
Abstract
This paper proposes a novel multi-layered gesture recognition method with Kinect. We explore the essential linguistic characters of gestures: the components concurrent character and the sequential organization character, in a multi-layered framework, which extracts features from both the segmented semantic units and the whole gesture sequence and then sequentially classifies the motion, location and shape components. In the first layer, an improved principle motion is applied to model the motion component. In the second layer, a particle-based descriptor and a weighted dynamic time warping are proposed for the location component classification. In the last layer, the spatial path warping is further proposed to classify the shape component represented by unclosed shape context. The proposed method can obtain relatively high performance for one-shot learning gesture recognition on the ChaLearn Gesture Dataset comprising more than 50,000 gesture sequences recorded with Kinect.
Editors: Sergio Escalera, Isabelle Guyon and Vassilis Athitsos
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others


Keywords
- Gesture recognition
- Kinect
- Linguistic characters
- Multi-layered classification
- Principle motion
- Dynamic time warping
13.1 Introduction
Gestures, an unsaid body language, play very important roles in daily communication. They are considered as the most natural means of communication between humans and computers (Mitra and Acharya 2007). For the purpose of improving humans’ interaction with computers, considerable work has been undertaken on gesture recognition, which has wide applications including sign language recognition (Vogler and Metaxas 1999; Cooper et al. 2012), socially assistive robotics (Baklouti et al. 2008), directional indication through pointing (Nickel and Stiefelhagen 2007) and so on (Wachs et al. 2011).
Based on the devices used to capture gestures, gesture recognition can be roughly categorized into two groups: wearable sensor-based methods and optical camera-based methods. The representative device in the first group is the data glove (Fang et al. 2004), which is capable of exactly capturing the motion parameters of the user’s hands and therefore can achieve high recognition performance. However, these devices affect the naturalness of the user interaction. In addition, they are also expensive, which restricts their practical applications (Cooper et al. 2011). Different from the wearable devices, the second group of devices are optical cameras, which record a set of images overtime to capture gesture movements in a distance. The gesture recognition methods based on these devices recognize gestures by analyzing visual information extracted from the captured images. That is why they are also called vision-based methods. Although optical cameras are easy to use and also inexpensive, the quality of the captured images is sensitive to lighting conditions and cluttered backgrounds, thus it is very difficult to detect and track the hands robustly, which largely affects the gesture recognition performance.
Recently, the Kinect developed by Microsoft was widely used in both industry and research communities (Shotton et al. 2011). It can capture both RGB and depth images of gestures. With depth information, it is not difficult to detect and track the user’s body robustly even in noisy and cluttered backgrounds. Due to the appealing performance and also reasonable cost, it has been widely used in several vision tasks such as face tracking (Cai et al. 2010), hand tracking (Oikonomidis et al. 2011), human action recognition (Wang et al. 2012) and gesture recognition (Doliotis et al. 2011; Ren et al. 2013). For example, one of the earliest methods for gesture recognition using Kinect is proposed in Doliotis et al. (2011), which first detects the hands using scene depth information and then employs Dynamic Time Warping for recognizing gestures. Ren et al. (2013) extracts the static finger shape features from depth images and measures the dissimilarity between shape features for classification. Although, Kinect facilitates us to detect and track the hands, exact segmentation of finger shapes is still very challenging since the fingers are very small and form many complex articulations.
Although postures and gestures are frequently considered as being identical, there are significant differences (Corradini 2002). A posture is a static pose, such as making a palm posture and holding it in a certain position, while a gesture is a dynamic process consisting of a sequence of the changing postures over a short duration. Compared to postures, gestures contain much richer motion information, which is important for distinguishing different gestures especially those ambiguous ones. The main challenge of gesture recognition lies in the understanding of the unique characters of gestures. Exploring and utilizing these characters in gesture recognition are crucial for achieving desired performance. Two crucial linguistic models of gestures are the phonological model drawn from the component concurrent character (Stokoe 1960) and the movement-hold model drawn from the sequential organization character (Liddell and Johnson 1989). The component concurrent character indicates that complementary components, namely motion, location and shape components, simultaneously characterize a unique gesture. Therefore, an ideal gesture recognition method should have the ability of capturing, representing and recognizing these simultaneous components. On the other hand, the movement phases, i.e. the transition phases, are defined as periods during which some components, such as the shape component, are in transition; while the holding phases are defined as periods during which all components are static. The sequential organization character characterizes a gesture as a sequential arrangement of movement phases and holding phases. Both the movement phases and the holding phases are defined as semantic units. Instead of taking the entire gesture sequence as input, the movement-hold model inspires us to segment a gesture sequence into sequential semantic units and then extract specific features from them. For example, for the frames in a holding phase, shape information is more discriminative for classifying different gestures.
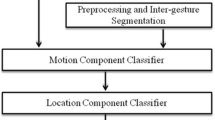
It should be noted that the component concurrent character and the sequential organization character demonstrate the essences of gestures from spatial and temporal aspects, respectively. The former indicates which kinds of features should be extracted. The later implies that utilizing the cycle of movement and hold phases in a gesture sequence can accurately represent and model the gesture. Considering these two complementary characters together provides us a way to improve gesture recognition. Therefore, we developed a multi-layered classification framework for gesture recognition. The architecture of the proposed framework is shown in Fig. 13.1, which contains three layers: the motion component classifier, the location component classifier, and the shape component classifier. Each of the three layers analyzes its corresponding component. The output of one layer limits the possible classification in the next layer and these classifiers complement each other for the final gesture classification. Such a multi-layered architecture assures achieving high recognition performance while being computationally inexpensive.

Multi-layered gesture recognition architecture
The main contributions of this paper are summarized as follows:
-
The phonological model (Stokoe 1960) of gestures inspires us to propose a novel multi-layered gesture recognition framework, which sequentially classifies the motion, location and shape components and therefore achieves higher recognition accuracy while having low computational complexity.
-
Inspired by the linguistic sequential organization of gestures (Liddell and Johnson 1989), the matching process between two gesture sequences is divided into two steps: their semantic units are matched first, and then the frames inside the semantic units are further registered. A novel particle-based descriptor and a weighted dynamic time warping are proposed to classify the location component.
-
The spatial path warping is proposed to classify the shape component represented by unclosed shape context, which is improved from the original shape context but the computation complexity is reduced from \(O(n^3)\) to \(O(n^2)\).
Our proposed method participated the one-shot learning CHALEARN gesture challenge and was top ranked (Guyon et al. 2013). The ChaLearn Gesture Dataset (CGD 2011) (Guyon et al. 2014) is designed for one-shot learning and comprises more than 50,000 gesture sequences recorded with Kinect. The remainder of the paper is organized as follows. Related work is reviewed in Sect. 13.2. The detailed descriptions of the proposed method are presented in Sect. 13.3. Extensive experimental results are reported in Sect. 13.4. Section 13.5 concludes the paper.
13.2 Related Work
Vision based gesture recognition methods encompasses two main categories: three dimensional (3D) model based methods and appearance based methods. The former computes a geometrical representation using the joint angles of a 3D articulated structure recovered from a gesture sequence, which provides a rich description that permits a wide range of gestures. However, computing a 3D model has high computational complexity (Oikonomidis et al. 2011). In contrast, appearance based methods extract appearance features from a gesture sequence and then construct a classifier to recognize different gestures, which have been widely used in vision based gesture recognition (Dardas 2012). The proposed multi-layered gesture recognition falls into the appearance based methods.
13.2.1 Feature Extraction and Classification
The well known features used for gesture recognition are color (Awad et al. 2006; Maraqa and Abu-Zaiter 2008), shapes (Ramamoorthy et al. 2003; Ong and Bowden 2004) and motion (Cutler and Turk 1998; Mahbub et al. 2013). In early work, color information is widely used to segment the hands of a user. To simplify the color based segmentation, the user is required to wear single or differently colored gloves (Kadir et al. 2004; Zhang et al. 2004). The skin color models are also used (Stergiopoulou and Papamarkos 2009; Maung 2009) where a typical restriction is wearing of long sleeved clothes. When it is difficult to exploit color information to segment the hands from an image (Wan et al. 2012b), motion information extracted from two consecutive frames is used for gesture recognition. Agrawal and Chaudhuri (2003) explores the correspondences between patches in adjacent frames and uses 2D motion histogram to model the motion information. Shao and Ji (2009) computes optical flow from each frame and then uses different combinations of the magnitude and direction of optical flow to compute a motion histogram. Zahedi et al. (2005) combines skin color features and different first- and second-order derivative features to recognize sign language. Wong et al. (2007) uses PCA on motion gradient images of a sequence to obtain features for a Bayesian classifier. To extract motion features, Cooper et al. (2011) extends haar-like features from spatial domain to spatio-temporal domain and proposes volumetric Haar-like features.
The features introduced above are usually extracted from RGB images captured by a traditional optical camera. Due to the nature of optical sensing, the quality of the captured images is sensitive to lighting conditions and cluttered backgrounds, thus the extracted features from RGB images are not robust. In contrast, depth information from a calibrated camera pair (Rauschert et al. 2002) or direct depth sensors such as LiDAR (Light Detection and Ranging) is more robust to noises and illumination changes. More importantly, depth information is useful for discovering the distance between the hands and body orthogonal to the image plane, which is an important cue for distinguishing some ambiguous gestures. Because the direct depth sensors are expensive, inexpensive depth cameras, e.g., Microsoft’s Kinect, have been recently used in gesture recognition (Ershaed et al. 2011; Wu et al. 2012b). Although the skeleton information offered by Kinect is more effective in the expression of human actions than pure depth data, there are some cases that skeleton cannot be extracted correctly, such as interaction between human body and other objects. Actually, in the CHALERAN gesture challenge (Guyon et al. 2013), the skeleton information is not allowed to use. To extract more robust features from Kinect depth images for gesture recognition, Ren et al. (2013) proposes the part based finger shape features, which do not depend on the accurate segmentation of the hands. Wan et al. (2013, 2014b) extend SIFT to spatio-temporal domain and propose 3D EMoSIFT and 3D SMoSIFT to extract features from RGB and depth images, which are invariant to scale and rotation, and have more compact and richer visual representations. Wan et al. (2014a) proposes a discriminative dictionary learning method on 3D EMoSIFT features based on mutual information and then uses sparse reconstruction for classification. Based on 3D Histogram of Flow (3DHOF) and Global Histogram of Oriented Gradient (GHOG), Fanello et al. (2013) applies adaptive sparse coding to capture high-level feature patterns. Wu et al. (2012a) utilizes both RGB and depth information from Kinect and an extended-MHI representation is adopted as the motion descriptors.
The performance of a gesture recognition method is not only related to the used features but also to the adopted classifiers. Many classifiers can be used for gesture recognition, e.g., dynamic time warping (DTW) (Reyes et al. 2011; Lichtenauer et al. 2008; Sabinas et al. 2013), linear SVMs (Fanello et al. 2013), neuro-fuzzy inference system networks (Al-Jarrah and Halawani 2001), hyper rectangular composite NNs (Su 2000), and 3D Hopfield NN (Huang and Huang 1998). Due to the ability of modeling temporal signals, Hidden Markov Model (HMM) is possibly the most well known classifier for gesture recognition. Bauer and Kraiss (2002) proposes a 2D motion model and performes gesture recognition with HMM. Vogler (2003) presentes a parallel HMM algorithm to model gestures, which can recognize continuous gestures. Fang et al. (2004) proposes a self-organizing feature maps/hidden Markov model (SOFM/HMM) for gesture recognition in which SOFM is used as an implicit feature extractor for continuous HMM. Recently, Wan et al. (2012a) proposes ScHMM to deal with the gesture recognition where sparse coding is adopted to find succinct representations and Lagrange dual is applied to obtain a codebook.
13.2.2 One-Shot Learning Gesture Recognition and Gesture Characters
Although a large number of work has been done, gesture recognition is still very challenging and has been attracting increasing interests. One motivation is to overcome the well-known overfitting problem when training samples are insufficient. The other one is to further improve gesture recognition by developing novel features and classifiers.
In the case of training samples being insufficient, most of classification methods are very likely to overfit. Therefore, developing gesture recognition methods that use only a small training dataset is necessary. An extreme example is the one-shot learning that uses only one training sample per class for training. The proposed work in this paper is also for one-shot learning. In the literature, several previous work has been focused on one-shot learning. In Lui (2012a), gesture sequences are viewed as third-order tensors and decomposed to three Stiefel Manifolds and a natural metric is inherited from the factor manifolds. A geometric framework for least square regression is further presented and applied to gesture recognition. Mahbub et al. (2013) proposes a space-time descriptor and applies Motion History Imaging (MHI) techniques to track the motion flow in consecutive frames. The Euclidean distance based classifiers is used for gesture recognition. Seo and Milanfar (2011) presents a novel action recognition method based on space-time locally adaptive regression kernels and the matrix cosine similarity measure. Malgireddy et al. (2012) presents an end-to-end temporal Bayesian framework for activity classification. A probabilistic dynamic signature is created for each activity class and activity recognition becomes a problem of finding the most likely distribution to generate the test video. Escalante et al. (2013) introduces principal motion components for one-shot learning gesture recognition. 2D maps of motion energy are obtained per each pair of consecutive frames in a video. Motion maps associated to a video are further processed to obtain a PCA model, which is used for gesture recognition with a reconstruction-error approach. More one-shot learning gesture recognition methods are summarized by Guyon et al. (2013).
The intrinsic difference between gesture recognition and other recognition problems is that gesture communication is highly complex and owns its unique characters. Therefore, it is crucial to develop specified features and classifiers for gesture recognition by exploring the unique characters of gestures as explained in Sect. 13.1. There are some efforts toward this direction and some work has modeled the component concurrent or sequential organization and achieved significant progress. To capture meaningful linguistic components of gestures, Vogler and Metaxas (1999) proposes PaHMMs which models the movement and shape of user’s hands in independent channels and then put them together at the recognition stage. Chen and Koskela (2013) uses multiple Extreme Learning Machines (ELMs) (Huang et al. 2012) as classifiers for simultaneous components. The outputs from the multiple ELMs are then fused and aggregated to provide the final classification results. Chen and Koskela (2013) proposes a novel representation of human gestures and actions based on component concurrent character. They learn the parameters of a statistical distribution that describes the location, shape, and motion flow. Inspired by the sequential organization character of gestures, Wang et al. (2002) uses the segmented subsequences instead of the whole gesture sequence as the basic units that convey the specific semantic expression for the gesture and encode the gesture based on these units. It is successfully applied in large vocabulary sign gestures recognition.
To our best knowledge, there is no work in the literature modeling both the component concurrent character and the sequential organization character in gesture recognition, especially for one-shot learning gesture recognition. It should be noted that these two characters demonstrate the essences of gestures from spatial and temporal aspects, respectively. Therefore, the proposed method that exploits both these characters in a multi-layered framework is desirable to improve gesture recognition.
13.3 Multi-layered Gesture Recognition
The proposed multi-layered classification framework for one-shot learning gesture recognition contains three layers as shown in Fig. 13.1. In the first layer, an improved principle motion is applied to model the motion component. In the second layer, a particle based descriptor is proposed to extract dynamic gesture information and then a weighted dynamic time warping is proposed for the location component classification. In the last layer, we extract unclosed shape contour from the key frame of a gesture sequence. Spatial path warping is further proposed to recognize the shape component. Once the motion component classification at the first layer is accomplished, the original gesture candidates are divided into possible gesture candidates and impossible gesture candidates. The possible gesture candidates are then fed to the second layer which performs the location component classification. Compared with the original gesture candidates, classifying the possible gesture candidates is expected to reduce the computational complexity of the second layer distinctly. The possible gesture candidates are further reduced by the second layer. In the reduced possible gesture candidates, if the first two best matched candidates are difficult to be discriminated, i.e. the absolute difference of their matching scores is lower than a predefined threshold, then the reduced gesture candidates are forwarded to the third layer; otherwise the best matched gesture is output as the final recognition result.
In the remaining of this section, the illuminating cues are first observed in Sect. 13.3.1. Inter-gesture segmentation is then introduced in Sect. 13.3.2. The motion, location and shape component classifiers in each layer are finally introduced in Sects. 13.3.3, 13.3.4 and 13.3.5, respectively.
13.3.1 Gesture Meaning Expressions and Illuminating Cues
Although from the point of view of gesture linguistics, the basic components and how gestures convey meaning are given (Stokoe 1960), there is no reference to the importance and complementarity of the components in gesture communication. This section wants to draw some illuminating cues from observations. For this purpose, 10 undergraduate volunteers are invited to take part in the observations.
Five batches of data are randomly selected from the development data of CGD 2011. The pre-defined identification strategies are shown in Table 13.1. In each test, all the volunteers are asked to follow these identification strategies. For example, in Test 2, they are required to only use the motion cue and draw simple lines to record the motion direction of each gesture in the training set. Then the test gestures are shown to the volunteers to be identified using these drawn lines. The results are briefly summarized in Table 13.1.
From the observations above, the following illuminating cues can be drawn:
-
During gesture recognition, gesture components in the order of importance are motion, location and shape.
-
Understanding a gesture requires the observation of all these gesture components. None of these components can convey the complete gesture meanings independently. These gesture components complement each other.
13.3.2 Inter-gesture Segmentation Based on Movement Quantity
The inter-gesture segmentation is used to segment a multi-gesture sequence into several gesture sequences.Footnote 1 To perform the inter-gesture segmentation, we first measure the quantity of movement for each frame in a multi-gesture sequence and then threshold the quantity of movement to get candidate boundaries. Then, a sliding window is adopted to refine the candidate boundaries to produce the final boundaries of the segmented gesture sequences in a multi-gesture sequence.
13.3.2.1 Quantity of Movement
In a multi-gesture sequence, each frame has the relevant movement with respect to its adjacent frame and the first frame. These movements and their statistical information are useful for inter-gesture segmentation. For a multi-gesture depth sequence I, the Quantity of Movement (QOM) for frame t is defined as a two-dimensional vector
where \(\textit{QOM}_{Local}(I,t)\) and \(\textit{QOM}_{Global}(I,t)\) measure the relative movement of frame t respective to its adjacent frame and the first frame, respectively. They can be computed as
where (m, n) is the pixel location and the indicator function \(\sigma (x, y)\) is defined as
where \(Threshold_{\textit{QOM}}\) is a predefined threshold, which is set to 60 empirically in this paper.
13.3.2.2 Inter-gesture Segmentation
We assume that there is a home pose between a gesture and another one in a multi-gesture sequence. The inter-gesture segmentation is facilitated by the statistical characteristics of \(\textit{QOM}_{Global}\) of the beginning and ending phases of the gesture sequences in the training data. One advantage of using \(\textit{QOM}_{Global}\) is that it does not need to segment the user from the background.
Firstly the average frame number L of all gestures in the training set is obtained. The mean and standard deviation of \(\textit{QOM}_{Global}\) of the first and last \(\lceil L/8 \rceil \) frames of each gesture sequence are computed. After that, a threshold \(Threshold_{inter}\) is obtained as the sum of the mean and the doubled standard deviation. For a test multi-gesture sequence T which has \(t_{s}\) frames, the inter-gesture boundary candidate set is defined as
The boundary candidates are further refined through a sliding window of size \(\lceil L/2 \rceil \), defined as \(\{j+1,j+2,\ldots ,j+\lceil L/2 \rceil \}\) where j starts from 0 to \(t_{s}-\lceil L/2 \rceil \). In each sliding window, only the candidate with the minimal \(\textit{QOM}_{Global}\) is retained and other candidates are eliminated from \(B_{inter}^{ca}\). After the sliding window stops, the inter-gesture boundaries are obtained, which are exemplified as the blue dots in Fig. 13.2. The segmented gesture sequences will be used for motion, location, and shape component analysis and classification.

An example of illustrating the inter-gesture segmentation results
13.3.3 Motion Component Analysis and Classification
Owing to the relatively high importance of the motion component, it is analyzed and classified in the first layer. The principal motion (Escalante and Guyon 2012) is improved by using the overlapping block partitioning to reduce the errors of motion pattern mismatchings. Furthermore, our improved principal motion uses both the RGB and depth images. The gesture candidates outputted by the first layer is then fed to the second layer.
13.3.3.1 Principal Motion
Escalante and Guyon (2012) uses a set of histograms of motion energy information to represent a gesture sequence and implements a reconstruction based gesture recognition method based on principal components analysis (PCA). For a gesture sequence, motion energy images are calculated by subtracting consecutive frames. Thus, the gesture sequence with N frames is associated to \(N-1\) motion energy images. Next, a grid of equally spaced blocks is defined over each motion energy image as shown in Fig. 13.3c. For each motion energy image, the average motion energy in each of the patches of the grid is computed by averaging values of pixels within each patch. Then a 2D motion map for each motion energy image is obtained and each element of the map accounts for the average motion energy of the block centered on the corresponding 2D location. The 2D map is then vectorized into an \(N_b\)-dimensional vector. Hence, an N frame gesture sequence is associated to a matrix Y of dimensions \((N-1)\times N_b\). All gestures in the reference set with size V can be represented with matrices \(Y_v\), \(v \in \{1,\ldots ,V\}\) and PCA is applied to each \(Y_v\). Then the eigenvectors corresponding to the top c eigenvalues form a set \(\mathcal {W}_v\), \(v=\{1, \ldots , V\}\).
In the recognition stage, each test gesture is processed as like training gestures and represented by a matrix S. Then, S is projected back to each of the V spaces induced by \(\mathcal {W}_v\), \(v\in \{1, \ldots , V\}\). The V reconstructions of S are denoted by \(R_1,\ldots ,R_{\mathcal {V}}\). The reconstruction error of each \(R_v\) is computed by
where n and m are the number of rows and columns of S. Finally, the test gesture is recognized as the gesture with label obtained by \(\arg \min _v\varepsilon (v)\).
13.3.3.2 Improved Principle Motion
Gestures with large movements are usually performed with significant deformation as shown in Fig. 13.3. In Escalante and Guyon (2012), motion information is represented by a histogram whose bins are related to spatial positions. Each bin is analyzed independently and the space interdependency among the neighboring bins is not further considered. The interdependency can be explored to improve the robustness of representing the gesture motion component, especially for the gestures with larger movement. To this end, an overlapping neighborhood partition is proposed. For example, if the size of bins is \(20\times 20\), the overlapping neighborhood contains \(3\times 3\) equally spaced neighboring bins in a \(60\times 60\) square region. The averaged motion energy in the square region is taken as the current bin’s value as shown in Fig. 13.3.

An example of a gesture with large movements. a, b Two frames from a gesture. c The motion energy image of a. The grid of equally spaced bins adopted by the Principle Motion (Escalante and Guyon 2012). d The motion energy image of b. The overlapped grid used by our method where the overlapping neighborhood includes all \(3\times 3\) equally spaced neighbor bins
The improved principle motion is applied to both the RGB and depth data. The RGB images are transformed into gray images before computing their motion energy images. For each reference gesture, the final V reconstruction errors are obtained by multiplying the reconstruction errors of the depth data and the gray data. These V reconstruction errors are further clustered by K-means to get two centers. The gesture labels associated to those reconstruction errors belonging to the center with smaller value are treated as the possible gesture candidates. The remaining gesture labels are treated as the impossible gesture candidates. Then the possible candidates are fed to the second layer.
We compare the performance of our improved principal motion model with the original principal motion model (Escalante and Guyon 2012) on the first 20 development batches of CGD 2011. Using the provided code (Guyon et al. 2014; Escalante and Guyon 2012) as baseline, the average Levenshtein distances (Levenshtein 1966) are 44.92 and 38.66% for the principal motion and the improved principal motion, respectively.
13.3.4 Location Component Analysis and Classification
Gesture location component refers to the positions of the arms and hands relative to the body. In the second layer, the sequential organization character of gestures is utilized in the gesture sequence alignment. According to the movement-hold model, each gesture sequence is segmented into semantic units, which convey the specific semantic meanings of the gesture. Accordingly, when aligning a reference gesture and a test gesture, the semantic units are aligned first, then the frames in each semantic unit are registered. A particle-based representation for the gesture location component is proposed to describe the location component of the aligned frames and a Weighted Dynamic Time Warping (WDTW) is proposed for the location component classification.
13.3.4.1 Intra-gesture Segmentation and Alignment
To measure the distance between location components of a reference gesture sequence \(R=\{R_1,R_2\ldots ,R_{L_R} \}\) and a test gesture sequence \(T=\{T_1,T_2\ldots ,T_{L_T} \}\), an alignment \(\Gamma =\{(i_k,j_k)| k=1, \ldots ,K, i_k \in \{1,\ldots , L_R \}, j_k \in \{1,\ldots , L_T \}\}\) can be determined by the best path in the Dynamic Time Warping (DTW) grid and K is the path length. Then the dissimilarity between two gesture sequences can be obtained as the sum of the distances between the aligned frames.

Intra-gesture segmentation and the alignment between test and reference sequences
The above alignment does not consider the sequential organization character of gestures. The movement-hold model proposed by Liddell and Johnson (1989) reveals sequential organization of gestures, which should be explored in the analysis and classification of gesture location component. \(\textit{QOM}_{Local}(I, t)\), described in Sect. 13.3.2.1, measures the movement between two consecutive frames. A large \(\textit{QOM}_{Local}(I, t)\) indicates that the t-th frame is in a movement phase, while a small \(\textit{QOM}_{Local}(I, t)\) indicates that the frame is in a hold phase. Among all the frames in a hold phase, the one with the minimal \(\textit{QOM}_{Local}(I, t)\) is the most representative frame and is marked as an anchor frame. Considering the sequential organization character of gestures, the following requirement should be satisfied to compute \(\Gamma \): each anchor frame in a test sequence must be aligned with one anchor frame in the reference sequence.
As shown in Fig. 13.4, the alignment between the test and reference sequences has two stages. In the first stage, DTW is applied to align the reference and test sequences. Each anchor frame is represented by “1” and the remaining frames are represented by “0”. Then the associated best path \(\widehat{\Gamma }=\{(\widehat{i_k},\widehat{j_k})|k=1,\ldots ,\widehat{K}\}\) in the DTW grid can be obtained. For each \((\widehat{i_k},\widehat{j_k})\), if both \(\widehat{i_k}\) and \(\widehat{j_k}\) are anchor frames, then \(\widehat{i_k}\) and \(\widehat{j_k}\) are the boundaries of the semantic units. According to the boundaries, the alignment between semantic units of the reference and test sequences is obtained. In the second stage, as shown in Fig. 13.4, each frame in a semantic unit is represented by \([\textit{QOM}_{Local}, \textit{QOM}_{Global}]\) and DTW is applied to align the semantic unit pairs separately. Then the final alignment \(\Gamma \) is obtained by concatenating the alignments of the semantic unit pairs.
13.3.4.2 Location Component Segmentation and Its Particle Representation
After the frames of the test and reference sequences are aligned, the next problem is how to represent the location information in a frame. Dynamic regions in each frame contain the most meaningful location information, which are illustrated in Fig. 13.5i.

Dynamic region segmentation
A simple thresholding-based foreground-background segmentation method is used to segment the user in a frame. The output of the segmentation is a mask frame that indicates which pixels are occupied by the user as shown in Fig. 13.5b. The mask frame is then denoised by a median filter to get a denoised frame as shown in Fig. 13.5c. The denoised frame is first binarized and then dilated with a flat disk-shaped structuring element with radius 10 as shown in Fig. 13.5d. The swing frame as shown in Fig. 13.5h is obtained by subtracting the binarized denoised frame from the dilated frame.The swing region (those white pixels in the swing frame) covers the slight swing of user’s trunk and can be used to eliminate the influence of body swing. From frame t, define set \(\Xi \) as
where \(F_1\) and \(F_t\) are the user masks of the first frame and frame t, respectively. \(Threshold_{\textit{QOM}}\) is the same as in Sect. 13.3.2.1. For each connected region in \(\Xi \), only if the number of pixels in this region exceeds \(N_p\) and the proportion overlapped with swing region is less than r, it is regarded as a dynamic region. Here \(N_p = 500\) is a threshold used to remove the meaningless connected regions in the difference frame as shown in Fig. 13.5g. If a connected region has less than \(N_p\) pixels, we think this region should not be a good dynamic region for extracting location features, e.g., the small bright region on the right hand of the user in Fig. 13.5g. This parameter can be set intuitively. The parameter \(r = 50\%\) is also a threshold used to complement with \(N_p\) to remove the meaningless connected regions in the difference frame. After using \(N_p\) to remove some connected regions, there may be a retained connected region which has more than \(N_p\) pixels but it may still not be a meaningful dynamic region for extracting position features if the connected region is caused by the body swing. Obviously we can exploit the swing region to remove such a region. To do this, we first compute the overlap rate between this region and the swing region. If the overlap rate is larger than r, it is reasonable to think this region is mainly produced by the body swing. Therefore, it should be further removed. As like \(N_p\), this parameter is also very intuitive to set and is not very sensitive to the performance.
To represent the dynamic region of frame t, a particle-based description is proposed to reduce the matching complexity. The dynamic region of frame t can be represented by a 3D distribution: \(P_t(x,y,z)\) where x and y are coordinates of a pixel and \(z=I_t(x,y)\) is the depth value of the pixel. In the form of non-parametric representation, \(P_t(x,y,z)\) can be represented by a set of \(\widehat{N}\) particles, \(P_{Location}(I_t)=\{(x_n,y_n,z_n)|_{n=1}^{\widehat{N}}\}\). We use K-means to cluster all pixels inside the dynamic region into \(\widehat{N}\) clusters. Note that for a pixel, both its spatial coordinates and depth value are used. Then the centers of clusters are used as the representative particles. In this paper, 20 representative particles are used for each frame, as shown in Fig. 13.6.

Four examples of particle representation of the location component (the black dots are the particles projected onto X-Y plane)
13.3.4.3 Location Component Classification
Assume the location component of two aligned frames can be represented as two particle sets, \(P=\{P_1,P_2\ldots P_{\widehat{N}}\}\) and \(Q=\{Q_1,Q_2\ldots Q_{\widehat{N}}\}\). The matching cost between particle \(P_i\) and \(Q_j\), denoted by \(C(P_i,Q_j)\), is computed as their Euclidean distance. The distance of the location component between these two aligned gesture frames is defined by the minimal distance between P and Q. Computing the minimal distance between two particle sets is indeed to find an assignment \(\Pi \) to minimize the cost summtion of all particle pairs
This is a special case of the weighted bipartite graph matching and can be solved by the Edmonds method (Edmonds 1965). Edmonds method which finds an optimal assignment for a given cost matrix is an improved Hungarian method (Kuhn 1955) with time complexity \(O(n^3 )\) where n is the number of particles. Finally, the distance of the location component between two aligned gesture frames is obtained
The distance between the reference sequence R and the test sequence T can be computed as the sum of all distance between the location components of the aligned frames in \(\Gamma \)
This measurement implicitly gives all the frames the same weights. However, in many cases gestures are distinguished by only a few frames. Therefore, rather than directly computing Eq. 13.10, we propose the Weighted DTW (WDTW) to compute the distance of location component between R and T as
where \(W^R = \{W_{i_k}^R |i_k \in \{1,\ldots ,L_R\}\}\) is the weight vector. Different from the method of evaluating the phase difference between the test and reference sequences (Jeong et al. 2011) and the method of assigning different weights to features (Reyes et al. 2011), we assign different weights to the frames of the reference gesture sequence. For each reference gesture sequence, firstly we use the regular DTW to calculate and record the alignment \(\Gamma \) between the current reference gesture sequence and all the other reference gesture sequences. Secondly for each frame in the current reference gesture sequence, we accumulate its corresponding distances with the matched frames in the best path in the DTW. Then, the current frame is weighted by the average distance between itself and all the corresponding frames in the best path. The detailed procedure of computing the weight vector are summarized in Algorithm 1.

Weighted dynamic time warping framework

In the second layer, we first use K-means to cluster the input possible gesture candidates into two cluster centers according to the matching scores between the test gesture sequence and the possible gesture candidates. The candidates in the cluster with smaller matching score are discarded. In the remaining candidates, if the first two best matched candidates are difficult to be distinguished, i.e. the absolute difference of their normalized location component distances is lower than a predefined threshold \(\upvarepsilon \), then these candidates are forwarded to the third layer; otherwise the best matched candidate is output as the final recognition result. Two factors influence the choice of the parameter \(\upvarepsilon \). The first one is the number of the gesture candidates and the other one is the type of gestures. When the number of the gesture candidates is large or most of the gesture candidates are the shape dominant gestures, a high threshold is preferred. In our experiments, we empirically set its value with 0.05 by observing the matching scores between the test sample and each gesture candidates (Fig. 13.7).
13.3.5 Shape Component Analysis and Classification
The shape in a hold phase is more discriminative than the one in a movement phase. The key frame in a gesture sequence is defined as the frame which has the minimization \(\textit{QOM}_{Local}\). Shape component classifier classifies the shape features extracted from the key frame of a gesture sequence using the proposed Spatial Path Warping (SPW), which first extracts unclosed shape context (USC) features and then calculates the distance between the USCs of the key frames in the reference and the test gesture sequences. The test gesture sequence is classified as the gesture whose reference sequence has the smallest distance with the test gesture sequence.
13.3.5.1 Unclosed Shape Segmentation
The dynamic regions of a frame have been obtained in Sect. 13.3.4.2. In a key frame, the largest dynamic region D is used for shape segmentation. Although shapes are complex and do not have robust texture and structured appearance, in most cases shapes can be distinguished by their contours. The contour points of D are extracted by the Canny algorithm. The obtained contour point set is denoted by \(C_1\) as shown in Fig. 13.8a. K-means is adopted to cluster the points in D into two clusters based on the image coordinates and depth of each point. If a user faces to the camera, the cluster with smaller average depth contains most of information for identifying the shape component. Canny algorithm is used again to extract contour points of the cluster with smaller average depth. The obtained closed contour point set is denoted by \(C_2\) as shown in Fig. 13.8b. Furthermore, an unclosed contour point set can be obtained by \(C_3=C_2\bigcap C_1\) as shown in Fig. 13.8c, which will be used to reduce the computational complexity of matching shapes.

Unclosed shape segmentation and context representation. a Is an example of point set \(C_1\), b is an example of point set \(C_2\) and c is an example of obtained point set \(C_3\); d Is the log-polar space used to decide the ranges of K bins
13.3.5.2 Shape Representation and Classification
The contour of a shape consists of a 2-D point set \(\mathbb {P}=\{p_1,p_2,\ldots ,p_N\}\). Their relative positions are important for the shape recognition. From the statistical point of view, Belongie et al. (2002) develops a strong shape contour descriptor, namely Shape Context (SC). For each point \(p_i\) in the contour, a histogram \(h_{p_i}\) is obtained as the shape context of the point whose k-th bin is calculated by
where bin(k) defines the quantification range of the k-th bin. The log-polar space for bins is illustrated in Fig. 13.8d.
Assume \(\mathbb {P}\) and \(\mathbb {Q}\) are the point sets for the shape contours of two key frames, the matching cost \(\Phi (p_i,q_j)\) between two points \(p_i\in \mathbb {P}\) and \(q_j\in \mathbb {Q}\) is defined as
Given the set of matching costs between all pairs of points \(p_i\in \mathbb {P}\) and \(q_j\in \mathbb {Q}\), computing the minimal distance between \(\mathbb {P}\) and \(\mathbb {Q}\) is to find a permutation \(\Psi \) to minimize the following sum
which can also be solved by the Edmonds algorithm as like solving Eq. 13.8.
An unclosed contour contains valuable spatial information. Thus, a Spatial Path Warping algorithm (SPW) is proposed to compute the minimal distance between two unclosed contours. Compared with the Edmonds algorithm, the time complexity of the proposed SPW is reduced from \(O(n^3)\) to \(O(n^2)\) where n is the size of the point set of an unclosed shape contour. As shown in Fig. 13.8c, the points on an unclosed contour can be represented as a clockwise contour point sequence. SPW is used to obtain the optimal match between two given unclosed contour point sequences. For two unclosed contour point sequences \(\{p'_1,\ldots , p'_n\}\), \(\{q'_1,\ldots ,q'_m\}\), a dynamic window is set to constrain the points that one point can match, which makes the matching more robust to local shape variation. We set the window size w with \(\max (L_s, abs(n-m))\). In most cases, the window size is the absolute difference between the lengths of the two point sequences. In extreme cases, if two sequences have very close lengths, i.e., their absolute difference is less then \(L_s\), we set the the window size with \(L_s\). The details of proposed SPW are summarized in Algorithm 2.

13.4 Experiments
In this section, extensive experiment results are presented to evaluate the proposed multi-layered gesture recognition method. All the experiments are performed in Matlab 7.12.0 on a Dell PC with Duo CPU E8400. The ChaLearn Gesture Dataset (CGD 2011) (Guyon et al. 2014) is used in all experiments, which is designed for one-shot learning. The CGD 2011 consists of 50,000 gestures (grouped in 500 batches, each batch including 47 sequences and each sequence containing 1–5 gestures drawn from one of 30 small gesture vocabularies of 8–15 gestures), with frame size \(240\times 320\), 10 frames/second, recorded by 20 different users.
The parameters used in the proposed method are listed in Table 13.2. Noted that the parameters c and \(N_b\) are set with the default values used in the sample code of the principal model.Footnote 2 The threshold for foreground and background segmentation is adaptively set to the maximal depth minus 100 for each batch data. For example, the maximal depth of the devel01 batch is 1964. Then the threshold for this batch is 1864. The number 100 is in fact a small bias from the maximal depth, which is empirically set in our experiments. We observed that slightly changing this number does not significantly affect the segmentation. Considering the tradeoff between the time complexity and recognition accuracy, in our experiments, we empirically set \(\widehat{N}\) to 20, which achieves the desired recognition performance.
In our experiments, Levenshtein distance is used to evaluate the gesture recognition performance, which is also used in the CHALERAN gesture challenge. It is the minimum number of edit operations (substitution, insertion, or deletion) that have to be performed from one sequence to another (or vice versa). It is also known as “edit distance”.
13.4.1 Performance of Our Method with Different layers
We evaluate the performance of the proposed method with different layers on the development (devel01–devel480) batches of CGD 2011 and Table 13.3 reports the results. If only the first layer is used for classification, the average Levenhstein distance is 37.53% with running time 0.54 s per gesture. If only the second layer is used for recognition, the average Levenhstein distance is 29.32% with running time 6.03 s per gesture. If only the third layer is used, the average Levenhstein distance is 39.12% with the running time 6.64 s per gesture. If the first two layers are used, the average Levenhstein distance is 24.36% with running time 2.79 s per gesture. If all three layers are used, the average normalized Levenhstein distance is 19.45% with running time 3.75 s per gesture.
From these comparison results, we can see that the proposed method achieves high recognition accuracy while having low computational complexity. The first layer can identify the gesture candidates at the speed of 80 fps (frames per second). The second layer has relatively high computational complexity. If we only use the second layer for classification, the average computing time is roughly 11 times of the first layer. Despite with relatively high computational cost, the second layer has stronger classification ability. Compared with using only the second layer, the computational complexity of using the first two layers in the proposed method is distinctly reduced and can achieve 16 fps. The reason is that although the second layer is relatively complex, the gesture candidates forwarded to it are significantly reduced by the first layer. When all three layers are used, the proposed method still achieve about 12 fps, which is faster than the video recording speed (10 fps) of CGD 2011.
13.4.2 Comparison with Recent Representative Methods
We compare the proposed method with other recent representative methods on the first 20 development data batches. Table 13.4 reports the performance of the proposed method on each batch and also the average performance on all 20 batches. The average performance of the proposed method and the compared methods are shown in Table 13.5.
For the comparison on each batch, the proposed method is compared with a manifold and nonlinear regression based method (Manifold LSR) (Lui 2012b), an extended motion-history-image and correlation coefficient based method (Extended-MHI) (Wu et al. 2012a), and a motion silhouettes based method (Motion History) (Mahbub et al. 2013). The comparison results are shown in Fig. 13.9.

Performance comparison on the 20 development batches in CGD 2011
In batches 13, 14, 17, 18, 19, the proposed method does not achieve the best performance. However, the proposed method achieves the best performance in the remaining 15 batches. In batches 3, 10 and 11, most of gestures consist of static shapes, which can be efficiently identified by the shape classifier in the third layer. Batches 1, 4, 7 and 8 consist of motion dominated gestures, which can be classified by the motion and location component classifiers in the first and second layers. In batches 18 and 19, the proposed method has relatively poor performance. As in batch 18, most of gestures have small motion, similar locations, and non-stationary hand shapes. These gestures may be difficult to be identified by the proposed method. In batch 19, the gestures have similar locations and hands coalescence, which is difficult to be identified by the second layer and the third layer classifiers in our method. Overall, the proposed method significantly outperforms other recent competitive methods.
The proposed method is further compared with DTW, continuous HMM (CHMM), semi-continuous HMM (SCHMM) and SOFM/HMM (Fang et al. 2004) on the development (devel01\(\sim \)devel480) batches of CGD 2011. All compared methods use one of three feature descriptors including dynamic region grid representation (DP), dynamic region particle representation (DG) and Dynamic Aligned Shape Descriptor (DS) (Fornés et al. 2010).
-
Dynamic region grid representation. For the dynamic region of the current frame obtained in Sect. 13.3.4.2, a grid of equally spaced cells is defined and the default size of grid is \(12\times 16\). For each cell, the average value of depth in the square region is taken as the value of current bin. So a \(12\times 16\) matrix is generated, which is vectorized into the feature vector of the current frame.
-
Dynamic region particle representation. The particles for the current frame obtained in Sect. 13.3.4.2 cannot directly be used as an input feature vector and they have to be reorganized. The 20 particles \(\{(x_{n},y_{n},z_{n})|^{20}_{n=1}\}\) are sorted according to \(\Vert (x_n,y_n)\Vert ^2\) and then the sorted particles are concatenated in order to get a 60-dimensional feature vector to represent the current frame.
-
Dynamic region D-Shape descriptor (Fornés et al. 2010) Firstly, the location of some concentric circles is defined, and for each one, the locations of the equidistant voting points are computed. Secondly, these voting points will receive votes from the pixels of the shape of the dynamic region, depending on their distance to each voting point. By locating isotropic equidistant points, the inner and external part of the shape could be described using the same number of voting points. In our experiment, we used 11 circles for the D-Shape descriptor. Once we have the voting points, the descriptor vector is computed.
Here, each type of HMM is a 3-state left-to-right model allowing possible skips. For CHMM and SCHMM, the covariance matrix is a diagonal matrix with all diagonal elements being 0.2. The comparison results are reported in Table 13.6.
Compared with these methods, the proposed method achieves the best performance. Noted that in all compared methods, SOFM/HMM classifier with the DS descriptor achieves the second best performance. As explained in Sect. 13.1, sequentially modeling motion, position and shape components is very important for improving the performance of gesture recognition. Except the proposed method, other compared methods do not utilize these components. On the other hand, statistical models like CHMM, SCHMM and SOFM/HMM need more training samples to estimate model parameters, which also affect their performance in the one-shot learning gesture recognition.
13.5 Conclusion
The challenges of gesture recognition lie in the understanding of the unique characters and cues of gestures. This paper proposed a novel multi-layered gesture recognition with Kinect, which is linguistically and perceptually inspired by the phonological model and the movement-hold model. Together with the illuminating cues drawn from observations, the component concurrent character and the sequential organization character of gestures are all utilized in the proposed method. In the first layer, an improved principle motion is applied to model the gesture motion component. In the second layer, a particle based descriptor is proposed to extract dynamic gesture information and then a weighted dynamic time warping is proposed to classify the location component. In the last layer, the spatial path warping is further proposed to classify the shape component represented by unclosed shape context, which is improved from the original shape context but needs lower matching time. The proposed method can obtain relatively high performance for one-shot learning gesture recognition. Our work indicates that the performance of gesture recognition can be significantly improved by exploring and utilizing the unique characters of gestures, which will inspire other researcher in this field to develop learning methods for gesture recognition along this direction.
Notes
- 1.
In this paper, we use the term “gesture sequence” to mean an image sequence that contains only one complete gesture and “multi-gesture sequence” to mean an image sequence which may contain one or multiple gesture sequences.
- 2.
Available at http://gesture.chalearn.org/data/sample-code.
References
T. Agrawal, S. Chaudhuri, Gesture recognition using motion histogram, in Proceedings of the Indian National Conference of Communications, 2003, pp. 438–442
O. Al-Jarrah, A. Halawani, Recognition of gestures in Arabic sign language using neuro-fuzzy systems. Artif. Intell. 133(1), 117–138 (2001)
G. Awad, J. Han, A. Sutherland, A unified system for segmentation and tracking of face and hands in sign language recognition, in Proceedings of the 18th International Conference on Pattern Recognition, vol. 1, 2006, pp. 239–242
M. Baklouti, E. Monacelli, V. Guitteny, S. Couvet, Intelligent assistive exoskeleton with vision based interface, in Proceedings of the 5th International Conference On Smart Homes and Health Telematics, 2008, pp. 123–135
B. Bauer, K.-F. Kraiss, Video-based sign recognition using self-organizing subunits, in Proceedings of the 16th International Conference on Pattern Recognition, vol. 2, 2002, pp. 434–437
S. Belongie, J. Malik, J. Puzicha, Shape matching and object recognition using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 24(4), 509–522 (2002)
Q. Cai, D. Gallup, C. Zhang, Z. Zhang, 3D deformable face tracking with a commodity depth camera, in Proceedings of the 11th European Conference on Computer Vision, 2010, pp. 229–242
X. Chen, M. Koskela, Online RGB-D gesture recognition with extreme learning machines, in Proceedings of the 15th ACM International Conference on Multimodal Interaction, 2013, pp. 467–474
H. Cooper, B. Holt, R. Bowden, Sign language recognition, in Visual Analysis of Humans, 2011, pp. 539–562
H. Cooper, E.-J. Ong, N. Pugeault, R. Bowden, Sign language recognition using sub-units. J. Mach. Learn. Res. 13, 2205–2231 (2012)
A. Corradini, Real-time gesture recognition by means of hybrid recognizers, in Proceedings of International Gesture Workshop on Gesture and Sign Languages in Human-Computer Interaction, 2002, pp. 34–47
R. Cutler, M. Turk, View-based interpretation of real-time optical flow for gesture recognition, in Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, 1998, pp. 416–416
N. Dardas, Real-time hand gesture detection and recognition for human computer interaction, Ph.D. thesis, University of Ottawa, 2012
P. Doliotis, A. Stefan, C. Mcmurrough, D. Eckhard, V. Athitsos, Comparing gesture recognition accuracy using color and depth information, in Proceedings of the 4th International Conference on PErvasive Technologies Related to Assistive Environments, 2011, p. 20
J. Edmonds, Maximum matching and a polyhedron with 0, 1-vertices. J. Res. Natl. Bur. Stand. B 69, 125–130 (1965)
H. Ershaed, I. Al-Alali, N. Khasawneh, M. Fraiwan, An Arabic sign language computer interface using the Xbox Kinect, in Proceedings of the Annual Undergraduate Research Conference on Applied Computing, vol. 1, 2011
H. Escalante, I. Guyon, Principal Motion, 2012, http://www.causality.inf.ethz.ch/Gesture/principal_motion.pdf
H.J. Escalante, I. Guyon, V. Athitsos, P. Jangyodsuk, J. Wan, Principal motion components for gesture recognition using a single-example, 2013, arXiv:1310.4822
S.R. Fanello, I. Gori, G. Metta, F. Odone, One-shot learning for real-time action recognition, in Pattern Recognition and Image Analysis, 2013, pp. 31–40
G. Fang, W. Gao, D. Zhao, Large vocabulary sign language recognition based on fuzzy decision trees. IEEE Trans. Syst. Man Cybern. A 34(3), 305–314 (2004)
A. Fornés, S. Escalera, J. Lladós, E. Valveny, Symbol classification using dynamic aligned shape descriptor, in Proceedings of the 20th International Conference on Pattern Recognition, 2010, pp. 1957–1960
I. Guyon, V. Athitsos, P. Jangyodsuk, H.J. Escalante, B. Hamner, Results and analysis of the Chalearn gesture challenge 2012, in Proceedings of International Workshop on Advances in Depth Image Analysis and Applications, 2013, pp. 186–204
I. Guyon, V. Athitsos, P. Jangyodsuk, H.J. Escalante, The chalearn gesture dataset (CGD 2011). Mach. Vis. Appl. 25(8), 1929–1951 (2014). doi:10.1007/s00138-014-0596-3
C.-L. Huang, W.-Y. Huang, Sign language recognition using model-based tracking and a 3D Hopfield neural network. Mach. Vis. Appl. 10(5–6), 292–307 (1998)
G.-B. Huang, H. Zhou, X. Ding, R. Zhang, Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. B 42(2), 513–529 (2012)
V.I Levenshtein, Binary codes capable of correcting deletions, insertions and reversals, in Soviet Physics Doklady, vol. 10, 1966, p. 707
Y.-S. Jeong, M.K. Jeong, O.A. Omitaomu, Weighted dynamic time warping for time series classification. Pattern Recognit. 44(9), 2231–2240 (2011)
T. Kadir, R. Bowden, E.J. Ong, A. Zisserman, Minimal training, large lexicon, unconstrained sign language recognition, in Proceedings of the British Machine Vision Conference, vol. 1, 2004, pp. 1–10
H.W. Kuhn, The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 2(1–2), 83–97 (1955)
J.F. Lichtenauer, E.A. Hendriks, M.J.T. Reinders, Sign language recognition by combining statistical DTW and independent classification. IEEE Trans. Pattern Anal. Mach. Intell. 30(11), 2040–2046 (2008)
S.K. Liddell, R.E. Johnson, American sign language. Sign Lang. Stud. 64, 195–278 (1989)
Y.M. Lui, Human gesture recognition on product manifolds. J. Mach. Learn. Res. 13(1), 3297–3321 (2012a)
Y.M. Lui, A least squares regression framework on manifolds and its application to gesture recognition, in Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2012b, pp. 13–18
U. Mahbub, T. Roy, M.S. Rahman, H. Imtiaz, One-shot-learning gesture recognition using motion history based gesture silhouettes, in Proceedings of the International Conference on Industrial Application Engineering, 2013, pp. 186–193
M.R. Malgireddy, I. Inwogu, V. Govindaraju, A temporal Bayesian model for classifying, detecting and localizing activities in video sequences, in Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2012, pp. 43–48
M. Maraqa, R. Abu-Zaiter, Recognition of Arabic Sign Language (ArSL) using recurrent neural networks, in Proceedings of the First International Conference on the Applications of Digital Information and Web Technologies, 2008, pp. 478–481
T.H.H. Maung, Real-time hand tracking and gesture recognition system using neural networks. World Acad. Sci. Eng. Technol. 50, 466–470 (2009)
S. Mitra, T. Acharya, Gesture recognition: a survey. IEEE Trans. Syst. Man Cybern. C 37(3), 311–324 (2007)
S. Mu-Chun, A fuzzy rule-based approach to spatio-temporal hand gesture recognition. IEEE Trans. Syst. Man Cybern. C 30(2), 276–281 (2000)
K. Nickel, R. Stiefelhagen, Visual recognition of pointing gestures for human-robot interaction. Image Vis. Comput. 25(12), 1875–1884 (2007)
I. Oikonomidis, N. Kyriazis, A. Argyros, Efficient model-based 3D tracking of hand articulations using Kinect, in Proceedings of the British Machine Vision Conference, 2011, pp. 1–11
E.-J. Ong, R. Bowden, A boosted classifier tree for hand shape detection, in Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, 2004, pp. 889–894
A. Ramamoorthy, N. Vaswani, S. Chaudhury, S. Banerjee, Recognition of dynamic hand gestures. Pattern Recognit. 36(9), 2069–2081 (2003)
I. Rauschert, P. Agrawal, R. Sharma, S. Fuhrmann, I. Brewer, A. MacEachren, Designing a human-centered, multimodal GIS interface to support emergency management, in Proceedings of the 10th ACM International Symposium on Advances in Geographic Information Systems, 2002, pp. 119–124
Z. Ren, J. Yuan, J. Meng, Z. Zhang, Robust part-based hand gesture recognition using Kinect sensor. IEEE Trans. Multimed. 15(5), 1110–1120 (2013)
M. Reyes, G. Dominguez, S. Escalera, Feature weighting in dynamic time warping for gesture recognition in depth data, in Proceedings of the IEEE International Conference on Computer Vision Workshops, 2011, pp. 1182–1188
Y. Sabinas, E.F. Morales, H.J. Escalante, A one-shot DTW-based method for early gesture recognition, in Proceedings of 18th Iberoamerican Congress on Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications, 2013, pp. 439–446
H.J. Seo, P. Milanfar, Action recognition from one example. IEEE Trans. Pattern Anal. Mach. Intell. 33(5), 867–882 (2011)
L. Shao, L. Ji, Motion histogram analysis based key frame extraction for human action/activity representation, in Proceedings of Canadian Conference on Computer and Robot Vision, 2009, pp. 88–92
J. Shotton, A.W. Fitzgibbon, M. Cook, T. Sharp, M. Finocchio, R. Moore, A. Kipman, A. Blake, Real-time human pose recognition in parts from single depth images, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2011, pp. 1297–1304
E. Stergiopoulou, N. Papamarkos, Hand gesture recognition using a neural network shape fitting technique. Eng. Appl. Artif. Intell. 22(8), 1141–1158 (2009)
W.C. Stokoe, Sign language structure: an outline of the visual communication systems of the American deaf. Studies in Linguistics, Occasional Papers, 8, 1960
C.P. Vogler, American Sign Language recognition: reducing the complexity of the task with phoneme-based modeling and parallel hidden Markov models, Ph.D. thesis, University of Pennsylvania, 2003
C. Vogler, D. Metaxas, Parallel hidden Markov models for American Sign Language recognition, in Proceedings of the Seventh IEEE International Conference on Computer Vision, vol. 1 1999, pp. 116–122
J. Wachs, M. Kolsch, H. Stem, Y. Edan, Vision-based hand-gesture applications. Commun. ACM 54(2), 60–71 (2011)
J. Wan, Q. Ruan, G. An, W. Li, Gesture recognition based on hidden Markov model from sparse representative observations, in Proceedings of the IEEE 11th International Conference on Signal Processing, vol. 2 2012a, pp. 1180–1183
J. Wan, Q. Ruan, G. An, W. Li, Hand tracking and segmentation via graph cuts and dynamic model in sign language videos, in Proceedings of IEEE 11th International Conference on Signal Processing, vol. 2 (IEEE, Piscataway, 2012b), pp. 1135–1138
J. Wan, Q. Ruan, W. Li, S. Deng, One-shot learning gesture recognition from RGB-D data using bag of features. J. Mach. Learn. Res. 14(1), 2549–2582 (2013)
J. Wan, V. Athitsos, P. Jangyodsuk, H.J. Escalante, Q. Ruan, I. Guyon, CSMMI: class-specific maximization of mutual information for action and gesture recognition. IEEE Trans. Image Process. 23(7), 3152–3165 (2014a)
J. Wan, Q. Ruan, W. Li, G. An, R. Zhao, 3D SMoSIFT: three-dimensional sparse motion scale invariant feature transform for activity recognition from RGB-D videos. J. Electron. Imaging 23(2), 023017 (2014b)
C. Wang, W. Gao, S. Shan, An approach based on phonemes to large vocabulary Chinese sign language recognition, in Proceedings of the IEEE Conference on Automatic Face and Gesture Recognition, 2002, pp. 411–416
J. Wang, Z. Liu, Y. Wu, J. Yuan, Mining actionlet ensemble for action recognition with depth cameras, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 1290–1297
S.-F. Wong, T.-K. Kim, R. Cipolla, Learning motion categories using both semantic and structural information, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2007, pp. 1–6
D. Wu, F. Zhu, L. Shao, One shot learning gesture recognition from RGBD images, in Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2012a, pp. 7–12
S. Wu, F. Jiang, D. Zhao, S. Liu, W. Gao, Viewpoint-independent hand gesture recognition system, in Proceedings of the IEEE Conference on Visual Communications and Image Processing, 2012b, pp. 43–48
M. Zahedi, D. Keysers, H. Ney, Appearance-based recognition of words in american sign language, in Proceedings of Second Iberian Conference on Pattern recognition and image analysis, 2005, pp. 511–519
L.-G. Zhang, Y. Chen, G. Fang, X. Chen, W. Gao, A vision-based sign language recognition system using tied-mixture density HMM, in Proceedings of the 6th International Conference on Multimodal Interfaces, 2004, pp. 198–204
Acknowledgements
We would like to acknowledge the editors and reviewers, whose valuable comments greatly improved the manuscript. Specially, we would also like to thank Escalante and Guyon who kindly provided us the principal motion source code and Microsoft Asian who kindly provided two sets of Kinect devices. This work was supported in part by the Major State Basic Research Development Program of China (973 Program 2015CB351804) and the National Natural Science Foundation of China under Grant No. 61272386, 61100096 and 61300111.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this chapter
Cite this chapter
Jiang, F., Zhang, S., Wu, S., Gao, Y., Zhao, D. (2017). Multi-layered Gesture Recognition with Kinect. In: Escalera, S., Guyon, I., Athitsos, V. (eds) Gesture Recognition. The Springer Series on Challenges in Machine Learning. Springer, Cham. https://doi.org/10.1007/978-3-319-57021-1_13
Download citation
DOI: https://doi.org/10.1007/978-3-319-57021-1_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-57020-4
Online ISBN: 978-3-319-57021-1
eBook Packages: Computer ScienceComputer Science (R0)