
Abstract
Reservoirs are the most important constructions for water resources management and flood control. Great concern has been paid to the effects of reservoir on downstream area and the differences between inflows and dam site floods due to the changes of upstream flow generation and concentration conditions after reservoir’s impoundment. These differences result in inconsistency between inflow quantiles and the reservoir design criteria derived by dam site flood series, which can be a potential risk and must be quantificationally evaluated. In this study, flood frequency analysis (FFA) and flood control risk analysis (FCRA) methods are used with the long reservoir inflow series derived from a multiple inputs and single output model and a copula-based inflow estimation model. The results of FFA and FCRA are compared and the influences on reservoir flood management are also discussed. The Three Gorges Reservoir (TGR) in China is selected as a case study. Results show that the differences between the TGR inflow and dam site floods are significant which result in changes on its flood control risk rates. The mean values of TGR’s annual maximum inflow peak discharge and 3 days flood volume have increased 5.58 and 3.85% than the dam site ones, while declined by 1.82 and 1.72% for the annual maximum 7 and 15 days flood volumes. The flood control risk rates of middle and small flood events are increased while extreme flood events are declined. It is shown that the TGR can satisfy the flood control task under current hydrologic regime and the results can offer references for better management of the TGR.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Flood is one of the most common and severest disasters in the world and also a major constraint to the social and economic actions (ICOLD 2006; Kussul et al. 2008; Uddin et al. 2013; Poussin et al. 2015; Gao et al. 2015; Kwon and Kang 2016). A large number of hydraulic projects have been built to control flood disasters, mitigate flood loss and protect lives and properties of people, of which the most significant ones are reservoirs. Reservoirs are widely regarded as one of the most efficient measures for integrated water resource management and development and usually have comprehensive benefits such as flood controlling, hydropower generation, water supplies for agricultural, industrial and municipal uses (Liu et al. 2013; Chen et al. 2016).
Nowadays, people have turned their attention from the benefits to the impacts of hydraulic projects as environmental protection is raised into the international agenda. Graf (2001) stated that the construction of reservoir will significantly change the natural hydrologic regime of the basin. Many other studies also show that reservoirs have major impacts on river hydrology through changes in the timing, magnitude, frequency of low and high flows, and result in hydrologic regime differing significantly from the natural flow regime (Magilligan and Nislow 2005; Graf 2006; Jung et al. 2015). With the construction of dams, part of upstream basin is submerged into water and the original riparian lands lose the ability for flood regulation, which will ultimately change the flood generation and concentration process of the upstream basin (Gregory 2006). Batalla et al. (2004) analyzed the impacts of dams on downstream hydrologic regime in the Ebro river basin, and found that the 2 and 10-day flood volumes both have reductions over 30%. Lajoie et al. (2007) studied the impacts of dams on a month time scale and revealed the flood magnitude, duration, frequency, skewness and kurtosis are all altered at different degrees. Lu et al. (2011) used linear regression method to compare the inflow and dam site flood series of Zhelin reservoir and found that the inflow peak discharge and daily mean discharge are larger than the dam site ones while the 3 days flood volumes show no obvious difference. However, the linear method is unable to describe the nonlinear characteristics of hydrologic events well. Duan et al. (2016) studied the impact of cascaded-reservoirs group on flow regime in the middle and lower reaches of the Yangtze River and predicted that the downstream regime will further alter in the future.
Considering the differences between inflow and dam site floods, Federal Emergency Management Agency (FEMA 2013) indicated that the inflow design flood is the flood hydrograph entering a reservoir, which should be used to design a specific dam and its appurtenant structures, especially spillway and outlet works capacity. Nevertheless, the available inflow flood series are usually very short in practice, commonly 30–80 years and even less for new built reservoirs. Hence in practical projects, dam site flood series are widely utilized to offer dominant references for the reservoirs’ design criteria since inflow flood series are unavailable before reservoir’s construction. The inconsistency between reservoir’s design criteria and the inflow flood features can be significant during flood season. Taking the Three Gorges Reservoir (TGR) as an example, the maximum observed flood peak discharge at Yichang station (the TGR’s dam site) is 70,600 m3/s since 1877, while two TGR inflow peak discharges (70,000 m3/s occurred on July 20, 2010 and 71,200 m3/s occurred on July 24, 2012) have been recorded after the TGR’s impoundment, which brought great concern and numerous queries about the TGR’s design criteria from the public. Therefore, it is very urgent and necessary to quantify the differences between the dam site and inflow floods, and further evaluate the design criteria derived from annual maximum flood series at dam site.
Flood frequency analysis (FFA) and flood control risk analysis (FCRA) methods are widely used in reservoir design and management. The FFA is a useful tool for describing flood features and a major hydrological method for design flood estimation (ICOLD 2003). The results of FFA are traditionally most evident in the design of major engineering structures such as dams, which are often represented by a series of quantiles (Bao et al. 1987; Tofiq and Guven 2014; Lázaro et al. 2016; Bezak et al. 2016). The FCRA is a method for quantifying the possible flood risk of hydraulic projects. Risk is often measured by both the probability of the event and the seriousness of the consequences (Plate 2002). As for the definition of flood control risk, there are different opinions such as the reservoir level above a critical level (e.g., the risk of dam overtopping or reaching the check flood level) and the reservoir release exceeds a critical discharge (Tung and Mays 1981). There have been many methods established for risk analysis in the field of hydrology and hydraulics, which can be generally classified into three categories: (1) Direct integration method (Jonkman et al. 2003; Hall et al. 2003); (2) Structural reliability analysis methods, including mean value first-order second-moment (MFOSM) method, advanced first-order second-moment (AFOSM) method and advanced checking-point (JC) method (Ganji and Jowkarshorijeh 2012; Chen et al. 2013; Goodarzi et al. 2014; Huang et al. 2014; Kim et al. 2015); (3) Sampling based methods, such as Monte Carlo simulation method and Latin hypercube sampling method (Kucherenko et al. 2015; Liu et al. 2011; Schiozer et al. 2015; Huang et al. 2016). Owing to the complexity of the inflow distribution, the model and parameter uncertainties, the Monte Carlo method are the most reliable method and benchmark for risk analysis (Turgeon 2005). With the computer performance improving faster and faster, the large computation burden of applying Monte Carlo method can be solved to a large degree.
Reservoir inflow flood series can be estimated and simulated by either hydrologic models or statistical methods. The underlying assumption of hydrologic models is that the model calibrated with the observed recordings are good enough for simulating flood hydrographs with precipitation series and the basin properties as input (Requena et al. 2016). Hydrologic models can be classified into two categories, lumped and distributed, resting with if the parameters are spatially distributed or not. Sherman (1932) proposed a unit hydrograph model to estimate runoffs with precipitation data. Wood et al. (1992) derived the variable infiltration capacity model by adding the soil layers of Xinanjiang model (Zhao 1992). Liang et al. (1992) used a multiple inputs and single output (MISO) model to simulate the runoffs at Yichang station, China. Garcia-Bartual (2002) developed artificial neural networks for short-term river flow forecasting. More recently, a lot of distributed physically-meaningful models have been developed with wider availability of distributed data products (Ewen et al. 2000; Kowen 2000; Liu and Todini 2002; Vivoni 2003; Guo et al. 2009; Cea and Rodriguez 2016). Another approach for flood series estimation is via statistical models. Since this method is purely mathematical, some argue that it makes little contribution for understanding the physical mechanism of hydrologic phenomena (Katz et al. 2002). However, previous researches show that this method is efficient and thus widely used in practice (Clarke 1979; Clarke 1980; Moog et al. 1999; Nelsen 1999; Wang 2001; Elsanabary and Gan 2015). The statistical method is usually applied to extend flood series by identifying its statistical relation with longer records of precipitation or hydrologic records of nearby stations. Clarke (1979) used two correlation models to extend annual stream flow records with precipitation data subject to heterogeneous errors. Hirsch (1982) compared four extending methods (regression, regression with noise and maintenance of variance extension type I and II) and found the second maintenance of variance extension (MOVE) method performed best and could overcome the shortage of underestimating variance. Moog et al. (1999) combined the MOVE method with Box–Cox transformation to improve accuracy in estimating order statistics of flow rate. Wang (2001) introduced a two-site joint probability approach for the transfer of flood information between two stations. By extending flood series, long flood series are obtained which can meet the data requirement of the FFA and FCRA methods with high return periods (Saad et al. 2015).
Recently, the copula theory introduced by Sklar (1959) provides a new approach for hydrologic data extension. Copula is a cluster of functions that connects multivariate probability distribution to their one-dimensional marginal distributions (Zhang and Singh 2006; Li et al. 2016). Since copula can overcome the shortcomings of traditional multivariate distributions, such as the assumption of a linear relation between the variables involved and that all the variables must have the same marginal distribution (Requena et al. 2016), it has been widely used in hydrologic multivariate analysis. Ganguli and Reddy (2013) assessed flood risks using trivariate copula on Delaware catchment, USA. Chen et al. (2015) used copula to simulate multisite monthly and daily streamflow and found the simulated series can preserve the spatial correlations among different stations. Chang et al. (2016) attempted to assess drought risk by using a copula-based method with an integer index in Weihe basin, China. Duan et al. (2016) applied bivariate FFA in the Huaihe basin and indicated that copula is a flexible and viable tool for quantifying the flood risks. As for flood series extension, Requena et al. (2016) delivered a method of combing a hydrologic model and a copula-based model, and results showed that their method can extend the flood series well.
Although researchers have well recognized the differences between inflow and dam site floods, its influence on flood risk management is seldom considered. In this study, we focus on identifying the differences between inflow and dam site flood series based on the FFA and FCRA methods. A multiple inputs and single output (MISO) model and a copula-based model are proposed to estimate and extend inflow flood series. The remainder of this paper is organized as follows. Section 2 gives a brief introduction of the TGR basin and presents the data used in this study. Section 3 shows the main methodologies. Section 4 gives results and discussions on the case study of the TGR. The final section displays the conclusions of this study.
2 Study area and data
2.1 The Three Gorges Reservoir
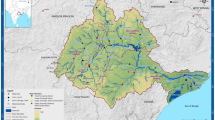
The Three Gorges Reservoir (TGR) is world-famous as the largest water conservancy project in the Yangtze River basin, which is a most social-economically developed area in China. The TGR is a multipurpose reservoir with several benefits such as flood control, hydropower generation, navigation improvement, ecology protection and etc. The TGR has a contributing area of about 1 million km2, while its intervening basin is only 5.6 × 104 km2 as shown in Fig. 1. The annual average discharge and runoff volume at the dam site are 14,300 m3/s and 4510 × 108 m3, respectively. The total storage capacity of the TGR is 393 × 108 m3, of which 221.5 × 108 m3 is flood control storage. The flood season of the TGR basin is June–October every year. The TGR started to impound water in 2003 and reached to the normal water level of 175 m in 2010 (MWR 2009; Li et al. 2014).

The TGR’s intervening basin
Yichang station is the control hydrologic station of upper Yangtze River basin and is 44 km below the TGR dam site. The records of Yichang station are regarded as flood series at dam site and used for designing the TGR project. Three typical flood hydrographs (1954, 1981 and 1982) at dam site were amplified to obtain design flood hydrographs and then transformed into inflow floods by inverse Muskingum routing method to offer reference for deciding the construction criteria (Xu et al. 2016).
2.2 Data set
The inflow flood of the TGR consists of three parts as shown in Fig. 1. They are the mainstream discharge gauged by Cuntan station, the tributary discharge gauged by Wulong station and the intervening precipitation runoff. Both the Cuntan and Wulong stations have gauged flow discharge data from 1960 to 2013. The precipitation data of 40 rainfall stations located over the intervening basin are also available from 1960 to 2013. The Yichang hydrological station was setup in 1877 and the observed flow discharge data are also available. The inflow data of the TGR are available from 2003 to 2013. The data sets above have a 6 h time interval, which are provided and quality controlled by Changjiang Water Resources Commission (CWRC), the official management agency of Yangtze River basin.
The reservoir inflow cannot be gauged and needs to be estimated or extend as previously mentioned. In this study, the estimation and extension of inflow flood series is divided into three periods: (1) For the period from 2003 to 2013 after the TGR’s impoundment, the data sets are used to calibrate and validate the MISO model. (2) For the period from 1960 to 2002, the upstream hydrologic data and precipitation recordings of intervening basin are available. The calibrated MISO model is used to estimate inflow flood series. (3) For the period from 1877 to 1959, only the dam site flood series at Yichang station are available. The inflow flood series are estimated by a copula-based model.
3 Methodology
3.1 Multiple inputs and single output model
The multiple inputs and single output (MISO) model is a linear modeling technique for flow routing and simulation on large catchments. The inflow flood series of the TGR from 2003 to 2013 were simulated by the MISO model following Liang et al. (1992), in which the TGR’s intervening basin was divided into six sub-basins considering the spatial distribution of precipitation. The formulation of the MISO for flood simulation can be expressed as follows:
where \(\widehat{Q}_{t}\) denotes the simulative inflow of the TGR at time t; \(Q_{t}^{c}\) and \(Q_{t}^{w}\) denote the gauged flood of Cuntan station and Wulong station at time t, respectively; \(A_{p}\) denotes the area of the pth sub-basin; \(dt\) denotes the time interval of the data series, which is 6 h in this research; \(h\left( \cdot \right)\) denotes the impulse responses of the corresponding input, which represents the contribution of each input to the streamflow; m denotes the memory length of the corresponding input, which is defined as the longest concentration time of each rainfall input; \(R_{p,t}\) denotes the net rainfall derived by rainfall-runoff relationship graph method (Fedora 1989) of the pth sub-basin at time t, the rainfall-runoff relationship curve for the TGR intervening basin is plotted in Fig. 2, and the antecedent precipitation index P a can be updated using the following equations:
where P a,t is the antecedent precipitation index for tth period; P t is the precipitation volume of the tth period; K is the evaporation reduction index, 0 < K<1; W m is the water storage capacity of the basin (mm), which is 40 mm for the TGR intervening basin.

Rainfall-runoff relationship curve for the TGR intervening basin
Equation (1) can be transformed into matrix format:
where \(H = \left[ {h_{1} ,h_{2} ,h^{(1)} , \ldots ,h^{(6)} } \right]^{T}\); \(X\) denotes the input matrix corresponding to \(H\).
The estimated \(\widehat{H}\) can be computed by the least square method (Liang et al. 1992):
where \(Q\) denotes inflow discharge. The parameter \(m\) can be estimated by the trial and error method and should keep relatively small to avoid model over-fitting.
Three indexes are chosen for evaluate the MISO’s model efficiency. They are the Nash–Sutcliffe coefficient of efficiency (NSCE), the mean relative error of the volumetric (RE) and the absolute relative error of flood peaks (AE). These indexes are calculated by following equations:
where \(Q_{t}\) and \(\widehat{Q}_{t}\) are the observed and simulated inflows at time t, respectively; \(\overline{Q}\) is the mean value of \(Q_{t}\); \(Q_{\hbox{max} ,i}\) and \(\widehat{Q}_{\hbox{max} ,i}\) are the observed and simulated peak discharges of ith year, respectively.
The NSCE is a widely used index for evaluating model efficiency, and a high NSCE value indicates good model performance. The other two indexes RE and AE represent the model’s ability for describing flood features, and the more approximately to zero the better.
3.2 Coupla-based extension model
\(F_{{_{i} }} (x_{i} )\) (\(i = 1,2, \ldots ,n\)) denotes the cumulative distribution function (CDF) of \(X_{i}\). According to Sklar’s theorem (1959), the multivariate distribution function \(H_{1,2, \ldots ,n} (x_{1} ,x_{2} , \ldots ,x_{n} )\) can be expressed in terms of its marginal and the associated dependence function:
where \(C\left( \cdot \right)\), called the copula function, is uniquely determined whenever \(F_{{X_{i} }} (x_{i} )\) are continuous, and captures the essential features of the dependence among the random variables.
Let X denotes the dam site series and Y denote the inflow series. The bivariate copula joint distribution can be expressed as:
where u = F X (x) and v = F Y (y) denote the marginal distribution of X and Y, respectively.
For a given x, the conditional CDF of Y can be expressed as:
And the corresponding conditional probability density function (PDF) is:
The most likely condition value of Y is used as the extension result and can be obtained by maximizing \(f_{Y|X} \left( y \right)\):
where \(y_{M}\) is the most likely value of Y conditioned on X = x.
For a given significance level \(\alpha\), specifically if \(\alpha = 0.10\), then the 5 and 95% quantiles compose the 90% estimation interval \(\left[ {y_{1} ,y_{2} } \right]\) of Y, which is used to describe the uncertainty of the estimation results, i.e.
Different families of copulas have been proposed and described by Nelsen (2006). Of all the copula families, the Archimedean family is the most suitable for hydrological analyses since it’s easy to be constructed and can be applied to whether the correlation among the hydrological variables is positive or negative. Three most widely used one-parameter Archimedean copula functions, including the Gumbel–Hougaard, Frank and Clayton copulas, have been applied in hydrologic fields by many authors (Favre et al. 2004; Zhang and Singh 2006; Salvadori and De 2007; Timonina et al. 2015; Xu et al. 2016). The PDFs of these copulas and their parameter \(\alpha\) estimated by Kendall correlation coefficient \(\tau\) were listed in Table 1.
The Cramér-von Mises test statistic S n (Genest et al. 2009) and the Akaike information criterion statistic AIC (Akaike 1974) were used to select a proper copula function. Let R i be the rank of x i among x i ,…, x n and S i is the rank of x i among x i ,…, x n , being i = 1,…, n and n the observed record length. S n can be written as:
in which
where C n is the empirical copula (a non-parametric rank-based estimator of the unknown copula), C θn is the parametric copula with the parameter previously estimated from the observed data and \(\varTheta \left( x \right)\) is the indicator function of the set X.
The p value associated to the test statistic S n is computed based on the parametric bootstrap technique introduced by Genest et al. (2009) to formally assess whether the selected model is suitable. The selected copula should have a lower value of the statistic S n relative to an admissible p-value (i.e. larger than 0.05).
The AIC can be expressed as following Zhang and Singh (2006):
where n is the length of data series; k is the number of model parameters, which is 1 for bivariate Archimedean copula functions; x i and \(\widehat{x}_{i}\) are the ith observed value and the corresponding simulated value, respectively. The best model is the one that has the smallest AIC value.
3.3 Flood frequency analysis
The Pearson Type Three (P3) distribution is recommended by Ministry of Water Resources of China for hydrological frequency analysis (MWR 2006; Hong et al. 2015; Xu et al. 2016). For a given sample series \(\{ x:\gamma < x < + \infty \}\), the PDF of P3 distribution is expressed as:
where \(\alpha\),\(\beta\) and \(\gamma\) are the shape, scale and location parameters, respectively, \(\varGamma ( \cdot )\) is the Gamma function.
The FFA is normally carried out by fitting an assumed theoretical PDF to the observed data and then estimate quantile for a given return period (Vogel and Wilson 1996). Given exceedance probability \(p \in \left( {0,1} \right)\), the corresponding quantile x p can be calculated by solving the integral equation:
where f(x) is the PDF of the P3 distribution; x p denotes the value which is larger than p of the totality. The p value is determined by the actual demands. For the TGR, four p values (0.01, 0.1, 1 and 5%), which corresponding to return periods 10,000, 1000, 100 and 20 years, respectively are considered in this study.
3.4 Flood control risk analysis
The FCRA is implemented by Monte Carlo method with the flood hydrographs generated by seasonal autoregressive model. Then the FCRA results are compared with the TGR’s design risk rates to quantify the differences.
3.4.1 Seasonal autoregressive model
The seasonal autoregressive (SAR) model has been widely used in hydrologic forecasting and stochastic runoff simulation (Salas et al. 1982; Modarres 2007; Unami et al. 2010). The SAR model for inflow flood simulation can be described as follow:
where \(\varphi_{i,\eta }\) denotes the ith auto-regression parameter of the \(\eta\)th day; \(Q_{t,\eta }\) denotes the tth simulated flood discharge of the \(\eta\)th day; \(\varepsilon_{t,\eta }\) denotes the error term. The parameter estimation method of SAR model is not discussed here and the readers can refer to Modarres (2007).
The typical design flood hydrographs of the TGR were 30 days in length. To make the analysis results comparable, the hydrographs of the TGR’s annual maximum 30 days inflow flood from 1877 to 2013 were selected to calibrate the SAR model. Totally 106 simulative hydrographs of the TGR’s annual maximum 30 days inflow flood were simulated by SAR model. The statistics of \(\overline{Q}\), Cv, Cs and linear correlation coefficient ρ were computed to evaluate the SAR performance. Following Li et al. (2016), the relative root mean square errors (RRMSE) of each variable above is computed by:
where n denotes the length of the data series; x i denotes the true values of the variable; \(\widehat{{x_{i} }}\) denotes the values of the simulative data. A small RRMSE value usually indicates a good simulation result.
3.4.2 Flood control risk analysis based on Monte Carlo method
The SAR simulated flood hydrographs were regulated referring the TGR’s flood control operation rules issued by the Ministry of Water Resource of China (MWR 2009). The highest reservoir water level for each hydrograph was recorded. The TGR takes compensation operation method considering the safety of Jinjiang river reach in practice. A brief introduction of the TGR’s operation rules is as follows:
-
1.
When the water level of the TGR is less than 171.0 m, the operation should ensure the water level of Shashi hydrologic station downstream the TGR less than 44.5 m;
-
2.
When the water level of the TGR is between 171.0 and 175.0 m, the operation should keep the discharge at Zhicheng hydrologic station less than 80,000 m3/s and the water level of Shashi station below 45.0 m, under the assistance of flooding detention facilities;
-
3.
The TGR’s discharge should not excess its discharge capacity.
The flood control risk of the TGR is defined as the probability of the reservoir water level excessing a critical value:
where \(Z_{i}\) denotes the maximum reservoir water level of ith operation trial; \(Z_{c}\) denotes the critical reservoir water levels, which come from the design flood hydrographs of the TGR; \(\varTheta \left( {Z_{i} > Z_{c} } \right) = 1\) when \(Z_{i} > Z_{c}\), otherwise \(\varTheta \left( {Z_{i} > Z_{c} } \right) = 0\); M denotes the number of Monte Carlo operation trial times.
4 Results and discussion
4.1 Simulated inflow series by the MISO model of the TGR
Inflow flood series of the TGR were used to calibrate and validate the MISO model. The calibration and validation periods were 2003–2010 and 2011–2013, respectively. Table 2 shows that the MISO model performs well with its NSCE up to 98% and very small RE and AE values for both the calibration and validation periods. Since the streamflows of Cuntan station and Wulong station account for up to 95% of the TGR’s inflow streamflow, the uncertainty of modelling results mainly comes from the intervening inflow, which is estimated with the intervening precipitation data.
The TGR’s inflows during 19060–2002 were estimated by the calibrated MISO model. Since there are not inflow records before the TGR’s impoundment, the estimated inflow series cannot be evaluated directly by comparing it with gauged data. Therefore, the estimated inflows of the TGR were routed from Qingxichang station (inflow point confirmed by CWRC) to Wanxian and then to Yichang station by Muskingum method (McCarthy 1938; Cunge 1969) and compared with gauged flood series at Yichang station. The routing path can be referred to Fig. 1 and the parameters of Muskingum equation were listed in Table 3. The routed and observed flood hydrographs at Yichang station during flood season of 1981 and 1982 (typical years for the TGR dam’s design criteria) were plotted in Fig. 3a, b, respectively.

Comparison of Muskingum Routed and gauged flood hydrographs of Yichang station. a 1981, b 1982
As Fig. 3 shown, the routed flood hydrograph can fit the observed flood hydrograph preferably for both years. Also, the routed hydrographs simulate the magnitude and occurrence time of flood peaks well. It is also observed in Fig. 3 that the inflow flood usually have higher and earlier peak discharge than the dam site flood with the same precipitation event. By statistically comparing the occurring time of annual maximum inflow and dam site peak discharges during 1960–2013, it is found that under the same precipitation condition, the inflow peak discharge usually appeared 1–2 days earlier than the dam site flood. In practical flood management work, the decision maker should notice this variation and make operation decision in advance.
4.2 Extension of the TGR’s inflow series by copula-based model
Three most widely used Archimedean copulas in hydrological analyses were assessed by Cramér-von Mises test and Akaike information criterion. Based on the observed dam site flood series and the inflow flood series estimated by the MISO model, the S n , p and AIC values of the three copulas for the annual maximum flood discharge (Q max ), 3, 7, 15 days flood volumes (W 3d , W 7d and W 15d ) were listed in Table 4. The p values were derived by 10,000 parametric bootstrap samples. With all the p values larger than 0.05, all three copula functions can pass the Cramér-von Mises test. Among the three copulas, Gumbel–Hougaard (GH) copula has the smallest AIC values, which means GH copula is the best one under the Akaike information criterion. Therefore, the GH copula is chosen because it has the advantage of upper tail dependence (Poulin et al. 2007) and is more suitable for extending inflow series.
The estimated parameters for GH copula were listed in Table 5 and the comparisons of the empirical plots and theoretical copula frequency curve of Q max , W 3d , W 7d and W 15d were plotted on Fig. 4a–d, respectively. The theoretical frequency curves can fit the empirical plots very well, which indicates an overall satisfactory agreement between the empirical and theoretical joint CDF. Figure 5a–d demonstrate the conditional most likely values and 90% confidence intervals of inflow Q max , W 3d , W 7d and W 15d , respectively. Most of the TGR’s inflow floods are located within the 90% confidence intervals. The interval width becomes narrow with larger dam site discharges. Given the dam site values of Q max , W 3d , W 7d and W 15d , the inflow Q max , W 3d , W 7d and W 15d during 1877–1959 were extended by the most likely values of the PDF conditioned on dam site values.

Comparison of the empirical plots and theoretical copula frequency curve. a Q max , b W 3d , c W 7d , d W 15d

Conditional most likely values and 90% confidence intervals of reservoir inflow flood based on Gumbel–Hougaard copula. a Q max , b W 3d , c W 7d , d W 15d
4.3 Flood frequency analysis results
The FFA was conducted with the inflow series of the TGR for 1877–2013. The parameters of the P3 marginal distributions were estimated by L-moment method (Hosking 1990; Yang et al. 2010) based on the TGR’s inflow flood series from 1877 to 2013. Chi Square goodness-of-fit and Kolmogorov–Smirnov (K–S) test were performed (Tsai et al. 2001; Rahman et al. 2010). Table 6 shows that the P3 distributions with the estimated parameters could not be rejected at the 5% significance level because χ 2 < \(\chi_{0.05}^{2}\) and all D n < D n,0.95 .
Table 7 displays the FFA results of the TGR inflows and dam site floods. The comparisons of inflow and dam site theoretical frequency curves for Q max , W 3d , W 7d and W 15d were plotted on Fig. 6. The relative bias (RB) values were calculated to quantify the differences between the FFA results of inflow and dam site floods, i.e.

Comparisons of the inflow and dam site theoretical frequency curves. a Q max , b W 3d , c W 7d , d W 15d
Significant differences can be observed with the RB values in Table 7. The mean values of inflow Q max and W 3d have increased by 5.58 and 3.85% relative to the dam site ones. The differences are significant by t-test (Haynes 2013) at 1% confidence level. However, the mean values of inflow W 7d and W 15d decline slightly by 1.82 and 1.72% than the dam site ones, respectively, and the differences are neither significant at 5% confidence level by t-test. Results reveal that the TGR’s inflow floods are larger than the dam site floods for flood volumes with shorter durations. A possible explanation of the decreases of long-duration flood volume (e.g. W 7d and W 15d ) mean values may be that the impoundment of the TGR has increased the water surface area and also the evaporation rate of the basin. On the other hand, the flood concentration velocity of reservoir is faster than the natural river channel since the flood wave feature has changed (Li and Singh 1993), which results in positive RB values of short-duration peak discharge and flood volumes (e.g. W 3d ). The coefficient of variation Cv reflects discreteness of the data series. All the Cv values of inflow flood series are larger than these at dam site ones, which reflects the TGR’s inflows are more asymmetric in temporal distribution.
Flood disaster is usually resulted by extreme inflow discharges, thus more attention should be paid to the upper tails of the frequency curves. Figure 6 shows that the frequency curves have much larger differences on the upper tails, which are the regions for the design values of the TGR dam. To further investigate these differences, the 0.01, 0.1, 1 and 5% quantiles of inflow and dam site Q max , W 3d , W 7d and W 15d were calculated and compared in Table 7. Q max shows the most significant variation among the four variables with RB values varying from 6.92 to 9.29% relative to the dam site ones. Other inflow quantiles also increased to different degrees with all the RB values larger than zero. It can be concluded that the construction criteria of the TGR derived by dam site FFA results are generally smaller than the inflow FFA results. This underestimation seems more evident for extreme flood events since the 0.01% quantiles had the largest RB values.
It should be highlighted that only annual maximum 6 h discharge data series were compared in this study due to the limitation of gauged data series. Fill (2003) demonstrated that instantaneous peak discharges may be considerably larger than 6 h time-averaged ones. The actual differences between the TGR’s inflow and dam site instantaneous peak discharges may be more significant. The inconsistency between inflows of the TGR and design criteria must be paid attention to when making flood operation decisions.
4.4 Flood control risk analysis results
Long-term flood series are necessary for applying the FCRA method based on Monte Carlo method. The SAR model was established to generate stochastic inflow series of the TGR. The calculated RRMSE values of \(\overline{Q}\), Cv, Cs and \(\rho\) are 0.0006, 0.0075, 0.0966 and 0.0065, respectively. All the RRMSE values are quite small, which indicate the SAR model can describe annual maximum 30 days inflow hydrographs well. As shown in Fig. 7, the inflow series generated by the SAR model have highly similar statistical parameters with the TGR’s annual maximum 30 days inflow hydrographs. 106 inflow hydrographs generated by SAR model were routed according to the TGR’s operation rules (MWR 2009; Guo et al. 2011) with an initial reservoir water of 145 m. The highest reservoir water level of each hydrograph was recorded and the flood control risk rate was calculated by Eq. (23).

Evaluation statistics for gauged and SAR simulated inflow series. a \(\overline{Q}\), b Cv, c Cs, d ρ
Table 8 shows that the flood control risks decline for higher water levels while increase for lower water levels. These results are in accordance with the FFA results in Table 7. For extreme flood events (e.g. 0.01 and 0.1%), the highest reservoir water level during the flood operation is dominated by the long-duration flood volume (e.g. W 7d and W 15d ). While for middle and small flood events (e.g. 1 and 5%), the dominant factor is the peak discharge or short-duration flood volume (e.g. W 3d ). Therefore, when the mean values of inflow W 7d and W 15d become smaller than the dam site ones, the flood control risk for high water level is also declined. On the contrary, with larger mean values of inflow Q max and W 3d , the flood control risk is also increased for low water levels.
It is noticed in Table 8 that among the 106 Monte Carlo inflow flood operation trails, all the highest reservoir water levels recorded are below 180.4 m and no overtopping event occurred, which means that the TGR can satisfy its design flood control demands and guarantee the dam’s safety. As for the increase of flood risk at low water level, it can be avoided by non-engineering measures, such as adjusting the flood operation strategy.
5 Conclusion
The reservoir impoundment changes the flood generation and concentration conditions of the natural river channel, which is more obvious and vital for large reservoirs. Quantification of the risk caused by differences between inflow and dam site floods can help reservoir administrators better understand the current hydrologic regime and make more efficient flood operation strategies.
To better understand the problem above, a case study of the TGR was explored to quantify the differences between reservoir inflow and dam site floods. A multiple inputs and single output (MISO) model and a copula-based model were proposed to estimate and extend reservoir inflow series with the longer dam site flood records of the Three Gorges Reservoir (TGR). Then, the differences between reservoir inflow and dam site floods are quantified by flood frequency analysis (FFA) and flood control risk analysis (FCRA) methods. The main conclusions derived from this study are as follow:
-
1.
The MISO model and the copula-based extension method are useful tools for extending reservoir inflow data series. The MISO model is very efficient to simulate inflows of the TGR and the most likely inflow values conditioned on dam site flood can be used to extend inflow series.
-
2.
The mean values of inflow Q max and W 3d have increased for 5.58 and 3.85% than the dam site values, respectively. While the mean values of inflow Q 7d and Q 15d have declined slightly for 1.82 and 1.72%. All the inflow design quantiles are larger than the dam site design quantiles to different degree, among which the Q max quantile has the largest variation.
-
3.
Flood control risks have increased about 2% for middle and small flood events while declined slightly for extreme flood events. It is revealed that the TGR can fulfill its flood control task and non-engineering measures are necessary to respond the increasing middle and small flood risks, such as adjusting the operation strategy.
References
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Autom Control 19(6):716–723
Bao Y, Tung YK, Hasfurther VR (1987) Evaluation of uncertainty in flood magnitude estimator on annual expected damage costs of hydraulic structures. Water Resour Res 23(11):2023–2029
Batalla RJ, Gomez CM, Kondolf GM (2004) Reservoir-induced hydrological changes in the Ebro River basin (NE Spain). J Hydrol 290(1):117–136
Bezak N, Brilly M, Šraj M (2016) Flood frequency analyses, statistical trends and seasonality analyses of discharge data: a case study of the Litija station on the Sava River. J Flood Risk Manag 2(9):154–168
Cea M, Rodriguez M (2016) Two-dimensional coupled distributed hydrologic-hydraulic model simulation on watershed. Pure Appl Geophys 173(3):909–922
Chang J, Li Y, Wang Y, Yuan M (2016) Copula-based drought risk assessment combined with an integrated index in the Wei River Basin, China. J Hydrol 540:824–834
Chen YC, Hsu YC, Kuo KT (2013) Uncertainties in the methods of flood discharge measurement. Water Resour Manag 27(1):153–167
Chen L, Singh VP, Guo SL, Zhou JZ, Zhang JH (2015) Copula-based method for multisite monthly and daily streamflow simulation. J Hydrol 528:369–384
Chen J, Shi HY, Sivakumar B, Peart MR (2016) Population, water, food, energy and dams. Renew Sustain Energy Rev 56:18–28
Clarke RT (1979) Extension of annual streamflow record by correlation with precipitation subject to heterogeneous errors. Water Resour Res 15(5):1081–1088
Clarke RT (1980) Bivariate gamma distributions for extending annual streamflow records from precipitation: some large-sample results. Water Resour Res 16(5):863–870
Cunge JA (1969) On the subject of a flood propagation computation method (Muskingum method). J Hydraul Res 7(2):205–230
Duan WX, Guo SL, Wang J, Liu DD (2016) Impact of cascaded-reservoirs group on flow regime in the middle and lower reaches of the Yangtze River. Water 8(6):218. doi:10.3390/w8060218
Elsanabary MH, Gan TY (2015) Evaluation of climate anomalies impacts on the Upper Blue Nile Basin in Ethiopia using a distributed and a lumped hydrologic model. J Hydrol 530:225–240
Ewen J, Parkin G, O’Connell PE (2000) SHETRAN: distributed river basin flow and transport modelling system. J Hydrol Eng 5(3):250–258
Favre AC, El Adlouni S, Perreault L, Thiémonge N, Bobée B (2004) Multivariate hydrological frequency analysis using copulas. Water Resour Res 40(1):W01101. doi:10.1029/2003WR002456
Fedora MA, Beschta RL (1989) Storm runoff simulation using an antecedent precipitation index (API) model. J Hydrol 112(1):121–133
FEMA (Federal Emergency Management Agency) (2013) Selecting and accommodating inflow design flood for dams. America
Fill HD, Steiner AA (2003) Estimating instantaneous peak flow from mean daily flow data. J Hydrol Eng 8(6):365–369
Ganguli P, Reddy MJ (2013) Probabilistic assessment of flood risks using trivariate copulas. Theor Appl Climatol 111(1–2):341–360
Ganji A, Jowkarshorijeh L (2012) Advance first order second moment (AFOSM) method for single reservoir operation reliability analysis: a case study. Stoch Environ Res Risk A 26(1):33–42
Gao C, Zhang Z, Zhai J, Qing L, Mengting Y (2015) Research on meteorological thresholds of drought and flood disaster: a case study in the Huai River Basin, China. Stoch Environ Res Risk A 29(1):157–167
Garcia-Bartual R (2002) Short term river flood forecasting with neural networks. iEMSs 2002 International Congress: Integrated Assessment and Decision Support
Genest C, Rémillard B, Beaudoin D (2009) Goodness-of-fit tests for copulas: a review and a power study. Insur Math Econ 44(2):199–213
Goodarzi E, Shui LT, Ziaei M (2014) Risk and uncertainty analysis for dam overtopping–Case study: the Doroudzan Dam, Iran. J Hydro-environ Res 8(1):50–61
Graf WL (2001) Damage control: restoring the physical integrity of America’s rivers. Ann Assoc Am Geogr 91(1):1–27
Graf WL (2006) Downstream hydrologic and geomorphic effects of large dams on American rivers. Geomorphology 79(3):336–360
Gregory KJ (2006) The human role in changing river channels. Geomorphology 79(3):172–191
Guo SL, Guo J, Zhang J, Chen H (2009) VIC distributed hydrological model to predict climate change impact in the Hanjiang basin. Sci China Ser E Technol Sci 52(11):3234–3239
Guo SL, Chen JH, Li Y, Liu P, Li TY (2011) Joint operation of the multi-reservoir system of the Three Gorges and the Qingjiang cascade reservoirs. Energies 4(7):1036–1050
Hall JW, Meadowcroft IC, Sayers PB, Bramley ME (2003) Integrated flood risk management in England and Wales. Nat Hazards Rev 4(3):126–135
Haynes W (2013) Student’s t-Test. Encyclopedia Syst Biol. Springer, New York, pp 2023–2025
Hirsch RM (1982) A comparison of four streamflow record extension techniques. Water Resour Res 18(4):1081–1088
Hong XJ, Guo SL, Xiong LH, Liu ZJ (2015) Spatial and temporal analysis of drought using entropy-based standardized precipitation index: a case study in Poyang Lake basin. China. Theor Appl Climatol 122(3–4):543–556
Hosking JRM (1990) L-Moments: analysis and estimation of distribution using linear combinations of order statistics. J R Stat Soc 52(1):105–124
Huang L, Li S, Si Z (2014) Research on designing for flood risk based on Advanced Checking-point (JC) method. Environ Eng Manag J 13(8):2119–2124
Huang D, Yu Z, Li Y, Han D, Zhao L, Chu Q (2016) Calculation method and application of loss of life caused by dam break in China. Nat Hazards. doi:10.1007/s11069-016-2557-9
International Commission on Large Dams (ICOLD) (2003) Dams and floods–guidelines and cases histories. Bulletin 125, Paris
International Commission on Large Dams (ICOLD) (2006) Roles of dams in flood mitigation–a review. Bulletin 131, Paris
Jonkman SN, Van Gelder P, Vrijling JK (2003) An overview of quantitative risk measures for loss of life and economic damage. J Hazard Mater 99(1):1–30
Jung Y, Kim NW, Lee JE (2015) Dam effects on spatial extension of flood discharge data and flood reduction scale II. J Korea Water Resour Assoc 48(3):221–231
Katz RW, Parlange MB, Naveau P (2002) Statistics of extremes in hydrology. Adv Water Resour 25(8):1287–1304
Kim JH, Lee SH, Paik I, Lee HS (2015) Reliability assessment of reinforced concrete columns based on the P-M interaction diagram using AFOSM. Struct Saf 55:70–79
Kowen N (2000) Conceptualization and scale in hydrology. J Hydrol 65:1–23
Kucherenko S, Albrecht D, Saltelli A (2015) Exploring multi-dimensional spaces: a Comparison of Latin Hypercube and Quasi Monte Carlo Sampling Techniques. arXiv preprint arXiv:1505.02350
Kussul N, Shelestov A, Skakun S (2008) Grid system for flood extent extraction from satellite images. Earth Sci Inform 1(3–4):105–117
Kwon HY, Kang YO (2016) Risk analysis and visualization for detecting signs of flood disaster in Twitter. Spatial Inf Res 24(2):127–139
Lajoie F, Assani AA, Roy AG, Mesfioui M (2007) Impacts of dams on monthly flow characteristics. The influence of watershed size and seasons. J Hydrol 334(3):423–439
Lázaro JM, Navarro JÁS, Gil AG, Romero VE (2016) Flood frequency analysis (FFA) in Spanish catchments. J Hydrol 538:598–608
Li JZ, Singh VP (1993) Celerity analysis of reservoir flood wave propagation. Int J Hydroelectr Energy 3:001
Li Y, Guo SL, Guo JL, Wang Y, Li TY, Chen J (2014) Deriving the optimal refill rule for multi-purpose reservoir considering flood control risk. J Hydro-Environ Res 8(3):248–259
Li TY, Guo SL, Liu ZJ, Xiong LH, Xu CJ, Yin JB (2016) Estimation of bivariate flood quantiles using copulas. Hydrol Res. doi:10.2166/nh.2016.049
Liang GC, Kachroo RK, Kang W, Yu XZ (1992) River flow forecasting. Part 4. Applications of linear modelling techniques for flow routing on large catchments. J Hydrol 133(1):99–140
Liu Z, Todini E (2002) Towards a comprehensive physically based rainfall-runoff model. Hydrol Earth Syst Sci 6:859–881
Liu XY, Guo SL, Liu P, Chen L, Li X (2011) Deriving optimal refill rules for multi-purpose reservoir operation. Water Resour Manag 25:431–448
Liu P, Lin KL, Wei XJ (2013) A two-stage method of quantitative flood risk analysis for reservoir real-time operation using ensemble-based hydrologic forecasts. Stoch Environ Res Risk A 29(3):803–813
Lu YZ, Lu BH, Lu GH, Wang T, Wang W, Zhou XX (2011) Dam site and reservoir inflow flood series of Zhelin Reservoir. J Hohai Univ (Nat Sci) 39(1):14–19
Magilligan FJ, Nislow KH (2005) Changes in hydrologic regime by dams. Geomorphology 71(1):61–78
McCarthy GT (1938) The unit hydrograph and flood routing, Conf. North Atlantic Div, US Corps of Engineers New London, Conn
Modarres R (2007) Streamflow drought time series forecasting. Stoch Environ Res Risk A 21(3):223–233
Moog DB, Whiting PJ, Thomas RB (1999) Streamflow record extension using power transformations and application to sediment transport. Water Resour Res 35(1):243–254
MWR (Ministry of Water Resources) (2006) Regulations for calculating design flood of water resources and hydropower projects. Water Resources and Hydropower Press, Beijing (in Chinese)
MWR (Ministry of Water Resources) of the People’s Republic of China (2009) Optimal operation rules for the Three Gorges Reservoir. Beijing (in Chinese)
Nelsen RB (1999) An introduction to copulas. Springer, New York
Nelsen RB (2006) An introduction to copulas, 2nd edn. Springer, New York
Plate EJ (2002) Flood risk and flood management. J Hydrol 267(1–2):2–11
Poulin A, Huard D, Favre AC, Pugin S (2007) Importance of tail dependence in bivariate frequency analysis. J Hydrol Eng 12(4):394–403
Poussin JK, Botzen WJW, Aerts JCJH (2015) Effectiveness of flood damage mitigation measures: empirical evidence from French flood disasters. Glob Environ Change 31:74–84
Rahman MM, Arya DS, Goel NK, Dhamy AP (2010) Design flow and stage computations in the Teesta River, Bangladesh, using frequency analysis and MIKE 11 modeling. J Hydrol Eng 16(2):176–186
Requena AI, Flores I, Mediero Garrote L (2016) Extension of observed flood series by combining a distributed hydro-meteorological model and a copula-based model. Stoch Environ Res Risk A 30(5):1363–1378
Saad C, El Adlouni S, St-Hilaire A, Gachon P (2015) A nested multivariate copula approach to hydrometeorological simulation of spring floods: the case of the Richelieu River (Quebec Canada) record flood. Stoch Environ Res Risk Assess 29:275–294
Salas JD, Boes DC, Smith RA (1982) Estimation of ARMA models with seasonal parameters. Water Resour Res 18(4):1006–1010
Salvadori G, De Michele C (2007) On the use of copulas in hydrology: theory and practice. J Hydrol Eng 12(4):369–380
Schiozer DJ, Avansi GD, dos Santos AAS (2015) Risk quantification combining geostatistical realizations and discretized Latin Hypercube. J Braz Soc Mech Sci 2015:1–13
Sherman LK (1932) Streamflow from rainfall by the unit graph method. J Hydrol 199:272–294
Sklar A (1959) Fonctions de répartition à n dimensions et leurs marges, vol 8. Publications de l’Institut de Statistique de L’Université, Paris, pp 229–231
Timonina A, Hochrainer-Stigler S, Pflug G, Jongman B, Rojas R (2015) Structured coupling of probability loss distributions: assessing joint flood risk in multiple river basins. Risk Anal 35(11):2102–2119
Tofiq FA, Guven A (2014) Prediction of design flood discharge by statistical downscaling and general circulation models. J Hydrol 517:1145–1153
Tsai CN, Adrian DD, Singh VP (2001) Finite Fourier probability distribution and applications. J Hydrol Eng 6(6):460–471
Tung YK, Mays LW (1981) Optimal risk-based design of flood levee systems. Water Resour Res 17(4):843–852
Turgeon A (2005) Daily operation of reservoir subject to yearly probabilistic constraints. J Water Resour Plan Manag 131(5):342–350
Uddin K, Gurung DR, Giriraj A, Shrestha B (2013) Application of remote sensing and GIS for flood hazard management: a case study from Sindh Province, Pakistan. Am J Geogr Inf Syst 2(1):1–5
Unami K, Abagale FK, Yangyuoru M, Alam AHMB, Kranjac-Berisavljevic G (2010) A stochastic differential equation model for assessing drought and flood risks. Stoch Environ Res Risk A 24(5):725–733
Vivoni ER (2003) Hydrologic modelling using triangulated irregular networks: terrain representation, flood forecasting and catchment response. Ph.D. Thesis, MIT, Cambridge, Mass., USA
Vogel RM, Wilson I (1996) Probability distribution of annual maximum, mean, and minimum streamflows in the United Sates. J Hydrol Eng 1(2):69–76
Wang QJ (2001) A Bayesian joint probability approach for flood record augmentation. Water Resour Res 37(6):1707–1712
Wood EP, Lettenmaier DP, Zartarian VG (1992) A land surface hydrology parameterization with subgrid variability for general circulation models. J Geophys Res 97(D3):2717–2728
Xu CJ, Yin JB, Guo SL, Liu ZJ, Hong XJ (2016) Deriving design flood hydrograph based on conditional distribution: a case study of Danjiangkou reservoir in Hanjiang basin. Math Probl Eng. doi:10.1155/2016/4319646
Yang T, Xu CY, Shao QX, Chen X (2010) Regional flood frequency and spatial patterns analysis in the Pearl River Delta region using L-moments approach. Stoch Environ Res Risk Assess 24(2):165–182
Zhang L, Singh VP (2006) Bivariate flood frequency analysis using the copula method. J Hydrol Eng 11(2):150–164
Zhao RJ (1992) The Xinanjiang model applied in China. J Hydrol 135(1):371–381
Acknowledgements
This study was supported by the National Natural Science Foundation of China (51539009 and 51579183) and the National Key Research and Development Plan of China (2016YFC0402206).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhong, Y., Guo, S., Liu, Z. et al. Quantifying differences between reservoir inflows and dam site floods using frequency and risk analysis methods. Stoch Environ Res Risk Assess 32, 419–433 (2018). https://doi.org/10.1007/s00477-017-1401-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-017-1401-4