
Abstract
Based on the error analysis of Extended Filon Method (EFM), we present an adaptive Filon method to calculate highly oscillatory integrals. The main idea is to allow interpolation points depend upon underlying frequency in order to minimize the error. Typically, quadrature error need be examined in two regimes. Once frequency is large, asymptotic behaviour dominates and we need to choose interpolation points accordingly, while for small frequencies good choice of interpolation points is similar to classical, non-oscillatory quadrature. In this paper we choose frequency-dependent interpolation points according to a smooth homotopy function and the accuracy is superior to other EFMs. The basic algorithm is presented in the absence of stationary points but we extend it to cater for highly oscillatory integrals with stationary points. The presentation is accompanied by numerical experiments which demonstrate the power of our approach.
Dedicated to Ian H. Sloan on the occasion of his 80th birthday.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others

Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
The focus of this paper is on the computation of the highly oscillatory integral
where f, g ∈C ∞[−1, 1] and ω ≥ 0 is the frequency. We assume that the phase function g(x) is normalised so that maxx ∈ [−1,1]|g(x)| = 1. Since this integral abounds in mathematics and computational engineering [2, 14, 15] and standard quadrature methods fail to calculate it well, it has been subjected to very active research effort in the last two decades. This has resulted in a significant number of efficient quadrature methods, such as the asymptotic expansion and Filon methods [5, 10, 11], Levin’s method [12, 13], numerical steepest descent [9], complex Gaussian quadrature [1, 3] and other efficient algorithms [4, 6].
Each of these methods has its own advantages and disadvantages and it would be rash to proclaim one as the definite approach to the integration of (1). They require the availability of different information (e.g., Filon methods and complex Gaussian quadrature require the computation of moments, numerical steepest descent relies on practical computation of steepest-descent paths in the complex plane) and might have critical shortcomings in some situations (Levin’s method cannot work in the presence of stationary points and explicit asymptotic expansions are exceedingly difficult once (1) is generalised to multivariate setting—a setting in which nothing is known of complex Gaussian quadrature).
Popularity of Filon-type methods owes much to their simplicity and flexibility. We just need to replace f by an interpolating polynomial and, assuming that moments \(\int _{-1}^1 x^m \mathrm {e}^{\mathrm {i}\omega g(x)}\mathrm {d} x\), m ≥ 0, are explicitly available, the new integral can be computed easily. The make-or-break issue, however, is the location of suitable interpolation points. The basic imperative is to select interpolation points that ensure good behaviour for large ω, and this is entirely governed by asymptotic analysis. Let us recap some basic facts from [10]. Assume first that there are no stationary points, i.e. that g′≠ 0 in [−1, 1]. Letting \(\tilde {p}\) be the interpolating polynomial, the error can be expanded into asymptotic series,

where
Moreover, σ m[h](x) is a linear combination (with coefficients depending on derivatives of g) of h (j)(x), j = 0, …, m [11]. It immediately follows that the Hermite-type interpolation conditions
imply that the error is \(\sim \mathscr {O}(\omega ^{-s-1})\) for ω ≫ 1. The outcome is the (plain-vanilla) Filon method,
Once g′ vanishes somewhere in [−1, 1], the oscillation of the integrand slows down in the vicinity of that point and the behaviour of (1) changes. In particular, the asymptotic expansion (2) is no longer valid. For example, if g′(c) = 0, g″(c) ≠ 0, for c ∈ (−1, 1) and g′(x) ≠ 0 elsewhere in [−1, 1], then

where
and
[11]. Note that the functions \(\tilde {\sigma }_m\) are C ∞[−1, 1], since the singularity at x = c is removable. This removable singularity is the reason why, while σ m[h](x) is a linear combination of h (j)(x), j = 0, …, m, for x ∈ [−1, 1] ∖{c}, at x = c we have a linear combination of h (j)(c), j = 0, …, 2m. The clear implication is that once, in addition to (3), we also impose the interpolation conditions
the plain-vanilla Filon method bears an error of \(\tilde {O}(\omega ^{-s-1/2})\) for ω ≫ 1.
For reasons that will become apparent in the sequel, it is important to consider also the case when c is at an endpoint: without loss of generality we let c = −1. In that case (4) need be replaced by
and \(\tilde {\sigma }_m^{\prime }(-1)\) is a linear combination of h (j)(−1), j = 0, …, 2m + 1 [8].
A plain-vanilla Filon method can be also implemented in a derivative-free manner, e.g. when the derivatives of f are unknown or not easily available. In that case we need to replace derivatives by finite differences with an \(\mathscr {O}(\omega ^{-1})\) spacing and this procedure does not lead to loss of asymptotic accuracy [10]. In particular, in place of (3), we may interpolate at the points
where the denominator ω + 1 ensures that the interpolation points do not blow up near ω = 0, while 0 < θ < (s − 1)−1 implies that the interpolation points are all distinct and live in [−1, 1].
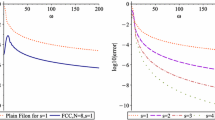
As an example, consider f(x) = (1 + x + x 2)−1, g(x) = x in (1). In Fig. 1 we plot on the left the interpolation points (5) with s = 5. The errors committed by Filon methods for s = 2 (hence with an asymptotic error decay of \(\mathscr {O}(\omega ^{-3})\)) based on (3) and (5) are displayed on the right in logarithmic scale. As can be seen, that the points (5) are equidistant at ω = 0 and bunch at the endpoints when ω increases. The derivative-free Filon method (5) (black dotted line) has essentially the same good behaviour as (3) (green solid line) for large ω.

The left: the interpolation points c k(ω) of (5) with k = 0, ⋯, 2s − 1 (from the bottom line to top) for s = 5,\(\theta = \frac 15\) and ω ∈ [0, 30]; The right: the logarithm (to base 10) of the error of both Filon methods, (3) (green solid line) and (5) (black dotted line), for f(x) = (1 + x + x 2)−1, g(x) = x, s = 2 and ω ∈ [0, 500]
The addition of extra interpolation points to (3) (or, for that matter, (5)) can be highly beneficial in reducing an error committed by a Filon method. Specifically, in the g′≠ 0 case, we choose distinct inner nodes c 1, …, c ν ∈ (−1, 1) and impose that 2s + ν interpolation conditions
This is the Extended Filon Method (EFM),
that has been carefully analysed in [7, 8]. Different choices of internal nodes result in different behaviour for small ω ≥ 0 or in greater simplicity in implementation although, for large ω, the rate of asymptotic decay of the error is always \(\mathscr {O}(\omega ^{-s-1})\). In particular, [8] examined two choices of internal nodes: Zeros of the Jacobi polynomial \(\mathscr {P}_\nu ^{(s,s)}\) and Clenshaw–Curtis points. In the first instance we have the best-possible behaviour for ω = 0 and in the second the coefficients are substantially simpler and, for large ν can be evaluated in just \(\mathscr {O}(\nu \log \nu )\) operations.
Regardless of the choice of internal nodes, the leading term of the asymptotic error can be expressed as

Similar formula applies in the presence of stationary points: quadrature error is reduced to interpolation error at the endpoints and stationary points. This error, in turn, can be analysed very precisely using the Peano Kernel Theorem [8] and the decrease in asymptotic error (as distinct to the asymptotic rate of decay of the error) can be very substantial.
To illustrate this we revisit the example from Fig. 1. Logarithmic errors of plain-vanilla Filon (the lime green solid line) and EFM with Jacobi points (the dark blue dotted line) are displayed in Fig. 2 with s = 2 and ν = 8. It can be observed that the rates of decay between plain-vanilla Filon and EFM are very different. For small ω, EFM is definitely superior by design, while as ω increases both of them decay as the asymptotic order  but EFM has much smaller error.
but EFM has much smaller error.

The logarithmic error \(\log _{10}|Q_\omega ^{\mathsf {F},2,0}[\,f]-I[\,f]|\) (the lime green solid line, the top) and \(\log _{10}|Q_\omega ^{\mathsf {F},2,8}[\,f]-I[\,f]|\) (the dark blue dotted line, the bottom) for f(x) = (1 + x + x 2)−1, g(x) = x, s = 2, ω ∈ [0, 30] (the left) and ω ∈ [0, 500] (the right)
Based on the above research, it is legitimate to ask what is the optimal choice of internal nodes. In reality, these are two questions. If we are concerned with choosing the same nodes for all ω then the two main choices in [8] are probably the best: if ‘optimal’ means the least uniform error then Jacobi wins but once we wish to optimize computation then Clenshaw–Curtis is the better choice. However, the situation is entirely different once the c ks are allowed to depend on ω. Now the answer is clear at the ‘extremities’:
-
For ω = 0 the optimal choice is Legendre points, lending themselves to classical Gaussian quadrature;
-
For ω ≫ 1 the optimal choice maximizes the asymptotic rate of error decay, whereby (5) emerges as the natural preference.
The challenge, though, is to bridge ω = 0 with ω ≫ 1, and this forms the core of this paper.
This is the place to mention a recent paper of Zhao and Huang [16], which combines the plain Filon with Exponentially Fitted method (EF), to propose an alternative version of adaptive Filon method. For large ω, the nodes in [16] are reduced to \(\mp 1 \pm \frac {k}{\omega }\), which is similar to our method, inspired by plain Filon method in [10]. For small ω, since the EF method introduces complex points, the method of [16] employs complex nodes derived from the computation of asymptotic expansion. The outcome is considerably more complicated and restricted to integrals without stationary points. The algorithm in this paper employs altogether different strategy for small ω. To connect the optimal nodes between Gauss–Legendre points when ω = 0 and \(\mp \left (1 - \frac {\theta k}{1 + \omega }\right )\) of large ω, the real nodes dependent ω are presented by constructing Filon homotopy. Moreover, our method is extended to the case of stationary points.
In Sect. 2 we discuss different choices of homotopy functions, connecting Gaussian weights for ω = 0 and points (5) for ω ≫ 1 in the absence of stationary points. Numerical experiments are provided to illustrate the effectiveness of the adaptive method. The adaptive approach to the Filon method is extended in Sect. 3 to the case of stationary points. Finally, in Sect. 4 we discuss the advantages and limitations of this approach.
2 Adaptive Filon Method Without Stationary Points
2.1 The Construction of ω-Dependent Interpolation Points
Throughout this section we assume that (1) has no stationary points, i.e. that g′≠ 0 in [−1, 1]. We define the vector function \(\mathbf {c}(\omega )=\{c_k(\omega )\}_{k=0}^{2s-1}\) as Filon homotopy once it obeys the following conditions:
-
1.
Each c k is a piecewise-smooth function of ω ≥ 0;
-
2.
\(c_k(0)=\xi _{k+1}^{(2s)}\), the (k + 1)st zero of the Legendre polynomial P2s (in other words, the (k + 1)st Gauss–Legendre point), arranged in a monotone order;
-
3.
$$\displaystyle \begin{aligned} c_k(\omega)=\left\{ \begin{array}{ll} \displaystyle -1+\frac{\theta k}{\omega+1}, & k=0,\ldots,s-1,\\ {} \displaystyle 1-\frac{\theta (2s-k-1)}{\omega+1}, & k=s,\ldots,2s-1 \end{array} \right.+\mathscr{O}(\omega^{-2}),\qquad \omega\gg1, \end{aligned}$$
where 0 < θ < (s − 1)−1;
-
4.
For every ω ≥ 0
$$\displaystyle \begin{aligned} -1\leq c_0(\omega)<c_1(\omega)<\cdots<c_{2s-1}(\omega)\leq 1. \end{aligned}$$
In other words, c is a vector of s trajectories connecting Gauss–Legendre points with (5), all distinct and living in [−1, 1].
A convenient way to construct Filon homotopy is by choosing any piecewise-smooth weakly monotone function κ such that κ(0) = 1, \(\kappa (\omega )=\mathscr {O}(\omega ^{-2})\) (or smaller) for ω ≫ 1 (therefore limω→∞ κ(ω) = 0), and setting
where
It is easy to prove that conditions 1–4 are satisfied and (8) is a Filon homotopy.
To illustrate our argument and in search for a ‘good’ Filon homotopy, we consider four functions κ,
- a.:
-
κ 1(ω) = Heaviside(10 − ω), where
$$\displaystyle \begin{aligned} \mathrm{Heaviside}(y)=\left\{ \begin{array}{ll} 1, & y\geq0,\\ {} 0, & y<0 \end{array}\right. \end{aligned}$$is the Heaviside function;
- b.:
-
κ 2(ω) = (1 + ω 2)−1;
- c.:
-
\(\kappa _3(\omega )=2/\left [1+\exp \left (\log ^4(1+\omega )\right )\right ]\);
- d.:
-
\(\kappa _4(\omega )=\cos \left (\frac {\pi }{2} \frac {\mathrm {e}^{\omega /2}-1}{256+\mathrm {e}^{\omega /2}}\right )\).
Figure 3 displays the four functions κ but perhaps more interesting is Fig. 4, where we depict the homotopy curves c k(ω) of (8) for the four choices of κ and s = 4. κ 1 essentially stays put at Gauss–Legendre points until ω = 10 and then jumps to the points (5), while κ 4 represents a smooth approximation to κ 1. κ 2 and κ 3 abandon any memory of Gauss–Legendre points fairly rapidly, implicitly assuming very early onset of asymptotic behaviour in the integral (1).

The functions κ j, j = 1, 2, 3, 4 (from the left to right)

Homotopy curves (8) c k(ω), k = 0, ⋯, 2s − 1 (from the bottom to top line) with s = 4 for each functions κ j, j = 1, 2, 3, 4 (from the left to right)
To gain basic insight into the differences among the functions κ j, we have applied them to the evaluation of the integral
using ten function evaluations and letting θ = 1∕s. To set the stage, in Fig. 5 we have calculated the integral using five different Extended Filon–Jacobi methods (6) with ν = 10 − 2s referenced from [8]: (1) s = 1, ν = 8; (2) s = 2, ν = 6; (3) s = 3, ν = 4, (4) s = 4, ν = 2 and (5) s = 5, ν = 0. The errors (to logarithmic scale) are displayed separately for ω ∈ [0, 20] and ω ∈ [0, 200].

Logarithmic errors for EFJ, applied to (9), with ten function evaluations: The lines corresponding to s vary in shades of blue between 1 (light) and 5 (dark), as well as in the line style, with ν = 10 − 2s
So far, the figure is not very surprising and we recall from the previous section that “large s, small ν” strategy is better for ω ≫ 1, while “small s, large ν” wins for small ω ≫ 0. However, let us instead solve (10) with adaptive Filon, using one of the four κ j functions above. Again, we need to distinguish between small and large ω and the corresponding plots are Figs. 6 and 7 respectively. It is clear that for large ω there is little to distinguish adaptive Filon from EFJ with s = 5 (which is also plain Filon): everything in this regime is determined by asymptotic analysis and the only relevant observation is that nothing of essence is lost once we replace derivatives by suitable finite differences. The big difference is for small ω ≥ 0, before the onset of asymptotics. At ω = 0 all four methods use Gauss–Legendre points and the error beats even EFJ with ν = 8, which corresponds to Lobatto points. However, the errors for κ 2 and κ 3 deteriorate rapidly and this is explained by the homotopy curves in Fig. 4, because interpolation points very rapidly move to their ‘asymptotic regime’. κ 1 and κ 4 are much better, except that κ 1 has an ungainly jump at ω = 10, a consequence of its discontinuity, while κ 4 seems to be the winner. Similar outcome is characteristic to all other numerical experiments that we have undertook.

Logarithmic errors for adaptive Filon, applied to (9), with ten function evaluations, \(\theta = \frac 15\), ω ∈ [0, 20] and κ j, j = 1, 2, 3, 4 (top left to bottom right)

Logarithmic errors for Adaptive Filon, applied to (9), with ten function evaluations, \(\theta = \frac 15\), ω ∈ [0, 200] and κ j, j = 1, 2, 3, 4 (top left to bottom right)
Another interpretation of κ 4 is that it tends to represent for every ω the best outcome for any EFJ with the same number of function evaluations. In other words, denoting the error of EFJ with ν = 10 − 2s by \(e_\omega ^{[s]}\) (the dark blue dotted line) and the error of adaptive Filon by \(\tilde {e}_\omega \) (the orange red solid line) derived by κ 4, we plot in Fig. 8
For larger values of ω the two curves overlap to all intents and purposes. For small ω, though, adaptive Filon is better than the best among the different EFJ schemes—the difference is directly attributable to Gauss–Legendre points being superior to Lobatto points.

A comparison between adaptive Filon (the orange red solid line) and the pointwise best scheme among different EFJ methods (the dark blue dotted line)
The function κ 4 is a special case of

using \(a=\frac 12\) and b = 256. In general, any κ a,b with small a > 0 and large b > 0 obeys the conditions for a Filon homotopy and, in addition, exhibits favourable behaviour—essentially, it is a smooth approximation to a Heaviside function, allowing for Gauss–Legendre points seamlessly segueing into (5), a finite-difference approximation of derivatives at the endpoints.
What is the optimal function κ? Clearly, this depends on the functions f and g, as does the pattern of transition from ‘small ω’ to asymptotic behaviour. Our choice, \(\kappa _{\frac 12,256}\), is in our experience a good and practical compromise.
2.2 The Adaptive Filon Algorithm
Let us commence by gathering all the threads into an algorithm. Given the integral (1) (without stationary points) and a value of ω,
-
1.
Compute the interpolation points c 0, …, c 2s−1 using θ = 1∕s, (8) and \(\kappa =\kappa _{\frac 12,256}\) given by (10).
-
2.
Evaluate the polynomial \(\tilde {p}\) of degree 2s − 1 which interpolates f at c 0, …, c 2s−1.
-
3.
Calculate
$$\displaystyle \begin{aligned} \mathscr{Q}_\omega^{\mathsf{AF},s}[\,f]=\int_{-1}^1 \tilde{p}(x) \mathrm{e}^{\mathrm{i}\omega g(x)}\mathrm{d} x. \end{aligned} $$(11)
Proposition 1
The asymptotic error of the adaptive Filon method \(\mathscr {Q}_\omega ^{\mathsf {AF},s}[\,f]\) is  .
.
Proof
For a fixed ω, adaptive Filon is a special case of EFM with derivatives at the endpoints replaced by suitable finite differences—we already know from [10] that this is consistent with the stipulated asymptotic behaviour. □
Alternatively, we can prove the proposition acting directly on the error term (7), this has the advantage of resulting in an explicit expression for the leading error term.
Needless to say, Proposition 1 represents just one welcome feature of adaptive Filon. The other is that it tends to deliver the best uniform behaviour for all ω ≥ 0.
3 Stationary Points
Let us suppose that g′ vanishes at r ≥ 1 points in [−1, 1]. We split the interval into subintervals I k such that in each I k = [α k, β k] there is a single stationary point residing at one of the endpoints—it is trivial to observe that there are at least \(\max \{1,2r-2\}\) and at most 2r such subintervals. We use a linear transformation to map each I k to the interval [−1, 1] so that the stationary point resides at − 1:
We thus reduce the task at hand into a number of computations of (1) with a single stationary point at x = −1.
In the sequel we assume that − 1 is a simple stationary point, i.e. that g′(−1) = 0 and g″(−1) ≠ 0. The extension of our narrative to higher-order stationary points is straightforward.
We commence with the EFM method and recall from [8] its asymptotic expansion,

where
We recall that \(\mu _0(\omega )=\int _{-1}^1 \mathrm {e}^{\mathrm {i}\omega g(x)}\mathrm {d} x\sim \mathscr {O}(\omega ^{-1/2})\) and that σ m[ f](1) is a linear combination of f (j)(1), j = 0, …, m, while σ m[ f]′(−1) is a linear combination of f (j)(−1), j = 0, …, 2m + 1. Putting all this together, we need to impose the interpolation conditions
to ensure that the error of (12) is \(\mathscr {O}(\omega ^{-s-1})\). (Alternatively, we can interpolate at − 1 up to j = 2s − 1, resulting in an asymptotic error of \(\mathscr {O}(\omega ^{-s-1/2})\)—we do not pursue this route here.) Alternatively to (13) (and the proof is identical to the case when stationary points are absent), we can take a leaf off (5) and interpolate at
where θ < 2∕(3s − 1) ensures that all interpolation points are distinct, by a polynomial \(\tilde {p}\) of degree 3s. This gives a derivative-free Filon á la [10]. To extend this to adaptive Filon we need to use (8) again by replacing the superscript 2s by 3s + 1, blending the φ ks with Gauss–Legendre points and employing \(\kappa =\kappa _{\frac 12,256}\). The outcome is no longer symmetric, as demonstrated in Fig. 9, but this should cause no alarm.

Homotopy curves c k(ω), k = 0, ⋯, 3s (from the bottom to top line), for (1) s = 3, θ = 2∕9 (the left) and (2) s = 4, \(\theta = \frac 16\) (the right)
The construction of adaptive Filon proceeds exactly along the same lines as when stationary points are absent. All that remains is to present a numerical example: instead of (9), we consider
and present the counterparts of Figs. 5, 6, 7, and 8, except that we plot only the results for \(\kappa =\kappa _4=\kappa _{\frac 12,256}\). All figures compare an implementation with 13 function evaluations.
It is vividly clear from Figs. 10, 11, and 12 that, again, adaptive Filon represents the best of all worlds: for small ω is it as good as Gaussian quadrature, for large ω it matches plain Filon and in the intermediate interval it converts smoothly and seamlessly between these two regimes.

Logarithmic errors for EFJ, applied to (16), with 13 function evaluations: s varies between 1 (light) and 4 (dark), with ν = 12 − 3s. The colours correspond to different values of s: the larger s, the darker the colour

Logarithmic errors for adaptive Filon, applied to (16), with 13 function evaluations

A comparison between adaptive Filon (the orange red solid line) and the pointwise best scheme among different EFJ methods (the dark blue dotted line) for 13 function evaluations
4 Conclusions
In this paper, we have developed an adaptive Filon method for the computation of a highly oscillatory integral with or without stationary points. The main feature of this method is that it optimises the choice of interpolation points between different oscillatory regimes relative to those EFM based on the analysis in [8].
Is adaptive Filon the best-possible implementation of the ‘Filon concept’, a method for all seasons? Not necessarily! To define ‘best’ we must first define the purpose of the exercise. If the main idea is to compute (1) for a small number of values of ω and we cannot say in advance whether these values live in a highly oscillatory regime (or if we wish a method which is by design good uniformly for al ω ≥ 0) then adaptive Filon definitely holds the edge in comparison to other implementations of the Filon method, in particular to Extended Filon. However, the method is not competitive once we require the computation of a very large number of integrals for the same function f but many different values of ω. The reason is simple. Conventional Filon methods use interpolation points which are independent of ω, hence we need to compute the values of f (or its derivatives) and form an interpolating polynomial just once: it can be reused by any number of values of ω. Adaptive Filon, though, re-evaluates f afresh for every ω and subsequently forms a new interpolating polynomial. Thus, increased accuracy and better uniform behaviour are offset by higher cost.
Numerical methods must be always used with care and claims advanced on their behalf must be responsible. Adaptive Filon is probably optimal in the scenario when just few values of (1) need be computed but considerably more expensive once a multitude of computations with different values of ω is sought.
References
Asheim, A., Huybrechs, D.: Complex Gaussian quadrature for oscillatory integral transforms. IMA J. Numer. Anal. 33(4), 1322–1341 (2013)
Chandler-Wilde, S.N., Graham, I.G., Langdon S., Spence, E.A.: Numerical-asymptotic boundary integral methods in high-frequency acoustic scattering. Acta Numer. 21, 89–305 (2012)
Deaño, A., Huybrechs, D., Iserles, A.: The kissing polynomials and their Hankel determinants. Technical Report, DAMTP, University of Cambridge (2015)
Domínguez, V., Ganesh, M.: Interpolation and cubature approximations and analysis for a class of wideband integrals on the sphere. Adv. Comput. Math. 39(3–4), 547–584 (2013)
Domínguez, V., Graham, I.G., Smyshlyaev, V.P.: Stability and error estimates for Filon–Clenshaw–Curtis rules for highly oscillatory integrals. IMA J. Numer. Anal. 31(4), 1253–1280 (2011)
Ganesh, M., Langdon, S., Sloan, I.H.: Efficient evaluation of highly oscillatory acoustic scattering surface integrals. J. Comput. Appl. Math. 204(2), 363–374 (2007)
Gao, J., Iserles, A.: A generalization of Filon–Clenshaw–Curtis quadrature for highly oscillatory integrals. BIT Numer. Math. 57, 943–961 (2017)
Gao, J., Iserles, A.: Error analysis of the extended Filon-type method for highly oscillatory integrals. Res. Math. Sci. 4(21/24) (2017). https://doi.org/10.1186/s40687-017-0110-4
Huybrechs, D., Vandewalle, S.: On the evaluation of highly oscillatory integrals by analytic continuation. SIAM J. Numer. Anal. 44(3), 1026–1048 (2006)
Iserles, A., Nørsett, S.P.: On quadrature methods for highly oscillatory integrals and their implementation. BIT Numer. Math. 44(4), 755–772 (2004)
Iserles, A., Nørsett, S.P.: Efficient quadrature of highly oscillatory integrals using derivatives. Proc. R. Soc. London Ser. A Math. Phys. Eng. Sci. 461(2057), 1383–1399 (2005)
Levin, D.: Fast integration of rapidly oscillatory functions. J. Comput. Appl. Math. 67(1), 95–101 (1996)
Olver, S.: Moment-free numerical integration of highly oscillatory functions. IMA J. Numer. Anal. 26(2), 213–227 (2006)
Trevelyan, J., Honnor, M.E.: A numerical coordinate transformation for efficient evaluation of oscillatory integrals over wave boundary elements. J. Integral Equ. Appl. 21(3), 447–468 (2009)
Van’t Wout, E., Gélat, P., Timo, B., Simon, A.: A fast boundary element method for the scattering analysis of high-intensity focused ultrasound. J. Acoust. Soc. Am. 138(5), 2726–2737 (2015)
Zhao, L.B., Huang, C.M.: An adaptive Filon-type method for oscillatory integrals without stationary points. Numer. Algorithms 75(3), 753–775 (2017)
Acknowledgements
The work of the first author has been supported by the Projects of International Cooperation and Exchanges NSFC-RS (Grant No. 11511130052), the Key Science and Technology Program of Shaanxi Province of China (Grant No. 2016GY-080) and the Fundamental Research Funds for the Central Universities.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this chapter

Cite this chapter
Gao, J., Iserles, A. (2018). An Adaptive Filon Algorithm for Highly Oscillatory Integrals. In: Dick, J., Kuo, F., Woźniakowski, H. (eds) Contemporary Computational Mathematics - A Celebration of the 80th Birthday of Ian Sloan. Springer, Cham. https://doi.org/10.1007/978-3-319-72456-0_19
Download citation
DOI: https://doi.org/10.1007/978-3-319-72456-0_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-72455-3
Online ISBN: 978-3-319-72456-0
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)