
Abstract
This paper is considered with the delay-dependent passivity analysis issue for uncertain neural networks with discrete interval and distributed time-varying delays. By constructing an augmented Lyapunov functional and combining integral inequality with approach to estimate the derivative of the Lyapunov–Krasovskii functional, which estimated some integral terms by Wirtinger’s inequality, sufficient conditions are established to ensure the passivity of the considered neural networks. Some useful information on the neuron activation function ignored in the existing literature is taken into account. Finally, numerical examples are given to illustrate the effectiveness of the proposed theoretical results.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The dynamics of neural networks have been extensively considered in the past two decades because of their great significance for both practical and theoretical purposes, for examples bidirectional associative memories, optimization and signal processing, image processing, pattern recognition problems, and so on [3–5]. However, considerable effort has been devoted to analyzing the stability of neural networks without a time delay. In recent years, the stability of delayed neural networks has also received attention [6, 17, 18] since time delay is frequently encountered in neural networks. Moreover, it is often a source of instability and oscillation in a system. In [19], the authors considered the problem of global asymptotic stability for a class of generalized neural networks with interval time-varying delays. Delay-dependent stability criteria of uncertain Markovian jump neural networks with discrete interval and distributed time-varying delays have been presented in [13]. Delay neural networks can be classified into two categories: delay-independent and delay-dependent. Delay-independent criteria do not employ any information on the size of the delay, while delay-dependent criteria make use of such information at different levels. The problem of delay-dependent in neural networks has been extensively studied for the sake of theoretical interest as well as applicable considerations [12, 20]. In [20], the authors considered the problem of global asymptotic stability analysis for delayed neural networks. By using a matrix-based quadratic convex approach to derive a sufficient condition, the positive definiteness of chosen LKF can be ensured. As a result, the constraint P > 0 in both Kim (2011) and Zhang et al. (2013) is removed.
On the other hand, the passivity theory has also received a great deal of attention, see [7–9, 14, 21, 23, 24]. Passivity theory is closely related to the circuit analysis method. The main scope of passivity theory is that the passive properties of system can keep the system internally stable. The passication problem is also called as the passive control problem. The objective of passive control problem designs for a controller so that the resulting closed-loop system is passive. Because of this feature, the passivity and passication problems have been an active area of research in the past decades. Considering neural networks with time-varying delays, passivity conditions has been presented in [15]. The authors considered the problem of delay-dependent passivity conditions for uncertain neural networks with discrete and distributed time-varying delays, which improved the passivity conditions in [1, 2, 24]. Improved conditions for passivity of neural networks with a time-varying delay are proposed in [16, 25], which construct a delay-interval-dependent Lyapunov–Krasovskii functional (LKF). In [10], the authors considered passivity criteria for continuous-time neural networks with mixed time-varying delays. However, it is worth pointing out that there still exist some points waiting for the improvement. In most of the works above [12, 20, 25], the augmented Lyapunov matrix P must be positive definite. In our work, we will remove this restriction by assuming that P are only real matrices. By utilizing a new type, LKF and some estimating are assumed in [20]. Moreover, we consider passivity analysis for neural networks that provides a powerful tool for analyzing the stability of system, which obtained distributed delay such that the system is more applicable for solving the general problem of recognized patterns in a time-dependent signal.
Motivated by above discussing, this paper investigates the delay-dependent approach to passivity analysis for uncertain neural networks with discrete interval and distributed time-varying delays. Based on delay partitioning, a LKF is constructed to obtain several improved delay-dependent passivity conditions which guarantee the passivity of uncertain neural networks. We consider the additional useful terms with the distributed delays and estimate some integral terms by Wirtinger’s inequality provided a tighter lower bound than Jensen’s inequality, so integral inequalities derived by Jensen’s inequality lead to less conservative results and some techniques in [20]. These conditions are expressed in terms of linear matrix inequalities (LMIs), which can be solved numerically and efficiently by resorting to numerical algorithms. The effectiveness is verified by two illustrating examples.
Notation
\(\mathcal {R}^{n}\) is the n-dimensional Euclidean space; \(\mathcal {R}^{m\times n}\) denotes the set of m×n real matrices; I n represents the n-dimensional identity matrix; λ(A) denotes the set of all eigenvalues of A; λ max(A)= max{Re λ;λ∈λ(A)}; \(C([0, t],\mathcal {R}^{n})\) denotes the set of all \(\mathcal {R}^{n}\)-valued continuous functions on [0,t]; \(L_{2}([0, t],\mathcal {R}^{m})\) denotes the set of all the \(\mathcal {R}^{m}\)-valued square integrable functions on [0,t]. The notation X≥0 (respectively, X > 0) means that X is positive semidefinite (respectively, positive definite); diag(⋯ ) denotes a block diagonal matrix; \(\left [ {\begin {array}{*{20}c} X & Y \\ \ast & Z \end {array}} \right ]\) stands for \(\left [ {\begin {array}{*{20}c} X & Y \\ Y^{T} & Z \end {array}} \right ]\). Matrix dimensions, not explicitly stated, are assumed to be compatible for algebraic operations.
2 Preliminaries
Consider the following neural networks with discrete interval and distributed time-varying delays:
where \(x(t)=[x_{1}(t),x_{2}(t),\dots ,x_{n}(t)] \in \mathcal {R}^{n}\) is the state of the neural, A = diag(a 1, a 2,…,a n ) > 0 represents the self-feedback term, W, W 1 and W 2 represent the connection weight matrices, g(⋅) = (g 1(⋅), g 2(⋅),…,g n (⋅))T represents the activation functions, u(t) and y(t) represent the input and output vectors, respectively; ϕ(t) is an initial condition. The variables τ(t) and k(t) are the discrete and distributed delays and satisfy the following conditions:
where τ 1, τ 2, μ and k are constants. The neural activation functions g k (⋅), k = 1,2,…,n satisfy g k (0)=0 and for \(s_{1}, s_{2} \in \mathcal {R}\), s 1≠s 2,
where \(l_{k}^{-}\), \(l_{k}^{+}\) are known real scalars. Moreover, we denote \(L^{+} = \text {diag}(l_{1}^{+},l_{2}^{+},\dots ,l_{n}^{+})\), \(L^{-} = \text {diag}\left (l_{1}^{-}, l_{2}^{-},\dots , l_{n}^{-}\right )\).
Definition 1
[8] The neural network (1) is said to be passive if there exists a scalar γ such that for all t f ≥ 0
and for all solutions of (1) with x(0) = 0.
Lemma 1
Let \(f_{1}, f_{2},\dots , f_{N}\in \mathcal {R}^{{m}}\rightarrow \mathcal {R}\) have positive values in an open subset \(\mathcal {D}\) of \(\mathcal {R}^{\mathrm {m}}\) . Then, the reciprocally convex combination of f i over \(\mathcal {D}\) satisfies
subject to
Lemma 2
[6] For any symmetric positive definite matrix M > 0, a scalar γ > 0 and a vector function \(x:[0,\gamma ]\rightarrow \mathcal {R}^{n}\) such that the integrations concerned are well defined, the following inequality holds:
Lemma 3
[12] For a given matrix R > 0, the following inequality holds for any continuously differentiable function \(x:[a,b]\rightarrow \mathcal {R}^{n}\) ,
where
Lemma 4
[20] Let τ(t) be a continuous function satisfying 0 ≤ τ 1 ≤ τ(t) ≤ τ 2. For any n × n real matrix R 1 > 0 and a vector \(\dot {x}:[-\tau _{2},0]\rightarrow \mathcal {R}^{n}\) such that the integration concerned below is well defined, the following inequality holds for any 2n × 2n real matrices D satisfying \(\left [ \begin {array}{cc} \bar {R}_{1} &D\\ \ast &\bar {R}_{1} \end {array}\right ]\geq 0\), and
where \(\bar {R_{1}}=\text {diag}\{R_{1},3R_{1}\}\) and
Lemma 5
[20] Let τ(t) be a continuous function satisfying 0 ≤ τ 1 ≤ τ(t) ≤ τ 2. For any n × n real matrix R 2 > 0 and a vector \(\dot {x}:[-\tau _{2},0]\rightarrow \mathcal {R}^{n}\) such that the integration concerned below is well defined, the following inequality holds for any \(\phi _{i1}\in \mathcal {R}^{q}\) and real matrices \(Z_{i}\in \mathcal {R}^{q\times q}\), \(B_{i}\in \mathcal {R}^{q\times n}\) satisfying \(\left [ \begin {array}{cc} Z_{i} &B_{i}\\ \ast &R_{2} \end {array}\right ]\geq 0 \ (i=1,2)\) and
where
Lemma 6
[20] Let \(\mathcal {P}_{0}\), \(\mathcal {P}_{1}\), and \(\mathcal {P}_{2}\) be m × m real symmetric matrices and a scalar continuous function τ satisfy τ 1 ≤ τ ≤ τ 2 where τ 1 and τ 2 are constants satisfying 0 ≤ τ 1 ≤ τ 2. If \(\mathcal {P}_{0} \geq 0\), then
Lemma 7
[6] Let H,E and F(t) be real matrices of appropriate dimensions with F(t) satisfying F T (t)F(t) < I. Then, for any scalar > 0,
Lemma 8
[6] (Schur complement) Given constant symmetric matrices X, Y, Z with appropriate dimensions satisfying X = X T, Y = Y T > 0. Then X + Z T Y −1 Z < 0 if and only if
3 Main Results
In this section, we consider robust passivity of the neural networks (1) with interval time-varying delays. For the sake of simplicity, we consider the LKF as
where
where \(\eta (t)=\text {col}\{x(t), x(t-\tau _{1}),{\int }_{t-\tau _{1}}^{t}x(s)ds, {\int }_{t-\tau (t)}^{t-\tau _{1}}x(s)ds, {\int }_{t-\tau _{2}}^{t-\tau (t)}x(s)ds\}\), Q i > 0, S i > 0, Y 1 > 0, Y 2 > 0, R 1 > 0, R 2 > 0, (i = 0, 1, 2, 3), U 1 = diag{ρ 1, ρ 2,…,ρ n } ≥ 0, U 2 = diag{σ 1, σ 2,…,σ n } ≥ 0 are to be determined, a real matrix P with appropriate dimension, τ 21 = τ 2−τ 1 and let
where υ(t)=col{x(t),g(x(t))}, G 1 = [I,0] and G 2 = [0,I].
For the sake of simplicity on matrix representation, e i (i = 1,2,…,11) are defined as block-row vectors of the 11n×11n identity matrix (For example, e 3 = [0 0 I 0 0 0 0 0 0 0 0]) and v(t) = e 1 ζ(t), \(v(t-\tau (t))=e_{2}\zeta (t),\dots ,\dot {x}(t-\tau _{1})=e_{11}\zeta (t)\) such that the notations of several matrices are defined as:
We apply a matrix-based quadratic convex approach combined with some improved boundary techniques for integral terms such as Wirtinger-based integral inequality; as a result, we obtain inequality encompassing the Jensen’s inequality and also go to tractable LMIs criteria to further reduce the conservatism over the existing results to derive a sufficient condition.
Remark 1
It is shown that using Lemmas 3, 4, 5 one can obtain some less conservative results than the other results [16, 25] that show the effectiveness in Table 1. However, these lemmas contain many free-weighting matrices which may lead to higher computational complexity than them.
Remark 2
Those of [9, 24], previous works only focused on some augment vectors but our work includes not only x(t), \({\int }_{t-\tau _{1}}^{t}x(s)ds\) but also x(t), x(t−τ 1), \({\int }_{t-\tau _{1}}^{t}x(s)ds\), \({\int }_{t-\tau (t)}^{t-\tau _{1}}x(s)ds\), \({\int }_{t-\tau _{2}}^{t-\tau (t)}x(s)ds\). We can see that the adaptation of new augmented variables, cross terms of variables and more multiple integral terms may lead to reduce to the conservatism.
Proposition 1
[20] For the Lyapunov–Krasovskii functional (4), and prescribed scalars τ 2 ≥ τ 1 > 0, there exist scalars 𝜖 1 > 0 and 𝜖 2 > 0 such that
if there exist real matrices M 1 and N 1 with appropriate dimensions such that
where
with
Proof
By [20] and \(V_{5}(x_{t})\leq k^{2}\max \{\lambda _{s_{0}}\}\|x_{t}\|_{W}^{2}\). □
Remark 3
The constraint P > 0 is removed from Proposition 1. Thus, we can see that the introduction of the vector ζ(t) plays a key role in deriving a quadratic convex combination Σ(τ(t)). So, a matrix-based quadratic convex technique can be used to design an LMI-based sufficient condition.
Then, we have the following result.
Theorem 1
Given scalars τ 1, τ 2 and k, the system (1) with (3) is passive for any delays τ(t) and k(t) satisfying (2) if there exist real matrices Q i > 0, S i > 0, Y 1 > 0, Y 2 > 0, R 1 > 0, R 2 >0 (i = 0, 1, 2, 3), real positive diagonal matrices U 1, U 2, T s , T ab (s = 1, 2, 3, 4; a = 1, 2, 3; b = 2, 3, 4; a < b), real matrices M 2, N 2, Z 1, Z 2, B 1, B 2, D, X 1, X 2 and P with appropriate dimensions, and a scalar γ > 0 such that the following linear matrix inequalities hold:
where \(\bar {R_{1}} = \text {diag}\{R_{1},3R_{1}\}\) and
with
Proof
Differentiating V(x t ) along the solution of (1), we get
where Σ11, Σ12, and Σ2 are defined in (10), (11), and (12) respectively. Applying Lemmas 3–5, it can be shown that
where \(\bar {R}_{1}=\text {diag}\{R_{1},3R_{1}\}\), (8) and
where Σ3, Σ4, and Σ5 are defined in (13)–(15), respectively.
On the other hand, for any matrices X 1 and X 2 with appropriate dimensions, it is true that
where Σ6 is defined in (16).
From (3), the nonlinear function g k (x k ) satisfies
Thus, for any t k > 0,(k = 1,2,…,n), we have
which implies
where T = diag{t 1, t 2,…,t n }. Let 𝜃 be t, t−τ(t), t−τ 1, and t−τ 2, and replace T by T s (s = 1,2,3,4), then we have
where s = 1,2,3,4 and
As another observation from (3), we have
Thus, for any t k > 0(k = 1,2,…,n) and Λ = g k (x(𝜃 1))−g k (x(𝜃 2)), we have
which implies
where Λ=col{Λ1,Λ2,…,Λ n }.
Let 𝜃 1 and 𝜃 2 take values in t, t−τ(t), t−τ 1 and t−τ 2, and replace T by T a b (a = 1,2,3;b = 2,3,4;b > a), then we have
where a = 1,2,3, b = 2,3,4, b > a.
From (33) and (35), it can be shown that
where Σ7 is defined in (17).
Next, to show the passivity of system (1), we set
where t f ≥ 0. Noting the zero initial condition, we have
From (18), (19), (29)–(32), and (36), we obtain
where \(\boldsymbol {\Sigma }(\tau (t),\dot \tau (t))\) is defined in (9). It is clear to see that \(\boldsymbol {\Sigma }(\tau (t),\dot \tau (t))\) is a quadratic convex combination of matrices on τ(t)∈[τ 1, τ 2] and \(\boldsymbol {\Sigma }(\tau (t),\dot \tau (t))\) is also a convex combination of matrices on \(\dot \tau (t)\in [0,\mu ]\).
If we have \(\boldsymbol {\Sigma }(\tau (t),\dot \tau (t))<0\), then \(\dot V(t,x_{t})-\gamma u(t)^{T}u(t)-2y(t)^{T}u(t)< 0\) for any ζ(t) ≠ 0. By (37), we have
for any t f ≥ 0, when (3) is satisfied. Thus, neural network (1) is passive. This completes the proof. □
Remark 4
Theorem 1 presents estimating of the integral terms in (23), (24), (25), and (26) by Wirtinger’s inequality and [20], which provided a tighter lower bound than Jensen’s inequality [24].
In the following, it is interesting to consider passivity condition of passivity analysis for uncertain neural networks with discrete interval and distributed time-varying delays:
where △A(t), △W(t), △W 1(t), and △W 2(t) represent the time-varying parameter uncertainties that are assumed to satisfy the following conditions:
where H, E 1, E 2, E 3, and E 4 are known real constant matrices, and F(⋅) is an unknown time-varying matrix function satisfying
Then, we have the following result.
Theorem 2
Given scalars τ 1, τ 2 and k, the uncertain system (38) with (3) is robust passive for any delays τ(t) and k(t) satisfying (2) if there exist real matrices Q i > 0, S i > 0, Y 1 > 0, Y 2 > 0, R 1 > 0, R 2 > 0(i = 0, 1, 2, 3), real positive diagonal matrices U 1, U 2, T s , T ab (s = 1, 2, 3, 4; a = 1, 2, 3; b = 2, 3, 4; a < b), real matrices M 2, N 2, Z 1, Z 2, B 1, B 2, D, X 1, X 2 and P with appropriate dimensions, and scalars γ > 0 and 𝜖> 0 such that the following linear matrix inequalities hold:
where
Σ and (41) are defined in Theorem 1.
Proof
Replacing A, W, W 1, and W 2 in (7) with A + H F(t)E 1, W + H F(t)E 2, W 1 + H F(t)E 3, and W 2 + H F(t)E 4 respectively, so we have
By Lemma 7, it can be deduced that 𝜖 > 0 and
is equivalent to (40) in the sense of the Schur complements Lemma 8. The proof is complete. □
4 Numerical Examples
In this section, we present examples to illustrate the effectiveness and the reduced conservatism of our results.
Example 1
Revisit nominal neural network with (1) with the following parameters:
The neural activation functions are assumed to be g i (x i (t)) = 0.5(|x i + 1| − |x i − 1|),i = 1, 2. It is easy to see
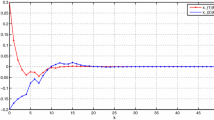
According to Theorem 1, we get the upper bounds of the time-varying delay τ(t) for various μ, and summarize them in Table 1 for comparison with the results obtained in [16, 25]. It is concluded that our results have improvements at the amount of 109.86%, 89.00%, and 92.64% for μ = 0.5,0.9 and μ ≥ 1 respectively, compared with the recent work [25]. Figure 1 gives the state trajectory of the neural network (1) under zero input, 0.3 ≤ τ(t) ≤ 2.8193 and the initial condition [x 1(t),x 2(t)]T = [0.3,−0.2]T, which shows that the neural network is stable.

State trajectory of neural network in Example 1
Remark 5
Our obtained results have been shown to be the less conservative than some existing results, but still have some comments because Wirtinger-based integral inequality approach still requires less decision variables to manipulate of Lyapunov–Krasovskii functional candidates. Recently, a new class of integral inequalities for quadratic functions via some intermediate terms called auxiliary functions, are recent bounding techniques because these inequalities turn into the existing inequality, such as the Jensen inequality, the Wirtinger based integral inequality and the Bessel–Legendre (B-L) inequality by appropriately choosing the auxiliary functions.
Example 2
Consider the uncertain neural networks (38) with the following parameters:
According to Theorem 2, we get the upper bounds of the interval time-varying delay τ(t) for various μ, and summarize them in Table 2 for comparison with the results obtained in [10]. On the other hand, the eigenvalues of P for 0.3 ≤ τ(t) ≤ 1.5714 and μ = 0.7 are 0.1813, −0.0284, −0.0206, −0.0000, 0.0001, 0.0121, 0.0418, 0.0556, 0.1581, 0.5081, and 0.5081. So, P is not a positive matrix.
Example 3
Consider the uncertain neural networks (38) with the following parameters:
By Theorem 2, we get the upper bounds of the interval time-varying delay τ(t) for various μ, and summarize them in Table 3 for comparison with the results obtained in [11, 22].
5 Conclusions
In this paper, the delay-dependent passivity analysis issue for uncertain neural networks with discrete interval and distributed time-varying delays was studied by the Lyapunov–Krasovskii functional method, via an LMIs approach. The delay-dependent passivity conditions have been considered for two types of time-varying delays. To estimate the derivative of the Lyapunov–Krasovskii functional, we applied Wirtinger’s inequality to provide a tighter lower bound than Jensen’s inequality, which established less conservative results. Numerical examples are given to illustrate the effectiveness of our theoretical results.
References
Chen, B., Li, H., Lin, C., Zhou, Q.: Passivity analysis for uncertain neural networks with discrete and distributed time-varying delays. Phys. Lett. A 373, 1242–1248 (2009)
Chen, Y., Qian, W., Fei, S.: Improved robust stability conditions for uncertain neutral systems with discrete and distributed delays. J. Frankl. Inst. 352, 2634–2645 (2015)
Chua, L.O., Yang, L.: Cellular neural networks: theory. IEEE Trans. Circ. Syst. 35, 1257–1272 (1988)
Cichocki, A., Unbehauen, R.: Neural Networks for Optimization and Signal Processing. Wiley, Hoboken, NJ (1993)
Cohen, M.A., Grossberg, S.: Absolute stability and global pattern formation and parallel memory storage by competitive neural networks. IEEE Trans. Syst. Man, Cybern. 13, 815–826 (1983)
Gu, K., Kharitonov, V.L., Chen, J.: Stability of Time-Delay System. Birkhäuser, Boston (2003)
Kwon, O.M., Park, M.J., Park, J.H., Lee, S.M., Cha, E.J.: Passivity analysis of uncertain neural networks with mixed time-varying delays. Nonlinear Dyn. 73, 2175–2189 (2013)
Li, C., Liao, X.: Passivity analysis of neural networks with time delay. IEEE Trans. Circ. Syst. II: Express Briefs 52, 471–475 (2005)
Li, H., Gao, H., Shi, P.: New passivity analysis for neural networks with discrete and distributed delays. IEEE Trans. Neural Netw. 21, 1842–1847 (2010)
Li, H., Lam, J., Cheung, K.C.: Passivity criteria for continuous-time neural networks with mixed time-varying delays. Appl. Math. Comput. 218, 11062–11074 (2012)
Li, Y., Zhong, S., Cheng, J., Shi, K., Ren, J.: New passivity criteria for uncertain neural networks with time-varying delay. Neurocomputing 171, 1003–1012 (2016)
Seuret, A., Gouaisbaut, F.: Wirtinger-based integral inequality: Application to time-delay systems. Automatica 49, 2860–2866 (2013)
Syed Ali, M., Arik, S., Saravanakumar, R.: Delay-dependent stability criteria of uncertain Markovian jump neural networks with discrete interval and distributed time-varying delays. Neurocomputing 158, 167–173 (2015)
Thuan, M.V., Trinh, H., Hien, L.V.: New inequality-based approach to passivity analysis of neural networks with interval time-varying delay. Neurocomputing 194, 301–307 (2016)
Wua, Z.-G., Park, J.H., Su, H., Chu, J.: New results on exponential passivity of neural networks with time-varying delays. Nonlinear Anal. RWA 13, 1593–1599 (2012)
Xu, S., Zheng, W.X., Zou, Y.: Passivity analysis of neural networks with time-varying delays. IEEE Trans. Circuits Syst. II 56, 325–329 (2009)
Zhang, X.-M., Han, Q.-L.: Novel delay-derivative-dependent stability criteria using new bounding techniques. Int. J. Robust. Nonlinear Control 23, 1419–1432 (2013)
Zhang, X.-M., Han, Q.-L.: New Lyapunov–Krasovskii functionals for global asymptotic stability of delayed neural networks. IEEE Trans. Neural Netw. 20, 533–539 (2009)
Zhang, X.-M., Han, Q.-L.: Global asymptotic stability for a class of generalized neural networks with interval time-varying delays. IEEE Trans. Neural Netw. 22, 1180–1192 (2011)
Zhang, X.-M., Han, Q.-L.: Global asymptotically stability analysis for delayed neural networks using a matrix-based quadratic convex approach. Neural Netw. 54, 57–69 (2014)
Zhang, D., Yu, L.: Passivity analysis for discrete-time switched neural networks with various activation functions and mixed time delays. Nonlinear Dyn. 67, 403–411 (2012)
Zhang, Z., Mou, S., Lam, J., Gao, H.: New passivity criteria for neural networks with time-varying delay. Neural Netw. 22, 864–868 (2009)
Zeng, H.-B., He, Y., Wu, M., Xiao, S.-P.: Passivity analysis for neural networks with a time-varying delay. Neurocomputing 74, 730–734 (2011)
Zeng, H.-B., Park, J.H., Shen, H.: Robust passivity analysis of neural networks with discrete and distributed delays. Neurocomputing 149, 1092–1097 (2015)
Zeng, H.-B., He, Y., Wu, M., Xiao, H.-Q.: Improved conditions for passivity of neural networks with a time-varying delay. IEEE Trans. Cybern. 44, 785–792 (2014)
Acknowledgments
We would like to thank referees for their valuable comments and suggestions. The first author was financially supported by the National Research Council of Thailand and Rajamangala University of Technology Isan 2017. The second author was financially supported by the Thailand Research Fund (TRF), the Office of the Higher Education Commission (OHEC), Khon Kaen University (grant number: MRG5880009), and Academic Affairs Promotion Fund, Faculty of Science, Khon Kaen University, Fiscal year 2016. The third author was financially supported by University of PhaYao, PhaYao, Thailand.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yotha, N., Botmart, T., Mukdasai, K. et al. Improved Delay-Dependent Approach to Passivity Analysis for Uncertain Neural Networks with Discrete Interval and Distributed Time-Varying Delays. Vietnam J. Math. 45, 721–736 (2017). https://doi.org/10.1007/s10013-017-0243-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10013-017-0243-1