
Abstract
Fault dictionary has two types of online and offline calculation. Online calculation is simple, but offline is excessive and time-consuming. In order to reduce the computation time and dimension of fault dictionary, optimal test points selection is very essential. So, the main purpose, fault isolation, is achieved in a short time. In this paper a new efficient method to select an optimum set of test points for fault diagnosis is proposed. At the first, a fault-isolated table is constructed to pick out the special test points from the candidates. Then, the isolation ability of special test points has been considered. If they can’t isolate all of faults, the fault dictionary is rearranged. Therefore, the special test points and isolated faults are eliminated from the table of fault dictionary. In this step, the test point with more single fault is added to special test points. This step is repeated to isolate all of faults. The proposed method is applied on two-stage operational amplifier. By this method, all of faults for this structure are isolated. The computation requirements are very simple than the other methods. In this circuit, the 0.045 s is needed to isolate all of circuit faults. According to the results, it’s clear that the method is a good solution to minimize the size of the test points set. Also, it can be a practical method for medium and large scale systems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Fault detection of analog circuits is divided to two types, including simulation before test and after test. Fault detection using fault dictionary is one of the simulation before test techniques [1]. There are three main steps in fault dictionary. The first step to create the dictionary is fault definition that predicts most of possible faults. The circuit is simulated considering these assumptive faults and circuit responses to these faults are obtained. Then, the circuit responses are stored in a dictionary as a signature. The second step is to select the test points. To estimate high degree of isolation with minimum test points and decrease the time of isolation, optimal test points selection can be important [2]. In the final step, the circuit under test is excited by the same input which used to construct the dictionary and signatures. The obtained signatures for this circuit are compared with stored signatures in dictionary. If these signatures were similar, this fault is similar to the stored fault in dictionary at previous step. Therefore, the faulty element can be detected. The proposed method in this paper focuses on the second part, optimum selection of test points.
To construct of fault dictionary in analysis domain can be divided to dc, frequency and time domain. Fault detection in the frequency and time domain has the better performance than the dc domain.
Fault detection in frequency domain has simple and easy online computation. So, to detect of analog circuit fault does not need much time at the test time. This is directly related to the cost and speed of testing. The problem of the fault dictionary techniques is the excessive offline computation and time-consuming. The large number of fault cases is considered in this method and a lot of test points need to isolate all of the faults. Therefore, the dimensions of fault dictionary will be too large; it takes a lot of time to process them. In order to reduce the computation time and dimensions of fault dictionary, optimal test points selection is very important. By virtue of this, extra computations are eliminated and the main purpose, fault isolation, is realized in less time.
The nomenclatures of this paper are as follows:
- fi :
-
The fault i
- nj :
-
The test point j
- m :
-
Total number of faults
- n :
-
Total number of test points
- NAj :
-
Number of ambiguity sets in test point nj
- Fij :
-
Total number of faults contained in ambiguity set I of test point nj
- S c :
-
Candidate test point set
- S opt :
-
Optimum test point set
2 Construction of fault dictionary
Detection of fault dictionary has two principal techniques, simulation before and after test. In simulation after test, most of the network simulations are performed at the testing time to identify the network parameters. These techniques are classified as linear and nonlinear according to the nature of the diagnosis equations [3]. In this technique, if the element value is been out of tolerance range, the element is considered as a faulty element. Fault detection using fault dictionary is in the simulation before test category. So, in simulation before the test, the circuit response is obtained by taking different faults and stored in a dictionary [4].
The construction of the dictionary is classified with input signals to the circuit, the analysis domain and the measured responses [3]. In this paper, the classification is based on the analysis domain. The frequency domain approximation is examined to verify this method.
2.1 Frequency domain approximation
Various approximations are proposed for linear and nonlinear networks. The frequency domain approximation has advantages such as: the used theory is much understood and required hardware is so simple [3]. In this method, the Zero and pole values should calculate to create a fault dictionary and choose the test frequencies. In this method, at least one of the test frequencies should be less than the lowest non-zero breakpoints, one greater than the highest break points and one between successive break points [5, 6]. So, four test frequencies will be selected. The basis of these choices is based on zeroes and poles are function in the network parameter. Therefore, the parameter deviation causes a change in the zero and pole location and finally change in the domain of transfer-function H(s). So, the test frequencies will be selected in neighborhood of zero and pole to consider cases that are most likely to be fault.
The process of creating the fault dictionary is summarized below:
-
1.
Computation of network zeroes and poles
-
2.
Selection the test frequency from the break points (zero and pole)
-
3.
Computation of gain in test frequency by using nominal value of elements
-
4.
Computation of gain in test frequency while assumptive faults applied to the circuit
-
5.
Creation a fault dictionary that rows show different faults and columns show different test points
The fault dictionary is created using above steps. As mentioned, the time computation and dimensions of fault dictionary decrease by optimum test points selection. So, the main purpose, fault isolation, is reached in less time. In next section, the new proposed algorithm to select the optimum test point is described.
3 New algorithm for test points selection
The new algorithm contains two parts: the inclusive part and the exclusive part which are discussed below:
Part1, the inclusive part [2]:
-
1.
Initialize the desired test-point set Sopt as a null set and let Sc consists of all candidate test points. Then, the integer-coded fault dictionary is constructed based on the frequency responses.
-
2.
Construct and extend the fault-isolated table to obtain the extended fault-isolated Table
-
3.
Check the column NIi of extended fault-isolated table, find all the corresponding test points (column) of which the NIi value equal to one, and add these test points to Sopt.
-
4.
In this step, if the test points of Sopt can isolate all the faults, this step is consider as the final step and all faults are isolated by the minimum test points. Otherwise, the algorithm goes to step 5.
-
5.
Rearrange the fault dictionary and eliminate the rows of the fault dictionary that can be isolate by test points in Sopt together. Remove the selected test points from Sc and eliminate the corresponding column of the fault dictionary.
Part2, exclusive part:
-
6.
In this step, after elimination of special test points and fault isolation, a fault dictionary with smaller dimensions is constructed. Then, the ambiguity sets of mini dictionary are constructed and the test point with more single fault is selected and added to Sopt. Notice, if the single fault in mini dictionary be over, the test point with more ambiguity sets in corresponding column is selected and added to Sopt. The algorithm goes to step 4.
Steps 4, 5, 6 repeated until the entire fault being isolated. These steps described below:
3.1 Integer-coded fault dictionary
The integer-coded fault dictionary technique was first proposed by Lin and Elcherif [7]. This technique is an important tool for optimum test point selection [8]. At the first, the fault dictionary is constructed that rows show the difficult faults and columns show the entire test points. Next, ambiguity sets is created. Ambiguity group is defined as any two faulty cases fall into the same ambiguity set if the gap between the gains values of their response is less than 1.5 dB [9,10,11]. After grouping the faults, the group number is assigned to each fault instead of the fault value. By this way the integer-coded fault dictionary is constructed [2].
For example, the integer-coded fault dictionary of analog circuit under different faulty conditions, include 19 faults and 11 test points, is shown in Table 1.
In step 1 of the proposed algorithm, the candidate test points set, Sc, is initialized as {n1,n2,n3,n4,n5,n6,n7,n8,n9,n10,n11}.
3.2 fault-isolated table
In many cases, some faults can only be detected and isolated by some special test points, whereas the other can be isolated by more than one test points [9]. In order to facilitate the isolation of these particular types of faults, special test points must be selected. As a result, the problem of selecting the test points is easily solved and computational costs are greatly reduced.
In order to find these special test points, a fault isolated table should be constructed and extended. Then, this table will be combined with the integer-coded fault dictionary to find the final solution. In the next section, the design of the fault isolated table will discuss in details.
3.2.1 Construction of fault isolated table
Since, the integer-coded fault dictionary represents the information of different faults at the different test points, the ambiguity group with one fault at each test point should be finding in the dictionary and mark them out. First of all, for each fault in the integer-coded fault dictionary, consider the integers along its row. Each integer in that row is compared with all the integers in its corresponding column, If the integer is not repeated at any row of the corresponding column, the element at the same place of the integer-coded fault dictionary table replaced by “1” and otherwise, it replaced by “0”. By this way, the fault isolated table is constructed. In the fault isolated table, the element “1” means the fault of this row can be isolated by the test point of this column, and the element “0” means opposite [2].
Table 2 gives the fault-isolated table based on the integer-coded fault dictionary that shows in Table 1.
3.3 Extension of the fault-isolated table
In order to access the special test points easily, a new column NIi is added to the fault isolated table to calculate the total number of test points which can isolate fault fi. In the fault-isolated table, the element “1” means the fault of this row can be isolated by the test point of this column, and the element “0” means opposite [2]. Result shows in Table 3.
According to the above steps, Sopt is obtained using Table 3 and NIi column. Sopt = {n2, n4, n6}
3.4 Checking the fault isolation
In this section, check whether the test points in Sopt can isolate the entire fault in integer-coded fault dictionary or not. As shown in Table 3, the test points in Sopt can’t isolate the entire fault in the integer-coded fault dictionary. So the algorithm goes to part 5.
3.5 Rewrite the integer-coded fault dictionary
Actually, Sopt can’t isolate the entire fault in the fault dictionary. Therefore, the rows of the fault dictionary that can be isolate by this special test points, eliminated from integer-coded fault dictionary. Also, the special test points removed from Sc and corresponding column of the integer-coded fault dictionary eliminated. Therefore, the mini integer-coded fault dictionary is constructed, as shown in Table 4. Notice, the test points are less than before, so the needed time for isolation of the faults has decreased.
3.6 The principle of adding test points
In this step, the ambiguity groups table is created for integer-coded fault dictionary as shown in Table 5. In this table, the test point with more single fault will be selected and added to Sopt. Then, test point n7 has these conditions and can isolate F9, F13, F14, and F15 faults. So, these faults eliminate from Table 4 and Sopt and the test point n7 added to Sopt. Then, the algorithm goes to step 4 and checks whether the test points in Sopt can isolate entire fault in fault dictionary or not and the answer is no. So, the steps 5 and 6 implemented for the remaining faults. Thus, the integer-coded is created for F7, F18 and F19 faults, as shown in Table 6. Ambiguity groups are created for these faults as shown in Table 7.
In Table 7, one of the test points n8, n9 and n11 can be selected. Because, each of these test points can isolate remaining faults, so the test point n8 added to Sopt. Thus, Sopt is initialized as {n2, n4, n6, n7, n8}.
Now, the algorithm goes to step 4 and checks that whether the test points in Sopt can isolate the entire faults or not and the answer is yes. So eleven test points decrease to five. Also, all of the faults are isolate by these test points. Hence, additional computations are eliminated and the main purpose, faults isolation, realized in less time.
4 Time complexity of test point selection [2]
As discussed above, the fault-isolated table consists of Nf rows and NT columns. On the other hand, the extended fault-isolated table has one more column. Now, by using the method that Pinjala and Prasad proposed for time computation [12, 13], the time complexity of step 3 is O(Nf(NT + 1)).
In step 4, suppose m1 test points are added to Sopt and these points can isolate Nf1 faults, and the time complexity is also O(Nf(NT + 1)). In case of Nf1 = Nf, the stop condition fulfills, the Sopt will be find directly and the time complexity will reduce quite a lot.
In step 6, suppose m2 test points are added into Sopt in the next algorithm iterations, the time complexity is calculated Refer to “(1),”
In step 5, delete all the corresponding rows and columns in the fault dictionary and the time complexity is O(Nf) + O(m1 + m2) = O(Nf) + O(m). Where m is the total number of test points in \({\text{S}}_{\text{opt }} \left( {{\text{m}} = \left| {{\text{S}}_{\text{opt }} } \right|} \right).\) Since, the total number of test points is NT > m so p’ ≫ NT. When, the last stage is running, the total time complexity is O(Nf m log Nf).
5 Experiment
To demonstrate the efficiency of the proposed algorithm, this algorithm is applied to three circuits that described as below.
5.1 Experiment on circuits
5.1.1 Two stage operation amplifier
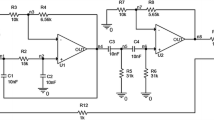
Two-stage operational amplifier is shown in Fig. 1. The first step is biasing the two stage amplifier in Fig. 1, using 0.18 μm standard CMOS technology; all the transistors are in saturation mode. Then, the fault dictionary in frequency domain will create.

Two stage operation amplifier [14]
In order to creating the fault dictionary, the test frequencies must be calculated, according to the described method in Sect. 2.1. As shown in Fig. 1, four test frequencies were obtained for operational amplifier. The nominal gain at each test frequency is obtained. To calculate the nominal gain, the entire elements have their nominal values. The results of nominal gain in four test frequencies are shown in Table 8.
In the next step, the value of parameter L for all transistors deviated from the nominal value at each test frequencies. By regarding the variations of these parameters, the gain is obtained again. By this way, the fault dictionary is created. The rows and column are shown the different faults and the different test points, respectively. The results are presented in Table 9. After creating the fault dictionary, the proposed algorithm of optimum test point selection applied (Table 9).
In step 1 of the proposed method, the initialized work is done. So, the candidate test point set Sc is initialized as {39 meg, 50 meg, 290 meg, 8 g}. Then, the ambiguity groups for this fault dictionary are created as shown in Table 10. Next, the integer-coded fault dictionary is created by using ambiguity groups table (Table 11).
In next step, the fault isolated and extended tables are constructed by the introduced procedures in Sect. 3.2. Extended Fault isolated table is shown in Table 12. In this table, the special test points can find (39 meg). So, this test point is selected and added to Sopt.
Then, the proposed algorithm is checked whether the test point in Sopt can isolate the entire faults in fault dictionary or not. Because, the element of the test point 39 meg for the entire fault is 1, as shown in Table 12, this test point can isolate the entire fault in fault dictionary and don’t need to consider next section.
Thus, the numbers of test points decreased from four to one and all of the faults are isolated using this test point. Therefore, the offline computation of the fault dictionary and the needed time for fault isolation is decreased. Due to isolating all faults in Sect. 3, the needed time to isolate all faults is O(Nf(NT + 1)). According to value of NT and Nf, the needed time is 0.045 s.
By comparing the final results of the proposed algorithm and Ref. [14] can released the proposed algorithm is very fast and efficiency.
The [14] is devoted to diagnose the fault of CMOS circuit and estimated the value of a set of potentially faulty process parameters. At the preliminary stage of the diagnosis process, the sensitivities of the output voltage due to variations of several parameters of all the transistors, for different input voltage, are calculated [14]. Because the proposed algorithm in [14] didn’t allow to test the transistors whose parameters have slightly influence in the output voltage, the fault of seven transistors was detected. Also, the faults were isolated using nonlinear equation that is very complicated and time-consuming. While, the fault isolation using the proposed algorithm has simple computation which decreased the time consuming.
The required time for isolation all of the faults in dictionary of Fig. 1 using the new algorithm is 0.045 s, Against, the consumption time of isolating one of the dictionary faults of Fig. 1 by mentioned method in Ref. [14] is 227.5 s. Also, as discuss above, the proposed algorithm in [14] can’t test all of the transistors, whereas the proposed algorithm examines all transistors and isolates all of the faults.
So, the proposed algorithm is efficient in sense of simple computation and less needed time for fault isolation and the degree of fault isolation is increased by this method.
5.1.2 Experiment on a negative feedback circuit
The negative feedback circuit is shown in Fig. 2. The input signal is a 1-KHz, 7 mV sinusoidal wave. Totally, there are 35 potential faults f1 to f35 (including the nominal case) and ten test points n1 to n10. The responses of all the test points under different faulty conditions are obtained by PSPICE simulation [2]. To demonstrate the efficiency of the proposed algorithm and compare with other algorithms, we use the integer–coded fault dictionary defined in ref. 2 which is shown in Table 13. In the table, “D” represents the integer code of dc voltage responses, and “A” represents the integer code of ac voltage responses. The extended fault-isolated table is shown in Table 14 [2].

Negative feedback circuit [2]
Now we apply our algorithm to Table 13. First the special test point should be finding and added to Sopt as shown below:
In next step with regard to test point in Sopt can’t isolate the entire fault in fault dictionary, the algorithm goes to step 5, in this step, the integer-coded fault dictionary is rearranged, and the corresponding column of special test point and corresponding rows of faults which can be isolated by them are eliminated from the integer-coded fault dictionary. Now the mini integer coded fault dictionary is constructed. In next step, any test point with more single fault in corresponding column will be selected and added to Sopt. So t18 and t5 are added to Sopt. The results are listed in Table 15, and shows that number of optimum test points of our algorithm is less than Yang’s algorithm and Dongshengs algorithm, and we estimated this result in less time. So by this way, we can isolate the faults of CUT using 7test points in a short time.
5.1.3 Leapfrog filter
The leapfrog filter circuit is shown in Fig. 3. We can find six operation amplifiers in the circuit and these amplifiers can be treated as modules in practice. We assume the amplifiers have low-input-impedance failure besides the resistance and capacitance’s catastrophic faults. The input signal is a 1-KHz, 4 V sinusoidal wave. Totally, there are 23 potential faults f1 to f23 (including the nominal case) and 12 test points n1 to n12. The responses of all the test points under different faulty condition are obtained by PSPICE simulation. According to the response voltage of the test point under different faulty mode, we construct the integer-coded fault dictionary and the extended fault-isolated table which is shown in Tables 16 and 17 respectively [2].

Leapfrog filter [2]
The proposed algorithm in this paper is applied on integer coded fault dictionary which shown in Table 16. First the special test point is selected and added to Sopt, as shown below:
Then checked whether the test point in Sopt can isolate the entire fault in fault dictionary or not, that in this step the answer is no. according to Extended fault-isolated table shown in Table 17, the special test point in Sopt can’t isolate the faults f2, f3, f4, f11, f12, f14, f16, f17, f22. So the algorithm goes to next step and the integer-coded fault dictionary is rearranged and mini dictionary is constructed. Then more test points will added to Sopt based on step6 that defined in this paper, as shown in below:
Now we isolated the entire faults in fault dictionary by 7 test points. Then the time complexity of proposed algorithm is calculated and the results show that we isolate the faults in less time comparison with other algorithms. As shown in Table 18.
5.2 Statistical experiment
To demonstrate efficiency of proposed algorithm, Statistical test is done on 100 hundred of fault dictionaries with 9 faults and 4 test points. These fault dictionaries is generated randomly using Monte Carlo and simulated by Hspice. The proposed algorithm are programmed by MATLAB and tested on Intel core f_4790 K, 4G-Hz with 8G RAM. The results show in Table 19.
6 Conclusion
For large-scale circuits with hundreds of elements, the problem is isolation all the faults of circuit by the minimum test point. The proposed methods are very costly and time-consuming.
In this paper, with respect to isolation all of the faults by the test points in Sopt in step 3, the time consumption of isolation the entire faults will be O(Nf(NT + 1)) and using the value of NT and Nf in the fault dictionary, the consumption time will be 0.045 s. Also, this algorithm has the high degree of isolation to isolate the fault of the entire transistor in two-stage operation amplifier circuit.
Finally, as shown the results, the proposed method has a better performance in sense of simple computation and less needed time for fault isolation and the degree of fault isolation increased by this method. Thus, this algorithm is a good solution to minimize the size of the test point-set and practical for large scale systems.
References
Rao, V. M., & Sundari, S. P. S. (2014). Optimized multi frequency approach to analog fault diagnosis using monte carlo analysis. Electrical and Electronic Engineering, 4, 25–30.
Zh, D., & Yuzhu, H. (2015). A new test points selection method for analog fault dictionary techniques. Analog Integrated Circuits and Signal Processing, 82, 435–448.
Bandler, J. (1985). Fault diagnosis of analog circuits. Proceedings of the IEEE, 73(8), 1279–1325.
Rao, S. V. M., & Sundari, K. S. (2014). Optimized multi frequency approach to analog fault diagnosis using Monte Carlo analysis. Electrical and Electronic Engineering, 4(2), 25–30.
Seshu, S., & Waxman, R. (1966). Fault isolation in conventional linear systems-a feasibility study. IEEE Transactions on Reliability, 15(1), 11–16.
Meanpaa, J. H., Stehman, C. J., & Stahl, W. J. (1969). Fault isolation in conventional linear systems: A progress report. IEEE Transactions on Reliability, 18(1), 12–14.
Lin, P. M., & Elcherif, Y. S. (1985). Analogue circuits fault dictionary—New approaches and implementation. The International Journal of Circuit Theory and Applications., 13(2), 149–172.
Yang, C. L., Tian, S. L., & Long, B. (2009). Test points selection for analog fault dictionary techniques. The Journal of Electronic Testing, 25(2–3), 157–168.
Yang, C. L., Tian, S. L., & Long, B. (2009). Application of heuristic graph search to test point selection for analog fault dictionary techniques. The IEEE Transactions on Instrumentation and Measurement, 58(7), 2145–2158.
Hochwald, W., & Bastian, J. D. (1979). A dc approach for analog fault dictionary determination. IEEE Transactions on Circuits and Systems, 26, 523–529.
Yang, C. L., Tian, S. L., & Long, B. (2010). A test points selection method for analog fault dictionary techniques. Analog Integrated Circuits and Signal Processing, 63(2), 349–357.
Prasad, V. C., & Babu, N. S. C. (2000). Selection of test nodes for analog fault diagnosis in dictionary approach. The IEEE Transactions on Instrumentation and Measurement., 49(6), 1289–1297.
Pinjala, K. K., & Bruce, C. K. (2003). An approach for selection of test points for analog fault diagnosis. In Proceedings of the 18th IEEE international symposium on defect and fault tolerance in VLSI systems (pp. 287–294).
Tadeusiewicz, M., & Hałgas, S. (2016). Multiple soft fault diagnosis of DC analog CMOS circuits designed in nanometer technology. Analog Integrated Circuits and Signal Processing, 88(1), 65–77.
Starzyk, J. A., Liu, D., Liu, Zh, Nelson, D. E., & Rutkowski, J. O. (2004). Entropy-based optimum test nodes selection for analog fault dictionary techniques. The IEEETransactions on Instrumentation and Measurement, 53, 754–761.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Saeedi, S., Pishgar, S.H. & Eslami, M. Optimum test point selection method for analog fault dictionary techniques. Analog Integr Circ Sig Process 100, 167–179 (2019). https://doi.org/10.1007/s10470-019-01453-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10470-019-01453-7