
Abstract
This study presents a comprehensive analysis of the capability of machine learning techniques in estimating the static liquefaction of sands containing plastic fines. In this regard, six methods, including backpropagation multi-layer perceptron, support vector regression (SVR), lazy K-star (LKS), decision table, random forest, and M5, are employed to predict the static liquefaction of saturated clayey sand. Static liquefaction susceptibility of soil is measured using the brittle index. The dataset includes 114 unconsolidated undrained triaxial shear tests performed on saturated sand containing various amounts of plastic fines. Results indicate that all employed models provide satisfactory predictions, with correlation coefficients ranging from 0.82 to 0.92 for testing set. Among all models, the SVR and LKS models make more accurate and reliable predictions. Furthermore, the significance of each input parameter is assessed through a series of sensitivity analyses, which shows that plasticity of fine particles, host sand gradation, and intergranular void ratio are more influential on static liquefaction. Additionally, some mathematical equations are presented for estimating the static liquefaction potential.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Soil liquefaction is a catastrophic flow failure of soil that causes severe damage to adjacent structures and can be set in by dynamic or monotonic undrained loading in saturated loose sandy soil. Liquefaction under undrained monotonic loading is called static liquefaction, accompanied by excessive positive pore pressure and low shear strength at high strains; consequently, the mean effective stress approaches zero. An approach for assessing static liquefaction susceptibility is to evaluate soil strain-softening behavior under undrained monotonic triaxial testing. For this purpose, the brittle index, IB, is defined as the ratio of post-peak loss of strength of a strain-softening soil, which can be calculated as follows (Bishop 1967):
As presented in Fig. 1, qp is the peak undrained shear strength (also known as the onset of static liquefaction), and qss is the steady-state undrained shear strength. The brittleness index ranges from 0 to 1. Higher values of the brittle index reveal the susceptibility to static liquefaction in soil. Therefore, in terms of undrained behavior, soils with IB = 1 are considered full liquefied soils, while soils with IB = 0 are considered non-liquefied soils. Previous studies found that IB is a helpful benchmark for assessing static liquefaction susceptibility (Keramatikerman et al. 2018; Sadrekarimi 2020; Talamkhani and Naeini 2021).

Static liquefaction in monotonic triaxial test
The occurrence of instabilities in some sites of sandy soils has drawn the attention of researchers toward its behavior (Ishihara 1993). The static liqueafaction of saturated sands containing plastic fines was dominated by some soil characteristics, such as the fines content, the plasticity of fines fraction, sand gradation, and void ratio of soil. Through experimental studies, several researchers have found that fines content and void ratio influence the undrained behavior of clayey sands in undrained monotonic triaxial tests (Georgiannou et al. 1990; Pitman et al. 1994; E Ovando-Shelley 1997; Bouferra and Shahrour 2004; Abedi and Yasrobi 2010; Naeemifar and Yasrobi 2012). Indeed, Papadopoulou and Tika (2016) introduced the plasticity of the clay particles as a dependent factor in altering the undrained behavior of clayey sand. From the perspective of sand gradation, Rahman and Lo (2008) revealed a dependency between static liquefaction behavior and host sand gradation.
In the scale of analytical and theoretical studies, the static liquefaction of sandy soils has also been investigated. Almost all of them focused on predicting the onset of liquefaction or the point in which soil exhibits an instable behavior at peak strength. A number of studies have employed mathematical equations derived from constitutive behavior models of sandy soils to predict the onset of liquefaction (Mróz et al. 2003; Park and Byrne 2004; Rahman and Lo 2012; Buscarnera and Whittle 2013). These constitutive models for sand behavior rely on state parameters of sand which are affected by stress and density. Prediction of the onset of static liquefaction using these constitutive models bears some challenges and limitations: these models are defined for some specific sand and calibrating these models for other types of sandy soils, particularly sands with plastic fines, has its challenges, may cause errors and imprecisions.
Further, empirical methods based on in-situ tests, including standard penetration test (SPT) and cone penetration test (CPT), have also been used to evaluate the triggering of static liquefaction (Stark and Mesri 1994; Olson and Stark 2002, 2003; Mesri 2007). These methods rely on a correlation of static liquefaction with overburden stress and strength parameters obtained from CPT and SPT tests. Obviously, performing in-situ tests are the requirements of these methods, for which there are associated costs and resources.
To propose a solution for the demanding and incalibrated methods of theoretical approaches and also the costly and time-consuming approaches of emprical methods, Sadrekarimi (2020) conducted an analytical study to predict the onset of static liqueafaction of sandy soils containing plastic and non-plastic fines. In his study, a series of correlations between normalized pore water pressure and the brittle index of sandy soils with different fines content and fines plasticity were performed to derive equations for estimating the normalized pore water pressure at steady state. These analytical interpretations were therefore exempt from fines content and soil initial state.
Recently, considering the practical and efficient application of machine learning techniques in a wide range of engineering areas (Savvides and Papadrakakis 2021; Goodarzi et al. 2021; Savvides and Papadopoulos 2022; Al Bodour et al. 2022), this state-of-the-art approaches are being utilized to predict liquefaction susceptibility of soil (Muduli and Das 2014; Kohestani et al. 2015; Atangana Njock et al. 2020; Kumar et al. 2021; Hanandeh et al. 2022). For static liquefaction assessment, Sabbar et al. (2019) employed two types of artificial neural network models to predict the potential of static liquefaction of clean sands with the ratio of qss/qpeak (Fig. 1). They considered nine input parameters concerning particle size and initial states of clean sand. The model they developed predicted the static liquefaction of clean sand with reasonable accuracy with a root mean squared error of 0.17 for the testing set. It should be noted that the approach they adopted was only applicable to clean sands.
Considering the destructive impacts of static liquefaction to the enviromental and human life, predicting the static liquefaction can prevent and cut these damages. Sandy soils containing plastic fines, as one of the susceptible soils to this hazard, neccesitates more attentions for further studies. Given that the current theoretical and empirical methods for assessing static liquefaction do not incorporate some influential features and condition of soil in liquefaction potential, which have been demonstrated by previous experimental studies, efficient and new approaches should be harnessed to resolve this inconsistency. Using machine learning as a means of predicting engineering properties and nonlinear mechanical behavior would be a useful solution to this problem. In order to extend the application of machine learning algorithms, this study aims to evaluate the competency of six algorithms in predicting static liquefaction of saturated sands containing plastic fines. Further, a sensitivity analysis is also performed to determine the relative importance of each feature in static liquefaction of sand with plastic fine.
2 Methodology
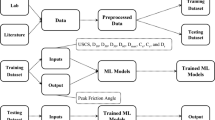
2.1 Dataset
The dataset contains 114 isotropic undrained monotonic triaxial tests conducted on saturated sands containing plastic fines that were compiled from previous studies (Lagunas 1992; Pitman et al. 1994; Bouferra and Shahrour 2004; Derakhshandi et al. 2008; Md. Rahman 2009; Abedi and Yasrobi 2010; Naeemifar and Yasrobi 2012; Papadopoulou and Tika 2016; Chou et al. 2016; Talamkhani 2018). Based on the literature, eight parameters were introduced as the input parameters to the algorithms, which can be classified into three classes: (a) host sand characteristics; (b) plastic fines characteristics; (c) soil condition.
Sand is characterized in regards to its physical dimension and gradation. In this study, two characteristics of sand, including the average grain size of host sand (D50) and the coefficient of uniformity of host sand (Cu), were incorporated into the input parameters.
Plastic fines were introduced to the algorithms using four input parameters consisting of the fines content (Fc), the liquid limit of clay fines (LL), the plasticity index of fines (PI), and the plasticity deviation of fines (ΔPI). The parameter of ΔPI denotes the plasticity deviation from the A-line in Casagrande's classification chart, which equation is as follows (Das 2013):
Das and Khaled (2014) and Khan et al. (2016) found that ΔPI is an influential parameter in predicting the shear strength of clayey soil. Hence, in the present study, ΔPI was considered one of the input parameters that attributes to plastic fines. The plasticity distribution of the fines fraction of the database is depicted in Fig. 2. A significant fraction (90%) of the fines is classified as clay, so a small proportion (10%) of the fines is plastic silt. Moreover, from the liquid limit point of view, only 36% percent have LL values greater than 50, classified as a high plasticity clay or silt, and the remaining are low plasticity fines.

Plasticity distribution of fines portion within the database
Two decisive parameters associated with the condition of soil, including the intergranular void ratio (eg) and the effective confining pressure (σ´c), were considered in this study. The parameter of eg is the void ratio concerning sandy soil containing fine particles, which is defined as follows (Thevanayagam 1998):
where e is the global void ratio and Fc is the fines content. The idea of the intergranular void ratio proposes that the fines occupy the voids created among the sand grains, so the behavior of sand with a modest quantity of fines could be dictated by the intergranular void ratio in preference to the global void ratio (Thevanayagam and Mohan 2000; Belkhatir et al. 2010, 2011).
On the other hand, the brittle index, IB, is used as the target. Figures 3 and 4 respectively depict the frequency histograms of input and target features throughout the dataset.

Frequency of inputs in the dataset

Frequency of target in the dataset
In order to validate the models, the dataset was divided into two subsets: the training set (70%) and the testing set (30%). The models were constructed first by learning from the training data; then, their performance was evaluated using the test data. Table 1 shows the statistical characteristics of both the input and target parameters of the training and testing sets.
2.2 Overview of the Employed Methods
In the present study, six methods, such as backpropagation multi-layer perceptron (BP-MLP), support vector regression (SVR), lazy K-star (LKS), decision table (DT), random forest (RF), and M5, were implemented to predict the brittle index of sand and plastic fine mixtures. Algorithms and mathematical features of the utilized methods are presented briefly in the following sections.
2.2.1 Backpropagation Multi-Layer Perceptron (BP-MLP)
Artificial neural networks (ANN) is a high-reputed method for predicting engineering properties in the geotechnical field of study, which is derived from the biological neural network (McCulloch and Pitts 1943). ANN architecture involves an input layer, one or more hidden layers, and one output layer. Each layer can include several neurons. Hidden layers connected to the input and output layers using weighted connections are incorporated to achieve accurate predictions.
Backpropagation multi-layer perceptron (BP-MLP) is a type of ANN that consists of one or more hidden layers (Rumelhart et al. 1986). It is trained with a backpropagated algorithm to estimate the optimized cost function. The value of each neuron is computed using a sigmoid activation function from the connected neurons in the previous layer. The activation function, g, is a sigmoid function for computing the hidden layer neurons, as follows:
It is important to note that output is computed by a linear function with the last hidden layer. The predicted value is compared to the actual value in a backpropagation procedure. If the mean squared error is greater than the desired error, the process is repeated until the mean squared error is optimized (Fu 1994).
2.2.2 Support Vector Regression (SVR)
Support vector regression (SVR) is a linear or hyperplane method for regression problems to cope with complex non-linearity of numerical data, which is accompanied by using kernel functions (Vapnik 1995; Smola and Schölkopf 2004). In the SVR algorithm, first, an error limit, ϵ, is introduced, then the goal is to find a function that has at most a deviation ϵ from the target values while being as flat as possible. To put it another way, the sensitivity to error is not essential until it is lower than ϵ; but any deviation greater than this will be rejected. Having a loss function with error limit of ϵ, the optimization problem can be solved through a standard dualization technique using Lagrange multipliers (Smola and Schölkopf 2004).
In non-linear problems, a kernel function can be utilized to locate the data into a higher-dimensional feature space where linear regression is conducted. The utilization of appropriate kernel function, depending on the dataset, contributes to reaching the precise prediction. In this study, the Pearson universal kernel (PUK) is employed in the SVR process, which outperformed better than other kernel functions (Üstün et al. 2006).
2.2.3 Lazy K-Star (LKS)
K-star is an instance-based classifier that the class of a test instance is determined by analogous training instances and defined by some similarity function (Cleary and Trigg 1995). The most straightforward instance-based learners are nearest neighbor algorithms (Cover and Hart 1967). These algorithms retrieve the single most comparable instance from the training set using a domain-specific distance function.
Using an entropy-based distance function, the K-star differs from other instance-based learners. The K-Star is a type of nearest-neighbor technique based on transformations using a generalized distance function. The method, which involves calculating the distance between two instances, is based on information theory. Thus, the distance between instances may be characterized as the complexity of transforming one instance into another. In order to define the length of the shortest string connecting the two instances, the Kolmogorov criterion between two instances was defined (Li and Vitányi 1993), which concentrates on just the shortest one out of the numerous potential transformations. Incidentally, the key point is that any sequence can have a probability.
2.2.4 Decision Table (DT)
The decision table is a straightforward learning algorithm that sometimes, depending on the dataset, can surpass other complex decision tree algorithms, attempting to predict a minimum set of features. The performance of DT is based on a decision table, assisted by the features, which searches for the best matches through the table for a given instance. This table, known as decision table majority (DTM), is made up of two components: (1) a schema, which is a collection of features included in the table; (2) a body, which is made up of labeled instances from the space specified by the features in the schema (Kohavi 1995). Development of DTM necessitates using a search algorithm to determine which features should be included in the schema; thus, the particle swarm optimization method (PSO) by using a continuous search space is used in this study to locate these features (Moraglio et al. 2007). It should be mentioned that only the assorted features in the schema are incorporated, and the others are ignored.
2.2.5 Random Forest (RF)
Random forest (RF) is a robust technique for solving regression, unsupervised learning, and classification issues originally presented by Breiman (2001). An extensive number of regression trees are combined parallelly during the training process of the RF, each of which depends on a random vector that has particular characteristics. The accuracy of the RF significantly depends on the strength of the individual trees. A randomly divided subset of the training set is used to build each tree. The RF then aggregates all the trees using the bootstrap aggregating (bagging) technique (Breiman 1996). Bagging formulates each classifier in the ensemble using a randomly generated set of data that each classifier contributes an equal vote for identifying unlabeled instances. By lowering the variation associated with prediction, bagging may increase the accuracy.
2.2.6 M5
M5 is a tree-based model accompanied by a multivariate linear model at the leaves to predict accurately (Quinlan 1992). A decision tree is built in which a splitting criterion is used to minimize the variation along each branch. The splitting procedure is based on the standard deviation of class values that reaches a node, indicating the error and calculating the expected reduction due to testing each attribute. Finally, multivariate linear regression is utilized to construct a linear model for each node based on the selected attributes for the nodes. A pruning technique, incidentally, is employed to minimize the estimated error (Wang and Witten 1997).
2.3 Accuracy Assessment
In this research, the performance of models in predicting the brittle index was controlled through three indicators, including R, RMSE, and MAE.
R is the correlation coefficient that measures the linear correlation between actual and predicted values. The R value ranges from 0 to 1, and the higher value represents the better performance of the model. The correlation coefficient R can be obtained as follows:
where: \({y}_{i}\) and \({p}_{i}\) are the actual and predicted values of the output, respectively; \(\overline{y}\) and \(\overline{p}\) are average of the actual and predicted output, respectively; m represents the number of instances.
RMSE is the abbreviation of root mean squared error, a measurement of produced error. Accordingly, a lower RMSE means a higher level of accuracy. The RMSE can be calculated as follows:
MAE stands for mean absolute error, indicating the average absolute error of predictions in all instances. The lower value of MAE reveals higher accuracy for a model. It can be calculated as the following equation:
2.4 Models Configuration
Throughout this study, all models were developed through WEKA 3.9.5, which is based on Java scripts (Witten and Frank 2002). As seen in the previous section, some models include hyperparameters that can affect the performance of each model. These parameters were selected based on two criteria: (a) precision; (b) quality of the correlations. In other words, the configurations of models were selected to make a prediction with high precision and proper fitting to avoid overfitting and underfitting. The process of hyperparameter tuning includes a series of test and trial of various configuration for each method with regards to bias and variance of train and test sets. The main goal of each series is to find the model that produces predictions with the least possible bias and variance. To put it simply, the optimum models are ones that are not significantly dependent on training data and are capable of producing accurate predictions for test data. To this end, the accuracy of models with various hyperparameters was monitored to find the optimized model with the highest accuracy for both test and training sets (primarily the test set). The hyperparameters of the optimized algorithm for each method are presented in Table 2.
3 Results and Discussion
3.1 Models Performance
Tables 3 and 4 provide a summary of the results of all methods using R, RMSE, and MAE for the training and testing sets, respectively. As shown in these tables, tested methods are sorted based on their accuracy. According to each accuracy criterion (R, RMSE, and MAE), all methods are graded such that a method with the highest level of accuracy would receive a higher score than other methods (with a high value of R and a low value of RMSE and MAE); otherwise, it would receive a lower score. As a means of clarifying the effectiveness of the methods, the results are presented with a color intensity model, in which a higher level of accuracy is indicated by a rich green color and a lower level of accuracy by a pale green color. The overall score of each method was equal to the sum up of all subscores corresponding to the method. Finally, all methods are sorted in respect of their overall scores.
Remarkably, it can be seen from that all methods predicted training set with very strong correlations with the experimental values, as the values of R ranged between 0.90 to 0.99 (Schober and Schwarte 2018). Indeed, in terms of RMSE and MAE, the models showed high accuracy that the values of RMSE corresponding to the training set experienced values between 0.034 and 0.132. Moreover, the values of MAE were between 0.019 to 0.099. Among all methods, the LKS, SVR, and RF models outperform other methods in predicting the training set.
As shown in Table 4, the utilized methods were successful in predicting the testing set with satisfactory accuracy. There was a strong correlation between the predicted and actual value of IB in all methods which predicted the testing set with an R parameter ranging from 0.82 to 0.92. The values of RMSE and MAE corresponding to the testing set provide complementary evidence for the suitability of employed methods. The values of the MAE parameter were found in a range of 0.092 to 0.134 for testing set, which means that the brittle index of a soil can be predicted with an average error of 0.092 to 0.134. In other words, the post-peak loss of strength of the clayey sand can be predicted with an average error of 10% for static liquefaction potential. Furthermore, the values of the RMSE parameter range from 0.133 to 0.178. (Fig. 5)

Experimental and predicted value of brittle index using SVM and LKS methods for: a training set, b testing set
By comparing the performance of all methods and their ranking, outperformed predictions were made through SVR and LKS. In order to clarify the performance of SVR and LKS, distribution of predicted values of these two models are plotted against actual values in Fig. 6. Parallel to the line of equality (1:1), error limits with ΔIB = 0.3 are also shown on both sides. As can be seen in Fig. 5, most of the test set falls within the error limit, indicating that almost all of the test set is predicted with an error of less than 0.3. In other words, using SVR or LKS methods to predict the brittle index of soil, the predicted value would have an error less than 0.3. This error threshold appears acceptable for estimating the behavior of clayey sands under monotonic loading when considering static liquefaction. To illustrate the distribution of errors for SVR or LKS methods, Figs. 7 and 8 show the error graphs for the training and testing sets, respectively. There is a normal distribution of error within the dataset, and most of the samples have lower errors. Few predictions, however, produced errors greater than 0.3, which may be the result of laboratory error occurring during the testing of the samples due to the high sensitivity of monotonic triaxial testing.

Experimental versus predicted brittle index of SVM and LKS for: a training set, b testing set

Error graphs of the training set: a error magnitude of SVR and LKS, b distribution of error in SVR, c distribution of error in LKS

Error graphs of the testing set: a error magnitude of SVR and LKS, b distribution of error in SVR, c distribution of error in LKS
Despite the superior performance of LKS to SVR in predicting the training set, both methods made almost similar estimations for the testing set. By comparing the distribution of error in Figs. 7 and 8, the similarity of the prediction can be corroborated. The LKS predicted the testing sets reasonably, while the difference between the precision of testing and training sets marks a degree of overfitting of the LKS model for this study. In addition, the difference between R values for training and testing sets is less in the SVR than in the LKS. This indicates that the SVR method is properly fitted.
3.2 Model Reliability
To determine the superiority and reliability of the algorithms, a reliability analysis is also performed. The Friedman analysis of variance by ranking was performed on the static liquefaction predictions of all utilized models (Shen et al. 2022). In this approach, for z models, the models are ranked based on the errors produced by their predictions from 1 (least error) to z (highest error). For a database with m data, the average ranking (Rj) for model j can be computed as follows:
where \({r}_{i}^{j}\) denotes the ranking of the ith data for model j.
In this study, the average rankings of all utilized models for the test set data were calculated that are plotted in Fig. 9. As can be seen, the two models of SVR and LKS hold the lowest Friedman rank among the other models throughout the test set which demonstrates their superior reliability. To find out whether this variation in performance is significant or not, chi-square is used to evaluate the distribution of rank in the Friedman ranks. Chi-square (\({\upchi }_{\mathrm{r}}^{2}\)) can be calculated using as follows:

Variation of Friedman rank for utilized algorithms on testing data
This equation relies on the null hypothesis with z–1 degrees of freedom for z models. According to Sheskin (2011), the null hypothesis would be rejected if the computed value of \({\upchi }_{\mathrm{r}}^{2}\) is equal to or greater than the critical chi-square at a prespecified level of significance. For a distribution of data with 5 degrees of freedom and 0.95 degree of significance, the critical chi-square is equal to 11.07. Considering that the value of \({\upchi }_{\mathrm{r}}^{2}\) of this study is equal to 11.32, the null hypothesis can be rejected, so a significant difference is found between the applied models.
3.3 Sensitivity Analysis
In order to determine the relative importance of brittle index to each input feature, a sensitivity analysis of the features was conducted. In this study, the Cosine amplitude method (CAM) is employed to explore the relative importance of input variables affecting the IB of clayey sand. In this approach, the sensitivity degree of input is obtained by setting an equation between input and output data pairs. For a set of data with n variable and m instances, the sensitivity degree, Ri, of the ith variable is calculated as the following equation (Yang and Zhang 1997):
where xik denotes the value of the ith variable for kth instance, and yk is the dependent parameter of kth instance. In other words, xik is an array of the input matrix (X) with n × m dimension and yk is an array of the target matrix (Y) with m × 1 dimension, so these matrices are defined as follows:
In this technique, if the value of Ri is near one, high dependence can be recognized. On the contrary, the value of Ri near zero indicates the independency of that input variable.
The results of the CAM analysis conducted on experimental results and all methods are presented in Fig. 10. For experimental results, five parameters, including D50, Cu, PI, LL, and, eg, ranging from 0.76 to 0.82, showed larger values of Ri than the others, which indicate that the brittle index depends greatly on these parameters. In other words, the static liquefaction of clayey sand is consistent with the gradation of the host sand, the plasticity of clay fraction, and the intergranular void ratio. The index of Ri corresponding to LL has the greatest value among all variables. On the other hand, the experimental Ri values corresponding to ΔPI are around 0.41, demonstrating a low correlation between ΔPI and IB. It should be noted that previous studies have found that ΔPI is an influential parameter in predicting the shear behavior of clay (Das 2013; Khan et al. 2016), whereas the feature importance analysis shows a weak relationship between static liquefaction and ΔPI of clayey sand. Additionally, the variables Fc and σ’c have values of Ri equal to 0.609 and 0.641 for experimental outputs, so a medium influence of fines content and confining pressure on the brittle index can be interpreted.

Importance of the input features resulted from CAM analysis for experimental and developed models predicted values
By comparing the values of Ri related to different models from Fig. 10, it can be noted that SVR and LKS have the slightest difference from the experimental values, indicating the superiority of these methods in predicting the brittle index.
The results of sensitivity analysis underline the importance of some characteristics of sand containing plastic fine in static liquefaction. However, as mentioned earlier in the literature review of this study, current approaches for estimating static liquefaction of sand containing plastic fines mainly rely on initial states of soil or are calibrated for a specific soil (Rahman and Lo 2012; Sadrekarimi 2020); thus, the sand physical characteristics are not incorporated in their approach. Further, the plasticity of the plastic fines and their content are not considered in any previously established method of estimating static liquefaction. However, as seen in this section, these features are influential in the static liquefaction of clayey sand, even the relative importance of parameters related to host sand gradation (D50 and Cu) and plasticity of plastic fines (PI and LL) are higher than the parameters related to initial state of soil (eg and σ’c). In summary, sensitivity analysis reveals the importance of soil physics and plasticity in static liquefaction which has previously been ignored.
4 Brittle Index Estimation
There are several practical benefits to using machine learning techniques, such as presenting equations, matrices, or trees for estimating targets without using computer-based programs so that new input can be applied to the equations to estimate the targets. The backpropagation multi-layer perceptron and the M5 are two methods of this study that yield equations for calculating brittle index. Presented in this section are the methods for estimating the brittle index using these two methods. It should be noted that when the computed brittle index returns a negative number, the behavior should be considered stable with IB = 0. On the other hand, computed IB > 1 should be considered as a full-liquefied soil with IB = 1. Further, the units of the input parameters are according to Table 1.
4.1 Backpropagation Multi-Layer Perceptron
As stated in previous sections, BP-MLP utilized a network of neurons to estimate the target. The network is defined by equations and matrices, so new input data can be given to the mathematical equations to calculate the target. As indicated in Fig. 11, a BP-MLP network compromising eight inputs, one hidden layer with four neurons, and output is harnessed for predicting the brittle index. As seen in Fig. 11, the hidden layer is calculated by the weight vector of w(1) connected to the input layer, and the output layer is obtained from the weight vector of w(2) connected to the hidden layer. These two weight factors obtained from the BP-MLP models are as below:

The backpropagation multi-layer perceptron architecture
It can be seen that w(1) is a matrix with 4 × (n + 1) dimension that n is the number of input features, which equals 8 in this study, and 4 is the number of hidden layer neurons. It should be noted that one extra column in matrix w(1) refers to the bias of the neurons (bi). Needless to say, the weight vector w(2) connects 4 hidden neurons to one output, so it is a 1 × (4 + 1) matrix. The hidden neuron values can be calculated from the sigmoid function of the linear multiplication of w(1) and the matrix of the input layer (X), so it means:
where the formulation of the sigmoid function, g, is defined in Eq. (3). Eventually, the value of brittle index can be obtained from the linear multiplication of w(2) and hidden layer (h) matrices, as follows:
4.2 M5
One of the advantages of M5 methods is formulating a decision tree consisting of linear regression functions at terminal leaves. The M5 tree produced by the dataset of this study is depicted in Fig. 12. The M5 tree for estimating the brittle index relies on two parameters of fines content, Fc, and coefficient of uniformity of host sand, Cu, and includes four linear models (LM) in four-terminal leaves. For calculating brittle index of a new datum, as an input, we should move downward from the head of the M5 tree to find the appropriate linear models based on the conditions (written in diamonds). At the first stage, the fines content of soil is the determining factor: for soil with Fc higher than 0.175, LM1 should be employed for calculating IB. If not, the coefficient of uniformity should be considered: for soil with Cu greater than 1.75 (in addition to Fc ≤ 0.175), LM2 should be employed for computing IB. If not, the fines content again comes out as the determining factor: for soils with Fc higher than 0.125 (in addition to.

The Generated tree based on the M5 model
Fc ≤ 0.175 and Cu ≤ 1.75), LM3 should be used and for ones with Fc lower than 0.125; otherwise, LM4 should be used.
5 Conclusion and Future Works
This study compiled a dataset from ten research papers reported undrained monotonic triaxial test results of sand containing plastic fines. The database incorporated 114 test results, including properties of host sand, plastic fines, and test conditions. The database was utilized in six different machine learning methods, including BP-MLP, SVR, LKS, DT, RF, and M5, for the purpose of predicting static liquefaction potential based on brittle index. A color intensity rating with the total ranking of all models concerning three error criteria of R, RMSE, and R was carried out.
An acceptable level of accuracy was found in all methods as the values of R corresponding to testing sets were in ranges of 0.82 to 0.92. Based on the total ranking, the SVR and LKS methods were found to be more accurate than the others, which predicted testing set with R, RMSE, and MAE values were respectively equal to 0.92, 0.135, and 0.096 for the SVR model and 0.908, 0.133, and 0.098 for the LKS model.
The sensitivity analysis highlighted the importance of the characteristics of host sand and plastic fines in static liquefaction. The features D50, Cu, PI, LL, and eg have a greater influence on the brittle index of clayey sand. Brittle index is less affected by the variables Fc and σ’c. Indeed, it was seen that ΔPI of the plastic fines had the least impact on the static liquefaction of clayey sand.
This study has shown that machine learning techniques are capable of predicting static liquefaction of sand containing plastic fines, which suggests that these algorithms, or some more complex algorithms, can be used to predict static liquefaction of other soils with similar vulnerabilities. Silty sand or sand containing non-plastic fines are some of those materials that have been known as one the most vulnerable soils to static liquefaction (Lade and Yamamuro 2011). Further, mine tailings (Macedo and Vergaray 2022) and losses (Yan et al. 2020) are the other static liquefaction susceptible soils. Developing machine learning algorithms may significantly contribute to the geotechnical community to identify and predict the static liquefaction of vulnerable sites.
Data Availability
The dataset for this study is available upon request from the corresponding author.
References
Abedi M, Yasrobi SS (2010) Effects of plastic fines on the instability of sand. Soil Dyn Earthq Eng 30:61–67. https://doi.org/10.1016/j.soildyn.2009.09.001
Al Bodour W, Hanandeh S, Hajij M, Murad Y (2022) Development of evaluation framework for the unconfined compressive strength of soils based on the fundamental soil parameters using gene expression programming and deep learning methods. J Mater Civ Eng 34:4021452. https://doi.org/10.1061/(asce)mt.1943-5533.0004087
Atangana Njock PG, Shen SL, Zhou A, Lyu HM (2020) Evaluation of soil liquefaction using AI technology incorporating a coupled ENN / t-SNE model. Soil Dyn Earthq Eng 130:105988. https://doi.org/10.1016/j.soildyn.2019.105988
Belkhatir M, Arab A, Della N et al (2010) Influence de l’indice des vides inter-granulaire sur la réponse monotone et cyclique non draine des sols sableux. Comptes Rendus-Mec 338:290–303. https://doi.org/10.1016/j.crme.2010.04.002
Belkhatir M, Missoum H, Arab A et al (2011) Undrained shear strength of sand-silt mixture: effect of intergranular void ratio and other parameters. KSCE J Civ Eng 15:1335–1342. https://doi.org/10.1007/s12205-011-1051-x
Bishop AW (1967) Progressive failure-with special reference to the mechanism causing it. Proc Geotech Conf Oslo 2:142–150
Bouferra R, Shahrour I (2004) Influence of fines on the resistance to liquefaction of a clayey sand. Gr Improv 8:1–5. https://doi.org/10.1680/grim.8.1.1.36366
Breiman L (1996) Bagging predictors. Mach Learn 24:123–140. https://doi.org/10.1007/bf00058655
Breiman L (2001) Random forests. Mach Learn 45:5–32. https://doi.org/10.1023/A:1010933404324
Buscarnera G, Whittle AJ (2013) Model prediction of static liquefaction: influence of the initial state on potential instabilities. J Geotech Geoenviron Eng 139:420–432. https://doi.org/10.1061/(asce)gt.1943-5606.0000779
Chou J-S, Yang K-H, Lin J-Y (2016) Peak shear strength of discrete fiber-reinforced soils computed by machine learning and metaensemble methods. J Comput Civ Eng. https://doi.org/10.1061/(asce)cp.1943-5487.0000595
Cleary JG, Trigg LE (1995) K*: an instance-based learner using an entropic distance measure. In: machine learning proceedings 1995. Morgan Kaufmann, pp 108–114
Cover TM, Hart PE (1967) Nearest neighbor pattern classification. IEEE Trans Inf Theory 13:21–27. https://doi.org/10.1109/TIT.1967.1053964
Das BM (2013) Principles of geotechnical engineering, 8th Editio
Derakhshandi M, Rathje EM, Hazirbaba K, Mirhosseini SM (2008) The effect of plastic fines on the pore pressure generation characteristics of saturated sands. Soil Dyn Earthq Eng 28:376–386. https://doi.org/10.1016/j.soildyn.2007.07.002
Fu LM (1994) Rule generation from neural networks. IEEE Trans Syst Man Cybern 24:1114–1124. https://doi.org/10.1109/21.299696
Georgiannou VN, Burland JB, Hight DW (1990) The undrained behaviour of clayey sands in triaxial compression and extension. Geotechnique 40:431–449. https://doi.org/10.1680/geot.1990.40.3.431
Goodarzi S, Kashani HF, Chrismer S, Ho CL (2021) Using large datasets for finding the correlation between the rate of track settlement and changes in geometry indices. Transp Geotech 31:100665. https://doi.org/10.1016/j.trgeo.2021.100665
Hanandeh SM, Al-Bodour WA, Hajij MM (2022) A comparative study of soil liquefaction assessment using machine learning models. Geotech Geol Eng 40:4721–4734. https://doi.org/10.1007/s10706-022-02180-z
Ishihara K (1993) Liquefaction and flow failure during earthquakes. Geotechnique 43:351–451. https://doi.org/10.1680/geot.1993.43.3.351
Keramatikerman M, Chegenizadeh A, Nikraz H, Sabbar AS (2018) Effect of flyash on liquefaction behaviour of sand-bentonite mixture. Soils Found 58:1288–1296. https://doi.org/10.1016/j.sandf.2018.07.004
Khan SZ, Suman S, Pavani M, Das SK (2016) Prediction of the residual strength of clay using functional networks. Geosci Front 7:67–74. https://doi.org/10.1016/j.gsf.2014.12.008
Kohavi R (1995) The power of decision tables. Lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics). Springer, Berlin, Heidelberg, pp 174–189
Kohestani VR, Hassanlourad M, Ardakani A (2015) Evaluation of liquefaction potential based on CPT data using random forest. Nat Hazards 79:1079–1089. https://doi.org/10.1007/s11069-015-1893-5
Kumar D, Samui P, Kim D, Singh A (2021) A novel methodology to classify soil liquefaction using deep learning. Geotech Geol Eng 39:1049–1058. https://doi.org/10.1007/s10706-020-01544-7
Lade PV, Yamamuro JA (2011) Evaluation of static liquefaction potential of silty sand slopes. Can Geotech J. https://doi.org/10.1139/T10-063
Lagunas AI (1992) Comportamiento de una arena con caolín ensayado en un sistema automático. National autonomous university of Mexico
Li M, Vitányi P (1993) An introduction to Kolmogorov complexity and its applications. Springer
Macedo J, Vergaray L (2022) Properties of mine tailings for static liquefaction assessment. Can Geotech J. https://doi.org/10.1139/cgj-2020-0600
McCulloch WS, Pitts W (1943) A logical calculus of the ideas immanent in nervous activity. Bull Math Biophys 5:115–133. https://doi.org/10.1007/BF02478259
Md. Rahman M (2009) Modelling the influence of fines on liquefaction behaviour. The University of New South Wales at Australian De
Mesri G (2007) Yield strength and critical strength of liquefiable sands in sloping ground. Géotechnique 57:309–311. https://doi.org/10.1680/geot.2007.57.3.309
Moraglio A, Di Chio C, Poli R (2007) Geometric particle swarm optimisation. Lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics). Springer, Berlin, Heidelberg
Mróz Z, Boukpeti N, Drescher A (2003) Constitutive model for static liquefaction. Int J Geomech 3:133–144. https://doi.org/10.1061/(asce)1532-3641(2003)3:2(133)
Muduli PK, Das SK (2014) CPT-based seismic liquefaction potential evaluation using multi-gene genetic programming approach. Indian Geotech J 44:86–93. https://doi.org/10.1007/s40098-013-0048-4
Naeemifar O, Yasrobi SS (2012) Collapse surface characteristics of clayey sands. Proc Inst Civ Eng Geotech Eng 165:379–390. https://doi.org/10.1680/geng.9.00058
Olson SM, Stark TD (2002) Liquefied strength ratio from liquefaction flow failure case histories. Can Geotech J 39:629–647. https://doi.org/10.1139/t02-001
Olson SM, Stark TD (2003) Yield strength ratio and liquefaction analysis of slopes and embankments. J Geotech Geoenviron Eng 129:727–737. https://doi.org/10.1061/(asce)1090-0241(2003)129:8(727)
Ovando-Shelley E, BP (1997) Undrained behaviour of clayey sands in load controlled triaxial tests. Geotechnique 47:97–111
Papadopoulou AI, Tika TM (2016) The effect of fines plasticity on monotonic undrained shear strength and liquefaction resistance of sands. Soil Dyn Earthq Eng 88:191–206. https://doi.org/10.1016/j.soildyn.2016.04.015
Park SS, Byrne PM (2004) Practical constitutive model for soil liquefaction. In: numerical models in geomechanics—9th proceedings of the international symposium on numerical models in geomechanics, NUMOG 2004. CRC Press, Boca Raton, FL, pp 181–186
Pitman TD, Robertson PK, Sego DC (1994) Influence of fines on the collapse of loose sands. Can Geotech J 31:728–739. https://doi.org/10.1139/t94-084
Quinlan JR (1992) Learning with continuous classes. Australian joint conference on artificial intelligence. World Scientific, Singapore, pp 343–348
Rahman MM, Lo S-CR (2008) Effect of sand gradation and fines type on liquefaction behaviour of sand-fines mixture. Am Soc Civil Eng. https://doi.org/10.1061/40975(318)90
Rahman MM, Lo SR (2012) Predicting the onset of static liquefaction of loose sand with fines. J Geotech Geoenviron Eng 138:1037–1041. https://doi.org/10.1061/(asce)gt.1943-5606.0000661
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning representations by back-propagating errors. Nature 323:533–536. https://doi.org/10.1038/323533a0
Sabbar AS, Chegenizadeh A, Nikraz H (2019) Prediction of liquefaction susceptibility of clean sandy soils using artificial intelligence techniques. Indian Geotech J 49:58–69. https://doi.org/10.1007/s40098-017-0288-9
Sadrekarimi A (2020) Forewarning of static liquefaction landslides. J Geotech Geoenviron Eng 146:4020090. https://doi.org/10.1061/(asce)gt.1943-5606.0002320
Savvides A-A, Papadopoulos L (2022) A neural network model for estimation of failure stresses and strains in cohesive soils. Geotechnics. https://doi.org/10.3390/geotechnics2040051
Savvides AA, Papadrakakis M (2021) A computational study on the uncertainty quantification of failure of clays with a modified Cam-Clay yield criterion. SN Appl Sci 3:1–26. https://doi.org/10.1007/s42452-021-04631-3
Schober P, Schwarte LA (2018) Correlation coefficients: appropriate use and interpretation. Anesth Analg 126:1763–1768. https://doi.org/10.1213/ANE.0000000000002864
Shen SL, Elbaz K, Shaban WM, Zhou A (2022) Real-time prediction of shield moving trajectory during tunnelling. Acta Geotech 17:1533–1549. https://doi.org/10.1007/s11440-022-01461-4
Sheskin DJ (2011) Handbook of parametric and nonparametric statistical procedures. Chapman and Hall/CRC, Fifth Edit
Smola AJ, Schölkopf B (2004) A tutorial on support vector regression. Stat Comput 14:199–222. https://doi.org/10.1023/B:STCO.0000035301.49549.88
Stark TD, Mesri G (1994) Undrained shear strength of liquefied sands for stability analysis. J Geotech Eng 120:1287. https://doi.org/10.1061/(ASCE)0733-9410(1994)120:7(1287)
Talamkhani SSAN (2018) Effect of plastic fines on the undrained behavior of clayey sands. Int J Geotech Geol Eng 12:525–528. https://doi.org/10.5281/zenodo.1340402
Talamkhani S, Naeini SA (2021) The undrained shear behavior of reinforced clayey sand. Geotech Geol Eng 39:265–283. https://doi.org/10.1007/s10706-020-01490-4
Thevanayagam S, Mohan S (2000) Intergranular state variables and stress-strain behaviour of silty sands. Geotechnique 50:1–23. https://doi.org/10.1680/geot.2000.50.1.1
Thevanayagam S (1998) Effect of fines and confining stress on undrained shear strength of silty sands. J Geotech Geoenviron Eng. https://doi.org/10.1061/(asce)1090-0241(1999)125:11(1024)
Üstün B, Melssen WJ, Buydens LMC (2006) Facilitating the application of support vector regression by using a universal Pearson VII function based kernel. Chemom Intell Lab Syst 81:29–40. https://doi.org/10.1016/j.chemolab.2005.09.003
Vapnik VN (1995) The nature of statistical learning theory. Springer, New York
Wang Y, Witten IH (1997) Induction of model trees for predicting continuous classes. In: Proceedings of the 9th European conference on machine learning poster papers. pp 128–137
Witten IH, Frank E (2002) Data mining: practical machine learning tools and techniques with Java implementations. Acm Sigmod Rec 31:76–77
Yan RX, Peng JB, Zhang JY, Wang SK (2020) Static liquefaction capacity of saturated undisturbed loess in South Jingyang platform. Water 12:2298. https://doi.org/10.3390/w12082298
Yang Y, Zhang Q (1997) A hierarchical analysis for rock engineering using artificial neural networks. Rock Mech Rock Eng 30:207–222. https://doi.org/10.1007/BF01045717
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by ST. The first draft of the manuscript was written by ST and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interests
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Talamkhani, S., Naeini, S.A. & Ardakani, A. Prediction of Static Liquefaction Susceptibility of Sands Containing Plastic Fines Using Machine Learning Techniques. Geotech Geol Eng 41, 3057–3074 (2023). https://doi.org/10.1007/s10706-023-02444-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10706-023-02444-2