
Abstract
Permeability is one of the important issues that must be considered in the investigation of dam sites. Determination of this parameter in the boreholes is time-consuming, costly, and in some cases impossible. In this study, the values of Q classification system, Lugeon and joint spacing in five-meter intervals of boreholes in limestone rocks of Bazoft and Khersan II dam sites, in south Iran were determined. Then, the Lugeon number was estimated based on Q classification system and joint spacing in control and trial grouting boreholes by statistical analysis (SA), multilayer perceptron neural network (MPNN) by feed-forward method, support vector regression (SVR), adaptive neuro-fuzzy inference system (ANFIS), and random forest (RF) methods. Results showed that rock mass is categorized in moderate permeability class based on mean Lugeon value and in the good category based on Q classification system. The Q classification system and joint spacing indicated the highest effect on the Lugeon and the depth showed the least effect on the Lugeon. The SA displayed that it is possible to predict Lugeon values by Q and Js with a precision higher than 78% based on the data of both dam sites. According to the criteria, the accuracy of the MPNN (R = 0.91), RF (R = 0.97), ANFIS (R = 0.93) and SA (R = 0.80–0.83) to estimate the Lugeon number was lower than SVR (R = 0.98) method.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
One of the important features in the rock mass study of civil and mining project sites is the permeability which is determined using the Lugeon test and is used to assess the groutability of the dam sites. In the construction of dams, water escape occurs more than through the joints and cracks of rocks due to hydraulic pressures of water behind the dam. Lack of attention to the permeability of the sites in recent decades has caused the failure of a number of dams or the main purpose of the dam in terms of water storage and safety of the dam structure has been questioned. In this regard, the assessment of permeability and leakage in the dam site is one of the necessary items in the initial studies of dams (Nonveiller 1989; Houlsby 1990; Fatahi Nafchi et al. 2021; Yin et al. 2022; Yang et al. 2014).
Barton (2004) investigated the relationship between Lugeon, hydraulic joint aperture, and joint spacing. Barton also introduced the Q logging system (i.e., determination of parameters of this classification system in boreholes) to determine the rock mass quality of the dam sites (Barton 2002). Many studies have been conducted to estimate Lugeon based on rock mass characteristics and have been stated that the characteristics of discontinuities have a great effect on rock mass permeability (Table 1). Qureshi et al. (2022) assessed the relationship between rock quality designation (RQD) and Lugeon number. Piscopo et al. (2018) and Chen et al. (2018) developed some experimental equations for estimating Lugeon number based on depth. Shahbazi et al. (2020) summarized the different methods for determining permeability and stated that rock mass quality and joint characteristics are the best parameters to estimate permeability. Morshedy et al. (2019) indicated that with increasing depth, the amount of Lugeon decreases and the quality of the rock mass increases. Kayabasi et al. (2015) used ANFIS and non-linear multiple regression to estimate Lugeon number. Ma et al. (2021) stated that cracks and joints angle is the most important factor affecting permeability and SVR method can accurately predict the rock mass permeability. Results of Matinkia et al. (2022) study, revealed that soft computing approaches such as multilayer perceptron (MLP) and MLP-PSO (particle swarm optimization) are capable to estimate rock permeability with determination coefficient more than 99%. Jamshidi Gohari et al. (2021) used ANN (artificial neural network) to estimate permeability of the carbonate rocks. Shi and Jian (2018) sated that Elman neural network could predict permeability with average relative error lees than 6.25%. Adegbite et al. (2021) used ANN, ANFIS, multiple linear regression (MLR) to predict permeability of the carbonate rocks. Li et al. (2019) estimated curtain grouting efficiency by ANFIS method. Akbarimehr and Aflaki (2019) used ANN and statistical methods to predict rock mass permeability. Zadhesh et al. (2015) estimated permeability at Cheraghvays dam site using ANN and multivariate linear regression (MVLR) approaches. Chen et al. (2021a, b) assessed Lugeon correlation with depth and rock mass classification system. Hariri-Ardebili and Salazar (2020) used RF, SVR, and ANN to assess engineering problems of the dam sites. Huang et al. (2020) estimated concrete permeability using RF method. Rosid et al. (2019) stated that RF is more accurate than Naive Bayes in estimating the permeability of intact rock. Zhang and Cai (2021) predicted carbonate rock permeability using RF algorithm.
As mentioned above, many studies have been conducted to estimate permeability using some intelligent methods. In previous researches, comprehensive studies with the aim of comparing intelligent methods in estimating rock permeability (especially rock mass) and at the site of dams (especially large dams) have not been used. In this research, six statistical and intelligent methods have been compared to estimate the permeability of rock mass at the site of large dams in Khersan II and Bazoft dam sites. The Q classification system, the joint spacing and the Lugeon number were calculated in 5 m intervals of the boreholes. For this purpose, 175 data related to the results of Lugeon test, depth, Q classification system and joint spacing in 5-m sections of trial and control boreholes dam sites were used. Statistical analysis was performed for assessing the effect of independent variables on the dependent variable. Finally, the performance of SR, MVLR, ANN, SVR, RF and ANFIS methods were evaluated using statistical indicators in estimating Lugeon number.
2 Study areas
The studied dam sites are located in the southwest of Iran in the Karun and Dez catchments and are of arched concrete type. Khersan II dam, with a proposed height of 240 m and a reservoir volume of 2142 million cubic meters, is located in Chahar-Mahal and Bakhtiari province, Iran. This dam is in the design stage. The dam site is situated on the Khersan River with coordinates of 31/25 degrees of north latitude and 50/36 degrees of east longitude in the southwestern region of Iran, in the Zagros Mountains. Asmari and Gachsaran formations form the abutments of the site (Figs. 1, 2). Data from four boreholes used in the analyses were taken from the Khersan II dam site. Bazoft dam with a proposed height of 211 m is also in the investigation stage. The geological formations of the Bazoft dam site include Jahrom and Asmari formations (Figs. 1, 2). Data from eight boreholes used in the analyses were taken from the Bazoft dam site.


3 Methodology
3.1 Water pressure test (WPT)
The WPT was conducted at different sections of trial and grouting boreholes. The test pressures are increased in steps to the maximum pressure and then reduced to the initial pressure. The amount of effective pressure (Pe) and flow value (q) recorded in each pressure step. Then, Pe-q curves were plotted and the flow behavior was analyzed. The Lugeon number (Lu) is calculated using Eq. 1 (Nonveiller 1989).
In Eq. 1, q is in Li/min; L is section length in m; and Pe is in atmosphere.
According to the flow behavior during the experimental pressures in the WPT, five behavior types are determined for the water flow in the rock mass (Fig. 3), (Kutzner 1985; Shroff and Shah 1999; Xu et al. 2022; Ewert 1997).
-
Laminar flow: The permeability values at five steps are approximately the same regardless of the test pressure. The equivalent permeability for this case is an average of five Lugeon values.
-
Turbulent flow: In this case, the amount of Lugeon decreases with increasing pressure, and the amount of Lugeon at the same pressures is almost the same. The permeability for this condition is the amount of recorded Lugeon by the maximum pressure.
-
Dilation flow: In this group, the amount of Lugeon resulting from the maximum pressure is greater than the amount of Lugeon obtained at medium and low pressures, and the Lugeon at similar pressures are approximately equal. In this case, temporary expansion of the rock joints occurred. High pressures can temporarily open the fractures or compress the joint fillers during the test (Kutzner 1985).
-
Washout flow: Consecutive increases in the amount of Lugeon during the test are a sign of permanent leaching of the joint fillers. Most of the time, this indicates very high test pressures. The representative permeability for this group is the amount of Lugeon obtained in the final step.
-
Void filling: Successive reduction of Lugeon amounts during the test process indicates that the water flow gradually fills the empty cavities and joints and forms them as closed networks. The permeability for this case is the amount of Lugeon obtained from the final step (Fig. 3).

Determination of hydromechanical behavior and Lugeon number (Kutzner 1985; Shroff and Shah 1999)
3.2 Q classification system
In this study, the Q classification system was determined in five-meter intervals of control and trial grouting boreholes using the relevant tables and graphs (Barton 2002; Barton et al. 1974). The Q classification system values are computed using Eq. 2.
where RQD is the percentage of cores with a length more than 100 mm in each drilling run (Deere 1989), Jn is the joint number score, Jr is joint roughness score, Ja is joint alteration score, Jw is water flow or pressure score, and stress reduction factor (SRF) is score of strength to stress ratio of the solid rock, swelling or crushing.
The permeability description and Q values based on the classification provided by Evert (1985) and Barton et al. (1974) are given in Table 2.
3.3 Multilayer perceptron neural network (MPANN)
In terms of learning algorithm and topology, ANN is divided into two classes based on learning algorithm and topology: feed-back neural network (FBNN) and feed–forward neural network (FFNN), (Idrisovich Ismagilov et al. 2020; Sun et al. 2020; Sharifi et al. 2016). In FFNN, the signal is transmitted only in the forward direction. These types of ANNs are simple and common networks and are commonly used for data mining. Perceptron neural networks are a type of FFNN (Rustamovich Sultanbekov et al. 2020; Zhao and Wang 2022).
In multilayer networks, there is an input layer that receives information. Input layer has a number of neurons. In principle, the existence of a hidden layer is useful when it is a nonlinear activation function, and finally, there is an output layer that results from calculations entering it and network output is reached (Abraham 2005; Ostad-Ali-Askari et al. 2017; Suthar 2020). In these networks, after comparing the outputs with real values, the error values are determined. The computed error is then circulated to adjust the weights and values of the network bias, a method called error propagation (Dianati Tilaki et al. 2020; Ghadimi and Ebrahimian 2015; Abraham 2005).
In current study, using MATLAB software, multilayer feed-forward Perceptron neural network was used to estimate Lugeon number.
3.4 The ANFIS
The ANFIS method is very suitable for modeling complex problems that have unknown variables. In classical logic, the membership function value of each member is 1 if it is in the set and 0 if it is not (Jalili et al. 2015; Mahdavi et al. 2015). In contrast, each member of the fuzzy set can have a membership function value between 0 and 1. According to mathematical laws, this is generally referred to as Eq. 3:
Membership function degree indicates the value of the level of dependence of the member on the fuzzy set. Gaussian membership function (GMFs) was used in this study. In various researches, two types of fuzzy systems are commonly used, which include Mamdani and Sugeno algorithms (Sobhani and Safarianzengir, 2020). Fuzzy inference systems (FIS) introduced as basic rule systems, which are made up of a set of linguistic rules and are able to denote any system with high precision which operates like an all-purpose predictor. Rule systems based on fuzzy logic (FL) theory use linguistic variables such as results and rules, where rules are expressed as inference or inequality (Sobhani and Safarianzengir 2020). The rule system based on FL is the if–then base rule system that is denoted by the if rule and the then result. ANFIS is a neuro-fuzzy system that permits fuzzy systems to learn variables by a back-propagation algorithm (Jang 1993; Rashidi Tazhan et al. 2019; Dorfan et al. 2020). In this study, Sugeno-type FIS was used in which each rule is specified as a linear grouping of inputs. The final output of the FIS is a simplification of the given mean weight of each output rule. A Sugeno FIS is a combination of inputs x, y. Hence, an output variable f is driven by two fuzzy rules (Gholami et al. 2020):
The summary of working with ANFIS system in MATLAB software environment is that first the inputs and outputs are introduced to the system and the system performs the learning stage. Then, to validate the model, a system test is performed.
3.5 The SVR approach
Support vector machine (SVM) theory was developed based on Vapnik's theory of statistical learning (Vapnik 1995). The support vector regression (SVR) fits the curve with ε thickness into the data to minimize error of test data. In this model, a set of functions (for example: f(x) = w.x + b) is used to estimate. Where w is the weight vector and x and b are the bias values. The weight vector must be minimized for minimizing test error. SVR uses a new error function to overlook errors that are at a certain distance from the actual data (Jiang et al. 2022; Fallah et al. 2021; Qasem et al. 2019; Tekin 2014; Maleki and Emami 2019). Hence, some deviation from ε must be overlooked. The deviation is described as Eq. 5 and is involved in Eq. 6 with considering \(\xi_{i}^{ + }\) and \(\xi_{i}^{ - }\) deficiency variables. Finally, using the structural error minimization(SEM), the error value is optimized by using Eq. 6.
In Eq. 6, \(\frac{1}{2}\left\| w \right\|^{2}\) is the regulatory elements, \(\xi_{i}^{ + }\) and \(\xi_{i}^{ - }\) are variables to make boundaries flexible, N is number of sample, ε is allowable error, C is the complexity balance coefficient to equilibrium the empirical risk with the regulatory elements, and the ε is acceptable error limit. Different kernel functions such as linear, quadratic, radial and polynomial are used in the SVR (Xie et al. 2021a; b; Yang et al. 2020). Usually, the radial kernel function has better performance for predicting. The main reason for choosing this function in the present study was its high generalizability in studies related to rock mechanics and geotechnics (Jiang et al. 2022; Kookalani and Cheng 2021; Mahmoodzadeh et al. 2021; Zhou et al. 2016). The equation of this kernel function is as follows.
where σ is radial kernel function width and k(xi, xj) is internal multiplication of variables. The prediction precision using SVR by the radial basis function (RBF) kernel depends on the choice of ε, γ and C. In current research, the SVR based on the RBF was used to estimate Lugeon number of the rock mass using MATLAB software.
3.6 Data normalization
One of the advantages of data normalization is the improvement of gradient descent performance on normalized data compared to abnormal data. Also, the input values are normalized to avoid a very large or very small effect on the network weight (Seyfi 2017; Zhao et al. 2022; Kalteh 2008). In this study, the data were normalized between − 1 and 1 based on Eq. 8.
where x is the experimental value, xmin is the minimum data between whole data, and xmax is the maximum data.
3.7 Performance evaluation of models
Correlation coefficient, the mean absolute percentage error (MAPE) (Eq. 9), root mean square error (RMSE) (Eq. 10), and variance account for (VAF) (Eq. 11) were used for evaluating the methods. These criteria have been widely used to evaluate the models and relationships obtained from soft computing approaches (Du et al. 2022; Dong et al. 2021; Zhu et al. 2022; Zhou et al. 2021a, 2021b).
In relationships 9–11, y is the measured value, y′ is the variable estimated by the relationship, n is total data and s2 is the variance of the samples.
4 Results and discussions
Due to the importance of recognizing the discontinuities in the dam sites, in addition to studying the discontinuities at the ground level, the joints were studied on the cores obtained from the boreholes. The study of exploratory galleries indicates the existence of three major categories of discontinuities (two sets of joints and a bedding system) at the Bazoft dam site and three categories of joints at the Khersan II dam site (Table 3).
4.1 Trial and control boreholes in the dam sites
In the Bazoft dam site, trial grouting operations have been conducted on the abutments (Fig. 4).

Overview of the position of trial grouting panels at and left abutment (A) right abutment (B) of the Bazoft dam site
The trial grouting boreholes at the Bazoft dam site are located above the water table and have been drilled vertically to a depth of 75 m. Simultaneously with the drilling operation in all boreholes, WPTs were conducted at intervals of 5 m to determine the Lugeon and to control the impact of the grouting. At the end of the cement grouting operation, for evaluating the trial grouting effect, in the center of each triangular a check borehole was drilled and Lugeon test was performed in 5-m sections. The depth of control boreholes in the right abutment is 90 m and in the left abutment is 75.20 m. A total of 8 boreholes (6 grouting boreholes and 2 control boreholes) were drilled at the Bazoft dam site.
In Khersan II dam site, according to the topographic conditions of the right abutment, trial grouting has been done on the left abutment. The proposed arrangement of the grouting boreholes is in the form of an equilateral triangle with sides of 3 m (similar to the arrangement of the trial grouting boreholes at Bazoft site). The boreholes of the trial grouting panel were located beyond the water table and were drilled vertically to a depth of 80 m. Simultaneously with the drilling operations by a thin-wall core samples in all boreholes, water pressure WPTs tests were performed at intervals of 5 m. At the end of the grouting operations, a check borehole was drilled at triangle center with a depth of 80 m to evaluate the effect of the grouting, and permeability was tested in 5-m sections. A total of 4 control and grouting boreholes were drilled in Khersan II dam site.
4.2 Rock quality designation (RQD)
Based on the average RQD, all sections of the left, right and riverbeds in the Bazoft dam site are classified in the excellent category. Also in Khersan II dam site, the rock mass is categorized in excellent condition in terms of RQD. In the Bazoft dam site, the average RQD of the left side is more than the right side.
4.3 Permeability and hydromechanical behavior of the sites
Figure 5 shows two examples of rock mass behavior at the depth of 10–15 m of the borehole GSR3 (Bazoft dam site) and CH1 borehole (Khersan II dam site). In these stages, the type of behavior is turbulent and dilation.

Examples of Lugeon test results: Bazoft dam site (top), Khersan II site (bottom)
In the Bazoft dam site, the permeability value more than 60% in the left abutment was 1.5%, while this permeability value was 29% in the right abutment. Lugeon higher than 100 on the left abutment are due to karst development. In this construction, the percentage of impermeable class (0–3) is the highest. In the site of Khersan II dam, frequency percentage of the Lugeon in the range of 0–3 is the maximum value (Fig. 6). This indicates low permeability of the site.

Lugeon distribution in the studied sites
Normally, permeability is expected to be low in sections with high RQD and high permeability in sections with low RQD. In nature, given the complexities involved, other relationships can prevail. Sometimes with increasing RQD, no decrease in permeability is observed. In some sections of the borehole, even with decreasing RQD, the permeability decreases. In general, the following conditions exist between RQD and Lugeon value (Ewert 1997):
-
(A)
High RQD and low Lugeon: In such sections, the rock mass has less joints and cracks, or the joints may be filled with fine materials.
-
(B)
High RQD and high Lugeon: This condition occurs mostly due to the phenomena of hydraulic failure, elastic opening of joints, crushing and roughness of their surfaces. In this case, high borehole permeability is not due to crushing of the rock mass and it can be related to the presence of a karst channel.
-
(C)
Low RQD and high Lugeon: In such cases, the rock mass is full of joints and cracks and the openings of the joints are relatively high and their filling is low.
-
(D)
Low RQD and low Lugeon: This condition indicates the filling of joints or lack of hydraulic connection of rock masses.
Lugeon has a direct corelation with RQD in karst sections (Assari et al. 2016; Hiller et al. 2011; Rastegarnia et al. 2017, 2019; White 2002).
Figure 7 shows the types of hydromechanical behavior in the sites of Khersan II and Bazoft dams. In the Bazoft dam site, the predominant flow type is laminar flow with 34% and the lowest percentage is related to turbulent flow with 4%. Also, the dilation flow is about 27%, the washout flow is about 5.5%, the void filling flow is about 17% and 13% is impermeable.

Percentage of the rock mass hydromechanical behavior of the sites
As shown in Fig. 7, the percentage of turbulent and washout behaviors in Khersan II dam site is zero. In this site, laminar flow is 20%, dilation is about 15%, void filling is about 12% and 54% is impermeable. The absence of turbulent behavior indicates the low groutability of the Khersan II dam site. Turbulence and washout flow types indicate that the condition of the rock mass is not suitable in terms of permeability and arrangements should be made for its sealing.
4.4 Statistical properties of variables
The used data for modeling were obtained from 12 trial and control grouting boreholes at the Bazoft and Khersan II dam sites. Table 4 shows the statistical characteristics of the variables used in the analysis. The histogram of the variables is also presented in Fig. 8. The average of Q and Lugeon in these two sites are 31.72 and 15.73, respectively. Based on the average of Lugeon (15.73), it can be said that the rock mass has moderate permeability.

Histogram of variables
In general, if the amount of skewness and kurtosis of the data is outside the distance of 3 to − 3, the data is not normally distributed and the data should be normalized. According to the results, it can be said that the data are normal (Table 4; Fig. 8). On the other hand, since the number of data is more than 25 (175 data), the data can be considered normal according to the Pearson suggestion (Bai et al. 2019; Bai et al. 2022; Wu et al. 2021; Zhou et al. 2021c). Some outlier data were deleted using box plot diagrams and engineering judgments. For example, in sections that Lugeon and RQD are both ascending (for example, both are equal to 100) are considered as karst areas. Most of these sections were corroborated by evidence in engineering geological reports such as drilling rod drop and no core recovery.
4.5 Lugeon relationship with Q classification system, depth and joint spacing
Characteristics of joints such as opening, roughness, continuity, orientation and slope of joints are effective parameters in the degree of permeability of the rock masses (Bell 2000; Liu et al. 2020; Yang et al. 2018; Zhang et al. 2021a, 2021b, 2021c, 2022b; Li et al. 2022a). Therefore, by assessing the relationship between Lugeon and the joint characteristics (i.e., joint aperture, number of joint sets, roughness, and persistence), the permeability of a site can be determined. Relationships of the Q classification system, depth and joint spacing (Js) with Lugeon number in 12 trial grouting and control boreholes in Bazoft and Khersan II dam sites (on 175 data) are presented in Fig. 9. The most accurate relationship is logarithmic function (Fig. 9). Most previous studies have reported logarithmic and exponential relationships between Lugeon and joint properties (Qureshi et al. 2014; Kayabasi et al. 2015; Jiang et al. 2009; Farid and Rizwan 2017; El-Naqa 2001).

Lugeon relationship with Q classification system, joint spacing (Js) and depth
Table 5 shows the evaluation results of bivariate relationships between Lugeon and rock mass characteristics based on different criteria. According to this table, joint spacing has the greatest effect on the Lugeon number.
4.6 Multivariate linear regression (MVLR) analysis
Table 4 shows developed equations for predicting Lugeon using the MVLR method. Durbin-Watson (DW), variance inflation factor (VIF), MAPE, and determination coefficient were used to appraise the relationships (Table 6). The results of analysis of variance (P value = 0.00) show that the models were appropriately developed. The suitability of the constant values and coefficients was evaluated in more detail by the T-test. The results of this test are presented in Table 7. The DW test is used to examine the independence of errors from each other. The DW value must be between 1.5 and 2. Based on results, the errors are independent from each other and it is possible to use the developed models. Because the DW values are placed between 1.5 and 2.5 (Table 6). The VIF criterion is also used to evaluate the correlation of independent variables. Results of the MVLR shows that with removing the depth (D) variable does not significantly change the accuracy of the model 2. Therefore, model 2 is recommended for estimating Lugeon. As well as Fig. 10 shows that depth has a small effect on the Lugeon value.

The relationship of measured Lugeon with forecasted values
4.7 Evaluation and comparison with previous studies
Several empirical relationships have been developed to predict Lugeon number (Table 1). In this study, using the relationships of previous researchers, Lugeon was estimated. Then, the relationship of estimated Lugeon with the measured Lugeon was investigated (Fig. 10). Results show that there is a good to moderate correlation between measured Lugeon with predicted ones based on previous studies (Fig. 10). This figure also shows the performance of the proposed MVLR model of the present study. The MVLR model with 79% is able to predict Lugeon number of Asmari limestone rocks at Bazoft and Khersan II dam sites. The determination coefficients for each of the evaluated relationships of previous researchers to estimate Lugeon values are presented in Fig. 10. Coefficient of determination from 0.32 for Oge and Çırak (2019) relationship to 0.71 for Jiang et al. (2009) relationship are variable.
Due to the various joint properties of the rocks, there isn’t a simple relationship with very high accuracy (R2 > 0.90) to estimate Lugeon number based on rock properties. Similar results have been presented by other researchers (Kutzner 1996; Ewert 1997; Nia et al. 2017). For this reason, in this study, intelligent methods for estimating Lugeon number were used. Many problems in geology are so complex that their separation and study are possible only by soft computational methods. Because these methods use technology and knowledge to build an intelligent system to solve complex problems (Davis 2002; Kayabasi et al. 2015; Li et al. 2022b). Previous studies showed that soft computing methods have higher accuracy than statistical methods for predicting rock mass properties (Kayabasi et al. 2015; Rahimi et al. 2019; Zadhesh et al. 2015; Shahbazi et al. 2020).
4.8 Multilayer Perceptron Neural Network (MPNN)
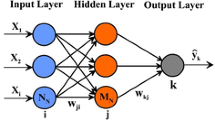
Today in the field of engineering, the neural networks have a good performance for predicting and modeling (Golmohammadi et al. 2014; Gholami et al. 2015; Mohan et al. 2021; Tabatabaei and Salehpour Jam 2017). The MPANN contains of three layers such as input layer, hidden layer and output layer. The number of neurons in the input layer depends on the number of independent variables (Alizadeh et al. 2022; Sun et al. 2021; Liu et al. 2021a). The output of the layer performances as a dependent variable and its number. The hidden layer as the interface leads to the process of computing the output (Rath et al. 2021; Li et al. 2017; Liu et al. 2021b; Çevik and Tabaru-Örnek 2020). In current study, different neurons were tested to achieve optimal results. The optimal MPNN contains of ten neurons in a hidden layer. The Q classification system and joint spacing (Js) were considered as inputs and Lugeon number was output. The whole data was categorized as three sets including training (70%), testing (15%) and validation (15%). For teaching the algorithm and obtaining the weights for the preferred outcomes the training group was used (Kavyanifar et al. 2020; Ghalandari et al. 2019; Zhang et al. 2022a; Meng et al. 2022). The validation set is used to ensure that the network does not depend on the training data set (Al-Masaeed et al. 2021; Ansari and Hashemi 2017; Shamsashtiany and Ameri 2018). The test set is used to test the network in predicting new data (Sanaei et al. 2015; Liu et al. 2021c; Zheng et al. 2021). The trained model should be verified by an independent set of experimental data (Moshahedi and Mehranfar 2021; Rastegarnia et al. 2021; Wang et al. 2022; Yang et al. 2022; Zhang et al. 2020). The performance of the Levenberg–Marquardt (LM) training algorithm for predicting output using inputs was examined by MATLAB software. Sigmoid and Purelin transfer functions were chosen for hidden and output layers, respectively. Figure 11 shows the optimum MPNN structure used in this study.

The optimum MPNN structure used in this research (with ten neurons)
Figure 12 shows the mean square error (MSE) variations by the LM algorithm in the optimum results. The lowest MSE was obtained at the first epoch for predicting Lugeon (Fig. 12). Also, Fig. 12 shows the correlation coefficient between Lugeon and inputs using the optimal MPNN model (Fig. 13).

The error trend using MPNN in the optimum model (in the tenth neurons)

The correlation coefficients using MPNN in the optimum model
4.9 ANFIS results for predicting Lugeon number
In this study, using ANFIS method as a combination of fuzzy logic with neural networks, an attempt was made to estimate Lugeon number. Prior to modeling using ANFIS, the data were categorized in training and testing sets with 75% and 25% of the whole data, respectively. To train the model in ANFIS method, the combined method of recursive error propagation with the least squares was used. In this research, obtained ANFIS models are based on the Sugeno method. The GENFIS2 command was used to form the ANFIS model using a differential clustering method. The input data for modelling include Q-system and joint spacing (Js) and the output parameter is Lugeon (Fig. 14). In this model, the membership functions (MFs) of input data for each of the variables are 4 and the MFs of the output data whose output is Lugeon, are shown in Fig. 14. In the input membership function (inputmf) layer, inputs pass through membership functions. The membership function degree indicates the membership level of the member to the fuzzy set (Suthar 2020).

ANFIS model structure, number of inputs, outputs and rules used
Rule viewer inference diagram is a MATLAB technical computing environment used to display fuzzy inference diagrams. This tool is used to identify and display the rules and how the functions affect the final results (Moshahedi and Mehranfar 2021) (Fig. 15). Each row corresponds to a rule, the number of each rule is shown on the left side of the charts, and each column corresponds to a variable.

Rule displayer (there are 4 rules for predicting data relationships)
The best performance of the ANFIS model was obtained after 3500 training sessions with clustering radius of 0.30 (Table 8). Figure 16 shows GMFs for Lugeon using ANFIS model.

Generated GMFs by Sugeno-FIS method for ANFIS model input variables
The ANFIS model led to the formation of 4 rules for Lugeon, which has the best answer among the ANFIS models with a differential clustering method. Figure 17 shows the correlation of the ANFIS model in the training stages. This figure shows that the ANFIS model can explain 87% of the Lugeon's changes by the Q classification system and joint spacing. A coefficient of determination greater than 60% indicates that the independent variables have largely been able to explain the changes in the dependent variable (Taylor 1990).

Correlation between real and predicted Lugeon by ANFIS model
The error histogram using ANFIS method is shown in Fig. 18. This shows the difference between the forecasted Lugeon using ANFIS method and actual value of Lugeon.

The error histogram using ANFIS method
4.10 The SVR Results
In this study, to train and test the models using radial basis function (RBF), 75% and 25% of the total data were used, respectively. The obtained optimal parameters of ε, γ and C to estimate Lugeon were 0.01, 92 and 80, respectively. Error histogram and relationships between measured and predicted Lugeon using SVR method for all data are demonstrated in Fig. 19. By comparing the results of the SVR method with other methods used in the present study, it is observed that SVR shows higher accuracy than other methods. Numerous studies have shown that on a small amount of data the SVR model has a high accuracy in predicting the dependent variable due to the use of structural risk optimization principle (SROP), (Al-Anazi and Gates 2012; Moghaddam et al. 2020). The SROP seeks to minimize the high limit of generalization error. The SVR solution can also be turned into a global optimum, while MPNN approaches tend to be a local optimal solution. Therefore, over fitting rarely occurs in the SVR method (Kim 2003; Luo et al. 2022a, b; Zhan et al. 2022; Chen et al. 2021a, b).

SVR results for predicting Lugeon number
4.11 The RF Results
The RF algorithm, which is a learning method based on a group of decision trees, was used to estimate the permeability of the dam sites. In this algorithm to form each tree, a different set of existing patterns are selected considering the replacement of each selected pattern. The size of the selected category will be equal to the total number of available patterns (Breiman 2001). RF was presented by Breiman (2001) as a method of a new development of decision trees, which combines the prediction of several individual algorithms together using rules-based. The general principles of group training techniques are based on the assumption that their accuracy is higher than other training algorithms (Kotsiantis and Pintelas 2004; Luo et al. 2022a, b).
In the RF method, bagging is used to create training data. This is done through random resampling of the original data set with replacement. In this step, none of the data selected from the input samples is removed to produce the next subset, and thus the variance is also reduced. Therefore, some data may be used more than once in training branches, while some other data that are not effective in modeling were never used. Therefore, more stability is obtained for the model and it makes the model more reliable against slight changes in the input data and increases its prediction accuracy (Breiman 2001). The set of samples that are not selected in the bagging process in the training of trees is included in a subset called Out-of-Bag (OOB) patterns. This part of the RF can be used to evaluate the performance of the model (Peters et al. 2007). In this way, RF can calculate an internal uncorrelated estimate of the generalization error without using external data subsets. The general trend of the RF algorithm is mentioned in various sources (Koohestani et al. 2022; Soleimannejad et al. 2018; Parsakhoo et al. 2016) In this research, the modeling process was done using the R software package (R 4.2.1), (Liaw and Wiener 2002). 75% of the samples (131 cases) were used for training the model and 25% of the samples (44 cases) were used to evaluate the constructed models. In order to determine the number of selected variables in each tree node as well as the number of trees, the tenfold cross-validation method was used. According to this method, 400 trees and two variables in each node have provided the most favorable conditions for the model. After modeling, the model was evaluated by experimental data. The importance of the input parameters is obtained based on the Gini importance index and permutation importance (Mantas et al. 2019). Accordingly, joint spacing is more important than the Q classification system. The RF model makes predictions using the OOB error value, and in this method, data is not used for testing (Chehata et al. 2009). Figure 20A shows the prediction results of the RF model against the observational data for permeability, which shows a high correlation between the estimated and observed permeability. Also, the distribution of the error values resulting from the RF model is shown in Fig. 20B. It can be seen that the accuracy of this model is the highest after the SVR method.

RF results for predicting Lugeon number
4.12 Comparison of results
Comparison of results based on various criteria shows that correlation coefficients of the used methods and previous works are higher than 50% (Table 9). Various criterial have been used by researchers to check the validity of the relationships and models (Fayaz et al. 2022; Srinivasareddy et al. 2021; Hassanzadeh et al. 2021; Wu et al. 2018; Saghi et al. 2019; Sui et al. 2020). Correlation coefficient higher than 70% and between 70 and 50% are considered as strong and moderate correlation, respectively (Taylor 1990). Precision of the used methods in current study is as following: MVLR < MPNN < ANFIS < RF < SVR. Also, results of most of the previous works show strong correlation.
5 Conclusions
In this study, the relationships of the Q classification system, joint spacing and depth with Lugeon number were investigated in five-meter sections of the boreholes in Bazoft and Khersan II dam sites, west of Iran. Based on the average Lugeon and Q classification system of both sites, the rock mass was classified as moderate permeability category in terms of Lugeon and good category in terms of strength (Q value). The SVR, MPNN, ANFIS, RF, MVLR, and simple regression methods were used to predict Lugeon based on Q-system and joint spacing (Js). The performance of the empirical relationships and models was evaluated using various criteria. Due to the use of structural risk minimization principles, the SVR (with R = 0.97) using radial basis function showed higher accuracy than other methods to estimate the Lugeon value. Precision of the used methods is as MVLR < MPNN < ANFIS < RF < SVR. Comparison of results with previous researches showed that there is a good to moderate correlation between measured Lugeon with predicted Lugeon based on previous studies. Analysis of all model criteria (R2, RMSE, MAPE, DW, analysis of variance, t-test, normality, VIF and VAF) using simple and multiple regression disclosed that it is possible to forecast the Lugeon number using the Q classification system and joint spacing.
Data availability
Enquiries about data availability should be directed to the authors.
References
Abraham A (2005) Artificial neural networks. Handbook of measuring system design. Wiley, Stillwater, pp 901–908
Adegbite JO, Belhaj H, Bera A (2021) Investigations on the relationship among the porosity, permeability and pore throat size of transition zone samples in carbonate reservoirs using multiple regression analysis, artificial neural network and adaptive neuro-fuzzy interface system. Pet Res 6(4):321–332
Akbarimehr D, Aflaki E (2019) Site investigation and use of artificial neural networks to predict rock permeability at the Siazakh Dam, Iran. Q J Eng Geol 52(2):230–239
Al-Anazi AF, Gates ID (2012) Support vector regression to predict porosity and permeability: effect of sample size. Comput Geosci 39:64–76
Al-Masaeed S, Alshareef HN, Johar MGM, Ab Yajid MS, Abdeljaber O, Khatibi A (2021) A study on educational research of artificial neural networks in the Jordanian Perspective Abstract. Euras J Educ Res 96(96):281–301
Alizadeh SM, Iraji A, Tabasi S, Ahmed AAA, Motahari MR (2022) Estimation of dynamic properties of sandstones based on index properties using artificial neural network and multivariate linear regression methods. Acta Geophys 70(1):225–242
Ansari Y, Hashemi A (2017) Neural Network approach in assessment of fiber concrete impact strength. J Civ Eng Mater Appl 1(3):88–97. https://doi.org/10.15412/J.JCEMA.12010301
Assari A, Mohammadi Z, Ghanbari RN (2016) Local variation of hydrogeological characteristics in the Asmari karstic limestone at the Karun IV Dam, Zagros region, Iran. Q J Eng Geol Hydrogeol 49:105–115. https://doi.org/10.1144/qjegh2015-047
Bai B, Rao D, Chang T, Guo Z (2019) A nonlinear attachment-detachment model with adsorption hysteresis for suspension-colloidal transport in porous media. J Hydrol 578:124080. https://doi.org/10.1016/j.jhydrol.2019.124080
Bai B, Wang Y, Rao D, Bai F (2022) The effective thermal conductivity of unsaturated porous media deduced by pore-scale SPH simulation. Front Earth Sci 10:943853. https://doi.org/10.3389/feart.2022.943853
Barton N (2002) Some new Q-value correlations to assist in site characterization and tunnel design. Int J Rock Mech Min 39(2):185–216
Barton N (2004) The theory behind high pressure grouting-part 1. Tunnels Tunnel Int 36(9):66
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Çevik M, Tabaru-Örnek G (2020) Comparison of MATLAB and SPSS software in the prediction of academic achievement with artificial neural networks: modeling for elementary school students. Int Online J Educ Sci 7(4):1689–1707
Chehata N, Guo L, Mallet C (2009) Airborne lidar feature selection for urban classification using random forests. Int Arch Photogram Remote Sens Spat Inf Sci 39:207–212
Chen YF, Ling XM, Liu MM, Hu R, Yang Z (2018) Statistical distribution of hydraulic conductivity of rocks in deep-incised valleys, Southwest China. J Hydrol 566:216–226
Chen J, Du L, Guo Y (2021a) Label constrained convolutional factor analysis for classification with limited training samples. Information 544:372–394. https://doi.org/10.1016/j.ins.2020.08.048
Chen K, Song Y, Zhang Y, Xue H, Rong J (2021b) Modification of the BQ system based on the Lugeon value and RQD: a case study from the Maerdang hydropower station, China. Bull Eng Geol Environ 80(4):2979–2990
Davis JC (2002) Statistics and data analysis in geology, 3rd edn. Wiley, USA, p 638
Dong J, Deng R, Quanying Z, Cai J, Ding Y, Li M (2021) Research on recognition of gas saturation in sandstone reservoir based on capture mode. Appl Radiat Isot 1(178):109939
Dorfan L, Mousavi Haghighi MH, Mousavi SN (2020) Optimized decision-making for shrimp fishery in Dayyer Port using the goal programing model. CJES 18(4):367–381
Du K, Li X, Su R, Tao M, Lv S, Luo J, Zhou J (2022) Shape ratio effects on the mechanical characteristics of rectangular prism rocks and isolated pillars under uniaxial compression. Int J Min Sci Technol. https://doi.org/10.1016/j.ijmst.2022.01.004
El-Naqa A (2001) The hydraulic conductivity of the fractures intersecting Cambrian sandstone rock masses, central Jordan. Environ 40(8):973–982
Ewert FK (1985) Rock grouting with emphasis on dam sites. Springer, Berlin, p 428
Ewert FK (1997) Permeability, groutability and grouting of rocks related to dam sites; part 4. Groutability and grouting of rock. Dam Eng 8(4):271–325
Fallah M, Pirali Zefrehei AR, Hedayati SA, Bagheri T (2021) Comparison of temporal and spatial patterns of water quality parameters in Anzali Wetland (southwest of the Caspian Sea) using Support vector machine model. Casp J Environ Sci 19(1):95–104
Farid AT, Rizwan M (2017) Prediction of in situ permeability for limestone rock using rock quality designation index. Int J Geotech Geol Eng 11(10):948–951
Fatahi Nafchi R, Yaghoobi P, Reaisi Vanani H et al (2021) Eco-hydrologic stability zonation of dams and power plants using the combined models of SMCE and CEQUALW2. Appl Water Sci 11(109):11–17. https://doi.org/10.1007/s13201-021-01427-z
Fayaz SA, Zaman M, Butt MA (2022) Numerical and experimental investigation of meteorological data using adaptive linear M5 model tree for the prediction of rainfall. RCER 9(1):1–12. https://doi.org/10.18488/76.v9i1.2961
Ghadimi H, Ebrahimian H (2015) MLP based islanding detection using histogram analysis for wind turbine distributed generation. UJRSET 3(3):16–26
Ghalandari M, Ziamolki A, Mosavi A, Shamshirband S, Chau KW, Bornassi S (2019) Aeromechanical optimization of first row compressor test stand blades using a hybrid machine learning model of genetic algorithm, artificial neural networks and design of experiments. Eng Appl Comput Fluid Mech 13(1):892–904
Gholami V, Darvari Z, Mohseni Saravi M (2015) Artificial neural network technique for rainfall temporal distribu-tion simulation (Case study: Kechik region). Casp J Environ Sci 13(1):53–60
Gholami S, Vafakhah M, Ghaderi K, Javadi MR (2020) Simulation of rainfall-runoff process using geomorphology-based adaptive neuro-fuzzy inference system (ANFIS). Casp J Environ Sci 18(2):109–122
Golmohammadi AM, Tavakkoli-Moghaddam R, Jolai F, Golmohammadi AH (2014) Concurrent cell formation and layout design using a genetic algorithm under dynamic conditions. UCT J Res Sci Eng Technol 2(1):8–15
Hariri-Ardebili MA, Salazar F (2020) Engaging soft computing in material and modeling uncertainty quantification of dam engineering problems. Soft Comput 24(15):11583–11604
Hassanzadeh R, Beiranvand B, Komasi M, Hassanzadeh A (2021) Investigation of data mining method in optimal operation of Eyvashan earth dam reservoir based on PSO algorithm. J Civ Eng Mater Appl 6:66. https://doi.org/10.22034/jcema.2021.302238.1063
Hiller T, Kaufmann G, Romanov D (2011) Karstification beneath dam-sites: from conceptual models to realistic scenarios. J Hydrol 398:202–211. https://doi.org/10.1016/j.jhydrol.2010.12.014
Houlsby AC (1990) Construction and design of cement grouting: a guide to grouting in rock foundations, vol 67. Wiley, Hoboken
Huang J, Duan T, Zhang Y, Liu J, Zhang J, Lei Y (2020) Predicting the permeability of pervious concrete based on the beetle antennae search algorithm and random forest model. Adv Civ Eng 2020:Article ID: 8863181,. https://doi.org/10.1155/2020/8863181
Idrisovich Ismagilov I, Ayratovich Murtazin A, Vladimirovna Kataseva D, Sergeevich Katasev A, Olegovna Barinova A (2020) Formation of a knowledge base to analyze the issue of transport and the environment. CJES 18(5):615–621
Jalili A, Firouz MH, Ghadimi N (2015) Firefly algorithm based on fuzzy mechanism for optimal congestion management. UJRSET 3(3):1–7
Jamshidi Gohari MS, Emami Niri M, Ghiasi-Freez J (2021) Improving permeability estimation of carbonate rocks using extracted pore network parameters: a gas field case study. Acta Geophys 69(2):509–527
Jang JSR (1993) ANFIS: adaptive network based fuzzy inference system. IEEE Trans Syst Man Cybern 23(3):665–685
Jiang X, Wan L, Wang X, Kang A, Huang J, Huang G (2009) Permeability heterogeneity in a fractured sandstone-mudstone rock mass in Xiaolangdi Dam Site, Central China. Acta Geol Sin Engl Ed 83(5):962–970
Jiang F, He P, Wang G, Zheng C, Xiao Z, Wu Y, Lv Z (2022) Q-method optimization of tunnel surrounding rock classification by fuzzy reasoning model and support vector machine. Soft Comput 66:1–14. https://doi.org/10.1007/s00500-021-06581-9
Kalteh AM (2008) Rainfall-runoff modelling using artificial neural networks (ANNs): modelling and understanding. Casp J Env Sci 6(1):53–58
Kavyanifar B, Tavakoli B, Torkaman J, Mohammad Taheri A, Ahmadi Orkomi A (2020) Coastal solid waste prediction by applying machine learning approaches (Case study: Noor, Mazandaran Province, Iran). Casp J Environ Sci 18(3):227–236
Kayabasi A, Yesiloglu-Gultekin N, Gokceoglu C (2015) Use of non-linear prediction tools to assess rock mass permeability using various discontinuity parameters. Eng Geol 185:1–9. https://doi.org/10.1016/j.enggeo.2014.12.007
Kim K (2003) Financial time series forecasting using support vector machines. Neuro-Computing 55:307–319
Koohestani M, Naderi S, Shadloo S (2022) Evaluation of habitat quality and determining the distribution of Wild goat (Capra aegagrus) in Roodbarak prohibited hunting region, Kelardasht, Iran. CJES 6:1–9
Kookalani S, Cheng B (2021) Structural analysis of GFRP elastic gridshell structures by particle swarm optimization and least square support vector machine algorithms. J Civ Eng Mater Appl 10(22034):304981 (2021.1064)
Kotsiantis S, Pintelas P (2004) Combining bagging and boosting. Comput Intell 1(4):324–333
Kutzner C (1996) Grouting of rock and soil. Balkema, Rotterdam, p 271
Li J, Xu K, Chaudhuri S, Yumer E, Zhang H, Guibas L (2017) Grass: generative recursive autoencoders for shape structures. ACM Trans Graph 36(4):1–4
Li X, Zhong D, Ren B, Fan G, Cui B (2019) Prediction of curtain grouting efficiency based on ANFIS. Bull Eng Geol Environ 78(1):281–309
Li M, Chen S, Shen Y, Liu G, Tsang IW, Zhang Y (2022) Online multi-agent forecasting with interpretable collaborative graph neural networks. IEEE Trans Neural Netw Learn Syst. https://doi.org/10.1109/TNNLS.2022.3152251
Li X, Li X, Wang Y, Hu Y, Zhou C et al (2022) Numerical investigation on stratum and surface deformation in underground phosphorite mining under different mining methods. Front Earth Sci. https://doi.org/10.3389/feart.2022.831856
Liaw A, Wiener M (2002) Classification and regression by random forest. R News 2(3):18–22
Liu B, Yang H, Karekal S (2020) Effect of water content on argillization of mudstone during the tunnelling process. Rock Mech Rock Eng 53(2):799–813
Liu K, Ke F, Huang X, Yu R, Lin F, Wu Y, Ng DW (2021a) DeepBAN: a temporal convolution-based communication framework for dynamic WBANs. IEEE Trans Comput 69(10):6675–6690
Liu Y, Zhang Z, Liu X, Wang L, Xia X (2021b) Efficient image segmentation based on deep learning for mineral image classification. Adv Powder Technol 32(10):3885–3903
Liu Y, Zhang Z, Liu X, Wang L, Xia X (2021c) Ore image classification based on small deep learning model: evaluation and optimization of model depth, model structure and data size. Miner Eng 172:107020
Luo G, Yuan Q, Li J, Wang S, Yang F (2022a) Artificial intelligence powered mobile networks: from cognition to decision. IEEE Netw 36(3):136–144
Luo G, Zhang H, Yuan Q, Li J, Wang FY (2022b) ESTNet: embedded spatial–temporal network for modeling traffic flow dynamics. IEEE Trans Intell Transp Syst 173:1–12. https://doi.org/10.1109/TITS.2022.3167019
Ma G, Chao Z, He K (2021) Predictive models for permeability of cracked rock masses based on support vector machine techniques. Geotech Geol Eng 39(2):1023–1031
Mahab Ghods Consulting Engineers Co (2009) Rock mechanics report of Khersan II project. Mahab Ghods Consulting Engineers Co., Tehran
Mahdavi A, Niknejad M, Karami O (2015) A fuzzy multi-criteria decision method for ecotourism development locating. CJES 13(3):221–236
Mahmoodzadeh A, Mohammadi M, Ali HFH, Abdulhamid SN, Ibrahim HH, Noori KMG (2021) Dynamic prediction models of rock quality designation in tunneling projects. Transp Geotech 27:100497
Maleki MA, Emami M (2019) Application of SVM for investigation of factors affecting compressive strength and consistency of geopolymer concretes. JCEMA 3(2):101–107
Mantas CJ, Castellano JG, Moral-García S, Abellán J (2019) A comparison of random forest based algorithms: random credal random forest versus oblique random forest. Soft Comput 23(21):10739–10754
Matinkia M, Hashami R, Mehrad M, Hajsaeedi MR, Velayati A (2022) Prediction of permeability from well logs using a new hybrid machine learning algorithm. Petrol. https://doi.org/10.1016/j.petlm.2022.03.003
Meng F, Zheng Y, Bao S, Wang J, Yang S (2022) Formulaic language identification model based on GCN fusing associated information. PeerJ Comput Sci 8:e984
Moghaddam DD, Rahmati O, Panahi M, Tiefenbacher J, Darabi H, Haghizadeh A, Haghighi AT, Nalivan OA, Bui DT (2020) The effect of sample size on different machine learning models for groundwater potential mapping in mountain bedrock aquifers. CATENA 187:104421
Mohan R, Ganapathy K, Rama A (2021) Brain tumour classification of magnetic resonance images using a novel CNN based medical image analysis and detection network in comparison with VGG16. J Popul Ther Clin 28(2):66. https://doi.org/10.47750/jptcp.2022.873
Morshedy AH, Torabi SA, Memarian H (2019) A hybrid fuzzy zoning approach for 3-dimensional exploration geotechnical modeling: a case study at Semilan dam, southern Iran. Bull Eng Geol Environ 78(2):691–708
Moshahedi A, Mehranfar N (2021) A comprehensive design for a manufacturing system using predictive fuzzy models. UJRSET 9(03):1–23
Niru G (2011) Hydro powerhouse feasibility studies of Bazoft dam site. Iran water and power resources development company (IWPC), Tehran, Iran, p 213
Nonveiller E (1989) Grouting theory and practice, development of geotechnical engineering. Elsevier
Oge İF, Çırak M (2019) Relating rock mass properties with Lugeon value using multiple regression and nonlinear tools in an underground mine site. Bull Eng Geol Environ 78(2):1113–1126
Ostad-Ali-Askari K, Shayannejad M, Ghorbanizadeh-Kharazi H (2017) Artificial neural network for modeling nitrate pollution of groundwater in marginal area of Zayandeh-rood River, Isfahan, Iran. KSCE J Civ Eng 21(1):134–140
Parsakhoo A, Eshaghi MA, Shataee Joybari S (2016) Design and evaluation of helicopter landing variants for firefighting in Golestan National Park, Northeast of Iran. CJES 14(4):321–329
Piscopo V, Baiocchi A, Lotti AEA, Biler AR, Ceyhan AH, Cüylan M, Dişli E, Kahraman S, Taşkın M (2018) Estimation of rock mass permeability using variation in hydraulic conductivity with depth: experiences in hard rocks of western Turkey. Bull Eng Geol Environ 77(4):1663–1671
Qasem SN, Samadianfard S, Sadri Nahand H, Mosavi A, Shamshirband S, Chau KW (2019) Estimating daily dew point temperature using machine learning algorithms. Water 11(3):582. https://doi.org/10.3390/w11030582
Qureshi MU, Khan KM, Bessaih N, Al-Mawali K, Al-Sadrani K (2014) An empirical relationship between in-situ permeability and RQD of discontinuous sedimentary rocks. Electron J Geotech Eng 19:4781–4790
Qureshi MU, Mahmood Z, Rasool AM (2022) Using multivariate adaptive regression splines to develop relationship between rock quality designation and permeability. J Rock Mech Geotech Eng. https://doi.org/10.1016/j.jrmge.2021.06.011
Rahimi E, Sharifi Teshnizi E, Rastegarnia A, Motamed Al-shariati E (2019) Cement take estimation using neural networks and statistical analysis in Bakhtiari and Karun 4 dam sites, in south west of Iran. Bull Eng Geol Environ 78(4):2817–2834
Rashidi Tazhan O, Pir Bavaghar M, Ghazanfari H (2019) Detecting pollarded stands in Northern Zagros forests, using artificial neural network classifier on multi-temporal lansat-8 (OLI) imageries (case study: Armarde, Baneh). CJES 17(1):83–96
Rastegarnia A, Sohrabibidar A, Bagheri V, Razifard M, Zolfaghari A (2017) Assessment of relationship between grouted values and calculated values in the Bazoft Dam Site. Geotech Geol Eng 35(4):1299–1310
Rastegarnia A, Lashkaripour GR, Ghafoori M, Farrokhad SS (2019) Assessment of the engineering geological characteristics of the Bazoft dam site, SW Iran. Q J Eng Geol 52(3):360–374
Rastegarnia A, Lashkaripour GR, Sharifi Teshnizi E, Ghafoori M (2021) Evaluation of engineering characteristics and estimation of static properties of clay-bearing rocks. Environ Earth Sci 80(18):1–24
Rath P, Mallick PK, Siddavatam R, Chae GS (2021) An empirical development of hyper-tuned CNN using spotted hyena optimizer for bio-medical image classification. J Nat Sci Biol Med 12(3):300–306
Rosid MS, Haikel S, Haidar MW (2019) Carbonate reservoir rock type classification using comparison of Naïve Bayes and Random Forest method in field “S” East Java. AIP Conf 2168(1):020019
Rustamovich Sultanbekov I, Yurievna Myshkina I, Yurievna Gruditsyna L (2020) Development of an application for creation and learning of neural networks to utilize in environmental sciences. CJES 18(5):595–601
Saghi H, Behdani M, Saghi R, Ghaffari AR, Hirdaris S (2019) Application of gene expression programming model to present a new model for bond strength of fiber reinforced polymer and concrete. JCEMA 3(1):15–29
Sanaei F, Kazemi MAA, Ahmadi H (2015) Designing and implementing fuzzy expert system for diagnosis of psoriasis. UJRSET 3(02):41–49
Seyfi R (2017) Application of artificial neural network in modeling separation of microalgae. UJRSET 5(04):43–49
Shahbazi A, Saeidi A, Chesnaux R (2020) A review of existing methods used to evaluate the hydraulic conductivity of a fractured rock mass. Eng Geo 265:105438
Shamsashtiany R, Ameri M (2018) Road accidents prediction with multilayer perceptron MLP modelling case study: roads of Qazvin, Zanjan and Hamadan. JCEMA 2(4):181–192
Sharifi A, Amini J, Pourshakouri F (2016) Development of an allometric model to estimate above-ground biomass of forests using MLPNN algorithm, case study: Hyrcanian forests of Iran. CJES 14(2):125–137
Shi Y, Jian S (2018) Permeability estimation of rock reservoir based on PCA and Elman neural networks. In: IOP conference series: earth and environmental science, vol 128, No 1. IOP Publishing, p 012001
Shroff AV, Shah DL (1999) Grouting technology in tunneling and dam construction. A.A. Balkema, Rotterdam
Sobhani B, Safarianzengir V (2020) Monitoring and prediction of drought using TIBI fuzzy index in Iran. CJES 18(3):237–250
Soleimannejad L, Bonyad AE, Naghdi R (2018) Remote sensing-assisted mapping of quantitative attributes in Zagros open forests of Iran. Casp J Environ Sci 16(3):215–230
Srinivasareddy DS, Narayana DY, Krishna DD (2021) Sector beam synthesis in linear antenna arrays using social group optimization algorithm. Int J Antennas Propag 3(2):6–6
Sui T, Marelli D, Sun X, Fu M (2020) Multi-sensor state estimation over lossy channels using coded measurements. Automatica 111:108561
Sun G, Cong Y, Wang Q, Zhong B, Fu Y (2020) Representative task self-selection for flexible clustered lifelong learning. IEEE Trans Neural Netw Learn Syst. https://doi.org/10.1109/TNNLS.2020.3042500
Sun G, Cong Y, Dong J, Liu Y, Ding Z, Yu H (2021) What and how: generalized lifelong spectral clustering via dual memory. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/TPAMI.2021.3058852
Suthar M (2020) Modeling of UCS value of stabilized pond ashes using adaptive neuro-fuzzy inference system and artificial neural network. Soft Comput 24(19):14561–14575
Tabatabaei M, Salehpour Jam A (2017) Optimization of sediment rating curve coefficients using evolutionary algorithms and unsupervised artificial neural network. Casp J Environ Sci 15(4):385–399
Taylor R (1990) Interpretation of the correlation coefficient: a basic review. J Diagn Med Sonogr 6(1):35–39
Tekin A (2014) Early prediction of students’ grade point averages at graduation: a data mining approach. Euras J Educ Res 54:207–226
Tilaki GAD, Jolandan MA, Gholami V (2020) Rangelands production modeling using an artificial neural network (ANN) and geographic information system (GIS) in Baladeh rangelands, North Iran. Casp J Environ Sci 18(3):277–290
Vapnik V (1995) The nature of statistical learning theory. Springer, New York
Wang J, Yang M, Liang F, Feng K, Zhang K, Wang Q (2022) An algorithm for painting large objects based on a nine-axis UR5 robotic manipulator. Appl Sci 12(14):7219
White WB (2002) Karst hydrology: recent developments and open questions. Eng Geol 65:85–105
Wu Z, Cao J, Wang Y, Wang Y, Zhang L, Wu J (2018) hPSD: a hybrid PU-learning-based spammer detection model for product reviews. IEEE Trans Cybern 50(4):1595–1606
Wu X, Zheng W, Xia X, Lo D (2021) Data quality matters: a case study on data label correctness for security bug report prediction. IEEE Trans Softw Eng 44(7):2541–2556
Xie W, Li X, Jian W, Yang Y, Liu H, Robledo LF, Nie W (2021a) A novel hybrid method for landslide susceptibility mapping-based GeoDetector and machine learning cluster: a case of Xiaojin County, China. ISPRS Int J Geoinf 10(2):93
Xie W, Nie W, Saffari P, Robledo LF, Descote P, Jian W (2021b) Landslide hazard assessment based on Bayesian optimization–support vector machine in Nanping City, China. Nat Hazards 109(1):931–948
Xu L, Cai M, Dong S, Yin S, Xiao T, Dai Z, Wang Y, Soltanian MR (2022) An upscaling approach to predict mine water inflow from roof sandstone aquifers. J Hydrol 612:128314
Yang HQ, Li Z, Jie TQ, Zhang ZQ (2018) Effects of joints on the cutting behavior of disc cutter running on the jointed rock mass. Tunn Undergr Space Technol 81:112–120
Yang H, Wang Z, Song K (2020) A new hybrid grey wolf optimizer-feature weighted-multiple kernel-support vector regression technique to predict TBM performance. Eng Comput 66:1–17
Yang H, Song K, Zhou J (2022) Automated recognition model of geomechanical information based on operational data of tunneling boring machines. Rock Mech Rock Eng. https://doi.org/10.1007/s00603-021-02723-5
Yin L, Wang L, Keim BD, Konsoer K, Zheng W (2022) Wavelet analysis of dam injection and discharge in three gorges dam and reservoir with precipitation and river discharge. Water 14(4):567
Zadhesh J, Rastegar F, Sharifi F, Amini H, Nasirabad HM (2015) Consolidation grouting quality assessment using artificial neural network (ANN). Indian Geotech J 45(2):136–144
Zhan C, Dai Z, Samper J, Yin S, Ershadnia R, Zhang X, Soltanian MR (2022) An integrated inversion framework for heterogeneous aquifer structure identification with single-sample generative adversarial network. J Hydrol. https://doi.org/10.1016/j.jhydrol.2022.127844
Zhang Z, Cai Z (2021) Permeability prediction of carbonate rocks based on digital image analysis and rock typing using random forest algorithm. ENFUEM 35(14):11271–11284
Zhang S, Yuan Y, Fang H, Wang F (2020) An application of soft computing for the earth stress analysis in hydropower engineering. Soft Comput 24(7):4739–4749
Zhang L, Huang M, Li M, Lu S, Yuan X, Li J (2021a) Experimental study on evolution of fracture network and permeability characteristics of bituminous coal under repeated mining effect. Nat Resour Res 31(1):463–486. https://doi.org/10.1007/s11053-021-09971-w
Zhang L, Huang M, Xue J, Li M, Li J (2021) Repetitive mining stress and pore pressure effects on permeability and pore pressure sensitivity of bituminous coal. Nat Resour Res 30(6):4457–4476. https://doi.org/10.1007/s11053-021-09902-9
Zhang L, Li J, Xue J, Zhang C, Fang X (2021c) Experimental studies on the changing characteristics of the gas flow capacity on bituminous coal in CO2-ECBM and N2-ECBM. Fuel 1(291):120115
Zhang X, Ma F, Dai Z, Wang J, Chen L, Ling H, Soltanian MR (2022a) Radionuclide transport in multi-scale fractured rocks: a review. J Hazard Mater 424:127550
Zhang L, Zhang H, Cai G (2022b) The multi-class fault diagnosis of wind turbine bearing based on multi-source signal fusion and deep learning generative model. IEEE Trans Instrum Meas 71:1–12. https://doi.org/10.1109/TIM.2022.3178483
Zhao L, Wang L (2022) A new lightweight network based on MobileNetV3. KSII T Internet Inf. https://doi.org/10.3837/Tiis.2022.01.001
Zhao L, Zhang Y, Cui Y (2022) An attention encoder-decoder network based on generative adversarial network for remote sensing image dehazing. IEEE Sens J 22(11):10890–10900. https://doi.org/10.1109/JSEN.2022.3172132
Zheng W, Liu X, Yin L (2021) Research on image classification method based on improved multi-scale relational network. PeerJ Comput Sci 21(7):e613
Zhou J, Li X, Mitri HS (2016) Classification of rockburst in underground projects: comparison of ten supervised learning methods. J Comput Civ Eng 30(5):04016003
Zhou J, Chen C, Wang M, Khandelwal M (2021) Proposing a novel comprehensive evaluation model for the coal burst liability in underground coal mines considering uncertainty factors. Int J Min Sci Technol 66:1–15
Zhou J, Qiu Y, Khandelwal M, Zhu S, Zhang X (2021b) Developing a hybrid model of Jaya algorithm-based extreme gradient boosting machine to estimate blast-induced ground vibrations. Int J Rock Mech Min Sci 145(104856):6
Zhu B, Zhong Q, Chen Y, Liao S, Li Z, Shi K, Sotelo MA (2022) A novel reconstruction method for temperature distribution measurement based on ultrasonic tomography. IEEE Trans Ultrason Ferroelectr Freq Control. https://doi.org/10.1109/TUFFC.2022.3177469
Acknowledgements
We sincerely thank the cooperation of Ghods Niroo and Mahab Ghods Consulting Engineering Companies in the realization of this research.
Funding
The authors have not disclosed any funding.
Author information
Authors and Affiliations
Contributions
S.M.A.: data analysis, analysis of results, compilation, writing, review and editing; A.I.: performing field investigations and collecting required data, rock mechanics advisor, review and editing the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed consent
The authors are fully aware and satisfied with the contents of the article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Alizadeh, S.M., Iraji, A. Application of soft computing and statistical methods to predict rock mass permeability. Soft Comput 27, 5831–5853 (2023). https://doi.org/10.1007/s00500-022-07586-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-022-07586-8