
Abstract
Key message
Chloroplast genome of Solanum commersonii and S olanum tuberosum were completely sequenced, and Indel markers were successfully applied to distinguish chlorotypes demonstrating the chloroplast genome was randomly distributed during protoplast fusion.
Abstract
Somatic hybridization has been widely employed for the introgression of resistance to several diseases from wild Solanum species to overcome sexual barriers in potato breeding. Solanum commersonii is a major resource used as a parent line in somatic hybridization to improve bacterial wilt resistance in interspecies transfer to cultivated potato (S. tuberosum). Here, we sequenced the complete chloroplast genomes of Lz3.2 (S. commersonii) and S. tuberosum (PT56), which were used to develop fusion products, then compared them with those of five members of the Solanaceae family, S. tuberosum, Capsicum annum, S. lycopersicum, S. bulbocastanum and S. nigrum and Coffea arabica as an out-group. We then developed Indel markers for application in chloroplast genotyping. The complete chloroplast genome of Lz3.2 is composed of 155,525 bp, which is larger than the PT56 genome with 155,296 bp. Gene content, order and orientation of the S. commersonii chloroplast genome were highly conserved with those of other Solanaceae species, and the phylogenetic tree revealed that S. commersonii is located within the same node of S. tuberosum. However, sequence alignment revealed nine Indels between S. commersonii and S. tuberosum in their chloroplast genomes, allowing two Indel markers to be developed. The markers could distinguish the two species and were successfully applied to chloroplast genotyping (chlorotype) in somatic hybrids and their progenies. The results obtained in this study confirmed the random distribution of the chloroplast genome during protoplast fusion and its maternal inheritance and can be applied to select proper plastid genotypes in potato breeding program.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Cytoplasmic genomes such as chloroplast (cp) and mitochondria (mt) have their own genomes and specific genes for important cellular functions, e.g., photosynthesis, male sterility, etc. (Jheng et al. 2012; Ruiz and Daniell 2005). Hosaka and Hanneman (1988) reported that potato has five basic cp types (A, C, S, T and W), and most cultivated potato has T-type cp genome, which is linked to the β-type mt genome. The major difference between T and all other cp types is the occurrence of a 241 bp deletion in the trnV-ndhC intergenic region in S. tuberosum (Hosaka 2002; Hosaka and Sanetomo 2012). Cp genome sequences are the main molecular targets as these sequences are conserved across plant species and show clear interspecies polymorphism, whereas intraspecies polymorphism is rare (Kim et al. 2015).
To date, characterization of the chloroplast genotype has relied on Southern hybridization or several universal primers homologous to conserved cp DNA sequences (Aversano et al. 2009; Bastia et al. 2000; Hosaka and Hanneman 1988; Lovene et al. 2007; Scotti et al. 2003; Tiwari et al. 2014). However, these techniques are time consuming and require high quality cp DNA. Moreover, universal primers are not unique and cannot distinguish specific species. Cp genome derived markers are highly reliable for authentication of plant species as the cp DNA is high copy and resistant to mechanical breakdown because of its small and stable circular form compared to nuclear DNA (Kim et al. 2015). In Solanum species, particular intergenic and intragenic regions of cp genome were used to differentiate chloroplast genotype within species and/or between species (Bastia et al. 2001; Lössl et al. 2000; Hosaka and Sanetomo 2012) and SSR markers developed with potato and tobacco cp genome were used to investigate genetic diversity of wild species (Gavrilenko et al. 2013). However, complete cp genome sequences were rarely used to discriminate Solanum species and to identify genetic diversity (Cho and Park 2016; Gargano et al. 2012). Additionally only a limited number of the complete cp genome sequences of Solanaceae species have been reported although approximately 530 complete cp genome sequences are available in GeneBank.
Solanum commersonii, a diploid species (2n = 2x = 24), has several desirable characteristics such as disease resistance, especially, to bacterial wilt and common scab and abiotic stress resistance such as cold and frost tolerance (Spooner et al. 1991). However, it is incompatible with S. tuberosum (2n = 4x = 48) owing to the different ploidy level of the genome and endosperm balance number (EBN) (Cho et al. 1997; Ortiz and Ehlenfeldt 1992). Somatic hybridization via protoplast fusion provides an opportunity to overcome sexual barriers for interspecific gene transfer in potato breeding programs (Ahn and Park 2013; Kim-Lee et al. 2005; Yu et al. 2013; Zhao et al. 2013). Previously Kim et al. (1993) produced somatic hybrids via protoplast fusion between S. commersonii clone (Lz3.2) and dihaploid of S. tuberosum cv Superior (PT56) and the hybrids have been identified to have bacterial wilt resistance. In addition, they reported that some progenies of BC1 (backcross) and BC2 populations generated from the fusion hybrids can be used as cross parents for further breeding (Kim-Lee et al. 2005).
Somatic hybrids create novel variability, not only at the nuclear level, but also in cytoplasmic DNA of the mitochondria and chloroplast (Lovene et al. 2007; Tiwari et al. 2014). Therefore, the exact characterization in somatic hybrids to confirm the hybridity of organelle DNA using molecular markers is an essential process (Cho et al. 2015) although resistance to bacterial wilt is not controlled by cp genome. However, characterization of the cytoplasmic genome composition of these somatic hybrids and their progenies has not been reported to date. Here, therefore, we present a first report of the complete cp genome sequences of S. commersonii clones (Lz3.2) and the dihaploid of S. tuberosum cv. Superior (PT56) for comparative analysis with Solanaceae plants. In addition, we characterized the cp genome composition in interspecific somatic hybrids between S. commersonii and S. tuberosum using Indel specific markers.
Materials and methods
Plant material
The S. commersonii clone, Lz3.2 (Kim-Lee et al. 2005) and dihaploid S. tuberosum cv. Superior clone, PT56 were used for the complete cp genome sequencing. Somatic hybrids (HA06-1, HA06-4, and HA06-9) derived from a fusion between Lz3.2 and PT56, and seven progeny lines derived from backcrossing the somatic hybrid lines with S. tuberosum were used for chloroplast genotyping (chlorotype). All clones were developed by Kim-Lee et al. (2005) and maintained in vitro at the Highland Agriculture Research Institute (Supplementary Fig. S1).
Chloroplast (CP) genome sequencing
Total genomic DNA of Lz3.2 and PT56 was isolated from approximately 100 mg of fresh leaves using a DNeasy Plant MiniKit (Qiagen, CA, USA). Genomic DNA was used for sequencing, which was conducted using the Illumina genome analyzer (Hiseq 2000) platform at Macrogen (http://www.macrogen.com/kor/). The cp genome assembly was performed by the de novo assembly protocol (Cho et al. 2015) via the Phyzen bioinformatics pipeline (http://phyzen.com). De novo assembly was conducted using trimmed reads by a CLC genome assembler with parameters of a minimum 200–600 bp autonomously controlled overlap size. The main contigs representing the cp genome were retrieved and assembled by the bioinformatics tool described in our previous paper (Cho et al. 2015; Cho and Park 2016). Gene annotation was accomplished using DOGMA (http://dogma.ccbb.utexas.edu/) and manual editing through a comparison with the reported cp genome sequence of S. tuberosum (NC_008096).
Comparative analysis of chloroplast genome
The chloroplast (cp) genome of six Solanaceae species including S. tuberosum, S. nigrum, S. lycopersicum, S. bulbocastanum and Capsicum annum and one out-group, Coffea arabica, were used for comparative analysis. GenBank accession numbers are listed in Supplementary Table S1. For sequence comparison of the protein coding genes, codon usage was examined using MEGA5 (Tamura et al. 2011), and gene diversity was calculated using Geneious 7.1.7 (Biomatters Ltd., Auckland, New Zealand) after alignment with ClustalX (Thompson et al. 1997). Tandem repeats were predicted using the Tandem repeat finder (Benson 1999) with 2, 7, and 7 parameters for match, mismatch, and Indels, respectively, and manual editing through CLC Main Workbench ver 7.6.4 (CLC bio A/S, Aarhus, Denmark). To compare genome rearrangements, we used the progressive Mauve (Darling et al. 2010) alignment with six Solanaceae species cp genomes.
Phylogenetic analysis of CP genome
Phylogenetic analysis was carried out by PAUP* v4.0b10 (Swofford 2001) using 100 replicates, MAXTREES = 200,000, random addition, TBR branch swapping, and MULTREES, with gaps treated as missing data. For the likelihood search, the same parameters employed in the maximum parsimony (MP) analyses were used under PAUP*. Support for the monophyletic groups revealed in the maximally parsimonious trees was examined using 1000 bootstrap replicates and a 50 % cutoff value for the bootstrap (BP) consensus tree. Maximum likelihood (ML) analysis was conducted under PAUP* using the evolutionary model parameters suggested by Modeltest3.7 (Posada and Crandall 1998), 100 replicates, random addition and TBR branch swapping.
Bayesian inference was conducted using MrBayes v3.0b3 (Huelsenbeck and Ronquist 2001), with the model parameters determined from the Modeltest3.7. The MCMC algorithm was run for 1,000,000 generations with four incrementally heated chains, starting from random trees and sampling one out of every 100 generations. The first 2000–5000 trees were discarded as burn-in, depending on when the chains appeared to have become stationary. The trees sampled from within the burn-in stage were excluded, and the remaining trees were assumed to be representative of the posterior probability (PP) distribution. The majority-rule consensus tree was calculated with PAUP*. Nodes with PP > 0.95 were considered statistically significant (Simpson 2010).
Indel marker analysis
Sequence alignment was performed with the cp genome sequences of PT56 and Lz3.2 to detect Indel regions, after which Indel specific primers were designed. Total genomic DNA was used for PCR analysis with the Indel specific primers. For PCR analysis, 20 ng of genomic DNA was amplified in a 20 µl PCR mixture containing 2 × TOP simple preMix-nTaq master mix (Enzynomics, Seoul, Korea) consisting of 0.2 U/µl n-Taq DNA polymerase, 3 mM Mg2+, and 0.4 mM each dNTP mixture with 10 pMol of each primer. The PCR reaction was performed in a thermocycler (Veriti, Applied Biosystems, CA, USA) using the following cycling parameters: initial denaturation at 94 °C for 5 min followed by 35 cycles of 94 °C for 30 s, 55 °C for 30 s, and 72 °C for 1 min and then final extension at 72 °C for 10 min. PCR products were analyzed on 1.8 % agarose gel and capillary electrophoresis using a Fragment Analyzer (Advanced Analytical Technologies Inc., USA) according to the manufacturer’s instruction.
Results and discussion
Complete chloroplast (cp) genome sequences of S. commersonii and S. tuberosum
The complete cp genome sequencing of S. commersonii and S. tuberosum (PT56) was performed by NGS (next generation sequencing) technology. Three major contigs covering the entire reported genome sequence of S. tuberosum (NC_008096) were obtained from the de novo assembly. The three contigs that showed an overlap of approximately 20 bp between the flanking contigs were joined as a single circular complete sequence by manual editing. The complete cp genome sequences of S. commersonii and S. tuberosum (PT56) have a total sequence of 155,525 and 155,296 bp and contain a large single copy (LSC) region of 85,973 and 85,737 bp, two copies of inverted repeats (IR) of 25,593 and 25,593 bp and a small single copy (SSC) region of 18,366 and 18,373 bp, respectively (Table 1).
Comparative analysis of chloroplast genome and hotspots
Genome content
The S. commersonii cp genome shares a similar gene content, order and orientation with that of S. tuberosum (Fig. 1). The total sequence length of S. commersonii (155,525 bp) is 229 bp longer than that of S. tuberosum (155,296 bp). The entire cp genome is separated into LSC and SSC regions by a pair of inverted repeats in both species. Both S. commersonii and S. tuberosum exhibited a similarity in other genome contents including an overall GC content of 62.1 %, total coding sequence (CDS) bases of 80,571 bp with an average CDS length of 926.01 bp and total RNA bases of 92,481 bp. Both the S. commersonii and S. tuberosum cp genomes contain 87 protein coding genes that include protein synthesis related genes as well as transcription and translation related genes (Table 1). Variation in the total size between S. commersonii and S. tuberosum cp genomes accounted for the 229 bp larger LSC region in S. commersonii.

Circular gene map of S. commersonii chloroplast genome. Genes shown inside the circle are transcribed clockwise, while those outside are transcribed counterclockwise
Comparison of IR region borders
The border regions of the S. commersonii cp genome were compared with six other Solanaceae species, including S. tuberosum (cv. Superior), S. nigrum, S. lycopersicum, S. tuberosum (cv. Desiree), S. bulbocastanum, and Capsicum annum, to analyze the expansion variation in junction regions. The gene content and organization of the S. commersonii cp genome is nearly identical to both cultivars of S. tuberosum (cv. Superior and Desiree). The rps19, ycf1, ndhF, and trnH genes are present at the junctions of IR/SSC and IR/LSC borders. The organization pattern of rps19, ycf1 and ndhF is identical in S. commersonii and the two S. tuberosum cultivars except for a difference in that 1 bp of the ycf1 gene is extended into the SSC region in S. tuberosum (cv. Desiree). However, considerable variation was observed in the expansion and contraction of the IR region in other Solanaceae species. At one end, 91 and 79 bp of the rps19 gene is extended into the IR region and 1119 and 1122 bp of the ycf1 gene are extended into the other end of the IR region in S. lycopersicum and S. bulbocastanum, respectively. In S. nigrum and C. annum, 28 and 65 bp of the rps19 gene and 1121 and 1094 bp of the ycf1 gene are extended into the IR regions, respectively (Fig. 2).

Comparison of IR boundaries among six Solanaceae species using chloroplast genome sequences. A S. commersonii, B S. tuberosum (cv. Superior), C S. tuberosum (cv. Desiree), D S. nigrum, E S. lycopersicum, F S. bulbocastanum, G Capsicum annum
Comparison of hotspot and tandem repeat
Hotspots, such as inversions, Indels, or base substitutions that are specific regions and highly diverged during genome evolution are detected in cp genomes in many species (Ames et al. 2007; Bohs and Olmstead 1997; Hosaka 2004; Jo et al. 2011). In our study, the IR region was highly conserved in two species, S. tuberosum and S. commersonii compared to other Solanaceae species. In addition, a small expansion and contraction was observed at the SSC/IRb junction area with a 2 bp ndhF gene expansion in the IRb region (Fig. 2). Haberle et al. (2008) reported that hotspots are associated with a large number of tandem repeats and tRNA sequences owing to recombination among these features. The majority of tandem repeats are distributed in the LSC and IR region in wild potato relatives (Table 2). We identified 24 tandem repeats in the S. commersonii cp genome, 13 of which are in the intergenic region and 11 are in coding regions (Supplementary Table S2). Additionally, 23 tandem repeats were observed in S. tuberosum, with 13 and 10 in the intergenic and coding regions, respectively. Moreover, 11 tandem repeats are conserved through wild potato relatives (Supplementary Table S2). Tandem repeats of the cp genome have been reported in several species in the same genus (Cho et al. 2015; Jo et al. 2011). These repeats were found to be related in structural variation, genome expansion, or rearrangement (Gargano et al. 2012). However, there were no rearrangement and copy number variations of the cp genome observed among wild potato relatives in this study (Supplementary Fig. S2). Among 11 highly conserved tandem repeats across wild potato relatives, eight are in the coding regions and half of these are found in the ycf2 gene (Supplementary Table S2). Especially, S. commersonii and S. tuberosum showed a higher percentage of shared sequence similarity of about 90 % when compared to S. nigrum and S. bulbocastanum. The longest and the shortest total lengths of tandem repeats, 1178 and 928 bp, were detected in S. commersonii and S. bulbocastanum, respectively, and there was no rearrangement and copy number variation in wild potato relatives compared to S. tuberosum. Jo et al. (2011) found that the only differences in tandem repeats within the solanaceous cp genome were the absence or presence of specific repeats, while no difference in copy number were observed. These results were consistent with the finding that there were no copy number variations in potato and its wild relatives. When the S. commersonii and S. tuberosum cp genomes were compared, the only difference was that there was one tandem repeat in S. tuberosum and two in S. commersonii. These findings are consistent with those of previous reports that S. commersonii is relatively close to S. tuberosum based on the analyses of the plastid genome and meiotic behavior (Bastia et al. 2000; Matsubayashi 1991; Perl et al. 1991), and thus confirm the close evolutionary relationship between S. tuberosum and S. commersonii.
Codon usage and genetic diversity
The protein coding genes of eight plastid genomes were encoded ranging from 22,855 (C. arabica) to 23,100 (C. annuum). Among them, leucine (2413–2445) is the most frequently occurring amino acid, followed by isoleucine (1937–1966), serine (1678–2025) and glycine (1603–1619). Cysteine (246–258) was the least frequently occurring amino acid (Supplementary Table S3). Most of these coding genes used the typical start codon (ATG) although the ACG start codon was observed in ndhD and psbL. Moreover, the ATA and GTG start codons were found in rps19 and infA, respectively.
Among 114 chloroplast genes, 112 were analyzed to identify gene diversity. Two genes (rps14 and ycf15) were excluded because of a pseudogene in S. tuberosum and a deletion in C. arabica. Total gene diversity from the C. arabica homolog was calculated for each of the 112 Solanaceae genes (Supplementary Table S4). Fifteen genes (14 tRNA and 1 rRNA) were invariable in the chloroplast genes of eight species. A total of 112 chloroplast genes were classified into eighteen functional gene groups, and the average gene diversity was calculated for each group. The average gene diversity of the 112 genes ranged from 5.398 (S. nigrum) to 5.700 (C. annuum). Maturase, c-type cytochrome synthesis gene, acetyl-CoA carboxylase and translational initiation factor appear to have evolved rapidly. In contrast, transfer RNA and ribosomal RNA are highly conserved.
Phylogenetic analysis
The total aligned length of the eight species was 163,954 bp. There were 146,838 constant characters, 15,481 variable characters that were parsimoniously uninformative and 1635 parsimoniously informative characters. Treating gaps as missing data, with C. arabica as an out-group, the maximum parsimony analysis produced only one tree with 18,214 steps, a consistency index (CI) of 0.98, a retention index (RI) of 0.81, and a rescaled consistency (RC) of 0.79. The model test suggested that TVM+I+G was the best fit model. The nucleotide diversity between S. commersonii Lz3.2 and S. tuberosum PT56 was found to be very low (0.001) (Supplementary Table S5). The phylogenetic relationship based on the total genome sequences of the eight species is presented in Fig. 3. Maximum parsimony (MP) analysis and maximum likelihood (ML) analysis produced the same topology. Moreover, all nodes of the phylogenetic trees were strongly supported by the 100 % bootstrap values (BP) and 1.00 Bayesian posterior probabilities (PP). The phylogenetic tree showed that C. annuum is the earliest diverging lineage in in-groups, which was identified as a sister to the other species and S. commersonii Lz3.2 formed the sister of S. tuberosum cv. Desiree and S. tuberosum PT56.

Phylogenetic analysis of six Solanaceae species based on complete chloroplast genome sequences. Bootstrap values are below the clades and the Bayesian posterior probabilities are shown above the clades. Coffea arabica was used as an out-group
Indel marker development and CP genotyping (chlorotype) in potato somatic hybrids
A total of nine Indels were found between S. commersonii and S. tuberosum, most of which were observed in IGS regions, with one Indel located in the intron of the genic sequence, ndhA. Similar results were reported in other species (Rousseau-Gueutin, et al. 2015; Yamane, et al. 2006). Although Bastia et al. (2001) reported polymorphism of the marker derived from the intergenic region in size between trnF and trnV existed in S. tuberosum and S. commersonii and no differences were observed among S. commersonii accessions, Indel was not found between the two species in this study. The different accession number of S. commersonii and genotype of S. tuberosum used in this study might cause the result indicating that there could be certain different regions of cp genomes within species as reported by Scotti et al. (2003).
The size of the Indels within the IGS ranged from 3 to 241 bp, while the one within the ndhA genic sequence was 5 bp (Table 3). Based on comparative analysis of the cp genome of S. commersonii and S. tuberosum, we developed Indel markers to distinguish chloroplast genotypes by PCR (Table 4). The size of the intergenic region between the ndhC and tRNA_V coding genes among various Solanum species ranged from 861 to 1186 bp. In both S. tuberosum cultivars (Desiree and PT56), the intergenic region was 861 bp with an intron size of 571 and 569 bp, respectively. Similarly, the intergenic region in S. commersonii was 1101 bp with an intron size of 569 bp (Supplementary Fig. S3). Sequence alignment of the intergenic region of S. commersonii (Lz3.2) and S. tuberosum (PT56) revealed a large deletion of a 241 bp sequence in the ndhC-trnV of S. tuberosum (Supplementary Fig. S4A). Although other shorter Indels were identified, a larger Indel_CT_01 marker of 241 bp and an Indel_CT_02 marker of 18 bp were successfully developed and further used for the cp genotyping of somatic hybrids (Supplementary Fig. S4A and S4B).
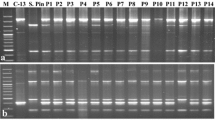
The two Indel markers developed in this study were used in the chlorotype of somatic hybrid plants in potato. The chlorotype of somatic hybrid plants suggested that among the three somatic hybrids, two (HA06-1 and HA06-4) were probably derived from PT56 (S. tuberosum) and one (HA06-9) was derived from Lz3.2 (S. commersonii) (Table 5). For introgression of bacterial wilt resistance from S. commersonii, somatic hybrid plants were backcrossed (BC) with cultivated potato (S. tuberosum) as the male parent (Supplementary Fig. S1) and the chlorotypes of BC progenies were also exploited. Backcrossed progeny lines obtained by reciprocally crossing between somatic hybrids HA06-4 and HA06-9 as female parents and S. tuberosum as the male parent were analyzed using Indel_CT_01 and Indel_CT_02. PCR analysis of seven BC progenies with the two Indel markers showed their respective maternal chlorotype implying that the cp genome was stably transferred after BC (Fig. 4).

PCR analysis performed by A agarose and B capillary gel electrophoresis using (A) Indel_CT_01 and (B) Indel_CT_02 markers defined in Table 3. M: 100 bp DNA ladder (Bioneer. Co., Daejeon, Republic of Korea), Lz3.2: S. commersonii, PT56: S. tuberosum, HA series: somatic hybrids, lanes 1–7: backcross generation with S. tuberosum. Lanes 1 and 2: BC plants with HA06-4 as female parent and lanes 3–7: BC plants with HA06-9 as female parent. Arrows indicate markers separated by size difference of Indel regions
Characterization of haplotypes using molecular markers in Solanum species is crucial to not only enhanced potato breeding programs, but also evolutionary studies (Bohs and Olmstead 1997; Hosaka and Sanetomo 2012, 2014). Furthermore, somatic hybrids induce new nuclear genome assortments and variable mitochondria and cp genomes (Aversano et al. 2009; Bastia et al. 2000; Scotti et al. 2003). The nuclear and cytoplasm genetic analysis of somatic hybrids using molecular markers showed a high frequency of recombination in the mitochondrial genome, but very little recombination in the cp genome. Moreover, somatic hybrids have random parental cp genomes. Lössl et al. (2000) reported skewed random segregation of cp genome indicating a higher performance of a certain type of cp genome during in vitro regeneration phase. These features were commonly observed in Solanum species (Chen et al. 2013; Smyda-Dajmund et al. 2016) and other plant species (Mohapatra et al. 1998; Xiang et al. 2004). However, cp genomes of both parents coexisted in some case (Wang et al. 2011). Overall, our findings confirmed random distribution of cp genome in somatic hybrids and their maternal inheritance. In addition, the Indel markers developed in this study can be utilized as biomarkers to discriminate S. commersonii and S. tuberosum, to select proper chlorotype from fusion products and BC generations, and further to facilitate faster breeding using S. commersonii.
Author contribution statement
K-S Cho conceived the design of the study, analyzed the data and drafted the manuscript. K-S Cheon and Y-SY performed the bioinformatics work. S-YH, J-HC, J-SI and MM collected background information and conducted all experiments. T-HP was responsible for data analysis and writing of the manuscript. All authors read and approved the final manuscript.
References
Ahn YK, Park TH (2013) Resistance to common scab developed by somatic hybrids between Solanum brevidens and Solanum tuberosum. Acta Agr Scand B-S P 63:595–603
Ames M, Salas A, Spooner DM (2007) The discovery and phylogenetic implications of a novel 41 bp plastid DNA deletion in wild potatoes. Plant Syst Evol 268:159–175
Aversano R, Savarese S, De Nova JM, Frusciante L, Punzo M, Carputo D (2009) Genetic stability at nuclear and plastid DNA level in regenerated plants of Solanum species and hybrids. Euphytica 165:353–361
Bastia T, Carotenuto N, Basile B, Zoina A, Cardi T (2000) Induction of novel organelle DNA variation and transfer of resistance to frost and Verticillium wilt in Solanum tuberosum through somatic hybridization with 1EBN S. commersonii. Euphytica 116:1–10
Bastia T, Scotti N, Cardi T (2001) Organelle DNA analysis of Solanum and Brassica somatic hybrids by PCR with ‘universal primers’. Theor Appl Genet 102:1265–1272
Benson G (1999) Tandem repeats finder: a program to analyze DNA sequences. Nucleic Acids Res 27:573–580
Bohs L, Olmstead RG (1997) Phylogenetic relationships in Solanum (Solanaceae) based on ndhF sequences. Syst Bot 22:5–17
Chen L, Guo X, Xie C, He L, Cai X, Tian L, Song B, Liu J (2013) Nuclear and cytoplasmic genome components of Solanum tuberosum + S. chacoense somatic hybrids and three SSR alleles related to bacterial wilt resistance. Theor Appl Genet 126:1861–1872
Cho K-S, Park T-H (2016) Complete chloroplast genome sequence of Solanum nigrum and development of markers for the discrimination of S. nigrum. Hortic Environ Biotechnol 57:69–78
Cho HM, Kim-Lee HY, Om YH, Kim JK (1997) Influence of endosperm balance number (EBN) in interploidal and interspecific crosses between Solanum tuberosum dihaploids and wild species. Korean J Breed 29:154–161
Cho K-S, Yun B-K, Yoon Y-H, Hong S-Y, Mekapogu M, Kim K-H, Yang T-J (2015) Complete chloroplast genome sequence of tartary buckwheat (Fagopyrum tataricum) and comparative analysis with common buckwheat (F. esculentum). PLoS One 10:e0125332
Daniell H, Lee S-B, Grevich J, Saski C, Quesada-Vargas T, Guda C, Tomkins J, Jansen PK (2006) Complete chloroplast genome sequences of Solanum bulbocastanum, Solanum lycopersicum and comparative analyses with other Solanaceae genomes. Theor Appl Genet 112:1503–1518
Darling AE, Mau B, Perna NT (2010) progressiveMauve: multiple genome alignment with gene gain, loss and rearrangement. PLoS One 5:e11147
Gargano D, Vezzi A, Scotti N, Gray JC, Valle G, Grillo S, Cardi T (2005) The complete nucleotide sequence genome of potato (Solanum tuberosum cv. Desiree) chloroplast DNA. In the abstracts of the 2nd Solanaceae Genome Workshop, p 107
Gargano D, Scotti N, Vezzi A, Bilardi A, Valle G, Grillo S, Cozzolino S, Cardi T (2012) Genome-wide analysis of plastome sequence variation and development of plastidial CAPS markers in common potato and related Solanum species. Genet Resour Crop Evol 59:419–430
Gavrilenko T, Antonova O, Shuvalova A, Krylova E, Alpatyeva N, Spooner DM, Novikova L (2013) Genetic diversity and origin of cultivated potatoes based on plastid microsatellite polymorphism. Genet Resour Crop Evol 60:1997–2015
Haberle RC, Fourcade HM, Boore JL, Jansen RK (2008) Extensive rearrangements in the chloroplast genome of Trachelium caeruleum are associated with repeats and tRNA genes. J Mol Evol 66:350–361
Hosaka K (2002) Distribution of the 241 bp deletion of chloroplast DNA in wild potato species. Am J Potato Res 79:119–123
Hosaka K (2004) Evolutionary pathway of T-type chloroplast DNA in potato. Am J Potato Res 81:153–158
Hosaka K, Hanneman RE Jr (1988) The origin of the cultivated tetraploid potato based on chloroplast DNA. Theor Appl Genet 76:172–176
Hosaka K, Sanetomo R (2012) Development of a rapid identification method for potato cytoplasm and its use for evaluating Japanese collections. Theor Appl Genet 125:1237–1251
Hosaka K, Sanetomo R (2014) Application of a PCR-Based cytoplasm genotyping method for phylogenetic analysis in potato. Am J Potato Res 91:246–253
Huelsenbeck JP, Ronquist F (2001) MRBAYES: Bayesian inference of phylogenetic trees. Bioinformatics 17:754–755
Jheng C-F, Chen T-C, Lin J-Y, Chen T-C, Wu W-L, Chang C-C (2012) The comparative chloroplast genomic analysis of photosynthetic orchids and developing DNA markers to distinguish Phalaenopsis orchids. Plant Sci 190:62–73
Jo YD, Park J, Kim J, Song W, Hur CG, Lee YH, Kang BC (2011) Complete sequencing and comparative analyses of the pepper (Capsicum annuum L.) plastome revealed high frequency of tandem repeats and large insertion/deletions on pepper plastome. Plant Cell Rep 30:217–229
Kim HY, Chae MS, Choi SU, Wielgus SM, Helgeson JP (1993) Identification of somatic hybrids produced by protoplast fusion between Solanum commersonii and S. tuberosum haploid. Korean J Plant Tissue Cult 20:337–344
Kim K, Lee SC, Lee J, Lee HO, Joh HJ, Kim NH, Park HS, Yang TJ (2015) Comprehensive survey of genetic diversity in chloroplast genomes and 45S nrDNAs within Panax ginseng species. PLoS One 10:e0117159
Kim-Lee HY, Moon JS, Hong YJ, Kim MS, Cho HM (2005) Bacterial wilt resistance in the progenies of the fusion hybrids between haploid of potato and Solanum commersonii. Am J Potato Res 82:129–137
Lössl A, Götz M, Braun A, Wenzel G (2000) Molecular markers for cytoplasm in potato: male sterility and contribution of different plastid-mitochondrial configurations to starch production. Eupytica 116:221–230
Lovene M, Savarese S, Cardi T, Frusciante L, Scotti N, Simon PW, Carputo D (2007) Nuclear and cytoplasmic genome composition of Solanum bulbocastanum (+) Solanum tuberosum somatic hybrids. Genome 50:443–450
Matsubayashi M (1991) Phylogenetic relationships in the potato and its related species. In: Tsuchiya T, Gupta PK (eds) Chromosome engineering in plants: genetics, breeding and evolution, part B. Elsevier, Amsterdam, pp 93–118
Mohapatra T, Kirti PB, Dinesh Kumar V, Prakash S, Chopra VL (1998) Random chloroplast segregation and mitochondrial genome recombination in somatic hybrid plants of Diplotaxis catholica + Brassica juncea. Plant Cell Rep 17:814–818
Ortiz R, Ehlenfeldt MK (1992) The importance of endosperm balance number in potato breeding and the evolution of tuber-bearing Solanum species. Euphytica 60:105–113
Perl A, Aviv D, Galun E (1991) Nuclear-organelle interaction in Solanum: interspecific cybridizations and their correlation with a plastome dendrogram. Mol Gen Genet 228:193–200
Posada D, Crandall KA (1998) MODELTEST: testing the model of DNA substitution. Bioinformatics 14:817–818
Rousseau-Gueutin M, Bellot S, Martin GE, Boutte J, Chelaifa H, Lima O, Michon-Coudouel S, Naquin D, Salmon A, Ainouche K, Ainouche M (2015) The chloroplast genome of the hexaploid Spartina maritima (Poaceae, Chloridoideae): comparative analyses and molecular dating. Mol Phylogenet Evol 93:5–16
Ruiz ON, Daniell H (2005) Engineering cytoplasmic male sterility via the chloroplast genome. Plant Physiol 138:1232–1246
Samson N, Bausher MG, Lee SB, Jansen RK, Daniell H (2007) The complete nucleotide sequence of the coffee (Coffea arabica L.) chloroplast genome: organization and implications for biotechnology and phylogenetic relationships amongst angiosperms. Plant Biotechnol J 5:339–353
Scotti N, Monti L, Cardi T (2003) Organelle DNA variation in parental Solanum spp. genotypes and nuclear-cytoplasmic interactions in Solanum tuberosum (+) S. commersonii somatic hybrid-backcross progeny. Theor Appl Genet 108:87–94
Simpson MG (2010) Plant systematics. Academic press, Oxford
Smyda-Dajmund P, Śliwka J, Wasilewicz-Flis I, Jakuczun H, Zimnoch-Guzowska E (2016) Genetic composition of interspecific potato somatic hybrids and autofused 4x plants evaluated by DArT and cytoplasmic DNA markers. Plant Cell Rep 35:1345–1358
Spooner DM, Bamberg J, Hjerting JP, Gomez J (1991) Mexico, 1988 Potato germplasm collecting expedition and utility of the Mexican potato species. Am Potato J 68:29–43
Swofford DL (2001) Phylogenetic analysis using parsimony (* and other methods). Sinauer Associates, Sunderland
Tamura K, Peterson D, Peterson N, Stecher G, Nei M, Kumar S (2011) MEGA5: molecular evolutionary genetics analysis using maximum likelihood, evolutionary distance, and maximum parsimony methods. Mol Biol Evol 28:2731–2739
Thompson JD, Gibson TJ, Plewniak F, Jeanmougin F, Higgins DG (1997) The CLUSTAL_X windows interface: flexible strategies for multiple sequence alignment aided by quality analysis tools. Nucleic Acids Res 25:4876–4882
Tiwari JK, Chandel P, Singh BP, Bhardwaj V (2014) Analysis of plastome and chondriome genome types in potato somatic hybrids from Solanum tuberosum x Solanum etuberosum. Genome 57:29–35
Wang J, Zhao C, Liu C, Xia G, Xiang F (2011) Introgression of Swertia mussotii gene into Bupleurum scorzonerifolium via somatic hybridization. BMC Biol 11:71
Xiang F, Xia G, Zhi D, Wang J, Nie H, Chen H (2004) Regeneration of somatic hybrids in relation to the nuclear and cytoplasmic genomes of wheat and Setaria italica. Genome 47:680–688
Yamane K, Yano K, Kawahara T (2006) Pattern and rate of Indel evolution inferred from whole chloroplast intergenic regions in sugarcane, maize and rice. DNA Res 13:197–204
Yu Y, Ye WX, He L, Cai XK, Liu T, Liu J (2013) Introgression of bacterial wilt resistance from eggplant to potato via protoplast fusion and genome components of the hybrids. Plant Cell Rep 32:1687–1701
Zhao QX, Zhao BX, Zhang QQ, Yu B, Cheng LX, Jin R, Wang YP, Zhang JL, Wang D, Zhang F (2013) Screening for chip-processing potato line from introgression of wild species’ germplasms with post-harvest storage and chip qualities. Am J Potato Res 90:425–439
Acknowledgments
This work was supported by the Korea Institute of Planning and Evaluation for Technology in Food, Agriculture, Forestry and Fisheries (IPET) through the Golden Seed Project funded by the Ministry of Agriculture, Food and Rural Affairs (MAFRA) (No. 213001-04-4-SB530), Republic of Korea.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Communicated by R. J. Rose.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Cho, KS., Cheon, KS., Hong, SY. et al. Complete chloroplast genome sequences of Solanum commersonii and its application to chloroplast genotype in somatic hybrids with Solanum tuberosum . Plant Cell Rep 35, 2113–2123 (2016). https://doi.org/10.1007/s00299-016-2022-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00299-016-2022-y