
Abstract
One effective technique that has recently been considered for solving classification problems is parametric \(\nu \)-support vector regression. This method obtains a concurrent learning framework for both margin determination and function approximation and leads to a convex quadratic programming problem. In this paper we introduce a new idea that converts this problem into an unconstrained convex problem. Moreover, we propose an extension of Newton’s method for solving the unconstrained convex problem. We compare the accuracy and efficiency of our method with support vector machines and parametric \(\nu \)-support vector regression methods. Experimental results on several UCI benchmark data sets indicate the high efficiency and accuracy of this method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Classification has numerous practical applications including medical science, letter and number recognition, voice recognition, face recognition and hand-writing (Joachims 1998; Cao and Tay 2001; Osuna et al. 1997; Ivanciuc 2007). The first idea of classification as a support vector machine (SVM) was introduced by Vapnik and Chervonenkis (1974). A new method to obtain the separating hyperplane has recently been considered, the parametric v-support vector classification (Par \(\nu \)-SVC) (Hao 2010).
To date, many methods have been proposed for the classification of data by SVM as a hyperplane with maximum margin [The maximum margin hyperplane was shown to minimize an upper bound of the generalization error according to the Vapnik theory (Vapnik and Chervonenkis 1974; Bennett and Bredensteiner 2000)], regression classifier, etc (Deng et al. 2012; Pappu et al. 2015; Xanthopoulos et al. 2014). The \(\nu \)-support vector regression is a new class of SVM. It can handle both classification and regression (Schölkopf et al. 2000; Schölkopf and Smola 2001; Pontil et al. 1998). Schölkopf et al. introduced a new parameter \(\nu \) which can control the number of support vectors and training errors.
Finally, a new method for obtaining the regression line that has recently been considered is the parametric \(\nu \)-support vector regression (Par \(\nu \)-SVR) (Hao 2010; Wang et al. 2014).
All the above-mentioned methods are used to solve constrained quadratic problems.
In this paper, we introduce a new idea for converting the constrained convex quadratic problem into an unconstrained convex problem.There are several approaches for solving unconstrained convex optimization problems (Resende and Pardalos 2002). One important and fast established methods for convex unconstrained problems is Newton’s method. Because in our case the objective function is not twice differentiable, we use the generalized Newton’s method.
Our notations are described as follows:
Let \(a = [a_i]\) be a vector in \( R^n \). By \(a_+\) we mean a vector in \( R^n\) whose ith entry is 0 if \( a_i <0\) and equals \( a_i\) if \( a_i \ge 0\). If f is a real valued function defined on the n-dimensional real space \(R^n\), the gradient of f at x is denoted by \(\bigtriangledown f(x)\) which is a column vector in \(R^n\), and the \(n \times n\) Hessian matrix of second partial derivatives of f at x is denoted by \(\bigtriangledown ^2f(x)\). By \(A^T\) we mean the transpose of matrix A, and \(\nabla f(x)^Td\) is called directional derivative of f at x in direction d. For the two vectors x and y in the \(~n-\)dimensional real space, \(x^Ty\) denotes the scalar product. For \(x\in R^n\), \(\Vert x\Vert \) denotes \(2-\)norm. A column vector of ones of arbitrary dimension will be indicated by e. For \(A \in R^{m \times n}\) and \(B \in R^{n \times l}\) ; the kernel K(A; B) is an arbitrary function which maps \(R^{m \times n} \times R^{n \times l}\) into \(R^{m \times l}\). In particular, if x and y are column vectors in \(R^n\) then, \(K(x^T; y)\) is a real number, \(K(x^T;A^T)\) is a row vector in \(R^m\) , and \(K(A;A^T)\) is an \(m \times m\) matrix. The convex hull of a set S has been shown by \(co\{S\}\). The identity \(n \times n\) matrix will be denoted by \(I_{n \times n}\).
2 Parametric \(\nu \)-support vector classification
For a classification problem, a data set \((x_i,y_i)\) is given for training with the input \(x_i \in R^n\) and the corresponding target value or label \(y_i = 1\) or \(-1\) i.e.:
A classification problem finds the unique hyperplane \(w^Tx+b=0\)\((w,x\in R^n, \ b\in R)\) that best separates the two classes of data.
Schölkopf et al. proposed a new class of support vector machines which called \(\nu \)-support vector machine or \(\nu \)-support vector classification (\(\nu \)-SVC) (Schölkopf et al. 2000; Schölkopf and Smola 2001). In \(\nu \)-SVC, there is a parameter \(\nu \) for controlling the number of support vectors and this parameter also can eliminate one of the other free parameters of the original support vector algorithms (Schölkopf and Smola 2001).
A modification of the \(\nu \)-SVC algorithm, called Par \(\nu \)-SVC, which considers a parametric-margin model of arbitrary shape (Hao 2010). In fact, in the Par \(\nu \)-SVC we consider a parametric margin \(g\left( x \right) ={{c}^{T}}x+d\) and hyperplane \(f\left( x \right) ={{w}^{T}}x+b\) that classify data if and only if:
For finding function \(f\left( x \right) \) and \(g\left( x \right) \) as follows using the minimization problem (Hao 2010)
where C and \(\nu \) are the penalty parameters.
In Par \(\nu \)-SVC, a margin of separation between the two pattern classes is maximized, and the solutions are those examples that lie closest to this margin (Boser et al. 1992).
Also, it is obvious that the objective function of Par \(\nu \)-SVC is an non-convex function and so we are motivated to consider other techniques for finding an approximate solution of (2).
We know that the regression is more general than classification and if we apply Par \(\nu \)-SVR to a binary classification dataset, then under some conditions, Par \(\nu \)-SVR gives the same solution as Par \(\nu \)-SVC. For this reason, we review \(\nu \)-SVR and Par \(\nu \)-SVR formulation for a linear two-class classifier.
In the \(\varepsilon \)-support vector regression (\(\varepsilon \)-SVR) (Schölkopf and Smola 2001) for classification, our goal is to solve the following constrained optimization problem
The \(\nu \)-SVR algorithm alleviates the problem (3) by considering \(\varepsilon \) part of the optimization problem because it is difficult to select appropriate value of the \(\varepsilon \) in \(\varepsilon \)-SVR (Schölkopf et al. 2000; Schölkopf and Smola 2001).
Then the minimization problem of \(\nu \)-SVR is as follows:
Everything above \(\varepsilon \) is captured in slack variables \(\xi _{i}\) and \(\xi _{i}^{*}\), which are penalized in the objective function via a regularization constant C, chosen a priori (Vapnik 1998). The size of \(\varepsilon \) is traded off against model complexity and slack variables via a constant \(\nu >0\).
In a Par \(\nu \)-SVR, we consider a parametric margin \(g\left( x \right) ={{c}^{T}}x+d\) instead of \(\varepsilon \) in \(\nu \)-SVR. Especially the hyperplane \(f\left( x \right) ={{w}^{T}}x+b\) classifies data if and only if (Hao 2010; Wang et al. 2014):
Using the following minimization problem, we find \(f\left( x \right) \) and \(g\left( x \right) \) simultaneously
where C and \(\nu \) are positive penalty parameters.
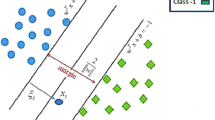
The point that is important here is that the Par \(\nu \)-SVR for classification leads to a convex problem. Figure 1 illustrates the Par \(\nu \)-SVR for classification graphically.

Illustration of parametric \(\nu \)-SVR for classification
The Lagrangian corresponding to the problem (4) is given by
where \(\alpha _i\) , \({\alpha _i}^*\), \(\beta _i\) and \({\beta _i}^*\) are the nonnegative Lagrange multipliers.
By using the Karush–Kuhn–Tucker (KKT) conditions, we obtain the dual optimization problem of (4) as (Boyd and Vandenberghe 2004)
By solving the above dual problem, we obtain the Lagrange multipliers \(\alpha _i\) and \(\alpha _i^*\), which give the weight vector w and c as a linear combination of \(x_i\):
while the bias terms b and d are determined by exploiting the KKT conditions, which are
for some i, j such that \(\alpha _i , \alpha _j^* \in (0,\frac{C}{n})\).
The regression function f(x) and the corresponding parametric insensitive function g(x) can be obtained as follows [see Chen et al. (2012a)]:
In the next section, we focus on solving the minimization problem (4).
3 Solving quadratic constrained programming problem
We see that the classical Par \(\nu \)-SVR formulation is equivalent to finding the f(x) and g(x) simultaneously . Using 2-norm slack variables \(\xi _i\) and \(\xi _i^*\) in objective function of (4) leads to the following minimization problem (Lee and Mangasarian 2001).
With respect to the Lagrangian function of (5) and KKT condition we have
where \(\xi ={{\left[ {{\xi }_{1}},\ldots ,{{\xi }_{n}} \right] }^{T}}\), \(Y={{\left[ {{y}_{1}},\ldots ,{{y}_{n}} \right] }^{T}}\) and \(A=\left[ {{x}_{1}},\ldots ,{{x}_{n}} \right] ^{T}\). According to the inequalities (6)–(8) we have (Lee and Mangasarian 2001)
and similarly, we can show
Thus the problem (5) is equivalent to the following problem:
In this way, we made some modifications of Par \(\nu \)-SVR that led to unconstrained convex problem (9) which we call Par \(\nu \)-SVRC\(^+\).
The main advantage of Par \(\nu \)-SVRC\(^+\) over Par \(\nu \)-SVC (Hao 2010) and Par \(\nu \)-SVR is solving an unconstrained convex problem rather than a large complexity of quadratic programming problem (QPP).
Our goal here is to solve the unconstrained problem (9). The objective function to problem (9) is piecewise quadratic, convex, and differentiable, but it is not twice differentiable (Chen et al. 2012b; Ketabchi and Moosaei 2012; Pardalos et al. 2014). To solve the problem (9), we have provided some definitions that deal with the objective function of this problem.
Class \(LC^1\) of functions is defined as follows (Hiriart-Urruty et al. 1984):
Definition 1
A function f is said to be an \(LC^1\) function on an open set A if:
-
1.
f is continuously differentiable on A,
-
2.
\(\nabla f\) is locally Lipschitz on A.
We know that if f is a \(LC^1\) function on an open set A , then the \(\nabla f\) is differentiable almost everywhere in A, and its generalized Jacobian in Clarkes sense can be defined (Clarke 1990).
Now, the generalized Hessian of f at x to be the set \(\partial ^2 f(x)\) of \(n \times n\) matrices is defined by:
\(\partial ^2 f(x) = co\{H \in R^{n \times n} : \exists x_k \rightarrow x \ ~~with ~~\nabla \ f \ differentiable \ at \ x_k \ and \ \partial ^2 \ f(x_k) \rightarrow H\}\).
By considering (9), we have
The formulation can be written
where \(T_1=[I_{n \times n} \ \ \ 0_{n \times n} \ \ \ 0_{n \times 1} \ \ \ 0_{n \times 1}]\), \(T_2= [A \ \ \ A^T \ \ \ e \ \ \ e]\), \(T_3=[A \ \ \ -A^T \ \ \ e \ \ \ -e]\) and \(u=[w^T \ \ c^T \ \ b^T \ \ d^T]^T\).
Note, we know (10) is not differentiable, but it satisfies Lipschitz conditions.
Theorem 1
\(\frac{\partial \varphi }{\partial w}\) is globally Lipschitz.
Proof
From (10) we have that
Then from (11) we conclude that is globally Lipschitz with constant \(K=\Vert T_1\Vert +\frac{2}{n}\Vert A\Vert \Vert T_2+T_3\Vert \). \(\square \)
Similarly, \(\frac{\partial \varphi }{\partial b}\), \( \frac{\partial \varphi }{\partial c}\) and \( \frac{\partial \varphi }{\partial d}\) are globally Lipschitz.
Theorem 2
\(\nabla \varphi (u)\) is globally Lipschitz continuous and the generalized Hessian of \(\varphi (u)\) is \(\partial ^2 \varphi (u) = (T_1+AD_1(u)T_2+AD_2(u)T_3 )\) where \(D_1(u)\) denotes the diagonal matrix whose ith diagonal entry \(u_i\) is equal to 1 if \((Y-T_2u)_i > 0\) ; \(u_i\) is equal to 0 if \((Y-T_2u)_i \le 0\) and \(D_2(u)\) also denotes the diagonal matrix whose ith diagonal entry \(u_i\) is equal to 1 if \((T_3u-Y)_i > 0\); \(u_i\) is equal to 0 if \((T_3u-Y)_i \le 0\) .
Proof
See (Hiriart-Urruty et al. 1984). \(\square \)
From the previous discussion and according to the above theorem, we know that the \( \nabla \varphi \) is differentiable almost everywhere, and the generalized Hessian of \(\varphi \) exists everywhere.
Therefore, to solve unconstrained problem (9), we can use the generalized Newton method.
3.1 A brief expression for nonlinear par \(\nu \)-SVRC\(^+\)
In the nonlinear case, we have the following minimization problem (Hao 2010):
where K( ., .) is any arbitrary kernel function and \(D=[A;B]\). Similarly, this constrained problem can be considered an unconstrained problem as follows:
4 Numerical experiments
In this section, we discuss our approach using two different performances: the accuracy and the learning speed of a classifier. Throughout this experimental part, we used the Gaussian kernel (i.e. \(K(x,y)=exp(-\gamma \Vert x-y\Vert ^2)\) , \(\gamma > 0\)) for all data. The method was implemented in MATLAB 8 and carried out on a PC with Corei5 2310 (2.9 GHz) and 8 GB main memory. In order to examine the efficiency of Par \(\nu \)-SVRC\(^+\), two samples of n-dimensional problems are given and we derive the separating hyperplanes by means of aforesaid algorithm. In the first problem, we determine randomly some arbitrary points in two classes of A and B which are approximately separated from each other linearly based on given MATLAB code in the “Appendix A” (here, we created 150 points for class A and 100 points for class B). These data are produced randomly within the interval \([-\,50,50]\). In Fig. 2, the given separating hyperplane has been shown by means of rendering Par \(\nu \)-SVRC\(^+\) with red color and also the parametric margin hyperplane are indicated by blue and violet color. The accuracy rate of separating in this problem is \(99.61\%\).
It is noted that by means of MATLAB code the problems with large-scale size are produced and the separating hyperplanes are derived by implementing the Par \(\nu \)-SVRC\(^+\).
The average accuracy of separation is approximately \(99\%\).

Classification results of linear Par \(\nu \)-SVRC\(^+\) on generated dataset
In another example, Ripleys synthetic standard data set have been adapted (Ripley 1996). These data comprise of 250 data samples out of which 125 data are placed in class of A and the next 125 of them in class B and they are not linearly separated (see Fig. 3). In Fig. 3 the separating hyperplane has been shown by red color. Likewise, the parametric margin hyperplanes, which have been derived by rendering this program, are identified by blue and violet dotted line. The accuracy rate of separating in this problem is \(84.80\%\).

Classification results of linear Par \(\nu \)-\(\hbox {SVRC}^+\) on Ripleys dataset
In the following, demonstrate applications to two real data expression profiles for lung cancer and colon tumor. Lung cancer data set was used by Hong and Young to show the power of the optimal discriminant plane even in ill-posed settings. Applying the KNN method in the resulting plane gave \(77\%\) accuracy (Hong and Yang 1991). Colon tumor data set contains 62 samples collected from colon-cancer patients. Among them, 40 tumor biopsies are from tumors (labeled as “negative”) and 22 normal (labeled as “positive”) biopsies are from healthy parts of the colons of the same patients. 2000 out of around 6500 genes were selected (Alon et al. 1999).
When we apply our method on these data sets we gain an accuracy of \(87.50\%\) for lung cancer and \(87.38\%\) colon tumor while MATLAB Quadprog gain 85.83% and \(84.29\%\), respectively. In Fig. 4 accuracy between the proposed method and the method of quadratic programming in MATLAB can be seen.

Performance comparisons of lung cancer and colon tumor data across Par \(\nu \)-SVR and Par \(\nu \)-\(\hbox {SVRC}^+\) methods
To further test the performance of Par \(\nu \)-SVRC\(^+\), we run this algorithm on several UCI benchmark data sets (Lichman 2013). We tested 13 UCI benchmark data sets, which are shown in Tables 1 and 2. To accelerate model selection, we tuned a set comprising randomly \(20\%\) of the training samples to select optimal parameters.
As we noted in the discussion on Par \(\nu \)-SVRC\(^+\), the generalization errors of the classifier depend on the values of the kernel parameter \(\gamma \), the regularization parameter C, and parameter \(\nu \). Tenfold cross-validation was used to evaluate the performance of the classifier and estimate the accuracy. Tenfold cross-validation followed these steps
-
The datasets were divided into ten disjoint subsets of equal size.
-
The classifier was trained on all the subsets except one.
-
The validation error was computed by testing it on the omitted subset left out.
-
This process was repeated for ten trials.
Tables 1 and 2, respectively, give the average accuracies, times, and kernel operations, of this method in the linear and nonlinear case of classification. In Par \(\nu \)-SVR we solve a constrained convex quadratic programming problem by using dual problem with MATLAB Quadprog optimization toolbox (the bolded values in the Tables 1, 2 represent highest accuracies obtained by corresponding classifiers).
In Table 1, we see that the accuracy of our linear Par \(\nu \)-SVRC\(^+\) is higher than linear Par \(\nu \)-SVR on various datasets. For example, for House-votes dataset the accuracy of our Par \(\nu \)-SVRC\(^+\) is 95.65% , while the accuracy of SVM is 94.96% and Par \(\nu \)-SVR is 78.62%. Beside on the another example, for Sonar datasets the accuracy of our Par \(\nu \)-SVRC\(^+\) is 77.01% , while the accuracy of SVM is 79.98% and Par \(\nu \)-SVR is 70.72%. Although SVM win in the accuracy, so our method is still winner in time. In other datasets, we also obtain similar results. Our Par \(\nu \)-SVRC\(^+\) is much far faster than the original SVM and Par \(\nu \)-SVR, indicating that the unconstrained optimization technique can improve the calculation speed. It can also be see that our Par \(\nu \)-SVRC\(^+\) is the fastest on all of datasets. The results in Table 2 are better condition in time and accuracy with that appeared in Table 1, and therefore confirm the above conclusions further.
As mentioned above, we have solved an unconstrained convex minimization problem instead of a constrained convex one. The Experimental results in Tables 1 and 2 demonstrate the high speed, efficiency and accuracy of the proposed method.
5 Concluding remarks
In this paper, we presented a new idea for solving the Par \(\nu \)-SVR classification problem. By using 2-norm of the slack variables in the objective function of (4) and the KKT conditions associated with this obtained problem, we converted the constrained quadratic minimization problem (4) into an unconstrained convex problem. Since the objective function of Par \(\nu \)-SVRC\(^+\) is an \(LC^1\) function, the generalized Newton method was proposed for solving it. In this way, we have derived much faster and accurately method than Par \(\nu \)-SVR which solves a constrained quadratic problem. The experimental results on several UCI benchmark data sets have shown that this method has high efficiency and accuracy both in the linear and nonlinear case.
References
Alon, U., Barkai, N., Notterman, D. A., Gish, K., Ybarra, S., Mack, D., et al. (1999). Broad patterns of gene expression revealed by clustering analysis of tumor and normal colon tissues probed by oligonucleotide arrays. Proceedings of the National Academy of Sciences, 96(12), 6745–6750.
Bennett, K. P., & Bredensteiner, E. J. (2000). Duality and geometry in SVM classifiers. In Proceedings of the seventeenth international conference on machine learning (pp. 57–64). San Francisco.
Boser, B. E., Guyon, I. M., & Vapnik. V. N. (1992). A training algorithm for optimal margin classifiers. In Proceedings of the fifth annual workshop on computational learning theory (COLT ’92) (pp. 144–152). ACM, New York, NY, USA.
Boyd, S., & Vandenberghe, L. (2004). Convex optimization. New York: Cambridge University Press.
Cao, L., & Tay, E. F. (2001). Financial forecasting using support vector machines. Neural Computing and Applications, 10(2), 184–192.
Chen, X., Yang, J., & Liang, J. (2012a). A flexible support vector machine for regression. Neural Computing and Applications, 21(8), 2005–2013.
Chen, X., Yang, J., Liang, J., & Ye, Q. (2012b). Smooth twin support vector regression. Neural Computing and Applications, 21(3), 505–513.
Clarke, F. (1990). Optimization and nonsmooth analysis. Philadelphia: Society for Industrial and Applied Mathematics.
Deng, N., Tian, Y., & Zhang, C. (2012). Support vector machines: Optimization based theory, algorithms, and extensions (1st ed.). Boca Raton: Chapman and Hall/CRC.
Hao, P. Y. (2010). New support vector algorithms with parametric insensitive/margin model. Neural Networks, 23(1), 60–73.
Hiriart-Urruty, J.-B., Strodiot, J.-J., & Nguyen, V. H. (1984). Generalized hessian matrix and second-order optimality conditions for problems with \(C^{1,1}\) data. Applied Mathematics and Optimization, 11(1), 43–56.
Hong, Z.-Q., & Yang, J.-Y. (1991). Optimal discriminant plane for a small number of samples and design method of classifier on the plane. Pattern Recognition, 24(4), 317–324.
Ivanciuc, O. (2007). Reviews in computational chemistry. London: Wiley.
Joachims, T. (1998). Text categorization with support vector machines: Learning with many relevant features. In Proceedings of the 10th European conference on machine learning, ECML’98 (pp. 137–142). Springer, London, UK.
Ketabchi, S., & Moosaei, H. (2012). Minimum norm solution to the absolute value equation in the convex case. Journal of Optimization Theory and Applications, 154(3), 1080–1087.
Lee, Y.-J., & Mangasarian, O. (2001). SSVM: A smooth support vector machine for classification. Computational Optimization and Applications, 20(1), 5–22.
Lichman, M. (2013). UCI machine learning repository. http://archive.ics.uci.edu/ml.
Osuna, E., Freund, R., & Girosit, F. (1997). Training support vector machines: An application to face detection. In Proceedings of the 1997 IEEE computer society conference on computer vision and pattern recognition (pp. 130–136).
Pappu, V., Panagopoulos, O. P., Xanthopoulos, P., & Pardalos, P. M. (2015). Sparse proximal support vector machines for feature selection in high dimensional datasets. Expert Systems with Applications, 42(23), 9183–9191.
Pardalos, P. M., Ketabchi, S., & Moosaei, H. (2014). Minimum norm solution to the positive semidefinite linear complementarity problem. Optimization, 63(3), 359–369.
Pontil, M., Rifkin, R., & Evgeniou, T. (1998). From regression to classification in support vector machines. Technical Report. Massachusetts Institute of Technology, Cambridge, MA, USA.
Resende, M. G. C., & Pardalos, P. M. (2002). Handbook of applied optimization. Oxford: Oxford University Press.
Ripley, B. (1996). Pattern recognition and neural networks datasets collection. www.stats.ox.ac.uk/pub/PRNN/.
Schölkopf, B., & Smola, A. J. (2001). Learning with kernels: Support vector machines, regularization, optimization, and beyond. Cambridge: MIT Press.
Schölkopf, B., Smola, A. J., Williamson, R. C., & Bartlett, P. L. (2000). New support vector algorithms. Neural Computation, 12(5), 1207–1245.
Vapnik, V. (1998). Statistical learning theory. New York: Wiley.
Vapnik, V., & Chervonenkis, A. (1974). Theory of pattern recognition. Moscow: Nauka. (in Russian).
Wang, Z., Shao, Y., & Wu, T. (2014). Proximal parametric-margin support vector classifier and its applications. Neural Computing and Applications, 24(3–4), 755–764.
Xanthopoulos, P., Guarracino, M. R., & Pardalos, P. M. (2014). Robust generalized eigenvalue classifier with ellipsoidal uncertainty. Annals of Operations Research, 216(1), 327–342.
Author information
Authors and Affiliations
Corresponding author
Matlab code
Matlab code
% Generate random M,N;
%Input: m1,m2 n; Output:M N
pl=inline(’(abs(x)+x)/2’);
M=rand(m1,n); M=100*(M-0.5*spones(M));
M(:,2)=M(:,1)+1*ones(m1,1)+100*rand(m1,1)+100*rand(m1,1);
N=rand(m2,n); N=100*(N-0.5*spones(N));
N(:,2)=N(:,1)-1*ones(m2,1)-100*rand(m2,1)-100*rand(m2,1);
uu=5*rand(3,n); uu1=uu;uu1(:,2)= uu1(:,1)+1*ones(3,1);
uu2=uu;uu2(:,2)= uu2(:,1)-1*ones(3,1);
M=[M;uu1;10 0]; N=[N;uu2;30 -20];m1=m1+4;m2=m2+4;m=m1+m2;
xM=[-50:40*rand: 50];yM=xM+1;xN=[-50:20*rand:50];yN=xN-1;
plot(M(:,1),M(:,2),’oblack’,N(:,1),N(:,2),’*bl’);
axis square
format short ;[m1 m2 n toc],[max(M(:,1)) min( N(:,1))]
Rights and permissions
About this article

Cite this article
Ketabchi, S., Moosaei, H., Razzaghi, M. et al. An improvement on parametric \(\nu \)-support vector algorithm for classification. Ann Oper Res 276, 155–168 (2019). https://doi.org/10.1007/s10479-017-2724-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-017-2724-8