
Abstract
The Soil Conservation Service curve number (SCS-CN) method, also known as the Natural Resources Conservation Service curve number (NRCS-CN) method, is popular for computing the volume of direct surface runoff for a given rainfall event. The performance of the SCS-CN method, based on large rainfall (P) and runoff (Q) datasets of United States watersheds, is evaluated using a large dataset of natural storm events from 27 agricultural plots in India. On the whole, the CN estimates from the National Engineering Handbook (chapter 4) tables do not match those derived from the observed P and Q datasets. As a result, the runoff prediction using former CNs was poor for the data of 22 (out of 24) plots. However, the match was little better for higher CN values, consistent with the general notion that the existing SCS-CN method performs better for high rainfall–runoff (high CN) events. Infiltration capacity (fc) was the main explanatory variable for runoff (or CN) production in study plots as it exhibited the expected inverse relationship between CN and fc. The plot-data optimization yielded initial abstraction coefficient (λ) values from 0 to 0.659 for the ordered dataset and 0 to 0.208 for the natural dataset (with 0 as the most frequent value). Mean and median λ values were, respectively, 0.030 and 0 for the natural rainfall–runoff dataset and 0.108 and 0 for the ordered rainfall–runoff dataset. Runoff estimation was very sensitive to λ and it improved consistently as λ changed from 0.2 to 0.03.
Résumé
La méthode du numéro de courbe du Service de la Conservation des Sols (SCS-CN), aussi connue sous le nom de la méthode du numéro de courbe du service de la Conservation des Ressources Naturelles (NRCS-CN), est populaire pour le calcul du volume d’eau de ruissellement direct pour un événement pluvieux donné. La performance de la méthode SCS-CN, basée sur un grand ensemble de données de pluies (P) et de ruissellement (Q) de bassins versants des Etats-Unis d’Amérique, est évaluée en utilisant un grand ensemble de données d’événements naturels pluvieux à partir de 27 parcelles agricoles en Inde. Dans l’ensemble, le CN estimé à partir des tables (chapitre 4) du manuel national d’ingénierie ne correspond pas aux valeurs dérivées des ensembles de données observées P et Q. Par conséquent, la prévision du ruissellement en utilisant les valeurs antérieures de CN était de mauvaise qualité pour 22 (sur 24) parcelles. Cependant, la comparaison était un peu mieux pour les valeurs les plus élevées de CN, en accord avec l’idée générale que la méthode existante SCS-CN donne de meilleurs résultats pour les événements avec des précipitations et ruissellement élevées (CN élevées). La capacité d’infiltration (fc) était la principale variable explicative de la production du ruissellement (ou CN) dans les parcelles d’étude car il montrait la relation inverse attendue entre le CN et la fc. L’optimisation graphique de données a abouti à des valeurs initiales de coefficient d’abstraction (λ) comprises entre 0 et 0.659 pour l’ensemble de données classées et entre 0 et 0.208 pour l’ensemble naturel des données (avec 0 comme la valeur la plus fréquente). Les valeurs moyennes et médianes λ étaient, respectivement, 0.030 et 0 pour l’ensemble de données de pluie–ruissellement naturel et 0.108 et 0 pour l’ensemble des données ordonnées de pluie–ruissellement. L’estimation du ruissellement était très sensible à λ et est amélioré de manière constante quand λ variait entre 0.2 et 0.03.
Resumen
El método del número de curva del Servicio de Conservación de Suelos (SCS-CN), también conocido como el método del número de curva del Servicio de Conservación de Recursos Naturales (NRCS-CN), es popular para calcular el volumen de escorrentía superficial directa para un evento de lluvia dada. El rendimiento del método SCS-CN, basado datos de grandes precipitaciones (P) y la escorrentía (Q) de las cuencas de los Estados Unidos, se evalúa usando un gran conjunto de datos de eventos de tormentas naturales a partir de 27 parcelas agrícolas en la India. En general, el CN calcula a partir de tablas del Manual Nacional de Ingeniería (Capítulo 4) que no se corresponden con las derivadas de los conjuntos de datos observados P y Q. Como resultado, la predicción de la escorrentía usando las anteriores CN era pobre para los datos de 22 (de 24) parcelas. Sin embargo, la coincidencia era un poco mejor para los valores más altos de CN, consistente con la noción general de que el actual método SCS-CN tiene un mejor rendimiento para eventos de alta precipitación–escorrentía (CN altos). La capacidad de infiltración (fc) fue la principal variable explicativa de la producción de escorrentía (o CN) en las parcelas de estudio, ya que exhibió la relación inversa esperada entre NC y fc. La optimización de la trama de datos dio valores iniciales del coeficiente de abstracción (λ) de 0 a 0.659 para el conjunto de datos ordenados y de 0 a 0.208 para el conjunto de datos naturales (siendo 0 el valor más frecuente). Los valores de la media y la mediana de λ fueron, respectivamente, 0.030 y 0 para el conjunto de datos de lluvia–escorrentía natural y 0.108 y 0 para el conjunto de datos de lluvia–escorrentía ordenados. La estimación de la escorrentía era muy sensible a λ y mejoró consistentemente con λ cambiado desde 0.2 a 0.03.
摘要
水土保持曲线数字法也称为自然资源保持曲线数字法,在计算某一特定降雨事件直接地表径流量中非常流行。根据美国流域大的降雨(P)和径流(Q)数据集,采用印度27块农田天然暴雨事件的大的数据集对水土保持曲线数字法的性能进行了评估。总的来说,国家工程手册(第四章)表中的曲线数字估算值与来源于观测的P和Q数据集并不匹配。结果是,采用以前的曲线数字对(24块中的)22块农田资料进行的径流预测结果很差。然而,对于较高的曲线数值匹配稍微好一点,符合总的认识,即现有的水土保持曲线数字法对于较高的降雨-径流(高曲线数字)事件表现较好。渗入能力(fc)在研究农田径流的产生中是主要的解释变量,因为其展现了所预料的曲线数字和fc之间的相反关系。农田资料最优化产生了初始损失系数(λ),有序数据集为0到0.659,自然数据集为0到0.208(0作为最频遇值)。天然降雨–径流数据集的λ平均值和λ中间值分别为0.030和0,有序降雨–径流数据集的λ平均值和λ中间值分别为0.108和0。径流估算结果对于λ来说非常敏感,随着λ从0.2变为0.03,径流估算结果不断改进。
Resumo
O método do número da curva do Serviço de Conservação de Solo (NC–SCS), também conhecido como o método do numero da curva do Serviço de Conservação de Recursos Naturais (NC-SCRN) é popular por computar o volume do escoamento superficial direto para um dado evento de precipitação. O desempenho do método NC-SCS, baseado em dados de precipitação (P) e escoamento (Q) em bacias hidrográficas nos Estados Unidos, foi avaliado utilizando um grande conjunto de dados sobre 27 eventos de precipitação em parcelas agrícolas na Índia. No geral, as estimativas do NC das tabelas do Manual Nacional de Engenharia (Capítulo 4) não coincidem com os valores obtidos através do conjunto de dados de P e Q observados. Como resultado, a previsão de escoamento superficial utilizando os NC antigos foi insuficiente para os dados de 22 (de 24) parcelas. Entretanto, a similaridade foi um pouco melhor para altos valores de NC, coerente com a noção geral de que o método NC-SCS existente apresenta um melhor desempenho em eventos com grande volume de precipitação-escoamento. A capacidade de infiltração (fc) foi a principal variável explicativa para a geração do escoamento superficial (ou NC) nas parcelas estudadas uma vez que mostrou a relação inversa à esperada entre o NC e a fc. A optimização dos dados das parcelas rendeu valores do coeficiente da abstração inicial (λ) de 0 a 0.659 para o conjunto de dados ordenados e de 0 a 0.208 para o conjunto de dados natural (com 0 sendo o valor mais frequente). Os valores médios e medianos de λ foram, respectivamente, 0.030 e 0 para o conjunto de dados de precipitação–escoamento natural e 0.108 e 0 para o conjunto de dados de precipitação–escoamento ordenado. A estimativa do escoamento superficial foi muito sensível a λ e melhorou consistentemente assim que λ mudou de 0.2 para 0.03.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Surface runoff is a function of many variables such as rainfall duration and intensity, soil moisture, land use/land cover, soil infiltration capacity, watershed slope etc. A number of models exist in the literature that consider the effect of different variables on surface runoff. Among them, the lumped conceptual models are quite useful for simple yet realistic analyses (Mishra and Singh 2003). The Soil Conservation Service curve number (SCS-CN) method (presently also known as the Natural Resources Conservation Service curve number (NRCS-CN) method) is widely used for predicting surface runoff from small agricultural watersheds, primarily because of its simplicity and the requirement of only two parameters for runoff prediction (Ponce and Hawkins 1996), which are the initial abstraction coefficient (λ) and the potential maximum retention (S) expressed in terms of curve number (CN).
In the course of continuous use of the SCS-CN model worldwide, several modifications have been proposed in the literature (Hawkins et al. 1985; Jain et al. 2006a; Mishra and Singh 2003; Mishra et al. 2006a; Sahu et al. 2010b, 2012; Suresh Babu and Mishra 2012; Woodward et al. 2002). These include the effect of slope (Huang et al. 2006; Lal et al. 2015; Sharpley and Williams 1990); improvement in λ (Hawkins et al. 2002; Jain et al. 2006b; Mishra and Singh 2004; Mishra et al. 2006b; Woodward et al. 2004; Yuan et al. 2014); the antecedent moisture on a continuous basis (Ajmal et al. 2015d, 2016; Durbude et al. 2011; Michel et al. 2005; Sahu et al. 2007; Singh et al. 2015); and the antecedent moisture for estimation of initial abstraction, I a (Mishra and Singh 2002; Mishra et al. 2006b; Sahu et al. 2012).
In practice, for ungauged watersheds, CNs are derived from the well-known National Engineering Handbook (NEH) tables using watershed characteristics such as hydrologic soil group (HSG), land use and land condition, and antecedent moisture condition (AMC). Empirical evidence however shows that the use of CN values from the handbook’s chapter 4 (NEH-4) tables normally over-designs the hydrological systems (Schneider and McCuen 2005) and, therefore, use of CN values based on observed rainfall (P) and runoff (Q) data (hereafter termed “P–Q” data) is recommended (Ajmal et al. 2015a; Hawkins 1993). It has been established that CN is not constant for a watershed, but rather has a variable identity which varies with rainfall (Hjelmfelt et al. 1982; McCuen 2002). For a set of observed P–Q data, various approaches for determining CN have been reported in the literature (Bonta 1997; Hjelmfelt 1980; Hauser and Jones 1991; Hawkins 1993; Hawkins et al. 2002, 2009; Sneller 1985; Van Mullem et al. 2002; Woodward et al. 2006; Yuan 1933). Of late, some studies have examined the accuracy of such methods (Ali and Sharda 2008; D’Asaro and Grillone 2012; D’Asaro et al. 2014; Feyereisen et al. 2008; Schneider and McCuen 2005; Stewart et al. 2012; Tedela et al. 2012) relative to CN values in the NEH-4 tables (D’Asaro et al. 2014; Fennessey 2000; Feyereisen et al. 2008; Hawkins 1984; Hawkins and Ward 1998; Sartori et al. 2011; Stewart et al. 2012; Titmarsh et al. 1989, 1995, 1996; Tedela et al. 2012; Taguas et al. 2015). However, in spite of wide-spread use of all approaches, there is no agreed procedure for estimating CN from observed P–Q data (Soulis and Valiantzas 2013) because none shows any particular advantage (Ali and Sharda 2008; Tedela et al. 2008).
An accurate assessment of the initial abstraction coefficient (λ) is essential as it is one of the crucial parameters used in watershed P–Q estimation. It largely depends on regional (i.e. geologic and climatic factors) conditions of the watershed (Mishra and Singh 2003; Ponce and Hawkins 1996); and consists mainly of interception, infiltration, and surface depression storage during the early parts of a storm (Taguas et al. 2015). The standard assumption of λ = 0.2 in the original SCS-CN equation has been frequently questioned by various researchers since its inception (Aron et al. 1977; Baltas et al. 2007; Cazier and Hawkins 1984; D’Asaro and Grillone 2012; D’Asaro et al. 2014; Elhakeem and Papanicolaou 2009; Fu et al. 2011; Hawkins and Khojeini 2000; Hawkins et al. 2002; Mishra and Singh 2004; Menberu et al. 2015; Shi et al. 2009; Woodward et al. 2002, 2004; Yuan et al. 2014; Zhou and Lei 2011) for its validity and applicability, invoking its critical examination for practical applications. Many studies have indicated λ to be variable from watershed to watershed and event to event—see Table SI of the electronic supplementary material (ESM). Its value of about 0.05 or less is said to be more practical for various other parts of the world including the United States. Of late, nonlinear I a–S relations have also been suggested (Elhakeem and Papanicolaou 2009; Jiang 2001; Jain et al. 2006a; Mishra et al. 2004, 2006a). It is however of common experience that the value of λ loses its significance as rainfall increases by a magnitude significantly higher than I a, for which the existing SCS-CN method was developed, which is because of generally high CN (and low S) values for high and low rain events, respectively. Alternatively, I a is insignificant if P is high enough.
Evidently, only a few experimental studies have investigated (1) CN values from NEH-4 tables compared to those based on observed data and (2) the effect of λ on runoff prediction. No systematic experimental effort appears to have been made for Indian watersheds, which invokes a need for such study. Thus, the objectives of this study are to (1) assess the rainfall−runoff behaviour in study plots; (2) compare CN values from NEH-4 tables with those derived from observed data; (3) determine the optimal λ and S (or CN) values by analyzing data from 27 plots; (4) assess the performance of the traditional (λ = 0.2) SCS-CN method; and (5) study λ sensitivity to runoff estimates.
SCS-CN method
The SCS-CN method consists of the following equations:
where Q (mm) is the direct surface runoff, P (mm) is the rainfall, I a is the initial abstraction (mm), and S (mm) is the potential maximum retention. In Eq. (1), I a is a fraction of S (i.e. I a = λS). Here, λ is the initial abstraction coefficient (λ = 0.2, a standard value). The use of I a = λS in Eq. (1) amplifies it as:
S can be calculated from observed P–Q data as follows (Hawkins 1973):
S can be transformed into CN, and vice versa by using the following equation:
In Eq. (4), S is in mm and CN is dimensionless.
Materials and methods
Site description
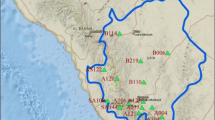
The study was conducted in an experimental field located at 29°50′09″ N and 77°55′21″ E, in Roorkee, district Haridwar, Uttarakhand (India) (Fig. 1). This field is located in the River Solani watershed, which is a sub-watershed of the River Ganga. River Solani emerges from the Shivalik range of the great Himalayas, which has three main topographic zones—hills, piedmont, and flat terrain. The study site is located in the flat terrain of the Solani watershed at about 30–60 km south of the foothills of the Himalayas and about 180 km north of New Delhi. The average topographic elevation of the site is about 266 m above mean sea level (amsl). The climate is humid sub-tropical type with three pronounced seasons, summer, monsoon and winter. In summer, the minimum and maximum monthly temperature values are generally 20 and 45 °C, respectively, whereas these are 10 and 27 °C, respectively, in winter. Annual rainfall varies from 1,120 to 1,500 mm and mostly concentrates between mid-June and mid-September, which is the monsoon season. The average annual potential evapotranspiration (PET) is of the order of 1,340 mm and average humidity varies from 30 to 99 %.

Layout of experimental plots located near Roorkee, Uttarakhand, India
The soil in Solani watershed is mainly comprised of loam, loamy sand, sandy loams, and sandy clay. The upper hilly area consists of sandy loam, whereas lower flat terrain (where the study site is located) is dominated by loam and loamy sand (Garg et al. 2013; Kumar et al. 2012). Forestland, bare soil, and vegetated land are the main classes of land cover in the study area. Forest cover is around 30 % of the total area especially in the hilly part of the watershed and more than 50 % is agricultural land in the lower flat terrain. A significant portion of the land lies in an agricultural area with more than 35 % of vegetal cover. Forests cover around 30 % of the total area, especially in the hilly part of the watershed, and more than 17 % of the total land is fallow. Sugarcane is the perennial crop and wheat, maize, potato and pulses are the seasonal crops (Garg et al. 2013).
Experiment setup and data collection
The selected agricultural field for the experimental work was divided into plots of 22 m length and 5 m width. Four different land uses were selected: sugarcane, maize, black gram and fallow land. The plots were constructed in such a way that each land use was represented with three different slopes (5, 3 and 1 %). The experimental work was conducted during August 2012–April 2015 in which rainfall (P) and runoff (Q) were monitored for a total of 27 experimental plots of various slopes, land uses, and hydrologic soil groups (HSGs; i.e. infiltration capacity). It is worth emphasizing that, for cultivation of crops, normal agricultural practices of mixing soil, seed selection etc. were followed throughout the study period.
The surface runoff generated from each plot was collected in collection chambers of 1 m × 1 m × 1 m in size and constructed at the outlet of each plot followed by a 3-m-long conveyance channel intercepted by a multi-slot divisor with five slots. The multi-slot devisors were used to reduce the volume of runoff to be measured in the collection chamber—in other words, it reduces the frequency of chamber filling. The volume of flow collected in these tanks when multiplied by 5 yielded the plot runoff for a storm-event (during the past 24 hr). Rainfall was recorded with the help of both a tipping bucket rain gauge and a non-recording rain gauge installed at the study site. The distribution of rainfall measured during the study period is shown in Table 1. As seen from this table, 101 rainfall events were captured with the rainfall amount varying from 0.5 to 93.8 mm, and only 42 events produced a significant amount of runoff for measurement. Infiltration tests were conducted for each plot using a double-ring infiltrometer (45/30) for identification of HSGs (SCS 1972). The resulting infiltration capacity (fc) and corresponding HSGs for different plots are shown in Table 2.
Estimation of the curve number
NEH-4 table curve number
These CN values of a plot are designated as CNHT (HT refers to the handbook tables). The representative class II (average) antecedent moisture condition curve number, AMC II CN (or CN2), values were derived from NEH-4 tables (SCS 1972) for all the plots based on their land use, HSG, and vegetation (Table 2).
Rainfall–runoff data based curve number
Firstly, event-wise CNs were derived for each plot using Eqs. (3) and (4) (λ = 0.2). Secondly, S (or CN) (with λ = 0.2) was estimated from observed P–Q data using least square (LS) fit, i.e. by minimizing the sum of the squares of residuals (Eq. 5; NRCS 1997) employing Microsoft Excel (Solver):
Here, Q i (mm) and Q ci (mm) are respectively the observed and predicted runoff for storm event i and n is the total number of storm events. These CN values of a plot are designated as CNLSn and CNLSo for natural and ordered datasets, respectively. The natural P–Q data consist of the actual observed dataset. In ordered data series, the observed P and Q values were first sorted separately and then realigned using a common rank-order basis to form a new set of P–Q pairs of an equal return period, in which runoff Q is not necessarily matched with that due to original rainfall P (Ajmal et al. 2015a; D’Asaro and Grillone 2012; Hawkins 1993; Hawkins et al. 2009; Lal et al. 2015; Soulis and Valiantzas 2013).
To derive λ values, both S and λ were optimized as before, consistent with the work of Hawkins et al. (2002), using both natural and ordered data consisting of only large storm events with a (arbitrary) P >15 mm criterion to avoid a biasing effect, but to retain a sufficient number of P–Q data for analysis. Only plots having at least 10 observed P–Q events were considered for the optimization study. Notably, model fitting yields only one value of λ from all P–Q events of the plot. The CN values (CNHT, CNLSn, and CNLSo) thus estimated are taken to correspond to the average antecedent moisture condition (AMC-II) of the plot. For wet (AMC-III) and dry (AMC-I) conditions, these CN values were adjusted using Eqs. (6) and (7), respectively, as follows (Hawkins et al. 1985):
In order to determine AMC of a rainfall event used in a runoff prediction, 5-day antecedent rainfall (P 5) was used as follows: AMC-I if P 5 < 35.56 mm in the growing season or P 5 < 12.7 mm in the dormant season, AMC-II if 35.56 ≤ P 5 ≤ 53.34 mm in the growing season or 12.70 ≤ P 5 ≤ 27.94 mm in the dormant season, and AMC-III if P 5 > 53.34 mm in the growing season or P 5 > 27.94 mm in the dormant season (Ajmal et al. 2015a, b, c; Mays 2005).
Performance evaluation
Performance of the existing SCS-CN model (Eq. 2) with traditional λ = 0.2 was compared with that employing an average λ = 0.030 value derived from the 27 natural P–Q plot-datasets (Table 2). The average is considered instead of the median as the former yielded the smallest standard error (Fu et al. 2011). Here, it is notable that all runoff-producing rainfall events only were used in analyzing the performance of λ = 0.03 over traditionally used λ = 0.20. The effect of variation in λ on CNs (or runoff) has been evaluated using data from five randomly selected plots (i.e. plots 1, 5, 12, 16 and 17 from Table 2). In addition, the relative change in estimated runoff with progressive changes in the λ-value was also analyzed as follows:
where ΔQ i is the relative change of runoff at step i, and Q ci and Q ca are respectively the estimated runoff at step i and step a. Initially, λ = 0.2 was fixed for step a and then reduced by 10 % at each step down to 0.02, and runoff was estimated at each step using Eq. (2). The average CNLSo (=78.92) was estimated from event-based CNs of the 27-plotdata (Table 2) and was used for the S computation in Eq. (4). P = 30 mm was used in Eq. (2) due to its having the highest frequency of occurrence (Table 1).
Statistical analysis
The goodness of fit was evaluated using the coefficient of determination (R 2), root mean square error (RMSE), Nash-Sutcliffe efficiency coefficient (NSE; Nash and Sutcliffe 1970), number of times n t that the observed variability is greater than the mean error, and percent bias (PBIAS). R 2 is expressed as:
where Q i (mm) and Q ci (mm) are respectively the observed and predicted runoff for storm event i, \( \overline{Q\mathrm{c}} \)(mm) is the average of predicted runoff for all storm events, n is the total number of storm events, and \( \overline{Q} \)(mm) is the average of observed runoff for all storm events. R 2 > 0.6 is considered as acceptable for satisfactory agreement between observed and predicted variables (Moriasi et al. 2007; Santhi et al. 2001; Van Liew et al. 2003).
NSE has been widely used to evaluate hydrological models (Ajmal et al. 2015a, b, c; EI-Sadek et al. 2001; Fentie et al. 2002; Sahu 2007; Sahu et al. 2007, 2010a; Shi et al. 2009; Yuan et al. 2014) and is expressed as follows:
According to Motovilov et al. (1999), Moriasi et al. (2007), Lim et al. (2006), Parajuli et al. (2007, 2009), Santhi et al. (2001), 0.75 NSE ≤ 1.0 indicates very good fit; 0.65 ˂ NSE ≤ 0.75, good fit; 0.50 ˂ NSE ≤ 0.65, satisfactory fit; and NSE ≤ 0.50 indicates an unsatisfactory fit. RMSE (Ajmal et al. 2015c; Deshmukh et al. 2013; Jain et al. 2006b; Mishra et al. 2004, 2006a; Sahu et al. 2007, 2010a) is defined as:
and n t is expressed as (Ritter and Muñoz-Carpena 2013):
where SD is the standard deviation. n t ≥ 2.2 indicates very good agreement; 1.2 ≤ n t < 2.2 implies good; 0.7 ≤ n t < 1.2 shows satisfactory; and n t < 0.7 indicates an unsatisfactory fit.
Percent bias (PBIAS) measures average tendency of the estimated data to be larger or smaller than their observed data (Ajmal et al. 2015c; Gupta et al. 1999; Moriasi et al. 2007) and is expressed as:
PBIAS indicates whether the method is consistently over-predicting or under-predicting—positive values indicate model underestimation, and negative values overestimation (Gupta et al. 1999; Moriasi et al. 2007; Yuan et al. 2014), while for perfect agreement, PBIAS = 0. According to Archibald et al. 2014; Donigian et al. 1983; Moriasi et al. 2007; Singh et al. 2004; Van Liew et al. 2003, PBIAS < ±10 % indicates very good fit; ±10 % ≤ PBIAS < ±15 %, good; ±15 % ≤ PBIAS < ±25 %, satisfactory; and PBIAS ≥ ±25 %, unsatisfactory fit.
To evaluate the improvement in performance of the modified model over the existing one, the r-statistic (Nash and Sutcliffe 1970; Ajmal et al. 2015d; Ajmal et al. 2016; Senbeta et al. 1999) is used and it is expressed as:
where NSE1 and NSE2 are the efficiencies due to the existing model and modified models, respectively. r > 10 % indicates significant improvement of the modified model (Senbeta et al. 1999).
In this study, performance evaluation is primarily based on R 2, NSE, n t, and PBIAS for individual plot data and then the arithmetic means of 27 values are taken as a rough estimate for the overall performance evaluation. The Kolmogorov-Smirnov test was used to assess the normality of data, and the non-parametric Kruskal-Wallis test to assess the significance level. Statistical analysis was carried out using SPSS version 20.0 (IBM 2011), and Microsoft Excel 2007 (Solver) was used for the least square fitting.
Results and discussion
Variation of rainfall threshold for runoff generation (I)
As in the aforementioned, the P–Q analysis is based on 42 natural P–Q events of the plots of different slopes, land uses, and HSGs observed during August 2012–April 2015 (i.e. three crop-growing seasons)—August 2012−May 2013, June 2013−May 2014, and June 2014−April 2015—at the experimental farm in Roorkee, India (Table 1). A total of 11, 18, and 13 runoff-producing events were captured during the first, second, and third years, respectively. In this study, the lowest rainfall value was 5.6 mm, which generated runoff in a year, whereas the highest rainfall of 17.6 mm did not generate runoff in another year, during which the highest storm rainfall was 75.8 mm.
The runoff initiation threshold, also known as rainfall threshold for runoff generation, was determined for each plot from daily P–Q data. Table 3 gives an overview of rainfall threshold (I) values and slope (m/m) of P–Q curves for all plots. As seen, both vary considerably among plots. The highest I was observed for the plots having HSGs A. In contrast, the lowest I was observed for the plots having HSGs C, whereas I for HSG B was in between HSGs A and C; thus, HSG (or indirectly soils infiltration capacity) seems to play a major role in controlling I in the plots.
Variation of mean runoff coefficient (Rcm)
As seen from the preceding, the concept of I is also supported by response of runoff to rainfall, i.e. runoff coefficient which followed a similar pattern as I. The mean runoff coefficient (Rcm) was higher for the plots having HSGs C followed by B and A (Table 3). This pattern for Rcm was followed by nearly all the plots with few exceptions (i.e. plots 12 and 21); Rcm of the plots ranged from 0.093 to 0.473.
Runoff coefficients (Rc) for individual rainfall events also varied considerably from less than 0.005 to over 0.60, depending on the nature of the event and plot type. The Kolmogorov-Smirnov test revealed that event-wise Rc for all individual plots was not normally distributed. The non-parametric Kruskal-Wallis test revealed a statistically significant difference between events Rc of all 27 study plots.
Relation among Q, P and θ
Correlations of the runoff (Q) and Rc with rainfall (P) and previous-day soil moisture (θ) (%) were determined for each plot separately and the results are shown in Table 4. As seen, non−linear variation of Rc with P is similar to the variation of Q with P, but the correlation between Rc and P is much lower than that between Q and P. An example of a non-linear relation between Q and P, and between Rc and P, for plot Nos. 1, 8, and 11 are shown in Fig. 2. The P–Q relationship was statistically significant (p < 0.05) for all the plots. The highest correlation was observed in plot 8 (maize land use), with a coefficient of determination (R 2) of 0.980; the poorest (R 2 = 0.411) was in plot 23 (fallow land use). In contrast, θ did not correlate well with Q as well as did Rc in the study plots (Fig. 3), for R 2 ranging from 0.028 to 0.391. Theoretically, higher θ means higher Q (or Rc); however, in the present study, Q is largely controlled by P, consistent with the findings of Nadal-Romero et al. (2008), Rodríguez-Blanco et al. (2012), Scherrer et al. (2007), and Zhang et al. (2011), rather than θ.

Plots showing relationship of a runoff (Q, mm) and b runoff coefficient (Rc) with rainfall (P, mm) for plot Nos. 1, 8 and 11

Plots showing relationship of a runoff (Q, mm) and b runoff coefficient (Rc) with previous-day soil moisture (θ) (%) for plot Nos. 1, 8 and 11
Effect of land use, infiltration capacity, and plot slope on Q (or Rc)
The effects of land use, infiltration capacity (fc), and slope on Q (or Rc) were also tested individually for their significance. To this end, plots located in the same land use, HSG, and slope were grouped separately to check their significance among studied variables. Since the data distribution fails to pass the normality test for all three of the individual groups (i.e. land use, HSG, and slope), the non-parametric Kruskal-Wallis test was used to test the significance level, whereby the results are shown in Table 5. The test revealed that land uses did not show any significant difference in Rc except sugarcane, which produced significantly (p < 0.05) higher Rc than blackgram and fallow land uses. In the case of HSGs, however, HSG C had significantly higher Rc than did B and A, but B and A did not differ from each other. In addition, slope did not show any effect on Rc as all three groups of slope were insignificantly different from each other. Thus, Rc (or Q) is more significantly influenced by infiltration capacity (fc) of soil rather than land uses or slopes. As shown in Fig. 4a, mean runoff (Q m) produced at the study plots was significantly (R 2 = 0.269; p < 0.01) influenced by soil permeability, described by infiltration capacity (fc). With an increase in fc, Q m decreased logarithmically, and vice versa.

Relationship of a mean runoff (Q m, mm) and b curve number (CN), antecedent moisture conditions II (AMC II), with infiltration capacity (fc, mm/hr) of soil for all 27 agricultural plots
P–Q data based CN determination
First, event-wise CN values were derived for individual plots using Eqs. (3) and (4) (with λ = 0.20). The derived CNs from all 27 plots were comparable. The Kolmogorov-Smirnov test revealed event-wise CNs for all individual plots to be normally distributed. The Student t-test for equality of means revealed a statistically significant difference between event CNs of all 27 study plots.
The effect of land use, infiltration capacity (fc), and slope on event-wise CNs was also studied using similar analysis (or tests) as discussed previously for Rc. As seen from Table 5, land uses did not show any significant difference in CNs except sugarcane, which produced significantly (p < 0.05) higher CNs than blackgram and fallow land uses. Furthermore, slope also did not show any effect on CNs as all three slope groups (i.e. 5, 3, and 1 %) were statistically insignificant. In the present study, CNs are seen to be influenced by the infiltration capacity (fc) of soil because all three groups of soil (i.e. A, B and C) exhibited significantly different CNs.
CNs were also estimated for 27 plots for both natural and ordered datasets using optimization (Eq. 5), and the results are presented in Table 2. As shown, CNs for study plots ranged widely from 64.73 to 90.33 and 67.47 to 90.59 for natural and ordered datasets, respectively. All 27 CNs, when combined into one group, were found to be normally distributed when tested using the Kolmogorov-Smirnov test.
As already analyzed, fc is the main explanatory variable for runoff production in the study plots. An inverse relationship between CN and fc for all 27 study plots was also detected with significant correlation (R 2 = 0.461, p < 0.01; Fig. 4b). The results from this analysis (Fig. 4b) support the applicability of NEH-4 tables where CNs decline with fc (or HSG).
Comparison of CNHT, CNLSn, and CNLSo
The NEH-4 curve numbers (CNHT) are compared with those due to both natural and ordered P–Q datasets observed on 27 plots (Table 2). CNHT ranged from 58 (plots 19, 20, and 21) to 88 (plots 25, 26, and 27). The optimized values of CNLSn ranged respectively from 64.73 (plot 19) to 90.33 (plot 25), and CNLSo from 67.47 to 90.59 for ordered dataset. Both CNLSn and CNLSo values were higher than CNHT (Table 2). As seen in Fig. 5a, CNHT and CNLSn do not compare well, as 17 out of 27 CNLSn values are higher than those for CNHT; and both exhibited a greater difference for values lower than 75; however, the difference diminishes with increasing values. The group of CNHT lower than 75 shows a higher PBIAS (= −12.84 %) than the group of CNHT higher than 75 (= 1.03 %). Overall, pair-wise comparison showed a significant difference (p < 0.05) existing between CNHT and CNLSn means. Such an inference is consistent with the general notion that the existing SCS-CN method performs better for high P–Q (or CN) events.

CN comparison for a CNLSn vs CNHT, b CNLSo vs CNHT, and c CNLSn vs CNLSo
From Fig. 5b, CNHT with CNLSo compare similar to that in Fig. 5a; however, PBIAS of the group of CNHT lower than 75 is = −14.87 % compared to 0.12 % for the group higher than 75. From Fig. 5c, CNLSo values are seen to be higher than those for CNLSn, which is consistent with that reported elsewhere (Ajmal et al. 2015a; D’Asaro and Grillone 2012; D’Asaro et al. 2014; Hawkins et al. 2009; Stewart et al. 2012). CN values derived for individual plots using ordered datasets differ from 0.15 to 3.22 CN compared with those derived from natural data (Table 2). The trend between CNLSo and CNLSn allows a conversion as follows:
Table S2 of the ESM shows the performance statistic used to test the accuracy of all three sets of CNs, with respect to CNHT, CNLSn, and CNLSo for the data of 24 plots (plots 1–24 of Table 2). Plot Nos. 25–27 were excluded from comparison due to unavailability of their corresponding P 5 data. Both NSE and R 2 show the estimated runoff based on all three CNs to be poorly matching (except for a few plots) the observed runoff. In general, CNLSo performed the best of all, and CNLSn better than CNHT. The reason for CNHT to have performed the most poorly is that these are the generalized values derived from small watersheds of the United States for high-magnitude P–Q events (or high CN values). As seen from Table S2 of the ESM, for 15 out of 24 plots, a simple mean of the observed runoff was a better estimate (due to negative NSE values) than that due to CNHT, the estimates of which reasonably correlated (NSE > 0.50) with observed runoff for only two plots. Similarly, the mean of the observed runoff series was a better estimate for 8 out of 24 plots than that due to CNLSn or CNLSo; while the runoff estimated by CNLSn and CNLSo was reasonably close (NSE > 0.50) to the observed runoff for 5 and 9 plots, respectively.
From Fig. 5a,b, Table 2 and Table S2 of the ESM, it is evident that the general agreement between CNHT and CNLSn or CNLSo is poor, which is consistent with that reported elsewhere (D’Asaro et al. 2014; Fennessey 2000; Feyereisen et al. 2008; Hawkins 1984; Hawkins and Ward 1998; Sartori et al. 2011; Stewart et al. 2012; Titmarsh et al. 1989, 1995, 1996; Tedela et al. 2012; Taguas et al. 2015). As an alternative to CNHT, the best CN-values based on the highest R 2, NSE (or lowest RMSE; from Table S2 of the ESM) are suggested for each of the 24 plots. As seen, CNLSo ranked first for 20 out of 24 plots, whereas each of CNHT and CNLSn ranked first on only 2 plots. Therefore, CNLSo is suggested as a preference over CNHT for use in areas with similar plot characteristics and climatic conditions.
Derivation of λ
From Table 2, the optimized λ-values derived for both natural (ranging from 0 to 0.208) and ordered (ranging from 0 to 0.659) P–Q datasets are seen to vary widely from plot to plot with 0 as the most frequent value. The cumulative frequency distribution of λ-values for both datasets shows that λ-values are larger for ordered data, the distribution is skewed, and most λ-values (26 for natural and 21 for ordered P–Q datasets out of total 27) are less than the standard λ = 0.20 value. The respective mean and median λ-values are 0.030 and 0 for natural, and 0.108 and 0 for ordered data, quite less than 0.20 but consistent with those reported elsewhere (Ajmal et al. 2015a; Baltas et al. 2007; D’Asaro and Grillone 2012; D’Asaro et al. 2014; Elhakeem and Papanicolaou 2009; Fu et al. 2011; Hawkins and Khojeini 2000; Hawkins et al. 2002; Menberu et al. 2015; Shi et al. 2009; Yuan et al. 2014; Zhou and Lei 2011). In addition, the existence of a I a–S relationship for different plots was also investigated using all the data of 27 plots. In contrast to the existing notion, I a when plotted against S (Fig. 6), exhibited no correlation for both natural and ordered datasets, which is consistent with the findings of Jiang (2001).

Relationship between I a and S for data from the 27 plots for a natural and b ordered data
Performance evaluation of the proposed model
Table 6 shows the performance indices (R 2, NSE, RMSE, n t and PBIAS) for fitting of Eq. (2) with λ = 0.20 (existing SCS-CN method i.e. M1) and λ = 0.030 (proposed method i.e. M2). As seen from the table, the runoff estimates with λ = 0.030 (M2) provide larger NSE and lower RMSE for 26 out of 27 plots than those due to λ = 0.20 (M1). Based on NSE, performance of the existing SCS-CN method (M1) is seen to be unsatisfactory, satisfactory, good, and very good for the data of 12, 5, 3, and 7 plots out of 27 plots, respectively. On the other hand, the performance of the proposed method (M2) is unsatisfactory, satisfactory, good, and very good on 8, 5, 5 and 9 plots out of 27 plots, respectively. Based on the mean values of NSE, M2 performed satisfactorily (NSE = 0.565) compared to M1 (NSE = 0.392).
The positive PBIAS values resulting for both the methods indicate that the existing SCS-CN method (i.e. M1) underestimated the average runoff; however, these values for M2 were much lower than those due to M1, indicating an improvement in model performance. M1 performance was unsatisfactory, satisfactory, good, and very good as regards the data of 6, 10, 1, and 9 plots out of 27 plots, respectively. On the other hand, M2 performance was unsatisfactory, satisfactory, good, and very good on 4, 4, 6 and 13 plots out of 27 plots, respectively; thus, based on the mean PBIAS values, M2 performance was good (= 10.78 %), whereas M1 performed satisfactorily (= 16.90 %). For further analysis based on n t, M1 exhibited satisfactory or good performance regarding 11 out of 27 plots. The performance improved for 16 plots when M2 was used. The improved M2 model performance is also supported by the higher r-value. As shown in Fig. 7, the significant improvement in NSE (or r) using the M2 model was observed in 26 out of the 27 study plots. In contrast, the runoff predictions by M2 model were debased (r ≤ 0) in only one plot. Overall, as seen from Table 6 and Fig. 7, M2 performed better than M1.

The cumulative frequency distribution of improvement using the r criterion
Sensitivity of λ to CN and runoff
This sensitivity analysis was carried out using the data of only 5 plots. To this end, as shown in Fig. 8, for a plot dataset and a given λ-value, S (or CN) was optimised using Eq. (2). As seen, the rising trends are similar to each plot. In general, CN is seen to increase with λ, which is due to the fact that for the given P–Q data, an increase in λ would require an increase in CN (or decrease in S) to obtain the same Q-value for a given P. Furthermore, variation in CN narrows down with increasing λ-values.

Variation in CNs (AMC II) with λ for data from five plots
To indicate the most appropriate λ-value, variation of NSE with λ was plotted (Fig. 9). In general, NSE showed a decreasing trend with λ for all five plots, consistent with the findings of Woodward et al. (2004) and Yuan et al. (2014), which implies that a low λ-value provides a better prediction of runoff, and vice versa. To show the sensitivity of λ to runoff (using Eq. 8), for a given CN = 78.92 and P = 30 mm, the estimated runoff increased by 165 % when λ decreased (by 90 %) from 0.2 to 0.02.

Variation in NSE with λ
Conversion of CN0.20 to CN0.030
The existing NEH-4 CNs are based on a λ value equal to 0.20; therefore, a transformation of CNs from λ = 0.20 to λ = 0.030 is imperative before using λ = 0.030 in runoff modeling. To this end, an empirical conversion equation, based on direct least squares fitting of 27 plots with natural datasets for converting CNs associated with λ = 0.20 (CN0.20) to λ = 0.030 (CN0.030), is proposed as follows:
In Eq. (16), maximum potential retention (S) is in mm and S 0.030 = S 0.20 at 7.148 mm or CN0.20 = 97.268. The ratio of S 0.030 to S 0.20 (i.e. S 0.030/S 0.20) was seen to be inversely related to the mean ratio of Q to P (i.e. Rcm). The substitution of Eq. (16) into the definition of CN yields
The applicability of Eq. (16) (or Eq. 17) to prediction of runoff using the NEH-4 tables curve number (CNHT) is also investigated. To this end, the estimated NEH-4 CNs (or CNHT0.20) based on plot characteristics for 24 plots (1–24 plots of Table 2) were first converted to CNHT0.030, and then employed for runoff estimation as shown in Table S3 of the ESM, along with R 2, NSE, and RMSE. As seen, CNHT0.030 from Eq. (16) estimates the runoff more accurately than did CNHT0.20. Besides, the r-statistic (Fig. 7) also shows the use of Eq. (16) to have significantly improved NSE in 22 out of 24 study plots.
Limitations of the study
The results of this study are limited to the experimental boundaries such as plot size, slopes, soils, agricultural land uses, and climatic conditions. Replication of such a study for a wider range of physical and climatic settings is imperative for indicating its broader applicability. In this regard, an automation of measurement of data may further help refine the results of the present study which is based on manual data collection.
Conclusions
The following conclusions can be drawn from the study:
-
1.
Compared to land use and slope, infiltration capacity (fc) is the main explanatory variable for runoff (or CN) production in the study plots.
-
2.
CN is inversely related to infiltration capacity (fc), which supports the applicability of CNs from the NEH-4 tables declining with fc (or HSG).
-
3.
P–Q derived CNs are higher than those from NEH-4 tables. However, these are closer for higher CN values, which is consistent with the general notion that the existing SCS-CN method performs better for high P–Q (or CN) events.
-
4.
Mean and median λ-values are respectively 0.030 and 0 for natural P–Q data, and 0.108 and 0 for ordered P–Q data. λ was greater than 0.20 for only one natural plot data and six ordered plot data.
-
5.
Runoff estimation improves as λ decreases, for 26 out of 27 plots by changing λ-value from 0.20 to 0.030.
-
6.
There exists a relationship between CN0.20 (λ = 0.20) and CN0.030 (λ = 0.030), useful for CN conversion for field application.
References
Ajmal M, Moon G, Ahn J, Kim T (2015a) Quantifying excess storm water using SCS-CN-based rainfall runoff models and different curve number determination methods. J Irrig Drain Eng 141(3):04014058
Ajmal M, Moon G, Ahn J, Kim T (2015b) Investigation of SCS and its inspired modified models for runoff estimation in South Korean watersheds. J Hydro Environ Res 9(4):592–603
Ajmal M, Waseem M, Ahn J, Kim T (2015c) Improved runoff estimation using event-based rainfall–runoff models. Water Resour Manag 29:1995–2010
Ajmal M, Waseem M, Wi S, Kim T (2015d) Evolution of a parsimonious rainfall–runoff model using soil moisture proxies. J Hydrol 530:623–633
Ajmal M, Waseem M, Kim HS, Kim T (2016) Potential implications of pre-storm soil moisture on hydrological prediction. J Hydro Environ Res 11:1–15
Ali S, Sharda VN (2008) A comparison of curve number based methods for runoff estimation from small watersheds in a semi-arid region of India. Hydrol Res 39(3):191–200
Archibald JA, Buchanan B, Fuka DR, Georgakakos CB, Lyon SW, Walter MT (2014) A simple, regionally parameterized model for predicting nonpoint source areas in the northeastern US. J Hydrol Reg Stud 1:74–91
Aron G, Miller AC, Lakatos DF (1977) Infiltration formula based on SCS curve number. J Irrig Drain Div 103(4):419–427
Baltas EA, Dervos NA, Mimikou MA (2007) Determination of the SCS initial abstraction ratio in an experimental watershed in Greece. Hydrol Earth Syst Sci 11:1825–1829
Bonta JV (1997) Determination of watershed curve number using derived distributions. J Irrig Drain Div 123(1):28–36
Cazier DJ, Hawkins RH (1984) Regional application of the curve number method, Proc., Water Today and Tomorrow, ASCE Irrigation and Drainage Division Special Conf. ASCE, Reston, VA
D’Asaro F, Grillone G (2012) Empirical investigation of curve number method parameters in the Mediterranean area. J Hydrol Eng 17:1141–1152
D’Asaro F, Grillone G, Hawkins RH (2014) Curve number: empirical evaluation and comparison with curve number handbook tables in Sicily. J Hydrol Eng 19(12):04014035, pp 1–13
Deshmukh DS, Chaube UC, Hailu AE, Gudeta AA, Kassa MT (2013) Estimation and comparison of curve numbers based on dynamic land use land cover change, observed rainfall–runoff data and land slope. J Hydrol 492:89–101
Donigian AS, Imhoff JC, Bicknell BR (1983) Predicting water quality resulting from agricultural nonpoint-source pollution via simulation: HSPF. In: Agricultural management and water quality. Iowa State University Press, Ames, IA, pp 200–249
Durbude DG, Jain MK, Mishra SK (2011) Long-term hydrologic simulation using SCS-CN-based improved soil moisture accounting procedure. Hydrol Process 25:561–579
EI-Sadek A, Feyen J, Berlamont J (2001) Comparison of models for computing drainage discharge. J Irrig Drain Eng ASCE 127(6):363–369
Elhakeem M, Papanicolaou AN (2009) Estimation of the runoff curve number via direct rainfall simulator measurements in the state of Iowa, USA. Water Resour Manag 23(12):2455–2473
Fennessey LA (2000) The effect of inflection angle, soil proximity and location on runoff. PhD Thesis, Pennsylvania State University, State College, PA, USA
Fentie B, Yu B, Silburn MD, Ciesiolka CAA (2002) Evaluation of eight different methods to predict hill-slope runoff rates for a grazing catchment in Australia. J Hydrol 261:102–114
Feyereisen GW, Strickland TC, Bosch DD, Truman CC, Sheridan JM, Potter TL (2008) Curve number estimates for conventional and conservation tillages in the southeast Coastal Plain. J Soil Water Conserv 63(3):120–128
Fu S, Zhang G, Wang N, Luo L (2011) Initial abstraction ratio in the SCS-CN method in the Loess Plateau of China. Trans ASABE 54(1):163–169
Garg V, Nikarn BR, Thakur PK, Aggarwal SP (2013) Assessment of the effect of slope on runoff potential of a watershed using NRCS-CN method. Int J Hydrol Sci Technol 3(2):l41–l159
Gupta HV, Sorooshian S, Yapo PO (1999) Status of automatic calibration for hydrologic models: comparison with multilevel expert calibration. J Hydrol Eng 4(2):135–143
Hauser VL, Jones OR (1991) Runoff curve numbers for the Southern High Plains. Trans Am Soc Agric Eng 34:142–148
Hawkins RH (1973) Improved prediction of storm runoff in mountain watershed. Irrig Drain Div ASCE 99:519–523
Hawkins RH (1984) A comparison of predicted and observed runoff curve numbers. Symposium proceedings, Water Today and Tomorrow. ASCE, Reston, VA, pp 702–709
Hawkins RH (1993) Asymptotic determination of runoff curve numbers from data. J Irrig Drain Eng 119(2):334–345
Hawkins RH, Khojeini AV (2000) Initial abstraction and loss in the curve number method. Hydrol Water Resour Arizona Southwest http://arizona.openrepository.com/arizona/handle/10150/296552. Accessed August 2016
Hawkins RH, Ward TJ (1998) Site and cover effects on event runoff, Jornada experimental range, New Mexico, Symp. Proc., Conf. on Rangeland Management and Water Resources. American Water Resources Associations, Middleburg, VA, pp 361–370
Hawkins RH, Hjelmfelt AT, Zevenbergen AW (1985) Runoff probability, storm depth, and curve numbers. J Irrig Drain Eng 111(4):330–340
Hawkins RH, Jiang R, Woodward DE, Hjelmfelt AT, van Mulle, JA, Quan QD (2002) Runoff curve number method: examination of the initial abstraction ratio In: Proceedings of the Second Federal Interagency Hydrologic Modeling Conference. ASCE, Las Vegas, NV
Hawkins RH, Ward TJ, Woodward DE, Van Mullem JA (2009) Curve number hydrology: state of practice. ASCE, Reston, VA, 106 pp
Hjelmfelt AT (1980) Empirical-investigation of curve number techniques. J Hydraul Eng Div 106(9):1471–1476
Hjelmfelt AT, Kramer KA, Burwell RE (1982) Curve numbers as random variables, Proc. Int. Symp. on Rainfall–Runoff Modeling. Water Resources, Littleton, CO, pp 365–373
Huang M, Jacgues G, Wang Z, Monique G (2006) A modification to the soil conservation service curve number method for steep slopes in the loess plateau of China. Hydrol Process 20(3):579–589
IBM (2011) IBM SPSS Statistics for Windows, version 20.0. IBM, Armonk, NY
Jain MK, Mishra SK, Suresh Babu P, Venugopal K, Singh VP (2006a) An enhanced runoff curve number model incorporating storm duration and non-linear Ia–S relation. J Hydrol Eng 11(6):631–635
Jain MK, Mishra SK, Suresh Babu P, Venugopal K (2006b) On the Ia–S relation of the SCS-CN method. Nord Hydrol 37(3):261–275
Jiang R (2001) Investigation of runoff curve number initial abstraction ratio. MSc Thesis, University of Arizona, Tucson, AZ, 120 pp
Kumar K, Hari Prasad KS, Arora MK (2012) Estimation of water cloud model vegetation parameters using a genetic algorithm. Hydrol Sci J 57(4):776–789
Lal M, Mishra SK, Pandey A (2015) Physical verification of the effect of land features and antecedent moisture on runoff curve number. Catena 133:318–327
Lim KJ, Engel BA, Tang Z, Muthukrishnan S, Choi J, Kim K (2006) Effects of calibration on L-THIA GIS runoff and pollutant estimation. J Environ Manag 78(1):35–43
Mays LW (2005) Water resources engineering, 2nd edn. Willey, Chichester, UK
McCuen RH (2002) Approach to confidence interval estimation for curve numbers. J Hydrol Eng 7(1):43–48
Menberu MW, Haghighi AT, Ronkanen AK, Kværner J, Kløve B (2015) Runoff curve numbers for peat-dominated watersheds. J Hydraul Eng 20(4):04014058
Michel C, Vazken A, Perrin C (2005) Soil conservation service curve number method: how to mend a wrong soil moisture accounting procedure. Water Resour Res 41(W02011):1–6
Mishra SK, Singh VP (2002) SCS-CN-based hydrologic simulation package, chapt. 13. In: Singh VP, Frevert DK (eds) Mathematical models in small watershed hydrology and applications. Water Resources, Littleton, CO, pp 391–464
Mishra SK, Singh VP (2003) Soil Conservation Service curve number (SCS-CN) methodology. Kluwer, Dordrecht, The Netherlands
Mishra SK, Singh VP (2004) Long-term hydrological simulation based on the Soil Conservation Service curve number. Hydrol Process 18:1291–1313
Mishra SK, Jain MK, Singh VP (2004) Evaluation of SCS-CN-based model incorporating antecedent moisture. Water Resour Manag 18(6):567–589
Mishra SK, Sahu RK, Eldho TI, Jain MK (2006a) A generalized relation between initial abstraction and potential maximum retention in SCS-CN-based model. J River Basin Manag 4(4):245–253
Mishra SK, Sahu RK, Eldho TI, Jain MK (2006b) An improved Ia–S relation incorporating antecedent moisture in SCS-CN methodology. Water Resour Manag 20(5):643–660
Moriasi DN, Arnold JG, Van Liew MW, Bingner RL, Harmel RD, Veith TL (2007) Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans ASABE 50(3):885–900
Motovilov YG, Gottschalk L, England K, Rodhe A (1999) Agric For Meteorol 98(99):257–277
Nadal-Romero E, Latron J, Lana-Renault N, Serrano-Muela P, Martí-Bono C, David Regüés D (2008) Temporal variability in hydrological response within a small catchment with badland areas, central Pyrenees. Hydrol Sci J 53:629–639
Nash JE, Sutcliffe JV (1970) River flow forecasting through conceptual models. Part I: a discussion of principles. J Hydrol 10:282–290
NRCS (1997) ‘Hydrology’ national engineering handbook, supplement A, section 4. Soil Conservation Service, USDA, Washington, DC
Parajuli P, Mankin KR, Barnes PL (2007) New methods in modeling source specific bacteria at watershed scale using SWAT. In: Watershed management to meet water quality standards and TMDLs (total maximum daily load), Proceedings. ASABE Publ. No. 701P0207, ASABE, St. Joseph, MI
Parajuli PB, Mankin KR, Barnes PL (2009) Source specific fecal bacteria modeling using soil and water assessment tool model. Bioresour Technol 100(2):953–963
Ponce VM, Hawkins RH (1996) Runoff curve number: has it reached maturity? J Hydrol Eng 1(1):11–19
Ritter A, Muñoz-Carpena R (2013) Performance evaluation of hydrological models: statistical significance for reducing subjectivity in goodness-of-fit assessments. J Hydrol 480:33–45
Rodríguez-Blanco ML, Taboada-Castro MM, Taboada-Castro MT (2012) Rainfall–runoff response and event-based runoff coefficients in a humid area (northwest Spain). Hydrol Sci J 57(3):445–459
Sahu RK (2007) Modifications to SCS-CN technique for rainfall–runoff modelling. PhD Thesis, Indian Institute of Technology, Bombay
Sahu RK, Mishra SK, Eldho TI, Jain MK (2007) An advanced soil moisture accounting procedure for SCS curve number method. J Hydrol Process 21(21):2872–2881
Sahu RK, Mishra SK, Eldho TI (2010a) An improved AMC-coupled runoff curve number model. Hydrol Process 24:2834–2839
Sahu RK, Mishra SK, Eldho TI (2010b) Comparative evaluation of SCS-CN-inspired models in applications to classified datasets. Agric Water Manag 97(5):749–756
Sahu RK, Mishra SK, Eldho TI (2012) An improved storm duration and AMC coupled SCS-CN concept-based model. J Hydrol Eng 17(11):1173–1179
Santhi C, Arnold JG, Williams JR, Dugas WA, Srinivasan R, Hauck LM (2001) Validation of the SWAT model on a large river basin with point and nonpoint sources. J Am Water Resour Assoc 37(5):1169–1188
Sartori A, Hawkins R, Genovez A (2011) Reference curve numbers and behavior for sugarcane on highly weathered tropical soils. J Irrig Drain Eng 137(11):705–711
Scherrer SF, Naef F, Faeh AO, Cordery I (2007) Formation of runoff at the hillslope scale during intense rainfall. Hydrol Earth Syst Sci 11:907–922
Schneider LE, McCuen RH (2005) Statistical guidelines for curve number generation. J Irrig Drain Eng 131(3):282–290
SCS (1972) ‘Hydrology’ national engineering handbook, supplement A, section 4. Soil Conservation Service, USDA, Washington, DC
Senbeta DA, Shamseldin AY, O’Connor KM (1999) Modification of the probability-distributed interacting storage capacity model. J Hydrol 224:149–168
Sharpley AN, Williams JR (1990) Epic-erosion/productivity impact calculator: 1. model determination, USDA technical bulletin, no. 1768, USDA, Washington, DC
Shi ZH, Chen LD, Fang NF, Qin DF, Cai CF (2009) Research on the SCS-CN initial abstraction ratio using rainfall–runoff event analysis in the Three Gorges Area, China. Catena 77:1–7
Singh J, Knapp HV, Arnald JG, Demissie M (2004) Hydrologic modeling of the Iroquois River watershed using HSPF and SWAT. J Am Water Resour Assoc 41(2):343–360
Singh PK, Mishra SK, Berndtsson R, Jain MK, Pandey RP (2015) Development of a modified SMA based MSCS-CN model for runoff estimation. Water Resour Manag 29(11):4111–4127
Sneller JA (1985) Computation of runoff curve numbers for rangelands from Landsat data. Technical report HL85-2, Agricultural Research Service, Hydrology Laboratory, Beltsville, MD
Soulis KX, Valiantzas JD (2013) Identification of the SCS-CN parameter spatial distribution using rainfall–runoff data in heterogeneous watersheds. Water Resour Manag 27(6):1737–1749
Stewart D, Canfield E, Hawkins RH (2012) Curve number determination methods and uncertainty in hydrologic soil groups from semiarid watershed data. J Hydrol Eng 17:1180–1187
Suresh Babu P, Mishra SK (2012) Improved SCS-CN-inspired model. J Hydrol Eng 17:1164–1172
Taguas E, Yuan Y, Licciardello F, Gómez J (2015) Curve numbers for olive orchard catchments: case study in southern Spain. J Irrig Drain Eng. doi:10.1061/(ASCE)IR.1943-4774.0000892
Tedela NH, McCutcheon SC, Rasmussen TC, Tollner EW (2008) Evaluation and improvement of the curve number method of hydrological analysis on selected forested watersheds of Georgia. Project report submitted to Georgia Water Resources Institute, Supported by the US Geological Survey, Reston, VA, 40 pp
Tedela NH, McCutcheon SC, Rasmussen TC, Hawkins RH, Swank WT, Campbell JL, Adams MB, Jackson CR, Tollner EW (2012) Runoff curve numbers for 10 small forested watersheds in the mountains of the eastern United States. J Hydrol Eng 17(11):1188–1198
Titmarsh GW, Pilgrim DH, Cordery I, Hossein AA (1989) An examination of design flood estimations using the U.S. soil conservation services method. Hydrology and Water Resources Symposium. The Institution of Engineers, Barton, Australia
Titmarsh GW, Cordery I, Pilgrim DH (1995) Calibration procedures for rational and USSCS design hydrographs. J Hydraul Eng 121(1):61–70
Titmarsh GW, Cordery I, Pilgrim DH (1996) Closure of calibration procedures for rational and USSCS design flood methods. J Hydraul Eng 122(3):177
Van Liew MW, Arnold JG, Garbrecht JD (2003) Hydrologic simulation on agricultural watersheds: choosing between two models. Trans ASAE 46(6):1539–1551
Van Mullem JA, Woodward DE, Hawkins RH, Hjelmfelt AT, Quan QD (2002) Runoff curve number method: beyond the handbook. Proc., 2nd Federal Interagency Hydrologic Modeling Conf., Advisory Committee on Water Information (ACWI), Washington, DC
Woodward DE, Hawkins RH, Quan QD (2002) Curve number method: origins, applications and limitations. Proc., Second Federal Interagency Hydrologic Modeling Conference: Hydrologic Modeling for the 21st Century, Subcommittee on Hydrology of the Advisory Committee on Water Information, Las Vegas, NV
Woodward DE, Hawkins RH, Jiang R, Hjelmfelt AT, Van Mullem JA, Quan QD (2004) Runoff curve number method: examination of the initial abstraction ratio In: Proceedings of the World Water and Environmental Resources Congress and Related Symposiums. ASCE, Philadelphia, PA
Woodward DE, Scheer CC, Hawkins RH (2006) Curve number update used for runoff calculation. Ann Warsaw Agric Univ Land Reclam Land Reclam 37:33–42
Yuan PT (1933) Logarithmic frequency distribution. Ann Math Stat 4(1):30–74
Yuan Y, Nie J, McCutcheon SC, Taguas EV (2014) Initial abstraction and curve numbers for semiarid watersheds in south eastern Arizona. Hydrol Process 28:774–783
Zhang Y, Wei H, Nearing MA (2011) Effects of antecedent soil moisture on runoff modeling in small semiarid watersheds of southeastern Arizona. Hydrol Earth Syst Sci 15:3171–3179
Zhou SM, Lei TW (2011) Calibration of SCS-CN initial abstraction ratio of a typical small watershed in the Loess Hilly-Gully region. China Agric Sci 44:4240–4247
Acknowledgements
This research was funded by the Indian National Committee on Surface Water (INCSW) (formerly Indian National Committee on Hydrology (INCOH)), and Ministry of Water Resources, Govt. of India, New Delhi, under the Research and Development project on “Experimental Verification of SCS Runoff Curve Numbers for Selected Soils and Land Uses”.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(PDF 307 kb)
Appendix: Notation
Appendix: Notation
- I a :
-
Initial abstraction (mm)
- Rcm :
-
Mean runoff coefficient of plot
- Rc:
-
Event runoff coefficient
- λ :
-
Initial abstraction coefficient
- P :
-
Rainfall (mm)
- Q :
-
Observed runoff (mm)
- Q m :
-
Mean observed runoff of plot (mm)
- Q c :
-
Predicted runoff (mm)
- CN0.20 :
-
Curve number associated with λ = 0.20
- CN0.030 :
-
Curve number associated with λ = 0.030
- NEH:
-
National engineering handbook
- NSE:
-
Nash-Sutcliffe efficiency coefficient
- CNHT :
-
Curve number derived from NEH-4 tables
- S :
-
Maximum potential retention (mm)
- θ :
-
Previous day soil moisture (%)
- HSG:
-
Hydrologic soil group
- P 5 :
-
5-day antecedent rainfall (mm)
- fc:
-
Infiltration capacity (mm/hr)
- CNLSn :
-
Curve number derived from P–Q data set using least square method (λ = 0.2) for natural data series
- CNLSo :
-
Curve number derived from P–Q data set using least square method (λ = 0.2) for ordered data series
- CNLSDn :
-
Curve number derived from P–Q data set using least square method (optimized λ) for natural data series
- CNLSDo :
-
Curve number derived from P–Q data set using least square method (optimized λ) for ordered data series
- CNHT0.20 :
-
NEH-4 tables CN associated with λ = 0.20
- CNHT0.030 :
-
NEH-4 tables CN associated with λ = 0.03
- I :
-
Rainfall threshold for runoff generation (mm)
- n :
-
Number of event (or observation)
- n t :
-
Statistic used for performance evaluation
- r :
-
Statistic used for showing the improvement in NSE
- R 2 :
-
Coefficient of determination
- RMSE:
-
Root mean square error (mm)
- PBIAS:
-
Percent bias (%)
- SD:
-
Standard deviation (mm)
- SPSS:
-
Statistical Package for the Social Sciences
- SE:
-
Standard error of estimate (mm)
Rights and permissions
About this article

Cite this article
Lal, M., Mishra, S.K., Pandey, A. et al. Evaluation of the Soil Conservation Service curve number methodology using data from agricultural plots. Hydrogeol J 25, 151–167 (2017). https://doi.org/10.1007/s10040-016-1460-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10040-016-1460-5