
Abstract
In this paper, an attempt has been made to implement various robust techniques to predict rock fragmentation due to blasting in open pit mines using effective parameters. As rock fragmentation prediction is very complex and complicated, and due to that various artificial intelligence-based techniques, such as artificial neural network (ANN), classification and regression tree and support vector machines were selected for the modeling. To validate and compare the prediction results, conventional multivariate regression analysis was also utilized on the same data sets. Since accuracy and generality of the modeling is dependent on the number of inputs, it was tried to collect enough required information from four different open pit mines of Iran. According to the obtained results, it was revealed that ANN with a determination coefficient of 0.986 is the most precise method of modeling as compared to the other applied techniques. Also, based on the performed sensitivity analysis, it was observed that the most prevailing parameters on the rock fragmentation are rock quality designation, Schmidt hardness value, mean in-situ block size and the minimum effective ones are hole diameter, burden and spacing. The advantage of back propagation neural network technique for using in this study compared to other soft computing methods is that they are able to describe complex and nonlinear multivariable problems in a transparent way. Furthermore, ANN can be used as a first approach, where much knowledge about the influencing parameters are missing.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Blasting is still practiced for fragmenting rocks in surface and underground mining projects. A huge amount of energy is generated during the blasting process and only a small portion of this energy is effectively used to fragment and displace the rock mass and the rest of the energy is wasted in the form of undesirable events, such as air blast, fly rock, ground vibration, etc. [1,2,3,4,5,6,7,8,9]. Therefore, optimizing blast design parameters should be targeted to get the best possible rock fragmentation to be efficient for subsequent operations, including loading, hauling and crushing [10,11,12]. As a matter of fact, there are several influencing uncontrollable (rock mass properties) and controllable (blast geometry) factors affecting fragmentation quality making blast design a process with high complexity [13,14,15].
Investigating 432 blasting events, Mehrdanesh et al. attempted to evaluate the effect of rock mass properties on fragmentation. They concluded that in comparison of controllable parameters, uncontrollable parameters are more effective on rock fragmentation. Their study results showed that, from the rock mass properties group, point load index, uniaxial compressive strength, Poisson’s ratio, cohesion and rock quality designation, respectively, are the most important parameters on rock fragmentation and from the blast geometry group, stemming, spacing and hole diameter are the least important parameters on the quality of rock fragmentation [13]. Numerous empirical Formulas have been introduced to model rock fragmentation due to blasting. However, due to the complex nature of the fragmentation and limitation of effective variables in conventional models, these formulas are not adequately accurate. Consequently, they will not be capable to predict rock fragmentation suitably. It seems that more precise techniques are needed to predict the rock fragmentation [16].
Nowadays, artificial intelligence (AI) is being applied in a range of geo-engineering projects and AI is a fruitful approach to cope with such types of problems [17,18,19,20,21]. In this regard, a number of research studies have been carried out to utilize various AI tools to improve blast design parameters obtained from conventional and empirical methods [13, 22,23,24]. Table 1 briefly summarizes some researchers’ work in rock fragmentation, where they have used different AI tools and techniques. In this paper, for which four different mines were adopted as case studies, various techniques including regression analysis, classification and regression tree, support vector regression and artificial neural network were applied to predict rock fragmentation in the open pits blasting operation.
2 Artificial neural network
Artificial neural network is a branch of artificial intelligence [36,37,38]. It is made of a multilayer topology in which the layers are connected to each other. The first layer is considered for placing inputs, whereas the last one is for output(s). In addition to the mentioned layers, there are one or more layers known as hidden (transitional) layers which are placed in between the first and last layer. In fact, the hidden layers’ components known as neurons are responsible for the required computations. Number of the neurons in each hidden layer is determined by a try and error mechanism. When facing very low correlation ANN would be the best possible solution as compared to the available conventional alternatives [12, 13]. Amongst various advantages of ANN modeling, function approximation and feature selection can be considered as a specific capability [39,40,41].
To start working with ANN, a reasonable number of data sets (a set of inputs and their respective outputs) should be collected and used for training various network architectures from which the best combination would be selected. Artificial neural network (ANN) is increasingly being used to solve various nonlinear complex problems, such as rock fragmentation. However, it is not clear that what appropriate sample size should be there when using ANN in this context. The amount of data required for ANN learning depends on many factors, such as the complexity of the problem or the complexity of the learning algorithm. Till now, it is not clear that how much sample data should be there in a predictive modeling problem. However, there are some empirically established rule-of-thumb are there to estimate sample size requirements when using ANN. For example, one rule-of-thumb is that the sample size needs to be at least a factor of ten times the number of features. During this process, first, the connections between the neurons should be assigned a random weight, thereafter the initial given weights would be updated in each modeling run to gain the best possible efficient network. The next important item which should be thought of is adopting a proper method of training such as a back propagation algorithm with many advantages as compared to the other existing approaches [42,43,44,45].
A trained network can be examined by comparison of the model outputs with that of the measured outputs. To do this four statistical indices including determination coefficient (R2), mean absolute error (MAE), root mean square of errors (RMSE), and variance account for (VAF) can be calculated [46,47,48,49,50]. The following formulae are the mathematical expressions of the aforesaid indices:
where \(O\), \({O}^{^{\prime}}\) and \(\tilde{O }\) are the measured, predicted and mean of the O (output) values, respectively, and N is the total number of data.
3 Case study
In this paper, the required database is obtained from four different open pit mines [13]. All the mines are situated in Iran (Fig. 1) and considered to be the main sources of copper and iron ore in the country. Table 2 gives some descriptions about the mines.

Location map of studied mines
4 Collection of data sets
In this research, the database has been collected by performing 353 blasting operations in 4 mines mentioned in chapter 3. Descriptive information of the data sets is given in Table 3. Controllable parameters including burden, spacing, stemming, bench height, hole diameter, powder factor and uncontrollable rock characteristics comprising universal compressive strength (UCS), uniaxial tensile strength (UTS), Is50, density, Young’s modulus, P-wave velocity, Schmidt hardness value, Poisson’s ratio, rock quality designation (RQD), cohesion and friction angle were considered to the inputs.
In this research, image analysis techniques were applied to calculate size distribution using Split-Desktop software. Fragmentation has been calculated on the basis of 50% of passing size (X50). Finally mean-blasted particle size (X50) was selected as output in the modeling process.
5 ANN architecture
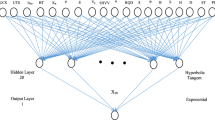
In this study, a total number of 353 data sets were used for training and testing groups. Back propagation approach was implemented for the model training. To have an applicable database and to improve efficiency of the training process, the whole data sets were normalized between values of − 1 and 1 [51]. After preprocessing of the data sets, to find out the best possible model with maximum accuracy and minimum error, numerous networks were created by varying pertinent elements, such as number of hidden layers and their respective neurons [52]. MAE, RMSE, VAF and R2 were determined for the various network topologies (Table 4). As it is seen in this table, the best model is a back propagation network with an architecture 18-14-1 and a hyperbolic-tangent transfer function in both the hidden and output layers (no.10). From Fig. 2, an optimum architecture of the ANN model is depicted. The determination coefficient was computed 0.9947, which is adequate to show competency of the developed ANN model.

Architecture of the optimum ANN model
6 Multivariate regression analysis (MRA)
Multivariate regression analysis was used to evaluate the relationship between the inputs and output. MRA is considered as a conventional method of trend analysis in scientific tasks [53,54,55]. Using Statistica 12.0 software [56,57,58], regression analysis was performed to develop a mathematical function for predicting mean size of the fragment size (X50) (Eq. 5). As it is deduced from this equation, burden, spacing mean in-situ block size, uniaxial compressive strength, Schmidt hardness value, cohesion, Young’s modulus and density have a direct relevance with X50, whereas bench height, hole diameter, stemming, powder factor, Poisson’s ratio, UTS, Is50, friction angle, P-wave velocity and RQD are indirectly effective in the X50 magnitude. The determination coefficient and RMSE were computed 0.8863 and 0.026, respectively, which indicates the relatively lower performance of the developed MRA model compared to the ANN model:
7 Classification and regression tree
Decision tree (DT) is fundamentally a branch of hierarchical approach which is used worldwide due to its capability to cope with classification-based problems. Structure of a tree contains different parts including, root, branches, leaves and nodes. DT is an ascending way of solution in which the root is placed at the topmost of the tree. In this technique, solution process is started with selecting a random node as a potential root for the tree. Each node represents a variable of the problem in hand and is divided into two branches. Division of the nodes is done with help of one of the independent variables. It is noted that a range has to be selected during the division process using a try and error mechanism. The selected range should be such a way that model performance indices such as root mean square error (RMSE) be minimized for each and every node [59, 60].
This method is also employed for regression analysis [61,62,63,64,65]. Due to various merits of classification and regression tree (CART) over other decision tree algorithms, it is normally preferred to be applied by many researchers [66,67,68]. In this paper, Matlab software was used to predict rock fragmentation incorporating the CART method. Developed decision tree for predicting X50 is shown in Fig. 3.

Developed CART model for predicting X50
8 Support vector regression
Support vector machine is applicable for solving both the classification and regression problems. In machine learning, support vector machines (SVM), which is well-known to handle structural risk minimization, is widely used in different fields of investigation [69,70,71]. Support vector regression (SVR), a subdivision of SVM, is suitable for dealing with interpolative and extrapolative problems using a specific predictive model. In this SVR technique, Vapnik–Chervonenkis (VC) theory is considered as the base for formulization [72,73,74]. Reasonable generalization reaches when VC dimension is quite low which in turn causes the error probability to be definitely low [75, 76]. Also, in this technique, a “loss function” is applied for regression estimation and function approximation. The function is defined as the difference between predicted value and tube radius (ε). Figure 4 shows the idea of the ε-insensitive loss function. As it is seen in this figure, samples situated out of the ± ε margin, would be considered non-zero slack variables and are kept apart from computations. It is obvious that the amount of loss function would be zero within ε-insensitive tube. It is noted that further details about SVM and SVR can be found out in the literature [77].

Graphic description of the SVR model
9 Performance evaluation of the models
Model evaluation of the developed MRA, CART, SVR and ANN models was performed with the 70 unused data sets in development process of the aforesaid models. The correlation between predicted and measured X50 for all the four models are shown in Figs. 5, 6, 7, 8, 9, 10, 11 and 12. Table 5 shows the calculated values of validation indexes. According to this table, performance of the ANN model with the highest accuracy and lowest is better as compared to the other employed models. On the contrary, efficiency of the conventional MRA is very low amongst the other utilized models. The MRA is bound to follow some valid statistical relations, whereas ANN is unbiased and can make its own relationship based on the sample data sets and due to that it has been found that ANN gives much better results compared to MRA in complex engineering problems. Rock fragmentation is also a very complex and complicated problem, influenced by several controllable and uncontrollable factors. Furthermore, results showed that facing problems with high complexity and nonlinearity such as fragmentation modeling, non-linear methods with high flexibility such as ANN have higher capabilities compared to classical linear methods such as MRA.

Scatter plot of the predicted vs. actual X50 for the MRA model (test)

Comparison of predicted and measured outputs for the MRA model

Scatter plot of the predicted vs. actual X50 for the CART model (test)

Comparison of predicted and measured outputs for the CART model

Scatter plot of the predicted vs. actual X50 for the ANN model (test)

Comparison of predicted and measured outputs for the ANN model

Scatter plot of the predicted vs. actual X50 for the SVR model (test)

Comparison of predicted and measured outputs for the SVR model
10 Sensitivity analysis
Normally, sensitivity analysis is performed to evaluate the effect of input variation on the relevant outputs. There are various methods of sensitivity analysis. One of the most frequently used methods is relevancy factor (RF) which is calculated by Eq. 6 [13, 78]:
where \({x}_{l,i}\) and \({\overline{x} }_{l}\) are the ith value and the average value of the lth input variable, respectively, \({y}_{i}\) and \(\overline{y }\) are the ith value and the average value of the predicted output, respectively.
As it is seen in Fig. 13, uncontrollable parameters are more effective on fragmentation quality as compared to controllable parameters. From the uncontrollable parameters, rock quality designation, Schmidt hardness value, mean in-situ block size and point load index are more effective on rock fragmentation. Accordingly, from the controllable parameters, hole diameter, burden and spacing are the least effective on the fragmentation quality.

Sensitivity analysis of the input variables on fragmentation
11 Conclusions
In this paper, artificial neural network, support vector regression, decision tree and regression analysis were implemented to investigate the effect of uncontrollable and controllable parameters on fragmentation quality in blasting operation of open pit mines. For this study, a database was prepared from four mines situated in different parts of Iran. In the first step superiority of the different models was inspected from which competence of the neural network modeling was approved. The values of MAE, RMSE, VAF and R2 for ANN model were 0.007, 0.009, 98.612% and 0.986, respectively. In this regard, MRA modelling with the obtained values of 0.021, 0.026, 87.896% and 0.886 in the validation phase for MAE, RMSE, VAF and R2, respectively, displayed the poorest performance. According to outcomes of the application of the network modeling, as a whole, it was concluded that in fragmentation quality uncontrollable parameters are more influential as compared to controllable parameters. Rock quality designation, Schmidt hardness value, mean in-situ block size and point load index from the former group play a vital role in the fragmentation quality and from the latter one, hole diameter, burden and spacing are the least effective parameters in this regard.
References
Bui X-N, Nguyen H, Le H-A, Bui H-B, Do N-H (2020) Prediction of blast-induced air over-pressure in open-pit mine: assessment of different artificial intelligence techniques. Nat Resour Res 29(2):571–591
Monjezi M, Khoshalan HA, Varjani AY (2012) Prediction of flyrock and backbreak in open pit blasting operation: a neuro-genetic approach. Arab J Geosci 5(3):441–448
Görgülü K, Arpaz E, Demirci A, Koçaslan A, Dilmaç MK, Yüksek AG (2013) Investigation of blast-induced ground vibrations in the Tülü boron open pit mine. Bull Eng Geol Environ 72(3–4):555–564
Hajihassani M, Armaghani DJ, Marto A, Mohamad ET (2015) Ground vibration prediction in quarry blasting through an artificial neural network optimized by imperialist competitive algorithm. Bull Eng Geol Environ 74(3):873–886
Raina A, Murthy V, Soni A (2014) Flyrock in bench blasting: a comprehensive review. Bull Eng Geol Environ 73(4):1199–1209
Yan P, Zhou W, Lu W, Chen M, Zhou C (2016) Simulation of bench blasting considering fragmentation size distribution. Int J Impact Eng 90:132–145
Jang H, Kitahara I, Kawamura Y, Endo Y, Topal E, Degawa R, Mazara S (2020) Development of 3D rock fragmentation measurement system using photogrammetry. Int J Min Reclam Environ 34(4):294–305
Armaghani DJ, Hajihassani M, Mohamad ET, Marto A, Noorani S (2014) Blasting-induced flyrock and ground vibration prediction through an expert artificial neural network based on particle swarm optimization. Arab J Geosci 7(12):5383–5396
Khandelwal M, Singh T (2006) Prediction of blast induced ground vibrations and frequency in opencast mine: a neural network approach. J Sound Vib 289(4–5):711–725
Liu R, Zhu Z, Li Y, Liu B, Wan D, Li M (2020) Study of rock dynamic fracture toughness and crack propagation parameters of four brittle materials under blasting. Eng Fract Mech 225:106460
Michaux S, Djordjevic N (2005) Influence of explosive energy on the strength of the rock fragments and SAG mill throughput. Miner Eng 18(4):439–448
Monjezi M, Rezaei M, Varjani AY (2009) Prediction of rock fragmentation due to blasting in Gol-E-Gohar iron mine using fuzzy logic. Int J Rock Mech Min Sci 46(8):1273–1280
Mehrdanesh A, Monjezi M, Sayadi AR (2018) Evaluation of effect of rock mass properties on fragmentation using robust techniques. Eng Comput 34(2):253–260
Thornton D, Kanchibotla S, Brunton I (2002) Modelling the impact of rockmass and blast design variation on blast fragmentation. Fragblast 6(2):169–188
Zhu Z, Mohanty B, Xie H (2007) Numerical investigation of blasting-induced crack initiation and propagation in rocks. Int J Rock Mech Min Sci 44(3):412–424
Sayadi A, Monjezi M, Talebi N, Khandelwal M (2013) A comparative study on the application of various artificial neural networks to simultaneous prediction of rock fragmentation and backbreak. J Rock Mech Geotech Eng 5(4):318–324
Parisi GI, Kemker R, Part JL, Kanan C, Wermter S (2019) Continual lifelong learning with neural networks: a review. Neural Netw 113:54–71
Atici U (2011) Prediction of the strength of mineral admixture concrete using multivariable regression analysis and an artificial neural network. Expert Syst Appl 38(8):9609–9618
Mohamad ET, Armaghani DJ, Momeni E, Abad SVANK (2015) Prediction of the unconfined compressive strength of soft rocks: a PSO-based ANN approach. Bull Eng Geol Environ 74(3):745–757
Mohamad ET, Hajihassani M, Armaghani DJ, Marto A (2012) Simulation of blasting-induced air overpressure by means of artificial neural networks. Int Rev Model Simul 5:2501–2506
Armaghani DJ, Hajihassani M, Bejarbaneh BY, Marto A, Mohamad ET (2014) Indirect measure of shale shear strength parameters by means of rock index tests through an optimized artificial neural network. Measurement 55:487–498
Asl PF, Monjezi M, Hamidi JK, Armaghani DJ (2017) Optimization of flyrock and rock fragmentation in the Tajareh limestone mine using metaheuristics method of firefly algorithm. Eng Comput 34(2):241–251
Mojtahedi SFF, Ebtehaj I, Hasanipanah M, Bonakdari H, Amnieh HB (2019) Proposing a novel hybrid intelligent model for the simulation of particle size distribution resulting from blasting. Eng Comput 35(1):47–56
Hasanipanah M, Amnieh HB, Arab H, Zamzam MS (2018) Feasibility of PSO–ANFIS model to estimate rock fragmentation produced by mine blasting. Neural Comput Appl 30(4):1015–1024
Bahrami A, Monjezi M, Goshtasbi K, Ghazvinian A (2011) Prediction of rock fragmentation due to blasting using artificial neural network. Eng Comput 27(2):177–181
Karami A, Afiuni-Zadeh S (2013) Sizing of rock fragmentation modeling due to bench blasting using adaptive neuro-fuzzy inference system (ANFIS). Int J Min Sci Technol 23(6):809–813
Shams S, Monjezi M, Majd VJ, Armaghani DJ (2015) Application of fuzzy inference system for prediction of rock fragmentation induced by blasting. Arab J Geosci 8(12):10819–10832
Bakhtavar E, Khoshrou H, Badroddin M (2015) Using dimensional-regression analysis to predict the mean particle size of fragmentation by blasting at the Sungun copper mine. Arab J Geosci 8(4):2111–2120
Ebrahimi E, Monjezi M, Khalesi MR, Armaghani DJ (2016) Prediction and optimization of back-break and rock fragmentation using an artificial neural network and a bee colony algorithm. Bull Eng Geol Environ 75(1):27–36
Trivedi R, Singh T, Raina A (2016) Simultaneous prediction of blast-induced flyrock and fragmentation in opencast limestone mines using back propagation neural network. Int J Min Miner Eng 7(3):237–252
Singh P, Roy M, Paswan R, Sarim M, Kumar S, Jha RR (2016) Rock fragmentation control in opencast blasting. J Rock Mech Geotech Eng 8(2):225–237
Hasanipanah M, Armaghani DJ, Monjezi M, Shams S (2016) Risk assessment and prediction of rock fragmentation produced by blasting operation: a rock engineering system. Environ Earth Sci 75(9):808
Prasad S, Choudhary B, Mishra A (2017) Effect of stemming to burden ratio and powder factor on blast induced rock fragmentation—a case study. In: IOP conference series: materials science and engineering, 2017. vol 1. IOP Publishing, p 012191
Asl PF, Monjezi M, Hamidi JK, Armaghani DJ (2018) Optimization of flyrock and rock fragmentation in the Tajareh limestone mine using metaheuristics method of firefly algorithm. Eng Comput 34(2):241–251
Murlidhar BR, Armaghani DJ, Mohamad ET, Changthan S (2018) Rock fragmentation prediction through a new hybrid model based on imperial competitive algorithm and neural network. Smart Constr Res 2(3):1–12
Hassoun MH (1995) Fundamentals of artificial neural networks. MIT Press, Cambridge
Beale HD, Demuth HB, Hagan M (1996) Neural network design. Pws, Boston
Russell S, Norvig P (2002) Artificial intelligence: a modern approach
Aggarwal CC (2018) Neural networks and deep learning, vol 10. Springer, Berlin, pp 973–978
Nielsen MA (2015) Neural networks and deep learning, vol 2018. Determination Press, San Francisco
Zurada JM (1992) Introduction to artificial neural systems. West Publishing Company, St. Paul
Gardner MW, Dorling S (1998) Artificial neural networks (the multilayer perceptron)—a review of applications in the atmospheric sciences. Atmos Environ 32(14–15):2627–2636
Pal SK, Mitra S (1992) Multilayer perceptron, fuzzy sets, classification In: IEEE Transactions on Neural Networks, vol 3, issue no 5, pp 683–697. https://doi.org/10.1109/72.159058
Lukoševičius M, Jaeger H (2009) Reservoir computing approaches to recurrent neural network training. Comput Sci Rev 3(3):127–149
Rezaeineshat A, Monjezi M, Mehrdanesh A, Khandelwal M (2020) Optimization of blasting design in open pit limestone mines with the aim of reducing ground vibration using robust techniques. Geomech Geophys Geo-Energy Geo-Resour 6(40). https://doi.org/10.1007/s40948-020-00164-y
Chai T, Draxler RR (2014) Root mean square error (RMSE) or mean absolute error (MAE)? Arguments against avoiding RMSE in the literature. Geosci Model Dev 7(3):1247–1250
Mukaka MM (2012) A guide to appropriate use of correlation coefficient in medical research. Malawi Med J 24(3):69–71
Li D, Moghaddam MR, Monjezi M, Jahed Armaghani D, Mehrdanesh A (2020) Development of a group method of data handling technique to forecast iron ore price. Appl Sci 10(7):2364
Bayat P, Monjezi M, Rezakhah M, Armaghani DJ (2020) Artificial neural network and firefly algorithm for estimation and minimization of ground vibration induced by blasting in a mine. Nat Resour Res. https://doi.org/10.1007/s11053-020-09697-1
Bayat P, Monjezi M, Mehrdanesh A, Khandelwal M (2021) Blasting pattern optimization using gene expression programming and grasshopper optimization algorithm to minimise blast-induced ground vibrations. Eng Comput. https://doi.org/10.1007/s00366-021-01336-4
Jayalakshmi T, Santhakumaran A (2011) Statistical normalization and back propagation for classification. Int J Comput Theory Eng 3(1):1793–8201
Monjezi M, Mehrdanesh A, Malek A, Khandelwal M (2013) Evaluation of effect of blast design parameters on flyrock using artificial neural networks. Neural Comput Appl 23(2):349–356
Montgomery DC, Peck EA, Vining GG (2012) Introduction to linear regression analysis, vol 821. Wiley, New York
Weisberg S (2005) Applied linear regression, vol 528. Wiley, New York
Kalton G (2020) Introduction to survey sampling, vol 35. SAGE Publications, Incorporated, New York
Sarumathi S, Shanthi N, Vidhya S, Ranjetha P (2015) STATISTICA software: a state of the art review. Int J Comput Inf Eng 9(2):473–480
Hilbe JM (2007) STATISTICA 7: an overview. Am Stat 61(1):91–94
Shulaeva EA, Ivanov AN, Uspenskaya NN (2018) Development of artificial neural networks to simulate the process of dichloroethane dehydration in the Statistica Software Program. In: 2018 XIV international scientific-technical conference on actual problems of electronics instrument engineering (APEIE), 2018. IEEE, pp 280–282
Utgoff PE, Berkman NC, Clouse JA (1997) Decision tree induction based on efficient tree restructuring. Mach Learn 29(1):5–44
Newendorp PD (1976) Decision analysis for petroleum exploration: petroleum Publ. Co., Tulsa, Oklahoma, p 668
Molnar C (2018) Interpretable machine learning: a guide for making black box models explainable
Timofeev R (2004) Classification and regression trees (CART) theory and applications. Humboldt University, Berlin, pp 1–40
Fonarow GC, Adams KF, Abraham WT, Yancy CW, Boscardin WJ, Committee ASA (2005) Risk stratification for in-hospital mortality in acutely decompensated heart failure: classification and regression tree analysis. JAMA 293(5):572–580
Kiers HA, Rasson J-P, Groenen PJ, Schader M (2012) Data analysis, classification, and related methods. Springer Science & Business Media, Berlin
Safavian SR, Landgrebe D (1991) A survey of decision tree classifier methodology. IEEE Trans Syst Man Cybern 21(3):660–674
Beniwal S, Arora J (2012) Classification and feature selection techniques in data mining. Int J Eng Res Technol (IJERT) 1(6):1–6
Stasis AC, Loukis E, Pavlopoulos S, Koutsouris D (2003) Using decision tree algorithms as a basis for a heart sound diagnosis decision support system. In: 4th international IEEE EMBS special topic conference on information technology applications in biomedicine, 2003. IEEE, pp 354–357
Prasad AM, Iverson LR, Liaw A (2006) Newer classification and regression tree techniques: bagging and random forests for ecological prediction. Ecosystems 9(2):181–199
Cristianini N, Shawe-Taylor J (2000) An introduction to support vector machines and other kernel-based learning methods. Cambridge University Press, Cambridge
Gunn SR (1998) Support vector machines for classification and regression. ISIS Tech Rep 14(1):5–16
Boswell D (2002) Introduction to support vector machines. Department of Computer Science and Engineering University of California San Diego, San Diego
Drucker H, Burges CJ, Kaufman L, Smola AJ, Vapnik V (1997) Support vector regression machines. In: Advances in neural information processing systems, pp 155–161
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20:273–297. https://doi.org/10.1007/BF00994018
Vapnik V, Golowich SE, Smola AJ (1997) Support vector method for function approximation, regression estimation and signal processing. In: Advances in neural information processing systems, pp 281–287
Ma J, Theiler J, Perkins S (2003) Accurate on-line support vector regression. Neural Comput 15(11):2683–2703
Awad M, Khanna R (2015) Support vector regression. In: Efficient learning machines. Springer, pp 67–80
Smola AJ, Schölkopf B (2004) A tutorial on support vector regression. Stat Comput 14(3):199–222
Chen G, Fu K, Liang Z, Sema T, Li C, Tontiwachwuthikul P, Idem R (2014) The genetic algorithm based back propagation neural network for MMP prediction in CO2-EOR process. Fuel 126:202–212
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Mehrdanesh, A., Monjezi, M., Khandelwal, M. et al. Application of various robust techniques to study and evaluate the role of effective parameters on rock fragmentation. Engineering with Computers 39, 1317–1327 (2023). https://doi.org/10.1007/s00366-021-01522-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-021-01522-4