
Abstract
The continuous development of metal additive manufacturing (AM) promises the flexible and customized production, spurring AM research towards end-use part fabrication rather than prototyping, but inability to well control process defects and variability has precluded the widespread applications of AM. To solve these issues, process monitoring and control is a powerful approach. Recently, a variety of monitoring methods have been proposed and integrated with metal AM machines, which enables a large volume of data to be collected during the process. However, the data analytics faces great challenges due to the complexity of the process, bringing difficulties on developing effective models for defects detection as well as feedback control to improve quality. To overcome these challenges, machine learning methods have been frequently employed in the model development. By using machine learning methods, the models can be built based on the collected dataset, while it is not necessary to fully understand the process. This paper reviews the applications of machine learning methods in metal powder-bed fusion process monitoring and control, illuminates the challenges to be solved, and outlooks possible solutions.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Additive manufacturing (AM) also known as “3D printing” builds parts from computer-aided design (CAD) models directly through stacking materials layer-by-layer (Technologies & Terminology, 2012). It opens new avenues to building parts with complex structures that are difficult or even impossible to be manufactured by other machining processes. Besides, it needs little lead time (Waterman & Dickens, 1994) and reduces material waste. Owing to these advantages, AM opens up new possibilities in manufacturing industry. Currently metal AM is approaching a paradigm shift from prototyping to end-use part fabrication. This makes quality assurance become a prominent and urgent issue to be solved. In the study we focus on powder-bed fusion (PBF) process, one category of metal AM processes, including selective laser melting (SLM) and electron beam melting (EBM). The PBF process can obtain good feature resolution and accuracy, making it appealing for precision applications where elimination of process defects and variability is of vital importance. To improve part quality, the National Institute of Standards and Technology (NIST) in the US reported the needs for the development of monitoring and control methods in the year of 2015 (Mani et al., 2015). In the last 5 years, a variety of monitoring methods have been proposed in both academic and industrial communities. Most of the companies selling PBF machines have developed their own monitoring systems and integrated with their advanced machines, such as EOS, SLM Solutions, Concept Laser and Renishaw. These systems commonly detect optical emissions, including visible light emission and infrared light emission which is highly related to temperature information. Besides, some other monitoring systems have been developed for feasibility exploration and further process understanding, including acoustic monitoring system (Eschner et al., 2018), X-ray assistant monitoring system (Calta et al., 2018), acoustic spectroscopy monitoring system (Dryburgh et al., 2019) and interferometric monitoring system (DePond et al., 2018).
Equipped with the monitoring systems, a large amount of data can be acquired in PBF process. On one hand, the researchers analysed the acquired data and expected to discover some variation rules and to link some sudden changes of the process signatures to the generation of process defects or variability (Bisht et al., 2018; Coeck et al., 2019; Fisher et al., 2018). Commonly a single process signature is selected and studied which is however insufficient due to the complexity of the process. On the other hand, machine learning is adopted to build the models, which reveal highly non-linear relationships between all process signatures and the defects and variability with little expertise on the process. Several review papers on PBF process monitoring and control have been published. For example, Tapia and Elwany (2014) and Everton et al. (2016) reviewed the in-situ monitoring methods in metal AM, including powder bed fusion process (PBF) and directed energy deposition (DED) process, mainly introducing the sensing and setup configurations. Spears and Gold (2016) also reviewed sensing and setup configurations in LPBF process. They all highlighted the importance of establishing correlations between process parameters, process signatures and quality metrics, and put forward the great challenge on managing a large volume of data in PBF process monitoring. Similarly, Grasso and Colosimo (2017) reviewed the monitoring methods both in academic and industrial communities. In addition, they summarized possible part defects in PBF process. Later they further updated the review paper which summarized the detectable defects with different sensing methods (M. L. G. Grasso et al., 2021). D. Chen et al. (2021) reviewed the application of the state-of-the-art sensing techniques in PBF process and mentioned the application of using intelligent algorithms for anomaly detection. McCann et al. (2021) reviewed the possible process defects, sensing techniques and process control methods. They emphasized the requirements for real-time control and listed the application of machine learning in process control. However, a systematic and detailed introduction and comparison on different machine learning methods in AM process monitoring and defect detection is still lacking. Therefore, this paper reviewed the process monitoring and control methods focusing on the application of machine learning methods. Moreover, this paper reviewed the sensing methods according to the spatial scale as it is important to estimate the possible information contained in the sensing data.
Machine learning (ML) has been developed for several decades (Jordan & Mitchell, 2015; Shalev-Shwartz & Ben-David, 2014), since the term ‘machine learning’ was proposed by Arthur Samuel in 1952. There have been numerous machine learning initiatives to date, promoting machine learning to evolve to a great extent. It did not take off until the late 1990s. The chess computer beat Kasparov, proving that machines were indeed capable of human-like intelligence. Since then, many scientists and researchers have devoted extensive efforts on machine learning and developed various new programs and algorithms. Machine learning has merged as the method of choice for computer vision, speech recognition, natural language processing, robot control and other applications. The algorithms can be categorized into three main classes: supervised learning, unsupervised learning and semi-supervised learning. The methods have been widely applied in fault diagnosis, condition monitoring and remaining life prediction in industrial equipment and systems (Liu et al., 2018; Stetco et al., 2018). For example, Ali et al. (2019) proposed a practical machine learning-based fault diagnosis method for induction motors using experimental data, and they used three classification algorithms for fault classification and provided nearly 100% classification accuracy. C. Yang et al. (2019) developed a reconstruction modeling technique combining support vector regression and sliding-time-window approaches. Residuals between the observed signal and the reconstructed signal are utilized to indicate whether the desired quantity is different from its normal operation condition or not. The developed model demonstrated improved performance in detecting wind turbine faults. J. Zhang, Hong, et al. (2018) studied the Long Short-Term Memory (LSTM) network to track the system degradation and to predict the remaining useful life, and they showed that compared with other machine learning techniques, LSTM turns out to be more powerful and accurate in revealing degradation patterns.
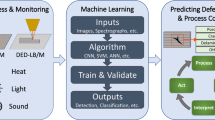
The success of using machine learning for industrial monitoring depends on several significant factors: sensing method, dataset preparation, feature selection and modeling algorithm. This paper reviews current status and challenges on these aspects in PBF process as well as data fusion and feedback control which are the next crucial steps towards high quality assurance after the development of monitoring system. The framework is shown in Fig. 1.

The framework on PBF process monitoring and control
The paper includes the following sections. “Sensing methods” section introduces the sensing methods in PBF process; “Type of defects and dataset preparation” section introduces the possible types of defects and data preparation methods; “Machine learning modeling” section introduces the machine learning modeling methods; “Data fusion” section introduces data fusion methods; “Feedback control” section introduces feedback control methods; the seventh introduces the future directions; and the last section draws the conclusions.
Sensing methods
Sensing is the first step toward the development of monitoring system, which is also significant for final monitoring performance as this step determines the information and data to be collected. Different from the previous papers that classified these sensing methods according to the type of sensors and setup configurations, we classify these sensing methods according to the spatial scale as it is important to estimate the possible information contained in the sensing data. Thus, we classify these sensing methods into three categories: melt pool-scale sensing methods, layer-scale sensing methods and volume-scale sensing methods.
Melt pool-scale sensing methods
The melt pool-scale sensing methods refer to the methods that measure the dynamic variation of melt pool both directly and indirectly. The direct sensing methods mean that the melt pool dynamic process can be observed directly, such as high-speed photographing or X-ray assistant high-speed photographing. To fully understand the mechanisms during the process, the direct melt pool sensing systems have been developed in several advanced labs, including the Argonne National Laboratory (Zhao et al., 2017) and Lawrence Livermore National Laboratory (Calta et al., 2018) in USA, and Heriot-Watt University in UK (Bidare et al., 2017). These provide significant information for discovering novel phenomena and revealing the physical mechanisms on the melting and cooling process. Particularly, the particle spattering by the entrainment effect of ambient gas (Ly et al., 2017; Matthews et al., 2016), vapor depressions during the transition from the thermal conduction mode to ‘keyhole’ mode (Cunningham et al., 2019), pore motion and elimination (Hojjatzadeh et al., 2019), pore dissolution and dispersion by laser re-melting (Leung et al., 2018), and large ejecta formation and interactions with melt pool formation (Nassar et al., 2019), have been observed and explained with unprecedented detail.
Although these advanced direct melt pool sensing systems are meaningful for process understanding and ultimately providing effective solutions for quality improvement, they are not suitable for online sensing in industrial applications, because they are high-cost and difficult to be integrated with commercial PBF machines. Therefore, several indirect melt pool sensing methods were also proposed and their feasibility for online application were studied. The indirect melt pool sensing methods detect the radiation signal during laser-melt pool interaction or the auxiliary signal after interacting with the melt pool. The detected signal reflects partial information on melt pool status, and then by virtue of the information melt pool status can be estimated. The commonly detected indirect signal of melt pool is optical radiation (as shown in Fig. 2), especially thermal optical radiation as it can be calibrated to temperature information that affects the formation of microstructure, thermal stress, and finally part quality. The optical radiation waveband is in a wide range, so the optical sensors sensitive to different wavebands were employed, including the visible waveband, near infrared waveband and infrared waveband. The sensors used contain photodiode (Berumen et al., 2010), pyrometer (Furumoto et al., 2013), CMOS camera (Clijsters et al., 2014), thermal camera (M. Grasso et al., 2018) and spectrometer (Dunbar et al., 2016). Apart from optical radiation, the acoustic emission is also studied. The acoustic emission is generated by the vibration of melt pool, ‘keyhole’ and ejected vapor, so it contains the information on melt pool dynamics and melt pool vaporization that are also related to the final part quality. The acoustic sensing systems have also been developed recently (Koester et al., 2018). Additionally, the interferometric imaging system (as shown in Fig. 3) was developed by Kanko et al. (2016) and DePond et al. (2018), and it is capable of sensing the information on melt pool morphology.

Optical set-up of melt pool monitoring system (Clijsters et al., 2014)

Interferometric imaging system set-up (Kanko et al., 2016)
The melt pool-scale sensing method collects signals at the minimum scale among the three categories of sensing methods. It provides high-resolution information both in spatial and in temporal, so it is suitable for the detection of small local defects which are generated transiently in the process, such as internal pores, cracks and inconsistent microstructures.
Layer-scale sensing methods
The layer-scale sensing methods collect the information on the whole platform before or after the scanning of each layer. The commonly used sensors for these methods are high-resolution visual cameras or high-resolution thermal cameras. The methods can detect the information on powder deposition condition, built surface morphology, as well as built surface thermal distribution. zur Jacobsmühlen et al. (2013) indicated that the sensing system with a visual camera can detect the super-elevation of part contours, missing powder and low energy input. Later they further discussed the possible spatial error and demonstrated that a repeated calibration is necessary for this sensing system (zur Jacobsmühlen et al., 2014). Foster et al. (2015) made it progress by considering the influence of lighting schedule in the chamber. Pagani et al. (2020) developed an edge segmentation approach to detect the out-of-control deviations from the nominal geometry, as shown in Fig. 4. Krauss et al. (2014) indicated that the sensing system with a thermal camera can identify hot spots in an early stage during solidification process. Furthermore, Rodriguez et al. (2015) developed a temperature calibration method aiming at detecting absolute surface temperature based on this sensing system.

Example of image segmentation for the layer signalled as out-of-control by the control chart for sample 1A; the color bar indicates the deviations from the nominal geometry along the reconstructed contour (Pagani et al., 2020) (Color figure online)
Apart from the sensing systems mentioned above, the feasibility of some novel layer-scale sensing methods was also studied. For instance, Zhang et al. (2016) developed a vision sensing method through capturing the fringe projection (as shown in Fig. 5) and demonstrated it can obtain the height maps of the powder-bed. Rieder et al. (2015) studied the ultrasonic sensing method and indicated that it can be used for process quality assessment by evaluating the backwall signals and the ultrasonic velocities. Smith et al. (2016) proposed a sensing method named spatially resolved acoustic spectroscopy (SRAS), which is a technique for material characterization based on robustly measuring the surface acoustic wave velocity. Their work showed that this method has the potential for the detection of internal pores and cracks. Z. Li et al. (2018) and Kalms et al. (2019) respectively built a sensing system with a projector and two cameras, which achieves the measurement of surface morphology.

a Set up of fringe projection system, b image on height map collected by fringe projection system (Zhang et al., 2016)
Compared with melt pool-scale sensing method, layer-scale sensing method can detect the geometric signatures of built region, making it suitable for the detection of part geometry variation (Imani et al., 2019). Additionally, layer-scale sensing method also has the potential for internal pores and cracks, however, its resolution is limited by the camera resolution and it is only able to detect the surface morphology defects after their generation rather than to detect the dynamic information during the melting and cooling process.
Volume-scale sensing methods
While no direct volume-scale sensing method has been proposed to date, the melt pool-scale sensing method and the layer-scale sensing method are both available for providing volume-scale information due to the layer-by-layer-built trait of AM processing. A variety of features extracted from the melt pool-scale or layer-scale sensing signals have been mapped into three-dimensional space to study their feasibility for the volume-scale defect detection. For instance, Clijsters et al. (2014) used the melt pool area as an indicator and mapped it to show the internal void detection results. They demonstrated that the void detection result is consistent with the X-ray measurement result on the position of void occurrence. Kriczky et al. (2015) mapped several indicators, including thermal gradient at the solidus-to-liquidus region, the maximum temperature in the melt pool, the melt pool area, and the length-to-width ratio of melt pool, for an L-shaped part. they found several anomalous trends based on their mapping results when using different process parameters, but they did not correlate their mapping results to any specific internal defects. Mahmoudi et al. (2019) employed Gaussion process (GP) to generate a melt pool indicator based on the melt pool images detected by two thermal cameras, and then they mapped the indicator and successfully detected the internal pores they intentionally created. Cheng et al. (2019) extracted acoustic signal intensity as an indicator, and the mapping result showed that two kinds of defects, metal defect and dried paste defect, can be identified. Gobert et al. (2018) extracted features from the layer-scale images as indicators, and the mapping result demonstrated that the internal pores can be detected. Coeck et al. (2019) used the melt pool event, the abrupt fluctuation in the melt pool signal, as an indicator for lack of fusion porosity prediction. They quantified the prediction sensitivity for the internal voids with different volume values. Their results showed that although the void prediction sensitivity is high, the false positive count, i.e., the events that are predicted as a defect by the mapping result but did not lead to a real defect as observed in the XCT measurement result, is also rather high, especially for the voids with small volumes, as shown in Fig. 6.

Overlay of XYZ point cloud from processed melt pool monitoring data (black) with the results from the CT scan (red) for a 10 × 10 × 10 mm sample (Coeck et al., 2019b) (Color figure online)
In summary, the preliminary works on volume-scale sensing are mostly based on mapping of the melt pool-scale or layer-scale sensing results. Therefore, the final defect detection performance depends on the melt pool-scale or layer-scale sensing performance. Currently, most of volume-scale defect sensing works focus on internal pores detection, and the performance still need to be improved for the pores with small sizes.
Type of defects and dataset preparation
Using machine learning for process monitoring, the model is built based on a prepared dataset that includes the input variables and the corresponding output responses. Here, the input variables are the signals collected by the sensing methods mentioned above, and the output responses are the defects that are expected to detect during the process. As different types of defects may be generated, before dataset preparation, which type of defect to be detected should be determined. Then the model should be built based on the defect generation mechanism. Therefore, this paper reviews possible defects and their generation mechanisms. According to the information volume required in the time range, the defects are categorized into two main categories: local defects and global defects. The local defects are generated in a short time due to some transient process variants. The global defects are formed as an accumulation effect of multiple layers.
Local defects
Porosity
Porosity is a dominant defect in the as-built parts and has detrimental effect on all mechanical properties, especially on fatigue tolerance (Edwards et al., 2013; Leuders et al., 2013; Sterling et al., 2016; Yadollahi et al., 2017). The investigations on characterizing porosity in the as-built parts and analysing the influence of processing parameters on porosity have been widely conducted (Gu et al., 2013; Slotwinski et al., 2014). Two types of pores are commonly observed using the X-ray Computed Tomography (XCT) measurement: spherical pores and non-spherical pores (Fig. 7). The spherical pores are formed because the gas bubbles are entrapped in the part instead of being released during the solidification process (Khairallah et al., 2016a; Weingarten et al., 2015). The gas bubbles could be generated due to different reasons: (1) the vaporization of low melting point constituents within the alloy (Gong, Gu, et al., 2014); (2) the collapse of ‘keyhole’ (Khairallah et al., 2016a); and (3) the gas entrapped in the powder particles during the atomization process (Murr et al., 2009). The non-spherical pores, also seemed as ‘cracks’ for those with large sizes, commonly appear at the connection positions of tracks and layers mainly caused by insufficient energy input as well as the resultant unstable melt flow (Qiu et al., 2015; Tammas-Williams et al., 2015). It is worth noting that not all the pores generated during the process can be detected in the as-built parts as some of them maybe released in the next layer of melting that re-melts a prior layer (Gong et al., 2014). Another possible reason on non-spherical pore generation is the removal of large particles attached on the top surface during the recoating process (Gong et al., 2014).

The pores under different energy densities. a Non-spherical pores; b no obvious pores; c near-spherical pores (Kasperovich et al., 2016)
Cracks
Cracking is known as the result of competition between the mechanical driving force to cracking and the material’s intrinsic resistance to cracking (Zhong et al., 2005) (Fig. 8). The cracking phenomenon on different materials were characterized and the cracking mechanisms were explained (Carter et al., 2012; J. Yang et al., 2015; Zhou et al., 2018). The liquation cracking behaviour was studied for Inconel 718 and it was found that the cracks initiate from the weak site near the fusion line in the pre-deposited layer and propagates along the interdendritic region with the further deposition proceeding layer by layer (Chen et al., 2016). Wang et al. studied the solidification cracks in single crystals and low angle bi-crystals, and they demonstrated that solidification cracking preferentially appears above a critical grain boundary angle, which produces a supercritical film length (N. Wang et al., 2004). Wei et al. studied the ductility dip cracking (DDC) of ERNiCrFe-7A Ni-based alloy, and concluded that the DDC susceptibility increases with the increase of grain misorientation in the local texture (Wei et al., 2016).

Cracks initiated at the grain boundaries in the DS superalloy substrate (Zhong et al., 2005)
Microstructural heterogeneities
The PBF process is characterized by high temperature gradients and cooling rates that lead to rapidly solidified, non-equilibrium microstructures. Any process variations may give rise to inconsistent local temperature gradients and cooling rates, resulting in heterogeneous microstructures (Fig. 9). Microstructural heterogeneity contains the differences in morphology, size, orientation, and chemical compositions of phases and grains (Kok et al., 2018). The influence of heterogeneous microstructures on mechanical properties is still an open issue. The related studies have been conducted to investigate the influence of microstructures on tensile properties (Carroll et al., 2015; Z. Wang et al., 2016), hardness (Hrabe & Quinn, 2013; Tucho et al., 2017) and fracture toughness (Cain et al., 2015; Van Hooreweder et al., 2012) for different materials.

EBSD phase maps (a, c, e) and IPF maps (b, d, f) on longitudinal cross-section at different heights of as-EBM-built rod showing variation in phase composition and grain morphology: a, b top region, c, d center region and e, f bottom region (Sun et al., 2015)
Global defects
Geometric variations
A variety of geometric variations have been observed and reported in literature, containing the phenomena of shrinkage (Sharratt, 2015; Thomas, 2009), warpage (Mercelis & Kruth, 2006), curling (Mousa, 2016; Sharratt, 2015), oversizing (Thomas, 2009) and edge elevating (Kleszczynski et al., 2012; Yasa et al., 2009) (Fig. 10). The geometric variations are commonly caused by the accumulation of thermal stress. The rapid melting and solidification process bring large thermal gradients between the different layers and the substrate. This leads to large thermal stress in the part, ultimately resulting in the geometric variations (Paul et al., 2014).

Geometric variations: a edge-elevating, b curling (Mousa, 2016), c warpage
Delamination
Delamination is the effect of crack initiation and growth. The cracks can be generated due to several reasons as mentioned in Sect. 3.1. The thermal stress in the part could aggravate the propagation of the initial cracks. When the thermal stress exceeds the binding ability between the adjacent layers, delamination occurs (Zäh & Lutzmann, 2010), as shown in Fig. 11. Consequently, the final part is a failure and the process has to be terminated.

Delamination (Zäh & Lutzmann, 2010)
Surface defects
Surface defects could lead to high surface roughness, and finally affects part quality. In SLM processed objects, the reasons of surface defect include melt pool instability, spatter attachment and semi-melt particle attachment. Melt pool instability is caused by improper parameter selection, which is susceptible to Plateau-Rayleigh instability. This melt pool instability leads to rolling surface morphology (Han et al., 2018; Yadroitsev & Smurov, 2011), as shown in Fig. 12, which may affect surface quality of the next layers, and finally results in rougher surface. Spatter attachment, especially some large-size spatter attachment, is another key reason to form rolling surface morphology. These spatters are caused by the recoil pressure and gas entrainment (Khairallah et al., 2016). They are ejected from the melt pool region and may fall back to the as-built surface to form surface defects. Semi-melt particles get attached to the surface (Strano et al., 2013), which is especially detrimental to the surface roughness of the side surfaces and down-skin surfaces (D. Wang et al., 2013). The poor surface roughness will result in poor fatigue performance.

Surface morphology with high surface roughness (Han et al., 2018)
Label of defects
In terms of machine learning modeling, especially for supervised and semi-supervised machine learning methods, object labelling is a key step to determine the model performance. False label or missing label will affect the accuracy and reliability of the model. Many machine learning methods that have been applied for SLM process monitoring labelled the built quality with the energy input (Caggiano et al., 2019; Shevchik et al., 2018). That is, different energy inputs correspond to different part qualities. This is the simplest labelling approach that can verify the effectiveness of the proposed methods, but it is not quite rational to build models for defect detection in practical applications. Because energy input is commonly optimized and kept constant during the processing, while some defects occur randomly. The generation of the defects is not fully determined by the energy input. In addition, another simple labelling approach is also frequently applied in some studies, which is to label the defects through direct observation by eyes (Baumgartl et al., 2020; Imani et al., 2019; Scime & Beuth, 2018a) (Fig. 13). However, the method is only appliable to some macro-defects (delamination, part failure, recoating defects and so on) that can be observed and distinguished easily.

Defects labelled by direct observation. a Recoater streaking, b Part failure (Scime & Beuth, 2018a)
In addition to the two simple labelling methods, some other methods have also proposed. Gobert et al. (2018) and Seifi et al. (2019) labelled the ground truth of internal pores based on the CT scan results. While CT scan is a powerful postprocessing tool for internal defect detection, it is high-cost and time-consuming. Yuan et al. (2019) proposed to label the width of a single track through their developed image processing method based on height measurement results. This method aims at labelling a single-track quality rather than a part quality. Up to now, the labelling of defects or quality in PBF is still an open problem. For different defect categories, more rational and feasible methods for effective labelling are necessary.
Machine learning modeling
Once monitoring data has been collected and labelled, the next step is to build a correlation between the monitoring data and the defects or quality. Since the correlation is highly complex, nonlinear and not fully understood yet, machine learning modeling is a suitable and efficient method to help build the correlation. A general procedure on machine learning modelling contains several steps: (1) data collection; (2) data pre-processing; (3) feature extraction; (4) feature selection; (5) pattern recognition; (6) model validation. Now in PBF process monitoring, many efforts have been made on feature extraction, feature selection and pattern recognition/model regression.
Feature extraction and feature selection
High-quality feature extraction and feature selection ensure that all useful features are selected without redundancy. This can be done by experts who understand the collected data and the process physics, so that appropriate features with physical foundation can be selected. For instance, Gobert et al. (2018) proposed a method to obtain the second derivatives of voxel intensity as a feature for discontinuity detection. Coeck et al. (2019b) used “melt pool signal event” to represent the process abnormality. “Melt pool signal event” is the melt pool light emission abnormality. Clijsters et al. (2014) extracted the melt pool area from the melt pool image as a key feature to detect process abnormalities. M. Grasso et al. (2018) extracted the plume area and plume intensity, and analysed their characteristics for different energy inputs. Repossini et al. (2017) developed methods to extract spatter-related features, including laser heated zone area, spatter number, average spatter area, and convex hull area. Y. Zhang, Hong, et al. (2018)) also developed an image processing method to exact the plume-related features and melt pool-related features simultaneously.
Unfortunately, the PBF process is rather complex, and still faces uncertainties and randomness. Even most experts can hardly select all the appropriate features with clear physical meaning that can lead to accurate detection for defects or process abnormalities. Therefore, except for the features with physical meaning, some features were also extracted based on mathematical methods. Scime and Beuth (2018a) utilized 37 image filters to convolve with the original image to extract different image features (Fig. 14). Okaro et al. (Okaro et al., 2019) applied singular value decomposition (SVD) to extract the features of time history data from two types of photodiode. Montazeri and Rao (2020) used graph Fourier transform coefficients as features for porosity detection. Scime and Beuth (2019) employed scale invariant feature transform (SIFT) to extract features from melt pool images. Although these mathematical features do not have corresponding physical meaning, they are still able to reveal relationships with the built quality through machine learning methods. To reduce computational complexity and improve model performance, feature selection methods are often adopted to reduce feature dimension and select highly related ones. In PBF process monitoring, principle component analysis (PCA) (Y. Zhang, Hong, et al., 2018; Zhang, Wang, et al., 2018) and spectral graph theoretic approach (Montazeri & Rao, 2018) have been applied in related works.

Flowchart of feature extraction and machine learning process implemented in Scime and Beuth (2018a)
In addition, the popular deep learning methods were also frequently used in PBF process monitoring (Caggiano et al., 2019; Scime & Beuth, 2018b; Shevchik et al., 2018). Deep learning methods can extract representative features automatically through training process, and this reduces the work load on feature selection by researchers. However, these features are extracted in a black box, so their interpretability and reliability are poor.
Melt pool state and defects identification
For a typical machine learning modeling process, the next step after feature extraction and feature selection is usually pattern recognition or model regression. In SLM process monitoring, some machine learning methods have been applied to recognize the pattern of melt pool or defects. Table 1 lists the methods used in recent publications. The machine learning methods include supervised methods, semi-supervised methods, unsupervised methods and reinforcement methods. The most commonly used method is supervised convolutional neural network (CNN) due to its popularity and outstanding performance on image processing and speech recognition. Besides, some traditional machine learning methods were also applied for quality classification, such as the Support vector machine (SVM), K-nearest neighbors (KNN), Decision tree (DT), and so on. The semi-supervised learning methods used include semi-supervised CNN and semi-supervised Gaussian Mixture Model (GMM). The unsupervised learning methods used include K-means clustering and Self-Organizing Maps (SOM). Duman and Özsoy (2022) and Li et al. (2021) tried to explore the application of transfer learning for process defects and quality classification with limited training data. Wasmer et al. (2019) attempted to employ reinforcement learning methods for the identification of melt pool state under different energy inputs. In addition, Knaak et al. (2021) proposed to use reinforcement learning for feedback control model development and they demonstrated the effectiveness of their proposed method for in-process parameter optimization.
Although the above-mentioned ML methods have been applied in PBF process monitoring, most of these works just use the mature algorithms and examine their feasibility on quality identification. In practice, the algorithm selection and improvement for a particular problem is crucial, which highly depends on the characteristics of the dataset collected. For example, Bayes classifier originated from classical mathematical theory, has a solid mathematical foundation. It performs well on small-scale databases, and it is less sensitive to missing data. KNN commonly can obtain a high accuracy and is insensitive to outlier. The KNN theory is simple and easy to implement, but KNN requires a lot of computing memory. For data sets with large sample sizes, the computation load is relatively large. DT is easy to understand and interpret, but it is prone to over fitting. SVM has a strong generalization ability, but it is sensitive to missing data. Seifi et al. (2019) proposed an approach for layer-wise quality classification. They extracted key process features based on layer-wise melt pool images and used principle component analysis (PCA) for feature selection. Then the selected features were classified by SVM as healthy and unhealthy conditions with an accuracy of 94%. Khanzadeh et al. (2018) compared the performance of identifying pores and normal melt pools by several different traditional machine learning methods, including KNN, SVM and DT. KNN results in the highest rate of accurately classifying melt pools. DT results in the lowest rate for incorrectly identifying normal melt pools as pores. Neural network (NN) can fully approximate the complex nonlinear relationship and obtain high accuracy, but it is a black box and requires a large amount of data. Gaikwad, Giera, et al. (2020) extracted low-level features representative of the melt pool dynamics from pyrometer signal and high-speed video. The sequential extracted features were used as the input of a NN model to classify a single track quality. They found that the proposed approach outperforms purely data-driven models, such as convolutional neural networks and recurrent neural networks.
K-means clustering and SOM are two typical clustering methods which have been applied in PBF process monitoring. For clustering methods, the dataset does not need to be labelled. K-means clustering follows a simple and easy way to classify a given data set through a certain number of clusters. The centroids in these clusters move after each iteration during training. For each cluster, the algorithm calculates the mean of all its data points and becomes the new centroid. K-means clustering is easier to implement and faster than most other clustering algorithms. Grasso et al. (2017) used k-means clustering to group the descriptors extracted from process images. Their results showed that the in-control process and out-of-control process can be identified. Taheri et al. (2019) tried to apply k-means clustering to classify identified acoustic signatures into four different process conditions and showed its potential for process monitoring. However, k-means clustering has a major shortcoming that the researchers need to specify the number of clusters (k value) and in most cases it is not easy to determine a good value for k. Additionally, k-means clustering commonly performs poorly on high-dimensional data. For high-dimensional data, an alternative unsupervised learning method is SOM. SOM has three layers. The last Kohonen layer is usually designed as two-dimensional arrangement of neurons that maps n-dimensional input to two dimensional. In the two-dimensional space, the relations of the dataset in the original space can also be kept. SOM has a characteristic of self-organization providing a topology-preserving mapping from the input space to the clusters. Khanzadeh et al. (2019) used SOM to analyse two-dimensional melt pool image streams to identify similar and dissimilar melt pools. Then they predicted the location of porosity based on melt pool identification results and obtained a prediction accuracy of almost 96%.
Deep learning methods were also frequently applied in PBF process monitoring as its superior performance compared to traditional machine learning methods. The most commonly used method is convolutional neural network (CNN) due to its popularity and outstanding performance on image processing. The input of CNN model is generally a melt pool image or a powder-bed layer-wise image. A typical CNN structure contains several stacked convolutional layers and pooling layers for feature learning followed by one or two fully connected layers for classification, such as AlexNet, VGG-Net, GoogleLeNet, and ResNet. Some of these typical structures have been applied in PBF process monitoring. Imani et al. (2019) used AlexNet CNN structure to detect surface flaws based on layerwise images after scanning. Similarly, Scime and Beuth (2018b) used AlexNet CNN structure to detect powder spreading flaws based on layerwise images after spreading. Both of their results showed AlexNet CNN structure can obtain a higher detection accuracy compared to traditional machine learning methods. Yazdi et al. (2020) proposed a hybrid deep neural network to classify different process conditions with different energy densities. The hybrid deep neural network contains two branches between input and output layers. One branch is created based on VGG-16 structure to extract features automatically. Another branch is developed based on statistical features extracted by wavelet transform and texture analysis and perceptron neural network (MLP). The proposed model demonstrated better performance compared to traditional machine learning methods.
Except for the typical CNN structures, some CNN structures specifically designed for PBF process monitoring were also proposed. Shevchik et al. (2018) used a spectral convolutional neural networks (SCNN) structure to classify acoustic features into poor, medium and high part qualities. Caggiano et al. (2019) proposed a bi-stream CNN structure and selected the optimal convolution kernels to extract features from both images collected after powder recoating and laser scanning. Their results showed that the method achieved an accuracy as high as 99.4% for defective condition identification. Zhang et al. (2019) proposed a hybrid CNN structure which contains two CNN models. The first CNN model is used to learn the spatial features from a single melt pool image. The second CNN model is used to learn temporal information from several sequential melt pool images. The proposed method demonstrated superior performance compared with traditional methods with handcrafted features on process condition recognition. Baumgartl et al. (2020) used a depthwise-separable CNN structure to achieve the detection of delamination and splatter defects with an accuracy of 96.8%. The depthwise-separable CNN is based on the Inception module, but the order between 1 × 1 convolution and 3 × 3 convolution is inverted, which extracts the spatial information first before a new feature map is created. Snow et al. (2021) designed a CNN structure through selecting appropriate number of layers, kernel sizes and pooling options to obtain highest average classification accuracy. Their proposed CNN model demonstrated significantly better performance than traditional neural networks across all tasks. In addition, the CNN model demonstrated improved generalizability, which means it can generalize to more diverse data than either the training or validation data sets with well performance. Kwon et al. (2020) explored to use CNN for laser power prediction based on melt pool images and showed more accurate results than traditional neural networks. The number of convolutional layers was fixed as 4 in their CNN structure. The filter size was selected based on its performance. R. Wang et al. (2022) proposed a deep learning approach based on an encoder-decoder network. The approach incorporated a detail-aware dilated convolutional neural network with a fine details feature map extractor designed to obtain final fine semantic features. Compared with the typical CNN structure, the proposed approach yielded better results.
The application of other deep learning methods is much less studied than that of CNN. Preliminary exploration of using deep belief network (DBN) and stacked auto-encoder (SAE) has been conducted. A typical DBN structure is composed of a stack of restricted Boltzmann machines (RBMs) and a neural network (NN) layer for classification. RBM is a kind of Boltzmann machine with no internal layer connection within both visible and hidden layers. The key idea of DBN is to initialize the RBMs with unsupervised pre-training with unlablled data. Then the weights of the top-most layer of RBMs are used as the initial weights of the NN. The NN is fine-tuned or trained using labelled data. Ye et al. (2018) applied DBN for identification of five process conditions based on acoustic emission. The results demonstrated that DBN can obtain higher classification accuracy compared to traditional machine learning methods by using the raw data as the input without any pre-processing. The SAE is an unsupervised deep neural network with multiple layers by stacking autoencoders. A typical autoencoder is a three-layer neural network consisting of an encoder and a decoder for learning effective representations. The encoder transforms the input data into the feature space with a lower dimension. The decoder reconstructs the input data from the feature space. Then the features can be extracted from high-dimensional data. Fathizadan et al. (2021) used convolutional auto-encoder (CAE) neural networks to learn representative features from melt pool images. The learned features were grouped by a clustering algorithm to detect anomalies. Compared with handcrafted features, the CAE learned features showed better performance of anomaly detection.
In summary, the classification performance of traditional machine learning methods highly depends on the features extracted and selected by the researchers. However, deep learning methods is capable of automatically learning representative features through training process, which saves the researchers’ effort on feature extraction and selection. In addition, the classification performance is generally better than traditional machine learning methods. Therefore, deep learning methods show great potential on PBF process monitoring. However, a disadvantage of deep learning methods is that it requires a large amount of data. Label of these data is time-consuming and expensive.
To solve this issue, transfer learning and semi-supervised learning are also introduced. Transfer learning adopts the knowledge learned from a prior assignment to the prediction of a new task. A reduced amount of data is required on training the new task because of the reuse of a pre-trained model. J. Li et al. (2021) explored the feasibility of using transfer learning to identify the part quality based on layer-wise images. They used a pre-trained VGG16 model as the basic model for transfer learning. The parameters of Conv and pooling layers are all frozen, and only the parameters of the last three fully connected layers are changed during the training process. They obtained classification accuracy as high as 99.89% with a total of 8895 images by the proposed transfer learning model. Pandiyan et al. (2022) proposed to use transfer learning method to learn similar features between different materials based on acoustic emission. They first trained a CNN model for quality classification based on the dataset collected during the processing of stainless steel. Then the trained model is re-trained using transfer learning for a similar classification task based on the dataset collected during the processing of bronze. Their results demonstrated that with only half of the bronze data it can obtain a well classification performance by the transfer learning model.
Semi-supervised leaning uses a small amount of labelled data for supervised learning and a large amount of unlabelled data for unsupervised learning. It provides the benefits of both unsupervised and supervised learning and avoids labelling a large amount of data. Yuan et al. (2019) used temporal ensemble method to achieve semi-supervised learning based on melt pool video information to classify the single-track quality. The temporal ensemble method takes two passes for data training. The supervised loss is still the standard cross entropy loss, and the unsupervised loss is the mean square difference between two passes’ output layers. The unsupervised portion helps to extract representative features and reduces the effect of overfitting to the small labelled dataset. The proposed method with a reduced number of labelled training data obtains a comparable accuracy with that of a supervised learning method with a large number of labelled training data. Pandiyan et al. (2021) proposed a semi-supervised method to identify process anomalies based on acoustic emissions. Only the normal data were labelled and used for a variational autoencoder model training. Then they determined a reconstruction loss threshold value based on the training results. Any reconstruction loss corresponding to a signal more than the threshold value was classified as a process anomaly. The proposed method obtained a classification accuracy as high as 96%.
Although a wide variety of machine learning methods have been applied in PBF process monitoring, the relevant studies on algorithm selection and improvement are still lacking. In addition, the current ML models in PBF process are all developed for object classification (e.g. classifying into different defect categories or classifying a specimen into normal or defective), and it is still necessary to develop more regression models on predicting the quality or defect levels. Furthermore, ML methods can be used for data analysis to find the underlying mechanisms for defects generation and identification. Reinforcement learning is also a powerful tool for developing the feedback control model for PBF process. These are worthy of further studies in the future.
Besides, physics-informed ML is emerging recently as it makes the training more efficient. Physic-informed ML allows researchers to use the prior knowledge to help the training of the neural network work, which means it will need fewer samples to train it well or to make the training more accurate (Karniadakis et al., 2021). Physic-informed ML also has been applied in metal AM. For example, R. Liu et al. (2021) developed a physics-informed machine learning model for porosity prediction. Their model interprets machine settings into physical effects, such as laser energy density and laser radiation pressure, and then these physical machine-independent effects are combined with a data-driven model for porosity prediction. The model proved to achieve good performances with the prediction error of 10–26%. Zhu et al. (Zhu et al., 2021) provided a physics-informed neural network framework that fuses both data and first physical principles, including conservation laws of momentum, mass, and energy, into the network to inform the learning processes. They showed that the framework can accurately predict the temperature and melt pool dynamics during metal AM processes with only a moderate amount of labelled data-sets. Kats et al. (Kats et al., 2022) developed a neural network model to identify the correlation between the local thermal features and their corresponding grain structure characteristics. The inputs and outputs of the neural network model are selected based on the governing physics. The model can quickly predict the grain structure for thin-wall builds, and the predictions are in good agreement with the numerical simulation results. In addition, physics-informed ML is explored to combine with the sensing data for in-process monitoring. Tian et al. (2020) proposed a physical-informed machine learning architecture for porosity prediction. Their model incorporated the melt pool features extracted from thermal images and melt pool features extracted from thermal simulations as the prediction model input. Their model can significantly improve the prediction performance for pore occurrence and size. Thus, it can be seen physic-informed ML is a powerful and promising method to overcome some limitations in data-only machine learning models. However, the relevant studies are still at an infant stage. To make physics-informed ML realize the full potentials in PBF monitoring process, a lot of efforts are required.
Data fusion
Data fusion is a powerful tool to combine information from different sources to make comprehensive assessment. It helps improve the accuracy and reliability of decision-making models. Data fusion has been widely applied for fault diagnosis/condition monitoring in manufacturing systems. In the PBF process, the relevant studies are still at an infant stage. This is because (1) most PBF machines are not equipped with multiple sensors; (2) the data fusion algorithms are still lacking in the PBF process monitoring. To solve these problems, some initial works have been done. Gökhan Demir et al. (2018) constructed a monitoring module which consists of three sensors with co-axial configuration, namely, visual camera, near-infrared camera, and a photodiode detecting the back-reflected laser emission. They analysed the characteristics of signals collected from the three sensors, respectively. Montazeri and Rao (2018) also collected signals from three types of sensors, including a photodiode, a visual camera and an infrared thermal camera. They showed the result about build condition classification based on the signals from the three sensors. Grasso, Gallina, et al. (2018)) proposed a method for the monitoring of multiple signals associated with the powder recoating operation, including pulse values from powder flow sensors, the rake current and rake positions, temperature, and so on. Then they fused the features from these signals. Using the SVM, they achieved the successful identification of out-of-control state. Y. Zhang, Hong, et al. (2018)) extracted features from the melt pool, plume and spatters, and also fused these features for the melt pool state classification. They demonstrated that feature fusion can improve the classification accuracy.
Until now, the works related to data fusion in the PBF process are very rare. However, more and more sensors and monitoring methods have been applied; in other words, more and more information can be obtained in the PBF process. Then data fusion is a necessary method to help us sufficiently utilize the information, so the development of data fusion method is necessary to advance the PBF process monitoring forward.
Feedback control
Feedback control to improve build quality online is an ultimate goal of the PBF process monitoring. However, the implementation of feedback control faces so many difficulties that only few works have been conducted. In terms of the melt pool scale feedback control, some works on direct energy deposition, a similar process to the PBF but mostly with much lower scanning speeds, have been carried out. Melt pool width and height were measured online, and then feedback controllers were designed to keep them stable through controlling appropriate process parameters, such as laser power or deposition flow rate (Mondal et al., 2020; Sammons et al., 2018; Tang & Landers, 2011; Xiong et al., 2016, 2019). In the PBF process, Craeghs et al. (2010) and Kruth et al. (2007) proposed similar methods to design feedback controller to keep melt pool optical emission and melt pool area stable through controlling laser power. Koga et al. (2020) developed a control method to drive melt pool depth to the desired set point. Since the melt pool depth cannot be measured directly in the PBF process, they proposed the feedback control law by reconstructing the temperature profile based on the measured interface position. However, the methods face the response delay issue due to the higher scanning speed than that of direct energy deposition, which has to be solved in future work.
The alternative feedback control methods in the PBF are layer-scale feedback control and part scale feedback control. Yao et al. (2018) developed a layer scale feedback control model based on Markov decision process, as shown in Fig. 15. They collected the layerwise image data to estimate the state of defects in each layer and predict the future evolution of defects from one layer to the next, and then they modelled the layer-to-layer defect evolution as a Markov process for the derivation of the optimal control. Garanger et al. (2020) reported a novel method to control the part stiffness based on measuring part width of each layer. They built the control model and validated against the manufacturing experiment of a cantilever beam. Riano et al. (2019) proposed a cloud-based AM feedback control architecture, which included the part scale feedback control. Leveraging the information collected in-process and the high computing performance on the cloud, the feedback control model could be built to correct part design and manufacturing planning. Indeed, to achieve layer-scale and part-scale feedback control in the PBF, the efficiency of the control model is critical, which highly depends on the understanding of the defects and causes. More related control models should be developed with the mastery of defect mechanisms. Before a thorough understanding of the defect mechanisms, machine learning is a good way to build efficient control models, although machine learning feedback control models are rare now.

Flow diagram of feedback control methodology in Yao et al. (2018)
Future directions
In this paper, various types of defects have been summarized. However, the causes of some defects are still open questions. To figure out the causes, advanced monitoring methods, signal processing methods, as well as machine learning modeling methods are required for data analytics. Based on the understanding of defect generation, databases of the monitoring signals are necessary to build machine learning models for defect detection or feedback control. Most of the reported datasets for machine learning modeling were aimed at identifying a particular defect or a process anomaly. A comprehensive database including all types of defect and anomalies are needed to build different models to identify all defects and process anomalies, as well as their correlations. Then the precise feedback control models can be built based on the thorough understanding of built status.
Although some progresses have been made on applying machine learning algorithms in PBF process monitoring, the synergy machine learning and PBF process is rather superficial. Most studies used existing machine learning models directly, and there lacks in-depth research on machine learning model structure and mechanism, as well as comparisons between different machine learning algorithms. A comprehensive study should not only focus on the accuracy of the proposed model. The hardware condition, specific application situation, and the complexity of the model are supposed to be considered as well. For example, the data collection is easier under normal condition than under abnormal conditions. Therefore, the machine learning models need to consider how to train the imbalanced dataset.
Computation efficiency is also a major bottleneck of achieving machine learning based online monitoring and control. In the PBF process, a large volume of data can be collected from various types of sensors. How to process the data in real-time is a difficult problem. Thus, the methods on compress sensing, data reduction and fast modeling are required. In addition, Adnan et al. (2019) proposed a fog computing paradigm to achieve real-time layer-wise closed-loop process control. In their paradigm, sensing data can be saved in local machines while using the data analysis and training applications provided by high-performance cloud computing. With the development of Internet of Things (IOT), clouding computing, fog computing and edge computing are gradually adopted in smart manufacturing. Therefore, it also a powerful solution to handle the big data in the AM process.
Another barrier of the machine learning model application is their poor performance on generalization. The models that work well on one machine for some materials may not perform well on other machines or for other materials. To solve this, the combination of machine learning models with physical-models are required. Recently, the digital twin concept has been introduced in the AM process, which provides a framework for the combination of the two types of models (Gaikwad, Yavari, et al., 2020; C. Liu et al., 2020; L. Zhang et al., 2020). In the framework, the data fusion methods on the two models are essential, which should be further studied in future work.
The feedback control in the PBF is the ultimate goal of online monitoring. As mentioned in Sect. 6, now the machine learning feedback control model is still rare. However, to achieve feedback control, especially for layer-scale and part-scale feedback control, developing machine learning model for decision making is an inevitable trend. Even the feedback control model can be developed for part design optimization, associated with the concepts of digital twin and cloud computing (C. Liu et al., 2020; L. Zhang et al., 2020), as shown in Fig. 16.

Overview of the cloud-based and deep learning-enabled metal AM layer defect analysis in C. Liu et al. (2020)
Conclusions
To ensure the PBF built quality, online monitoring and feedback control system are highly required. Process sensing and prior knowledge on defect generation are preconditions on the system development, which are reviewed in this paper. Based on the sensing methods, a large volume of data could be collected during the PBF process, and then how to correlate the sensing data with process defects, and how to eliminate the defects to improve built quality are the crucial issues. This paper reviews the relevant efforts on machine learning modeling. Although the efforts clearly demonstrated machine learning is an effective way to achieve defect detection, more works on dataset preparation, feature extraction and selection, algorithms selection and improvement are still needed. Since several sensing methods using different sensors have been developed, sensor fusion or data fusion are required to help improve defect detection performance through comprehensively analyzing these sensing signals. To achieve the final goal of quality improvement, feedback control is also an important issue worthy of extensive investigations. With the development of smart manufacturing, the techniques on Internet of Things, digital twin, and clouding computing can be introduced in the AM process monitoring and control. They provide new concepts that may help handle the large volume sensing data and improve the machine learning model performance.
References
Ali, M. Z., Nasmus, S. M., Khan, S., Liang, X., Zhang, Yu., & Hu, T. (2019). Machine learning-based fault diagnosis for single-and multi-faults in induction motors using measured stator currents and vibration signals. IEEE Transactions on Industry Applications, 55(3), 2378–2391.
Adnan, M., Lu, Y., Jones, A., & Cheng, F. T. (2019). Application of the Fog computing paradigm to additive manufacturing process monitoring and control. SSRN 3785854.
Baumgartl, H., Tomas, J., Buettner, R., & Merkel, M. (2020). A deep learning-based model for defect detection in laser-powder bed fusion using in-situ thermographic monitoring. Progress in Additive Manufacturing, 5(3), 277–285.
Berumen, S., Bechmann, F., Lindner, S., Kruth, J.-P., & Craeghs, T. (2010). Quality control of laser-and powder bed-based Additive Manufacturing (AM) technologies. Physics Procedia, 5, 617–622.
Bidare, P., Maier, R. R., Josef, B., Rainer, J., Shephard, J. D., & Moore, A. J. (2017). An open-architecture metal powder bed fusion system for in-situ process measurements. Additive Manufacturing, 16, 177–185.
Bisht, M., Ray, N., Verbist, F., & Coeck, S. (2018). Correlation of selective laser melting-melt pool events with the tensile properties of Ti-6Al-4V ELI processed by laser powder bed fusion. Additive Manufacturing, 22, 302–306.
Caggiano, A., Zhang, J., Alfieri, V., Caiazzo, F., Gao, R., & Teti, R. (2019). Machine learning-based image processing for on-line defect recognition in additive manufacturing. CIRP Annals, 68(1), 451–454.
Cain, V., Thijs, L., Van Humbeeck, J., Van Hooreweder, B., & Knutsen, R. (2015). Crack propagation and fracture toughness of Ti6Al4V alloy produced by selective laser melting. Additive Manufacturing, 5, 68–76.
Calta, N. P., Wang, J., Kiss, A. M., Martin, A. A., Depond, P. J., Guss, G. M., Thampy, V., Fong, A. Y., Weker, J. N., Stone, K. H., Tassone, C. J., Kramer, M. J., Toney, M. F., Van Buuren, A., & Matthews, M. J. (2018). An instrument for in situ time-resolved X-ray imaging and diffraction of laser powder bed fusion additive manufacturing processes. Review of Scientific Instruments, 89(5), 055101.
Carroll, B. E., Palmer, T. A., & Beese, A. M. (2015). Anisotropic tensile behavior of Ti–6Al–4V components fabricated with directed energy deposition additive manufacturing. Acta Materialia, 87, 309–320.
Carter, L. N., Attallah, M. M., & Reed, R. C. (2012). Laser powder bed fabrication of nickel-base superalloys: Influence of parameters; characterisation, quantification and mitigation of cracking. Superalloys, 2012, 577–586.
Chen, D., Wang, P., Pan, Ri., Zha, C., Fan, J., Kong, S., Li, Na., Li, J., & Zeng, Z. (2021). Research on in situ monitoring of selective laser melting: A state of the art review. The International Journal of Advanced Manufacturing Technology, 113(11), 3121–3138.
Chen, Y., Zhang, K., Huang, J., Hosseini, S. R. E., & Li, Z. (2016). Characterization of heat affected zone liquation cracking in laser additive manufacturing of Inconel 718. Materials & Design, 90, 586–594.
Cheng, B., Lei, J., & Xiao, H. (2019). A photoacoustic imaging method for in-situ monitoring of laser assisted ceramic additive manufacturing. Optics & Laser Technology, 115, 459–464.
Clijsters, S., Craeghs, T., Buls, S., Kempen, K., & Kruth, J.-P. (2014). In situ quality control of the selective laser melting process using a high-speed, real-time melt pool monitoring system. The International Journal of Advanced Manufacturing Technology, 75(5–8), 1089–1101.
Coeck, S., Bisht, M., Plas, J., & Verbist, F. (2019). Prediction of lack of fusion porosity in selective laser melting based on melt pool monitoring data. Additive Manufacturing, 25, 347–356.
Craeghs, T., Bechmann, F., Berumen, S., & Kruth, J.-P. (2010). Feedback control of Layerwise Laser Melting using optical sensors. Physics Procedia, 5, 505–514.
Cunningham, R., Zhao, C., Parab, N., Kantzos, C., Pauza, J., Fezzaa, K., Sun, T., & Rollett, A. D. (2019). Keyhole threshold and morphology in laser melting revealed by ultrahigh-speed x-ray imaging. Science, 363(6429), 849–852.
DePond, P. J., Guss, G., Ly, S., Calta, N. P., Deane, D., Khairallah, S., & Matthews, M. J. (2018). In situ measurements of layer roughness during laser powder bed fusion additive manufacturing using low coherence scanning interferometry. Materials & Design, 154, 347–359.
Dryburgh, P., Patel, R., Pieris, D. M., Hirsch, M., Li, W., Sharples, S. D., Smith, R. J., Clare, A. T., & Clark, M. (2019). Spatially resolved acoustic spectroscopy for texture imaging in powder bed fusion nickel superalloys. Paper presented at the AIP Conference Proceedings.
Duman, B., & Özsoy, K. (2022). A deep learning-based approach for defect detection in powder bed fusion additive manufacturing using transfer learning. Journal of the Faculty of Engineering, & University, Architecture of Gazi, 37(1), 361–375.
Dunbar, Alexander J, Nassar, Abdalla R, Reutzel, Edward W, & Blecher, Jared J. (2016). A real-time communication architecture for metal powder bed fusion additive manufacturing. Paper presented at the Solid Freeform Fabrication Symposium (SFF), Austin, TX.
Edwards, P., O’conner, A., & Ramulu, M. (2013). Electron beam additive manufacturing of titanium components: Properties and performance. Journal of Manufacturing Science and Engineering, 135(6), 061016.
Eschner, N, Weiser, L, Häfner, B, & Lanza, G. (2018). Development of an acoustic process monitoring system for selective laser melting (SLM). Paper presented at the Solid Freeform Fabrication 2018: Proceedings of the 29th Annual International Solid Freeform Fabrication Symposium–An Additive Manufacturing Conference Reviewed Paper.
Everton, S. K., Hirsch, M., Stravroulakis, P., Leach, R. K., & Clare, A. T. (2016). Review of in-situ process monitoring and in-situ metrology for metal additive manufacturing. Materials, & Design, 95, 431–445.
Fathizadan, S., Ju, F., & Lu, Y. (2021). Deep representation learning for process variation management in laser powder bed fusion. Additive Manufacturing, 42, 101961.
Fisher, B. A., Lane, B., Yeung, Ho., & Beuth, J. (2018). Toward determining melt pool quality metrics via coaxial monitoring in laser powder bed fusion. Manufacturing Letters, 15, 119–121.
Foster, B, Reutzel, E, Nassar, A, Hall, B, Brown, S, & Dickman, C. (2015). Optical, layerwise monitoring of powder bed fusion. Paper presented at the Solid Freeform Fabrication Symposium, Austin, TX, Aug.
Furumoto, T., Ueda, T., Alkahari, M. R., & Hosokawa, A. (2013). Investigation of laser consolidation process for metal powder by two-color pyrometer and high-speed video camera. CIRP Annals, 62(1), 223–226.
Gaikwad, A., Giera, B., Guss, G. M., Forien, J.-B., Matthews, M. J., & Rao, P. (2020). Heterogeneous sensing and scientific machine learning for quality assurance in laser powder bed fusion–a single-track study. Additive Manufacturing, 36, 101659.
Gaikwad, A., Yavari, R., Montazeri, M., Cole, K., Bian, L., & Rao, P. (2020). Toward the digital twin of additive manufacturing: Integrating thermal simulations, sensing, and analytics to detect process faults. IISE Transactions, 52(11), 1204–1217.
Garanger, K., Khamvilai, T., & Feron, E. (2020). Validating feedback control to meet stiffness requirements in additive manufacturing. IEEE Transactions on Control Systems Technology, 28(5), 2053–2060.
Gobert, C., Reutzel, E. W., Petrich, J., Nassar, A. R., & Phoha, S. (2018). Application of supervised machine learning for defect detection during metallic powder bed fusion additive manufacturing using high resolution imaging. Additive Manufacturing, 21, 517–528.
Gökhan Demir, A., De Giorgi, C., & Previtali, B. (2018). Design and implementation of a multisensor coaxial monitoring system with correction strategies for selective laser melting of a maraging steel. Journal of Manufacturing Science, & Engineering 140(4), 041003.
Gong, H., Gu, H., Zeng, K., Dilip, J., Deepankar, P., Stucker, B., Christiansen, D., Beuth, J., & Lewandowski, J. J. (2014). Melt pool characterization for selective laser melting of Ti–6Al–4V pre-alloyed powder. Paper presented at the Solid freeform fabrication symposium.
Gong, H., Rafi, K., Gu, H., Starr, T., & Stucker, B. (2014). Analysis of defect generation in Ti–6Al–4V parts made using powder bed fusion additive manufacturing processes. Additive Manufacturing, 1, 87–98.
Grasso, M., Laguzza, V., Semeraro, Q., & Colosimo, B. M. (2017). In-process monitoring of selective laser melting: spatial detection of defects via image data analysis. Journal of Manufacturing Science, & Engineering. 139(5).
Grasso, M., & Colosimo, B. M. (2017). Process defects and in situ monitoring methods in metal powder bed fusion: A review. Measurement Science, & Technology, 4, 044005.
Grasso, M., Demir, A. G., Previtali, B., & Colosimo, B. M. (2018). In situ monitoring of selective laser melting of zinc powder via infrared imaging of the process plume. Robotics and Computer-Integrated Manufacturing, 49, 229–239.
Grasso, M., Gallina, F., & Colosimo, B. M. (2018). Data fusion methods for statistical process monitoring and quality characterization in metal additive manufacturing. Procedia CIRP, 75, 103–107.
Grasso, M. L. G., Remani, A., Dickins, A., Colosimo, B. M., & Leach, R. K. (2021). In-situ measurement and monitoring methods for metal powder bed fusion—an updated review. Measurement Science, & Technology, 32, 112001.
Gu, H., Gong, H., Pal, D., Rafi, K., Starr, T., & Stucker, B. (2013). Influences of energy density on porosity and microstructure of selective laser melted 17-4PH stainless steel. Paper presented at the 2013 solid freeform fabrication symposium.
Han, X., Zhu, H., Nie, X., Wang, G., & Zeng, X. (2018). Investigation on selective laser melting AlSi10Mg cellular lattice strut: Molten pool morphology, surface roughness and dimensional accuracy. Materials, 11(3), 392.
Hojjatzadeh, S. M., Parab, H., Niranjan D, Yan, Wentao, Guo, Qilin, Xiong, Lianghua, Zhao, Cang, Qu, L., Escano, L. I., Xiao, X., Fezzaa, Kamel, Everhart, W., Sun, T., Chen, L. (2019). Pore elimination mechanisms during 3D printing of metals. Nature Communications, 10(1), 3088.
Hrabe, N., & Quinn, T. (2013). Effects of processing on microstructure and mechanical properties of a titanium alloy (Ti–6Al–4V) fabricated using electron beam melting (EBM), Part 2: Energy input, orientation, and location. Materials Science and Engineering: A, 573, 271–277.
Imani, F., Chen, R., Diewald, E., Reutzel, E., & Yang, H. (2019). Deep learning of variant geometry in layerwise imaging profiles for additive manufacturing quality control. Journal of Manufacturing Science and Engineering, 141(11), 1–16.
Jayasinghe, S., Paoletti, P., Sutcliffe, C., Dardis, J., Jones, N., & Green, P. L. (2021). Automatic quality assessments of laser powder bed fusion builds from photodiode sensor measurements. Progress in Additive Manufacturing, 7(2), 143–160.
Jordan, M. I., & Mitchell, T. M. (2015). Machine learning: Trends, perspectives, and prospects. Science, 349(6245), 255–260.
Kalms, M., Narita, R., Thomy, C., Vollertsen, F., & Bergmann, R. B. (2019). New approach to evaluate 3D laser printed parts in powder bed fusion-based additive manufacturing in-line within closed space. Additive Manufacturing, 26, 161–165.
Kanko, J. A., Sibley, A. P., & Fraser, J. M. (2016). In situ morphology-based defect detection of selective laser melting through inline coherent imaging. Journal of Materials Processing Technology, 231, 488–500.
Karniadakis, G. E., Kevrekidis, I. G., Lu, Lu., Perdikaris, P., Wang, S., & Yang, L. (2021). Physics-informed machine learning. Nature Reviews Physics, 3(6), 422–440.
Kasperovich, G., Haubrich, J., Gussone, J., & Requena, G. (2016). Correlation between porosity and processing parameters in TiAl6V4 produced by selective laser melting. Materials, & Design, 105, 160–170.
Kats, D., Wang, Z., Gan, Z., Liu, W. K., Wagner, G. J., & Lian, Y. (2022). A physics-informed machine learning method for predicting grain structure characteristics in directed energy deposition. Computational Materials Science, 202, 110958.
Khairallah, S. A., Anderson, A. T., Rubenchik, A., & King, W. E. (2016a). Laser powder-bed fusion additive manufacturing: Physics of complex melt flow and formation mechanisms of pores, spatter, and denudation zones. Acta Materialia, 108, 36–45.
Khanzadeh, M., Chowdhury, S., Marufuzzaman, M., Tschopp, M. A., & Bian, L. (2018). Porosity prediction: Supervised-learning of thermal history for direct laser deposition. Journal of Manufacturing Systems, 47, 69–82.
Khanzadeh, M., Chowdhury, S., Tschopp, M. A., Doude, H. R., Marufuzzaman, M., & Bian, L. (2019). In-situ monitoring of melt pool images for porosity prediction in directed energy deposition processes. IISE Transactions, 51(5), 437–455.
Kleszczynski, S., Zur Jacobsmühlen, J., Sehrt, J., & Witt, G. (2012). Error detection in laser beam melting systems by high resolution imaging. Paper presented at the Proceedings of the Solid Freeform Fabrication Symposium.
Knaak, C., Masseling, L., Duong, E., Abels, P., & Gillner, A. (2021). Improving Build Quality in Laser Powder Bed Fusion Using High Dynamic Range Imaging and Model-Based Reinforcement Learning. IEEE Access, 9, 55214–55231.
Koester, Lucas W, Taheri, Hossein, Bigelow, Timothy A, Bond, Leonard J, & Faierson, Eric J. (2018). In-situ acoustic signature monitoring in additive manufacturing processes. Paper presented at the AIP Conference Proceedings.
Koga, S., Krstic, M., & Beaman, J. (2020). Laser Sintering Control for Metal Additive Manufacturing by PDE Backstepping. IEEE Transactions on Control Systems Technology, 28(5), 1928–1939.
Kok, Y., Tan, X. P., Wang, P., Nai, M. L. S., Loh, N. H., Liu, E., & Tor, S. B. (2018). Anisotropy and heterogeneity of microstructure and mechanical properties in metal additive manufacturing: A critical review. Materials & Design, 139, 565–586.
Krauss, H., Zeugner, T., & Zaeh, M. F. (2014). Layerwise monitoring of the selective laser melting process by thermography. Physics Procedia, 56, 64–71.
Kriczky, D. A., Irwin, J., Reutzel, E. W., Michaleris, P., Nassar, A. R., & Craig, J. (2015). 3D spatial reconstruction of thermal characteristics in directed energy deposition through optical thermal imaging. Journal of Materials Processing Technology, 221, 172–186.
Kruth, J.-P., Mercelis, P., Van Vaerenbergh, J., & Craeghs, T. (2007). Feedback control of selective laser melting. Paper presented at the Proceedings of the 3rd international conference on advanced research in virtual and rapid prototyping.
Kwon, O., Kim, H. G., Kim, W., Kim, G.-H., & Kim, K. (2020). A convolutional neural network for prediction of laser power using melt-pool images in laser powder bed fusion. IEEE Access, 8, 23255–23263.
Leuders, S., Thöne, M., Riemer, A., Niendorf, T., Tröster, T., Richard, H. A., & Maier, H. J. (2013). On the mechanical behaviour of titanium alloy TiAl6V4 manufactured by selective laser melting: Fatigue resistance and crack growth performance. International Journal of Fatigue, 48, 300–307.
Leung, C. L., Alex, M., Sebastian, A., Robert, C., Towrie, M., Withers, P. J., & Lee, P. D. (2018). In situ X-ray imaging of defect and molten pool dynamics in laser additive manufacturing. Nature Communications, 9(1), 1355.
Li, J., Zhou, Q., Huang, X., Li, M., & Cao, L. (2021). In situ quality inspection with layer-wise visual images based on deep transfer learning during selective laser melting. Journal of Intelligent Manufacturing 1–15.
Li, Z., Liu, X., Wen, S., He, P., Zhong, K., Wei, Q., Shi, Y., & Liu, S. (2018). In situ 3d monitoring of geometric signatures in the powder-bed-fusion additive manufacturing process via vision sensing methods. Sensors, 18(4), 1180.
Liu, C., Le Roux, L., Körner, C., Tabaste, O., Lacan, F., & Bigot, S. (2020). Digital tin-enabled collaborative data management for metal additive manufacturing systems. Journal of Manufacturing Systems, 62, 857–874.
Liu, R., Liu, S., & Zhang, X. (2021). A physics-informed machine learning model for porosity analysis in laser powder bed fusion additive manufacturing. The International Journal of Advanced Manufacturing Technology, 113(7), 1943–1958.
Liu, R., Yang, B., Zio, E., & Chen, X. (2018). Artificial intelligence for fault diagnosis of rotating machinery: A review. Mechanical Systems and Signal Processing, 108, 33–47.
Ly, S., Rubenchik, A. M., Khairallah, S. A., Guss, G., & Matthews, M. J. (2017). Metal vapor micro-jet controls material redistribution in laser powder bed fusion additive manufacturing. Scientific Reports, 7(1), 4085.
Mahmoudi, M., Ezzat, A. A., & Elwany, A. (2019). Layerwise Anomaly Detection in Laser Powder-Bed Fusion Metal Additive Manufacturing. Journal of Manufacturing Science and Engineering, 141(3), 031002.
Mani, M., Feng, S., Lane, B., Donmez, A., Moylan, S., & Fesperman, R. (2015). Measurement science needs for real-time control of additive manufacturing powder bed fusion processes. In Additive manufacturing handbook. Tayor & Francis.
Matthews, M. J., Guss, G., Khairallah, S. A., Rubenchik, A. M., Depond, P. J., & King, W. E. (2016). Denudation of metal powder layers in laser powder bed fusion processes. Acta Materialia, 114, 33–42.
McCann, R., Obeidi, M. A., Hughes, C., McCarthy, É., Egan, D. S., Vijayaraghavan, R. K., Joshi, A. M., Garzon, V. A., Dowling, T. P., McNally, P. J., & Brabazon, D. (2021). In-situ sensing, process monitoring and machine control in Laser Powder Bed Fusion: A review. Additive Manufacturing, 45, 102058.
Mercelis, P., & Kruth, J.-P. (2006). Residual stresses in selective laser sintering and selective laser melting. Rapid Prototyping Journal, 12(5), 254–265.
Mondal, S., Gwynn, D., Ray, A., & Basak, A. (2020). Investigation of Melt Pool Geometry Control in Additive Manufacturing Using Hybrid Modeling. Metals, 10(5), 683.
Montazeri, M., Nassar, A. R., Dunbar, A. J., & Rao, P. (2020). In-process monitoring of porosity in additive manufacturing using optical emission spectroscopy. IISE Transactions, 52(5), 500–515.
Montazeri, M., & Rao, P. (2018). Sensor-based build condition monitoring in laser powder bed fusion additive manufacturing process using a spectral graph theoretic approach. Journal of Manufacturing Science, & Engineering. 140(9), 091002.
Mousa, A. A. (2016). Experimental investigations of curling phenomenon in selective laser sintering process. Rapid Prototyping Journal, 22, 405–415.
Murr, L. E., Quinones, S. A., Gaytan, S. M., Lopez, M. I., Rodela, A., Martinez, E. Y., Hernandez, D. H., Martinez, E., Medina, F., & Wicker, R. B. (2009). Microstructure and mechanical behavior of Ti–6Al–4V produced by rapid-layer manufacturing, for biomedical applications. Journal of the Mechanical Behavior of Biomedical Materials, 2(1), 20–32.
Nassar, A. R., Gundermann, M. A., Reutzel, E. W., Guerrier, P., Krane, M. H., & Weldon, M. J. (2019). Formation processes for large ejecta and interactions with melt pool formation in powder bed fusion additive manufacturing. Scientific Reports, 9(1), 5038.
O’Loughlin, S., Dutton, B., Semaj, G., Snell, E., Rindler, J., & Groeber, M. A. (2021). Towards In-process Prediction of Voids in Laser Powder Bed Fusion. JOM Journal of the Minerals Metals and Materials Society, 73(11), 3240–3249.
Okaro, I. A., Jayasinghe, S., Sutcliffe, C., Black, K., Paoletti, P., & Green, P. L. (2019). Automatic fault detection for laser powder-bed fusion using semi-supervised machine learning. Additive Manufacturing, 27, 42–53.
Pagani, L., Grasso, M., Scott, P. J., & Colosimo, B. M. (2020). Automated layerwise detection of geometrical distortions in laser powder bed fusion. Additive Manufacturing, 36, 101435.
Pandiyan, V., Drissi-Daoudi, R., Shevchik, S., Masinelli, G., Le-Quang, T., Logé, R., & Wasmer, K. (2021). Semi-Supervised Monitoring of Laser Powder Bed Fusion Process Based on Acoustic Emissions, 16(4), 481–497.
Pandiyan, V., Drissi-Daoudi, R., Shevchik, S., Masinelli, G., Le-Quang, T., Logé, R., & Wasmer, K. (2022). Deep transfer learning of additive manufacturing mechanisms across materials in metal-based laser powder bed fusion process. Journal of Materials Processing Technology, 303, 117531.
Paul, R., Anand, S., & Gerner, F. (2014). Effect of thermal deformation on part errors in metal powder based additive manufacturing processes. Journal of Manufacturing Science and Engineering, 136(3), 031009.
Qiu, C., Panwisawas, C., Ward, M., Basoalto, H. C., Brooks, J. W., & Attallah, M. M. (2015). On the role of melt flow into the surface structure and porosity development during selective laser melting. Acta Materialia, 96, 72–79.
Repossini, G., Laguzza, V., Grasso, M., & Colosimo, B. M. (2017). On the use of spatter signature for in-situ monitoring of Laser Powder Bed Fusion. Additive Manufacturing, 16, 35–48.
Riaño, C., Rodriguez, E., & Alvares, A. J. (2019). A Closed-Loop Inspection Architecture for Additive Manufacturing Based on STEP Standard. IFAC-PapersOnLine, 52(13), 2782–2787.
Rieder, H., Dillhöfer, A., Spies, M., Bamberg, J., & Hess, T. (2015). Ultrasonic online monitoring of additive manufacturing processes based on selective laser melting. Paper presented at the AIP Conference Proceedings.
Rodriguez, E., Mireles, J., Terrazas, C. A., Espalin, D., Perez, M. A., & Wicker, R. B. (2015). Approximation of absolute surface temperature measurements of powder bed fusion additive manufacturing technology using in situ infrared thermography. Additive Manufacturing, 5, 31–39.
Sammons, P. M., Gegel, M. L., Bristow, D. A., & Landers, R. G. (2018). Repetitive process control of additive manufacturing with application to laser metal deposition. IEEE Transactions on Control Systems Technology, 27(2), 566–575.
Scime, L., & Beuth, J. (2018a). Anomaly detection and classification in a laser powder bed additive manufacturing process using a trained computer vision algorithm. Additive Manufacturing, 19, 114–126.
Scime, L., & Beuth, J. (2018b). A multi-scale convolutional neural network for autonomous anomaly detection and classification in a laser powder bed fusion additive manufacturing process. Additive Manufacturing, 24, 273–286.
Scime, L., & Beuth, J. (2019). Using machine learning to identify in-situ melt pool signatures indicative of flaw formation in a laser powder bed fusion additive manufacturing process. Additive Manufacturing, 25, 151–165.
Seifi, S. H., Tian, W., Doude, H., Tschopp, M. A., & Bian, L. (2019). Layer-wise modeling and anomaly detection for laser-based additive manufacturing. Journal of Manufacturing Science & Engineering, 141(8), 081013.
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding machine learning: From theory to algorithms. Cambridge University Press.
Sharratt, B. M. (2015). Non-destructive techniques and technologies for qualification of additive manufactured parts and processes. Literature Review.
Shevchik, S. A., Kenel, C., Leinenbach, C., & Wasmer, K. (2018). Acoustic emission for in situ quality monitoring in additive manufacturing using spectral convolutional neural networks. Additive Manufacturing, 21, 598–604.
Slotwinski, J. A., Garboczi, E. J., & Hebenstreit, K. M. (2014). Porosity measurements and analysis for metal additive manufacturing process control. Journal of Research of the National Institute of Standards and Technology, 119, 494.
Smith, R. J., Hirsch, M., Patel, R., Li, W., Clare, A. T., & Sharples, S. D. (2016). Spatially resolved acoustic spectroscopy for selective laser melting. Journal of Materials Processing Technology, 236, 93–102.
Snow, Z., Diehl, B., Reutzel, E. W., & Nassar, A. (2021). Toward in-situ flaw detection in laser powder bed fusion additive manufacturing through layerwise imagery and machine learning. Journal of Manufacturing Systems, 59, 12–26.
Spears, T. G., & Gold, S. A. (2016). In-process sensing in selective laser melting (SLM) additive manufacturing. Integrating Materials, & Innovation, Manufacturing, 5(1), 16–40.
Sterling, A. J., Torries, B., Shamsaei, N., Thompson, S. M., & Seely, D. W. (2016). Fatigue behavior and failure mechanisms of direct laser deposited Ti–6Al–4V. Materials Science and Engineering: A, 655, 100–112.
Stetco, A., Dinmohammadi, F., Zhao, X., Robu, V., Flynn, D., Barnes, M., John, K., & Nenadic, G. (2018). Machine learning methods for wind turbine condition monitoring: A review. Renewable Energy, 133, 620–635.
Strano, G., Hao, L., Everson, R. M., & Evans, K. E. (2013). Surface roughness analysis, modelling and prediction in selective laser melting. Journal of Materials Processing Technology, 213(4), 589–597.
Sun, S.-H., Koizumi, Y., Kurosu, S., Li, Y.-P., & Chiba, A. (2015). Phase and grain size inhomogeneity and their influences on creep behavior of Co–Cr–Mo alloy additive manufactured by electron beam melting. Acta Materialia, 86, 305–318.
Taheri, H., Koester, L. W., Bigelow, T. A., Faierson, E. J., & Bond, L. J. (2019). In situ additive manufacturing process monitoring with an acoustic technique: Clustering performance evaluation using K-means algorithm. Journal of Manufacturing Science & Engineering, 141(4), 041011.
Tammas-Williams, S., Zhao, H., Léonard, F., Derguti, F., Todd, I., & Prangnell, P. B. (2015). XCT analysis of the influence of melt strategies on defect population in Ti–6Al–4V components manufactured by Selective Electron Beam Melting. Materials Characterization, 102, 47–61.
Tang, L., & Landers, R. G. (2011). Layer-to-layer height control for laser metal deposition process. Journal of Manufacturing Science & Engineering, 133(2), 021009.
Tapia, G., & Elwany, A. (2014). A review on process monitoring and control in metal-based additive manufacturing. Journal of Manufacturing Science & Engineering, 136(6), 60801–60811.
Technologies, ASTM Committee F42 on Additive Manufacturing, & Terminology, ASTM Committee F42 on Additive Manufacturing Technologies. (2012). Subcommittee F42. 91. Standard terminology for additive manufacturing technologies: ASTM International.
Thomas, D. (2009). The development of design rules for selective laser melting. University of Wales.
Tian, Q., Guo, S., & Guo, Y. (2020). A physics-driven deep learning model for process-porosity causal relationship and porosity prediction with interpretability in laser metal deposition. CIRP Annals, 69(1), 205–208.
Tucho, W. M., Cuvillier, P., Sjolyst-Kverneland, A., & Hansen, V. (2017). Microstructure and hardness studies of Inconel 718 manufactured by selective laser melting before and after solution heat treatment. Materials Science and Engineering: A, 689, 220–232.
van Hooreweder, B., Moens, D., Boonen, R., Kruth, J.-P., & Sas, P. (2012). Analysis of fracture toughness and crack propagation of Ti6Al4V produced by selective laser melting. Advanced Engineering Materials, 14(1–2), 92–97.
Wang, Di., Yang, Y., Yi, Z., & Su, X. (2013). Research on the fabricating quality optimization of the overhanging surface in SLM process. The International Journal of Advanced Manufacturing Technology, 65(9–12), 1471–1484.
Wang, N., Mokadem, S., Rappaz, M., & Kurz, W. (2004). Solidification cracking of superalloy single-and bi-crystals. Acta Materialia, 52(11), 3173–3182.
Wang, R., Cheung, C. F., Wang, C., & Cheng, M. N. (2022). Deep learning characterization of surface defects in the selective laser melting process. Computers in Industry, 140, 103662.
Wang, Z., Palmer, T. A., & Beese, A. M. (2016). Effect of processing parameters on microstructure and tensile properties of austenitic stainless steel 304L made by directed energy deposition additive manufacturing. Acta Materialia, 110, 226–235.
Wasmer, K., Le-Quang, T., Meylan, B., & Shevchik, S. A. (2019). In situ quality monitoring in AM using acoustic emission: A reinforcement learning approach. Journal of Materials Engineering, & Performance, 28(2), 666–672.
Waterman, N. A., & Dickens, P. (1994). Rapid product development in the USA, Europe and Japan. World Class Design to Manufacture, 1(3), 27–36.
Wei, X., Xu, M., Wang, Q., Zhang, M., Liu, W., Xu, J., Chen, J., Lu, H., & Yu, C. (2016). Effect of local texture and precipitation on the ductility dip cracking of ERNiCrFe-7A Ni-based overlay. Materials & Design, 110, 90–98.
Weingarten, C., Buchbinder, D., Pirch, N., Meiners, W., Wissenbach, K., & Poprawe, R. (2015). Formation and reduction of hydrogen porosity during selective laser melting of AlSi10Mg. Journal of Materials Processing Technology, 221, 112–120.
Xiong, J., Liu, G., & Pi, Y. (2019). Increasing stability in robotic GTA-based additive manufacturing through optical measurement and feedback control. Robotics, & Manufacturing, Computer-Integrated, 59, 385–393.
Xiong, J., Yin, Z., & Zhang, W. (2016). Closed-loop control of variable layer width for thin-walled parts in wire and arc additive manufacturing. Journal of Materials Processing Technology, 233, 100–106.
Yadollahi, A., Shamsaei, N., Thompson, S. M., Elwany, A., & Bian, L. (2017). Effects of building orientation and heat treatment on fatigue behavior of selective laser melted 17–4 PH stainless steel. International Journal of Fatigue, 94, 218–235.
Yadroitsev, I., & Smurov, I. (2011). Surface morphology in selective laser melting of metal powders. Physics Procedia, 12, 264–270.
Yang, C., Liu, J., Zeng, Y., & Xie, G. (2019). Real-time condition monitoring and fault detection of components based on machine-learning reconstruction model. Renewable Energy, 133, 433–441.
Yang, J., Li, F., Wang, Z., & Zeng, X. (2015). Cracking behavior and control of Rene 104 superalloy produced by direct laser fabrication. Journal of Materials Processing Technology, 225, 229–239.
Yao, B., Imani, F., & Yang, H. (2018). Markov decision process for image-guided additive manufacturing. IEEE Robotics, & Letters, Automation, 3(4), 2792–2798.
Yasa, Evren, Deckers, Jan, Craeghs, Tom, Badrossamay, Mohsen, & Kruth, Jean-Pierre. (2009). Investigation on occurrence of elevated edges in selective laser melting. Paper presented at the International Solid Freeform Fabrication Symposium, Austin, TX, USA.
Yazdi, R. M., Imani, F., & Yang, H. (2020). A hybrid deep learning model of process-build interactions in additive manufacturing. Journal of Manufacturing Systems, 57, 460–468.
Ye, D., Hong, G. S., Zhang, Y., Zhu, K., & Fuh, J. Y. H. (2018). Defect detection in selective laser melting technology by acoustic signals with deep belief networks. The International Journal of Advanced Manufacturing Technology, 96(5), 2791–2801.
Yuan, B., Giera, B., Guss, G., Matthews, I., & McMains, S. (2019). Semi-supervised convolutional neural networks for in-situ video monitoring of selective laser melting. Paper presented at the 2019 IEEE winter conference on applications of computer vision (WACV).
Zäh, M. F., & Lutzmann, S. (2010). Modelling and simulation of electron beam melting. Production Engineering, 4(1), 15–23.
Zhang, B., Ziegert, J., Farahi, F., & Davies, A. (2016). In situ surface topography of laser powder bed fusion using fringe projection. Additive Manufacturing, 12, 100–107.
Zhang, J., Wang, P., Yan, R., & Gao, R. X. (2018). Long short-term memory for machine remaining life prediction. Journal of Manufacturing Systems, 48, 78–86.
Zhang, L., Chen, X., Zhou, W., Cheng, T., Chen, L., Guo, Z., Han, B., & Lu, L. (2020). Digital twins for additive manufacturing: A state-of-the-art review. Applied Sciences, 10(23), 8350.
Zhang, Y., Hong, G. S., Ye, D., Zhu, K., & Fuh, J. Y. H. (2018). Extraction and evaluation of melt pool, plume and spatter information for powder-bed fusion AM process monitoring. Materials & Design, 156, 458–469.
Zhang, Y., Soon, H. G., Ye, D., Fuh, J. Y. H., & Zhu, K. (2019). Powder-bed fusion process monitoring by machine vision with hybrid convolutional neural networks. IEEE Transactions on Industrial Informatics, 16(9), 5769–5779.
Zhao, C., Fezzaa, K., Cunningham, R. W., Wen, H., De Carlo, F., Chen, L., Rollett, A. D., & Sun, T. (2017). Real-time monitoring of laser powder bed fusion process using high-speed X-ray imaging and diffraction. Scientific Reports, 7(1), 3602.
Zhong, M., Sun, H., Liu, W., Zhu, X., & He, J. (2005). Boundary liquation and interface cracking characterization in laser deposition of Inconel 738 on directionally solidified Ni-based superalloy. Scripta Materialia, 53(2), 159–164.
Zhou, Z., Huang, L., Shang, Y., Li, Y., Jiang, L., & Lei, Q. (2018). Causes analysis on cracks in nickel-based single crystal superalloy fabricated by laser powder deposition additive manufacturing. Materials & Design, 160, 1238–1249.
Zhu, Q., Liu, Z., & Yan, J. (2021). Machine learning for metal additive manufacturing: Predicting temperature and melt pool fluid dynamics using physics-informed neural networks. Computational Mechanics, 67(2), 619–635.
zur Jacobsmühlen, J., Kleszczynski, S., Schneider, D., & Witt, Gerd. (2013). High resolution imaging for inspection of laser beam melting systems. Paper presented at the 2013 IEEE international instrumentation and measurement technology conference (I2MTC).
zur Jacobsmühlen, J., Kleszczynski, S., Witt, G., & Merhof, D. (2014). Robustness analysis of imaging system for inspection of laser beam melting systems. Paper presented at the Proceedings of the 2014 IEEE Emerging Technology and Factory Automation (ETFA).
Acknowledgements
Wentao Yan acknowledges the support by the Ministry of Education, Singapore, under its Academic Research Fund Tier 2 (MOE-T2EP50121-0017).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhang, Y., Yan, W. Applications of machine learning in metal powder-bed fusion in-process monitoring and control: status and challenges. J Intell Manuf 34, 2557–2580 (2023). https://doi.org/10.1007/s10845-022-01972-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10845-022-01972-7