
Abstract
Multi-sensor information fusion plays an important role in practical application. Although D-S evidence theory can handle this information fusion task regardless of prior knowledge, counter-intuitive conclusions may arise when dealing with highly conflicting evidence. To address this weakness, an improved algorithm of evidence theory is proposed. First, a new distribution distance measurement method is first proposed to measure the conflict between the evidences, and the credibility degree of the evidences can be obtained. Next, a modified information volume calculation method is also introduced to measure the effect of the evidence itself, and the information volume of the evidences can be generated. Afterwards, the credibility degree of each evidence can be modified based on the information volume to obtain the weight of each evidence. Ultimately, the weights of the evidences will be used to adjust the body of evidence before fusion. A numerical example for engine fault diagnosis exhibits the availability and effectiveness of the proposed method, where the BPA of the true fault is 89.680%. Furthermore, an application for target recognition is given to show the validity of the proposed algorithm, where the BPA of the true target is 98.948%. The experimental results show that the proposed algorithm has the best performance than other methods.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The information obtained from observed objects in a multi-sensor system is multi-attribute information, so the description of this information is more accurate than the description of the single-attribute information obtained from a single sensor. In a multi-sensor system, a sensor generally obtains information of only one attribute, each sensor has the corresponding sensing range, and together they construct a mutually independent and complementary sensing system to describe observed objects in as much detail as possible. Such a detailed description can be extracted through multi-sensor data fusion, but cannot be obtained from a single sensor. So far, multi-sensor data fusion technology has been widely used in various fields such as military [1, 2], robotics [3, 4], navigation [5, 6], medical diagnosis [7, 8], environmental monitoring [9, 10], and so on. However, multi-source data inevitably has some problems, such as data redundancy, conflicting information and uncertainty. How to deal with the data obtained from multi-sensor is still an open issue.
To address this issue, a series of theories have been proposed, such as probability theory [11, 12], fuzzy theory [3, 13], possibility theory [11], rough theory [14], and Dempster-Shafer evidence theory [15, 16]. As a frequently used technique, Dempster-Shafer evidence theory may generate some counter-intuitive conclusions when fusing conflicting data. The primary option is to modify Dempster’s combination rule, and others are to preprocess the evidences. Here, the main focus is on the latter, such as Murphy’s simple average approach of bodies of evidences [17], Deng et al’s weighting average method of the masses based on the distances of different evidences [18], Zhang et al’s cosine theory-based approach [19], Yuan’s entropy-based method [20] and Xiao’s belief divergence-based method [21]. Deng et al’s weighting average method overcomes the shortcomings of Murphy’s method and better reflects the correlation between conflicting evidences. Zhang et al. introduce the concept of vector space to handle conflicting evidence. By considering the evidence itself, Yuan’s method introduces the belief entropy to show the effect of the evidence itself. Inspired by Jensen-Shannon divergence [22], Xiao solves the problem of highly conflicting evidence based on belief divergence. However, there is still a lot of room for improvement to increase the credibility of practical applications.
In order to further improve the credibility of fusing conflict evidence, a new Distance measurement method based on Square Mean (DSM) is first proposed to measure the distance between evidences in this paper. Based on this, the new algorithm for fusing conflicting information in multi-sensor system is presented by integrating DSM with the modified information volume. The proposed method not only considers the credibility between the evidences, but also considers the uncertainty of the weights of the evidences, so that a more appropriate weighted average evidence can be obtained before using Dempster’s combination rule. The proposed method includes the following steps. Firstly, the proposed DSM method is used to measure the credibility of evidence. Then, the relative importance of the evidence is represented by the belief entropy to obtain the information volume of each evidence. Next, the weighted average evidence is generated based on the credibility of the evidence and the corresponding information volume. Finally, the weighted average evidence is fused by Dempster’s rule. After analyzing other methods, the proposed new algorithm for fusing conflict information in multi-sensor systems has better performance than other methods.
The rest of this paper is organized as follows: Section 2 is some preliminaries of the algorithm proposed in this paper. The proposed new distributed distance measurement method, the modified information volume and the proposed multi-sensor conflict data fusion algorithm are illustrated in Section 3. In Section 4, a numerical example is used to verify the better performance of the proposed algorithm compared with other methods. In Section 5, an application is given to show the best performance of the proposed algorithm over other methods. The conclusion and outlook are presented in Section 6.
2 Preliminaries
2.1 Dempster-Shafer evidence theory
Dempster-Shafer evidence theory [15, 16] is proposed by Arthur P. Dempster and Glenn Shafer, which is a reasoning method with the ability to deal with uncertain information. Compared with Bayesian probability [23], it can directly express uncertain and imprecision information.
Definition 2.1
Discernment Frame: The discernment frame Ω is defined as a non-empty set. H1,H2,...,HN represent mutually exclusive and exhaustive hypotheses. Ω is shown as follows:
The power set of the discernment frame Ω contains 2Ω elements, which means:
Definition 2.2
Mass Function(or Basic Probability Assignment, BPA): In the discernment frame, the BPA function m is defined to represent uncertain information. It is a mapping of the power set 2Ω on the interval [0, 1], and the mapping function is:
And the conditions to be satisfied are:
Definition 2.3
Dempster’s Combination Rule: Under the framework of evidence theory, two independent BPA functions m1 and m2 can be fused by the following Dempster’s combination rule:
with
Here, B,C ∈ 2Ω. K is a coefficient for measuring the degree of conflict between evidences, and K < 1.
2.2 Jensen-Shannon divergence measure
Lin [22] introduces a method for measuring the difference between two or more BPAs’ distributions based on information theory, which is called the Janson-Shannon (JS) difference. Unlike others, the main characteristic of JS divergence is that it does not require the condition of absolute continuity in the probability distribution. JS divergence defines a true metric in the space of probability distribution, in fact, it is the square of the metric [24].
Definition 2.4
The JS between Two Probability Distributions: Suppose X is a discrete random variable, P1 and P2 are two probability distribution functions of X, and JS is defined as follows:
with
Here, S(P1,P2) is the Kullback-Leibler divergence [25, 26] and \({\sum }_{i} P_{ji} = 1\) must be satisfied for Pji, i = 1,2,3,...,M; j = 1, 2. Xiao [21] replaces the probability distribution P with belief function m, and proposes Belief Jensen-Shannon divergence(BJS) as follows:
with
Here, \({\sum }_{i} m_{j}(A_{i}) = 1\), i = 1,2,3,...,M; j = 1, 2.
2.3 Cui et al.’s entropy
Deng Entropy [11, 27] can deal with more complex situations of focus elements. However, Deng Entropy has certain limitations when the propositions intersect. Cui et al. proposes a correction function by considering the size of the discernment frame and the impact of the intersection between evidences on uncertainty, and this function is a promising method for measuring uncertain information. Cui et al.’s Entropy [28] is defined as follows:
3 The proposed method
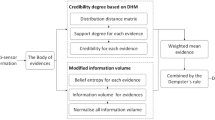
In this section, the four parts of the proposed new multi-sensor information fusion algorithm will be explained in detail. As shown in Fig. 1, the four modules are illustrated as follows:
-
(1)
Section 3.1: Proposing a new distribution distance measurement method based on square mean which referred to as DSM;
-
(2)
Section 3.2: Computing the credibility degree of all evidences in discernment frame based on DSM as shown in the “Credibility degree based on DSM” module of Fig. 1;
-
(3)
Section 3.3: Obtaining the modified information volume of each evidence as shown in the “Modified information volume” module of Fig. 1;
-
(4)
Section 3.4: Using the information volume in the third step to optimize the credibility degree in the second step, then obtain the weighted average evidence to combine by utilizing Dempster’s rule.

The flowchart of the proposed multi-sensor information fusion algorithm
3.1 New distribution distance measure of BPAs(DSM)
In Dempster-Shafer evidence theory, measuring the difference between the evidences is critical for fusing information. Inspired by JS, a new distribution measurement method based on the squared mean of entropy of BPAs is proposed, considering that the greater the probability of the event, the greater the probability of the occurrence of the event. The DSM divergence between the two BPAs m1 and m2 is defined as:
Here, \(D(m_{1}|m_{2})={\sum }_{i}m_{1}(A_{i})log\frac {m_{1}(A_{i})}{m_{2}(A_{i})}\), is the relative entropy. mj(j = 1,2) satisfies \({\sum }_{i} m_{j}(A_{i}) = 1\). Obviously, DSM is the squared mean of \(D(m_{1}|\sqrt {\frac {{m_{1}^{2}}+{m_{2}^{2}}}{2}})\) and \(D(m_{2}|\sqrt {\frac {{m_{1}^{2}}+{m_{2}^{2}}}{2}})\). From the definition, similar to JS, DSM has the following properties: (1) DSM is symmetric, that is, DSM(m1,m2) is equal to DSM(m2,m1); (2) the value of DSM is between 0 and 1.
Example 1
,Suppose the complete discernment frame Ω = {A,B,C} has two BPAs such as m1 and m2, their probabilities are assigned as follows:
From the above results, DSM(m1,m2) and DSM(m2,m1) have the same value. So it is confirmed that DSM is symmetrical.
Example 2
,Suppose the complete discernment frame Ω = {A,B,C} has two BPAs such as m1 and m2, their probabilities are assigned as follows:
From this example, DSM(m1,m2) is 0 when m1 has the same BPAs as m2, that is, m1(A) = m2(A), m1(B) = m2(B) and m1(C) = m2(C). The intuitive result of this example further confirms the effectiveness of DSM.
Example 3
, Suppose the complete discernment frame Ω = {A,B} has two BPAs such as m1 and m2, their probabilities are assigned as follows:
As shown in Example 3, the BPAs for m2 are set as variable value such as m2(A) = α and m2(B) = 1 − α. As the parameter α changes from 0 to 1, the value of DSM between m1 and m2 will be depicted in Fig. 2.

The DSM value with changing parameter α
Obviously, the value of DSM(m1,m2) is symmetric on both sides of the α = 0.5 which is the first property of DSM. When α changes from 0 or 1 to 0.5, the variation of DSM gradually becomes 0. This explains the intuitive phenomenon when m1 and m2 are gradually the same. In the same way, the value of DSM between m1 and m2 gradually increases when α gets farther and farther from 0.5. Therefore, the range of variable DSM is between 0 and 1 according to Fig. 2. The second property of DSM is also verified.
3.2 Credibility degree based on DSM
In order to make the newly proposed distribution distance measurement method DSM has an effect on evidence fusion, the evidence credibility measurement method is modified based on DSM. The processes are described as follows:
-
(1)
Calculate the divergence distance between the pair of evidences based on DSM, and construct the distribution distance measurement matrix, named DMM. It is defined as follows:
$$ DMM= \left[ \begin{array}{ccccc} 0&\cdots&DSM_{1j}&\cdots&DSM_{1k} \\ \vdots&\cdots&\vdots&\vdots& {\vdots} \\ DSM_{i1}&\cdots&0&\cdots& DSM_{ik} \\ \vdots&\cdots&\vdots&\vdots&{\vdots} \\ DSM_{k1}&\cdots&DSM_{kj}&\cdots& 0 \end{array} \right] $$(13)Here, DSMik means the divergence distance between mi and mk.
-
(2)
Obtain the average evidence distance \(D\bar {S}M_{i}\) of evidence mi. The formula is defined as follows:
$$ D\bar{S}M_{i}=\frac{{\sum}_{j=1,j\neq j}^{k} DSM_{ij}}{k-1}, i,j \in [1,k]. $$(14) -
(3)
Calculate the support degree Sup of the evidence for mi, which denotes as follows:
$$ Sup_{i}=\frac{1}{D\bar{S}M_{i}}, i\in [1,k]. $$(15) -
(4)
Normalize support degree Supi to generate credibility degree of each evidence in discernment frame. The corresponding definition is defined as follows:
$$ Crd_{i}=\frac{Sup_{i}}{{{\sum}_{s}^{k}} Sup_{s}}, i\in [1,k]. $$(16)
3.3 Modified information volume
Belief entropy represents the information volume of evidence. The greater the uncertainty of evidence, the greater the entropy. In addition to credibility degree, the information volume is also regarded as the critical part for generating weighted average evidence. Taking into account the cardinal number of the discernment frame and the interaction between the evidences, the modified information volume is proposed based on Cui et al. entropy. The process of measuring modified information volume of the evidences is described as follows:
-
(1)
Compute belief entropy of each evidence mi,i = 1,2,3,...,k by (11).
-
(2)
In order to avoid the value obtained as 0, the belief entropy index of e is used to generate the information volume(IV ) of each evidence, and it is defined as follows:
$$ IV_{i}=e^{E}=e^{-{\sum}_{A\subseteq X} m(A) log(\frac{m(A)}{2^{|A|}-1}e^{{\sum}_{B\subseteq X, B \ne A}\frac{|A\cap B|}{2^{|A|}-1}})}, i\in [1,k]. $$(17) -
(3)
The normalized IV is expressed as:
$$ \bar{IV}_{i}= \frac{IV_{i}}{{\sum}_{s=1}^{k} IV_{s}}, i\in [1,k] $$(18)
3.4 New algorithm for fusing multi-sensor information
In the above steps, the credibility degree of the evidence based on the DSM and the modified information volume has been proposed. This part will explain the method of calculating the weighted average evidence.
-
(1)
Use the information volume IV of the evidence to adjust the credibility degree Crd of the evidence and establish the jointed credibility degree Crd_IV, which is defined as follows:
$$ Crd\_IV_{i}= Crd_{i} \times \bar{IV}_{i} , i\in [1,k] $$(19) -
(2)
Normalize the jointed credibility degree of the evidence, and generate the weight \(\bar {Crd\_IV}\) of the evidence
$$ \bar{Crd\_IV}_{i}= \frac{Crd\_IV_{i}}{{\sum}_{s=1}^{k} Crd\_IV_{s}}, i\in [1,k] $$(20) -
(3)
Generate the weighted average evidence WAE based on \(\bar {Crd\_IV}\). The corresponding equation is as follows:
$$ WAE(m)= {\sum}_{i=1}^{k} \bar{Crd\_IV}_{i} \times m_{i}, i\in [1,k] $$(21) -
(4)
The result of multi-sensor evidence fusion will be generated by fusing the weighted average evidence WAE with k − 1 times by using Dempster’s combination rule.
4 Experiment
In this section, an example for engine fault diagnosis will be used to verify that the proposed multi-sensor evidence fusion algorithm performs better than other methods, and the empirical data is shown in Table 1. In the table, the S1, S2 and S3 are different sensor information, and the corresponding BPAs functions are m1, m2 and m3 respectively. In the complete discernment frame Ω = {F1,F2,F3}, the possible hypotheses are {F1}, {F2}, {F2,F3} and {F1,F2,F3}. In addition, two parameters, one is the sufficiency index μ(m) and another is the importance index ν(m), are listed in Table 2, will be used in generating weights of the evidences for the engine fault diagnosis application [29].
4.1 Process evolution
In the application of engine fault diagnosis, the calculation process of the proposed multi-sensor evidence fusion algorithm will be demonstrated step by step. The variable values listed in the paper only retain the value of four decimal places, and the actual values which participate in the calculation are float64 variables in python 2.7.
-
(1)
Generate the distribution distance measurement matrix DMM = (DSM)k×k as follows:
$$ DMM= \left[ \begin{array}{ccc} 0.0&0.0988&0.0035 \\ 0.0988&0.0&0.1139 \\ 0.0035&0.1139&0.0 \end{array} \right] $$(22) -
(2)
Calculate the average distance of evidence \(D\bar {S}M\).
$$ \begin{array}{c} D\bar{S}M_{1}=0.0511;\\ D\bar{S}M_{2}=0.1064;\\ D\bar{S}M_{3}=0.0587; \end{array} $$(23) -
(3)
Compute the support degree Sup of the evidences.
$$ \begin{array}{c} Sup_{1}=19.5527;\\ Sup_{2}=9.4016;\\ Sup_{3}=17.0448; \end{array} $$(24) -
(4)
Obtain the credibility degree Crd of each evidence by normalizing the support degree Sup of the evidences.
$$ \begin{array}{c} Crd_{1}=0.4251;\\ Crd_{2}=0.2044;\\ Crd_{3}=0.3705; \end{array} $$(25) -
(5)
Compute the belief entropy of the evidences based on Cui et al.’s entropy E.
$$ \begin{array}{c} E_{1}=2.2909;\\ E_{2}=1.3819;\\ E_{3}=1.7960; \end{array} $$(26) -
(6)
Convert the belief entropy E to the information volume IV of the evidences.
$$ \begin{array}{c} IV_{1}=9.8840;\\ IV_{2}=3.9825;\\ IV_{3}=6.0256; \end{array} $$(27) -
(7)
Normalize the information volume IV as \(\bar {IV}\) of the evidences.
$$ \begin{array}{c} \bar{IV}_{1}=0.4969;\\ \bar{IV}_{2}=0.2002;\\ \bar{IV}_{3}=0.3029; \end{array} $$(28) -
(8)
Adjust the credibility degree Crd as Crd_IV of each evidence with the information volume \(\bar {IV}\) of the evidences.
$$ \begin{array}{c} Crd\_IV_{1}=0.2112;\\ Crd\_IV_{2}=0.0409;\\ Crd\_IV_{3}=0.1122; \end{array} $$(29) -
(9)
Calculate the static reliability SR of each evidence with μ(m) and ν(m) by formula as follows:
$$ SR_{i}=\mu_{i} \times \nu_{i} $$(30)and
$$ \begin{array}{c} SR_{1}=1.0000;\\ SR_{2}=0.2040;\\ SR_{3}=1.0000; \end{array} $$(31) -
(10)
Adjust the credibility degree Crd_IV as Crd_IV _SR with the static reliability SR of each evidence. The equation and results are shown as follows:
$$ Crd\_IV\_SR_{i}=Crd\_IV_{i} \times SR_{i} $$(32)and
$$ \begin{array}{c} Crd\_IV\_SR_{1}=0.2112;\\ Crd\_IV\_SR_{2}=0.0083;\\ Crd\_IV\_SR_{3}=0.1122; \end{array} $$(33) -
(11)
Normalize Crd_IV _SR to generate the weight \(\bar {Crd\_IV}\) of the evidence mentioned above.
$$ \begin{array}{c} \bar{Crd\_IV}_{1}=0.6366;\\ \bar{Crd\_IV}_{2}=0.0252;\\ \bar{Crd\_IV}_{3}=0.3383; \end{array} $$(34) -
(12)
Obtain the weighted average evidence WAE as follows:
$$ \begin{array}{c} WAE(\{F_{1}\})=0.6200;\\ WAE(\{F_{2}\})=0.1176;\\ WAE(\{F_{2},F_{3}\})=0.0987;\\ WAE(\{F_{1},F_{2},F_{3}\})=0.1637; \end{array} $$(35) -
(13)
Generate the fusion result by combining 2(k − 1) times weighted average evidence WAE with the Dempster’s combination rule. The results are shown in Table 3, Figs. 3 and 4.

Comparison of BPAs generated by different methods for {F1}, {F2}, {F2,F3} and {F1,F2,F3}

Comparison of BPAs generated by different methods for {F1}
4.2 Discussion and analysis
In Table 3, multi-sensor evidences fusion results of engine fault diagnosis and corresponding faults of Dempster, Fan and Zuo’s method,Yuan et al.’s method and our proposed algorithm are listed for comparative analysis. The names of these methods are listed in the first column, the first row is the hypothesis of the discernment frame, and the last column is the diagnosed fault. After reasonable analysis, this paper concludes as follows:
-
In the example of engine fault diagnosis, evidence m2 is obviously not supported by other evidences in the body of evidence. Directly using Dempster’s combination rule for fusing multi-sensor evidences, the counter-intuitive engine fault “F2” is derived, and this conclusion has verified Dempster rule’s open issue when fusing conflicting data.
-
Except for Dempster’s combination rule, Fan and Zuo’s method and Yuan’s entropy-based method have avoided the weakness of fusing conflicting evidences by using Dempster’s combination rule, the correct engine fault “F1” is diagnosed, and the reliability of multi-sensor fusion systems is better guaranteed.
-
The new algorithm proposed in this paper correctly diagnoses the engine fault “F1”. Besides, the reliability of the decision reachs 89.68% when evidences are fused by the new algorithm, which is 0.2% higher than Yuan et al.’s method.
In order to make the analysis more visual and intuitive, this paper visualizes the data in Table 3 as Figs. 3 and 4. In the two figures, the horizontal axis represents the possible hypotheses under the discernment frame, and the vertical axis shows the possible belief probability assignment(BPA) value for the hypothesis. Figure 3 is the comparison of BPAs generated by different methods for {F1}, {F2}, {F2,F3} and {F1,F2,F3}. Obviously, all methods except Dempster give “F1” the highest probability. Figure 4 is the comparison of BPAs generated by different methods for only {F1}. Obviously, the method proposed in this paper has the highest credibility degree for diagnosing fault {F1}.
All in all, the excellent performance of the new distributed distance measurement method(DSM) proposed in this paper has been illustrated by the numerical examples, and combined with the modified information volume, the proposed optimized multi-sensor evidence fusion algorithm has also achieved better performance than other methods on the basis of solving Dempster rule’s defects when fusing conflicting information. Therefore, it can be considered that the proposed new algorithm for fusing information in multi-sensor systems achieves better performance than other methods.
5 Application
In this section, the proposed algorithm is applied to a case study on target recognition of multi-sensor system, where the data in [19] is used to compare with other methods.
5.1 Problem statement
Supposing that the discernment frame Ω = {A,B,C} includes four possible hypotheses: {A}, {B}, {C} and {A,C}. The collected sensor reports which are modeled as BPAs are listed in Table 4, where m1(⋅), m2(⋅), m3(⋅), m4(⋅) and m5(⋅) indicate BPAs reported from CCD sensor(S1), sound sensor(S2), infrared sensor(S3), radar(S4) and ESM sensor(S5), respectively.
5.2 Discussion and analysis
In Table 5, multi-sensor evidences are fused by Dempster, Yager [30], Murphy [17], Deng et al. [18], Zhang et al. [19], Yuan et al. [20], Xiao [21] and our proposed algorithm, and their target recognition and corresponding reliability are listed for comparative analysis. The first column is the name of different methods, the last column is the target identified by the corresponding method, and the other column is the credibility of the corresponding hypothesis. Moreover, the visualization of Table 5 is shown in Figs. 5 and 6. In the two figures, the horizontal axis and the vertical axis represent the possible hypotheses and BPA of the corresponding target identified by different methods, respectively. After reasonable analysis, some conclusions are as follows:

Comparison of BPAs generated by different methods for {A}, {B}, {C} and {A,C}

Comparison of BPAs generated by different methods for {A}
-
In the body of evidence for target recognition, evidence m2 is in great conflict with other evidences. Although the other four evidences support the correct target “A”, the fusion system by using Dempster’s combination rule produces counter-intuitive result and identifies target “C” as the correct target. In other words, the conclusion of the fusion system is not in line with the reality and fallacious.
-
In addition to directly fusing evidence through Dempster, Yager’s method, Murphy’s simple average approach, Deng et al’s weighting average method, Zhang et al’s cosine theory-based approach, Yuan’s entropy-based method and Xiao’s belief divergence-based method avoid the trap of fusing highly conflicting evidence. And the correct target “A” is identified, and the reliability of the decision is better and better.
-
The improved evidence fusion algorithm proposed in this paper not only avoids the weakness of fusing conflicting evidences by using directly Dempster’s combination rule, correctly identifies target “A”, but also shows higher reliability than other methods, achieving the reliability of 98.948% in the application of target recognition.
To summarize, the proposed algorithm not only overcomes the defect of Dempster’s rule and avoids the counter-intuitive conclusion, but also achieves better reliability of decision than other methods in a multi-sensor fusion system for target recognition. So, the improved evidence fusion algorithm proposed in this paper achieves the best performance, whether in fault diagnosis examples or in the application of target recognition.
6 Conclusion and outlook
This paper has the following three main contributions: (1) Based on the squared mean, a new distance measurement method for the distribution of belief probability assignment is proposed and it is verified with three numerical examples; (2) Taking into account the cardinal number of the discernment frame and the influence of other evidences, the method of measuring information volume is modified by using Cui et al.’s entropy; (3) Based on the above two items, a new multi-sensor evidence fusion algorithm is proposed, the comparative analysis experiments are carried out in the example of engine fault diagnosis and the application of target recognition. From the analysis of experimental results, our proposed method not only overcomes the defects of Dempster’s combination rule, but also performs better than other methods.
In the future, our research work may be carried out from the following aspects. First, how to apply evidence theory to multi-sensor information fusion to ensure the authenticity of the manual data, and this is very important in some specific scenarios such as traceability, investigation and so on. Second, using machine learning algorithms to determine the weight of the evidence in the discernment frame to achieve better performance is also a very promising research direction.
References
Wu Y, Patterson A, Santos R D, Vijaykumar N L (2014) Topology preserving mapping for maritime anomaly detection, pp 313–326. https://doi.org/10.1007/978-3-319-09153-2_24
Callen M, Isaqzadeh M, Long J D, Sprenger C (2014) Violence and Risk Preference: Experimental Evidence from Afghanistan. Amer Econ Rev 104(1):123–148. https://doi.org/10.1257/aer.104.1.123
Abdulhafiz W, Khamis A (2014) Bayesian approach with pre- and post-filtering to handle data uncertainty and inconsistency in mobile robot local positioning. J Intell Syst 23. https://doi.org/10.1515/jisys-2013-0078
Meng W, Hong B-R, Han X-D (2003) Lunar robot information fusion based on D-S evidence theory. J Harbin Instit Technol 35:1040–2
Koch W (2013) Tracking and sensor data fusion: Methodological framework and selected applications, vol 8
Filipowicz W (2014) Mathematical Theory of Evidence in Navigation. In: Cuzzolin F (ed) Belief Functions: Theory and Applications. Third International Conference, BELIEF 2014. Proceedings: LNCS 8764. Belief Functions: Theory and Applications. Third International Conference, BELIEF 2014, Oxford. Springer International Publishing, Cham, p 199–208
Jin Z, Wang X, Gui Q, Liu B, Song S (2013) Improving diagnostic accuracy using multiparameter patient monitoring based on data fusion in the cloud. Lect Notes Electr Eng 276. https://doi.org/10.1007/978-3-642-40861-8_66
Fortino G, Galzarano S, Gravina R, Li W (2014) A framework for collaborative computing and multi-sensor data fusion in body sensor networks. Inf Fusion 22. https://doi.org/10.1016/j.inffus.2014.03.005
Yang D, Zhenghai W, Lin X, Tiankui Z (2014) Online bayesian data fusion in environment monitoring sensor networks. Int J Distrib Sens Netw 2014:1–10. https://doi.org/10.1155/2014/945894
Vinodini Ramesh M (2018) Wireless sensor network for disaster monitoring
Dubois D, Prade H (2001) Possibility theory, probability theory and multiple-valued logics: A clarification. Ann Math Artif Intell 32(1-4):35–66. https://doi.org/10.1023/A:1016740830286
Broemeling L D (2011) An account of early statistical inference in arab cryptology. Amer Stat 65(4):255–257. https://doi.org/10.1198/tas.2011.10191
Klaua D (1967) Ein ansatz zur mehrwertigen mengenlehre. Math Nachrichten 33(5-6):273–296. https://doi.org/10.1002/mana.19670330503
Pawlak Z (1982) Rough sets. Int J Comput Inf Sci 11(5):341–356. https://doi.org/10.1007/BF01001956
Dempster A P (1967) Upper and lower probabilities induced by a multivalued mapping, pp 57–72. https://doi.org/10.1007/978-3-540-44792-4_3
Shafer G (1976) A mathematical theory of evidence, vol 42
Murphy C K (2000) Combining belief functions when evidence conflicts. Decis Support Syst 29 (1):1–9. https://doi.org/10.1016/S0167-9236(99)00084-6
Yong D, WenKang S, ZhenFu Z, Qi L (2004) Combining belief functions based on distance of evidence. Decis Support Syst 38(3):489–493. https://doi.org/10.1016/j.dss.2004.04.015
Zhang Z, Liu T, Chen D, Zhang W (2014) Novel algorithm for identifying and fusing conflicting data in wireless sensor networks. Sens (Basel, Switzerland) 14:9562–9581. https://doi.org/10.3390/s140609562
Yuan K, Xiao F, Fei L, Kang B, Deng Y (2016) Modeling sensor reliability in fault diagnosis based on evidence theory. Sensors 16:113. https://doi.org/10.3390/s16010113
Xiao F (2019) Multi-sensor data fusion based on the belief divergence measure of evidences and the belief entropy. Inf Fusion 46:23–32. https://doi.org/10.1016/j.inffus.2018.04.003
Lin J (1991) Divergence measures based on the shannon entropy. IEEE Trans Inf Theory 37 (1):145–151. https://doi.org/10.1109/18.61115
Cox R T (1946) Probability, frequency, and reasonable expectation. Am J Phys 14(2):1–13. https://doi.org/10.2307/2272983
Lamberti P W, Majtey A P (2003) Non-logarithmic jensen-shannon divergence. Physica A: Stat Mech Appl 329(1):81–90. https://doi.org/10.1016/S0378-4371(03)00566-1
Kullback S, Leibler R A (1951) On information and sufficiency. Ann Math Statist 22(1):79–86. https://doi.org/10.1214/aoms/1177729694
Kullback S (1962) Information theory and statistics. Popul (French Ed) 17:377. https://doi.org/10.2307/1527125
Deng Y (2016) Deng entropy. Chaos Solitons Fractals 91:549–553. https://doi.org/10.1016/j.chaos.2016.07.014
Cui H, Liu Q, Zhang J, Kang B (2019) An improved deng entropy and its application in pattern recognition. IEEE Access 7:18284–18292. https://doi.org/10.1109/ACCESS.2019.2896286.
Fan F, Zuo M (2006) Fault diagnosis of machines based on d-s evidence theory. part 1: D-s evidence theory and its improvement. Pattern Recogn Lett 27:366–376. https://doi.org/10.1016/j.patrec.2005.08.025
Yager R R (1987) On the dempster-shafer framework and new combination rules. Inf Sci 41 (2):93–137. https://doi.org/10.1016/0020-0255(87)90007-7
Acknowledgments
This research was funded by National Key Research and Development Program of China, grant number 2016YFB0501805.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhao, K., Sun, R., Li, L. et al. An improved evidence fusion algorithm in multi-sensor systems. Appl Intell 51, 7614–7624 (2021). https://doi.org/10.1007/s10489-021-02279-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-021-02279-5