
Abstract
Quantum-dot cellular automata (QCA) offer a promising design paradigm for complementing conventional integrated circuits. The XOR plays a crucial role in arithmetic circuits and communications. Existing design schemes consume more operational components and thus are inefficient in terms of area and QCA cost at present. In this paper, a coplanar XOR composed of an NAND-NOR-Inverter (NNI) and a five-input majority voter (M5) is proposed for the first time. This new structure not only excludes complex crossovers but also has full accessibility to its input/output pins. The simulation waveforms and performance figures verify the functionality and merits of the proposed circuits. The implementation of the proposed XOR scheme in QCA consumes less overhead than that of its counterparts. Its occupied area and QCA cost are respectively reduced by 9.26% and 33.33% compared with the state-of-the-art XOR. To prove its practicability, multi-bit parity generators are also proposed in the means of hierarchically cascading the proposed XOR gates. The area and cost of the proposed 32-bit generator are respectively reduced by 39.47% and 33.33% compared with the existing best design.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In the process of scaling feature size of complementary metal oxide semiconductor (CMOS) devices, several fatal flaws, i.e. short-channel effects and leakage power dissipation, compel researchers to investigate alternative technologies for complementing conventional CMOS-based integrated circuits technique [1, 2]. The probable technologies, i.e. carbon nanotube (CNT), single electron transistor (SET) and quantum-dot cellular automata (QCA), have been put forward to seek out a promising one [3,4,5]. Among them, QCA provide a hopeful computing paradigm and information transmission pattern in the nanoscale regime [6]. The ultra-high integration, extremely low power consumption and high processing speed make QCA more promising in applications [6]. To achieve the steady operation of a system at ambient working temperature, nanomagnetic logic and molecular QCA may be hopeful in physical implementations [7, 8]. Recently, silicon atom dangling bonds were successfully realized to implement logic gates on a H-Si (100)-2 × 1 surface [9,10,11].
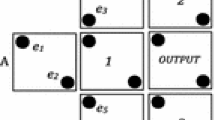
The binary information in QCA is represented by the positions of electrons confined in a cell as shown in Fig. 1a, either binary 1 or binary 0. The data transmission between cells is purely performed by the Coulomb interaction, thus it just avoids the leakage current occurred in conventional circuits [5]. The typical semiconductor-based cell model is defined as 18 nm width and height, 2 nm spacing between two nearest cells in QCADesigner [12]. As illustrated in Fig. 1b, the three-input majority voter (M3) is a basic logic component in QCA. The logic function for a M3 with inputs A, B, and C is F = M3(A, B, C) = AB + AC + BC, which tends to produce the majority of three inputs to get a lowest electrostatic energy level. The NAND-NOR-Inverter (NNI) is a composite logic gate, which needs a set of gates to realize its function. Its layout in QCA technique is very simple as shown in Fig. 1c. The logic function is expressed as \( F= NNI\left(A,\overline{B},\overline{C}\right)=A\overline{B}+A\overline{C}+\overline{B}\overline{C} \), where input signals B and C are inverted to output. Another frequently used voter is a five-input majority voter (M5), as shown in Fig. 1d, whose logic function is F = M5(A, B, C, D, E) = ABC + ABD+ ABE + ACD + ACE + ADE + BCD + BCE + BDE + CDE [13]. A M5 can further reduce the complexity of complex QCA circuits by properly replacing M3 s. In addition, if two cells are diagonally placed to each other, they will take opposite polarizations because of the Coulomb interaction between them. With this diagonal configuration, an inverter for realizing NOT operation is then realized in QCA.

QCA basics (a) QCA cells (b) three-input majority voter (c) five-input majority voter
To control the direction of signals propagating between cells and ensure a circuit to remain in instantaneous ground state, the quasi-adiabatic switching mechanism was introduced and it results in four clock zones [5]. Each zone is composed of four phases: switch, hold, release, and relax, as shown in Fig. 2. Taking the clock0 as an example, the inter-dot barrier will gradually increase during the switch phase from t = 0 to t = π/2 and then peaks in the hold phase. During the hold phase, the cells in clock1 are polarized by cells in clock0. After the hold phase, the tunnel barrier continually decreases in the release phase in clock0, while the cells in clock1 keep polarized. When the inter-dot barrier reaches the minimum value, the cells completely lose their polarizations and do not have any influence on neighboring cells while getting ready for the next cycle at t = 2π. Data will be propagated from the hold phase in clock0 to the next one in clock1, then to clock2 and finally to clock3 as the arrow lines denoted. To distinguish the cells in each clock zone, four colors (green, purple, teal and white) are used to indicate them as in the right side in Fig. 2. These cells in various colors will be sequentially polarized. One clock period in a QCA circuit is a clock cycle from clock0, clock1, clock2 to clock3.

QCA four-phase clock mechanism
With the majority voters, inverters and four-phase clock, one can implement any complex circuit in QCA. Several simple Boolean logic functions were also realized by using the intercellular Coulomb interaction [14, 15]. Although this method can get an efficient circuit in terms of area and delay, it is immature and time consuming; the cells in the circuit cannot be fully saturated and thus are unstable [16]. The approach to map AND and OR gates to majority voters is straightforward, thus it is costly and inefficient. Logic synthesis methodologies using the M3 s and inverters were put forward to design QCA circuits with less logic gates so that logic gate-based design method is the mainstream in QCA at present [17,18,19,20,21,22]. Meanwhile, basic logic arithmetic and memory circuits were realized as well [23,24,25,26]. Further, the XOR occupies an important position in digital logic circuits and communications, which has been deeply studied in existing works [27,28,29,30,31,32,33,34,35]. An important thing in circuit design is to handle the complex crossovers. Researchers tried to minimize the number of wire crossings for simplifying QCA circuits [36,37,38]. Several above XORs include a crossover, while others exclude it. These XOR schemes will be comprehensively analyzed in Section 2 Related work to show their merits and limitations.
In this paper, to get an efficient XOR with respect to reliability, cell count, circuit area, latency, QCA cost and dissipated energy, we propose a coplanar scheme using NAND-NOR-Inverter (NNI) and five-input majority voter (M5). The main contributions of this paper are as follows:
- 1)
We analyze existing gate-based XORs and parity generators to show their advantages and limitations in detail.
- 2)
We then propose a coplanar XOR consisting of NNI and M5 to get an efficient layout for the first time.
- 3)
The multi-bit parity generators are proposed by using the proposed XOR to show its merits.
- 4)
We perform a detailed analysis regarding validity, reliability, performances, power dissipation, complexity and QCA cost for the proposed circuits.
The rest of this paper is organized as follows: Section 2 describes the existing XORs and parity generators to show their limitations and advantages. Section 3 proposes a coplanar XOR and the proposed multi-bit parity generators. Section 4 shows the analysis results for the proposed circuits. Finally, Section 5 concludes this paper.
2 Related Work
Due to the critical role of an XOR in logic circuit design, it has attracted much attention in QCA. The existing gate-based XORs in [27,28,29,30,31,32,33,34,35] are classified as five categories as listed in Table 1. The third column gives the gate-based logic expression for each type of XORs. The fourth column shows the schematic for each XOR according to its corresponding gate-based logic expression. We utilize four items to evaluate their advantages and limitations in fifth and sixth columns respectively as follows:
- 1)
Gate count: the total number of M3 s, M5 s, NNIs and inverters in a circuit. The complexity of a circuit increases with an increasing number of gates.
- 2)
Clock delay: the number of clock cycles in a circuit. The processing speed increases for a QCA system with less clock delay.
- 3)
Structure: either coplanar layout or multilayer layout with crossovers. The QCA cost increases for a QCA system with multilayer crossovers.
- 4)
I/O accessibility: the accessibility to input and output pins. The cascade is readily to be achieved for circuits with I/O accessibility.
As listed in Table 1, a coplanar layout in Ref. [27] gets rid of unstable crossovers to realize the I/O accessibility, while it is costly due to the 5 logic gates and 1 clock cycle. The XORs designed by using this scheme in QCA have a high complexity and low processing speed. The XOR scheme in Refs. [28, 29] introduces a crossover and consists of 5 operational gates. The QCA cost dramatically increases, leading to an inefficient XOR implementation in QCA. In Ref. [30], a M5 is employed to perform a coplanar XOR, which clearly demonstrates that the M5 can effectively reduce the complexity of an XOR. This scheme also has 4 logic gates. Another deformation scheme in Refs. [31,32,33,34] was proposed to simplify the XOR by reducing one inverter. Further, a coplanar XOR using 4 NNI gates was achieved in Ref. [35], while it consumes 4 logic gates and 1 clock cycle. With above analyses, we can conclude that the XOR scheme in [31,32,33,34] should be the best one among them, by means of the aforementioned criteria.
Accordingly, various gate-based XORs were implemented in QCA by using aforementioned schemes, as shown in Fig. 3. The design in Ref. [27] utilizes four M3 s to implement a coplanar XOR. This gate consumes 1.5 clock cycles for completing computation. The designs in Refs. [28, 29] realize a coplanar XOR by employing coplanar crossovers with rotated cells or placing input cells inside a circuit, respectively. The implementation in Ref. [29] is difficult to cascade XORs for constructing complex systems. With a M3, M5 and two inverters, a coplanar XOR is realized in small area and clock delay. The schemes in Fig. 3e, f, g and h are based on one M3, M5 and inverter. The design in Ref. [31] has a clock-based coplanar crossover, occupies 1.25 clock cycles and large area. By embedding the inverter to either the M3 or M5, one can get efficient XORs in Refs. [32,33,34]. These implementations not only get small area and complexity, but also make the information processing speed fast. In addition, two designs in Refs. [33, 34] in QCA are almost the same except the positions of output cells. The last design in Ref. [35] consists of four NNI gates, whose delay is 1.0 clock cycle. The performance figures for these XORs will be quantified in Section 4 Simulation results to compare with the proposed XOR.

In digital communications, parity bits are utilized to detect errors in coded messages. The basic element of a parity generator is an XOR, thus multi-bit parity generators are usually illustrated to verify the performances of designed XORs. The generators can be implemented by hierarchically connecting XORs. Fig. 4 shows the 4-bit parity generators in Refs. [30,31,32,33,34,35]. Except the design using two XORs in Ref. [31], others are regularly composed of three XORs. The design in Ref. [31] also uses the clock-based crossovers to get full I/O accessibility to connect XORs; other schemes are implemented without crossovers due to the I/O accessibility of the utilized XORs. Moreover, we can see that the least clock delay for 4-bit parity generators is 1.25 clock cycles. Again, the performance figures for these generators will be shown in Section 4 Simulation results.

3 Proposed XOR and Parity Generators
3.1 XOR
As mentioned above, the main method for circuit design in QCA at present is connecting logic components to implement complex systems. A NNI and M5 are used to design an efficient coplanar XOR as shown in Fig. 5a, where A and B are input ports; F is output. The logic function of a NNI is \( NNI\left(A,B,C\right)=\overline{A}\overline{B}+\overline{A}C+\overline{B}C \), which implicitly realizes the NOT operation in ports A and B. By fixing the value of input C in binary 1, we have \( NNI\left(A,B,1\right)=\overline{A}+\overline{B} \), which is usually realized by a majority voter and an inverter. Thus, one NNI gate fulfils the NAND operation of inputs A and B. The logic expression for the proposed XOR is \( F=M5\left(A,B, NNI\left(A,B,1\right), NNI\left(A,B,1\right),0\right)=\overline{A}B+A\overline{B} \). The implementation for the proposed XOR in QCA is shown in Fig. 5b. In this circuit, each clock zone has at least two cells to keep all cells fully polarized. The proposed coplanar XOR has 27 cells, occupies 0.0196 μm2 and 0.75 clock cycles. Note that the area of a circuit in QCA technique is computed by using the area of a smallest rectangle the circuit occupied in this paper. The truth table of the XOR verifies its correctness as shown in Table 2. It is worth pointing out that input and output cells of the proposed XOR are not surrounded by other cells so that the I/O accessibility is realized and one can readily design complex systems by cascading the proposed XORs.

The proposed coplanar XOR (a) schematic (b) implementation in QCA
3.2 Parity Generators
As aforementioned, the multi-bit parity generators can be constructed by hierarchically connecting XORs. Fig. 6a demonstrates the design method for a 4-bit parity generator that consists of three XORs. Due to the full I/O accessibility of the proposed XOR, it is able to connect any number of XORs in this means. Fig. 6b shows the implementation in QCA for a 4-bit parity generator, which has only 84 cells, consumes 1.25 clock cycles and occupies 0.0840 μm2. Table 3 lists the truth table for the proposed generator, which indicates the input vectors and corresponding output signals. The generator generates 0 for even number of 1 s in inputs and produces 1 for odd number of 1 s. It is clear that the generator can complete its intended functions. To show the expansibility of the circuit design approach, we also design 8-bit, 16-bit and 32-bit parity generators. The 32-bit parity generator is realized by serially connecting 31 XORs, as shown in Fig. 7. As illustrated in these figures, the presented designs provide regular structures, full I/O accessibility, perfect expansibility, and efficient area and clock delay.

The proposed 4-bit parity generator using the proposed XOR (a) schematic (b) implementation in QCA

The proposed 32-bit parity generator using the proposed XOR
4 Simulation Results
4.1 Coplanar XORs
First, we consider the reliability of the proposed coplanar XOR scheme and its counterparts in Table 1, by using probabilistic transfer matrix that provides a method for computing the reliability of a combinational circuit [39]. Fig. 8 shows the calculation results, where the device probability of failure means the probability of each component to be faulty; the XOR probability of failure denotes the possibility of generating error outputs. It is clear that the proposed XOR has smallest probability of failure so that the XOR has highest stability among these schemes. Specifically, the designs consisting of the M3 gates in Refs. [27,28,29] get larger probability of failure than others as increasing the device probability of failure. The NNI-based XOR in Ref. [35] has almost the same stability as the schemes composed of the M3 and M5 in Refs. [30,31,32,33,34].

XOR probability of failure versus device probability of failure
For validating our method to design XOR using NNI and M5, Tables 4 and 5 list the performance figures and power dissipation for M3 and NNI gates, respectively. The dissipated power is simulated by using QCAPro [40], where average energy dissipation is the sum of average leakage energy dissipation and average switching energy dissipation. It is clear that although the physical features of them are similar, the dissipated power of the NNI gate is much less than that of the M3 gate, at various tunneling energy and at 2 K operating temperature.
The bistable approximation simulation engine in QCADesigner 2.0.3 is used to verify the functions of the proposed circuits [12]. The simulation parameters are listed in Table 6. Due to the Coulomb interaction between two cells dramatically decays with the increasing distance between them, 41 nm for the radius of effect is usually sufficient for a simulation. Other parameters are set as default in the software. Fig. 9 is the simulation results for the proposed XOR. The first pair of input/output values is labelled, which directly verifies the correctness of this gate. In addition, we can see that the output signals of this gate are delayed by 0.75 clock cycles; each signal can achieve a stable waveform.

Simulation results for the proposed XOR
We then begin to qualify the proposed XOR in QCA and its counterparts. Table 7 lists their performance figures. The new XOR has the least cell count as the design in Ref. [34] and least clock delay as the designs in Refs. [30, 32, 34]. In addition, the occupied area of the proposed XOR is reduced by 9.26% compared with the state-of-the-art design in Ref. [30]. Moreover, the new XOR not only gets rid of complex crossovers but also has full I/O accessibility.
Table 8 gives the upper bound of dissipated energy for these XORs. Although the designs in Refs. [30, 34] slightly outperform the proposed XOR at low tunneling energy in terms of average energy dissipation, the performance of our circuit will surpass them with the increasing tunneling energy. Moreover, the new XOR is superior to others in respect to power dissipation. Figure 10 shows the power dissipation map for the proposed XOR gate at 0.5Ek tunneling energy level and 2.0 K temperature, which shows the cell that dissipates more energy than others because the darker the cell is, the more energy it dissipates.

Power dissipation map for the proposed XOR gate at 0.5Ek tunneling energy level and 2.0 K temperature
Further, the complexity of a system is expressed as
where M, I and C are the number of M3 s, inverters, crossovers [41]. It is used to calculate the number of operational gates in a system. In this paper, we extend this equation by taking account of the NNI and M5 gates because they also realize simple logical operations like a M3. This metric does not account for the information processing speed of a system, so that QCA cost was introduced by including clock delay. The QCA cost function is also employed to evaluate these circuits, which is represented as
where M, I, C and L are the number of M3 s, inverters, crossovers, and clock delay of a circuit; x, y, and z are the exponential weightings for these parameters, respectively [41]. In this paper, we assume x = y = z = 1, thus QCA cost is equal to the product of complexity and clock delay. Figures 11 and 12 illustrate the complexity and QCA cost for the proposed XOR and aforementioned existing XORs, resepctively. It is clear that the proposed one has the least complexity and cost among all circuits. For example, the complexity and QCA cost of proposed XOR is reduced by 33.33% and 33.33% compared with the best one in Ref. [34], respectively. With above analyses, one can briefly conclude that the proposed XOR is more efficient than previous designs with respect to cell count, area, clock delay, power dissipation, complexity and QCA cost.

Complexity for XORs

QCA Cost = (M + I + C) × L for XORs
4.2 Parity Generators
Figure 13 provides the simulation results for the proposed 4-bit parity generator. Again, the generator generates 0 for even number of 1 s and produces 1 for odd number of 1 s. These results authenticate the validity of this circuit. The first pair of input and output signals is marked by dotted lines. This result also shows that the proposed 4-bit parity generator consumes 1.25 clock cycles to complete signal transmission. Additionally, each output signal can achieve a stable waveform in this figure.

Simulation results for the proposed 4-bit parity generator
Table 9 lists the comparisons for the proposed multi-bit parity generators and their counterparts. Although the number of cells of designs in Ref. [34] is slightly less than that of our circuits for 16-bit and 32-bit generators, the proposed generators are superior to others with respect to cell count. Most importantly, the new parity generators save large occupied area compared with all counterparts. For example, the areas of the proposed 4-bit and 32-bit generators is reduced by 12.50% and 39.47% compared with the state-of-the-art designs in Ref. [34]. Moreover, the proposed circuits hold a minimum clock delay. In addition, the designs in Ref. [31] employ the clock-based crossovers to realize coplanar structures, while other circuits exclude the crossovers. Again, the new coplanar parity generators have full I/O accessibility because of the I/O accessibility of the proposed XOR.
Table 10 shows the power dissipation for the 4-bit parity generators at different tunneling energy, at 2.0 K temperature. We can see that the parity generator in Ref. [30] has a slightly smaller power consumption than our proposed scheme at 0.5Ek for average energy dissipation. With the increasing tunneling energy, the proposed circuit will be superior to the design. For example, the average energy dissipation of the proposed 4-bit generator is reduced by 1.36% at 1.5Ek compared with the scheme in Ref. [30]. Further, the proposed design outperforms others in terms of the average energy dissipation at various tunneling energy. Figure 14 shows the power dissipation map for the proposed 4-bit parity generator at 0.5Ek tunneling energy level and 2.0 K temperature.

Power dissipation map for the proposed 4-bit parity generator at 0.5Ek tunneling energy level and 2.0 K temperature
Figures 15 and 16 display the complexity and QCA cost for the proposed and existing multi-bit parity generators in Refs. [30,31,32,33,34,35], respectively. It is clear that the proposed parity generators rank first among them regarding the complexity and cost. Specifically, as for the 32-bit generators, the complexity of the proposed generators is reduced by 71.05%, 37.32%, 61.40%, 63.33%, 33.33%, and 72.50%; the cost of the generators is reduced by 50.00%, 3.13%, 33.33%, 33.33%, 33.33%, and 50.00% compared with these counterparts, respectively.

Complexity for parity generators

QCA Cost = (M + I + C) × L for parity generators
5 Conclusion
To solve the deficiencies of conventional integrated circuits, quantum-dot cellular automata (QCA) provide a prospective design paradigm. The XOR occupies an important position in digital logic circuits and communctions. To get an efficient XOR gate, this paper proposes a coplanar scheme using a NAND-NOR-Inverter (NNI) and five-input majority voter (M5) for the first time. Reliability analysis by using probabilistic transfer matrix reveals that the proposed XOR scheme has higher stability than previous ones. The proposed XOR is also implemented in QCA regime, whose correctness is verified by using simulation results on QCADesigner. Its performance figures show that the proposed XOR utilizes less overhead in terms of area and QCA cost than the state-of-the-art design. Most importantly, the proposed XOR excludes the complex crossovers and keeps full accessibility to its input and output pins, so that it has a scalable structure. To demonstrate its scalability, multi-bit parity generators including 4-bit, 8-bit, 16-bit and 32-bit generators are also designed by hierarchically connecting the XORs. The analysis results account for their improvements with respect to occupied area and cost.
References
Khouri, K.S., Jha, N.K.: Leakage power analysis and reduction during behavioral synthesis. IEEE Trans. Very Large Scale Integr. VLSI Syst. 10(6), 876–885 (2002). https://doi.org/10.1109/TVLSI.2002.808436
Adan, A.O., Higashi, K., Fukushima, Y.: Analytical threshold voltage model for ultrathin SOI MOSFETs including short-channel and floating-body effects. IEEE Trans. Electron Devices. 46(4), 729–737 (1999). https://doi.org/10.1109/16.753707
Awano, Y., Sato, S., Nihei, M., Sakai, T., Ohno, Y., Mizutani, T.: Carbon nanotubes for VLSI: interconnect and transistor applications. Proc. IEEE. 98(12), 2015–2031 (2010). https://doi.org/10.1109/JPROC.2010.2068030
Anu, Sharma, A., Khan, M.S., Srivastava, A., Husain, M., Khan, M.S.: High-performance single-electron transistor based on metal–organic complex of thiophene: first principle study. IEEE Trans. Electron Devices. 64(11), 4628–4635 (2017). https://doi.org/10.1109/TED.2017.2756106
Lent, C.S., Tougaw, P.D.: A device architecture for computing with quantum dots. Proc. IEEE. 85(4), 541–557 (1997). https://doi.org/10.1109/5.573740
Tougaw, P.D., Lent, C.S.: Logical devices implemented using quantum cellular automata. J. Appl. Phys. 75(3), 1818–1825 (1994). https://doi.org/10.1063/1.356375
Riente, F., Turvani, G., Vacca, M., Roch, M.R., Zamboni, M., Graziano, M.: ToPoliNano: a CAD tool for Nano magnetic logic. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 36(7), 1061–1074 (2017). https://doi.org/10.1109/TCAD.2017.2650983
Pulimeno, A., Graziano, M., Sanginario, A., Cauda, V., Demarchi, D., Piccinini, G.: Bis-Ferrocene molecular QCA wire: Ab initio simulations of fabrication driven fault tolerance. IEEE Trans. Nanotechnol. 12(4), 498–507 (2013). https://doi.org/10.1109/Tnano.2013.2261824
Livadaru, L., Xue, P., Shaterzadeh-Yazdi, Z., DiLabio, G.A., Mutus, J., Pitters, J.L., Sanders, B.C., Wolkow, R.A.: Dangling-bond charge qubit on a silicon surface. New J. Phys. 12, 1–15 (2010). https://doi.org/10.1088/1367-2630/aa8b88
Pitters, J.L., Livadaru, L., Haider, M.B., Wolkow, R.A.: Tunnel coupled dangling bond structures on hydrogen terminated silicon surfaces. J. Chem. Phys. 134(6), 1–6 (2011). https://doi.org/10.1063/1.3514896
Kawai, H., Ample, F., Wang, Q., Yeo, Y.K., Saeys, M., Joachim, C.: Dangling-bond logic gates on a Si(100)-(2 x 1)-H surface. J. Phys.-Condes. Matter. 24(9), 1–13 (2012). https://doi.org/10.1088/0953-8984/24/9/095011
Walus, K., Dysart, T.J., Jullien, G.A., Budiman, R.A.: QCADesigner: a rapid design and simulation tool for quantum-dot cellular automata. IEEE Trans. Nanotechnol. 3(1), 26–31 (2004). https://doi.org/10.1109/TNANO.2003.820815
Navi, K., Farazkish, R., Sayedsalehi, S., Rahimi Azghadi, M.: A new quantum-dot cellular automata full-adder. Microelectron. J. 41(12), 820–826 (2010). https://doi.org/10.1016/j.mejo.2010.07.003
Chabi, A.M., Roohi, A., Khademolhosseini, H., Sheikhfaal, S., Angizi, S., Navi, K., DeMara, R.F.: Towards ultra-efficient QCA reversible circuits. Microprocess. Microsyst. 49, 127–138 (2017). https://doi.org/10.1016/j.micpro.2016.09.015
Farazkish, R., Azghadi, M.R., Navi, K., Haghparast, M.: New method for decreasing the number of quantum dot cells in QCA circuits. World Appl. Sci. J. 4(6), 793–802 (2008)
Berarzadeh, M., Mohammadyan, S., Navi, K., Bagherzadeh, N.: A novel low power exclusive-OR via cell level-based design function in quantum cellular automata. J. Comput. Electron. 16(3), 875–882 (2017). https://doi.org/10.1007/s10825-017-0986-7
Momenzadeh, M., Huang, J., Tahoori, M.B., Lombardi, F.: Characterization, test, and logic synthesis of and-or-inverter (AOI) gate design for QCA implementation. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 24(12), 1881–1892 (2005). https://doi.org/10.1109/TCAD.2005.852667
Zhang, R., Walus, K., Wang, W., Jullien, G.A.: A method of majority logic reduction for quantum cellular automata. IEEE Trans. Nanotechnol. 3(4), 443–450 (2004). https://doi.org/10.1109/TNANO.2004.834177
Zhang, R., Gupta, P., Jha, N.K.: Majority and minority network synthesis with application to QCA-, SET-, and TPL-based nanotechnologies. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 26(7), 1233–1245 (2007). https://doi.org/10.1109/TCAD.2006.888267
Kong, K., Shang, Y., Lu, R.: An optimized majority logic synthesis methodology for quantum-dot cellular automata. IEEE Trans. Nanotechnol. 9(2), 170–183 (2010). https://doi.org/10.1109/TNANO.2009.2028609
Wang, P., Niamat, M.Y., Vemuru, S.R., Alam, M., Killian, T.: Synthesis of majority/minority logic networks. IEEE Trans. Nanotechnol. 14(3), 473–483 (2015). https://doi.org/10.1109/TNANO.2015.2408330
Soeken, M., Amaru, L.G., Gaillardon, P.E., De Micheli, G.: Exact synthesis of majority-inverter graphs and its applications. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 36(11), 1842–1855 (2017). https://doi.org/10.1109/tcad.2017.2664059
Abedi, D., Jaberipur, G.: Decimal full adders specially designed for quantum-dot cellular automata. IEEE Trans. Circuits Syst. II Express Briefs. 65(1), 106–110 (2018). https://doi.org/10.1109/TCSII.2017.2703942
Perri, S., Corsonello, P., Cocorullo, G.: Area-delay efficient binary adders in QCA. IEEE Trans. Very Large Scale Integr. VLSI Syst. 22(5), 1174–1179 (2014). https://doi.org/10.1109/TVLSI.2013.2261831
Kianpour, M., Sabbaghi-Nadooshan, R.: A novel quantum-dot cellular automata X-bit × 32-bit SRAM. IEEE Trans. Very Large Scale Integr. VLSI Syst. 24(3), 827–836 (2016). https://doi.org/10.1109/TVLSI.2015.2418278
Taskin, B., Hong, B.: Improving line-based QCA memory cell design through dual phase clocking. IEEE Trans. Very Large Scale Integr. VLSI Syst. 16(12), 1648–1656 (2008). https://doi.org/10.1109/TVLSI.2008.2003171
Mustafa, M., Beigh, M.R.: Design and implementation of quantum cellular automata based novel parity generator and checker circuits with minimum complexity and cell count. Indian J. Pure Appl. Phys. 51(1), 60–66 (2013). https://doi.org/10.1140/epjh/e2012-30008-3
Kianpour, M., Sabbaghi-Nadooshan, R., Navi, K.: A novel design of 8-bit adder/subtractor by quantum-dot cellular automata. J. Comput. Syst. Sci. 80(7), 1404–1414 (2014). https://doi.org/10.1016/j.jcss.2014.04.012
Khosroshahy, M.B., Moaiyeri, M.H., Angizi, S., Bagherzadeh, N., Navi, K.: Quantum-dot cellular automata circuits with reduced external fixed inputs. Microprocess. Microsyst. 50, 154–163 (2017). https://doi.org/10.1016/j.micpro.2017.03.009
Singh, G., Sarin, R.K., Raj, B.: A novel robust exclusive-OR function implementation in QCA nanotechnology with energy dissipation analysis. J. Comput. Electron. 15(2), 455–465 (2016). https://doi.org/10.1007/s10825-016-0804-7
Angizi, S., Alkaldy, E., Bagherzadeh, N., Navi, K.: Novel robust single layer wire crossing approach for exclusive OR sum of products logic design with quantum-dot cellular automata. J. Low Power Electron. 10(2), 259–271 (2014). https://doi.org/10.1166/jolpe.2014.1320
Sasamal, T.N., Ghanekar, U., Singh, A.K.: Design and analysis of ultra-low power QCA parity generator circuit. In: Garg, A., Bhoi, A., Sanjeevikumar, P., Kamani, K. (eds.) Lecture Notes in Electrical Engineering, vol. 436, pp. 347–354. Springer, Singapore (2018)
Sheikhfaal, S., Angizi, S., Sarmadi, S., Moaiyeri, M.H., Sayedsalehi, S.: Designing efficient QCA logical circuits with power dissipation analysis. Microelectron. J. 46(6), 462–471 (2015). https://doi.org/10.1016/j.mejo.2015.03.016
Mohammadi, H., Navi, K.: Energy-efficient single-layer QCA logical circuits based on a novel XOR gate. J. Circuits Syst. Comput. (2018). https://doi.org/10.1142/S021812661850216X
Poorhosseini, M., Hejazi, A.R.: A fault-tolerant and efficient XOR structure for modular design of complex QCA circuits. J. Circuits Syst. Comput. 27(7), 1–24 (2017). https://doi.org/10.1142/S0218126618501153
Chaudhary, A., Chen, D.Z., Hu, X.S., Whitton, K., Niemier, M., Ravichandran, R.: Eliminating wire crossings for molecular quantum-dot cellular automata implementation. In: ICCAD-2005. IEEE/ACM International Conference on Computer-Aided Design, 2005, San Jose, 6–10 Nov. 2005, pp. 565–571. IEEE
Chung, W.J., Smith, B., Lim, S.K.: QCA physical design with crossing minimization. In: 5th IEEE conference on nanotechnology, 2005, Nagoya, 15–15 July 2005, pp. 108–111. IEEE
Smith, B.S., Lim, S.K.: QCA channel routing with wire crossing minimization. In: 2005 ACM Great Lakes symposium on VLSI, GLSVLSI'05, Chicago, IL, United states, April 17–19, 2005 2005. Proceedings of the ACM Great Lakes Symposium on VLSI, GLSVLSI, pp. 217–220. Association for Computing Machinery
Krishnaswamy, S., Viamontes, G.F., Markov, I.L., Hayes, J.P.: Probabilistic transfer matrices in symbolic reliability analysis of logic circuits. ACM Trans. Des. Autom. Electron. Syst. 13(1), 1–8 (2008). https://doi.org/10.1145/1297666.1297674
Srivastava, S., Sarkar, S., Bhanja, S.: Estimation of upper bound of power dissipation in QCA circuits. IEEE Trans. Nanotechnol. 8(1), 116–127 (2009). https://doi.org/10.1109/TNANO.2008.2005408
Liu, W., Lu, L., Oneill, M., Swartzlander, E.E.: A first step toward cost functions for quantum-dot cellular automata designs. IEEE Trans. Nanotechnol. 13(3), 476–487 (2014). https://doi.org/10.1109/TNANO.2014.2306754
Acknowledgements
This work is supported by the Fundamental Research Funds for the Central Universities of China (No. JZ2019HGTB0092).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhang, Y., Deng, F., Cheng, X. et al. A Coplanar XOR Using NAND-NOR-Inverter and Five-Input Majority Voter in Quantum-Dot Cellular Automata Technology. Int J Theor Phys 59, 484–501 (2020). https://doi.org/10.1007/s10773-019-04343-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10773-019-04343-w