
Abstract
This study draws attention on the extreme precipitation changes over the eastern Himalayan region of the Teesta river catchment. To explore the precipitation variability and heterogeneity, observed (1979–2005) and statistically downscaled (2006–2100) Coupled Model Intercomparison Project Phase Five earth system model global circulation model daily precipitation datasets are used. The trend analysis is performed to analyze the long-term changes in precipitation scenarios utilizing non-parametric Mann–Kendall (MK) test, Kendall Tau test, and Sen’s slope estimation. A quantile regression (QR) method has been applied to assess the lower and upper tails changes in precipitation scenarios. Precipitation extreme indices were generated to quantify the extremity of precipitation in observed and projected time domains. To portrait the spatial heterogeneity, the standard deviation and skewness are computed for precipitation extreme indices. The results show that the overall precipitation amount will be increased in the future over the Himalayan region. The monthly time series trend analysis based results reflect an interannual variability in precipitation. The QR analysis results showed significant increments in precipitation amount in the upper and lower quantiles. The extreme precipitation events are increased during October to June months; whereas, it decreases from July to September months. The representative concentration pathway (RCP) 8.5 based experiments showed extreme changes in precipitation compared to RCP2.6 and RCP4.5. The precipitation extreme indices results reveal that the intensity of precipitation events will be enhanced in future time. The spatial standard deviation and skewness based observations showed a significant variability in precipitation over the selected Himalayan catchment.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Precipitation is a vital component and has great vitality for the living beings and ecosystem. Excessive or high-intensity precipitation is often hazardous (Choi et al. 2014; Pervez and Henebry 2014). Future changes in extreme multi-day precipitation will influence the probability of flood events in river channels (Pelt et al. 2014; Pervez and Henebry 2014; Trenberth et al. 2011). The recent floods in the Kedarnath area, Western Himalayas of Uttarakhand are the classic examples of flash floods in the Mandakini River that devastated the country by killing thousands of people besides livestock (Rao et al. 2014). Therefore, it is suggested that the quantitative and qualitative projections of changes in climate on regional scales are necessarily necessary to overcome this issue for hydrologist and decision makers (Grimm 2011). Such projections are available from the outputs of (downscaled) global climate models (GCMs). The outputs from the climate models can be further processed by impact models, e.g. hydrological models (Leeds et al. 2015; Taylor et al. 2012).
Due to climate change, the rate of extreme precipitation events have increased in last few years (Shivam et al. 2016; Choi et al. 2014). The frequency and intensity of precipitation have affected enormously in different regions of the world (Guo et al. 2014; Choi et al. 2014; Goyal 2014; Lupikasza 2010). Many studies revealed that the frequency and intensity of extreme precipitation events have been increased (Agarwal et al. 2014; Choi et al. 2014; Meehl et al. 2005). According to some recent global-scale assessments, the heavy precipitation days and daily intensity of precipitation have increased (Khaliq et al. 2014; Donat et al. 2013; Alexander et al. 2006; Kunkel 2003). The impact of climate change on extreme precipitation conditions in the future time domain is determined by Agarwal et al. (2014) and Goyal (2014). The GCMs based assessment of precipitation scenarios indicated a positive change in summer, autumn, and annual precipitation, but an adverse change in spring precipitation. Several recent studies utilized gridded rainfall data to analyze the daily extreme rainfall events over India (Goyal 2014; Mondal et al. 2015; Guhathakurta et al. 2011; Krishnamurthy et al. 2009; Ghosh et al. 2009) showed a significant heterogeneity in the precipitation events. They also revealed an increment in the precipitation intensity over the Indian sub-continents (Guhathakurta et al. 2011).
Few studies revealed climate change will most likely be expressed through changes in freshwater availability due to increasing precipitation variability, higher melting due to temperature increments, and severe runoff conditions (Shivam et al. 2016; Singh and Goyal 2016) because of extreme precipitation events. The changes in precipitation are expected to affect the cryospheric processes and hydrology of the headwater catchments in the Himalayas (Immerzeel et al. 2012; Buytaert et al. 2010; Yao et al. 2009). Goyal (2014) studied on the precipitation variations in Assam, India utilized 102 years data from 1901 to 2002 and found most probable year of change was 1959 in annual precipitation. The climate change studies performed over snow-glacier induced Himalayan watersheds also showed the enormous changes in precipitation (Shivam et al. 2016; Kulkarni et al. 2010; Shrestha et al. 2009; Bajracharya et al. 2008; Yamada 2000). To plan adaptation strategies for changing climatic conditions, decision makers require quantitative projections on regional along with local scales, depending on their purpose (Goyal 2014). The description starts from increased surface temperature due to atmospheric heating as well as global warming, thereby raising potential evapotranspiration (Khaliq et al. 2014). Furthermore, the higher temperature will lead to specific humidity, and thus, precipitation occurs with more water vapor, leading to enhanced precipitation rates (Choi et al. 2014).
A few authors evaluated the applicability of GCMs in the projection of long-term precipitation trends (Shivam et al. 2016; Wilby et al. 2014; Harpham and Wilby 2005). However, the GCMs based projection of precipitation scenarios may be uncertain due to the GCM resolution, downscaling methods and the inherent internal variability of climate (Taylor et al. 2012). This uncertainty arises because of differences in the numerical and physical formulations of GCMs (e.g. spatial resolution, vertical layers, the representation of clouds, the convection process, the boundary layer, etc.) (Agarwal et al. 2014; Taylor et al. 2012). Most modeling groups worldwide are participating in latest CMIP5 GCMs. CMIP5 GCMs have higher spatial resolution than previous versions such as CMIP3 (Singh and Goyal 2016; Wang and Yang 2016; Taylor et al. 2012). Thus, the CMIP5 GCMs based climate projections were generated by adopting various downscaling approaches. The usefulness of CMIP5 GCMs has already assessed in several hydrological studies (Brands et al. 2013; Pervez and Henebry 2014; Harding et al. 2014; Shashikanth et al. 2014; Sengupta and Rajeevan 2013; Kharin et al. 2013).
One of the most vulnerable regions in India is its northeastern part comprising of the Sikkim Himalayas. During the last decades (Palazzi et al. 2015; Pervez and Henebry 2014; Ravindranath et al. 2011), no comprehensive research has been conducted to determine the precipitation variability in this region. Most of the studies are confined to only north, central and south India. Changes in precipitation in Sikkim Himalayan region, which comes under the eastern Himalayas, did not receive enough concern globally and locally and no comprehensive studies have been carried out at local/regional scale about climate change as per the author’s best knowledge. Therefore, our main objective is to reveal the current scenario of climatic changes and its influence on extreme precipitation events. For this reason, a statistical cum stochastic downscaling model (SDSM) has been used to downscale precipitation datasets at each sub-basin (SB) scale by utilizing observed precipitation data sets (Wilby et al. 2014; Mahmood and Babel 2013; Taylor et al. 2012; Goyal and Ojha 2011a).
Another objective of this study was to highlight the precipitation changes over Sikkim Himalayan catchment by applying non-parametric tests and extreme indices (Choi et al. 2014) in a spatiotemporal domain. Precipitation extreme indices (PEI) using different percentiles (99th, 90th, 80th) of daily total precipitation (>1 mm) in a year and the number of days per year with daily precipitation exceeding 20 mm (N20), 40 mm (N40) were calculated to detect the precipitation extremity. The other relevant PEI such as dry days is also calculated. These indices represent both magnitude and frequency taking into account several previous studies (Choi et al. 2014; De Lima et al. 2014; Romano et al. 2013; Donat et al. 2013). The quantile regression (QR) (Choi et al. 2014; Koenker 2005) based linear trend analysis was performed to detect the higher order and lower order changes in extreme precipitation scenarios.
2 Observational data, model output, and method
2.1 Study area
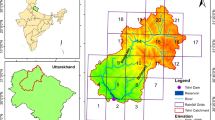
In this study, the Teesta river Himalayan catchment (up to Chungthang) has been selected for the analysis (Fig. 1), which corresponded to around 2552.57 km2 area. Teesta River originated from the Chhombo Chhu from a glacial lake Khangchung Chho at an elevation of 5280 m situated in the northeastern corner of the Sikkim Himalayas. Teesta river flows southward through gorges and rapids in the Sikkim Himalaya (total length 309 km) (Bawa and Ingty 2012; Rahman et al. 2010). It is fed by rivulets arising in the Thangu, Yumthang and Donkia-La ranges. The major tributary of the Teesta River is Lachung River which meets the Teesta River at Chungthang gauge station. The humid climate of the Teesta catchment in Sikkim is characterized with enormous water surpluses. The prevalent monsoon climates have supported evergreen rainforests including grasses which become dense and luxuriant in some parts of middle Teesta catchment near to Lachung. The southwest monsoon season, which is the principle rainy period for almost the entire Teesta basin, is responsible for more than 80% of the total annual rainfall in these mountainous ecological sites, and is significant in controlling the water balance. The average annual maximum, minimum and average precipitation during the years 1979–2005 varies across all the SBs between 3238.60 and 3354.60 mm, 1399–1569 mm, 2346.71–2460.05 mm, respectively (Fig. 2). The upstream catchment is mostly fed by snow and glaciers only, whereas lower part of the catchment also contributes to rainfall during monsoon and summer season.

Study area map showing Teesta river catchment (up to Chungthang)

Average annual precipitation trend over the study area based on observed precipitation (1979–2005)
2.2 Spatial interpolation of the precipitation datasets
In this study, we have used daily gridded (0.5° × 0.5° scale) precipitation data sets which collected from Indian Meteorological Department (IMD) for the year 1979–2005. This dataset prepared from the quality-controlled observed precipitation/rainfall data from more than 1800 gauges (Vittal et al. 2013). Many authors utilized this dataset for different hydrological studies (Shivam et al. 2016; Subas and Sikka 2013; Goyal 2014; Vittal et al. 2013; Sen Roy and Balling 2004). For the two gauge stations such as Lachung and Chungthang, a point source measured daily precipitation data sets (1979–2005) were also available; and hence, used in this study. The six grids and two gauge stations which were falling inside/near to study area utilized for the analysis. This catchment corresponded to extreme elevation variations.
The selected study area is divided into seven SBs to highlight the local scale changes in precipitation. The selected study area such as upper part of the Teesta river catchment varies their elevations from moderate 1495 to extreme 7392 m. The SB1 corresponded to upstream portion and SB7 corresponded to lowest portion. Therefore significant precipitation gradient change (around maximum 40 mm/km-year) was observed between these two SBs (Singh and Goyal 2016). As per the above elevation variations, precipitation has been adjusted to each SB scale as the methodology presented by Singh and Goyal (2016) and Neitsch et al. (2011).
2.3 Downscaling and bias correction of precipitation datasets
After the spatial adjustment of observed hydro-meteorological variables at each SB, daily precipitation datasets were downscaled at each SB utilizing ESM-2M GCM with low (RCP2.6), moderate (RCP4.5) and extreme (RCP8.5) RCP experiments. The ESM-2M GCM datasets utilized by various researchers for the assessment of climate variability in hydrological scenarios (Shivam et al. 2016; Singh and Goyal 2016; Zhang et al. 2014; Kharin et al. 2013). The six GCM grids (2.5° × 2.5°) surrounding the study region were selected as the spatial domain of the 16 most relevant GCM predictors to adequately cover the various circulation domains of the predictors as suggested by previous authors (Shivam et al. 2016; Zhang et al. 2014; Taylor et al. 2012). These six GCM grid points are spatially interpolated at each SB using an Inverse Distance Weighting Approach (IDWA) (Snell 1998; Snell et al. 2000). Previously many authors successfully utilized IDWA for the GCM interpolations (Kharin et al. 2013; Goyal and Ojha 2011b). The IDWA method interpolates the GCM grid point as per the weighting average of each grid point at the known observed grid point and thus it assigns the maximum weight to the closet distance point (Snell et al. 2000).
For the downscaling of daily precipitation datasets, we utilized Statistical Downscaling Model (SDSM) (Harpham and Wilby 2005). The main strength of the SDSM tool is that it provides the station-scale climate information from GCM-scale output (Wilby et al. 2014; Wilby and Dawson 2013; Dibike and Coulibaly 2005). In this study, the large-scale variable fields from GCMs or reanalysis data (e.g. 16 predictors) are chosen such that they are strongly related to the local scale conditions of interest (Shivam et al. 2016; Singh and Goyal 2016) to produce more realistic results.
SDSM involves linear regressions and thus the selection of the predictors has done based on the correlation or partial correlation analysis between the interested predict and the predictors, and weights of the predictors which are estimated through ordinary least-square method (Wilby et al. 2014). SDSM can be classified as a conditional weather generator in which regression equations are used to estimate the parameters of daily precipitation rate and amount, separately (Hashmi et al. 2011). Therefore it is considerably more refined than a straightforward regression model. The SDSM model was setup on a monthly time step utilizing observed daily precipitation datasets (predictand) and reanalysis GCM datasets (predictors) for the year 1979–2005.
Due to the coarser resolution of GCM, it may also contain some bias (Shivam et al. 2016) in their downscaled scenarios (e.g. daily precipitation). Therefore, the bias correction of GCM outputs were corrected as also similarly applied by previous researchers (Shivam et al. 2016; Ahmed et al. 2013; Goyal and Ojha 2011a, b; Kidson and Thompson 1998). The bias corrections of precipitation datasets have done as per the method already used by Mahmood and Babel (2013) (Eq. 1).
where, P deb is the de-biased (corrected) daily time series of precipitation for future periods. SCEN represents the scenario data downscaled by SDSM for future periods (e.g., 2006–2100), and CONT represents downscaled data by SDSM for the present period (e.g., 1979–2005). P scen is the daily time series of precipitation generated by SDSM for future periods respectively. P cont is the long term values for precipitation for the control period simulated by SDSM. \(P_{obs}\) represents the long-term monthly observed values for precipitation. The \(\bar{P}\) shows the long-term average. The comparison results between the observed and SDSM based simulated precipitation datasets have shown in Table 1. The results found comparable to the previous studies (Shivam et al. 2016; Wilby et al. 2014).
2.4 Analysis methods
Seasonal (e.g. months) non-parametric Mann–Kendall (MK) test and Kendall’s Tau (τ) coefficient (Mann 1975; Kendall 1975; Sen 1968) are calculated to detect the trends in precipitation scenarios (Goyal 2014). The purpose of the Seasonal MK (SMK) test is to test the precipitation scenarios over time are expected to change in the same direction (increase or decrease), but the trend may or may not be linear (Choi et al. 2014; Goyal 2014). It does not require that the data are normally distributed. However, the regression analysis requires that the residuals from the fitted regression line be normally distributed. The presence of seasonality implies that the data have different distributions for different seasons of the year.
The change in the time series data sets was estimated using Sen’s slopes (Sen 1968). The Sen’s slope represents the rate of change of precipitation per year (Oliveira et al. 2014). The Sen’s slopes used to highlight the precipitation changes in both the historical (1979–2005) and future times (2006–2100). The Sen’s slopes significantly used so far by various researchers in other regions (Goyal 2014; Choi et al. 2014; Oliveira et al. 2014; Jena et al. 2014; Subas and Sikka 2013; Goyal and Ojha 2011a, b). The significance level alpha (α) was chosen as 0.05 for a two-sided test (Goyal 2014; Choi et al. 2014). Based on the significance level, values of the test statistic Z larger than +1.96 or lower than −1.96, indicate the positive (increasing) or negative (decreasing) trends (Goyal 2014; Choi et al. 2014).
To enumerate the linear trends in annual precipitation at high tails (high order changes), the QR (Koenker 2005) was applied to all the RCP experimental scenarios. QR estimates the conditional quantiles of a response variable distribution in the linear model that provides the complete view of possible causal relationships between variables (Tareghian and Rasmussen 2013). The main benefit of QR is its flexibility for modeling data with heterogeneous conditional distributions. Therefore, QR calculates multiple rates of change (slopes) from the minimum to maximum response. The QR model allows one to examine changes in specific parts (quantiles) of the distribution (Choi et al. 2014). Thus, this model is suitable for calculating extreme event values (Choi et al. 2014; Tareghian and Rasmussen 2013).
In this study, the “year” has taken as an explanatory variable and annual precipitation was taken as an independent variable. As per the Choi et al. (2014), the τth quantile (0 < τ < 1) represents the value of the variable below which the proportion of population is τ. The central location of a distribution is represented by the median that is 0.5th quantile (Koenker 2005). In the standard regression, the expectation of the dependent variable Y, given the observation of X = x, can be described as (Eq. 2):
where β 0 and β 1 are the intercept and slope coefficient of the linear regression line, respectively. The standard regression focuses on determining a conditional mean. The QR is mainly concerned with the determination of a conditional quantile (Choi et al. 2014; Koenker 2005). The linear conditional quantile function can be written in the following form (Eq. 3):
where Q y (τ|x) is the expected y for the τth quantile of x and β 0(τ) and β 1(τ) are the intercept and slope coefficient of the τth QR line, respectively. For example, for τ = 0.90, Q y (0.90|x) is the 90th percentile of the distribution of y conditional on the values of x; in other words, 90% of the values of y are less than or equal to the specified function of x (see Hao and Naiman 2007; Koenker 2005 for further details).
Precipitation extreme indices (PEI) were calculated and compared at each SB scale to highlight the spatio-temporal variations in precipitation extremity. The six PEIs were generated as per the previous guidelines (Choi et al. 2014; Santos and Fragoso 2013) and their details have shown in Table 2. The first five indices such as 99th percentile, 90th percentile, 80th percentile, N20 and N40 show intensity based changes, while the last one such as dry days shows frequency based changes. These PEIs were generated to highlight the magnitude of change of precipitation.
To examine the spatio-temporal heterogeneity of the extreme precipitation indices, spatial standard deviation and spatial skewness are calculated for both the time series. To determine deviation of index values from the mean across space, standard deviation of each index across the SBs for each year was calculated. Higher values indicate larger deviation across the SB from the mean and lower values smaller deviation (Choi et al. 2014). To set off spatial standard deviation as a measure of changeability, spatial skewness of each index for each year for both the time series are also calculated. Skewness s of the data x (index values from all the SBs) can be written as (Eq. 4):
where μ is the mean of x and σ is the standard deviation of x and E(t) represents the expected value of the quantity t. Positive skewness indicates that the data is spread out to the right of the mean and negative to the left. The skewness of a perfectly symmetric distribution is zero.
3 Results
Figure 2 shows the average annual scenarios of precipitation for the historical time series (1979–2005). The average annual precipitation varies between 2446.71 and 2460.05 mm across all the SBs calculated from observed datasets (Fig. 2). The upstream SBs (e.g. between SB1 and SB2) show higher variations in precipitation amount which vary from 2346. 71 mm to 2457.85 mm while in lower SBs (e.g. between SB6 and SB7), it ranges from 2446.41 to 2473.05 mm. As per the annual precipitation scenario (1979–2005), the maximum amount of precipitation (cumulative) have occurred during June to October months over the selected Teesta river catchment.
The outcomes from MK, Kendall’s Tau and Sen’s slopes are presented in Tables 3 and 4. These tests show significant changes in precipitation scenarios as per observed (1979–2005) and CMIP5 ESM2 M GCM based RCP experimental scenarios (2006–2100). Table 3 shows monthly precipitation trend analysis for historical time (1979–2005). The observed scenario indicates that the precipitation amount has increased during historical time (1979–2005). As per MK test static Z, the precipitation trends for February, March and April months show a significant increase in precipitation across all the SBs except September which shows a significant decrease in precipitation amount. These observations reveal a significant shift in precipitation pattern over the Himalayan region. The monsoon months (e.g. July to September) show a decrease in precipitation across all the SBs while pre-monsoon months show an increase in precipitation. The rate of change of precipitation was computed through Sen’s slopes.
As per Table 3, the higher rate of changes in precipitation was calculated for upstream SBs such as SB1 and SB2, and downstream SBs such as SB6 and SB7. As per the observations, the maximum negative rate of change in precipitation has been recorded at downstream SBs which vary from −9.19 to −9.44 (Table 3). The maximum positive Sen’s slopes range from 4.07 (SB1) to 5.77 (SB5). Table 4 shows the monthly precipitation trend analysis results for forecasted time (2006–2100) as per CMIP5 ESM-2M RCP experimental scenarios. The projected trends of precipitation enable the climatic variations in a spatiotemporal domain. The RCP based precipitation scenarios show moderate (e.g. RCP2.6 and RCP4.5) to extreme change in precipitation (e.g. RCP8.5). Therefore, for every RCP experiment, the separate trend has been computed at each SB scale. The MK results have presented in Table 4 on a monthly time step, illustrating the seasonal variations in precipitation amount for the year 2006–2100.
As per Table 4, the MK Z shows a significant increase (SI) in precipitation during January to June and October to November months across all the SBs; while in the July to September months, the precipitation trends show significant decrease across all the SBs (Table 4). However, a few observations did not account any significant increase or decrease. As per Table 4, the precipitation trends have recorded highly significant for the RCP4.5 and RCP8.5 experimental scenarios than RCP2.6. The RCP8.5 experiments based trends show the maximum increase and decrease in precipitation. The April and May months show a maximum increase in precipitation across all the SBs (e.g. their MK Z varied from 7.03 to 8.11 for RCP4.5 and RCP8.5 at SB5 during May, respectively). The Sen’s slopes show a rate of change in precipitation during both the time scenarios. The results indicate high magnitude of change during monsoon period (July–September). The intensity or magnitude of change of precipitation vary across all the SBs and RCP experiments and it shows the high magnitude of change for the RCP 4.5 and RCP 8.5 (Table 4).
The Sen’s slopes correspond to both positive (+) and negative (−) values (Tables 3, 4). For the future time, the slopes vary from 0.00 to 1.77, 0.00–1.61 and 0.02–2.16 for the RCP2.6, RCP4.5, and RCP8.5, respectively across the SBs. Likewise, the negative Sen’s slopes vary from −0.09 to −1.75, −0.05 to −1.45 and −0.02 to −2.54 (Table 4). These test statistics show that the RCP8.5 scenario represented extreme conditions in this overall analysis. In overall comparison, for all the RCPs, most of the months have shown increasing trends of precipitation events, which illustrate that the precipitation will enhance in the future time domain. Kendall’s Tau results show the slope of the average monthly precipitation trends (Tables 3, 4). As per Tables 3 and 4, Kendall’s Tau positive slopes are computed mostly for the spring season (October to March) precipitation, whereas negative slopes are recorded for the monsoon season precipitation events (April–September) for all the RCP scenarios across all the SBs. However, the intensity of positive and negative slopes vary for all the RCPs across all the SBs.
Figure 3a, b shows the SB wise results for the QR model applied on annual average precipitation scenarios for both the time periods. Table 5 shows the hypothesis test results for statistical significance of the estimated trends such as t test (Sawilowsky 2005 for more details) and p-value test (Chamaillé-Jammes et al. 2007 for more information). The different order quantiles such as e.g. 99th, 95th and 90th 85th and 80th were generated for all the SBs and RCP scenarios to evaluate the trends. As per Fig. 3a, b, QR diagrams have plotted to visualize the temporal change in precipitation scenarios under different quantiles (99th, 95th, 90th, 85th, 80th) as per their data distribution. In order to identify the changes in precipitation, the 95% confidence interval based on the slope of the regression model for the median quantile (which is also a 50th quantile) has plotted (Fig. 3a, b).


a Quantile regression (QR) plots for annual precipitation at each sub-basin (SB) during observed time and b QR plots for annual precipitation at each SB during future time as per different RCP experiments
Figure 3a shows the results for QRs for the historical time series data (1979–2005). Figure 3b shows the QRs for future time (2006–2100). All quantile-based regression plots show the decrease and increase in the average annual precipitation scenarios at each SB scale. In Fig. 3a, the higher quantiles (e.g. 99th, 95th and 90th) show an increase across all the SBs expect SB5 and SB6. The lower quantiles (e.g. 85th and 80th) and a 99th quantile for SB5 show significant increase during historical time (1979–2005) (Fig. 3a; Table 5). In Fig. 3a, the range for the higher quantile of 99th has recorded higher data values for the SB5 than other SBs.
As per Fig. 3b, most of the trends show increase in precipitation at each quantile (e.g. 99th, 95th, 90th, 85th, 80th). In case of future precipitation scenarios, the p-values are recorded less than 0.05 (p < 0.05) in most of SBs as shown in Table 5 except very few one. These results demonstrate that the precipitation has significantly enhanced over the future time domain in all of the quantile ranges or orders. Table 3 clearly shows that the RCP4.5 and RCP8.5 showed significant increase in precipitation from the year 2006–2100 in all the quantiles. However, a very few trends showed decrease in precipitation as also observed in the MK results during August and September. The overall QR plots and their statistics reveal a significant increase in precipitation amount in both the time period. The RCP8.5 and 80th percentile have shown maximum increase in the precipitation, which ranged their t-test values from 5.1 to 7.1 across all the SBs (Table 5).
Figure 2 shows the comparison between observed (1979–2005) and future (2006–2100) PEIs (for all RCPs). These indices have computed as per the annual average of PEIs. The description and details of the precipitation indices such as 99th percentile, 90th percentile, 80th percentile, N20, N40 and dry days have shown in Table 4. These precipitation indices initially calculated for historical time series based on the daily precipitation datasets (1979–2005), and then they compared to the projected time series data sets (2006–2100) for all the RCPs at each SB scale, respectively.
To highlight the spatial distribution of precipitation amounts (based on the precipitation indices) at all the SBs, an IDW approach based interpolation has been applied, which is an inbuilt function of vector data based GIS (geographical information system) tool ArcGIS (Nagi 2012; Childs 2004). The highest value of 99th percentile at any SB was found almost five times and the total annual precipitation is just about two times the mean. The average values of precipitation extreme indices such as 99th, 90th, 80th percentiles for historical time series (1979–2005) vary from 55.28 to 62.08, 28.22–30.77 and 19.77–20.90, respectively across all the SBs.
Figure 4 portrays the historical precipitation indices (1979–2005), which show significant variations in the intensity and frequencies of the precipitation in spatial scale and temporal domain. For the historical time series precipitation indices (1979–2005) (Fig. 4), the SB5 has shown extreme condition. As per the comparison done between the historical (1979–2005) and projected PEIs (2006–2100), the counts of dry days have increased. The intensity based precipitation Indices such as N20 and N40 show enormous increase in precipitation from the year 2006 to 2100. As per the 99th, 90th, 80th percentiles, the middle part of the catchment (e.g. SB2, SB3, SB4 and SB5) shows high intensity precipitation changes (or increase) than upper (e.g. SB1) and lower parts (e.g. SB6 and SB7).

Spatial variations in average annual precipitation indices at catchment scale as per observed (1979–2005) and ESM-2M GCM based RCP (2006–2100) scenarios
Figure 5 shows the comparison between observed and RCPs based PEIs as per their minimum and maximum statistics. The minimum and maximum statistics of all PEIs have been computed at each SB scale for both the time scenarios. The SB wise comparison plots show a significant variability in all the PEIs as per the minimum and maximum indices. The RCP4.5 and RCP8.5 show maximum variations than observed and RCP2.6. The percentile based indices significantly show the higher variations in PEIs as they were recoded for maximum indices. As per minimum indices, all the RCPs show almost similar trend to observed scenario; while in case of maximum indices, a significant variations can be noticed. For example 99th percentile, N20 and dry days showed different RCP trends than observed trend. The observed trend line does not overlap with RCPs trends. However, in case of maximum indices, the observed trend line overlaps to the RCPs trend lines. These statistics reveal that the precipitation changes are more significant to the extreme events. As per minimum statistics, the dry days are computed between 100 and 120 across all the SBs, while the RCPs computed 150–180 across the whole catchment. In case of maximum, the dry days are calculated from 190 to 235 for all the scenarios including observed and RCPs.

Sub-catchment wise comparison of observed (1979–2005) and RCP (2006–2100) based Indices based on their minimum and maximum values
The intensity based PEIs (e.g. 99th, 90th, 80th percentiles), which are calculated for the RCP2.6 and RCP4.5, show high intensity precipitation changes in lower part of the catchment (e.g. SB5 and SB7). However, the RCP8.5 gives a mix response. In RCP4.5 (Fig. 5), the 99th percentile shows maximum intensity over the middle and lower parts of the catchment (e.g. SB5 and SB7), whereas the 90th and 80th percentiles show high precipitation intensity in only lower part of the catchment (SB7) (Fig. 5). The N20, N40 and dry days indices are varied significantly from the upstream to downstream portion over the catchment and can be observed in Fig. 5. In the above spatiotemporal investigation of all precipitation indices, the frequency based indices such as N20, N40 and dry days are identified as the key indices to visualize and comparing the precipitation changes in both the time domains.
The geographical and spatial variability in extreme precipitation indices have been analyzed using spatial standard deviation and spatial skewness at the catchment scale by doing an average of all SBs (Figs. 6, 7). The spatial heterogeneity of PEIs is calculated for both of the time series (1979–2005 and 2006–2100). Figure 6 shows the trends in the geographical heterogeneity of the extreme precipitation indices as standard deviation. In the observed time series (1979–2005), magnitude indices of extreme precipitation show high peaks after 1995s (Fig. 6) with increase. In Fig. 6, RCP2.6 shows diverse heterogeneity and the high peaks are mostly observed after 2050s, though several moderate high peaks can also be observed during earlier 2030s. The RCPs 4.5 and RCP8.5 show continuous high peaks from 2030s to 2100s except dry days indices (Fig. 6) with increase.

Comparison of averaged spatial standard (SD) deviation (for all stations) for extreme precipitation indices as per observed and RCP experimental scenarios

Comparison of averaged spatial skewness (for all stations) for extreme precipitation indices as per observed and RCP experimental scenarios
As per the frequency based PEIs such as N20 and N40, all the scenarios tend to increase. In Fig. 6, one can easily observe that the RCP8.5 scenario based extreme precipitation indices has shown markedly high standard deviations (most of the values recorded in the range as 8–16) than other scenarios. In the overall plots (Fig. 6), the spatial standard deviation based upon the spatially averaged indices revealed a positive and noteworthy correlation with varying degrees, proposing spatiotemporal heterogeneity tended to increase with the indices. Figure 7 shows the heterogeneity in the extreme indices using spatial skewness. Except for dry days, all RCPs have shown positive skewness in all extreme precipitation indices. The frequency indices such as dry days has shown variable heterogeneity in different RCPs. The dry days show decreasing trend with dominant negative skewness. The lower percentiles (90th, 85th, 80th) based extreme indices especially for the RCP 4.5 has shown significant variations in their high peaks during the time. The observed time series based extreme indices show similar levels of positive and negative skewness (Fig. 7). In Fig. 7, except in few plots, the skewness tends to fluctuate between −2 and 3 but mostly positive since 2030s.
4 Discussion
To explore variability in extreme precipitation under the current climate conditions, we used latest CMIP5 ESM-2M GCM model with multiple RCP experiments to highlight extreme precipitation variability across the snow glaciers induced Himalayan catchment. Very few studies have analyzed the extremity of precipitation over Himalayan region (Shivam et al. 2016). The outcomes of this study clearly showed that the precipitation variability would be increased in future due to climate change as observed by latest CMIP5 ESM-2M GCM with their moderate to extreme RCP scenarios. The monthly time series projections showed an enormous heterogeneity existed in the precipitation trends (Figs. 3, 4, 5, 6). The CMIP5 GCM based projections of extreme precipitation tended to increase precipitation variability over Himalayan regions as also observed by Shivam et al. (2016) and Taylor et al. (2012). Taylor et al. (2012) and Gosling et al. (2011) found that the global average annual temperature had been increased rapidly, and thus the precipitation pattern will be influenced by temperature changes very frequently in future. This will tend to increases precipitation variability around the globe, and similar trends are observed in this study.
The MK based results revealed that the precipitation will increase in pre-monsoon season, while main monsoon season (e.g. August and September) showed the decrease in precipitation (Tables 3, 4). Ravindranath et al. (2011) did the work on climate change vulnerability over North-East states of India and told that this region is suffered from the collectively less rainfall in summer months. Mainly this happened in the last several years. In the case of seasonal MK test, the seasonality of the series is taken into account. This means that for monthly data with the seasonality of 12 months, one will try to find out if there is a trend in the one month of January to another and from one month July and another, and so on.
Apart from this, the overall trends on the annual and monthly basis show significant increments in their amount and frequencies during both time series. The analysis of the PEI based on SB wise calculation increased the understanding to interpret the heterogeneity in this long term spatiotemporal domain. The trend analysis in our study shows that magnitude precipitation indices such as 99th, 90th and 80th were increased over time. One most important point is also noticed that these indices also have significant variability and heterogeneity as per different RCPs. The results clearly revealed the higher variability in precipitation among all the indices with different RCPs are considered. The frequency based indices such as N20 has shown significant variations with increasing across the SBs including all the scenarios.
As per the Choi et al. (2014), the frequency indices significantly increased or decreased in very limited parts of the USA, meaning virtually no change statewide. Similar statistics also revealed by Shivam et al. (2016) over Subansiri river Himalayan catchment. In this study, we found most of the indices had shown consistently increasing or decreasing trends and similarly observed by Shivam et al. (2016) over Subansiri river basin. As per the Sen’s slope and MK significant tests on monthly time series scenarios, we found consistently increasing trends for most of the months (October to June). Palazzi et al. (2015) worked on the Hindu Kush-Karakoram-Himalayan region (combination of eastern and western Himalayas) using CMIP5 climate ensembles and also told that the models differ considerably in the seasonal climatology of precipitation in these two regions.
In this study, the frequency of the extreme precipitation events was tested as per the N20 and N40 indices. Here, it is observed that the higher frequency indices such as N40 have shown decreasing trend with increasing time duration even at all the SBs and for all the scenarios based on RCPs. Mondal et al. (2015) used the MK and Sen’s slope tests on the monthly time series of precipitation data sets and found significant decreasing trend in the precipitation (−0.33 mm/year and −13.29%) especially in the month of August. He also found increasing trends in the March–April and November across the Sikkim, West Bengal and North-East India. In our study, we also revealed the similar outcomes and therefore the MK test results for annual and monthly basis time series are found meaningful. The Sen’s slope inspected how the magnitudes of a range of precipitation varied across the SBs in a temporal domain, and the results are comparable to other studies (Shivam et al. 2016; Mondal et al. 2015; Goyal 2014; Guo et al. 2014).
Choi et al. (2014) mentioned that the precipitation data not meant to predict precipitation for a given day at the particular location; they are rather suitable for showing general trends and variability. In the quantile-based regression analysis, we found significant increment in the precipitation trends especially for the RCP 8.5 as comparable to Choi et al. (2014). This study focuses on the several important considerations and consequences which were noticed in the spatiotemporal domain of the study catchment. The first is that in this research work we emphasized this study only on the precipitation variability across the state. Future works may extend this research work through the multivariate trends tests on precipitation along with temperature so one can compare the precipitation variability with increasing trend of temperature scenario. In this study, the projection of precipitation was done utilizing CMIP5 ESM-2M GCM model so that another research work may be emphasized on the RCM model, especially over Himalayan catchments. The precipitation variability and heterogeneity assessment can be taken into account for the downstream river flows and flood based hydrological hazard assessment studies.
5 Conclusion
In this research, the magnitude and frequency of extreme precipitation analyzed over Sikkim Himalayan region in a spatiotemporal domain. The observed precipitation (1979–2005) and CMIP5 based ESM-2M GCM datasets with multiple RCPs (2006–2100) successfully utilized to explore extreme precipitation changes over Teesta river Himalayan catchment. The MK and Sen’s slope revealed a significant increase in precipitation amount in the historical and projected time domains. The results showed that the spatial and temporal variability and heterogeneity in precipitation would be enhanced in the 21st century, as illustrated by different PEIs. The spatial heterogeneity explained using spatial standard deviation and spatial skewness through precipitation extreme indices and the high scale variability and changes in extreme precipitation are also revealed by quantile-based linear regression models. Our results showed a high level of geographical heterogeneity existed in the precipitation trends. We concluded that the increasing trends were mostly observed in annual time series, and the decreasing trends are prevailing for high extreme events and less extreme events, respectively. The MK test, Sen’s slopes, and QRs methods were successfully applied to check the precipitation variability and heterogeneity in a spatiotemporal domain over Sikkim Himalayan catchment.
References
Agarwal A, Babel MS, Maskey S (2014) Analysis of future precipitation in the Koshi river basin, Nepal. J Hydrol 513:422–434
Ahmed KF, Wang G, Silander J, Wilson AM, Allen JM, Horton R, Anyah R (2013) Statistical downscaling and bias correction of climate model outputs for climate change impact assessment in the US northeast. Glob Planet Change 100:320–332
Alexander LV, Zhang X, Peterson TC, Caesar J, Gleason B, Klein Tank AMG, Vazquez-Aguirre JL (2006) Global observed changes in daily climate extremes of temperature and precipitation. J Geophys Res (1984–2012) 111:D05109
Bajracharya SR, Mool PK, Shrestha BR (2008) Global climate change and melting of Himalayan glaciers. Melting glaciers and rising sea levels: Impacts and implications, pp 28–46
Bawa KS, Ingty T (2012) Climate Change in Sikkim: A Synthesis. Climate Change in Sikkim, Patterns, Impacts and Initiatives, pp 19–48
Brands S, Herrera S, Fernández J, Gutiérrez JM (2013) How well do CMIP5 earth system models simulate present climate conditions in Europe and Africa? Clim Dyn 41(3–4):803–817
Buytaert W, Vuille M, Dewulf A, Urrutia R, Karmalkar A, Célleri R (2010) Uncertainties in climate change projections and regional downscaling: implications for water resources management. Hydrol Earth Syst Sci Discuss 7:1821–1848
Chamaillé-Jammes S, Fritz H, Murindagomo F (2007) Detecting climate changes of concern in highly variable environments: QRs reveal that droughts worsen in Hwange National Park, Zimbabwe. J Arid Environ 71(3):321–326
Childs C (2004) Interpolating surfaces in ArcGIS spatial analyst. ArcUser, July–September, 32–35
Choi W, Tareghian R, Choi J, Hwang CS (2014) Geographically heterogeneous temporal trends of extreme precipitation in Wisconsin, USA during 1950–2006. Int J Climatol 34:2841–2852
De Lima MIP, Santo FE, Ramos AM, Trigo RM (2014) Trends and correlations in annual extreme precipitation indices for mainland Portugal, 1941–2007. Theor Appl Climatol 119(1):55–75
Dibike YB, Coulibaly P (2005) Hydrologic impact of climate change in the Saguenay watershed: comparison of downscaling methods and hydrologic models. J Hydrol 307(1):145–163
Donat MG, Alexander LV, Yang H, Durre I, Vose R, Dunn RJH, Kitching S (2013) Updated analyses of temperature and precipitation extreme indices since the beginning of the twentieth century: the HadEX2 dataset. J Geophys Res 118(5):2098–2118
Ghosh S, Luniya V, Gupta A (2009) Trend analysis of Indian summer monsoon rainfall at different spatial scales. Atmos Sci Lett 10:285–290
Gosling SN, Taylor RG, Arnell NW, Todd MC (2011) A comparative analysis of projected impacts of climate change on river runoff from global and catchment-scale hydrological models. Hydrol Earth Syst Sci 15(1):279–294
Goyal MK (2014) Statistical analysis of long term trends of rainfall during 1901–2002 at Assam, India. Water Resour Manag 28(6):1501–1515
Goyal MK, Ojha CSP (2011a) Evaluation of linear regression methods as downscaling tools in temperature projections over the Pichola Lake Basin in India. Hydrol Process 25(9):1453–1465
Goyal MK, Ojha CSP (2011b) PLS regression-based pan evaporation and minimum–maximum temperature projections for an arid lake basin in India. Theor Appl Climatol 105(3–4):403–415
Grimm AM (2011) Interannual climate variability in South America: impacts on seasonal precipitation, extreme events, and possible effects of climate change. Stoch Env Res Risk Assess 25(4):537–554
Guhathakurta P, Shreejith OP, Menon PA (2011) Impact of climate change on extreme rainfall events and flood risk in India. J Earth Syst Sci 120(3):359–373
Guo Z, Wang N, Kehrwald NM, Mao R, Wu H, Wu Y, Jiang X (2014) Temporal and spatial changes in Western Himalayan firn line altitudes from 1998 to 2009. Glob Planet Change 118:97–105
Hao L, Naiman DQ (Eds.) (2007) QR (No. 149). Sage
Harding RJ, Weedon GP, Van Lanen HAJ, Clark DB (2014) The future for global water assessment. J Hydrol 518:186–193
Harpham C, Wilby RL (2005) Multi-site downscaling of heavy daily precipitation occurrence and amounts. J Hydrol 312(1):235–255
Hashmi MZ, Shamseldin AY, Melville BW (2011) Comparison of SDSM and LARS-WG for simulation and downscaling of extreme precipitation events in a watershed. Stoch Env Res Risk Assess 25(4):475–484
Immerzeel WW, Van Beek LPH, Konz M, Shrestha AB, Bierkens MFP (2012) Hydrological response to climate change in a glacierized catchment in the Himalayas. Clim Change 110(3–4):721–736
Jena PP, Chatterjee C, Pradhan G, Mishra A (2014) Are recent frequent high floods in Mahanadi basin in eastern India due to increase in extreme rainfalls? J Hydrol 517:847–862
Kendall MG (1975) Rank correlation methods. Griffin, London
Khaliq MN, Sushama L, Monette A, Wheater H (2014) Seasonal and extreme precipitation characteristics for the watersheds of the Canadian Prairie Provinces as simulated by the NARCCAP multi-RCM ensemble. Clim Dyn 44(1):255–277
Kharin VV, Zwiers FW, Zhang X, Wehner M (2013) Changes in temperature and precipitation extremes in the CMIP5 ensemble. Clim Change 119(2):345–357
Kidson JW, Thompson CS (1998) A comparison of statistical and model-based downscaling techniques for estimating local climate variations. J Clim 11(4):735–753
Koenker R (2005) QR (No. 38). Cambridge university press
Krishnamurthy CKB, Lall U, Kwon HH (2009) Changing frequency and intensity of rainfall extremes over India from 1951 to 2003. J Clim 22(18):4737–4746
Kulkarni AV, Rathore BP, Singh SK, Ajai (2010) Distribution of seasonal snow covers in central and western Himalaya. Ann Glaciol 51(54):123–128
Kunkel KE (2003) North American trends in extreme precipitation. Nat Hazards 29(2):291–305
Leeds WB, Moyer EJ, Stein ML, Doan TK, Haslett J, Parnell AC, Philbin R, Jun M (2015) Simulation of future climate under changing temporal covariance structures. Adv. Stat. Climatol. Meteorol. Oceanogr. 1:1–14
Lupikasza E (2010) Spatial and temporal variability of extreme precipitation in Poland in the period 1951–2006. Int J Climatol 30(7):991–1007
Mahmood R, Babel MS (2013) Evaluation of SDSM developed by annual and monthly sub-models for downscaling temperature and precipitation in the Jhelum basin, Pakistan and India. Theoret Appl Climatol 113(1–2):27–44
Mann HB (1975) Nonparametric tests against trend. Econometrica 13:245–259
Meehl GA, Covey C, McAvaney B, Latif M, Stouffer RJ (2005) Overview of the coupled model intercomparison project. Bull Am Meteor Soc 86:89–93
Mondal A, Khare D, Kundu S (2015) Spatial and temporal analysis of rainfall and temperature trend of India. Theor Appl Climatol 122:143. doi:10.1007/s00704-014-1283-z
Nagi R (2012) Maintaining detail and color definition when integrating color and grayscale rasters using No Alteration of Grayscale or Intensity (NAGI) fusion method. In Proceedings, pp. 16–18
Neitsch SL, Arnold JG, Kiniry JR, Williams JR (2011) SWAT theoretical documentation version 2011. Grassland, Soil and Water Research Laboratory, Agricultural Research Service, Temple, TX
Oliveira PTS, Nearing MA, Moran MS, Goodrich DC, Wendland E, Gupta HV (2014) Trends in water balance components across the Brazilian Cerrado. Water Resour Res 50(9):7100–7114
Palazzi E, von Hardenberg J, Terzago S, Provenzale A (2015) Precipitation in the Karakoram-Himalaya: a CMIP5 view. Clim Dyn 45:21. doi:10.1007/s00382-014-2341-z
Pelt SCV, Beersma JJ, Buishand TA, Van den Hurk BJM, Schellekens J (2014) Uncertainty in the future change of extreme precipitation over the Rhine basin: the role of internal climate variability. Clim Dyn 1–12
Pervez MS, Henebry GM (2014) Projections of the Ganges-Brahmaputra precipitation-Downscaled from GCM predictors. J Hydrol 517:120–134
Rahman MM, Arya DS, Goel NK, Dhamy AP (2010) Design flow and stage computations in the Teesta River, Bangladesh, using frequency analysis and MIKE 11 modeling. J Hydrol Eng 16(2):176–186
Rao KHV, Rao VV, Dadhwal VK, Diwakar PG (2014) Kedarnath flash floods: a hydrological and hydraulic simulation study. Curr Sci 106(4):598–603
Ravindranath NH, Rao S, Sharma N, Nair M, Gopalakrishnan R, Rao AS, Bala G (2011) Climate change vulnerability profiles for North East India. Curr Sci 101(3):384–394
Romano E, Del Bon A, Petrangeli AB, Preziosi E (2013) Generating synthetic time series of springs discharge in relation to standardized precipitation indices. Case study in Central Italy. J Hydrol 507:86–99
Santos M, Fragoso M (2013) Precipitation variability in Northern Portugal: data homogeneity assessment and trends in extreme precipitation indices. Atmos Res 131:34–45
Sawilowsky SS (2005) Misconceptions leading to choosing the t test over the Wilcoxon Mann–Whitney test for shift in location parameter. J Modern Appl Stat Methods, 4(2):598–600. Retrieved, 2014-06-18
Sen PK (1968) Estimates of regression coefficients based on Kendall’s tau. J Am Stat Assoc 63:1379–1389
Sen Roy S, Balling RC (2004) Trends in extreme daily precipitation indices in India. Int J Climatol 24(4):457–466
Sengupta A, Rajeevan M (2013) Uncertainty quantification and reliability analysis of CMIP5 projections for the Indian summer monsoon. Curr Sci 105(12):1692
Shashikanth K, Salvi K, Ghosh S, Rajendran K (2014) Do CMIP5 simulations of Indian summer monsoon rainfall differ from those of CMIP3? Atmos Sci Lett 15(2):79–85
Shivam, Goyal MK, Sarma AK (2016) Analysis of the change in temperature trends in Subansiri River basin for RCP scenarios using CMIP5 datasets. Theor Appl Climatol. doi:10.1007/s00704-016-1842-6
Shrestha DL, Kayastha N, Solomatine DP (2009) A novel approach to parame- ter uncertainty analysis of hydrological models using neural networks. Hydrol Earth Syst Sci 13:1235–1248
Singh V, Goyal MK (2016) Analysis and trends of precipitation lapse rate and extreme indices over north Sikkim eastern Himalayas under CMIP5 ESM2-M RCPs experiments. Atmos Res. doi:10.1016/j.atmosres.2015.07.005
Snell SE (1998) Spatial interpolation of surface air temperatures using artificial neural networks: evaluating their use for downscaling GCMs. J Clim 13:886–895
Snell SE, Gopal S, Kaufmann RK (2000) Spatial interpolation of surface air temperatures using artificial neural networks: Evaluating their use for downscaling GCMs. J Clim 13(5):886–895
Subash N, Sikka AK (2013) Trend analysis of rainfall and temperature and its relationship over India. Theor Appl Climatol 117(3):449–462
Tareghian R, Rasmussen P (2013) Analysis of Arctic and Antarctic sea ice extent using QR. Int J Climatol 33(5):1079–1086
Taylor KE, Stouffer RJ, Meehl GA (2012) An overview of CMIP5 and the experiment design. Bull Am Meteorol Soc 93(4):485–498
Trenberth KE, Fasullo JT, Mackaro J (2011) Atmospheric moisture transports from ocean to land and global energy flows in reanalyses. J Clim 24:4907–4924. doi:10.1175/2011JCLI4171.1
Vittal H, Karmakar S, Ghosh S (2013) Diametric changes in trends and patterns of extreme rainfall over India from pre-1950 to post-1950. Geophys Res Lett 40:3253–3258. doi:10.1002/grl.50631
Wang X, Yang T, Li X (2016) Spatio-temporal changes of precipitation and temperature over the Pearl River basin based on CMIP5 multi-model ensemble. Stoch Env Res Risk Assess. doi:10.1007/s00477-016-1286-7
Wilby RL, Dawson CW (2013) Statistical downscaling model–decision centric (SDSM-DC) version 5.1 supplementary note. Loughborough University, Loughborough
Wilby RL, Dawson CW, Murphy C, O’Connor P, Hawkins E (2014) The statistical DownScaling model-decision centric (SDSM-DC): conceptual basis and applications. Clim Res 61:259–276
Yamada T (2000) Glacier lake outburst floods in Nepal. Seppyo 62(2):137–147 (in Japanese with English summary)
Yao T, Zhou H, Yang X (2009) Indian monsoon influences altitude effect of δ18O in precipitation/river water on the Tibetan Plateau. Chin Sci Bull 54(16):2724–2731
Zhang X, Tang Q, Zhang X, Lettenmaier DP (2014) Runoff sensitivity to global mean temperature change in the CMIP5 Models. Geophys Res Lett 41(15):5492–5498
Acknowledgements
This present research work has been carried out under DST research project entitled “Assessment of snowmelt and glacier melt runoff contribution in upstream part of Teesta river catchment using hydrological modeling and field based measurements” No. YSS/2014/000878 and financial support is gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Singh, V., Goyal, M.K. Spatio-temporal heterogeneity and changes in extreme precipitation over eastern Himalayan catchments India. Stoch Environ Res Risk Assess 31, 2527–2546 (2017). https://doi.org/10.1007/s00477-016-1350-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-016-1350-3