
Abstract
This study proposes a new parallel local search algorithm (Par-LS) for solving the maximum vertex weight clique problem (MVWCP) in large graphs. Solving the MVWCP in a large graph with millions of edges and vertices is an intractable problem. Parallel local search methods are powerful tools to deal with such problems with their high-performance computation capability. The Par-LS algorithm is developed on a distributed memory environment by using message passing interface libraries and employs a different exploration strategy at each processor. The Par-LS introduces new operators parallel(\(\omega \),1)-swap and parallel(1,2)-swap, for searching the neighboring solutions while improving the current solution through iterations. During our experiments, 172 of 173 benchmark problem instances from the DIMACS, BHOSLIB and Network Data Repository graph libraries are solved optimally with respect to the best/optimal reported results. A new best solution for the largest problem instance of the BHOSLIB benchmark (frb100-40) is discovered. The Par-LS algorithm is reported as one of the best performing algorithms in the literature for the solution of the MVWCP in large graphs.
Similar content being viewed by others


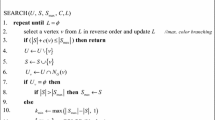
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The maximum vertex weight clique problem (MVWCP) is a general form of the maximum clique problem (MCP) (Wu and Hao 2016; Zhou et al. 2017a). The MVWCP decides a clique with the maximum total value of vertices’ weight. When each vertex of a graph has weight 1, then MVWCP becomes the classical MCP (Wu and Hao 2015b; Wu et al. 2012). The MCP is NP-complete, and MVWCP is at least as hard as MCP (Alidaee et al. 2007; Dijkhuizen and Faigle 1993). Given an undirected graph G = (V, E) with vertex set of V = {1,..., n} and edge set of \( E \subseteq V \times V\). Let \(w : V \rightarrow Z^+ \) be a weighting function that assigns each vertex \(v \in V\) a positive value. The MVWCP has many applications in different areas such as computer vision (Ma and Latecki 2012), coding theory (Zhian et al. 2013), bioinformatics (Zheng et al. 2007), protein structure prediction (Mascia et al. 2010), community (cluster) detection (Tepper and Sapiro 2013), combinatorial auctions (Wu and Hao 2015a; Li et al. 2018).
Exact (brute-force) algorithms that are proposed for solving the MVWCP require too much time and computation power due to the intractable nature of this problem. Therefore, local search techniques and heuristics are more feasible approaches for large and dense graph instances, because they can obtain high-quality solutions in practical times. Here, we can list some of the most important algorithms that are proposed for the solution of the MC and MVWCP. Kumlander (2004) proposes a backtrack tree search algorithm that relies on a heuristic coloring-based vertex order. The algorithm is a brute-force algorithm that is based on a fact that vertices from the same independent set could not be included in the same maximum clique. Those sets are obtained from a heuristic vertex coloring. Color classes and a backtrack search are used for pruning branches of the maximum weight clique search tree. Warren and Hicks (2006) propose three B&B algorithms for the maximum weight independent set problem. The algorithms use weighted clique covers to generate upper bounds, and all perform branching and using according to the method of Balas and Yu (1986). Pullan and Hoos (2006) propose a new stochastic local search algorithm (DLS-MC) for the maximum clique problem. The DLS-MC algorithm alternates between phases of iterative improvement, during which suitable vertices are added to the current clique, and plateau search, during which vertices of the current clique are swapped with vertices not contained in the current clique. Wu et al. (2012) introduce a tabu search heuristic whose key features include a combined neighborhood and a dedicated tabu mechanism using a randomized restart strategy for diversification. Benlic and Hao (2013) present breakout local search (BLS) algorithm. The BLS can be applied to both MC and MVWCP problems without any particular adaptation. BLS explores the search space by joint use of local search and adaptive perturbation strategies. Wang et al. (2016a) recast the MVWCP into a model that is solved by a probabilistic tabu search algorithm designed for binary quadratic programming (BQP). El Baz et al. (2016) propose a parallel ant colony optimization-based meta-heuristic (PACOM) for solving MVWCP. Zhou et al. (2017b) introduce a move operator called PUSH that generalizes the conventional add and swap operators commonly used and can be employed in a local search process for the MVWCP. Nogueira et al. (2017) introduce a hybrid iterated local search technique for the maximum weight independent set (MWIS) problem, which is related to MVWCP. Nogueira and Pinheiro (2018) present a CPU–GPU local search heuristic for solving the MWCP in massive graphs. The neighborhoods are explored using an efficient procedure that is suitable to be mapped onto a GPU-based massively parallel architecture. The algorithm outperforms the best-known heuristics for the MWCP with its speed-up of up to 12 times over the CPU-only implementation. Kiziloz and Dokeroglu (2018) propose a robust and cooperative parallel tabu search algorithm (PTC) for the MVWCP.
Cai et al. (2016) propose a new method that interleaves between clique construction and graph reduction. They propose three novel approaches and design FastWClq algorithm. Wang et al. (2016b) introduce two heuristics and propose two local search algorithms for the MWCP, strong configuration checking (SCC), and develop a local search algorithm named LSCC. In order to improve the performance, a low-complexity heuristic best from multiple selection (BMS) is applied to select the swapping vertex pair quickly and effectively (LSCC+BMS algorithm). The proposed algorithms outperform the state-of-the-art local search algorithm MN/TS and its improved version MN/TS+BMS.
An exact algorithm, branch and bound (B&B) for the MVWCP (WLMC), is suited for large vertex-weighted graphs by Jiang et al. (2017). A new B&B algorithm (TSM-MWC) for the MVWCP is proposed by Jiang et al. (2018). The proposed algorithm is an exact algorithm and uses MaxSAT reasoning to reduce the search space. Another B&B MWCP algorithm (WC-MWC) that reduces the number of branches of the search space incrementally is proposed by Li et al. (2018). Experimental results show that the algorithm WC-MWC outperforms some of the best-performing exact and heuristic MWCP algorithms on both small/medium graphs and real-world massive graphs.
Parallel local search algorithms have been reported to be effective tools for the optimization of NP-hard problems for the last few decades (Kiziloz and Dokeroglu 2018; Cantú-Paz 1998; Dokeroglu 2015; Dokeroglu and Mengusoglu 2017; Kucukyilmaz and Kiziloz 2018). In our opinion, a scalable parallel heuristic algorithm with intelligent and cooperative operators can improve the solution quality of an optimization process significantly. Our study proposes a novel parallel local search algorithm (Par-LS) for the solution of the MVWCP in large graphs. The Par-LS algorithm is specially developed for very large in-memory graphs with millions of edges and vertices. Exploring and exploiting the search space of large graphs requires a great deal of computation power. The search space is intractable, and exact (brute-force) algorithms are not efficient enough to solve the MVWCP in feasible execution times. The Par-LS algorithm introduces a new parallel local search technique with new operators parallel(\(\omega \),1)-swap and parallel(1,2)-swap for searching neighboring solutions. The operators are adapted to parallel computation to diversify the exploration by selecting different vertices during the addition and deletion of the vertices. These operators are used in parallel for the first time in the literature (Lourenço et al. 2010; Hansen et al. 2010). The local search Par-LS algorithm uses some algorithmic parameters as it is required by most of the meta-heuristic algorithms. As we experience from our previous studies, tuning the parameters of a heuristic algorithm increases the performance of a local search algorithm significantly. Therefore, we develop and employ a simple and efficient parameter-setting technique for the optimization process of the Par-LS. At each processor, we use a different set of parameters for the Par-LS algorithm. The parameters are randomly selected from a range of values.

Parallel (\(\omega \),1)-swap operator is concurrently operating with several processors on different solution candidates that are different than one another. Processor 1 inserts vertex d into the current solution and removes vertices a, b, and c. Processor n inserts vertex c into the current solution while vertices a and b are being removed
The Par-LS is an enhanced parallel version of a recent algorithm called a hybrid iterated local search (ILS-VND) that is proposed for the maximum weight independent set problem (Nogueira et al. 2017). We adapt this algorithm to the MVWCP by evolving its operators to the parallel environment, introducing a new parallel parameter tuning technique and a seeding mechanism for each processor that provides a diversified searching capability. 173 problem instances are optimized from the DIMACS, BHOSLIB and Network Data Repository graph libraries. 172 problems are solved optimally with respect to the optimal/best-known solutions of the problem instances. A new best solution for the largest problem instance of the BHOSLIB benchmark (frb100-40) is discovered. The evaluation of the experiments shows that the Par-LS algorithm can outperform most of the state-of-the-art heuristic algorithms and can be reported as one of the best algorithms.
The Par-LS algorithm is introduced in Sect. 2. Section 3 gives the details for the performance evaluation of the experimental results and comparison of the algorithm to the state-of-the-art algorithms on selected set of large graphs. Concluding remarks and future work are provided in the last section.
2 Proposed parallel local search algorithm, Par-LS
In this section, we present our proposed Par-LS algorithm for the MVWCP. Par-LS is an enhanced parallel version of the ILS-VND algorithm introduced by Nogueira et al. (2017). The Par-LS is developed by using C++ and Message Passing Interface (MPI) library. A seeding function is used to diversify random number generation at each node while initializing a starting point. A star communication topology is used between processors. The master node/processor controls the slaves and receives their best solutions at the end of the optimization process.
Parallel (\(\omega \),1)-swap operator adds a new vertex, v, to the existing solution and deletes vertices that are neighbors of the v. This is the newer parallel version of the operators introduced by Nogueira et al. (2017). The total weight of the new generated clique is calculated, and if its vertex weight is better than the existing one, it replaces the older clique. With its distributed nature and a seeding function that makes use of the ranks of the processors in the environment, parallel (\(\omega \),1)-swap operator generates and searches the new cliques efficiently by selecting diversified vertices at each processor. In Fig. 1, we can see how the parallel (\(\omega \),1)-swap operator works on the current solutions at different processors concurrently. If there are n number of processors in the computation environment, randomly selected vertices are inserted to the current solution and its neighbors inside the clique are removed. The parallel (\(\omega \),1)-swap operator provides a diversified exploration search space and it is a very efficient way of optimizing the maximum vertex weight clique.

parallel(1,2)-swap operator is concurrently operating with several processors. Processor 1 inserts the vertices a and b into the current solution and removes the vertices c. Processor n inserts vertices a and b into the current solution while vertex c is being removed

Flowchart of the Par-LS algorithm
Parallel (1,2)-swap operator deletes one vertex and adds two vertices to the current solution. Depending on the rank number of the processors, the selection of the vertices for insertion and deletion is executed from well-diversified locations. Therefore, our new enhanced operators, parallel (\(\omega \),1)-swap and parallel (1,2)-swap operators are very efficient while exploring the search space of large graphs. In Fig. 2, we can follow how the parallel(1,2)-swap operator works on different candidate solutions concurrently. The parallel(1,2)-swap selects two vertices from outside of the current solution.
Generate_a_random_Clique function selects a random vertex number and continues adding new vertices to construct an initial maximum vertex weight clique. This procedure is repeated until there is no examined vertex left. The perturbation function changes the current clique by adding new vertices and removing older ones randomly depending on the seeding mechanism of the processor. Local Search function uses our two new distributed operators parallel (\(\omega \),1)-swap and parallel (1,2)-swap during the optimization. The selection of the new vertices continues until the new vertex fails to improve the quality of the solution.
Acceptance function monitors the exploration and intensification processes during the optimization. If a new clique is better, it is always accepted. Parameters (\(p_1, p_2, p_3, p_4\)) are used as search exploration and intensification parameters in the Par-LS algorithm. \(p_1\) is for shrinking the non-solution vertices set where uniformly chosen non-solution vertices into the current solution. The smaller the size is, the shorter the search time will be. \(p_2\) is for limiting the search space whenever a local maximum is met. This will decrease the search time. \(p_3\) is similar to \(p_2\). When a global maximum is reached, the counter is adjusted for less exploring the search space. \(p_4\) is similar to \(p_1\) which commonly takes the values between 1 and 4. It again forces and squeezes the search space for spending less exploration time. The flowchart of the algorithm is presented in Fig. 3. Algorithms 1, 2, and 3 give the details of the Par-LS Algorithm.
Parameter tuning technique of the Par-LS algorithm The performance of the local search algorithms mostly depends on selecting the best algorithmic specific parameters. Deciding the algorithmic parameters is a crucial process for good performance. In order to provide (near-)optimal settings for the Par-LS algorithm, we apply a simple mechanism that generates different sets of parameters at each processor. The Par-LS algorithm uses these four parameters during the optimization, and each parameter set is selected as a different set at each processor. The parameters are randomly decided within a range of values. This technique provides an efficient way to optimize with different set of values. In addition to this, the structure of the optimization problems is varied. Therefore, an optimized set of parameters may not be a good preference for all the problem instances (Pullan 2008).



3 Performance evaluation of the experimental results
We give details of our high-performance computation environment, problem instances, solution quality, execution time, speed-up, and scalability evaluations of the Par-LS algorithm. We discuss the Par-LS algorithm and compare its performance with state-of-the-art MVWCP algorithms for DIMACS,Footnote 1 BHOSLIB,Footnote 2 and selected large graphs from Network Data Repository.Footnote 3

The effect of increasing the number of iterations on MANN-a45 problem instance
3.1 Experimental setup and problem instances
Our experiments are performed on a high-performance cluster (HPC) computer, HP ProLiant DL585 G7, that has AMD Opteron 6212 CPU running at 2.6 GHz and having 8 cores. CPU has 64-bit computing capacity and AMD SR5690 chipset. The server uses 128 GB PC3-10600 RAM and 1.5 TB hard disk. The software comprises: a Scientific Linux v4.5 64-bit operating system, Open MPI v1.2.4, and C++. We have performed our experiments with 64 processors. We carry out our experiments with large graphs that fit in our main memory and do not use virtual memory. Because using virtual memory has a dramatic negative effect on the performance of the optimization process, we observe that it may cause thousands of times longer execution time due to the paging process of virtual memory. The selected large graph instances are run 10 times, and their best/average results and execution times are reported. The time to read the problem instance from the disk is not included in the execution time of the Par-LS algorithm.
The Par-LS algorithm is tested on 173 graphs from DIMACS benchmark (80 problem instances), the BHOSLIB benchmark (40 instances) and the Network Data Repository (53 instances). All the benchmark instances are originally unweighted. In order to provide the standard weighted instances, we use the literature and give each vertex i a weight given by (imod 200) + 1 (Pullan 2008). In Table 4, we give the details of the large graphs that are used in our experiments. The number of nodes, number of vertices, the density of the graph, the best and average results discovered by the Par-LS algorithm, execution time, and the number of processors used during the optimization are presented in the Table. At first, we try to solve the problem instances with five processors. These are the easier problem instances like bio-dmela, bio-yeast, and ca-AstroPh. At the next step, we apply 64 processors for harder problem instances that need more computation power. hamming10-4, p-hat1000-2, and san1000 are the examples of harder large graphs in the problem set.
3.2 The effect of iterations and increasing the number of processors
In Fig. 4, we give the effect of the iterations for the Par-LS algorithm. The experiments are run with the MANN-a45 problem instance from BHOSLIB benchmark library. The figure presents the obtained results with increasing number of iterations. Increasing the number of iterations has a positive effect on the optimization process of the Par-LS algorithm. 1,800,000 iterations are used during the optimization process of all problem instances. Most of the time, the Par-LS algorithm was able to obtain the optimal/best results at earlier iterations. The reported execution time of the Par-LS algorithm is the average execution time of the ten runs that the optimal/best results are discovered. The improvement of the optimization is observed to be 0.6% in the average when the number of iterations is increased from 1 to 100,000. Although there is an improvement in the quality of the solutions, the robustness of the Par- LS algorithm is also affected significantly, which means that larger number of iterations can guarantee the same results with less deviation than lower number of iterations.
We analyze the effect of increasing the number of processors for the Par-LS algorithm. Table 1 gives the effect of increasing the number of processors for the MANN-a45 problem instance. The number of processors is 1 with the initial tests, and we double this value by two with every new experiment up to 128 processors. The positive effect of the increasing number of processors is observed during the experiments. 0.4% improvement is obtained. It can be seen that optimizations performed with larger number of processors are less prone to stagnation. As the number of processors is increased, better results are observed at earlier phases of the optimization.
3.3 Experiments with DIMACS-W and BHLOBS-W benchmark instances
In this part of our experiments, we carry out some experiments with the well-known problem instances from the graph libraries DIMACS-W and BHLOBS-W. Although most of the problem instances of these benchmarks are not large graphs, obtaining the performance results of the PAR-LS algorithm will give valuable evaluations about the robustness, scalability, and speed-up performance of the algorithm. The size of the maximum vertex weight clique size, execution time of the algorithm, and obtained best results are reported for the problem instances. At the last column of Tables 2 and 3, we report the number of the processors that we use during the optimization process. For easier problem instances, we try to minimize the number of processors while we are using 64 processors for harder problems.
During the experiments performed with DIMACS-W problem instances, all the problem instances are observed to be solved optimally with respect to the reported optimal/best results. The average execution time of the algorithm is 79.4 s. These results outperform those of state-of-the-art algorithms in the literature. Except the frb50-23-4 problem instance (the optimal result is reported to be 5454, we discover 5453) from BHOSLIB library, all the problems are solved optimally by finding the best/optimal results. For the problem instance frb53-24-3, the BHLOBS-W library reports 5640 as the optimal solution. We obtain 5665 value for the same problem instance during our experiments, which has been only reported by ILS-VND algorithm so far. The average execution time of the algorithm is reported to be 20.4 s for the problems in BHLOBS-W library. It is interesting that we discover some maximum vertex size clique sizes that are smaller than the maximum clique of the optimized graph. It shows that the size of the maximum vertex weight clique can be smaller than maximum clique in the graph but the weight of the vertices can be larger. Although ILS-VND algorithm obtains most of the optimal/best results reported in the benchmark libraries, Par-LS is better in the average results and also there are new best results that have been reported by the Par-LS algorithm.
We compare our results with state-of-the-art heuristic algorithms in the literature for the DIMACS-W and BHLOBS-W problem instances: phased local search (PLS) (Pullan 2008), multi-neighborhood tabu search (MN/TS) (Wu et al. 2012), breakout local search (BLS) (Benlic and Hao 2013), ReTS-I (Zhou et al. 2017b), iterated local search variable neighborhood descent (ILS-VND) (Nogueira et al. 2017), and BQP problem with the probabilistic tabu search algorithm (BQP-PTS) (Alidaee et al. 2007). For the other 119 instances, the Par-LS algorithm provides better or the same results that have been found by the other algorithms. Even for the hard problem instances, MANN-a45 and MANN-a81, the Par-LS performs better than the other algorithms. Detailed performance comparison of the Par-LS algorithm is presented in Table 8 for large graph problem instances.
3.4 Performance analysis of the Par-LS algorithm on large graphs
Experiments are carried out with 61 different large graph instances from DIMACS, BHOSLIB, and Network Data Repository. The number of vertices, edges and the density of the edges of the graphs is presented in Table 4. We report two weight results (the best and the average). The best results are the maximum values obtained during experiments. Average results are the mean of ten different executions. First, we try to solve the problem instances with five processors. If we cannot get good performance, then we increase our number of processors up to 64. Tables 5, 6, and 7 report the selected vertices of the maximum vertex weight cliques for some of the large graphs. A new best solution is reported for the largest graph instance of BHOSLIB benchmark (frb100-40). All of the other results are the best/optimal results that have been reported by researchers up to now. The average of the execution time is observed as 268.9 s. The simple parameter setting mechanism of the Par-LS algorithm is observed to provide better results. We carried out a set of experiments on the MANN-a81 problem instance. It was possible to obtain the maximum vertex weight value as 111,400 when we use different parameters for each processor. With 10 different runs, it was not possible to get the value, 111,400, when the simple parameter setting mechanism is not used.
3.5 Comparison with state-of-the-art algorithms
The Par-LS algorithm is compared with state-of-the-art large MVWCP algorithms for large graphs. LSCC (Wang et al. 2016b), MN/TS (Wang et al. 2016b), ReTS-I (Zhou et al. 2017b), and GPULS (CPU)-R (Nogueira and Pinheiro 2018) are the selected best performing recent algorithms. Table 8 gives the details of comparison with the algorithms. LSCC, MN/TS, ReTS-I and GPULS(CPU)-R obtain 57, 56, 57, and 57 of the optimal results, respectively, whereas the Par-LS algorithm is able to find 61 optimal results. When the average value results are considered, the Par-LS algorithm outperforms the other four algorithms. Although the Par-LS algorithm spends more time for some of the problem instances, its execution time can be considered as reasonable when compared with the others. Parallel ant colony optimization-based meta-heuristic (PACOM) for solving the MVWCP is a high-performance algorithm (El Baz et al. 2016). The Par-LS performs better than the PACOM algorithm with all the instances. WLMC is a recent exact B&B algorithm that is reported to be very efficient for large graphs (Jiang et al. 2017). With its limited (3600 s) optimization process, Par-LS finds the same or better results than this algorithm. WLMC reports 111,139 for the MANN-a81 instance, whereas the Par-LS reports 111,400.
In order to evaluate the performance of our algorithm, the available results of experiments for FastWClq (Cai and Lin 2016) and LSCC+BMS (Wang et al. 2016b) are added to Table 8. The execution time of the FastWClq is fast. It finds the solutions in a few seconds. Due to space limitation of the page, we are not able to give the details of each algorithm’s execution time. The cutoff times for FastWClq and LSCC+BMS are 100 s. Some of the problems cannot be solved optimally by these two algorithms, whereas Par-LS is capable of finding optimal/best results for 172 of 173 problem instances. The execution time of Par-LS is worse than these two algorithms.
TSM-MWC (Jiang et al. 2018) and WC-MWC (Li et al. 2018) are exact algorithms that we can compare Par-LS algorithm to. In a recent study by Li et al. (2018), comprehensive experimental results can be observed for these exact algorithm. WC-MWC algorithm has the highest performance on DIMACS and BHOSLIB problem instances. The Par-LS algorithm again has the longest execution times (but still reasonable when compared with brute-force approaches) when compared with these algorithms. However, the performance of the Par-LS is higher than the other algorithms while finding optimal/best solutions.
3.6 Speed-up and scalability performance
Since the Par-LS algorithm is a kind of island parallel heuristic algorithm, it does not spend much time due to the dependent jobs that will be sent by the other processors. The speed-up of an algorithm is described as the ratio of the sequential execution of the algorithm for solving a problem to the time obtained by the parallel algorithm. The Par-LS algorithm provides nearly a linear speed-up. This is one of the best properties of this algorithm. For each processor, a different local search algorithm with different parameter settings and with a different clique selection is processed. With the increasing number of processors, the delay of the parallel algorithm is observed to be very small. Therefore, we can evaluate the Par-LS algorithm as a scalable parallel algorithm with an almost linear speed-up performance. Stagnation is a critical drawback of local search algorithms. A scalable and diversified parallel algorithm that performs a (near)-linear speed-up can provide good performance while dealing with the stagnation problem.
4 Conclusions and future work
In this study, we introduce a novel parallel local search algorithm for the solution of the MVWCP in large graphs. Single-processor computers have reached to their computation limitations due to the technological restrictions and power wall problem. Therefore, we believe that large NP-Hard problem instances will be solved better with parallel computation tools. Our experiments prove that we have obtained significantly improved results. We report a new best result for the largest problem instance of the BHOSLIB benchmark and better average maximum values for large graph instances. Absolutely, intelligent operators are still important means of optimization algorithms. We introduce new operators parallel(\(\omega \),1)-swap and parallel(1,2)-swap by using parallel computation techniques. The Par-LS algorithm is observed to be a scalable algorithm during the experiments. This means that increasing the number of processors will positively influence the optimization quality of the Par-LS algorithm. Stagnation is a common problem of the optimization algorithms. Parallel computation that starts each optimization process from a different starting point (vertex) and works with diversified vertices can be considered as a mechanism to prevent stagnation of local search optimization techniques. As future work, the performance of the Par-LS can be improved by using CUDA programming. Hyper-heuristics that make use of several heuristic approaches is a hot topic and it can also be applied to the MVWCP.
References
Alidaee B, Glover F, Kochenberger G, Wang H (2007) Solving the maximum edge weight clique problem via unconstrained quadratic programming. Eur J Oper Res 181:592–597
Balas E, Yu CS (1986) Finding a maximum clique in an arbitrary graph. SIAM J Comput 15:1054–1068
Benlic U, Hao J-K (2013) Breakout local search for maximum clique problems. Comput Oper Res 40:192–206
Cai S, Lin J (2016) Fast solving maximum weight clique problem in massive graphs. In: IJCAI, pp 568–574
Cantú-Paz E (1998) A survey of parallel genetic algorithms. Calculateurs paralleles, reseaux et systems repartis 10:141–171
Dijkhuizen G, Faigle U (1993) A cutting-plane approach to the edge-weighted maximal clique problem. Eur J Oper Res 69:121–130
Dokeroglu T (2015) Hybrid teaching-learning-based optimization algorithms for the quadratic assignment problem. Comput Ind Eng 85:86–101
Dokeroglu T, Mengusoglu E (2017) A self-adaptive and stagnation-aware breakout local search algorithm on the grid for the steiner tree problem with revenue, budget and hop constraints. Soft Comput 22:1–19
Dokeroglu T, Sevinc E, Cosar A (2019) Artificial bee colony optimization for the quadratic assignment problem. Appl Soft Comput 76:595–606
El Baz D, Hifi M, Wu L, Shi X (2016) A parallel ant colony optimization for the maximum-weight clique problem. In: IEEE international parallel and distributed processing symposium workshops, 2016, IEEE, pp 796–800
Hansen P, Mladenović N, Brimberg J, Pérez JAM (2010) Variable neighborhood search. In: Gendreau M, Potvin JY (eds) Handbook of metaheuristics. Springer, Berlin, pp 61–86
Jiang H, Li C-M, Manya F (2017) An exact algorithm for the maximum weight clique problem in large graphs. In: AAAI, pp 830–838
Jiang H, Li C-M, Liu Y, Manya F (2018) A two-stage maxsat reasoning approach for the maximum weight clique problem. In: AAAI
Kiziloz HE, Dokeroglu T (2018) A robust and cooperative parallel tabu search algorithm for the maximum vertex weight clique problem. Comput Ind Eng 118:54–66
Kucukyilmaz T, Kiziloz HE (2018) Cooperative parallel grouping genetic algorithm for the one-dimensional bin packing problem. Comput Ind Eng 125:157–170
Kumlander D (2004) A new exact algorithm for the maximum-weight clique problem based on a heuristic vertex-coloring and a backtrack search. In: Proceedings of 5th international conference on modelling, computation and optimization in information systems and management sciences, Citeseer, pp 202–208
Li C-M, Liu Y, Jiang H, Manyà F, Li Y (2018) A new upper bound for the maximum weight clique problem. Eur J Oper Res 270:66–77
Lourenço HR, Martin OC, Stützle T (2010) Iterated local search: framework and applications. In: Gendreau M, Potvin JY (eds) Handbook of metaheuristics. Springer, Berlin, pp 363–397
Ma T, Latecki L J (2012) Maximum weight cliques with mutex constraints for video object segmentation. In: IEEE Conference on computer vision and pattern recognition (CVPR), 2012 IEEE, pp 670–677
Mascia F, Cilia E, Brunato M, Passerini A (2010) Predicting structural and functional sites in proteins by searching for maximum-weight cliques. In: AAAI
Nogueira B, Pinheiro RG (2018) A CPU-GPU local search heuristic for the maximum weight clique problem on massive graphs. Comput Oper Res 90:232–248
Nogueira B, Pinheiro RG, Subramanian A (2017) A hybrid iterated local search heuristic for the maximum weight independent set problem. Optim Lett 12:1–17
Pullan W (2008) Approximating the maximum vertex/edge weighted clique using local search. J Heuristics 14:117–134
Pullan W, Hoos HH (2006) Dynamic local search for the maximum clique problem. J Artif Intell Res 25:159–185
Tepper M, Sapiro G (2013) Ants crawling to discover the community structure in networks. In: Iberoamerican congress on pattern recognition. Springer, Berlin, pp 552–559
Wang Y, Hao J-K, Glover F, Lü Z, Wu Q (2016a) Solving the maximum vertex weight clique problem via binary quadratic programming. J Comb Optim 32:531–549
Wang Y, Cai S, Yin M (2016b) Two efficient local search algorithms for maximum weight clique problem. In: AAAI, pp 805–811
Warren JS, Hicks IV (2006) Combinatorial branch-and-bound for the maximum weight independent set problem. Relatório Técnico, Texas A&M University, Citeseer 9:17
Wu Q, Hao J-K (2015a) Solving the winner determination problem via a weighted maximum clique heuristic. Exp Syst Appl 42:355–365
Wu Q, Hao J-K (2015b) A review on algorithms for maximum clique problems. Eur J Oper Res 242:693–709
Wu Q, Hao J-K (2016) A clique-based exact method for optimal winner determination in combinatorial auctions. Inf Sci 334:103–121
Wu Q, Hao J-K, Glover F (2012) Multi-neighborhood tabu search for the maximum weight clique problem. Ann Oper Res 196:611–634
Zheng C, Zhu Q, Sankoff D (2007) Removing noise and ambiguities from comparative maps in rearrangement analysis. IEEE/ACM Trans Comput Biol Bioinf 4:515–522
Zhian H, Sabaei M, Javan N T, Tavallaie O (2013) Increasing coding opportunities using maximum-weight clique. In: 5th computer science and electronic engineering conference (CEEC), 2013, IEEE, pp 168–173
Zhou Y, Hao J-K, Duval B (2017a) Opposition-based memetic search for the maximum diversity problem. IEEE Trans Evol Comput 21:731–745
Zhou Y, Hao J-K, Goëffon A (2017b) Push: a generalized operator for the maximum vertex weight clique problem. Eur J Oper Res 257:41–54
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Human and animals participants
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed consent
There is no individual participant included in the study.
Additional information
Communicated by V. Loia.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Sevinc, E., Dokeroglu, T. A novel parallel local search algorithm for the maximum vertex weight clique problem in large graphs. Soft Comput 24, 3551–3567 (2020). https://doi.org/10.1007/s00500-019-04122-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-019-04122-z