
Abstract
This paper proposes a robust asynchronous controller for continuous-time Markov jump linear systems (MJLSs). The asynchronous structure considers a case in which the Markov chain governing candidate controllers does not match the chain which manages the switching between system modes. This type of asynchronousy arises because the real-time, exact and precise detection of the system modes is not practical; therefore, the observed modes slightly differ with the actual modes. This paper models the asynchronousy through an additional, observed Markov chain which depends on the original Markov chain of the system according to uncertain transition probabilities. By this representation, the whole system is viewed as a non-homogeneous MJLS, and the sufficient stabilizability conditions as well as the controller gains are obtained through multiple mode-dependent Lyapunov functions. This approach leads to less conservative design results than the previous mode-independent schemes and proposes a much simple methodology to obtain the controller than the previous mode-dependent studies. For more generality, the proposed controller also takes the possible gain variations occurring in the implementation procedures into account and reports all the results in terms of linear matrix inequalities. Simulation results on a vertical takeoff and landing helicopter are presented and compared with the common mode-independent controller to illustrate the effectiveness of the developed method.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In the past decades, tremendous advances have occurred in the study of Markov jump linear systems [5, 8, 28, 34, 41, 48]. The motivation for concentrating on such systems is their widespread applications in power systems [22, 26], biomedicine [23], aerospace [3], and networked control systems (NCSs) [25]. This system can successfully describe the structural variations induced by external or internal discrete events such as random failures, repairs, changing subsystem interconnections and unexpected configuration conversions [2, 20]. MJLSs arise as a special class of both hybrid and stochastic systems. They consist of a set of continuous dynamics, the so-called modes, usually described by linear difference or differential equations that are affected by discrete events governed by a Markov chain with a finite number of states.
Up to now, various researches have been dedicated to the stabilization [5, 6, 8, 15, 34, 41] and control [16, 23, 43, 48] problems of MJLSs. In these studies [5, 6, 8, 15, 16, 34, 41, 43, 48], one key assumption is that the controller is strongly synchronous to the system, i.e., the Markov process which orchestrates switching between the controller modes is exactly the same as the Markov chain governing the system dynamic variations. This assumption does not come true in practice because the Markovian states of the system may not always be available to the controller instantly. In other words, the actual and the observed Markov chains may not be matched or synchronous. An example of this type of asynchronous switching is found at NCSs without time stamp information [4, 38].
One introduced solution in case of inaccurate mode observations is the mode-independent controller [2, 22]. By the mode-independent design, it means that all the system variations are neglected and the controller has a simple non-switching structure. However, the mode-independent controller simplifies the studies and has a practical appeal in case of non-accessible mode information, but it is very conservative and cannot deal with the complex asynchronous phenomenon between the system and the controller. Unlike the mode-independent structure, the asynchronous scheme takes the advantage of an observed Markov chain to deal with the system variations. In this case, the observed modes depend on the system modes according to some probabilities. Toward relaxing the assumption of perfectly synchronously controlled systems, different types of asynchronous phenomenon have been considered by researchers [3, 9,10,11, 18, 21, 27, 30, 31, 35,36,37,38,39, 45,46,47]. These studies can be categorized into two general categories: the studies dedicated to the deterministic switched systems and those devoted to stochastic switched systems. In deterministic switched system, the synchronous phenomenon is generally modeled by lags between the modes of the controller and system modes [18, 21, 27, 36, 37, 45,46,47]. This type of asynchronous phenomenon generally arises in mechanical [3, 31] or chemical systems [21]. For predetermined lags, stability problems are discussed in [9, 35], controllers are designed in [10, 31, 36, 37], and asynchronous filters are developed in [47]. Unlike the deterministic switching systems, the asynchronous switching in the stochastic systems has not gained much attention. The asynchronousy in Markovian systems is discussed in [2, 22, 32] through mode-independent designs and in [45, 46] by assuming a random switching lag between the system and the controller by a Bernoulli distribution. In [30, 45, 46], the Markov chains of the system and the controller (filter) are supposed to be completely independent. This assumption is conservative because the observed chain contains useful information on the original chain, and ignoring this information can lead to performance loss. This assumption is eliminated by [11, 38]; however, these studies are limited to the state estimation problems, acquire perfectly known Markovian properties of the observed chain and involve multiple design and slack variables which make the design too complex.
The motivation of this study is to design a more practical control scheme for MJLSs such that following two problems could be dealt with simultaneously:
-
The imperfect observation of the switching mechanism of a MJLS.
-
The imperfect implementation of the controller gains.
Practically, not only the Markovian states of the system may not always be available to the controller instantly, but also the specifications of the observed chain, namely the transition rates (TRs), may not precisely be obtained and may include uncertainties. On the other hand, the controller gains face implementation limitations which may result in relatively different designed and implemented gains due to finite word length in digital systems, the inherent imprecision in analog systems, and analog to digital or digital to analog transformers [12]. These factors lead to a poor design or an undesired or even unstable response of the implemented controller.
The robust, non-fragile asynchronous controller proposed in this study is a solution to the above mentioned problems. Such a scheme is applicable to more practical and realistic situations. It not only involves less computational effort when modeling the system’s Markov chain, but also minimizes the influence of unknown environmental disturbances that affect the observed mode information or the controller gains. To design the robust, non-fragile, asynchronous controller, the asynchronousy is expressed through an additional Markov chain which is mismatched with the system’s Markov chain but depends on it probabilistically. This additional chain also considers the effect of the inaccurate modeling in the form of uncertain, but bounded TRs. Then, the whole system is viewed as a piecewise homogeneous MJLS as a special case of non-homogeneous MJLSs [1] in which the TRs are time-varying but invariant within an interval [6, 8, 13, 42, 44]. The controller is also assumed to contain additive bounded uncertainties which represent the inaccuracies of the implementation procedures. In this framework, the analysis and controller synthesis procedures are fulfilled by the multiple, piecewise Lyapunov function.
Compared with the previous works, this paper mainly has the following four advantages:
(i) Unlike the well-known mode-independent structures [2, 22, 32], the proposed controller is mode-dependent; it imports the information of subsystems and their interactions in the multiple Lyapunov functions; thus, it is a less conservative design. (ii) The controller is designed based on an observation of the system’s switching signal and not on the actual switching signal of the system which is usually unavailable. (iii) In comparison with other similar mode-dependent asynchronous design schemes [11, 38], this scheme removes the assumption of exactly known TRs of the observed Markov process. (iv) It leads to a simpler set of LMIs with fewer number of design variables compared with similar asynchronous schemes [11, 30, 38], due to the non-homogeneous Markovian model utilized for the asynchronousy description. Simulation results and comparisons with the controller referred at [2] show the potentials of the proposed method.
The remainder of the paper is organized as follows. In Sect. 2, the preliminaries are provided and the problem is formulated. In the Sect. 3, the robust stochastic stabilization problem is tackled and a sufficient condition is derived. Then, the asynchronous non-fragile controller gains are designed and some discussions are provided about the important implementation issues of the proposed method. Section 4 includes a practical example and the comparisons related to a VTOL subject to faults. Finally, there are concluding remarks in Sect. 5.
Notation All the notations in the present paper are standard and can be found in the relevant literature of Markovian switching systems. Additionally, all the matrices contain real values with proper dimensions.
2 Preliminaries and Problem Formulation
Consider a complete probability space, (\(\varOmega , F, \rho \)) satisfying usual conditions, where \(\varOmega , F\) and \(\rho \) represent the sample space, the algebra of events and the probability measure on F, respectively. The uncertain MJLS is described over the probability space by Eq. (1),
where \(x(t)\in {\mathbb {R}}^{n}\) is the system state vector of dimension n,\(u(t)\in {\mathbb {R}}^{m}\) is the controlled input vector of dimension m and \(x(t_0 )=x_0 \) is the initial state vector. The jumping parameter {\(r_{t}, t \ge \) 0} represents a time-homogeneous Markov chain with discrete values of the finite set, \({\underline{N}}=:\{1,2,\ldots ,N\}.\) Here \(r_{t_0 } =r_0 ,\)is the initial condition, and the Markov chain has a square transition rate matrix specified by
in which the transition probabilities are as the following with h as the sojourn time.
In Eq. (3), \(\lambda _{ij} \) denotes the transition rates from mode i at time t to mode j at time \(t+h\) with the following conditions:
The condition (4) means that TRs are never negative. By condition (5), it is guaranteed that the system moves from mode i to some mode j with probability one. It is assumed that the Markov chain is irreducible, possible to move from any modes to another in a countable number of jumps.
In Eq. (1), \(A(r_t )\) and \(B(r_t )\) are linear mode-dependent system matrices with appropriate dimensions. For this system, the following controller is assumed.
The matrix \(K(\sigma _{t},t)\) is the mode-dependent, time-varying controller gain with the compatible dimension, designed to make the closed-loop system robustly, stochastically stable. The parameter {\(\sigma _{t}, t \ge \) 0} is the Markov chain governing switching between candidate gains of \(K(\sigma _{t},t)\). It is a continuous-time, discrete-valued Markov process defined in finite set, \({\underline{M}}=:\left\{ {1,2,\ldots ,M} \right\} \) with the initial mode \(\sigma _{t_0 } =\sigma _0 ,\) a generator square matrix in the form of (7) and elements given by (8).
Here \(p_{mn}^{r_t } \ge 0\) with the condition of \(p_{mm}^{r_t } =-\sum _{n=1,n\ne m}^M {p_{mn}^{r_t } } \) is the transition rate from mode m of the controller at time t to mode n at time \(t+h\). In the stochastic variation, the Markov chain \(r_{t}\) is assumed to be independent on the \(\sigma \)-algebra generated by \(\sigma _{t}\).
The controller (6) is an asynchronous structure because the Markov chain governing the controller switching is different from the Markov process orchestrating the system modes. However, the controller modes are mismatched with the modes of the system, but depend on them according to certain probabilities. This dependency is shown by defining Eq. (9).
As mentioned before, generally it is difficult to determine the exact values of the conditional TRs (8). Thus, it is assumed that the controller chain is modeled by uncertain transition specifications. In this case, the exact values of the TR entries are not known, but their upper bounds and lower bounds are available. Such an uncertain TR matrix is specified as \(P^{r_t }=\bar{{P}}^{r_t }+\Delta P^{r_t }\) here, where \(\bar{{P}}^{r_t }=[\bar{{p}}_{mn}^{r_t } ],\bar{{p}}_{mm}^{r_t } =-\sum _{n=1,n\ne m}^M {\bar{{p}}_{mn}^{r_t } } \) and \(\Delta P^{r_t }=[\Delta p_{mn}^{r_t } ], \Delta p_{mm}^{r_t } =-\sum _{n=1,n\ne m}^M {\Delta p_{mn}^{r_t } } \) denote the nominal TRs and the uncertain part of TRs. It is supposed that the TR uncertainty is bounded by a maximum value of \(\zeta _{_{mn} }^{r_t } >0\), i.e., \(\left| {\Delta p_{mn}^{r_t } } \right| \le \zeta _{mn}^{r_t } m\ne n.\)
The proposed asynchronous control structure in which the controller Markov chain \(\sigma _{t}\) is an uncertain observation of the system Markov process \(r_{t}\) is shown in Fig. 1.

Architecture of the asynchronous control scheme
The transition rates of the Markov process which governs the switching between the controller modes are not continuously time-varying so the Markov process is not purely non-homogeneous. The time variation of the TRs of \(\sigma _{t}\) is due to their dependency to the signal \(r_{t}\); considering the fact that \(r_{t}\) is a piecewise constant signal, the TRs of \(\sigma _{t}\) are piecewise constant functions of time t, i.e., they are varying but invariant within an interval. Therefore, \(\sigma _{t }\) is a piecewise homogeneous Markov chain. Since the system of Eq. (1) is a time-homogeneous MJLS and the controller structure evolves with a piecewise homogeneous Markov chain, the closed-loop system involves two decoupled Markov processes and generally is a piecewise homogeneous Markov jump linear system.
To include uncertainties in the controller, the controller gain is assumed as \(K(\sigma _t ,t)=\bar{{K}}(\sigma _t )+\Delta K(\sigma _t ,t).\bar{{K}}(\sigma _t )\) is the nominal gain to be designed while \(\Delta K(\sigma _t ,t)\) represents the time-varying, norm-bounded parametric uncertainty of the controller. \(\Delta K(\sigma _t ,t)\) is an unknown, mode-dependent matrix with the following form,
in which \(D_{K}(\sigma _{t})\), and \(E_{K}(\sigma _{t})\) are known real-valued constant matrices, and \(F_{K}(\sigma _{t},t)\) is unknown time-varying matrix with Lebesgue measurable elements satisfying \(F_K^T (\sigma _t ,t)F_K (\sigma _t ,t)\le I.\)
Before obtaining the main results and designing the asynchronous controller, an important definition and lemma are recalled.
Definition
[2] For any initial mode \(r_{0}\), and any given initial state vector \(x_{0}\), the uncertain system of Eq. (1) with u(t) = 0 is said to be robustly stochastically stable, if for all admissible uncertainties the following condition holds
where E{\(\cdot {\vert }\cdot \)} is the expectation conditioning on the initial values of \(x_{0}\) and \(r_{0}\).
Lemma
[40] Let Y be a symmetric matrix, H and E be given matrices with the appropriate dimensions and F satisfy \(F^{T}F\le I\), then the following equivalent relations hold:
-
1.
For any \(\varepsilon >0,{} HFE+E^{T}F^{T}H^{T}\le \varepsilon HH^{T}+\varepsilon ^{-1}E^{T}E\)
-
2.
\( Y+HFE+E^{T}F^{T}H^{T}<0\) holds if and only if there exists a scalar \(\varepsilon>\) 0 such that\(Y+\varepsilon HH^{T}+\varepsilon ^{-1}E^{T}E<0.\)
After introducing the system and the controller structure, finally the problem is formulated; consider a MJLS and derive stabilizability conditions for the closed-loop system which involves an asynchronous controller. Additionally, design non-fragile, state-feedback gains which are only dependent to the observed chain such that the closed-loop system is robustly, stochastically stable.
3 Main Results
The purpose of this section is to deal with the stabilization problem. By a sufficient condition, the existence of the asynchronous, non-fragile, state-feedback controller is checked, and then, the gains (6) are designed such that the system (1) is stochastically stable over all admissible uncertainties in the system and controller. The condition as well as the feedback gains are reported in terms of a set of coupled LMIs which can be solved systematically and effectively.
Consider the control law (6), substituting the controller gains into Eq. (1) yields the dynamic of the closed-loop system described by
where
The upcoming theorem presents a sufficient stabilizability condition.
Remark 1
Hereafter in the whole paper, for the convenience of notations \(r_{t }=i\) is used. It specifies the modei of the system. Thus, matrices are labeled as \(A(i), B(i), K(m), \Delta \)K(\(m,t), E_{K}(m), D_{K}(m)\) and \(F_{K}(m, t)\). The initial time is set to be zero, \(t_{0}\) = 0. Additionally, the initial state vector, \(x_{0 }\) and the initial modes, \(r_{0}\) and \(\sigma _{0 }\), are supposed to be available.
Theorem
There exist controller gains \(K({ \sigma }_{t},t)\) such that the closed-loop system \({\dot{x}}(t)=\bar{{A}}(r_t ,\sigma _t ,t)x(t)\) with the initial conditions \(x(t_0 )=x_0 , r_{t_0 } =r_0 ,{} \sigma _{t_0 } =\sigma _0 ,\) is robustly stochastically stable, if there exists a set of square, symmetric, positive definite mode-dependent matrices X(m) and P(m), a set of mode-dependent matrices Y(m), V(m), Z(m) and a set of positive mode-dependent scalars \(\varepsilon _{K}(i),\varepsilon _p^i(m,n),\) such that the following set of constraints hold for all \(i\in {\underline{N}}\) and \(m\in {\underline{M}}.\)
where
then, the stabilizer gain is obtained as\( K(m)=Y(m)X^{-1}(m)\).
Proof
Construct the multiple quadratic Lyapunov candidate as
The function is multiple because of the variations of the dynamics and controller gains. P(m) denounce symmetric and positive definite matrices.
The infinitesimal generator of the Lyapunov function is as Eq. (22).
Applying the law of total probability and using the property of the conditional expectation, the infinitesimal generator is written as Eq. (23).

For the system of (1), the probabilities of the both Markov chains are involved. Considering decoupled Markov chains of the two levels; it can be found that Pr (\(r_{t+h}=j\), \(\sigma \)\(_{t+h}=n\) \({\vert }\) \(r_{t}=i\), \(\sigma \)\(_{t}=m)\) = Pr (\(r_{t+h}=j\) \({\vert }\) \(r_{t }=i\), \(\sigma \)\(_{t+h}=n\), \(\sigma \)\(_{t}=m)\) = Pr ( \(\sigma \)\(_{t+h}=n\) \({\vert }\) \(r_{t}=i\), \(\sigma \)\(_{t}=m)\). Thus, the infinitesimal generator of the Lyapunov function will be computed as:

By using the relations \(\sum _{n\in \underline{ \hbox {{M},}} n\ne m} {p_{mn} +} p_{mm} =\sum _{n\in \underline{\hbox {{M}}}} {p_{mn} } \) and \(\sum _{j\in \underline{\hbox {{N},}} j\ne i} {\lambda _{ij} P(m)}+ \lambda _{ii} P(m)=\sum _{j\in \underline{\hbox {{N}}}} {\lambda _{ij} P(m)} ,\) Eq. (24) can be written as (25);

Consider \(\sum _{j=1}^N {\lambda _{ij} } P(m)=0,\) as a result of the total probability law and the conditions of (4) and (5), if the following inequality holds,
there exist stabilizing state-feedback gains K(m) such that one has \(\hbox {L}V(x(t),i,m)<0.\) By considering a similar line in the proof of Theorem 4 in Section 2.2 of [2], the closed-loop system is stochastically stable and the Definition 1 is verified for the closed-loop system (11).
To derive the controller gains (6), replace \(\bar{{A}}(i,m,t)\) with \(A(i)+B(i)\left( K(m)+\Delta K(m,t) \right) \) in Eq. (26), thus, the following is achieved.
If substitute the uncertain TRs of the observed chain by \(p^{r_t }=\bar{{p}}^{r_t }+\Delta p^{r_t },\) Eq. (27) turns to Eq. (28).
Based on Lemma 1, the following inequalities can be written for the uncertain parts of (28),
where \(\varepsilon \)\(_{K}(m)\) and \(\varepsilon _p^i (m,n),\) specify the degree of robustness of the system.
Taking the advantage of the inequalities (29) and (30), Eq. (28) can be rewritten in the form of the following.
Define \(V(m)=Z^{-1}(m)\) such that
By defining Q(i, m), S(m) and R(m) in the form of Eqs. (18), (19) and (20) and applying the Schur complement lemma to Eq. (32), the inequality (14) of the theorem is achieved.
Furthermore, Eq. (31) leads to (33) if one takes the advantage of Eq. (32).
The condition of Eq. (33) is nonlinear in P(m) and K(m). In order to find controller gains it is desired to transform (33) into a linear form, let \(X(m)= P^{-1}(m)\). Pre- and post-multiplying (33) by X(m) provides (34).
Let \(Y(m)=K(m)X(m)\), then the inequality of (35) is obtained from (34).
By definingJ(i, m) as (17) and using the Schur complement equivalence mentioned in Lemma 2, the inequality of (35) can be written in the form of inequality (13). Finally, the state-feedback gains are derived as \(K(m)=Y(m)X^{-1}(m)\) which ends the proof. \(\square \)
Remark 2
It should be noted that, due to the uncertainties in the system (1), the theorem is only a sufficient condition on the stochastic stabilizability of the system. Thus, further works need to be done to improve the conditions.
Remark 3
Compared with the Markov jump systems, semi-Markov jump systems (S-MJLSs) are more practical stochastic models for real-world applications [7, 17, 29]. While MJLSs are characterized by a fixed matrix of transition rates, S-MJLSs are identified by time-dependent TRs with relaxed conditions on the sojourn time probability distributions. Definitely, the method of this study can be extended to deal with the asynchronous switching phenomenon in the control of semi-Markov jump systems. In that case, the switching of the system and the controller could be modeled by two distinguished semi-Markov processes. By considering both processes integrated in the closed-loop system, the controller can be readily designed.
3.1 Discussions
3.1.1 Design Parameters
A drawback of the proposed method is that the conditions depend on a number of parameters \(\varepsilon \) that must be suitably tuned. These parameters rise due to the lemma used for dealing with the system uncertainty. According to [40], this lemma holds for any \(\varepsilon > 0\). Although these parameters could take any values, it is preferred to select them properly. The reason is that these parameters determine the system degree of robustness and improper values may increase conservativeness and even lead to infeasible LMI sets. There exist two approaches for dealing with the parameters \(\varepsilon \). The first approach is to select them a priori to afford a prescribed degree of robustness. This approach is extensively used in the robust controller design problems [40] and is also preferred by the authors in the current study. The main advantage of this approach is providing the conditions of a fair comparison between the multiple results. The second approach is to optimize the parameters \(\varepsilon \) which is addressed in [24].
3.1.2 Uncertainties
As mentioned before, the uncertainty in the proposed control structure appears both in the observed Markov chain and the gains of the controller. Both uncertainties are a result of imperfect system information and modeling errors. The TR uncertainty is specified by a bound of \(\zeta _{mn}^{r_t } \), and the controller gains’ uncertainty is specified by the matrices of \(E_{K}(m), D_{K}(m)\) and \(F_{K}(m,t)\). Generally, these specifications are determined empirically from an admissible portion (for example up to, 20%) of the nominal value of the transition rates and the system gains after lots of statistics in practice. In this study, these bounds and matrices are supposed to be a priori available from the modeling procedure.
3.1.3 Number of the Controller Modes
There is no specific relation between the number of system modes and the number of the controller modes. In other words, M and N may either be equal or not. Although in normal situations M and N are supposed to be equal, in a case where the mode information is not complete and some modes are not observable, M may be less than N. Also, in noisy and disturbed situations, the number of observed modes may be more than the number of actual modes. In this study, it is assumed that both M and N are previously known. Obtaining the Markov chain of the controller, or the problem of how to observe its parameters, is beyond the scopes of this paper and may be a significant and interesting problem for further investigations.
3.1.4 Feasibility of the Controller from Implementation and Computational Point of Views
The asynchronous controller is highly feasible from the implementation point of view, but it is also subject to some technical limitations. These limitations are relevant to the implementation of state-feedback gains and the construction of the switching mechanism. In case of feedback gain implementation, the proposed scheme faces difficulties exactly similar to those that come up in the implementation of a normal control gain for a linear system and it is not a major concern. In case of Markov chain construction and the mode identification, the proposed controller is also feasible and there exist plenty of studies dedicated to the Markov chain implementations [33]. Remarkably, the presented switching controller is more feasible than the traditional control scheme for MJLSs since it does not require perfect access to the Markov chain of the system but depends on the observed chain. From the computational point of view, the factors that affect the feasibility of the controller are the uncertainty bounds of the TRs and feedback gains involved in the LMI constraints. Although the LMIs are essentially convex constraints and easily solvable by optimization algorithms and software, large uncertainty bounds may reduce the feasibility of the LMIs.
4 Illustrative Example
In this section, simulation results are provided to test the effectiveness and the applicability of the proposed theory. For this purpose, an stabilizing non-fragile asynchronous controller is designed and applied to a vertical takeoff–landing vehicle extended from [14] which is modeled as a MJLS. To get the simulation results, MATLAB 2016b, and for LMI solving, YALMIP [19] is used here. Also, the computer is an Intel \( \circledR Core^{\mathrm{TM}}\) I7-6700HQ 2.60 GHz CPU with 16 GB RAM.
Due to the stochastic nature of the Markovian systems, the simulation results cannot be convincing on the basis of a single realization; therefore, the results are obtained for 10 multiple runs and also represented as the average of 10,000 Monte Carlo runs. Furthermore, to show the superiority of the proposed controller, the results are compared to the mode-independent controller referred at [2].
The VTOL states, \(x(t) = [x_{1}(t), x_{2}(t), x_{3}(t), x_{4}(t)\)], are defined in Table 1.
The vertical takeoff–landing vehicle is a fault-prone system and can be represented by a Markovian jump linear model. The VTOL system matrices are A(1) and B(1) in the normal working conditions. The fault scenario in this system is the lost effectiveness of the collective pitch control input \(u_{1}(t)\) to the vertical velocity \(x_{2}(t)\) by 50%. Under such fault circumstances, the system matrices are A(2) (= A(1)) and B(2), in which the first element of the second row of the input matrix B(2) is half of that of B(1). Without loss of generality, only one type of fault is considered in the numerical example, so \(N_{ }=_{ }M_{ }=_{ }\)2. System matrices are as the following.
The TR matrix of the fault process is (37), and the nominal observed transition rate matrices are as (38).
It is assumed that the observed chain has uncertainties up to 50% of the nominal values. It means that the upper and lower bounds of the TRs are assumed to be \(\left| {\Delta p_{mn} } \right| \le p_{mn} /2\, m\ne n.\)
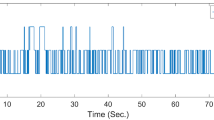
A single mode evolution of the Markov process \(r_{t}\) which demonstrates the fault occurrence trajectory is depicted in Fig. 2. The corresponding, observed Markov chain, \(\sigma _{t }\) is also illustrated in Fig. 3.
The controller gain uncertainties in this example are assumed to be (39).
The uncontrolled states of the VTOL system are depicted in Fig. 4 by the initial conditions and modes of \(x_{1}\)(0) = -1.2, \(x_{2}\)(0) = 0.9, \(x_{3}\)(0) = 0.2, \(x_{4}\)(0) = -1, \(r_{0 }=_{ }\) \(\sigma \)\(_{0 }=_{ }\)1. It is clear that all the states of the uncontrolled system are unstable.

Fault occurrence trajectory of the VTOL

States of the observed Markov process

Uncontrolled states of the VTOL system
By solving the conditions of Theorem in Sect. 3, with the prescribed degree of robustness \(\varepsilon \)\(_{A}\)(1) = \(\varepsilon \)\(_{B}\)(1) = 0.5, \(\varepsilon \)\(_{A}\)(2) = \(\varepsilon \)\(_{B}\)(2) = 0.1, and \(\varepsilon _p^i (m,n)\)= 0.5, the following controllers are obtained.
By the initial conditions mentioned above, the state trajectories of the controlled system and the corresponding control signals are illustrated in Figs. 5 and 6 for 10 individual runs.

Controlled states of the VTOL for 10 runs

Control signals of the VTOL for 10 runs
For a better understanding, the average state responses and the relevant control efforts are also shown in Figs. 7 and 8 for 10,000 Monte Carlo runs.

Average controlled states of the VTOL for 10,000 Monte Carlo runs

Average control signals of the VTOL for 10,000 Monte Carlo runs
For more investigation, denote the settling time, \(T_{s}\) given by (41),
Statistics of the settling time and the approximated normal distribution are summarized in Fig. 9.

Statistics of the settling time of the controlled states for 10,000 Monte Carlo runs
The figures clearly demonstrate that by the asynchronous controller the states tend to the origin. Also, the control signals are enough smooth. Consequently, the proposed non-fragile controller can effectively manage the effect of the mismatched Markov chains of the system and the controller as well as the controller uncertainties.
In order to show the superiority of the developed method to the mode-independent controller in case of mismatched chains, the results are compared with the mode-independent controller referred at [2]. By solving the conditions for the non-fragile case, the controller is obtained as (42).
The average controlled states of 10,000 Monte Carlo runs are depicted in Fig. 10 with the relevant control efforts of Fig. 11. The histogram and the normal distribution of the settling time are also depicted in Fig. 12.
Notably, to provide a fair comparison, the uncertainty bounds and the robustness degrees are selected equal to the asynchronous controller.

Average controlled states of the VTOL under the mode-independent control [2] for 10,000 Monte Carlo runs

Average control signals of the VTOL under the mode-independent control [2] for 10,000 Monte Carlo runs

Statistics of the settling time of the controlled states under the mode-independent control [2] for 10,000 Monte- Carlo runs
As the figures show, the asynchronous controller shows faster response (smaller settling time) than the mode-independent controller. The following table summarizes the comparison results (Table 2).
The reason of the more efficient performance of the proposed control scheme is that the mode-independent controller ignores the switching information of the dynamics, thus leading to more conservative gains. It is fairly admitted that, the cost of this improvement is the more number of LMIs to be solved. Although the asynchronous controller has more computational complexity, in complex asynchronous situations it is more likely to provide feasible results.
5 Conclusions
In this study, an asynchronous control scheme is proposed for the continuous-time MJLS. The proposed scheme includes an additional uncertain Markov chain as an observation of the original chain. This chain is slightly different from the original chain, but depends on it according to certain probabilities. It also contains uncertain TR information to take account for the imperfect observation procedures. Such a scheme is capable to deal with practical situations in which the real-time, exact and precise detection of the system modes is not possible. This design also takes inaccuracies of the controller implementation into account and helps reducing the implementation cost. Here, the piecewise homogenous Markov chain approach helps obtaining the results in the form of LMIs which are easily solvable. The proposed method to deal with the asynchronous phenomenon of MJLSs is superior to the previous techniques in case of conservativeness of the stability analysis conditions and the designed controller gains; the reason is that it provides a more realistic representation for the asynchronous switching. It is also more likely to provide feasible results in comparison with the previous methods. Remarkably, the proposed method is capable of being extended to multi-objective problems such as asynchronous controller design for MJLSs subject to disturbances or noises. It can also be generalized to deal with S-MJLSs with asynchronous switching between the system and controller modes.
References
E. Allen, Modeling with Itô Stochastic Differential Equations (Springer, Dordrecht, 2007)
E.K. Boukas, Stochastic Switching Systems: Analysis and Design (Birkhäuser, Basel, 2005)
H. Cheng, C. Dong, W. Jiang, Q. Wang, Y. Hou, Non-fragile switched \(H_{\infty }\) control for morphing aircraft with asynchronous switching. Chin. J. Aeronaut. 30(3), 1127–1139 (2017)
C.E. de Souza, A. Trofino, K.A. Barbosa, Mode-independent \(H_{\infty }\) filters for Markovian jump linear systems. IEEE Trans. Autom. Control 51(11), 1837–1841 (2006)
N.T. Dzung, Stochastic stabilization of discrete-time Markov jump systems with generalized delay and deficient transition rates. Circuits Syst. Signal Process. 36(6), 1–21 (2017)
M. Faraji-Niri, M.R. Jahed-Motlagh, Stochastic stability and stabilization of Markov jump linear system with instantly time-varying transition probabilities. ISA Trans. 65, 51–61 (2016)
M. Faraji-Niri, M.R. Jahed-Motlagh, Stochastic stability and stabilization of semi-Markov jump linear systems with uncertain transition rates. J. Inf. Technol. Control 46(1), 37–52 (2017)
M. Faraji-Niri, M.R. Jahed-Motlagh, M. Barkhordari-Yazdi, Stochastic stability and stabilization of a class of piecewise-homogeneous Markov jump linear systems with mixed uncertainties. Int. J. Robust Nonlinear Control 27(6), 894–914 (2017)
L. Gao, D. Wang, Input-to-state stability and integral input-to-state stability for impulsive switched systems with time-delay under asynchronous switching. Nonlinear Anal. Hybrid Syst. 20, 55–71 (2016)
S. Huang, Z. Xiang, Robust \(L_{\infty }\) reliable control for uncertain switched nonlinear systems with time delay under asynchronous switching. Appl. Math. Comput. 222, 658–670 (2013)
S. Huo, M. Chen, H. Shen, Non-fragile mixed \(H_{\infty }\) and passive asynchronous state estimation for Markov jump neural networks with randomly occurring uncertainties and sensor nonlinearity. Neurocomputing 227, 46–53 (2017)
R.S.H. Istepanian, J.F. Whidborne (eds.), Digital Controller Implementation and Fragility: A Modern Perspective (Springer, London, 2001)
S.H. Kim, Control design of non-homogeneous Markovian jump systems via relaxation of bilinear time-varying matrix inequalities. IET Control Theory Appl. 11(1), 47–56 (2016)
E. Kiyak, O. Cetin, A. Kahvecioglu, Aircraft sensor fault detection based on unknown input observers. Aircr. Eng. Aerosp. Technol. 80(5), 545–548 (2008)
N.K. Kwon, B.Y. Park, P. Park, Less conservative stabilization conditions for Markovian jump systems with incomplete knowledge of transition probabilities and input saturation. Optim. Control Appl. Methods 37(6), 1207–1216 (2016)
H. Li, P. Shi, D. Yao, Adaptive sliding mode control of Markov jump nonlinear systems with actuator faults. IEEE Trans. Autom. Control 62(4), 1933–1939 (2017)
F. Li, L. Wu, P. Shi, C.C. Lim, State estimation and sliding mode control for semi-Markovian jump systems with mismatched uncertainties. Automatica 51, 385–393 (2015)
J. Lian, Y. Ge, Robust \(H_{\infty }\) output tracking control for switched systems under asynchronous switching. Nonlinear Analy. Hybrid Syst. 8, 57–68 (2013)
J. Löfberg, YALMIP: A toolbox for modeling and optimization in MATLAB, in 2004 IEEE International Symposium on Computer Aided Control Systems Design, Taipei, Taiwan, 2–4 Sept 2004, pp. 284–289
M. Mariton, Jump Linear Systems in Automatic Control (Marcel Dekker, New York, 1990)
P. Mhaskar, N.H. El-Farra, P.D. Christofdes, Robust predictive control of switched systems: satisfying uncertain schedules subject to state and control constraints. Int. J. Adapt. Control Signal Process. 22(2), 161–179 (2008)
R.C.L.F. Oliveira, A.N. Vargas, J.B.R. do Val, P.L.D. Peres, Mode-independent \(H_{2 }\) control of a DC motor modeled as a Markov jump linear system. IEEE Trans. Control Syst. Technol. 22(5), 1915–1919 (2013)
F.R. Pour Safaei, K. Roh, S.R. Proulx, J.P. Hespanha, Quadratic control of stochastic hybrid systems with renewal transitions. Automatica 50(11), 2822–2834 (2014)
N. Poursafar, H.D. Taghirad, M. Haeri, Model predictive control of non-linear discrete time systems: a linear matrix inequality approach. IET Control Theory Appl. 4(10), 1922–1932 (2010)
L. Qiu, S. Li, B. Xu, G. Xu, \(H_{\infty }\) control of networked control systems based on Markov jump unified model. Int. J. Robust Nonlinear Control 25(15), 2770–2786 (2015)
M. Rasheduzzaman, M.O. Rolla, T. Paul, J.W. Kimball, Markov jump linear system analysis of microgrid stability, in American Control Conference, pp. 5062–5066, Portland, USA, 4–6 June (2014)
W. Ren, J. Xiong, Stability and stabilization of switched stochastic systems under asynchronous switching. Syst. Control Lett. 97, 184–192 (2016)
P. Shi, F. Li, A survey on Markovian jump systems: modeling and design. Int. J. Control Autom. Syst. 13(1), 1–16 (2015)
P. Shi, F. Li, L. Wu, C.C. Lim, Neural network-based passive filtering for delayed neutral-type semi-Markovian jump systems. IEEE Trans. Neural Netw. Learn. Syst. 28(9), 2101–2114 (2017)
Z. Shu, J. Xiong, J. Lam, Asynchronous output-feedback stabilization of discrete-time Markovian jump linear systems, in 51st IEEE Conference on Decision and Control, Maui, HI, USA, pp. 1307–1312, 10–13 Dec (2012)
Y. Tingting, L. Aijun, N. Erzhuo, Robust dynamic output feedback control for switched polytopic systems under asynchronous switching. Chin. J. Aeronaut. 28(4), 1226–1235 (2015)
M.G. Todorov, M.D. Fragoso, New methods for mode-independent robust control of Markov jump linear systems. Syst. Control Lett. 90, 38–44 (2016)
A.N. Vargas, L.P. Sampaio, L. Acho, L. Zhang, J.B.R. do Val, Optimal control of DC–DC buck converter via linear systems with inaccessible Markovian jumping modes. IEEE Trans. Control Syst. Technol. 24(5), 1820–1827 (2016)
J. Wang, S. Ma, C. Zhang, Finite-time stabilization for nonlinear discrete-time singular Markov jump systems with piecewise-constant transition probabilities subject to average dwell time. J. Frankl. Inst. 354(5), 2102–2124 (2017)
Y.E. Wang, X.M. Sun, Lyapunov–Krasovskii functionals for switched nonlinear input delay systems under asynchronous switching. Automatica 61, 126–133 (2015)
R. Wang, J. Xing, P. Wang, Q. Yang, Z. Xiang, \(L_{\infty }\) control with finite-time stability for switched systems under asynchronous switching. Math. Probl. Eng. (2012). https://doi.org/10.1155/2012/929503
J. Wen, L. Peng, S.K. Nguang, Asynchronous \(H_{\infty }\) control of constrained Markovian jump linear systems with average dwell time. Int. J. Sens. Wirel. Commun. Control 3(1), 45–58 (2013)
Z.G. Wu, P. Shi, H. Sua, J. Chua, Asynchronous \(l_{2}\)-\(l_{\infty }\) filtering for discrete-time stochastic Markov jump systems with randomly occurred sensor nonlinearities. Automatica 50(1), 180–186 (2014)
Y. Wua, J. Cao, Q. Li, A. Alsaedi, F.E. Alsaadi, Finite-time synchronization of uncertain coupled switched neural networks under asynchronous switching. Neural Netw. 85, 128–139 (2017)
L. Xie, Output-feedback \(H_{\infty }\) control of systems with parameter uncertainty. Int. J. Control 63(4), 741–750 (1996)
Z. Yan, Y. Song, J.H. Park, Finite-time stability and stabilization for stochastic Markov jump systems with mode-dependent time delays. ISA Trans. 68, 141–149 (2017)
Y. Yin, Z. Lin, Constrained control of uncertain nonhomogeneous Markovian jump systems. Int. J. Robust Nonlinear Control 27(17), 3937–3950 (2017)
Y. Yin, P. Shi, F. Liu, K.L. Teo, Robust control on saturated Markov jump systems with missing information. Inf. Sci. 265, 123–138 (2014)
L. Zhang, \(H_{\infty }\) estimation for discrete-time piecewise homogeneous Markov jump linear system. Automatica 45(11), 2570–2576 (2009)
R. Zhang, Y. Zhang, C. Hu, M.Q.H. Meng, Q. He, Asynchronous \(H_{\infty }\) filtering for a class of two-dimensional Markov jump systems. IET Control Theory Appl. 6(C), 979–984 (2012)
Y. Zhang, R. Zhang, A.G. Wu, Asynchronous \(l_{2}-l_{\infty }\) filtering for Markov jump systems, in Australian Control Conference, Perth, Australia, pp. 99–103, 4–5 Nov (2013)
R. Zhang, Y. Zhang, Y. Zhao, J. Liao, B. Li, Extended \(H_{\infty }\) estimation for two-dimensional Markov jump systems under asynchronous switching. Math. Probl. Eng. (2012). https://doi.org/10.1155/2013/734271
Y. Zhu, L. Zhang, M.V. Basin, Nonstationary \(H_{\infty }\) dynamic output feedback control for discrete time Markov jump linear systems with actuator and sensor saturations. Int. J. Robust Nonlinear Control 26(5), 1010–1025 (2016)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Faraji-Niri, M. Robust Non-fragile Asynchronous Controller Design for Continuous-Time Markov Jump Linear Systems: Non-homogeneous Markov Process Approach. Circuits Syst Signal Process 37, 4234–4255 (2018). https://doi.org/10.1007/s00034-018-0767-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-018-0767-y