
Abstract
Genetic Network Programming (GNP) is a relatively recently proposed evolutionary algorithm which is an extension of Genetic Programming (GP). However, individuals in GNP have graph structures. This algorithm is mainly used in decision making process of agent control problems. It uses a graph to make a flowchart and use this flowchart as a decision making strategy that an agent must follow to achieve the goal. One of the most important weaknesses of this algorithm is that crossover and mutation break the structures of individuals during the evolution process. Although it can lead to better structures, this may break suitable ones and increase the time needed to achieve optimal solutions. Meanwhile, all the researches in this field are dedicated to test GNP in deterministic environments. However, most of the real-world problems are stochastic and this is another issue that should be addressed. In this research, we try to find a mechanism that GNP shows better performance in stochastic environments. In order to achieve this goal, the evolution process of GNP was modified. In the proposed method, the experience of promising individuals was saved in consecutive generations. Then, to generate offspring in some predefined number of generations, the saved experiences were used instead of crossover and mutation. The experimental results of the proposed method were compared with GNP and some of its versions in both deterministic and stochastic environments. The results demonstrate the superiority of our proposed method in both deterministic and stochastic environments.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
It is proven that there is no optimization method that can be better than all others to solve all types of optimization problems. This theory is known as No-Free-Lunch Theorem [1]. So, different meta-heuristic algorithms such as Genetic Algorithm (GA) [2], Genetic Programming (GP) [3, 4], Particle Swarm Optimization (PSO) [5], Ant Colony Optimization (ACO) [6, 7], Artificial Bee Colony (ABC) [8], the Estimation of Distribution Algorithm (EDA) [9] and many new variants are continuously invented and being used to solve various optimization problems [10,11,12,13,14,15,16,17,18]. Genetic Network Programming (GNP) [19,20,21] as an extension of GP is one of them. However, instead of using the tree structure as in GP, the graph structure is used to represent the individuals to improve GNP expression ability. In the GNP algorithm, the graph structure of individuals makes this algorithm suitable for decision making in agent control problems [22]. The graph structure has been composed of judgment and processing nodes enabling the individuals to represent a decision making process as a flowchart. Indeed, they are similar to GP’s elementary functions. Judgment and processing nodes correspond to non-terminal and terminal nodes of GP respectively. In GNP, the individuals are composed by connecting these nodes. The first difference between GNP and GP is that in former, the processing or action nodes are terminal nodes while in latter there is no terminal node. It means that in GP, the processing or action nodes are not connected to other ones. But in GNP, they may have a connection to other nodes. As a result, decisions in GNP are made according to not only the current condition of the environment but also the actions done in the past. It means that implementing some structures such as loops which are essential in generating strategies for agents is easy using GNP structures while it is not convenient at all to generate these types of strategies in GP. For example, suppose that it needs to generate the following instruction: if condition c1 is true do action a1, then action a2 and again action a2, then while condition c2 is true do actions a3 and a2 respectively. Although generating these types of instructions may be possible in GP, it needs too many modifications on crossover, mutation and the structures of individuals in GP. In addition, GP has an inherent bloat of tree problem [23]. However, GNP does not have this problem because the number of nodes of each individual does not change during the evolution process. Meanwhile, GNP can generate compact and sophisticated structures considering only needed judgment and processing nodes according to necessity [20].
There are also some other network-oriented structure evolutionary methods such as Parallel Algorithm Discovery and Orchestration (PADO) [24], Cartesian Genetic Programming (CGP) [25, 26] and Evolutionary Programming (EP) [27]. PADO proposes an evolutionary computation algorithm on graph like automata which is so similar to GNP. It is formed by three main components. They are the main program, Automatically Defined Function (ADF) programs and indexed memory. There are a start and an end nodes in the main program of PADO. ADF is a function set which is automatically defined in the program runs. PADO is executed from the start node and ends in the end node in the network. CGP was proposed about 20 years ago for the first time. It explores the graph based GP motivated by a general representation of the graph structure compared with the tree structure of GP. It can represent the solutions of computational problems as graphs. Its encoding is an integer string that denotes the list of node connections and functions. It also includes redundant genes to help for effective evolutionary search. EP has also a graph structure that for the first time proposed by Fogel. It is an evolutionary computation algorithm like GA and GP. However, generally, it uses only mutation as the evolutionary operator. EP is used as a method for the synthesis of finite state machines automatically which is used for solving sequence prediction problems.
However, GNP is different from these methods. While GNP can evolve programs in both static and dynamic environments, PADO aims to evolve them in only static environments [28]. Meanwhile, nodes in PADO have both function (processing) and branching (judgment) behavior. They are governed by stack and index memory [29]. Different from CGP, GNP emphasizes the information transition inside the graph. There is not any terminal or output node that halts the program explicitly. Consequently, this structure is suitable to make the behavior sequences for agents [30]. In addition, there are some notable differences between CGP and GNP. For example, In CGP, the individuals are in the form of directed acyclic graphs while in GNP having cycles is an important feature of individuals that helps it to produce behavioral strategies for agents. Meanwhile, CGP uses 1 + λ EA in its evolution process. Commonly crossover is not used in the evolution process of CGP. There is no explicit notion of time delay in CGP. Finally, another important difference between GNP and CGP is that in GNP, judgment nodes provide expert-designed high-level functionality based on the task whereas CGP functions are usually standard mathematic functions.
There are some essential differences between GNP and EP. While in EP, the transition rule for all combinations of states and inputs must be defined, in GNP, nodes are connected by necessity. In each situation, only the essential inputs are used in the network flow. So, the structure of the GNP is quite compact [31].
Overall, GNP has some advantages with respect to other evolutionary algorithms. The reusability of the nodes that make the structure more compact, creating connections according to necessity and make decisions according to not only the current state of environment but also according to actions which were done in the past are some of them.
For the performance improvement of GNP, various modifications were suggested. It is also used in various applications. For example, In [19], Q-learning [32] was used to improve the efficiency of GNP. The combination of GNP and Q-learning has also been used in [28, 33] for faster adaptation in dynamic environments. SARSA algorithm [32] is another reinforcement learning algorithm used in [34, 35]. It has been applied on Khepera robot control process [36] to improve GNP efficiency. Another combination of GNP with reinforcement learning (RL) was proposed in [31]. In this version, there are several functions in each node. During the evolution process, a function is selected according to its Q value. In addition, crossover and mutation operators are defined differently from standard GNP. Defining more than one start node is another modification proposed by Mabu and Hirasawa [37]. They want to extract several programs from an individual.
Li et al. [38, 39] used EDA in their proposed method. In each iteration of their algorithm, the structure of elite individuals is used to calculate the probabilistic model. Then, next generation is produced according to the estimated probabilistic model. In other words, crossover and mutation were substituted by this probabilistic model. This mechanism was used by Li et al. [38] to find association rules in a traffic forecasting system. EDA and RL are also used to produce next generation in [40]. Finally, these papers are summarized in [41].
In standard GNP, the branches have an equal chance when using crossover and mutation operators. In individuals with high fitness values, inappropriate branches may exist. To fix this problem, the non-uniform mutation is introduced by Meng et al. [42]. In evolutionary algorithms, it is common to start the evolution process from scratch. To prevent this problem, Li et al. [43] used knowledge transfer. This leads to the shorter evolution process. In this algorithm, knowledge was formulated using the rules extracted from individuals. Then, this knowledge was used as a guideline in the evolution process. Meanwhile, RL was used to transfer knowledge automatically.
There are also some researches that used this algorithm or some other versions of it for different applications, especially in single/multi agent decision making problems. Coordination of the agents in a multi-agent system is an example of GNP applications [44, 45]. GNP was used in these studies to generate a strategy in the pursuit domain [46]. Automatically creation of a multi-agent system using GNP is another research done by Itoh et al. [47]. Making a Learning Classifier System (LCS) using GNP is proposed in [48, 49]. In their proposed method, the rules were extracted from the structure of individuals.
Swarm intelligence was also combined with GNP. ACO as one of the most successful swarm intelligence algorithms was used in [50,51,52] in order to make better exploitation ability in GNP. To make a good tradeoff between exploration and exploitation, Lu et al. [50, 51] dedicated one iteration to ACO in every 10 iterations of GNP in their proposed method. ABC is another swarm intelligence algorithm that was used in [53].
In [54, 55], an investigation on one of the important features of GNP i.e. transition by necessity was done theoretically and empirically. Standard operators of GNP treat all branches equally during evolution. In addition, the fitness of individuals only depends on the nodes which are used during evaluation. So, new genetic operators were proposed in these papers.
Overall, according to [40, 41], breaking the useful structures when using crossover and mutation is one of the most important weaknesses of GNP. Since an individual in GNP represents a strategy that agents must follow to achieve their goal, the dependency of nodes in the individual’s structure is high. Crossover and mutation break the connections frequently and completely randomly. Meanwhile, when the agents use the strategy proposed by an individual in a stochastic environment, its fitness is not precise. Solving this problem needs several time evaluation process of each individual. However, as the fitness evaluation is commonly the most time consuming section in evolutionary algorithms, several time evaluation process of each individual is not a suitable solution for solving this problem. In this research, both of these issues are considered.
In the proposed algorithm, the reproduction probability of useful structures is increased using the experience of promising individuals during the evaluation process. It reduces the destructive effect of crossover and mutation. In addition, the proposed method was applied to deterministic and stochastic environments. In stochastic environments, the experience of promising individuals could help us to estimate the fitness of each individual more precisely. Keeping a good balance between exploration and exploitation is another goal of our proposed method.
This paper is organized as follows. The GNP algorithm is reviewed in Sect. 2. Section 3 describes the stochastic environments. Our proposed algorithm is presented in detail in Sect. 4. In Sects. 5 and 6, the experimental results and discussion are presented, respectively. In the end, conclusions and future works are discussed in Sect. 7.
2 GNP
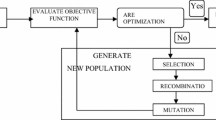
As it is shown in Algorithm 1, GNP includes three steps. As the first step, some directed graphs are produced. Then, they are evaluated and finally according to their fitness some offspring are generated using crossover and mutation.
2.1 Population structure
Unlike GP that individuals have a tree structure, in GNP, they have a graph structure. This structure increases its expressive ability. It can describe more complex strategies. As it is clear in Fig. 1, a directed graph like a flowchart can model a strategy that an agent must follow to achieve its goal. The directed graph is made of these three types of nodes. They are start node as the indicator that the strategy starts, the judgment nodes that investigate the conditions in the environment and the processing nodes that are defined according to the actions that the agents can do. As it is shown in the genotype structure of an individual, each node has an identification number i and is composed of two sections. The first section is Node Gene and the second section is Connection Gene. The Node Gene is composed of three subsections. The first subsection is NTi. It denotes the type of node i. The second subsection is NFi that denotes the function that node i executes and the last subsection is di that shows the time delay of node i function execution. Connection Gene section which is named Bi is the set of node i branches. It is composed of two subsections. Subsection Cij determines the node that jth branch of node i is connected to and the subsection dij shows the transition time delay of the jth branch of node i.

a Phenotype and b Genotype structure of an individual in GNP algorithms
As it is shown in Fig. 1b, NT, NF and d subsections of start node are set to zero. The start node only denotes the node from which the strategy must be started. Consequently, only the Connection Gene of this node is assigned. For judgment nodes, NT is set to one and the number of connections in the Connection Gene is more than one. Each branch in a Connection Gene corresponds to a specific condition in the environment. In processing nodes, NT is set to two and the number of connections in the Connection Gene is one because there is no conditional branch in them.
This structure shows a strategy that agents follow in the environment. For example, suppose that an agent wants to use the individual presented in Fig. 1 as its strategy. The agent starts at Node 1. According to this node, it must go to Node 2. Node 2 is a judgment node. The agent executes the J1 function. This function investigates the state of environment. If according to the environment state, the agent has to follow the third branch of Node 2, it goes to Node 6 and executes P1 as the process specified in this node. Then, it goes to Node 5 and executes the process of this node i.e. P2.
In the GNP structure, there are two types of time delay. di is the time delay for node i execution and dij is the time delay needed for the transition between nodes of individuals. These two types of time delays are introduced to model the delays in the human decision making process. They can be used to define the steps in the decision making process. The number of steps is considered a terminal condition during the decision making process.
2.2 Crossover
As it is clear in Fig. 2, two offspring are generated by crossover operator applied on two parents selected by an algorithm of choice such as tournament selection [23]. During crossover operation, in the selected parents, a pair of nodes with the same identification number exchange their connections with a predefined probability Pc.

In GNP, the crossover operator exchanges the bold connections between nodes 3 and 5
2.3 Mutation
For mutation, as it is illustrated in Fig. 3, each branch of Connection Gene is changed to another randomly selected node identification number with probability Pm.

In GNP, mutation operator changes the bold connections of nodes 1 and 2
3 Deterministic and stochastic environments
According to [56], if the current state of an environment and executed action of an agent completely determine the next state of the environment, then this type of environment is known as deterministic. If this feature does not exist, the environment is known as stochastic. An example model of a stochastic environment is shown in Fig. 4. In these environments, with a specific probability named as the deterministic parameter, each action achieves the intended outcome. Suppose the agent wants to move forward. In this case, the probability of moving forward is 60% and there is 20% chance of moving left and 20% chance of moving right.

An example of stochastic model [56]
4 Proposed algorithm
Our proposed algorithm is named Tasks Decomposition Genetic Network Programming (TDGNP). This algorithm is composed of two phases. These phases are named exploration oriented phase and exploitation oriented phase. To produce new individuals in the exploration oriented phase of TDGNP, standard operators of GNP i.e. mutation and crossover are used. In addition, during this phase, promising individuals distribute their fitness on the sequences of nodes’ connections used by the agents. This distribution is done according to our proposed method which is explained in the following. Before that, we need to define two concepts: (1) sequence and (2) task. A sequence is defined as the trail of some tasks. A task is defined as some judgment nodes followed by some processing nodes that an agent uses according to the structure of an individual when that individual is used as the strategy of the agent. In Fig. 5, an example of a sequence composed of two tasks is shown.

There are two tasks in this sequence
In the proposed method, a value is assigned to all possible connections proportional to the fitness of promising individuals within the exploration oriented phase. Then, within the exploitation oriented phase, these values as the accumulated experience of previous generations are used to produce the next generation. Algorithm 2 clearly describes our proposed method. Like other evolutionary algorithms, TDGNP is an iterative algorithm and in every K iterations, exploration and exploitation oriented phases take turn. There are exploration and exploitation in both of these phases but their names are chosen based on the dominant feature. During the exploration phase, next generation is produced using standard operators of GNP i.e. crossover and mutation. However, during exploitation phase, the individuals are generated according to the accumulated experience of promising individuals.
According to [22], the philosophy behind GNP is finding the optimal strategy for decision making of agents in the environments. It was mentioned in this reference that using GNP, we want to find which condition(s) must be investigated and according to each condition, which action(s) must be done. Then, according to what has been performed so far, the next conditions or actions are selected to be investigated or executed, respectively. Using task decomposition, we try to improve the quality of producing these types of structures. The value assigned to the connections of each task in each sequence is proportional to its importance in goal achievement. In GP, because of the tree structure of its individuals, applying this mechanism is not straightforward.
In the following, we will explain how this accumulated experience is calculated. In each iteration of exploration oriented phase, crossover and mutation of standard GNP produce the individuals of the next generation. However, within the iterations of the exploitation oriented phase, branch b of node i which is shown by bi is connected to node n with probability p(bi,n). This probability is calculated according to Eq. 1. This is done for all branches of all nodes in the structures of an individual to produce a new one.
In this equation, N shows the number of nodes in the structure of an individual. In the structure of individuals, the indegree of the first node (start node) is zero. So, in this equation, variable m is set to 2. Finally, v(bi,n) is the value assigned to the bi assuming it is connected to node n.
To calculate the experience of successive generations, as the first step, the effectiveness of the connections in the tasks of the sequences is assigned according to Eq. 2.
In this equation, the effectiveness of bi if it is connected to node n is shown by e(bi, n). Parameter λ (0 < λ ≤ 1) is a discounting factor. Connections in the later tasks have larger e(bi, n) than connections in the earlier tasks. Then, the fitness of each M promising individual is distributed on the connections according to Eqs. 3, 4 and 5.
In these equations, g and α show the generation number and updating factor of v(bi, n) respectively. In each iteration, M promising individuals update values of tasks’ connections using Eq. 3. fitnessk is the fitness of kth promising individual. In these equations, σ(bi, n)k is set to one whenever bi is used by an agent that executes individual k as its strategy. To prevent the value of connections from rapid growth, the log function is used in Eq. 4. This can prevent premature convergence in the evolution process. What we are looking for is the expected value of bi when it is connected to node n. These equations can approximate this expected value proportional to its effectiveness in the goal achievement.
When an individual is produced, the agents use it as their strategy to interact with the environment. Based on the interaction results, the fitness of individuals is estimated. After calculating individuals’ fitness, the sequences generated during the interaction of M promising individuals with the environment are extracted. Then, the tasks in each sequence are determined. Finally, for each of M promising individuals, we use Eq. 3 to distribute its fitness on the connections of its tasks.
It was mentioned that if bi which is connected to node n is used during individual execution, σ(bi, n)k is set to one. It not only takes into account the existence of a connection but also shows how useful it is. Consequently, during an individual execution, only the value of the used connections is updated. This way, the usefulness of connections can be learned. In addition, when a connection of an individual is used several times, its effectiveness should not increase repeatedly. We only reset it to one. Using this mechanism, the high accumulation of fitness on the connections that participated in the loops is avoided.
5 Experimental results
Our proposed method was applied to Tile-world [57] and Pursuit-domain [46] benchmarks to test its effectiveness. These problems are two agent control problems that are commonly used in GNP research [20, 21, 28, 41, 44, 45, 49].
5.1 Tile-world
In this benchmark, we have some agents that try to push some tiles into the holes while there are some obstacles in the environment. An example of this problem can be seen in Fig. 6.

Tile-world environmen
The interactions of the agents with the environment are based on judgment and processing functions defined for them. These functions are listed in Table 1. An example of using judgment functions is shown in Fig. 7. According to the results of these judgment functions, agents select one or more processing functions to execute in the environment. When a tile is dropped into a hole, the hole is filled by the tile and both of them are vanished. The corresponding cell is also converted into the floor. The program of controlling the agents’ behaviors can be generated by combining judgment and processing functions.

a How an agent can sense the directions in Tile-world and b the outputs of using these judgment functions
The behavior of agents is evaluated by the method proposed in [41]. According to that method, the fitness of an individual is calculated based on the number of tiles which is dropped into the holes, the speed of agents in dropping the tiles and if the agents cannot drop all tiles into the holes, how much they can push the tiles nearer to the holes. These three factors are taken into accounts in the Eq. 6.
In this equation, SUB is the predefined number of steps that the agents are allowed to move in the environment. The number of dropped tiles into the holes within SUB steps is shown by DT. Sused is used to measure the speed of agents to drop all tiles into the holes. It shows how many steps the agents use to achieve their goals. T is the number of tiles which is not dropped into the holes. The initial and final distance of each tile from its nearest hole is shown by ID and FD, respectively. Finally, the weight of these three factors is shown by wt, ws and wd. In this research, SUB, wt, ws and wd are set to 60, 100, 3 and 20, respectively. The goal of this experiment is to find an individual that can achieve the highest fitness value when agents are controlled according to this individual.
5.2 Pursuit-domain
Pursuit-domain or prey and predator problem is also used as a benchmark to test the performance of agent control algorithms. Pursuit-domain consists of some adjacent cells like Tile-world. A segment of the environment of this benchmark is shown in Fig. 8a. In this study, the pursuit domain is a 20 × 20 2D toroidal environment [46] with one prey and four predators in it. The cells of this environment may contain prey or predator. Otherwise, they are considered as floor. If the prey is put in a situation like Fig. 8b, it means that it was captured by the predators. The judgment and processing functions that correspond to the sensors and the actors of predators respectively are described in Table 2. Meanwhile, the prey moves randomly in the environment. In this research, the speed of the prey is half of the predators’ speed.

a Prey and predators in Pursuit-domain, b The predators capture the prey
Like Tile-world, the fitness of individuals in this benchmark is calculated according to three factors. The first factor is the predator’s ability in chasing after the prey. The second factor is the number of predators which is placed in the adjacent cells of the prey and the third factor is how fast the prey can be hunted by the predators. We formulate these three factors as Eq. 7.
In this equation, ES shows the environment size. In step i, the distance of predator j from the prey is shown by \(DP2P_{i}^{j}\). Sused is the number of taken steps to hunt the prey and NoP is the number of predators in the environment. Agents are allowed to move at most SUB steps in the environment. After this number of steps, the number of immediately adjacent cells that are occupied by predators is shown by cPos. In world number w and run number r, fitnessr,w is calculated according to Eq. (7).
Pursuit-domain is a dynamic environment. So, each individual is run R times on W environments with different positions of the predators and prey. Consequently, the final fitness of each individual is estimated according to Eq. 8.
5.3 Experimental analysis
In this section, the performance of TDGNP was compared with GNP [19,20,21] and some other states-of-the-art extensions of GNP which we call GNP-ACO1 [51], GNP-ACO2 [50] and GNP-ABC [53]. Some other algorithms like SARSA, Q-learning and GP were compared with GNP and some of its versions [41, 53]. According to the reported results, their performances are almost always in the next rank of GNP. So, we did not implement and investigate them again in this research.
We conducted experiments for different values of the deterministic parameter defined in Sect. 3 on both of the above mentioned benchmarks. The deterministic parameter values used in the experiments are 0.5, 0.75 and 1.0. This helps us to see how the performance of the investigated algorithms varies with respect to deterministic parameter changes. Meanwhile, the various number of instance of each node indexed in Tables 1 and 2 is used in each individual. In other words, it is possible to have more than one instance of each judgment and processing nodes in an individual. When there is more than one instance of each node, making different structures in an individual is more flexible. Suppose that in the optimal strategy, two instances of a node are needed. If there is only one instance of that node, it must be used in the position that the individual shows better performance. However, if there are two instances, they can be used in two different situations and the evolutionary algorithm is not forced to have a selection between two situations that needs that specific node. In this research, this parameter which is named program size is set with different values 1, 3, 5 and 10 to investigate its effectiveness on the algorithms. The other parameters of these algorithms are set to the optimal values as suggested in their references (see Table 3). Each algorithm was run 30 times. So, 30 independent solutions were created which their performance will be compared.
5.3.1 Tile world problem experimental results
In this section, the algorithms are applied to Tile-world shown in Fig. 6 and their performances are compared and analyzed. Termination condition in these algorithms is the maximum number of fitness evaluation and in this benchmark, we set it to 300,000.
When the deterministic parameter is set to 1, i.e. the environment is deterministic, the fitness of investigated algorithms is illustrated in Fig. 9. This figure exhibits that in all tests, TDGNP surpasses other algorithms particularly when program size is set to 1. Others show more or less similar performance. GNP-ACO2 performance is better than GNP-ACO1 because GNP-ACO2 accumulates its previous experience during the evolution process while in GNP-ACO1, after a predefined number of iterations, the accumulated experience is reset. GNP-ABC could achieve results similar to other methods but at a slower rate because of its weaker exploration ability [53].

Performance curve in Tile-world when the deterministic parameter is 1 and program size is a 1, b 3, c 5 and d 10
The experimental results are detailed in Tables 4, 5, 6, 7, 8, 9, 10 and 11. For clarity, the results of the best algorithm are marked in boldface. They reveal that TDGNP is better than other algorithms. However, according to the p-values of the Wilcoxon test at 0.05 significant level [58], in some cases, there is no significant difference between TDGNP and some other algorithms when program size is more than one. Strategies generated by individuals lack sufficient representation power when program size is one. For example, suppose that the optimal strategy requires at least two processing nodes that cause agents to move forward. When only one is available (due to program size of one), the algorithm cannot create the eligible individual to achieve the goal. So, the algorithms must investigate the search space more precisely to find better solutions. It needs an excellent balance between exploration and exploitation. On the other hand, when the program size is large, the dimension of search space is increased drastically. But the representation power of generated individuals is also increased. In both of these cases, TDGNP and GNP-ACO2 are in the first and second ranks, respectively. It shows that these two algorithms exhibit better exploration–exploitation balance during the evolution process.
Another topic of interest is the overall mean of fitness in these tables. When the deterministic parameter is one, they are about 449, 574, 593 and 596 corresponding to the program size of one, three, five and ten, respectively. Obviously, when the program size is increased from one to three, the performance of algorithms significantly improved. However, this notable improvement does not continue especially when we change the program size from five to ten. Considering the exponential growth of search space with respect to the program size and negligible performance improvement beyond program size of five, increasing program size more than 5 is not reasonable. In this environment, when the deterministic parameter is less than 1, i.e. the environment is stochastic, the calculated fitness is not correct if an individual is run just once. It is necessary to run each individual several times and calculate expected fitness. So, when the deterministic parameter is set to 0.50 or 0.75, the best individual in each run is averaged over 100 times of execution to calculate its fitness more precisely. When the environment is stochastic, the fitness of individuals is decreased. This is due to the fact that executing the selected actions in a stochastic environment does not necessarily lead to the same outcome. This phenomenon leads astray the evolution process which hurts performance. However, TDGNP performance is still better than others because it uses accumulated fitness distributed on the connections during the evolution process to generate offspring. Indeed, accumulated fitness can tackle the stochastic condition in the environment because it uses the experience of a group of individuals, not just one.
The last two columns of Tables 4, 5, 6, 7, 8, 9, 10 and 11 are some other criteria that can be used to compare algorithms. They show the success rate of final goal achievement and the number of steps taken to do so. For example, according to Table 4, TDGNP, as the best algorithm could be successful 21 times out of 30 trials. In these 21 times, the goal has been achieved in 31.14 steps on average. So, TDGNP is not only the most successful algorithm but also is the fastest one. In our experiments, each step is defined as using a processing node or at most five judgment nodes in the structure of individuals.
5.3.2 Pursuit-domain experimental results
In this section, the algorithms were applied to Pursuit-domain and their performances were compared. Solving Pursuit-domain seems easier than Tile-world. However, due to its dynamic nature, learning is more challenging. During this test, algorithms were run 30 times independently. In each run, because of the dynamic nature of the problem, each individual was applied to 20 environments with different positions of predators and prey. It means that in Eq. 8, R and W were set to 30 and 20 respectively. The termination condition in this test is the maximum number of fitness evaluations which is set to 20,000.
When the deterministic parameter is set to one, the fitness curves of different algorithms are shown in Fig. 10. In these tests, TDGNP is the best algorithm. GNP, GNP-ACO2, GNP-ACO1 and GNP-ABC, are in the next ranks, respectively.

Performance curve in Pursuit-domain when the deterministic parameter is set to one and program size is a 1, b 3, c 5 and d 10
The detailed results are shown in Tables 12, 13, 14, 15, 16, 17, 18 and 19. The results of the best algorithm are marked in boldface. As it is apparent, in a deterministic environment, TDGNP as the best algorithm is significantly better than others according to the p-values. The results also illustrate TDGNP superiority in deterministic and dynamic conditions. Differently from Tile-world, increasing the program size in Pursuit-domain leads to decreasing the performance of algorithms. Increasing the program size makes the search space large. Consequently, finding solutions will be so hard especially when the environments are dynamic. This degradation is also observable in the last two columns of these tables. The number of successful runs for hunting the prey is reduced from 231 for program size of one to 122 for program size of ten.
When the environment is stochastic, although TDGNP is significantly better than others for program size of five and a deterministic parameter of 0.75, it cannot retain its superiority when program size changes to ten or deterministic parameter is reduced to 0.50. This is due to the fact that learning in extremely large search space is hard and agents’ actions do not yield the expected outcome due to the working in a stochastic environment. In these conditions, learning takes much more time. In other words, although our proposed method is better than others in stochastic environments, it cannot afford huge stochasticity. It does not mean that other algorithms can do this. Indeed, in this condition, learning is extremely difficult and none of the algorithms can handle this condition because commonly the actions do not lead to the intended outcomes. The results in Tables 16 and 19 confirm this. According to the results in these tables, almost all the algorithms are in the same rank and there is no significant difference between the final results. In addition, their achieved fitness is not good at all. It shows that almost no learning has happened. For example, in Table 19, there is no significant difference between GNP-ACO1 as the first rank algorithm and others except GNP-ABC. Like other tests, GNP-ABC is so slow in learning and almost always is in the last place.
In addition, in most experiments, the number of successful runs in TDGNP is higher than others. However, in some cases such as Table 13, GNP overtakes TDGNP. GNP was successful in 305 runs while TDGNP had 301 successful runs. But it should be noted that for GNP, this number of successful runs happened during 520.78 steps on average while TDGNP could achieve 301 successful runs in only 120.64 steps on average which is much faster than GNP.
6 Discussion
The algorithm proposed in this research i.e. TDGNP consists of two phases. In the exploration oriented phase, the algorithm investigates good individual structures while it is biased to explore in the search space. During this search, the algorithm tries to save its experience. In the exploitation oriented phase, using the saved experience, the new individuals are generated. In other words, the new population is generated according to the experience of promising individuals during the evolution process. By the combination of these two phases, our algorithm could overtake other ones. The concluding remarks are as follows:
-
When program size is 1, the representation power of an individual is low. So, a better balance between exploration and exploitation is needed and our method could better achieve this feature. In the Tile-world, which is simpler than Pursuit-domain, when program size is 1, our algorithm shows better performance than others. However, it cannot keep its superiority when the program size is increased. When Pursuit-domain is used as the benchmark, as it is a more complex problem (because it is a dynamic environment), our algorithm is significantly better than others especially when the deterministic parameter is less than 1 (the environment is stochastic).
-
As the convergence rate of GNP-ABC is low, its performance is not good at all, especially when it runs in more dynamic and stochastic environments.
-
The performance of GNP-ACO2 and GNP-ACO1 are almost the same in Pursuit-domain and GNP is better than both of them. It shows that in Pursuit-domain as a dynamic environment when the deterministic parameter is one, exploration is more important than exploitation. But it is not true when the environment is stochastic. It is obvious that when the environment is stochastic, previous experiences have a high influence on the performance of algorithms.
-
Unlike GNP-ACO2 and GNP-ACO1 which actually are a combination of GNP and ACO, in TDGNP, updating the value of the connections is not done according to their usage frequency. In these methods, the individuals are used in the role of flowcharts. Consequently, some parts of them may be considered as a loop and used many times by the agents that behave according to them. If the values of connections of tasks in a sequence are updated according to their usage frequency, their values increase improperly. Therefore, in our proposed method, the connections’ values of tasks in a sequence are updated depending on whether they are used in the individual or not regardless of their usage frequency.
-
In TDGNP, the behavior of agents are handled more efficiently by the management of the sequence of tasks that they do. This algorithm helps the agents to extract a more suitable sequence of tasks to achieve their goals. TDGNP could achieve this object by distributing the fitness of promising individuals on the more useful sequences of tasks.
7 Conclusion and future work
In this paper, a new algorithm was proposed to adapt GNP to be used in more complex environments i.e. dynamic and stochastic environments. In this new algorithm, the more useful and efficient sequences of tasks which agents select their behaviors according to them are extracted. Then, the value of the connections that makes these tasks are increased proportional to their usefulness in the algorithm. In addition, a better tradeoff between exploration and exploitation is achieved by defining two different phases during the evolution process. In the exploration oriented phase, standard crossover and mutation were used inclined toward exploration. During this phase, promising individuals were also selected and their experiences were saved. The experiences were used in the exploitation oriented phase to generate new individuals. These modifications improve the efficiency of the purposed method in comparison with some other versions of GNP in both deterministic and stochastic environments.
It is clear that some tasks can achieve better fitness if they are executed consecutively. In this case, it is better not to decompose them. However, our proposed method lacks the ability to detect and exploit such scenarios. So, as a field for future research, it is worth working on a mechanism which is able to prevent these types of tasks from decomposition. We have to find a method to use these tasks together in the generation of new individuals. As a result, the algorithm can produce promising individuals faster. Meanwhile, we can investigate the performance of the proposed algorithm on more complex benchmarks for better evaluation of the algorithms. Another important subject that must be considered as the future work is parameter tuning of the used algorithms. We know that it is one of the important factors in their performance [59, 60]. Automatic parameter tuning is an appropriate approach for parameter tuning and fairness in the comparisons. We could also consider using multi-objective fitness since a composed fitness is used in our experiments. In addition, testing and comparing the proposed method on a larger set of problems could better show the proposed algorithm ability.
References
D.H. Wolpert, W.G. Macready, No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1, 67–82 (1997)
J.H. Holland, Adaptation in Natural and Artificial Systems. An Introductory Analysis with Application to Biology, Control, and Artificial Intelligence (University of Michigan Press, Ann Arbor, MI, 1975).
J.R. Koza, Genetic Programming II: Automatic Discovery of Reusable Subprograms (MA, USA, Cambridge, 1994).
J. R. Koza, Genetic programming: on the programming of computers by means of natural selection vol. 1: MIT press, 1992.
J. Kennedy and R. Eberhart, "Particle swarm optimization," in Proceedings of ICNN'95 - International Conference on Neural Networks, 1995, pp. 1942–1948.
M. Dorigo, M. Birattari, T. Stutzle, Ant colony optimization. IEEE Comput. Intell. Mag. 1, 28–39 (2006)
M. Dorigo, V. Maniezzo, A. Colorni, “Ant system: optimization by a colony of cooperating agents,” IEEE Transactions on Systems, Man, and Cybernetics. Part B (Cybernetics) 26, 29–41 (1996)
D. Karaboga, B. Basturk, On the performance of artificial bee colony (ABC) algorithm. Applied Soft Computing 8, 687–697 (2008)
M. Pelikan, "Probabilistic model-building genetic algorithms," presented at the Proceedings of the 10th annual conference companion on Genetic and evolutionary computation, Atlanta, GA, USA, 2008.
G. Dhiman, V. Kumar, KnRVEA: A hybrid evolutionary algorithm based on knee points and reference vector adaptation strategies for many-objective optimization. Appl. Intell. 49, 2434–2460 (2019)
M. Roshanzamir, M.A. Balafar, S.N. Razavi, Empowering particle swarm optimization algorithm using multi agents’ capability: A holonic approach. Knowl.-Based Syst. 136, 58–74 (2017)
M. Roshanzamir, M.A. Balafar, S.N. Razavi, A new hierarchical multi group particle swarm optimization with different task allocations inspired by holonic multi agent systems. Expert Syst. Appl. 149, 113292 (2020)
L. Araujo, Genetic programming for natural language processing. Genet. Program Evolvable Mach. 21, 11–32 (2020)
V. Ciesielski, Linear genetic programming. Genet. Program Evolvable Mach. 9, 105–106 (2008)
N. Pillay, The impact of genetic programming in education. Genet. Program Evolvable Mach. 21, 87–97 (2020)
A. Lensen, M. Zhang, B. Xue, Multi-objective genetic programming for manifold learning: balancing quality and dimensionality. Genet. Program Evolvable Mach. 21, 399–431 (2020)
W. La Cava, J.H. Moore, Learning feature spaces for regression with genetic programming. Genet. Program Evolvable Mach. 21, 433–467 (2020)
T. Hu, M. Tomassini, W. Banzhaf, A network perspective on genotype–phenotype mapping in genetic programming. Genet. Program Evolvable Mach. 21, 375–397 (2020)
S. Mabu, K. Hirasawa, J. Hu, J. Murata, Online Learning of Genetic Network Programming. IEEJ Transactions on Electronics, Information and Systems 122, 355–362 (2002)
H. Katagiri, K. Hirasawa, J. Hu, and J. Murata, "Network structure oriented evolutionary model-genetic network programming-and its Comparison with genetic programming," presented at the Proceedings of the 3rd Annual Conference on Genetic and Evolutionary Computation, San Francisco, California, USA, 2001.
H. Katagiri, K. Hirasama, and J. Hu, "Genetic network programming - application to intelligent agents," in IEEE International Conference on Systems, Man, and Cybernetics, 2000, pp. 3829–3834 vol.5.
S. Mabu, K. Hirasawa, M. Obayashi, T. Kuremoto, A variable size mechanism of distributed graph programs and its performance evaluation in agent control problems. Expert Syst. Appl. 41, 1663–1671 (2014)
A. E. Eiben and J. E. Smith, Introduction to evolutionary computing vol. 53: Springer, 2003.
A. E. Teller and M. Veloso, "PADO: Learning Tree Structured Algorithms for Orchestration into an Object Recognition System," Carnegie Mellon University1995.
J. F. Miller and P. Thomson, "Cartesian Genetic Programming," Berlin, Heidelberg, 2000, pp. 121–132.
J.F. Miller, Cartesian genetic programming: its status and future. Genet. Program Evolvable Mach. 21, 129–168 (2020)
D.B. Fogel, An introduction to simulated evolutionary optimization. IEEE Trans. Neural Networks 5, 3–14 (1994)
S. Mabu, K. Hirasawa, and J. Hu, "Genetic Network Programming with Reinforcement Learning and Its Performance Evaluation," in Genetic and Evolutionary Computation Conference, GECCO, Seattle, WA, USA, June 26–30. Proceedings, Part II, K. Deb, Ed., ed Berlin, Heidelberg: Springer Berlin Heidelberg, 2004, pp. 710–711.
T. Atkinson, D. Plump, and S. Stepney, "Evolving Graphs by Graph Programming," Cham, 2018, pp. 35–51.
Q. Meng, S. Mabu, Y. Wang, and K. Hirasawa, "Guiding the evolution of Genetic Network Programming with reinforcement learning," in IEEE Congress on Evolutionary Computation, 2010, pp. 1–8.
S. Mabu, K. Hirasawa, J. Hu, A Graph-Based Evolutionary Algorithm: Genetic Network Programming (GNP) and Its Extension Using Reinforcement Learning. Evol. Comput. 15, 369–398 (2007)
R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction vol. 1: MIT press Cambridge, 1998.
S. Mabu, K. Hirasawa, and J. Hu, "Genetic network programming with learning and evolution for adapting to dynamical environments," in The Congress on Evolutionary Computation 2003, pp. 69–76 Vol.1.
P. Sung Gil, S. Mabu, and K. Hirasawa, "Robust Genetic Network Programming using SARSA Learning for autonomous robots," in ICCAS-SICE, 2009, pp. 523–527.
S. Mabu, H. Hatakeyama, K. Hirasawa, and H. Jinglu, "Genetic Network Programming with Reinforcement Learning Using Sarsa Algorithm," in IEEE International Conference on Evolutionary Computation, 2006, pp. 463–469.
O. Michel, "Khepera simulator package version 2.0: Freeware mobile robot simulator written at the University of Nice-Sophia-Antipolis by Olivier Michel," Khepera Simulator version 2. 0, 1996.
S. Mabu and K. Hirasawa, "Evolving plural programs by genetic network programming with multi-start nodes," in IEEE International Conference on Systems, Man and Cybernetics, 2009, pp. 1382–1387.
X. Li, S. Mabu, H. Zhou, K. Shimada, and K. Hirasawa, "Genetic Network Programming with Estimation of Distribution Algorithms for class association rule mining in traffic prediction," in IEEE Congress on Evolutionary Computation, 2010, pp. 1–8.
X. Li, S. Mabu, K. Hirasawa, Towards the Maintenance of Population Diversity: A Hybrid Probabilistic Model Building Genetic Network Programming. Transaction of the Japanese Society for Evolutionary Computation 1, 89–101 (2010)
X. Li, B. Li, S. Mabu, and K. Hirasawa, "A novel estimation of distribution algorithm using graph-based chromosome representation and reinforcement learning," in IEEE Congress of Evolutionary Computation, 2011, pp. 37–44.
X. Li, S. Mabu, K. Hirasawa, A Novel Graph-Based Estimation of the Distribution Algorithm and its Extension Using Reinforcement Learning. IEEE Trans. Evol. Comput. 18, 98–113 (2014)
Q. Meng, S. Mabu, and K. Hirasawa, "Genetic Network Programming with Sarsa Learning Based Nonuniform Mutation," in IEEE International Conference on Systems, Man and Cybernetics, 2010, pp. 1273–1278.
X. Li, W. He, and K. Hirasawa, "Learning and evolution of genetic network programming with knowledge transfer," in IEEE Congress on Evolutionary Computation, 2014, pp. 798–805.
A. T. Naeini and M. Ghaziasgar, "Improving coordination via emergent communication in cooperative multiagent systems: A Genetic Network Programming approach," in IEEE International Conference on Systems, Man and Cybernetics, 2009, pp. 589–594.
A. T. Naeini and M. Palhang, "Evolving a multiagent coordination strategy using Genetic Network Programming for pursuit domain," in IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), 2008, pp. 3102–3107.
M. Benda, V. Jagannathan, R. Dodhiawala, “On Optimal Cooperation of Knowledge Sources - An Empirical Investigation,” Technical Report BCS-G2010-28 (Boeing Advanced Technology Center, Boeing Computing Services, Seattle, WA, USA, 1986).
H. Itoh, N. Ikeda, and K. Funahashi, "Heterogeneous Multi-agents Learning Using Genetic Network Programming with Immune Adjustment Mechanism," in New Advances in Intelligent Decision Technologies: Results of the First KES International Symposium IDT, K. Nakamatsu, G. Phillips-Wren, L. C. Jain, and R. J. Howlett, Eds., ed Berlin, Heidelberg: Springer Berlin Heidelberg, 2009, pp. 383–391.
X. Li and K. Hirasawa, "Extended rule-based genetic network programming," presented at the Proceedings of the 15th annual conference companion on Genetic and evolutionary computation, Amsterdam, The Netherlands, 2013.
X. Li, M. Yang, S. Wu, Niching genetic network programming with rule accumulation for decision making: An evolutionary rule-based approach. Expert Syst. Appl. 114, 374–387 (2018)
Y. Lu, Z. Jin, M. Shingo, H. Kotaro, H. Jinglu, and M. Sandor, "Elevator group control system using genetic network programming with ACO considering transitions," in SICE Annual Conference, 2007, pp. 1330–1336.
Y. Lu, Z. Jin, M. Shingo, H. Kotaro, H. Jinglu, and S. Markon, "Double-deck Elevator Group Supervisory Control System using Genetic Network Programming with Ant Colony Optimization," in IEEE Congress on Evolutionary Computation, 2007, pp. 1015–1022.
M. Roshanzamir, M. Palhang, A. Mirzaei, Graph structure optimization of Genetic Network Programming with ant colony mechanism in deterministic and stochastic environments. Swarm and Evolutionary Computation 51, 100581 (2019)
X. Li, G. Yang, and K. Hirasawa, "Evolving directed graphs with artificial bee colony algorithm," in 14th International Conference on Intelligent Systems Design and Applications, 2014, pp. 89–94.
X. Li, H. Yang, M. Yang, Revisiting Genetic Network Programming (GNP): Towards the Simplified Genetic Operators. IEEE Access 6, 43274–43289 (2018)
X. Li, W. He, and K. Hirasawa, "Genetic Network Programming with Simplified Genetic Operators," in Neural Information Processing: 20th International Conference, ICONIP 2013, Daegu, Korea, November 3–7, 2013. Proceedings, Part II, M. Lee, A. Hirose, Z.-G. Hou, and R. M. Kil, Eds., ed Berlin, Heidelberg: Springer Berlin Heidelberg, 2013, pp. 51–58.
S. Russell and P. Norvig, Artificial Intelligence: A Modern Approach: Prentice Hall Press, 2009.
M. Pollack and M. Ringuette, "Introducing the Tileworld: experimentally evaluating agent architectures," environment, pp. 183–189, 1990.
F. Wilcoxon, Individual Comparisons by Ranking Methods. Biometrics Bulletin 1, 80–83 (1945)
V. Nannen, S. K. Smit, and A. E. Eiben, "Costs and Benefits of Tuning Parameters of Evolutionary Algorithms," Berlin, Heidelberg, 2008, pp. 528–538.
A.E. Eiben, R. Hinterding, Z. Michalewicz, Parameter control in evolutionary algorithms. IEEE Trans. Evol. Comput. 3, 124–141 (1999)
Author information
Authors and Affiliations
Corresponding author
Additional information
Area Editor: Sebastian Risi.
Rights and permissions
About this article

Cite this article
Roshanzamir, M., Palhang, M. & Mirzaei, A. Efficiency improvement of genetic network programming by tasks decomposition in different types of environments. Genet Program Evolvable Mach 22, 229–266 (2021). https://doi.org/10.1007/s10710-021-09402-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10710-021-09402-y