
Abstract
We consider a problem of association test in high dimension. A new test statistic is proposed based on the covariance of random vectors and its asymptotic properties are derived under both the null hypothesis and the local alternatives. Furthermore power enhancement technique is utilized to boost the empirical power especially under sparse alternatives. We examine the finite-sample performances of the proposed test via Monte Carlo simulations, which show that the proposed test outperforms some existing procedures. An empirical analysis of a microarray data is demonstrated to detect the relationship between the genes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Traditional statistical methods for measuring the association between random vectors are generally based on coefficient (covariance). See Wilks (1935), Anderson (2003), Robert et al. (1985), Székely et al. (2007) and among others. Wilks (1935) introduced an effective likelihood ratio test (LRT) for block independence under Gaussian population and Anderson (2003) detailed LRT for the Gaussian population. RV correlation coefficient proposed by Escoufier (1973) was considered in Robert et al. (1985) to measure multivariate association between two sets of variables. Székely et al. (2007) developed distance covariance and distance correlation, and provided an approach to the problem of testing the joint independence of random vectors. The asymptotic properties of these classical procedures aforementioned are established under the scheme that the sample size n tends to infinity and the dimensions(p and q) are fixed. This is the so-called “small p and q, large n” paradigm.
However, high-dimensional data, such as microarray analysis, tumor classification and biomedical imaging, tend to have a dimension ( p and (or) q ) comparable to, or much larger than, the sample size n. This brings great challenges to these traditional methods. For example, the empirical power of the conventional test may be largely impacted by the increasing dimension, and even converges to the significance level \(\alpha \) due to “the curse of dimensionality”, which means that the test cannot distinguish the null hypothesis from the alternatives. Therefore more and more statisticians are pursuing new methods to address the high-dimensional problems. To accommodate the large-dimensionality, Jiang et al. (2013) proposed the corrected likelihood ratio test and large-dimensional trace criterion to test the independence of two large sets of multivariate variables when the dimensions \(p+q\) and the sample size n tend to infinity simultaneously. To make the RV coefficient be applicable for high-dimensional data, some test procedures are introduced in the following two papers. Srivastava and Reid (2012) proposed a new statistic based on the RV coefficient for testing the independence of two sub-vectors, and obtained its asymptotic properties under the scheme that \(\min (p,q,n)\rightarrow \infty \), \( p/(p+q)\rightarrow d_1>0, q/(p+q)\rightarrow d_2>0\) and \(n=O((p+q)^{\delta })\) for some constant \(\delta >0\). By constructing an unbiased estimator for the numerator of the RV coefficient, Li et al. (2017) considered the independence test under the assumption that only one random vector has a divergent dimension, that is, \(\min (p,n)\rightarrow \infty \) and q is fixed. The asymptotic properties in these three papers (Jiang et al. 2013; Srivastava and Reid 2012; Li et al. 2017) are established under the assumption that the random vectors are multivariate normal distributed. Without normal constraint, Yang and Pan (2015) proposed a test statistic based on regularized canonical correlation coefficients, and they obtained the limiting distributions when both p and q are comparable to the sample size n. Discovering that the empirical distance correlation of the two vectors converges to one even though they are independent as dimensions tend to infinity, Székely and Rizzo (2013) extended the distance correlation with a modified version in high-dimensional settings, and obtained a distance correlation t-test for independence of random vectors in arbitrarily high dimension. Heller et al. (2012) presented a powerful test of association based on ranks of distances which is consistent against all alternatives and can be applied in any dimensions p and q even greater than n. On the basis of power enhancement technique introduced by Fan et al. (2015), Zheng et al. (2022) developed a powerful test on block-structured correlation of a high dimensional-random vector for sparse or non-sparse alternatives without normality assumption, and obtained the statistical properties under the asymptotic regime that \((p+q)/n\rightarrow y \in (0,\infty )\).
This paper aims to develop a new and powerful test on high-dimensional association under no strict distributional assumptions. To this end, we propose a U-statistic of order four based on the RV covariance introduced in Escoufier (1973). To boost the power especially under sparse alternatives a screening term is added. It is worth mentioning that the proposed test statistic is effective not only for non-sparse alternatives but also for sparse alternatives. Four distinguishing features can be summarized as follows. First, although the proposed U-statistic is order four, it can be fast implemented with an estimated U-statistic of order two. Second, the asymptotic distributions of the U-statistic under both null hypothesis and local alternatives are derived in the scheme that \(p+q\) tends to infinity. It is noteworthy that this scheme can be divided into two cases: one is that only p or q is much more than or comparable to the sample size n; the other is that both p and q tend to infinity with n simultaneously. Third, the power enhancement technique can dramatically improve the performance of the proposed test, which is demonstrated by Monte Carlo simulations. Last but not least is some examples under specific structures are given to gain more insights on the regularity conditions.
The rest of this work is organized as follows. A new statistic for testing the association between two random vectors is proposed on the basis of RV covariance, and its asymptotic properties are established in Sect. 2. In Sect. 3 we investigate the properties of the screening term based on the power enhancement technique. Numerical studies and real data analysis are listed in Sect. 4 to examine the size and power of our proposed test. The Appendix is devoted to gather the technical proofs.
2 Association test in high dimension
In this part, our interest is to study and test the association between two random vectors \(\textbf{X}=(X_1,\ldots ,X_p)^\top \in {\mathbb {R}}^p\) and \(\textbf{Y}= (Y_1,\ldots ,Y_q)^\top \in {\mathbb {R}}^q\). Let \(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\) denote the population covariance matrix of \(\textbf{X}\) and \(\textbf{Y}\). Our association test hypothesis can be represented as follows:
It is worth noting that \(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}=0_{p\times q}\) if and only if the two random vectors are uncorrelated. Escoufier (1973) defined \(\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})\) as the “covariance” of two random vectors \(\textbf{X}\) and \(\textbf{Y}\), where \(\textrm{tr}(\cdot )\) denotes the trace operator. It is evident to see that \(\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})= 0\) is equivalent to \(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}=0_{p\times q}\). This motivates us to utilize \(\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})\) to quantify the discrepancy between \(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\) and \(0_{p\times q}\). Adopting the idea of \({\mathcal {U}}\)-centring in Székely and Rizzo (2014) and Yao et al. (2018), we can construct an unbiased estimator, denoted by \(T_{n,p,q}(\textbf{X},\textbf{Y})\), of \(\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})\). Suppose that \(\textbf{Z}_i=(\textbf{X}_i,\textbf{Y}_i)^{^\top }\in {\mathbb {R}}^{p+q}\) are random samples of \(\textbf{Z}=(\textbf{X},\textbf{Y})^{^\top }\) in which \(\textbf{X}_i=(X_{i1},\ldots ,X_{ip})^\top \) and \(\textbf{Y}_i=(Y_{i1},\ldots ,Y_{iq})^\top \). Then \(T_{n,p,q}(\textbf{X},\textbf{Y})\) is given by
where
and the summation is over all 24 permutations of the 4-tuples of indices (1, 2, 3, 4).
It is obvious to see that \(T_{n,p,q}(\textbf{X},\textbf{Y})\) is a U-statistic of order four and it is an unbiased estimator of \(\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})\).
Remark 1
Tests for high-dimensional regression coefficients in Zhong and Chen (2011) and Cui et al. (2018) can be seen as a special case of our test hypothesis with respect to measuring the discrepancy. Consider a linear regression model
where \(\varvec{\beta }=(\beta _1,\ldots ,\beta _p)^\top \in {\mathbb {R}}^p\) is a \(p-\)dimensional vector of regression coefficients of interest and \(\alpha \) is a nuisance intercept parameter. \(\varepsilon \) is random error with mean zero and variance \(\sigma ^2\), and is independent of \(\textbf{X}\). Testing the high-dimensional regression coefficients simultaneously in the linear model can be formulated as follows:
It tests the overall significance of linear regression coefficients. Both (Zhong and Chen 2011) and (Cui et al. 2018) adopted \(\varvec{\beta }^\top \varvec{\Sigma }_{\textbf{X}}^2\varvec{\beta }\) as an effective measure of the difference between \(\varvec{\beta }\) and \(0_{p \times 1}\). Simple calculation shows that \(\textrm{tr}(\varvec{\Sigma }_{\textbf{X}Y}\varvec{\Sigma }_{Y\textbf{X}})=\varvec{\beta }^\top \varvec{\Sigma }_{\textbf{X}}^2\varvec{\beta }\).
Remark 2
\(\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})\), the squared distance covariance dCov\(^2(\textbf{X},\textbf{Y})\) introduced by Székely et al. (2007) and the squared martingale difference divergence MDD(\(Y|\textbf{X})^2\) proposed in Shao and Zhang (2014) can be constructed in an analogous way. In fact, write
where \(\textbf{Z}'=(\textbf{X}',\textbf{Y}')^\top \) and \(\textbf{Z}''=(\textbf{X}'',\textbf{Y}'')^\top \) are independent copies of \(\textbf{Z}=(\textbf{X},\textbf{Y})^\top \). When \(\alpha =\beta =1\), \(\tau (\textbf{X},\textbf{Y})=\text {dCov}^2(\textbf{X},\textbf{Y})\) and it characterizes independence of random vectors \(\textbf{X}\) and \(\textbf{Y}\). \(\tau (\textbf{X},Y)= 2\text {MDD}(Y|\textbf{X})^2\) as \(\alpha =1\) and \(\beta =2\), and it measures the departure of conditional mean independence between a scalar response variable Y and a vector predictor variable \(\textbf{X}\). When \(\alpha =\beta =2\), \(\tau (\textbf{X},\textbf{Y})=4\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})\). Furthermore, it is worth mentioning that \(\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})\) can degenerate into the squared covariance of random variable X and Y, when \(p=q=1\). This suggests us consider not only the simultaneous measure between random vectors \(\textbf{X}\) and \(\textbf{Y}\), but also the marginal quantization between their components \(X_i\) and \(Y_j,i=1,\ldots ,p,j=1,\ldots ,q\) due to the curse of dimensionality.
Remark 3
According to the Székely and Rizzo (2014) and Yao et al. (2018), \(T_{n,p,q}(\textbf{X},\textbf{Y})\) can be fast implemented. Define the respective \({\mathcal {U}}\)-centred versions of \(a_{ij}=\textbf{X}_i^\top \textbf{X}_j\) and \({b}_{ij}=\textbf{Y}_i^\top \textbf{Y}_j\) as follows:
Then \(T_{n,p,q}(\textbf{X},\textbf{Y})\) has the following reformulation:
which is shown to be a quick implementation in numerical simulations.
2.1 Asymptotic analysis of \(T_{n,p,q}(\textbf{X},\textbf{Y})\) under null hypothesis
In this subsection the asymptotic properties of \(T_{n,p,q}(\textbf{X},\textbf{Y})\) are investigated under some regularity assumptions. Some notations are introduced before studying the properties of the proposed statistic. Write \(L_1(\textbf{Z},\textbf{Z}')=\textrm{E}\{L(\textbf{Z},\textbf{Z}'')L(\textbf{Z}',\textbf{Z}'')|(\textbf{Z},\textbf{Z}')\}\), and \(\zeta ^2=\textrm{E}\{L(\textbf{Z},\textbf{Z}')^2\}\), where \(L(\textbf{Z},\textbf{Z}')=\textbf{X}^\top \textbf{X}'\textbf{Y}^\top \textbf{Y}'\). To obtain the asymptotic distribution of \(T_{n,p,q}(\textbf{X},\textbf{Y})\) we require the following technical assumption.
(A1) \(\textrm{E}\{L_1(\textbf{Z},\textbf{Z}')^2\}=o(\zeta ^4)\), \(\textrm{E}\{(\textbf{X}^\top \textbf{X}'\textbf{Y}^\top \textbf{Y}')^4\}\) \(=o(n\zeta ^4)\), \(\textrm{E}\{(\textbf{X}^\top \textbf{X}'\textbf{Y}^\top \textbf{Y}'')^4\}=o(n\zeta ^4)\) and \(\textrm{E}\{(\textbf{X}^\top \textbf{X}')^4\}\textrm{E}\{(\textbf{Y}^\top \textbf{Y}')^4\}=o(n\zeta ^4)\).
The following theorem presents the limiting null distribution of \(T_{n,p,q}(\textbf{X},\textbf{Y})\).
Theorem 1
Suppose assumption (A1) holds. Then under \(H_0\), as \((n,p+q)\rightarrow \infty \) we have that
and a ratio consistent estimator of \(\zeta ^2\) is
where \(\overset{d}{\longrightarrow }\ \) denotes convergence in distribution.
By referring to Zhang et al. (2018) and its supplementary material, we impose assumption (A1) to ensure the asymptotic normality of the degenerate U-statistic \(T_{n,p,q}(\textbf{X},\textbf{Y})\) under the null hypothesis. Meanwhile this assumption guarantees that \(\zeta ^2_n\) is ratio-consistent. To further understand this assumption, the following proposition is established when \(\textbf{Z}=(\textbf{X},\textbf{Y})^{^\top }\) follows a multivariate normal distribution.
Proposition 1
Suppose that \(\textbf{Z}=(\textbf{X},\textbf{Y})^{^\top }\sim {\mathcal {N}}(0_{(p+q)\times 1},\textbf{I}_{p+q})\). Then we have
Proposition 1 may shed light on the assumption (A1). It indicates that when \(\textbf{Z}\) follows a standard multivariate normal distribution, this condition holds automatically as long as n and \(p+q\) tend to infinity, which implies that condition (A1) is imposed reasonably.
Remark 4
Theorem 1 states that the asymptotic null distribution of \(T_{n,p,q}\) is normal, and we can reject \(H_0\) at a significance level \(\alpha \) if
where \(z_{\alpha }\) denotes the upper \(\alpha \) quantile of \({\mathcal {N}}(0,1)\).
2.2 Asymptotic analysis of \(T_{n,p,q}(\textbf{X},\textbf{Y})\) under the local alternatives
In this subsection, we turn to the asymptotic analysis of \(T_{n,p,q}(\textbf{X},\textbf{Y})\) under the local alternatives.
The following assumption is required for theoretical study.
(A2) \(\textrm{E}\{(\textbf{X}^\top \varvec{\Sigma }_{\textbf{X}\textbf{Y}}\textbf{Y})^2\}=o(n^{-1}\zeta ^2)\) and \(\textrm{E}\{(\textbf{X}^\top \varvec{\Sigma }_{\textbf{X}\textbf{Y}}\textbf{Y}')^2\}=o(\zeta ^2)\).
Theorem 2
Suppose that assumptions (A1) and (A2) hold. Then as \((n,p+q)\rightarrow \infty \) we have
and \(\zeta _n^2\) is still a ratio-consistent estimator of \(\zeta ^2\).
Assumption (A2) characterizes the local alternative in the sense that the alternative is not too far away from the null hypothesis, and thus shows that our proposed statistic is a degenerate U-statistic. It is noteworthy that this assumption holds automatically under the null hypothesis and it is given in light of Zhang et al. (2018). In following we illustrate the assumptions (A1) and (A2) under linear regression model.
Proposition 2
Assume that \(\textbf{Y}=\textbf{X}^\top \varvec{\beta }+\varepsilon \) where \(\textbf{X}\) and \(\varepsilon \) are independent with \(\textbf{X}\sim {\mathcal {N}}(0_{p\times 1},\textbf{I}_p)\) and \(\varepsilon \sim {\mathcal {N}}(0,1)\). Then we have
Proposition 2 implies that assumption (A1) holds automatically as \((n,p)\rightarrow \infty \). Furthermore, assumption (A2) can be satisfied when \(\Vert \varvec{\beta }\Vert ^2/(1+\Vert \varvec{\beta }\Vert ^2)=o(p/n)\). Therefore, assumption (A2) can be viewed as local alternatives.
Remark 5
It can be inferred from theorem 2 that the asymptotic power of the proposed test under the local alternatives is
where \(\Phi (\cdot )\) is the cumulative distribution function of the standard normal distribution. It is clear to see that this power is dominantly affected by signal to noise ratio term \(\eta (\varvec{\Sigma }_{\textbf{X}\textbf{Y}})=\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})/\sqrt{2\zeta ^2}\). Specially, the power tends to \(\alpha \) when \(\eta (\varvec{\Sigma }_{\textbf{X}\textbf{Y}})=o(n^{-1})\), which implies that the test fails to make a distinction between the null hypothesis and the local alternatives. Meanwhile, if \(\eta (\varvec{\Sigma }_{\textbf{X}\textbf{Y}})\) has a higher order of \(n^{-1}\), the power converges to 1 and thus it is a consistent test.
3 Power enhancement technique
In Sect. 2, \(T_{n,p,q}\) is constructed based on \(\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})\), and its asymptotic distributions are obtained under regularity conditions (A1)–(A2). It is worth noting that it is a simultaneous measure for association, and its power is adversely affected by the increasing dimensions, especially under the sparse alternatives. We adopt the power enhancement technique introduced by Fan et al. (2015), and utilize the marginal association to boost the empirical power in this case. Define
where \(\delta _{n,p,q}=c\log (\log (n))/\log (\log (pq))(pq)^{1/4}(\log (n))^{3/4}/n\) and \(\rho (X_i,Y_j)\) is the Pearson correlation coefficient.
The conditions below are imposed to derive the limiting properties of \({\mathcal {R}}_n(X_i,Y_j)\).
(A3) \(pq=O(n^\kappa ),0<\kappa <4\) and \(\textrm{E}\{(\textbf{X}^\top \textbf{X}'\textbf{Y}^\top \textbf{Y}')^4\}\) exists.
(A4) \(\max \limits _{1\le i\le p,1\le j\le q} \xi _{ij} =O((pq)^{-1/2})\), where \(\xi _{ij}=\sigma ^2(X_i,Y_j)\textrm{Var}\{(X_i-\textrm{E}(X_i))(Y_j-\textrm{E}(Y_j))\}\) and \(\sigma (X_i,Y_j)\) is the covariance of random variables \(X_i\) and \(Y_j\).
We present the following result regarding the asymptotic behavior of \({\mathcal {R}}_n(X_i,Y_j)\) under both the null hypothesis and the alternatives.
Theorem 3
Suppose conditions (A3)–(A4) hold. Then we have that
(1) under \(H_0\), almost surely
(2) when \({\mathcal {S}} \ne \emptyset \), almost surely
Assumptions (A3)–(A4) are imposed based on the results of Section 5.3 in Serfling (1980). \(pq=O(n^\kappa ),0<\kappa <4\) has an explicit relationship between p, q and n, and means \(\delta _{n,p,q} \) converges to 0 as n tends to infinity. It is worth noting that assumption (A3) ensures an almost sure representation of the difference between U-statistic \(T_{n,1,1}(X_i,Y_j)\) and its projection. As for condition (A4), it holds automatically under the null hypothesis and shows that \(\xi _{ij}\) is of order \((pq)^{-1/2}\) uniformly among pq components under sparse alternatives, which guarantees an almost sure representation for the projection of U-statistic \(T_{n,1,1}(X_i,Y_j)\). Details can be seen in the proof of Theorem 3 in the Appendix.
Remark 6
In light of theorem 3, the screening term used for enhancing the empirical power can be constructed as follows:
where \(\textbf{1}{(\cdot )}\) is an indicator function. It can be inferred from this theorem that \(T_{n,p,q}^{0}\) is negligible under null hypothesis whereas it will diverge to infinity when \({\mathcal {S}} \ne \emptyset \). Therefore the power of the test will be well enhanced if add the term \(T_{n,p,q}^{0}\) owing to taking into account of more information from the alternative. Similar to the discussion in Fan et al. (2015), a general form of the test statistic can be proposed as follows:
It is clear to see from Theorems 1 and 3 that the test statistic \(\widehat{T}_{n,p,q}\) shares the same distribution as \(T_{n,p,q}\), which implies that the proposed test reject \(H_0\) at the significance level \(\alpha \) if \(\widehat{T}_{n,p,q}\ge z_\alpha \). Furthermore, it yields from Theorems 2 and 3 that the empirical power of \(\widehat{T}_{n,p,q}\) can tend to 1 under some regularity conditions. This also indicates that the power enhancement technique can be utilized to boost the power as long as a test statistic has a limiting null distribution such as normal approximation.
Remark 7
Given that the kernel function of U-statistic \(T_{n,1,1}(X_i,Y_j)\) has finite fourth moments, the convergence rate, \((\log (n))^{3/4}/n\), of difference between a U-statistic and its projection is obtained in Theorem 5.3.3 of Serfling (1980). \(\max _{1\le i\le p,1\le j\le q}|{\mathcal {R}}_n(X_i,Y_j)|\) refers to the maximum of pq marginal correlation, which indicates that the convergence rate should be multiplied by a function of pq. In light of the fact that the kernel function of \(T_{n,1,1}(X_i,Y_j)\) has finite fourth moments, we choose \((pq)^{1/4}\). More details can be found in the proof of Theorems 3. Furthermore, it is worth noting that the choice of tuning parameter c will affect the performance of the proposed test in both empirical size and empirical power. To be specific, given the sample size and the dimension, larger c can lead to a higher probability of controlling the empirical size while smaller c has a greater chance of boosting the empirical power, which indicates that the choice of c becomes a trade-off between controlling the empirical size and boosting the empirical power. In practical applications a series of values are given to identify which ones can meet the need of size control. Based on the selected values, we choose the smallest value as c, which can increase the empirical power. More details can be found from the Example 1 in the simulation studies.
4 Numerical studies
In this section we illustrate the proposed test procedure by investigating its finite sample performance through simulations and a real microarray gene data analysis. For the purpose of comparison, we also consider the following methods. The first one proposed in Zheng et al. (2022) adopts the Frobenius distance between covariance matrix. The second procedure is based on the trace of covariance matrix advocated in Li et al. (2017). The third one utilizes the modified distance correlation established in Székely and Rizzo (2013). The fourth one is built based on ranks of distances in Heller et al. (2012) and the remaining one is \(T_{n,p,q}\) proposed in this paper. To be specific, we denote the method used in this section as follows:
-
NEW1: the test based on \(T_{n,p,q}\);
-
NEW: the test based on \(\widehat{T}_{n,p,q}\);
-
FDS: the test of Zheng et al. (2022);
-
TCM: the test of Li et al. (2017);
-
MDC: the test of Székely and Rizzo (2013);
-
HHG: the test of Heller et al. (2012).
To implement MDC and HHG test procedures, we adopt the dcor.ttest function in the energy package and the hhg.test function in the HHG package, respectively. We set the sample size \(n=100,200\), and the dimension \(p+q=500\). The nominal significance level is fixed at \(\alpha =0.05\), and the number of independent replications is 1000. All simulation studies are conducted using R version 4.1.2.

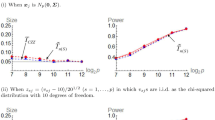
The empirical size of the proposed test NEW under different values of c in Example 1 when \(n=100\)

The empirical size of the proposed test NEW under different values of c in Example 1 when \(n=200\)
Example 1
This example is designed to compare the finite sample performance of the test procedures. In this example, we assume that
where the components of \(\textbf{W}=(W_1,\ldots ,W_{p+q})^{^\top }\) are i.i.d., and \(W_1\) is from the standard normal distribution \({\mathcal {N}}(0,1)\), the uniform distribution \(U(-\sqrt{3},\sqrt{3})\), the scaled student distribution \(t(6)/\sqrt{6/4}\) and the scaled chi-square distribution \((\chi ^2(6)-6)/\sqrt{12}\) with 6 degrees of freedom, respectively. In this example, the dimension is \(p=1,5,10,20,50,100\).
Recall from Remark 7, it is of importance to determine c under different choice of (n, p, q). Thus we set \(c=(0.1,0.2,\ldots ,2)\) and investigate their empirical size of our proposed test when \(\varvec{\Sigma }=\textbf{I}_{p+q}\). Note that the choice of c should not be affected by the distribution of \(W_1\). Here we choose \(W_1\sim {\mathcal {N}}(0,1)\). Figures 1 and 2 display the empirical size of the proposed test procedure NEW and show that \(c=1\) can be applied to all the settings except for the case \((n,p,q)=(100,1,499)\) in this Example. We choose \(c=1.5\) when \((n,p,q)=(100,1,499)\).
Based on the choice of c, we investigate the empirical size of these tests when \(\varvec{\Sigma }=\textbf{I}_{p+q}\). Table 1 presents the results and shows that all the empirical sizes are close to the nominal significance level \(\alpha =0.05\). Meanwhile, the fact that little difference existing between the empirical sizes of NEW and NEW1 indicates that the screening term \(T_{n,p,q}^0\) has little effect on the size under the null hypothesis.
To examine the powers of these test procedures, we set \(\varvec{\Sigma }=(0.5^{|i-j|})_{i,j=1}^{p+q}\). The simulation results are summarized in Table 2. From this table it is convenient to see that the performance of NEW and FDS outperform the remaining methods, especially when \(n=200\), which can be attributed to the adoption of the power enhancement technique. Furthermore, it is worth noting that the empirical power of each procedure as \(n=200\) is much higher than that under the setting \(n=100\), which shows the large sample theory.
Example 2
The power of the test procedures are evaluated via the model studied in Jiang et al. (2013). They define the populations \(\textbf{X}\) and \(\textbf{Y}\) as
where \(\textbf{U}_1=(U_{11},\ldots ,U_{1p})^{^\top }\) and \(\textbf{U}_2=(U_{21},\ldots ,U_{2q})^{^\top }\) are independent, \(\textbf{U}_2^p\) is a subset of \(\textbf{U}_2\) consisting of its first p variables, and the factor \(\gamma \) represents the degree of dependence. In this example \(\gamma =0.3\). We assume that \(U_{11},\ldots , U_{1p}, U_{21},\ldots , U_{2q}\) are i.i.d., and follow the same distribution as \(W_1\) in Example 1. The dimension is \(p=20,50,100\) when the sample size is \(n=100\). As for the sample size \(n=200\), the dimension is \(p=5,10,20\). From this model it is easy to calculate that the covariance matrices are respectively
where \(O_{p,q-p}\) denotes a \(p\times (q-p)\) zero matrix. Table 3 displays the performance of these methods, and shows the empirical power of each procedure increases with the increasing dimension p, which implies that these methods are effective against the dense alternatives. At the same time to achieve the same performance for each of these test procedures, the dimension p under the setting that \( n=200\) can be much smaller than that of \( n=100\), which implies that the powers of these methods can tend to be 1 as long as the sample size n is sufficiently large.
Example 3
To illustrate the application of our proposed procedure in high-dimensional settings, we analyze a microarray data reported in Scheetz et al. (2006). In order to gain a broad perspective of gene regulation in the mammalian eye and to identify genetic variation relevant to human eye disease, 120 twelve-week-old male offspring were chosen for tissue harvesting from their eyes and microarray analysis. 18,976 probes on the array which was used to analyze the RNA from the eyes of these F2 animals were detected sufficiently expressed and variable. More details of the experiment can be found in Scheetz et al. (2006).
Note that 1389163_at, one of the 18,976 sufficiently expressed probes, is from the gene TRIM32. This gene is found in Chiang et al. (2006) to cause an extremely heterogeneous human obesity syndrome known as Bardet-Biedl syndrome. The relationship between the probe 1389163_at and the remaining 18,975 ones is first investigated. The P-values of the three tests are listed in Table 4 and denoted by \(p=18{,}975\), which suggests that gene TRIM32 and the rest of gene exhibit some type of association. Huang et al. (2008) verified this situation and further studied the data set. They used the adaptive Lasso in sparse high-dimensional linear regression models and selected 19 genes whose expression are most correlated with that of gene TRIM32. Excluding these 19 probes, we take another test to check whether the probe 1389163_at is associated with the 18,956 ones or not. To remove the effects of these 19 genes on TRIM32, we replace the value of TRIM32 with the residual from a multiple linear regression on the response variable TRIM32 and these 19 genes being the predictors. Table 4 also presents the result when \(p=18,956\), which shows the absence of a linear relationship between the gene TRIM32 and the 18,956 ones.
References
Anderson T (2003) An introduction to multivariate statistical analysis, 3rd edn. Wiley, New York
Chiang AP, Beck JS, Yen HJ, Tayeh MK, Scheetz TE, Swiderski RE, Sheffield VC (2006) Homozygosity mapping with SNP arrays identifies TRIM32, an E3 ubiquitin ligase, as a BardetCBiedl syndrome gene (BBS11). Proc Natl Acad Sci 103(16):6287–6292
Cui H, Guo W, Zhong W (2018) Test for high-dimensional regression coefficients using refitted cross-validation variance estimation. Ann Stat 46(3):958–988
Escoufier Y (1973) Le traitement des variables vectorielles. Biometrics 29(4):751–760
Fan J, Liao Y, Yao J (2015) Power enhancement in high-dimensional cross-sectional tests. Econometrica 83(4):1497–1541
Hall P, Heyde CC (1980) Martingale limit theory and its application. Academic Press, New York
Heller R, Heller Y, Gorfine M (2012) A consistent multivariate test of association based on ranks of distances. Biometrika 100(2):503–510
Huang J, Ma S, Zhang CH (2008) Adaptive Lasso for sparse high-dimensional regression models. Stat Sin 18:1603–1618
Jiang D, Bai Z, Zheng S (2013) Testing the independence of sets of large-dimensional variables. Sci China Math 56(1):135–147
Li W, Chen J, Yao J (2017) Testing the independence of two random vectors where only one dimension is large. Stat 51(1):141–153
Loève M (1978) Probability theory II, 4th edn. Springer, New York
Robert P, Cléroux R, Ranger N (1985) Some results on vector correlation. Comput Stat Data Anal 3:25–32
Scheetz TE, Kim KYA, Swiderski RE, Philp AR, Braun TA, Knudtson KL, Sheffield VC (2006) Regulation of gene expression in the mammalian eye and its relevance to eye disease. Proc Natl Acad Sci 103(39):14429–14434
Serfling RJ (1980) Approximation theorems of mathematical statistics. Willey, New York
Shao X, Zhang J (2014) Martingale difference correlation and its use in high-dimensional variable screening. J Am Stat Assoc 109(507):1302–1318
Srivastava MS, Reid N (2012) Testing the structure of the covariance matrix with fewer observations than the dimension. J Multivar Anal 112:156–171
Székely GJ, Rizzo ML (2013) The distance correlation t-test of independence in high dimension. J Multivar Anal 117:193–213
Székely GJ, Rizzo ML (2014) Partial distance correlation with methods for dissimilarities. Ann Stat 42(6):2382–2412
Székely GJ, Rizzo ML, Bakirov NK (2007) Measuring and testing independence by correlation of distances. Ann Stat 35(6):2769–2794
Taskinen S, Oja H, Randles RH (2005) Multivariate nonparametric tests of independence. J Am Stat Assoc 100(471):916–925
Wilks SS (1935) On the independence of k sets of normally distributed statistical variables. Econometrica 3(3):309–326
Yang Y, Pan G (2015) Independence test for high dimensional data based on regularized canonical correlation coefficients. Ann Stat 43(2):467–500
Yao S, Zhang X, Shao X (2018) Testing mutual independence in high dimension via distance covariance. J R Stat Soc B 80(3):455–480
Zhang X, Yao S, Shao X (2018) Conditional mean and quantile dependence testing in high dimension. Ann Stat 46(1):219–246
Zheng S, He X, Guo J (2022) Hypothesis testing for block-structured correlation. Stat Sin 32(2):719–735
Zhong PS, Chen SX (2011) Tests for high-dimensional regression coefficients with factorial designs. J Am Stat Assoc 106(493):260–274
Acknowledgements
This work is supported by National Natural Science Foundation of China (No. 12031016, 11971324,12371294, 11901406,11471223), Beijing Natural Science Foundation (Z210003), R &D Program of Beijing Municipal Education Commission (KM202110028017), the Interdisciplinary Construction of Bioinformatics and Statistics, and the Academy for Multidisciplinary Studies, Capital Normal University, and New Young Teachers’ Research Initiation Fund Project, Capital University of Economics and Business (XRZ2021046).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Proof of Theorem 1
Without loss of generality, we can assume that \(\textrm{E}(\textbf{X})=0_{p\times 1}\) and \(\textrm{E}(\textbf{Y})=0_{q\times 1}\) hereafter. Define that \(\xi _c=\textrm{Var}\{h_c(\textbf{Z}_1,\ldots ,\textbf{Z}_{c})\}\), where \(h_c(z_1,\ldots ,z_c)=\textrm{E}\{h(z_1,\ldots ,z_c,\textbf{Z}_{c+1},\ldots ,\textbf{Z}_{4})\}\) for \(c=1,2,3,4\). Denote \(G(\textbf{X},\textbf{X}')=\textbf{X}^\top \textbf{X}'\) and \(H(\textbf{Y},\textbf{Y}')=\textbf{Y}^\top \textbf{Y}'\). Observe that \(\textrm{E}\{L(\textbf{Z},\textbf{Z}')\}=\textrm{E}\{L(\textbf{Z},\textbf{Z}')|\textbf{Z}\}=\textrm{E}\{L(\textbf{Z},\textbf{Z}')|\textbf{Z}'\}=0\) under the null, and that \(\textrm{E}\{G(\textbf{X},\textbf{X}')|\textbf{X}\}=\textrm{E}\{G(\textbf{X},\textbf{X}')|\textbf{X}'\}=\textrm{E}\{H(\textbf{Y},\textbf{Y}')|\textbf{Y}\}=\textrm{E}\{H(\textbf{Y},\textbf{Y}')|\textbf{Y}'\}=0\). Then we can obtain under the null hypothesis that
Under Assumption (A1) we have
Applying the Hoeffding’ decomposition in Serfling (1980), we get that
Write \(M_j=\sum _{i=1}^{j-1}L(\textbf{Z}_i,\textbf{Z}_j)\), \(S_u =\sum _{j=2}^u\sum _{i=1}^{j-1}L(\textbf{Z}_i,\textbf{Z}_j)=\sum _{j=2}^u M_j\) and the filtration \(\mathscr {F}_u=\sigma \{\textbf{Z}_1, \ldots ,\textbf{Z}_u\}\). Since \(\textrm{E}\{L(\textbf{Z},\textbf{Z}')\} =\textrm{E}\{L(\textbf{Z},\textbf{Z}')|\textbf{Z}\} =\textrm{E}[L(\textbf{Z},\textbf{Z}')|\textbf{Z}'\}=0\), then \(\textrm{E}(S_u)=0\) and for \(u<v\),
This implies that \(S_u\) is adaptive to \(\mathscr {F}_u\) and thus it is a mean-zero martingale sequence.
To obtain the asymptotic normality of \(\sum _{1\le i< j\le n}L(\textbf{Z}_i,\textbf{Z}_j))/\sqrt{\left( {\begin{array}{c}n\\ 2\end{array}}\right) \zeta ^2}\), we only need to verify the two following conditions given by Corollary 3.1 in Hall and Heyde (1980).
Condition (1): the conditional variance
and Condition (2): the conditional Lindeberg condition, that is, for all \(\varepsilon >0\),
To prove condition (1), it is sufficient to prove that
and
Notice again that \(\textrm{E}\{L(\textbf{Z},\textbf{Z}')\}=\textrm{E}\{L(\textbf{Z},\textbf{Z}')|\textbf{Z}\} =\textrm{E}\{L(\textbf{Z},\textbf{Z}')|\textbf{Z}'\}=0\). We then show that
Next we will prove that
Recall that \(L_1(\textbf{Z},\textbf{Z}')=\textrm{E}\{L(\textbf{Z},\textbf{Z}'') L(\textbf{Z}',\textbf{Z}'')| (\textbf{Z},\textbf{Z}')\}\). It is easy to check that
Then we have that
When assumption (A1) is true, we thus obtain that
which ensures condition (1).
Next condition (2) will be verified. Direct calculation shows that
Again under assumption (A1), it is easy to show that
which implies that
Notice that for all \(\varepsilon >0\),
which implies condition (2).
Therefore, we can show that
Using the Slutsky theorem we obtain that
In the following, we will show the consistency of \(\zeta ^2_n\). That is,
To obtain this result, it is sufficient to verify \(\textrm{E}(\zeta ^2_n/\zeta ^2)\rightarrow 1\) and \(\textrm{Var}(\zeta ^2_n/\zeta ^2)\rightarrow 0\), respectively. Recall the definition of \(A_{ij}\) and \(B_{ij}\), we can rewrite them in the following form:
Notice that \(\textrm{E}\{G(\textbf{X},\textbf{X}')|\textbf{X}\}=0\) and \(\textrm{E}\{H(\textbf{Y},\textbf{Y}')|\textbf{Y}\}=0\), we have for \(1\le i \ne j\le n\),
which implies that
By the Cauchy–Schwarz inequality, we have under condition (A1) that
Then it is trivial to check that
From the computations above we can conclude under assumption (A1) that
Using similar technique we also show under assumption (A1) that
This proof is thus completed.
\(\square \)
Proof of Proposition 1
Note that \(\textbf{Z}=(\textbf{X},\textbf{Y})^{^\top }\) is from multivariate normal distribution \({\mathcal {N}}(0_{(p+q)\times 1},\textbf{I}_{(p+q)})\). Then we can conclude that \(\textbf{X}\) and \(\textbf{Y}\) are independent, \(\textbf{X}\sim {\mathcal {N}}(0_{p\times 1},\textbf{I}_{p})\) and \(\textbf{Y}\sim {\mathcal {N}}(0_{q\times 1},\textbf{I}_{q})\). Therefore we only need to compute \(\zeta ^2\), \(\textrm{E}\{L_1(\textbf{Z},\textbf{Z}^{\prime })^2\}\) and \(\textrm{E}\{(\textbf{X}^\top \textbf{X}'\textbf{Y}^\top \textbf{Y}')^4\}\) since \(\textrm{E}\{(\textbf{X}^\top \textbf{X}'\textbf{Y}^\top \textbf{Y}')^4\}=\textrm{E}\{(\textbf{X}^\top \textbf{X}'\textbf{Y}^\top \textbf{Y}'')^4\} =\textrm{E}\{(\textbf{X}^\top \textbf{X}')^4\}\textrm{E}\{(\textbf{Y}^\top \textbf{Y}'')^4\}.\) Direct calculations show that
\(\square \)
Proof of Theorem 2
Recall the expression of \(h_4(\textbf{Z}_1,\textbf{Z}_2,\textbf{Z}_3,\textbf{Z}_4)\) in the proof of Theorem 1, and the fact that \(\textrm{E}\{G(\textbf{X},\textbf{X}')|\textbf{X}\}=\textrm{E}\{G(\textbf{X},\textbf{X}')|\textbf{X}'\}=0\) and \(\textrm{E}\{H(\textbf{Y},\textbf{Y}')|\textbf{Y}\}=\textrm{E}\{H(\textbf{Y},\textbf{Y}')|\textbf{Y}'\}=0\), we obtain the corresponding \(h_1(\textbf{Z}_1),h_2(\textbf{Z}_1,\textbf{Z}_2)\) and \(h_3(\textbf{Z}_1,\textbf{Z}_2,\textbf{Z}_3)\) under the local alternative as follows.
where \(K(\textbf{X}_i,\textbf{Y}_j)=\textbf{X}_i^\top \varvec{\Sigma }_{\textbf{X}\textbf{Y}}\textbf{Y}_j\). Again using the Hoeffding decomposition in Serfling (1980). we can show under assumptions (A1) and (A2) that
where \(\widetilde{L}(\textbf{Z}_i,\textbf{Z}_j) =L(\textbf{Z}_i,\textbf{Z}_j)-K(\textbf{X}_i,\textbf{Y}_i)-K(\textbf{X}_j,\textbf{Y}_j)+\textrm{tr}(\varvec{\Sigma }_{\textbf{X}\textbf{Y}}\varvec{\Sigma }_{\textbf{Y}\textbf{X}})\).
Note that \(\textrm{E}(\widetilde{L}(\textbf{Z},\textbf{Z}'))=\textrm{E}(\widetilde{L}(\textbf{Z},\textbf{Z}')\mid \textbf{Z})=\textrm{E}(\widetilde{L}(\textbf{Z},\textbf{Z}')\mid \textbf{Z}')=0\). Using similar arguments by replacing \(L(\textbf{Z}_i,\textbf{Z}_j)\) in the proof of Theorem 1 with \(\widetilde{L}(\textbf{Z}_i,\textbf{Z}_j)\), we can show that
which yields that
Applying similar technique in proving the ratio-consistency in theorem 1, it is easy to show that
provided that conditions (A1) and (A2) hold. We thus complete this proof.
\(\square \)
Proof of Proposition 2
For \(\Vert \varvec{\beta }\Vert \ne 0\), we assume that U is a \(p\times p\) orthogonal matrix whose first column is \(\varvec{\beta }/\Vert \varvec{\beta }\Vert \). Then \(\textbf{S}=(S_1,\ldots ,S_p)^\top =U^\top \textbf{X}\sim {\mathcal {N}}(0_{p\times 1},\textbf{I}_p)\). Moreover, \(\textbf{S}'=(S_1',\ldots ,S_p')^\top =U^\top \textbf{X}'\) and \(\textbf{S}''=(S_1'',\ldots ,S_p'')^\top =U^\top \textbf{X}''\) can be viewed as copies of \(\textbf{S}\). Note that \(\textrm{E}(S_1)=0\), \(\textrm{E}(S_1^2)=1\) and \(\textrm{E}(S_1^4)=3\). Elemental calculations show that
We then calculate \(\textrm{E}\{(\textbf{X}^\top \varvec{\Sigma }_{\textbf{X}\textbf{Y}}\textbf{Y})^2\}\) and \(\textrm{E}\{K(\textbf{X}^\top \varvec{\Sigma }_{\textbf{X}\textbf{Y}}\textbf{Y}')^2\}\). It is easy to show that \(\textbf{X}^\top \varvec{\Sigma }_{\textbf{X}\textbf{Y}}\textbf{Y}=\textbf{X}^\top \varvec{\beta }\textbf{Y}\) and \(\textbf{X}^\top \varvec{\Sigma }_{\textbf{X}\textbf{Y}}\textbf{Y}' =\textbf{X}^\top \varvec{\beta }\textbf{Y}'\). Then we can obtain that
Next we consider \(\textrm{E}\{L_1(\textbf{Z},\textbf{Z}^{\prime })^2\}\).
Careful calculations show that
Thus this proof is completed. \(\square \)
Proof of Theorem 3
(1) Let \(\lambda _{n,p_n,q_n}=n(p_nq_n)^{-1/4}(\log n)^{-3/4}\). It suffices to show that, for any \(\varepsilon >0\), almost surely \(\lambda _{n,p_n,q_n}\max \limits _{1\le i \le p_n,1\le j \le q_n}|{\mathcal {R}}_n(X_i,Y_j)|<\varepsilon \) for all n sufficiently large, that is,
Applying the Borel–Cantelli lemma, it suffices to show that
Notice that \(T_{n,1,1}(X_i,X_i)\) and \(T_{n,1,1}(Y_j,Y_j)\) are U-statistics of order 4. By the Theorem 5.4.C in Serfling (1980), it is easy to check that for each i, \(1\le i \le p,1\le j\le q\), almost surely
provided the assumption (A3) holds. In addition, under \(H_0,\) \(\textrm{E}\{G(X_{i},X_{i}')H(Y_j,Y_j')\}=K(X_{i},Y_j) =0\). We can obtain from a standard result in section 32 of Loève (1978) and Markov’s inequality that
where the last equality follows from Theorem 5.3.2 in Serfling (1980). Thus the result in (1) can be obtained.
(2) We need to show that almost surely
To obtain the result, it is sufficient to prove that
since
Write the projection of U-statistic \(T_{n,1,1}(X_i,Y_j)\) as
Thus we obtain that
where \(K(X_{ti},Y_{tj})=\sigma (X_i,Y_j)X_{ti}Y_{tj}\). Similar to prove (1), it is easy to check that almost surely
Hence, we only need to show that
Similarly, we have that
where the last equality is true when (A4) holds. Therefore, we have almost surely that
This proof is thus completed.
\(\square \)
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chen, Y., Guo, W. & Cui, H. On the test of covariance between two high-dimensional random vectors. Stat Papers 65, 2687–2717 (2024). https://doi.org/10.1007/s00362-023-01500-6
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-023-01500-6