
Abstract
Understanding climate change’s effects on dam basins is very important for water resource management because of their important role in providing essential functions such as water storage, irrigation, and energy production. This study aims to investigate the impact of climate change on temperature and precipitation variables in the Altınkaya Dam Basin, which holds significant potential for hydroelectric power generation in Türkiye. These potential impacts were investigated by using ERA5 reanalysis data, six GCMs from the current CMIP6 archive, and two Shared Socioeconomic Pathways (SSP2 − 4.5 and SSP5 − 8.5) scenario data. Four Multi-Model Ensemble (MME) models were developed by using an Artificial Neural Network (ANN) approach (ENS1), simple averaging (ENS2), weighted correlation coefficients (ENS3), and the MARS algorithm (ENS4), and the results were compared to each other. Moreover, quantile delta mapping (QDM) bias correction was used. The 35-year period (1980–2014) was chosen as the reference period, and further evaluations were conducted by dividing it into three future periods (near (2025–2054), mid-far (2055–2084), and far (2085–2100)). Considering the results achieved from the MMEs, variations are expected in the monthly, seasonal, and annual assessments. Projections until the year 2100 indicate that under optimistic and pessimistic scenarios, temperature increases could reach up to 3.11 °C and 5.64 °C, respectively, while precipitation could decrease by as much as 19% and 43%, respectively. These results suggest that the potential changes in temperature and precipitation within the dam basin could significantly impact critical elements such as future water flow and energy production.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
In recent years, global climate change has caused increasing concerns regarding its potential effects on environmental, economic, and social systems, making it a top priority for all countries (WMO 2016). One of these effects is the changes in water resources, which are particularly critical for reservoirs and hydroelectric power generation. Reservoirs play an important role in ensuring essential aspects such as water storage, irrigation, and energy production, so understanding the effects of climate change on precipitation and temperature in reservoirs is critical for water resource management. Uncertainties in water resources can lead to changes in flow patterns and fluctuations in water levels. Therefore, the operation of reservoirs and energy production is anticipated to be affected by these variations.
As stated in the 6th Assessment Report (AR6) of the Intergovernmental Panel on Climate Change (IPCC), global mean surface temperatures are rapidly increasing, largely due to human-induced greenhouse gas emissions. Similarly, it is emphasized that temperature increases worsen extreme weather events such as heatwaves, droughts, heavy rainfall, and hurricanes (IPCC 2021). Furthermore, examining each sequential ten-year timeframe within the previous 40 years individually, it can be seen that increases in temperature in each decade exceeded those observed in the previous decade.
General circulation models (GCMs) are referred to as models developed to simulate the complex climate system involving the atmosphere, oceans, land, and ice. Even though there are different approaches to determining future climate and climate parameters (precipitation, temperature, evaporation, etc.), scenarios created using GCM outputs have been preferred by researchers because they offer much more reliable results when compared to others (Wilby and Harris 2006; Islam et al. 2012; Kumar et al. 2022). However, the low resolution of the used GCMs poses limitations in accurately determining the effects of climate change at the regional level. Therefore, it is necessary to downscale GCM outputs from a global scale to a regional or station scale to predict the effects of climate change on climate parameters, hydrological cycles, and water resources. In the literature, there are two downscaling methods: dynamic and statistical. Dynamic downscaling, incorporating topographical features, allows for operation at higher resolutions (Crane and Hewitson 1988). However, the application, setup, and optimization of such models require prolonged and meticulous efforts, which makes it difficult to customize them for different regions. Therefore, statistical downscaling methods, establishing statistical relationships between extensive atmospheric variables and local surface variables, are frequently utilized thanks to their adaptability and efficiency (Fistikoglu and Okkan 2011; Nacar et al. 2019; Baghanam et al. 2020).
As can be seen in previous studies carried out on the application of downscaling methods, researchers made use of reanalysis data obtained from meteorological satellites and the global land observation network (Su et al. 2016; Okkan and Karakan 2016; Baghanam et al. 2020; Nacar et al. 2022; San et al. 2024). Reanalysis data consists of datasets created through spectral statistical interpolation methods that compile global atmospheric analyses spanning from historical to current periods. These datasets incorporate data from national archives, meteorological observation stations, observations from ships and aircraft, satellite data, and outputs from weather forecasting models. These datasets are provided by various organizations for atmospheric studies, as well as modeling climate events. It was reported in several studies that the ERA5 reanalysis dataset provides more detailed results in comparison to others thanks to its ability to provide high-resolution temporal and spatial data (Liu et al. 2021; Nacar et al. 2022). ERA5 differs from other reanalysis datasets by offering more detailed results. Accordingly, this study utilized ERA5 reanalysis data, which succeeded the ERA-Interim. It features a substantially improved resolution, from 80 km to 31 km intervals, and offers lower prediction uncertainty (Hersbach et al. 2020).
CMIP6, the Coupled Model Intercomparison Project, is a part of the global climate change studies carried out by the IPCC to provide information to policymakers and researchers. It enables the climate science community to evaluate the performance of different models and develop projections and scenarios related to climate change. It facilitates the aggregation and comparison of various climate models to understand the potential effects of global climate change. CMIP6 includes more advanced and complex climate models in comparison to previous versions. Many studies were carried out by using GCMs selected from CMIP5 and CMIP6 in order to examine the effects of climate change on precipitation and temperature. Even though these changes are generally similar to each other, they are more clearly seen in CMIP6 than in CMIP5 (Chen et al. 2020; Zamani et al. 2020). Similarly, a pairwise comparison suggests an enhancement in climate models from CMIP5 to CMIP6 regarding climatological temperature and precipitation (Jiang et al. 2020).
SSP (Shared Socioeconomic Pathway) refers to a set of roadmaps that define the social and economic factors underlying climate change scenarios. These scenarios were developed based on various carbon emission levels, resulting in a total of five different SSPs (SSP1, SSP2, SSP3, SSP4, and SSP5). As with many scientific studies, this study considers the SSP2-4.5 scenario, which represents a mean pathway, as well as the SSP5-8.5 scenario, which represents the highest emission levels and the most adverse climate scenarios (Qin et al. 2022; Haider et al. 2023). While the SSP2-4.5 scenario, which assumes the radiative forcing in the atmosphere remaining at the level of 4.5 W/m2, is described as an optimistic scenario throughout the study, the SSP5-8.5 scenario, which keeps it at the level of 8.5 W/m2, is considered a pessimistic scenario.
Bias correction is an important process in climate change studies and weather forecasting. Even though General Circulation Models (GCMs) are widely used in climate modeling thanks to their comprehensive coverage, they are also known to contain biases due to their coarse resolution and limited capabilities in accurately modeling certain atmospheric processes. Therefore, addressing these biases is essential to improve the reliability of predictions in climate modeling studies. This adjustment ensures that the projections better reflect actual conditions and can be trusted for more precise decision-making in climate-related policies and strategies (Kırdemir and Okkan 2019). These methods are performed by applying various distribution moments of the data of the climate parameter examined and based on the distribution structure of the parameter. Although there are multiple bias correction methods, there are studies in the literature comparing these methods with each other (Teutschbein and Seibert 2012; Chen et al. 2013; Cannon et al. 2015; Dai et al. 2020). As a result of these studies, it was concluded that distribution-based methods corrected rainfall simulations in a way that increased hydrological model performance. Therefore, in the present study, bias corrections were made by using the quantile delta mapping technique (QDM).
Modeling climatic events is inherently complex, and predictions made by using a single model often carry a degree of uncertainty due to various limitations. Since different models have their unique strengths and weaknesses, combining multiple models can help mitigate these deficiencies. This approach, which is known as multi-model ensemble forecasting, effectively reduces uncertainty and improves both the accuracy and overall reliability of climate predictions (Nourani et al. 2019; Ahmed et al. 2020). The Multi-Model Ensemble (MME) strategy will help model developers understand the advantages of their individual global circulation models (GCMs) and avoid associated weaknesses. The development of MME at the basin scale is a feasible way to reduce parameter and structural uncertainties in GCM simulations. Moreover, it will also help reservoir basin modelers make appropriate modeling decisions.
Located in the subtropical zone within the Mediterranean macroclimatic region, Türkiye is one of the nations that are most susceptible to the effects of climate change (Turkes 2020). Additionally, Türkiye also experienced a rapid increase in its annual and seasonal mean temperatures (IPCC 2021; Seker and Gumus 2022). The number of studies carried out in Türkiye and investigating the potential effect of climate change on temperature and precipitation parameters by using Global Climate Models (GCMs) is very limited. The several studies carried out in different regions of Türkiye and focusing on projections and assessments of future climate conditions highlighted key findings such as a significant decline in precipitation, increased drought intensity, and a more arid climate in certain regions. The warming rate in Türkiye is expected to exceed global averages (Turkes et al. 2020; Bağçaci et al. 2021; IPCC 2021). In addition, in a study in which future projections regarding total precipitation and average temperatures were made by focusing on the comparison of CMIP5 and CMIP6, it was emphasized that whether the studied area is in a coastal area or not and its altitude might cause differences (Seker and Gumus 2022).
Many studies were carried out on the effects of climate change on dams around the world (Beyene et al. 2010; Chernet et al. 2014; Tofiq and Güven 2015; Qin et al. 2022). There are various climate studies carried out on dams and aiming to assess the effects of climate change on the water resources of dams, understand water management strategies, and evaluate risks for future water sources in Türkiye. Studies covering reservoir areas were also carried out on how global climate change will affect parameters such as precipitation, temperature, and flow (Fujihara et al. 2008; Okkan and Kirdemir 2018; Okkan et al. 2023). In addition, different studies include the investigation of basin-reservoir uncertainty in climatic terms, evaluating changes in flood frequency and severity, and determining the water supply reliability of a multi-purpose reservoir (Kara et al. 2016; Yalcin 2023).
The researchers often emphasized that global data should be downscaled to the local level in order to provide more sensitive results. Statistical downscaling models were established with different methods in order to reduce the uncertainties of the models on a global scale and increase their accuracy and reliability (Valverde et al. 2014; Sharma et al. 2020; Wang et al. 2021; Nacar et al. 2022). ANN is frequently used in the field of hydrometeorology in weather, flood, wind energy forecasting, water resources management, water pollution, and satellite data analyses (Iliadis and Maris 2007; Sharma and Mutreja 2013; Paul and Das 2014; Ahmad and Simonovic 2005; Marugán et al. 2018; Abu-Ali et al. 2019). This machine-learning model inspired by the biological neural networks of the human brain is one of the methods used reliably as a statistical downscaling method (Goyal and Ojha 2012; Okkan and Kirdemir 2018). Similarly, the multivariate adaptive regression splines (MARS) algorithm has been effectively used and validated across various domains, including predicting software maintainability, pile drivability, air temperature, energy dissipation, discharge coefficient, water pollution, sediment estimation, and statistical downscaling (Zhou and Leung 2007; Zakeri et al. 2010; Zhang and Goh 2016; Ramesh and Anitha 2014; Parsaie et al. 2016; Kisi and Parmar 2016; Parsaie and Haghiabi 2017; Yilmaz et al. 2018; Nacar et al. 2022). In this study, the MARS algorithm was used in establishing the ensemble model, whereas ANN was used in both the downscaling and ensemble model creation phases.
Examining studies on climate change, it can be seen that Türkiye will experience a range of issues across almost all its regions. These challenges include escalating temperatures, diminishing water quantity and quality, an increase in flood events due to brief yet intense rainfall, and a rise in the frequency and magnitude of extreme weather events, including droughts stemming from excessive heat. Consequently, it is anticipated that the issues arising from climate change may closely affect significant aspects at the reservoir basin scale, such as evaporation, precipitation, dam flows, water levels, and energy production.
In 2020, the water in the Altınkaya Dam basin, which is the fifth-largest dam in Türkiye with its body volume and was constructed on the Kızılırmak River, receded for kilometers due to the decrease in precipitation by almost half. Accordingly, with the visibly decreasing mean flow rate, agricultural lands emerged, and fishing boats were observed to run aground when the water receded. It was stated that this important problem in the region is related to drought. It is thought that this study will contribute to the literature in order to highlight the existence of a real-life problem and to have advanced knowledge about predicting future damages. Although there are only few studies carried out in Türkiye, the number of studies previously examining the dam area is very insufficient. To the best of the authors’ knowledge, in the literature, there is no previous study examining this study area to determine the potential effects of climate change on precipitation and temperatures using high-resolution ERA5 reanalysis data, six different GCMs from the most up-to-date CMIP6 archive which incorporates the latest climate data, and two different Shared Socioeconomic Pathways (SSP2-4.5 and SSP5-8.5) scenario data.
This study consists of 6 sections. Section 2 provides information about the study area and the datasets used in the study. Section 3 discusses the methods applied in the study and its stages. Section 4 presents the findings obtained, while Sect. 5 includes the discussion section where the findings are evaluated and interpreted. Finally, Sect. 6 presents the conclusions achieved in this study.
2 Study area and datasets
2.1 Study area
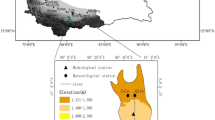
Altınkaya Dam is located at 41° 16′ 34″ north latitude and 35° 25′ 23″ east longitude. It was built between the years 1980 and 1988 in order to generate energy on Kızılırmak River, which is the longest river and originates from Sivas Kızıldağ and pours into the Black Sea in Bafra (Fig. 1).

The locations of the Altınkaya dam with observation stations
Besides generating electrical energy, the purpose of establishing the dam was to provide a continuous and regular water supply and control the flood to Derbent Dam, located 20 km downstream of the dam. The dam was built in a clay core rockfill type. The catchment area is 75,165 km², the mean annual flow is 4,019 hm³, the annual mean precipitation is 490 mm/year, the active volume is 2,892 hm³, the maximum operating level is 190 m, the maximum operating volume is 5,763 hm³, the minimum operating volume is 2,871 hm³, and the spillway crest elevation is 195 m.
Altınkaya Dam, which is one of the largest hydroelectric power plants in Türkiye, consists of 4 units (175 MW each), with a total installed power of 700 MW and an annual electricity generation capacity of 1 billion 632 million kWh (Oztan 2011).
It was observed that the water level of Altınkaya Dam, which is the 5th largest dam in Türkiye with a body volume of 1,615.92 hm³, has significantly decreased in recent years due to factors such as reduced precipitation in the basin and increasing temperatures. Changes in rainfall and temperature in the dam basin significantly affected the water flow. The insufficient flow into the dam due to the decreased flow rate of the river led to problems such as the emergence of agricultural lands and the stranding of fishing boats. Thus, the decrease in water resources can lead to the deterioration of environmental balance, damage to ecosystems, and social and economic problems due to water stress.
2.2 Datasets
2.2.1 Observed data
Monthly total precipitation and monthly mean temperature data, which are considered to represent the Altınkaya Dam Basin, were obtained from the General Directorate of Meteorology of the Republic of Türkiye Ministry of Environment, Urbanization, and Climate Change. In this study, observation data for the period between 1980 and 2014 were utilized for all stations, each having different ranges of observation. The missing observed monthly mean temperature and total precipitation data of Boyabat station were derived from Merzifon station due to the high correlation values between the two stations (R = 0.99 for temperature, R = 0.76 for precipitation). Thiessen polygons were created by using the ARCGIS program in order to find the areal mean precipitation of the basin among the meteorological stations selected to represent the monthly precipitation of the Dam Basin. The weight coefficients showing the importance of each station on the basin are presented in Table 1.
Considering the high correlation between the mean temperature values at the stations (0.99; 0.97 and 0.96 for Samsun, Merzifon, and Boyabat stations, respectively), the slope of the regression line being close to 1, and the high ratio of the areal mean representing the dam, it was accepted that Bafra station represents the temperature of Altınkaya dam basin (Okkan 2013).
2.2.2 Re-analysis dataset
Re-analysis data sets are provided by various organizations for atmospheric studies and modeling of climate events. ERA5 is the 5th generation ECMWF (The European Centre for Medium-Range Weather Forecasts) atmospheric reanalysis of the global climate covering the period from January 1940 to the present. It is produced by the Copernicus Climate Change Service (C3S) at ECMWF (https://www.ecmwf.int/en/forecasts/dataset/ecmwf-reanalysis-v5).
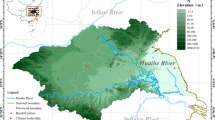
The re-analysis data sets cover the data of many atmospheric variables. While determining the variables to be used in establishing the downscaling models, attention was paid to ensuring that the selected variables were also included in the scenario data sets of GCMs. In most of previous studies using a downscaling model, these variables were determined as precipitation and temperature parameters (Busuioc et al. 2001; Tohver et al. 2014; Najafi and Kermani, 2017; Araya-Osses et al. 2020; Erlandsen et al. 2020; Tefera et al. 2023). As mentioned before, the coarse spatial resolution of GCM projections are not consistent with the local features needed for regional impact assessments. In order to evaluate the effect of large-scale atmospheric variables at the basin scale, spatial statistical downscaling method were used. In this study, ERA5 monthly total precipitation and mean temperature data retrieved between 1980 and 2014 were used for the downscaling models. Downscaling models were established by taking the average of 28 grids covering the study area and stations and shown in a red frame in Fig. 2.

Location of Türkiye and Altınkaya Dam Basin with ERA5 grid coverage
2.2.3 Climate models dataset
CMIP6 is a project that represents the sixth phase of the Coupled Model Intercomparison Project (CMIP). The main objective of this project is to bring together climate models from around the world to increase scientific understanding of climate change and improve climate change projections. The monthly precipitation and temperature CMIP6 data outputs used within the scope of this study, are available and can be downloaded from the Earth System Grid Federation (ESGF) website (https://esgfnode.llnl.gov/projects/cmip6/).
CMIP6 uses various future scenarios to examine how climate change might occur under different greenhouse gas emissions scenarios (Riahi et al. 2017). SSP2-4.5 and SSP5-8.5 climate scenarios represent future global climate change projections until 2100. SSP2-4.5 scenario represents a moderate sustainability path around the world and is associated with the implementation of policies and measures focusing on energy efficiency and reducing carbon emissions (Fricko et al. 2017). Considering the SSP5-8.5 scenario, if greenhouse gas emissions continue to increase rapidly and sustainability measures are not taken, the increase in global mean temperature might be much higher than in other scenarios.
In the selection of GCMs, attention was paid to ensuring that they had a data range covering the common reference period with both the reanalysis data set (ERA5) and observation data. Another important factor is that the selected GCMs are among the top 10 circulation models that exhibited superior performance for precipitation in a previous study carried out for Türkiye (Bağçaci et al. 2021). In another study carried out similarly, it was seen that this inference was supported (Oruc 2022). The primary reason for making this selection on precipitation is that, in a large proportion of studies on climate, the precipitation parameter is more sensitive than temperature and has lower prediction success and correlation in modeling. In this regard, six different general circulation models (GCM) selected from the CMIP6 archive (CNRM-CM6-1, GFDL-ESM4, MRI-ESM2-0, CNRM-CM6-1-HR, MIROC6, and ACCESS-CM2) were used. The grids covering the study area and stations of each GCM were determined and the averages of these grids were taken and converted into a single data set as in the re-analysis data set and defined as input variables to the downscaling models. The resolutions of the GCMs used in the study institute variant labels and the number of grids used in the generation of average values in each GCM are given in (Table 2). Monthly mean temperature and total precipitation data were produced based on the reference period (1980–2014), for the near (2025–2054), mid-far (2055–2084), and far future (2085–2100) periods under optimistic (SSP2-4.5), and pessimistic (SSP5-8.5) scenarios.
3 Methodology
The flow chart of the present study is given in Fig. 3. The steps taken to model the monthly total precipitation and mean temperature spatially are given below.

Flow chart of the study
3.1 Classical regression analysis (CRA)
Three CRA equations [CRA-LF (linear), CRA-EF (exponential), and CRA-QF (quadratic)] were used as the downscaling model, in which the ERA5 re-analysis data were used as the independent variable and the observed temperature values as the dependent variable. These are expressed as follows, respectively,
In these equations, y refers to the estimated value when the independent variables are x1 and regression coefficients are b0, b1,..,bm.
3.2 Artificial neural network (ANN)
The basic components of this method include input layer, output layer, hidden layer, neurons, weights, and activation functions. Each layer is completely connected to the next layer by interconnect weights. The weight values determined at the beginning are gradually changed at each iteration throughout the training process. Subsequently, the predicted outputs are compared to the known outputs. The necessary weight adjustments to minimize errors in the backpropagation process are then determined by reversing any errors (Yilmaz et al. 2019). More detailed information about MLP and the process steps can be accessed from the relevant source (Ali et al. 2017).
3.3 Multivariate adaptive regression splines (MARS)
MARS algorithm developed by Friedman (1991) is a form of non-parametric regression analysis. In many applied fields, non-parametric regression methods are used to represent events where there is no linearity among variables. The main advantage of this model is its ability to explain the complex and non-linear relationship between the predictor variable and the dependent variable (Kisi and Parmar 2016). MARS algorithm does not assume any relationship between dependent and independent variables. The model is constructed based on basic functions and associated coefficients depending on the available data. This method divides the independent variable values into regions and explains each region with a regression equation. Moreover, the response variable is predicted by using the contributions of the basic functions that arise from both explanatory variables and their interactions.
The MARS algorithm consists of two stages: forward and backward steps. The forward-step algorithm used in the first stage is more complex than desired. So, in the second stage, the backward step algorithm is employed to sequentially eliminate base functions in order to reach the optimal model. Detailed information about the MARS algorithm is given in a study carried out by Friedman (1991).
3.4 Preparation of data sets
The standardization process was applied to the datasets of both input and output variables. This process is very important since it helps to minimize the discrepancies between the model results and the observed values, ensuring more accurate and consistent outcomes. At the end of the downscaling, the reverse standardization process was applied to the data, and they were returned to their previous scales. This process was conducted on the data sets using Eq. 4.
In the ANN model, many operations can be performed to achieve the best result by trial and error. Some of these are to increase the number of interlayers from 5 to 15 with increments of five, to give different values (0.1, 0.5, and 1) to the learning and momentum coefficients in the study. The maximum number of iterations in network training is set to 10.000. The hyperbolic tangent sigmoid transfer function (tansig) and linear transfer function (purelin) were respectively used for activation of the hidden and output layers of the network. While establishing the ANN models, 60% of the data (1980–2000 period) was used for training, 20% (2001–2007 period) for validation, and 20% (2008–2014) for the test set. In order to make it easier to compare the used methods to each other and to interpret them as a whole, the data sets were divided into the same ratio in the CRA method, as in the ANN method.
3.5 Generating of MMEs
Although there is no number or rule that needs to be determined for GCMs when applying multi-model ensemble, they are generally chosen between 3 and 10 (Ahmed et al. 2019). All individual GCMs used in the present study are included in the ensemble model in some studies. However, since this process takes into account models that do not perform well, the success of the ensemble model may decrease. Furthermore, this may be more burdensome due to the prior downscaling process performed. Therefore, choosing the optimum number of GCMs becomes important when creating an ensemble model.
In this study, MME was created using four different models, namely ENS1, ENS2, ENS3, and ENS4. ENS1 was created based on ANN, ENS2 on simple average, ENS3 on weighting of correlation coefficients, and ENS4 based on MARS algorithm. While ENS1 and ENS4 were being created, in the ANN and MARS models, the data of reference periods of individual GCMs constituted the inputs, and observed values constituted the outputs. The method (ENS2), in which simple averages are taken, is based on the arithmetic average created by assuming that each of the individual GCMs is equally important. In the method of weighting correlation coefficients, the correlation coefficients were created first. These coefficients were used to determine the importance of individual models on ensemble models. Since variables with high correlation coefficients have a stronger relationship than others, it is assumed that they have more weight in parallel with the coefficients. Weightings were made with the help of the equation below.
In this equation, WR is the weighted correlation, R is the correlation coefficient of each model, and N is the number of members in the MME.
3.6 Performance statistics
Performance statistics are metrics and values used to measure and evaluate the performance of a model or a system. Multiple evaluation criteria were used to make a better comparison between models and to evaluate the results more accurately. The performances of the downscaling models were evaluated with the lowest normalized root mean square error (nRMSE), highest coefficient of correlation (R), and Nash-Sutcliffe coefficient (NS). While determining the most successful models of GCM outputs, in addition to nRMSE, Kling-Gupta efficiency (KGE) and modified index of agreement (md) metrics were also calculated since they are frequently used in climate model studies using GCMs (Bağçaci et al. 2021; Seker and Gumus 2022). nRMSE, which is more advantageous than RMSE, was used to evaluate model performance. This metric, which can be used regardless of whether the data is scaled or transformed, yields more reliable results when working with variables at different scales. The NS coefficient is used to evaluate the predictive ability of hydrological models and it expresses the extent to which the observed and calculated data converge, and values close to 1 indicate that a model with more predictive ability has been proposed (Nash and Sutcliffe 1970). The correlation coefficient was also used to understand how strong, in which direction, and how regular the relationship between two variables is. KGE is another statistical measure used to evaluate model performance in the fields of hydrology and hydrometeorology. KGE evaluates how well the model fits the real data in a versatile way by considering certain features of the model. The closer the KGE value is to 1, the better the model fits the observed data and the better its predictive ability. The md is a useful metric for evaluating hydrological model performance as well as comparing different models. This value usually ranges between 0 and 1. Ideally, the md value should be close to 1.
Moreover, for the monthly precipitation and temperature parameters, Taylor diagrams, which is a graphical method to understand the success of the performance of the GCMs used within the scope of the study on a single figure, were created. The centered root-mean-square difference (RMSD) was used, which shows the ratio of the difference between the simulated and observed models and the distance to the point defined as “observed” on the x-axis (Taylor 2005). Standard deviation, correlation coefficient, and RMSD values were calculated based on the reference period outputs of 6 different GCMs (1980–2014) and observed data.
The equations used in the calculations of these criteria are given below.
In equations, \({P}_{O}\) refers to the observation value, \({P}_{\text{m}}\) to the model output, \(\stackrel{-}{{P}_{O}}\) to the mean of the observation values, \(\stackrel{-}{{P}_{m}}\) to the mean of the model output, \({\sigma }_{m}\)\({\sigma }_{o}\) to the standard deviation of the simulated and observed data, and 𝑛 to the number of data.
Ranking the success by each performance evaluation criterion of GCM outputs, uncertainty and multiplicity emerge. Therefore, to eliminate this uncertainty and make the final decision between models, the Comprehensive Rating Index (CRI), which is an index that comprehensively evaluates the system performance, was used in Eq. (12) (Seker and Gumus 2022; He et al. 2023).
In this equation, n is the number of performance evaluation criteria and m is the number of GCMs used in the study. Rank refers to the sum of the success order of each model according to each performance statistic. The most successful case is expressed as 1. The closer the value found as a result of equality approaches 1, the greater the success.
3.7 Bias correction
The QDM method was introduced by Cannon et al. (2015) and it corrects the biases in the modeled data by taking direct relative changes into account. QDM-corrected precipitation and temperature values are calculated with the help of Eq. 13.
In this study, bias in the reference period and future period scenarios was corrected by using Eq. 13. In this equation, 𝑦𝑐𝑜𝑟 (t) is the corrected values at time t, 𝑦mod(t) is the values of the reference period scenario or future period scenarios obtained from the climate model at time t, 𝜃reference, and 𝜃𝑜𝑏𝑠 are the distribution parameters obtained from the simulated reference period scenario data and observed data, respectively. F(.) and F-1(.) represent the additive probability function of the distribution of the reference period scenario data and the inverse cumulative probability function of the observed data, respectively. Within the scope of this study, QDM bias correction procedure was applied to correct biases arising from models or various factors. Bias correction was applied to individual GCM projections after downscaling, while it was applied after the ensemble model generation process for ensemble models. More detailed information about QDM bias correction method can be obtained from the relevant source (Cannon et al. 2015).
4 Results
4.1 Statistical downscaling model results
CRA and ANN-based downscaling models were established by using temperature and precipitation variables in the ERA5 reanalysis data sets. The performance statistics of training, validation, and test data sets of downscaling models established based on ANN and CRA are given in Table 3.
Considering the test set, the minimum nRMSE and maximum R and NS coefficients were calculated to be 0.040 °C/0.151 mm, 0.992/0.756, and 0.979/0.547 from the QF for temperature and precipitation, respectively, in the CRA method. It was determined that the EF is the most unsuccessful function for all data sets. Obtained from the ANN-based model, nRMSE was found to be 0.036 °C, NS coefficient to be 0.983, and R-value to be 0.992 for the temperature variable, and nRMSE to be 0.147 mm, NS coefficient to be 0.572, and R-value to be 0.762 for the precipitation. In summary, considering all performance evaluation criteria for both parameters together, it can be seen that the CRA-QF method is the most successful method among all CRA methods. Despite this, especially when the validation and test sets were evaluated, the success of the ANN method was seen to be superior to all methods.
In a relevant study examining temperature data, it was observed that the Nash-Sutcliffe (NS) efficiency values for all established models fell into the category classified as ‘very good’ according to the given performance criteria (Moriasi et al. 2007). For precipitation data, this evaluation was determined to be in the ‘satisfactory’ range for all models.
Scatter plots and time series of the downscaling model outputs and the observation values measured from the station are shown in Fig. 4 for the test data set. Examining the graphs presented in the present study, since the data in the scatter graph of the temperature parameter is distributed on the line, it indicates that the model accuracy is higher than that of the precipitation parameter. The coefficient of determination (R2) obtained from the models was 0.985 for temperature and 0.579 for precipitation.

Scatter plots and comparison of monthly mean values of the test data set obtained from the statistical downscaling model
4.2 Evaluation of GCMs
Climate studies widely use the process of evaluating GCM simulations with the data covering a reference period (1980–2014) before examining changes in future climate projections. This evaluation is thought to increase the reliability of the climate projections of GCMs by determining the advantages and disadvantages of the climate models used for a particular region. This evaluation will also be useful in the selection of community members in the future MME process.
The performances of 6 different CMIP6 GCMs in reproducing the monthly precipitation and temperature by different metrics are shown in Table 4.
Since multiple performance evaluation criteria were used to assess the performances of the models employed in this study, it is necessary to compute comprehensive model rankings. The ranking produced based on the CRI for both temperature and precipitation parameters is shown in the last column of Table 4.
Taylor diagrams were also created to determine the agreement of GCM model outputs with observation values. As can be seen from the diagrams in both Fig. 5; Table 4, the MRI-ESM2-0 was the most successful model in the success ranking based on error values. The ACCES-CM2 model was excluded from the ensemble models since it ranked the lowest for both parameters. It was removed in order to mitigate the potential negative effect on the overall success of the ensemble model. For this reason and in parallel with previous studies, the ensemble model membership was chosen to be 5 in this study (Ahmed et al. 2019; Bağçaci et al. 2021).

Taylor Diagram of GCMs (a): Temperature, (b): Precipitation
4.3 Future change results
For each of the GCM models and for each of the ensemble models created by combining these models using different methods, the amounts of change were calculated and presented in the tables and figures in this section. Ensemble models were created using four different models. namely ENS1, ENS2, ENS3, and ENS4. ENS1 was created based on ANN, ENS2 on simple average, ENS3 on weighting of correlation coefficients, and ENS4 based on MARS algorithm. The basic functions and the model equations obtained from the MARS algorithm are presented in Table 5 for both parameters (T and P). Given the results obtained by comparing the reference period with the temperature and precipitation among the 4 different MME models applied, the ANN-based ENS1 model had the lowest error value (Table 6).
The differences (Δt) between the model outputs for the three different periods of the future and the reference period scenario were calculated to assess changes over time. Radar charts showing monthly and annual changes are illustrated in Figs. 6 and 7 for temperature and precipitation parameters, respectively.
In a general examination of all radar graphics, it was observed that the temperature increase was the highest in months where the outer diagonals of the radar are located, and the lowest in months where the inner diagonals are located. Negative temperature increases amounts, in other words, decreases in temperatures, are indicated. Considering these graphics, it can be concluded that there may be a significant temperature increase during the summer months, including July and August, for all single models. In parallel, examining all the radar graphs for precipitation, it can be stated that the precipitation increase will be at a higher level in the months with the outer diagonals of the radar, and the least in the months with the inner diagonals, or if these values are negative, there will be a decrease in precipitation.

Change in long − term monthly mean temperature values between future period scenario results (SSP2 − 4.5 and SSP5 − 8.5) and bias − corrected reference period results (Δt, °C)

Changes in long-term monthly total precipitation values between future period scenario results (SSP2-4.5 and SSP5-8.5) and bias − corrected reference period results (%)
In monthly assessments for the temperature parameter (Table 7), it is expected that there will be an increase in temperatures in the CNRM-CM6, MIROC6, and MRI-ESM2-0 models, for both scenarios (SSP2-4.5 and SSP5-8.5) and three separate period intervals (2025–2054, 2055–2084, 2085–2100). However, in the GFDL-ESM4 and CNRM-CM6-1-HR models, temperature is expected to decrease in January by − 0.64 to − 1.39 °C and − 1.05 to − 2.6 °C, respectively, whereas it is predicted to increase in all other months. Examining the long-term period means, it is predicted that there will be increases in all scenarios of all models. Considering the monthly changes, in the CNRM-CM6 model, it is anticipated that the temperature increase will reach up to approximately 4.40 and 8.69 °C monthly for the SSP2-4.5 and SSP5-8.5 scenarios, respectively. These values are 5.03, 6.26 °C in the GFDL-ESM4 model, 4.93, 6.41 °C in MIROC6 model, 3.39, 6.20 °C in MRI-ESM2-0 model, 6.64, 10.94 °C in CNRM.CM6-1-HR model, for the SSP2-45 and SSP5-85 scenarios, respectively.
Considering the monthly changes illustrated in Table 8, it can be seen that, for both scenarios and almost all models throughout all periods, the times with the highest decreases in precipitation occur, especially in the summer months of July and August. The months with increases in precipitation are mostly the winter and spring months, particularly March, April, and January.
Examining the graph illustrated in Fig. 8 in terms of the long-term mean values for temperatures, the temperature increases in the CNRM-CM6 model are expected to be 1.13, 1.78 °C for the near, 2.06, 3.89 °C for the mid-far, and 2.71,5.86 °C for the far future under the SSP2-4.5 and SSP5-8.5 scenario, respectively. For the GFDL-ESM4 model under the SSP2-4.5 scenario, the expected increases are 1.78, 1.51, 2.77, 2.9 °C, and 3.21, 4.25 °C for the near, mid-far and far future, respectively. In the MIROC6 model, the anticipated increases are 2.12, 2.36, 2.60, 3.99 °C, and 3.20, 4.90 °C, whereas the expected increases are 1.55, 2.07, 2.27, 3.45 °C, and 2.39, 4.44 °C for the near, mid-far and far future, respectively, in the MRI-ESM2-0 model. In the CNRM.CM6-1-HR model, the anticipated increases are 2.19, 3.00, 3.32, 4.93 °C, and 3.82, 6.93 °C for the near, mid-far, and far future, under the SSP2-4.5 and SSP5-8.5 scenarios, respectively. The graphs clearly show that higher increases are expected in temperature values in the later periods. The changes expected in the long-term mean temperature values are most pronounced in the CNRM.CM6-1-HR model and are in the direction of an increase.
Considering the mean values presented in Fig. 9, a decrease in precipitation is expected in the CNRM-CM6, GFDL-ESM4, and MIROC6 models for both scenarios (SSP2-4.5 and SSP5-8.5) and across three different periods (2025–2054, 2055–2084, and 2085–2100). The CNRM-CM6-1-HR model is expected to show an increase in precipitation across all scenarios and periods, whereas the MRI-ESM2-0 model is anticipated to experience an increase in the SSP2-4.5 scenario and a decrease in the SSP5-8.5 scenario. In the long-term means, the CNRM-CM6.1 model is predicted to undergo changes of approximately 2.06%, − 4.30%, and − 7.39%, respectively, for the near, mid-far, and far future periods under the SSP2-4.5 scenario. Considering the SSP5-8.5 scenario, these anticipated values are 0.5%, − 12.34%, to − 13.78%. In the specified periods and under the SSP2-4.5 scenario, the corresponding values are projected to be approximately − 1.33%, − 4.56%, and − 4.84% for the GFDL-ESM4 model, and − 3.47%, − 5.93%, and − 9.41% for the MIROC6 model. The MRI-ESM2-0 model is expected to show variations of 7.35%, 3.92%, and 15.31%. As for the CNRM-CM6-1-HR model, the forecasted changes are 43.43%, 47.91%, and 39.98%, respectively. In the SSP-8.5 scenario, the expected changes in precipitation for the specified periods are 0.5%, − 12.34%, and − 13.78% in CNRM-CM6.1, − 0.64%, 15.85%, and − 19.39% in GFDL-ESM4, − 5.39%, − 5.05%, and − 9.57% in MIROC6, − 25.45%, − 35.58%, and − 33.93% in the MRI-ESM2-0 model, and 49.33%, 38.52%, and 28.56% in the CNRM-CM6-1-HR model.

Changes between the annual mean temperature values of the future period (2025–2054, 2055–2084, and 2085–2100) of the SSP2-4.5 and SSP5-8.5 scenarios of GDMs and the annual mean temperature values of the reference period scenario (Δt)

Changes of annual total precipitation values for the SSP2-4.5 and SSP5-8.5 scenarios of GDMs in the future period (2025–2054, 2055–2084, and 2085–2100) compared to the reference period scenario annual total precipitation values (%)
Examining the outputs of the ENS1 model from Fig. 8, even though it seems possible that temperature decreases for some months may be possible under the optimistic scenario, it was observed that there may be an increasing tendency in temperatures in general. Under the pessimistic scenario, an increase is expected in mean temperature for all months and many years. While these values vary in a small range, such as -0.18° C and 0.45 ° C in the optimistic scenario, they vary in a wider range between 4.36 ° C and 6.79 ° C in the pessimistic scenario. Although no increase is expected in the mean temperature in the summer months under the optimistic scenario, increases ranging around 3–7 °C are expected in all months in the pessimistic scenario. Temperature increases in winter are slightly more pronounced than in summer. Examining the ENS2 and ENS3 models, the weights calculated in ENS3 have almost the same weight for all models. Since the temperature correlations are around 0.96 for all models. Therefore, ENS3 yielded approximately the same results as ENS2 calculated by simple averaging. In these models, increases in temperatures are expected for both scenarios, based on all-month and long-term means. These values are expected to be between 1.77 °C and 3.06 °C in the optimistic scenario and between 2.12 °C and 5.27 °C in the pessimistic scenario. In the ENS4 model, there is an increasing trend in temperatures for both scenarios in the long-term mean values. These values are projected to be in the range of − 1.24 °C to 0.05 °C in the optimistic scenario, while they are expected to be between − 0.68 °C and 2.10 °C for the pessimistic scenario. The temperature increase during summer months is higher than during winter months according to both models (Figs. 6 and 8). In the ENS4 model, there is an increasing trend in temperatures for both scenarios in the long − term mean values. These values are projected to be in the range of − 1.24 °C to 0.05 °C in the optimistic scenario, while they are expected to be between − 0.68 °C and 2.10 °C in the pessimistic scenario. Overall, the most significant temperature increases are observed towards the end of the century.
Considering the results of total precipitation values, it is expected that total monthly precipitation will decrease in almost all months and long-term means when compared to ENS1 for both scenarios and all periods (Figs. 7 and 9). Annual changes are expected to be between − 19.04% and − 17.02% in the optimistic scenario, and this change is expected to be between − 40.74% and − 45.65% in the pessimistic scenario. It is expected that the decrease in precipitation may occur at certain rates in all months rather than manifesting itself in a particular month or season. According to ENS2, annual mean precipitation is projected to vary between 9.68% and 6.79% in the optimistic scenario, and between 3.73% and − 9.55% in the pessimistic scenario. When evaluated by months, the decrease is estimated in precipitation between May and October. Annual mean changes are expected to vary between 1.17% and 4.19% in ENS3 and between − 7.76% and − 19.54% in the pessimistic scenario. The decrease in precipitation is expected to occur mostly in June and October in the optimistic scenario, and it is expected to occur in months covering a wider range under the pessimistic scenario. In the ENS4 model, a decrease in annual means is expected as moving away from the near period. These values are anticipated to range between 4.19% and 1.17% in the optimistic scenario and between − 7.76% and − 19.54% in the pessimistic scenario. It was concluded that decreases in precipitation rates may be higher during the summer months for both scenarios. Based on long-term means in all MME models for precipitation, it can be concluded that precipitation has a decreasing pattern (Fig. 9).
Monthly mean temperature and monthly total precipitation values produced for the 3 future periods (2025–2054, 2055–2084, and 2085–2100) under SSP2-4.5 and SSP5-8.5 scenarios of all ensemble models are shown in Figs. 10 and 11.

Monthly mean temperature values for the future period (2025–2054, 2055–2084, and 2085–2100) under the influence of SSP2-4.5 and SSP5-8.5 scenarios of all ensemble models

Monthly total precipitation values for the future period (2025–2054, 2055–2084, and 2085–2100) under the influence of SSP2-4.5 and SSP5-8.5 scenarios of all ensemble models
5 Discussion
The conclusion drawn from the models established with the ERA5 reanalysis dataset suggests that ANN-based models are typically more successful than regression-based models such as CRA-LF, CRA-EF, and CRA-QF. This difference is associated with the presence of a nonlinear component in the predictors/predicted and relationships (Hernanz et al. 2022). However, it was determined that the temperature parameter exhibited higher accuracy in comparison to the precipitation parameter in all models. Wilby et al. (2002) suggested that precipitation is a complex variable, and its inherent heterogeneity poses challenges for accurate simulation. In addition, some studies also stated that the percentage of variance explained for temperature will probably exceed 70%, while this value may be below 40% for precipitation (Mahmood and Babel 2013; Nacar et al. 2022).
Considering the graphs and tables prepared for the dam area within the scope of this study, it was concluded that the GCM with the highest expected temperature increase was CNRM-CM6.1-HR among the climate models used for both temperature and precipitation parameters. The evaluation, grounded in the observational data from the reference period and the study area, revealed that MRI-ESM2-0 was the most successful model. Although the number of climate studies conducted specifically within the borders of Türkiye using the CMIP6 dataset is limited, this model was considered successful for studies in different research areas (Bağçaci et al. 2021; Oruc 2022). Among 6 models used in this study, the ACCESS-CM2 model was found to be the least successful model in terms of both parameters for this region.
The created MME models eliminate the uncertainties and weaknesses of GCMs. The fact that MMEs perform better than the MRI-ESM2-0 model, which is considered the most successful model, and other single models support this result (Nourani et al. 2019; Ahmed et al. 2020; Seker and Gumus 2022). ENS1 model, based on the ANN method, yielded more accurate results in general, but it was still insufficient to predict the maximum and minimum values in the optimistic scenario. ANN aims to minimize error values during the learning phase. In addition to error values, the model’s generalizability should also be considered. In this study, it was observed that the error values for the precipitation parameter in the ENS1 model, which is based on ANNs, were significantly lower in comparison to other models. However, examining the monthly variations, it was noted that this model yielded results different from ENS2 and ENS3 models. For instance, the overall trend in all single and ensemble models in the present study suggests an increase in summer temperatures, with precipitation increasing in the winter and decreasing in the summer. However, examining the ENS1 model, it was observed that, while the annual means of the model results align with other models, no consensus could be reached for monthly values. In short, the ANN algorithm, which is successful as a statistical downscaling method in all aspects, is not very suitable for the full development of MMEs from the point of monthly and seasonal assessment (Ahmed et al. 2020). The MARS algorithm, which is known for its ability to model non-linear and complex relationships, was also included in the present study as the ENS4 model. Assessing the outcomes of building the ENS4 model, it falls short of being as satisfying as ENS1, despite yielding a lower error value and superior prediction performance in comparison to ENS2 and ENS3. In the context of long − term mean results, it yielded a higher level of accuracy in relation to the reference period when compared to MME models relying on averaging and weighting correlation coefficients. The results from monthly and seasonal evaluations align with the trends observed in ENS1.
Evaluating the long-term means of the SSP2-4.5 and SSP5-8.5 scenarios, it was observed that the changes in the SSP5-8.5 scenario vary in a wider range and are more pronounced. In addition, it can be stated that there is a significant difference in temperature and precipitation in each period between the SSP2-4.5 scenario outputs and the SSP5-8.5 scenario outputs. It was concluded that, in the pessimistic scenario, more water stress may be experienced, and more droughts may occur due to temperature increases. The importance of this difference was emphasized in many studies (Bağçaci et al. 2021; Gumus et al. 2023).
No climate projection study that utilizes either downscaling models or the latest version of CMIP6 datasets for the selected dam area could be found in the literature. Therefore, any comparison with other studies would not be objective. For that reason, despite there are only few efforts were made to draw conclusions from studies carried out at the basin and country levels. For instance, a study encompassing temperature and precipitation parameters conducted across the entire Kızılırmak Basin in 2016, utilizing three different General Circulation Models (GCM) available in the CMIP5 dataset, suggests potential increases of up to 5.8 °C (Moaf 2016). For the precipitation parameter, it was emphasized that, while there was no significant increase or decrease in the total values, the highest decreases could be seen at the end of the century. Although the scenarios and GCMs used are different and older versions when compared to the present study, it was observed that the general trend is the same as in this study. Considering the climate projections in another study, in which the study area was selected as Türkiye at a country level, it was predicted that there would be a change of approximately between 20% and 40% in precipitation decreases towards the end of the 21st century, depending on the reference period. In addition, it was also emphasized that there may be a significant increase in winter precipitation in the Black Sea Region (Yavaşlı and Erlat 2023). In this study, it was concluded that particular increases in winter precipitation could occur in all single models, except for MIROC6 models.
6 Conclusion
This study examined the potential effects of global climate change on future temperature and precipitation trends in Altınkaya Dam Basin. Located in Türkiye and characterized by a Mediterranean climate, this region is notably important for hydroelectric power generation.
Determining the regional impacts of climate change often involves one of the most commonly used methods, which is the downscaling of global-scale General Circulation Model (GCM) outputs to a regional scale. For this purpose, outputs from six different global climate models (GCMs) were selected from the latest climate projection archive CMIP6. These models include CNRM-CM6-1, GFDL-ESM4, MRI-ESM2-0, CNRM-CM6-1-HR, MIROC6, and ACCESS-CM2. The selected GCMs were downscaled from a global scale to a regional scale, representing the historical period with a reference scenario and the future period with optimistic and pessimistic scenarios (SSP2-4.5 and SSP5-8.5). The CRA and ANN were employed as the statistical downscaling techniques. ERA5 reanalysis dataset was used as input data, and the output consists of temperature and precipitation data for the period 1980–2014 from stations that are considered to best represent the dam basin and have at least 30 years of observational data. Each station’s control area was determined by using Thiessen polygons. Model outputs were compared by using various statistics, and the downscaling model that yielded the best results was used to generate reference and future period data. Subsequently, these data underwent bias correction and were divided into three periods (2025–2054, 2055–2084, and 2085–2100). Based on the reference period scenario outputs, the performance rankings of individual GCM models were determined. Then, four ensemble models (ENS1, ENS2, ENS3, and ENS4) were established by using a combination of these models through different methods.
The results achieved in this study led to the following conclusions:
-
The results obtained from downscaling the temperature variable by using reanalysis data were more successful than those obtained for the precipitation. Models built with ANN yielded lower error values than those built with CRA.
-
It was observed that each of the ensemble models created with GCM gives more successful results than the individual models. Individual GCM models and almost all ensemble models are expected to show an increasing trend in temperature and a decreasing trend in precipitation. However, in ENS1 and ENS4 models, there were differences in comparison to the ENS2 and ENS3 models at seasonal and monthly levels.
-
Examining the future data of GCMs during the projection period in the dam basin, the increase in temperature data is expected to be approximately 0–3 °C in the optimistic scenario and approximately 4–7 °C in the pessimistic scenario. Considering precipitation data, while model results predict increases and decreases in precipitation in the optimistic scenario, they indicate that precipitation deficiency will be more dominant when compared to the pessimistic scenario. In summary, considering all model results, although precipitation decreases are generally expected in the basin, precipitation increases are also expected in some periods.
-
As a general evaluation by months and seasons, it is expected that the temperature increases in the summer season, particularly in July and August, may be at the highest levels. It is thought that there may be an increase in precipitation in winter and autumn and a decrease in summer.
The expected increases in temperatures and decreases in precipitation can lead to evaporation and changes in water flow and water levels in dams, causing drought. It can reduce the efficiency of hydroelectric power plants and negatively affect energy production. These adverse effects emphasize the need for the energy sector to develop strategies to cope with climate change. Sustainable water resource management, diversification of energy production systems, and policies in line with climate change can help address future challenges in hydroelectric energy production, particularly in this dam basin that has a high electric production potential.
Data availability
The data sets generated and/or analyzed during the current study are not publicly available due to ongoing research but are available from the corresponding author on reasonable request.
References
Abu-Ali H, Nabok A, Smith TJ (2019) Electrochemical inhibition bacterial sensor array for detection of water pollutants: artificial neural network (ANN) approach. Anal Bioanal Chem 411:7659–7668. https://doi.org/10.1007/s00216-019-01853-8
Ahmad S, Simonovic SP (2005) An artificial neural network model for generating hydrograph from hydro-meteorological parameters. J Hydrol 315(1–4):236–251. https://doi.org/10.1016/j.jhydrol.2005.03.032
Ahmed K, Sachindra DA, Shahid S, Demirel MC, Chung ES (2019) Hydrol Earth Syst Sci 23:4803–4824. https://doi.org/10.5194/hess-23-4803-2019. Selection of multi-model ensemble of general circulation models for the simulation of precipitation and maximum and minimum temperature based on spatial assessment metrics
Ahmed K, Sachindra DA, Shahid S, Iqbal Z, Nawaz N, Khan N (2020) Multi-model ensemble predictions of precipitation and temperature using machine learning algorithms. Atmos Res 236:104806. https://doi.org/10.1016/j.atmosres.2019.104806
Ali Z, Hussain I, Faisal M, Nazir HM, Hussain T, Shad MY, Hussain Gani S (2017) Forecasting drought using multilayer perceptron artificial neural network model. Adv Meteorol. https://doi.org/10.1155/2017/5681308
Araya-Osses D, Casanueva A, Román-Figueroa C, Uribe JM, Paneque M (2020) Climate change projections of temperature and precipitation in Chile based on statistical downscaling. Clim Dyn 54:4309–4330. https://doi.org/10.1007/s00382-020-05231-4
Bağçaci SÇ, Yucel I, Duzenli E, Yilmaz MT (2021) Intercomparison of the expected change in the temperature and the precipitation retrieved from CMIP6 and CMIP5 climate projections: a Mediterranean hot spot case, Türkiye. Atmos Res 256:105576. https://doi.org/10.1016/j.atmosres.2021.105576
Baghanam AH, Eslahi M, Sheikhbabaei A, Seifi AJ (2020) Assessing the effect of climate change over the northwest of Iran: an overview of statistical downscaling methods. Theoret Appl Climatol 141:1135–1150. https://doi.org/10.1007/s00704-020-03271-8
Beyene T, Lettenmaier DP, Kabat P (2010) Hydrologic effects of climate change on the Nile River Basin: implications of the 2007 IPCC scenarios. Clim Change 100(3–4):433–461. https://doi.org/10.1007/s10584-009-9693-0
Busuioc A, Chen D, Hellström C (2001) Performance of statistical downscaling models in GCM validation and regional climate change estimates: application for Swedish precipitation. Int J Climatology: J Royal Meteorological Soc 21(5):557–578. https://doi.org/10.1002/joc.624
Cannon AJ, Sobie SR, Murdock TQ (2015) Bias correction of GCM precipitation by quantile mapping: how well do methods preserve changes in quantiles and extremes. J Clim 28:17, 6938–6959. https://doi.org/10.1175/JCLI-D-14-00754.1
Chen J, Brissette FP, Chaumont D, Braun M (2013) Finding appropriate bias correction methods in downscaling precipitation for hydrologic effect studies over North America. Water Resour Res 49(7):4187–4205. https://doi.org/10.1002/wrcr.20331
Chen H, Sun J, Lin W, Xu H (2020) Comparison of CMIP6 and CMIP5 models in simulating climate extremes. Sci Bull 65(17):1415–1418. https://doi.org/10.1016/j.scib.2020.05.015
Chernet HH, Alfredsen K, Midttømme GH (2014) Safety of hydropower dams in a changing climate. J Hydrol Eng 19(3):569–582. https://doi.org/10.1061/(ASCE)HE.1943-5584.0000836
Crane RG, Hewitson BC (1998) Doubled CO2 precipitation changes for the Susquehanna Basin: down-scaling from the Genesis general circulation model. Int J Climatology: J Royal Meteorological Soc 18(1):65–76. https://doi.org/10.1002/(SICI)1097-0088(199801)18:1%3C65::AID-JOC222%3E3.0.CO;2-9
Dai A, Rasmussen RM, Ikeda K, Liu C (2020) A new approach to construct representative future forcing data for dynamic downscaling. Clim Dyn 55:315–323. https://doi.org/10.1007/s00382-017-3708-8
Erlandsen HB, Parding KM, Benestad R, Mezghani A, Pontoppidan M (2020) A hybrid downscaling approach for future temperature and precipitation change. J Appl Meteorol Climatology 59(11):1793–1807. https://doi.org/10.1175/JAMC-D-20-0013.1
Fistikoglu O, Okkan U (2011) Statistical downscaling of monthly precipitation using NCEP/NCAR reanalysis data for Tahtali River Basin in Türkiye. J Hydrol Eng 16(2):157–164. https://doi.org/10.1061/(ASCE)HE.1943-5584.0000300
Fricko O, Havlik P, Rogelj J, Klimont Z, Gusti M, Johnson N, Riahi K (2017) The marker quantification of the Shared Socioeconomic pathway 2: a middle-of-the-road scenario for the 21st century. Glob Environ Change 42:251–267. https://doi.org/10.1016/j.gloenvcha.2016.06.004
Friedman JH (1991) Multivariate adaptive regression splines. Ann Stat 19:1–67. https://doi.org/10.1214/aos/1176347963
Fujihara Y, Tanaka K, Watanabe T, Nagano T, Kojiri T (2008) Assessing the effects of climate change on the water resources of the Seyhan River Basin in Türkiye: Use of dynamically downscaled data for hydrologic simulations. J Hydrol 353(1–2):33–48. https://doi.org/10.1016/j.jhydrol.2008.01.024
Goyal MK, Ojha CSP (2012) Downscaling of surface temperature for lake catchment in an arid region in India using linear multiple regression and neural networks. Int J Climatol 32:552–566. https://doi.org/10.1002/joc.2286
Gumus B, Oruc S, Yucel I, Yilmaz MT (2023) Effects of Climate Change on Extreme Climate indices in Türkiye Driven by High-Resolution Downscaled CMIP6 climate models. Sustainability 15(9):7202. https://doi.org/10.3390/su15097202
Haider S, Masood MU, Rashid M, Alshehri F, Pande CB, Katipoğlu OM, Costache R (2023) Simulation of the potential effects of projected climate and land use change on runoff under CMIP6 scenarios. Water 15(19):3421. https://doi.org/10.3390/w15193421
He M, Chen Y, Sun H, Liu J (2023) Projected changes in Precipitation based on the CMIP6 optimal Multi-model Ensemble in the Pearl River Basin, China. Remote Sens 15(18):4608. https://doi.org/10.3390/rs15184608
Hernanz A, García-Valero JA, Domínguez M, Ramos‐Calzado P, Pastor‐Saavedra MA, Rodríguez‐Camino E (2022) Evaluation of statistical downscaling methods for climate change projections over Spain: present conditions with perfect predictors. Int J Climatol 42(2):762–776. https://doi.org/10.1002/joc.7271
Hersbach H, Bell B, Berrisford P, Hirahara S, Horanyi A, Munoz-Sabater J, Thepaut JN et al (2020) The ERA5 global reanalysis. Q J R Meteorol Soc 146(730):1999–2049. https://doi.org/10.1002/ qj. 3803
Iliadis LS, Maris F (2007) An artificial neural network model for mountainous water-resources management: the case of Cyprus mountainous watersheds. Environ Model Softw 22(7):1066–1072. https://doi.org/10.1016/j.envsoft.2006.05.026
IPCC (2021) In: Masson-Delmotte V, Zhai P, Pirani A, Connors SL, Berger S, Caud N, Chen Y, Goldfarb L., Gomis MI, Huang M, Leitzell K, Lonnoy E, Matthews JBR, Waterfield TKMT, Yelekçi O, Zhou RYB (Eds.), Climate Change 2021a: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change, p. 3949. Cambridge, UK
Islam A, Ahuja LR, Garcia LA, Ma L, Saseendran AS (2012) Modeling the effect of elevated CO2 and climate change on reference evapotranspiration in the semi-arid Central Great Plains. Trans ASABE 55(6):2135–2146. https://doi.org/10.13031/2013.42505
Jiang D, Hu D, Tian Z, Lang X (2020) Differences between CMIP6 and CMIP5 models in simulating climate over China and the east Asian monsoon. Adv Atmos Sci 37:1102–1118. https://doi.org/10.1007/s00376-020-2034-y
Kara F, Yucel I, Akyurek Z (2016) Climate change effects on extreme precipitation of water supply area in Istanbul: use of ensemble climate modelling and geo-statistical downscaling. Hydrol Sci J 61(14):2481–2495. https://doi.org/10.1080/02626667.2015.1133911
Kirdemİr U, Okkan U (2019) Implementation of different bias correction methods to statistically downscaled precipitation projections J. BAUN Inst Sci Technol 21(2):868–881 (in Turkish)
Kisi O, Parmar KS (2016) Application of least square support vector machine and multivariate adaptive regression spline models in long term prediction of river water pollution. J Hydrol 534:104–112. https://doi.org/10.1016/j.jhydrol.2015.12.014
Kumar S, Narjary B, Vivekanand, Islam A, Yadav RK, Kamra SK (2022) Modeling climate change impact on groundwater and adaptation strategies for its sustainable management in the Karnal district of Northwest India. Clim Change 173(1):3. https://doi.org/10.1007/s10584-022-03393-0
Liu L, Gu H, Xie J, Xu YP (2021) How well do the ERA-Interim, ERA‐5, GLDAS‐2.1 and NCEP‐R2 reanalysis datasets represent daily air temperature over the Tibetan Plateau? Int J Climatol 41(2):1484–1505. https://doi.org/10.1002/joc.6867
Mahmood R, Babel MS (2013) Evaluation of SDSM developed by annual and monthly sub-models for downscaling temperature and precipitation in the Jhelum basin, Pakistan and India. Theoret Appl Climatol 113:27–44. https://doi.org/10.1007/s00704-012-0765-0
Marugán AP, Márquez FPG, Perez JMP, Ruiz-Hernández D (2018) A survey of artificial neural network in wind energy systems. Applied energy, 228, 1822–1836. https://doi.org/10.1016/j.apenergy.2018.07.084Get rights and content
MoAF (2016) T.R. Ministry of Forestry and Water Affairs, General Directorate of Water Management Effect of Climate Change on Water Resources Project, Project Final Report. Annex 17 – Kızılırmak Basin
Moriasi DN, Arnold JG, Van Liew MW, Bingner RL, Harmel RD, Veith T (2007) Model evaluation guidelines for systematic quantification of accuracy. Watershed Simulations Trans ASABE 50(3):885–900. https://doi.org/10.13031/2013.23153
Nacar S, Kankal M, Okkan U (2019) Statistical downscaling of monthly mean air temperature using NCEP/NCAR re-analysis data: a case study for the Eastern Black Sea Basin. In 3rd International Conference on Advanced Engineering Technologies
Nacar S, Kankal M, Okkan U (2022) Evaluation of the suitability of NCEP/NCAR, ERA-Interim and, ERA5 reanalysis data sets for statistical downscaling in the Eastern Black Sea Basin, Türkiye. Meteorol Atmos Phys 134(2):39. https://doi.org/10.1007/s00703-022-00878-6
Najafi R, Hessami Kermani MR (2017) Uncertainty modeling of statistical downscaling to assess climate change effects on temperature and precipitation. Water Resour Manage 31:1843–1858. https://doi.org/10.1007/s11269-017-1615-8
Nash JE, Sutcliffe JV (1970) River flow forecasting through conceptual models part I—A discussion of principles. J Hydrol 10(3):282–290. https://doi.org/10.1016/0022-1694(70)90255-6
Nourani V, Paknezhad NJ, Sharghi E, Khosravi A (2019) Estimation of prediction interval in ANN-based multi-GCMs downscaling of hydro-climatologic parameters. Journal of Hydrology, 579, 124226. https://doi.org/10.1016/j.jhydrol.2019.124226Get rights and content
Okkan U (2013) Assessments of Climate Change Effects on River Flows (Doctoral dissertation, DEÜ) (in Turkish)
Okkan U, Kirdemir U (2018) Investigation of the behavior of an agricultural-operated dam reservoir under RCP scenarios of AR5-IPCC. Water Resour Manage 32:2847–2866. https://doi.org/10.1007/s11269-018-1962-0
Okkan U, Fistikoglu O, Ersoy ZB, Noori AT (2023) Investigating adaptive hedging policies for reservoir operation under climate change effects. J Hydrol 619:129286. https://doi.org/10.25092/baunfbed.654535
Oruc S (2022) Performance of bias corrected monthly CMIP6 climate projections with different reference period data in Türkiye. Acta Geophys 70(2):777–789. https://doi.org/10.1007/s11600-022-00731-9
Oztan AF (2011) Altınkaya dam and HEPP geotechnical studies, Ankara
Parsaie A, Haghiabi AH (2017) Improving modelling of discharge coefficient of triangular labyrinth lateral weirs using SVM, GMDH and MARS techniques. Irrig Drain 66:636–654. https://doi.org/10.1002/ird.2125
Parsaie A, Haghiabi AH, Saneie M, Torabi H (2016) Prediction of energy dissipation on the stepped spillway using the multivariate adaptive regression splines. ISH J Hydraul Eng 22:281–292. https://doi.org/10.1080/09715010.2016.1201782
Paul A, Das P (2014) Flood prediction model using artificial neural network. Int J Comput Appl Technol Res 3(7):473–478
Qin P, Xu H, Liu M, Liu L, Xiao C, Mallakpour I, Sorooshian S (2022) Projected effects of climate change on major dams in the Upper Yangtze River Basin. Clim Change 170(1–2):8. https://doi.org/10.1007/s10584-021-03303-w
Ramesh K, Anitha R (2014) MARSpline model for lead seven-day maximum and minimum air temperature prediction in Chennai, India. J Earth Syst Sci 123:665–666
Riahi K, Van Vuuren DP, Kriegler E, Edmonds J, O’neill BC, Fujimori S, Tavoni M (2017) The Shared Socioeconomic pathways and their energy, land use, and greenhouse gas emissions implications: an overview. Glob Environ Change 42:153–168. https://doi.org/10.1016/j.gloenvcha.2016.05.009
San M, Nacar S, Kankal M, Bayram A (2024) Spatiotemporal analysis of transition probabilities of wet and dry days under SSPs scenarios in the semi-arid Susurluk Basin, Türkiye. Sci Total Environ 912:168641. https://doi.org/10.1016/j.scitotenv.2023.168641
Seker M, Gumus V (2022) Projection of temperature and precipitation in the Mediterranean region through multi-model ensemble from CMIP6. Atmospheric Research, 280, 106440. https://doi.org/10.1016/j.atmosres.2022.106440Get rights and content
Sharma P, Mutreja U (2013) Analysis of satellite images using artificial neural network. Int J Soft Comput Eng 2:276–278
Sharma K, Khandelwal S, Kaul N (2020) Downscaling of coarse resolution land surface temperature through vegetation indices based regression models. In: Ghosh J, da Silva I (eds) Applications of Geomatics in Civil Engineering. Lecture notes in civil engineering, vol 33. Springer, Singapore, pp 625–636
Su B, Huang J, Gemmer M, Jian D, Tao H, Jiang T, Zhao C (2016) Statistical downscaling of CMIP5 multi-model ensemble for projected changes of climate in the Indus River Basin. Atmos Res 178:138–149. https://doi.org/10.1016/j.atmosres.2016.03.023
Taylor KE (2005) Taylor diagram primer. Work. Pap, pp 1–4
Tefera GW, Ray RL, Wootten AM (2023) Evaluation of statistical downscaling techniques and projection of climate extremes in central Texas, USA. Weather Clim Extremes 100637. https://doi.org/10.1016/j.wace.2023.100637
Teutschbein C, Seibert J (2012) Bias correction of regional climate model simulations for hydrological climate-change effect studies: review and evaluation of different methods. J Hydrol 456:12–29. https://doi.org/10.1016/j.jhydrol.2012.05.052
Tofiq FA, Güven A (2015) Potential changes in inflow design flood under future climate projections for Darbandikhan Dam. J Hydrol 528:45–51. https://doi.org/10.1016/j.jhydrol.2015.06.023
Tohver IM, Hamlet AF, Lee SY (2014) Impacts of 21st-century climate change on hydrologic extremes in the Pacific Northwest region of North America. JAWRA J Am Water Resour Association 50(6):1461–1476. https://doi.org/10.1111/jawr.12199
Turkes M (2020) Climate and Drought in Türkiye. In: Harmancioglu NB, Altinbilek D (eds) Water resources of Türkiye, World Water resources, vol 2. Springer, Cham, pp 85–125
Turkes M, Turp MT, An N, Ozturk T, Kurnaz ML (2020) Effects of climate change on precipitation climatology and variability in Türkiye. Water resources of Türkiye, pp 467–491
Valverde MC, Araujo E, Velho H (2014) Neural network and fuzzy logic statistical downscaling of atmospheric circulation-type specifc weather pattern for rainfall forecasting. Appl Soft Comput 22:681–694. https://doi.org/10.1016/j.asoc.2014.02.025
Wang F, Tian D, Lowe L, Kalin L, Lehrter J (2021) Deep learning for daily precipitation and temperature downscaling. Water Resour Res 57. https://doi.org/10.1029/2020WR029308. e2020WR029308
Wilby RL, Harris I (2006) A framework for assessing uncertainties in climate change effects: low-flow scenarios for the River Thames, UK. Water Resour Res 42(2). https://doi.org/10.1029/2005WR004065
Wilby RL, Dawson CW, Barrow EM (2002) SDSM—a decision support tool for the assessment of regional climate change effects. Environ Model Softw 17(2):145–157. https://doi.org/10.1016/s1364-8152(01)00060-3
World Meteorological Organization (2016) WMO statement on the status of the global climate in 2015
Yalcin E (2023) A CMIP6 multi-model ensemble-based analysis of potential climate change effects on irrigation water demand and supply using SWAT and CROPWAT models: a case study of Akmese Dam, Türkiye. Theoret Appl Climatol 1–21. https://doi.org/10.1007/s00704-023-04657-0
Yavaşlı DD, Erlat E (2023) Climate model projections of aridity patterns in Türkiye: a comprehensive analysis using CMIP6 models and three aridity indices. Int J Climatol 43(13):6207–6224. https://doi.org/10.1002/joc.8201
Yilmaz B, Aras E, Nacar S, Kankal M (2018) Estimating suspended sediment load with multivariate adaptive regression spline, teaching-learning based optimization, and artificial bee colony models. Sci Total Environ 639:826–840. https://doi.org/10.1016/j.scitotenv.2018.05.153
Yilmaz B, Aras E, Kankal M, Nacar S (2019) Prediction of suspended sediment loading by means of hybrid artificial intelligence approaches. Acta Geophys 67:1693–1705. https://doi.org/10.1007/s11600-019-00374-3
Zakeri IF, Adolph AL, Puyau MR, Vohra FA, Butte NF (2010) Multivariate adaptive regression splines models for the prediction of energy expenditure in children and adolescents. J Appl Physiol 108:128–136. https://doi.org/10.1152/japplphysiol.00729.2009
Zamani Y, Hashemi Monfared SA, Azhdari Moghaddam M, Hamidianpour M (2020) A comparison of CMIP6 and CMIP5 projections for precipitation to observational data: the case of northeastern Iran. Theoret Appl Climatol 142:1613–1623. https://doi.org/10.1007/s00704-020-03406-x
Zhang W, Goh AT (2016) Multivariate adaptive regression splines and neural network models for prediction of pile drivability. Geosci Front 7:45–52. https://doi.org/10.1016/j.gsf.2014.10.003
Zhou Y, Leung H (2007) Predicting object-oriented software maintainability using multivariate adaptive regression splines. J Syst Softw 80:1349. https://doi.org/10.1016/j.jss.2006.10.049
Acknowledgements
The authors would like to thank the Earth System Grid Federation (ESGF) for providing access to climate data in the CMIP6 archive. ECMWF (The European Center for Medium-Range Weather Forecasts) for access to ERA5 re-analysis data and the Turkish State Meteorological Service for providing the observed monthly data of the study area. The authors also would like to thank the reviewers for their constructive comments and suggestions which helped to improve the manuscript.
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Contributions
B.Y. wrote the full text by implementing all methods. E.A. and S.N. outlined the roadmap for the subject and methods, and checked the entire manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yılmaz, B., Aras, E. & Nacar, S. A CMIP6-ensemble-based evaluation of precipitation and temperature projections. Theor Appl Climatol 155, 7377–7401 (2024). https://doi.org/10.1007/s00704-024-05066-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-024-05066-7