
Abstract
We present in this paper the tool HStriver, an extensible stream runtime verification tool for monitoring real-time event streams. Real-time event streams are formed by events that contain rich data and can occur at arbitrary times. The rich expressivity of HStriver allows the specifications of quantitative semantics of logics like signal temporal logic (STL), including different notions of robustness. Stream runtime verification is a specification family of languages based on the clean separation between temporal dependencies and data computations. To encode the data values contained in the events (both read as inputs and produced as the result of computation) HStriver borrows a large subset of data-types from Haskell. These types are transparently lifted into the HStriver specification language and incorporated in the temporal engine, so they can be used as the types of the input (observations), output (verdicts), and intermediate streams. The temporal evaluation engine is agnostic of the types used in the specification. The resulting extensible language is then embedded into Haskell as an embedded Domain Specific Langauge. The availability of functional features in the specification language enables the direct implementation of desirable features in HStriver like parametrization (using functions that return stream definitions), etc. The resulting tool, HStriver, is a flexible and extensible stream runtime verification engine for real-time streams. We illustrate the use of HStriver on many sophisticated real-time specifications, including realistic STL properties of existing designs.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
Runtime Verification (RV) [1,2,3] is a lightweight dynamic formal technique for systems reliability. The main concerns of RV are how to generate monitors from formal specifications, and algorithms that use the generated monitors to process, one at at time, traces of the system under analysis. The first RV specification languages, proposed almost twenty years ago, were based on temporal logics like past LTL [4] adapted to finite traces [5,6,7], regular expressions [8], rewriting [9], fix-point logics [10], rule based languages [11]. In these languages, verdicts (and many times observations) are Boolean, because these logics borrowed from static verification–-where decidability is crucial.
Stream runtime verification (SRV) [12, 13] attempts to generalize these monitoring algorithms to richer datatypes, including observations and verdicts. This richer setting allows the computation of quantitative values and summaries, the computation of witnesses, models for the collection of representative data, etc. The keystone of SRV is to cleanly separate the temporal engine (the when) that specifies the moments at which values are collected and processed during the computation, from the individual data operations (the what). Therefore, temporal monitoring algorithms are designed abstractly and then instantiated to concrete types and data operations. SRV languages offer declarative specifications where offset expressions allow accessing streams at different moments in time, including future instants. The first SRV developments [12] were synchronous, similar to the so-called synchronous languages like Esterel [14] or Lustre [15]. These languages force causality because their intention is to describe systems and not observations or monitors, while SRV removes the causality assumption allowing the reference to future values. Synchronous SRV languages have been extended in recent years to event-based systems for monitoring real-time event streams [16,17,18,19,20]. Most SRV efforts to date, synchronous and event-based, have focused on efficiently implementing the temporal engine, only offering a handful of hard-wired data-types. However, in practice, adding a new datatype requires modifying the parser, the internal representation and the runtime system, which becomes a cumbersome activity. More importantly, these tools are shipped as monolithic tools with a few hard-wired datatypes which the user of the tool cannot extend.
In this paper we describe the tool HStriver, an extensible implementation of an event-based real-time SRV languageFootnote 1. The core language is based on Striver [18], and enables the extension to arbitrary datatypes, implemented as an embedded DSL in Haskell. There are other RV tools implemented as eDSLs [22,23,24] but a main novelty of HStriver is the use of lift deep embedding, that allows borrowing Haskell types transparently and embedding the resulting language back into Haskell [25].
Most of the HStriver datatypes were introduced after the temporal engine was completely implemented, requiring no re-implementation of the engine. Similarly, users of HStriver can also extend the collection of datatypes easily. The second contribution of HStriver is the implementation of a novel efficient asynchronous engine for the temporal part, described in Sect. 2.5. Implementing HStriver as a Haskell eDSL enables the use of higher-order functions which in turn allows writing code that produces stream declarations from stream declarations. In turn, this enables features like stream parametrization, which requires costly ad-hoc implementations in previous tools. This idea is used to pack HStriver libraries that describe complex logics like STL, both with Boolean and quantitative semantics, in just a few lines.
1.1 Related work
There have been runtime verification tools for the monitoring of event-based streams (see [26] for a survey). R2U2 [27] is based on a variation of metric interval temporal logic (MITL) for finite (real-time) traces. Since R2U2 uses logic as a specification formalism, the observations and verdicts are based on Boolean values. BeepBeep [28, 29] is a framework to build runtime verification tools based on connecting streaming blocks. Even though BeepBeep could be used as a programming framework for tools like HStriver, in comparison to HStriver, BeepBeep lacks semantics both in terms of the data-types, the assumptions on the temporal domain and lacks a way to compute the resources needed. MonPoly [30, 31] is a monitoring tool based on first-order MITL. Even though the tool can produce witnesses for the quantifiers, in comparison with SRV, FO-MITL cannot compute values of arbitrary data-types like the computation of statistics and quantitative semantics of logics. Copilot [32] is a Haskell implementation that offers a collection of building blocks to transform streams, but Copilot does not offer explicit time accesses and offsets (and in particular future accesses). Also, Copilot is based on synchronous time. The closest tools to HStriver are RTLola [19, 33] and TeSSLa [16] which are SRV tools extending Lola [12] with capabilities to real-time event streams. The main difference are that RTLola and TeSSLa come with a predefined collection of data-types, while HStriver enjoys the Haskell capabilities to import and create new types without changing HStriver. Also, HStriver incorporates an asynchronous pull engine and borrows flexible data-types and functional features from the host language. Additionally, HStriver allows event-generation, while RTLola is restricted to be event-driven or periodic events. Compared with TeSSLa, HStriver is an explicit timed language while TeSSLa uses stream transformers.
1.2 Contributions and structure
The main contributions of this paper are:
-
a description of the implementation of HStriver, an SRV tool for real-time event streams using a lift deep embedding in Haskell;
-
a novel pull algorithm to implement an asynchronous temporal engine and;
-
examples that illustrate many of the HStriver features.
The additional contributions of this journal version with respect to the short version [21] are:
-
a more detailed description of the implementation of the core of HStriver;
-
a deep discussion of the lift-deep embedding;
-
a new section about static analysis;
-
nested specifications, which in turn leads to a new example (RobustSTL) and
-
an empirical evaluation of the engine.
The rest of the paper is structured as follows. Section 2 introduces SRV and describes the internals of HStriver. Section 3 illustrates many features by example. Section 4 contains an empirical evaluation using HStriver. Finally, Sect. 5 concludes.
2 The HStriver Tool
Stream Runtime Verification generalizes monitoring algorithms (which are typically defined for Boolean observations and verdicts) to arbitrary data. Data is abstracted using multi-sorted first-order interpreted signatures. The resulting data-types are called data theories in the SRV terminology. The signatures are interpreted in the sense that every functional symbol \(\texttt {f}\) used to build terms of a given type is accompanied with an evaluation function f (the interpretation) that allows the computation of values given values of the arguments. The main idea of a specification is to provide, declaratively, the relation between outputs (verdicts) and input (observations). The temporal dependencies in these declarations are used to determine how to traverse input streams, fetch individual data and ultimately produce each individual output event. These events consist of a value from a data theory, and a timestamp from a specification-fixed temporal domain. The concrete operations used in the specification are used for the details on how to compute the output data. In the context of event-streams, a specification not only needs to declare the values of output streams (based on input and output streams) but also the temporal instants at which there are events in the output streams.
Consider the following example in which we define a stream
 that computes if a company has acquired debt above
\(30\%\) of its liquidity.
that computes if a company has acquired debt above
\(30\%\) of its liquidity.


Timeline of
 events
events
This stream is updated whenever the input streams
 or
or
 produce new values, and computes if the current value of
produce new values, and computes if the current value of
 is greater than 0.3 times the current value of
is greater than 0.3 times the current value of
 . Figure 1 on the right shows graphically the asynchrony of the event trace, and how
. Figure 1 on the right shows graphically the asynchrony of the event trace, and how
 produces values when the other streams do.
produces values when the other streams do.
The temporal core of the tool HStriver is based on the Striver specification language, whose theoretical foundations are described in [18]. A specification \(\langle I,O,E,T\rangle \) consists of
-
a set of typed input stream variables I, which correspond to the input observations;
-
a set of typed output stream variables O which represent outputs of the monitor and intermediate observations; and
-
a collection of defining equations, which associate every output \(y\in O\) with two stream expressions: \(T_y\), which describes when there is an event in y, and \(E_y\) which describes what the value is whenever there is an event.
Tick expressions \(T_y\) are built from constant time-instants (that model the existence of an event at a specific time point), and operators for the union, shift and delays of the ticking instants of streams. Stream Expressions \(E_y\) are built from constants values, function symbols and offset expressions that allow referring to the previous and next-events in streams, according to the time-stamps of events. The language is explained in depth in Sect. 2.2. The simple online algorithm proposed in [18] is a push algorithm that processes input events in the order of their time-stamps and produces output events also in increasing time order. The algorithm implemented in the HStriver tool, and explained in Sect. 2.5, is a much more efficient pull algorithm, which attempts to compute events in output streams fetching the necessary events from other streams.
2.1 HStriver architecture
The architecture of HStriver is shown in Fig. 2.

Software architecture of HStriver
An HStriver specification defines event streams following the syntax explained in Sect. 2.2 below, where one distinguishing feature is that it borrows Haskell datatypes and type members for the syntax of HStriver data expressions. A specification can also borrow Haskell notation and features such as list comprehension and let-clauses, represented by the red dashed arrow in Fig. 2. Then, a very simple translator generates Haskell code with the implementation explained in Sect. 2.3 from the source specification. This translator does not parse or interpret the source code, but only performs simple rewritings introduced to make the specification cleaner for HStriver programmers. The resulting Haskell code is then combined with the execution engine described in Sect. 2.5, written fully in Haskell, and compiled using the GHC to obtain the binary for the specification monitor. In this manner, the HStriver tool can be easily extended with new data-theories, and Haskell programs can directly use HStriver specifications as part of their code.
2.2 The tool HStriver
In this section we present informally the semantics of the language HStriver, which proceeds inductively over the trace. A more thorough formal description of the semantics can be found in [20]. We have chosen this inductive approach opposed to, for example, the search for a fixpoint using small-step semantics as in [34, 35] because we believe that an inductive semantics makes it easier to prove the correctness of the operational semantics. A stream declaration in an HStriver specification can be either:
-
An input declaration, which is bound to a name and a type using the following syntax:

-
An output declaration, which is bound to a name, a tick expression \(\textit{te}\) assigned to the field
 and a value expression
\(\textit{ve}\) assigned to the field
and a value expression
\(\textit{ve}\) assigned to the field
 , using the following syntax:
, using the following syntax:


 and a value expression
and a value expression
 , using the following syntax:
, using the following syntax:

where
 is an optional set of constraints over the polymorphic types handled by the stream expressed in Haskell notation, and
is an optional set of constraints over the polymorphic types handled by the stream expressed in Haskell notation, and
 is an optional list of arguments of the form
is an optional list of arguments of the form

 . We can define
. We can define
 as an alias for the stream
as an alias for the stream
 with
with
 . We can also use
. We can also use
 instead of
instead of
 to define an intermediate stream, whose values are not reported if defined in a specification, and which are not accessible if defined in a library, just like in HLola.
to define an intermediate stream, whose values are not reported if defined in a specification, and which are not accessible if defined in a library, just like in HLola.
The types of the streams have to be Haskell
 types, which is a very general class of types, enough for the purpose of SRV data theories. The types of
types, which is a very general class of types, enough for the purpose of SRV data theories. The types of
 streams have to be parseable from JSON using the Haskell
streams have to be parseable from JSON using the Haskell
 library (i.e., they have to be an instance of the
library (i.e., they have to be an instance of the
 class), and the output streams have to be serializable to JSON using the
class), and the output streams have to be serializable to JSON using the
 library (this is, they have to implement the
library (this is, they have to implement the
 class). Also, the current HStriver frontend imposes some minor syntactic restrictions (the work reported in this paper focuses on an efficient implementation with rich data theories, while future work includes bringing the specification language closer to Striver).
class). Also, the current HStriver frontend imposes some minor syntactic restrictions (the work reported in this paper focuses on an efficient implementation with rich data theories, while future work includes bringing the specification language closer to Striver).
The tick expression of an output stream
 indicates when
indicates when
 might contain an event, and is defined by the following recursive datatype:
might contain an event, and is defined by the following recursive datatype:
-
A single point in time
 , which we write
, which we write
 , where
, where
 is a value of type
is a value of type
 . This type represents the temporal domain of the specification. For example, the expression
. This type represents the temporal domain of the specification. For example, the expression
 indicates that
indicates that
 may contain an event with timestamp 5.
may contain an event with timestamp 5. -
The instants at which a stream
 contains an event, written
contains an event, written

 .
.For example, the expression

 indicates that
indicates that
 may contain events at the timestamps of the events of
may contain events at the timestamps of the events of
 .
. -
The instants of the events of
 shifted by a constant
shifted by a constant
 , written
, written


 .
. -
The instants at which a stream
 of type
of type
 contains an event, delayed by the value in the event which we write
contains an event, delayed by the value in the event which we write

 ,
,

 , or
, or

 depending on the sign of the values of
depending on the sign of the values of
 . Note that the
. Note that the
 operator works with a predefined constant, while
operator works with a predefined constant, while
 can read the delay value from a stream.
can read the delay value from a stream. -
The union of two tick expressions
 and
and
 , which we write
, which we write



 , which we write
, which we write
 , where
, where
 is a value of type
is a value of type
 . This type represents the temporal domain of the specification. For example, the expression
. This type represents the temporal domain of the specification. For example, the expression
 indicates that
indicates that
 may contain an event with timestamp 5.
may contain an event with timestamp 5. contains an event, written
contains an event, written

 .
.
 indicates that
indicates that
 may contain events at the timestamps of the events of
may contain events at the timestamps of the events of
 .
. shifted by a constant
shifted by a constant
 , written
, written


 .
. of type
of type
 contains an event, delayed by the value in the event which we write
contains an event, delayed by the value in the event which we write

 ,
,

 , or
, or

 depending on the sign of the values of
depending on the sign of the values of
 . Note that the
. Note that the
 operator works with a predefined constant, while
operator works with a predefined constant, while
 can read the delay value from a stream.
can read the delay value from a stream. and
and
 , which we write
, which we write



When writing specifications it is very convenient to be able to access the data contained in those events that make a stream tick according to its tick expression. For this reason, we add specific syntax to access the values carried by those events that made the stream wake up to facilitate the computation of the value expression. The value expression of an output stream indicates if the stream will contain an event at a ticking point, and with which value. The value expression is built with the following syntax:
-
The constructor
 o encapsulates an element o from a data-theory. This constructor represents the lift stage of the lift-deep embedding technique explained in Sect. 2.3. For example, we can lift the element True from the Boolean theory from Haskell using
o encapsulates an element o from a data-theory. This constructor represents the lift stage of the lift-deep embedding technique explained in Sect. 2.3. For example, we can lift the element True from the Boolean theory from Haskell using
 . We sometimes indicate the arity of the object o being lifted for clarity or to aid the type inference. For example, if
. We sometimes indicate the arity of the object o being lifted for clarity or to aid the type inference. For example, if
 is a function of the theory that takes two arguments, we would write
is a function of the theory that takes two arguments, we would write
 . Constant values have an arity of 0, so we can write
. Constant values have an arity of 0, so we can write
 if necessary. To improve readability, some operators have been overridden by default by their lifted version, such as
if necessary. To improve readability, some operators have been overridden by default by their lifted version, such as
 .
. -
Function application is juxtaposition and has the greatest precedence. Parentheses are used to impose a different association between functions and values.
-
The value
 contains the value carried by the tick expression.
contains the value carried by the tick expression.For example, if the tick expression is
 , the value of
, the value of
 will be the value of
will be the value of
 at that time. The value carried by a singleton expression
at that time. The value carried by a singleton expression
 , is unit.
, is unit. -
The constructor
 is used to refrain from producing a value. If at some point the value expression of a stream definition is
is used to refrain from producing a value. If at some point the value expression of a stream definition is
 , then the stream will not produce an event at all. This expression is typically used within
, then the stream will not produce an event at all. This expression is typically used within
 expressions and is useful to filter streams. For example, the expression
expressions and is useful to filter streams. For example, the expression
 will generate events with the (numeric) carried value only when the carried value is greater than ten.
will generate events with the (numeric) carried value only when the carried value is greater than ten.
 o encapsulates an element o from a data-theory. This constructor represents the lift stage of the lift-deep embedding technique explained in Sect.
o encapsulates an element o from a data-theory. This constructor represents the lift stage of the lift-deep embedding technique explained in Sect.  . We sometimes indicate the arity of the object o being lifted for clarity or to aid the type inference. For example, if
. We sometimes indicate the arity of the object o being lifted for clarity or to aid the type inference. For example, if
 is a function of the theory that takes two arguments, we would write
is a function of the theory that takes two arguments, we would write
 . Constant values have an arity of 0, so we can write
. Constant values have an arity of 0, so we can write
 if necessary. To improve readability, some operators have been overridden by default by their lifted version, such as
if necessary. To improve readability, some operators have been overridden by default by their lifted version, such as
 .
. contains the value carried by the tick expression.
contains the value carried by the tick expression. , the value of
, the value of
 will be the value of
will be the value of
 at that time. The value carried by a singleton expression
at that time. The value carried by a singleton expression
 , is unit.
, is unit. is used to refrain from producing a value. If at some point the value expression of a stream definition is
is used to refrain from producing a value. If at some point the value expression of a stream definition is
 , then the stream will not produce an event at all. This expression is typically used within
, then the stream will not produce an event at all. This expression is typically used within
 expressions and is useful to filter streams. For example, the expression
expressions and is useful to filter streams. For example, the expression
 will generate events with the (numeric) carried value only when the carried value is greater than ten.
will generate events with the (numeric) carried value only when the carried value is greater than ten.Two additional HStriver constructors allow accessing timestamps and values of different streams:
-
The expression

 accesses the resulting timestamp of a time expression
accesses the resulting timestamp of a time expression (also called a tau expression), and
(also called a tau expression), and -
The projection constructor
 , which accesses the value of a stream s at a tau expression
, which accesses the value of a stream s at a tau expression
 , and returns the value unless the time calculation results in “falling off the trace”, this is, the result being lower than the minimum temporal value or greater than the maximum temporal value, in which case
\( v \) is returned. The syntax also offers the variant
, and returns the value unless the time calculation results in “falling off the trace”, this is, the result being lower than the minimum temporal value or greater than the maximum temporal value, in which case
\( v \) is returned. The syntax also offers the variant
 which returns a supertype of s with additional values to indicate the falling off the trace, and the variant
which returns a supertype of s with additional values to indicate the falling off the trace, and the variant
 which is only legal if the offset of the tau expression is guaranteed to exist (the type system guarantees this).
which is only legal if the offset of the tau expression is guaranteed to exist (the type system guarantees this).

 accesses the resulting timestamp of a time expression
accesses the resulting timestamp of a time expression (also called a tau expression), and
(also called a tau expression), and , which accesses the value of a stream s at a tau expression
, which accesses the value of a stream s at a tau expression
 , and returns the value unless the time calculation results in “falling off the trace”, this is, the result being lower than the minimum temporal value or greater than the maximum temporal value, in which case
, and returns the value unless the time calculation results in “falling off the trace”, this is, the result being lower than the minimum temporal value or greater than the maximum temporal value, in which case
 which returns a supertype of s with additional values to indicate the falling off the trace, and the variant
which returns a supertype of s with additional values to indicate the falling off the trace, and the variant
 which is only legal if the offset of the tau expression is guaranteed to exist (the type system guarantees this).
which is only legal if the offset of the tau expression is guaranteed to exist (the type system guarantees this).The value of the expression
 may be a value of the type of
may be a value of the type of
 or one of the special vualues out or -out , which represent that the access has fallen off the trace (i.e., that there is no previous/next value of
or one of the special vualues out or -out , which represent that the access has fallen off the trace (i.e., that there is no previous/next value of
 , depending on the operator). Similarly, the expression
, depending on the operator). Similarly, the expression

 can return either a value from the time domain or one of the special values infty or -infty .
can return either a value from the time domain or one of the special values infty or -infty .
Finally, the datatype for tau expressions, which allows offsets in time is:
-
 which represents the current time.
which represents the current time. -
The constructor
 , which allows referring to the last event in stream
, which allows referring to the last event in stream
 strictly before the value of the tau expression
\( te \).
strictly before the value of the tau expression
\( te \). -
The constructor
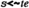 , which is like
, which is like
 but also considers
\( te \) as a candidate, this is,
but also considers
\( te \) as a candidate, this is,
 allows referring to the event in
allows referring to the event in
 exactly at time
exactly at time
 , but it behaves like
, but it behaves like
 if such event does not exist.
if such event does not exist. -
The constructors
 and
and
 , which are the future duals of
, which are the future duals of
 and
and
 respectively.
respectively.
 which represents the current time.
which represents the current time. , which allows referring to the last event in stream
, which allows referring to the last event in stream
 strictly before the value of the tau expression
strictly before the value of the tau expression
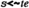 , which is like
, which is like
 but also considers
but also considers
 allows referring to the event in
allows referring to the event in
 exactly at time
exactly at time
 , but it behaves like
, but it behaves like
 if such event does not exist.
if such event does not exist. and
and
 , which are the future duals of
, which are the future duals of
 and
and
 respectively.
respectively.We show a summary of the stream access operators in Fig. 3.

Stream access operators and their behaviors when there is an event at
 or not
or not
We also define versions of
 and
and
 that are decorated with a time limit b for the next event to be considered, which we write
that are decorated with a time limit b for the next event to be considered, which we write
 and
and
 respectively, and are useful to efficiently capture logics like STL, as we show in Sect. 3.2. The syntax of HStriver contains some syntactic sugar for stream accesses to make them more compact and improve legibility. Thus,
respectively, and are useful to efficiently capture logics like STL, as we show in Sect. 3.2. The syntax of HStriver contains some syntactic sugar for stream accesses to make them more compact and improve legibility. Thus,
 becomes
becomes
 ,
,
 becomes
becomes
 ,
,
 becomes
becomes
 , and
, and
 becomes
becomes
 . We also define
. We also define
 as a synonym of
as a synonym of

 . Also, HStriver allows the declaration of a top level constant value or function
. Also, HStriver allows the declaration of a top level constant value or function
 (with definition
\( def \)) using
(with definition
\( def \)) using
 or
or
 .
.
The current version of HStriver offers the possibility to work with two temporal domains:
 and
and
 . The former option uses the Haskell type
. The former option uses the Haskell type
 as the time domain, while the latter uses the Haskell library
as the time domain, while the latter uses the Haskell library
 of the Haskell package
of the Haskell package
 . We specify the time domain for a specification with the directive
. We specify the time domain for a specification with the directive
 followed by either
followed by either
 or
or
 .
.
HStriver libraries and theories are imported with
 , which allows the access to functions and streams from the imported file. The main difference between a
, which allows the access to functions and streams from the imported file. The main difference between a
 and a
and a
 file is that the former contains utilities for streams manipulation and definitions, while a theory is agnostic of the Striver concepts and comprises functions and constants from a specific application domain. Data theories are implemented directly in the host language, which let us use native types and functions, as well as third parties off-the-shelf implementations, and even define our own custom types and functions as data theories with the directive
file is that the former contains utilities for streams manipulation and definitions, while a theory is agnostic of the Striver concepts and comprises functions and constants from a specific application domain. Data theories are implemented directly in the host language, which let us use native types and functions, as well as third parties off-the-shelf implementations, and even define our own custom types and functions as data theories with the directive
 . In this manner, the syntactic name of a Haskell function definition (or its lambda expression in the case of anonymous functions) make up the functional symbols used to build terms, while their semantics in the Haskell language are the functions interpretations. This characteristic of the language illustrates the extensibility of HStriver in terms of data theories. We can also import arbitrary Haskell libraries with the directive
. In this manner, the syntactic name of a Haskell function definition (or its lambda expression in the case of anonymous functions) make up the functional symbols used to build terms, while their semantics in the Haskell language are the functions interpretations. This characteristic of the language illustrates the extensibility of HStriver in terms of data theories. We can also import arbitrary Haskell libraries with the directive
 .
.
When we import a library, a theory or a Haskell library
 , we can include the reserved word
, we can include the reserved word
 after
after
 to avoid name clashes. This forces us to prepend the name of the library or theory before accessing a definition
to avoid name clashes. This forces us to prepend the name of the library or theory before accessing a definition
 from it, as in
from it, as in
 . We can access functions and constants in the Haskell Prelude by prepending
. We can access functions and constants in the Haskell Prelude by prepending
 to their names.
to their names.
Example 1
The following specification defines a stream
 that filters out the negative values of an integer input stream
that filters out the negative values of an integer input stream
 . The stream
. The stream
 over-approximates its tick instants as the tick instants of
over-approximates its tick instants as the tick instants of
 , and then delegates the filtering to its value expression.
, and then delegates the filtering to its value expression.

Example 2
In this example we show the definition of an
 stream
stream
 to calculate the stock of a certain product based on two input event streams:
to calculate the stock of a certain product based on two input event streams:
 –-that represents the sales of such product–-, and
–-that represents the sales of such product–-, and
 –-which represents the arrivals of the same product. The output stream
–-which represents the arrivals of the same product. The output stream
 is defined to tick when either
is defined to tick when either
 or
or
 (or both) tick. The value carried by the tick expression is of type
(or both) tick. The value carried by the tick expression is of type
 and represents the units of the product sold and received at a given point in time. Notice that at least one of the members will be a
and represents the units of the product sold and received at a given point in time. Notice that at least one of the members will be a
 value.
value.

We use the function
 from Haskell, we apply it to the Haskell integer
from Haskell, we apply it to the Haskell integer
 , and we lift the resulting (partially applied) function to safely get the number of sold and received products, defaulting to 0 if the corresponding input stream is not ticking.
, and we lift the resulting (partially applied) function to safely get the number of sold and received products, defaulting to 0 if the corresponding input stream is not ticking.
HStriver also allows the static parameterization of streams, which lets us reuse stream definitions and instantiate these for different parameters in static time.
Example 3
The following specification generalizes Example 2 for multiple products. This example uses the
 operator to set up a timer and raise an alarm in case the stock of any product has been low for too long.
operator to set up a timer and raise an alarm in case the stock of any product has been low for too long.

2.3 Language implementation
The core of the HStriver language is implemented as an embedded Domain Specific Language (eDSL) in Haskell. In this section we explain the benefits and the drawbacks of this approach and the use of the novel technique of lift-deep embedding.
2.3.1 The host language Haskell
Haskell [36] is a pure statically typed functional programming language that allows custom parametric polymorphic datatypes, which eases the definition of new data theories in HStriver and enables us to abstract away the types of the streams, effectively allowing the expression of type-generic specifications.
As a design principle, and in order to facilitate type independent temporal engines, when a specification is processed, we drop the information about the types of the streams so streams of different types can be mixed and used in the same specification. One drawback of this approach is that the Haskell type-system can no longer track the original type of a stream, but this step is made after Haskell has type-checked the specification, guaranteeing that the engine is forgetting the type information of a well-typed specification. The HStriver engine keeps enough information to parse the values from input streams and to produce output values given a stream name, avoiding type mismatches when converting from and to dynamically-typed objects. As a result, a runtime type error can only be produced when processing an input event whose value received as input is not of the expected type. Otherwise, types are guaranteed to be respected during the computation.
Output streams of HStriver are defined using functions from data theories. These are functions in the mathematical sense, meaning that they do not have side effects and the tool does not make assumptions about when these functions will be called. Data theory functions are expected to yield the same result when applied to the same arguments twice, which is aligned with the Haskell purity of (total) functions.
A language that offers means to define new datatypes must not only provide the constructs to define them, but it also must implement the encoding and decoding of user defined custom datatypes. Extensible encoding and decoding of datatypes in the theory is not trivial and such a feature might account for a large portion of the code-base in other implementations, draining implementation and maintenance effort from more fundamental aspects of the tool. Haskell allows defining custom datatypes via the
 statement which once defined can be used just like any other type in Haskell. HStriver relies on Haskell’s facilities to easily define how to encode and decode datatypes in JSON format, most of the times automatically from their definitions using Haskell’s
statement which once defined can be used just like any other type in Haskell. HStriver relies on Haskell’s facilities to easily define how to encode and decode datatypes in JSON format, most of the times automatically from their definitions using Haskell’s
 mechanism.
mechanism.
Haskell allows redefining functions that are typically native in other languages, such as Boolean operators
 and
and
 , and the arithmetic operators
, and the arithmetic operators
 ,
,
 and
and
 , as well as define and use custom infix operators. Haskell also offers let-bindings, list comprehensions, anonymous functions, higher-order, and partial function application, all of which improves specification legibility. We use higher-order functions to describe transformations that produce stream declarations from stream declarations, obtaining static parameterization for free, which allows the programmatic definition of specifications.
, as well as define and use custom infix operators. Haskell also offers let-bindings, list comprehensions, anonymous functions, higher-order, and partial function application, all of which improves specification legibility. We use higher-order functions to describe transformations that produce stream declarations from stream declarations, obtaining static parameterization for free, which allows the programmatic definition of specifications.
Using eDSLs brings benefits beyond data theories, including leveraging Haskell’s parsing, compiling, type-checking, and modularity. The HStriver engine uses Haskell’s module system to allow modular specifications, to build language extensions, and to import third parties libraries. As a result, HStriver allows collecting reusable code and stream transformers in libraries, which specifications can then import to aid the stream definitions.
One drawback of using eDSLs is that specifications have to be compiled with a Haskell compiler, but once a specification is compiled, the resulting binary is agnostic of the fact that an eDSL was used. Therefore, any target platform supported by Haskell can be used as a target of HStriver. Moreover, improvements in the Haskell compiler and runtime systems will be enjoyed seamlessly, and new features will be ready to be used in the engines right away.
2.3.2 Lift-deep embedding
DSLs allow implementing a language by embedding a guest language (in our case HStriver) into a host language (in our case Haskell). A deep embedding is typically used for DSLs since the structure of the programs of the guest language is faithfully represented as a data-type in the host language. Typically, a DSL is designed as a complete language upfront, first defining the types and terms of the language (this is, the underlying theory), which is then implemented–-either as an eDSL or as a standalone DSL–-, potentially mapping the types of the DSL into types of the programming language used in the implementation. However, our intention is to fulfill the promise in SRV of the clean separation between data theories and temporal engines. Therefore, we pursue a solution as a language where datatypes are not decided upfront but can be added on demand without requiring any re-implementation.
A DSL with user-defined data types has a general internal format for representing terms of these types. We define a lifting operator that takes Haskell terms into the term representation of HStriver. As a consequence, HStriver borrows (almost) arbitrary types from the host language Haskell, resulting in a tool that is agnostic from the types handled and even allows types to be defined and included after the implementation of the language. This technique allows us to incorporate Haskell datatypes into HStriver, and enables the use of many features from the host language in the SRV engine. We seek to represent many data theories of interest for RV and to incorporate new ones transparently, so we abstract away concrete types in the eDSL. For example, we want to use the theory of Boolean without adding the constructors that a usual deep embedding would require. To accomplish this goal we revisit the very essence of functional programming. Every expression in a functional language–-as well as in mathematics–-is built from two basic constructions: values and function applications. Therefore, to implement our SRV engine we use these two constructions plus additional stream access primitives to capture the corresponding offset expressions in HStriver, as explained below.
The engine defines expressions in Haskell as parametric datatypes with a polymorphic argument
 . The generic
. The generic
 is automatically instantiated in static time by the Haskell compiler, effectively performing the desired lifting of Haskell datatypes to types of the theory in the language. The resulting concrete Expressions constitute a typical deeply embedded DSL. This technique allows us to lift Haskell datatypes to HStriver and then perform a single deep embedding for all lifted datatypes, saving us from defining a constructor for all elements in the data theory, and making the incorporation of new types transparent. The application of this technique fulfills the promise of a clean separation of time and data and eases the extensibility to new data theories, while keeping the amount of code at a minimum.
is automatically instantiated in static time by the Haskell compiler, effectively performing the desired lifting of Haskell datatypes to types of the theory in the language. The resulting concrete Expressions constitute a typical deeply embedded DSL. This technique allows us to lift Haskell datatypes to HStriver and then perform a single deep embedding for all lifted datatypes, saving us from defining a constructor for all elements in the data theory, and making the incorporation of new types transparent. The application of this technique fulfills the promise of a clean separation of time and data and eases the extensibility to new data theories, while keeping the amount of code at a minimum.
2.3.3 Language internals
We define the stream declarations of HStriver in Haskell as a parametric datatype
 with a polymorphic argument:
with a polymorphic argument:
-
The following constructor represents the definition of an
 stream from its name and the names of its arguments:
stream from its name and the names of its arguments:
-
Similarly, the output constructor represents an
 stream, and associates a stream with its name, its tick expression and its value expression:
stream, and associates a stream with its name, its tick expression and its value expression:
 stream from its name and the names of its arguments:
stream from its name and the names of its arguments:
 stream, and associates a stream with its name, its tick expression and its value expression:
stream, and associates a stream with its name, its tick expression and its value expression:
We explain the datatypes that represent the tick and the value expressions respectively. First, tick expressions are modeled by a parametric datatype
 whose polymorphic argument indicates the type of the carried value:
whose polymorphic argument indicates the type of the carried value:
-
The literal instant
 constructor is:
constructor is:
-
The union constructor
 is implemented by:
is implemented by:
-
The
 is implemented as follows:
is implemented as follows:
A special case of this constructor (specifying a deviation of 0) represents the
 operator.
operator. -
Finally, the
 operator is implemented by the following constructor:
operator is implemented by the following constructor:
The direction
 indicates the sign of the delay stream, and can be either
indicates the sign of the delay stream, and can be either
 or
or
 . The
. The
 and
and
 operators are translated to a
operators are translated to a
 expression with
expression with
 direction, and the
direction, and the
 operator generates a
operator generates a
 expression with
expression with
 direction.
direction.
 constructor is:
constructor is:
 is implemented by:
is implemented by:
 is implemented as follows:
is implemented as follows:
 operator.
operator. operator is implemented by the following constructor:
operator is implemented by the following constructor:
 indicates the sign of the delay stream, and can be either
indicates the sign of the delay stream, and can be either
 or
or
 . The
. The
 and
and
 operators are translated to a
operators are translated to a
 expression with
expression with
 direction, and the
direction, and the
 operator generates a
operator generates a
 expression with
expression with
 direction.
direction.Value expressions are implemented as a parametric datatype
 whose polymorphic arguments indicate the type of the carried value (
whose polymorphic arguments indicate the type of the carried value (
 ) and the type of the expression itself (
) and the type of the expression itself (
 ):
):
-
The lift
 expression is implemented by the following constructor:
expression is implemented by the following constructor:
This operator constructs a value expression with the type of its argument, regardless of the type of the carried value.
-
The carried value expression
 is implemented by the following constructor:
is implemented by the following constructor:
The
 operator constructs a value expression with the type of the carried value.
operator constructs a value expression with the type of the carried value. -
The reserved value
 is implemented as:
is implemented as:
The
 operator constructs a value expression of any type.
operator constructs a value expression of any type. -
The special function
 is implemented by the constructor:
is implemented by the constructor:
-
The following constructor allows obtaining the
 a tau expression:
a tau expression: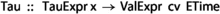
The type
 includes the possibility that the expression returns an infinite value ( infty or -infty ).
includes the possibility that the expression returns an infinite value ( infty or -infty ). -
Similarly, the following constructor allows obtaining the event in a tau expression:

The type
 includes the possibility that the expression returns an outside value ( out or -out ).
includes the possibility that the expression returns an outside value ( out or -out ).
 expression is implemented by the following constructor:
expression is implemented by the following constructor:
 is implemented by the following constructor:
is implemented by the following constructor:
 operator constructs a value expression with the type of the carried value.
operator constructs a value expression with the type of the carried value. is implemented as:
is implemented as:
 operator constructs a value expression of any type.
operator constructs a value expression of any type. is implemented by the constructor:
is implemented by the constructor:
 a tau expression:
a tau expression: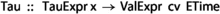
 includes the possibility that the expression returns an infinite value ( infty or -infty ).
includes the possibility that the expression returns an infinite value ( infty or -infty ).
 includes the possibility that the expression returns an outside value ( out or -out ).
includes the possibility that the expression returns an outside value ( out or -out ).Finally, tau expressions are represented as a parametric datatype
 whose polymorphic argument indicates the type of the stream being accessed:
whose polymorphic argument indicates the type of the stream being accessed:
-
The constructor
 represents the reserved symbol
represents the reserved symbol
 .
. -
The constructor
 represents the tau expression
represents the tau expression
 .
. -
The constructor
 represents the tau expression
represents the tau expression
 .
. -
The constructor
 represents the tau expression
represents the tau expression
 .
. -
Finally, the constructor
 represents the tau expression
represents the tau expression
 .
.
 represents the reserved symbol
represents the reserved symbol
 .
. represents the tau expression
represents the tau expression
 .
. represents the tau expression
represents the tau expression
 .
. represents the tau expression
represents the tau expression
 .
. represents the tau expression
represents the tau expression
 .
.For example, the specification of Example 1, in which the stream
 filters out the negative values of an input stream
filters out the negative values of an input stream
 is translated in the eDSL of HStriver as follows:
is translated in the eDSL of HStriver as follows:

The tick expression of
 is the times at which
is the times at which
 ticks, shifted by 0. Then, the value expression is
ticks, shifted by 0. Then, the value expression is
 if the application of the (data theory) unary function
if the application of the (data theory) unary function
 to the current value of
to the current value of
 returns True, and the current value of
returns True, and the current value of
 otherwise. This illustrates how tick expressions are maintained simple, delegating the actual generation of the event to the value expression.
otherwise. This illustrates how tick expressions are maintained simple, delegating the actual generation of the event to the value expression.
2.4 Static analysis
Even though the Haskell compiler takes care of most of the static checks that guarantee that the input specification is legal–-like syntactic errors and type mismatches–-lightening the burden of implementing these checks in HStriver, some remaining syntactic checks are specific to the language, and require us to run additional analyses over the specification to confirm its validity.
The work that introduced Striver [20] contains a detailed discussion on the syntactic conditions that ensure the semantic well-definedness of a Striver specification. The condition essentially corresponds to the lack of (certain kind of) cycles in the dependency graph of the specification, which indicates if a stream can depend on past, present or future values of another stream (including itself). Then, HStriver first computes the dependency graph of the specification by traversing the stream definitions recursively. After that, it assesses that the closed paths in every maximal strongly connected component are either all past, or all future paths, deciding the well-formedness condition of the input specification. Additionally, HStriver also checks that
 is used only in a branch of an
is used only in a branch of an
 expression, possibly nested, but not as an argument of a function or as a function itself. Note that we could have used the type system of Haskell to enforce the correct usage of
expression, possibly nested, but not as an argument of a function or as a function itself. Note that we could have used the type system of Haskell to enforce the correct usage of
 expressions by requesting that the Value Expressions return a
expressions by requesting that the Value Expressions return a
 value, and interpreting the absence of value (
value, and interpreting the absence of value (
 ) as a
) as a
 , but we believe that this alternative would have polluted the syntax and added an overhead that is irrelevant for most specifications.
, but we believe that this alternative would have polluted the syntax and added an overhead that is irrelevant for most specifications.
The following is the dependency graph of the filter specification from Example 1.

We can see here that
 on the present value of
on the present value of
 , due to the use of
, due to the use of
 and
and
 and it also depends on past values of
and it also depends on past values of
 due to the presence of
due to the presence of
 .
.
2.5 The engine
The online monitoring algorithm proposed in [18] is limited to past offsets only, and it processes input events in strictly increasing time, producing outputs also in increasing time. We call this a push algorithm, because input events are pushed into the monitor. Instead, the implementation of HStriver follows a novel pull approach: the engine computes events for the output streams, which requires pulling events from other streams, and eventually pulling events from inputs. The performance of both execution approaches is similar for the common fragment of the language (i.e., for the past-only fragment of Striver). Using a pull procedure, we gain expressivity in exchange for a slightly more complex execution design. In this section we focus on how the engine works and we explain the pull algorithm in detail. See [37, 38] for the proof of correctness of the engine algorithm, whose showcasing is the main goal of this tool paper.
Input events are read from named pipes in JSON format. The main algorithm maintains the following state that is updated at each step in the computation:
-
one Leader for each stream declared, and
-
one Pointer from one stream to another for every
 or projection used.
or projection used.
 or projection used.
or projection used.The task of the Leader is to fetch the next event in a stream when required. The leader for an input stream will pull the next input event, while the leader for an output stream will use its definition to calculate the next event, pulling from the pointers in the value and tick expressions if necessary. Leaders can also discover the lack of events, which is useful data for referring streams, and is necessary to prevent the system from hanging trying to calculate a real event.
A Pointer represents a relevant position in the sequence of events of a stream. Pointers advance from past to future traversing or generating the events of a stream. The events in the past of a pointer have already been used, while the events in the future will be used later in the computation. When a pointer needs an event that has not yet been computed, it will use the corresponding leader to fetch it. When all the pointers pointing to a stream pass beyond an event, this event can be forgotten, keeping the number of events in memory at the minimum. For example, the leader for the stream
 in Example 3 maintains one pointer to each of the three
in Example 3 maintains one pointer to each of the three
 streams to determine when to generate the unit value. In particular,
streams to determine when to generate the unit value. In particular,
 will pull from every
will pull from every
 stream at the beginning and then keep
stream at the beginning and then keep

pulling from the pointer at the minimum position. Each of the
 streams also maintains a pointer to its corresponding
streams also maintains a pointer to its corresponding
 , to calculate if the corresponding
, to calculate if the corresponding
 is low for too long, so it produces a unit value. In particular, the leader will pull from
is low for too long, so it produces a unit value. In particular, the leader will pull from
 one event to check the next timestamp and value; and one more to determine whether the timer is reset or not. The engine maintains an extra pointer for every output stream, which it uses to pull events and print them. The diagram on the right shows how the pointers are updated every time the output stream
one event to check the next timestamp and value; and one more to determine whether the timer is reset or not. The engine maintains an extra pointer for every output stream, which it uses to pull events and print them. The diagram on the right shows how the pointers are updated every time the output stream
 is pulled. The big box of each stream represents its leader. Everything at the right of the leader has not yet been discovered, hence the dashed line. The leader of the stream
is pulled. The big box of each stream represents its leader. Everything at the right of the leader has not yet been discovered, hence the dashed line. The leader of the stream
 maintains one pointer to the last event of each other stream, plus an extra pointer to its own last event (not considering the event that is being computed). The events shown in grey are events that can be forgotten by the engine because all the pointers that point to their corresponding streams have passed beyond those events.
maintains one pointer to the last event of each other stream, plus an extra pointer to its own last event (not considering the event that is being computed). The events shown in grey are events that can be forgotten by the engine because all the pointers that point to their corresponding streams have passed beyond those events.
2.5.1 Nested specifications
We describe now a feature of HStriver that simplifies specifications in many occasions by allowing the creation of new data theories as the result of the computation of a monitor, in order to use the results in higher monitoring activities. We call this feature nested monitoring or nested specifications.
The main function that implements the monitoring algorithm is
\( runSpec \), which takes an HStriver specification and an input trace for every
 stream and returns the successive events of the
stream and returns the successive events of the
 streams. As a by-product of developing HStriver as an eDSL in Haskell, the datatypes that constitute an HStriver specification and the function
\( runSpec \) are defined in Haskell and as such can be lifted to be a theory of the language HStriver itself. This has enabled the use of HStriver specifications as a theory from within the language [37]. This feature does not extend the expressive power of HStriver, but it enables us to consider the language itself as a theory that can be used to define specifications, in the same way as static parameterization lets us reuse definitions without extending HStriver itself.
streams. As a by-product of developing HStriver as an eDSL in Haskell, the datatypes that constitute an HStriver specification and the function
\( runSpec \) are defined in Haskell and as such can be lifted to be a theory of the language HStriver itself. This has enabled the use of HStriver specifications as a theory from within the language [37]. This feature does not extend the expressive power of HStriver, but it enables us to consider the language itself as a theory that can be used to define specifications, in the same way as static parameterization lets us reuse definitions without extending HStriver itself.
Nested specifications allow spawning and executing monitors dynamically, collecting the result in each invocation and using it as a value in the caller monitor. Defining an inner specification involves giving it a name and adding an extra clause:
 where
where
 is a stream of any type and
is a stream of any type and
 is a
is a
 stream. The type of the stream
stream. The type of the stream
 determines the type of the value returned when the specification is invoked dynamically. Optionally, we can provide parameters when defining the nested specification, which are considered constants within the monitor. Once we have defined an inner specification
determines the type of the value returned when the specification is invoked dynamically. Optionally, we can provide parameters when defining the nested specification, which are considered constants within the monitor. Once we have defined an inner specification
 , we can execute it with the function
\( runSpec \), providing the necessary parameters and lists of values for the input streams, in the order in which they are defined in
, we can execute it with the function
\( runSpec \), providing the necessary parameters and lists of values for the input streams, in the order in which they are defined in
 . When an inner specification with a return clause
. When an inner specification with a return clause
 is executed, the computation will return the value of the stream
is executed, the computation will return the value of the stream
 at the first time
at the first time
 becomes
\( true \), or the last value of
becomes
\( true \), or the last value of
 if
if
 never holds in the execution. If
never holds in the execution. If
 did not produce a value when
did not produce a value when
 becomes
\( true \) the value of the execution is the special value -out .
becomes
\( true \) the value of the execution is the special value -out .
An inner specification is compiled by the frontend preprocessor to a special folder in the HStriver Haskell codebase so it is available for a caller monitor to import it as a module with the directive
 .
.
Using the rich expressive power of HStriver we can define a stream
 that contains the events of a stream
that contains the events of a stream
 in a window of length
in a window of length
 as shown in the following program:
as shown in the following program:

The output stream
 updates the list of events when an event of
updates the list of events when an event of
 is leaving the sliding window of events (i.e., when
is leaving the sliding window of events (i.e., when
 is producing a value). This definition also uses the
is producing a value). This definition also uses the
 operator to retrieve the future values of the stream
operator to retrieve the future values of the stream
 and incorporate them to the sliding window.
and incorporate them to the sliding window.
The following parametric auxiliary stream
 is offered by HStriver with the following signature
is offered by HStriver with the following signature

The stream returns the timestamped values of the stream
 within the interval
within the interval
 along with the last value of
along with the last value of
 before
before
 . We will usually use slices as input streams for inner specifications. The incorporation of nested specifications and slices as libraries in the language greatly simplifies some stream definitions when we let
. We will usually use slices as input streams for inner specifications. The incorporation of nested specifications and slices as libraries in the language greatly simplifies some stream definitions when we let
 be syntactic sugar to refer to slices.
be syntactic sugar to refer to slices.
2.6 How to run HStriver
To compile an HStriver specification or library we execute the hstriverc program–-which is shipped with the tool–-indicating a set of filenames, of which at most one can be a runnable specification, while the rest have to be library definitions or inner specifications. The result of successfully running hstriverc will be an executable monitor, with the name specified using the flag -o \( filename \), or a.out if no output filename was specified.
To run our monitor over input data, the program generated has to be executed with a parameter indicating the directory where the input data is located: monitor \( dir \). For every non-parameterized input stream s, the monitor will read its events from the file \( dir \)/s.json. For a parameterized input stream s with parameters \( arg_0 \ldots arg_n \), the monitor will read the events for the instantiated input streams from the files \( dir \)/ \( arg_0 \)/ \(\ldots \)/ \( arg_n \).json. The input events have to be of the form {"Time": \( ts \), "Value": \( val \)}, where \( val \) is the value of the stream at the instant \( ts \), and there has to be one event per line, with a monotonically increasing timestamp. The monitor will then produce a list of events with the form {"Id": \( id \), "Time": \( ts \), "Value": \( val \)}, where \( val \) is the value of the stream \( id \) at the instant \( ts \).
Note that the input files can be named pipes, which will be consumed when it is necessary to compute the next output event, following the pull algorithm explained in Sect. 2.5, effectively allowing the monitor to be run over data generated in real time. It is easy to write a wrapper that acts as a sink for different input events and dispatches every event to its corresponding named pipe, if necessary.
Consider the specification in Example 1, whose definition is in the file stock.hstriver, and suppose we want to execute with the input streams in the directory ins in the working directory. Then, we need to run:

There needs to be two input stream files in the directory ins: ins/sale.json and ins/arrival.json. The monitor will print the events of stock to the standard output progressively when the information is available in the input stream files.
To run the specification in Example 2, where paramstock.hstriver contains the definitions and the input streams are in the sub-directory paramins of the current directory, we need to run

and there need to be two directories in the directory ins: ins/sale and
ins/arrival, with three input files inside each of them, namely

The monitor will print an event whenever there is a shortage of any product. The tool webpage https://software.imdea.org/hstriver contains several example specifications along with input and output data.
3 Example specifications
In this section we show a selection of HStriver specifications, each of which illustrates a particular interesting feature of the language.
3.1 Example #1: clock
The following specification demonstrates the use of the
 operator to define a specification with no input streams and one output stream
operator to define a specification with no input streams and one output stream
 , which contains a unit value at each instant multiple of 5. ticks at instants where no input streams have an event.
, which contains a unit value at each instant multiple of 5. ticks at instants where no input streams have an event.

In this specific case, we could have used the
 operator instead with identical results. This example illustrates that HStriver is not only event-driven, and can generate ticks at instants where no input stream has an event. TeSSla [16] can also implement this feature but most other systems, like RTLola [33], can only tick at periodic instants or at points at which inputs have events.
operator instead with identical results. This example illustrates that HStriver is not only event-driven, and can generate ticks at instants where no input stream has an event. TeSSla [16] can also implement this feature but most other systems, like RTLola [33], can only tick at periodic instants or at points at which inputs have events.
3.2 Libraries
We can use HStriver to collect reusable code and stream transformers in libraries (that do not have output streams). Libraries are declared using the directive
 . Specifications can then import the definitions in the library. Some libraries are time domain agnostic and do not require the definition of a time domain. We leverage the module system of the host language to implement this feature. Many libraries contain definitions of stream declarations from stream declarations, which shows the high-order nature of HStriver. Here we show the implementation of the library
. Specifications can then import the definitions in the library. Some libraries are time domain agnostic and do not require the definition of a time domain. We leverage the module system of the host language to implement this feature. Many libraries contain definitions of stream declarations from stream declarations, which shows the high-order nature of HStriver. Here we show the implementation of the library
 , which contains useful stream operators that are used extensively in the rest of the examples.
, which contains useful stream operators that are used extensively in the rest of the examples.

The parametric stream
 applies a given function to every event in another stream. We use the stream
applies a given function to every event in another stream. We use the stream
 to only replicate the events that represent a change of the current value of a signal. Finally,
to only replicate the events that represent a change of the current value of a signal. Finally,
 is a utility to apply an offset to the timestamps of all the events in a stream.
is a utility to apply an offset to the timestamps of all the events in a stream.
We also show part of the implementation of the library
 which implements the operators of the signal temporal logic [39], a temporal logic widely used to describe system properties of continuous signals, which are represented as timestamped event streams.
which implements the operators of the signal temporal logic [39], a temporal logic widely used to describe system properties of continuous signals, which are represented as timestamped event streams.


The parameterized stream
 represents the application of a function to the values of an input stream. We define the auxiliary streams
represents the application of a function to the values of an input stream. We define the auxiliary streams
 and
and
 to filter only the True or False events of a stream, respectively.
to filter only the True or False events of a stream, respectively.
The
 operator is defined as follows. Given
operator is defined as follows. Given
 streams
streams
 and
and
 , and given the window offsets a and b, the property
\((x {\mathcal {U}}_{[a,b]} y)\) is True if there is a point
\(t'\) in the window
\([t+a,t+b]\) where y holds, and x holds continuously from t to
\(t'\). In particular, if y holds somewhere in the range
\([t+a,t]\), the property is True. The definition of
, and given the window offsets a and b, the property
\((x {\mathcal {U}}_{[a,b]} y)\) is True if there is a point
\(t'\) in the window
\([t+a,t+b]\) where y holds, and x holds continuously from t to
\(t'\). In particular, if y holds somewhere in the range
\([t+a,t]\), the property is True. The definition of
 finds the first time point at which
finds the first time point at which
 is True in the range
\([t+a, \infty )\) (which we call min_yT) and compare it with the first time point at which
is True in the range
\([t+a, \infty )\) (which we call min_yT) and compare it with the first time point at which
 is False in the range
\([t,\infty )\) (which we call min_xF). For the property to be true, two things must happen:
is False in the range
\([t,\infty )\) (which we call min_xF). For the property to be true, two things must happen:
-
that min_yT \(\le t+b\) (i.e., that
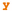 be True somewhere in the window
\([t+a,t+b]\)), and
be True somewhere in the window
\([t+a,t+b]\)), and -
that min_yT < min_xF (i.e., that
 be True before the first time
be True before the first time
 is False after t)
is False after t)
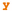 be True somewhere in the window
be True somewhere in the window
 be True before the first time
be True before the first time
 is False after t)
is False after t)The expression min_yT contains the earliest time at which
 becomes True after
becomes True after
 \(+a\) (considering the possibility of (
\(+a\) (considering the possibility of (
 \(+a\)) itself if
\(+a\)) itself if
 is already True at that point). Similarly,
is already True at that point). Similarly,
 contains the earliest time at which
contains the earliest time at which
 becomes False (considering the possibility of
becomes False (considering the possibility of
 itself if
itself if
 is already False). With these auxiliary definitions, the value expression of
is already False). With these auxiliary definitions, the value expression of
 simply checks that
simply checks that
 becomes True within [a, b] and that
becomes True within [a, b] and that
 is True from
is True from
 up-to that point.
up-to that point.
The tick expression of the stream indicates the times at which its value can change, namely when a
 event enters or leaves the sliding window defined by
\([t+a, t+b]\), or when a
event enters or leaves the sliding window defined by
\([t+a, t+b]\), or when a
 event enters or leaves the sliding window defined by
\([t, t+b]\).
event enters or leaves the sliding window defined by
\([t, t+b]\).
3.3 Example #2: STL
The next example illustrates a simple STL specification: “if the input becomes
becomes , then
, then will decelerate continuously until reaching an admissible speed (
will decelerate continuously until reaching an admissible speed (
 ) within 10 time units (represented by the stream
) within 10 time units (represented by the stream ).”
).”
We say that the vehicle is moving too fast if its speed is greater than 3, and we define a safe speed as a speed under 1. We can write this property in STL as follows:

We translate this property into HStriver using the following specification. As opposed to the original STL property, our specification does not assume the existence of a Boolean input signal
 that indicates whether the vehicle is decelerating. Instead, it uses the unique input signal
that indicates whether the vehicle is decelerating. Instead, it uses the unique input signal
 to calculate if the vehicle is decelerating, comparing its value every time the signal changes with its next reported value.
to calculate if the vehicle is decelerating, comparing its value every time the signal changes with its next reported value.

This example shows a straightforward use of the STL library to define temporal properties as streams.
3.4 RobustSTL
In [40] the authors propose a quantitative semantics of the Signal Temporal Logic, which they call Robust STL. The robustness of a formula \(\varphi \) relative to a trace w and a time t, denoted by \(\rho (\varphi , w, t)\), is defined as follows:
We use the extensions in HStriver to define these quantitative semantics of STL. The translation of the operators \(\mu \), \(\lnot \) and \(\wedge \) are straightforward – they consist of the application of a function to one or two streams. We show here the definition of \(\varphi \mathbin {\mathcal {U}}_{[a,b]}\psi \).

For the implementation of
\(\varphi \mathbin {\mathcal {U}}_{[a,b]}\psi \) we define two slices: the slice of the events of
 in
in
 in line
in line
 and the slice of the events of
and the slice of the events of
 in
in
 , in line
, in line
 . Whenever an event enters or leaves any of the slices, we need to recompute the value of the stream, which is why we use the aforementioned slices phis and psis as the ticking points of
. Whenever an event enters or leaves any of the slices, we need to recompute the value of the stream, which is why we use the aforementioned slices phis and psis as the ticking points of
 . Since we interpret the events of a stream as its change points, we use the value of the last event in the past of the slices, which is provided as the first element in the tuple of a slice, to access the value of the signal at the beginning of the sliding window. We override the time of the first event of phis with the current time (
. Since we interpret the events of a stream as its change points, we use the value of the last event in the past of the slices, which is provided as the first element in the tuple of a slice, to access the value of the signal at the beginning of the sliding window. We override the time of the first event of phis with the current time (
 ) in line
) in line
 and the first event of psis with
and the first event of psis with
 in line
in line
 . The helper function stampFst is defined in the last two lines, namely
. The helper function stampFst is defined in the last two lines, namely
 and
and
 , and simply stamps the previous value of the slice (if it exists) and prepends it to the list of events in the sliding window. Finally, we execute the nested specification
, and simply stamps the previous value of the slice (if it exists) and prepends it to the list of events in the sliding window. Finally, we execute the nested specification
 with the resulting slices.
with the resulting slices.
The nested specification
 is defined as follows:
is defined as follows:

The input streams
 and
and
 contain the successive changepoints of the original
contain the successive changepoints of the original
 and
and
 within a sliding window. We first define in lines
within a sliding window. We first define in lines
 to
to
 a
a
 stream called
stream called
 that is always False, which we will use to return the value of the last event of
that is always False, which we will use to return the value of the last event of
 via the return statement in line
via the return statement in line
 . Note that the return clause would be equivalent if we define the value expression of
. Note that the return clause would be equivalent if we define the value expression of
 as
as
 instead of False.
instead of False.
The intermediate stream
 defined in lines
defined in lines
 to
to
 maintains the successive historical minimums of
maintains the successive historical minimums of
 within the slice, and the intermediate stream
within the slice, and the intermediate stream
 defined in lines
defined in lines
 to
to
 computes the minimum between the current value of
computes the minimum between the current value of
 and the current historical minimum of
and the current historical minimum of
 .
.
Finally,
 in lines
in lines
 to
to
 keeps the maximum value that was ever taken by
keeps the maximum value that was ever taken by
 . The last value of
. The last value of
 is returned as the result of the computation.
is returned as the result of the computation.
3.5 Example #3 : cost computation
The following example calculates the accumulated energy cost incurred by a monitor, based on a cost model for
-
(a)
waking up the monitor,
-
(b)
processing an event,
-
(c)
going to sleep,
-
(d)
being idle,
-
(e)
being awake,
which are encoded in the return values of the functions
 of type
of type
 and
and
 , of type
, of type
 . The cost calculation also depends on how long does the monitor wait for a new event before going to sleep, represented by the constant
\( patience \). This specification contains the definition of an output stream
. The cost calculation also depends on how long does the monitor wait for a new event before going to sleep, represented by the constant
\( patience \). This specification contains the definition of an output stream
 which is the quantitative result of a progressive computation, as opposed to typical Boolean output streams. In this example the event production is unpredictable and not governed by a predefined ratio. This example uses custom datatype definitions, and event generation at instants where there is no input event.
which is the quantitative result of a progressive computation, as opposed to typical Boolean output streams. In this example the event production is unpredictable and not governed by a predefined ratio. This example uses custom datatype definitions, and event generation at instants where there is no input event.

The stream
 produces the value
produces the value
 every time there is a new event, and it is used to delay the value of
every time there is a new event, and it is used to delay the value of
 by exactly
by exactly
 time units. Since
time units. Since
 is a constant in our specification, we could have used the stream
is a constant in our specification, we could have used the stream
 from
from
 to achieve the same result.
to achieve the same result.
The stream
 indicates if the system is Alert or Sleeping. When a new event is received, the system is Alert, and if the patience after the last event is consumed, then the system goes to sleep.
indicates if the system is Alert or Sleeping. When a new event is received, the system is Alert, and if the patience after the last event is consumed, then the system goes to sleep.
Finally,
 produces an event every time the
produces an event every time the
 (potentially) changes, with the cost of transitioning from the previous state to the current one, plus the accumulated cost of having been in the previous state until now.
(potentially) changes, with the cost of transitioning from the previous state to the current one, plus the accumulated cost of having been in the previous state until now.
3.6 Example #4: powerTrain
Our fourth example makes a heavy use of the STL library to implement STL properties for the verification of a powertrain control verification from [41], where input signals change asynchronously.

As in [41] we use input data computed from a MatLab simulation of the powertrain. This example shows how to import and use the STL operators to describe properties. We have refrained from using let and where clauses to maintain the syntax of the original properties, which are commented in MatLab above each definition.
3.7 Example #5: smart home
This example models a smart home specification that uses the Orange4Home data-set [42]. The following monitor calculates how much time residents spend watching TV per day, assessing that every day the people living the house should not watch more than three hours of TV (
 ).
).


More interesting is
 , which states that residents should not watch thirty minutes more than the total average of TV watched historically. This threshold is dynamic, and requires declaring intermediate quantitative streams that compute the average and current day TV time.
, which states that residents should not watch thirty minutes more than the total average of TV watched historically. This threshold is dynamic, and requires declaring intermediate quantitative streams that compute the average and current day TV time.
4 Empirical evaluation
In this section, we report on an empirical evaluation of HStriver. This empirical evaluation is not aimed at comparing the performance of HStriver with similar tools, but it intends to demonstrate that the memory efficiency of HStriver is consistent with the theoretical analysis/prediction; and its memory footprint makes it good enough to be used in real life scenarios. We believe that the best choice of a tool is not exclusively based on its performance, but that expressivity and usability are more decisive, considering similar memory usages. All the experiments were executed on a MacBook Pro with MacOS Catalina Version 10.15.4, with an Intel Core i5 at 2.5 GHz and 8 GB of RAM.

Empirical evaluation of hypotheses (H1), (H2), and (H3)
We evaluate empirically the following hypotheses:
-
(H1) The memory consumed is constant throughout an execution if we restrict the specification to use only past references, that is, where the memory required is trace length independent.
-
(H2) The resources necessary to monitor a specification grows with respect to its number of streams.
-
(H3) The resources necessary to monitor a specification grows with respect to the events it needs to keep in memory.
-
(H4) The memory consumed is constant throughout the execution of an STL property with the efficient version of the \(\mathcal {U}\) operator.
-
(H5) The resources necessary to monitor an STL specification grows similarly with respect to variations in the interval size and with respect to variations in the event density.
-
(H6) The version of the \(\mathcal {U}\) operator that uses bounded future accesses, is more efficient and memory-wise stable than the version of the operator that uses unbounded future accesses.
We run experiments to measure the memory usage and assess hypotheses (H1), (H2), and (H3) for two collections of specifications:
-
Stocks. The first collection generalizes Example 2 computing the stocks of
 independent products, similar to Example 3, but without the alarms. These specifications contain a number of streams proportional to
independent products, similar to Example 3, but without the alarms. These specifications contain a number of streams proportional to
 , where each defining equation is of the same size.
, where each defining equation is of the same size.

-
Average. The second collection computes the average of the last
 sales of a fixed product, via streams that tick at the selling instants and compute the sum of the last
sales of a fixed product, via streams that tick at the selling instants and compute the sum of the last
 sales. The resulting specifications have depth proportional to
sales. The resulting specifications have depth proportional to
 .
.

 independent products, similar to Example
independent products, similar to Example  , where each defining equation is of the same size.
, where each defining equation is of the same size.

 sales of a fixed product, via streams that tick at the selling instants and compute the sum of the last
sales of a fixed product, via streams that tick at the selling instants and compute the sum of the last
 sales. The resulting specifications have depth proportional to
sales. The resulting specifications have depth proportional to
 .
.

We instantiate
 for values between 10 and 500 and run each resulting specification with a set of automatically generated random input traces.
for values between 10 and 500 and run each resulting specification with a set of automatically generated random input traces.
For this experiment we ran the synthesized monitors over long traces, and we measured the memory consumption. The results shown in Fig. 4a illustrate that the memory needed to monitor each specification is independent of the length of the trace, since the curves are roughly constant throughout the entire executions, validating (H1). The bars in Fig. 4b indicate that the memory needed to monitor both specifications increases with the parameter
 , with stock increasing more rapidly than average, valdating (H2) and (H3). The reason for this is that the number of streams in the stock specification gets higher when
, with stock increasing more rapidly than average, valdating (H2) and (H3). The reason for this is that the number of streams in the stock specification gets higher when
 gets larger and also has to keep in memory more events (the last event of every stream); while the average specification also has to remember a higher number of events when
gets larger and also has to keep in memory more events (the last event of every stream); while the average specification also has to remember a higher number of events when
 gets larger, but the number of streams in the specification remains constant (even though the stream definition of
gets larger, but the number of streams in the specification remains constant (even though the stream definition of
 gets larger, this introduces negligible overhead compared to the overhead of the number of streams that affects the stock specification).
gets larger, this introduces negligible overhead compared to the overhead of the number of streams that affects the stock specification).

Empirical evaluation of hypotheses (H4), (H5), and (H6)
We have designed a set of experiments to assess the validity of the hypotheses (H4), (H5), and (H6), for which we consider the following STL specification from Section 3.3:

In the first set of experiments, we vary the size of the interval for the
\(\mathcal {U}\) operator adding a parameter
 to the stream
to the stream
 to analyse how it affects the performance of the engine:
to analyse how it affects the performance of the engine:

We also vary the amount of events per second in the input stream, which we call the density of the signal, to assess its impact on performance. The input data for the experiments are generated programatically.
Figure 5a shows the memory consumption of the monitor of the specification with diverse interval sizes and event density, which in all cases remains constant throughout the execution, albeit with different constants, validating (H4).
Figure 5b shows the maximum memory consumed by the monitor of the specification with increasing event density and constant interval size (represented by the blue bars) and increasing interval sizes and constant event density (represented by the red bars), illustrating that the amount of memory necessary to monitor this specification increases with the number of events that fit in an interval, either because the interval is larger, or because there are more events per second, which validates (H5).
Figure 5c shows the input signal
 at the top, and underneath, the regions where
\(\varphi \) holds (in green) or not (in red).
at the top, and underneath, the regions where
\(\varphi \) holds (in green) or not (in red).
The definition of the parametric
 stream in the library
stream in the library
 uses the
uses the
 operator, which ensures that the memory consumption is bounded by the interval size and the event density. If we use the implementation of
operator, which ensures that the memory consumption is bounded by the interval size and the event density. If we use the implementation of
 with unbounded future operators, then the memory requirement depends on the behavior of the input signal and is no longer solely determined by the interval size and input event density.
with unbounded future operators, then the memory requirement depends on the behavior of the input signal and is no longer solely determined by the interval size and input event density.
We have run the specification over the input data shown at the bottom of Fig. 5(d) using the efficient (bounded) and inefficient (unbounded) version of
 , and we have measured their memory usage, which can be seen in the plot at the top of Fig. 5(d). The black curve represents the memory consumption of the efficient implementation of the
\(\mathcal {U}\) operator, and the red curve represents the memory consumption of the inefficient implementation of the operator. In the specification with unbounded future accesses, the
\(\mathcal {U}\) expression needs to retrieve the next instant at which the vehicle decelerates and also the next instant at which its speed is safe. If one of these instants is far in the future, the monitor needs to consume and store all the input up to that point. This causes a rapid increase in the memory consumption, which is now visible in the shape of the input signal and unknown beforehand. Once the relevant instants are found, the input signal is consumed up to that point, which causes a rapid decrease in memory consumption. As a result of this, we observe that memory usage presents peaks during the execution, in concordance with the behavior of the input signal. By the end of the execution, the input signal
, and we have measured their memory usage, which can be seen in the plot at the top of Fig. 5(d). The black curve represents the memory consumption of the efficient implementation of the
\(\mathcal {U}\) operator, and the red curve represents the memory consumption of the inefficient implementation of the operator. In the specification with unbounded future accesses, the
\(\mathcal {U}\) expression needs to retrieve the next instant at which the vehicle decelerates and also the next instant at which its speed is safe. If one of these instants is far in the future, the monitor needs to consume and store all the input up to that point. This causes a rapid increase in the memory consumption, which is now visible in the shape of the input signal and unknown beforehand. Once the relevant instants are found, the input signal is consumed up to that point, which causes a rapid decrease in memory consumption. As a result of this, we observe that memory usage presents peaks during the execution, in concordance with the behavior of the input signal. By the end of the execution, the input signal
 accelerates continuously, making the engine consume and store the input indefinitely, until it reaches the maximum memory allowed, which was set at 1 GB, without computing a value for the output stream
accelerates continuously, making the engine consume and store the input indefinitely, until it reaches the maximum memory allowed, which was set at 1 GB, without computing a value for the output stream
 , even though that much memory is not necessary for the computation, as demonstrated by the memory consumption of the efficient implementation of
\(\mathcal {U}\), in black. This experiment validates (H6).
, even though that much memory is not necessary for the computation, as demonstrated by the memory consumption of the efficient implementation of
\(\mathcal {U}\), in black. This experiment validates (H6).
5 Conclusion
We have a presented HStriver, a stream runtime verification tool for real-time event-streams, implemented as an eDSL with Haskell as the host language, based on a technique called lift-deep embedding. One drawback of our approach is that the Haskell runtime system uses garbage collection, which is usually forbidden for critical applications. However, HStriver has been used in (non-critical) UAV missions, and we are exploring the generation of Misra-C code from (a restricted set of) HStriver specifications.
Another undesired byproduct of having developed HStriver as an eDSL is that we do not have full control over the syntax and we have to adapt it to that of Haskell. This also means that errors are reported by the Haskell compiler and are usually cryptic and hard to follow. Future work includes the development of a frontend that allows adapting the input syntax to particular use cases, offering a friendly syntax and the necessary types and features from HStriver, while also giving us complete control over error reports.
An alternative way of defining the semantics of the underlying language HStriver is by searching for a fixpoint using small-step semantics. Future work includes defining the semantics of HStriver following this alternative approach and analyse how this definition impacts on the design, development and assessment of the tool HStriver.
Notes
An earlier short version of this paper appeared in [21].
References
Havelund K, Goldberg A (2005) Verify your runs. In: Proceedings of verified software: theories, tools, and experiments (VSTTE’05), LNCS, vol 4171. Springer, Heidelberg, pp 374–383
Leucker M, Schallhart C (2009) A brief account of runtime verification. J Log Algebr Program 78(5):293–303
Bartocci E, Falcone Y (eds) (2018) Lectures on runtime verification—introductory and advanced topics. LNCS, vol 10457. Springer, Cham
Manna Z, Pnueli A (1995) Temporal verification of reactive systems. Springer, New York
Bauer A, Leucker M, Schallhart C (2011) Runtime verification for LTL and TLTL. ACM Trans Softw Eng Methodol 20(4):14
Eisner C, Fisman D, Havlicek J, Lustig Y, McIsaac A, Campenhout DV (2003) Reasoning with temporal logic on truncated paths. In: Proceedings of the 15th international conference on computer aided verification (CAV’03). LNCS, vol 2725. Springer, Heidelberg, pp 27–39
Havelund K, Roşu G (2002) Synthesizing monitors for safety properties. In: Proceedings of the 8th international conference on tools and algorithms for the construction and analysis of systems (TACAS’02). LNCS, vol 2280. Springer, Heidelberg, pp 342–356
Sen K, Roşu G (2003) Generating optimal monitors for extended regular expressions. In: Electronic notes in theoretical computer science, vol 89. Elsevier, Amsterdam
Roşu G, Havelund K (2005) Rewriting-based techniques for runtime verification. Automat Softw Eng 12(2):151–197
Barringer H, Goldberg A, Havelund K, Sen K (2004) Rule-based runtime verification. In: Proceedings of the 5th international conference on verification, model checking and abstract interpretation (VMCAI’04). LNCS, vol 2937. Springer, Heidelberg, pp 44–57
Barringer H, Rydeheard D, Havelund K (2007) Rule systems for run-time monitoring: from Eagle to RuleR. In: Proceedings of the 7th international workshop on runtime verification (RV’07). LNCS, vol 4839. Springer, Heidelberg, pp 111–125
D’Angelo B, Sankaranarayanan S, Sánchez C, Robinson W, Finkbeiner B, Sipma HB, Mehrotra S, Manna Z (2005) LOLA: runtime monitoring of synchronous systems. In: Proceedings of the 12th international symposium of temporal representation and reasoning (TIME’05). IEEE CS Press, Washington DC, pp 166–174
Sánchez C (2018) Online and offline stream runtime verification of synchronous systems. In: Proceedings of the 18th international conference on runtime verification (RV’18). LNCS, vol 11237. Springer, Cham, pp 138–163
Berry G (2000) The foundations of Esterel. Proof, language, and interaction: essays in honour of Robin Milner. MIT Press, Cambridge, MA, pp 425–454
Halbwachs N, Caspi P, Pilaud D, Plaice JA (1987) Lustre: a declarative language for programming synchronous systems. In: Proceedings of the 14th ACM symposium on principles of programming languages (POPL’87). ACM Press, New York, NY, pp 178–188
Convent L, Hungerecker S, Leucker M, Scheffel T, Schmitz M, Thoma D (2018) TeSSLa: temporal stream-based specification language. In: Proceedings of the 21st. Brazilian symposium on formal methods (SBMF’18). LNCS, vol 11254. Springer, Cham
Leucker M, Sánchez C, Scheffel T, Schmitz M, Schramm A (2018) TeSSLa: runtime verification of non-synchronized real-time streams. In: Proceedings of the 33rd symposium on applied computing (SAC’18). ACM Press, New York, NY
Gorostiaga F, Sánchez C (2018) Striver: stream runtime verification for real-time event-streams. In: Proceedings of the 18th international conference on runtime verification (RV’18). LNCS, vol 11237. Springer, Cham, pp 282–298
Faymonville P, Finkbeiner B, Schledjewski M, Schwenger M, Stenger M, Tentrup L, Hazem T (2019) StreamLAB: stream-based monitoring of cyber-physical systems. In: Proceeings of the 31st international conference on computer-aided verification (CAV’19). LNCS, vol 11561. Springer, Cham, pp 421–431
Gorostiaga F, Sánchez C (2021) Stream runtime verification of real-time event-streams with the Striver language. Int J Softw Tools Technol Transf 23:157–183
Gorostiaga F, Sánchez C (2021) HStriver: a very functional extensible tool for the runtime verification of real-time event streams. In: Proceedings of the 24th international symposium on formal methods (FM’21). LNCS, vol 13047. Springer, Cham, pp. 563–580. https://doi.org/10.1007/978-3-030-90870-6_30
Havelund K (2015) Rule-based runtime verification revisited. Int J Softw Tools Technol Transf 17(2):143–170
Barringer H, Havelund K (2011) TraceContract: a scala DSL for trace analysis. In: Proceedings of the 17th international symposium on formal methods (FM’11). LNCS, vol 6664. Springer, Heidelberg, pp. 57–72
Stolz V, Huch F (2005) Runtime verification of concurrent Haskell programs. Electronic notes on theoretical computer science, vol 113. Elsevier, Amsterdam, pp 201–216
Ceresa M, Gorostiaga F, Sánchez C (2020) Declarative stream runtime verification (hLola). In: Proc. of the 18th Asian Symposium on Programming Languages and Systems (APLAS’20). LNCS, vol 12470. Springer, Cham, pp 25–43
Falcone Y, Krstic S, Reger G, Traytel D (2018) A taxonomy for classifying runtime verification tools. In: Proceedings of the 18th international conference on runtime verification (RV’18). LNCS, vol 11237. Springer, Cham, pp 241–262
Reinbacher T, Rozier KY, Schumann J (2014) Temporal-logic based runtime observer pairs for system health management of real-time systems. In: Proceedings 20th International Confer on Tools and Algorithms for the Construction and Analysis of Systems (TACAS’14). LNCS, vol 8413. Springer, Heidelberg, pp 357–372
Hallé S (2016) When RV meets CEP. In: Proceedings of the 16th international conference on runtime verification (RV’16). LNCS, vol 10012. Springer, Cham, pp 68–91
Hallé S, Khoury R (2017) Event stream processing with BeepBeep 3. In: Proceedings of the international workshop on competitions, usability, benchmarks, evaluation, and standardisation for runtime verification tools (RV-CUBES). Kalpa Publications in Computing. EasyChair, pp 81–88
Basin D, Harva M, Klaedtke F, Zalinescu E (2011) MONPOLY: monitoring usage-control policies. In: Proceedings of the 2nd international conference on runtime verification (RV’11). LNCS, vol 7186. Springer, Heidelberg, pp 360–364
Basin DA, Klaedtke F, Zalinescu E (2017) The MonPoly monitoring tool. In: Proceedings of the international workshop on competitions, usability, benchmarks, evaluation, and standardisation for runtime verification tools (RV-CUBES). Kalpa Publications in Computing. EasyChair, pp 19–28
Pike L, Goodloe A, Morisset R, Niller S (2010) Copilot: a hard real-time runtime monitor. In: Proceedings of the 1st international conference on runtime verification (RV’10). LNCS, vol 6418. Springer, Heidelberg, pp 345–359
Faymonville P, Finkbeiner B, Schwenger M, Torfah H(2017) Real-time stream-based monitoring. CoRR arXiv:1711.03829
Aguado J, Mendler M, Pouzet M, Roop P, von Hanxleden R (2018) Deterministic concurrency: a clock-synchronised shared memory approach. In: Ahmed A (ed) Programming languages and systems. Springer, Cham, pp 86–113
Talpin J-P, Brandt J, Gemünde M, Schneider K, Shukla S (2013) Constructive polychronous systems. In: Artemov S, Nerode A (eds) Logical foundations of computer science. Springer, Berlin, Heidelberg, pp 335–349
Marlow S (2010) Haskell language report
Gorostiaga F, Sánchez C (2021) Nested monitors: monitors as expressions to build monitors. In: Proceedings of the 21st international conference on runtime verification (RV’21). LNCS, vol 12974. Springer, Heidelberg, pp 164–183
Gorostiaga F (2022) Theory and practice of stream runtime verification for sequences and real-time event based systems. https://oa.upm.es/70504/
Maler O, Nickovic D (2004) Monitoring temporal properties of continuous signals. In: Proceedings of the joint international conference on formal techniques, modelling and analysis of timed and fault-tolerant systems, and formal modelling and analysis of timed systems (FORMATS/FTRTFT 2004). LNCS, vol 3253. Springer, Heidelberg, pp 152–166
Donzé A, Ferrère T, Maler O (2013) Efficient robust monitoring for STL. In: Proceedings of the 25th international conference on computer aided verification (CAV’13). LNCS, vol 8044. Springer, Heidelberg, pp 264–279
Jin X, Deshmukh JV, Kapinski J, Ueda K, Butts K (2014) Powertrain control verification benchmark. In: Proceedings of the 17th international conference on hybrid systems: computation and control (HSCC’14). ACM, New York, pp 253–262
Cumin J, Lefebvre G, Ramparany F, Crowley J (2017) A dataset of routine daily activities in an instrumented home. In: Proceedings of the 11th international conference on ubiquitous computing and ambient intelligence (UCAmI’17). LNCS, vol 10586. Springer, Cham, pp 413–425
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was funded in part by the Madrid Regional Government under project “S2018/TCS-4339 (BLOQUES-CM)”, by Spanish National Project “BOSCO (PGC2018-102210-B-100)”, and by FPU Grant FPU18/04362 granted by the Spanish Ministry of Science, Innovation and Universities.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Gorostiaga, F., Sánchez, C. Runtime verification of real-time event streams using the tool HStriver. Form Methods Syst Des 61, 3–34 (2022). https://doi.org/10.1007/s10703-023-00428-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10703-023-00428-9