
Abstract
Cloud computing has attracted scientists to deploy scientific applications by offering services such as Infrastructure-as-a-service (IaaS), Software-as-a-service (SaaS), and Platform-as-a-Service (PaaS). The research community is able to get access to resources on-demand within a short period of time. But, as the demand for cloud resources is dynamic in nature, this affects resource availability during scheduling. Hence, there is a need for efficient management of resources so that tasks can be scheduled based on their execution requirements. To provide a solution, a resource prediction based scheduling approach has been introduced in this paper which automates the resource allocation for scientific applications in a virtualized cloud environment. This research work focuses on the design of an optimized prediction based scheduling approach which maps the tasks of scientific application with the optimal VM by combining the features of swarm intelligence and TOPSIS. The proposed approach minimizes the execution time, cost, and SLA violation rate in comparison to existing scheduling heuristics.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Cloud computing offers unlimited resources to its users in the form of services like Infrastructure-as-a-service (IaaS), Software-as-a-service (SaaS), and Platform-as-a-service (PaaS). Virtualization is a key process in cloud computing that segregates the resources of a physical machine (PM) to create more than one execution environment and enable the concept of multi-tenancy. These peculiar characteristics of the cloud environment lead to certain major challenges such as load-balancing, fault-tolerance, and scheduling. Task scheduling (TS) is a multi-objective NP hard optimization problem whose objective is to achieve successful mapping between tasks and VMs by minimizing the execution time, cost, and service level agreement (SLA) violations between cloud user and provider.
Virtualized cloud systems have become popular in hosting complex scientific applications such as montage, cybershake, inspiral, sipht, etc. Cloud clients deploy the applications onto the VMs in the cloud with dedicated resource requirements for performance guarantee, which is specified in terms of Service Level Agreement (SLA). The workload of VMs varies all the time and some may exhibit weekly or seasonal variability. To guarantee good performance at periods of peak demand, VMs processing capacity is often over-provisioned. This leads to poor scheduling and cloud providers are unable to exploit the benefits out of cloud services. Thus, it is still a challenging problem for cloud providers to schedule the virtualized resource adaptively in order to handle variable workloads without SLA violation. The significant prediction of resource usage is essential to achieve optimal resource scheduling for cloud computing [1]. Hence, prediction based scheduling is the motivation behind this research work.
This research work focuses on the design of an Optimized Prediction based Scheduling Approach (OPSA) which maps the tasks of scientific application with the optimal VM. The existing approaches have not focused on predicting the set of resources required for executing a scientific application and simultaneously scheduling the resources based on the prediction in an optimized manner. The proposed work takes the predicted set of resources as input and schedules these scientific applications by the efficient utilization of resources while simultaneously reducing the SLA violations at runtime, thereby achieving cost-effectiveness and desired performance. To handle the problem of multi-objective task scheduling, a multi-criteria decision making algorithm ``TOPSIS" is incorporated. TOPSIS is a mathematical multi-criteria decision based algorithm which supports the working of swarm intelligence algorithm by finding local optimum solutions. Here, TOPSIS is used to compute the fitness value of tasks which is further utilized by swarm intelligence algorithm to schedule the tasks of scientific application.
2 Related work
Various researchers have proposed prediction and scheduling techniques but to perform prediction based scheduling is still a challenging problem. Prediction is basically used to enhance the effectiveness of scheduling algorithms. Zhiping et al. [2] have proposed a Deep-Q network based online resource scheduling framework that combines the capabilities of prediction and scheduling. The authors have used Google Cluster Usage Traces for conducting the experiments. The focus of paper is on two optimization objectives namely task makespan and energy consumption. Bo et al. [3] in their survey paper has stated that cloud is a cost-efficient way to address the issue of resource scarcity for meeting the peak demands of its users. Resource utilization, cost, SLA violation are few major challenges which researchers need to address. Fatemah and Seyed [4] proposed an autonomic task scheduling algorithm for executing the dynamic workloads in a cloud environment. They used the combination of prediction technique ANFIS and autonomous load balancing technique for minimizing the response time and maximizing the utilization of available cloud resources. Mahmood, and Kamran [5] introduced BCFramework with focus a on provisioning and scheduling of public cloud resources for big data. The proposed approach minimizes the average tuple latency and public cloud resource utilization cost but it does not consider a prediction model for handling big data fluctuations. Haion et al. [6] proposed a multi-prediction based scheduling approach which reduces the task failures and increases the resource utilization for hybrid workload in the cloud data center.
Table 1 summarizes the existing resource prediction based scheduling approaches. This table presents the prediction and scheduling techniques used, problem solved, computational requirements, outcomes, and forthcoming challenges. From the literature review, it can be inferred that a lot of work has been done towards prediction based scheduling of resources but none of the approaches is application specific. Moreover, there is need to improve the execution time, cost, and SLA violations as mentioned in the challenges of the surveyed research work. Therefore, there is a lot of scope to apply these approaches specifically for scientific applications in cloud environment and enhance the performance in terms of execution time, cost and SLA violations.
2.1 The main contributions of this research work are
-
In this proposed research work (OPSA), the predicted CPU & memory usages have been taken as input.
-
The application resource requirements for execution have been compared against the availability of resources on VMs.
-
Applications are mapped to suitable VMs.
-
The tasks of the mapped application were scheduled using a combination of swarm intelligence and Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS).
-
TOPSIS, a multi-criteria decision making algorithm, has been used to compute the fitness value of the tasks in the swarm algorithm to optimize the scheduling of resources.
-
The fitness values calculated by TOPSIS have been assigned as local best (\(pbest\)) values of tasks.
-
The task with the highest fitness value has been considered as global best (\(gbest\)) and it has been assigned to VM for execution and the process has been repeated until all the tasks were scheduled.
The key objectives of the proposed approach have been the reduction of execution time, cost, and SLA violation rate. The proposed approach has been validated by comparing the results with existing scheduling heuristics.
2.2 Problem formulation
The objective of the task scheduling algorithm in this research work is to solve the problem of scheduling n tasks of a scientific application on a set of m heterogeneous VMs to attain certain goals such as minimizing total execution time, minimizing cost, and reducing SLA violations. So, there is a need for an efficient scheduling algorithm which can take into consideration multiple objectives. Many parameters have been initialized as shown in Table 2 and various terms used in problem formulation are given in Table 3.
The following objective problems are taken into account for developing an optimal scheduling algorithm.
2.2.1 Total execution time
The time taken by a job to execute on a particular VM is known as execution time [13]. \({ET}_{n}\) is the execution time of the jobs running in VMs on the nth node and is defined as Eq. 1:
where \({ET}_{nmk}\) is the execution time for k jobs running on m VMs on the nth node. Hence, the total execution time (ET) is Eq. 2:
where M is the total number of nodes.
2.2.2 Total execution cost
The cost of executing a job on a VM is computed by Eq. 3:
2.2.3 SLA violation (SLAV)
The end users state the QoS requirements to the Cloud Service Providers (CSPs) in the form of Service Level Agreements (SLAs) [14]. It is the responsibility of the CSPs to make sure that an appropriate amount of resources are allocated to an application in order to fulfill the users’ demands and minimize the SLA Violations (SLAV). The formula to compute SLAV is given in Eq. 4:
here, \(prev\,Requested\) is the total amount of CPU MIPS and memory bytes requested/required by a job for execution. This is computed using the ensemble algorithm (Algorithm 1) which provides the predicted set of resources (CPU and Memory). \(prevAllocated\) is the total amount of CPU MIPS and memory bytes allocated for the execution. These two parameters in the practical scenario are obtained using the cloudsim classes “getAvailableMIPS()” and “getCurrentsize()”. The total amount of available CPU MIPS and available memory is recorded and allocated using the proposed prediction based scheduling algorithm (Algorithm 2).
2.2.4 Average CPU utilization
At any given time, for nth node, the CPU utilization \({ACU}_{n}\) can be given as Eq. 5:
where \({v}_{n}\) is the number of VMs running on the nth node and \({j}_{n}\) is the number of jobs assigned to \({v}_{n}\) VMs. \({JCT}_{nmk}\) is the CPU utilization of k jobs running on m VMs on the nth node. The CPU utilization in percentage is calculated as Eq. 6:
where,
2.2.5 Average memory utilization
At any given time, for nth node, the memory utilization \({AMU}_{n}\) can be given as Eq. 7:
where \({v}_{n}\) is the number of VMs running on the nth node and \({j}_{n}\) is the number of jobs assigned to \({v}_{n}\) VMs. \({JMU}_{nmk}\) is the memory utilization of k jobs running on m VMs on the nth node. The memory utilization in percentage is calculated as Eq. 8:
where \({TMU}_{n}\) is the total memory utilization for the nth node.
2.3 Fitness value formulation
In this research work, the problem formulation for minimizing objective criterion mentioned in Eqs. 1–3 can be optimized. The Relative Closeness Score (\(RCS\)) for each task is calculated using a multi-criteria decision making algorithm, TOPSIS [15, 16]. This algorithm will enhance the proficiency of task scheduling by supporting multiple objectives. The \(RCS\) value computed by TOPSIS is taken as Fitness Value (\(FV\)) of the tasks for the proposed scheduling algorithm.
\({FV}_{t1}\) | = \({RCS}_{t1}\) |
\({FV}_{t2}\) | = \({RCS}_{t2}\) |
– | – |
– | – |
– | – |
\({FV}_{ti}\) | = \({RCS}_{ti}\) |
where \(RCS\) of tasks obtained using TOPSIS is \({RCS}_{t}= {RCS}_{t1}, {RCS}_{t2},\dots ,{RCS}_{ti}\) which corresponds to the \(FV\) of tasks \({FV}_{t}= {FV}_{t1}, {FV}_{t2},\dots , {FV}_{ti}\), respectively. Fitness Value (\(FV\)) is unique to problems and is used to calculate particle efficiency. The search space represents the number of particles in the population. Particles are randomly initialized and each particle has a \(FV\) obtained using TOPSIS. The best results (i.e. \(FV\)) obtained so far by the particle is the \(pbest\) of a particle, while \(gbest\) is \(FV\) of the best particle in the search space. The TOPSIS algorithm for computing \(RCS\) of tasks is elaborated in the next section.
3 Resource prediction based scheduling framework
To achieve highly effective computations and the best Quality of Service (QoS) of the cloud, it is vital to perform the scheduling of tasks in an efficient manner. The mapping of the submitted applications and VMs are considered to be successful if attained minimum execution time, cost, SLA violations, and maximum utilization of resources has been attained. To solve the problem of multi-objective task scheduling an Optimized Prediction based Scheduling Approach (OPSA) has been proposed in this paper.
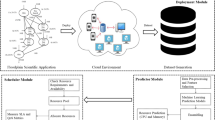
This section details the framework of the proposed RPS technique as portrayed in Fig. 1. This framework contains three modules: deployment, prediction, and scheduler which are explained further.

Proposed RPS framework
In the deployment module, the scientific application is executed on the WorkflowSim (a cloud simulator for scientific applications) [17]. Here, “Cybershake” and “Floodplain” are used as two different case studies in this research work. The scientific applications considered here are based on workflows and every workflow has a different number of execution levels. When level 1 is completed, the execution of level 2 is started, and so on. Therefore, each workflow is divided into execution levels. The tasks at every level have different execution requirements and those execution requirements are gathered using Microsoft Azure cloud instances and Algorithm 1 is used for future resource usage prediction.
Once the application is deployed, a resource usage dataset is generated and passed onto the prediction module for further processing. The proposed method used the simulation programming to the scientific application being deployed on the cloud and corresponding resource usage data from the Microsoft Azure Cloud instances rented in real time, then extracts data features to form the sample dataset and finally makes the resource usage prediction. The prediction module performs the preprocessing of data so that there are no null values and converts the alphabetic values to numeric for smooth processing. It also selects the relevant features using a Genetic Algorithm, a meta-heuristic feature selection approach. Finally, this module predicts the usage of resources by implementing an ensemble algorithm [18] as proposed in our previous research work.
3.1 Machine learning models
Machine learning is a process of modeling and analyzing learning processes that enhance system efficiency and improve the performance of an application. Machine learning can be categorized as supervised, unsupervised, and reinforcement learning. Numerous applications of machine learning involve only those tasks that can be employed as supervised. It enables the systems to learn from data, identify the hidden patterns, and make decisions with the least human interference.
-
Bayesian ridge regression: Bayesian ridge regression (BRR) [19] model comprises special cases like t-test and anova. This model was intended to fit parametric regression models utilizing distinctive kinds of shrinkage techniques. BRR is formulated as depicted in Eq. 9:
$$Y=XB+e$$(9)here, Y is the dependent variable, X is the independent Variable, B is the regression coefficient, e is the Error. B is calculated as: BOLS = (XT X) − 1 XT Y [OLS: Ordinary Least Squares] where XTX = R and R is a Correlation Matrix.
-
Bayesian regularized neural network: The need for lengthy cross-validation is eliminated or reduced by Bayesian regularized neural networks (BRNN) [20, 21] as they are better than standard back-propagation nets. In this mathematical method of Bayesian regularization, non-linear regression is converted to a “well-posed” statistical problem in the manner of ridge regression. The formula to compute BRNN is shown in Eq. 10:
$${Y}_{i}=g\left({X}_{i}\right)+{e}_{i}={\sum }_{k=1}^{s}{w}_{k}{g}_{k}\left({b}_{k}+\sum_{j=1}^{p}{X}_{ij}{\beta }_{j}^{\left[k\right]}\right)+{e}_{i};\quad i=1,\dots,\,n$$(10)here, \({e}_{i}\) ~ N(0,\({\sigma }_{e}^{2}\)), s is number of neurons, \({w}_{k}\) is weight of the kth neuron, k = 1,…….,s, \({b}_{k}\) is a bias for the kth neuron, k = 1,…….,s, \({\beta }_{j}^{[k]}\) is the weight of the jth input to the net, j = 1,…….,p, \({g}_{k}\)(.) is the activation function, \({g}_{k}\)(x) = (exp(2x ) −1)/(exp(2x) + 1), The software will minimize F = \(\beta {E}_{D}+ \alpha {E}_{w}\) where\({E}_{D}=\sum_{i=1}^{n}{({y}_{i}-{\widehat{y}}_{i})}^{2}\). Error sum of squares, \({E}_{w}\) is the sum of squares of network parameters (weights and biases), \(=\beta= 1/(2{\sigma }_{e}^{2}\),\( \alpha = 1/(2\sigma _{\theta }^{2})\), \({\sigma }_{\theta }^{2}\) is a dispersion parameter for weights and biases.
-
Neural network: Neural networks (NN) are distinguished under various types such as artificial neural network, recurrent neural network, recursive neural network, and so on. These are statistical learning models that deal with neurons similar to biological neural networks [20]. These neurons are interconnected to each other which exchange messages and the values are calculated using supervised or unsupervised learning. The connections within the network can be systematically adjusted based on the inputs and outputs and we can process them using various propagation techniques. NN is formulated as shown in Eq. 11:
$${P}_{j}\left(t\right)= {\sum }_{i}^{n}{O}_{i}\left(t\right){w}_{ij}$$(11)here, \({P}_{j}\left(t\right)\) is input to the neuron j, \({O}_{i}\left(t\right)\) is output of the predecessor neurons (used to calculate \({P}_{j}\)), i is the number of neurons in a level, w is the assigned weight and t is the value of the neuron.
-
Support vector machine: Support Vector Machine (SVM) [22] is a machine learning algorithm which is used for both regression and classification problems. The main principle used is the optimal separation. The one which is a good classifier is the one with the maximum distance between data points of different classes. The output of the algorithm is a hyperplane that is used for categorizing new data. SVM is formulated as depicted in Eq. 12:
$${\mathrm{min}}_{\mathrm{\alpha },{\mathrm{\alpha }}^{*}}\frac{1}{2}{\left(\mathrm{\alpha }-{\mathrm{\alpha }}^{*}\right)}^{\mathrm{T}}\mathrm{Q}\left(\mathrm{\alpha }-{\mathrm{\alpha }}^{*}\right)+{\mathrm{Z}}^{\mathrm{T}}\left({\mathrm{\alpha }}_{\mathrm{i}}-{{\mathrm{\alpha }}_{\mathrm{i}}}^{*}\right)$$(12) -
Subject to \(0\le {\mathrm{\alpha }}_{\mathrm{i}}, {{\mathrm{\alpha }}_{\mathrm{i}}}^{*}\mathrm{C };{\mathrm{e}}^{\mathrm{T}}\left(\mathrm{\alpha }-{\mathrm{\alpha }}^{*}\right)=0 ; {\mathrm{e}}^{\mathrm{T}}\left(\mathrm{\alpha }+{\mathrm{\alpha }}^{*}\right)={\mathrm{C}}_{\mathrm{v}}\)here, e is the unity vector, C is the upper bound, Q is l by l positive semi-definite matrix, \({\mathrm{Q}}_{\mathrm{ij}}={\mathrm{y}}_{\mathrm{i}}{\mathrm{y}}_{\mathrm{j}}\mathrm{K}\left({\mathrm{x}}_{\mathrm{i}},{\mathrm{x}}_{\mathrm{j}}\right),{\mathrm{Kx}}_{\mathrm{i}},{\mathrm{x}}_{\mathrm{j}}=\uptheta {({\mathrm{x}}_{\mathrm{i}})}^{\mathrm{T}}\uptheta ({\mathrm{x}}_{\mathrm{j}})\).
-
Decision tree (regression tree): Decision tree (DT) [23] classifies instances by starting at the root of the tree and moving through it till a leaf node. We will calculate the probability of occurrence of all the events at each level using the ID3 algorithm. This consists of a decision node which specifies each attribute, edge which splits one attribute into many. We also have a leaf node which tells us about the target attribute and its probability of occurrence. We also have a path that specifies the attributes to make a final decision.
-
For the given data: \(\mathrm{y}\in {\mathrm{R}}^{\mathrm{n}},\mathrm{ x}\in {\mathrm{R}}^{\mathrm{n}*\mathrm{p}}\); each observation \({(\mathrm{y}}_{\mathrm{i}}, {\mathrm{x}}_{\mathrm{i}})\in {\mathrm{R}}_{\mathrm{p}+1};\) i = 1, ………, n. Suppose we have partition of \({\mathrm{R}}_{\mathrm{p}}\) into m regions \({\mathrm{R}}_{1}\), ………..,\({\mathrm{R}}_{\mathrm{m}}\). We predict the response using a constant on each\({\mathrm{R}}_{\mathrm{i}}\).The formulation for DT is shown in Eq. 13:
$$f\left(x\right)=\sum_{i=1}^{m}{{C}_{i}.1}_{(x\in {R}_{i})}$$(13) -
Inorder to minimize \({\sum }_{i=1}^{n}{({y}_{i}-f\left({x}_{i}\right))}^{2}\) one needs to choose: \(({\widehat{C}}_{i}) = ave ({y}_{j}:{x}_{j}\in {R}_{i})\). Consider splitting variable \(j\in 1,\dots .,p\) and splitting point \(S\in R\). Define two half planes: \({R}_{1}\left(j,s\right)=\{x\in {R}^{p}:{x}_{j}\le s\}\) and \({R}_{2}\left(j,s\right)=\{x\in {R}^{p}:{x}_{j}>s\}\).
-
Extreme learning machine: This model [24] is a learning algorithm for the single hidden layer neural networks used in classification and regression [25]. The ELM used for single hidden layer feedforward neural network training can adaptively set the hidden layer node number and it can randomly assign the input weights so that output layer weights obtained by the least square method, the whole learning process completed with very little error(minimum number of error). The training speed compared with the traditional BP algorithm based on experiments is improved.
For N arbitrary distinct samples \(\left({x}_{i},{t}_{j}\right)\in {R}^{n}*{R}^{m}\)
Standard SLFNs with L hidden nodes and activation function g(x) are mathematically modeled as \(\mathrm{H\beta }=\mathrm{T}\) which is equivalent to Eq. 14,
$${\sum }_{i=i}^{L}{\beta }_{i}G({a}_{i},{b}_{i},{x}_{j})={t}_{j};{\quad}j=1,\dots,\,N$$(14)here, \({a}_{i}\) is the input weight vector connecting the ith hidden node and the input nodes, \({\beta }_{i}\) is the weight vector connecting the ith hidden node and the output node, \({b}_{i}\) is the threshold or impact factor of the ith hidden node and H is hidden layer output matrix.
-
Linear regression model: Linear Regression (LR) is the most commonly used category of predictive analysis [19]. It is used to show relationship between two or more variables where there are two types of variables one is dependent and the other is explanatory. LR is formulated as depicted in Eq. 15:
$$Y=\beta X + A + e$$(15)here, \(\beta \) is slope of the line (predicted increase or decrease for Y scores for each unit increasing X), X is the independent variable, A is Y-intercept (level of Y when X is 0) and e is the random error term.
-
Random forest: Random forest (RF) is a learning method that works by developing a huge number of choice trees at time of training and outputs the mean forecast (regression) of the individual trees. The formula for computing RF is shown in Eq. 16:
$${\mathrm{h}}_{k}\left(X\right)=h\left(X|{\theta }_{k}\right);{\quad}k=1,\dots,\,n$$(16)here, \({\theta }_{k}\): are independent identically distributed random vectors, X is input variable, n is the number of trees and h = {\({\mathrm{h}}_{1}\) (X),……..,\({\mathrm{h}}_{k}\) (X)} ensemble of classifiers.
The methods are available in R open source software [26] which is licensed under GNU GPL. To obtain better results, the parameters of the models need to be tuned. The brief detail of the methods with the required packages and their tuning parameters is described in Table 4.
The selected machine learning models are further assembled using the proposed ensemble algorithm which is discussed further.
3.2 Ensembling
Ensembling is the process of stacking multiple machine learning models and improving the prediction accuracy or decrease variance, by combining the capabilities of models. The machine learning regression models are applied to the generated dataset for predicting resource usage. These models are further grouped based on the proposed ensemble Algorithm 1.

This algorithm explains how the application requirements are obtained. It is an ensemble algorithm which provides the best combination of machine learning models and enhances the prediction accuracy. This ensembled model is applied to the generated resource usage dataset from Microsoft Azure for predicting future resource usage. The output produced by the ensembled Algorithm 1 is used as an input parameter in Algorithm 2 which further schedules the resources in an optimized manner.

In the proposed algorithm, a variety of combinations is formed for different models and means accuracy \(acc\) is calculated for each combination. The computed accuracy rate is further compared with the best accuracy \(BestAcc\) already generated. If the calculated \(acc\) is better than \(BestAcc\) then \(BestAcc\) is replaced with the calculated \(acc\) and the provided combination of models is returned as the best model set to ensemble. The primary focus of the proposed algorithm is to generate the best set of models which can be assembled to enhance the performance of regression models for predicting the usage of resources.
The working of the scheduler module depends upon the output of the prediction module. In this module, the availability of the resources is checked from the resource pool. Then, the resources are scheduled efficiently based on the usage requirements of the application for further processing as discussed in Algorithm 2. The aim of this scheduling algorithm is to improve the performance in terms of execution time, cost, and SLA by efficiently allocating the resources to the tasks.
3.3 Proposed algorithm
The objective of this algorithm is to find an optimal solution by considering multiple criteria. Therefore, the features of swarm intelligence are combined with TOPSIS. The former technique is very quick at determining the optimal solutions and the latter helps to make a decision based on multiple criteria. Swarm Intelligence is a simple optimization technique that performs the parallel execution of tasks to handle global optimization issues. It works with a swarm of individuals also known as particles. Each particle is a representation of a candidate solution. Particles observe basic conduct: imitate the performance of adjacent particles and success achieved on its own. Therefore, the location of a particle is determined by the best particle in the neighborhood \(pbest\) and by the best solution found by all the particles in the whole population \(gbest\). TOPSIS is a mathematical multi-criteria decision based algorithm which supports the working of swarm optimization by finding local optimum solutions. The traditional TOPSIS approach tries to pick alternatives that have the shortest distance from the ideal-positive solution at the same time and the farthest distance from the ideal-negative solution. The ideal-positive approach maximizes the benefits and minimizes the cost, while the negative optimal solution optimizes the cost criteria and the benefit criteria are minimized. TOPSIS makes good use of information on the attributes, offers a cardinal ranking of alternatives and does not require individual attribute preferences. To apply TOPSIS, the values of the attributes must be an integer (either in increasing order or decreasing).
In this algorithm, the resources are scheduled on the basis of a predicted set of resources by ensemble algorithm [18]. Initially, the average CPU utilization \(({AP}_{cp})\) and average memory utilization \(({AP}_{mem})\) requirement of a scientific application is checked against the available CPU and memory size of the firstIdleVm. If the CPU and memory requirements of the application are less than the available MIPS and current size of VM, then the application is mapped to that particular VM. Further, to schedule the tasks of mapped application, an optimization approach is followed. Each particle is represented by means of velocity \(({v}_{i})\) and position \(({p}_{i})\) that can be obtained using formula 17 and 18. Each particle determines its velocity \(({v}_{i})\) and position \(({p}_{i})\) according to its best position \(pbest\) and the best particle position in each generation \(gbest\). The values assigned to each particle’s dimensions reflect the computational resources allocated to VM. Therefore, a particle reflects the mapping of the tasks and available VM resources. The parameters are the tasks which are also allocated to the available VMs.
where \({V}_{i[k+1]}\) is current velocity and \({V}_{i\left[k\right]}\) is the previous velocity of particle i. \({P}_{i[k+1]}\) is current position and \({P}_{i[k]}\) is the previous position of the particle i. \(c1\) and \(c2\) are acceleration coefficients whose value can be taken between 1 and 2. \(rand1\) and \(rand2\) are the random numbers whose values lie between 0 and 1. In the traditional swarm optimization algorithm, the random values \((rand1\,and\,rand2)\) are generated by a uniform distribution method in the range of [0,1] (U[0,1]). The probability of each random value is similar in the range. This random parameter plays an important role in the overall performance, as it avoids premature convergences, increasing the most likely global optima. Particle's best position is denoted by \(pbest\) and the position of the best particle in the entire population is denoted as \(gbest\). \(w\) is the inertia weight usually lie between 0 and 1. Fitness Value (\(FV\)) is used as an evaluation tool to measure the performance of a particle. The \(FV\) for each task is computed using TOPSIS algorithm which is explained in Sect. 3.3. If the current fitness value of a task is less than its \(pbest\) value, then current fitness value is assigned as its \(pbest\) value and the same process is repeated for all the tasks. Next, all the personal best values \((pbest\)) are compared and the highest \(pbest\) value is assigned as the global best value \((gbest).\) Again, if the current \(gbest\) value is less than the current fitness value, then current fitness value is assigned as \(gbest\) value and the task with the highest \(gbest\) value is given to VM for execution. The same procedure is applied to the rest of the tasks of all the mapped applications.
3.4 TOPSIS- a multi-criteria decision making algorithm
Several heuristic techniques such as Particle Swarm Optimization (PSO), ANT Colony Optimization (ACO), Artificial Bee Colony (ABC), etc. have been utilized by various researchers for optimizing single criteria based problems. PSO is a stochastic evolutionary algorithm (EA) search process, based on population, modeling the behavior of bird flocks. This type of algorithm is suitable for solving problems where a point of optimal solution is within multidimensional parameter space. ACO is an optimization technique in which the task is to find the best possible path along with a graph. It basically works on the behavior of the ants looking for a path between the source of food and their colony. In ACO, the solutions are built on the basis of two factors (a) attractiveness: desire to take move for state transition and, (b) pheromone trail: social interaction among agents to follow the path. ABC simulates the smart foraging behavior of a swarm of honeybees. This algorithm comprises of three main components (a) food sources: a possible solution to the optimization problem, (b) employed foragers, and (c) unemployed foragers are the number of possible solutions for the given optimization problem. These optimization techniques lack the ability to handle decision making based on multiple criteria. In order to attain better optimized results for problems based on multiple criteria, a multi-objective decision making algorithm named "TOPSIS" is incorporated [15, 16]. This method takes multiple factors into consideration while computing the fitness value for tasks. Algorithm 3 depicts the overall process followed by TOPSIS algorithm.
Initially, a decision matrix is constructed of size \(t*c\), where t are the number of tasks (alternatives) and c represents the number of criterion as shown in Table 5.
Next, the decision matrix is normalized using Eq. 19.
where i = {1,2,…,t}, j = {1,2,…,c} and (\({DM}_{n}\left[j\right][i])\) are the elements of the decision matrix corresponding to \({i}^{th}\) alternative and \({j}^{th}\) criteria. Further, the elements of \({(DM}_{n}\left[j\right][i])\) are multiplied by inertia weight as shown in Eq. 20, provided by the decision maker as per the importance of criteria in the scheduling process.
Now, calculate the \({Att}_{p}\) and \({Att}_{n}\), where \({Att}_{p}\) are the set of attributes that have positive impact and \({Att}_{n}\) are those set of attributes which have negative impact on the solution.
Next step is to evaluate the separation measure for \({Att}_{p}\) and \({Att}_{n}\) for each attribute using Eqs. 21 and 22.

Finally, compute the relative closeness score (\(RCS\)) using Eq. 23 and update the velocity of tasks (particles) in Algorithm 2 for determining the \(gbest\) value for scheduling.
The final computed RCS is shown in Table 6. The score is sent as FV for the tasks in Algorithm 2 for scheduling.
4 Experimental setup and results
The tools used to set up a testbed for experiments include Netbeans IDE 8.2, CloudSim 3.0, WorkflowSim 1.0, Java SDK 8, Microsoft Azure. WorkflowSim extends the features of CloudSim that facilitates simulating cloud environments by creating datacentres, hosts, VMs, cloudlets, etc. This has been used to collect the resource usage requirements of scientific applications. OpenStack, an open source software platform for cloud computing, is installed on the server (HP DL380) to setup a cloud environment.
Further, four heterogeneous virtual machines are created for parallel execution of application. The performance of the proposed resource prediction model has been validated in a cloud environment.
The characteristics of the VMs are mentioned in Table 7 which clearly indicates that all the four VMs have different configurations which creates a distributed environment for deploying applications. The resource usage of the VMs before deploying the application is shown in Table 8.
4.1 Scenario 1: Cybershake scientific application
CyberShake represents the aleatory variability in wave excitation through conditional hypocenter distributions and conditional slip distributions, and it characterizes the epistemic uncertainty in the wavefield calculations in terms of alternative 3D seismic-velocity models [27]. There are four different CyberShake applications namely cyber30, cyber50, cyber100, and cyber1000, which vary in number of instances. The resource usage requirement of these applications is shown in Table 9. The application requirements have been obtained using the prediction algorithm (Algorithm 1). In this algorithm, the previous usage of resources along with application size and various other factors has been taken into input. Finally, based on the historical data and by applying our ensemble algorithm, the application resource requirements are predicted.
The proposed prediction based scheduling approach has been compared with the existing heuristics namely DataAware, FCFS, MaxMin, MinMin, and MCT on the basis of execution time and cost. The results are also validated on the basis of SLA violation rate and the comparative analysis is shown between proposed and existing scheduling approaches.
4.1.1 Results: Cybershake scientific application
• Case 1: execution time
The performance of proposed approach has been analyzed with Cybershake application with 30, 50, 100 and 1000 tasks. The time taken by existing and proposed scheduling approach for executing cyber30, cyber50, cyber100 and cyber1000 can be seen in Fig. 2.

Execution time comparison of existing and proposed scheduling approach
The time taken by RPS approach for executing Cyber30 is 30.18 ms while the existing heuristics DataAware, FCFS, MaxMin, MCT and MinMin executed the applications in 62.59 ms, 84.005 ms, 125.76 ms, 71.63 ms and 49.04 ms, respectively. Similarly, for Cyber50, Cyber100 and Cyber1000, the proposed approach took 42.63 ms, 53.70 ms and 73.03 ms respectively. In comparison, the DataAware approach executed Cyber50, Cyber100 and Cyber1000 in 76.83 ms, 83.78 ms, and 94.45 ms respectively. Further, FCFS executed Cyber50 in 137.08 ms, Cyber100 in 154.46 ms and Cyber1000 in 189.99 ms. Also, the execution time taken by MaxMin is 154.73 ms, 155.16 ms and 169.81 ms for Cyber50, Cyber100 and Cyber1000, respectively. Next, MCT accomplished the execution of Cyber50, Cyber100 and Cyber1000 in 85.37 ms, 95.36 ms and 150.40 ms, respectively. At last, MinMin executed Cyber 50 in 63.41 ms, Cyber100 in 93.89 ms and Cyber1000 in 103.49 ms.
The results shown in Fig. 2 clearly states that the proposed prediction based scheduling approach took far less execution time when compared to existing scheduling approaches. The overall execution time is curtailed by 35.59% using the proposed approach.
• Case 2: cost
With every action during the application execution there is a cost associated with it, for example- cost for resource usage, data transfer cost, and execution cost. The cost incurred by existing and proposed approaches is depicted in Fig. 3. The cost obtained by the proposed approach for executing 30 jobs of Cybershake is 144.54 INR which is least amongst existing scheduling heuristics whereas, MaxMin attained the highest cost of 602.21 INR. For executing 50 jobs, RPS approach obtained cost of 204.16 INR while MaxMin executed the jobs with highest cost of 740.92 INR, FCFS with 656.40 INR. Similarly, for executing 100 & 1000 jobs of cybershake the proposed RPS approach incurred the minimal cost of 257.14 INR and 349.72 INR whereas MaxMin (742.98 INR) and FCFS (909.75 INR) obtained the highest cost to execute 100 & 1000 jobs of cybershake. Hence, the proposed approach is better than the existing approaches as it has minimum execution cost.

Cost comparison of existing and proposed scheduling approach
• Case 3: SLA violation rate
It is very important that there should be minimal violation of SLAs so that cloud providers are able to retain their users. Another major goal of the proposed approach was to reduce the SLA violation. The results of the SLA violation rate can be seen in Fig. 4.

SLA Violation rate comparison of existing and proposed scheduling approach
FCFS has the highest SLA violation rate of 10.32%, followed by DataAware and MCT with 5.44% and 2.25%. The MaxMin and MinMin have very minute difference between SLA violation, the former attained 1.14% while the latter obtained 1.70%. The proposed approach has 0.91% of SLA violation rate, which is the least amongst existing scheduling approaches. It can be clearly seen that the proposed approach has the minimum rate of SLA violation. Therefore, the proposed prediction based scheduling approach is better than the existing approaches.
4.2 Scenario 2: floodplain scientific application
Floodplain application [28, 29] is committed to developing an accurate simulation for frequent surges in storms at North Carolina's coastal regions. Currently, a four model system is deployed which comprises of different models namely Hurricane Boundary Layer which is focused on winds, ADCIRC is for surges in the storms, SWAN and Wavewatch III are directed towards waves generated by winds at near-shore along with oceans. To achieve accuracy in analysis and floodplain mapping in a given region, broader coverage of parametric space is needed which also describes the characteristics of storms. The application's instance executes in about a day, hence demanding large computational and storage resources. There are four different sizes of Floodplain applications namely flood10, flood20, flood30, and flood50, which vary in number of jobs. The resource usage requirement of Floodplain application with different number of jobs like 10, 20, 30, and 50 is shown in Table 10.
The proposed prediction based scheduling approach has been compared with the existing heuristics namely DataAware, FCFS, MaxMin, MinMin, and MCT on the basis of execution time and cost. The results are also validated on the basis of SLA violation rate and the comparative analysis is shown between proposed and existing scheduling approaches. The proposed RPS approach has been executed and tested on Microsoft Azure Cloud by incorporating Azure Scheduler. Firstly, a resource group has been set up in the cloud where VMs have been created for executing scientific applications. Further, the jobs of scientific applications have been uploaded in the scheduler job collections directory for execution. Finally, the resources are scheduled efficiently to the application for further processing as discussed in Algorithm 2.
4.2.1 Results: floodplain scientific application
• Case 1: execution time
The performance of the proposed scheduling approach has been analyzed for floodplain application with 10, 20, 30, and 50 jobs where every single job can comprise of hundred to thousand tasks. It is evident from Fig. 5 that the proposed scheduling approach has minimal execution time (20.65 ms) for flood application with 10 jobs, whereas Max–Min has the maximal execution time of (68.65 ms). The performance of the proposed approach is also verified by incrementing the size of application to 20, 30, and 50 jobs.

Execution time comparison of existing and proposed scheduling approach
The proposed approach obtains the least execution time of (32.106 ms) for 20 jobs, while FCFS attains the highest execution time (73.68 ms). Similarly, for 30 and 50 jobs the proposed approach has the lowest execution time (48.84 ms) and (62.719 ms), wherein MCT and Max–Min give the highest execution time (91.36 ms) and (109.53 ms), respectively. The experimental results shown in Fig. 5 clearly states that the execution time taken by the proposed prediction based scheduling approach is far less than the execution time taken by existing scheduling approaches.
• Case 2: cost
With every action during the application execution there is a cost associated with it, for instance- cost for execution, resource usage and data transfer. The cost incurred by existing and proposed approaches is depicted through Fig. 6. The proposed approach obtained the cost of 98.87 INR for executing flood application with 10 jobs which is least amongst existing approaches, whereas Max–Min scheduling approach incurred highest cost of 328.71 INR. Similarly, the cost incurred by proposed RPS approach for 20, 30 and 50 jobs is 153.73 INR, 233.85 INR and 300.31 INR respectively. On the contrary, FCFS attained the maximum cost of 352.80 INR for flood application with 20 jobs, MCT incurred highest expense of 437.45 INR for flood application with 30 jobs and Max–Min obtained the cost of 524.45 INR for flood application with 50 jobs, respectively. It is apparent that for all the different sizes of application the proposed approach have least execution cost, therefore the proposed RPS approach is better in comparison to existing scheduling heuristics.

Cost comparison of existing and proposed scheduling approach
• Case 3: SLA violation rate
It is very important that there should be minimal violation of SLAs so that cloud providers are able to retain their users. Another major goal of the proposed approach was to reduce the SLA violation. FCFS has the highest SLA violaton rate of 8.21%, followed by DataAware and MCT with 6.04% and 2.19%. Thr MaxMin and MinMin have very minute difference between SLA violation, the former attained 1.92% while the latter obtained 1.13%. The proposed approach has 0.74% of SLA violation rate, which is least amongst existing scheduling approaches.
The graphical representation of the above mentioned results is depicted using Fig. 7. It can be clearly seen that the proposed approach has the minimum rate of SLA violation. Therefore, the proposed prediction based scheduling approach is better than the existing approaches.

SLA Violation rate comparison of existing and proposed scheduling approach
5 Conclusion and future scope
This research work focused on the importance of optimized prediction based scheduling approach for scientific applications in a cloud environment. It elaborated the characteristics chosen through the feature selection approach and discusses a cloud testbed that was set up for testing and validating the proposed approach. The results of the proposed prediction based scheduling approach are validated for “Cybershake” and “Floodplain” scientific applications along with existing scheduling heuristics. The proposed OPSA approach outperforms the existing approaches in terms of execution time, cost and SLA violation rate. In the future, the proposed research work can be extended for different applications such as montage, epigenomics, weather prediction, and predicting anomalies.
References
Kaur, G., Bala, A.: A survey of prediction-based resource scheduling techniques for physics-based scientific applications. Mod. Phys. Lett. B 32(25), 1850295 (2018)
Peng, Z., Lin, J., Cui, D., Li, Q., He, J.: A multi-objective trade-off framework for cloud resource scheduling based on the deep q-network algorithm. Clust. Comput. (2020). https://doi.org/10.1007/s10586-019-03042-9
Wang, B., Wang, C., Song, Y., Cao, J., Cui, X., Zhang, L.: A survey and taxonomy on workload scheduling and resource provisioning in hybrid clouds. Clust. Comput. (2020). https://doi.org/10.1007/s10586-020-03048-8
Ebadifard, F., Babamir, S.M.: Autonomic task scheduling algorithm for dynamic workloads through a load balancing technique for the cloud-computing environment. Clust. Comput. (2020). https://doi.org/10.1007/s10586-020-03177-0
Mortazavi-Dehkordi, M., Zamanifar, K.: Efficient deadline-aware scheduling for the analysis of big data streams in public cloud. Clust. Comput. 23(1), 241–263 (2020)
Jiang, H., Haihong, E., Song, M.: Multi-prediction based scheduling for hybrid workloads in the cloud data center. Clust. Comput. 21(3), 1607–1622 (2018)
Borkowski, M., Schulte, S., Hochreiner, C.: Predicting cloud resource utilization. In: 2016 IEEE/ACM 9th international conference on utility and cloud computing (UCC), pp. 37–42, IEEE (2016).
Li, J., Ma, X., Singh, K., Schulz, M., de Supinski, B.R., McKee, S.A.: Machine learning based online performance prediction for runtime parallelization and task scheduling. In: 2009 IEEE international symposium on performance analysis of systems and software, pp. 89–100, IEEE.
Kang, S., Veeravalli, B., Aung, K.M.M.: Dynamic scheduling strategy with efficient node availability prediction for handling divisible loads in multi-cloud systems. J. Parallel Distrib. Comput. 113, 1–16 (2018)
Ghobaei-Arani, M., Jabbehdari, S., Pourmina, M.A.: An autonomic resource provisioning approach for service-based cloud applications: a hybrid approach. Fut. Gener. Comput. Syst. 78, 191–210 (2018)
Choudhary, A., Gupta, I., Singh, V., Jana, P.K.: A GSA based hybrid algorithm for bi-objective workflow scheduling in cloud computing. Fut. Gener. Comput. Syst. 83, 14–26 (2018)
Zhang, N., Yang, X., Zhang, M., Sun, Y., Long, K.: A genetic algorithm-based task scheduling for cloud resource crowd-funding model. Int. J. Commun. Syst. 31(1), e3394 (2018)
Kansal, N.J., Chana, I.: Artificial bee colony based energy-aware resource utilization technique for cloud computing. Concurr. Comput.: Pract. Exp. 27(5), 1207–1225 (2015)
Emeakaroha, V.C., Netto, M.A., Calheiros, R.N., Brandic, I., Buyya, R., De Rose, C.A.: Towards autonomic detection of SLA violations in cloud infrastructures. Fut. Gener. Comput. Syst. 28(7), 1017–1029 (2012)
Behzadian, M., Otaghsara, S.K., Yazdani, M., Ignatius, J.: A state-of the-art survey of topsis applications. Expert Syst. Appl. 39(17), 13051–13069 (2012)
Jahanshahloo, G.R., Lot, F.H., Izadikhah, M.: An algorithmic method to extend topsis for decision-making problems with interval data. Appl. Math. Comput. 175(2), 1375–1384 (2006)
Chen, W., Deelman, E.: Workflowsim: a toolkit for simulating scientific workflows indistributed environments. In: 2012 IEEE 8th international conference on E-science, pp. 1–8, IEEE
Kaur, G., Bala, A., Chana, I.: An intelligent regressive ensemble approach for predicting resource usage in cloud computing. J. Parallel Distrib. Comput. 123, 1–12 (2019)
Fumo, N., Biswas, M.R.: Regression analysis for prediction of residential energy consumption. Renew. Sustain. Energy Rev. 47, 332–343 (2015)
Zhang, W., Duan, P., Yang, L.T., Xia, F., Li, Z., Lu, Q., Gong, W., Yang, S.: Resource requests prediction in the cloud computing environment with a deep belief network. Softw. Pract. Exp. 47(3), 473–488 (2017)
Takai, S., Yang, T., Cafeo, J.A.: A Bayesian method for predicting future customer need distributions. Concurr. Eng. 19(3), 255–264 (2011)
Islam, S., Keung, J., Lee, K., Liu, A.: Empirical prediction models for adaptive resource provisioning in the cloud. Fut. Gener. Comput. Syst. 28(1), 155–162 (2012)
Gupta, N., Ahuja, N., Malhotra, S., Bala, A., Kaur, G.: Intelligent heart disease prediction in cloud environment through ensembling. Expert Syst. 34(3), e12207 (2017)
Huang, G., Huang, G.-B., Song, S., You, K.: Trends in extreme learning machines: a review. Neural Netw. 61, 32–48 (2015)
Ismaeel, S., Miri, A.: Using elm techniques to predict data centre vm requests. In: 2015 IEEE 2nd international conference on cyber security and cloud computing, pp. 80–86, IEEE
R. D. C. Team: The R project for statistical computing. (2018). https://www.r-project.org/. Accessed 5 Dec 2020
Maechling, P., Deelman, E., Zhao, L., Graves, R., Mehta, G., Gupta, N., Mehringer, J., Kesselman, C., Callaghan, S., Okaya, D., et al.: Scec cybershake workflows automating probabilistic seismic hazard analysis calculations. In: Workflows for e-Science, pp. 143–163. Springer, London (2007)
Ramakrishnan, L., Gannon, D.: A survey of distributed workflow characteristics and resource requirements, pp. 1–23. Indiana University, Bloomington (2008)
Ramakrishnan, L., Plale, B.: A multi-dimensional classification model for scientific workflow characteristics. In: Proceedings of the 1st international workshop on workflow approaches to new data-centric science, p. 4, ACM
Acknowledgements
One of the authors, Gurleen Kaur, acknowledges the Maulana Azad National Fellowship, UGC, Government of India, for awarding the scholarship which helped to avail the required resources to carry out this research work.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kaur, G., Bala, A. OPSA: an optimized prediction based scheduling approach for scientific applications in cloud environment. Cluster Comput 24, 1955–1974 (2021). https://doi.org/10.1007/s10586-021-03232-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-021-03232-4