
Abstract
Efficient energy conservation to maximize the network lifetime is always the most critical challenge in wireless sensor networks due to their energy-constrained nodes and harsh working environments. Clustering routing is considered the most popular method to lessen energy utilization at present. In this paper, a fuzzy logic and particle swarm optimization-based clustering routing protocol called PFCRE is proposed to improve energy efficiency, mitigate the energy holes and enhance the network lifetime as well. The proposed PFCRE considers energy minimum and balance to form clusters by using an improved particle swarm optimization algorithm. Moreover, a fuzzy inference system is employed to find the optimal route for each CH, which considers effective parameters including residual energy, distance to base station and number of being selected as relay so as to not only minimize energy consumption but also balance traffic load. Especially, the rules of the fuzzy inference system are tuned by another particle swarm optimization algorithm. Furthermore, an adaptive maintenance mechanism is used to organize the clusters instead of periodic clustering to further diminish computation and message overheads. The performance of PFCRE is evaluated by extensive experiments, and the results indicate that it outperforms IBRE-LEACH, EAUCA, DAPFL, IPSOGWO along with FMSFLA in terms of network lifetime, throughput, energy consumption, and standard deviation of CH’s traffic load.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Wireless sensor networks (WSNs) are composed of massive tiny, inexpensive sensor nodes equipped with limited process, storage, and energy resources, which are arranged in hostile or inaccessible environments in most cases. Hence, replacing or recharging the power supplies of the sensor nodes is usually impossible. Then, energy preservation of sensor nodes becomes the most important challenge for WSNs. Clustering routing has been verified as one of the most effective ways for this purpose [1, 2]. In clustering and routing approaches, the randomly deployed nodes are formed into groups called clusters. And a cluster head (CH) is selected to perform tasks such as data collection, aggregation, forwarding and cluster management in each cluster. Non-CH nodes join appropriate clusters as cluster members (CMs), who transmit sensed data to the assigned CHs. Accordingly, the clusters are formed, followed by a route finding from a source CH to the base station (BS) to transfer data efficiently in single or multiple hop communication mode. Compared with forwarding data directly to the BS in single-hop mode, routing in multi-hop mode offers advantages such as low energy consumption, low collision and attenuation loses, high scalability, while clustering has advantages including bandwidths and overhead reduction, redundant message prevention, collision avoidance, and implement ability of administrative strategies [3, 4]. Hence, with the support of clustering routing, WSNs have been widely used in industry, agriculture, military, aerospace and other fields [4, 5]. In turn, the plentiful applications have promoted the in-depth study of clustering and routing techniques.
Low energy adaptive clustering hierarchy (LEACH) is the pioneer clustering and routing protocol, in which CHs’ choice is achieved by probability-based scheme, and non-CH nodes as CMs find their nearest CHs to form clusters [6]. Every CM sends the sensed data to its CH based on the TDMA schedule, and the CH forwards aggregated data to the BS directly. Due to several drawbacks of LEACH such as predetermined number of CHs, probability-based selection of CHs, CM joining the nearest cluster, single-hop data forwarding between CH and BS, and period cluster maintenance in round, therefore, a large number of methods have been proposed to improve the whole network performance from one or more above mentioned aspects [3]. Generally, the optimal number of CHs can be determined by geometric computing [7], and intelligent computing such as harmony search [8], instead of preset in LEACH. Also, the optimal CHs selection can be achieved by improved threshold function definition with more parameters than LEACH [9], deterministic weight value [10], and intelligent computing such as fuzzy logic [11], particle swarm optimization (PSO) [12], genetic algorithm (GA) [13], chicken swarm optimization [14], and honey badger algorithm [15]. Similarly, CMs joining clusters to form proper clusters can be reached by considering other factors than only distance to CH in LEACH [10], intelligent computing such as fuzzy logic [11], chaotic genetic algorithm [16]. Moreover, multi-hop rather than single hop is utilized to route data to the BS by deterministic weight value [7], intelligent computing such as Grey wolf optimization [12], chaotic genetic algorithm [16], African vulture optimization [15], and grasshopper optimization algorithm [17]. Finally, variable round [18] and on-demand re-clustering [19] are usually used for better cluster maintenance. Without doubt, all these methods can enhance the network performance to a certain extend to prolong the network lifetime. However, little attention is paid on hot spot issue.
Data transmission with multi-hop communication in clustering and routing protocols makes the nodes near to the BS have more data traffic load as compared to those distant nodes, in other words, these nodes consume energy faster than the further ones because of their additional data forwarding, which causes energy holes or hot spot regions near the BS [4]. Unequal clustering is the widely used scheme to resolve the hot spot problem by forming different size of clusters according to the competitive radius, the closer to the BS, the smaller the formed cluster. Usually, the competitive radius in unequal clustering can be determined by deterministic weight value considering different parameters such as residual energy and distance [20] or intelligent computing such as fuzzy logic [21]. In addition, energy balance among CHs based approaches also can be used to mitigate the hot spot problem by intelligent computing such as fuzzy logic [22] and genetic algorithm [1]. Finally, BS mobility-based methods also can diminish the hot spot hot problem [23]. However, the hard decision on cluster size and energy balance without considering the whole network situation make it hard to cope with the hot spot problem thoroughly. Moreover, the constraint of optimal path planning and additional delay by using mobile BS also make it difficult to be used in practical real time applications. From the above mentioned content, few clustering and routing literature has been proposed to boost the overall performance of the network from six aspects including determination of cluster number, CH selection, CM joining cluster, route finding, and cluster maintenance, as well as hot spot mitigation.
Faced with intricate optimization challenges, the selection of an appropriate metaheuristic algorithm becomes imperative. In this investigation, the Particle Swarm Optimization algorithm is chosen for its notable efficacy in addressing optimization challenges within high-dimensional search spaces. Firstly, PSO is renowned for its simplicity and efficiency, facilitating ease of implementation and adjustment, which extends to solving intricate problems. Secondly, PSO excels in addressing both continuous and discrete problems, offering a versatile solution to the diversity challenges inherent in our study. Additionally, in opting for the fuzzy logic system, the decision was made to embrace the Mamdani model, grounded in a comprehensive evaluation of our research problem's nature and the attributes of the Mamdani model. The Mamdani model boasts a robust theoretical foundation rooted in fuzzy set theory, contributing to its exceptional performance in managing fuzzy information and uncertainty. Its versatility renders it applicable to various problem types, thereby presenting an extensive array of application possibilities for our research. Simultaneously, the Mamdani model furnishes a rule-based representation aligning with the expert knowledge present in our system. This representation enables us to articulate intricate relationships and decision-making processes in a structured manner, thereby augmenting the transparency and interpretability of the model.
1.1 Contributions
In this paper, a PSO and fuzzy logic-based clustering and routing protocol called PFCRE is proposed to enhance the energy efficiency, mitigate the hot spot problem and enhance the network lifetime. Different from other wireless sensor network clustering routing protocols. In PFCRE, energy-efficient clusters are established through the implementation of a lightweight Particle Swarm Optimization algorithm, concurrently addressing cluster number determination, Cluster Head selection, and Cluster Member integration. Additionally, a fuzzy inference system is incorporated to identify energy-efficient routes for CHs while excluding hotspots, guided by rules fine-tuned through another PSO algorithm. This secondary PSO algorithm integrates a fitness function that takes into account both energy efficiency and load balance considerations. Furthermore, an adaptive maintenance mechanism is employed to dynamically reorganize clusters, thereby contributing to a more substantial reduction in energy consumption. The major contributions of the proposed protocol include:
-
A clustering and routing protocol is introduced to establish optimal clusters and determine optimal routes using Particle Swarm Optimization and a fuzzy inference system, respectively;
-
The parameters of the fuzzy inference system are adjusted using PSO, incorporating a fitness function that simultaneously accounts for energy efficiency and load balance;
-
An adaptive mechanism is employed to manage clusters and routes, replacing periodicity to reduce computational and message overheads at both local and global levels.
The rest of this paper is organized as follows. The latest clustering and routing protocols considering hot spot mitigation are reviewed in Sect. 2. The system model are given in Sect. 3. The detail introduction of the proposed protocol is addressed in Sect. 4. The performance comparison is provided in Sect. 5 in detail. Finally, Conclusions are drawed and future directions are showed clearly in Sect. 6.
2 Related works
Inspired by the advantages of LEACH, lots of clustering and routing protocols have been proposed to boost the network lifetime, scalability and stability. In IBRE-LEACH [24], residual energy is considered as an additional factor for CH selection compared to LEACH so as to exclude the node with low energy becoming CH. When forming clusters, a threshold is defined to restrict the number of cluster member. Once this happens, the node cannot join its nearest cluster. In the worst case, a node becomes abandoned node (AN) if it cannot join any cluster. Moreover, a node with highest residual energy and lowest distance to the BS is selected as the root to minimize the overload on the BS and reduce energy dissipation. Afterwards, each CH and AN generate a routing table in which contains distances to other CHs, ANs, the root, and the BS in small to large. The one with smaller distance to the BS than itself is selected as its next hop. Simulation results validates its good performance in terms of stability, network lifetime, throughput, and energy consumption. However, only distance considered during the process of route finding maybe result in premature death of the relays with low remaining energy. In addition, the number of clusters determined by a preset proportion of nodes is easy to cause unbalanced energy consumption. Hence, in EOCGS [25], the optimal number of clusters is calculated firstly by considering the minimum energy consumption of the network. Then, nodes with more residual energy and closer centroid distance are selected as CHs. CMs join their nearest CH respectively like in LEACH. And if the total number of clusters is less than the calculated optimal number, the CHs send their aggregated data to the BS directly. Otherwise, a certain percentage of CHs are selected as grid head (GH) based on a fitness function considering CH’s residual energy, BS’s location, cluster’s centroid, and relative Euclidean distance of CHs for high energy efficiency. The higher the fitness function value, the greater the chance of CH becoming GH. The CHs send their fused data to their respective nearest GH, and each GH sends its data to the BS in single-hop or multi-hop mode based on its distance to the BS. EOCGS can provide better coverage, enhance network energy efficiency, as well as improve network stability. However, fixed round time maybe deplete the CH energy and lose more data. Therefore, in EM-LEACH [26], a variable round time is calculated to save energy dissipation of the whole network. Moreover, level-based topology is used to simplify the clusters formation and route finding, in which a node is located by analyzing the level setup package it receives. For CH selection, the residual energy is considered as a parameter in the threshold function, then the more residual energy, the greater the probability that a node becomes CH. Once the CHs are selected, each normal node joins the cluster with its closest CH in the same or adjacent level, otherwise, it aggregates data and forwards it directly to the BS if no CH around. At the same time, each CH aggregates the received data from its CMs and sends it to the closest CH located in the next level, till to the BS eventually. EM-LEACH can reduce and balance energy dissipation as well as increase packet delivery. But the hot spot problem is not taken into account in EM-LEACH, EOCGS and IBRE-LEACH. So, in CUCMA [27], the cluster radius is identified by distance to the BS and node distribution density. The closer to the BS, the greater the node density, then the smaller the cluster radius. Thus, the CHs’ traffic loads are balanced, and the hot spot problem is settled. In addition, a node decides whether it is selected as CH based on residual energy, distance to BS, distance to selected CHs, and number of neighbors. After selecting CHs, each normal node finds its nearest CH to form cluster. Then, CMs send gathered data to their CHs, and each CH forwards the fused data to the BS in multi-hop mode. CUCMA can equalize the CHs’ traffic loads and reduce the network energy dissipation, resulting in prolonged network lifetime. However, missing details of multi-hop scheme and round based re-clustering mechanism bring uncertainty of performance improvement, more computing and message overhead. Thereupon, in EAUCA [20], firstly, the competition radius of each node is calculated according to its remaining energy and distance to BS, which is adopted to create the unequal sized clusters, i.e. clusters near the BS has smaller radius than the further ones. Moreover, the node with more residual energy and higher node degree is nominated as CH. After CHs selection, normal nodes along with their nearest CHs form clusters by message interaction like in CUCMA. Different from traditional route-finding scheme, EAUCA nominates separate relay nodes to transfer inter-cluster data to the BS instead of CHs, and the nodes with more residual energy, lower node degree, and nearer distance to BS are more likely to be selected as relay nodes. Once the relay nodes are determined, CHs send their fused data from CMs to the nearest relay node in order to decrease the traffic burden of the CHs. Thereafter, the data is accumulated to the BS finally through multiple relay nodes closest to each other. More importantly, restructuring the network into unequal clusters after certain rounds instead of every round in EAUCA diminishes the clustering overheads, resulting in a decline in energy depletion. Simulation results demonstrates that EAUCA effectively mitigates the hot spot problem and significantly extends the network lifetime. However, above mentioned probability and deterministic weight-based protocols are difficult to find the optimal solution for clustering and routing which is considered as NP-hard [1, 15, 22]. Therefore, intelligent computing-based protocols have been proposed to solve this problem.
In [15], HBAC-AVOR is proposed to effectually cluster the nodes and efficiently organize the routes by using honey badger and African vulture optimization, respectively. Firstly, the honey badger algorithm is utilized to rapidly search the optimal CHs based on a novel fitness function considering residual energy, average and Euclidean distance of node to BS, and number of neighbors. However, arbitrary places initialization of honey badgers and the diversity of population determined by reducing factor only based on the number of iterations will reduce the convergence speed and easily fall into local optimum. Secondly, African vulture optimization is applied to select the optimal routes. Based on the fitness values of vultures considering residual energy and distance to BS, the optimum group of routes are obtained by updating the positions of vultures in the end. Simulation results indicate that HBAC-AVOR can lengthen the network lifetime and improve the network energy efficiency. However, energy balance is not considered and more parameters need to be determined in HBAC-AVOR. In [12], IPSO-GWO is presented to select optimal CHs and paths in the network. Above all, CHs selection is treated as an optimization issue in IPSO-GWO resolved by improved particle swarm optimization (IPSO) with objectives minimizing the ratio of CHs average residual energy to non-CH nodes’ residual energy, and the ratio of maximum distance among the non-CH nodes and the BS to the average distance among BS and CHs. Moreover, the inertial weight is adaptively changed to avoid trapping into local optimum. Similar to HBAC-AVOR, random particle initialization may reduce the convergence speed too. Once the CHs are selected by IPSO, normal nodes with their respective nearest CHs form clusters by message interactions. Afterwards, Grey Wolf Optimization (GWO) is used to select the optimal paths whose objectives are minimizing the distance traversal and count of hops. And the best solution is obtained by updating speed and location of wolves. However, residual energy is not considered for paths selection. Simulation outcome exhibits that IPSO-GWO can offer maximum energy efficacy with improvised network lifetime. In [28], PSO-EEC is proposed to select CHs and find relay nodes both based on PSO so as to extend the network lifetime and decrease the network energy expenditure. For CH selection, each particle consists of components representing the positions of the sensor nodes to be selected as CHs. And a fitness function is defined to evaluate the quality of particles considering the ratio of nodes’ initial energy and residual energy, distance between cluster member nodes and CH, and node degree so as to nominate the best nodes as CHs. Iteratively, the position and velocity are updated according to the local and global best fitness values until reach the final global optimum solution. After selecting CHs, the normal nodes associate with their expective nearest CHs to form clusters. Then, PSO is utilized to find the optimal relay nodes of CHs so as to save energy consumption. Similar to PSO used for CH selection, another fitness function is presented to determine the local and global best, which considers parameters residual energy of CH and distance to BS. The CHs with higher residual energy and smaller distance to BS have greater chance of selecting as relay nodes. The simulation results show that PSO-EEC can enhance the network lifetime and performance. However, uncertainties are not considered occurring in CH selection and route finding. Hence, in [29], F-GWO is proposed to deal with the uncertainties in CH selection by using fuzzy logic, and grey wolf optimization (GWO) is used to find the optimal routes during communication so as to lessen amount of energy and extend the network lifetime. At first, fuzzy logic with descriptors residual energy, node centrality, and neighborhood overlap is used to select the most acceptable CHs. Once the CHs are identified, then advertisement messages are communicated among the CHs and non-CH nodes to form appropriate clusters. Second, GWO is adopted to search the optimal path for each CH like in IPSO-GWO. And a fitness function is defined to ensure that the CHs having higher energy, nearer sink distance, smaller intra-cluster distance and balancing factor have higher probability of being selected as relay nodes. Simulation results show that F-GWO excels in network lifetime, packet delivery ratio, end-to-end delay, and so on. However, ignoring hot spot problem undoubtedly reduce the whole network performance.
In [1], GA-UCR is presented to form unequal clusters for mitigation of hot spot problem by using genetic algorithm. At first, the CHs are selected by applying a genetic algorithm with a fitness function considering cluster head remaining energy, distance between CH and BS, separation between CHs. Moreover, a competition radius is assigned to each CH based on its residual energy and distance to BS. The closer to the BS, the smaller the radius of the CH. The normal nodes join the corresponding clusters with the nearest CH, which locate in the competition radius of their CHs. Especially, the CH selection is repeatedly performed only when a CH’s energy is lower than a preset threshold instead of in each round so as to further reduce energy consumption. Next, another genetic algorithm is employed to find the optimal relays of the CHs, whose fitness function considers remaining energy of cluster heads, distance between CH and BS, number of hops. Simulation results show that GA-UCR can enhance the network performance with respect to energy consumption, lifetime and scalability. However, distance-based cluster member joining cluster requires more message overhead, and re-clustering only based on a predefined energy threshold may lead to more frequent clustering process. In [22], a distributed clustering routing protocol called DAPFL is proposed to improve the network energy efficiency and alleviate the hot spot problem. Different from GA-UCR, affinity propagation instead of GA is utilized to ascertain the number of clusters and naminate optimal CHs, which considers residual energy and distance between nodes. By updating the responsibility and availability iteratively, the nodes with more residual energy, larger average similarity of neighbors are selected as CHs, at the same time clusters are formed without extra message overhead. Different from traditional competition radius-based scheme to deal with the hot spot problem, fuzzy logic system (FLS) is utilized to seek out the optimal next-hop CH for each CH with residual energy, data length and distance to BS as descriptors, whose objective is to equalize the energy consumption among the CHs. Simulation results validate the performance of DAPFL with respect to network energy consumption, standard deviation of residual energy, network throughput and lifetime. However, uncertainties are not considered during the process of CH selection, which is difficult to find the optimal solution for clustering. Hence, in EEFUC [30], fuzzy logic is adopted to deal with the uncertainties happening in the process of competition radius calculation, CH selection, CM joining, and next-hop CH selection. First, a fuzzy logic system with three descriptors residual energy, distance to BS, and node degree is used to determine the competition radius for each node. Second, combined with the determined competition radius, CH chance output from the second fuzzy logic system with the similar parameters as competition radius determination is applied to select the optimal CHs. Thus, the nodes with higher residual energy, shorter distance to BS, and higher node degree have higher chance to become CHs. Third, after CH selection, each normal node decides which cluster to join by utilizing the third fuzzy logic system with residual energy of CH located in the cluster and distance to the CH as descriptors. Finally, the forth fuzzy logic system is designed to discover the best next-hop CH for data forwarding, whose inputs contains residual energy of the next CH, distance to the next CH, and distance to the crossover point between the communication circle and the straight line from CH to BS. Accordingly, each CH selects one of its neighbor CHs with higher residual energy and lower distances as its final next-hop CH. Simulations demonstrate that EEFUC can achieve promising performance with respective to network lifetime and energy usage. However, the fuzzy rules are defined manually which restricts its adaptive applications. So, in [31], LEACH-SF is presented to achieve energy efficiency in different practical heterogeneous wireless sensor networks. Balanced clusters in LEACH-SF are formed by using fuzzy c-means with the objective function minimizing the distance between nodes and cluster centroid. Once the clusters are formed, a Sugeno fuzzy logic system is used to calculate an impact factor (IF) within in [0,1] for each node based on residual energy, distance from the sink, and distance from the cluster centroid. Moreover, artificial bee colony algorithm is used to adjust the fuzzy rules, whose fitness function considers lifetime in different applications. Consequently, the optimal IF is obtained for each node, and the larger IF, the more priority to be selected as CH. Finally, the node with the maximum IF becomes the CH of each cluster. The operation and calculations mentioned before are completed by the sink. After CHs selection, the sink broadcasts an advertisement message to the CHs telling their CH identity and included members, and CHs inform their CMs about its ID, and their allotted timeslot. Simulation results validate that LEACH-SF can not only efficiently form balanced clusters but also maximize the network lifetime. In [19], an on-demand fuzzy clustering algorithm is presented to improve the network energy efficiency and throughput. At first, a new threshold function is defined to probably select candidate CHs considering more parameters than LEACH including nodes’ residual energy and optimal number of clusters, which ensures that the responsibility of being a CH gets rotated among all the nodes and the nodes with higher residual energy than other nodes are elected to be CHs. In order to improve the network performance, a Mamdani fuzzy logic system is used to calculate chance for each node, which uses node degree, node centrality and packet drop probability as descriptors. Moreover, PSO with fitness function maximizing the chance value is adopted to obtain the best ranges of membership functions for inputs and output of the fuzzy logic system. In the end, a candidate CH with higher chance value is selected as the final CH. Once the final CHs are selected, the other nodes become cluster member and join the nearest CH based on received signal strength. For data transmission, the CMs transmit sensed data to their respective CH based on TDMA scheme, and the CHs receive and aggregate the data and forward it to the BS. Finally, only when CHs’ residual energy is lower than a threshold defined by \({\upgamma }E_{initial} \left( {0 < \gamma < 1} \right)(E_{initial}\) is the inital energy of nodes), the CH sends a message to the BS who is responsible for informing all the nodes to perform re-clustering. Simulation results show that the proposed algorithm can reduce the network energy consumption and improve packet delivery ratio. In [32], FMSFLA is proposed to maximize the network lifetime and throughput by using fuzzy logic system with automatic rule tuning based on the features of corresponding applications. In FMSFLA, CHs are selected from the nodes with higher residual energy rates, shorter distance to BS, and shorter distances to neighbors by using a fuzzy logic system. Similarly, the relay nodes are also selected from the CHs with higher residual energy, shorter actual distances, and lower path loads by employing another fuzzy logic system. Moreover, the rules in both fuzzy logic systems are tuned by using shuffled frog leaping algorithm with a novel fitness function considering network lifetime. Therefore, the fuzzy rules can be adjusted to meet the application features. Once the CHs and relay nodes are determined, the normal nodes join respective cluster where locates their nearest CH to form clusters. And then non-CH nodes send their data to the corresponding CH which aggregates the data and forwards it to the BS directly or through their relay nodes. Simulation results show that FMSFLA can achieve steady network workload, reduce the network energy consumption, and prolong the network lifetime. However, centralized decision and interaction-based cluster formation undoubtedly increases the message overhead, and round by round based cluster maintenance leads to more computation and message costs. More importantly, the tuned fuzzy rules by shuffled frog leaping algorithm may not be optimal because the network lifetime of an actual application cannot be predicted in advance which is used to define its fitness function.
The comparison of related clustering and routing protocols with the proposed PFCRE is illustrated in Table 1.
3 System model
3.1 Network model
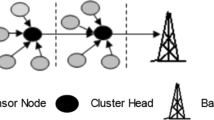
There are n sensor nodes N = {s1, s2…,sn} randomly deployed in the network, and the nodes have the same process, storage, energy and other resources. Additionally, all the nodes keep stationary and are grouped into clusters. Some optimal nodes are nominated as CHs. The only BS is static and can be located inside or outside of the target region. Especially, the nodes send data to the BS in multi-hop mode and the BS can directly communicate with all the nodes. Also, round is used as data transmission cycle, in which CMs send data to CH and CH forwards fused data to the BS hop by hop. Hence, the energy holes occur near the BS. Both cluster size adjustment and energy balance forwarding can be used to diminish this issue, as shown in Fig. 1.

Clustered WSN with hot spot mitigation
In addition, some additional presumptions are made for the network:
-
ID number is used to identify the nodes.
-
No energy constraint is attached to the BS.
-
Symmetric links are used for communications among nodes and the BS.
-
The positions of the nodes can be determined by received signal strength indicator (RSSI).
-
The transmission power of nodes can be adjusted as required.
3.2 Energy model
In this paper, the same simplified energy model as discussed in [6] is used to calculate the energy consumption between the transmitter si and the receiver sj. When the Euclidean distance d between si and sj is less than the distance threshold \(d_{0}\) estimated by \(d_{0} = \sqrt {\varepsilon_{fs} /\varepsilon_{mp} }\), then the free space model is applied. Otherwise, the multi-path model is utilized. Accordingly, the energy consumption of data transmission with k-bit message between nodes si and sj over distance d can be obtained by [16]:
where \(E_{elec}\) depicts the electronics energy consumption required to transmit or receive \(1\)-bit. \(\varepsilon_{fs}\) and \(\varepsilon_{mp}\) are the amplifier coefficients used for free space and multi-path model, respectively. Similarly, the energy consumption of node i for receiving k-bit data from node j is given as [16]:
Moreover, the energy consumed for aggregating k-bit data can be estimated by [16]:
where \(E_{pDb}\) is the energy consumed for fusing 1-bit data [16].
4 The proposed protocol
The purpose of the proposed PFCRE is to form best clusters and find optimal routes to enhance the network energy efficiency, prolong the network lifetime, and eliminate the hot spot problem as well. PSO and FLS are used in PFCRE to achieve the set goals. PFCRE consists of three parts i.e. cluster formation, route finding, and cluster and route maintenance. The details of each part of PFCRE are introduced as follows.
4.1 Cluster formation
PSO is one of the most famous methods to solve the optimization problems with many advantages such as easy implementation, availability to escape from local optima, and quick convergence [33]. So, PFCRE also adopts PSO to form optimal clusters which is different from conventional PSO based methods [12, 34] only focusing on get the best CHs. There is no need to determine the number of clusters in advance and to form clusters with message interaction among non-CH and CH, hence, PFCRE is more lightweight and energy saving. The detail description of cluster formation based on PSO is given in Fig. 2.

Flowchart of cluster formation based on PSO
Particle initialization is used to assign appropriate value to each component of a particle denoted by \(p_{i} = \{ x_{i1} ,x_{i2} , ...,x_{in}\)}, and there are \(n_{p}\) particles in total. Each particle provides the formed clusters whose dimension is the same as the number of nodes n. Each component of a particle represents the index of a candidate CH. In order to accelerate the convergence speed, only the neighbors j with residual energy higher than the neighbors’ average residual energy \(\left( {Res_{j} > \frac{1}{{\left| {N_{i} } \right|}}\mathop \sum \limits_{1}^{{\left| {N_{i} } \right|}} Res_{k} } \right)\) can be selected as its candidate CH for every node i. Moreover, random selection from the candidate set of CHs instead of traditional randomly generated number also further promotes the convergence of the algorithm. An illustration on a particle initialization is given in Fig. 3, where a WSN contains 10 sensor nodes, and each node knows its candidate CHs.

Illustration of particle initialization
As shown in Fig. 3, particle i has 10 components generated by assigned random number ranged in (0,1], i.e. \(p_{i} = \left\{ {0.34, 0.15, 0.78, 0.53, 0.62, 0.97, 0.05, 0.76, 0.81, 0.37} \right\}\).And the number of candidates for node 1 to 10 is 2, 3, 2, 2, 3, 2, 1, 2, 2, 2, respectively. Multiplying the number of candidates by the component value of the particle one by one, we can obtain result = \(\left\{ {0.34 \times 2 = 0.68, 0.15 \times 3 = 0.45, 0.78 \times 2 = 1.56, 0.53 \times 2 = 1.06, 0.62 \times 3 = 1.86, 0.97 \times 2 = 1.94, 0.05 \times 1 = 0.05, 0.76 \times 2 = 1.52, 0.81 \times 2 = 1.62, 0.37 \times 2 = 0.74} \right\}\). Then the index of the selected CH can be determined by rounding the result, i.e. the index of the selected = Ceiling(result) = {1, 1, 2, 2, 2, 2, 1, 2, 2, 1}, each of whose element implies that the corresponding candidate is selected as CH. Moreover, the nodes will no longer participate in the CH selection once they are selected as CHs. Obviously, nodes 2, 5 and 9 are selected as CHs, and three clusters {\(s_{1} ,s_{2} ,s_{7}\)}, {\(s_{3} ,s_{4} ,s_{5} ,s_{10}\)}, and {\(s_{6} ,s_{8} ,s_{9}\)} are formed. Similarly, the initial population can be achieved by generating the \(n_{p}\) particles.
One of the objectives of cluster formation is energy efficiency improvement, in other words, minimizing all the intra-cluster energy dissipation. Let \(f_{1}\) denote the total intra-cluster energy dissipation, and minimize represent the optimization objective. From each particle, the number of clusters \(m\), and number of CMs \(l_{i}\) in cluster i can be obtained. The mathematical formulation can be succinctly stated as:
where \(E_{Tji} { },{ }E_{Rji}\) and \(E_{DA}\) is defined in the energy model. The other objective of cluster formation is load balance in clusters, which can be expressed as:
where \(L_{i} = \mathop \sum \nolimits_{j = 1}^{{l_{j} }} L_{ji} + L_{DA}\) indicates the load overhead of cluster i, and \(L_{avg} = \frac{{\mathop \sum \nolimits_{i = 1}^{m} \left( {\mathop \sum \nolimits_{j = 1}^{{l_{j} }} L_{ji} + L_{DA} } \right)}}{m}\) denotes the average load overhead of clusters. Therefore, the fitness function is defined to obtain the global optimal solution, which can be given as follows
where \({\upalpha } \in \left[ {0,1} \right]\) is the coefficient used to regulate the influence between energy efficiency and load balance factors. The lower the fitness value, the better is the particle position, in other words, the better is the formed clusters. Afterwards, the fitness values of the particles are calculated to initialize the \(p_{i} best\), \(gbest\). Of course, the maximum \(p_{i} best\) is assigned to \(gbest\). Moreover, the values of components in each particle are updated iteratively accordingly to the following equations [35, 36].
where \(1 \le i \le n_{p, } 1 \le d \le n\), t is the current number of iterations, \(r_{1} , r_{2}\) are two uniformly distributed random numbers in the range [0,1]. \(c_{1} {\text{ and }}c_{2}\) are constants named as acceleration coefficients, and \(\omega\) denotes the inertial weight which can be adaptively adjusted as follows [35, 36].
where \(t_{max}\) denotes the predetermined maximum number of iterations, \(\omega_{max}\),\(\omega_{min}\) are two constants which are usually set to 0.9 and 0.4, respectively [35, 36]. Next, the fitness values of the updated particles are also calculated to update \(p_{i} best\), \(gbest\). It is clear that no updating is carried out when the new fitness value is not greater than the original value. The update process is repeated until the number of iterations reaches the preset \(t_{max}\). The particle with the maximum fitness value \(gbest\) is the global optimal solution, which implies the optimal formed clusters accordingly.
4.2 Route finding
Once the clusters are formed, the route for each CH should be determined to transmit data to the BS. In PFCRE, the popular Mamdani fuzzy inference system is employed to make decision on optimal routes which consists of fuzzifier, fuzzy inference engine, fuzzy rules, and defuzzifier. The objectives of routing finding are improving energy efficiency and mitigate hot spot problem. The residual energy of a node constitutes a pivotal factor, as energy depletion may lead to node failure, thereby impacting network stability and lifespan. Deliberating on the remaining energy of relay nodes offers the potential to enhance the overall energy efficiency and life cycle of the network. Additionally, the proximity of a relay node to the Cluster Head emerges as a crucial parameter. Opting for a relay node in closer proximity to the CH facilitates the reduction of transmission delay, enhancement of data transmission efficiency, and minimization of energy consumption. Moreover, the distance to the base station significantly influences the energy consumption across the entire network and the reliability of data transmission. The consideration of the number of being selected relay nodes is imperative for maintaining load balancing within the network. Utilizing these parameters as fuzzy inputs and employing a fuzzy logic system for decision-making enables a more comprehensive evaluation of relay node adaptability. Consequently, the protocol becomes capable of adapting more flexibly to diverse network conditions. This holistic approach contributes to the amelioration of efficiency, reliability, and adaptability within cluster routing protocols. To this end, the effective parameters residual energy of relay, summation of distance to source CH and BS, and number of being selected relay are considered as the fuzzy inputs. The more the residual energy, the smaller the distance summation, the less the number of being relay, and the more likely the neighbor CH will be selected as the final relay, as shown in Fig. 4. CH4 is more suitable as the relay of CH1 in terms of summation of distance. However, the final relay is CH2 because of its being selected as relay for CH4 before. Fuzzy rules are vital for decision making, so the rules are tuned by a PSO algorithm. Fuzzy inference engine is used to evaluate the fuzzy inputs and obtain the fuzzy output probability. The neighbor CH with highest probability is selected as the relay.

Relay selection focusing on hot spot problem
Fuzzifier turns the crisp values into linguistic fuzzy variables by using different membership functions. However, the input variables usually have various range, which limits the scope of application, so all the input variables are normalized in the range of [0,1]. To avoid introducing excessive computational complexity, the membership function is chosen as in most protocols. Five membership functions (very small, small, medium, large, very large) are utilized for the three inputs variables residual energy of relay, summation of distance to source CH and BS, and number of being selected relay. And seven membership functions are used for the fuzzy output including very low, low, rather low, medium, high, rather high, very high. In addition, trapezoidal membership function is applied for very small, very large, very low and very high, and triangular member function for others. The member ship function for inputs and output are depicted in Fig. 5, respectively.

The member ship function
After fuzzification of the crisp input variables, the fuzzy inference engine applies the IF-THEN rules to calculate the fuzzy output. According to the inputs and output, the fuzzy rules can be derived as shown in Table 2.
Another PSO similar to the one in cluster formation is utilized to tune the rules in Table 2. Each particle denoted by \(p_{i} = \left\{ {x_{i1} ,x_{i2} ,...,x_{in} } \right\}\) with dimension n = 125 is utilized to represent a desired fuzzy output indicated by its seven membership functions very low, low, rather low, medium, high, rather high, very high, an illustration is given in Fig. 6.

An illustration of a particle representation relating to the fuzzy output
Like this, the initial population of particles is randomly generated, and iteratively update their position and velocity according to their local best and global best so as to reach the global optima. Moreover, a fitness function is designed to reach the objective of rule tuning i.e. maximizing the probability value by defuzzifier, which can be expressed as:
Maximize:
where \(c_{i}\) denotes the output of rule i, k means the number of rules, and \(\mu_{i}\) indicates the centroid of the fuzzy output membership function. Once the iteration stops, the optimal rules are generated by decoding the global best \(gbest\), which can be described as:
Rule 1: if \({\varvec{E}}_{{{\varvec{res}}}}\) = very small, \(\user2{ S}_{{{\varvec{to}}}} {\varvec{D}}\) = very small, \({\varvec{N}}_{{{\varvec{bd}}}}\) = very small, then probability = high
Rule 2: if \({\varvec{E}}_{{{\varvec{res}}}}\) = very small, \(\user2{ S}_{{{\varvec{to}}}} {\varvec{D}}\) = very small, \(\user2{ N}_{{{\varvec{bd}}}}\) = small, then probability = medium
Rule 3: if \({\varvec{E}}_{{{\varvec{res}}}}\) = very small, \({\varvec{S}}_{{{\varvec{to}}}} {\varvec{D}}\) = very small, \(\user2{ N}_{{{\varvec{bd}}}}\) = medium, then probability = rather low
Rule 4: if \({\varvec{E}}_{{{\varvec{res}}}}\) = very small, \({\varvec{S}}_{{{\varvec{to}}}} {\varvec{D}}\) = very small, \(\user2{ N}_{{{\varvec{bd}}}}\) = large, then probability = low
Rule 5: if \({\varvec{E}}_{{{\varvec{res}}}}\) = very small, \({\varvec{S}}_{{{\varvec{to}}}} {\varvec{D}}\) = very small, \({\varvec{N}}_{{{\varvec{bd}}}}\) = very large, then probability = low
Rule 125: if \({\varvec{E}}_{{{\varvec{res}}}}\) = very large, \({\varvec{S}}_{{{\varvec{to}}}} {\varvec{D}}\) = very large, \({\varvec{N}}_{{{\varvec{bd}}}}\) = very large, then probability = rather low
As shown in Fig. 2, the size of the population \(n_{p}\) and the number of iterations Iteration are pre-defined, and the particles are initialized by using the uniform random numbers with their respective range values like in Table 2. At the same time, the individual best \(p_{i} best\) and global best \(gbest\) are set to zero. Afterwards, the population is updated by using Eqs. (7) and (8), and the quality of the particles is evaluated by using the fitness function Eq. (10). Accordingly, the values of \(p_{i} best\) and \(gbest\) are also updated based on the fitness values of particles. Iteratively, the particles get converged to the global optima. Thus, the global best \(gbest\) is obtained, which can be decoded to achieve the optimal fuzzy rules.
Finally, defuzzifier is used to get the crisp output, and the neighbor CH with the greatest probability value is selected as the relay. Once all the CHs find their relays, data transmission in multi-hop mode begins, each CM send data including its residual energy to the corresponding CHs, and each CH forwards data to its relay until to the BS, the IDs are also contained in the data packet by routing order.
4.3 Cluster and route maintenance
A novel maintenance mechanism is employed to further decrease energy consumption and boost the network lifetime in PFCRE. At first, each CH acts as its role for a certain upcoming round until its residual energy is lower than the average residual energy of the cluster. Once this happens, the CH announces the nearest CM with more residual energy as the cluster head, which still acts as the relay for other CHs and sends the received data to the CH. In addition, the BS monitors the frequency of CH role change according to the IDs in the received data packet. When one-time role change in any cluster occurs in a round, the BS broadcasts a message to the CHs, and the CHs forward the residual energy of their CMs and themselves to the BS. Cluster formation based PSO starts to form optimal clusters again, and the cluster information is broadcast to the network by the BS like before. And the CHs use fuzzy logic optimized by PSO to find the optimal routes, followed by the data transmission process. It goes repeatedly until the network dies. The overall flow of the PFCRE protocol is shown in Fig. 7.

The overall flow of the PFCRE
4.4 Time complexity analysis
In PFCRE, the time complexity includes the time complexity of cluster formation, route finding and cluster and route maintenance. PFCRE adopts PSO to form optimal clusters, and the PSO has time complexity \(O\left( {n \times n_{p} } \right)\), where n is the number of sensor nodes, and \(N_{p}\) means the population size. Moreover, only one message is needed to broadcast the cluster information, the time complexity is \(O\left( 1 \right)\). For route finding, fuzzy logic is used to find the best relay for each CH, so its time complexity is \(O\left( {n_{ch} \times n_{rule} } \right)\), where \(n_{ch}\) is the number of CHs, and \(n_{rule}\) indicates the number of fuzzy rules which equals 125 in PFCRE. Furthermore, the fuzzy rules are tuned by another PSO whose time complexity is \(O\left( {(n_{d} + n_{rule} } \right) \times n_{p} )\), where \(n_{d}\) is the dimension of the particle which equals \(n_{rule}\). So the time complexity of route finding is \(O\left( {n_{ch} + 2n_{p} } \right) \times n_{rule} )\). During the cluster and route maintenance, local cluster maintenance needs only one announcing message. In addition, a message broadcasting from BS and \(n_{ch}\)-1 data forwarding message at most are needed to be processed. Then the time complexity of cluster and route maintenance is \(O\left( {n_{ch} } \right).\) Hence, the time complexity of PFCRE is \(O\left( {n \times n_{p} + 1 + \left( {n_{ch} + 2n_{p} } \right) \times n_{rule} + n_{ch} } \right)\). Generally, \(n_{p}\), \(n_{ch}\) and \(n_{rule}\) are much less than \(n\), therefore, the time complexity of PFCRE is \(O\left( {n^{2} } \right)\).
5 Simulation results
The experiments were conducted on a computer running the Windows 10 operating system, equipped with an AMD Ryzen 5 3500X 6-Core processor, 16GB of RAM, and a 500GB SSD. The MATLAB R2022a platform is used to simulate and test the performance of the proposed PFCRE. To ensure the robustness of the results, we repeated the experiments 50 times and calculated the average to draw the conclusions.
5.1 Simulation settings
We utilized identical simulation parameters as the majority of protocols, and the details of the network and radio energy models, which can be found in Table 3. In this study, the network lifetime, throughput, standard deviation of cluster head loading, and energy consumption of the proposed PFCRE protocol are evaluated by varying the size of the network area, the number of nodes, and the cluster head occupancy ratio.
In order to rigorously validate the performance of the proposed PFCRE protocol, a comparative analysis has been carried out. The analysis is compared with excellent protocols that use different approaches, including IBRE-LEACH [24], which improves on the most classical LEACH protocol; EAUCA [20], which uses an unequal clustering approach, DAPFL [22], which combines fuzzy logic with affinity propagation, IPSOGWO [12], which combines two intelligent optimization algorithms, and FMSFLA [31], which combines intelligent algorithms with affinity propagation. intelligent algorithms with fuzzy logic rules, FMSFLA [32]. The setting of the parameters of the simulation algorithm can be adjusted according to the actual needs, such as \(c_{1}\) and \(c_{2}\) in the PSO algorithm, which controls the equilibrium state of the population between the individual optimum and the global optimum, and the parameters of the algorithm used are given in Table 4 [37, 38].
5.2 Simulation result and discussion
5.2.1 Network lifetime
First, the network lifetime is tested in both scenarios with different numbers of nodes and areas. The network lifetime directly relates to the quantity of surviving nodes, and usually FND (first node die), HND (half nodes die), LND (last node die) are used to measure its performance. The comparison results of PFCRE with IBRE-LEACH, EAUCA, DAPFL, IPSOGWO and FMSFLA are depicted in Table 5, and Fig. 8.

Comparison of the number of alive nodes
It can be seen from Table 5 that PFCRE outperforms IBRE-LEACH, EAUCA, DAPFL, IPSOGWO and FMSFLA in terms of network lifetime. In scenario #1 and scenario #2, the performance of PFCRE in extending the network lifetime is 19.65%, 17.73%, 36.85% and 31.33% higher than IBRE-LEACH, 39.93%, 33.02%, 19.90% and 31.66% higher than EAUCA, 10.45%, 24.92%, 26.16% and 9.50% higher than DAPFL, and 14.70%, 31.63%, 46.80% and 32.83% higher than IPSOGWO,11.28%, 12.60%, 32.67% and 31% higher than FMSFLA.
As can be seen from Fig. 8, Due to its probability-based CH selection mechanism, IBRE-LEACH may select some nodes with low residual energy to become CHs, and result in uneven CHs distribution. Moreover, only distance between CHs, ANs, and root considered for data forwarding undoubtedly leads to energy waste in the improper paths. Hence, its network lifetime is affected, especially if the network area is large. Although EAUCA divides the CHs and relay nodes, the uppermost relay node near the BS receives almost all the data of the network during data forwarding process, which can lead to unbalanced load on the network and premature death of relay nodes thus affecting the overall network lifetime, which leads to the overall poor performance of the EAUCA protocol. IPSOGWO uses two optimization algorithms in clustering and routing processes, respectively. However, the routing process considers only distance and hop count and does not filter the nodes for their residual energy, which may make low energy but closer to the BS to act as a relay node, which results in a shorter survival time of the network. Although DAPFL combines affinity propagation and fuzzy logic, its fuzzy inference rules need to be improved in terms of their setup in order to extend the network lifetime. To overcome the problem of node’s early death due to the low energy of the selected CH, FMSFLA selects nodes with residual energy greater than the average energy of the network to participate in CH selection and uses an optimization algorithm to adjust the fuzzy rules in CH selection. However, the traffic load on the parent nodes in FMSFLA is high, which affects the network lifetime. PFCRE overcomes the shortcomings of other protocols by being more comprehensive in the selection of CHs and relay nodes, by adapting the rules of the fuzzy inference system by using the PSO method, and by taking into account energy efficiency and load balancing, which extends the network lifetime. Adaptive mechanisms are also used to maintain clustering and routing on a non-recurring basis to reduce local and global computational and information overheads, and therefore it usually has a larger number of surviving nodes than other protocols.
5.2.2 Network throughput
Throughput constitutes a crucial performance metric employed to characterize the volume of data or information that a network can effectively transmit within a given time frame. Typically, Throughput serves as a standard measure for assessing a network's data transfer capacity and overall performance. Enhanced throughput can significantly enhance network performance, diminish transmission latency, and broaden the range of supported application scenarios, including monitoring, control, and data transfer. The results are shown in Fig. 9.

Comparison of network throughput
Low network throughput can be attributed to high energy consumption and shortened network lifetime due to overloaded relay nodes. Observed from Fig. 9, PFCRE has higher network throughput than IBRE-LEACH, EAUCA, DAPFL IPSOGWO and FMSFLA in both scenarios. In scenarios #1 and #2, the network throughput of PFCRE is 11.44%, 6.78%, 54.98% and 50.96% higher than that of IBRE-LEACH, 26.11%, 18.66%, 15.31% and 37.34% higher than that of EAUCA, 6.6%,18.44%, 44.35% and 29.5% higher than that of DAPFL, and 8.73%, 21.41%, 44.35% and 30.45% higher than that of IPSOGWO, and 8.02%, 0.21%, 11.25% and 15.43% higher than that of FMSFLA, respectively. Obviously, PFCRE not only prolongs the network lifetime, but also increases the amount of data transferred and further improves the network energy efficiency.
5.2.3 Standard deviation of CH’s traffic load
Standard deviation of CH’s traffic load is tested to compare PFCRE performance of load balance with IBRE-LEACH, EAUCA, DAPFL, IPSOGWO and FMSFLA. Due to the almost same load of cluster members, only load deviation of cluster heads is performed. The results are shown in Fig. 10.

Comparison of Standard deviation of CH’s traffic load
As can be seen from Fig. 10, in Scenario 1, when the network size and the number of hops used for routing are small, the standard deviation of the CH’s traffic load of the PFCRE protocol is smaller than that of the IBRE-LEACH, EAUCA, DAPFL, IPSOGWO and FMSFLA protocols, and remains stable. This is because PFCRE considers load balancing when finding routing paths, thus mitigating the hot spot problem. Since the selection of CH nodes in IBRE-LEACH is more random compared to other protocols, it performs relatively poorly in cluster head load standard deviation. In Scenario 2, as both EAUCA and FMSFLA protocols transmit data to relay nodes, the load standard deviation of CH increases as the network size and the number of hops transmitted increases. However, at larger network sizes, PFCRE can still show its more obvious load balancing advantage. the DAPFL and IPSOGWO protocols forward data to the BS by selecting reasonable paths during the routing process, so the change in the load standard deviation of CH is smaller as the network size increases. The experimental results show that the mean value of the load standard deviation of CHs for PFCRE is 77.14%, 50.22%, 45.98% and 39.61% lower than that of the IBRE-LEACH protocol, 40.89%, 13.27%, 40.13% and 35.99% lower than that of the EAUCA protocol, 52.48%, 49.32% and 6.8% lower than that of the DAPFL,72.77%, 54.18% and 19.69% lower than that of the IPSOGWO protocol. In addition, in scenario#2 10% CHs, the mean load standard deviation of CHs for PFCRE was 17.33% and 4.88% higher than for DAPFL and IPSOGWO. 31.21%, 20.78%, 17.91% and 32.16% lower than that of the FMSFLA protocol in scenarios 1 and 2, respectively. Therefore, PFCRE is more effective in solving hot spot problems.
5.2.4 Energy consumption
Finally, Energy consumption is a critical performance metric that quantifies the battery energy utilized by wireless sensor nodes during their tasks and communication. Wireless sensor nodes are typically battery-powered, making energy consumption a pivotal factor. The less the total energy consumption, the better the network performance. The results are displayed in Fig. 11.

Comparison of the network energy consumption
It can be seen from Fig. 11 that the network energy consumption increases with the number of running rounds, but the network energy consumption curve of PFCRE remains basically under other protocols. In IBRE-LEACH, since the CH communicates directly with the BS, the CHs far away from the BS consume a large amount of energy as the size of the network area and the number of nodes increase. both EAUCA and FMSFLA select relay nodes during data transmission, which reduces the network energy consumption to a certain extent. However, both protocols cause nodes close to the BS or with greater residual energy to be selected as relays, which tends to result in closer and more energetic nodes being repeatedly selected as relays, which in turn affects network lifetime. DAPFL selects next-hop CHs based on fuzzy logic outputs during routing, which reduces network energy consumption to a certain extent. However, this also increases the energy consumption of the CHs close to the BS. IPSOGWO optimizes the best clustering through the particle swarm algorithm and uses the GWO algorithm to select the best route during the data transmission phase, selecting a closer and less hoppy routing path to transmit the data to the base station without considering the energy, which also affects the network lifetime. PFCRE aims to minimize the total energy consumption of the network and adds the number of times a relay node is selected to the fuzzy input, by designing adaptation function to achieve this objective, adaptive mechanisms are also used to maintain clustering and routing on a non-recurring basis to reduce local and global computational and information overheads. As a result, in scenarios #1 and #2, which consume half of the network energy, PFCRE runs 11.51%, 9.05%, 40.38% and 19.23% more rounds than IBRE-LEACH, 33.23%, 26.55%, 22.43% and 42.1% more rounds than EAUCA, 7.05%,20.47%, 33.33% and 28.07% more rounds than DAPFL, and 8.77%, 23.73%, 42.94% and 22.8% more rounds than IPSOGWO, and 6.61%, 3.26%, 47.43% and 42.98% more rounds than FMSFLA, respectively.
6 Conclusion
This paper presents a lightweight clustering and routing protocol to improve the network energy efficiency, enhance the network lifetime and diminish the hot spot problem by using fuzzy logic and particle swarm optimization, namely, PFCRE. There are three main stages including cluster formation using PSO, route finding based on fuzzy logic optimized by PSO, and cluster and route maintenance in local cluster and whole network. Several novel mechanisms with less message and computing overheads are applied in the stages to achieve the desire objectives. To verify the performance of PFCRE, it has been compared with IBRE-LEACH, EAUCA, DAPFL, IPSOGWO and FMSFLA in several scenarios with respect to network lifetime, throughput, standard deviation of CH’s traffic load and energy consumption. Specifically, the average network lifetime of PFCRE has increased by 26.39%, 31.12%, 17.75%, 31.49%, 21.88%, compared to IBRE-LEACH, EAUCA, DAPFL, IPSOGWO and FMSFLA, respectively. At the same time, PFCRE outperforms IBRE-LEACH, EAUCA, DAPFL, IPSOGWO and FMSFLA by 31.04%, 24.35%, 24.72%, 26.23%, 8.72% in terms of the average network throughput. For the average standard deviation of CH’s traffic load, PFCRE decreases it by 53.23% over IBRE-LEACH, 32.57% over EAUCA, 22.81% over DAPFL, 35.44% over IPSOGWO and 25.51% over FMSFLA. Finally, PFCRE also reduces the energy consumption by 20.04%, 31.07%, 22.23%, 24.56%, 25.07% as compared to IBRE-LEACH, EAUCA, DAPFL, IPSOGWO and FMSFLA, respectively. Although this work achieves good results with respect to network lifetime, throughput, energy efficiency and balance, there are still some limitations to be addressed in the future. The proposed PFCRE protocol is more limited in its usage scenarios, and this paper only demonstrates the homogeneous nodes in a static network environment where both the nodes and the BS cannot be mobile, and it does not consider the network attacks that will be suffered during the data transmission process. In addition, we consider using deep reinforcement learning to replace intelligent algorithms to optimize the clustering routing protocol of wireless sensor networks. Finally, the tests are performed based on the ideal network model, practical scenarios will be used to test the proposed protocol for applicability verification.
Data availability
Data will be provided by the corresponding author upon reasonable request by the reader.
References
Gunjan, Sharma, A.K., Verma, K.: GA-UCR: genetic algorithm based unequal clustering and routing protocol for wireless sensor networks. Wirel. Pers. Commun. 128(2023), 537–558 (2023)
Carolina, D.V.S., Alma, R., Cesar Podolfo, A.P.: A survey of energy-efficient clustering routing protocols for wireless sensor networks based on metaheuristic approaches. Artif. Intell. Rev. 56(9), 9699–9770 (2023)
Daanoune, I., Abdennaceur, B., Ballouk, A.: A comprehensive survey on LEACH-based clustering routing protocols in wireless sensor networks. Ad Hoc Netw. 2021(114), 1–21 (2021)
Jain, A.: Unequal clustering protocols for wireless sensor networks-taxonomy, comparison and simulation. Wirel. Pers. Commun. 2022(124), 517–571 (2022)
Yick, J., Mukherjee, B., Ghosal, D.: Wireless sensor network survey. Comput. Netw. 2008(52), 2292–2330 (2008)
Heinzelman, W.R., Chandrakasan, A., Balakrishnan, H.: Energy-efficient communication protocol for wireless microsensor networks. In: Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, vol. 1, IEEE Comput. Soc., Maui, HI, USA, p. 10 (2000)
Liu, Y., Zhao, T., Tie, Y., et al.: An improved energy-efficient routing protocol for wireless sensor networks. Sensors 2019(19), 1–20 (2010)
Alia, O.M.: A dynamic harmony search-based fuzzy clustering protocol for energy-efficient wireless sensor networks. Ann. Telecommun. 73(5), 353–365 (2018)
Heinzelman, W.B., Chandrakasan, A.P., Balakrishnan, H.: An application-specific protocol architecture for wireless microsensor networks. IEEE Trans. Wirel. Commun. 1(4), 660–670 (2002)
Khoulalene, N., Medijkoune, L.B., Aissani, D., et al.: Clustering with load balancing-based routing protocol for wireless sensor networks. Wirel. Pers. Commun. 2018(103), 2155–2175 (2018)
Sreedevi, P., Venkateswarlu, S.: FOC-MOP: Fuzzy optimal clustering based multi-objective parameter route selection for energy efficiency. Wirel. Pers. Commun. 126(1), 773–794 (2022)
Eihoseny, M., Rajan, R.S., Hammoudeh, M.: Swarm intelligence-based energy efficient clustering with multi-hop routing protocol for sustainable wireless sensor networks. Int. J. Distrib. Sens. Netw. 16(9), 1–12 (2020)
Sreedevi, P., Venkateswarlu, S.: An efficient intra-cluster data aggregation and finding the best sink location in WSN using EEC-MA-PSOGA approach. Int. J. Commun. Syst. 35(8), e5110 (2022)
Osamy, W., EI-Sawy, A., Salim, A.: CSOCA: chicken swarm optimization based clustering algorithm for wireless sensor networks. IEEE Access 8(2022), 60676–60688 (2020)
Arutchelvan, K., Priya, R.S., Bhuvaneswari, C.: Honey badger algorithm based clustering with routing protocol for wireless sensor networks. Intell. Autom. Soft Comput. 35(3), 3199–3212 (2023)
Wang, C.H., Liu, X.L., Hu, H.H., et al.: Energy-efficient and load-balanced clustering routing protocol for wireless sensor networks using a chaotic genetic algorithm. IEEE Access 2020(8), 158082–158096 (2020)
Bhushan, B., Sahoo, G.: FLEAC: fuzzy logic-based energy adequate clustering protocol for wireless sensor networks using improved grasshopper optimization algorithm. Wirel. Pers. Commun. 2022(124), 573–606 (2022)
Osamy, W., Khedr, A.M.: Adaptive and dynamic mechanism for round length determination in cluster based wireless sensor networks. Wirel. Pers. Commun. 114(2), 1155–1175 (2020)
Nimisha, G., Indrajit, B., Sherratt, R.S.: On-demand fuzzy clustering and ant-colony optimization based mobile data collection in wireless sensor network. Wirel. Netw. 2019(25), 1829–1845 (2019)
Chauhan, V., Soni, S.: Energy aware unequal clustering algorithm with multi-hop routing via low degree relay nodes for wireless sensor networks. J. Ambient. Intell. Humaniz. Comput. 2021(12), 2469–2482 (2021)
Adnan, M., Yang, L., Ahmad, T., et al.: An unequally clustered multi-hop routing protocol based on fuzzy logic for wireless sensor network. IEEE Access 2021(9), 38531–38545 (2021)
Wang, C.H., Hu, H.H., Zhang, Z.G., et al.: Distributed energy-efficient clustering routing protocol for wireless sensor networks using affinity propagation and fuzzy logic. Soft. Comput. 2022(26), 7143–7158 (2022)
Temene, N., Sergiou, C., Georgiou, C., et al.: A survey on mobility in wireless sensor networks. Ad Hoc Netw. 2022(125), 1–17 (2022)
Daanoune, I., Baghdad, A.: IBRE-LEACH: improving the performance of the BRE-LEACH for wireless sensor networks. Wirel. Pers. Commun. 126(4), 3495–3513 (2022)
Panchal, A., Singh, R.K.: EOCGS: energy efficient optimum number of cluster head and grid head selection in wireless sensor networks. Telecommun. Syst. 2021(78), 1–13 (2021)
Sara, A.S., Ridha, O.: Reliable and energy-efficient multi-hop LEACH-based clustering protocol for wireless sensor networks. Sustain. Comput. 2018(20), 1–13 (2018)
Liu, J., Su, S.B., Liu, Y.H., et al.: A competition-based unequal clustering multi-hop approach for wireless sensor networks. Secur. Commun. Netw. 2021(10), 1–10 (2021)
Piyush, R., Siddhartha, C.: Particle swarm optimization-based energy efficient clustering protocol in wireless sensor network. Neural Comput. Appl. 33(21), 14147–14165 (2021)
Singh, J., Deepika, J., Zaheeruddin, et al.: Energy-efficient clustering and routing algorithm using hybrid fuzzy with grey wolf optimization in wireless sensor networks. Secur. Commun. Netw. 5, 1–12 (2022)
Phoemphon, S., Soin, C., Aimtongkham, P., et al.: An energy-efficient fuzzy-based scheme for unequal multi-hop clustering in wireless sensor networks. J. Ambient. Intell. Humaniz. Comput. 2021(12), 873–895 (2021)
Mohammad, S., Ali, J.: Optimized sugeno fuzzy clustering algorithm for wireless sensor networks. Eng. Appl. Artif. Intell. 2017(60), 16–25 (2017)
Fanian, F., Rafsanjani, M.K.: A new fuzzy mult-hop clustering protocol with automatic rule tuning for wireless sensor networks. Appl. Soft Comput. 2020(89), 1–24 (2020)
Azharuddin, M., Jana, P.K.: PSO-based approach for energy-efficient and energy-balanced routing and clustering in wireless sensor networks. Soft. Comput. 2017(21), 6825–6839 (2017)
Choudhary, S., Sugumaran, S., Belazi, A., et al.: Linearly decreasing inertia weight PSO and improved weight factor-based clustering algorithm for wireless sensor networks. J. Ambient Intell. Humanized Comput. 11(21), 1–19 (2023)
Chen, Y.L., Wang, N.C., Chen, M.Y., et al.: A concentric clustering architecture with particle swarm optimization algorithm in a wireless sensor network. Sens. Mater. 26(5), 325–332 (2014)
Duan, Y.X., Chen, N., Chang, L.J., et al.: CAPSO: chaos adaptive particle swarm optimization algorithm. IEEE Access 2022(10), 29393–29405 (2022)
Trojovská, E., Dehghani, M., Leiva, V.: Drawer algorithm: a new metaheuristic approach for solving optimization problems in engineering. Biomimetics 8(2), 239 (2023)
Nadimi-Shahraki, M.H., Zamani, H., Fatahi, A., et al.: MFO-SFR: an enhanced moth-flame optimization algorithm using an effective stagnation finding and replacing strategy. Mathematics 11(4), 862 (2023)
Funding
This work is supported by the science and technology development project of Jilin province [Grant numbers 20210201051GX and 20210203161SF], and the education department project of Jilin province [Grant number JJKH20220686KJ].
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Conceptualization and Writing—original draft preparation: [Huangshui Hu]; Methodology: [Xinji Fan]; Formal analysis and investigation: [Chuhang Wang]; Writing—review and editing: [Tingting Wang], [Yuhuan Deng].
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Research involving human and animal rights
This article does not contain any studies with human participants or animals performed by any of the authors. No violation of Human and animal rights is involved.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Hu, H., Fan, X., Wang, C. et al. Particle swarm optimization and fuzzy logic based clustering and routing protocol to enhance lifetime for wireless sensor networks. Cluster Comput 27, 9715–9734 (2024). https://doi.org/10.1007/s10586-024-04453-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-024-04453-z