
Abstract
We give an overview of the theory of rings satisfying a polynomial identity and use this to give a proof of a characterization due to Berstel and Reutenauer of automatic and regular sequences in terms of two properties, which we call the shuffle property and the power property. These properties show that if one views an automatic sequence f as a map on a free monoid on k-letters to a finite subset of a ring, then the values of f are closely related to values of f on related words obtained by permuting letters of the word. We use this characterization to give answers to three questions from Allouche and Shallit, two of which have not appeared in the literature. The final part of the chapter deals more closely with the shuffle property, and we view this as giving a generalization of regular sequences. We show that sequences with the shuffle property are closed under the process of taking sums and taking products; in addition we show that there is closure under a noncommutative product, which turns the collection of shuffled sequences into a noncommutative algebra. We show that this algebra is very large, in the sense that it contains a copy of a free associative algebra on countably many generators. We conclude by giving some open questions, which we hope will begin a more careful study of shuffled sequences.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others

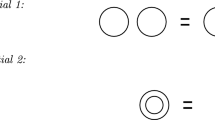

4.1 Introduction
We recall that, given a finite set Δ, a sequence \(f:\mathbb {N}\to \varDelta \) is said to be k-automatic if the nth term of this sequence is generated by a finite-state machine taking the base-k expansion of n as input, starting with the least significant digit. Automatic sequences appear in many different contexts (see, e.g., [14, 189]), and there are many examples of their application to algebra, such as their involvement in the characterization of algebraic power series over finite fields [14, Chapter 12]. The purpose of this chapter, however, is to look at applications of algebra, in particular the theory of polynomial identities, in giving a characterization of automatic sequences due to Berstel and Reutenauer [77, Chapter 3] and to use this characterization to answer some open questions about automatic and regular sequences.
Another way of defining the k-automatic property comes from looking at the k-kernel of a sequence. The k-kernel of a sequence f(n) is defined to be the collection of sequences of the form f(kin + j) where i ≥ 0 and 0 ≤ j < ki. A sequence is k-automatic if and only if its k-kernel is finite. Using this definition of k-automatic sequences, Allouche and Shallit [14, 16] generalized the notion of k-automatic sequences, defining k-regular sequences.
Let K be a field. Given a sequence f(n) taking values in K, we create a vector subspace of \(K^{\mathbb {N}}\), V (f(n);k), which is defined to be the subspace spanned by all sequences f(kin + j), where i ≥ 0 and 0 ≤ j < ki.
Definition 4.1.1
A sequence is k-regular if V (f(n);k) is a finite-dimensional K-vector space.
Since the k-kernel of a sequence f(n) spans V (f(n);k) as a K-vector space, we see that a k-automatic sequence is necessarily k-regular. We remark that one can adopt a slightly more general viewpoint by replacing the field K by a commutative ring and asking that submodules generated by elements of the kernel be finitely generated. Everything we do in this chapter holds in this more general setting, but for ease of exposition we restrict to the case where our sequences are K-valued with K a field.
In the first half of this chapter, we take a ring theoretic look at automatic sequences and regular sequences and prove a result due to Berstel and Reutenauer [77, Chapter 3], which is not as well known as it probably should be. Part of the reason for this is that their result is written in the context of noncommutative rational series, so we give a straightforward translation of these results into our setting. In fact, we shall give a quantitative version of their result, which we hope will be of future use. We then give some applications of this result.
Let \(\mathcal {A}\) be a finite alphabet. We let \(\mathcal {A}^*\) denote the free monoid on \(\mathcal {A}\); that is, \(\mathcal {A}\) is the collection of all words on \(\mathcal {A}\). We let ε denote the empty word on \(\mathcal {A}\).
We are interested in maps \(f:\mathcal {A}^*\rightarrow K\), where \(\mathcal {A}\) is some finite alphabet and K is a field. In the case that \(\mathcal {A}=\{1,2,\ldots ,k\}\) for some positive integer k, we can regard a word in \(\mathcal {A}\) as an integer as follows. We associate 0 to the empty word ε, and for nontrivial words \(a_m\cdots a_0\in \mathcal {A}^*\) with 1 ≤ a i ≤ k, we associate a positive integer using the correspondence
Observe that this gives a bijection between \(\mathcal {A}^*\) and the natural numbers and hence, in this case, we may think of f as being a sequence indexed by the nonnegative integers taking values in K. We note that it is more common to use the alphabet {0, 1, …, k − 1} and instead restrict to the regular sublanguage of the monoid {0, …, k − 1} consisting of words whose first letter is not zero when dealing with k-automatic and k-regular sequences. The point of view we adopt is completely equivalent, but we find the framework used in this chapter easier to deal with.
Using this correspondence and the k-kernel definition of a k-automatic sequence, we see that we can think of a k-automatic sequence taking values in a field K as being a map f : {1, 2, …, k}∗→ K with the property that the collection of maps fu(w) := f(wu) obtained by taking a word u ∈{1, 2, …, k}∗ is finite. Similarly, if the vector space of set maps from {1, …, k}∗ to K generated by the maps of the form fu is finite-dimensional, then f is k-regular. We shall give an overview of the work of Berstel and Reutenauer [77, Chapter 3], describing k-automatic and k-regular sequences, in terms of two additional properties, which for the purposes of this chapter we shall call the shuffle property and the power property. These properties are defined in Section 4.2 and Section 4.3, respectively. In Section 4.4 we present some results from the theory of rings satisfying a polynomial identity which will be necessary in giving the aforementioned characterization of k-regular sequences. In Section 4.5 we show that for a sequence, possessing these two properties is equivalent to being regular. If in addition to having these two properties, the sequence only takes on a finite number of values, the sequence is automatic. In Section 4.6 and Section 4.7, we use our characterization to answer some questions of Allouche and Shallit about whether certain sequences are k-regular and k-automatic. In Section 4.8 we develop the basic properties of sequences with the shuffle property and show that they have nice closure properties. In Section 4.9, we conclude with some open problems and some useful remarks.
4.2 The Shuffle Property
In this section we define the shuffle property and show that regular sequences necessarily possess this property. Let \(\mathcal {A}\) be a finite alphabet and let K be a field. Given a map \(f:\mathcal {A}^{*}\rightarrow K\), we say that f has the d-shuffle property if for any words \(w,w_1,\ldots ,w_d, w'\in \mathcal {A}^*\) we have
We define the dth-shuffle function
Example 4.2.1
Let \(\mathcal {A}=\{0,1\}\), let K be the field of rational numbers, and define f(w) to be the number of ones in the word \(w\in \mathcal {A}^*\). Then f has the 2-shuffle property.
Example 4.2.2
Let \(\mathcal {A}=\{0,1\}\) and define f(w) to be the nonnegative integer whose binary expansion is equal to w. Then f has the 4-shuffle property, but does not have the 3-shuffle property.
We postpone the proof of the fact that f has the 4-shuffle property till after the proof of Proposition 4.2.8. To see that f does not have the 3-shuffle property, take w1 = 0, w2 = 1, w3 = 10. Then f(w1 w2 w3) = [0110]2 = 6. Similarly, f(w1 w3 w2) = 5, f(w2 w3 w1) = 12, f(w2 w1 w3) = 10, f(w3 w1 w2) = 9, f(w3 w2 w1) = 10. Thus
The motivation for this shuffle property definition comes from the following theorem of Amitsur and Levitzki [20].
Theorem 4.2.3 (Amitsur-Levitzki [20])
Let A1, …, A2m be m × m matrices with entries in a commutative ring C. Then
Before we prove this result, we need a basic result about matrices.
Lemma 4.2.4
Let C be a commutative \(\mathbb {Q}\) -algebra and let Y ∈ M n (C). Suppose that Y has the property that the trace of Yi is zero for i = 1, 2, …, n. Then Yn = 0.
Proof
Let yi,j denote the (i, j)-entry of Y. Then we may assume without loss of generality that C is generated by the yi,j. Now let \(R=\mathbb {Q}[x_{i,j}\colon 1\le i,j\le n]\) and let Z ∈ M n (R) be the matrix whose (i, j)-entry is xi,j. We note that if we impose the constraints on the xi,j that give that the trace of Zi is equal to zero for i = 1, 2, …, n, then we obtain a homomorphic image R′ of R and by hypothesis the map xi,j↦yi,j gives a surjective map \(\mathbb {Q}\)-algebra homomorphism from R′ to C. Thus it is sufficient to show that Zn = 0 in M n (R′). We note that there is a \(\mathbb {Q}\)-algebra S that contains R and is a finite R-module and that contains all the eigenvalues of the matrix Z. Then the relations imposed by setting the trace of Zi to zero for i = 1, 2, …, n give a homomorphic image S′ of S that is a finite R′-module. Now Z is triangularizable in M n (S′) and so we may assume that Z is upper triangular. Then if λ1, …, λ n ∈ S′ are the diagonal entries of Z, then we have \(\sum _{i=1}^n \lambda _i^j =0\) for j = 1, 2, …, n. We now claim that λ1, λ2, ⋯ , λ n are nilpotent elements of S′. Once we establish this claim, we see that some power of Z is strictly upper triangular and so Z is nilpotent. Then the Cayley-Hamilton theorem gives that Zn = 0 in M n (S′) and hence in M n (R′), and so we get Yn = 0.
To establish the claim, we note that it is sufficient to show that if C is a finitely generated commutative \(\mathbb {Q}\)-algebra and λ1, …, λ n ∈ C satisfy \(\sum _{i=1}^n \lambda _i^j =0\) for j = 1, 2, …, n then λ1, …, λ n are nilpotent. Let N denote the nil radical of C (the set of all nilpotent elements of C). Then we may replace C by C/N, and we see that it is sufficient to show that if C is a finitely generated reduced (i.e., it has no nonzero nilpotent elements) commutative \(\mathbb {Q}\)-algebra and λ1, …, λ n ∈ C satisfy \(\sum _{i=1}^n \lambda _i^j =0\) for j = 1, 2, …, n, then λ1, …, λ n are all zero. Since a reduced commutative ring embeds in a direct product of integral domains, we then see we can use projection maps to reduce to the case of an integral domain. So we prove the more general fact that if C is a commutative \(\mathbb {Q}\)-algebra that is an integral domain and λ1, …, λ n ∈ C are distinct and nonzero and β1, …, β n ∈ C are nonzero then \(\sum \beta _i \lambda _i^j \neq 0\) for some j = 1, …, n. We note that the original claim follows easily from this more general statement (but this requires characteristic zero). To see this general claim, we note that since we are in an integral domain, we get the result for n = 1. Now suppose that the result holds for n < d and consider the case where n = d. Then if \(\sum _{i=1}^d \beta _i \lambda _i^j = 0\) for j = 1, 2, …, d, we see that
for j = 1, 2, …, d − 1. Simplifying, we see that
for j = 1, …, d − 1. But this contradicts the induction hypothesis, and we get the claim. This finishes the proof. □
Proof (Proof of Theorem 4.2.3)
We only prove the case when C is an integral domain, which is sufficient for the considerations of this chapter. Here we give an argument due to Rosset [512] (we note that Rosset does the more general case of a commutative ring). We note that one can immediately reduce to the case when C is a field of characteristic zero, since an integral domain C of positive characteristic is a homomorphic image of an integral domain C′ of characteristic zero, and one can show that if the result holds for the field of fractions of C′ then it holds for C. Now let A1, …, A2n be 2n elements in M n (C) and let V be a 2n-dimensional C-vector space with basis e1, …, e2n. For each i ≥ 0, we recall that there is a d-th exterior product, ∧dV is formed by taking the vector space \(V_d:=\otimes _{i=1}^d V\) and then forming the quotient V d /W d where W d is the subspace of V d spanned by elements of the form \(\mathbf {e}_{i_1}\otimes \cdots \otimes \mathbf {e}_{i_d} - \mathrm {sgn}(\sigma )\mathbf {e}_{\sigma (i_1)}\otimes \cdots \otimes \mathbf {e}_{\sigma (i_d)}\), where σ ∈ S d and 1 ≤ i1, …, i d ≤ 2n. Then we let \(\mathbf {e}_{i_1}\wedge \cdots \wedge \mathbf {e}_{i_d}\) denote the image of \(\mathbf {e}_{i_1}\otimes \cdots \otimes \mathbf {e}_{i_d}\) in this quotient. Then one can check that ∧dV is a \({2n\choose d}\)-dimensional space with basis consisting of elements of the form \(\mathbf {e}_{i_1}\wedge \cdots \wedge \mathbf {e}_{i_d}\) with i1 < i2 < ⋯ < i d .
Now let \(E=\bigoplus _{d=0}^{2n} \wedge ^i(V)\); this is called the exterior algebra on V . Notice that E is a ring with multiplication formed by taking the natural bilinear “wedge” map ∧i(V ) ×∧j(V ) →∧i+j(V ) given by
Then E is generated as a C-algebra by e1, …, e2n. Let E e denote the subalgebra of E consisting of the direct sum of ∧iV with i even. Then E e is generated by elements of the form e i ∧e j as an algebra, and it is straightforward to check, using the relations given above, that these elements commute with one another and so E e is a commutative ring of characteristic zero. Now consider B := M n (C) ⊗ C E≅M n (E). Let X = A1 ⊗e1 + ⋯ + A2n ⊗e2n ∈ B. Then
Notice that Y has trace zero, as it is an E e -linear combination of commutators. More generally,
which is equal to
It is straightforward to check that \(\mathsf {S}_{2i}(\mathbf {A}_{j_1},\ldots ,\mathbf {A}_{j_{2i}})\) always has trace zero for i ≥ 1 and so we see that the trace of Yi is zero for i = 1, 2, …, n. Thus Y is an n × n matrix over the commutative \(\mathbb {Q}\)-algebra E e , and it has the property that the trace of all of its powers is equal to zero. By Lemma 4.2.4, we have that Yn = 0. Thus Yn = X2n = 0. As before, we have X2n = S2n(A1, …, A2n)e1 ∧⋯ ∧e2n and so we get the desired result. □
We now show that the d-shuffle property implies all larger shuffle properties hold.
Proposition 4.2.5
If f has the d-shuffle property, then f has the e-shuffle property for all e ≥ d.
Proof
By induction, it is sufficient to prove this when e = d + 1. Notice that
where \(\widehat {w_i}\) means that w i is omitted from the list. Hence if f has the d-shuffle property, it must also have the (d + 1)-shuffle property. □
We now introduce some notation. Given a finite alphabet \(\mathcal {A}\), a field K, a word \(w\in \mathcal {A}^*\) and a function \(f:\mathcal {A}\rightarrow K\), we define two functions \(f_w,f^{w}:\mathcal {A}\rightarrow \mathcal {A}\) by
We now give some definitions.
Definition 4.2.6
Given a finite alphabet \(\mathcal {A}\), a field K, and a function \(f:\mathcal {A}^*\rightarrow K\), we say that f is left (resp. right) \(\mathcal {A}\)-regular if the K-vector space spanned by the functions \(\{f_w~|~w\in \mathcal {A}^*\}\) (resp. \(\{f^w~|~w\in \mathcal {A}^*\}\)) is finite-dimensional. If in addition to being left (resp. right) \(\mathcal {A}\)-regular, the range of f is a finite subset of K, we say that f is left (resp. right) \(\mathcal {A}\)-automatic.
Later, we will give Kleene’s theorem, which states that being left \(\mathcal {A}\)-regular is equivalent to being right \(\mathcal {A}\)-regular. Thus we will omit the words left and right and just use the term \(\mathcal {A}\)-regular. In the case that \(\mathcal {A}=\{1,2,\ldots , k\}\), we shall say that a right \(\mathcal {A}\)-regular function is k-regular and shall say that a right \(\mathcal {A}\)-automatic function is k-automatic.
Notice that this definition of k-regular coincides with the definition of k-regular given by Allouche and Shallit [14] and the definition of k-automatic coincides with the conventional definitions of the k-automatic property.
For convenience, we use the following notation. Given a finite alphabet \(\mathcal {A}\), a field K, and a function \(f:\mathcal {A}^*\rightarrow K\), we let L(f) denote the K-vector space spanned by the functions \(\{f_w~|~w\in \mathcal {A}^*\}\), and we let R(f) denote the vector space spanned by \(\{f^w~|~w\in \mathcal {A}^*\}\).
Proposition 4.2.7
Let \(\mathcal {A}\) be a finite alphabet and let f be a left (resp. right) \(\mathcal {A}\) -regular function taking values in a field K. Let m denote the dimension of L(f) (resp. the dimension of R(f)). Then there exist some m ≥ 1, m × m matrices \(\{\mathbf {A}_a~|~a\in {\mathcal A}\}\) with entries in K, and v, w ∈ Kd×1 such that
for all words \(x_1\cdots x_i \in {\mathcal A}^*\).
Proof
Choose \(\varepsilon =w_1,\ldots ,w_m\in {\mathcal A}^*\) such that \(f_{w_1},\ldots ,f_{w_m}\) span the vector space L(f). Given \(x\in \mathcal {A}\), for each i pick ci,j ∈ K, j ≤ m, such that
Define the m × m matrix A x whose (i, j)-entry is given by ci,j. Take v to be the m × 1 column vector whose ith coordinate is f(w i ). Notice that if \(x_1,\ldots ,x_i\in \mathcal {A}\), then
In the case that f is right \(\mathcal {A}\)-regular, an analogous construction gives the same result. □
Proposition 4.2.8
Let \(\mathcal {A}\) be a finite alphabet, let K be a field, and let \(f:\mathcal {A}^*\rightarrow K\) be a left (resp. right) \(\mathcal {A}\) -regular sequence. Then f has the d-shuffle property for d = 2dim(L(f)) (resp. d = 2dim(R(f))).
Proof
Let m denote the dimension of L(f). Since f is left \(\mathcal {A}\)-regular, there exist m × m matrices \(\{\mathbf {A}_x~|~x\in \mathcal {A}\}\) with entries in K and some vector v ∈ Kd×1 such that
for all words \(x_1\cdots x_m\in \mathcal {A}^*\). Let d = 2m. We claim that f has the d-shuffle property. To see this, let w1, …, w d , w, w′ be words in \(\mathcal {A}^*\). Let \(\mathcal {S}\) denote the monoid on \(\{\mathbf {A}_x~|~x\in \mathcal {A}^*\}\). Then there exist matrices U1, …, U d , U, U ′ in \(\mathcal {S}\) which correspond to w1, …, w d , w, w′, respectively, given by the correspondence ε↦I d and
Then
Hence
where the last step follows from the Amitsur-Levitzki theorem. □
We now prove that the function given in Example 4.2.2 has the 4-shuffle property. We note that if \(f:\{0,1\}^*\rightarrow {\mathbb Q}\) is the function which maps a word w to [w]2, where [w]2 is the natural number whose binary expansion is equal to w, then the \({\mathbb Q}\)-vector space R(f) is two-dimensional, spanned by f and the constant function g which sends every word to 1. To see this, notice that fw(u) = [uw]2 = 2length(w)[u]2 + [w]2 and so
Clearly f and g are both in R(f) and are linearly independent. Thus dim(R(f)) = 2 and so f has the 4-shuffle property.
4.3 The Power Property
In this section we define the power property , which is the second ingredient of the characterization of automatic and regular sequences of Berstel and Reutenauer. Given a finite alphabet \(\mathcal {A}\) and a field K, we say that \(f:\mathcal {A} \rightarrow K\) has the d-power property if for any word w0, there exists a polynomial Φ(t) ∈ K[t] of degree at most d with constant coefficient 1 such that for any words w, w′ we have
is a polynomial in K[t] of degree at most d. We shall say that f has the power property if f has the d-power property for some d ≥ 1.
Lemma 4.3.1
Let K be a field and let X be a d × d matrix with entries in K. Then
for some matrix Y with entries in K[t] of degree at most d − 1.
Proof
Let Y(t) denote the classical adjoint of 1 − t X. Then Y(t) is a matrix with entries given by polynomials in t of degree at most d − 1 and
Notice that
and so
□
Proposition 4.3.2
Let f be a \(\mathcal {A}\) -regular function taking values in a field K. Then f has the m-power property, where m is the dimension of L(f).
Proof
It suffices to show that for any word w0 and w, w′ that
is a rational function in t whose numerator and denominator have degrees that are at most m (with denominator independent of w, w′ and depending only upon w0 and having constant coefficient 1). By Proposition 4.2.7, there exists some m and m × m matrices U, U0, U ′ such that \(f(ww_0^{i}w')=\mathbf {e}_1^{\mathrm {T}}\mathbf {U}\mathbf {U}_0^{i}\mathbf {U}'\mathbf {v}\). We then have
where Y(t) is the classical adjoint of 1 −U0 t. This expression is easily seen to be a rational function of the form
and the numerator and denominator have degree at most m and Φ(0) = 1 and Φ depends only upon U0 and hence only on w0. □
4.4 Shirshov’s Height Theorem
We now introduce an important result in combinatorial ring theory: Shirshov’s theorem. We have seen that \(\mathcal {A}\)-regular functions have both the shuffle and power properties. In fact, it is the case that the shuffle and power properties characterize regular sequences. To deduce this we need a famous combinatorial result due to Shirshov. We first take a detour and survey the beautiful field of polynomial identity algebras.
Definition 4.4.1
Let K be a field and let B be a K-algebra. We say that B is a polynomial identity ring if there exists a nonzero, noncommutative polynomial p(x1, …, x d ) with coefficients in K, such that p(b1, …, b d ) = 0 for all b1, …, b d ∈ B. In this case the polynomial p is called a polynomial identity for B. The total degree of the polynomial identity p of B of least positive degree is called the PI degree of B.
Example 4.4.2
Any commutative algebra B is a polynomial identity ring since it satisfies the identity x1 x2 − x2 x1 = 0.
Example 4.4.3 (Wagner)
The ring of 2 × 2 matrices over a field K satisfies the identity [x1, [x2, x3]2] = 0, where [a, b] = ab − ba.
Proof
Notice that if X is a 2 × 2 matrix then by the Cayley-Hamilton theorem
Hence if X has trace 0, then its square is a scalar matrix. In particular the square of a commutator must commute with every 2 × 2 matrix. □
An important fact is that if a ring B satisfies a nontrivial polynomial identity, then it in fact satisfies a homogeneous multilinear identity (i.e., each monomial occurring in the identity has degree precisely one in each variable).
Proposition 4.4.4
Let K be a field and let B be a K-algebra satisfying a polynomial identity of degree at most d. Then B satisfies a multilinear homogeneous identity of degree at most d.
Proof
Let m(f) be the maximum degree of a variable appearing in f. Among all nonzero polynomial identities, we pick one with the property that m(f) is minimal. Let us call this minimum m. Among all such identities with m(f) = m, we pick one with the property that the number of variables of degree m is minimal. Let f(x1, …, x d ) be such a minimal polynomial identity for the ring B. By permuting the variables, if necessary, we may assume that m is the degree of x1 in f. Consider the identity g(x1, y1, x2, …, x d ) := f(x1+y1, …, x d )−f(x1, …, x d )−f(y1, …, x d ) ∈ K{x1, y1, x2, …, x d }. We note that this is an identity for B. Then it is straightforward to see that this transforms any monomial of degree m in x1 to a monomial of total degree m in x1 and y1 and no terms of degree m in just x1 or just y1. That means that either m(g) < m or m(g) = m but the number of variables of degree m in g is strictly less than that of f. By minimality of f we have that g = 0. But this occurs only if m = m(f) = 1. So having m = 1 says that every monomial appears with degree at most 1. Now pick a monomial occurring in f with nonzero coefficient of smallest degree, say r ≤ d, By relabeling indices, we may assume that the monomial is x1⋯x r . Then consider f(x1, …, x r , 0, …, 0). This is nonzero and must be homogeneous by minimality of r.
Notice this process yields an algorithm to convert a polynomial identity into a homogeneous multilinear identity. One begins with an identity, and if it is of degree strictly greater than one in some variable, say x1, then we add a new variable y1, and we look at f(x1 + y1, …) − f(x1, …) − f(y1, …). This creates an additional variable, but the total degree does not increase. If we keep repeating this process, the argument above shows that it must terminate and so we obtain an identity in some set of variables in which each variable occurs with degree at most 1. Then we pick a monomial of minimal length and set all variables not occurring in this monomial equal to zero to get a homogeneous multilinear identity. Notice that the total degree never increases at any step, so we see the total degree of the homogeneous multilinear identity we ultimately produce is at most that of the original identity. □
Remark 4.4.5
We note that in the case that the polynomial p(x1, …, x d ) is multilinear and homogeneous, to check that a K-algebra B satisfies this identity, it is sufficient to check that p(b1, …, b d ) = 0 for (b1, …, b d ) ∈ Yd where Y is a K-spanning set for B.
Proof
To see this, we remark that if a1, …, a d ∈ B then we can write each a i as a K-linear combination of elements of Y . Then using multilinearity, we can write p(a1, …, a d ) as a K-linear combination of elements of the form p(b1, …, b d ) with (b1, …, b d ) ∈ Yd. Thus if the latter all vanish, then p is necessarily an identity for B. □
We will make use of this fact for algebras B of the form B := K{x1, …, x k }/I, where I is a two-sided ideal of the free algebra on noncommuting variables x1, …, x k . In this case, we can take the images of the words in x1, …, x k to be our spanning set, and so to check that a homogeneous multilinear identity holds for an algebra B, it suffices to check that it vanishes when evaluated at elements from the semigroup generated by a finite set of generators. Arguably, the most important types of identities studied in the theory of polynomial identities are the standard identities , which we already encountered, albeit in a different form, when addressing the shuffle property. The nth standard identity is defined as follows:
The Amitsur-Levitzki theorem shows that the ring of n × n matrices over a commutative ring satisfies the 2nth standard identity. In fact, every finitely generated algebra satisfying a polynomial identity must satisfy one of these standard identities.
Theorem 4.4.6 (Braun)
Let K be a field and let B be a finitely generated K-algebra satisfying an identity. Then B satisfies the identity S n for some n ≥ 1.
Proof
See Braun [105] or Amitsur and Small [21, Corollary 1.2.8A]. □
We recall that if we are given a free monoid \(\mathcal {A}^*\) with \(\mathcal {A}=\{x_1,\ldots ,x_k\}\), we can put a pure lexicographic order ≼ on \(\mathcal {A}^*\) by declaring that
In this order we declare that if w is a proper initial factor of w′ then w ≺ w′. So, for example, x1 ≼ x1 x3 and x2 x3 x4 ≺ x3 x1. We note that this lexicographic order extends to right infinite words on \(\mathcal {A}\). If we alter the order somewhat and use the pure lexicographic order to order words of the same length and for words of different length declare that the longer word is bigger, then this new order is called the degree lexicographic order .
Using intricate combinatorial techniques, Shirshov proved the following beautiful result.
Theorem 4.4.7 (Shirshov)
Let \(\mathcal {A}=\{x_1,\ldots ,x_k\}\) be a finite alphabet, and let m be a positive integer. If w is a right-infinite word over the alphabet \(\mathcal {A}\) , then either there is some nontrivial word \(w_0\in \mathcal {A}^*\) such that \(w_0^d\) is a factor of w for every d ≥ 1 or w contains a finite factor of the form w1 w2⋯w m where w1 ≻ w2 ≻⋯ ≻ w m are nontrivial words in \(\mathcal {A}^*\) with no w i equal to a prefix of w j for i ≠ j and ≻ is the pure lexicographic order induced by x1 ≻ x2 ≻⋯ ≻ x k .
We postpone the proof of Shirshov’s theorem until we have developed a few basic combinatorial tools.
To prove Theorem 4.4.7, we require two basic combinatorial tools. The first is König’s infinity lemma; the second is a theorem of Furstenberg.
Theorem 4.4.8 (König’s infinity lemma)
Let \(\mathcal {A}\) be a finite alphabet, and let \(\mathcal {S}\) be an infinite subset of \(\mathcal {A}^*\) that is closed under the process of taking factors. Then there exists \(w\in \mathcal {A}^{\mathbb {N}}\) such that every finite factor of w is in \(\mathcal {S}\).
Proof
We define w = a1 a2⋯ as follows. Since \(\mathcal {S}\) is infinite, there is some \(a_1\in \mathcal {A}\) such that a1 is the first letter of infinitely many elements of \(\mathcal {S}\); now suppose that for every i ≥ 1 we have defined a word a1 a2⋯a i with the property that it is a prefix of infinitely many elements of \(\mathcal {S}\). Then since \(\mathcal {A}\) is finite, there is some \(a_{i+1}\in \mathcal {A}\) such that a1 a2⋯a i ai+1 is a prefix of infinitely many elements of \(\mathcal {S}\). Continuing in this way, we obtain an infinite word w with the desired property. □
The next result is Furstenberg’s theorem, which is part of a more general result in Ergodic theory. We give an algebraic proof in the case in which we are interested. We recall that a right-infinite word is uniformly recurrent if each factor u has the property that there is some natural number N = N(u) such that whenever u occurs as a factor, its next occurrence is at most N positions later in our right-infinite word. As far as we know, this rather simple proof (which requires the axiom of choice) does not appear in the literature.
Theorem 4.4.9 (Furstenberg’s theorem)
Let \(\mathcal {A}\) be a finite alphabet and let \(w\in \mathcal {A}^{\mathbb {N}}\) . Then there is a uniformly recurrent word \(u\in \mathcal {A}^{\mathbb {N}}\) such that every finite factor of u is a factor of w.
Proof
Let K be a field. Write \(\mathcal {A}=\{x_1,\ldots ,x_k\}\), and consider the algebra B = K{x1, …, x k }/I, where I is the ideal generated by all monomials that do not occur as a factor of w. Then B is infinite-dimensional as a K-vector space since w is infinite and the images of the factors of w are linearly independent in B. Now let \(\mathcal {S}\) denote the collection of ideals J of K{x1, …, x k } that are generated by monomials, contain I, and have the property that B/J is infinite-dimensional. Then \(\mathcal {S}\) is nonempty since I is in \(\mathcal {S}\). We note that \(\mathcal {S}\) is closed under unions of chains, for if L is the union of a chain in \(\mathcal {S}\), then L is certainly generated by monomials and contains I; if K{x1, …, x k }/L is finite-dimensional, then there is some N such that L contains all monomials of length ≥ N. In particular, L is finitely generated as it generated by all monomials of length exactly N along with the finite set of monomials of length < N that are in L. Since L is the union of a chain in \(\mathcal {S}\), and L is finitely generated, there is some element in our chain that must be equal to L. Thus we can pick a maximal element L of \(\mathcal {S}\) by Zorn’s lemma. Now since L is generated by monomials, K{x1, …, x k }/L is spanned by the images of all monomials over x1, …, x k that are not in the ideal L. Since K{x1, …, x k }/L is infinite-dimensional and the collection of words that are not in L is closed under taking factors, we see by König’s infinity lemma that there is a right-infinite word u with the property that all factors of u are not in L. In particular, they are not in I, and so all factors of u are factors of w.
We claim that u is uniformly recurrent. If not, there is some finite factor u0 such that there are arbitrarily long factors of u that avoid u0. Then let L′ be the ideal generated by u0 and L. Then since there are arbitrarily long words in u that avoid u0, we see that these words have nonzero image in the ring K{x1, …, x k }/L′, and so K{x1, …, x k }/L′ is infinite-dimensional. But this contradicts maximality of L in \(\mathcal {S}\). The result follows. □
Proof (Proof of Theorem 4.4.7)
We follow the proof of Pirillo [484]. By Furstenberg’s theorem, there is some uniformly recurrent right-infinite word v such that every factor of v is a factor of w. Now if v is eventually periodic, then \(v=v_0 w_0^{\omega }\) for some v0, w0 with w0 nontrivial, and we get the claim. If v is not eventually periodic, then v must have at least m distinct factors of length m − 1 (see [14, Theorem 10.2.6]). Let w1, …, w m be these distinct factors and suppose that w1 ≻ w2 ≻⋯ ≻ w m . Since v is uniformly recurrent, there is a factor v0 of v that can be written in the form v0 = v1⋯v m where w i is a prefix of v i . Then we see that vσ(1)⋯vσ(m) ≺ v1⋯v m , where the inequality is strict whenever σ is not the identity. □
Shirshov’s theorem has as an immediate application the following result about algebras satisfying a polynomial identity.
Corollary 4.4.10 (Shirshov)
Let K be a field and let B be a finitely generated K-algebra with generators x1, …, x k that satisfies a polynomial identity. Then either B is finite-dimensional as a K-vector space or there is some word w ∈{x1, …, x d }∗ such that the images of 1, w, w2, … in the algebra B are linearly independent over K.
Proof
We put the degree lexicographic order, ≺, on the monomials in {x1, …, x k }∗ induced by the x1 ≻ x2 ≻⋯ ≻ x k . We let ≺ p be the corresponding pure lexicographic order. Let I be the two-sided ideal of K{x1, …, x k } generated by the collection of monomials w ∈{x1, …, x k }∗ with the property that the image of w in B can be expressed as a K-linear combination of the image of monomials that are strictly smaller than w in the degree lexicographic order. Since B satisfies a polynomial identity, we know that it satisfies a homogeneous multilinear identity by Proposition 4.4.4. We may write this identity as
It then follows that if w1 ≻ p w2 ≻ p w3 ≻ p ⋯ ≻ p w m with no w i equal to a prefix of w j for i ≠ j then the identity f shows that w1 w2⋯w m can be written as a K-linear combination of strictly smaller words in the degree lexicographic order.
Now if K{x1, …, x k }/I is finite-dimensional, then B is finite-dimensional since by construction the images in B of words over {x1, …, x k }∗ that are not in I span B as a K-vector space. So if B is infinite-dimensional over K, then K{x1, …, x k }/I must be infinite-dimensional. Then there are arbitrarily long words on {x1, …, x k }∗ that are not in the ideal I, and so by König’s infinite lemma, we see that there is a right-infinite word w whose factors all lie outside of the ideal I. But by the remarks above, we see that w cannot contain any factor of the form w1 w2⋯w m with w1 ≻ p w2 ≻ p w3 ≻ p ⋯ ≻ p w m with no w i equal to a prefix of w j for i ≠ j. Thus, by Shirshov’s theorem, there is a nontrivial word w0 such that for every d ≥ 1, \(w_0^d\) is a factor of w. This means that \(w_0, w_0^2,\ldots \) are not in I. By definition of I this means that their images in B are linearly independent in B. □
In fact, there is an even stronger version of Shirshov’s theorem for rings satisfying a polynomial identity, which we give now.
Theorem 4.4.11 (Strong version of Shirshov’s theorem)
Let C be a commutative ring, and let B be a finitely generated C-algebra with generators x1, …, x k and which satisfies a polynomial identity of degree d. Then every element in B is a C-linear combination of elements of the form
where m ≤ d5kd and w1, …, w m are words of length less than d.
Proof
See Theorem 1.2.2 of Amitsur and Small [21]. □
We have the following unexpected application of Shirshov’s theorem to functions with a shuffle property.
Corollary 4.4.12
Let K be a field and let \(f:\mathcal {A}\rightarrow K\) have the d-shuffle property. Then the vector space L(f) (resp. R(f)) is spanned by elements of the form \(f_{w_1^{j_1}\cdots w_m^{j_m}}\) (resp. \(f^{w_1^{j_1}\cdots w_m^{j_m}}\) ) with \(m\le d^5|\mathcal {A}|{ }^d\) and w1, …, w m words of length at most d.
Proof
Write \(\mathcal {A}=\{x_1,x_2,\ldots ,x_k\}\). Let B = K{x1, …, x k } be the free K-algebra on k-variables, i.e., the ring of “noncommutative polynomials” in k variables with coefficients in K.
We define an ideal I ⊆ K{x1, …, x k } as follows. Given words w1, …, w m in x1, …, x k , we declare that
if
We note that all such relations form an ideal. Notice that since f has the d-shuffle property, for any d words w1, …, w d , we have
Since the function
is multilinear, we see that S d (b1, …, b d ) ∈ I for all b1, …, b d in B. Consequently, B/I satisfies a polynomial identity. It follows from Theorem 4.4.11 that every element of B/I is a K-linear combination of the images of elements of the form \(w_1^{j_1}\cdots w_m^{j_m}\) with \(m\le d^5|\mathcal {A}|{ }^d\), j1, …, j m ≥ 0 and w1, …, w m words of length at most d. It follows that any word w ∈{x1, …, x k }∗ there is some b ∈ I such that w − b can be written as a linear combination of words of the form \(w_1^{j_1}\cdots w_m^{j_m}\) with \(m\le d^5|\mathcal {A}|{ }^d\) and w1, …, w m of length at most d. By definition of I we then have
We thus obtain the desired result. A similar argument works for the vector space R(f). □
4.5 Characterization of \(\mathcal {A}\)-Regular Sequences
In this section, we are finally able to give the general version of Kleene’s theorem along with the structure result of Berstel and Reutenauer.
Lemma 4.5.1
Let K be a field, let d and e be positive integers, and let \(f:\mathcal {A}^*\rightarrow K\) be a function with the e-power property and let m be at most \(d^5|\mathcal {A}|{ }^d\) and let w1, …w m be words of length at most d. Then there exists e ≥ 0 such that the K-vector space spanned by \(\{f_{w_1^{i_1}\cdots w_m^{i_m}}~|~i_1,\ldots ,i_m\ge 0\}\) (resp. \(f^{w_1^{i_1}\cdots w_m^{i_m}}~|~i_1,\ldots ,i_m\ge 0\}\) ) is spanned by
(resp. \(\{f_{w_1^{i_1}\cdots w_m^{i_m}}~|~0\le i_1,\ldots ,i_m\le e\}\) ).
Proof
By the e-power property, there exist polynomials Φ1, …, Φ m of degree at most e with constant coefficient 1 such that for every word u we have
is a polynomial in K[t] of degree at most e. Let e be the maximum of the degrees of P, Φ1, …, Φ m . Now suppose that it is not the case that \(\{f_{w_1^{i_1}\cdots w_m^{i_m}}~|~0\le i_1,\ldots ,i_m\le e\}\) spans \(\{f_{w_1^{i_1}\cdots w_m^{i_m}}~|~i_1,\ldots ,i_m\ge 0\}\). Then there exist j1, …, j m with j i > e for some i such that \(f_{w_1^{j_1}\cdots w_m^{j_m}} \) is not in the span of \(\mathcal {S}\). It is no loss of generality to assume that (j1, …, j m ) has the property that if \((j_1^{\prime },\ldots ,j_m^{\prime })\) satisfies:
-
\(j_k^{\prime }\le j_k\) for 1 ≤ k ≤ m; and
-
\((j_1^{\prime },\ldots ,j_m^{\prime })\neq (j_1,\ldots ,j_m)\),
then
By assumption j i > e and by the e-power property, we have
where c k is the coefficient of xk in Φ i . Hence
since Φ i has constant coefficient 1. By minimality, we deduce that \(f_{w_1^{j_1}\cdots w_m^{j_m}}\) is in the span of \(\{f_{w_1^{i_1}\cdots w_m^{i_m}}~|~0\le i_1,\ldots ,i_m\le e\}\), a contradiction. The result follows. □
Theorem 4.5.2 (Berstel-Reutenauer)
Let K be a field and let \(f:\mathcal {A}^*\rightarrow K\) . Then the following are equivalent:
-
1.
f is right k-regular;
-
2.
f is left k-regular;
-
3.
f has the d-shuffle and the d-power property for some d;
-
4.
f has the d-shuffle and the d-power property for all sufficiently large d.
Proof
From Propositions 4.2.5, 4.2.8, and 4.3.2, we have that if f is either right or left k-regular, then f has the d-shuffle and the d-power property for all sufficiently large d. Hence (1) and (2) both imply (4). Clearly (4) implies (3). Thus, it is sufficient to show that if f has the d-shuffle and the d-power property for some d, then f is both left and right regular. Suppose that f has the d-shuffle and the d-power property. We claim that the K-vector space L(f) is finite-dimensional. To see this, notice that by Corollary 4.4.12, the vector space L(f) is spanned by elements of the form \(f_{w_1^{i_1}\cdots w_m^{i_m}}\) with \(m\le d^5|\mathcal {A}|{ }^d\) and w1, …, w m having length at most d. Since f has the d-power property, by Lemma 4.5.1 for any words w1, …, w m of length at most d with \(m\le d^5|\mathcal {A}|{ }^d\), the K-vector space spanned by \(\{f_{w_1^{i_1}\cdots w_m^{i_m}}~|~i_1,\ldots ,i_m\ge 0\}\) is spanned by
It now follows that L(f) is in the K-span of the set
Thus L(f) is finite-dimensional and so f is left \(\mathcal {A}\)-regular. A similar argument shows that f is right \(\mathcal {A}\)-regular and hence (3) implies both (1) and (2). □
As a result of the equivalence between left and right regularity, we drop the words left and right and talk only of \(\mathcal {A}\)-regular functions from now on.
Corollary 4.5.3
Let \(f:\mathcal {A}^*\rightarrow A\) . Then the following are equivalent:
-
1.
f is k-automatic;
-
2.
f has the d-shuffle and the d-power property for some d and has a finite range;
-
3.
f has the d-shuffle and the d-power property for all sufficiently large d and has a finite range.
We make the following remark that follows from the proof of Theorem 4.5.2. This gives a bound on the dimension of the vector space in terms of the quantities d and e for which one has the d-shuffle and e-power property, which is undoubtedly far from optimal, but has the advantage of being explicit in terms of d and e.
Remark 4.5.4
If \(|\mathcal {A}|\ge 2\) and \(f:\mathcal {A}^*\to K\) has the d-shuffle property and the e-power property, then L(f) and R(f) are both at most N-dimensional where
Proof
The proof of Theorem 4.5.2 shows that L(f) is in the K-span of the set
Since there are at most \(|\mathcal {A}|{ }^{d+1}\) words of length at most d, we see that the number of m-tuples of words of length at most d with \(m\le d^5|\mathcal {A}|{ }^d\) is at most
Now for each such m-tuple, we pick up a space of dimension at most (e + 1)m in our spanning set, and so the dimension of L(f) is at most \((e+1)^{d^5 |\mathcal {A}|{ }^d} |\mathcal {A}|{ }^{2d^6|\mathcal {A}|{ }^d}\). A similar argument works for R(f). □
4.6 Sandwich Functions
In this section we introduce a special type of function that is produced from a K-valued function on a free monoid, where K is a field; these functions will be called, for reasons that will soon become apparent, sandwich functions. We will then characterize all automatic sandwich functions.
Let \(\mathcal {A} = \{ x_1,\ldots ,x_k\}\) be a finite alphabet. We put a pure lexicographic order ≼ on \(\mathcal {A}^*\) by declaring that
We note that this lexicographic order extends to right infinite words over the alphabet \(\mathcal {A}\).
Let w1 and w2 be two (possibly right-infinite) words on \(\mathcal {A}\) with w1 ≼ w2. In dealing with right-infinite words, it will be convenient to use wω to denote the right-infinite word wwww⋯. We define \(f:\mathcal {A} \rightarrow \{0,1\}\) by f(w) = 1 if w1 ≼ w ≼ w2 and f(w) = 0 otherwise. We call f a sandwich function since the words which get mapped to 1 are sandwiched between w1 and w2.
Example 4.6.1
Let \(\mathcal {A}=\{x_1,\ldots ,x_k\}\). Then the constant function 1 and the constant function 0 are both sandwich functions.
Proof
To get the constant function 1, take w1 = ε and take \(w_2=x_k^{\omega }\). To get the constant function 0, take \(w_1=w_2=x_k^{\omega }\). □
Example 4.6.2
Let \(\mathcal {A}=\{x_1,\ldots ,x_k\}\). Then the function f which sends words beginning with x1 to 1 and all other words to 0 is a sandwich function.
Proof
Take w1 = x1 and take \(w_2=x_1x_k^{\omega }\). Then the sandwich function given by these words is f. □
We now characterize \(\mathcal {A}\)-automatic sandwich functions. To do this we first prove some basic results. As notation for the following lemma, we introduce the function χ which inputs a statement and outputs 1 if the statement is true and 0 if the statement is false.
Lemma 4.6.3
Let w be a (possibly right-infinite) word on a finite alphabet \(\mathcal {A}\) which is either finite or eventually periodic. Then the functions f(u) := χ(u ≼ w) and g(u) = χ(u ≽ w) are both \(\mathcal {A}\) -automatic.
Proof
If w is finite, notice that if v is a word whose length is greater than the length of w, then
Hence the vector space L(f) is contained in the space spanned by the constant function 1 and the functions {f v | length(v) ≤length(w)}. Thus L(f) is finite-dimensional. A similar argument shows that L(g) is finite-dimensional. If w is eventually periodic, then we can write \(w=w_1w_2^{\omega }\). Notice that if v is not an initial factor of w, then
which is a constant function. If v is an initial factor of w of length at least length(w1) + 2length(w2), then \(f_v=f_{v'}\), where v′ is an initial factor of v obtained by removing the last length(w2) letters from v. Hence L(f) is again contained in a finite-dimensional vector space and hence must be finite-dimensional. A similar argument works for L(g). □
We need a lemma about monotonic subsequences.
Lemma 4.6.4
Let w be a right-infinite word on a finite alphabet \(\mathcal {A}\) which is not eventually periodic. Then for any d ≥ 1, there exist finite words u1, …, u d such that:
-
length(u1) < length(u2) < ⋯ < length(u d );
-
the sequence u1, …, u d is monotonic with respect to ≺;
-
for 2 ≤ i ≤ d, there exists a word \(u_i^{\prime }\neq u_i\) of the same length as u i which does not have ui−1 as an initial factor and has the property that \(u_{i-1},u_i^{\prime },u_i\) is monotonic;
-
u1 u2⋯u d is a factor of w.
Proof
For i ≥ 0 define w i to be the right-infinite word obtained by removing the first i letters from w. Since w is not eventually periodic, the words w0, w1, … are all distinct. It follows that they are totally ordered by ≺. It follows that there is a monotonic (with respect to ≺) subsequence \(w_{i_1},w_{i_2},\ldots \) of w0, w1, …. Without loss of generality \(w_{i_1} \prec w_{i_2} \prec \cdots .\) Let \(v_j=w_{i_j}\) for j ≥ 1. Pick k1 = 1. Since v1 ≺ v2 and v2 is not eventually periodic, there exists some number m1 such that the first m1 letters of v1 differ from the first m1 letters of v2 and the first m1 letters of v2 differ with the first m1 letters of v3. Choose j1 ≥ m1 such that if we remove the first j1 letters of v1 be obtain a word \(v_{k_2}\) with k2 ≥ 3. Define u1 to be the first j1 letters of v1. Now \(v_{k_2}\prec v_{k_2+1}\) and hence there is some m2 such that the first m2 letters of \(v_{k_2}\) differ from the first m2 letters of \(v_{k_2+1}\) and the first m2 letters of \(v_{k_2+1}\) differ from the first m2 letters of \(v_{k_2+2}\). As before, we choose \(j_2>\max (j_1, m_2)\) such that if we remove the first j2 letters of \(v_{k_2}\) we obtain some word \(v_{k_3}\) with k3 ≥ k2 + 2. We define u2 to be the first j2 letters of \(v_{k_2}\) and \(u_2^{\prime }\) to be the first j2 letters of v2. Notice that \(u_1\prec u_2^{\prime }\prec u_2\) and \(u_2^{\prime }\neq u_2\), and it cannot have u1 as an initial factor of u1. Continuing in this manner, we see that we can write
with u some initial factor and words u1, u2, …, u d , \(u_1^{\prime },\ldots ,u_d^{\prime }\) satisfying the conditions in the statement of the lemma. □
Theorem 4.6.5
Let w 1 and w 2 be (possibly right-infinite) words on a finite alphabet. Then the sandwich function f corresponding to w 1 and w 2 is \(\mathcal {A}\) -automatic if and only if w 1 and w 2 are both either finite or ultimately periodic.
Proof
Suppose that w1 is neither finite nor ultimately periodic. Write \(w_1=w_1^{\prime }w_1^{\prime \prime }\) where \(w_1^{\prime }\) is a finite word which is not an initial factor of w2 and \(w_1^{\prime \prime }\) is a right-infinite word. Then \(w_1^{\prime \prime }\) is not eventually periodic and hence by Lemma 4.6.4, for any d we can find words u, u1, u2, …, u d such that \(w_1=w_1^{\prime }uu_1\cdots u_du'\) for some right-infinite word u′; u1, …, u d is monotonic with respect to ≺;
and for i ≥ 2 there exist words \(u_i^{\prime }\) with \(u_{i-1},u_i^{\prime },u_i\) monotonic with \(u_i^{\prime }\neq u_i\), \(\mathrm {length}(u_i^{\prime })=\mathrm {length}(u_i)\) and ui−1 not an initial factor of \(u_i^{\prime }\). We have two cases: Case I u1 ≺ u2 ≺⋯ ≺ u d . In this case take \(v_d = u_d^{\prime }\) and for 1 ≤ i ≤ d − 1 take v i = u i . Consider
Notice that since \(w_1^{\prime }u\) is lexicographically less than the initial factor of w2 of the same length and since v1 ≺ v2 ≺⋯ ≺ v d , we have that
unless σ is the identity. When σ is the identity, we have \(w_1 \ \not \preceq \ w_1^{\prime }uv_1\cdots v_d\) and hence
Thus f cannot have the d-shuffle property. Since d is arbitrary we conclude that f is not \(\mathcal {A}\)-automatic. Case II: u1 ≻ u2 ≻⋯ ≻ u d . In this case take \(v_d = u_d^{\prime }\) and for 1 ≤ i ≤ d − 1 take v i = u i . In this case we have
Thus the result again holds in this case. In either case, the d-shuffle property fails to hold for any d, and so our function cannot be \(\mathcal {A}\)-regular. A similar argument shows that f is not \(\mathcal {A}\)-regular if w2 is right-infinite and not eventually periodic.
Next consider what happens if w1 and w2 are finite or eventually periodic. Then by the lemma
and hence f is the coordinate-wise product of two \(\mathcal {A}\)-automatic sequences. It follows that f is automatic. □
4.7 Applications
4.7.1 The Logarithm and Automaticity
We now give an application of our description of automatic sandwich functions to answer a question of Allouche and Shallit. We note that this question had been answered via a different method by Yossi [425] in 2008.
Proposition 4.7.1
Let \(\alpha \in \mathbb {R}\) . Then the sequence given by f(0) = 1 and
is k-regular if and only if k α is rational.
Proof
We may assume that α ∈ [0, 1). It is easy to verify that the function g(0) = 0 and g(n) = ⌊log k n⌋ for n ≥ 1 is k-regular. Let us consider the function f(n) − g(n). This function takes values in {0, 1} and is 1 at an integer n ≥ 1 if and only if there is some integer m such that
Equivalently, we must have
Write
with a i ∈{1, 2, 3, …, k}. Let w1 = ε and let w2 be the right-infinite word a1 a2 a3⋯. Let w be the word in {1, 2, …, k} which corresponds to n using the correspondence described in equation (4.1). Then if we regard h := f − g as a function on {1, 2, …, k}∗, then h(w) = 1 if and only if w ≼ w2, where ≺ is the lexicographic order induced by taking 1 ≺ 2 ≺⋯ ≺ k; equivalently, h(w) = 1 if w1 ≼ w ≼ w2 and is 0 otherwise. Hence h is a sandwich function. Notice that w2 is a right-infinite word which is eventually periodic if and only if kα is rational. Thus h is k-regular if and only if kα is rational. Since f = g + h and g is k-regular, we see that f is k-regular if and only if h is k-regular. The result now follows. □
Allouche and Shallit [14] ask whether the sequence \(\lfloor \log _2 n + \frac {1}{2}\rfloor \) is 2-automatic; since \(\sqrt {2}\) is irrational, we deduce that it is not.
4.7.2 The 2-Adic Behavior of the Logarithm
Allouche and Shallit [14, Section 16.7, Q. 4] ask whether the sequence
is 2-regular, where v2(i) is the 2-adic valuation; that is, v2(i) satisfies \(2^{v_2(i)}|i\) but \(2^{v_2(i)+1}\not |i\). We show that it is not. Here we use the fact that right regularity and left regularity are equivalent properties to answer a question which is difficult to handle using the traditional definition of regularity in terms of right regularity, but which is easily handled if one uses the notion of left regularity.
Proposition 4.7.2
Let
Then f(n) is not 2-regular.
Proof
Let \(\mathcal {A}=\{0,1\}\). Let \(w_i=1^i0\in \mathcal {A}^*\). Consider the subspace of L(f) generated by \(\{f_{w_i} ~|~i\ge 0\}\). Suppose that f is \(\mathcal {A}\)-regular. Then since L(f) is finite-dimensional, there exists some m ≥ 3 such that this subspace is spanned by \(\{f_{w_i}~|~i\le m\}.\) Let \(d=2^{2^m}\). By assumption, there exist integers c0, …, c m such that
In particular, we have
for all j ≥ 0. Observe that for [w i w j ]2 = 2i+j+2 − 2 − 2j. Hence
In particular, if m ≤ j ≤ 2m, we have f(w d w j ) = 2d+j+2 − d − j − 2 and f(w i w j ) = 2i+j+2 − 2j − j for 1 ≤ i ≤ m. Using equation (4.7), we see that for m ≤ j ≤ 2m we have
Simplifying, we deduce
for m ≤ j ≤ 2m. Let
and let
Then we have
for m ≤ j ≤ 2m. Consider the function G(x) = 2xA + xB − (d + 2). We have G(m) = G(m + 1) = ⋯ = G(2m) = 0 and hence by Rolle’s theorem \(G'(x)=2^x A \log 2 + B\) must have at least 2m − m ≥ 2 real zeros. This implies that A = B = 0 since the function G′(x) is monotonic. Then the fact that G(m) = 0 along with A = B = 0 now implies that d + 2 = 0, which is a contradiction. It follows that f(n) is not a 2-regular function. □
4.7.3 Nim Sums and Nim Products
In this subsection we consider the 2-regularity of sequences constructed using nim sums and nim products. Given nonnegative integers n and m, we define the nim sum , n ⊕ m, of n and m as follows. We write n = [a d ⋯a0]2 with a i ∈{0, 1} and m = [b d ⋯b0]2 with b i ∈{0, 1}, where we may pad the binary expansion of either a or b with zeros at the beginning to ensure that they have the same length. We then define
For example, if m = 12 and n = 21, then
The nim product , ⊗, is defined as follows:
The product is then defined for all pairs of natural numbers using associativity and distributivity. For example,
The nim sum and nim products have the following properties, which can be found in Conway [162, Chap. 6]:
-
\(2^{2^a}\otimes x = 2^{2^a}x\) for \(0\le x<2^{2^a}\);
-
the set of nonnegative numbers less than \(2^{2^a}\) is a field under ⊕ and ⊗.
Allouche and Shallit [14, Section 16.7, Q. 5,6] ask the following questions:
-
Is the nim sum of two 2-regular sequences a 2-regular sequence?
-
Is the sequence {n ⊗ n} a 2-regular sequence?
We show the answer to these questions is “no.” In fact, Allouche and Shallit ask questions involving 2-dimensional arrays of numbers, but negative answers to the above questions imply negative answers to their questions about arrays. This time, we use the power property and show that it fails to hold.
Lemma 4.7.3
Let i be a nonnegative integer. Then 2i ⊗ 2i = 3 ⋅ 2i−1 if and only if i is a power of 2.
Proof
If i is a power of 2, then 2i ⊗ 2i = 3 ⋅ 2i−1 by the definition of the nim product. Next suppose that i is not a power of 2. Then there is some a such that i = 2a + j with 0 < j < 2a. Then
where we are using the two facts from Conway mentioned above to obtain these equalities.
Observe that if 2i ⊗ 2i = 3 ⋅ 2i−1, then the binary expansion of 2i ⊗ 2i cannot have any 1’s appearing in the 2a + j − 1 least significant digits. In particular it must have 0’s appearing in the 2a least significant digits. Since \(2^{2^a}\otimes (2^j\otimes 2^j)\) has this property, \( 2^{2^a-1}\otimes (2^j\otimes 2^j)\) must also have this property if 2i ⊗ 2i = 3 ⋅ 2i−1, as the nim sum of these two numbers is 2i ⊗ 2i. But since \(\{0,1,\ldots ,2^{2^a}-1\}\) is a field under ⊗ and ⊕, we see that \(2^{2^a-1}\otimes (2^j\otimes 2^j)\) is a nonzero number less than \(2^{2^a}\). We conclude that 2i ⊗ 2i ≠ 3 ⋅ 2i−1. □
Proposition 4.7.4
The sequence {m ⊗ m} is not 2-regular.
Proof
To do this, we show that the sequence does not have the power property. It is sufficient to show that the power series
is not rational. Suppose that F(x) is rational. Then
must also be rational. Notice that by Lemma 4.7.3 the coefficient of xn is zero in G(x) if and only if n is a power of 2. If follows from the Skolem-Mahler-Lech theorem (see [282]) that G(x) is not rational. We conclude that F is not rational and so {n ⊗ n} is not 2-regular. □
Proposition 4.7.5
There exist 2-regular sequences f(n) and g(n) such that f(n) ⊕ g(n) is not 2-regular.
Proof
Let f(n) be defined by
Then it is easy to check that f(n) is 2-shuffled and has the power property. Hence f is 2-regular. Let
Then g(n) is 2-regular. Observe that f(2m) ⊕ g(2m) = f(2m) − g(2m) if and only if the binary expansion of m has 0’s in all the even positions (beginning the count from the least significant digit). Suppose that f(n) ⊕ g(n) is 2-regular. Then the power property gives that the sequence
must satisfy a linear recurrence. If this is the case, then by the Skolem-Mahler-Lech theorem (see [282]), the set of m such that \(f(2^m)\oplus g(2^m)=\frac {4^m-1}{3}-m\) must contain an infinite arithmetic progression. But
In other words, the density of the set of m such that \(f(2^m)\oplus g(2^m)=\frac {4^m-1}{3}-m\) is 0. But this is a contradiction, since by the Skolem-Mahler-Lech theorem, the density must be positive. It follows that f ⊕ g is not 2-regular. □
We note that if f(n) and g(n) are k-automatic, then both f(n) ⊗ g(n) and f(n) ⊕ g(n) are k-automatic; this follows easily from the fact that k-automatic sequences assume only finitely many different values.
4.8 Shuffled Sequences
In this section we develop the basic properties of sequences possessing the shuffle property. We will find it more useful to work with abelian groups rather than fields in obtaining some of our closure properties, so we shall adopt this point of view in this section.
Definition 4.8.1
Let \(\mathcal {A}\) be a finite alphabet and let A be an abelian group. We say that \(f:\mathcal {A}^*\rightarrow A\) is an \(\mathcal {A}\)-shuffled sequence if f has the d-shuffle property for some positive integer d. In the case that \(\mathcal {A}=\{1,2,\ldots ,k\}\), we say that f is k-shuffled. We point out that being k-shuffled is not the same as having the k-shuffle property; when we use the word shuffled, the k is making reference to the underlying alphabet and when we use the word shuffle, the k is making reference to the shuffle identity satisfied by a function.
In the case that no confusion will arise, we will drop the alphabet and refer to a sequence as being a shuffled sequence. We note that the shuffle property, although originally defined in the case where our abelian group is a field (with group law given by addition), makes sense in this more general setting.
We have the following containments:
It is well known [14, Theorem 16.3.1] that a k-regular sequence \(f:\mathbb {N}\to \mathbb {Z}\) has polynomially bounded growth in the sense that there is some d > 0 such that |f(n)|≤ nd for all sufficiently large n. The following example shows that no such growth restriction on shuffled sequences holds.
Example 4.8.2
A k-shuffled sequence can have arbitrarily rapid growth.
Proof
Let a1, a2, … be a sequence of integers and let \(f:\{1,2\}^*\rightarrow \mathbb {C}\) be defined by
Then f(w) has the 2-shuffle property and hence is a shuffled sequence. Since the a d are arbitrary, we see that shuffled sequences can have arbitrarily rapid growth. □
We now give some closure properties for shuffled sequences.
Proposition 4.8.3
Let A and B be two abelian groups, and let \(\mathcal {A}\) be a finite alphabet. If \(f:\mathcal {A}^*\rightarrow A\) and \(g:\mathcal {A}^*\rightarrow B\) are shuffled sequences, then so are \((f\oplus g):\mathcal {A}^*\rightarrow A\oplus B\) and \(f\otimes g:\mathcal {A}^*\rightarrow A\otimes _{\mathbb Z} B\) . (Here f ⊕ g)(w) = f(w) ⊕ g(w) and f ⊗ g(w) = f(w) ⊗ g(w).)
Proof
Create the ideals I1 and I2 in \(\mathbb {Z}\{x_1,\ldots ,x_k\}\) as follows. Let I1 be the set of elements of the form c1 w1 + ⋯c d w d such that
for all \(w,w'\in \mathcal {A}^*\). Similarly, define I2 to be the set of elements of the form c1 w1 + ⋯c d w d with
for all \(w,w'\in \mathcal {A}^*\). Then I1 and I2 are ideals and \(R_1:=\mathbb {Z}\{x_1,\ldots ,x_k\}/I_1\) and \(R_2:=\mathbb {Z}\{x_1,\ldots ,x_k\}/I_2\) both satisfy the identity S d and hence satisfy polynomial identities. It follows from Regev’s theorem [498], that \(R_1\otimes _{\mathbb Z} R_2\) also satisfies a polynomial identity. Since it is finitely generated as a \(\mathbb {Z}\)-algebra, it satisfies the standard identity S m for some m ≥ 0. Now suppose that the image of \(\sum c_{i,j} w_i\otimes w_j\) is zero in \(R_1\otimes _{\mathbb Z} R_2\). Then by construction, we have
for all words w, w′. Let \(R\subseteq R_1\otimes _{\mathbb Z} R_2\) be the subalgebra generated by the images of x1 ⊗ x1, …, x k ⊗ x k . Then R must also satisfy the identity S m , since it is a subring of R1 ⊗ R2. Consequently, the sequence f ⊗ g must have the m-shuffle property. □
Remark 4.8.4
Let \(\mathcal {A}\) be a finite alphabet and let A and B be abelian groups. If \(f:\mathcal {A}^*\rightarrow A\) is a shuffled sequence and ϕ : A → B is a homomorphism of abelian groups, then \(\phi \circ f:\mathcal {A}^*\rightarrow B\) is a shuffled sequence.
Corollary 4.8.5
Let \(\mathcal {A}\) be a finite group and let A be an abelian group. If \(f,g:\mathcal {A}\rightarrow A\) are shuffled, then (f + g) is shuffled. If, in addition, A is a ring then f ⋅ g is shuffled.
Proof
For the first part, use Proposition 4.8.3 and Remark 4.8.4, taking the homomorphism ϕ : A ⊕ A → A given by ϕ(a, a′) = a + a′. For the product, again use Proposition 4.8.3 and Remark 4.8.4, this time taking the homomorphism ϕ : A ⊗ A → A given by ϕ(a ⊗ a′) = aa′. □
Sometimes it is easier to verify that a sequence is shuffled by showing that an identity holds other than the standard identity of the shuffle property holds. We make this more precise in the next theorem.
Theorem 4.8.6
Let n be a nonnegative integer. Suppose that there exist integers {c σ | σ ∈ S n }, at least one of which is equal to 1, such that
for all words \(w,w_1,\ldots ,w_n,w'\in \mathcal {A}^*\) . Then f is shuffled.
Proof
Write \(\mathcal {A}=\{x_1,\ldots ,x_k\}\). We define an ideal I in the algebra \(\mathbb {Z}\{x_1,\ldots ,x_k\}\) as follows. We declare that \(\sum a_w w \in I\) if
for all \(w',w''\in \mathcal {A}^*\). Notice that \(R=\mathbb {Z}\{x_1,\ldots ,x_k\}/I\) satisfies a polynomial identity, as it satisfies the multilinear, homogeneous polynomial identity \(\sum _{\sigma \in S_n} c_{\sigma } t_{\sigma (1)}\cdots t_{\sigma (n)}\). Since R is finitely generated, it satisfies a standard identity S m for some m (cf. Theorem 4.4.6 and see, also, Braun [105]). Consequently,
for all \((w_1,\ldots ,w_m) \in (\mathcal {A}^*)^m\). Hence
for all \(w,w_1,\ldots ,w_m,w'\in \mathcal {A}^*\). □
Let \(\mathcal {A}\) be a finite alphabet and let R be a ring. The set of maps \(f:\mathcal {A}^*\rightarrow R\) has a multiplication defined as follows: Given \(x_1,\ldots ,x_d\in \mathcal {A}\), we define
where f(x1⋯x i ) is taken to mean f(ε) when i = 0 and we take g(xi+1⋯x d ) to be g(ε) when i = d. This product, along with ordinary sum, turns the set of maps \(f:\mathcal {A}^*\rightarrow R\) into an associative ring [77]. We show that the shuffled sequences form a subalgebra.
Proposition 4.8.7
If \(f:\mathcal {A}^*\rightarrow A\) and \(f:\mathcal {A}^*\rightarrow A\) are shuffled, then f ⋆ g is shuffled.
Proof
We may pick d such that f and g both have the d-shuffled property. We claim that if \(w_1,\ldots ,w_d,u_1,\ldots ,u_d,w,w'\in \mathcal {A}^*\), then
To see this, let
Then
If v1 v2 = v(σ, τ) then either v1 = v1(σ, τ) contains wwσ(1)⋯wσ(d) as an initial factor, or v2 = v2(σ, τ) contains uτ(1)⋯uτ(d) w′ as a terminal factor (or both). Notice that if \(v_1=ww_{\sigma (1)}\cdots w_{\sigma (d)}v_1^{\prime }\), then \(v_1^{\prime }\) and v2 depend only on τ. Hence
since f has the d-shuffled property. Similarly, if v2 contains the terminal factor uτ(1)⋯uτ(d) w′, then the fact that g has the d-shuffled property guarantees that
Observe that S d × S d embeds in S2d by taking an ordered pair (σ, τ) and letting σ act on {1, 2, …, d} and letting τ act on {d + 1, …, 2d}. Given μ ∈ S2d, we define c μ = sgn(σ)sgn(τ) if μ corresponds to (σ, τ) under this inclusion and we take c μ = 0 otherwise. Then from Theorem 4.8.6, we see that f ⋆ g is shuffled. □
We let \(\mathcal {S}_k\) denote the collection of k-shuffled sequences taking values in \(\mathbb {C}\). Then we have just shown that \((\mathcal {S}_k,+,\star )\) is a \(\mathbb {C}\)-algebra. The following proposition shows that in some sense this algebra is very large.
Proposition 4.8.8
The algebra \((\mathcal {S}_k,+,\star )\) contains a copy of the free \(\mathbb {C}\) -algebra on infinitely many generators.
Proof
Since the free algebra on two generators contains a copy of the free algebra on infinitely many generators, it is sufficient to do show we contain a copy of the free algebra on two generators. Let \(f_0:\{1,2,\ldots ,k\}^*\rightarrow \mathbb {C}\) be defined to be 1 on words of the form 12i and be defined to be 0 on all other words. Let \(f_1:\{1,2,\ldots ,k\}^*\rightarrow \mathbb {C}\) be defined to be i on the word 12i and to be 0 on words not of the form 12i. Then it is easy to check that f0 and f1 are k-shuffled sequences. We claim that f0 and f1 generate a free algebra. Suppose that
for some d with \(\alpha _{i_1,\ldots ,i_d}\neq 0\) for some (i1, …, i d ) ∈{0, 1}d. Notice that if w is a word of the form \(12^{a_1}12^{a_2} \cdots 12^{a_d}\) then \(f_{i_1}\star \cdots \star f_{i_k}(w)=0\) for k < d. Hence
by assumption G is identically 0 and hence the polynomial
vanishes on all points \((x_1,\ldots ,x_d)\in \mathbb {N}^d\). But this implies that H is the zero polynomial, which contradicts the fact that \(\alpha _{i_1,\ldots ,i_d}\neq 0\) for some (i1, …, i d ) ∈{0, 1}d. We conclude that the algebra generated by f0 and f1 is free. This completes the proof. □
4.9 Open Problems and Concluding Remarks
One of the fundamental theorems from the theory of automatic sequences is Cobham’s theorem. Two integers p and q are multiplicatively independent if pa ≠ qb for (a, b) ≠ (0, 0). Cobham’s theorem [14, Chapter 11] states that if a sequence is p-automatic and q-automatic and p and q are multiplicatively independent, then the sequence is eventually periodic . Given a sequence f(n) taking values in an abelian group, by the correspondence described in item 4.1, it makes sense to talk about the sequence being a k-shuffled sequence.
Question 4.9.1
Suppose a \(\mathbb {Z}\)-valued sequence f(n) is both p-shuffled and q-shuffled for two multiplicatively independent integers p and q. What can be said about f(n)? For instance, does f(n) satisfy a linear recurrence?
Another question comes from looking at closure properties. In Section 4.8 we showed that shuffled sequences are closed under ordinary products and under the ⋆ product. We now ask if shuffled sequences are closed under Cauchy products.
Question 4.9.2
Given integer-valued sequences f(n) and g(n) that are k-shuffled, is the Cauchy product of f(n) and g(n) also k-shuffled?
In Section 4.8 we showed that the set \(\mathcal {S}_k\) of k-shuffled sequences taking values in \(\mathbb {C}\) forms a \(\mathbb {C}\)-algebra under the ⋆ product.
Question 4.9.3
Can one find nice generating sets for the \(\mathbb {C}\)-algebra \((\mathcal {S}_k,+,\star )\)?
Question 4.9.4
Can one extend the notion of shuffled sequences to nonconstant length substitutions ? See, for example, Shallit [542] and Allouche, Scheicher, and Tichy [13].
Two final questions we pose come from the nim sum and nim product. In Section 4.7 we studied sequences defined using the nim sum and the nim product. In each example, we showed that the power property failed to hold. We did not show, however, that the shuffle property fails to hold.
Question 4.9.5
Let ⊕ and ⊗ denote, respectively, the nim sum and the nim product. Is the sequence {m ⊗ m} a 2-shuffled sequence? If f(n) and g(n) are 2-shuffled sequences, is f(n) ⊕ g(n) also a 2-shuffled sequence?
Question 4.9.6
Does {2n ⊕ 3n} satisfy a linear recurrence? We note that this is related to Mahler’s study of Z-numbers [406].
We note that throughout we have been looking at sequences taking values in a field or occasionally in an abelian group. In fact, we can work more generally by using a commutative ring C and look at sequences taking values in a C-module. Allouche and Shallit [16] define the more general notion of a (C, k)-regular sequence. We note that since Shirshov’s height theorem is over a more general base ring C, all the results in this paper which relate to k-regular sequences have analogues in this more general context of (C, k)-regular sequences.
References
Allouche, J.-P., Scheicher, K., Tichy, R.F.: Regular maps in generalized number systems. Math. Slovaca 50, 41–58 (2000)
Allouche, J.-P., Shallit, J.: Automatic Sequences: Theory, Applications, Generalizations. Cambridge University Press, Cambridge (2003)
Allouche, J.-P., Shallit, J.O.: The ring of k-regular sequences. In: Choffrut, C., Lengauer, T. (eds.) STACS 90, Proceedings of the 7th Symposium on Theoretical Aspects of Computer Science. Lecture Notes in Computer Science, vol. 415, pp. 12–23. Springer, Berlin (1990)
Amitsur, A.S., Levitzki, J.: Minimal identities for algebras. Proc. Am. Math. Soc. 1, 449–463 (1950)
Amitsur, S.A., Small, L.W.: Affine algebras with polynomial identities. Rend. Circ. Mat. Palermo (2) Suppl. 31, 9–43 (1993). Recent developments in the theory of algebras with polynomial identities (Palermo, 1992)
Berstel, J., Reutenauer, C.: Noncommutative rational series with applications. Encyclopedia of Mathematics and Its Applications, vol. 137. Cambridge University Press, Cambridge (2011)
Braun, A.: The nilpotency of the radical in a finitely generated PI ring. J. Algebra 89(2), 375–396 (1984)
Conway, J.H.: On Numbers and Games. Academic Press, New York (1976)
Dekking, F.M., Mendès France, M., Poorten, A.J.v.d.: Folds! Math. Intelligencer 4, 130–138, 173–181, 190–195 (1982). Erratum, 5 (1983), 5
Hansel, G.: A simple proof of the Skolem-Mahler-Lech theorem. In: Brauer, W. (ed.) Proceedings of the 12th International Conference on Automata, Languages, and Programming (ICALP). Lecture Notes in Computer Science, vol. 194, pp. 244–249. Springer, Berlin (1985)
Mahler, K.: An unsolved problem on the powers of 3/2. J. Aust. Math. Soc. 8, 313–321 (1968)
Moshe, Y.: On some questions regarding k-regular and k-context-free sequences. Theor. Comput. Sci. 400(1-3), 62–69 (2008)
Pirillo, G.: A proof of Shirshov’s theorem. Adv. Math. 124(1), 94–99 (1996)
Regev, A.: Existence of identities in A ⊗ B. Isr. J. Math. 11, 131–152 (1972)
Rosset, S.: A new proof of the Amitsur-Levitski identity. Isr. J. Math. 23(2), 187–188 (1976)
Shallit, J.O.: A generalization of automatic sequences. Theor. Comput. Sci. 61, 1–16 (1988)
Acknowledgements
I thank Jean-Paul Allouche and Jeffrey Shallit for many helpful comments. I also thank Jean-Paul Allouche for raising Question 4.9.4.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this chapter

Cite this chapter
Bell, J. (2018). Some Applications of Algebra to Automatic Sequences. In: Berthé, V., Rigo, M. (eds) Sequences, Groups, and Number Theory. Trends in Mathematics. Birkhäuser, Cham. https://doi.org/10.1007/978-3-319-69152-7_4
Download citation
DOI: https://doi.org/10.1007/978-3-319-69152-7_4
Published:
Publisher Name: Birkhäuser, Cham
Print ISBN: 978-3-319-69151-0
Online ISBN: 978-3-319-69152-7
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)