
Abstract
This work considers the problem of design centering. Geometrically, this can be thought of as inscribing one shape in another. Theoretical approaches and reformulations from the literature are reviewed; many of these are inspired by the literature on generalized semi-infinite programming, a generalization of design centering. However, the motivation for this work relates more to engineering applications of robust design. Consequently, the focus is on specific forms of design spaces (inscribed shapes) and the case when the constraints of the problem may be implicitly defined, such as by the solution of a system of differential equations. This causes issues for many existing approaches, and so this work proposes two restriction-based approaches for solving robust design problems that are applicable to engineering problems. Another feasible-point method from the literature is investigated as well. The details of the numerical implementations of all these methods are discussed. The discussion of these implementations in the particular setting of robust design in engineering problems is new.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
This work discusses the theoretical and practical issues involved with solving design centering problems. The problems considered will be in the general form
where \(Y \subset \mathbb {R}^{n_y}\), \(\mathbf {g}: Y \rightarrow \mathbb {R}^m\), \(G = \{ \mathbf {y}\in Y : \mathbf {g}(\mathbf {y}) \le \mathbf {0} \}\), \(X \subset \mathbb {R}^{n_x}\), D is a set-valued mapping from X to \(\mathbb {R}^{n_y}\) (denoted \(D : X \rightrightarrows \mathbb {R}^{n_y}\)), and \(\mathrm {vol}(\cdot )\) denotes the “volume” of a set (or some suitable proxy- in this work D will either be ball- or interval-valued, and the choice of volume/proxy will be clear). \(D(\mathbf {x})\) is called a “candidate” design space, which is feasible if \(D(\mathbf {x})\) is a subset of G, and optimal if it is the “largest” such feasible design space.
Ensuring feasibility of the solution is typically of paramount importance in any method for the solution of (DC). An application of (DC) is to robust design problems. In this case, \(\mathbf {g}\) represents constraints on a system or process. Given some input parameters \(\mathbf {y}\), one desires, for instance, on-specification product, or perhaps more importantly, safe system behavior, indicated by \(\mathbf {g}(\mathbf {y}) \le \mathbf {0}\). In robust design, one seeks a nominal set point \(\mathbf {y}_c\) at which to operate the system, and further determine the amount one can deviate from this set point (with respect to some norm) and still have safe process behavior. Then the result is that one seeks a set \(D(\mathbf {y}_c, \delta ) = \{ \mathbf {y}: \left\| \mathbf {y}- \mathbf {y}_c \right\| \le \delta \} \subset G\). One goal might be to maximize operational flexibility, in which case the largest \(D(\mathbf {y}_c,\delta )\) is sought, i.e. \((\mathbf {y}_c,\delta )\) with the largest \(\delta \). This example provides some basic motivation for the focus of this work: The focus on the case that D is ball- or interval-valued comes from the fact that a solution should yield an explicit bound on the maximum acceptable deviation from some nominal set point. The focus on solution methods that are feasible point methods comes from the fact that a solution which violates \(D(\mathbf {x}) \subset G\) is not acceptable, especially when safety is concerned.
Under some subtle assumptions (discussed in Sect. 2), problem (DC) is equivalent to a generalized semi-infinite program (GSIP) expressed as
We note that problem (GSIP) is a specific instance of the broader class of generalized semi-infinite programs, in which \(\mathbf {g}\) is allowed dependence on the variables \(\mathbf {x}\). Because design centering problems are a particular instance of GSIP, this work approaches design centering problems from the perspective of and with tools from the GSIP literature (see Stein (2012) for a recent review). This approach is hardly original (Stein 2006; Stein and Winterfeld 2010; Winterfeld 2008), however, bringing together these ideas in one work is useful. Further, this work compares different numerical approaches from the GSIP literature. In particular, global optimization methods are considered; as a consequence, challenges and advantages appear that are not present when applying local optimization methods.
The end goal of this work is the case when the constraints of the system \(\mathbf {g}\) are implicitly defined by the solution of systems of algebraic or differential equations, as is often the case for robust design in engineering applications. In this case, explicit expressions for \(\mathbf {g}\) and its derivatives are, in general, difficult to obtain, and many methods for GSIP require this information in a numerical implementation. Consequently, the focus turns toward approximate solution methods inspired by global, feasible point methods. This discussion, and in particular the challenges in implementing the numerical methods, is original. Some of these approximations come from restrictions of (DC) which are apparent when considering the GSIP reformulation. Other approximations come from terminating a feasible point method early.
Connections to previous work in the literature are pointed out throughout this work. We mention a few references which do not quite fit into the rest of the organization of this work. Approaches to robust design and design centering specific to various application domains abound. In mechanical engineering, robust design of structures is considered in Parkinson et al. (1993). A design centering method is applied to a complex system such as a life-support system in Salazar and Rocco (2007). A design centering applied to circuit design is considered in Abdel-Malek and Hassan (1991). An approach in the specific case that \(n_y = 3\) is considered in Nguyen and Strodiot (1992), with the classic application of gemstone cutting.
The rest of this work is organized as follows. Section 2 discusses some important concepts and the relationship between (DC) and (GSIP), and assumptions that will hold for the rest of this work. Some interesting cases of (DC) and connections to other problems including “flexibility indices” are also discussed. Section 3 discusses the case when \(\mathbf {g}\) is an affine function. Reformulations as smooth, convex programs with polyhedral feasible sets are possible in this case. The main purpose of this section is to point out this special and tractable case. These reformulations are not necessarily apparent when approaching (DC) from the more general perspective taken in the GSIP literature, which is to use duality results for the lower level programs (see Sect. 2) to reformulate the infinite constraints. This approach is the subject of Sect. 4; thus in this section the lower level programs are convex programs, or more generally, strong duality holds for the lower-level programs. A number of reformulations of (DC) to simpler problems (finite nonlinear programs (NLPs) or standard semi-infinite programs (SIPs)) are possible. The application of global optimization methods to these reformulations reveals some interesting behavior that is not apparent when applying local methods, as in previous work; see Sect. 4.2.2. A numerical example demonstrates that infeasible points can be found when applying a global method to previously published reformulations. Section 5 discusses the most general case, when the lower-level programs are not necessarily convex, and the subsequent need for the aforementioned approximate solution methods inspired by global, feasible point methods. The numerical developments in this section are new, and in particular the result that a significant amount of the implementation can rely on commercially available optimization software is interesting. Examples of robust design from engineering applications are considered. Section 6 concludes with some final thoughts.
2 Preliminaries
2.1 Notation
As already seen, vectors are denoted by lowercase bold letters, while matrices are denoted by uppercase bold letters. A vector of ones whose size is inferred from context is denoted \(\mathbf {1}\). Similarly, a vector or matrix of zeros whose size is inferred from context is denoted \(\mathbf {0}\). Sets are typically denoted by uppercase italic letters. A vector-valued function \(\mathbf {f}\) is called convex if each component \(f_i\) is convex, and similarly for concavity. Denote the set of symmetric matrices in \(\mathbb {R}^{n\times n}\) by \(\mathbb {S}^{n \times n}\). For a symmetric matrix \(\mathbf {M}\), the notation \(\mathbf {M} \succeq \mathbf {0}\) (\(\mathbf {M} \preceq \mathbf {0}\)) means that \(\mathbf {M}\) is positive (negative) semidefinite. Similarly, \(\mathbf {M} \succ \mathbf {0}\) (\(\mathbf {M} \prec \mathbf {0}\)) means \(\mathbf {M}\) is positive (negative) definite. For vectors, inequalities hold componentwise. Denote the determinant of a matrix \(\mathbf {M}\) by \(\det (\mathbf {M})\) and a square diagonal matrix with diagonal given by the vector \(\mathbf {m}\) by \(\mathrm {diag}(\mathbf {m})\). Denote the dual norm of a norm \(\left\| \cdot \right\| \) by \(\left\| \cdot \right\| _*\).
2.2 Equivalence of (DC) and (GSIP)
Throughout this work, the terms “equivalent” and “equivalence” are used to relate two mathematical programs in the standard way.
Definition 1
(Equivalence) Two mathematical programs
are said to be equivalent if for each \(\mathbf {x}\in X\), there exists \(\mathbf {z}\) such that \((\mathbf {x},\mathbf {z}) \in S\), and for each \((\mathbf {x},\mathbf {z}) \in S\), \(\mathbf {x}\in X\).
It is clear that if two programs are equivalent, then the solution sets (if nonempty) have the same “\(\mathbf {x}\)” components since the objective functions are the same.
Next, we state an assumption under which it is shown that (DC) and (GSIP) are equivalent. Nearly all of the results in this work include hypotheses which imply this assumption.
Assumption 1
Assume that in (DC), \(D(\mathbf {x})\) is a subset of Y for all \(\mathbf {x}\in X\).
Consider the lower level programs (LLPs) of (GSIP), for \(\mathbf {x}\in X\) and \(i \in \{1, \ldots , m\}\):

In the context of robust design, \(\mathbf {y}\) represents parameters or inputs to a system. In the context of GSIP, \(\mathbf {y}\) are called the lower (level) variables, while \(\mathbf {x}\) are called the upper variables. For \(\mathbf {x}\in X\), it is clear that if \(D(\mathbf {x})\) is nonempty, then \(\mathbf {x}\) is feasible in (GSIP) iff \(g^*_i(\mathbf {x}) \le 0\) for each i. On the other hand, if \(D(\mathbf {x})\) is empty, then no constraints are required to hold in (GSIP), and so \(\mathbf {x}\) is feasible (alternatively one could define the supremum of a real function on the empty set as \(-\infty \)).
Consider the fact that G is defined as a subset of Y. If Assumption 1 did not hold, the constraints in (GSIP) would need to be modified to read
However, this leads to complications. If, for instance, \(D(\mathbf {x})\) is nonempty, but \(D(\mathbf {x}) \cap Y\) is empty, then neither \(D(\mathbf {x})\) nor \(D(\mathbf {x}) \cap Y\) are acceptable solutions to (DC).
Understanding this, the equivalence of (DC) and (GSIP), established in the following result, is intuitive.
Proposition 1
Under Assumption 1, problems (DC) and (GSIP) are equivalent.
Proof
Since the objective functions in (DC) and (GSIP) are the same, we just need to establish that their feasible sets are the same. So consider \(\mathbf {x}\) feasible in (DC). Then \(\mathbf {x}\in X\) and \(D(\mathbf {x}) \subset G\). This means that for all \(\mathbf {y}\in D(\mathbf {x})\), \(\mathbf {y}\in Y\) and \(\mathbf {g}(\mathbf {y}) \le \mathbf {0}\). We immediately have that \(\mathbf {x}\) is feasible in (GSIP).
Conversely, choose \(\mathbf {x}\) feasible in (GSIP). Again, \(\mathbf {x}\in X\) and for all \(\mathbf {y}\in D(\mathbf {x})\), \(\mathbf {g}(\mathbf {y}) \le \mathbf {0}\). Under Assumption 1, \(D(\mathbf {x})\) is a subset of Y, and so for all \(\mathbf {y}\in D(\mathbf {x})\), we have \(\mathbf {y}\in G\). Thus \(D(\mathbf {x}) \subset G\) and \(\mathbf {x}\) is feasible in (DC). \(\square \)
2.3 Related problems
A related problem is that of calculating a “feasibility index” for process design under uncertainty. This idea goes back to Halemane and Grossmann (1983), Swaney and Grossmann (1985a, b), and has been addressed more recently in Floudas et al. (2001), Stuber and Barton (2011) and Stuber and Barton (2015). This problem can be written equivalently as an SIP in the forms
One interpretation of this problem is that \(\mathbf {x}\) represents some process design decisions, while \(\mathbf {y}\) is a vector of uncertain model parameters. The goal is to minimize some economic objective f of the design variables which guarantees safe process design for any realization of the uncertain parameter \(\mathbf {y}\) (indicated by \({\widetilde{g}}(\mathbf {x},\mathbf {y}) \le 0\), for any \(\mathbf {y}\in \widetilde{Y}\)).
The definition of the “flexibility index” in Equation 8 of Swaney and Grossmann (1985a) is a kind of GSIP. The rest of that work focuses on conditions that allow this definition to be reformulated as an SIP of the form (1). The results in Swaney and Grossmann (1985a) focus on the case when D is interval-valued. A similar argument is repeated below, which depends on having a design space which is the image of the unit ball under an affine mapping. In this case the proxy for volume is taken to be the determinant of the matrix in the affine transformation.
Proposition 2
Suppose \(X \subset Y \times \mathbb {R}^{n_y \times n_y}\), \(D : (\mathbf {y}_c, \mathbf {P}) \mapsto \{ \mathbf {y}_c + \mathbf {P} \mathbf {y}_d : \left\| \mathbf {y}_d \right\| \le 1 \}\) for some norm \(\left\| \cdot \right\| \) on \(\mathbb {R}^{n_y}\), \(D(\mathbf {y}_c, \mathbf {P}) \subset Y\) for all \((\mathbf {y}_c, \mathbf {P}) \in X\), and \(\mathrm {vol}(D(\mathbf {y}_c,\mathbf {P})) = \det (\mathbf {P})\). Then (GSIP) is equivalent to the SIP
Proof
The reformulation is immediate given the form of D. But to be explicit, consider the problem for given \((\mathbf {y}_c, \mathbf {P}) \in X\)
For \(\mathbf {y}\) feasible in (LLP i), by definition there exists \(\mathbf {y}_d \in B_1\) such that \(\mathbf {y}= \mathbf {y}_c + \mathbf {P} \mathbf {y}_d\). Thus \(g_i^*(\mathbf {y}_c,\mathbf {P}) \le g_i^{**}(\mathbf {y}_c,\mathbf {P})\). Conversely, for \(\mathbf {y}_d \in B_1\), there exists \(\mathbf {y}\in D(\mathbf {y}_c, \mathbf {P})\) with \(\mathbf {y}= \mathbf {y}_c + \mathbf {P} \mathbf {y}_d\). Thus \(g_i^{**}(\mathbf {y}_c,\mathbf {P}) \le g_i^{*}(\mathbf {y}_c,\mathbf {P})\), and together the inequalities imply that the feasible sets of (GSIP) and (2) are the same, and so equivalence follows. \(\square \)
In robust design applications, an extra step is required to make use of this form of D. To check that an operating condition or process parameters \(\mathbf {y}\) are in the calculated design space requires checking that the norm of the solution \(\mathbf {y}_d\) of \(\mathbf {y}- \mathbf {y}_c = \mathbf {P} \mathbf {y}_d\) is less than one. Consequently, the LU factorization of the optimal \(\mathbf {P}\) should be computed to minimize this computation, especially if it is to be performed online. Further, SIP (2) is still a somewhat abstract problem and assuming more structure leads to more tractable restrictions such as
where in effect the variable \(\mathbf {P}\) in SIP (2) has been restricted to (a subset of) the space of diagonal positive-definite matrices (see also the proof of Corollary 5 for justification of the use of the logarithm of the objective). Of course (3) is still a semi-infinite problem, but under further assumptions on \(\mathbf {g}\) and the norm used, finite convex reformulations are possible (see Sect. 3.2).
3 Affine constraints
This section deals with the case that \(\mathbf {g}\) is an affine function and \(Y = \mathbb {R}^{n_y}\). Specifically, assume that for each \(i \in \{1, \ldots , m\}\),
for some \(\mathbf {c}_i \in \mathbb {R}^{n_y}\) and \(b_i \in \mathbb {R}\). Consequently, G is a (convex) polyhedron. Reformulations for different forms of D are given; in each case the reformulation is a convex program.
In Sect. 4, reformulations of (GSIP) are presented which rely on strong duality holding for each (LLP). Consequently, the reformulations in Sect. 4 will be applicable to the current situation with \(\mathbf {g}\) affine and D convex-valued. However, in the best case those reformulations involve nonconvex NLPs, which do not reduce to convex programs under the assumptions of the present section. Thus, it is worthwhile to be aware of the special reformulations in the present section.
3.1 Ball-valued design space
Let the upper variables \(\mathbf {x}\) of (DC) be \((\mathbf {y}_c, \delta ) \in \mathbb {R}^{n_y} \times \mathbb {R}\), and let \(D(\mathbf {x})\) be the closed \(\delta \)-ball around \(\mathbf {y}_c\) for some norm \(\left\| \cdot \right\| \): \(D : (\mathbf {y}_c,\delta ) \mapsto \{ \mathbf {y}: \left\| \mathbf {y}- \mathbf {y}_c \right\| \le \delta \}\). Then problem (DC) becomes
Assumption 1 holds, since \(D(\mathbf {y}_c, \delta )\) must trivially be a subset of \(Y = \mathbb {R}^{n_y}\).
Problem (4) can be reformulated as a linear program (LP), following the ideas in §8.5 of Boyd and Vandenberghe (2004). Problem (4) is related to the problem of Chebyshev centering. For specific norms, this reformulation also appears in Hendrix et al. (1996).
Theorem 3
Problem (4) is equivalent to the LP
Proof
See Boyd and Vandenberghe (2004, § 8.5.1). \(\square \)
3.2 General ellipsoidal design space
A convex reformulation is also possible when the design space is an ellipsoid and its “shape” is a decision variable. This is a special case of the reformulation in Proposition 2. In this case, let \(X \subset \{ (\mathbf {y}_c, \mathbf {P}) \in \mathbb {R}^{n_y} \times \mathbb {S}^{n_y \times n_y} : \mathbf {P} \succ \mathbf {0} \}\) and \(D : (\mathbf {y}_c, \mathbf {P}) \mapsto \{ \mathbf {y}_c + \mathbf {P} \mathbf {y}_d : \left\| \mathbf {y}_d \right\| _2 \le 1 \}\), i.e., the design space is the image of the unit two-norm ball under an affine transformation, and thus an ellipsoid. Let \(\mathrm {vol}(D(\cdot )) : (\mathbf {y}_c, \mathbf {P}) \mapsto \det ( \mathbf {P} )\) and \(Y = \mathbb {R}^{n_y}\). Problem (DC) becomes
Similarly to the result in Theorem 3 (and taking the logarithm of the objective), this becomes
Problem (6) is in fact a convex program and enjoys a rich history of analysis; see Boyd and Vandenberghe (2004, § 8.4.2), Nesterov and Nemirovski (1994, Sections 6.4.4 and 6.5), Khachiyan and Todd (1993). However, further reformulation to a “standard” form (such as a semidefinite program) is necessary in order to apply general-purpose software for cone programs such as (YALMIP 2015; Lofberg 2004) and CVX (Grant and Boyd 2008, 2014) (both of which provide front-ends for the solvers SeDuMi (Sturm 1999; SeDuMi 2015) and MOSEK (MOSEK (2015)). This is possible by the arguments in Nesterov and Nemirovski (1994, § 6.4.4) or Ben-Tal and Nemirovski (2001, § 4.2).
3.3 Interval-valued design space
In the case of the infinity-norm, one can generalize the form of the design space a little more, and still obtain a fairly tractable formulation. In this case, let the upper variables \(\mathbf {x}\) of (DC) be \((\mathbf {y}^L,\mathbf {y}^U) \in \mathbb {R}^{n_y} \times \mathbb {R}^{n_y}\), and let \(D(\mathbf {y}^L,\mathbf {y}^U)\) be a nonempty compact interval: \(D : (\mathbf {y}^L,\mathbf {y}^U) \mapsto [\mathbf {y}^L, \mathbf {y}^U]\). Again with affine \(\mathbf {g}\), problem (DC) becomes
The constraints \(\mathbf {y}^L \le \mathbf {y}^U\) ensure that \(D(\mathbf {y}^L,\mathbf {y}^U)\) is nonempty.
The reformulation of this problem has been considered in Bemporad et al. (2004) and Seifi et al. (1999).
Theorem 4
Consider the linearly-constrained NLP
where \(\mathbf {M}_i^L\) and \(\mathbf {M}_j^U\) are diagonal \(n_y\) by \(n_y\) matrices where the \(j^{th}\) element of the diagonals, \(m_{i,j}^L\) and \(m_{i,j}^U\), respectively, are given by
Problem (8) is equivalent to problem (7).
Proof
Begin by analyzing the lower-level programs of (7): \(g_i^*(\mathbf {y}^L,\mathbf {y}^U) = \sup \{ \mathbf {c}_i ^{\mathrm {T}}\mathbf {y}: \mathbf {y}\in [\mathbf {y}^L, \mathbf {y}^U] \} - b_i\). Again, if \((\mathbf {y}^L,\mathbf {y}^U)\) is feasible in (7), then \(g_i^*(\mathbf {y}^L, \mathbf {y}^U) \le 0\). Further, the lower-level programs are linear programs with box constraints, and consequently can be solved by inspection: an optimal solution \(\mathbf {y}^i\) of the \(i^{th}\) lower-level program can be constructed by letting \(y_j^i = y_j^U\) if \(c_{i,j} \ge 0\) and \(y_j^i = y_j^L\) otherwise (where \(c_{i,j}\) denotes the jth component of \(\mathbf {c}_i\)).
The constraint in (7) that \(\mathbf {c}_i ^{\mathrm {T}}\mathbf {y}- b_i \le 0\), for all \(\mathbf {y}\in [\mathbf {y}^L, \mathbf {y}^U]\), is equivalent (when \(\mathbf {y}^L \le \mathbf {y}^U\)) to \(\sup \{ \mathbf {c}_i ^{\mathrm {T}}\mathbf {y}: \mathbf {y}\in [\mathbf {y}^L, \mathbf {y}^U] \} \le b_i\), which by the previous discussion is equivalent to \(\mathbf {c}_i ^{\mathrm {T}}\mathbf {M}_i^L \mathbf {y}^L + \mathbf {c}_i ^{\mathrm {T}}\mathbf {M}_i^U \mathbf {y}^U \le b_i\), which are the constraints in (8). Finally, both formulations include the constraints \(\mathbf {y}^L \le \mathbf {y}^U\), thus the feasible sets of Problems (8) and (7) are equivalent. Since the objective functions are the same, the problems are equivalent. \(\square \)
A more numerically favorable restriction of (8) is possible, at the expense of the restriction potentially being infeasible if G is “thin.”
Corollary 5
Consider the convex program
where \(\epsilon > 0\), and \(\mathbf {M}_i^L\) and \(\mathbf {M}_j^U\) are defined as in Theorem 4. If an optimal solution \((\mathbf {y}^{L,*}, \mathbf {y}^{U,*})\) of problem (7) satisfies \(\mathbf {y}^{U,*} - \mathbf {y}^{L,*} \ge \epsilon \mathbf {1}\), then this is also a solution of problem (9).
Proof
Since \(\ln (\cdot )\) is a nondecreasing concave function and for each j, \((y_j^L,y_j^U) \mapsto (y_j^U - y_j^L)\) is a concave function, then the objective function \(\sum _j \ln (y_j^U - y_j^L)\) is concave on the convex feasible set, and so this maximization problem is indeed a convex program.
Denote the feasible set of problem (9) by \(X_R\). Denote the objective function of (7) by \(f(\mathbf {y}^L,\mathbf {y}^U) = \prod _j (y_j^U - y_j^L)\). Note that f is positive on \(X_R\). If an optimal solution \((\mathbf {y}^{L,*}, \mathbf {y}^{U,*})\) of problem (7) satisfies \(\mathbf {y}^{U,*} - \mathbf {y}^{L,*} \ge \epsilon \mathbf {1}\), then clearly \((\mathbf {y}^{L,*}, \mathbf {y}^{U,*}) \in X_R\). Since \(\ln (\cdot )\) is increasing, \(\arg \max \{ f(\mathbf {y}^L,\mathbf {y}^U) : (\mathbf {y}^L,\mathbf {y}^U) \in X_R \} = \arg \max \{ \ln ( f(\mathbf {y}^L,\mathbf {y}^U) ) : (\mathbf {y}^L,\mathbf {y}^U) \in X_R \}\), and so \((\mathbf {y}^{L,*}, \mathbf {y}^{U,*})\) is a solution of problem (9). \(\square \)
4 Convex LLP
For the most part, in this section it is assumed that the LLPs are convex programs (and so \(\mathbf {g}\) is a concave function), but to be more accurate, the main focus of this section is when duality results hold for each LLP. When this is the case, a number of reformulations provide a way to solve (GSIP) via methods for NLPs or SIPs. In Sect. 4.1.4, the LLPs have a specific form and the concavity of \(\mathbf {g}\) is not necessary. Reformulation results from the literature are reviewed and numerical examples considered.
Before continuing, we mention a connection to another field. As mentioned, the main focus of this section is when duality results hold for each LLP. A similar approach is taken in the study of the “robust” formulation of mathematical programs with uncertain data (Ben-Tal and Nemirovski 1998, 1999). In that work, the robust mathematical program is typically a semi-infinite program. These SIPs are reduced to finite NLPs through similar techniques that are employed in this section.
4.1 Reformulation
4.1.1 KKT conditions
In the literature, one of the first reformulations of (GSIP) when the LLPs are convex programs comes from replacing the LLPs with algebraic constraints which are necessary and sufficient for a maximum; i.e., their KKT conditions. This approach can be found in Stein and Still (2003) and Stein and Winterfeld (2010), for instance. The following result establishes the equivalence of (GSIP) with a mathematical program with complementarity constraints (MPCC), a type of NLP. Refer to MPCC (10) as the “KKT reformulation.”
Proposition 6
Suppose Y is a nonempty, open, convex set. Suppose \(D(\mathbf {x})\) is compact for each \(\mathbf {x}\in X\) and \(D(\mathbf {x}) = \{ \mathbf {y}\in Y : \mathbf {h}(\mathbf {x},\mathbf {y}) \le \mathbf {0} \}\) for some \(\mathbf {h}: X \times Y \rightarrow \mathbb {R}^{n_h}\) where \(\mathbf {h}(\mathbf {x},\cdot )\) is convex and differentiable for each \(\mathbf {x}\in X\). Suppose that for each \(i \in \{1,\dots , m\}\) and each \(\mathbf {x}\in X\) the Slater condition holds for (LLP): there exists a \(\mathbf {y}_s \in Y\) such that \(\mathbf {h}(\mathbf {x},\mathbf {y}_s) < \mathbf {0}\). Suppose that \(\mathbf {g}\) is concave and differentiable. Then (GSIP) is equivalent to the MPCC
Proof
See Stein and Still (2003, § 3). \(\square \)
Note that the assumptions imply that \(D(\mathbf {x})\) is nonempty and a subset of Y for all \(\mathbf {x}\in X\); thus Assumption 1 is still satisfied. For each \(i \in \{1,\ldots ,m\}\), the hypotheses imply that (LLP i) is a differentiable convex program (satisfying a constraint qualification) which achieves its maximum; thus there exists a \(\varvec{\mu }^i \in \mathbb {R}^{n_h}\) such that \((\mathbf {y}^i,\varvec{\mu }^i)\) is a KKT point iff \(\mathbf {y}^i\) is a global optimum of (LLP i). It can be shown that the result in Proposition 6 holds under weaker conditions than the Slater condition for the LLPs, as in Stein and Still (2003). However, the Slater condition has a natural interpretation in design centering problems; a design space must have some minimum size or afford some minimum amount of operational flexibility. The Slater condition is common to many reformulations in this work. Indeed, a Slater-like condition has already been used in Corollary 5 and will be used throughout the rest of Sect.4.
The constraints \(\mu ^i_j h_j(\mathbf {x},\mathbf {y}^i) = 0\), \(\mu ^i_j \ge 0\), and \(h_j(\mathbf {x},\mathbf {y}^i) \le 0\) in NLP (10) are the complementarity constraints which give the class of MPCC its name. Unfortunately, there are numerical difficulties involved in solving MPCCs. This relates to the fact that the Mangasarian–Fromovitz Constraint Qualification is violated everywhere in its feasible set (Diehl et al. 2013). This motivates the reformulation of Sect. 4.1.3.
4.1.2 Lagrangian dual
It is helpful to analyze a reformulation of (GSIP) based on Lagrangian duality at this point. Assume \(D(\mathbf {x}) = \{ \mathbf {y}\in Y : \mathbf {h}(\mathbf {x},\mathbf {y}) \le \mathbf {0} \}\) for some \(\mathbf {h}: X \times Y \rightarrow \mathbb {R}^{n_h}\). Define the dual function \(q_i(\mathbf {x},\cdot )\) and its effective domain by
Then define the (Lagrangian) dual problem of (LLP) by
Under appropriate assumptions, one can establish that \(g_i^*(\mathbf {x}) = q_i^*(\mathbf {x})\) (known as strong duality) for each \(\mathbf {x}\). This forms the basis for the following results. The first result establishes that one can always obtain an SIP restriction of (GSIP). The set M is included to facilitate certain numerical developments; see § 5.1.2.
Proposition 7
(Proposition 3.1 in Harwood and Barton (2016)) Suppose \(D(\mathbf {x}) = \{ \mathbf {y}\in Y : \mathbf {h}(\mathbf {x},\mathbf {y}) \le \mathbf {0} \}\) for some \(\mathbf {h}: X \times Y \rightarrow \mathbb {R}^{n_h}\). For any \(M \subset \mathbb {R}^{n_h}\) and for any \((\mathbf {x}, \varvec{\mu }^1, \dots , \varvec{\mu }^m)\) feasible in the SIP
\(\mathbf {x}\) is feasible in (GSIP).
The next result establishes that SIP (12) is equivalent to (GSIP) under hypotheses similar to those in Proposition 6.
Proposition 8
Suppose Y is convex. Suppose \(D(\mathbf {x}) = \{ \mathbf {y}\in Y : \mathbf {h}(\mathbf {x},\mathbf {y}) \le \mathbf {0} \}\) for some \(\mathbf {h}: X \times Y \rightarrow \mathbb {R}^{n_h}\). For all \(\mathbf {x}\in X\), suppose \(\mathbf {g}\) is concave, \(\mathbf {h}(\mathbf {x},\cdot )\) is convex, \(g_i^*(\mathbf {x})\) (defined by (LLP)) is finite for all i, and there exists a \(\mathbf {y}_s(\mathbf {x}) \in Y\) such that \(\mathbf {g}(\mathbf {y}_s(\mathbf {x})) > -\mathbf {g}_b\) for some \(\mathbf {g}_b > \mathbf {0}\) and \(\mathbf {h}(\mathbf {x},\mathbf {y}_s(\mathbf {x})) \le -\mathbf {h}_b\) for some \(\mathbf {h}_b > \mathbf {0}\). Then for compact \(M = [\mathbf {0}, \mathbf {b}^*] \subset \mathbb {R}^{n_h}\) (where \(b_j^* = \max _i\{ g_{b,i} \}/ h_{b.j}\)), (GSIP) is equivalent to SIP (12).
Proof
Follows from Lemmata 3.3 and 3.4 and Theorem 3.2 in Harwood and Barton (2016).
4.1.3 Wolfe dual
To obtain a more numerically tractable reformulation than the KKT reformulation (10), one follows the ideas in Diehl et al. (2013) to obtain a reformulation of (GSIP) which does not have complementarity constraints. This follows by looking at the dual function \(q_i(\mathbf {x},\cdot )\) and noting that if Y is a nonempty open convex set and \(g_i\) and \(-\mathbf {h}(\mathbf {x},\cdot )\) are concave and differentiable, then for \(\varvec{\mu }\ge \mathbf {0}\), the supremum defining the dual function is achieved at \(\mathbf {y}\) if and only if \(\nabla g_i(\mathbf {y}) - \nabla _{\mathbf {y}} \mathbf {h}(\mathbf {x},\mathbf {y}) \varvec{\mu }= \mathbf {0}\). Consequently, one obtains the Wolfe dual problem of (LLP i):
Under suitable assumptions (namely, that (LLP i) achieves its supremum and a Slater condition), strong duality holds. An alternate proof follows, based on (much better established) Lagrangian duality results. See also Section 6.3 in Geoffrion (1971).
Lemma 9
Suppose Y is a nonempty open convex set. For a given \(\mathbf {x}\in X\) and \(i \in \{1,\dots , m\}\), suppose the following: \(D(\mathbf {x})\) is compact and \(D(\mathbf {x}) = \{ \mathbf {y}\in Y : \mathbf {h}(\mathbf {x},\mathbf {y}) \le \mathbf {0} \}\) for some \(\mathbf {h}(\mathbf {x},\cdot ) : Y \rightarrow \mathbb {R}^{n_h}\) which is convex and differentiable. Suppose that the Slater condition holds for (LLP i) (there exists a \(\mathbf {y}_s \in Y\) such that \(\mathbf {h}(\mathbf {x},\mathbf {y}_s) < \mathbf {0}\)). Suppose \(g_i\) is concave and differentiable. Then there exists \((\mathbf {y}^i,\varvec{\mu }^i)\) satisfying \(\varvec{\mu }^i \ge \mathbf {0}\), \(\mathbf {y}^i \in Y\), \(\nabla g_i(\mathbf {y}^i) - \nabla _{\mathbf {y}} \mathbf {h}(\mathbf {x},\mathbf {y}^i) \varvec{\mu }^i = \mathbf {0}\), and \(g_i^*(\mathbf {x}) = g_i(\mathbf {y}^i) - (\varvec{\mu }^i) ^{\mathrm {T}}\mathbf {h}(\mathbf {x},\mathbf {y}^i)\). Further, \(q_i^W(\mathbf {x}) = g_i^*(\mathbf {x})\).
Proof
First, it is established that the Wolfe dual is weaker than the Lagrangian dual (11) (i.e. \(q_i^W(\mathbf {x}) \ge q_i^*(\mathbf {x})\), thus establishing weak duality between (LLP i) and the Wolfe dual). As before, since Y is a nonempty open convex set and \(g_i\) and \(-\mathbf {h}\) are concave and differentiable, then for \(\widetilde{\varvec{\mu }} \ge \mathbf {0}\), \(\sup \{ g_i(\mathbf {y}) - \widetilde{\varvec{\mu }} ^{\mathrm {T}}\mathbf {h}(\mathbf {x},\mathbf {y}) : \mathbf {y}\in Y \}\) is achieved at \(\widetilde{\mathbf {y}} \in Y\) if and only if \(\nabla g_i(\widetilde{\mathbf {y}}) - \nabla _{\mathbf {y}} \mathbf {h}(\mathbf {x},\widetilde{\mathbf {y}}) \widetilde{\varvec{\mu }} = \mathbf {0}\). Let
Thus, for all \((\widetilde{\mathbf {y}},\widetilde{\varvec{\mu }}) \in F_W\), we have
which also implies that \(\widetilde{\varvec{\mu }} \in \mathrm {dom}(q_i(\mathbf {x},\cdot ))\). It follows that for all \((\widetilde{\mathbf {y}},\widetilde{\varvec{\mu }}) \in F_W\), we have \(\widetilde{\varvec{\mu }} \ge \mathbf {0}\), \(\widetilde{\varvec{\mu }} \in \mathrm {dom}(q_i(\mathbf {x},\cdot ))\), and \(q_i(\mathbf {x},\widetilde{\varvec{\mu }}) = g_i(\widetilde{\mathbf {y}}) - \widetilde{\varvec{\mu }} ^{\mathrm {T}}\mathbf {h}(\mathbf {x},\widetilde{\mathbf {y}})\). Therefore, by definition of the dual problem (11), for all \((\widetilde{\mathbf {y}},\widetilde{\varvec{\mu }}) \in F_W\), we have
Consequently, taking the infimum over all \((\widetilde{\mathbf {y}}, \widetilde{\varvec{\mu }}) \in F_W\) yields \(q_i^*(\mathbf {x}) \le q_i^W(\mathbf {x})\), by the definition of the Wolfe dual. Note that \(F_W\) may be empty, in which case the infimum in the definition of \(q_i^W(\mathbf {x})\) is over an empty set, and the inequality \(q_i^*(\mathbf {x}) \le q_i^W(\mathbf {x})\) holds somewhat trivially.
Next we establish \(q_i^W(\mathbf {x}) \le g_i^*(\mathbf {x})\), using strong duality for the Lagrangian dual. Since \(g_i\) is differentiable on Y, it is continuous on Y and since \(D(\mathbf {x})\) is compact, (LLP i) achieves its supremum (since \(D(\mathbf {x})\) is nonempty under the Slater condition). Under the convexity assumptions and Slater conditions, strong duality holds for (LLP i); i.e. \(q_i^*(\mathbf {x}) = g_i^*(\mathbf {x})\) (see for instance Proposition 5.3.1 in Bertsekas (2009)). Further, a duality multiplier exists; that is, there exists \(\varvec{\mu }^i \ge \mathbf {0}\) such that \(g_i^*(\mathbf {x}) = \sup \{ g_i(\mathbf {y}) - (\varvec{\mu }^i) ^{\mathrm {T}}\mathbf {h}(\mathbf {x},\mathbf {y}) : \mathbf {y}\in Y \}\). Since (LLP i) achieves its supremum, there exists a maximizer \(\mathbf {y}^i\) of (LLP i). Because a duality multiplier exists, by Proposition 5.1.1 in Bertsekas (1999), we have \(\mathbf {y}^i \in \arg \max \{ g_i(\mathbf {y}) - (\varvec{\mu }^i) ^{\mathrm {T}}\mathbf {h}(\mathbf {x},\mathbf {y}) : \mathbf {y}\in Y \}\), and thus
Again, since Y is a nonempty open set we have \(\nabla g_i(\mathbf {y}^i) - \nabla _{\mathbf {y}} \mathbf {h}(\mathbf {x},\mathbf {y}^i) \varvec{\mu }^i= \mathbf {0}\). In other words, \((\mathbf {y}^i, \varvec{\mu }^i) \in F_W\) defined before, which establishes the first claim. Finally, applying the definition of \(q_i^W(\mathbf {x})\) as an infimum over \(F_W\), we get that \(g_i^*(\mathbf {x}) \ge q_i^W(\mathbf {x})\). But since \(g_i^*(\mathbf {x}) = q_i^*(\mathbf {x})\) and \(q_i^*(\mathbf {x}) \le q_i^W(\mathbf {x})\) (established above), we have \(g_i^*(\mathbf {x}) = q_i^W(\mathbf {x})\). \(\square \)
With this, one can establish an NLP reformulation of (GSIP) which does not have complementarity constraints. Refer to NLP (14) as the “Wolfe reformulation.”
Proposition 10
Suppose Y is a nonempty open convex set. Suppose \(D(\mathbf {x})\) is compact for each \(\mathbf {x}\in X\) and \(D(\mathbf {x}) = \{ \mathbf {y}\in Y : \mathbf {h}(\mathbf {x},\mathbf {y}) \le \mathbf {0} \}\) for some \(\mathbf {h}: X \times Y \rightarrow \mathbb {R}^{n_h}\) where \(\mathbf {h}(\mathbf {x},\cdot )\) is convex and differentiable for each \(\mathbf {x}\in X\). Suppose that for each \(i \in \{1,\dots , m\}\) and each \(\mathbf {x}\in X\) the Slater condition holds for (LLP i): there exists a \(\mathbf {y}_s \in Y\) such that \(\mathbf {h}(\mathbf {x},\mathbf {y}_s) < \mathbf {0}\). Suppose \(\mathbf {g}\) is concave and differentiable. Then (GSIP) is equivalent to the NLP
Proof
Choose \(\mathbf {x}\in X\) feasible in (GSIP), then \(g_i^*(\mathbf {x}) \le 0\) for each i. By Lemma 9, there exists \((\mathbf {y}^i,\varvec{\mu }^i)\) such that \(\varvec{\mu }^i \ge \mathbf {0}\), \(\mathbf {y}^i \in Y\), \(\nabla g_i(\mathbf {y}^i) - \nabla _{\mathbf {y}} \mathbf {h}(\mathbf {x},\mathbf {y}^i) \varvec{\mu }^i = \mathbf {0}\), and \(g_i^*(\mathbf {x}) = g_i(\mathbf {y}^i) - (\varvec{\mu }^i) ^{\mathrm {T}}\mathbf {h}(\mathbf {x},\mathbf {y}^i)\). In other words, \((\mathbf {x},\mathbf {y}^1,\varvec{\mu }^1, \dots , \mathbf {y}^m,\varvec{\mu }^m)\) is feasible in (14).
Conversely, choose \((\mathbf {x},\mathbf {y}^1,\varvec{\mu }^1, \dots , \mathbf {y}^m,\varvec{\mu }^m)\) feasible in (14). Again, by Lemma 9 (in fact, weak duality between (LLP i) and the Wolfe dual (13) suffices), we must have \(g_i^*(\mathbf {x}) \le 0\) for each i, which establishes that \(\mathbf {x}\) is feasible in (GSIP). Equivalence follows. \(\square \)
One notes that indeed NLP (14) does not have the complementarity constraints that make MPCC (10) numerically unfavorable. Proposition 10 is similar to Corollary 2.4 in Diehl et al. (2013). The difference is that the latter result assumes that \(-\mathbf {g}\) and \(\mathbf {h}(\mathbf {x},\cdot )\) are convex on all of \(Y = \mathbb {R}^{n_y}\). As this is a rather strong assumption, this motivates the authors of Diehl et al. (2013) to weaken this, and merely assume that \(\mathbf {g}\) is concave on \(D(\mathbf {x})\) for each \(\mathbf {x}\). They then obtain an NLP which adds the constraints \(\mathbf {h}(\mathbf {x},\mathbf {y}^i) \le \mathbf {0}\) to NLP (14). In design centering applications, assuming that \(\mathbf {g}\) is concave on Y versus assuming \(\mathbf {g}\) is concave on \(D(\mathbf {x})\) for all \(\mathbf {x}\) is typically not much stronger anyway.
4.1.4 General quadratically constrained quadratic LLP
When \(Y = \mathbb {R}^{n_y}\), \(D(\mathbf {x})\) is defined in terms of a ball given by a weighted 2-norm, and each \(g_i\) is quadratic, a specific duality result can be used to reformulate (GSIP). It should be stressed that this does not require that the LLPs are convex programs, despite the fact that this is part of a section titled “Convex LLP.” This duality result applies to the general case of a quadratic program with a single quadratic constraint; given \(\mathbf {A}_0\), \(\mathbf {A} \in \mathbb {S}^{n_y \times n_y}\), \(\mathbf {b}_0\), \(\mathbf {b} \in \mathbb {R}^{n_y}\), and \(c_0\), \(c \in \mathbb {R}\), define
The (Lagrangian) dual of this problem is
Noting that the Lagrangian of (15) is a quadratic function, for given \(\mu \ge 0\) the supremum defining the dual function \(q^Q\) is achieved at \(\mathbf {y}^*\) iff the second-order conditions \(\mathbf {A}_0 - \mu \mathbf {A} \preceq \mathbf {0}\), \((\mathbf {A}_0 - \mu \mathbf {A}) \mathbf {y}^* = -(\mathbf {b}_0 - \mu \mathbf {b})\), are satisfied; otherwise the supremum is \(+\infty \). This leads to
(note the similarity to the Wolfe dual in Sect. 4.1.3). Whether or not program (15) is convex, strong duality holds assuming (15) has a Slater point. That is to say, \(p^* = d^*\) (and the dual solution set is nonempty) assuming there exists \(\mathbf {y}_s\) such that \(\mathbf {y}_s ^{\mathrm {T}}\mathbf {A} \mathbf {y}_s + 2 \mathbf {b} ^{\mathrm {T}}\mathbf {y}_s + c < 0\). A proof of this can be found in Appendix B of Boyd and Vandenberghe (2004). The proof depends on the somewhat cryptically named “S-procedure,” which is actually a theorem of the alternative. A review of results related to the S-procedure or S-lemma can be found in Polik and Terlaky (2007). The required results are stated formally in the following.
Lemma 11
Consider the quadratically constrained quadratic program (15) and its dual (16). Suppose there exists \(\mathbf {y}_s\) such that \(\mathbf {y}_s ^{\mathrm {T}}\mathbf {A} \mathbf {y}_s + 2 \mathbf {b} ^{\mathrm {T}}\mathbf {y}_s + c < 0\). Then \(p^* = d^*\). Further, if \(p^*\) is finite, then the solution set of the dual problem (16) is nonempty.
Proof
See Boyd and Vandenberghe (2004, § B.4) \(\square \)
Lemma 12
Consider problem (15) and its dual (16). If \(p^* = d^*\) (strong duality holds), and there exists \((\mu ^*, \mathbf {y}^*)\) with \(\mu ^*\) in the solution set of the dual (16) and \(\mathbf {y}^*\) in the solution set of problem (15), then \((\mu ^*, \mathbf {y}^*)\) is optimal in problem (17).
Proof
Since there is no duality gap, \(\mu ^*\) is a duality multiplier (see Proposition 5.1.4 in Bertsekas (1999)). Thus, any optimal solution of the primal problem (15) maximizes the Lagrangian for this fixed \(\mu ^*\), i.e. \(q^Q(\mu ^*) = (\mathbf {y}^*) ^{\mathrm {T}}(\mathbf {A}_0 - \mu ^* \mathbf {A}) \mathbf {y}^* + 2(\mathbf {b}_0 - \mu ^* \mathbf {b}) ^{\mathrm {T}}\mathbf {y}^* + c_0 - \mu ^* c\) (see Proposition 5.1.1 in Bertsekas (1999)). Thus the second-order conditions \(\mathbf {A}_0 - \mu ^* \mathbf {A} \preceq \mathbf {0}\), \((\mathbf {A}_0 - \mu ^* \mathbf {A}) \mathbf {y}^* = -(\mathbf {b}_0 - \mu ^* \mathbf {b})\), are satisfied. Since \(d^* = q^Q(\mu ^*)\), \((\mu ^*,\mathbf {y}^*)\) must be optimal in (17). \(\square \)
A reformulation of (GSIP) when the LLPs are quadratically constrained quadratic programs follows.
Proposition 13
Suppose \(Y = \mathbb {R}^{n_y}\), and that for \(i \in \{1,\dots , m\}\) there exist \((\mathbf {A}_i, \mathbf {b}_i, c_i) \in \mathbb {S}^{n_y \times n_y} \times \mathbb {R}^{n_y} \times \mathbb {R}\) such that \(g_i : \mathbf {y}\mapsto \mathbf {y}^{\mathrm {T}}\mathbf {A}_i \mathbf {y}+ 2 \mathbf {b}_i ^{\mathrm {T}}\mathbf {y}+ c_i\). Suppose \(X \subset \{ (\mathbf {P},\mathbf {y}_c) \in \mathbb {S}^{n_y \times n_y} \times \mathbb {R}^{n_y} : \mathbf {P} \succ \mathbf {0} \}\). Suppose that \(D(\mathbf {P},\mathbf {y}_c) = \{ \mathbf {y}: (\mathbf {y}- \mathbf {y}_c)^{\mathrm {T}}\mathbf {P} (\mathbf {y}- \mathbf {y}_c) \le 1 \}\) and \(\mathrm {vol}(D(\mathbf {P},\mathbf {y}_c)) = \det (\mathbf {P})^{-1}\). Then (GSIP) is equivalent to the program
Proof
Note that \(D(\mathbf {P},\mathbf {y}_c) = \{ \mathbf {y}: \mathbf {y}^{\mathrm {T}}\mathbf {P} \mathbf {y}- 2 \mathbf {y}_c ^{\mathrm {T}}\mathbf {P} \mathbf {y}+ \mathbf {y}_c ^{\mathrm {T}}\mathbf {P} \mathbf {y}_c - 1 \le 0 \}\). Also, for all \((\mathbf {P},\mathbf {y}_c) \in X\), a solution exists for (LLP i) for each i since \(\mathbf {P}\) is constrained to be positive definite and so \(D(\mathbf {P},\mathbf {y}_c)\) is compact. Further, by assumption on X, \(\mathbf {y}_c\) is a Slater point for each LLP for all \((\mathbf {P},\mathbf {y}_c) \in X\). Consequently, by Lemma 11, strong duality holds for each LLP and an optimal dual solution exists.
Choose \((\mathbf {P},\mathbf {y}_c)\) feasible in (GSIP). Then for all i, \(g_i^*(\mathbf {P},\mathbf {y}_c) \le 0\). Then by Lemma 12, there exists \((\mu _i, \mathbf {y}^i)\) optimal in the dual of (LLP i) written in the form (17), and combined with strong duality \((\mathbf {P},\mathbf {y}_c, \varvec{\mu }, \mathbf {y}^1, \dots , \mathbf {y}^m)\) is feasible in (18). Conversely, choose \((\mathbf {P},\mathbf {y}_c, \varvec{\mu }, \mathbf {y}^1, \dots , \mathbf {y}^m)\) feasible in (18). Weak duality establishes that \(g_i^*(\mathbf {P},\mathbf {y}_c) \le 0\) for each i, and so \((\mathbf {P},\mathbf {y}_c)\) is feasible in (GSIP). Equivalence follows. \(\square \)
Note that program (18) contains nonlinear matrix inequalities. Consequently, many general-purpose software for the solution of NLP cannot handle this problem. Choosing \(\mathbf {P}\) by some heuristic leads to a more practical reformulation. Further, Y can be restricted to a subset of \(\mathbb {R}^{n_y}\) by taking advantage of strong duality. Refer to NLP (19) as the “Quadratic reformulation.”
Corollary 14
Suppose that for \(i \in \{1,\dots , m\}\) there exist \((\mathbf {A}_i, \mathbf {b}_i, c_i) \in \mathbb {S}^{n_y \times n_y} \times \mathbb {R}^{n_y} \times \mathbb {R}\) such that \(g_i : \mathbf {y}\mapsto \mathbf {y}^{\mathrm {T}}\mathbf {A}_i \mathbf {y}+ 2 \mathbf {b}_i ^{\mathrm {T}}\mathbf {y}+ c_i\). Suppose \(\mathbf {P} \in \mathbb {S}^{n_y \times n_y}\) is given and \(\mathbf {P} \succ \mathbf {0}\), and further \(X \subset \{ (\mathbf {y}_c, \delta ) : \mathbf {y}_c \in \mathbb {R}^{n_y}, \delta \ge \epsilon \}\) for some \(\epsilon > 0\). Suppose that \(D(\mathbf {y}_c,\delta ) = \{ \mathbf {y}: (\mathbf {y}- \mathbf {y}_c)^{\mathrm {T}}\mathbf {P} (\mathbf {y}- \mathbf {y}_c) \le \delta ^2 \}\), \(\mathrm {vol}(D(\mathbf {y}_c,\delta )) = \delta \), and that \(Y \subset \mathbb {R}^{n_y}\) satisfies \(D(\mathbf {y}_c, \delta ) \subset Y\) for all \((\mathbf {y}_c, \delta ) \in X\). Then (GSIP) is equivalent to the program
Proof
The proof is similar to that of Proposition 13. The added constraint that the \(\mathbf {y}^i\) components of the solutions of (19) are in Y does not change the fact that (19) is a “restriction” of (GSIP) (i.e. for \((\mathbf {y}_c, \delta , \varvec{\mu }, \mathbf {y}^1, \dots , \mathbf {y}^m)\) feasible in (19), \((\mathbf {y}_c, \delta )\) is feasible in (GSIP)).
We only need to check that for \((\mathbf {y}_c, \delta )\) feasible in (GSIP), that there exist \((\mu _i, \mathbf {y}^i)\) such that \((\mathbf {y}_c, \delta , \varvec{\mu }, \mathbf {y}^1, \dots , \mathbf {y}^m)\) is feasible in (19) (specifically that \(\mathbf {y}^i \in Y\) for each i). But this must hold since we can take \(\mathbf {y}^i\) and \(\mu _i\) to be optimal solutions of (LLP i) and its dual, respectively, for each i. Thus \(\mathbf {y}^i \in D(\mathbf {y}_c, \delta ) \subset Y\) for each i, and so by strong duality and Lemma 12, \((\mathbf {y}_c, \delta , \varvec{\mu }, \mathbf {y}^1, \dots , \mathbf {y}^m)\) is feasible in (19). \(\square \)
The Quadratic reformulation (19) is still nonlinear and nonconvex, but the matrix inequality constraints are linear, and as demonstrated by the example in Sect. 4.2.2, these can sometimes be reformulated as explicit constraints on \(\varvec{\mu }\).
4.1.5 Convex quadratic constraints
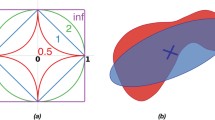
This section discusses a special case of what was considered in Sect. 4.1.4, when \(D(\mathbf {x})\) is defined in terms of a ball given by a weighted 2-norm, and each \(g_i\) is convex and quadratic. In this case, a convex reformulation is possible. This case has the geometric interpretation of inscribing the maximum volume ellipsoid in the intersection of ellipsoids, and has been considered in Ben-Tal and Nemirovski (2001, § 4.9.1), Boyd et al. (1994, § 3.7.3), Boyd and Vandenberghe (2004, § 8.5). The representation of the design space is a little different from what has been considered so far; it depends on the inverse of the symmetric square root of a positive semidefinite matrix.
Proposition 15
Suppose \(Y = \mathbb {R}^{n_y}\), and that for \(i \in \{1,\dots , m\}\) there exist \((\mathbf {A}_i, \mathbf {b}_i, c_i) \in \mathbb {S}^{n_y \times n_y} \times \mathbb {R}^{n_y} \times \mathbb {R}\), with \(\mathbf {A}_i \succ \mathbf {0}\), such that \(g_i : \mathbf {y}\mapsto \mathbf {y}^{\mathrm {T}}\mathbf {A}_i \mathbf {y}+ 2 \mathbf {b}_i ^{\mathrm {T}}\mathbf {y}+ c_i\). Suppose \(X \subset \{ (\mathbf {P},\mathbf {y}_c) \in \mathbb {S}^{n_y \times n_y} \times \mathbb {R}^{n_y} : \mathbf {P} \succ \mathbf {0} \}\). Suppose that \(D(\mathbf {P},\mathbf {y}_c) = \{ \mathbf {y}: (\mathbf {y}- \mathbf {y}_c)^{\mathrm {T}}\mathbf {P}^{-2} (\mathbf {y}- \mathbf {y}_c) \le 1 \}\) and \(\mathrm {vol}(D(\mathbf {P},\mathbf {y}_c)) = \det (\mathbf {P})\). Then (GSIP) is equivalent to the program
Proof
The proof depends on the following characterization of (in essence) the dual function of (LLP) in this case: Assuming \(\mathbf {P}\), \(\mathbf {A}_i\) are positive definite symmetric matrices and \(\mu _i \ge 0\), we have
if and only if
A proof of this equivalence can be found in §3.7.3 of Boyd et al. (1994).
Choosing \((\mathbf {P}, \mathbf {y}_c)\) feasible in (GSIP), by strong duality (Lemma 11) we have that for each i there exists \(\mu _i \ge 0\) such that the dual function is nonpositive (i.e. Inequality (21) holds). Thus \((\mathbf {P}, \mathbf {y}_c, \varvec{\mu })\) is feasible in problem (20). Conversely, for \((\mathbf {P}, \mathbf {y}_c, \varvec{\mu })\) feasible in problem (20), by the above equivalence and weak duality \((\mathbf {P}, \mathbf {y}_c)\) is feasible in (GSIP). \(\square \)
The matrix constraints in problem (20) are linear inequalities, and reformulating the objective along the lines of the discussion in Sect. 3.2 yields an SDP. As another practical note, the explicit matrix inverses in problem (20) could be removed, for instance, by introducing new variables \((\mathbf {E}_i, \mathbf {d}_i, f_i)\) and adding the linear constraints \(\mathbf {A}_i \mathbf {E}_i = \mathbf {I}\), \(\mathbf {A}_i \mathbf {d}_i = \mathbf {b}_i\), \(\mathbf {b}_i ^{\mathrm {T}}\mathbf {d}_i = f_i\), for each i.
4.2 Numerical examples
In this section global NLP solvers are applied to the reformulations of design centering problems discussed in the previous sections. The studies are performed in GAMS version 24.3.3 (GAMS Development Corporation 2014). Deterministic global optimizers BARON version 14.0.3 (Tawarmalani and Sahinidis 2005; Sahinidis 2014) and ANTIGONE version 1.1 (Misener and Floudas 2014) are employed. Algorithm 2.1 in Mitsos (2011), a global, feasible-point method, is applied to the SIP reformulation. An implementation is coded in GAMS, employing BARON for the solution of the subproblems (see also the discussion in Sect. 5.1.2). The initial parameters are \(\epsilon ^{g,0} = 1\), \(r = 2\), and \(Y^{LBP,0} = Y^{UBP,0} = \varnothing \). These examples have a single infinite constraint (single LLP), and so the subscripts on g and solution components are dropped. All numerical studies were performed on a 64-bit Linux virtual machine allocated a single core of a 3.07 GHz Intel Xeon processor and 1.28 GB RAM.
4.2.1 Convex LLP with interval design space
The following design centering problem is considered:
where \(\mathrm {vol}([\mathbf {y}^L, \mathbf {y}^U]) = (y_1^U - y_1^L)(y_2^U - y_2^L)\).
For the KKT and Wolfe reformulations, letting \(Y = (-2,2) \times (-2,2)\), \(X = \{ (\mathbf {y}^L,\mathbf {y}^U) \in [-1,1]^2 \times [-1,1]^2 : y_1^U - y_1^L \ge 0.002, y_2^U - y_2^L \ge 0.002 \}\), and
it is clear that the hypotheses of Propositions 6 and 10 hold. The corresponding reformulations are solved to global optimality with BARON and ANTIGONE. The relative and absolute optimality tolerances are both \(10^{-4}\). The solution obtained in each case is \((\mathbf {y}^L, \mathbf {y}^U) = (0,-1, 1,1)\). The other components of the solution and the solution times are in Table 1.
Meanwhile, the SIP reformulation from Proposition 8 holds for \(M = [\mathbf {0}, \mathbf {b}^*]\), where \(\mathbf {b}^* = (18 \times 10^3) \mathbf {1}\) (for instance, by noting that \(g(\mathbf {y}) \ge -18\) for all \(\mathbf {y}\in Y\) and taking \(h_{b,i} = 0.001\)). However, to apply the feasible-point, global solution method for SIP from Mitsos (2011), Y needs to be compact, and so let \(Y = [-2,2] \times [-2,2]\) for the purposes of this reformulation. This method requires continuous objective, g, and \(\mathbf {h}\), and this clearly holds. The overall relative and absolute optimality tolerances for the method in Mitsos (2011) each equal \(10^{-4}\), and the subproblems required by the method are all solved with relative and absolute optimality tolerances equal to \(10^{-5}\). The method terminates in 28 iterations and the solution obtained is \((\mathbf {y}^L, \mathbf {y}^U) = (-1,-1,1,0)\). Although different from what was obtained with the NLP reformulations, the optimal objective value is the same and it is still optimal. The solution time is included in Table 1.
As expected, the NLP reformulations are quicker to solve than the SIP reformulation. What is somewhat surprising is that the KKT reformulation, which is an MPCC, solves more quickly than the Wolfe reformulation, which omits the complementarity constraints. This is perhaps due to the nature of the global solvers BARON and ANTIGONE, which can recognize and efficiently handle the complementarity constraints (Sahinidis 2014), and overall make use of the extra constraints to improve domain reduction through constraint propagation.
However, note that the KKT and Wolfe reformulations involve the derivatives of \(\mathbf {g}\) and \(\mathbf {h}\). Subsequently, solving these reformulations with implementations of global methods such as BARON and ANTIGONE requires explicit expressions for these derivatives. In a general-purpose modeling language such as GAMS, supplying these derivative expressions typically must be done by hand which is tedious and error prone. In contrast, the solution method for the SIP (12) from Mitsos (2011) involves the solution of various NLP subproblems which are defined in terms of the original functions \(\mathbf {g}\) and \(\mathbf {h}\).
4.2.2 Nonconvex quadratic LLP
The following design centering problem is considered:
Note that g is a nonconvex quadratic function, and that the lower-level program is a quadratically-constrained quadratic program. Lemma 11 asserts that strong duality holds for the lower-level program assuming a Slater point exists. Each of the reformulations of Sect. 4 are considered. This is to demonstrate what happens when strong duality holds for the lower-level program, but an inappropriate reformulation is used. It will be seen that the KKT and Wolfe reformulations fail to give a correct answer, while the SIP reformulation succeeds.
Let \(X = \{ (\mathbf {y}_c,\delta ) : \left\| \mathbf {y}_c \right\| _2 \le 2, 0.1 \le \delta \le 2 \}\). Let
where \(\mathbf {I}\) is the identity matrix, so that \(g(\mathbf {y}) = \mathbf {y}^{\mathrm {T}}\mathbf {A} \mathbf {y}\) and \(D(\mathbf {y}_c,\delta ) = \{ \mathbf {y}: (\mathbf {y}- \mathbf {y}_c) ^{\mathrm {T}}\mathbf {P} (\mathbf {y}- \mathbf {y}_c) \le \delta ^2 \}\). With \(Y = [-4,4] \times [-4,4]\), the Quadratic reformulation (19) is applicable by Corollary 14. Further, since \(\mathbf {A}\) and \(\mathbf {P}\) are diagonal, the matrix inequality constraint \(\mathbf {A} - \mu \mathbf {P} \preceq \mathbf {0}\) in that problem can be reformulated as nonpositivity of the diagonal elements of \(\mathbf {A} - \mu \mathbf {P}\), which reduces to \(\mu \ge 1\) (and \(\mu \ge -1\), but this is redundant). General-purpose solvers can handle this form of the constraint more easily.
The Quadratic reformulation (19) is solved to global optimality with BARON and ANTIGONE. The relative and absolute optimality tolerances are both \(10^{-4}\). The solution obtained in each case is \(\mathbf {y}_c = (0,-2)\), \(\delta = 1.414\). The other components of the solution and solution statistics are in Table 2.
The SIP reformulation is also applicable in this case. The center of the design space \(\mathbf {y}_c\) is a Slater point for the lower-level program for all \((\mathbf {y}_c, \delta ) \in X\), and so \(g(\mathbf {y}_c) \ge -4\) for all \((\mathbf {y}_c, \delta ) \in X\). Further, let \(h(\mathbf {y}_c,\delta , \mathbf {y}) = (\mathbf {y}- \mathbf {y}_c) ^{\mathrm {T}}\mathbf {P} (\mathbf {y}- \mathbf {y}_c) - \delta ^2\), so that \(h(\mathbf {y}_c,\delta ,\mathbf {y}_c) = -\delta ^2 \le -0.01\) for all \((\mathbf {y}_c, \delta ) \in X\). With Lemma 3.4 in Harwood and Barton (2016) and the strong duality result from Lemma 11, the conclusion of Proposition 8 holds with \(M = [0, 400]\). The overall relative and absolute optimality tolerances for the method in Mitsos (2011) each equal \(10^{-4}\), and the subproblems required by the method are all solved with relative and absolute optimality tolerances equal to \(2 \times 10^{-5}\). The method terminates in 33 iterations and the solution obtained is \((\mathbf {y}_c,\delta ) = (0,2,1.414)\), a different optimal solution for (23). What is interesting to note is that the SIP solution method is competitive with the solution of the Quadratic reformulation for this example; see Table 2.
Not surprisingly, the KKT and Wolfe reformulations fail to provide even a feasible solution. Quite simply, this is due to the omission of the constraint \(\mu \ge 1\), which is the only difference between the Wolfe reformulation (14) and the Quadratic reformulation (19). Consequently, even when strong duality holds, one must be careful if attempting to apply the KKT and Wolfe reformulations when global optima are sought. Meanwhile, in Diehl et al. (2013), the authors apply reformulations similar to (10) and (14) to a problem with quadratic LLPs, but do not include the constraint on the duality multiplier for a nonconvex LLP. However, the focus of that work is on local solutions and methods. In particular, for the numerical results, convergence of a local solution method to an infeasible point might not be observed if the starting point is sufficiently close to a local minimum.
5 Nonconvex LLP
In this section, approaches for finding a feasible solution of (GSIP) are considered, with optimality being a secondary concern. To this end, the focus is on constructing restrictions of (GSIP) which can be solved to global optimality practically. This has the benefit that these methods do not rely on initial guesses that typically must be supplied to a local optimization method.
Furthermore, the motivation of this section are those instances of (GSIP) when \(\mathbf {g}\) might not be explicitly defined. For instance, in many engineering applications, the design constraints \(\mathbf {g}\) may be defined implicitly by the solution of a system of algebraic or differential equations; the example in Sect. 5.2.1 provides an instance. In this case, many solution methods are impractical if not impossible to apply. For example, in the previous section, global solution of the NLP reformulations (10) and (14) typically requires explicit expressions for the derivative of \(\mathbf {g}\). Thus applying these reformulations does not lead to a practical method. In the context of SIP, (Stuber and Barton 2015) provides a good discussion of why many methods (for SIP) cannot be applied practically to infinitely-constrained problems in engineering applications.
5.1 Methods
5.1.1 Interval restriction with branch and bound
In this section, a method for solving a restriction of (GSIP) is described. The restriction is constructed by noting that the constraint \(g_i(\mathbf {y}) \le 0\) for all \(\mathbf {y}\in D(\mathbf {x})\) is equivalent to \(g_i^*(\mathbf {x}) \le 0\), where \(g_i^*\) is defined by (LLP i). To describe the restriction and solution method, make the following assumption; as in Sect. 3.3, it is assumed that a candidate design space is an interval parameterized by its endpoints.
Assumption 2
Let \(\mathbb {I} Y\) denote the set of all nonempty interval subsets of Y (\(\mathbb {I} Y = \{ [\mathbf {v},\mathbf {w}] \subset Y : [\mathbf {v},\mathbf {w}] \ne \varnothing \}\)). Suppose that \(X \subset \{ (\mathbf {v},\mathbf {w}) \in \mathbb {R}^{n_y} \times \mathbb {R}^{n_y} : \mathbf {v}\le \mathbf {w}\}\) and denote the upper variables of (GSIP) as \(\mathbf {x}= (\mathbf {y}^L, \mathbf {y}^U)\) and let \(D(\mathbf {y}^L,\mathbf {y}^U) = [\mathbf {y}^L,\mathbf {y}^U]\). Assume that for interval A, \(\mathrm {vol}(A)\) equals the volume of A. Assume that for each i, the function \(g_i^U: \mathbb {I} Y \rightarrow \mathbb {R}\) satisfies \(g_i^U(D(\mathbf {x})) \ge g_i^*(\mathbf {x})\), for all \(\mathbf {x}\in X\). Assume that each \(g_i^U\) is monotonic in the sense that \(g_i^U(A) \le g_i^U(B)\) for all A, \(B \in \mathbb {I}Y\) with \(A \subset B\).
Under Assumption 2, the following program is a restriction of (GSIP):
One could take \(g_i^U(A) = \max \{ g_i(\mathbf {y}) : \mathbf {y}\in A \}\) (so that \(g_i^U(D(\mathbf {x})) = g_i^*(\mathbf {x})\) trivially). There exist a number of results dealing with such mappings; (Aubin and Frankowska 1990; Bank et al. 1983; Klatte and Kummer 1985; Ralph and Dempe 1995) are among a few dealing with the continuity and differentiability properties of such maps. Then one approach to solve (GSIP) might be to analyze (24) as an NLP using some of these parametric optimization results. This characterizes the “local reduction” approaches in Hettich and Kortanek (1993), Kanzi and Nobakhtian (2010), Rückmann and Shapiro (1999) and Still (1999), as well as a local method for SIP which takes into account the potential nonsmoothness of \(g_i^*\) in Polak (1987).
The subject of this section is a different approach, where the restriction (24) is solved globally with branch and bound. In this case, one can take advantage of \(g_i^U\) which are cheap to evaluate. For instance, let \(G_i\) be an interval-valued mapping on \(\mathbb {I}Y\). \(G_i\) is said to be inclusion monotonic if it satisfies \(G_i(A) \subset G_i(B)\) for all A, \(B \in \mathbb {I}Y\) with \(A \subset B\). Further, \(G_i\) is said to be an inclusion function of \(g_i\) if it satisfies \(G_i(A) \ni g_i(\mathbf {y})\), for all \(\mathbf {y}\in A\), \(A \in \mathbb {I}Y\). Then letting \(g_i^U\) be the upper bound of \(G_i\), we have that \(g_i^U\) satisfies Assumption 2. See Moore et al. (2009) for an introduction to interval arithmetic and inclusion functions. The benefit is that the interval-valued inclusion functions are typically cheaper to evaluate than the global optimization problems defining \(g_i^*\). The idea of using interval arithmetic to construct a restriction is related to the method in Rocco et al. (2003), except that the optimization approach in that work is based on an “evolutionary” optimization algorithm. Conceptually similar are the methods for the global solution of SIP in Bhattacharjee et al. (2005a, b).
To solve problem (24) via branch and bound, one needs to be able to obtain lower bounds and upper bounds on the optimal objective values of the subproblems
where \(X_k \subset X\). For this discussion assume \(X_k\) is a nonempty interval subset of X. This means \(X_k\) will have the form \([\mathbf {v}_k^L,\mathbf {v}_k^U] \times [\mathbf {w}_k^L, \mathbf {w}_k^U]\) for \(\mathbf {v}_k^L\), \(\mathbf {v}_k^U\), \(\mathbf {w}_k^L\), \(\mathbf {w}_k^U \in \mathbb {R}^{n_y}\). Under Assumption 2, one always has \(\mathbf {y}^L \le \mathbf {y}^U\) for \((\mathbf {y}^L,\mathbf {y}^U) = \mathbf {x}\in X\). Thus, if \(X_k\) is a subset of X, one has \(\mathbf {v}_k^U \le \mathbf {w}_k^L\). Furthermore,
Consequently, \(UB_k = \mathrm {vol}( [\mathbf {v}_k^L,\mathbf {w}_k^U] )\) is an upper bound for the optimal subproblem objective \(f_k^*\). Meanwhile, any feasible point provides a lower bound. In the context of the current problem, there are two natural choices:
-
1.
The point \((\mathbf {v}_k^L,\mathbf {w}_k^U)\) represents the “largest” candidate design space possible in \(X_k\). Consequently, if feasible, it gives the best lower bound for this node.
-
2.
The point \((\mathbf {v}_k^U, \mathbf {w}_k^L)\) represents the “smallest” candidate design space possible in \(X_k\), and thus is more likely to be feasible, and thus to provide a nontrivial lower bound. However, if it is infeasible, i.e. if \(g_i^U(\mathbf {v}_k^U, \mathbf {w}_k^L) > 0\) for some i, then \(g_i^U(\mathbf {y}^L,\mathbf {y}^U) > 0\) for all \((\mathbf {y}^L, \mathbf {y}^U) = \mathbf {x}\in X_k\) (by the monotonicity property in Assumption 2), and thus \(X_k\) can be fathomed by infeasibility.
As noted, with the definition \(g_i^U(D(\mathbf {x})) = g_i^*(\mathbf {x})\), determining whether either of these points is feasible requires evaluating \(g_i^*\), which is still a global optimization problem. In contrast, if the \(g_i^U\) are cheap to evaluate, these lower and upper bounds are also cheap to obtain.
Under mild assumptions, if (GSIP) has a solution, so does the restriction (24), although it may be a somewhat trivial solution. Assume \(g_i^U([\mathbf {y},\mathbf {y}]) = g_i(\mathbf {y})\) for all \(\mathbf {y}\) (as is the case when \(g_i^U\) is the upper bound of an interval extension of \(g_i\)). Let \(D(\mathbf {x}^*) = [\mathbf {y}^{L,*}, \mathbf {y}^{U,*}]\) be a solution of (GSIP); then for any \({\widehat{\mathbf {y}}} \in D(\mathbf {x}^*)\), one has \(g_i({\widehat{\mathbf {y}}}) \le 0\) for all i, and so \([{\widehat{\mathbf {y}}}, {\widehat{\mathbf {y}}}]\) is feasible in the restriction (24), assuming \(({\widehat{\mathbf {y}}}, {\widehat{\mathbf {y}}}) \in X\). Although \([{\widehat{\mathbf {y}}}, {\widehat{\mathbf {y}}}]\) would violate the Slater condition that has been present in many results, it is unnecessary in this approach.
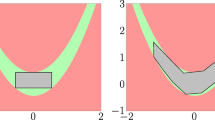
Numerical experiments (see Sect.5.2.1) show that the branch and bound algorithm applied to this problem can be slow. To try to explain why this might be the case, consider the lower and upper bounds described above. For a nonempty interval subset \(X_k = [\mathbf {v}_k^L,\mathbf {v}_k^U] \times [\mathbf {w}_k^L, \mathbf {w}_k^U]\) of X, in the worst case \(f_k^{*} = \mathrm {vol}( D(\mathbf {v}_k^U, \mathbf {w}_k^L) )\), while the upper bound is \(UB_k = \mathrm {vol}( D(\mathbf {v}_k^L, \mathbf {w}_k^U) )\). In one dimension (\(n_y = 1\)), for example, \(\mathrm {vol}( D(y^L, y^U) ) = y^U - y^L\), so \(f_k^{*} = w_k^L - v_k^U\) and \(UB_k = w_k^U - v_k^L\). Meanwhile, the width (or diameter) of \(X_k\) is \(\,\mathrm {diam}(X_k) = \max \{ (w_k^U - w_k^L), (v_k^U - v_k^L) \}\). Thus one has
Thus, the bounding procedure described is at least first-order convergent (see Definition 2.1 in Wechsung (2013), noting that the present problem is a maximization). See “Appendix” for the general case. However, also note that for all \(\alpha > 0\), there exists nonempty \(\widetilde{X} = [\widetilde{v}^L,\widetilde{v}^U] \times [\widetilde{w}^L, \widetilde{w}^U]\) sufficiently small so that \(\widetilde{w}^U -\widetilde{w}^L > \alpha (\widetilde{w}^U - \widetilde{w}^L)^2\) and \(\widetilde{v}^U -\widetilde{v}^L > \alpha (\widetilde{v}^U - \widetilde{v}^L)^2\) which implies
This establishes that the method is not, in general, second-order convergent. When the solution is unconstrained, a convergence order of two or greater is required to avoid the “cluster problem” when applying the branch and bound method; this refers to a phenomenon that hinders the efficiency of the branch and bound method (see Du and Kearfott (1994) and Wechsung et al. (2014)). A deeper understanding of these issues might be wise if attempting to develop the method in this section further.
5.1.2 SIP restriction
Proposition 7 provides the inspiration for another restriction-based method; for \(M \subset \mathbb {R}^{n_h}\) with nonempty intersection with the nonnegative orthant, SIP (12) is a restriction of (GSIP) (this follows from weak duality). If this SIP restriction is feasible, subsequently solving it with a feasible-point method yields a feasible solution of (GSIP).
In contrast, the other duality-based reformulations of (GSIP), such as those in Propositions 6 and 10, do not provide restrictions if the assumption of convexity of the LLPs is dropped. Furthermore, as mentioned in the discussion in Sect. 4.2.1, solving these reformulations globally would require explicit expressions for the derivatives of \(\mathbf {g}\). Since the overall goal of this section is to be able to handle robust design problems where \(\mathbf {g}\) might be defined implicitly by the solution of systems of algebraic or differential equations, such information can be difficult to obtain.
The discussion in Sect. 4.2.2 also demonstrates that the SIP reformulation can take advantage of strong duality even in the cases that the specific hypotheses of Proposition 8 fail. In other words, if strong duality happens to hold for the LLPs of a specific problem, there is hope that the global solution of SIP (12) will also be the global solution of the original problem (GSIP).
For simplicity assume \(m= 1\) (so there is a single LLP) and drop the corresponding index. Global solution of SIP (12) by the feasible-point method from Mitsos (2011) (at a specific iteration of the method) requires the solution of the subproblems
and for given \((\mathbf {x}, \varvec{\mu })\),
for finite subsets \(Y^{LBP} \subset Y\), \(Y^{UBP} \subset Y\), and \(\epsilon ^{g} > 0\). Note that each subproblem is a finite NLP that is defined in terms of the original functions g and \(\mathbf {h}\), and not their derivatives. As their names suggest, (UBP) and (LBP) aim to furnish upper and lower bounds, respectively, on SIP (12) that converge as the algorithm iterates.
A source of numerical difficulty that can arise in applying this method follows. A part of the algorithm is determining the feasibility (in SIP (12)) of the optimal solution \((\mathbf {x}, \varvec{\mu })\) of either (UBP) or (LBP). This requires solving (SIP LLP) and checking that \(q(\mathbf {x},\varvec{\mu }) \le 0\). One must either guarantee that \(q(\mathbf {x}, \varvec{\mu }) \le 0\), or else find \(\mathbf {y}\in Y\) such that \(g(\mathbf {y}) - \varvec{\mu }^{\mathrm {T}}\mathbf {h}(\mathbf {x}, \mathbf {y}) > 0\). In the latter case, \(\mathbf {y}\) is added to the discretization set \(Y^{UBP}\) (or \(Y^{LBP}\)). Typically global optimization methods find such guaranteed bounds and feasible points, but in practice one can often have the situation on finite termination that the approximate solution \(\mathbf {y}\) of (SIP LLP) and its guaranteed upper bound \(UB^{llp}\) satisfy \(g(\mathbf {y}) - \varvec{\mu }^{\mathrm {T}}\mathbf {h}(\mathbf {x}, \mathbf {y}) \le 0 < UB^{llp}\). In this case, one cannot guarantee that the point \((\mathbf {x}, \varvec{\mu })\) is feasible in SIP (12). Meanwhile, adding \(\mathbf {y}\) to the discretization set \(Y^{UBP}\) does not eliminate the previous optimal solution \((\mathbf {x},\varvec{\mu })\), since \(g(\mathbf {y}) - \varvec{\mu }^{\mathrm {T}}\mathbf {h}(\mathbf {x}, \mathbf {y}) \le 0\). Consequently, it is highly likely that the numerical method used to solve (UBP) produces the same solution in the next iteration, and the same ambiguity arises when solving (SIP LLP). The cycle repeats, and the upper bound that the method provides fails to improve. A similar effect can occur with the lower-bounding problem (LBP).
This effect can be overcome by redefining g by adding a constant tolerance to its value. Consider that the pathological case \({\widetilde{g}} = g(\mathbf {y}) - \varvec{\mu }^{\mathrm {T}}\mathbf {h}(\mathbf {x}, \mathbf {y}) \le 0 < UB^{llp}\) occurs, where \(\mathbf {y}\) is the approximate solution found for (SIP LLP). Assume that the relative and absolute optimality tolerances for the global optimization method used are \(\varepsilon _{rtol} \le 1\) and \(\varepsilon _{atol}\), respectively. In this case \(UB^{llp} - {\widetilde{g}} > \varepsilon _{rtol} \left| {\widetilde{g}} \right| \). So assuming that the termination criterion of the global optimization procedure is \(UB^{llp} - {\widetilde{g}} \le \max \{ \varepsilon _{atol}, \varepsilon _{rtol} \left| {\widetilde{g}} \right| \}\), it is easy to see that one must have \(UB^{llp} - {\widetilde{g}} \le \varepsilon _{atol}\) and thus \(UB^{llp} \le {\widetilde{g}} + \varepsilon _{atol}\).
To determine if \((\mathbf {x}, \varvec{\mu })\) is feasible, solve (SIP LLP) and let the solution be \(\mathbf {y}\). Then, if \(g(\mathbf {y}) + \varepsilon _{atol} - \varvec{\mu }^{\mathrm {T}}\mathbf {h}(\mathbf {x},\mathbf {y}) \le 0\), by the preceding discussion one can guarantee that \((\mathbf {x}, \varvec{\mu })\) is feasible in the SIP (12). However, if \(g(\mathbf {y}) + \varepsilon _{atol} - \varvec{\mu }^{\mathrm {T}}\mathbf {h}(\mathbf {x},\mathbf {y}) > 0\), adding the point \(\mathbf {y}\) to the discretization set \(Y^{UBP}\) actually does restrict the upper-bounding problem (UBP), where g is redefined as \(g \equiv g + \varepsilon _{atol}\). In effect, the following restriction of SIP (12)
is being solved with a method which does not quite guarantee feasibility (in (25)) of the solutions found. However, the solutions found are feasible in the original SIP (12).
For concreteness, further aspects of this approach are discussed in the context of the example considered in Sect. 5.2.1.
5.1.3 Generically valid solution
Methods for the general case of GSIP, and related problems such as bi-level programs, with nonconvex lower-level programs have been presented in Mitsos et al. (2008), Mitsos and Tsoukalas (2014) and Tsoukalas et al. (2009). We investigate the method from Mitsos and Tsoukalas (2014) as another approach to solving a robust design problem.
We assume the same setting as in Sect. 4.1.2 and the previous section: for \(\mathbf {x}\in X\), \(D(\mathbf {x}) = \{ \mathbf {y}\in Y : \mathbf {h}(\mathbf {x},\mathbf {y}) \le \mathbf {0} \}\) for some mapping \(\mathbf {h}: X \times Y \rightarrow \mathbb {R}^{n_h}\). Then the work in Mitsos and Tsoukalas (2014) is based on the reformulation of (GSIP) as
This is a mathematical program with an infinite number of disjunctive constraints. These constraints are encoding the same information as in (GSIP); a given \(\mathbf {x}\) is feasible if for each i, and for each \(\mathbf {y}\in Y\), either \(g_i(\mathbf {y}) \le 0\) or \(\mathbf {y}\) is infeasible in (LLP) (in this case, if some constraint \(h_j(\mathbf {x},\mathbf {y}) \le 0\) is violated). The presence of the strict inequality makes numerical solution difficult, and so (26) is relaxed to
This problem is then equivalent to the following SIP with nonsmooth constraints
The numerical solution method in Mitsos and Tsoukalas (2014) is based on applying the SIP method from Mitsos (2011) (upon which the method of Sect. 5.1.2 is based) to the SIP (28).
Strictly, then, the numerical method is solving a relaxation of (GSIP), and there may be some concern that an infeasible point is found. However, we can say that the feasible set of (27) (or (28)) is “typically” the closure of the feasible set of (GSIP). The technical term is that the property is generically valid; see Günzel et al. (2007, 2008). Further, assuming that \(\mathbf {x}\mapsto \mathrm {vol}(D(\mathbf {x}))\) is continuous, maximizing it over the original feasible set or its closure yields the same optimal objective value. Further, the method is still a feasible point method, and the feasibility of candidate solutions is validated by solving the original lower-level programs (LLP i) of (GSIP) (and not, for instance, the lower-level program of the relaxation (28)). Thus, we refer to the method of this section as the “generically valid” solution.
The method in Mitsos and Tsoukalas (2014) for the generically valid solution of (GSIP) requires the solution of the subproblems at a specific iteration (again, assuming \(m=1\) and dropping the subscripts)
and for given \(\mathbf {x}\),
and
where \(\alpha \in (0,1)\) is a fixed parameter, and again, \(Y^{LBP}\) and \(Y^{UBP}\) are finite subsets of Y and \(\epsilon _g\) and \(\epsilon _h\) are positive parameters that may change from iteration to iteration.
In practice, the disjunctive constraints (or equivalent nonsmooth constraints) in (GSIP-UBP) and (GSIP-LBP) are reformulated by introducing binary variables as in Mitsos and Tsoukalas (2014). We obtain
and
where \(g^{\max } \ge \sup \{ g(\mathbf {y}) : \mathbf {y}\in Y\}\) and \(\bar{h}_j^{\max } \ge \sup \{ -h_j(\mathbf {x},\mathbf {y}) : (\mathbf {x},\mathbf {y}) \in X \times Y \}\). Since \(Y^{UBP}\) is finite, for instance, the notation \(z_g(\mathbf {y})\) merely means that we are indexing a vector of binary variables \(\mathbf {z}_g\) by \(\mathbf {y}\in Y^{UBP}\). Note that this implies that the number of variables in the upper and lower bounding problems grows as the discretized sets \(Y^{UBP}\) and \(Y^{LBP}\) grow (which they do from iteration to iteration).
5.2 Numerical examples
We look at two different examples in which the design constraints are implicitly defined; in one, \(\mathbf {g}\) is defined by a dynamic system, and in the another \(\mathbf {g}\) is defined by the solution of a system of algebraic equations. These numerical studies were performed on a 64-bit Linux (Ubuntu 14.04) laptop with a 2.53GHz Intel Core2 Duo processor (P9600) and 3.8 GB RAM. Any compiled code is compiled with GCC version 4.8.4 with the -O3 optimization flag. Some of the methods require GAMS; version 24.3.3 is used (GAMS Development Corporation 2014), which employs BARON version 14.0.3 (Tawarmalani and Sahinidis 2005; Sahinidis 2014).
5.2.1 LLP defined by dynamic system
Consider the following robust design problem. In a batch chemical reactor, two chemical species \(\mathrm {A}\) and \(\mathrm {B}\) react according to mass-action kinetics with an Arrhenius dependence on temperature to form chemical species \(\mathrm {C}\). However, \(\mathrm {A}\) and \(\mathrm {C}\) also react according to mass-action kinetics with a dependence on temperature to form chemical species \(\mathrm {D}\). The initial concentrations of \(\mathrm {A}\) and \(\mathrm {B}\) vary from batch to batch, although it can be assumed they are never outside the range [0.5, 2] (M). Although temperature can be controlled by a cooling element, it too might vary from batch to batch; it can be assumed it never leaves the range [300, 800] (K). What are the largest acceptable ranges for the initial concentrations of \(\mathrm {A}\) and \(\mathrm {B}\) and the operating temperature to ensure that the mole fraction of the undesired side product \(\mathrm {D}\) is below 0.05 at the end of any batch operation?
As a mathematical program this problem is written as (since there is one LLP the subscript on g is dropped)
where \(\mathbf {z}= (z_{\mathrm {A}},z_{\mathrm {B}},z_{\mathrm {C}},z_{\mathrm {D}})\) is a solution of the initial value problem in parametric ordinary differential equations
on the time interval \([t_0, t_f]\), with initial conditions \(\mathbf {z}(t_0, \mathbf {y}) = (y_1, y_2, 0,0)\). See Table 3 for a summary of the parameter values used and the expressions for the kinetic parameters \(k_1\) and \(k_2\). Note that the variables \(y_1\) and \(y_2\) correspond to the initial concentrations of A and B, respectively, while \(y_3\) is a scaled temperature. This scaling helps overcome some numerical issues. Further, note the use of the logarithm to “convexify” the objective, which requires the constraint that any candidate design space have a minimum size. The concave objective can help speed up some of the methods.
5.2.2 SIP restriction
First consider applying the SIP restriction method discussed in Sect. 5.1.2. Let
and
Thus it is clear that X, Y, and M are compact, and that the objective and constraints of the SIP restriction (12) are continuous; the latter (specifically, the continuity of g) follows from standard parametric analysis of initial value problems from, for instance, Chapter II of Mattheij and Molenaar (2002). The value of M is somewhat arbitrary; the SIP restriction is still valid for any M. If M is too large, there can be numerical issues and solving the subproblems can be slow, but as M becomes smaller, the restriction can become more conservative.
Consider the subproblems (LBP), (UBP), and (SIP LLP) that must be solved. The lower-level program of the SIP restriction for this example is a global dynamic optimization problem. This problem must be solved repeatedly in the course of the SIP solution algorithm as a test for feasibility. Although this may seem daunting, the computational time is reasonable. Here, the “direct method” approach of control parameterization (sometimes called single-shooting) is taken; see §1.1 of Schaber (2014). A C++ code implementing dynamic relaxations and branch-and-bound along the lines of Schaber (2014, Ch. 2) Scott (2012, Ch. 10) is used to solve (SIP LLP) at the required values of \((\mathbf {x},\varvec{\mu })\).
Next consider (UBP) and (LBP). Although the function g appears in the constraints of these problems, this does not make them dynamically-constrained problems for this specific example. For this example, only the finite set of values \(\{ g(\mathbf {y}) : \mathbf {y}\in Y^{LBP} \cup Y^{UBP} \}\) is required at any iteration. These values can be obtained without too much extra effort in the course of solving the (SIP LLP) (since \(Y^{UBP}\) and \(Y^{LBP}\) are populated with the maximizers of the lower-level program). Meanwhile, \(\mathbf {h}\) is a known, explicit function of \(\mathbf {x}\) and \(\mathbf {y}\), as are the objectives of (UBP) and (LBP), and overall their solution is no more arduous than in the cases considered in Sect. 4. The (UBP) and (LBP) are solved in GAMS with BARON. The user-defined extrinsic function capability of GAMS is used to communicate with the C++ code solving (SIP LLP).
Meanwhile, suppose that a ball-valued design space was being used in this example, and contrast this with the situation of trying to solve the SIP reformulation from Proposition 2. Since the SIP method from Mitsos (2011) holds for general SIP, one could attempt to solve an exact SIP reformulation similar to the form (2). However, the upper bounding problem for that reformulation would be
The complication here is that the upper-level variables \((\mathbf {y}_c,\delta )\) are required to evaluate g; that is, in contrast to above, a finite set of values does not suffice, and in fact the upper and lower bounding problems become dynamic optimization problems in addition to the lower-level program. However, applying the solution method from Stuber and Barton (2015) to the SIP reformulation from Proposition 2 might lead to a successful method for design centering problems when \(\mathbf {g}\) is defined by the solution of a system of algebraic equations.
For the results in Sect. 5.2.1, the initial discretizations are \(Y^{LBP,0} = Y^{UBP,0} = \varnothing \), the initial right-hand side restriction parameter is \(\varepsilon ^{g,0} = 1\), the right-hand side restriction parameter reduction factor is \(r = 2\), and the subproblems (UBP), (LBP), and (SIP LLP) are solved with relative and absolute tolerances of \(5\times 10^{-4}\) and \(10^{-4}\), respectively. (thus \(\varepsilon _{atol} = 10^{-4}\) in (25) and the preceding discussion). We will not use any overall relative or absolute optimality termination criteria, but rather look at the best objective value for various solution times.
5.2.3 Generically valid solution
The same definitions as for the SIP restriction method are used for X, Y and \(\mathbf {h}\).
Note that, similarly to (LBP) and (UBP), the subproblem (GSIP-LBP) (or its equivalent reformulation with binary variables (GSIP-LBP-B)) only depends on a finite list of values \(\{ g(\mathbf {y}) : \mathbf {y}\in Y^{LBP} \}\), and similarly for the upper bounding problem. Meanwhile, it is assumed we have the functional form of \(\mathbf {h}\), and so the subproblems are mixed-integer nonlinear programs (MINLP), and they are solved to global optimality in GAMS with BARON. (LLP) and (LLPAUX) are solved similarly to (SIP LLP), with a C++ code employing branch-and-bound.
Note that since \(\mathbf {h}\) is linear in \(\mathbf {x}\), the constraints of (GSIP-LBP-B) and (GSIP-UBP-B) are linear. Combined with the concave objective, these subproblems are mixed-integer convex programs and are fairly quick to solve, despite the fact that the number of variables and constraints grows with each iteration. This actually makes this method quite attractive for interval design centering.
Since the algorithm for solving SIP from Mitsos (2011) is similar to the algorithm for solving GSIP from Mitsos and Tsoukalas (2014), similar parameters are used as for the SIP restriction method; the initial discretizations are \(Y^{LBP,0} = Y^{UBP,0} = \varnothing \), the initial right-hand side restriction parameter is \(\varepsilon ^{g,0} = 1\), the right-hand side restriction parameter reduction factor is \(r = 2\), and the subproblems (GSIP-LBP), (GSIP-UBP), (LLPAUX) and (LLP) are solved with relative and absolute tolerances of \(5\times 10^{-4}\) and \(10^{-4}\), respectively. Additionally, we have \(\alpha = 0.5\) in (LLPAUX), and in (GSIP-LBP-B) and (GSIP-UBP-B) we use \(g^{\max } = 11\) and \(\bar{h}_j^{\max } = 9\) for each j. As above, we will not use any overall relative or absolute optimality termination criteria, but rather look at the best objective value for various solution times.
5.2.4 Interval restriction with branch and bound
To apply the interval restriction method from Sect. 5.1.1, Assumption 2 must be satisfied. The main challenge is defining the upper bound function \(g^U\). In the robust design problem (29), g is defined in terms of the solution of an initial value problem in ordinary differential equations, and so the dynamic bounding method from Scott and Barton (2013) is used. This method provides interval bounds on each component of \(\mathbf {z}(t_f, \cdot )\), the solution of the embedded differential equations. Combined with interval arithmetic, one obtains an inclusion monotonic interval extension (and thus an inclusion function) of g. Subsequently, the upper bound of this inclusion function (denote it \(g^U\)) satisfies the relevant parts of Assumption 2. A C++ implementation of the dynamic bounding method from Scott and Barton (2013) is used in conjunction with the interval arithmetic capabilities of MC++ (Chachuat 2015; Mitsos et al. 2009) to calculate the value of \(g^U\).
The same C++ code implementing the branch-and-bound framework is used as in the previous section for solving (SIP LLP). The bounding scheme discussed in Sect. 5.1.1 is implemented with this branch-and-bound framework. The “convexified” objective does not help much with this bounding scheme. Thus the objective used is just \(\prod _j (y_j^U - y_j^L)\). Again, we will not use any overall relative or absolute optimality termination criteria, but rather look at the best objective value for various solution times.
Careful inspection of the dynamic bounding method used to construct \(g^U\) reveals that the interval restriction method is in fact a restriction for the problem
In words, one is looking for the largest acceptable ranges for the initial concentrations of \(\mathrm {A}\) and \(\mathrm {B}\) and range for the temperature control profile to ensure that the mole fraction of \(\mathrm {D}\) is below the threshold. This is due to the fact that the bounding method from Scott and Barton (2013) indeed produces an interval \([\mathbf {z}^L(\mathbf {y}^L,\mathbf {y}^U), \mathbf {z}^U(\mathbf {y}^L,\mathbf {y}^U)]\) satisfying
Continuing the evaluation of g in interval arithmetic then guarantees that \(g(\mathbf {y}) \le g^U([\mathbf {y}^L, \mathbf {y}^U])\) for all \(\mathbf {y}\in [y_1^L, y_1^U] \times [y_2^L, y_2^U] \times \mathcal {U}(y_3^L, y_3^U)\). Thus the restriction (24) still holds. Consequently, this restriction, when applied to dynamic problems, has ties to robust dynamic optimization problems, such as those considered in Houska et al. (2012).
5.2.5 Results and discussion
The results of the three methods applied to the robust design problem (29) are summarized in Table 4 and Fig. 1. Table 4 lists the best solutions for each method for the alotted solution time. In this case, each method was given approximately 10 min. But since each method is a feasible point method, it is interesting to see how the objective evolves over time, and in particular, with respect to a guaranteed upper bound which would give the optimality gap. This is summarized in Fig. 1. Solutions are visualized in Fig. 2.

Best feasible objective value (\(\prod _j (y_j^U - y_j^L)\)) versus time for various methods applied to problem (29). The best upper bound for each method is plotted as a dotted line

From Fig. 1, it is clear that the generically valid method produces better feasible points for any solution time; indeed, all of its feasible points have an objective value greater than the upper bounds of the other methods. However, the best upper bound of the generically valid method is 3.5, and so there is a fair amount of gap left. Meanwhile, the SIP restriction method converges in about 70 s, when the upper-bounding problem (UBP) produces a feasible, and thus optimal (for the restriction) point.
Finally, the interval restriction method has an upper bound that is much lower than the best objectives of the other methods. It does make a fair amount of progress to closing the optimality gap in the 10 min of solution time. However, one could argue that problem (30) is a harder problem than (29); problem (30) has a lower-level variable that takes values in a function space. If such a robust dynamic optimization problem is of interest, the interval restriction method provides an approach to obtaining a feasible point.
5.2.6 LLP defined by implicit function
We investigate the performance of the SIP restriction and the generically valid solution approaches on a system in which the design constraints are given by an implicit function solving a system of algebraic equations.
We consider steady-state operation of a continuously-stirred tank reactor with constant heat capacity of its contents. Reactant \(\mathrm {A}\) flows in at a fixed concentration. The volume flow rate of this feed can be set in the range [0.05, 2] (\(\mathrm {L}\mathrm {s}^{-1}\)). In the reactor, \(\mathrm {A}\) isomerizes to form species \(\mathrm {B}\), which in turn can isomerize to form species \(\mathrm {C}\). Both isomerization reactions are exothermic, so the reactor is jacketed and cooling water at a fixed temperature can be used to cool the reactor. The volume flow rate of the cooling water can be set in the range [0.4, 2] (\(\mathrm {L}\mathrm {s}^{-1}\)). What are the maximum acceptable ranges on the reactant feed flow rate and cooling water flow rate to ensure that the temperature of the reactor does not exceed 350 (\(\mathrm {K}\))?
First, the state of the system is given by the value of the vector \(\mathbf {z}\); \(z_1\) is the concentration of \(\mathrm {A}\); \(z_2\) is the concentration of \(\mathrm {B}\); \(z_3\) is the concentration of \(\mathrm {C}\); \(z_4\) is the temperature inside the reactor; \(z_5\) is the temperature of the cooling water flowing out of the jacketing; and \(z_6\) is an artificial variable equalling the difference between \(z_4\) and \(z_5\). These variables satisfy the system of equations \(\mathbf {0} = \mathbf {f}(\mathbf {p},\mathbf {z})\), where \(p_1\) is the volume flow of the feed and \(p_2\) is the volume flow of the cooling water, and

See Loeblein and Perkins (1998, § 3) for a similar system. Other parameters and expressions are given in Table 5. We will assume that \(\mathbf {z}\) takes values in the set \(Z = [0,20] \times [0,20] \times [0,20] \times [302,400] \times [301,399] \times [1,200]\).
The function g defining the design constraint that temperature remain below a certain limit is then given by \(g : (\mathbf {p},\mathbf {z}) \mapsto z_4 - 350\), where it is implied that the domain of g is the set of \((\mathbf {p},\mathbf {z})\) such that \(\mathbf {f}(\mathbf {p},\mathbf {z}) = \mathbf {0}\). Consequently, define \(P = [0.05,2] \times [0.4,2]\) and
We note Y is compact, since \(\mathbf {f}\) is continuous and Y is defined in terms of a preimage of \(\mathbf {f}\).
Then, as a mathematical program, the robust design problem is formulated as
It might not be immediately apparent that this can be put into the same form as (GSIP); however, take
We note that the main difference is that only a subset of the lower-level variables (namely, \(\mathbf {p}\)) are considered in the design space.
The SIP restriction and generically valid methods discussed in Sects. 5.1.2 and 5.1.3 apply to the present problem. Define
Given the form of Y, (SIP LLP), for instance, becomes
Since \(Y^{UBP}\) in subproblem (UBP) is populated with optimal solutions of (SIP LLP), we must have \(Y^{UBP} \subset Y\). Thus no changes are required of (LBP) and (UBP). Similar reasoning holds for the subproblems (GSIP-UBP) and (GSIP-LBP) in the generically valid method.
For both methods, all necessary subproblems are solved with BARON in GAMS. For the SIP restriction, take \(M = [\mathbf {0}, (100)\mathbf {1} ]\). The algorithmic parameters in both cases are similar to before; the initial discretizations are \(Y^{LBP,0} = Y^{UBP,0} = \varnothing \), the initial right-hand side restriction parameter is \(\varepsilon ^{g,0} = 1\), the right-hand side restriction parameter reduction factor is \(r = 2\), and the overall relative and absolute optimality tolerances of 0.05 and 0.01, respectively, while the subproblems (UBP), (LBP), (SIP LLP), (GSIP-UBP), (GSIP-LBP), (LLPAUX) and (LLP) are solved with relative and absolute tolerances of \(5\times 10^{-5}\) and \(10^{-5}\), respectively. Additionally, we have \(\alpha = 0.5\) in (LLPAUX), and in (GSIP-LBP-B) and (GSIP-UBP-B) we use \(g^{\max } = 1.393\) and \(\bar{h}_j^{\max } = 4.55\) for each j.
The SIP restriction method requires 13 iterations, totalling 680 s, converging to the solution \([0.05,0.23] \times [0.4, 2.0]\) with objective 0.290. The generically valid method requires 146 iterations, totalling 290 s, converging to the solution \([0.05,0.25] \times [0.53, 2.0]\) with objective 0.295. Both methods perform comparably, although the generically valid method is certainly better. It is interesting to note that the SIP restriction method requires much fewer iterations, with a much more expensive lower-level program (solution of (SIP LLP) requires over 400 s of the total solution time). Meanwhile, the generically valid method requires many more iterations, but which are much cheaper (for instance, the total solution time of (LLP) and (LLPAUX) is only 30 s).
6 Conclusions and future work
This work has discussed a number of approaches to solving design centering problems, motivated by the specific instance of robust design in engineering applications. Reformulations to simpler problems were reviewed; many of these are inspired by duality-based reformulations from the GSIP literature. Two approaches for determining a feasible solution of a design centering problem were discussed and applied to an engineering application of robust design. The two methods are successful, with the SIP restriction-based approach (Sect. 5.1.2) performing better for this example.
One aspect of the restriction-based approaches in Sect. 5 that was not considered was the case of multiple infinite constraints (i.e. multiple LLPs). The interval restriction (Sect. 5.1.1) can likely handle multiple constraints in practice without much numerical difficulty. Meanwhile, Mitsos (2011) mentions a potential way to extend the basic SIP algorithm; this simply depends on using separate discretization sets and restriction parameters for each LLP. Unfortunately, numerical experiments show that such an extension to the method performs poorly for design centering problems. The upper-bounding problem (UBP) has trouble finding a feasible point, and so the algorithm is slow to converge. Extending the SIP method from Mitsos (2011) and the GSIP method (Mitsos and Tsoukalas 2014) merits further investigation.
References
Abdel-Malek HL, Hassan AKSO (1991) The ellipsoidal technique for design centering and region approximation. IEEE Trans Comput Aided Des Integr Circuits Syst 10(8):1006–1014
Aubin J-P, Frankowska H (1990) Set-valued analysis. Birkhauser, Boston
Bank B, Guddat J, Klatte D, Kummer B, Tammer K (1983) Non-linear parametric optimization. Birkhauser, Boston
Bemporad A, Filippi C, Torrisi FD (2004) Inner and outer approximations of polytopes using boxes. Comput Geom 27(2):151–178
Ben-Tal A, Nemirovski A (1998) Robust convex optimization. Math Oper Res 23(4):769–805
Ben-Tal A, Nemirovski A (1999) Robust solutions of uncertain linear programs. Oper Res Lett 25(1):1–13
Ben-Tal A, Nemirovski A (2001) Lectures on modern convex optimization: analysis, algorithms, and engineering applications. SIAM, Philadelphia
Bertsekas DP (1999) Nonlinear programming, 2nd edn. Athena Scientific, Belmont
Bertsekas DP (2009) Convex optimization theory. Athena Scientific, Belmont
Bhattacharjee B, Green WH, Barton PI (2005) Interval methods for semi-infinite programs. Comput Optim Appl 30(1):63–93
Bhattacharjee B, Lemonidis P, Green WH, Barton PI (2005) Global solution of semi-infinite programs. Mathematical Programming, Series B 103:283–307
Boyd S, El Ghaoui L, Feron E, Balakrishnan V (1994) Linear matrix inequalities in system and control theory. SIAM, Philadelphia
Boyd S, Vandenberghe L (2004) Convex optimization. Cambridge University Press, New York
Chachuat B (2015) MC++: A Versatile Library for McCormick Relaxations and Taylor Models. http://www.imperial.ac.uk/people/b.chachuat/research.html
Diehl M, Houska B, Oliver Stein, Steuermann P (2013) A lifting method for generalized semi-infinite programs based on lower level Wolfe duality. Comput Optim Appl 54(1):189–210
Du K, Kearfott RB (1994) The cluster problem in multivariate global optimization. J Global Optim 5(3):253–265
Floudas CA, Gümüş ZH, Ierapetritou MG (2001) Global optimization in design under uncertainty: feasibility test and flexibility index problems. Ind Eng Chem Res 40:4267–4282
GAMS Development Corporation (2014) GAMS: General Algebraic Modeling System. http://www.gams.com
Geoffrion AM (1971) Duality in nonlinear programming: a simplified applications-oriented development. SIAM Rev 13(1):1–37
Grant M, Boyd S (2008) Graph implementations for nonsmooth convex programs. In: Blondel V, Boyd Stephen, Kimura H (eds) Recent advances in learning and control, lecture notes in control and information sciences. Springer, Berlin, pp 95–110
Grant M, Boyd S (2014) CVX: Matlab software for disciplined convex programming, version 2.1. http://cvxr.com/cvx
Günzel H, Jongen HTh, Stein O (2007) On the closure of the feasible set in generalized semi-infinite programming. Central Eur J Oper Res 15(3):271–280
Günzel H, Jongen H Th, Stein O (2008) Generalized semi-infinite programming: on generic local minimizers. J Global Optim 42(3):413–421
Halemane KP, Grossmann IE (1983) Optimal process design under uncertainty. AIChE J 29(3):425–433
Harwood SM, Barton PI (2016) Lower level duality and the global solution of generalized semi-infinite programs. Optimization 65(6):1129–1149
Hendrix EMT, Mecking CJ, Hendriks THB (1996) Finding robust solutions for product design problems. Eur J Oper Res 92(1):28–36
Hettich R, Kortanek KO (1993) Semi-infinite programming: theory, methods, and applications. SIAM Rev 35(3):380–429
Houska B, Logist F, Van Impe J, Diehl M (2012) Robust optimization of nonlinear dynamic systems with application to a jacketed tubular reactor. J Process Control 22(6):1152–1160
Kanzi N, Nobakhtian S (2010) Necessary optimality conditions for nonsmooth generalized semi-infinite programming problems. Eur J Oper Res 205(2):253–261
Khachiyan LG, Todd MJ (1993) On the complexity of approximating the maximal inscribed ellipsoid for a polytope. Math Programm 61(1–3):137–159
Klatte D, Kummer B (1985) Stability properties of infima and optimal solutions of parametric optimization problems. Lect Notes Econ Math Syst 255:215–229
Loeblein C, Perkins JD (1998) Economic analysis of different structures of on-line process optimization systems. Comput Chem Eng 22(9):1257–1269
Lofberg J (2004) YALMIP: A toolbox for modeling and optimization in MATLAB. In: 2004 IEEE international conference on computer aided control systems design, pp 284–289
Mattheij R, Molenaar J (2002) Ordinary differential equations in theory and practice. SIAM, Philadelphia
Misener R, Floudas CA (2014) ANTIGONE: algorithms for coNTinuous/integer global optimization of nonlinear equations. J Global Optim 59(2–3):503–526
Mitsos A, Lemonidis P, Barton PI (2008) Global solution of bilevel programs with a nonconvex inner program. J Global Optim 42(4):475–513
Mitsos A, Chachuat B, Barton PI (2009) McCormick-based relaxations of algorithms. SIAM J Optim 20(2):573–601
Mitsos A (2011) Global optimization of semi-infinite programs via restriction of the right-hand side. Optimization 60(10–11):1291–1308
Mitsos A, Tsoukalas A (2014) Global optimization of generalized semi-infinite programs via restriction of the right hand side. J Global Optim 61(1):1–17
Moore RE, Kearfott RB, Cloud MJ (2009) Introduction to interval analysis, SIAM, Philadelphia
MOSEK (2015) http://www.mosek.com/
Nesterov Y, Nemirovski A (1994) Interior-point polynomial algorithms in convex programming. SIAM, Philadelphia
Nguyen VH, Strodiot J-J (1992) Computing a global optimal solution to a design centering problem. Math Programm 53(1–3):111–123
Parkinson A, Sorensen C, Pourhassan N (1993) A general approach for robust optimal design. J Mech Des 115(1):74–80
Polak E (1987) On the mathematical foundations of nondifferentiable optimization in engineering design. SIAM Rev 29(1):21–89
Polik I, Terlaky T (2007) A Survey of the S-Lemma. SIAM Rev 49(3):371–418
Ralph D, Dempe S (1995) Directional derivatives of the solution of a parametric nonlinear program. Math Programm 70:159–172
Rocco CM, Moreno J, Carrasquero N (2003) Robust design using a hybrid-cellular-evolutionary and interval-arithmetic approach: a reliability application. Reliab Eng Syst Saf 79(2):149–159
Rückmann J-J, Shapiro A (1999) First-order optimality conditions in generalized semi-infinite programming. J Optim Theory Appl 101(3):677–691
Sahinidis NV (2014) BARON 14.0.3: global optimization of mixed-integer nonlinear programs, user’s manual. http://www.minlp.com/downloads/docs/baronmanual.pdf
Salazar DE, Rocco CM (2007) Solving advanced multi-objective robust designs by means of multiple objective evolutionary algorithms (MOEA): A reliability application. Reliab Eng Syst Saf 92(6):697–706
Schaber SD (2014) Tools for dynamic model development. PhD thesis, Massachusetts Institute of Technology
Scott JK (2012) Reachability analysis and deterministic global optimization of differential-algebraic systems. PhD thesis, Massachusetts Institute of Technology
Scott JK, Barton PI (2013) Bounds on the reachable sets of nonlinear control systems. Automatica 49(1):93–100
SeDuMi (2015): Optimization over symmetric cones. http://sedumi.ie.lehigh.edu/
Seifi A, Ponnambalam K, Vlach J (1999) A unified approach to statistical design centering of integrated circuits with correlated parameters. IEEE Trans Circuits Syst I Fundam Theory Appl 46(1):190–196
Stein O (2006) A semi-infinite approach to design centering. In: Dempe S, Kalashnikov V (eds) Optimization with mulitvalued mappings, chapter 1. Springer, Berlin, pp 209–228
Stein O (2012) How to solve a semi-infinite optimization problem. Eur J Oper Res 223(2):312–320
Stein O, Still G (2003) Solving semi-infinite optimization problems with interior point techniques. SIAM J Control Optim 42(3):769–788
Stein O, Winterfeld A (2010) Feasible method for generalized semi-infinite programming. J Optim Theory Appl 146(2):419–443
Still G (1999) Generalized semi-infinite programming: theory and methods. Eur J Oper Res 119:301–313
Stuber MD, Barton PI (2011) Robust simulation and design using semi-infinite programs with implicit functions. Int J Reliab Saf 5(3–4):378–397
Stuber MD, Barton PI (2015) Semi-infinite optimization with implicit functions. Ind Eng Chem Res 54(5):307–317
Sturm JF (1999) Using SeDuMi 1.02, A Matlab toolbox for optimization over symmetric cones. Optim Methods Soft 11(1–4):625–653
Swaney RE, Grossmann IE (1985a) An index for operational flexibility in chemical process design–part I: formulation and theory. AIChE J 31(4):621–630
Swaney RE, Grossmann IE (1985b) An index for operational flexibility in chemical process design–part II: computational algorithms. AIChE J 31(4):631–641
Tawarmalani M, Sahinidis NV (2005) A polyhedral branch-and-cut approach to global optimization. Math Programm 103(2):225–249
Tsoukalas A, Rustem B, Pistikopoulos EN (2009) A global optimization algorithm for generalized semi-infinite, continuous minimax with coupled constraints and bi-level problems. J Global Optim 44(2):235–250
Wechsung A (2013) Global optimization in reduced space. PhD thesis, Massachusetts Institute of Technology
Wechsung A, Schaber SD, Barton PI (2014) The cluster problem revisited. J Global Optim 58(3):429–438
Winterfeld A (2008) Application of general semi-infinite programming to lapidary cutting problems. Eur J Oper Res 191(3):838–854
YALMIP (2015) http://users.isy.liu.se/johanl/yalmip/
Acknowledgements
Funding was provided by Novartis Pharmaceuticals Corporation (IDOEJOAE572).
Author information
Authors and Affiliations
Corresponding author
Additional information
This research was funded by Novartis Pharmaceuticals as part of the Novartis-MIT Center for Continuous Manufacturing.
Appendices
Appendix
Convergence of bounding method from Sect. 5.1.1
Let \([\mathbf {v}^U, \mathbf {w}^L] \subset [\mathbf {v}^L, \mathbf {w}^U] \subset [{\bar{\mathbf {y}}}^L, {\bar{\mathbf {y}}}^U] \subset \mathbb {R}^{n_y}\). Let
for each \(j \in \{1, \dots , n_y\}\). Then it is easy to see that the “outer” interval \([\mathbf {v}^L, \mathbf {w}^U]\) is a subset of \([\mathbf {v}^U, \mathbf {w}^L] \cup \big ( \bigcup _j (Y_j^v \cup Y_j^w) \big )\); for any \(\mathbf {y}\in [\mathbf {v}^L, \mathbf {w}^U]\), each component \(y_j\) lies in one of \([v_j^L, v_j^U]\), \([v_j^U, w_j^L]\), or \([w_j^L,w_j^U]\), which is included in the definition of one of \(Y_j^v\), \([\mathbf {v}^U, \mathbf {w}^L]\), or \(Y_j^w\).
Thus
Let \(\alpha = \,\mathrm {diam}([{\bar{\mathbf {y}}}^L, {\bar{\mathbf {y}}}^U])\). Then \((w_k^U - v_k^L) \le \alpha \) for each k. If \(X' = [\mathbf {v}^L,\mathbf {v}^U] \times [\mathbf {w}^L, \mathbf {w}^U]\), then \((v_j^U - v_j^L) + (w_j^U - w_j^L) \le 2 \,\mathrm {diam}(X')\) for each j. Putting all these inequalities together one obtains
Thus assuming \([\mathbf {y}^L,\mathbf {y}^U] \subset [{\bar{\mathbf {y}}}^L, {\bar{\mathbf {y}}}^U]\) for all \((\mathbf {y}^L,\mathbf {y}^U) \in X\), this establishes that the bounding method described in § 5.1.1 is at least first-order convergent.
Rights and permissions
About this article

Cite this article
Harwood, S.M., Barton, P.I. How to solve a design centering problem. Math Meth Oper Res 86, 215–254 (2017). https://doi.org/10.1007/s00186-017-0591-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00186-017-0591-3