
Abstract
A non-dominated sorting modified teaching–learning-based optimization (NSMTLBO) is proposed to obtain the optimum solution for a multi-objective problem related to machining Polytetrafluoroethylene. Firstly, an experimental design is done and the L27 orthogonal array with three-level of cutting speed \( \left( {V_{c} } \right) \), feed rate (f), depth of cut (ap) and nose radius \( \left( {N_{r} } \right) \) is formulated. A CNC turning machine is used to perform experiments with cemented carbide tool at an insert angle of 80° and the response variables known as surface finish and material removal rate are measured. A response surface model is rendered from the experimental results to derive the minimization function of surface roughness \( \left( {R_{a} } \right) \) and maximization function of material removal rate (MRR). Both optimization functions are solved simultaneously using NSMTLBO. A fuzzy decision maker is also integrated with NSMTLBO to determine the preferred optimum machining parameters from Pareto-front based on the relative importance level of each objective function. The best responses Ra = 2.2347 µm and MRR = 96.835 cm3/min are predicted at the optimum machining parameters of Vc = 160 mm/min, f = 0.5 mm/rev, ap = 0.98 mm and Nr = 0.8 mm. The proposed NSMTLBO is reported to outperform other six peer algorithms due to its excellent capability in generating the Pareto-fronts which are more uniformly distributed and resulted higher percentage of non-dominated solutions. Furthermore, the prediction results of NSMTLBO are validated experimentally and it is reported that the performance deviations between the predicted and actual results are lower than 3.7%, implying the applicability of proposed work in real-world machining applications.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Polytetrafluoroethylene (PTFE) is a fluoropolymer that has many excellent properties such as high hydrophobicity, high oleophobicity, high chemical resistance, high antifouling property, high sliding property, high thermal resistance, high weather resistance, low relative permittivity, and low dielectric loss tangent. It has been used in many applications including polymer bearing, gaskets, gears, valve seats, piston rings, seals, bushes, hose assemblies, high voltage switches, extension joints, cook wears, clinical, containers and pipework for reactive and corrosive chemicals. It has also been used in biomedical applications such as oxygenator membrane, vascular graft and catheter coating. The virgin PTFE rods or components are manufactured through sintering or compression molding. The specific grade of PTFE which has the greater dielectric strength is frequently used in wire and cable wrap, and to separate conductive surfaces in capacitors.
As an instance, thick walled close tolerance extruded PTFE can be machined into standoff insulators and can also be used in high voltage encapsulation devices for miniature components with high dimensional accuracy and integrity. These components may require further machining operations to have net shape, suitable for the specific application. The accuracy of the machining process is decided by the control parameters such as feed, depth of cut, speed, nose radius etc. The poorly set control parameters do increase the surface roughness and lead to the poor net shape. The current research is aimed to determine the optimum control parameters for obtaining the minimum surface roughness and maximum material removal rate of material during machining of PTFE. The minimization surface roughness increases the quality of the products and the maximization of material remove rate increases the production rate (quantity) of the products.
In most existing literatures, the regression models were developed as nonlinear functions consisting of several input process parameters with boundary limits. Although the idea of utilizing optimization method to solve a given regression model is proven feasible to obtain the optimum machining parameters, the solutions produced by traditional optimization algorithms (e.g., nonlinear programming, quadratic programming, dynamic programming and etc.) tend to stagnate into local optima due to the difficulty of achieving good guess of initial solutions (Mukherjee and Ray 2006). The emergence of new metaheuristic search algorithms (Lim and Isa 2015; Ji et al. 2017; Al-Omoush et al. 2019; Hu et al. 2019; Fan and Yan 2016) has become the popular alternative to overcome these challenges. Because, these algorithms do not strongly rely on the quality of initial solutions and the gradient information of objective functions to solve an optimization problem. The substantial amounts of real-world optimization problems have been tackled using the metaheuristic search algorithms due to their promising search robustness. These include the energy management optimization (Yao et al. 2015, 2017; Mathew et al. 2018; Zhao et al. 2013; Zhao et al. 2012), robust control system design (Tang et al. 2013, 2014; Solihin et al. 2009, 2010), machine vision and image processing (Senthilnath et al. 2016; Li et al. 2011; Jiao and Pan 2019; Mistry et al. 2017; Van and Kang 2016), just to name a few.
Majority of machining problems are formulated as the multi-objective optimization problems (MOPs) due to the simultaneous consideration of multiple performance characteristics. There could be three to four control parameters involved in the optimization of response variables. There are generally two popular approaches used to tackle the MOPs, namely the priori method and the posterior method (Collette and Siarry 2003). In contrast to the priori method that only be able to produce one optimum solution at each trial of simulation by considering the predefined relative importance levels of objective functions, the posterior method is able to produce a complete set of trade-off optimal solutions with single run. Referring to the relative importance of objective functions that normally not known in advance, the process planner can choose a unique solution from the complete set of trade-off solutions obtained (Abbas et al. 2016). Due to its excellent capability to cater the frequent changes of customer requirements in real-world scenario of machining process, the posterior method is considered as a more promising approach than the priori method to address the machining problems with MOP characteristic. In addition, the performance selection index method for solving machining multi-criteria decision making problems was discussed by Petković et al. (2017).
Substantial research works have been reported to design various posterior version of multi-objective evolutionary algorithms (MOEAs), aiming to effectively optimize different multi-objective machining problems. These MOEAs can be generally categorized under two different frameworks known as the Pareto-dominance-based (Deb et al. 2005; Corne et al. 2001; Zitzler et al. 2001) and decomposition-based (Zhang and Li 2007; Deb and Jain 2014). The micro-Electric Discharge Machining (microEDM) of Stainless Steel (SS) 316L was modelled with response surface methodology (RSM). Three machining parameters known as discharge current, pulse-on and pulse-off times were optimized by a multi-objective genetic algorithm (Suresh et al. 2014) in order to achieve the maximization of material removal rate and the minimization of tool wear rate simultaneously. Three process parameters for the electrochemical machining (ECM) of die tool steel with nanofluid coolant (i.e., tool feed rate, applied voltage and electrolyte discharge rate) were optimized using a multi-objective genetic algorithm developed by Sathiyamoorthy et al. (2015a). Sathiyamoorthy et al. (2015b) also attempted to optimize the machining of AISI 202 Austenitic stainless steel by considering multiple objectives. A regression model was developed by Viswanathan et al. (2017) to correlate the response variable of cutting temperature for AZ91 Magnesium alloy with three process parameters knowns as the depth of rate, cutting speed and feed rate. Notably, the cutting speed was reported to play significant role in minimizing the cutting zone temperature. The multi-objective ultrasonic machining process was addressed by Teimouri et al. (2015) with an imperialist competitive algorithm (ICA), while the particle swarm optimization was employed by Mohanty et al. (2016) to address the multi-response optimization of electric discharging machining process. Recently, the cuckoo optimization algorithm and hoopoe heuristic were employed by Mellal and Williams (2016) to optimize the process parameters of two traditional machining processes (i.e., drilling process and grinding process) and four modern machining processes (i.e., abrasive jet machining, abrasive water jet machining, ultrasonic machining and water jet machining). A multi-objective version of Jaya algorithm has been proposed by Rao et al. (2017b) to optimize four non-traditional machining processes, i.e., focused ion beam (FIB) micro-milling, laser cutting, wire-electric discharge machining (WEDM) and ECM. Similar multi-objective Jaya algorithm was further applied by Rao et al. (2019) to optimize the process parameters of abrasive waterjet machining process and a multi-objective decision making method was incorporated to select a preferred solution from Pareto front based on the predefined requirements of process planner. The electrical discharge machining (EDM) of polycrystalline diamond (PCD) was modelled by Ong et al. (2018) using a radial basis function neural network. A multi-objective moth search algorithm was then applied to determine the optimal machining parameters, aiming to maximize the material removal rate and minimize the electrode wear rate simultaneously. The teaching–learning-based optimization (TLBO) and most of its modified versions have emerged as the popular optimizers to solve various traditional and modern machining processes, because these approaches do not require the fine tuning of any algorithm-specific control parameters. For instance, the simultaneous minimization of operation time incurred and carbon emission produced from a turning process were achieved with the multi-objective TLBO (MOTLBO) proposed by Lin et al. (2015). A nonlinear regression was used by Abhishek et al. (2017) to formulate the machining model of carbon fibre reinforced polymer (CFRP) composite using single point high-speed steel cutting tool. A prior method developed using TLBO was then applied to optimize four machining parameters known as the spindle speed, feed rate, depth of cut and fibre orientation angle, aiming to achieve satisfactory machining performances in terms of material removal rate, surface roughness and cutting force. A non-dominated sorting TLBO (NSTLBO) was designed to find the optimum parameters settings of four non-traditional machining processes of FIB micro-milling, laser cutting, ECM and WEDM (Rao et al. 2018). An enhanced multi-objective TLBO (EMOTLBO) was proposed by Natarajan et al. (2018) to achieve the maximization of material removal rate and the minimization of surface roughness for the machining process of Delrin material. Apart from the machining process, other practical applications of MOTLBO and its variants can be found in existing literatures (Sultana and Roy 2014; Rao and Waghmare 2015; Yu et al. 2015; Li et al. 2016; Rao et al. 2016, 2017a).
This research aims to address the multi-response optimization of machining of PTFE. Given its overwhelming demands for industrial applications, substantial works related to investigation of mechanical and wear properties of unfilled PTFE and reinforced PTFE have been conducted. Nevertheless, the investigation on the machining characteristics of PTFE has yet to be conducted based on the best of the authors’ knowledge. In order to bridge this research gap, the first major contribution of this paper, as presented in Sect. 2, focused on the experimental design, derivation of regression model of PTFE based on the experimental results. The second major contribution (in Sect. 3) focused on designing an enhanced version of multi-objective algorithm known as the non-dominated sorting modified teaching–learning-based optimization (NSMTLBO), aiming to optimize the machining parameters of PTFE that respond to the minimum surface roughness and maximum material removal rate simultaneously. Some modifications were incorporated into the proposed NSMTBLO in order to solve the MOPs effectively. For instance, a teacher selection mechanism based on the nearest Euclidean distance and the derivation of weighted mean position for each learner were introduced into the modified teacher phase to enhance the exploitation search capability of algorithm. A self-learning mechanism was also integrated into the modified learner phase, aiming to enhance the exploration search of algorithm through a probabilistic mutation. Finally, a fuzzy decision maker (Aghaei et al. 2011) was also applied to determine the most suitable machining parameters from the Pareto front obtained, based on the relative importance of all objective functions that may change frequently. Comprehensive simulation and experimental studies were performed and discussed in Sect. 4, followed by the concluding remarks in Sect. 5.
Experimental design and modelling of PTFE
Experimental details
The virgin PTFE rod in 30 mm diameter, prepared by sintering process was used for experimental analysis. The virgin PTFE is a pure and higher grade material which does not have recycled or reclaimed materials. It is in white colour and preferred to use in industries for its hygienic, better frictional resistance, excellent chemical resistance, outstanding electrical properties and excellent flexural properties. Table 1 shows the physical and mechanical properties of the material. Three levels of cutting speed (Vc), feed rate (f), depth of cut (ap) and nose radius (Nr) were used in design of experiments (DOE) to design L27 orthogonal array (4 × 27). The nose radius of Nr = 0.4, 0.8 and 1.2 mm as per the guidance from the cutting tool manufacture was used. The machining parameters and levels used for DOE is shown in Table 2. The surface roughness \( \left( {R_{a} } \right) \) and material removal rate (MRR) were considered as response variables. The CNC turning centre (Model: Sprint 16TC Fanuc 0i T Mate Model C) was used for machining. The experiments were carried out with servo super cut coolant 32t according to DOE. The time taken for each pass of the required length was recorded. Each sample’s surface roughness was instantaneously measured with Mitutoyo make surf tester. Four trials were done for each experiment and the average of the measurements was recorded. The MRR value was computed by referring to the rate of material’s volume removed from the sample as specified in Eq. (1) shown below:
where MRR refers to material removal rate (cm3/min); \( D_{initial} \) and \( D_{final} \) refer to the initial and final diameters of PTFE sample (cm) before and after machining processes, respectively; L refers to the length of cut (cm); T refers to the time taken to cut the sample (min). The experimental design involved three (3) center runs which vary from low to high (− 1 is low, 0 is medium and + 1 is high). The values − 1, 0 and 1 represent the first level, second level and third level of each control parameter respectively. Figure 1 shows the machined sample, while Table 3 presents the control parameters and the corresponding response variables for each experiment conducted.

Machined PTFE sample
Response surface methodology (RSM)
Response surface methodology (RSM) is a common modelling technique used to investigate the effects of several input control variables and one or more output response variables. In this study, RSM was used to explore the relationship between four input machining parameters known as cutting speed \( \left( {V_{c} } \right) \), feed rate (f), depth of cut (ap) and nose ratio \( \left( {N_{r} } \right) \) on two output response variables of surface roughness \( \left( {R_{a} } \right) \) and material removal rate (MRR).
Without loss of generality, a second-degree polynomial RSM model is represented as follows:
where Y represents the response term;\( \alpha_{0} \) represents the free term of regression equation; \( X_{1} ,X_{2} , \ldots ,X_{I} \) represent the set of control variable terms; \( \beta_{i} ,\;\beta_{ii} \) and \( \beta_{ij} \) refer to the linear coefficient, quadratic coefficient and interacting coefficient terms, respectively. In this research, the response variable Y is associated with the four control variables, viz. \( V_{c} \), f, ap and \( N_{r} \), hence the function denoted as \( \psi \left( { \cdot , \cdot , \cdot , \cdot } \right) \) is,
Let \( \psi_{1} \left( { \cdot , \cdot , \cdot , \cdot } \right) \) and \( \psi_{2} \left( { \cdot , \cdot , \cdot , \cdot } \right) \) be the operators used to return the output response variables of \( R_{a} \) and MRR, respectively, based on the four control variables of \( V_{c} \), f, ap and \( N_{r} \), where:
The regression models represented by Eqs. (4) and (5) are the second-degree polynomial regression model which can be determined with RSM-Box-Behnken design-uncoded units in Design Expert software. The coefficients of \( \alpha_{0} \),\( \beta_{i} \),\( \beta_{ii} \) and \( \beta_{ij} \) in Eq. (2) were determined from the measured experimental data, which further used for obtaining quadratic regression models (Mia 2018; Chabbi et al. 2017; Natarajan et al. 2018). The quadratic regression models of \( R_{a} \) and MRR are expressed as:
Problem formulation of PTFE machining
The objective functions for solving the multiobjective optimization machining optimization of PTFE were developed based on the regression models stated in Eqs. (6) and (7). The four input parameters to be optimized in the multiobjective machining model of PTFE include the cutting speed, feed rate, depth of cut and nose ratio denoted as \( V_{c} \), f, ap, and \( N_{r} \), respectively. Meanwhile, the surface roughness and material removal rate, represented by \( R_{a} \) and MRR, respectively, are two contradict objective functions to be optimized because these output responses imply the quality and quantity of products, respectively.
The mathematical formulation of multi-response optimization of PTFE machining process was presented in Eq. (8). The optimal parameters of \( V_{c} \), f, ap, and \( N_{r} \) were solved using the proposed NSMTLBO as explained in the following sections. For sake of convenience, the maximization problem of MRR was converted into the minimization of negative MRR so that both objective functions can be expressed as the minimization problems.
Proposed methodology
Teaching–learning-based optimization
The teaching–learning-based optimization (TLBO) algorithm was inspired by the classical teaching and learning processes in school (Rao et al. 2011). A group of learners with the population size of N are randomly initialized at the beginning stage of optimization. Each of the n-th learner, denoted as \( X_{n} = \left[ {X_{n,1} , \ldots ,X_{n,d} , \ldots ,X_{n,D} } \right] \), is assumed to be the candidate solution of a given optimization problem, where \( d \in \left[ {1,D} \right] \) and D represent the index and the total dimensional size of problem, respectively. Let \( \varPsi \left( {X_{n} } \right) \) be the objective function value of each n-th solution and it is used to represent the knowledge level of each n-th learner in a classroom that can be enhanced via the teacher or learner phases.
During the teacher phase, all learners can improve their knowledge by learning from the teacher denoted as \( X^{teacher} \), i.e., an individual with the best fitness in population, by considering the average knowledge level of all learners in the population represented as \( X^{mean} \), where:
Let \( r_{1} \in \left[ {0,1} \right] \) be a random number obtained from uniform distribution; \( T_{f} \in \left\{ {1,2} \right\} \) be a teaching factor used to emphasize the importance of learner’s average quality \( X^{mean} \). During the teacher phase, a new solution of n-th learner, denoted as \( X_{n}^{new} \), can be obtained as:
For learner phase, each of the n-th learner aims to improve its knowledge level (i.e., fitness) by interacting with its peers in the population. Let s be the index of a learner randomly selected by the n-th learner from population for peer learning, where \( s \in \left[ {1,N} \right] \) and \( s \ne n \); \( r_{2} \in \left[ {0,1} \right] \) is a random number generated from the uniform distribution. If the learner \( X_{s} \) that is randomly selected from the population has better fitness than \( X_{n} \), the latter learner is attracted towards the former one as shown in Eq. (11). Otherwise, a repel mechanism is introduced in Eq. (12) to prevent the convergence of a learner \( X_{n} \) towards the peer learner \( X_{s} \) with inferior fitness.
If the new solution \( X_{n}^{new} \) generated from the teacher or learner phases has better fitness than the n-th learner, the latter solution will be replaced by the former one. Both of the teacher and learner phases are repeated in until the termination criteria of TLBO are met. The teacher solution \( X^{teacher} \) is considered as best solution obtained from the optimization process.
Non-dominated sorting modified teaching–learning-based optimization
In this section, the non-dominated sorting modified teaching–learning-based optimization (NSMTLBO) is proposed as an improved posterior approach to solve the multi-objective optimization problems. The modified versions of teacher phase and learner phase are introduced into NSMTLBO to enhance its exploration and exploitation capabilities while searching for the optimal solutions in the parameter spaces. Two core concept known as the fast non-dominated sorting and crowding distance (Deb et al. 2002) are also incorporated into NSMTLBO to ensure that the proposed work can solve multi-objective optimization problems effectively and efficiently. Without loss of generality, the minimization problems are considered in the remaining subsections, while explaining the search mechanisms of NSMTLBO in detail here.
Pareto dominance concept
Suppose that a total M objective functions are considered in a given multi-objective optimization problem. Let \( \varPsi_{m} \left( {X_{n} } \right) \) be the objective function value of the n-th learner \( X_{n} \) for the m-th objective function. For a single objective optimization, it is intuitive to compare the quality of different solutions based on its objective function values. Nevertheless, it is nontrivial to rank all solutions from the best to worst for multi-objective optimization problems due to the presence of multiple conflicting objectives.
Pareto dominance concept is a commonly used approach to overcome the challenges of multi-objective optimization problems (Deb et al. 2002). For the self-contained purpose, the definitions of Pareto dominance are presented as follows:
Definition 1
A solution \( X_{n} \) is considered to dominate another solution \( X_{s} \) if \( X_{n} \) shows better or equal objective values on all objectives and produce a better result in at least one objective function. In other words,\( X_{n} \succ X_{s} \) if and only if \( \varPsi_{i} \left( {X_{n} } \right) \le \varPsi_{i} \left( {X_{s} } \right) \) for \( \forall i \in \left\{ {1,2, \ldots ,M} \right\} \) and \( \varPsi_{j} \left( {X_{n} } \right) < \varPsi_{j} \left( {X_{s} } \right) \) for \( \exists j \in \left\{ {1,2, \ldots ,M} \right\} \), or vice versa.
Definition 2
A solution denoted as \( X^{*} \) is considered as a Pareto optimal solution if there is no existence of another solution X such that \( X^{*} \succ X \). A Pareto optimal set can be determined from these Pareto optimal solutions.
Definition 3
Pareto front can be obtained by mapping the Pareto optimal set in the objective space.
Fast non-dominated sorting and crowding distance
An initial population of NSMTLBO denoted as \( {\mathbf{P}} = \left[ {X_{1} , \ldots ,X_{n} , \ldots ,X_{N} } \right] \) consisting of N learners is randomly generated. Similar with majority posteriori version of multi-objective algorithms, NSMTLBO aims to generate an approximated Pareto front consisting of a set of non-dominated solutions that are evenly distributed. In order to solve the multi-objective optimization problems effectively and efficiently, both of the fast non-dominated sorting approach and the crowding distance mechanism are incorporated into NSMTLBO to determine the ranking of all learners.
The fast non-dominated sorting approach is employed in NSMTLBO to ensure that only non-dominated solutions are selected to guide the learners during the search process in order to ensure the population can converge towards the true Pareto front. During the fast non-dominated sorting process, two entities are computed for each n-th learner \( X_{n} \), i.e., (i) the domination count denoted as \( C_{n} \) to indicate the number of solutions that dominate the learner \( X_{n} \) and (ii) a set denoted as \( S_{n} \) to store the solution sets that are dominated by the learner \( X_{n} \)-. All non-dominated solutions with \( C_{n} = 0 \) found in the first round of sorting process are allocated in the first front denoted as \( F_{1} \). For every n-th learner with \( C_{n} = 0 \) stored in the first front \( F_{1} \), each of the s-th learner \( X_{s} \) stored in the set \( S_{n} \) is visited to reduce its domination count by one. If the domination count \( C_{s} \) of any s-th learner is reduced to zero, it is stored into a new list denoted as Q to form the second front \( F_{2} \). The same process is repeated for all members stored in list Q to identify the third front \( F_{3} \). From Fig. 2, the fast non-dominated sorting process continues until the non-domination rank \( {\mathbf{Rank}} = \left[ {Rank_{1} , \ldots ,Rank_{n} , \ldots ,Rank_{N} } \right] \) and fronts \( {\mathbf{F}} = \left[ {F_{1} , \ldots ,F_{r} , \ldots ,F_{R} } \right] \) of all N learners are found, where r and R represent the index and upper limit of front counters, respectively.

The pseudo-code of fast non-dominated sorting approach
In order to prevent premature convergence, it is crucial for NSMTLBO to maintain the diversity of its Pareto optimal solution sets by choosing the non-dominated solutions from sparse regions as teacher in guiding the search process of remaining learners. The crowding distance (Deb et al. 2002) denoted as \( \Delta_{n} \) is a metric used to measure the density of solution \( X_{n} \) around the n-th learner in population by calculating the average distance of two nearest solutions on both sides of \( X_{n} \) along each of the M objectives. Suppose that \( \left| {F_{r} } \right| \) is to the number of members allocated to the r-th front. The initial crowding distance of each a-th member is set as \( \Delta_{a,r} = 0 \), where \( a = 1, \ldots ,\left| {F_{r} } \right| \). For every m-th objective function, a sorting process is performed on all members allocated to the r-th front in ascending manner by referring to their respective objective values and a list represented as Lm,r is used to store all sorted members. Suppose that for the r-th front, the a-th member is sorted to become the j-th element denoted as \( L_{m,r} \left[ j \right] \) for the m-th objective, where \( j = 1, \ldots ,\left| {F_{r} } \right| \). Then, the crowding distance for every j-th sorted member with the objective function value denoted as \( \varPsi_{m} \left( {X_{{L_{m,r} \left[ j \right]}} } \right) \) can be calculated as:
From Eq. (13), the front members with larger crowding distances are located on the more sparse regions of objective space and vice versa. For every m-th objective function, the boundary solutions stored in the sorted list \( L_{m,r} \) are assigned with infinite crowding distance values. Similar procedures are repeated for all M objective functions and all R fronts as shown in Fig. 3. A set denoted as \( {\varvec{\Delta}} = \left[ {\Delta_{1} , \ldots ,\Delta_{n} , \ldots ,\Delta_{N} } \right] \) used to store the overall crowding-distance value of each n-th learner is then computed as the sum of individual distance values corresponding to each m-th objective function value.

The pseudo-code of computing the crowding distance value of each learner
Referring to the non-domination rank \( Rank_{n} \) and the crowding distance \( \Delta_{n} \) of each n-th learner, a crowding-comparison operator denoted as \( \prec_{cco} \) is used to compare the superiority of two solutions during the selection process so that a uniformly spread-out optimal Pareto front can be generated to solve the given multi-objective optimization problem. From Eq. (14), if both learners of \( X_{n} \) and \( X_{s} \) have different non-domination ranks,\( X_{n} \) is preferred over \( X_{s} \) if the former solution has better (i.e., lower) rank than the latter one. If both learners belong to the same rank, the solution located in the less crowded regions with larger \( \Delta_{n} \) value is preferred as follow:
Modified teacher phase
During the teacher phase of TLBO, each of the n-th learner adjusts its position \( X_{n} \) based on the differences between the teacher \( X^{teacher} \) and the mainstream knowledge of population denoted as a mean value \( X^{mean} \) as shown in Eq. (10). For single objective optimization problem, the selection of teacher is intuitive and can be achieved by identifying the learner with best objective function value from population. On the other hand, the existance of mutually contradictory objectives in the multi-objective optimization problems tends to produce multiple non-dominated learners that are able to guide other learners as teachers in searching for the Pareto front.
A modified teacher selection scheme is introduced for teacher phase of NSMTLBO, aiming to leverage the expertise of multiple teachers in solving the multi-objective optimization problems. In contrast to the conventional TLBO where a same teacher is assigned to guide the search processes of all learners, the nearest non-dominated learner stored in the Pareto front \( F_{1} \) is assigned as the teacher for every n-th learner during the teacher phase of NSMTLBO. Let \( \left| {F_{1} } \right| \) be the number of candidate teachers contained in the Pareto front \( F_{1} \) and D represents total numbers of design variables that need to be optimized. Let \( X_{d}^{U} \) and \( X_{d}^{L} \) be the d-th dimensional component of the upper and lower limits, respectively, where \( d = 1, \ldots ,D \). Denote \( X_{a,d}^{Cand} \) and \( X_{n,d} \) as the d-th dimension of the a-th candidate teacher and n-th learner, where \( a = 1, \ldots ,\left| {F_{1} } \right| \) and \( n = 1, \ldots ,N \), respectively. Then, the normalized Euclidean distance between the n-th learner and the a-th candidate teacher represented with \( E_{n,a} \) are computed as follow:
As shown in Fig. 4, the computation of normalized Euclidean distances between the n-th learner and all \( \left| {F_{1} } \right| \) candidate teachers are repeated using Eq. (15). Based on the \( E_{n,a} \) values, the closest candidate teacher denoted as \( X_{n}^{teacher} \) is identified as the teacher for the n-th learner during the teacher phase. The adopted teacher selection mechanism is anticipated to enhance the exploitation capability of NSMTLBO because each learner is guided by its closest teacher. The diversity of Pareto front can also be preserved due to the employment of different teachers in guiding different learners during the teacher phase of NSMTLBO.

The pseudo-code of finding the closest teacher for each learner in the teacher phase
For conventional TLBO, the contributions of all learners are equal in determining the mean value of population \( X^{mean} \). It is anticipated that the conventional TLBO is susceptible to premature convergence because the same values of \( X^{teacher} \) and \( X^{mean} \) are used to update all of the learners in each generation. If the most knowledgeable teacher is trapped in a local optimum, it tends to misguide the rest of learners searching towards the local optimum and produce the same mean position \( X^{mean} \). When both of the \( X^{teacher} \) and \( X^{mean} \) becomes undistinguishable, the position of learners cannot be updated and stuck at local optimum because the second term of Eq. (10) tends to approach zero value when teaching factor obtained by all learners are \( T_{f} = 1 \).
In order to address this issue, an alternate approach in obtaining the mean knowledge of population is proposed for the teacher phase of NSMTLBO. Unlike TLBO, the proposed NSMTLBO only leverages the benefits of useful information carried by the non-dominated learners stored in Pareto front \( F_{1} \) as the source of influences in guiding the search process of other learners. In order to prevent the diversity loss in second component of Eq. (10), each a-th non-dominated learner from \( F_{1} \) is assigned with different weightage to reflect its unique contribution in constructing the weighted mean position of the n-th learner. Denote \( r_{a} \in \left[ {0,1} \right] \) as the random number obtained from a uniform distribution for each a-th non-dominated learner in \( F_{1} \) with the position value of \( X_{a} \). Suppose that \( \tilde{X}_{n}^{mean} \) represents the weighted mean position of n-th learner, then
Given the closest teacher \( X_{n}^{teacher} \) and weighted mean \( \tilde{X}_{n}^{mean} \), the new position of each n-th NSMTLBO learner is updated through the modified teacher phase, where
where \( r_{3} \) and \( r_{4} \) are the random number with the range of 0 to 1 generated from uniform distribution;\( T_{f1} \) and \( T_{f2} \) are the teaching factors with the range of 1 to 2 generated from uniform distribution, where \( T_{f1} ,T_{f2} \in \left[ {1,2} \right] \) (Rao and Patel 2013; Lin et al. 2015). As shown in Fig. 5 and Eq. (17), each of the n-th NSMTLBO learner can learn directly from multiple teachers by updating its knowledge based on the differences between its current knowledge and (i) the closest teacher’s knowledge and (ii) weighted mean knowledge of other teachers in classroom. These uniform distributions of \( T_{f1} \) and \( T_{f2} \) are used to emulate a more realistic classroom paradigm by generating the learners with different levels of learning tendency from the teachers. Particularly, the NSMTLBO learner is assumed to learn everything from the teachers successfully when \( T_{f1} \) and \( T_{f2} \) are equal to 2, while the learner fails to learn anything when \( T_{f1} = T_{f2} = 1 \) (Rao and Patel 2013; Lin et al. 2015).

The pseudo-code of modified teacher phase in NSMTLBO
Modified learner phase
The learner phase of TLBO promotes the exploration search of algorithm by introducing the repelling mechanism in Eq. (12) when the n-th learner is randomly assigned to an inferior peer. As the iterative generation of TLBO becomes larger, the changes in population tends to be stabilized because all learners tend to converge towards a particular region of search space. Without the notable changes of population diversity, it becomes challenging for a randomly selected learner to assist the particular learner to break out from sub-optimal region, especially if the optimization problem consists of a complicated Pareto front. It is also more difficult for the learner in a multi-objective algorithm to randomly choose another peer that is completely dominated by it, hence the likelihood of triggering repelling mechanism in Eq. (12) is reduced further.
In order to address these challenges, a modified learner phase is proposed for NSMTLBO. A probabilistic mutation scheme is first designed as an alternative learning strategy in the learner phase of NSBTLBO, aiming to perturb the learners with a mutation probability represented as \( P_{mut} = {1 \mathord{\left/ {\vphantom {1 D}} \right. \kern-0pt} D} \). From the perspective of classroom teaching–learning paradigm, different types of learners exist in the same classroom and some learners might prefer to improve their knowledge level via self-learning rather than interacting with their peers. The inclusion of this mutation operator is to facilitate the self-learning of some NSMTLBO learners during the learner phase after they complete the teacher phase. When the self-learning mechanism is triggered for the n-th learner with probability \( P_{mut} \), a random dimensional component of n-th learner, denoted as \( d_{r} \in \left[ {1,D} \right] \), is selected for perturbation, where
where \( r_{5} \in \left[ { - 1,1} \right] \) is a random number obtained from uniform distribution;\( X_{{n,d_{r} }}^{new} ,\;X_{{n,d_{r} }}^{U} \) and \( X_{{n,d_{r} }}^{L} \) are the \( d_{r} \)-th dimensional component of the n-th learner, the upper and lower boundary limits of decision variables, respectively. The pseudocode of self-learning mechanism is described in Fig. 6.

The pseudo-code of self-learning mechanism in the modified learner phase
For the n-th learner that prefer to improve its knowledge by interacting with other peers, a random peer learner denoted as \( X_{s} \) is chosen from population to update \( X_{n} \) using Eq. (11) or Eq. (12), where \( n,s \in \left[ {1,N} \right] \) and \( s \ne n \). If the randomly chosen peer learner \( X_{s} \) dominates the learner \( X_{n} \), the latter learner is attracted towards the former one as shown in Eq. (11). On the other hand, the learner \( X_{n} \) tends to be driven away from the inferior peer learner \( X_{s} \) using Eq. (12) to prevent the premature convergence of population in sub-optimal regions of fitness lanscapes. If both of the learner \( X_{n} \) and peer \( X_{s} \) are non-dominated with each other, one of the learning strategy expressed using Eq. (11) or Eq. (12) will be randomly selected with an equal chance for updating the n-th learner at the modified learner phase of NSMTLBO as shown in Fig. 7.

The pseudo-code of modified learner phase in NSMTLBO
Fuzzy decision maker
After obtaining the Pareto front \( F_{1} \) of a given multi-objective optimization problem, a fuzzy decision maker is then used by NSMTLBO to determine the most suitable solution from the Pareto front obtained by referring to the relative importance levels of all objective functions stated by the stakeholders.
Denote \( {\varvec{\Psi}}^{{\mathbf{U}}} = \left[ {\varPsi_{1}^{U} , \ldots ,\varPsi_{m}^{U} , \ldots ,\varPsi_{M}^{U} } \right] \) as the utopia point of a given multi-objective optimization problem consisting of M objective functions. Utopia point is a specific point located in objective space with all objective function values demonstrate the best possible values. On the other hand, the pseudo nadir point denoted as \( {\varvec{\Psi}}^{{{\mathbf{SN}}}} = \left[ {\varPsi_{1}^{SN} , \ldots ,\varPsi_{m}^{SN} , \ldots ,\varPsi_{M}^{SN} } \right] \) is another extreme point in objective space that consisting of the worst values for all objective functions. In order to select the most preferred optimal solution from Pareto front \( F_{1} \), the membership value of every a-th Pareto front member with \( a = 1, \ldots ,\left| {F_{1} } \right| \) for the m-th objective function is computed by calculating the relative distances between the objective function value of a-th Pareto front member, denoted as \( \varPsi_{m} \left( {X_{a} } \right) \), and both of the utopia and pseudo nadir points in each m-th objective function. For any m-th objective function, if the a-th Pareto optimal solution is closer to the utopia point, the higher membership value denoted as \( \mu_{a}^{m} \) is assigned to indicate the higher degree of optimality for the a-th Pareto front member in the m-th objective function and vice versa.
For minimization problem, the fuzzification process used to determine the membership value \( \mu_{a}^{m} \) of each a-th Pareto front member with the objective function value \( \varPsi_{m} \left( {X_{a} } \right) \) in the m-th objective function is shown as follow:
The value of \( \mu_{a}^{m} \) for maximization problem is computed as:
Assume that \( w_{m} \) represents the relative importance level of every m-th objective function given by stakeholders, while \( \mu_{a} \) refers to the total degree of optimality for every a-th Pareto front member. Then,
From Fig. 8, the a-th Pareto front member with the largest value of \( \mu_{a} \) is selected from \( F_{1} \) as the most preferred Pareto optimal solution denoted as \( X^{preferred} \) because it produces better optimization on all objective functions of a given multi-objective optimization problem as compared with other Pareto front members by referring to the relative importance of all objective functions.

The pseudo-code of fuzzy decision maker
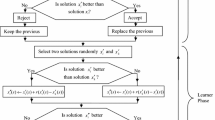
The complete NSMTLBO algorithm
The complete procedures of NSMTLBO are presented in Fig. 9, where \( \gamma \) and \( \varGamma \) denote the counter of function evaluations and maximum fitness evaluation numbers, respectively. During the initialization stage of NSMTLBO, a population P consists of N learners is randomly generated, followed by the function evaluation of these N learners in all M objective functions. The front number, non-domination rank and crowding distance of all learners are then computed, followed by the sorting of members of population P from the best to worst by referring to these metrics.

The pseudo-code of complete NSMTLBO
During the search process, the new solution \( X_{n}^{new} \) of each n-th learner is generated via the modified teacher or learner phases and stored in an offspring population denoted as \( {\mathbf{P}}^{{{\mathbf{off}}}} \) with the population size of N. A combined population denoted as \( {\mathbf{P}}^{{{\mathbf{comb}}}} = {\mathbf{P}} \cup {\mathbf{P}}^{{{\mathbf{off}}}} \) with the population size of 2 N is constructed and all members of \( {\mathbf{P}}^{{{\mathbf{comb}}}} \) are sorted from the best to worst based on their non-domination ranks and crowding distances. An operator denoted as \( Trunc\left( { \cdot , \cdot } \right) \) is then applied to truncate the best N members with the lowest \( Rank_{n} \) and largest \( \Delta_{n} \) in \( {\mathbf{P}}^{{{\mathbf{comb}}}} \), aiming to create a new population of P for the next phase or next generation. These procedures are repeated until the termination condition is satisfied, i.e., when the values of fitness evaluation counter exceed the maximum fitness evaluation numbers, i.e.,\( \gamma > \varGamma \). When the proposed NSMTLBO is terminated, the preferred optimal solution denoted as \( X^{preferred} \) is determined from the Pareto front of \( F_{1} \) with the fuzzy decision maker based on the relative importance level specified for each objective function.
Performance metrics
Two evaluation metrics are adopted in this study to compare the optimization performances of all algorithms in tackling the multi-response optimization of PTFE machining problem. The first metric used for performance comparison of two Pareto fronts is a coverage operator of two sets by computing the percentage of members of one Pareto front to be dominated by those of another Pareto front (Zitzler et al. 2000). Denote \( C\left( { \cdot , \cdot } \right) \) as the coverage operator used to compare two Pareto fronts of \( F_{1}^{A} \) and \( F_{1}^{B} \), then
If \( C\left( {F_{1}^{A} ,F_{1}^{B} } \right) = 1 \), it implies that all members of the Pareto front \( F_{1}^{B} \) are dominated or perform equally to all members from \( F_{1}^{A} \). In contrary,\( C\left( {F_{1}^{A} ,F_{1}^{B} } \right) = 0 \) means that none of the solution in \( F_{1}^{B} \) are covered by those of \( F_{1}^{A} \). Notably, it is not guarantee that \( C\left( {F_{1}^{A} ,F_{1}^{B} } \right) \) must be equal to \( 1 - C\left( {F_{1}^{B} ,F_{1}^{A} } \right) \), therefore it is crucial to obtain both results during performance comparisons.
Spacing metric (Coello et al. 2004) is the second metric used for performance comparison by measuring the uniformity of Pareto fronts distribution obtained by different algorithms. Suppose that M refers to the numbers of objective functions to be optimized, while \( \left| {F_{1} } \right| \) represents the number of non-dominated solutions obtained from Pareto front. Then, the smallest Euclidean distance between the a-th and b-th Pareto optimal solutions for each m-th objective function in the objective space is:
The average value of all \( d_{a} \) is then computed as:
Define S as the spacing measure to quantify the distance variance of neighbouring Pareto optimal solutions, then
The spacing measure of \( S = 0 \) is the best possible value produced by a compared algorithm because it implies that all of the Pareto front members are equidistant from each other.
Experimental studies
In this section, the capability of the proposed PTFE regression model to fit in the given experimental data is first investigated. The quantitative and qualitative analyses of Pareto fronts produced by NSMTLBO and another six well-established algorithms are then conducted and compared thorough simulation studies. Based on the optimized machining parameters obtained from simulations, the performance deviations between the actual and simulated results were then investigated through further validation experiments in order to confirm the practicability NSMTLBO in solving the PTFE machining problem.
Evaluation of PTFE modelling using analysis of variances (ANOVA)
The goodness-of-fit of the measured data and model was done using a statistical tool known as ANOVA. SD, R2 and P are the output parameters of ANOVA that represent the standard deviation, percentage of variation of data and significance of the control variable (adequacy), respectively. The parameter SD represents how far the date values fall from the fitted values, which seems to be an indicator to show how good of a model in describing the response. The percentage of data variation in the response is qualified using the parameter R2 with the range of 0–100%, where greater values of R2 implies for better fitting in modelling. The probability P is used to check if the tested parameters are essential in determining the responses of model. If \( P < 5\% \), it indicates that the parameters are significant on responses of an adequate model. On the other hand, the parameter is concluded to be insignificant on the responses of an adequate model for \( P > 5\% \).
The Box-Behnken uncoded units were used in this study and the 95% confidence interval was set to find the variance among input machining parameters (Vc, f, ap and Nr) and output responses \( R_{a} \) and MRR. The contribution of each process parameter on the output responses were calculated as shown in Tables 4 and 5. Table 6 shows the parameter R2 which is used to assess the percentage of data variance to the response. It is seen that 97% variability of data of MRR and 95% variability data of surface roughness are around the mean. In other words, the higher R2 shown above, reveals the strength of the relationship between the model and the dependent variable. It is the evidence of the fitness of the models.
Performance analysis of NSMTLBO in PTFE machining problem
The parameter settings of all involved multi-objective optimization algorithms considered in solving the proposed PTFE machining optimization problem are first presented. It is followed by the presentation and discussion of simulation results obtained by all algorithms. Both of the qualitative and quantitative analyses are used to compare the optimization performance demonstrated by each compared methods. Finally, the performance deviations between the simulated and experiment results obtained for the surface roughness and material removal rate are compared based on the selected optimized machining parameters.
Parameter settings for simulation and experimental studies
Extensive performance evaluation of NSMTLO was conducted by comparing it with another six well-established algorithms. This included the multi-objective particle swarm optimization (MOPSO) (Coello et al. 2004), non-dominated sorting genetic algorithm II (NSGA-II) (Deb et al. 2002), multi-objective grey wolf optimizer (MOGWO) (Mirjalili et al. 2016), multi-objective teaching–learning based optimization (MOTLBO) (Lin et al. 2015), multi-objective improved teaching–learning based optimization (MO-ITLBO) (Patel and Savsani 2016) and non-dominated sorting teaching–learning based optimization (NSTLBO) (Rao et al. 2018). The concept of external archive is used by MOPSO, MOGOW and MO-ITLBO to store the non-dominated solution found during the optimization. Meanwhile, both mechanisms of fast non-dominated sorting and crowding distance are incorporated into NSGA-II, MOTLBO and NSTLBO for determining the quality of solutions obtained in solving the multi-objective optimization problems. The excellent performances of these six selected algorithms in handling different multi-objective optimization problems were verified in their literatures, hence the performance comparison between NSMTLBO and these peer algorithms are expected to be convincing.
The parameter settings of all compared algorithms were tuned as shown in Table 7 based on the recommendations of their respective literatures. The inertia weight \( \omega \) of MOPSO was set to be reduced from 0.9 to 0.4 in linear manner, while the parameter settings of both acceleration coefficients were given as c1 = c2 = 2.05. For MOPSO and MOGWO, the parameters of grid inflation and number of grid per dimension that are crucial in constructing the external archive were set as \( \alpha = 0.1 \) and \( nGrid = 10 \), respectively. The teaching factor \( T_{f} \) of NSTLBO was randomly generated as 1 or 2, while the NSGA-II has a crossover rate of \( P_{cr} = 0.9 \). A multiple group learning approach with the group number of \( nGroup = 4 \) was adopted by MO-ITLBO during the teaching phase and its archive was managed by epsilon-dominance method with \( \varepsilon = 0.007 \) (Patel and Savsani 2016). For NSMTLBO, the mutation probability were set similar as MOPSO and NSGA-II, i.e., \( P_{mut} = {1 \mathord{\left/ {\vphantom {1 D}} \right. \kern-0pt} D} \) (Deb et al. 2002; Coello et al. 2004). The teaching factors of MOTLBO, MO-ITLBO and NSMTLBO were generated as the values between 1 and 2 to show the different capabilities of learners to improve their knowledge level from the teachers.
Different population sizes of N = 20, 30 and 40 were set to investigate the effect of population sizes on the optimization performances of all compared algorithms based on the recommendation of selected previous works (Natarajan et al. 2018; Rao et al. 2017b). For MOPSO, MOGWO and MO-ITLBO, the archive size \( \left| A \right| \) was set equal to N. Based on most official documents that specify the rules of competition among optimization algorithms the same maximum fitness evaluation number needs to be used as the termination condition of all compared algorithms for the sake of fair performance comparison (Suganthan et al. 2005; K. Tang et al. 2010; Liang et al. 2013). In this study, the maximum fitness evaluation number is set as \( \varGamma = 20,000 \). All algorithms were implemented with a Matlab 2017a software on the workstation consisting of Intel ®Core i7-7500 CPU @ 2.70 GHz. Each compared algorithm was run 20 times independently to obtain their average results.
Results and discussions
Table 8 presents the mean and standard deviation (SD) values of coverage metric obtained by all compared algorithms for N = 20, 30 and 40. The proposed NSMTLBO is reported to have the most competitive optimization performance because of its capability to produce the Pareto fronts with larger percentages of non-dominated solutions as compared with the remaining six peer algorithms in all population sizes. For instance, it is observed that 32.9% of the members of Pareto front obtained by NSGA-II are inferior to those of NSMTLBO for N = 40, whereas only 0.8% of the Pareto front members of NSMTLBO are inferior to those of NSGA-II. There are 17.5% and 6.5% of Pareto front members of MOPSO and MOGWO, respectively, in N = 20 are worse than those of NSMTLBO. In contrary, all Pareto optimal solutions obtained by NSMTLBO are non-dominated by those of MOPSO and MOGWO. For all three TLBO variants considered in benchmarking, MOTLBO demonstrates the worst results because the percentages of its Pareto optimal solutions dominated by NSMTLBO increase with population sizes, i.e., 5.0%, 10.3% and 16.9% for N = 20, 30 and 40, respectively. In contrary, the Pareto optimal solutions of NSMTLBO that are dominated by those of MOTLBO are at least ten times lesser for all population sizes. It is also observed that the performance differences between NSTLBO and NSMTLBO are relatively small because not more than 2.5% of NSTLBO’s Pareto optimal solutions are dominated by NSMTLBO, while there are not more than 0.5% of the Pareto front members produced by NSMTLBO are worse than those of NSTLBO for the population sizes of N = 20, 30 and 40.
Remark
The Pareto fronts generated by NSMTLBO, MOPSO, NSGA-II, MOGWO, MOTLBO, MO-ITLBO and NSTLBO algorithms are represented with RP, SP, TP, UP, VP, Wp and Xp respectively.
The mean and SD values of spacing metric obtained by MOPSO, NSGA-II, MOGWO, MOTLBO, MO-ITLBO, NSTLBO and NSMTLBO for the 20 independent runs in all population sizes are summarized in Table 9. It is reported that the quality of Pareto fronts generated by NSMTLBO are the best for having the non-dominated solution sets that are diversified and yet uniformly distributed as indicated by the lowest spacing values obtained for N = 20, 30 and 40. Among all compared algorithms, the Pareto fronts obtained by NSGA-II in solving the PTFE machining problem has the worst quality because not only majority of the Pareto front members are dominated by those of NSMTLBO, but they also have the poorest distributions. While the MOPSO, MOGWO and MOTLBO can produce lesser Pareto optimal solutions dominated by NSMTLBO, the uniformity and diversity of their Pareto fronts are at least two times worse than those of NSMTLBO according to the spacing metric. It is noteworthy that the Pareto fronts generated by MO-ITLBO and NSTLBO have shown different observations. For MO-ITLBO, the Pareto fronts generated have second best spacing values but they consist of more inferior solutions dominated by NSMTLBO. In contrary, the Pareto fronts produced by NSTLBO have much higher spacing values although it can produce more non-dominated solutions. The poor quality of Pareto fronts obtained by NSTLBO reveals the existence of duplicated non-dominated solutions and this explains the better coverage and yet inferior spacing values. As compared with MO-ITLBO and NSTLBO, the proposed NSMTLBO has more competitive performance in producing the Pareto fronts with better quality and well distributed solutions.
In order to evaluate the computational efficiency of each compared algorithm, the mean computation time incurred by MOPSO, NSGA-II, MOGWO, MOTLBO, MOITLBO, NSTLBO and NSMTLBO in 20 independent runs in all population sizes are presented in Table 10. The proposed NSMTLBO has demonstrated promising computation efficiency because the computational time incurred to optimize the PTFE multi-objective machining problems is lesser than those of NSGA-II, MOGWO, MOTLBO and NSTLBO for all population sizes of N = 20, 30 and 40. Although the mean computational time incurred by MOPSO and MO-ITLBO are lower than NSMTLBO in most population sizes, the performance differences of computational efficiency between these three algorithms are not significant. In addition, the proposed NSMTLBO has better performance than MOPSO and MO-ITLBO for being able to produce the Pareto fronts consisting of higher percentages of non-dominated solutions and more uniformly distributed of solution sets. Based on the simulation results shown in Table 10, it is suggested that the proposed modifications incorporated into NSMTLBO can achieve better tradeoff between the extra computational overheads consumed and performance enhancement achieved as compared with majority of peer algorithms.
The Pareto-fronts of PTFE machining problem obtained by MOPSO, NSGA-II, MOGWO, MOTLBO, MO-ITLBO, NSTLBO and NSMTLBO for N = 30 are illustrated in Fig. 10. In general, the qualitative results of Fig. 10 are aligned with the quantitative performance analyses reported in Tables 2 and 3. NSGA-II shows the worst optimization performance not only because it has Pareto-front with uneven distribution of solutions, but some solutions obtained are also dominated by the other compared algorithms. For instance, the material removal rate of solution produced by NSGA-II is around 20 cm3/mm when the surface roughness value is 1.6 μm, while other peer algorithms such as MOGWO, MOTLBO, MO-ITLBO, NSTLBO and NSMTLBO can produce the material removal rates higher than 40 cm3/mm with same surface roughness. In addition, it is observed that the Pareto-fronts generated by MOPSO, MOGWO, MOTLBO, MO-ITLBO and NSTLBO are inferior than that of NSMTLBO because the proposed approach can produce higher percentages of non-dominated solutions, especially those at the boundary regions of objective space. For instance, the proposed NSMTLBO is able to obtain five Pareto solutions when surface roughness changes from 1.4 to 1.6 μm, while the MOPSO, MOGWO, MOTLBO and NSTLBO can only produce one, four, four and three Pareto solutions, respectively, for the same range of surface roughness. In contrast to NSMTLBO, the Pareto fronts of MOTLBO, MO-ITLBO and NSTLBO fail to detect a Pareto front member with the surface roughness of 2.7 μmand the material removal rate of 98 cm3/mm. The capability of NSMTLBO in identifying the Pareto optimal solutions located in the boundary regions of objective space is attributed to the promising exploitation strength offered by the modified teacher phase. The mechanism of assigning the nearest non-dominated solution as teacher of each learner allows the refinement of search process around a promising solution. Meanwhile, the unique mean positions generated for each learner by considering different weight contributions of all non-dominated solutions allow the learners to search the regions slightly beyond the promising solutions in order to reach other unvisited non-dominated solutions. Finally, the proposed NSMTLBO also outperforms the MOPSO, MOGWO, MOTLBO and MO-ITLBO for being able to produce the Pareto front with better uniformity. The extra momentum offered by the probabilistic self-learning mechanism in the modified learner phase during the search process can prevent the stagnation of NSMTLBO at the local Pareto-front as well as maintaining the diversity of solutions in Pareto-front.

The Pareto fronts of (a) MOPSO, b NSGA-II, c MOGWO, d MOTLBO, e MO-ITLBO, f NSTLBO and g NSMTLBO
After completing the quantitative and qualitative analyses of Pareto-fronts obtained by NSMTLBO, it is equally crucial to validate the optimal process parameters obtained by considering relative importance levels of all objective functions with those actual values of surface roughness (Ra) and material removal rate (MRR) obtained from experiments. Define \( w_{1} \) and \( w_{2} \) as the weightage to imply the importance levels of objectives in minimizing Ra and maximizing MRR, respectively, where \( w_{1} + w_{2} = 1 \). In this section, the weightage setting of \( w_{1} = w_{2} = 0.5 \) are considered on both contradict objectives. This implies that the equal emphasis levels were considered in maximizing the quality and quantity of PTFE product simultaneously during the machining process. The proposed NSMTLBO was first executed with a population size of N = 30 to produce a Pareto-front similar to that of in Fig. 10g. A fuzzy decision maker was then applied to determine the preferred optimum machining parameters based on the predefined weights of \( w_{1} \) and \( w_{2} \) using Eqs. (19) to (21). The predicted and experimental values of \( R_{a} \) and MRR obtained based on the optimum machining parameters were presented in Table 11 together with their error values.
Given the equal weightage values of \( w_{1} = w_{2} = 0.5 \), the optimum machining parameters obtained by the proposed NSMTLBO are Vc = 160 m/min, f = 0.50 mm/rev, ap = 0.98 mm and Nr = 0.8 mm. The predicted values of surface roughness and material removal rate based on the simulation with these machining parameter settings are \( R_{a} \)= 2.2347 μm and MRR = 96.8347 cm3/mm, respectively. By referring to the validation results presented in Table 11, it is observed that the deviations between the predicted and experimental values of \( R_{a} \) and MRR are 3.26% and 3.7%, respectively. Referring to these negligibly small performance deviations, it can be concluded that the good consistency between the simulated and actual experimental results is achieved.
Conclusions
The experimental design was done and the L27 orthogonal array consisting of three-level of cutting speed \( \left( {V_{c} } \right) \), feed (f), depth of cut (ap) and nose radius \( \left( {N_{r} } \right) \) was formulated. The experiments were performed using a CNC turning machine with cemented carbide tool at an insert angle of 80°. The surface roughness was measured and material removal rate was computed instantly in each experiment. The response surface model (RSM) was rendered from the experimental results and the minimization function of surface roughness and maximization function of material removal rate were derived. ANOVA was applied to determine the relationship between the dependent variable and independent variables.
Apart from developing the regression model of PTFE, an enhanced version of multi-objective optimization algorithm abbreviated as NSMTLBO was designed to tackle the multi-objective machining problem. Some notable modifications were introduced into the proposed NSMTLBO, including: (i) a modified teacher phase consisting of the teacher selection mechanism based on the nearest Euclidean distance and the derivation of weighted mean position for each learner, (ii) a modified learner phase consisting of the probabilistic mutation operator to emulate the self-learning mechanism of learner and (iii) a fuzzy decision maker to determine the preferred non-dominated solution from Pareto front based on the predefined importance levels of objective functions. The optimization performance of NSMTLBO was evaluated through extensive simulation studies and it was proven that the proposed approach can outperform the other six peer algorithms due to its excellent capability in generating the Pareto fronts with better uniformity and higher numbers of non-dominated solutions. Finally, the simulation results obtained by NSMTLBO were validated and it was reported that the performance deviations between the simulated and experimental results of both surface roughness and material removal rates for PTFE are less than 3.70%, implying the applicability of proposed work in machining of PTFE.
Abbreviations
- CFRP:
-
Carbon fibre reinforced polymer
- DOE:
-
Design of experiment
- ECM:
-
Electrochemical machining
- EDM:
-
Electric discharge machining
- EMOTLBO:
-
Enhanced multi-objective teaching–learning-based optimization
- FIB:
-
Focused ion beam
- ICA:
-
Imperialist competitive algorithm
- microEDM:
-
Micro-electric discharge machining
- MOEA:
-
Multi-objective evolutionary algorithms
- MOGWO:
-
Multi-objective grey wolf optimizer
- MO-ITLBO:
-
Multi-objective improved teaching–learning based optimization
- MOP:
-
Multi-objective optimization problem
- MOPSO:
-
Multi-objective particle swarm optimization
- MOTLBO:
-
Multi-objective teaching–learning-based optimization
- NSGA-II:
-
Non-dominated sorting genetic algorithm II
- NSMTLBO:
-
Non-dominated sorting modified teaching–learning-based optimization
- NSTLBO:
-
Non-dominated sorting teaching–learning-based optimization
- PSO:
-
Particle swarm optimization
- PCD:
-
Polycrystalline diamond
- PTFE:
-
Polytetrafluoroethylene
- RSM:
-
Response surface model
- TLBO:
-
Teaching-learning-based optimization
- WEDM:
-
Wire-electric discharge machining
- d :
-
Index of each dimension component of learner
- m :
-
Index of objective function
- n :
-
Index of learner
- r :
-
Index to indicate the rank of a given front
- s :
-
Index of learner that is randomly selected for comparison
- \( F_{r} \) :
-
Set containing all learners with the r-th rank value
- \( L_{m,r} \) :
-
Set containing all sorted members of the r-th front for the m-th objective
- Q :
-
Set containing all learners to create the next front
- \( S_{n} \) :
-
Set containing all solutions dominated by the n-th learner
- \( {\mathbf{Rank}} \) :
-
Set containing all non-domination rank values of N learners
- \( {\mathbf{F}} \) :
-
Set containing all members from R fronts
- \( {\varvec{\Delta}} \) :
-
Set containing the crowding distances of all N learners
- \( {\mathbf{P}} \) :
-
Set containing all population members
- \( {\mathbf{P}}^{{{\mathbf{off}}}} \) :
-
Set containing all offspring members
- \( {\mathbf{P}}^{{{\mathbf{comb}}}} \) :
-
Set containing the combination of both population and offspring members
- \( {\varvec{\Psi}}^{{\mathbf{U}}} \) :
-
Set containing the utopia point of a multi-objective optimization problem with M objective functions
- \( {\varvec{\Psi}}^{{{\mathbf{SN}}}} \) :
-
Set containing the pseudo nadir point of a multi-objective optimization problem with M objective functions
- R P :
-
Set containing the Pareto non-dominated solution set of NSMTLBO
- S P :
-
Set containing the Pareto non-dominated solution set of MOPSO
- T P :
-
Set containing the Pareto non-dominated solution set of NSGA-II
- U P :
-
Set containing the Pareto non-dominated solution set of MOGWO
- V P :
-
Set containing the Pareto non-dominated solution set of MOTLBO
- W P :
-
Set containing the Pareto non-dominated solution set of MO-ITLBO
- X P :
-
Set containing the Pareto non-dominated solution set of NSTLBO
- \( \psi \left( { \cdot , \cdot , \cdot , \cdot } \right) \) :
-
An operator that returns the response variable value based on the given control variables
- \( \varPsi_{m} \left( \cdot \right) \) :
-
An operator that returns the value of the m-th objective function based on the given individual solution
- \( Trunc\left( { \cdot , \cdot } \right) \) :
-
An operator that returns the best N members with the lowest ranking and highest crowding distance values
- \( C\left( { \cdot , \cdot } \right) \) :
-
An operator that returns the percentage of solution set from one Pareto front that is dominated by solution set from another Pareto front
- \( \prec_{cco} \) :
-
Crowding-comparison operator to compare the superiority of two solutions
- \( V_{c} \) :
-
Cutting speed
- f :
-
Feed rate
- ap :
-
Depth of cut
- \( N_{r} \) :
-
Nose radius
- \( R_{a} \) :
-
Surface roughness
- \( \Delta R_{a} \) :
-
Error rate of surface roughness
- MRR :
-
Material removal rate
- \( \Delta MRR \) :
-
Error rate of material removal rate
- \( D_{initial} \) :
-
Initial diameter of PTFE sample before machining process
- \( D_{final} \) :
-
Final diameter of PTFE sample after machining process
- L :
-
Length of cut of PTFE sample
- T :
-
Time taken to cut PTFE sample
- Y :
-
Response term of regression equation
- \( \alpha_{0} \) :
-
Free term of regression equation
- \( X_{i} \) :
-
Control variable term of regression equation
- \( \beta_{i} \) :
-
Linear coefficient term of regression equation
- \( \beta_{ii} \) :
-
Quadratic coefficient term of regression equation
- \( \beta_{ij} \) :
-
Interacting coefficient term of regression equation
- D :
-
Number of decision variables to be optimized
- N :
-
Population size
- \( T_{f} \) :
-
Teaching factor that can be set as either 1 or 2
- \( T_{f1} ,T_{f2} \) :
-
Teaching factors with the range of 1 to 2 generated from uniform distribution
- \( C_{n} \) :
-
Domination count to indicate the number of solutions dominate the n-th learner
- \( Rank_{n} \) :
-
Non-domination rank value of the n-th learner
- \( \Delta_{a,r} \) :
-
Crowding distance of the a-th member in the r-th front
- R :
-
Upper limit of front counter
- \( \left| {F_{r} } \right| \) :
-
Number of members in the r-th front
- \( X_{n,d} \) :
-
The d-th component of n-th candidate solution
- \( X^{teacher} \) :
-
Solution vector that represents the best solution known as teacher
- \( X^{mean} \) :
-
Solution vector that represents the average knowledge level of population
- \( X_{n}^{new} \) :
-
New solution vector produced by the n-th learner during the teacher or learner phases
- \( X_{d}^{U} \) :
-
Upper limit of the d-th dimensional component
- \( X_{d}^{L} \) :
-
Lower limit of the d-th dimensional component
- \( X_{a,d}^{Cand} \) :
-
Solution vector of the d-th dimensional component of a-th candidate teacher
- \( X^{preferred} \) :
-
Solution vector of most preferred Pareto optimal solution
- \( X_{n}^{teacher} \) :
-
Solution vector of teacher assigned to the n-th learner
- \( \tilde{X}_{n}^{mean} \) :
-
Weighted mean position vector assigned to the n-th learner
- \( E_{n,a} \) :
-
Normalized Euclidean distance between the n-th learner and the a-th candidate teacher
- \( r_{1} ,r_{2} ,r_{3} ,r_{4} \) :
-
Random numbers with the range of 0 to 1 generated from uniform distribution
- \( r_{5} \) :
-
Random numbers with the range of − 1 to 1 generated from uniform distribution
- \( P_{cr} \) :
-
Crossover rate
- \( P_{mut} \) :
-
Mutation probability
- \( d_{r} \) :
-
Randomly selected dimensional component for mutation
- \( \varPsi_{m}^{U} \) :
-
Utopia point of a multi-objective optimization problem in the m-th objective function
- \( \varPsi_{m}^{SN} \) :
-
Pseudo nadir point of a multi-objective optimization problem in the m-th objective function
- \( \mu_{a}^{m} \) :
-
Membership value of the a-th Pareto optimal solution in the m-th objective function
- \( \mu_{a} \) :
-
Total degree of optimality of each a-th Pareto optimal solution
- \( w_{m} \) :
-
Relative importance of each m-th objective function
- \( w_{1} \) :
-
Relative importance level of minimizing surface finish
- \( w_{2} \) :
-
Relative importance level of maximizing material removal rate
- \( \gamma \) :
-
Counter of function evaluations
- \( \varGamma \) :
-
Maximum fitness evaluation numbers
- \( d_{a} \) :
-
Smallest Euclidean distance between the a-th and b-th Pareto optimal solutions
- \( \bar{d} \) :
-
Average value of all smallest Euclidean distance
- S :
-
Spacing measure
- SD :
-
Standard deviation
- R 2 :
-
Percentage of variation of data
- P :
-
Significance of control variables
- \( c_{1} ,c_{2} \) :
-
Acceleration coefficients
- \( \alpha \) :
-
Grid inflation rate
- \( nGrid \) :
-
Number of grid per dimension
- \( nGroup \) :
-
Number of group created for multiple group learning
- \( \varepsilon \) :
-
Parameter used for epsilon dominance method
- \( \left| A \right| \) :
-
Archive size
References
Abbas, A. T., Aly, M., & Hamza, K. (2016). Multiobjective optimization under uncertainty in advanced abrasive machining processes via a fuzzy-evolutionary approach. Journal of Manufacturing Science and Engineering,138(7), 071003–071009. https://doi.org/10.1115/1.4032567.
Abhishek, K., Rakesh Kumar, V., Datta, S., & Mahapatra, S. S. (2017). Parametric appraisal and optimization in machining of CFRP composites by using TLBO (teaching–learning based optimization algorithm). Journal of Intelligent Manufacturing,28(8), 1769–1785. https://doi.org/10.1007/s10845-015-1050-8.
Aghaei, J., Amjady, N., & Shayanfar, H. A. (2011). Multi-objective electricity market clearing considering dynamic security by lexicographic optimization and augmented epsilon constraint method. Applied Soft Computing,11(4), 3846–3858. https://doi.org/10.1016/j.asoc.2011.02.022.
Al-Omoush, A. A., Alsewari, A. A., Alamri, H. S., & Zamli, K. Z. (2019). Comprehensive review of the development of the harmony search algorithm and its applications. IEEE Access,7, 14233–14245. https://doi.org/10.1109/access.2019.2893662.
Chabbi, A., Yallese, M. A., Nouioua, M., Meddour, I., Mabrouki, T., & Girardin, F. (2017). Modeling and optimization of turning process parameters during the cutting of polymer (POM C) based on RSM, ANN, and DF methods. The International Journal of Advanced Manufacturing Technology,91(5), 2267–2290. https://doi.org/10.1007/s00170-016-9858-8.
Coello, C. A. C., Pulido, G. T., & Lechuga, M. S. (2004). Handling multiple objectives with particle swarm optimization. IEEE Transactions on Evolutionary Computation,8(3), 256–279. https://doi.org/10.1109/tevc.2004.826067.
Collette, Y., & Siarry, P. (2003). Multiobjective optimization: Principles and case studies. Berlin: Springer.
Corne, D. W., Jerram, N. R., Knowles, J. D., & Oates, M. J. (2001). PESA-II: Region-based selection in evolutionary multiobjective optimization. In Paper presented at the proceedings of the 3rd annual conference on genetic and evolutionary computation, San Francisco, California.
Deb, K., & Jain, H. (2014). An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: Solving problems with box constraints. IEEE Transactions on Evolutionary Computation,18(4), 577–601. https://doi.org/10.1109/tevc.2013.2281535.
Deb, K., Mohan, M., & Mishra, S. (2005). Evaluating the ε-domination based multi-objective evolutionary algorithm for a quick computation of pareto-optimal solutions. Evolutionary Computation,13(4), 501–525. https://doi.org/10.1162/106365605774666895.
Deb, K., Pratap, A., Agarwal, S., & Meyarivan, T. (2002). A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation,6(2), 182–197. https://doi.org/10.1109/4235.996017.
Fan, Q., & Yan, X. (2016). Self-adaptive differential evolution algorithm with zoning evolution of control parameters and adaptive mutation strategies. IEEE Transactions on Cybernetics,46(1), 219–232. https://doi.org/10.1109/tcyb.2015.2399478.
Hu, P., Chen, S., Huang, H., Zhang, G., & Liu, L. (2019). Improved alpha-guided grey Wolf optimizer. IEEE Access,7, 5421–5437. https://doi.org/10.1109/access.2018.2889816.
Ji, J., Gao, S., Wang, S., Tang, Y., Yu, H., & Todo, Y. (2017). Self-adaptive gravitational search algorithm with a modified chaotic local search. IEEE Access,5, 17881–17895. https://doi.org/10.1109/access.2017.2748957.
Jiao, K., & Pan, Z. (2019). A novel method for image segmentation based on simplified pulse coupled neural network and gbest led gravitational search algorithm. IEEE Access,7, 21310–21330. https://doi.org/10.1109/access.2019.2894301.
Li, Y., Gong, H., Feng, D., & Zhang, Y. (2011). An adaptive method of speckle reduction and feature enhancement for SAR images based on curvelet transform and particle swarm optimization. IEEE Transactions on Geoscience and Remote Sensing,49(8), 3105–3116. https://doi.org/10.1109/tgrs.2011.2121072.
Li, D., Zhang, C., Shao, X., & Lin, W. (2016). A multi-objective TLBO algorithm for balancing two-sided assembly line with multiple constraints. Journal of Intelligent Manufacturing,27(4), 725–739. https://doi.org/10.1007/s10845-014-0919-2.
Liang, J., Qu, B.-Y., Suganthan, P., & Hernandez-Diaz, A. (2013). Problem definitions and evaluation criteria for the CEC 2013 special session and competition on real-parameter optimization. In Tech. Rep. Zhengzhou, China: Computational Intelligence Laboratory, Zhengzhou University.
Lim, W. H., & Isa, N. A. M. (2015). Particle swarm optimization with dual-level task allocation. Engineering Applications of Artificial Intelligence,38, 88–110. https://doi.org/10.1016/j.engappai.2014.10.022.
Lin, W., Yu, D. Y., Wang, S., Zhang, C., Zhang, S., Tian, H., et al. (2015). Multi-objective teaching–learning-based optimization algorithm for reducing carbon emissions and operation time in turning operations. Engineering Optimization,47(7), 994–1007. https://doi.org/10.1080/0305215x.2014.928818.
Mathew, D., Rani, C., Kumar, M. R., Wang, Y., Binns, R., & Busawon, K. (2018). Wind-driven optimization technique for estimation of solar photovoltaic parameters. IEEE Journal of Photovoltaics,8(1), 248–256. https://doi.org/10.1109/jphotov.2017.2769000.
Mellal, M. A., & Williams, E. J. (2016). Parameter optimization of advanced machining processes using cuckoo optimization algorithm and hoopoe heuristic. Journal of Intelligent Manufacturing,27(5), 927–942. https://doi.org/10.1007/s10845-014-0925-4.
Mia, M. (2018). Mathematical modeling and optimization of MQL assisted end milling characteristics based on RSM and Taguchi method. Measurement,121, 249–260.
Mirjalili, S., Saremi, S., Mirjalili, S. M., & Coelho, L. D. S. (2016). Multi-objective grey wolf optimizer: A novel algorithm for multi-criterion optimization. Expert Systems with Applications,47, 106–119. https://doi.org/10.1016/j.eswa.2015.10.039.
Mistry, K., Zhang, L., Neoh, S. C., Lim, C. P., & Fielding, B. (2017). A micro-GA embedded PSO feature selection approach to intelligent facial emotion recognition. IEEE Transactions on Cybernetics,47(6), 1496–1509. https://doi.org/10.1109/tcyb.2016.2549639.
Mohanty, C. P., Mahapatra, S. S., & Singh, M. R. (2016). A particle swarm approach for multi-objective optimization of electrical discharge machining process. Journal of Intelligent Manufacturing,27(6), 1171–1190. https://doi.org/10.1007/s10845-014-0942-3.
Mukherjee, I., & Ray, P. K. (2006). A review of optimization techniques in metal cutting processes. Computers and Industrial Engineering,50(1), 15–34. https://doi.org/10.1016/j.cie.2005.10.001.
Natarajan, E., Kaviarasan, V., Lim, W. H., Tiang, S. S., & Tan, T. H. (2018). Enhanced multi-objective teaching-learning-based optimization for machining of delrin. IEEE Access,6, 51528–51546. https://doi.org/10.1109/access.2018.2869040.
Ong, P., Chong, C. H., Bin Rahim, M. Z., Lee, W. K., Sia, C. K., & Bin Ahmad, M. A. H. (2018). Intelligent approach for process modelling and optimization on electrical discharge machining of polycrystalline diamond. Journal of Intelligent Manufacturing. https://doi.org/10.1007/s10845-018-1443-6.
Patel, V. K., & Savsani, V. J. (2016). A multi-objective improved teaching–learning based optimization algorithm (MO-ITLBO). Information Sciences,357, 182–200. https://doi.org/10.1016/j.ins.2014.05.049.
Petković, D., Madić, M., Radovanović, M., & Gečevska, V. (2017). Application of the performance selection index method for solving machining MCDM problems. Petković,15(1), 97–106.
Rao, R. V., More, K. C., Taler, J., & Ocion, P. (2016). Optimal design of stirling heat engine using an advanced optimization algorithm. Sadhana,41(11), 1321–1331.
Rao, R. V., More, K. C., Taler, J., & Ocłoń, P. (2017a). Multi-objective optimization of thermo-acoustic devices using teaching-learning-based optimization algorithm. Science and Technology for the Built Environment,23(8), 1244–1252. https://doi.org/10.1080/23744731.2017.1296319.
Rao, R. V., & Patel, V. (2013). Multi-objective optimization of heat exchangers using a modified teaching-learning-based optimization algorithm. Applied Mathematical Modelling,37(3), 1147–1162. https://doi.org/10.1016/j.apm.2012.03.043.
Rao, R. V., Rai, D. P., & Balic, J. (2017b). A multi-objective algorithm for optimization of modern machining processes. Engineering Applications of Artificial Intelligence,61, 103–125. https://doi.org/10.1016/j.engappai.2017.03.001.
Rao, R. V., Rai, D. P., & Balic, J. (2018). Multi-objective optimization of machining and micro-machining processes using non-dominated sorting teaching–learning-based optimization algorithm. Journal of Intelligent Manufacturing,29(8), 1715–1737. https://doi.org/10.1007/s10845-016-1210-5.
Rao, R. V., Rai, D. P., & Balic, J. (2019). Multi-objective optimization of abrasive waterjet machining process using Jaya algorithm and PROMETHEE method. Journal of Intelligent Manufacturing,30(5), 2101–2127. https://doi.org/10.1007/s10845-017-1373-8.
Rao, R. V., Savsani, V. J., & Vakharia, D. P. (2011). Teaching–learning-based optimization: A novel method for constrained mechanical design optimization problems. Computer-Aided Design,43(3), 303–315. https://doi.org/10.1016/j.cad.2010.12.015.
Rao, R. V., & Waghmare, G. G. (2015). Multi-objective design optimization of a plate-fin heat sink using a teaching-learning-based optimization algorithm. Applied Thermal Engineering,76, 521–529. https://doi.org/10.1016/j.applthermaleng.2014.11.052.
Sathiyamoorthy, V., Sekar, T., & Elango, N. (2015a). Optimization of processing parameters in ECM of die tool steel using nanofluid by multiobjective genetic algorithm. The Scientific World Journal,2015, 6. https://doi.org/10.1155/2015/895696.
Sathiyamoorthy, V., Sekar, T., Suresh, P., Vijayan, R., & Elango, N. (2015b). Optimization of processing parameters in electrochemical machining of AISI 202 using response surface methodology. Journal of Engineering Science and Technology,10(6), 780–789.
Senthilnath, J., Kulkarni, S., Benediktsson, J. A., & Yang, X. S. (2016). A novel approach for multispectral satellite image classification based on the bat algorithm. IEEE Geoscience and Remote Sensing Letters,13(4), 599–603. https://doi.org/10.1109/lgrs.2016.2530724.
Solihin, M. I., Akmeliawati, R., Muhida, R., & Legowo, A. Guaranteed robust state feedback controller via constrained optimization using Differential Evolution. In 2010 6th International colloquium on signal processing and its applications, 2010 (pp. 1–6). https://doi.org/10.1109/cspa.2010.5545279.
Solihin, M. I., Wahyudi, & Akmeliawati, R. PSO-based optimization of state feedback tracking controller for a flexible link manipulator. In 2009 International conference of soft computing and pattern recognition, 2009 (pp. 72–76). https://doi.org/10.1109/socpar.2009.26.
Suganthan, P., Hansen, N., Liang, J., Deb, K., Chen, Y.-P., Auger, A., et al. (2005). Problem definitions and evaluation criteria for the CEC 2005 special session on real-parameter optimization. In Tech. Rep. Singapore: Nanyang Technological University.
Sultana, S., & Roy, P. K. (2014). Multi-objective quasi-oppositional teaching learning based optimization for optimal location of distributed generator in radial distribution systems. International Journal of Electrical Power and Energy Systems,63, 534–545. https://doi.org/10.1016/j.ijepes.2014.06.031.
Suresh, P., Venkatesan, R., Sekar, T., Elango, N., & Sathiyamoorthy, V. (2014). Optimization of intervening variables in MicroEDM of SS 316L using a genetic algorithm and response-surface methodology. Strojniski Vestnik/Journal of Mechanical Engineering,60(10), 9–10. https://doi.org/10.5545/sv-jme.2014.1665.
Tang, S. H., Ang, C. K., Ariffin, M. K. A. B. M., & Mashohor, S. B. (2014). Predicting the motion of a robot manipulator with unknown trajectories based on an artificial neural network. International Journal of Advanced Robotic Systems,11(10), 176. https://doi.org/10.5772/59278.
Tang, S. H., Ang, C. K., Nia, D. N., Ariffin, M. K. A. M., & Khaksar, W. (2013). Planning for redundant manipulator based on back-propagation neural network. Advanced Science Letters,19(11), 3307–3310. https://doi.org/10.1166/asl.2013.5151.
Tang, K., Li, X., Suganthan, P., Yan, Z., & Wiese, T. (2010). Benchmark Functions for the CEC 2010 Special Session and Competition on Large-Scale Global Optimization. In Tech. Rep. Hefei, China: School of Computer Science and Technology, University of Science and Technology of China.
Teimouri, R., Baseri, H., & Moharami, R. (2015). Multi-responses optimization of ultrasonic machining process. Journal of Intelligent Manufacturing,26(4), 745–753. https://doi.org/10.1007/s10845-013-0831-1.
Van, M., & Kang, H. (2016). Bearing defect classification based on individual wavelet local fisher discriminant analysis with particle swarm optimization. IEEE Transactions on Industrial Informatics,12(1), 124–135. https://doi.org/10.1109/tii.2015.2500098.
Viswanathan, R., Ramesh, S., Elango, N., & Kamesh Kumar, D. (2017). Temperature measurement and optimisation in machining magnesium alloy using RSM and ANOVA. Pertanika Journal of Science and Technology,25(1), 255–262.
Yao, L., Damiran, Z., & Lim, W. H. Energy management optimization scheme for smart home considering different types of appliances. In 2017 IEEE international conference on environment and electrical engineering and 2017 IEEE industrial and commercial power systems Europe (EEEIC/I&CPS Europe), 2017 (pp. 1–6). https://doi.org/10.1109/eeeic.2017.7977565.
Yao, L., Lai, C., & Lim, W. H. Home energy management system based on photovoltaic system. In 2015 IEEE international conference on data science and data intensive systems, 2015 (pp. 644–650). https://doi.org/10.1109/dsdis.2015.42.
Yu, K., Wang, X., & Wang, Z. (2015). Self-adaptive multi-objective teaching-learning-based optimization and its application in ethylene cracking furnace operation optimization. Chemometrics and Intelligent Laboratory Systems,146, 198–210. https://doi.org/10.1016/j.chemolab.2015.05.015.
Zhang, Q., & Li, H. (2007). MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Transactions on Evolutionary Computation,11(6), 712–731. https://doi.org/10.1109/tevc.2007.892759.
Zhao, Z., Lee, W. C., Shin, Y., & Song, K. (2013). An optimal power scheduling method for demand response in home energy management system. IEEE Transactions on Smart Grid,4(3), 1391–1400. https://doi.org/10.1109/tsg.2013.2251018.
Zhao, J., Wen, F., Dong, Z. Y., Xue, Y., & Wong, K. P. (2012). Optimal dispatch of electric vehicles and wind power using enhanced particle swarm optimization. IEEE Transactions on Industrial Informatics,8(4), 889–899. https://doi.org/10.1109/tii.2012.2205398.
Zitzler, E., Deb, K., & Thiele, L. (2000). Comparison of multiobjective evolutionary algorithms: Empirical results. Evolutionary Computation,8(2), 173–195. https://doi.org/10.1162/106365600568202.
Zitzler, E., Laumanns, M., & Thiele, L. (2001). SPEA2: Improving the strength Pareto evolutionary algorithm for multiobjective optimization. In Proceedings of the evolutionary methods for design, optimization and control with applications to industrial problems, Athens. Greece.
Acknowledgements
This work is partially supported by UCSI University Pioneer Scientist Incentive Fund (PSIF) with Project Code of Proj-In-FETBE-34 and Proj-In-FETBE-50.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Natarajan, E., Kaviarasan, V., Lim, W.H. et al. Non-dominated sorting modified teaching–learning-based optimization for multi-objective machining of polytetrafluoroethylene (PTFE). J Intell Manuf 31, 911–935 (2020). https://doi.org/10.1007/s10845-019-01486-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10845-019-01486-9