
Abstract
In terms of the model of errors-in-variables, this article analyses the causes of deviation based on the existing method of subspace identification in the closed-loop system; then, it puts forward another method of subspace identification with an auxiliary variable based on orthogonal decomposition. The auxiliary variables can be selected and improved by this method, improving the quality of system identification.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the past two decades, the subspace identification method (SIM) has undergone rapid development in both theory and practice [1,2,3,4,5,6,7]. In the actual industrial process, because of factors such as safety, economical efficiency and operation stability, the system should be operated under closed loop conditions; biased estimation may be obtained when identifying the system model through the method of open-loop subspace identification. This is a result of feedback when identifying models in the closed loop, causing the “future” inputs to be relevant to the “past” noise in the system; thus, the method of orthogonal projection applied by open-loop subspace identification will not be able to eliminate noise. Scholars have proposed different solutions in the field of closed-loop identification. Verhaege [8] applied the method of MOESP (Multivariable Output Error State Space) in closed-loop identification with the input and output state space model. However, a model order reduction process should be required in this method. Ljung and McKelvey [9] regarded the high-order ARX models obtained from the input and output data as a multi-step forward output predictor, assuming that the vector of the multi-step output prediction can be obtained when the input is zero and that system parameters are obtained by the state space regression equation. However, only the output noise is considered in these methods, and the input variables are noise free. Obviously, the assumption is not consistent with reality because all the observed variables will be affected by noise pollution.
For the EIV (errors-in-variables) model structure, namely, the input and output, both are affected by noise pollution. Chou and Verhaegen [10] put forward a new method of subspace identification. The method eliminates noise effects by regarding the past input/output data as auxiliary variables. Gustafsson and Tony [11] changed the steps of the traditional SIM and proposed a new subspace auxiliary variable method (Subspace-based Identification using Instrumental Variables, SIVs). The algorithm presented in literature [12] was included, and the identification precision was improved after the algorithm was modified. In terms of the algorithm itself, the input being independent of noise assumption is not involved in the two methods; thus, it seems that they can be applied for identification in a closed-loop system. However, this is not the case based on simulation examples; these two types of algorithms used in closed-loop identification do not obtain consensus estimates in some cases.
On the other hand, Wang and Qin [13,14,15] introduced the concept of parity space, i.e., considering the input and output variables at the same time. The EIV mode was identified in subspace through Principal Component Analysis, PCA, called SIMPCA. On the basis of this, through the model combining input/output, Huang [16,17,18] analysed the reason why the deviation exists in SIMPCA when the external excitation signal is white noise in closed-loop identification and then proposed the improvement on the new auxiliary variables. In the process of algorithm implementation, SVD should be applied twice to solve the orthogonal complement space in the two methods [19, 20]. It is difficult to determine the dimensions of the orthogonal complement space when the system order is unknown. According to the theory of stochastic implementation with external input, Katayama [20,21,22] decomposed the signal into a deterministic part and a random part by using orthogonal decomposition; thus, the system model can be estimated through the deterministic part.
This article first proposed auxiliary variables based on orthogonal projection in the framework of SIVs as an improved strategy of the SIM. Compared with the existing SIM based on instrumental variables, on the premise of ensuring high identification, the algorithm of this method is simpler and the computational complexity is lower. Through the analysis of the closed-loop identification problem, this article explains the cause of the possible errors in estimation through the method under the condition of closed-loop identification. To eliminate the deviation of the identification, it can be improved by new auxiliary variables proposed in this paper, and in addition, it is compared with PCA and methods of auxiliary variable subspace identification. The method proposed in this paper only depends on the choice of auxiliary variables; the algorithm is simpler and direct and is easy to implement. In the process of identification, SVD was implemented only once; the amount of the computation for derived matrix dimensions can be greatly reduced under the condition of unknown system order time. In addition, one should discuss the mode of choosing a variety of secondary variables and simultaneously validating the results with numerical simulation.
2 Description of the problem and assumptions
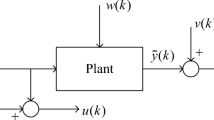
Assuming the system is defined as shown in Fig. 1, the discrete-time linear time-invariant model can be represented as the following state space form:

EIV model structure
\(x(k) \in \Re^{n},u^{\ast}(k) \in \Re^{l},y^{\ast}(k) \in \Re^{m}\) are state variables, noise-free input, and noise-free output; \(p(k) \in \Re^{n}\) is the process noise. The observable input u(k) and output y(k) are used for identification:
We assume that \(v(k) \in \Re^{l} ,o(k) \in \Re^{m}\) denote the input noise and output noise. They are considered according to the description based on the method of symmetry [10].
Here, the following assumptions are introduced:
-
A1
The system is asymptotically stable, for example, all the eigenvalues of A are strictly inside the unit circle.
-
A2
(A,C) is observable.
-
A3
Process noise p(k), measurement noise o(k) and v(k) are white noise, and they have past statistical independence from the noise input u*(k), e.g.,
$$E\left\{ {u^{\ast}\left( k \right)\left[ \begin{aligned} p\left( j \right) \hfill \\ o\left( j \right) \hfill \\ v\left( j \right) \hfill \\ \end{aligned} \right]^{T} } \right\} = 0\;j \ge k$$(3) -
A4
v(k) and o(k) are independent input noise and output noise, respectively, of the state sequence x(k); process noise p(k) (k ≥ 1) is independent of the initial state x(1), for example [10],
$$E\left[ {x ^{\ast} \left( k \right)p^{T} \left( j \right)} \right],\;{\text{for}}\;j \ge k \ge 0$$ -
A5
Three white noise sequences are relevant, and their covariance is determined by the following unknown matrix:
$$E\left\{ {\left[ {\begin{array}{*{20}c} {p(k)} \\ {o(k)} \\ {v(k)}\\ \end{array} } \right][\begin{array}{*{20}c} {p(j)^{T} } & {o(j)^{T} } & {v(j)^{T} } \\ \end{array} ]} \right\} = \left[ {\begin{array}{*{20}c} {R_{{pp}} } & {R_{{po}} } & {R_{{pv}} } \\ {R_{{po}}^{T} } & {R_{{oo}} } & {R_{{ov}} } \\ {R_{{pv}}^{T} } & {R_{{ov}}^{T} } & {R_{{vv}}} \\ \end{array} } \right]\delta _{{kj}}$$(4)
δkj is the Kronecker delta function. Noise-free input u*(k) meets the condition of “persistent excitation”.
Because of the dynamics of system modelling, we apply the extended state space model, e.g., stacking relationships between continuous variables. Regarding any time k as the current time, define the past and the future output vectors and the Hankel matrix output in the following form:
Iterating formulas (1) and (2), there exists
which is an extended observable matrix with rank n.
are Toeplitz matrices with two blocks;
vectors \(v_{f} (k) \in \Re^{lf} ,o_{f} (k) \in \Re^{mf} ,p_{f} (k) \in \Re^{nf} ,y_{f} (k)\) and yf(k) have similar definitions.
Define
Formula (9) is rewritten as
Once Hankel matrix data are used to replace the data vector, the extended model can be rewritten as follows:
Uf, Ef and Yf have the same structure, and formula (15) can be converted to formula (16) and augmented data matrix Zf:
Based on orthogonal subspace projection (ORT), the problem of EIV model identification is converted into giving input and output data of the noise disturbance,{u(k)}, {y(k)}, and setting point signal data if necessary; thus, the consensus estimates of the rank of the system and the system matrices for A, B, C, and D can be obtained.
3 Subspace Variable Method based on Orthogonal projection (ORT)
Stacking the vector in formulas(9)-(12)and replacing the block Hankel matrix, we can obtain
The key point in the method of subspace identification is to estimate the first term on the right side of formula (17); the extended observable matrix Γf or the state sequence Xk can be estimated after SVD. Therefore, we can estimate the parameter matrix in the system generally in the method of subspace identification. First, the second term of formula (17) (future input) can be eliminated by projection; then, the last three terms on the right side of formula (17) can also be eliminated by auxiliary variables, which is applicable in terms of the open-loop system. However, for the closed-loop system, a correlation exists between the input and output future noise; results may appear as a deviation caused by these identification steps. This situation can be improved if we change these two steps.
Step 1 Eliminate the noise terms. Suppose \(Z_{p} \equiv \left[ \begin{aligned} Y_{p} \hfill \\ U_{p} \hfill \\ \end{aligned} \right] \in \Re^{(lp + mp) \times N}\) then, make an orthogonal projection for Zp on both sides of formula (17),
Define \({\mathcal{K}}_{f} = G_{f} P_{f} + V_{f} - H_{f} O_{f}\)
This definition is similar to the rest because input in the past is irrelevant to output in the future; therefore,
When \(j \to \infty ,\) formula (18) can be rewritten as
Suppose \(\Uptheta = \Uppi_{Z_{p}}\); obviously \(\Uptheta^{T} = \Uptheta ,\) so
In fact, Θ is an auxiliary variable matrix.
Step 2 Eliminate the impact of future input data by orthogonal projection.
Project formula (21) onto the null space of \(\widehat{{\mathcal{Q}}}_{{u_{f} \xi }}\)
Obviously,
Range(*) stands for range space.
The next steps are similar to the method of typical subspace identification; first, obtain the augmented matrix through singular value decomposition (SVD), and then, the system matrix can be calculated.
Thus, we can obtain Γf = U1T, where T stands for a non-singular transformation matrix, usually a valued unit matrix or \(T = \Upsigma_{1}^{1/2}\) (Table 1).
Obviously, there are many other forms of auxiliary variables available; here, we choose the form based on the orthogonal projection called SIVort,
The above four algorithms are proposed in terms of the EIV model structure. Thus, the auxiliary variables in CSIV are the most simple and direct; the CSIV algorithm can be obtained by standardizing the method of CSIV. Literature [11] has described that the estimation accuracy can be further improved by these changes.
Therefore, in terms of estimates of the augmented observable matrix, the two algorithms SIV and SIVort are essentially the same. However, from the perspective of algorithm development, the inverse square root needs to be solved if we want to use standardized auxiliary variables, which requires a large calculation. Apparently, using the auxiliary variables in the form of orthogonal projection is much simpler.
In the algorithm, first perform RQ decomposition for the three algorithms:
Thus, we can obtain \(\widehat{{\mathcal{Q}}}_{{y_{f} \xi }} \Uppi_{{u_{f} \xi }}^{ \bot } = R_{22} Q_{2}^{T} R{\text{ange(}}\Upgamma_{f} ) {\text{ = Range(R}}_{22} ).\)
The estimation of R22 can be obtained based on SVD, so we can estimate the system matrix.
To date, it seems that the structure of EIV algorithms, such as CSIV, CSOPIM and CSIVort, can be applied for data in closed-loop identification because they do not require the input signal be independent of noise. However, some simulation results show that these algorithms may be inconsistent with the closed-loop estimation in some cases. Next, this issue will be specifically analysed.
4 Method of subspace identification based on auxiliary variable orthogonal projection
4.1 Analysis of the closed-loop solutions
Since the above algorithm performed well in open-loop system identification, the problem must be generated by the controller because both of them performed well in an open-loop condition. To determine the problem, the controller state-space model is as follows:
r stands for setpoint, and c stands for controller.
We can obtain the controller by subspace symbols as follows:
Rf and Rp are the Hankel data matrix for set points.
X c p and X c f are the state matrix for the controller, Γ c i is the extended observable matrix, and H c i is a three blocked Toeplitz matrix.
Formula (28) can be rewritten as:
Multiplying ΘT on the right of both sides of formula (28),
If the condition is satisfied, we can obtain
Thus,
Compared with formula (21), it is obvious that both \(\widehat{{\mathcal{Q}}}_{{x^{c} \xi }}\) and \(\widehat{{\mathcal{Q}}}_{x\xi }\) are included in \(\left[ {\widehat{{\mathcal{Q}}}_{{u_{f} \xi }} \;\;\;\widehat{{\mathcal{Q}}}_{{y_{f} \xi }} } \right]^{T}\) in terms of the row space. The models obtained from identification may be the process model, controller model or mutual interference model. Therefore, to ensure independence between the identified models and controllers, only the dynamics of the process need to be described, i.e., to make the auxiliary variables satisfy both conditions simultaneously:
Specifically, the selected auxiliary variables should be irrelevant to the various system noise and should be relevant to pumping signals of the set point at the same time.
4.2 Selection of the auxiliary variables based on orthogonal projection
Since the selection of auxiliary variables has a great impact on the results of recognition, we should treat this issue with caution. Combined with the results of the preceding analysis, it is natural that more information about Rf should be contained in the auxiliary variables.
Thus, the auxiliary variable matrix can be determined according to the following method:
To facilitate the description, the auxiliary variables are divided into three categories:
The direct form, e.g., CSOPIM and SOPIM
-
(1)
The standard form, e.g., CSIV and SIV
-
(2)
The Orthogonal projection form, e.g., CSIVort and SIVort
Given data \(u(k),r(k),y(k),k = 1 \ldots N,\) parameters in the time domain are f,p.
The improved subspace methods are as follows:
-
Step 1 Establish the block Hankel matrix \(U_{p} ,U_{f} ,Y_{p} ,Y_{f} ,R_{f} ,R_{p};\)
-
Step 2 Select the auxiliary variable matrix Θ according to \(\Uppi_{{Z_{p} }}\) or methods in formula (37);
-
Step 3 Perform an RQ decomposition as in formula (25);
-
Step 4 Perform a singular value decomposition in SVD on R22, so \(\Upgamma_{f} = U_{1} ;\)
-
Step 5 Compute system matrices A,B,C,D.
Remark 1 Different algorithms are required because of different auxiliary variables; apart from the previous forms of auxiliary variables, we have many other forms.
Remark 2 We should consider the model of noise, for example, the output forecast; the new system can be introduced in the following form:
Here, the variances of the Kalman gain K and new sequence e(k) need to be estimated. After obtaining the estimations for \(\Upgamma_{f} ,H_{f} ,\)K and Re can be obtained by using the method described in the literature [14].
5 Simulation study
In this section, the benchmark will be utilized to evaluate the raised method and compare it with a type of existing SIM. We will use the representative subspace algorithms described in the following literature: subspace identification algorithms in the EIV model proposed in the literature [1, 8, 10, 11, 14, 15], e.g., CSOPIM, CSIV, CSIMPCA and CSIVort. To follow the practice in the literature for subspace identification [10, 15], Monte Carlo simulations are performed and plotted with averaged Bode values. The estimated error variance can be presented by a scatter plot of estimated poles.
Consider the system described in literature [8], which is also a comparison of a benchmark problem used for a closed-loop subspace identification algorithm in literature [15]. In Fig. 1, the block diagram of the original system is displayed. This new model is presented in the form of an information state space represented by formulas (1)–(2), with values as follows:
The state space models of feedback control are as follows:
The conditions of simulation are exactly the same as those previously published (15); et is a Gaussian white noise sequence with a variance of \(\frac{1}{9}.\) The input reference r(k) denotes Gaussian white noise with a variance of 1. The simulation carried out at each time generates 1500 data points, and Monte Carlo simulation is performed 100 times by using the same input reference r(k) but a different noise sequence e(k).
In this simulation, we will reproduce the results previously described in literature [10,11,12, 14, 15] and compare them with the proposed CSIVort algorithms; the simulation results are depicted in Figs. 2 and 5. In terms of bias and variance, we find that the proposed CSIVort algorithm achieves better performance than the CSIMPCA algorithm. However, the proposed algorithm only needs to perform SVD once during the identification process, greatly reducing the amount of calculation for the dimension of the matrix derived under the condition of an unknown system. To determine the advantages of the proposed algorithm, we should consider the EIV cases of measured input ut and output yt with white noise. We ran the Monte Carlo simulation twice for EIV using a measured noise variance of 0.2 and 0.5. According to Figs. 3 and 5, if there is measured noise, it can be concluded that the proposed algorithm performed better than the CSOPIM algorithm and that there is a certain bias in CSOPIM.

Comparison between simulation results of CSIMPCA and real object

Comparison between simulation results of CSIV and real object
The proposed algorithm can be applied to open-loop identification because it is a closed-loop identification algorithm. There is a problem in its application method for open-loop identification. Therefore, we ran the Monte Carlo simulation using an open-loop device without feedback control. The results and other auxiliary variable subspace identification algorithm results are shown in Figs. 4 and 5; it can be seen that the CSIVort algorithm achieved consistent estimation.

Comparison between simulation results of CSOPIM and real object

Comparison between identical results of CSIVort and real object
Finally, we verify that when the external pumping signals are white noise, the identification algorithm CSIV with auxiliary variables based on orthogonal subspace projection enables consistent estimates in closed-loop identification, but the deviation will be reduced if the external stimulus is auto-correlative and the bias will be eliminated effectively by the CSIMPCA algorithm, as shown in Fig. 2. Simulation results of closed-loop CSIVort are shown in Fig. 5. In Fig. 5, there is an external excitation of white noise with unit variance; the right column corresponds to the relevant external excitation r, where r is white noise with a filter; the filter is a one rank system, with the pole of 0.9, and the variance of the excitation signal is 1. The results showed that (1) external incentives of auto-relevance can indeed reduce the deviation of CSIMPCA and (2) CSIVort performed significantly better than CSIMPCA.
6 Conclusion
In this paper, we develop an algorithm for subspace orthogonal projection identification based on the EIV model structure. However, when the external excitation signal is white, it will produce a bias for closed-loop identification. With the analysis of deviation in CSOPIM, CSIMPCA, and CSIV, we find that the same deviation is also included in other existing auxiliary variable SIMs in a closed loop, so these methods can only provide a partial solution for closed-loop identification. Based on this, we proposed an algorithm of closed-loop subspace with auxiliary variable identification (CSIVort) based on orthogonal decomposition; in addition, the calculation has been reduced effectively. Simulation of the benchmark allowed comparison of the proposed algorithm with several typical subspace auxiliary variable algorithms and verified its feasibility and closed-loop adaptability.
References
Liu, T., Shao, C.: An extended closed-loop subspace identification method for error-in-variables systems. Chin. J. Chem. Eng. 20(6), 1136–1141 (2012)
Liu, T., Huang, B., Qin, S.J.: Bias-eliminated subspace model identification under time-varying deterministic type load disturbance. J. Process Control 25, 41–49 (2015)
Danesh Pour, N., Huang, B., Shah, S.L.: Consistency of noise covariance estimation in joint input–output closed-loop subspace identification with application in LQG benchmarking. J. Process Control 19(10), 1649–1657 (2009)
Akhenak, A., Duviella, E., Bako, L., et al.: Online fault diagnosis using recursive subspace identification: application to a dam-gallery open channel system. Control Engineering Practice 21(6), 797–806 (2013)
Mercère, G., Lovera, M.: Convergence analysis of instrumental variable recursive subspace identification algorithms. Automatica 43(8), 1377–1386 (2007)
Miller, D.N., de Callafon, R.A.: Subspace identification with eigenvalue constraints. Automatica 49(8), 2468–2473 (2013)
Zhao, Y., Qin, S.J.: Subspace identification with non-steady Kalman filter parameterization. J. Process Control 24(9), 1337–1345 (2014)
van der Veen, G.J., van Wingerden, J.W., Bergamasco, M., Lovera, M., Verhaegen, M.: Closed-loop subspace identification methods: an overview. IET Control Theory Appl. 7(10), 1339–1358 (2013)
Bako, L., Merciare, G., Lecoeuche, S.: On-line structured subspace identification with application to switched linear systems. Int. J. Control 82(8), 1496–1515 (2009)
Verhaegen, M.: Application of a subspace model identification technique to identify LTI systems operating in closed-loop. Automatica 29(4), 1027–1040 (1993)
Ljung, L., Mckelvey, T.: Subspace Identification from Closed Loop Data. Signal Processing 52(2), 209–215 (1995)
Chou, C.T., Verhaegen, M.: Subspace algorithms for the identification of multivariable dynamic errors-in-variables models. Automatica 33(10), 1857–1869 (1997)
Gustafsson, T.: Subspace identification using instrumental variable techniques. Automatica 37(12), 2005–2010 (2001)
Wang, J., Qin, S.J.: A new subspace identification approach based on principal component analysis. J. Process Control 12, 841–855 (2002)
Qin, S.J.: An overview of subspace identification. Comput. Chem. Eng. 30(10–12), 1502–1513 (2006)
Wang, J., Qin, S.J.: Closed-loop subspace identification using the parity space. Automatica 42(2), 315–320 (2006)
Weng, J.H., Loh, C.H.: Recursive subspace identification for on-line tracking of structural modal parameter. Mechanical Systems and Signal Processing 25(8), 2923–2937 (2011)
Huang, B., Ding, S.X., Qin, S.J.: Closed-loop subspace identification: an orthogonal projection approach. J. Process Control 15(1), 53–66 (2005)
Katayama, T., Tanaka, H.: An approach to closed-loop subspace identification by orthogonal decomposition. Automatica 43(9), 1623–1630 (2007)
Katayama, T., Kawauchi, H., Picci, G.: Subspace identification of closed loop systems by the orthogonal decomposition method. Automatica 41(5), 863–872 (2005)
Zhang, P., Yang, D.Y., Chan, W.K., et al.: Adaptive wide-area damping control scheme with stochastic subspace identification and signal time delay compensation. IET Gener. Transm. Distrib. 6(9), 844–852 (2012)
Wang, L.-Y., Zhao, W.-X.: System identification: new paradigms, challenges, and opportunities. Acta Autom. Sin. 39(7), 933–942 (2013)
Acknowledgements
The authors are grateful to the associate editor and the referees for their scrupulous reading and for pointing out several errors in earlier versions of this manuscript. And we gratefully acknowledge the financial supported by the Science and Technology Research Program of Chongqing Municipal Education Commission (Grant No. KJ1729403).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
She, M., Ding, B. Closed-loop subspace identification of multivariable dynamic errors-in-variables models based on ORT. Cluster Comput 22 (Suppl 2), 4907–4915 (2019). https://doi.org/10.1007/s10586-018-2441-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-018-2441-3