
Abstract
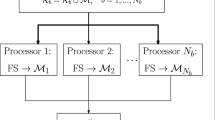
Feature selection is often required as a preliminary step for many machine learning problems. However, most of the existing methods only work in a centralized fashion, i.e. using the whole dataset at once. In this paper we propose a new methodology for distributing the feature selection process by samples which maintains the class distribution. Subsequently, it performs a merging procedure which updates the final feature subset according to the theoretical complexity of these features, by using data complexity measures. In this way, we provide a framework for distributed feature selection independent of the classifier and that can be used with any feature selection algorithm. The effectiveness of our proposal is tested on six representative datasets. The experimental results show that the execution time is considerably shortened whereas the performance is maintained compared to a previous distributed approach and the standard algorithms applied to the non-partitioned datasets.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Bache, K., Lichman, M.: UCI machine learning repository (2013). http://archive.ics.uci.edu/ml (accessed January 2015)
Zhao, Z.A., Liu, H.: Spectral feature selection for data mining. Chapman & Hall/CRC (2011)
Guyon, I.: Feature extraction: foundations and applications, vol. 207. Springer, Heidelberg (2006)
Saeys, Y., Inza, I., Larrañaga, P.: A review of feature selection techniques in bioinformatics. Bioinformatics 23(19), 2507–2517 (2007)
Chan, P.K., Stolfo, S.J.: Toward parallel and distributed learning by meta-learning. In: AAAI workshop in Knowledge Discovery in Databases, pp. 227–240 (1993)
Ananthanarayana, V.S., Subramanian, D.K., Murty, M.N.: Scalable, distributed and dynamic mining of association rules. In: Prasanna, V.K., Vajapeyam, S., Valero, M. (eds.) HiPC 2000. LNCS, vol. 1970, pp. 559–566. Springer, Heidelberg (2000)
Tsoumakas, G., Vlahavas, I.: Distributed data mining of large classifier ensembles. In: Proceedings Companion Volume of the Second Hellenic Conference on Artificial Intelligence, pp. 249–256 (2002)
Das, K., Bhaduri, K., Kargupta, H.: A local asynchronous distributed privacy preserving feature selection algorithm for large peer-to-peer networks. Knowledge and information systems 24(3), 341–367 (2010)
McConnell, S., Skillicorn, D.B.: Building predictors from vertically distributed data. In: Proceedings of the 2004 Conference of the Centre for Advanced Studies on Collaborative Research, pp. 150–162. IBM Press (2004)
Skillicorn, D.B., McConnell, S.M.: Distributed prediction from vertically partitioned data. Journal of Parallel and Distributed computing 68(1), 16–36 (2008)
Rokach, L.: Taxonomy for characterizing ensemble methods in classification tasks: A review and annotated bibliography. Computational Statistics & Data Analysis 53(12), 4046–4072 (2009)
Banerjee, M., Chakravarty, S.: Privacy preserving feature selection for distributed data using virtual dimension. In: Proceedings of the 20th ACM international conference on Information and knowledge management, pp. 2281–2284. ACM (2011)
Bolón-Canedo, V., Sánchez-Maroño, N., Cerviño-Rabuñal, J.: Scaling up feature selection: a distributed filter approach. In: Bielza, C., Salmerón, A., Alonso-Betanzos, A., Hidalgo, J.I., Martínez, L., Troncoso, A., Corchado, E., Corchado, J.M. (eds.) CAEPIA 2013. LNCS, vol. 8109, pp. 121–130. Springer, Heidelberg (2013)
de Haro García, A.: Scaling data mining algorithms. Application to instance and feature selection. Ph.D. thesis, Universidad de Granada (2011)
Basu, M., Ho, T.K.: Data complexity in pattern recognition. Springer (2006)
Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., Witten, I.H.: The Weka data mining software: an update. ACM SIGKDD Explorations Newsletter 11(1), 10–18 (2009)
Hall, M.A.: Correlation-based feature selection for machine learning. Ph.D. thesis, The University of Waikato (1999)
Dash, M., Liu, H.: Consistency-based search in feature selection. Artificial intelligence 151(1), 155–176 (2003)
Zhao, Z., Liu, H.: Searching for interacting features. In: IJCAI, vol. 7, pp. 1156–1161 (2007)
Hall, M.A., Smith, L.A.: Practical feature subset selection for machine learning. Computer Science 98, 181–191 (1998)
Kononenko, I.: Estimating attributes: analysis and extensions of relief. In: Bergadano, F., De Raedt, L. (eds.) ECML 1994. LNCS, vol. 784, pp. 171–182. Springer, Heidelberg (1994)
Quinlan, J.R.: C4. 5: programs for machine learning. Morgan kaufmann (1993)
Rish, I.: An empirical study of the naive bayes classifier. In: IJCAI 2001 workshop on empirical methods in artificial intelligence, vol. 3, pp. 41–46 (2001)
Aha, D.W., Kibler, D., Albert, M.K.: Instance-based learning algorithms. Machine learning 6(1), 37–66 (1991)
Vapnik, V.N.: Statistical learning theory. Wiley (1998)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Bolón-Canedo, V., Sánchez-Maroño, N., Alonso-Betanzos, A. (2015). A Distributed Feature Selection Approach Based on a Complexity Measure. In: Rojas, I., Joya, G., Catala, A. (eds) Advances in Computational Intelligence. IWANN 2015. Lecture Notes in Computer Science(), vol 9095. Springer, Cham. https://doi.org/10.1007/978-3-319-19222-2_2
Download citation
DOI: https://doi.org/10.1007/978-3-319-19222-2_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-19221-5
Online ISBN: 978-3-319-19222-2
eBook Packages: Computer ScienceComputer Science (R0)