
Abstract
Seismic intensity, measured through the Mercalli–Cancani–Sieberg (MCS) scale, provides an assessment of ground shaking level deduced from building damages, any natural environment changes and from any observed effects or feelings. Generally, moving away from the earthquake epicentre, the effects are lower but intensities may vary in space, as there could be areas that amplify or reduce the shaking depending on the earthquake source geometry, geological features and local factors. Currently, the Istituto Nazionale di Geofisica e Vulcanologia analyzes, for each seismic event, intensity data collected through the online macroseismic questionnaire available at the web-page www.haisentitoilterremoto.it. Questionnaire responses are aggregated at the municipality level and analyzed to obtain an intensity defined on an ordinal categorical scale. The main aim of this work is to model macroseismic attenuation and obtain an intensity prediction equation which describes the decay of macroseismic intensity as a function of the magnitude and distance from the hypocentre. To do this we employ an ordered probit model, assuming that the intensity response variable is related through the link probit function to some predictors. Differently from what it is commonly done in the macroseismic literature, this approach takes properly into account the qualitative and ordinal nature of the macroseismic intensity as defined on the MCS scale. Using Markov chain Monte Carlo methods, we estimate the posterior probability of the intensity at each site. Moreover, by comparing observed and estimated intensities we are able to detect anomalous areas in terms of residuals. This kind of information can be useful for a better assessment of seismic risk and for promoting effective policies to reduce major damages.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Italy is one of the most earthquake prone country of Europe; its seismic network is composed by hundreds of seismograph stations (ITalian ACcelerometric Archive, ITACA http://itaca.mi.ingv.it/) used to estimate magnitude values and other seismological parameters (to this regard see the Italian Seismological Instrumental and parametric Data-basE, http://iside.rm.ingv.it). Even if these empirical data are reliable, obtaining a detailed definition and description of shaking is still a challenge, basically due to the high variability of ground motion. In addition to these instrumental data, there are also macroseismic data which refer to earthquake intensities measured by the Mercalli–Cancani–Sieberg scale (MCS; Sieberg 1930) or the European macroseismic scale (EMS; Grünthal 1998). In particular, macroseismic data regard earthquake effects on buildings, structures and people, and can be considered as a proxy of ground shaking deduced from building damages, from any natural environment changes and from any observed effects or feelings. These macroseismic data are usually provided by expert operators who collect information from direct observation in each village and evaluate the intensity through a critical analysis. These data are then collected in historical catalogues which in Italy date back to 461 B.C. It is worth to note that both the MCS and EMS intensity scales are qualitative and ordinal with categories ranging from I to XII. This means that we can surely say that the effects occurred in a municipality with intensity VIII are stronger than those associated with intensity IV, but there is not a well defined relation between intensity degrees and magnitude. In other words, we can not affirm quantitatively how intensity VIII relates to intensity IV as no precise numerical function is available to define the difference between intensity categories.
Concurrently with historical data, since 2007 INGV has been collecting macroseismic data through a web-survey available at www.haisentitoilterremoto.it (“hai sentito il terremoto?”, hereafter HSIT, literally “did you feel the quake?”). This tool allowed to gather more than 700,000 questionnaires regarding earthquakes widespread all over the Italian territory and felt by population. Even if derived from information provided by non-experts, the HSIT macroseismic intensities are reliable as shown in Sbarra et al. (2010), Tosi et al. (2015) and Mak et al. (2015), where agreements with values coming from traditional surveys and other web-based datasets were found. Moreover, differently from historical macroseismic catalogue, the HSIT database includes a large amount of low degree intensity data, generally disregarded by traditional macroseismic investigation and analysis (Pasolini et al. 2008). These data refer to areas far from the epicentre of high magnitude earthquakes or to areas at a short distance from low magnitude earthquakes.
The main aim of this work is the definition of a new intensity prediction equation (IPE) for Italian earthquakes using the macroseismic data available through the HSIT survey. The IPE describes the decay of macroseismic intensity as a function of the magnitude and distance from the epicentre/hypocentre and it is paramount in the analysis and interpretation of both recent and historical macroseismic intensity data. Moreover, it can be useful for prevention of damages, since it allows to compare expected (estimated by IPE) and observed intensities for detecting areas at major or minor risk to experience damages (Kamat 2014; Goda and Song 2015). In literature many IPEs (also named attenuation models or laws) have been proposed (see for example Gómez Capera 2006 and Mak et al. 2015), where the intensity (or its difference with the epicentral intensity) is a function of some covariates as epicentral intensity, quake depth and magnitude, site type, epicentral/hypocentral distance, etc. However, these IPEs are based on historical databases which suffer from lack of accuracy for long distance and lack of data of low magnitude earthquakes.
The models for intensity decay can be specified using a deterministic (Atkinson and Wald 2007) or a probabilistic approach (Magri et al. 1994; Pasolini et al. 2008) and, in the latter case, a statistical distribution is assumed for the response variable or the error term. Regardless of the adopted approach, so far intensities have been commonly treated as realizations of a quantitative distribution (continuous or discrete). As a result, numerical scores are (improperly) assigned to ordered intensity categories and least squares method are used to estimate the IPE parameters. Ignoring the ordinality of the response can yield predicted values which are not consistent with the ordinal nature of the intensity scale. More appropriate methodologies, which take into account the categorical nature of data, are proposed by Rotondi et al. (2008) and Zonno et al. (2009), even if applied on a small subset of data from the historical catalogue. Recently, a similar approach was adopted in Rotondi et al. (2015) for the large Italian macroseismic database DBMI11 and in Azzaro et al. (2013) for modeling macroseismic intensity attenuation in the Mt. Etna region taking into account anisotropy.
The novel contribution of this work consists in defining a new intensity prediction equation which takes properly into account the qualitative and ordinal nature of the macroseismic intensity, by using a large amount of data provided by HSIT web-survey. To do this, we adopt an ordered probit model (Agresti 2010; Charvet et al. 2014) where the intensity response variable is related through the probit link function to some predictors, such as the distance from the hypocentre and the earthquake magnitude. Through this method, we are able to estimate the macroseismic intensity at all the desired locations, thus obtaining a new reliable IPE. Finally, an evaluation of anomalous areas is provided through ad-hoc residual analysis, i.e. by deriving the probability distribution of the difference between observed and expected intensities.
The paper is structured as follows: in Sect. 2 we introduce the web-based macroseismic survey of www.haisentitoilterremoto.it. In particular we describe the macroseismic questionnaire and the kind of data which are collected through it. The ordered probit model and the Bayesian estimation procedure via MCMC are detailed in Sect. 3, while Sect. 4 presents the results of the application with HSIT data. Section 5 concludes the paper by summarizing the main findings and includes some avenues for future research.
2 Macroseismic data from www.haisentitoilterremoto.it
The online macroseismic questionnaire, which is compiled by volunteers after having felt an earthquake, is composed by questions regarding the effects on the population and buildings evaluated following the MCS and EMS macroseismic scale (see Tosi et al. 2015 for a complete description). The questions regard: (i) personal information and geographic location at the time of the earthquake; (ii) transient effects evaluated through personal reactions, movement and/or fall of objects, and activity of the observer during the earthquake (sleeping, walking, being still); (iii) building damages. In addition to volunteers, there exists also a permanent and constantly increasing group of compilers (approximately 25,000), who are alerted via e-mail immediately after the occurrence of an earthquake near their municipality. Visiting the HSIT web-page of the considered event, they provide the location at the moment of the occurrence and declare if they felt or not the earthquake; in the first case, the macroseismic questionnaire can be filled in.
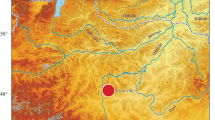
Using the procedure described in Tosi et al. (2015), an automated procedure controls the reliability of questionnaires and discharges those which either contain contradictory answers or insufficient information. Then, an algorithm is applied to the valid questionnaires in order to assign an unique intensity value (located on the centroid) for each municipality. Macroseismic intensity maps (both for MCS and EMS scales) are produced in real-time from the processing of the questionnaires and immediately displayed on the HSIT web-site (see Fig. 1 for an example). Through the survey, thus, it is possible to obtain a real-time and widespread evaluation of earthquake intensities thanks to the amount of available data which is extremely larger than the one provided by direct observation of expert operators.
Note that the intensities provided by the HSIT procedure are given as real numbers, as a result of the algorithm described in Tosi et al. (2015), and in this work are approximated to the nearest integer value in accordance to the MCS and EMS degrees between II and VIII. Moreover, it is known that intensity web-based data collected for earthquakes very close in time could be affected by compilation errors. We thus excluded all aftershocks of magnitude lower than 4.5 occurred within 8 h from each widely felt mainshock (identified as an earthquake of magnitude greater than or equal to 4.5 having more than 300 reports). Finally, we discarded the firstly felt earthquake before the mainshock, because, in case of a strong event, respondents often fail to choose the right event from the automatic list that appears on the HSIT web-site.

Macroseismic intensity map from the HSIT web-site concerning the L’Aquila earthquake (April, 6th 2009, magnitude 5.8)
3 The ordered probit model
For ordinal data several multinomial models are available in literature and a comprehensive presentation can be found in Agresti (2010). Among those, a predominant role is played by the class of cumulative link models which link cumulative probabilities to a linear predictor. The most commonly used link functions are the logit and probit, the second one being the inverse of the standard Normal cumulative distribution function (cdf). The probit link was the most natural solution for this work as our model includes Gaussian distributions. Moreover, as specified in Albert and Chib (1993) and Cowles (1996), this choice gives rise to some computational benefits from the inferential point of view (see Sect. 3.1).
For municipality \(i=1,\ldots ,I\) and earthquake \(c=1,\ldots ,C\) let \(y_{ic}\) be the felt intensity estimated through the HSIT web-survey. The response \(y_{ic}\) is one of the values in the set \(\{II,\ldots ,VIII\}\) of 7 intensity categories. The value \(y_{ic}\) can be defined as a realization of the Multinomial distribution \(Y_{ic}\) with 7 categories and one trial; we denote this as
with \(\pi _{j}=p(Y_{ic}=j)\) for \(j\in \{II,\ldots ,VIII\}\).
We introduce now a latent (i.e. non observable) continuous and normally distributed variable \(Y_{ic}^{\star }\) defined as
where \({\varvec{X}}_{ic}=(X_{ic1},\ldots ,X_{ick},\ldots ,X_{icK})\) is the vector of K covariates (i.e. explanatory variables) with coefficients \({\varvec{\beta }}=(\beta _1,\ldots , \beta _k, \ldots , \beta _K)^T\) and \(\epsilon _{ic}\) is a Gaussian random variable defined as \(\epsilon _{ic}\sim {\text{ N }}\,(0,\sigma ^{2})\) independently for each i and c. The latent variable represents the actual strength of the ground shaking for which we can observe only the effects through \(y_{ic}\).
The relationship between \(Y_{ic}\) and \(Y_{ic}^{\star }\) is given by
where \({\text {r}}(\cdot)\) is the rank function (e.g. \({\text {r}}(II)=2\)) and \({\varvec{\tau }}=(\tau _{1},\ldots ,\tau _{6})\) is the vector of ordered thresholds to be estimated. The number of thresholds is given by the number of intensity categories minus 1. To illustrate this relationship, we consider a simple example with intensities ranging from II to VI, thus involving 5 categories and 4 thresholds \({\varvec{\tau }}=(\tau _{1},\ldots ,\tau _{4})\). Figure 2 displays the distribution of the latent variable \(Y_{ic}^{\star }\) and the corresponding intensity probabilities obtained using the relationship defined in Eq. (1).

Latent variable \(Y_{ic}^{\star }\) and corresponding intensity probabilities
To compute the probability of having an intensity equal to II we proceed as follows:
where \(\Phi (\cdot )\) is the cdf of the standard Normal distribution. In the same way the probability for a generic intensity \(j\in \{III,\ldots ,VII\}\) is given by
Moreover, for the last intensity it holds that \(p(Y_{ic}=VIII)=1-p(Y_{ic}\le VII)\), where the cumulative probability for \(j\in \{II,\ldots ,VII\}\) is defined as
with the property that \(0<p(Y_{ic}\le II)<p(Y_{ic}\le III)<\ldots <p(Y_{ic}\le VIII)=1\).
Following Agresti (2010), the cumulative probit model is defined as
for \(j\in \{II,\ldots ,VII\}\), where \(\Phi ^{-1}(\cdot )\) is the inverse of the Gaussian cdf which represents the so called probit function that links the cumulative probability to the linear predictor given by \(\frac{\tau _{\text {r}(j)-1}-{\varvec{X}}_{ic}{\varvec{\beta }}}{\sigma }\).
For identifiability reasonFootnote 1, for probit models it is common to fix the first threshold \(\tau _{1}\) equal to 0. Moreover, as mentioned in Agresti (2010), since the observed ordinal scale provides no information about the variability of the latent variable \(Y_{ic}^{\star }\), without loss of generality, we can set its standard deviation \(\sigma\) equal to 1. So Eq. (3) becomes
for \(j\in \{II,\ldots ,VII\}\).
To illustrate the cumulative probit model and the interpretation of the covariate coefficients, we get back to the simple example introduced before with 5 categories (from II to VI) by assuming to have just one explanatory variable (thus \(K=1\) and \({\varvec{X}}_{ic}\) is a scalar simply denoted by \(x_{ic}\)) which can take real values in the interval \([-6,+6]\). Moreover, we assume that the covariate coefficient \(\beta\) is positive. The top plot in Fig. 3 depicts the cumulative probabilities \(p(Y_{ic}\le j)\) for different values of the covariate. It is worth noting that each curve (each one corresponds to a differ intensity) has the same shape since the coefficient \(\beta\) is common to all the categories, i.e. the covariate effect does not change according to the intensity. Moreover, it can be observed that for a given intensity j, when \(x_{ic}\) increases, the corresponding cumulative probability decreases, hence \(Y_{ic}\) is less likely to assume a value lower or equal to category j (and therefore values greater than j are more likely to occur). In fact, the bottom plot in Fig. 3, which displays the probability \(p(Y_{ic}=j)\) for different values of the covariate, shows that for small values of \(x_{ic}\) the lowest category occurs with the highest probability and the highest category happens for high values of \(x_{ic}\). Note that for a given value of \(x_{ic}\) the sum of the 5 probabilities is equal to 1. For the case \(\beta <0\) (not reported here) the opposite happens: the cumulative probabilities increase as the covariate increases and the lowest category is more likely to happen for high values of \(x_{ic}\).

Cumulative probabilities (top) and category probability distribution (bottom) for different values of the covariate when considering 6 categories and \(\beta >0\)
3.1 Estimation procedure in a Bayesian framework
The parameter vector for the cumulative probit model defined in the previous section is given by \({\varvec{\theta }}={(\varvec{\tau }},{\varvec{\beta })}\). Bayesian inference via MCMC is carried out following the approach of Albert and Chib (1993) which is based on the data augmentation method Tanner and Wong (1987) that treats the latent variable \(Y^{\star }\) as an additional parameter.
Let \({\varvec{X}}=\left({ \varvec{X}}_1^T,\dots ,{\varvec{X}}_{n}^T,\dots ,{\varvec{X}}_N^T\right) ^T\) be the \((N\times K)\) covariate matrix, \({\varvec{y}}=\left( y_1,\dots ,y_{n},\dots ,y_N\right) ^T\) the \((N\times 1)\) vector of observations and \({\varvec{Y}}^\star =\left( Y^\star _1,\dots , Y^\star _{n}, \dots , Y^\star _N\right) ^T\) the \((N\times 1)\) latent variable vector. Note that the total number of cases \(N\le I\times C\) (I and C being the n. of municipalities and earthquakes respectively) since not all the earthquakes are felt in all the municipalities. The index \(n=1,\ldots ,N\) refers to the case identified by the couple (i, c) with \(i\in \{1,\ldots ,I\}\) and \(c\in \{1,\ldots ,C\}\).
Given this notation and following the Gibbs sampler algorithm described in Albert and Chib (1993), the following full conditionals are derived when diffuse prior for \({\varvec{\beta }}\) and \({\varvec{\tau }}\) are used:
-
1.
\(p\left({\varvec{\beta }}\mid {\varvec{Y}}^\star ,{\varvec{y}}\right) =\text{ N }\left( ({\varvec{X^T X}})^{-1} {\varvec{X^T}}{\varvec{Y^\star }},({\varvec{X^T X}})^{-1}\right)\),
-
2.
\(p\left( Y_{ic}^{\star }\mid {\varvec{\beta }}, {\varvec{\tau }},y_{ic}\right) ={\text{ N }}{(\varvec{X}}_{ic}{\varvec{\beta }},1)\) truncated at the left by \(\tau _{\text {r}(j)-1}\) and at the right by \(\tau _{\text {r}(j)}\) with \(j\in \{II,\ldots ,VII\},\)
-
3.
\(p\left( \tau _{\text {r}(j)-1}\mid {\varvec{Y}}^\star ,{\varvec{\beta }},{\varvec{y}}s,\{\tau _{\text {r}(k)},k\ne j \}\right) ={\text {Unif}}\left( \gamma ,\delta \right)\), where \(\gamma ={\text {max}}\{{\text {max}} \; \{Y_{ic}^\star :Y_{ic}=j\},\tau _{\text {r}(j)-2}\}\), \(\delta ={\text {min}}\{{\text {min}}\;\{Y_{ic}^\star :Y_{ic}=j+1\},\tau _{\text {r}(j)}\}\), with \(j\in \{II,\ldots ,VII\}\), \(\tau _0=-\infty\) and \(\tau _7=+\infty\).
To simulate values from the joint posterior \(p({\varvec{\theta }}\mid {\varvec{y}})\) the Gibbs sampler draws values iteratively from all the conditional distributions. For implementing such a procedure we resort to the MCMCoprobit function of the MCMCpack R package (R Core Team 2015), whose details are reported in Andrew et al. (2011).
4 Application
4.1 Data and model specification
The considered data refer to \(C=1917\) earthquakes occurred in the Italian territory from January 2009 to August 2015 with local magnitude (\(M_L\)) ranging from 2 to 5.9, depth lower than 35 km and \(log_{10}\)-hypocentral distance (logD) larger than 0.5 in 99.8 % of the cases. Most of the events had \(M_{L}\) between 2 and 4 (about 95 %) while the percentage of earthquakes with a magnitude greater than 5 is about 0.5 %. The intensities (on the MCS scale) range from II to VII with the modal intensity II occurring in 46 % of the cases.
In order to have more reliable data, we selected the macroseismic intensities of the municipalities having more than ten questionnaires for each seismic event, resulting in \(I=945\) municipalities. Each municipality may have experienced more than one seismic event, so that the final database consists of \(N=6723\) cases. Besides intensity, for each municipality and earthquake, the \(log_{10}\)-hypocentral distance and the magnitude are available. Thus, the covariate vector for each case is given by \({\varvec{X}}_{ic} = (1,{M_{L}}_{ic}, {{\text {logD}}_{ic})}\), where the term 1 refers to the intercept with \(\beta _0\) coefficient. As there are 6 intensity categories (from II to VII) we have 5 thresholds \({\varvec{\tau }}=(\tau _1=0,\tau _2,\ldots ,\tau _5)\) and the vector of unknown parameters is \({\varvec{\theta }}=({\varvec{\tau }}, \beta _0, \beta _{{M_{L}}}, \beta _{\text {logD}})\).
In order to ensure convergence of the Gibbs sampler, we ran chains of 2,500,000 iterations, with a burn-in of 500000 and a thin interval of 200. Convergence was assessed by monitoring the mixing of the chains, through trace plots, together with the Gelman–Rubin and Geweke diagnoses (Gelman and Rubin 1992; Geweke 1992).
4.2 Results
Convergence diagnoses indicated a good chain mixing for all parameters. In particular, the Geweke z statistics (in absolute value) range from 0.24 to 0.78 with p-values bigger than 0.43, thus suggesting the convergence achievement. Similarly, the Gelman–Rubin diagnoses, computed by running two independent chains for each parameter, produce a potential scale reduction factor lower than 1.1 for all parameters.
The posterior parameter estimates are reported in Table 1. It can be seen that all the parameters are significantly different from zero (95 % HPD intervals do not include zero). Moreover, the magnitude coefficient \(\beta _{{M_{L}}}\) is positive with posterior mean equal to 2.464. This means that (keeping all the other covariates fixed) a change in the magnitude of 1 degree causes an increase in the latent variable \(Y^\star\) of 2.464 (on average). Concerning the influence of \(M_{L}\) on the response variable (i.e. the intensity), we can conclude that when the magnitude increases the cumulative probability of observing an intensity lower than or equal to the generic category decreases (and the probability of observing a higher intensity increases). This is a situation similar to the one plotted in Fig. 3. Differently, the posterior mean of the distance coefficient \(\beta _{\text {logD}}\) is equal to \(-5.229\). This means that (keeping all the other covariates fixed) a change distance of 1 (on the kilometer logarithmic scale) causes an average change in the latent variable of \(-5.229\). As expected, with respect to the response variable, when the distance increases, the cumulative probability of observing a given intensity, or one lower, increases (and the probability of observing a higher intensity decreases). This is reasonable and in line with the nature and the geophysical characteristic of the phenomenon under study (Schubert 2015).
Once the model parameters have been estimated, it is possible to compute, for any desired value of the log-hypocentral distance and of the magnitude, the intensity posterior distribution, i.e. the posterior probabilities of occurrence for every intensity value \(j\in \{II, \ldots ,VII\}\) using the following formula:
where the hat notation is used to denote the posterior parameter mean. As mentioned in Sect. 3, \(\sigma\) is fixed equal to 1 and for the first and last category the formula is adapted accordingly.
Figure 4 displays the intensity probability distribution for two given values of \(M_{L}\) (3.5, 5) and logD (1 and 2); the category with the highest probability (i.e. the modal intensity) is depicted by a star. As we can see, with a moderate magnitude (\(M_{L}\) = 3.5) and with a short distance \({\mathrm{(logD=1)}}\) the modal intensity is IV (with a probability of about 0.85); instead, when \({\mathrm{(logD=2)}}\), the modal intensity becomes II. Coherently, with a higher magnitude (\(M_{L}\) = 5) the modal intensity (with a probability of about 0.5) is V for the shorter distance and decreases down to III at the longer distance.

Probability distribution of intensity given some values of magnitude (3.5 and 5) and logD (1 and 2). The star denotes the highest probability intensity (modal intensity)
We focus now on the main objective of this work, i.e. the definition of a new intensity prediction equation based on the intensity probability distribution. In particular, we analyze the effect of a distance change on the intensity distribution [computed using Eq. (4)] by determining the modal intensity for different values of \(M_{L}\) (3.5 and 5) and logD (100 values between 0.5 and 3). Figure 5 displays the modal intensity according to distance (i.e. the estimated IPE). Each point represents the modal intensity with its corresponding probability (using the classes [0,0.5], (0.5,0.8], (0.8,1]). In particular, with \(M_{L}\) = 3.5 and \({\mathrm {logD \simeq 1}}\) the intensity IV (dark gray point) has a probability of occurrence in (0.8, 1]; the same probability class is reached for distance larger than 1.7 by intensity II. Notably, we consider the probability associated to each intensity as a measure of uncertainty. The segments departing from each point indicate which intensities have to be accounted, together with the modal one, for reaching an occurrence probability of at least 0.8. Looking, for example, at the bottom panel of Fig. 5, with \({\mathrm {logD=2}}\) the modal intensity is III with a probability lower than 0.5 (light gray point). From this point a light gray segment departs toward intensity IV, that has an occurrence probability of about 0.38 (see bottom-right panel of Fig. 4): this means that the probabilities of degree III and IV together reach at least 0.8. In this sense, points with no segment refer to very reliable intensities (i.e., probability bigger than 0.8), whereas point with one or two segments refer to more uncertain modal intensity.
By comparing several IPEs (not reported here), we can conclude that with lower magnitudes the IPEs decrease more rapidly and show less uncertainty with respect to those generated from earthquakes with higher magnitudes.

IPE for some values of magnitude (3.5 and 5) and logD (100 values between 0.5 and 3). The color of points represents the probability (in classes) associated with the modal intensity. The segments of each point indicate which intensities have to be accounted, together with modal intensity, for reaching an occurrence probability of at least of 0.8.
4.3 Analysis of residuals
Once IPE is defined for a given magnitude, it can be used as an operative tool to compute expected intensities (and probabilities) as a function of the hypocentral distance. Computing the residuals between observed and expected intensities is paramount in defining anomalous areas, with positive (negative) residuals possibly associated with seismic waves amplification (attenuation) (Papoulia and Stavrakakis 1990).
Considering the range of observed macroseismic intensities (from II to VII), in order to improve the seismic interpretability of residuals, we exclude from the analysis the cases with estimated modal intensity equal to the minimum and maximum values (II and VII) because they would give rise to residuals which are always positive/negative or equal to zero.
For each municipality i, where a number of \(m_i\) earthquakes were felt, \(m_i\) observed intensities \(I^{Obs}\) are available from the HSIT web-site (approximated to the nearest integer as discussed in Sect. 2), together with \(m_i\) intensity probability distributions with modal category \(\hat{I}\) obtained by the ordered probit model. It is thus possible to derive for each municipality \(m_i\) residual probability distributions, each being a discrete random variable defined as \((I^{Obs}_{ic}-\hat{I}_{ic})\) with probabilities \(p_{ic}\) obtained by Eq. (4) and \(c=1,\ldots ,m_i\).
Then we calculate the random variable sum of residuals denoted by \(R_i\), obtained by summing the \(m_i\) residual probability distributions. Finally, for each municipality we are able to estimate the mean residual and its corresponding variance as the expected value and variance of the random variable mean of residuals \(R_i/m_i\).
We are aware that this approach is not the standard one for computing residuals in the case of ordinal outcome (e.g. Pearson residuals; Agresti 2002); moreover, one drawback is that while computing residuals we are implicitly assigning equal-distance scores to the ordered categories. However, we think that this proposal is reasonable for the purpose of this paper (i.e. evaluation of anomalous areas) and has the advantage of providing a single residual value for each municipality (considering all the felt earthquakes) which has to be interpreted as a measure of total discrepancy between observed and predicted intensities.
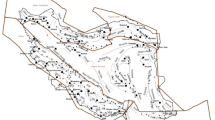
Figure 6 shows the obtained mean residuals and standard deviations. Blue circles correspond to municipalities where observed intensities are lower than estimated intensities, suggesting seismic attenuation; while red points, with positive residuals, point out seismic amplification. Gray shaded areas correspond to high values of the residual standard deviation. Interestingly, positive (red) and negative (blue) values tend to be spatially aggregated, whereas the areas of high standard deviation correspond to a greater uncertainty of the municipality intensity data. The prevalence of orange circles in North Italy highlights an amplification area localized in between the Alps chain and the Padana plain. This could be caused by the presence of sedimentary basin trapping and amplifying seismic waves. The greater part of municipalities near the North Apennines have negative residuals revealing an attenuation area. Furthermore, we can highlight other two areas with prevalence of positive mean residuals: one in central Italy with a North-South elongation, and the second one located at the south of Naples.

Map of the mean and standard deviation of residuals. Geographic coordinates are between 6.6\(^\circ\) and 20\(^\circ\) East longitude and between 36.6\(^\circ\) and 46.7\(^\circ\) North latitude. Colored circles represent the municipality and the gray shaded contours represent the corresponding standard deviations
5 Discussion
Italy, as one of the most seismically active countries, needs an effective and reliable analysis of seismic risk. The possibility of defining zones of high seismic shaking is a crucial goal for promoting effective policy to prevent major damages. In this regard, a reliable IPE definition is the necessary step. It offers an operative way to calculate the expected intensity given the earthquake magnitude and the hypocentral distance. On the other hand, it is worth to note that the intensity evaluation based only on the IPE is not complete, due to several factors which may significantly change the observed shaking. For this reason a common procedure consists in performing a residual analysis with observed and estimated intensity data. If these residuals are spatially homogeneous they can be caused by the influence of regional geological condition or by the predominant source mechanism (Sbarra et al. 2012). Analyzing several events for each municipality, the source mechanism contribution to the intensity is reduced, thus evidencing a possible local effect related, for example, to geological characteristics, which could be potentially included, if available, in the model as covariates.
Further confirmation are necessary to validate our findings because of the short length of the HSIT data series (2009–2015) which could not be fully representative of a seismicity of long period. However, our results are consistent with those found in previous works (see e.g. Albarello et al. 2002) and, at the same time, provide an interesting new benchmark for comparison with any other risk maps carried out for this kind of data. In this sense, our work can be considered as a first step to detect local responses to seismic shaking in Italy.
From a methodological point of view, we employed the ordered probit model using a Bayesian approach. Although this model is well established in the statistical literature, its application to a large amount of macroseismic intensity data is original and unavoidable for defining a reliable IPE which takes properly into account the ordinal nature of data.
A possible extension of this work could deal with the spatial structure of the data by including a spatial process in the model equations. In literature, models for spatially correlated ordered categorical data are relatively new (Brewer et al. 2004; Higgs and Hoeting 2010). The main obstacle to implement such models concerns the computational burden that can negatively impact the performance of MCMC model-fitting algorithms (Berrett and Calder 2012), making the estimation procedure for large data set unfeasible. Unfortunately, as far as we know, not even other more efficient algorithms alternative to MCMC, such as the Integrated Nested Laplace Approximation (INLA, Serra et al. 2013; Blangiardo and Cameletti 2015), can be applied as they are not available for ordinal response data. Thus, the development of computationally effective ad-hoc algorithms needs to be addressed in the future research for analyzing the complete HSIT dataset through a spatial model. Another possibility would consist in restricting the analysis to a small target area—identified for example using the residual map in Fig. 6—in order to apply the algorithm proposed by Higgs and Hoeting (2010).
Notes
The model parameters \({\varvec{\beta }}, {\varvec{\tau }},\sigma\) are not identified as any change in the scale parameter \(\sigma\) can be offset by changes in \({\varvec{\tau }}\) and \({\varvec{\beta }}\).
References
Agresti A (2002) Categorical data analysis. Wiley, New York
Agresti A (2010) Analysis of ordinal categorical data. Wiley, New York
Albarello D, Bramerini F, D’ Amico V, Lucantoni A, Naso G (2002) Italian intensity hazard maps: a comparison of results from different methodologies. Boll Geofis Teor Appl 43:249–262
Albert JH, Chib S (1993) Bayesian analysis of binary and polychotomous response data. J Am Stat Assoc 88:669–679
Andrew DM, Kevin M, Jong Hee P (2011) MCMCpack: Markov Chain Monte Carlo in R. J Stat Softw 42:1–21
Atkinson G, Wald D (2007) “Did you feel it?” intensity data: a surprisingly good measure of earthquake ground motion. Seismol Res Lett 78:362–368
Azzaro R, D’Amico S, Rotondi R, Tuvé T, Zonno G (2013) Forecasting seismic scenarios on etna volcano (italy) through probabilistic intensity attenuation models: a Bayesian approach. J Volcanol Geotherm Res 251:149–157
Berrett C, Calder C (2012) Data augmentation strategies for the Bayesian spatial probit regression model. Comput Stat Data Anal 56:478–490
Blangiardo M, Cameletti M (2015) Spatial and spatio-temporal Bayesian models with R-INLA. Wiley, Chichester
Brewer MJ, Elston DA, Hodgson M, Stolte AM, Nolan AJ, Henderson DJ (2004) A spatial model with ordinal responses for grazing impact data. Stat Probab 4:127–143
Charvet I, Suppasri A, Imamura F (2014) Empirical fragility analysis of building damage caused by the 2011 great east japan tsunami in Ishinomaki city using ordinal regression, and influence of key geographical features. Stoch Environ Res Risk Assess 28(7):1853–1867
Cowles M (1996) Accelerating Monte Carlo Markov Chain convergence for cumulative-link generalized linear models. J Am Stat Assoc 6:101–111
Gelman A, Rubin D (1992) Inference from iterative simulation using multiple sequences. Stat Sci 7:457–472
Geweke J (1992) Evaluating the accuracy of sampling-based approaches to the calculation of posterior moments. In: Bernardo JM, Berger JO, Dawid AP, Smith AFM (eds) Bayesian statistics 4. Oxford University Press, Oxford, pp 169–193
Goda K, Song J (2015) Uncertainty modeling and visualization for tsunami hazard and risk mapping: a case study for the 2011 tohoku earthquake. Stoch Environ Res Risk Assess 1–15
Gómez Capera AA (2006) Seismic hazard map for the Italian territory using macroseismic data. Earth Sci Res J 10:67–90
Grünthal GE (1998) European macroseismic scale 1998. Cahiers du Centre Européen de Geodynamique et de Séismologie 15:1–99
Higgs MD, Hoeting JA (2010) A clipped latent-variable model for spatially correlated ordered categorical data. Comput Stat Data Anal 54:1999–2011
Kamat R (2014) Planning and managing earthquake and flood prone towns. Stoch Environ Res Risk Assess 29(2):527–545
Magri L, Mucciarelli M, Albarello D (1994) Estimates of site seismicity rates using ill-defined macroseismic data. Pure Appl Geophys 143:617–632
Mak S, Clements RA, Schorlemmer D (2015) Validating intensity prediction equations for Italy by observations. Bull Seismol Soc Am 105(6):2942–2954
Papoulia JE, Stavrakakis GN (1990) Attenuation laws and seismic hazard assessment. Nat Hazards 3:49–58
Pasolini C, Albarello D, Gasperini P, D’Amico V, Lolli B (2008) The attenuation of seismic intensity in Italy, part II: modeling and validation. Bull Seismol Soc Am 98:692–708
Core Team R (2015) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna
Rotondi R, Tertulliani A, Brambilla C, Zonno G (2008) The intensity attenuation of Colfiorito and other strong earthquakes: the viewpoint of forecasters and data gatherers. Ann Geophys 51:499–507
Rotondi R, Varini E (2015) Probabilistic modelling of macroseismic attenuation and forecast of damage scenarios. Bull Earthq Eng 4:1–20
Sbarra P, Tosi P, De Rubeis V (2010) Web-based macroseismic survey in Italy: method validation and results. Nat Hazards 54(2):563–581
Sbarra P, De Rubeis V, Di Luzio E, Mancini M, Moscatelli M, Stigliano F, Tosi P, Vallone R (2012) Macroseismic effects highlight site response in Rome and its geological signature. Nat Hazards 62:425–443
Schubert G (2015) Treatise on geophysics. Elsevier Science, Amsterdam
Serra L, Saez M, Juan P, Varga D, Mateu J (2013) A spatio-temporal poisson hurdle point process to model wildfires. Stoch Environ Res Risk Assess 28(7):1671–1684
Sieberg A (1930) Handb der Geophys 2:552–555
Tanner T, Wong W (1987) The calculation of posterior distributions by data augmentation. J Am Stat Assoc 82:528–550 (with discussion)
Tosi P, Sbarra P, De Rubeis V, Ferrari C (2015) Macroseismic intensity assessment method for web questionnaires. Seismol Res Lett 86(3):985–990
Zonno G, Rotondi R, Brambilla C (2009) Mining macroseismic fields to estimate the probability distribution of the intensity at site. Bull Seismol Soc Am 99:2876–2892
Acknowledgments
This research was partially founded by INGV-DPC agreement S2-2012—Constraining Observations into Seismic Hazard. The authors would like to thank two anonymous reviewers who provided valuable comments.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Cameletti, M., De Rubeis, V., Ferrari, C. et al. An ordered probit model for seismic intensity data. Stoch Environ Res Risk Assess 31, 1593–1602 (2017). https://doi.org/10.1007/s00477-016-1260-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-016-1260-4