
Abstract
The maximum entropy (ME) method is a promising tool for structural reliability analysis by estimating the unknown probability density function (PDF) of given model response from its moment constraints. However, the classic ME algorithm has to resort to an iterative procedure due to non-linear constraints, and the required high order moment estimations may have large statistical error. In this paper, we (i) propose an analytical ME method based on integration by parts algorithm to transform the non-linear constraints to a system of linear equations and (ii) derive the polynomial chaos expansion (PCE) multiplication for improving higher order moment calculation required in the previous step efficiently. Thus, an analytical formula of response PDF is obtained directly without intensively iterative procedure and associated convergence error, and it is followed by probability failure estimation using numerical integration computation. Two structural engineering cases are implemented to illustrate the accuracy and efficiency of the proposed method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Structure reliability analysis is one of the most important issues in engineering practice because of uncertainties in geometry parameters, operating conditions, material properties, applied loadings, etc. It is usually concerned with the probability of a limit state violation of a structural component. For simplicity, the failure probability is the integration of joint probability density function (PDF) of the input variables over failure domain.
Generally speaking, except for some very simple cases, it is an intractable problem to solve the failure probability. Such difficulty arises due to implicit limit state function as well as associated failure domain. In this way, the numerical simulation methodology, such as the Monte Carlo simulation (MCS) and versions including various importance sampling strategies, is widely employed for failure probability or reliability calculation (Zio 2013). Although these numerical methods are straightforward, it could lead to huge computation burden when structures or systems in consideration are large and complex, e.g., the finite element model. Therefore, researchers have developed the semi-analytical methodology, e.g., the first order reliability method (FORM) and the second order reliability method (SORM) (Zhao and Ono 1999), to mitigate this problem. These methods find an approximate analytical solution of procedure instead of many samplings. However, the gradients required in these methods are often calculated by the finite difference algorithm, and it is also time-consuming for complicated structures.
In addition, the response surface methodology is proposed to deal with the issue of implicit limit state function. The basic idea is to fit the true limit state function by approximate technologies, which makes function evaluation much easier for further computation (Shi et al. 2014). And such approximation is known as the response surface. Typically, it is chosen to be first or second order polynomials, high-dimensional model representation (HDMR) or dimensional reduction method (DRM) (Rabitz 1999), Kriging model (Kaymaz 2005), radial basis function (Jamshidi and Kirby 2010), etc. Then, the numerical simulation methodology and the approximate methodology could execute using the response surface instead of the original one. However, all these methods are computationally efficient but at the expense of accuracy (Chakraborty and Chowdhury 2015). Besides, Bucher and Most also concluded that relative accuracy of various response surface approaches might depend on the specific problem under consideration (Bucher and Most 2008).
Another distinguished idea is the statistical response characterization methodology (Shi et al. 2014). Unlike those discussed above whose foundation is input joint PDF integration over failure domain, this methodology represents PDF of limit state function response explicitly and obtains the probability of failure by employing numerical integration of this PDF directly. Researchers have extended the spectral stochastic finite element method (SSFEM) for PDF estimation of any response quantity by combining FORM sensitivity analysis (Sudret and Der Kiureghian 2002), and taken MCS for assumed PDF fitting (Huang et al. 2014). However, the former one may become a weakness when it comes to small failure probabilities, while the latter one might not be able to capture the response characterization when the assumed PDF form is far from the truth, and it is also short of computational efficiency.
An alternative way to obtain the PDF of response is the maximum entropy (ME) method, which is proposed by Jaynes as a rational approach to estimate unknown PDF (Jaynes 1957). The ME principle states that the PDF of response is the one having the maximum entropy under given moment constraints. Thus, a typical three-step method is widely adopted (Li and Zhang 2011; Shi et al. 2014; Chakraborty and Chowdhury 2015; Lasota et al. 2015). In the first step, several moments of response are obtained. In the second step, the explicit response PDF is derived from ME principle with moment constraints, where the Newton algorithms are employed in computation process since the constraints are non-linear in most cases. Finally, failure probability or some other results could come out. In the last few decades, a number of ME algorithms have been developed and applied in various fields, like structural reliability analysis (Zhang and Pandey 2013; Dai et al. 2016; Fan et al. 2018), structural damage assessment (Meruane and Ortiz-Bernardin 2015), extreme significant wave heights prediction (Petrov et al. 2013), and rotor-shaft dynamic responses modeling (Lasota et al. 2015).
However, there are practical difficulties suffered by ME method. First of all, Newton algorithms are iterative, which causes additional computation and convergence issue. And there might be unbalanced non-linearities and ill-conditioned Jacobian matrices in Newton algorithms (Abramov 2007). Besides, the moment estimations may have large statistical errors by traditional sampling approach, especially for high order moment. In order to overcome these shortcomings, researchers have conducted many studies. For one thing, Bandyopadhyay proposed an improved scaling iterative approach without matrix inversion (Bandyopadhyay et al. 2005). Some researchers use Chebyshev polynomials (Gotovac and Gotovac 2009), Fup basis functions (Gotovac and Gotovac 2009), or other orthogonal polynomials in fitting response PDF (Abramov 2007). Although these approaches make the ME method more stable and suitable when high order moments are given, the iterative procedure remains and the algorithm convergence is a potential problem. Zhang introduced the fractional moment concept to avoid high order moment (Zhang and Pandey 2013), but this approach introduces additional constraints and associated iterative resolution process for fractional values. It would increase algorithm complexity, while fractional moment might not apply in the case where the moment value is negative. For another, Shi made an attempt to get response PDF by classic ME fitting method and FORM was combined to compute failure probability, while K-S tests are used to check goodness of both moment estimations and PDF fitting (Shi et al. 2014). Chakraborty (Chakraborty and Chowdhury 2015) and Lasota (Lasota et al. 2015) use polynomial chaos expansion (PCE), which is a typical surrogate response under HDMR, to obtain low order moment instead of sampling accurately, because PCE converges in the L2 sense for any arbitrary stochastic process with finite second moment, and the accuracy of PCE could be improved by increasing PCE degree (Xiu and Em Karniadakis 2002; Sudret 2008). But higher order moment calculation is obtained by PCE sampling, which may introduce additional sampling error and computational costs. Moreover, the univariate dimension reduction method (UDR) is also proposed to compute high order moments efficiently (Rahman and Xu 2004), but previous research indicated that the lack of accuracy of UDR is inherent to its mathematical formulation and may not be reduced (Gherlone et al. 2013). As a whole, these works also do not change the existing framework of iterative algorithm, and the moment estimations are mostly based on consuming sampling principle.
In this paper, we explore an analytical method to improve the existing ME method, which could mitigate problems discussed above. Since the formula of response PDF is an exponential form according to ME principle, the key idea is to separate parameters in PDF using integration by parts. So, the constraints could be converted into a system of linear equations. Thus, the PDF would be obtained without convergence error. However, it may lead to a higher moment estimation requirement in solving procedure than classic ME method. To deal with this challenge, we make an attempt to use PCE and multiplication algorithm to obtain high order moments within limited statistical error.
The presentation of this work is structured as follows. Section 2 presents the proposed analytical maximum entropy method. In Section 3, the polynomial chaos expansion for high order statistical moment calculation is introduced. The procedure of proposed method is presented in Section 4. The proposed method for structural reliability analyses is illustrated by two examples in Section 5. Conclusions are summarized in the last section as well as Appendix 1, 2, 3, and 4.
2 Maximum entropy method for reliability analysis
2.1 Maximum entropy principle and classic algorithm
The maximum entropy principle is of particular use in characterizing the specific PDF of a random variable (Jaynes 1957; Bandyopadhyay et al. 2005; Petrov et al. 2013). According to information theory, the entropy of a continuous random variable y∈Ωy with PDF f(y) is defined as
The ME principle states that the PDF which best represents the current information or constraints is the one with the largest entropy. Thus, if these constraints are known as statistical moments of arbitrary basis functions (hi(y); i = 0, ..., m), the ME method can be defined as the following optimization problem:
where μi is the moment of the ith basis function.
The above optimization problem could be solved by introducing Lagrangian function L with the corresponding multiplier λi, written as
Thus, this optimization problem is reduced to find the maximum value of (3):
Therefore, the generic form of the PDF f(y) is
where λi becomes undetermined parameter which makes PDF satisfy constraints in (2). Furthermore, if basis function hi(y) is taken as monomial yi, the zeroth normalized condition is given as \( {\int}_{y\in {\Omega}_y}f(y) dy=1 \).
Since (2) and (5) are non-linear, a number of optimization techniques, such as Newton method or its improved versions (Kelley 1999) and the BFGS procedure (Abramov 2009), could be utilized to solve this problem. We would not go into detail on these algorithms here. However, the common feature of them is that all of these methods suffer the iterative procedure which is confronted with the challenge of convergence, especially when it comes to high order moment. However, high order moment information may be necessary for more accurate estimation of PDF in general. So, it might pose a dilemma for ME method. Although some researchers propose to mitigate this problem by introducing orthogonal polynomials like Chebyshev or Lagrange polynomials for PDF fitting, many numerical difficulties still remain. In addition, the high order moment evaluations are also a problem in practice.
2.2 Proposed analytical maximum entropy method
To overcome the problems discussed above, we first attempt to solve the optimization problem analytically. And then, we employ PCE algorithm to deal with high order moment calculation. The later one will be discussed in Section 3. The original idea behind the proposed method is to avoid iterative procedure by using the exponential form of response PDF f(y). In other words, the undetermined parameters λi could be separated from exponential function using integration by parts for each moment constraint in (2), while the form of exponent remains and it could be converted to several different order moment constraints. Note the fact that the moment constraint itself could be treated as a whole and replaced by a known moment value, λi could become independent from original non-linear PDF f(y) after separation. In this way, with the known moment information, the optimization problem could be transformed into a system of linear equations, and λi could be solved analytically.
However, there is a potential problem with this idea, that is, higher order moments required in our method may be computationally instable. This phenomenon would lead to unbalanced non-linearities and ill-conditioned matrix for linear equations mentioned above. To deal with this problem, we introduce the well-known Chebyshev polynomials to improve the quality of matrix. The detail is given as follows.
Consider the limit state function y = g(x) where x = (x1,…,xn) ∈Ωn is an n-dimensional random input. We assume that the form of response PDF is given as
where Tj(y) is the jth Chebyshev polynomial (see Appendix 1 (Mason and Handscomb 2002)). Without loss of generality, we would solve this problem and associated unknown λi in the interval [− 1, 1]. Other cases could be discussed at the end of this section. Thus, (6) is subject to the following constraints:
where Mi is the moment associated with ith Chebyshev polynomial Ti(y). To avoid confusion with the classic monomial moment, e.g., E(y), E(y2), etc., we call Mi as Chebyshev moment here.
According to the recurrence relation of Chebyshev polynomials in Appendix 1, a linear transformation is available as (8) or (9)
and for i ≥ 2
In this way, the key step of the proposed method is to separate unknown λi in (5) with integration by parts. The reason why we take (1 − y2)Ti(y) instead of Ti(y) as basis function is to avoid definite integral term after parameter separation. For all i > 0, we have
By implementing the relations among Chebyshev polynomials, (10) is derived as (11)-(12) if all Chebyshev moment information is given
and for i ≥ 2
Appendix 2 provides the details of solving procedure. The (11)-(12) is a system of linear equations, and it could be rewritten as the following matrix form:
where \( {A}_{11}=\frac{1}{16}\left(2{M}_2-{M}_4-{M}_0\right) \)
The equations could be used to solve λi analytically. The result is an exact solution without convergence error.
Moreover, if i = 0, we have the following equation:
That is, λ0 is derived as
Therefore, the failure probability of given model could be computed by integration as follows:
In addition, since Ti(y) itself is a polynomial form based on monomial y lower than ith order, the Chebyshev moment Mi corresponding to Ti(y) could be calculated by the linear combination of traditional monomial moments, e.g., M4 = 8E(y4) − 8E(y2) + 1. It is shown that each Chebyshev moment includes both high order and low order classical monomial moment information. This property could avoid unbalanced non-linearities. It is because the value of response domain is within the interval [− 1, 1], and there would not be divergence of monomial moments as well as Chebyshev moments. In addition, even if the moment value is close to zero as the order of monomial moment increase, the low order monomial moment in Chebyshev moment could compensate for this and the high order Chebyshev moment would not be zero, which makes the matrix of (13) non-singular.
It should be noted that the analytical method mentioned above requires that the response of given model should belong to the interval [− 1, 1], which may be violated in many cases. Thus, the arc-tangent transformation is taken as (17) where the value domain of response is [− 1, 1].
The reasons of this transformation are (1) the magnitude of high order moment is under control without divergence; (2) The interval [− 1, 1] is in accord with Chebyshev polynomials, and the fitting accuracy is assured; (3) it could avoid truncated error of integral interval during calculation procedure if the interval of response is unknown and an assumed interval is taken.
In general, the existing methods are developed based on classic ME algorithm framework, which obtains results by iterative procedure using low order moments, and the accuracy of these methods depends on iteration times. Compared with these ME methods, the efficiency of our analytical method could be significantly improved, because it could avoid iterative procedure based on high order moment.
2.3 Example
The efficiency of our method is inherently better than classic methods, and we test two examples to illustrate the accuracy of proposed method. The first one is a complicated bi-model, which is used to test failure PDF fitting in structural reliability analysis, and the second one is a difficult step function, which is used to test the stability of our algorithm. Without loss of generality, the initial values of unknowns in classic ME are all zeros. In addition, the evaluation criteria of PDF fitting is the root mean square error (RMSE), which is defined as
where f(x) is the original PDF and fME(x) is the ME PDF obtained by our method or classic ME method. n is the number of discrete points within the interval [− 1, 1], and xi is the sequential discrete point. In our cases, n is chosen to be 10,000.
The bi-modal PDF is a sum of two Gaussian PDFs. Its total area is normalized to [− 1, 1]. The results presented in Fig. 1 and Table 1 indicate that the accuracy and efficiency of our method are both better than the classic method. When m is 8, RMSE of our method is 4.3026 × 10−2, and RMSE of the classic method is 4.8732 × 10−2 with 30 iteration. What’s more, if the accuracy is not acceptable when m is 8, our method could improve the accuracy using larger moments, e.g., when m = 16, the PDF fitting is close to the exact one, whose RMSE is about 0.00125. While, the classic method may not be able to execute due to unbalanced non-linearities and ill-conditioned Jacobian matrices.

The approximation of bi-modal PDF. a The results obtained by proposed method. b The results obtained by classic method
Then, we would compare the results of step PDF fitting with our method and the classic method in Fig. 2 and Table 2. Since the step PDF is a difficult function, both methods may not be able to describe it precisely. The accuracy of our method is less than that of the classic method; however, our method could improve its performance by increasing the moment constraints. When m is 16, RMSE of step PDF fitting using our method is 6.3264. While, the classic method may not execute due to unbalanced non-linearities and ill-conditioned Jacobian matrices. Besides, there is no iterative procedure using our method, which is more efficient than the classic method. With equivalent calculation cost, our method is more accurate than the classic method. For example, when m is 2, the RMSE of our method is 13.8951 × 10−2, and that of the classic method is 19.3571 × 10−2 with 1 iteration.

The approximation of step PDF. a The results obtained by proposed method. b The results obtained by classic method
Thus, the proposed method may be an efficient algorithm for PDF fitting in reliability analysis compared with the classic method at similar accuracy.
When it comes to engineering applications, it may not be able to obtain moment information directly. The traditional MCS approach is time-consuming and unstable for high order moment calculation. Thus, we propose to take PCE algorithm to provide such information as in Ref. (Chakraborty and Chowdhury 2015; Lasota et al. 2015). However, it may not be convenient for PCE to offer high order moments except for the first two moments. Therefore, the key point of proposed method then becomes high order computation based on PCE.
3 PCE for high order moment calculation
In this section, the classic PCE would be extended for high order moment calculation, which then would be used as inputs for ME method above. We would first introduce the classic PCE and its global statistical properties for the first two order moments. Then, the classic PCE would be developed for high order moments by PCE multiplication, while the accuracy of these results would be proved.
3.1 The PCE algorithm
PCE, which was originally introduced by Wiener, employs the Hermite polynomials in the random space to approximate the Gaussian stochastic processes. In Xiu and Em Karniadakis (2002), Xiu and Karniadakis developed the PCE under Wiener-Askey scheme that could be applied for non-Gaussian scenarios. It could uniformly approximate any random process with finite second order moments.
Consider the model y = g(x) in Section 2.1 again. Then, let \( {\left\{{\xi}_i\right\}}_{i=0}^n \) be independent standardized orthogonal random variables associated with \( {\left\{{x}_i\right\}}_{i=1}^n \). For example, if xi~N(2, 0.5), then we have xi = 0.5ξi + 2 where ξi is subject to the standardized normal distribution N(0, 1).
Then, the PCE of the limit state function is (Sudret 2008)
where \( {\left\{{c}_j\right\}}_{j=0}^{\infty } \) are the coefficients, and \( {\psi}_s\left({\xi}_{i_1},\cdots, {\xi}_{i_s}\right) \) denotes the polynomial chaos basis of sth degree in terms of multi-dimensional standardized random variables ξ = (ξ1, ⋯, ξn)T. In addition, the expansion bases \( {\left\{{\psi}_s\right\}}_{s=0}^{\infty } \) are multi-dimensional hyper-geometric polynomials, which are defined as tensor products of the corresponding one-dimensional orthogonal polynomial \( {\left\{{\phi}_k\right\}}_{k=0}^{\infty } \), that is,
where ϕi is a one-dimensional orthogonal basis with orthogonality relation
where δij is the Kronecker delta, <•,•> denotes the ensemble average which is the inner product in Hilbert space. And αk is the vector of index, which is subjected to non-negative integer.
The type of orthogonal polynomials depends on the distributed type of input variables, e.g., the orthogonal polynomials corresponding to normal distribution are Hermite polynomials, while the orthogonal polynomials corresponding to uniform distribution are Legendre polynomials. If the distribution types of input variables are not the same, Isukapalli provided several distribution transformation relationships that map different distributions as functions of normal random variables (Isukapalli 1999). With the pre-processing, the problem of inconsistent distribution could be overcome.
In engineering practice, the PCE is truncated to finite terms. So, considering an n-dimensional orthogonal polynomial with the degree not exceeding p, (19) can be rewritten as another form with limited terms, that is,
where the subscript α is a tuple defined as α = (α1,…, αn), and \( {\varphi}_{i_1,\cdots, {i}_s} \) is defined as a realization of α = tuple so that only the indices {i1,…,is} are non-zeros:
Correspondingly, the expansion bases \( {\psi}_{\boldsymbol{\alpha}}\left(\boldsymbol{\xi} \right)=\prod \limits_{k=1}^n{\phi}_{\alpha_k}\left({\xi}_k\right) \), where \( \sum \limits_{k=1}^j{\alpha}_k\le p \). Denote N as the total number of polynomials, and then we have
Generally, (22) can be further simplified as
where coefficient cj and expansion base ψj(ξ) are corresponding to (22) sequentially.
Let \( {\left\{{\xi}^i\right\}}_{i=1}^M \) denote a set of the random variable samples, and it could be determined by probabilistic collocation method (PCM). Again Let \( {\left\{g\left({\boldsymbol{\xi}}^i\right)\right\}}_{i=1}^M \) denote the corresponding set of model output or response, where M is the number of samples. Denoting c = (c0,…,cN − 1)T, an approximation \( \hat{\boldsymbol{c}} \) could be given by least squares algorithm:
where M is suggested to be selected as M = 2(N + 1) (Isukapalli 1999).
Due to the orthogonality of the basis, the mean value and the variance of y in (25) can be calculated as (Sudret 2008)
3.2 PCE for high order moment calculation
As could be seen above, the PCE could provide the first two order moments accurately. However, there are some difficulties for high order moment calculation. Consider the fact that PCE consists of orthonormal bases, and the product of two PCEs in (25) can be expanded as a linear combination of Hermite polynomials, we could make multiplication of orthogonal polynomials to obtain high order moments by (27). In Luo (2006), the generalization form of PCE multiplication based on (19) is presented. In this paper, we would apply this theory to the truncated PCE, and prove that the multiplication form could provide an accurate high order moment estimation under appropriate PCE degree.
Suppose u and v have PCE formula with the same n-dimensional standardized random variables ξ = (ξ1, ⋯, ξn)T but different degree pα and pβ respectively. That is, \( u=\sum \limits_{\left|\boldsymbol{\alpha} \right|\le {p}_{\alpha }}{u}_{\boldsymbol{\alpha}}{\psi}_{\boldsymbol{\alpha}}\left(\boldsymbol{\xi} \right) \), \( v=\sum \limits_{\left|\boldsymbol{\beta} \right|\le {p}_{\beta }}{v}_{\boldsymbol{\beta}}{\psi}_{\boldsymbol{\beta}}\left(\boldsymbol{\xi} \right) \). If E(|uv|2) < ∞, then the product of u and v has the PCE formula
and
where the subscripts α, β, r, and θ are tuples associated with PCE terms, e.g., α = (α1, α2, …, αn). We say β ≤ θ if βi ≤ θi for all i = 1,2,…,n. The operation of these subscripts, such as + or −, is also defined as component-wise. Especially, the factorial of tuples is defined like α! = ∏i αi!. The proof is provided in Appendix 3.
Specifically, the mean of uv is
Based upon the preparation above, we could calculate the high order moments of PCE by replacing u and v with two PCEs respectively. That is, u and v in (28) could be replaced by yp, \( {y}_p^2 \), \( {y}_p^3 \), …, respectively as (31). Thus, the high order moments could be computed analytically.
where ⌊•⌋ is rounded down and ⌈•⌉ is rounded up.
In addition, if E(yk(ξ)) is required, it is not necessary to calculate the coefficients of yk(ξ) when k is a positive even number. Instead, it could be obtained by an alternative approach as
Since the PCE is L2 convergence in the corresponding Hilbert functional space, that is
We could prove that moment evaluations by (32) are also accurate with L2 convergence as
The detail is presented in Appendix 4. Specifically, for a given function or model, the main source of error for high order moment estimation comes from PCE approximation procedure itself, and there is no additional source of error in following PCE multiplication for high order moment estimation. In addition, the error of PCE decreases as the increasing of PCE degree, which in turn leads to error reduction of high order moment estimation. In this way, we could obtain the moment information precisely and efficiently using PCE multiplication above. And we also employ an example to show the accuracy of this method for high order moment estimation. Consider a function
where x1~N(2, 0.2), x2~N(3, 0.5), and x3~N(1, 0.3). PCE of increasing degrees (p = 3, 5, 7) are used to estimate high order moments. The results are presented in Table 3 and Fig. 3. It is shown that the relative error of PCE for higher order moment estimation becomes larger as the order of moment increases. However, the relative error of moment estimations decreases with the increasing degree of PCE. This means that the error of proposed method could be controlled.

The relative error of high order moment estimations with different PCE degrees
In real engineering application, it may introduce much computational burden if PCE degree is taken too large. A practical way is to calculate PCEs with small p and p + 1 degree respectively, which is followed by comparing the difference. If the difference is less than a pre-defined threshold, the PCE with p + 1 degree are adopted. Otherwise, PCE with p + 2 degree is used to repeat this procedure. Thus, the accuracy and efficiency are balanced for engineering practice.
4 Summary of proposed method
With the preparation of moment calculation algorithm and response PDF solving algorithm based on ME, this section presents a summary for structural reliability analysis using proposed analytical ME method. The difference between classic ME method and the proposed method is illustrated in Fig. 4. The general procedure of our method is shown as follows:
-
(i)
Compute the high order moment estimations by PCE and associated multiplication algorithm.
-
Provide distribution type and distribution parameters of the input random variables, and then map these distributions into the same standard normal distribution.
-
Compute PCE for limit state function using (26) where the response is converted to the interval [− 1, 1] by arc-tangent function as (17).
-
Determine the number of moment constraints, which is marked as m. During this procedure, make multiplication of PCE and derive the moment order as (32), which is followed by computing associated Chebyshev moments according to the form of Chebyshev polynomials.
-
(ii)
Compute (13) and (15) analytically, which leads to explicit ME PDF. First, a pre-defined threshold value is taken. And then execute the proposed method with m constraints and m + 2 constraints respectively. If the difference of failure probabilities of two computations is less than a threshold value, we terminate the solving process and take the latter failure probability as the final result. Otherwise, another two higher moment constraints are used. The entire procedure is repeated until the convergence condition or threshold value is reached.
-
(iii)
Compute the failure probability by integration in interval [− 1, 0] as (16).

The difference between classic ME method and proposed method
5 Application
In this section, two examples are taken to illustrate the performance of proposed method. The first example is a composite beam, and the second one is about a truss bridge structure. Both examples are conducted by MCS, FORM, SORM, the classic methods as well as the proposed method for comparison in accuracy and efficiency. Besides, the classic methods are implemented by two different moment calculation algorithms, that is, the sampling algorithm and the PCE algorithm.
5.1 A composite beam example
This example is taken from Ref. (Chakraborty and Chowdhury 2015). It is about a composite beam with an enhancement layer fastened to its bottom face as shown in Fig. 5. There are 20 independent random variables including cross-section geometric parameters of beam A and B with associated Young’s modulus Ew, cross-section geometric parameters of enhancement layer C and D with associated Young’s modulus Ea. Besides, six external forces P1, P2, P3, P4, P5, and P6 and their location are at a distance of L1, L2, L3, L4, L5, and L6 from the left end. Finally, the allowable stress is S. The details of these variables are presented in Table 4. And the limit state function is given as
where

The composite beam considered in Section 5.1
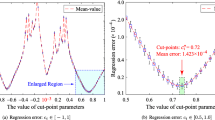
The results obtained from various methods are listed in Table 5. It is shown that proposed method could obtain an accurate result compared with other methods. Compared with the classic ME method, our method takes significantly fewer function evaluations. And compared to the classic ME method whose moment information is provided by PCE (Chakraborty and Chowdhury 2015), our method could generate a more accurate result without any iterative procedure even when the times of function evaluations are the same. Also, compared with the FORM or SORM when number of function evaluation is similar to our method, the accuracy of FORM and SORM is close to that of our method. Besides, the error of FORM or SORM is inherent to its mathematical formulation, and it may not be able to mitigate within its calculation process. When it comes to the proposed method, the error could be reduced by increasing the PCE degree, which is marked as p, and moment constraints, which is marked as m. For further demonstrating the performance, the convergent tendency of proposed method is presented in Table 6 where m = 2, 4, 6, and 8 are implemented successively. Besides, the relative error of power moments is also presented in Fig. 6 which takes m = 8 as example. It should be noted that the original response is transformed to interval [− 1, 1] by 2/π *atan(y/10), so the moments are less than 1. It is shown that the proposed method is convergent and both moment calculation and response PDF unknown solving are precise.

The error curve of example 1 by proposed method
5.2 A truss bridge example
In this example, a truss bridge is considered. The problem consists of steel bars and concrete deck subjected to gravity load and external force as shown in Figs. 7 and 8. For simplicity, all steel bars are the same I-steel. The length of each bar is 12 m, while width and thickness of the I-steel are 400 and 16 mm respectively. The thickness of concrete deck is 30 mm. The external force considered in this example is 10 kN. Six input variables, including the size of steel bar, Young’s modulus, and the external force, are all normally distributed, and their distribution parameters can be seen in Table 7. Besides, the limit state function is assumed to be g = 0.0085 − Δy, where Δy is the maximum displacement of the truss bridge.

The front view of truss bridge considered in Section 5.2

The finite element model considered in Section 5.2
The MCS, FORM, SORM, two classic ME methods with different moment calculation algorithms, and the proposed method are employed to calculate the failure probability, and the results are presented in Table 8.
It could be seen that the proposed method with p = 5 and m = 6 obtains the best approximate result compared to the benchmark solution obtained using MCS. And the number of function evaluations of the proposed method is significantly less than MCS and the classic ME methods with traditional moment calculation algorithm. Thus, the performance of our method is better than classic ME method. On the other hand, if the efficiency is preferred, the proposed method could reduce the computational burden by decreasing PCE degree and moment constraints. Although the number of function evaluation of proposed method is slightly less than FORM or SORM when p = 3 and m = 2, the accuracies of these methods are also close. Therefore, the proposed method may be an alternative method for structural reliability analysis.
6 Conclusion
The paper presents a generic method for calculating structural reliability analytically. It is based on the maximum entropy principle in which Chebyshev polynomials are employed and unknown parameters in response probability density function are solved by an analytical approach. In addition, the polynomial chaos expansion and associated multiplication are introduced for accurate high order moment calculation, and the results are presented as inputs for analytical ME method above. The proposed method mainly has two advantages:
First of all, in contrast to popular ME algorithm, this method could exhibit excellent efficiency and convergence because the parameters in ME PDF is obtained analytically without iterative procedure. And the Chebyshev polynomials adopted in ME PDF mitigate the ill-conditional matrix during calculation procedure above.
Second, the PCE-based multiplication algorithm decreases the number of original limit state function evaluations to about 2(n + p)!/n!/p!, where p is the PCE order and n is the dimension of input. It could make high order moment evaluations efficient and accurate with a mean square convergent.
Third, compared with well-known FORM and SORM, the accuracy of proposed method is similar to that of FORM or SORM when the number of function evaluation is close. Moreover, the proposed method could improve the accuracy by increasing the PCE degree and moment constraints.
Several examples are presented to illustrate the numerical accuracy and efficiency of proposed method. It is shown that this method provides an alternate and efficient approach to analyze structural reliability problems.
References
Abramov RV (2007) An improved algorithm for the multidimensional moment-constrained maximum entropy problem. J Comput Phys 226(1):621–644
Abramov RV (2009) The multidimensional moment-constrained maximum entropy problem: a BFGS algorithm with constraint scaling. J Comput Phys 228(1):96–108
Bandyopadhyay K, Bhattacharya AK et al (2005) Maximum entropy and the problem of moments: a stable algorithm. Phys Rev E Stat Nonlinear Soft Matter Phys 71(2):057701
Bucher C, Most T (2008) A comparison of approximate response functions in structural reliability analysis. Probab Eng Mech 23(2):154–163
Chakraborty S, Chowdhury R (2015) A semi-analytical framework for structural reliability analysis. Comput Methods Appl Mech Eng 289:475–497
Dai H, Zhang H et al (2016) A new maximum entropy-based importance sampling for reliability analysis. Struct Saf 63:71–80
Fan J, Liao H et al (2018) Local maximum-entropy based surrogate model and its application to structural reliability analysis. Struct Multidiscip Optim 57:373–392
Gherlone M, Mattone MC et al (2013) A comparative study of uncertainty propagation methods in structural problems. Comput Methods Appl Sci 26:87–111
Gotovac H, Gotovac B (2009) Maximum entropy algorithm with inexact upper entropy bound based on Fup basis functions with compact support. J Comput Phys 228(24):9079–9091
Huang W, Mao J et al (2014) The maximum entropy estimation of structural reliability based on Monte Carlo simulation. ASME 2014 33rd International Conference on Ocean, Offshore and Arctic Engineering
Isukapalli SS (1999) Uncertainty analysis of transport-transformation models. The State University of New Jersey, Rutgers
Jamshidi AA, Kirby MJ (2010) Skew-radial basis function expansions for empirical modeling. SIAM J Sci Comput 31(6):4715–4743
Jaynes ET (1957) Information theory and statistical mechanics. Phys Rev 106(4):620–630
Kaymaz I (2005) Application of kriging method to structural reliability problems. Struct Saf 27(2):133–151
Kelley CT (1999) Iterative methods for optimization. Society for Industrial and Applied Mathematics
Lasota R, Stocki R et al (2015) Polynomial chaos expansion method in estimating probability distribution of rotor-shaft dynamic responses. Bull Pol Acad Sci Tech Sci 63(2):413–422
Li G, Zhang K (2011) A combined reliability analysis approach with dimension reduction method and maximum entropy method. Struct Multidiscip Optim 43(1):121–134
Luo W (2006) Wiener chaos expansion and numerical solutions of stochastic partial differential equations. California Institute of Technology
Mason JC, Handscomb DC (2002) Chebyshev polynomials. CRC Press
Meruane V, Ortiz-Bernardin A (2015) Structural damage assessment using linear approximation with maximum entropy and transmissibility data. Mech Syst Signal Process 54-55:210–223
Petrov V, Soares CG et al (2013) Prediction of extreme significant wave heights using maximum entropy. Coast Eng 74(5):1–10
Rabitz HAAC (1999) General foundations of high-dimensional model representations. J Math Chem 25(2):197–233
Rahman S, Xu H (2004) A univariate dimension-reduction method for multi-dimensional integration in stochastic mechanics. Probab Eng Mech 19(4):393–408
Savin E, Faverjon B (2017) Higher-order moments of generalized polynomial chaos expansions for intrusive and non-intrusive uncertainty quantification. 19th AIAA Non-Deterministic Approaches Conference
Shi X, Teixeira AP et al (2014) Structural reliability analysis based on probabilistic response modelling using the maximum entropy method. Eng Struct 70(9):106–116
Sudret B (2008) Global sensitivity analysis using polynomial chaos expansions. Reliab Eng Syst Saf 93(7):964–979
Sudret B, Der Kiureghian A (2002) Comparison of finite element reliability methods. Probab Eng Mech 17(4):337–348
Xiu D, Em Karniadakis G (2002) Modeling uncertainty in steady state diffusion problems via generalized polynomial chaos. Comput Methods Appl Mech Eng 191(43):4927–4948
Zhang X, Pandey MD (2013) Structural reliability analysis based on the concepts of entropy, fractional moment and dimensional reduction method. Struct Saf 43(9):28–40
Zhao YG, Ono T (1999) A general procedure for first/second-order reliabilitymethod (FORM/SORM). Struct Saf 21(2):95–112
Zio E (2013) The Monte Carlo simulation method for system reliability and risk analysis. Springer, London
Acknowledgements
The authors would like to extend their sincere thanks to anonymous reviewers for their valuable comments.
Funding
This work was supported by the National Natural Science Foundation of China (NSFC 61304218).
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible Editor: Pingfeng Wang
Appendices
Appendix 1
1.1 Chebyshev polynomials
The definition of Chebyshev polynomials is
and the most well-known form of Chebyshev polynomials is given by the recurrence relation
where x∈[− 1, 1]. This definition is also referred as Chebyshev polynomials of the first kind, and there is another definition of Chebyshev polynomials of the second kind:
The relationship between these two kinds of Chebyshev polynomials are given as (41)-(44):
with the convention U−1 ≡ 0.
1.2 Hermite polynomials
The Hermite polynomials {Hn(x)}n ≥ 0 are defined as
and the well-known recursive relation of the Hermite polynomials is
Appendix 2
In this section, the derivation details of (12) is provided.
Consider (10), and take \( {F}_1^{(i)}(y)={\int}_{-1}^1\left(1-{y}^2\right)\exp \left(-1-\sum \limits_{j=0}^m{\lambda}_j{T}_j(y)\right)\frac{1}{2\left(i+1\right)}{dT}_{i+1}(y) \) and \( {F}_2^{(i)}(y)={\int}_{-1}^1\left(1-{y}^2\right)\exp \left(-1-\sum \limits_{j=0}^m{\lambda}_j{T}_j(y)\right)\frac{1}{2\left(i-1\right)}{dT}_{i-1}(y) \) for simplicity. Then, we would solve the two parts separately.
First of all, F1(i)(x) could be transformed as
Take (39) into consideration, the first integral term above is derived as
Then, take (41) and (42) into consideration, the second integral term in (47) is derived as
where the Chebyshev polynomials of the second kind come as intermediate polynomials.
By using (44), the polynomial multiplication of Chebyshev polynomials in (49) is given as the following:
Substitute (50) into (49), the second integral term in (47) is derived as follows:
By Combining (48) and (51), we have the following relationship:
Secondly, when it comes to F2(i)(x), it is a little more complicated. When i = 1, since T0(x) is a constant according to the definition of Chebyshev polynomials. Otherwise, when i ≥ 2, we could derive F2(i)(x) with a similar procedure as (47)-(51) with the following result:
What is more, consider (8) and (9), we would establish the following equations. When i = 1, we have
and it could be rewritten as
and for i ≥ 2
Appendix 3
In this section, we would prove the formula of two PCEs multiplication.
First of all, for any non-negative integer α and β, the product of two Hermite polynomials can be expressed as (Savin and Faverjon 2017)
Then, this formula could be generalized to multi-dimensional form as (58).
where \( B\left(\boldsymbol{\alpha}, \boldsymbol{\beta}, \boldsymbol{r}\right)={\left[\left(\begin{array}{l}\boldsymbol{\alpha} \\ {}\boldsymbol{r}\end{array}\right)\left(\begin{array}{l}\boldsymbol{\beta} \\ {}\boldsymbol{r}\end{array}\right)\left(\begin{array}{c}\boldsymbol{\alpha} +\boldsymbol{\beta} -2\boldsymbol{r}\\ {}\boldsymbol{\alpha} -\boldsymbol{r}\end{array}\right)\right]}^{\frac{1}{2}} \), and the meaning of the notations above is shown in Section 3.2.
With the preparation, we could derive the multiplication of two PCEs as follows.
Suppose u and v have PCE formula with the same n-dimensional standardized random variables ξ = (ξ1, ⋯, ξn)T but different order pα and pβ respectively. Namely, we have \( u=\sum \limits_{\left|\boldsymbol{\alpha} \right|\le {p}_{\alpha }}{u}_{\boldsymbol{\alpha}}{\psi}_{\boldsymbol{\alpha}}\left(\boldsymbol{\xi} \right) \), \( v=\sum \limits_{\left|\boldsymbol{\beta} \right|\le {p}_{\beta }}{v}_{\boldsymbol{\beta}}{\psi}_{\boldsymbol{\beta}}\left(\boldsymbol{\xi} \right) \). So the multiplication of u and v is
Let \( \tilde{\boldsymbol{\alpha}}=\boldsymbol{\alpha} -\boldsymbol{r} \), \( \tilde{\boldsymbol{\beta}}=\boldsymbol{\beta} -\boldsymbol{r} \), then r = min(α, β) is equivalent to \( \tilde{\boldsymbol{\alpha}},\tilde{\boldsymbol{\beta}}\ge 0 \). Alternatively, \( \boldsymbol{\alpha} =\tilde{\boldsymbol{\alpha}}+\boldsymbol{r} \), \( \boldsymbol{\beta} =\tilde{\boldsymbol{\beta}}+\boldsymbol{r} \) and the above summation can be rewritten as
For simplicity, we still denote \( \boldsymbol{\alpha} =\tilde{\boldsymbol{\alpha}} \) and \( \boldsymbol{\beta} =\tilde{\boldsymbol{\beta}} \). Then, let θ = α + β, thus α = θ − β ≥ 0 and 0 ≤ β ≤ θ. The above summation is equivalent to
For simplicity, denote
Thus, we have
which completes the proof.
Appendix 4
In this section, we would prove the statement in Section 3.2 that the multiplication of two PCEs converges in the L2 sense. Let us consider a system as y = g(x) with independent distribution input x. And assume that the PCE approximation of this system is expressed as yp = gPCE(ξ), where p is the order of PCE, and ξ is the standard normal variable associated with input x. Then, since PCE is L2 convergence, we have
where Ω is the domain of input x, and f(x) is the joint PDF that subjects to ∫Ωf(x)dx = 1.
Therefore, ∀ 0 < ε < 1, ∃ n > N where N is a positive integer,
Now considering the fact that (yp − y)2 ≥ 0, if (yp − y)2 ≥ 1, we would derive that
which is in contradiction with (65). So, we would have 0 ≤ (yp − y)2 < 1. This means that |yp − y| is bounded.
Noting that the absolute value of response of given system is less than 1 in our proposed method, namely, |y| ≤ 1. So, we could obtain that
Now, we would prove the convergence of PCE multiplication. First of all, we would prove a basis inequality as
where k means the order of required moment.
Then, with this preparation, we could derive that for a limited number k,
This means that if yp is L2 convergence with given system, the k-power of yp also converges to yk in L2 sense. Thus, the approach of PCE multiplication could provide an accurate estimation of high order moment information. So, the proof completes.
Rights and permissions
About this article

Cite this article
Guo, J., Zhao, J. & Zeng, S. Structural reliability analysis based on analytical maximum entropy method using polynomial chaos expansion. Struct Multidisc Optim 58, 1187–1203 (2018). https://doi.org/10.1007/s00158-018-1961-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-018-1961-z