
Abstract
Reversible data hiding in encrypted domain(RDH-ED) can not only protect the privacy of 3D mesh models and embed additional data, but also recover original models and extract additional data losslessly. However, due to the insufficient use of model topology, the existing methods have not achieved satisfactory results in terms of embedding capacity. To further improve the capacity, a RDH-ED method is proposed based on the topology of the 3D mesh models, which divides the vertices into two parts: embedding set and prediction set. And after integer mapping, the embedding ability of the embedding set is calculated by the prediction set. It is then passed to the data hider for embedding additional data. Finally, the additional data and the original models can be extracted and recovered respectively by the receiver with the correct keys. Experiments declare that compared with the existing methods, this method can obtain the highest embedding capacity.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Data hiding [1] is a method to achieve copyright protection and covert communication by embedding additional data into the cover media and extracting the data without errors. However, the original media can not be restored losslessly by the traditional data hiding methods. It is a fatal problem in the military, medical and other fields where data integrity is strictly required. To solve this problem, reversible data hiding(RDH) is proposed.
RDH can embed additional data in the cover media and restore both media and data without errors. Over the years, researchers have devised many methods. They can be divided into three main categories: lossless compression [3], difference expansion [11] and histogram shifting [7]. In lossless compression methods, some features of the original media are discovered and losslessly compressed, making room for storing additional data. Difference expansion explores redundancy between adjacent pixels and embeds additional data into their difference. Histogram shifting embeds additional data by shifting peak points toward zero points in the pixel distribution histogram.
With the boom in cloud computing and privacy protection, many multimedia are uploaded, such as digital images, audio, 3D mesh models, etc., to the cloud for storage and transmission. In order to protect the privacy and security of data, media will be encrypted before uploading. In this scenario, RDH-ED has caught the attention of many researchers. There are two main categories of RDH-ED: vacating room after encryption (VRAE) [15, 18, 19] and reserving room before encryption (RRBE) [6, 8, 16]. Zhang et al. [18] introduced a RDH scheme for encrypted images based on VRAE. The encrypted images were divided into non-overlapping blocks, and each block can store 1 bit of data by flipping the 3 least significant bits (LSB) of the encrypted data. In [19], a separable RDH-ED method was proposed. In this method, a specific matrix multiplication was designed to losslessly compress the LSB of the encrypted image, which implemented the separability of data extraction and image restoration. However, the embedding ability of these methods is low due to encrypted image entropy maximization. To increase the embedding capacity and reduce the bit error rate, Ma et al. [6] first proposed a method based on RRBE, which implemented both data extraction and image recovery losslessly based on histogram shifting. Although many RDH-ED methods have obtained considerable outcomes, there is not enough research on 3D mesh models.
As an emerging digital media following images, audio and videos, 3D mesh models are applied in many fields, such as medical treatment, construction, video games, etc. To protect the privacy security and verification copyright of 3D mesh models in massive application scenarios, it is essential to study the RDH-ED methods of 3D mesh models. Jiang et al. [4] first proposed the RDH method based on VRAE for 3D mesh models in encrypted domain. However, the data extracted may be errors and the capacity of this method is not satisfactory. Shah et al. [9] and van Rensburg et al. [13] applied homomorphic encryption to RDH-ED method and embedded data in dual domain. Although homomorphic encryption increases the capacity of the method, the computational cost is high. Tsai [12] proposed a native method by spatial subdivision and space encoding. However, If the parameters are not chosen properly, errors may occur during extraction. Xu et al. [14] proposed the most significant bit(MSB) prediction, which implemented extraction and recovery separably. In [17], the embeddable room is extended to multi-MSB. However, the vertices are not fully utilized. Lyu et al. [5] made the use of vertices more fully by adding labels. However, the topology of 3D mesh models is not utilized and the division of vertices is not sufficient. Therefore, this study proposes a vertex division method based on the model topology and manages to the highest embedding capacity compared with state-of-the-art methods.
The main contributions of the proposed method are as follows:
-
1)
We take full advantage of the topology of the 3D mesh models and propose a more reasonable vertex division method.
-
2)
Our division method enables the correlation between vertices to be further exploited. Experiments declare that the proposed method has the highest embedding capacity compared to other methods.
The remainder of this paper is organized as follows: The related works are presented in Sect. 2. Section 3 presents the proposed method. The experimental results and analysis are shown in Sect. 4. Finally, the paper is concluded in Sect. 5.
2 Related Works
In this section, we introduce the types of research models and the existing RDH-ED methods for 3D mesh models.
In computer-aided design, 3D mesh models are usually represented as triangular or polygonal models, which are composed of vertex data and face data. This paper studies the most popular triangular 3D mesh models. Vertex data includes vertex coordinates and is represented as \(V=\{v_i|1 \le i \le n\}\) where n donates the number of vertices. In the rectangular coordinate system of space, each vertex has three values in the x, y, and z directions. Topological relationships between vertices are contained in face data, which is represented as \(F=\{f_1,f_2,...,f_m\}\) and m is the number of the face. Each face f contains three vertices. The corresponding file format is shown in Table 1.
Jiang et al. [4] introduced the RDH method to 3D mesh models in encrypted domain for the first time. The vertices were first mapped to integers and encrypted by stream cipher. After encryption, additional data was embedded into the multi-LSB. However, this method is not satisfactory in terms of embedding capacity and there may be errors in data extraction. Shah et al. [9] proposed a two-tier RDH-ED framework. The authentication information was embedded by the data sender in the first tier and additional data was embedded by the cloud server in the second tier. This method improves the embedding capacity by applying homomorphic encryption, but this method brings the file size increments and the encryption process is expensive. Van Rensburg et al. [13] applied Paillier encryption to 3D mesh models and proposed an improved two-layer RDH method. This method minimizes file size increments as much as possible and improves the capacity. However, the original mesh models cannot be restored losslessly. Tsai [12] proposed a separable RDH method based on spatial subdivision and space encoding for encrypted 3D mesh models. However, this method has the problem of bit error during extracting data. Xu et al. [14] used the MSB prediction and proposed a new method based on RRBE, which increased the embedding capacity. Vertices were divided into embedding set and reference set by traversing the face data. The reference set is used for predicting the embedding set. After division and MSB prediction, the additional data was embedded in the MSB plane of the embedding set. Based on [14], Yin et al. [17] implemented higher embedding capacity by utilizing multi-MSB to hide data. However, this method does not adaptively assign payload to the vertices of the embedding set. Lyu et al. [5] introduced vertex labels as auxiliary information and improved the utilization of vertices. However, this method has shortcomings in the division of vertices. This method only divided the vertices by the index of vertex data and ignored the face data. To divide the vertices more reasonably, we propose a vertex division method based on model topology, which has much improved the embedding capacity compared with state-of-the-art methods.

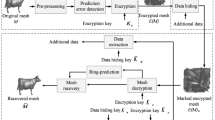
Method flowchart.
3 Proposed Method
In this section, the proposed method is described in detail. As shown in Fig. 1, the proposed method consists of four parts: (1) The mesh models are preprocessed to make room for embedding additional data. (2) The 3D mesh models are encrypted by stream ciphers. (3) The encrypted additional data is embedded in the encrypted model by the data hider. (4) The additional data and original models can be extracted and recovered losslessly by the data receiver who has the corresponding key.
3.1 Room Reservation
Vertices Division. We propose a new division method and increase the number of the embedding vertices reasonably. In [4, 14, 16], the vertices were divided according to the face data. Each face was traversed in numbering order, and at most 1 vertex in each face was added to the embedding set. This method is not sufficient for the utilization of vertex data, and can only reach 33% of the vertex utilization for embedding. In [5], the vertices were divided according to the parity of the vertex index. This method applied more vertices to embedding additional data and the vertex utilization ratio reached 50%. However, only the vertex data was used to divide vertices. To divide the vertices more reasonably, a native division method combining vertex data and face data is proposed.

(a) Mushroom, (b) Labeled local topology of Mushroom.
In our method, the vertices are divided into two parts first according to the parity of the vertex index. For the convenience of introduction, here we select the even-numbered part as the prediction set \(S_p\) and the odd-numbered part as the embedding set \(S_e\). Some vertices in \(S_p\) are redundant and unsuitable to use as prediction vertices. We traverse the vertices in \(S_p\) one by one and filter out the vertices that are suitable for embedding additional data. In order to ensure that some vertices in \(S_p\) with excellent predictive ability are not classified into the \(S_e\), vertices are added to the \(S_e\) only when the number of odd-numbered vertices around the vertices does not exceed twice the number of even-numbered vertices. Besides, in order to ensure the prediction accuracy, the vertices must also be guaranteed that they can be predicted by at least 2 vertices. An example of the vertices screening process is shown in Fig. 2. The vertex \(v_8\) has four even neighbor vertices which means that this vertex can be accurately predicted with multi-MSB and the number of odd-neighbored vertices does not exceed twice the number of even-numbered vertices. Therefore, \(v_8\) is more suitable for the \(S_e\). After that, the predicted vertices for \(v_1\) will have \(v_8\) removed.
Integer Mapping. Uncompressed vertex coordinate values are stored in the computer as 32-bit floating point numbers. [2] suggested that 3D mesh models do not require this level of accuracy for most applications. Therefore, lossy compression is performed on the values of vertices. The value of vertices is expanded to between \(-10^p\) and \(10^p\), where \(p \epsilon (1,33)\). The expanded value is processed into an integer by
where \(\lfloor . \rfloor \) is the round down function. The receiver can restore the coordinates to floating point coordinates by
The bit length l of the integer is determined by the value of p, and the conversion relationship between them can be expressed as

Prediction error labels for \(v_1\) in x-axis.
Prediction Error Bit Record. The embedding vertex is predicted by the vertices around it. In Fig. 3, the process of predicting error labels is illustrated in detail. The \(v_1\) has three neighbor vertices in \(S_p\), which are \(v_2\),\(v_4\) and \(v_6\). From the MSB to the LSB, the predicted value of each bit plane is determined according to the mode of all corresponding bit planes of the prediction vertices. If the number of 0 and 1 is the same, 1 is chosen as the final value. For example, in the 17th digit of index 2, 4 and 6, 0 appears the most. So the predicted value is chosen to be 0. The embeddable length is obtained by comparing the predicted value with \(v_1\) and records as a label. Since a vertex has coordinates in three directions, the label selection for a vertex will finally be the minimum of the three directions. In Fig. 3, \(v_1\) has a label value of 19 in x-axis. But the final label value of \(v_1\) still needs to be determined by the other two directions y-axis and z-axis. The embeddable length of each vertex is recorded in the location map, which is compressed by arithmetic coding and then embedded into the 3D mesh models as auxiliary information.
3.2 Model Encryption
The 3D mesh model is encrypted by stream cipher in this paper. First, the coordinate of each vertex is converted to a binary representation. Each binary bit can be obtained by
Then, the data sender uses the stream cipher function to generate pseudo-random bits \(c_{i,j,k}\), and the encrypted bits are obtained by
where \(\oplus \) means exclusive OR. Finally, the encrypted vertices can get by
3.3 Data Embedding
The process of data embedding is shown in Fig. 4. The room obtained in Sect. 3.1 is used for data hiding. First, the data hider divides the binary representation of vertex values in \(S_{e}\) into two parts according to the location map, the embeddable part and the non-embeddable part. Then, the encrypted additional data and auxiliary information are embedded into the embeddable part by substitution. Finally, the vertices are reconstructed.

Process of data embedding.
3.4 Data Extraction and Model Recovery
The data receiver who has the correct key can decrypt the encrypted data. The additional data can be extracted with the key \(k_a\) and original mesh models can be recovered with the key \(k_m\). Therefore, here are three possible scenarios:
Case 1: The receiver only holds \(k_a\). All the additional data can be extracted from the encrypted model and plaintext data is decrypted with \(k_a\).
Case 2: The receiver only holds \(k_m\). The data receiver extracts the auxiliary data and decrypts the mesh models through the key \(k_m\). However, the embedding set in the decrypted mesh model is not the same as the original one. Then, the prediction set is applied to restore the embedding set with the help of the auxiliary data.
Case 3: The receiver holds both keys \(k_a\) and \(k_m\). At this time, the data receiver can obtain additional data and restore the original models at the same time. The procedure is the same as in case 1 and case 2, but model decryption is performed after data extraction.
4 Experiment Results and Analysis
4.1 Visual Quality and Quantitative Analysis
Four test mesh models are demonstrated in Fig. 5. Despite the slight distortion introduced to the models during the preprocess stage, there is little difference between the original models and the recovered models based on human visual observations. This shows that our method is feasible in the application. To further demonstrate the feasibility of the method, we introduce signal-to-noise ratio(SNR) and Hausdorff distance to quantitatively measure the gap between the original models and the recovered ones.

Models presentation at different stages(p = 5): (a) original models; (b) encrypted models; (c) data-embedded models; (d) recovered models.
SNR can calculate the gap between two models. The larger the SNR, the smaller the gap between the two models. SNR can be obtained by
where \(v_{i,x}, v_{i,y}, v_{i,z}\) are the values of original coordinates, \(\bar{v}_{x}, \bar{v}_{y}, \bar{v}_{z}\) are the average values of original coordinates, and \(v_{i,x}'', v_{i,y}'', v_{i,z}''\) are the values of recovery coordinates.
Hausdorff distance measures the maximum distance value among the closest distances between two model vertices. The smaller the Hausdorff distance, the smaller the gap between the two models. Assuming there are two sets \(A=(a_1,a_2,...,a_u)\) and \(B=(b_1,b_2,...,b_u)\), Hausdorff distance can be calculated as
where \(\left\| .\right\| \) is the Euclidean distance, and u denotes the number of elements in each set.
The ER of the model Beetle under different p values is given in Fig. 6 and the values of SNR and Hausdorff distance of model Beetle under different p values are shown in Fig. 7. It can be seen that as p becomes larger, although the disturbance introduced into the model becomes smaller, ER also becomes smaller.

ER of Beetle under different p

ER of Beetle under different p
Under the trade-off of embedding capacity and the requirements of practical applications, the value of p is to be 5. The results of four test models are shown in Table 2. As can be seen in the table, the SNR of the four test models has reached a high value, and the Hausdorff distance is almost zero.
4.2 Capacity Analysis
The embedding rate(ER) is one of the important indicators of the RDH-ED methods for 3D mesh models in encrypted domain, which is presented by bit per vertex(bpv). ER can be calculated by
where \(l_p\) is the total capacity and \(l_{ai}\) is the length of auxiliary information.
The comparison of ER on four test models is shown in Table 3. Jiang et al. [4] used multi-LSB for data embedding. The embedding rate of this method is not high enough, and it does not exceed 1 bpv at most. Shah et al. [9] designed a two-layer embedding method. Additional data was embedded in the first layer through histogram expansion and shifting techniques. The second layer utilized the self-blinding property of the Paillier cryptosystem to embed additional data. The final embedding rate of this method is 6 bpv. Compared with [9, 13] adjusted the encryption bit length of the coordinates to reduce the file size increment. Tsai [12] exploited the ratio of vertex value normalization for model encryption and data embedding and realized 7.68 bpv. Xu et al. [14] proposed to embed data in MSB. Although the embedding rate is improved, the relationship between the adjacent vertices has not been used fully. Yin et al. [17] extended the embedding range to multi-MSB and achieved a substantial increase in capacity. Lyu et al. [5] further improved the embedding capacity and improved the utilization of vertices by labeling vertices. Due to the topology of 3D mesh models, the same vertex can be included in multiple faces and associated with multiple vertices. Furthermore, many correct prediction bits can be obtained with the help of two or three vertices by rationally utilizing the strong multi-MSB correlation between adjacent vertices. However, among the aforementioned methods, the topological structure of the models is not used to divide the vertices and the division of vertices is not reasonable enough. The proposed method addresses this issue and implemented the state-of-the-art results on the average ER. The division results of the embedded vertices and predicted vertices on four test models are displayed in Table 4. Except for the Mushroom model, the number of embedded vertices does not increase greatly after vertex division due to the small number of vertices and faces, the other three models all obtained a high vertex utilization ratio. The utilization of model topology increases the number of embedded vertices, and finally the ER of the models is improved.

Average capacity comparison with other methods on the Princeton dataset.
To be more persuasive, the proposed method is tested on the Princeton dataset [10] which consists of 380 different 3D mesh models. The caparison with other methods is shown in Fig. 8 and our method also obtains state-of-the-art experimental results on the average ER.
4.3 Features Analysis
The comparison of features with other methods is shown in Table 5. Jiang et al. [4] used the smoothness function, which would lead to errors in data extraction, making the model and data inseparable during recovery and extraction. In [9, 13], it is expensive to apply homomorphic encryption to the models and the computational complexity of these methods is very high. In [12], the selection of a suitable threshold is crucial, otherwise the data extraction will be wrong. [5, 14, 16] are MSB-based methods that make room for embedding additional data by exploiting the correlations between vertices. The proposed method can not only recover the model and additional data reversibly, but also recover and extract them separably. Besides, the computational complexity of using stream cipher encryption is lower than that of homomorphic encryption.
5 Conclusion
In this paper, we study a RDH method for 3D mesh models with high capacity in encrypted domain. The vertices are divided into two parts reasonably by utilizing the vertex data and face data. One is used for data embedding, the other one is used for model recovery. The experiments demonstrate that the proposed method reaches state-of-the-art performance. In the future, we consider to enhance the robustness of the method to resist channel interference of data during network transmission. Besides, a method that does not require the transmission of auxiliary information from the data sender to the data hider is also our next research direction.
References
Barton, J.M.: Method and apparatus for embedding authentication information within digital data. US Patent 5,646,997, 8 Jul 1997
Deering, M.: Geometry compression. In: Proceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques, pp. 13–20 (1995)
Fridrich, J., Goljan, M., Du, R.: Lossless data embedding for all image formats. In: Security and Watermarking of Multimedia Contents IV, vol. 4675, pp. 572–583. SPIE (2002)
Jiang, R., Zhou, H., Zhang, W., Yu, N.: Reversible data hiding in encrypted three-dimensional mesh models. IEEE Trans. Multimedia 20(1), 55–67 (2017)
Lyu, W.L., Cheng, L., Yin, Z.: High-capacity reversible data hiding in encrypted 3D mesh models based on multi-MSB prediction. Signal Process. 201, 108686 (2022)
Ma, K., Zhang, W., Zhao, X., Yu, N., Li, F.: Reversible data hiding in encrypted images by reserving room before encryption. IEEE Trans. Inf. Forensics Secur. 8(3), 553–562 (2013)
Ni, Z., Shi, Y.Q., Ansari, N., Su, W.: Reversible data hiding. IEEE Trans. Circuits Syst. Video Technol. 16(3), 354–362 (2006)
Puteaux, P., Puech, W.: An efficient MSB prediction-based method for high-capacity reversible data hiding in encrypted images. IEEE Trans. Inf. Forensics Secur. 13(7), 1670–1681 (2018)
Shah, M., Zhang, W., Hu, H., Zhou, H., Mahmood, T.: Homomorphic encryption-based reversible data hiding for 3D mesh models. Arab. J. Sci. Eng. 43(12), 8145–8157 (2018). https://doi.org/10.1007/s13369-018-3354-4
Shilane, P., Min, P., Kazhdan, M., Funkhouser, T.: The Princeton shape benchmark. In: Proceedings Shape Modeling Applications, 2004, pp. 167–178. IEEE (2004)
Tian, J.: Reversible data embedding using a difference expansion. IEEE Trans. Circuits Syst. Video Technol. 13(8), 890–896 (2003)
Tsai, Y.Y.: Separable reversible data hiding for encrypted three-dimensional models based on spatial subdivision and space encoding. IEEE Trans. Multimedia 23, 2286–2296 (2020)
Van Rensburg, B.J., Puteaux, P., Puech, W., Pedeboy, J.P.: Homomorphic two tier reversible data hiding in encrypted 3D objects. In: 2021 IEEE International Conference on Image Processing (ICIP), pp. 3068–3072. IEEE (2021)
Xu, N., Tang, J., Luo, B., Yin, Z.: Separable reversible data hiding based on integer mapping and MSB prediction for encrypted 3D mesh models. Cogn. Comput. 14(3), 1172–1181 (2022). https://doi.org/10.1007/s12559-021-09919-5
Yin, Z., Luo, B., Hong, W.: Separable and error-free reversible data hiding in encrypted image with high payload. Sci. World J. 2014 (2014)
Yin, Z., Xiang, Y., Zhang, X.: Reversible data hiding in encrypted images based on multi-MSB prediction and Huffman coding. IEEE Trans. Multimedia 22(4), 874–884 (2019)
Yin, Z., Xu, N., Wang, F., Cheng, L., Luo, B.: Separable reversible data hiding based on integer mapping and multi-MSB prediction for encrypted 3D mesh models. In: Ma, H., et al. (eds.) PRCV 2021. LNCS, vol. 13020, pp. 336–348. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-88007-1_28
Zhang, X.: Reversible data hiding in encrypted image. IEEE Signal Process. Lett. 18(4), 255–258 (2011)
Zhang, X.: Separable reversible data hiding in encrypted image. IEEE Trans. Inf. Forensics Secur. 7(2), 826–832 (2011)
Acknowledgements
This research work is partly supported by National Natural Science Foundation of China (62172001, 61872003).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Tang, Y., Cheng, L., Lyu, W., Yin, Z. (2023). High Capacity Reversible Data Hiding for Encrypted 3D Mesh Models Based on Topology. In: Zhao, X., Tang, Z., Comesaña-Alfaro, P., Piva, A. (eds) Digital Forensics and Watermarking. IWDW 2022. Lecture Notes in Computer Science, vol 13825. Springer, Cham. https://doi.org/10.1007/978-3-031-25115-3_14
Download citation
DOI: https://doi.org/10.1007/978-3-031-25115-3_14
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-25114-6
Online ISBN: 978-3-031-25115-3
eBook Packages: Computer ScienceComputer Science (R0)