The authors would like to thank the referees and the editors for their helpful remarks and suggestions. This work has been funded by the CONSEIL REGIONAL DE LORRAINE (under the Programme “Chercheur d’Excellence 2013”).
Author information
Authors and Affiliations
Corresponding author
Additional information
The short version of this paper has been presented at ISCO’2014 conference (2014).
Appendices
Appendix 1: Proof of Theorem 5
First, we recall the idea of the dynamic programming algorithm which is necessary to explain the proof. Indeed, the problem can be optimally solved by applying the following dynamic programming algorithm APS. This algorithm generates iteratively some sets of states. At every iteration j, a set \({\mathcal {X}}_{j}\) composed of states is generated (\(1\le j\le \overline{n}\)). Each state \(\left[ t,f\right] \) in \({\mathcal {X}}_{j}\) can be associated to a feasible schedule for the first j jobs. Variable t denotes the completion time of the last job scheduled before \(T_{1}\) and f is the maximum lateness of the corresponding schedule. This algorithm can be described as follows:

Let UB be an upper bound on the optimal maximum lateness for problem \( \left( \mathcal {T}^{\prime \prime }\right) \). If we add the restriction that for every state \(\left[ t,f\right] \) the relation \(f\le UB\) must hold, then the running time of APS can be bounded by \(\overline{n}T_{1}UB\). Indeed, t and f are integers and at each step j, we have to create at most \( T_{1}UB\) states to construct \({\mathcal {X}}_{j}\). Moreover, the complexity of APS is proportional to \(\sum _{k=1}^{\overline{n}}\left| {\mathcal {X}} _{k}\right| \). In the remainder of the paper, Algorithm APS denotes the version of the dynamic programming algorithm by taking \(UB=\mathcal { \varphi }_{JS}\left( \mathcal {T}^{\prime \prime }\right) \).
The main idea of the FPTAS is to remove a special part of the states generated by the algorithm. Therefore, the modified algorithm \( APS_{\varepsilon }^{\prime }\) becomes faster and yields an approximate solution instead of the optimal schedule. The approach of modifying the execution of an exact algorithm to design FPTAS, was initially proposed by Ibarra and Kim for solving the knapsack problem (Ibarra and Kim 1975). It is noteworthy that during the last decades numerous combinatorial problems have been addressed by applying such an approach [for instance, see Sahni (1976) and Gens and Levner (1981)]. The worst-case analysis of our FPTAS is based on the comparison of the execution of algorithms APS and \( APS_{\varepsilon }^{\prime }\) as described in the following lemma.
Lemma 13
For every state \(\left[ t,f\right] \) in \({\mathcal {X}}_{j}\) there exists a state \(\left[ t^{\#},f^{\#}\right] \) in \({\mathcal {X}}_{j}^{\#}\) such that:
and
Proof
By induction on j. First, for \(j=1\) we have \({\mathcal {X}}_{1}^{\#}={\mathcal {X}}_{1}\). Therefore, the statement is trivial.Now, assume that the statement holds true up to level \(j-1\). Consider an arbitrary state \(\left[ t,f\right] \) \(\in \) \({\mathcal {X}}_{j}\). Algorithm APS introduces this state into \({\mathcal {X}}_{j}\) when job j is added to some feasible state for the first \(j-1\) jobs. Let \(\left[ t^{\prime },f^{\prime } \right] \) be the above feasible state. Two cases can be distinguished: either \(\left[ t,f\right] =\left[ t^{\prime }+p_{j},\max \left\{ f^{\prime },t^{\prime }+p_{j}+q_{j}\right\} \right] \) or \(\left[ t,f\right] =\left[ t^{\prime },\max \left\{ f^{\prime },T_{2}+\sum _{i=1}^{j}p_{i}-t^{\prime }+q_{j}\right\} \right] \) must hold. We will prove the statement for level j in the two cases.
1st case: \(\left[ t,f\right] =\left[ t^{\prime }+p_{j},\max \left\{ f^{\prime },t^{\prime }+p_{j}+q_{j}\right\} \right] \) Since \(\left[ t^{\prime },f^{\prime }\right] \in {\mathcal {X}}_{j-1}\), there exists \(\left[ t^{\prime \#},f^{\prime \#}\right] \in {\mathcal {X}}_{j-1}^{\#}\) such that \(t^{\prime \#}\le t^{\prime }\le t^{\prime \#}+\left( j-1\right) \delta _{2}\) and \(f^{\prime \#}\le f^{\prime }+\left( j-1\right) \max \{\delta _{1},\delta _{2}\}\). Consequently, the state \(\left[ t^{\prime \#}+p_{j},\max \left\{ f^{\prime \#},t^{\prime \#}+p_{j}+q_{j}\right\} \right] \) is generated by Algorithm \( APS_{\varepsilon }^{\prime }\) at iteration j. However it may be removed when reducing the state subset. Let \(\left[ \lambda ,\mu \right] \) be the state in \( {\mathcal {X}}_{j}^{\#}\) that is in the same box as \(\left[ t^{\prime \#}+p_{j}, \max \left\{ f^{\prime \#},t^{\prime \#}+p_{j}+q_{j}\right\} \right] \). Hence, we have:
Moreover,
which implies
Finally,
Consequently, the statement holds for level j in this case.
2nd case: \(\left[ t,f\right] =\left[ t^{\prime },\max \left\{ f^{\prime },T_{2}+\sum _{i=1}^{j}p_{i}-t^{\prime }+q_{j}\right\} \right] \)Since \(\left[ t^{\prime },f^{\prime }\right] \in {\mathcal {X}}_{j-1}\), there exists \(\left[ t^{\prime \#},f^{\prime \#}\right] \in {\mathcal {X}}_{j-1}^{\#}\) such that \(t^{\prime \#}\le t^{\prime }\le t^{\prime \#}+\left( j-1\right) \delta _{2}\) and \(f^{\prime \#}\le f^{\prime }+\left( j-1\right) \max \{\delta _{1},\delta _{2}\}\). Consequently, the state \(\left[ t^{\prime \#},\max \left\{ f^{\prime \#},T_{2}+\sum _{i=1}^{j}p_{i}-t^{\prime \#}+q_{j}\right\} \right] \) is generated by algorithm \(APS_{\varepsilon }^{\prime }\) at iteration j. However it may be removed when reducing the state subset. Let \(\left[ \lambda ^{\prime },\mu ^{\prime }\right] \) be the state in \({\mathcal {X}}_{j}^{\#}\) that is in the same box as \([t^{\prime \#},\max \{f^{\prime \#},T_{2}+\ \sum _{i=1}^{j}p_{i}\) \(-t^{\prime \#}+q_{j}\}]\). Hence, we have:
Moreover,
which implies
and
In conclusion, the statement holds also for level k in the second case, and this completes our inductive proof. \(\square \)
Now, we give the proof of Eq. (2) in Theorem 5. By definition, the optimal solution can be associated to a state \(\left[ t^{*},f^{*}\right] \) in \( {\mathcal {X}}_{\overline{n}}\). From Lemma 13, there exists a state \(\left[ t^{\#},f^{\#}\right] \) in \({\mathcal {X}}_{\overline{n}}^{\#}\) such that:
Since \(\mathcal {\varphi }_{APS_{\varepsilon }^{\prime }}\left( {\mathcal {I}} ^{\prime \prime }\right) \le f^{\#}\), we conclude that Equation (5) holds.
Appendix 2: Proof of Lemma 6
The first step consists in applying heuristic JS, which can be implemented in \(O\left( \overline{n}\ln \overline{n}\right) \) time. In the second step, algorithm \(APS_{\varepsilon }^{\prime }\) generates the state sets \({\mathcal {X}} _{j}^{\#}\) (\(j\in \left\{ 1,2,\ldots ,\overline{n}\right\} \)). Since \(\left| {\mathcal {X}}_{j}^{\#}\right| \le \left( \omega _{1}+1\right) \left( \omega _{2}+1\right) \), we deduce that
Note that algorithm \(APS_{\varepsilon }^{\prime }\) generates \({\mathcal {X}} _{j}^{\#}\) by associating every new created state to its corresponding box if and only if such a state has a smaller value of t (in this case, the last state associated to this box will be removed). Otherwise, the new created state will be immediately removed. This allows us to generate \( {\mathcal {X}}_{j}^{\#}\) in \(O\left( \omega _{1}\omega _{2}\right) \) time. Hence, our method can be implemented in \(O\left( \overline{n}\ln \overline{n}+ \overline{n}^{3}/\varepsilon ^{2}\right) \) time and this completes the proof.
Rights and permissions
About this article

Cite this article
Kacem, I., Kellerer, H. & Seifaddini, M. Efficient approximation schemes for the maximum lateness minimization on a single machine with a fixed operator or machine non-availability interval. J Comb Optim 32, 970–981 (2016). https://doi.org/10.1007/s10878-015-9924-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10878-015-9924-4