
Abstract
Fine adjustment of manufacturing parameters as a function of the experience of the technical manpower plays a vital role in any production line. The objective of this study was to propose an adaptive controller framework to improve the overall accuracy of the parameters regulating particleboard manufacturing. This framework has four main steps: (1) In the data gathering process, the production parameters and the sample test results were collected from the randomly picked and tested specimens in each round, (2) Relevance analysis was used to select high-power relevant variables influencing the overall quality of the final product. Those relevant variables will be inputs to construct the classification model, (3) A decision tree was employed to construct the classification model and reveal split points of the process parameters to determine the distinction between passed and failed panels, and (4) The production parameters in the next round will be adjusted according to the defined split points so the quality of the particleboard can be enhanced. Continuous improvement of the production parameters, within the perspective of the proposed framework, enables us to go back to step (1) again as desired, especially in the long production run. Based on the findings of this work, the experimental results revealed that the model could classify the failed particleboard with a specific rate of 92.50%. The model also demonstrated that resin characteristics, namely pH value and viscosity, impacted the overall performance of the particleboard.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Particleboard, as presented in Fig. 1, is a composite panel manufactured from wood flakes and other lignocellulosic materials with a combination of different types of adhesives under high temperature and pressure. Additives are also mixed with the flakes during manufacturing to improve additional characteristics of the final product (EN 309:2005). In general, the density of particleboard ranges between 640 and 800 kg/m3 (American Society for Testing and Materials 2010). Some advantages of particleboard over solid wood-based materials include its cost, higher density, and uniformity. It is widely used as underlayment, furniture manufacture, kitchen cabinets, and building units. According to FAO (2023), Thailand has several particleboard plants with an annual production capacity of approximately 4 million cubic meters contributing more than $7 billion to the economy of Thailand in 2021.

Three-layer particleboard and rubberwood flakes
In a typical commercial-scale production, it is difficult to determine the manufacturing parameters required to produce the desired quality of particleboard when operating conditions are modified. To control the product quality and cost, only 3% of production capacity can be rejected because of defects such as delamination, weak internal bonding, and low strength. One of the best solutions to handle such waste is to develop advanced knowledge, understand the complications of process parameters, and quantify the interrelation between process parameters and the expected quality of the final product.
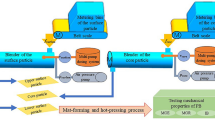
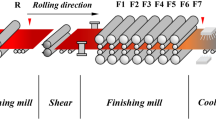
The particleboard manufacturing process includes various workstations, as illustrated in Fig. 2. Shmulsky and Jones (2019) describe that the small logs are cut into wood chips and processed into flakes. Next, flakes are dried to decrease the moisture content to 2–3% w/w before they are screened into different fractions according to their size to be used for the surface and core layers. The screened flakes are mixed with thermosetting adhesives and other additives. The resinated flakes are formed into the mat. Later, the mat is compressed at high pressure and temperature before cooling and sanding operations are carried out. Finally, the finished panels are tested for their different properties.
The internal bond strength (IB) is the tensile strength required to rupture bonds perpendicular to the board surface. It is a critical quality index to measure the bond strength between flakes in particleboard. According to EN 319:1993, the samples with 50 mm × 50 mm in dimension are pulled cross-section apart to maximum stress until they fail. Unfortunately, IB cannot be evaluated during the production line until samples are examined in the laboratory using destructive tests. The data collection found that there could be a 60–90-min gap between production and testing, during which a large amount of production occurred. Suppose the resulting IB of the processing parameters of the particleboard can be predicted, and the parameters can be continuously adjusted throughout the production time. This can improve the process, reduce raw materials, and decrease the number of rejected panels. This method could result in cost savings from precisely forecasting the real-time IB.

The adaptive controller framework of the particleboard manufacturing process
From the literature reviews, several studies have used machine learning to improve the manufacturing process of particleboard, Medium Density Fiberboard (MDF), and various products (André et al. 2008; Ismail et al. 2011; Wong et al. 2021; Zhang et al. 2022). Most research focuses on the prediction of the quality of the final product. Ismail et al. (2011) used a multilayer perceptron neural network (MLP) to construct a prediction model of MDF properties. They recommended that manufacturers could perform only the 2-h board properties test and omit the 24-h test to save time and cost because the results were enough based on the 2-h test. Riegler et al. (2013) proposed a real-time process adaptation in manufacturing high-density fibreboards. When predicting the IB of fibreboards using the real-time dataset in the current process, the regression model is regularly validated, and, if necessary, calibration is carried out with the offline database using datasets from the most recent previous process. Zhang et al. (2022) constructed a nonlinear regression prediction model using grey relation analysis (GRA) and support vector regression (SVR) to predict the internal bond strength of particleboard based on the particle gluing parameters in the production process. The predicted values were in good agreement with the experimental values. Variable selection in multivariate analysis was quite an essential step. André et al. (2008) utilized genetic algorithms (GA) to select variables and used several statistical methods, such as radial basis function (RBF) neural networks, to predict IB of MDF. The prediction models performed better than those without variable selection. Wong et al. (2021) compared and evaluated three different neural network models for modeling the elastoplastic response of Medium Density Fiberboard (MDF) based sandwich structures. The results suggested the optimal number of hidden neurons to form the neural network structure with the highest performance.
Interpretability refers to the level of understanding and insight that the predictor provides. Neural networks (NN) and even modern algorithms such as deep learning (DL) have high learning performance but low interpretability. It is difficult for humans to interpret the symbolic meaning behind the network’s learned weights and hidden neurons (Han et al. 2022). Furthermore, it is difficult to determine how one variable affects another variable and the quality of the final product. Therefore, the predictive models used in the previous research are unsuitable for suggesting tuning the value of parameters in the particleboard manufacturing process. Neural networks require several parameters typically best determined empirically, such as the network structure. They also need massive data and a long training time to construct a good model.
The decision tree, one of the classification algorithms, is a helpful tool for selecting a subset of relevant variables and defining split points of the process variable’s value in places that may help improve classification accuracy (Han et al. 2022). Moreover, it takes much less time to train the model and is very interpretable. Humans can easily understand the decision-making conditions that affect the output. Therefore, this model type allows us to recommend fine-tuning variables in the particleboard production process.
The most prediction models from the literature reviews mentioned above were created to predict the quality characteristics of the final product from experimental or historical data of the finished production line. As a result, the manufacturing process would reduce the number of actual laboratory tests, effort, and raw material costs of the later production line. Another group of researchers aims to suggest fine adjustments to the parameters in the current manufacturing process to have high-quality panels. However, it is a known fact that the value of the process parameters affecting the final product quality may not be the same in every production line. It clearly depends on the production environment, such as the value of different process parameters, board specifications, and raw material characteristics. The production model created from only historical data could also not accurately predict the quality of the final product in the later production environment.
To solve the shortcomings mentioned above, the objective of this study was to build and evaluate the adaptive controller framework that can identify variables that play an important role in the quality of the particleboard in a given production run. Moreover, the results proposed the significant manufacturing parameters influencing the particleboard performance and indicated the optimum parameters that enhance the board’s internal bonding strength to meet the required standard. The framework aims to enable the machine learning method for automatic parameter tuning to produce high-quality particleboard-although which is not currently possible.
2 Methodology
The adaptive controller framework of the particleboard manufacturing process consists of six parts, namely data description, data gathering, dataset preparation, relevance analysis, model construction, and parameter adjustment.
2.1 Data description
This study’s dataset was obtained from a particleboard manufacturer in Thailand as part of a research confidentiality agreement. Variable names in the datasets were altered to respect the terms of the confidentiality agreement.
In this case, the particleboards (E2-grade) with a nominal thickness of 15 mm were compiled and used for analysis because their IB values did not pass the standard requirement (BS EN 312:2010). Therefore, they were selected for analysis to find the cause and finely tune the variables in the real production in the future. The dataset of both pass and failed particleboards (as shown in Table 1) was produced and tested between January to February 2022.
Figure 2 shows a typical chart of the particleboard manufacturing process, collection of a total of 31 variables including resin viscosity, resin gel time, resin pH, resin density, resin content in the surface layer, resin content in the core layer, emulsion content in the surface layer, emulsion content in the core layer, catalyst content in the surface layer, catalyst content in the core layer, surface layer moisture content, core layer moisture content, water spray content on the top surface, water spray content on the bottom surface, surface layer bulk density 1 and 2, core layer bulk density, surface layer proportion 1 and 2, core layer proportion 1 and 2, mat weight, press speed, press factor, pressing temperature zone 1–6, and IB data gathered from the destructive testing lab.
The dried and screened flakes were mixed with urea-formaldehyde adhesive with Grade E2, and other additives were processed through forming steps until the mats were hot-pressed into the final product. It is a continuous process with an approximate duration of 30 min.
According to the company’s standard testing and work instructions, six samples were randomly collected from the production line at 1-h periodic intervals or when the product type was changed. These samples were tested for tensile strength perpendicular to the plane of the board according to EN 319:1993.
2.2 Data gathering
All production parameters and the results from the sample tests were collected into the computer database for analysis. All data were also further analyzed to fine-adjust the parameter values to obtain the higher-quality particleboard. The above process was an iterative loop that took around 90 min per cycle until the board properties reached the standard requirement. Then, the production continued until the product quantity was achieved.
2.3 Dataset preparation
According to BS EN 312:2010, the minimum allowed IB value for particleboard type P2 is 0.35 MPa. Therefore, samples with IB value more than 0.35 MPa were classified as pass, while samples with IB value less than 0.35 MPa were classified as fail. In this study, 172 samples were categorized as pass (49 samples) and fail (123 samples).
The 172 samples are randomly divided into a training set (2/3) for model construction and a test set (1/3) for accuracy estimation. Table 1 shows 114 samples for the training set and 58 samples for the test set, with approximately the percentage of each class in the overall database.
2.4 Relevance analysis
Variable selection in multivariate analysis is crucial to exclude non-informative variables that produce better results even with simpler models (André et al. 2008). Relevance analysis can be used to perform variable relevance analysis and filter out statistically irrelevant or weakly relevant variables from the descriptive mining process (Han et al. 2022). The experiment used the attribute selection function of Weka software version 3.8.6 (www.cs.waikato.ac.nz/ml/weka), a collection of machine learning algorithms for data mining tasks, to select variables important to the class. In this case study, class means the quality of the particleboard (pass/fail). Five evaluators were used for attribute selection as displayed in Table 2 and were selected common variables from them. For evaluators using the ranker search method, the results are relevance scores of each variable, so the variables with the top three relevance scores are selected. For evaluators using the GreedyStepwise and BestFirst, the results are variables recommended by the evaluator, so all recommended variables are selected.
2.5 Model construction
A decision tree is one of the most popular machine-learning algorithms for supervised learning problems. It has been widely used and is still being actively researched since it shows relatively good predictive performance and provides easy-to-understand and interpretable decision rules (Hwang et al. 2020). The attribute selection method in decision tree induction specifies a heuristic procedure for selecting the attribute that best discriminates the given samples according to class (Han et al. 2022). This method also determines the splitting criterion that tells us which attribute (variable) is best to separate and may indicate a split point. The splitting criterion is chosen so that, ideally, the resulting partitions at each branch are as pure as possible. A partition is pure if all its samples belong to the same class.
The variables obtained from the preliminary selection in the previous step were used in this step. Other variables which were irrelevant could then be excluded from consideration. We used the C4.5 decision tree in Weka software version 3.8.6 for selecting a subset of relevant variables and defining split points of the process variable’s value in places that may help improve the particleboard classification accuracy.
Metrics for evaluating the model include accuracy, sensitivity as true positive rate, and specificity as true negative rate. True positive (TP), the number of pass particleboard (positive samples), were correctly classified by the model. True negative (TN), the number of failed particleboard (negative samples), were correctly classified by the model. False positive (FP), the number of failed particleboard, were incorrectly classified by the model (e.g., samples of failed particleboard for which the model classified as pass particleboard). False negative (FN), the number of pass particleboard, were incorrectly classified by the model (e.g., samples of pass particleboard for which the model classified as failed particleboard).
where P is positive samples, and N is negative samples.
2.6 Parameter adjustment
The production parameters have an important impact on particleboard performance. Due to the lack of theoretical guidance related to the production parameters, tuning its parameters can only be completed based on the actual experiences of staff. It is challenging to meet the accuracy of parameter regulation in the process.
Workers could use the recommendation from the decision tree model or extracted rules to adjust the variable’s value in the process. All production parameters are saved in the database for data analytics in the next round.
3 Results and discussion
3.1 Relevance variables
With the five evaluators mentioned above, the experimental results reveal that five of the 31 variables are significantly relevant to particleboard class, i.e., resin pH, mat weight, resin viscosity, resin gel time, and resin density.
3.2 Recommended optimum parameters from the model
The five variables obtained from the preliminary selection in the previous step were used in the experiment. The decision tree model for classifying the quality of the particleboard class (pass/fail) is shown in Fig. 3. The results show that the resin pH and viscosity are selected as relevant variables, and the recommended split points are shown in the model. This case study can be considered a class imbalance problem; the dataset distribution reflects a significant majority of one class and a minority of another. In this case, we aimed to investigate failed particleboard; therefore, we used specificity to evaluate the model. The experimental results on the test set showed that the model had a “Fail” particleboard specificity rate of 92.5%.

The decision tree model for particleboard classification
The decision tree model in Fig. 3 can be converted to classification IF-THEN rules easier for humans to understand.
Rule1: IF (Resin pH > 8.39) THEN particleboard = Fail.
Rule2: IF (Resin pH < = 8.39 AND Resin Viscosity > 284.5) THEN particleboard = Fail.
Rule3: IF (Resin pH < = 8.39 AND Resin Viscosity < = 284.5) THEN particleboard = Pass.
It should be noted that the split point is often taken as the midpoint of two known adjacent values of the attribute, and it may not be a preexisting attribute value from the training data.
It is well-accepted that various processing parameters have affected the resultant particleboard performances, particularly internal bonding strength (Kelly 1977; Riegler et al. 2015; De Palacios et al. 2018; Zhang et al. 2022). However, the results of this dataset analysis show that resin characteristics, namely pH value and viscosity, significantly affected the internal bond strength of the samples.
3.3 Influence of resin characteristics
Resin characteristics such as resin types, resin content, resin reactivity, chemical structure and composition, degree of condensation, molar mass distribution, mole ratio, viscosity, and resin curing rate affect the bonding strength of wood composites (Hse et al. 1994; Gavrilović-Grmuša et al. 2012; Gadhave et al. 2017; Gonçalves et al. 2018; Jeong and Park 2019).
Based on the decision tree analysis, the resin’s pH affected the samples’ IB value. When the pH value exceeds 8.39, the IB does not meet the EN standard requirement. It can be explained by the effect of resin pH value on the curing rate. The condensation reaction between urea and formaldehyde makes UF resin. It is an acid-catalyzed curing resin. This resin can be cured quickly in the presence of an acid catalyst and by applying heat. In industrial production, UF resin is manufactured in two main steps. In the first step, the addition reaction is carried out in a pH range of 8–9 to formulate Hydroxymethylureas.
In contrast, the mixture is carried out under acidic conditions, generally in the range of 4.8–5.3, and the condensation reaction is completed until it reaches the desired viscosity in the second step. Then, the reaction is arrested by cooling and increasing the pH level being more than 8 to achieve a suitable shelf life or storage life (Dunky and Pizzi 2002). It is well-known fact that UF resin is an acid-catalyzed curing resin, and under the hot-pressing process, the pH of UF resin is decreased by an acidic addition, which quickly causes the resin to cure (Maloney 1993). Xing et al. (2006) reported that the initial pH value of UF resin played a significant role in the beginning of the resin-curing rate. They explained that when the pH value of UF resin was above neutral, the gel time of UF resin dramatically increased, which affected the bonding strength of wood composites. To achieve a shorter resin gel time, adding an acid catalyst can increase and accelerate the curing rate of UF resin. Thus, its pH should be kept at neutral, which is around 7, where this resin stores well, and it can be quickly brought to curing pH by adding a small amount of the acid catalyst.
The results also showed that the initial viscosity of liquid resin influences IB value. The IB does not satisfy the EN standard requirement when viscosity exceeds 284.5 CenterPoint. The effect of resin viscosity on the bonding interface area might explain this circumstance. Gavrilović-Grmuša et al. (2012) reported that UF resin with low viscosity penetrated deeper into the wood than UF resin with high viscosity. They also explained that since the amount of adhesive on the particles creating a good glue line provides bond performance, strengthening the wood in the interface will affect bond strength and stiffness.
4 Possibility to apply the proposed adaptive controller framework in the industrial scale
From this point of view, this analysis method can be used to find the cause and finely tune the variables (or processing parameters) that improve the particleboard’s internal bonding strength to meet the required standard. Moreover, it can reduce the defects or sample waste from production and decrease the raw material usage due to fewer sample tests. This technique could become an important tool for wood technologists, process engineers, and particleboard manufacturing personnel. Such an approach can be expected to enhance particleboard production and the properties of the final product.
The method presented in this study could enhance the panels’ production efficiency and business competitiveness. It can reduce the cost of raw materials and energy, allowing us to know some parameters that are otherwise difficult to observe and optimize the properties of particleboard so that the required standard can be achieved.
Our proposed framework can be adapted to other production environments or even to other products. This is because the production parameters from a given production run can be collected, analyzed, and then recommended fine-tuning parameter adjustments in such production process. Moreover, this framework can be adapted by replacing the decision tree with other machine learning methods that can reveal optimal split points of the process parameters to determine the distinction between passed and failed panels.
5 Conclusion
The adaptive controller framework was presented to improve the accuracy of parameter regulation in particleboard manufacturing using the machine learning method. For this dataset as a case study, the model was constructed to classify the quality as pass or fail of the internal bonding strength for the 15 mm thick particleboard grade E2. Thirty-one identified variables were used as input to assess the impact on the mechanical properties of the samples. With the relevance analysis method, five of the 31 variables affect particleboard class. Those five variables were used as inputs to construct the classification model. The experimental results showed that the model could classify the failed particleboard with a specific rate of 92.5%. The model demonstrated that resin characteristics, including pH value and viscosity, impacted the particleboard’s performance.
The resin pH and viscosity contributed to the internal bonding strength with a high specific rate value between the properties. The results presented here have shown significant relationships among variables that can be used to predict the performance of particleboard.
Data availability
Data are contained within the article.
References
American Society for Testing and Materials (2010) Standard terminology relating to wood-base fiber and particle panel materials. ASTM D 1554–2010
André N, Cho H, Baek SH, Jeong M, Young TM (2008) Prediction of internal bond strength in a medium density fiberboard process using multivariate statistical methods and variable selection. Wood Sci Technol 42(7):521–534. https://doi.org/10.1007/s00226-008-0204-7
De Palacios P, Fernándes FG, Iruela AG, Rodrigo BG, Esteban LG (2018) Study of the influence of the physical properties of particleboard type P2 on the internal bond of panels using artificial neural networks. Comput Electron Agric 15:142–149. https://doi.org/10.1016/j.compag.2018.10.012
Dunky M, Pizzi A (2002) Wood adhesives. In: Dillard DA, Pocius AV, Chaudhury M (eds) Adhesion science and engineering. Elsevier, Amsterdam, The Netherlands, pp 1039–1103
European Norm (2010) Particleboards - specification. BS EN 312:2010
European Norm (2005) Particleboards - definition and classification. EN 309:2005
European Norm (1993) Particleboards and fibreboards - determination of tensile strength perpendicular to the plane of the board. EN 319:1993
Food and Agriculture Organization (2023) FAOSTAT. https://www.fao.org/faostat/en/#data/FO. Assessed 25 September 2023.
Gadhave R, Mahanwar P, Gadekar P (2017) Factor affecting gel time/process-ability of urea formaldehyde resin based wood adhesives. Open J Polym Chem 7:33–42. https://doi.org/10.4236/ojpchem.2017.72003
Gavrilović-Grmuša I, Dunky M, Miljkovic J, Djiporovic-Momcilovic M (2012) Influence of the viscosity of UF resins on the radial and tangential penetration into poplar wood and on the shear strength of adhesive joints. Holzforschung 66(7):1–8. https://doi.org/10.1515/hf-2011-0177
Gonçalves C, Pereira J, Paiva NT, Ferra JM, Martins J, Magalhães F, Barros-Timmons A, Carvalho L (2018) Statistical evaluation of the effect of urea-formaldehyde resins synthesis parameters on particleboard properties. Polym Test 68:193–200. https://doi.org/10.1016/j.polymertesting.2018.04.007
Han J, Pei J, Tong H (2022) Data mining: Concepts and techniques, 4th edn. Morgan Kaufmann Publishers, Massachusetts, CA, USA
Hse CY, Xia ZY, Tomita B (1994) Effects of reaction pH on properties and performance of urea-formaldehyde resins. Holzforschung 48(6):527–532. https://doi.org/10.1515/hfsg.1994.48.6.527
Hwang S, Yeo HG, Hong JS (2020) A new splitting criterion for better interpretable trees. IEEE Access 99:1–13. https://doi.org/10.1109/ACCESS.2020.2985255
Ismail FS, Noor Elaiza Abd Khalid N, Bakar A, Mamat R (2011) Optimizing oil palm fiberboard properties using neural network. In: 3rd conference on data mining and optimization (DMO), Putrajaya, Malaysia, 28–29 June 2011, pp. 271–275, https://doi.org/10.1109/DMO.2011.5976540
Jeong B, Park BD (2019) Effect of molecular weight of urea–formaldehyde resins on their cure kinetics, interphase, penetration into wood, and adhesion in bonding wood. Wood Sci Technol 53:665–685. https://doi.org/10.1007/s00226-019-01092-1
Kelly MW (1977) Critical literature review of relationships between processing parameters and physical properties of particleboard. General Technical Report FPL-10, Forest Products Laboratory, Forest Service, U.S. Department of Agriculture, Wisconsin, USA
Maloney TM (1993) Modern particleboard and dry-process fiberboard manufacturing, updated edn. Miller Freeman, San Francisco, USA
Riegler M, Spangl B, Weigl M, Wimmer R, Muller U (2013) Simulation of a real-time process adaptation in the manufacture of high-density fibreboards using multivariate regression analysis and feedforward control. Wood Sci Technol 47:1243–1259. https://doi.org/10.1007/s00226-013-0571-6
Riegler M, André N, Gronalt M, Young TM (2015) Real-time dynamic simulation of continuous bulk material flow to improve the statistical modelling of final product strength properties. Int J Prod Res 53(21):6629–6636. https://doi.org/10.1080/00207543.2015.1055844
Shmulsky R, Jones PD (2019) Forest product and wood science: an introduction, 7th edn. John Wiley & Sons Ltd., New Jersey, USA
Wong YJ, Mustapha KB, Shimizu Y, Kamiya A, Arumugasamy SK (2021) Development of surrogate predictive models for the nonlinear elasto-plastic response of medium density fibreboard-based sandwich structures. Int J Lightweight Mater Man 4(3):302–314. https://doi.org/10.1016/j.ijlmm.2021.02.002
Xing C, Zhang SY, Deng J, Wang S (2006) Urea–formaldehyde-resin gel time as affected by the pH value, solid content, and catalyst. J Appl Polym Sci 103(3):1566–1569. https://doi.org/10.1002/app.25343
Zhang B, Hua J, Cai L, Gao Y, Li Y (2022) Optimization of production parameters of particle gluing on internal bonding strength of particleboards using machine learning technology. J Wood Sci 68:21. https://doi.org/10.1186/s10086-022-02029-2
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
T.P. contributed to the design and implementation of the research to the analysis of the results and verified the analytical methods; T.W. contributed to sample preparation and carried out the experiment; S.H. helped supervise the project and conceived the original idea; P.C. analyzed the results and discussion and the writing of the manuscript with support from T.P. and S.H. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Ethical approval
Not applicable.
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Phetkaew, T., Watcharakan, T., Hiziroglu, S. et al. Using machine learning as an adaptive controller framework for optimizing properties of particleboard. Eur. J. Wood Prod. 82, 1061–1068 (2024). https://doi.org/10.1007/s00107-024-02059-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00107-024-02059-1