
Abstract
This chapter describes the fundamental principles of Light-field particle image velocimetry (LF-PIV) where accurate detection and reconstruction of seeding particle locations for 3D flow field measurements are of primary concern. Reconstruction of raw light-field particle images and their post-processing based on the dense ray-tracing MART (DRT-MART) approach will firstly be covered, before LF-PIV approach is compared to current Tomo-PIV approach to better understand their unique advantages and disadvantages. A dual light-field camera approach to further improve upon a single light-field camera-based LF-PIV will also be described and discussed here.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
Introduction
The development of LF-PIV can be better appreciated from a brief history of the authors’ earlier works involving other PIV approaches. In earlier investigations, most of the authors’ experiments surrounded the use of relatively straight-forward and cost-effective in-house 2D time-resolved particle image velocimetry (TR-PIV) systems. These systems typically comprised of a 532 nm, continuous-wave laser which would be formed into thin laser sheets using appropriate beam steering and sheet-forming optics for illumination purposes. A high-speed camera would then be used to capture the seeded flow fields at a sufficiently high frame-rate (and hence, short-time interval \(\Delta t\)) to resolve the transient motions associated with the flow scenarios. After careful calibrations similar to conventional 2D-PIV approaches, the captured particle images could then be post-processed sequentially with the known time interval to arrive at the velocity components based on the typical cross-correlation processing. The main difference between such a TR-PIV approach and conventional 2D-PIV approaches lies in the elimination of the need for a more costly double-pulsed laser and triggering systems. Having said that, the maximum velocity limit for such in-house TR-PIV systems is constrained by the high-speed camera maximum frame-rate, since the minimum time interval is entirely dependent upon it. Furthermore, as the high-speed camera frame-rate increases (with shorter exposure time), the power level required from the continuous-power laser increases as well. Hence, such in-house TR-PIV systems were used for low-to-moderate flow velocities involving water-based experiments, at least for the authors.
The effectiveness of the above in-house TR-PIV systems can be seen in the range of the flow scenarios studied by the authors over the years, especially when information on the transient flow behaviour and quantities are desired. The availability of temporally-resolved velocity field data from the use of these systems also offered a major benefit, in terms of enabling further data-reduction to obtain phase-averaged, Proper Orthogonal Decomposition (POD) and Dynamic Mode Decomposition (DMD) results, take for instance. Provided that sufficiently large number of data is captured over an adequate number of flow cycles (if the flow scenario is cyclical), mean velocity fields and other derived flow quantities are also possible. However, it has to be mentioned that the TR-PIV approach remains 2D in nature and measurements taken along multiple planes continue to be required to provide a more 3D appreciation, especially when attempting to explain the flow physics underpinning the various flow mechanisms. The next logical step will be to utilise Tomo-PIV, though its multi-camera approach is generally more costly and complex, as well as potentially taking up more experimental space. As such, it may not always be the most ideal technique to capture 3D flow measurements non-intrusively.
On the other hand, the idea of using a plenoptic or light-field camera for measurement purposes was explored through a series of systematic studies since the early 2010s, especially by B. Thurow at Auburn University. These developments initially focused on particle-image velocimetry before branching out into other areas such as Background-Oriented Schlieren (BOS), depth measurements, high-temperature measurements, time-resolved measurements and other measurement applications. Whilst the idea of light-field cameras is not new with the first practical implementation demonstrated almost 20 years earlier, where it was shown that light-field cameras could be implemented in a straight-forward manner by putting a layer of MLA slightly ahead of the camera sensor (Adelson and Wang 1992), it was in 2004 and thereafter that these cameras were explored for more commercial usage. The ability to make use of the depth information from light-field cameras to refocus a photo after it has been taken was initially heralded as a breakthrough in photography, though the initial enthusiasm did not catch on with the professional photographers and sales of consumer level light-field cameras did not meet the targets. Unfortunately, they were eventually discontinued but this proved to be step forward towards cost-effective light-field cameras that are well-understood. It was around this point that B. Thurow started to explore the use of light-field cameras for PIV and other flow related measurements (Lynch and Thurowy 2011; Fahringer and Thurow 2012; Lynch et al. 2012; Fahringer and Thurow 2013, 2014, 2015; Thurow and Fahringer 2013; Thomason et al. 2014; Fahringer et al. 2015; Deem et al. 2016; Roberts and Thurow 2017; Klemkowsky et al. 2017; Hall et al. 2018, 2019, amongst others). These studies motivated many further studies, especially those conducted by the authors in terms of furthering the use of light-field cameras in flow measurements and other applications. This chapter will summarise the authors’ journey in laying out the design, construction, implementation and post-processing details that pertain towards the use of light-field cameras for measuring a wide range of flow scenarios. In particular, the authors’ specific approaches towards an efficient and accurate post-processing algorithm with modern high-speed GPUs will be described here, with a view towards real-time or almost real-time post-processing as the end-goal in mind.
Dense Ray Tracing-based MART 3D Reconstruction of Light-field Particle Images
Light-field particle reconstruction is similar to Tomo-PIV in the sense that they both rely on 2D projections of a tracer particle to reconstruct its 3D image. It is therefore reasonable to expect that MART approach would be a desirable alternative for solving such inverse problem in LF-PIV, as it has been shown to be a very robust one in Tomo-PIV (Scarano 2013). However, the fundamental difference is that rays from a tracer particle in LF-PIV would be recorded by multiple pixels beneath different lenslet (Fig. 2.4), whereas in Tomo-PIV rays from a tracer particle are recorded by multiple cameras from different perspectives. Such a discrepancy would imply a significant challenge when applying MART in light-field particle image reconstruction. For Tomo-PIV, the weighting coefficient could be directly calculated according to the intersection of voxel and pixel line-of-sight, which is normally determined directly from multiple camera calibration (Wieneke 2008, 2018). In contrast, the correspondence of voxel and pixel in light-field imaging is a one-to-multiple mapping (i.e. one voxel affects tens of pixels) as detailed in Chap. 3. As such, the storage of weighting coefficient and direct MART reconstruction are very time-consuming and computationally intensive. For example, the weighting matrix for a 300 × 200 × 200 voxel volume requires 350 GB of storage, even if only non-zero voxel values were to be stored. The reconstruction of such a small volume using the standard MART method takes approximately 1.5h on a 12-core workstation (Fahringer and Thurow 2015).
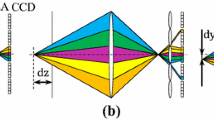
As with any existing volumetric-based 3D PIV approach, the key towards achieving accurate results depends on accurate reconstruction of the particle images in the 3D space right from the beginning. Seeding particle density for volumetric PIV tends to be sparse, as it facilitates better particle reconstruction processes. In particular, Atkinson and Soria (2009) demonstrated that the reconstruction process can be significantly accelerated by predetermining the non-zero voxels through the use of a multiplicative line-of-sight (MLOS) approach. This could lead to up to 5.5 times faster particle reconstructions during post-processing as compared to non-MLOS-based approaches, which represent a drastic reduction in the time taken. For volumetric PIV measurements involving a large number of images from multiple cameras, this is a significant breakthrough towards getting 3D PIV measurements faster than ever. However, it should also be noted that the MLOS approach was proposed based on Tomo-PIV technique and cannot be directly used for LF-PIV without modifications. For Tomo-PIV, camera calibration information can be used to work out the line-of-sight of a pixel, where the non-zero voxels may then be identified subsequently by multiplying the corresponding pixels. The situation for LF-PIV is far more complicated however, as illustrated in Fig. 2.4. The figure depicts the lines-of-sight for a point light source (or illuminated tracer particle) located at the focal plane, at some distances dz away from the focal plane and dy away from the camera axis, for a light-field camera. As can be seen from the depiction, the line-of-sight of a pixel is highly sensitive towards the particle location and non-zero voxels must be identified through inverse ray-tracing to find the concerned pixels. This can however be done if the central light ray for each discretised section of the main lens were to be raytraced and provide information for particle reconstruction. To demonstrate this principle, Fig. 4.1 illustrates the proposed approach using an example of five pixels for each lenslet of the MLA, where the red region represents a voxel in the measurement region. Through this approach, pixels associated with each voxel can be ascertained and a straight-forward multiplication of their values can be used to differentiate the non-zero voxels. Such a technique is actually similar to that utilised by MLOS approach. Once the non-zero voxels have been identified, the intensity of the voxel can subsequently be calculated using:

Illustration of proposed approach where a hypothetical number of five pixels are associated with each lenslet
where \(E\left( {X_j ,Y_{j,} Z_j } \right)\) is the intensity of the jth voxel; \(I\left( {x_i ,y_i } \right)\) is the intensity of the ith pixel, which is known from the captured light-field image; and \(w_{ij}\) is the weighting coefficient, which is the contribution of light intensity from the jth voxel to the ith pixel value.
As with particle reconstruction used for Tomo-PIV, a weighting coefficient will need to be determined, though it will be very different for LF-PIV due to the different line-of-sight principles between Tomo-PIV and LF-PIV. Shi et al. (2016) proposed that the weighting coefficient can be calculated from ray-tracing technique, where it will be used to relate between the voxel, lenslets and pixels. In fact, the weighting coefficient, \(w\), is calculated from two different parts, \(w_1\) and \(w_2\), and a result of their product (i.e. \(w = w_1 \times w_2\)). In particular, \(w_1\) is calculated from the overlapping area between the light beam and lenslet as shown, whereas \({w}_{2}\) is calculated from the overlapping area between the light beam and the pixels. To better explain the rationale and principles behind the weighting coefficient \(w\), assume that there are 5 × 5 pixels behind each lenslet as shown in Fig. 4.2a. Subsequently, discretised light bundles are traced from the voxel under consideration to the microlens plane. Take for example the lower yellow light bundle in Fig. 4.2a, ray tracing will enable the determination of its location, which in turn allows its overlap area with three adjacent lenslets to be calculated for \({w}_{1}\). As physical pixel geometries are almost always squarish, the projection of the light bundle on the microlens plane is illustrated using squares. With \({w}_{1}\) taken care of, procedures to obtain \({w}_{2}\) will now be elaborated. To do that, consider the continuing tracing of the light bundle from the microlens to the image sensor plane, such that the position of the centre light ray is determined as shown in Fig. 4.2c. Once that is ascertained, \({w}_{2}\) may then be calculated as the overlap area between the affected pixels and the projected sub-light bundle. To demonstrate the efficacy of this weighting coefficient for LF-PIV, Fig. 4.3a shows a synthetically generated light-field image whilst Fig. 4.3b and c shows the weighting coefficient distributions (depicted as an image) calculated by the preceding procedures. It can be observed that the present procedures are able to obtain significantly more accurate weighting coefficient distributions, and hence form the basis of what the authors termed as “dense ray tracing MART” or DRT-MART reconstruction technique. The next few sections will compare the performance and efficacy of DRT-MART against MART in terms of some common considerations when reconstructing 3D particle images.

Schematics depicting weighted ray tracing principles on a how ray tracing can be used to locate the affected lenslet and pixels beneath, b overlapping area between light ray and lenslet and c overlapping area between light ray and pixel

a Synthetic light-field image of a point light, b weighting coefficient calculated by ray tracing method and c weighting coefficient calculated by sphere–cylinder intersection algorithm (Shi et al. 2016)
Reconstructed 3D Particle Elongations
Just like in Tomo-PIV, LF-PIV imaging tends to produce elongation of particle images along the optical axis. This is in fact a known issue with Tomo-PIV even though multiple cameras are used (Soria and Atkinson 2008; Scarano 2013). For typical LF-PIV, this is caused by the use of a single-camera-based approach. To better understand this elongation phenomenon and compare between the MART and DRT-MART approaches, a study was conducted based on synthetic volumetric 3D particle images, where the particles were randomly distributed. These synthetic images then were post-processed by both MART and DRT-MART approaches to reconstruct the light-field particle images systematically. Subsequently, the diameters of reconstructed particles were determined at locations where voxel intensity was less than two standard deviations away from the maximum voxel values, which defines a diameter of 3 voxels for an ideal particle image. Note that both MART and DRT-MART approaches used here should incur the same computational time, such that the accuracy levels achieved within the same time can be compared directly. As such, the iteration numbers for MART and DRT-MART are 23 and 400 respectively. Increasing the iteration number for MART approach further is impractical as that will drastically increase the computational time. Perhaps more importantly, results to be presented later also show that the DRT-MART approach is superior over MART approach even if the latter is allowed to undergo 400 iterations. For a closer look, Fig. 4.4 shows the reconstructed 3D particle images obtained by DRT-MART and MART approaches with 400 iterations, as well as MART approach with 23 iterations. It can be observed from the figure that DRT-MART approach leads to smaller elongation of the reconstructed particle within a shorter reconstruction time. This significantly better performance is due to the dense ray-tracing eliminating the zero voxels before the reconstruction stage. In contrast, MART approach does not do this and instead, reconstructs both the non-zero voxels and the neighbouring zero voxels, as its weighting coefficient is unable to ascertain the exact affected lenslet and pixels.

Reconstructed 3D particle images obtained by a DRT-MART and b MART approaches with 400 iterations, as well as c MART approach with 23 iterations
To quantify the above, probability distribution functions (PDF) of the reconstructed particle diameter in the three primary directions (i.e. \(x\), \(y\) and \(z\)) were determined for both DRT-MART and MART approaches and compared in Fig. 4.5. Whilst it is clear that particle elongations in the \(x\) and \(y\) directions are not that significant for both approaches, DRT-MART approach nevertheless leads to generally smaller particle diameters of approximately 2–4 pixels in these directions, whilst MART approach produces slightly large particle diameters of about 5–7 pixels. The discrepancy becomes much larger however in the \(z\) direction (i.e. depth direction along the optical axis for the present analysis) are compared. In this case, DRT-MART achieves significantly smaller particle diameters of about 10–25 pixels, whereas MART approach produces about 35–45 pixel particle diameters. The outcome is clearly much more severe for the MART approach in the depth direction.

Probability density functions of reconstructed particle diameters in the a \(x\), b \(y\) and c \(z\) directions. Note that \(z\) direction is also the depth direction along the camera axis
Reconstruction Quality and Speed
Reconstruction quality is known to be influenced by iteration number, relaxation factor and particle density, amongst others, and this section will take a systematic look at how each of these three factors influences the subsequent accuracy levels associated with DRT-MART and MART approaches. Firstly, a typical 3D volume, albeit a small one, of 0.1 particle per microlens (PPM) was used to generate synthetic light-field particles images. These images were subjected to reconstructions by DRT-MART and MART approaches, where a range of iteration numbers and relaxation factors were used to study how the latter will impact the reconstruction quality of the two approaches. The reconstructions were carried out by discretising the volume with pixel-voxel ratios of 1:1 in the \(x\) and \(y\) directions, as well as 10:1 in the \(z\) direction, respectively. A \(Q_{{\text{Recon}}}\) factor was used to quantify the reconstruction quality (Elsinga et al. 2006) and defined as
where \(E_0 \left( {x,y,z} \right)\) is the exact voxel intensity approximated by a Gaussian distribution with three voxel diameter, and \(E_1 \left( {x,y,z} \right)\) is the voxel intensity of the reconstructed particle image.
Figure 4.6 shows the variations in the reconstruction quality level with respect to changes in the iteration number and relaxation factor \(\mu\), after the preceding analysis. Firstly, it can be appreciated from these results that DRT-MART approach is able to reach consistently higher reconstruction quality levels than MART approach, the reason being DRT-MART approach produces less elongated particles with more Gaussian-like voxel intensities. Secondly, the relaxation factor and iteration number for both DRT-MART and MART approaches in LF-PIV need to be larger than that for Tomo-PIV for comparable reconstruction quality levels. This is due to the fact that a more significant number of pixels are affected by every voxel in LF-PIV, as opposed to just several pixels per voxel in Tomo-PIV. In fact, even more pixels will be affected in LF-PIV if the voxel is located further away from the focal plane. This can be appreciated in Fig. 4.7 where the plots show how the maximum voxel intensity varies as the depth-of-field changes, and how the use of DRT-MART and MART approaches affect it. Regardless of the exact approach used, it can be seen that the maximum voxel intensity levels do not vary very much when close to the focal plane (i.e. 80–110 voxel) and much of the iterations beyond the 20th iteration were actually going towards reconstruction efforts further away from the focal plane. This leads to the understanding that the calculations will have to consider the number of pixels and their relative contributions towards the final voxel intensity, and explain why LF-PIV generally needs more iterations and larger relaxation factors to reach high reconstruction quality levels.

Impact of iteration number and relaxation factor upon the reconstruction quality for a DRT-MART and b MART approaches

Variations of maximum voxel intensity with depth-of-field changes (i.e. in the \(z\) direction) for DRT-MART approach with a 20 iterations and b 400 iterations, as well as MART approach with c 20 iterations and d 200 iterations
As mentioned earlier, volumetric PIV measurement techniques such as Tomo-PIV and LF-PIV tend to make use of relatively low particle densities within the measurement volumes for satisfactory 3D particle reconstruction outcomes. Theoretically speaking, high particle densities should be used as they could provide smaller interrogation volumes and hence higher measurement resolutions, and the use of low particle densities seems to be counter-intuitive. However, it had been discovered in earlier Tomo-PIV studies that a higher particle density leads to more ghost particles that prevent high reconstruction quality (Elsinga et al. 2006; Scarano 2013), even though multiple cameras were utilised. LF-PIV faces the same problem, especially since it typically makes use of a single light-field camera. To have a better appreciation of the issue, synthetic light-field particle images were once again generated but with different particle densities, where they were reconstructed using both DRT-MART and MART approaches with 400 and 200 iterations respectively. Other than that, a 2.5 relaxation factor and pixel-voxel ratios of 1:1 (in x and y directions) and 10:1 (in the z direction) were maintained throughout. The outcomes of this particular analysis are shown in Fig. 4.8, and it is quite clear that DRT-MART approach attains better reconstruction quality level than MART approach at the same particle density. Furthermore, the reconstruction quality deteriorates as the particle density increases, regardless of either approach, similar to Tomo-PIV. Note that no ghost particles are observed during the particle reconstruction stage for DRT-MART and MART approaches, due to information made available by the multiple perspectives offered by the microlens (Ng 2006). To confirm this, particle reconstruction was extended in the \(z\) direction in both positive and negative directions to include volumes which did not have any seeding particles and this was done on 30 synthetic light-field particle images. The reconstruction results were summed up and the voxel intensity levels were then averaged along the x–z plane. These results were plotted and presented in Fig. 4.9 for a closer look at how they vary along the pertinent direction/plane. As Fig. 4.9a shows, the summed-up voxel intensity clearly shows zero intensity beyond the region where particles exist (i.e. blue region) and that the voxel intensity is generally lower along \(z=0\) (i.e. greenish line). The latter can be attributed to the reconstructed particles around the focal plane occupying more voxels (elongation effect) with reduced intensity, which is due to lower resolution close to the focal plane as highlighted earlier on. This can be better appreciated in greater detail in Fig. 4.9b, where the average voxel intensity taken in the z direction along \(x=0\). The dip in the voxel intensity close to the focal plane (i.e. \(z=0\)) and the abrupt drop to zero levels beyond the seeded region can be easily discerned.

A comparison of the impact upon reconstruction quality level due to particle density for DRT-MART and MART approaches

Variations in the a sum of 30 reconstructed light-field particle images taken along the x–z plane, and b average voxel intensity level along the \(z\) direction
Last but not least, another comparison of interest between DRT-MART and MART approaches here will be their computational speeds. To do that, the same synthetic light-field particle images were used for reconstruction by DRT-MART and MART approaches, where 400 and 200 iterations were used for the former and latter respectively. Furthermore, the particle density was varied as part of the computational efficiency comparison, since it is expected that increasingly higher particle density will lead to greater computational loads. The results are presented in Fig. 4.10, where the computational time for MART approach was non-dimensionalised by that for DRT-MART approach and plotted as a function of particle density. As the figure shows, DRT-MART approach is faster than MART approach until about 2PPM. However, note that 1PPM is typically the upper particle density limit for such 3D particle reconstructions, it remains clear that DRT-MART continues to enjoy a significant speed advantage over MART approach by being about 4 times faster at that particle density.

Computational time taken by MART approach relative to DRT-MART approach, as a function of particle density
Reconstruction Accuracy Under Unsteady Flow Conditions
The previous section discussed upon the reconstruction efficacy of DRT-MART and MART approaches with respect to the particle seeding condition and reconstruction details, using light-field particle images of randomly dispersed particles. Whilst it demonstrates the potential of LF-PIV, it is not representative of the largely unsteady flow fields that are typically encountered in fluid dynamics and aerodynamics research. Therefore, this section will examine the two reconstruction approaches based on more complex flow fields, such that a better grasp of their accuracy levels under these circumstances can be attained. For this particular analysis, a variety of unsteady oscillatory flow fields were used to ascertain the relative performance of DRT-MART and MART approaches. To be more specific, the flow fields can be divided into two types:
Type A where the oscillatory motion is only in the x-direction:
And Type B where the oscillatory motion is only in the z-direction:
Each of these two types was further divided into four different configurations and Table 4.1 shows the details of these configurations. Synthetic light-field particle images were subsequently generated according to these flow scenarios for further analysis. Of particular interest will be the effects of pixel–voxel ratio, iteration number and velocity gradient on the hypothetical measurement accuracy on DRT-MART and MART approaches. Seeding density of 0.5PPM was used, whilst pixel–voxel ratios (PVR) of 1, 2 and 3 were adopted for \(x\) and \(y\) directions. As for reconstructions, DRT-MART and MART approaches made use of 400 and 200 iterations respectively, with a relaxation factor of 2.5. 3D multi-grid cross-correlations (Soria 1996; Atkinson and Soria 2009) were used to process the reconstructed particle images with an overlapping ratio of 0.75, as well as initial and final interrogation volumes of 320 × 320 × 32 voxel and 160 × 160 × 16 voxel, respectively.
To compare how well DRT-MART and MART approaches perform here, displacement errors between the known flow field and measured results for Case A1 in the \(x\) and \(y\) directions are determined and their PDF presented in Fig. 4.11a. It can be seen that DRT-MART approach performs better than MART approach at PVR = 1 and 2, whilst there is little difference between PVR = 1 and 2 for DRT-MART approach. Although PVR = 1 could in theory offer smaller interrogation volume and hence better measurement resolution, the number of particles within a single interrogation volume may not meet the requirement for accurate cross-correlation. Equally important, using PVR = 2 rather than 1 will actually accelerate the DRT-MART reconstruction by up to 4 times. Moving on to the z-direction, the displacement error PDF for Case B1 is now presented in Fig. 4.11b, where PVR = 5, 10 and 20 in z direction were used whilst PVR = 1 was maintained in the \(x\) and \(y\) directions. Results show that DRT-MART achieves best performance at PVR = 10, the latter of which produces a 2-voxel diameter particle that conforms well with an idealised 3D Gaussian-type geometry. In contrast, the significantly poorer performance put up by MART approach is due to the resulting much larger reconstructed particle sizes.

Displacement error PDF in the a x and y directions, as well as b z direction under different PVR values
Next, the effects of iteration number on the displacement errors are considered and Fig. 4.12 shows the relationships between the RMS values of the displacement errors and iteration number in both the \(x\) and \(z\) directions. In the x direction, about 50 iterations lead to satisfactorily low measurement errors in the \(x\) (and \(y\)) direction, whilst approximately 200 iterations will be needed to reduce the measurement errors in the \(z\) direction to a sufficiently low level. This is consistent with the earlier finding that a higher iteration number is necessary to achieve satisfactory reconstruction of particles that are located further away from the focal plane.

Relationships between RMS velocity errors and iteration number in the a x and b z directions for DRT-MART approach
Last but not least, attention is now turned towards understanding how the presence of significant velocity gradients will impact upon the measurement accuracy level. This will be of significant interest as most engineering flows involve turbulent shear flow scenarios and therefore, a more extensive comparison based on all 8 configurations will be shown here. All test cases were based on synthetic light-field particle images generated at 0.5PPM, relaxation factor of 2.5, PVR = 1 in the \(x\) and \(y\) directions, and PVR = 5 in the \(z\) directions. For a more consistent comparison, similar computational times were allocated to DRT-MART and MART approaches, which lead to 200 and 23 iterations for the former and latter respectively. Subsequently, 3D multi-grid cross-correlations with 75% overlapping ratio, as well as initial and final interrogation volumes of 320 × 320 × 32 voxels and 160 × 160 × 16 voxels, were used respectively. Similar to the preceding comparisons, displacement error PDF results are presented in Figs. 4.13 and 4.14 for all test cases to compare and evaluate the two different reconstruction approaches.

Comparison of displacement error PDF in the x direction between DRT-MART and MART approaches for a case A1, b case A2, c case A3 and d case A4

Comparison of displacement error PDF in the \(z\) direction between DRT-MART and MART approaches for a case B1, b case B2, c case B3 and d case B4
As expected and shown in Fig. 4.13, higher measurement accuracies will be achieved for low and moderate velocity gradient scenarios (i.e. \(\omega = 0.25\) and 0.5) for both reconstruction approaches. However, it remains clear that DRT-MART approach is still discernibly better than MART approach. It is also noteworthy to point out that it is only when the \(u\) velocity component varies along the \(z\) direction in Case A4 that the performance of both reconstruction approaches suffers a significant drop in measurement accuracy. This can be appreciated from the fact that the measurement resolution is lower along the depth and hence \(z\) direction. As for Fig. 4.14, similar outcomes can be observed as well, where the lowest measurement accuracy is for Case B4 where the \(w\) velocity component varies in the \(z\) direction (and depth direction). In this case, measurement accuracy is far worse than the situation for Case A4. These observations reinforce the notion that the light-field camera axis should not be aligned in the direction where the most dominant velocity component exists, but instead perpendicular to it for higher measurement accuracy levels.
Experimental Validations
Up to this point, all testing had been done based on synthetic light-field particle images and as much as theoretical oscillating velocity fields make things more realistic, they are still not based on real-world flow scenarios. Nevertheless, all the testing thus far had provided confidence and much needed understanding on the advantages and disadvantages of the proposed DRT-MART approach. So, undertaking LF-PIV measurements and making use of DRT-MART on captured light-field particle images to arrive at the 3D flow fields of real-world flow scenarios will be the key “litmus test”. To do that, one of the first validation experiments was conducted on a canonical laminar, incompressible round water jet flow at a Reynolds number of 2000. The design of the experimental setup was generally similar to those adopted by earlier studies on various jet flow phenomena (New and Tsai 2007; New and Tsovolos 2012; Shi and New 2013; Long and New 2015, 2016, 2019) and its operations will hence only be briefly described here. With reference to Fig. 4.15, water from a small reservoir was channelled into the jet apparatus by a centrifugal water pump, where it passed through a diffuser, honeycomb, three layers of fine screens and a contraction chamber. Water would subsequently exhaust from a D = 20 mm diameter round nozzle into a large Plexiglas water tank filled with quiescent water. To ensure a constant static pressure head, excess water would be channelled out of the water tank via an overflow pipe and back into the small reservoir, thus closing the flow circuit. Flow velocity adjustments were done using a needle valve and monitored using an electromagnetic flowmeter. To ensure high fidelity during the measurements, the measurement volume was restricted to 1.9D × 1.3D × 0.5D located at 2.25D above the nozzle exit. The aim was to capture the regular and coherent vortex roll-ups along the jet shear layer due to Kelvin–Helmholtz hydrodynamic instabilities. 20 μm polyamide seeding particles of 1.03 g/cm3 density were dispersed and circulated throughout the flow circuit and water tank at about 0.4PPM. 10 mm thick laser sheets were produced by a 200 mJ/pulse, 532 nm wavelength Nd:YAG laser to provide volumetric illuminations and an in-house light-field camera (Shi et al. 2016) was used to record the light-field particle images. Additionally, main lens aperture was 4 and magnification factor was −0.95. At the same time, a 2 ms time interval was used to ensure that the one-quarter particle displacement rule for satisfactory cross-correlations was adhered to.

Schematics of the experimental setup and flow circuit used for the experimental testing
Before reconstructing the 200 captured light-field particle images, the global background was subtracted from them to better filter out the zero-voxels. Subsequently, DRT-MART and MART approaches were used to reconstruct the 3D particle images based on 400 and 23 iterations respectively. The reconstruction involved 3300 × 2200 × 182 voxels, used a relaxation factor of 2.5, and PVR = 2 in the \(x\) and \(y\) directions, as well as PVR = 10 in the z direction. 3D multi-grid cross-correlations were used to process the reconstructed particle images, where 75% overlapping ratio, initial and final interrogation volumes of 320 × 320 × 64 voxels and 160 × 160 × 32 voxels, as well as a 3-point × 3-point median filter to reject spurious vectors. Before touching upon the results however, one issue associated with practical experimentation using LF-PIV will need to be highlighted. Figure 4.16 shows the distributions of the voxel intensity levels along the x–z plane and \(z\) direction, similar to what had been before for synthetic light-field particle images and shown in Fig. 4.9 earlier. Unlike what had been observed for Fig. 4.9 earlier, the voxel intensity levels along and close to the focal plane are actually much higher than at locations further away. Further investigation revealed that the Gaussian distribution of the laser beam (and hence laser sheet) intensity is responsible for this phenomenon, where the situation is exacerbated by the significantly lower intensity levels even further away from the focal plane. Note that calibration errors for the microlens and optical aberration would have contributed towards the lower intensity levels as well.

Variations in the a sum of 30 reconstructed light-field particle images taken along the x–z plane, and b average voxel intensity level along the \(z\) direction
Figure 4.17 shows the post-processed results produced by both DRT-MART and MART approaches and it should be recalled that the aim was to capture the coherent vortex-roll-ups along jet shear layer. From that perspective, it would appear that the present LF-PIV configuration, as well as DRT-MART and MART approaches were able to resolve the 3D flow behaviour within the measurement volume well. By most accounts, the vortex roll-up structure and behaviour captured by the two different approaches appear to be very similar from that 3D orientation, barring some minor differences. However, it should be noted that the velocity vector field is along the x–y plane and \(y = 0\) and little information on the \(z\) direction can be inferred from there. To inspect closer, Fig. 4.18 shows the top-views of the results corresponding to Fig. 4.17. From this orientation, it becomes clear that MART approach produces significant number of erroneous \(w\) velocity vectors at the furthest distances away from the focal plane located at \(y = 0\). In contrast, DRT-MART approach produces reasonable \(w\) velocity vector distributions in the same regions. This discrepancy seen in the experimental results produced by DRT-MART and MART approaches attested to the findings arising from the earlier study based on synthetic light-field particle images. In fact, this further reinforces the notion that utilising synthetic particle images continues to be very useful in testing out novel PIV techniques and post-processing procedures.

Instantaneous velocity vector field and vorticity isosurfaces generated by a DRT-MART and b MART approaches

Top-views of the instantaneous 3D flow fields corresponding to Fig. 4.17
Comparison with Tomo-PIV
Tomo-PIV is currently the most popular volumetric approach when it comes to 3D flow measurements and it will be very useful to compare the preceding single camera LF-PIV approach with conventional multi-camera Tomo-PIV approach. In particular, since one of the biggest benefits of LF-PIV approach has been its potential to make use of a single light-field camera instead of multiple cameras, it will be instructive to compare their accuracy levels. In addition, it will also be interesting to find out at what light-field camera Tomo-camera pixel ratio will a single camera LF-PIV be able to achieve similar accuracy levels as with Tomo-PIV. This is especially important since advances in imaging sensor technology meant that sensor pixel numbers will continue to increase rapidly and may one day be sufficiently dense and cost-effective that the convenience offered by LF-PIV drives a higher adoption rate. To find out more, synthetic light-field and tomographic particle images were used to study the impact of camera number in Tomo-PIV, as well as pixel resolution ratio between light-field and tomographic cameras, upon the overall accuracy levels of the reconstructed 3D flow fields. Once that had been accomplished, further comparisons were conducted based on actual experiments on laminar, incompressible jet flows for a better understanding of the practical experimental challenges and implications associated with the two different volumetric 3D PIV approaches.
Synthetic Particle Image Generation and Analysis
Before the details of how the synthetic particle image were generated and analysed by LF-PIV and Tomo-PIV approaches, it is important to firstly highlight the inherent differences between these two approaches and how they will affect the generation of synthetic particle images. For Tomo-PIV, it is well known that the number of cameras and particle density have strong influences upon its accuracy levels (Elsinga et al. 2006; Atkinson and Soria 2009). This is different from LF-PIV where the situation is more complex, depending on how the MLA is configured. As introduced in Chapter 2, a light-field camera where the MLA is located at one focal length distance away from the imaging sensor will produce the highest angular resolution possible. On the other hand, different spatial and angular resolutions will result if the distance between the MLA and imaging sensor deviates from that (Georgiev and Intwala 2006; Lumsdaine and Georgiev 2009) in unfocused light-field cameras. For the purpose of volumetric velocity measurements, it is preferable to have a higher angular resolution than spatial resolution, since it means the ability to gather more information on the out-of-plane particle displacements. It had been shown in earlier studies that LF-PIV approach is heavily influenced by the pixel-microlens ratio (PMR) and a higher MLA resolution can better handle higher particle densities that lead to higher spatial resolution. In fact, the larger the number of pixels associated with each microlens, the higher the angular resolution. Coupled with the desired higher MLA resolution, it is unsurprising that the capability of LF-PIV approach increases with the imaging sensor pixel resolution.
For a more consistent comparison between LF-PIV and Tomo-PIV, a light-field camera to Tomo-camera pixel ratio defined as
was used to quantify theoretically how much times higher a light-field camera resolution needs to be over than all the Tomo-camera resolutions added together. On top of that, it also shed some light upon the cost of a LF-PIV setup relative to a Tomo-PIV setup. One thing that needs to be highlighted is that synthetic light-field images generated for LF-PIV and Tomo-PIV approaches here will be based on the most favourable particle density associated with each of them, rather than being the same throughout. The reason for this is that Tomo-PIV approach is able to handle higher particle densities than LF-PIV due to its use of multiple cameras (Scarano 2013; Fahringer et al. 2015; Shi et al. 2016, 2017). However, it will be desirable to compare the two approaches when they are optimised for a given field-of-view, so that their full capabilities can be better compared here.
For the present comparison, particular attention was paid towards how variations in PMR, LTPR and the number of cameras for Tomo-PIV will impact the relative advantages of LF-PIV approach. In particular, results from Direct Numerical Simulations (DNS) of a \({\text{Re}} = 2500\) incompressible jet flow were used to generate the synthetic particle images for LF-PIV and Tomo-PIV, as shown in Fig. 4.19. Note that the measurement volume was taken at one jet diameter above the nozzle exit, so that vortex roll-ups (see inset of Fig. 4.19) would be captured in the results. With reference to the figure, orientation of the hypothetical light-field camera is arranged such that its optical axis is along the \(z\) direction, whilst its imaging sensor is facing the x–y plane. Briefly describing, to begin generating the synthetic light-field particle images, particles are randomly dispersed in the very first frame first, before they were been displaced based on the DNS jet flow result for a fixed time interval that satisfy the one-quarter rule for PIV particle displacements. With the particle locations determined for each synthetic particle images, their corresponding light-field particle images would be generated by using 5 million rays per particle. These rays were then traced from each particle through the main lens and MLA according to principles laid out in Georgiev and Intwala (2006) and Shi et al. (2016).

A snapshot of the \(\mathrm{Re}=2500\) incompressible jet flow simulated using DNS. The inset shows the details of a vortex roll-up along the jet shear layer
For LF-PIV, two different hypothetical light-field camera resolutions of 800 × 800 pixels and 1600 × 1600 pixels with PMR = 7, 14 and 28 were tested. The MLA were also assumed to comprise of hexagonal lenslets for higher resolutions. As for Tomo-PIV, each camera was assumed to have a resolution of 160 × 160 pixels with a possibility of 4, 6 and 8 camera combinations. The preceding test cases produce LTPR of 3.13, 4.17, 6.25, 12.5, 16.67 and 25, covering a significant range of ratios. Generally speaking, the aperture between the main lens and microlenses should be matched to optimise the resolution. However, maintaining this optimal condition will lead to changes to other parameters when the operating condition changes. For instance, a change in PMR results in a change in the lenslet size and the focal length of the latter will need to be adjusted to ensure aperture number is maintained. Figure 4.20 depicts several scenarios to demonstrate how different PMR will lead to changes to the separation distance between the MLA and imaging sensor. Readers can refer to Table 1 of Shi et al. (2018) for the different combinations of parameters used here for both LF-PIV and Tomo-PIV for better clarity. Last but not least, 0.5PPM was used as it was found to produce optimal results (Shi et al. 2016). With the preceding settings, synthetic light-field particle images could then be generated and some of them are shown in Fig. 4.21a–c.

Schematics showing how changes to PMR will lead to changes to the separation distance between the MLA and imaging sensor. a PMR = 7, LTPR = 3.13, 4.17, 6.25; b PMR = 14, LTPR = 3.13, 4.17, 6.25; c PMR = 28, LTPR = 3.13, 4.17, 6.25; d PMR = 7, LTPR = 12.5, 16.67, 25; e PMR = 14, LTPR = 12.5, 16.67, 25; f PMR = 28, LTPR = 12.5, 16.67, 25

Example synthetic particle images generated for reconstruction by LF-PIV and Tomo-PIV approaches a LF-PIV (LTPR = 3.13, 4.17, 6.25, PMR = 7, 0.5PPM); b LF-PIV (LTPR = 3.13, 4.17, 6.25, PMR = 14, 0.5PPM); c LF-PIV (LTPR = 3.13, 4.17, 6.25, PMR = 28, 0.5PPM); d Tomo-PIV (0.05PPP)
Moving to Tomo-PIV synthetic particle image generation, they were generated based on equally spaced cameras (i.e. 4, 6 and 8) along a semi-circle arc in the x–z plane as shown in Fig. 4.22. The pinhole camera model (Tsai 1986) was used to calculate the projected views of a particle in 3D space upon the 2D imaging sensor with a focal length of 85 mm. Image and object distances of 93.4 and 946.5 mm were used as well, for a 0.075 mm/pixel magnification factor. For multiple cameras in Tomo-PIV, projections of all the particles upon imaging sensors were determined using the camera matrix and particle centre locations. To achieve a reasonable particle diameter size of about 3 pixels, a Gaussian distribution was applied for particle images and this was repeated for all cameras used. This would produce the first instance of the synthetic particle images to be studied by Tomo-PIV here. Similar to what was adopted for LF-PIV, DNS results were then used to displace the particles according to the simulated velocity fields over a selected time interval and the earlier procedures were repeated again for subsequent synthetic particle images. To post-process the synthetic particle images using LF-PIV and Tomo-PIV techniques, DRT-MART (Shi et al. 2017) and MLOS-SMART (Atkinson and Soria 2009) approaches were used respectively. In the case for Tomo-PIV, a 1:1 pixel-voxel ratio was used. In contrast, pixel-voxel ratios used in the x, y and z direction were set to 2, 2 and 10, in accordance to earlier findings that show their suitability for LF-PIV approach. To arrive at the 3D velocity fields, 3D multi-grid cross-correlations similar to what had been used earlier on were used and their details can be found in Table 2 of Shi et al. (2018). Note also that the particle centres were calculated based on peak centroid method, instead of Gaussian peak fitting.

Multi-camera Tomo-PIV configurations used in present comparison
The first comparison focused on how much the reconstructed particle centre locations deviated from the simulation results and the PDF of the reconstruction errors in all three directions for both LF-PIV and Tomo-PIV approaches (Fig. 4.23). For Tomo-PIV, it is not surprising to see that increasing the camera number and decreasing particle density led to improvements in the reconstruction accuracy levels. As earlier studies had shown (Elsinga et al. 2006; Scarano 2013), elongations of reconstructed particles and ghost particles can be mitigated by adopting wider viewing angles (i.e. more cameras) and lower particle densities. On the other hand, LF-PIV approach is more affected by camera resolution, as increasing it produces much higher reconstruction accuracy levels in the z and y directions. Furthermore, reconstruction accuracy in the z direction is determined more by PMR (Shi et al. 2016) and to a certain extent, the LTPR. For instance, a larger LTPR leads to higher reconstruction accuracy since it will improve MLA resolution, which in turn leads to the light rays being captured by more lenslets/pixels and better reconstruction of the particle z direction displacement.

PDF of reconstruction errors in the particle centres for both Tomo-PIV and LF-PIV analysis of synthetic particle images. a Tomo-PIV, 0.05PPP, b Tomo-PIV, 0.1PPP, c LF-PIV, low LTPR and d LF-PIV, high LTPR
Next, discrepancies between the LF-PIV and Tomo-PIV velocity field results were compared with the DNS jet flow results through the RMS errors for each velocity components individually, as shown in Fig. 4.24. Starting with the low-LTPR LF-PIV case, it should be noted that whilst a higher PMR produces better depth resolution, it also leads to larger measurement errors. Furthermore, a higher PMR means that the lenslet physical size has to increase and therefore, a lower number of total lenslets that can be deployed. What this implies is that maximum acceptable particle density will decrease, with significant impact upon the minimum interrogation volume that can be used for cross-correlations and hence measurement accuracy. When the LF-PIV camera resolution is increased significantly as shown in the figure, the measurement accuracies in all three directions can be seen to increase correspondingly. In particular, a PMR = 14 value appears to strike a good compromise between PMR and MLA resolution. Moving on to the results for Tomo-PIV, it is within expectations to see that the measurement errors reduce when more cameras were used (Elsinga et al. 2006; Atkinson and Soria 2009), particularly in the y direction. This is because the y direction is parallel to all the cameras and more cameras will serve to improve the reconstruction quality along that direction. Also, in contrast to LF-PIV where ghost particles do not pose a problem, they are presented here and could be behind the observation that a higher particle density of 0.1PPP produces higher errors than 0.05PPP (Elsinga et al. 2006; Scarano 2013). The key takeaway from the above is that LF-PIV is able to produce comparable results when compared to Tomo-PIV, at least based on the DNS results here, even for a relatively low pixel resolution ratio test case such as the one associated with LTPR = 3.13, 4.17, 6.25 at PMR = 7. In fact, the present analysis shows that LF-PIV has the potential to produce comparable or better accuracy levels than Tomo-PIV for the same field-of-view, especially when camera and MLA resolution continue to improve over time.

Velocity error RMS when compared with DNS results. a LF-PIV for the low (PTPR = 3.13, 4.17, 6.25) and high resolution (PTPR = 12.5, 16.67, 25) light-field cameras b Tomo-PIV (pixel size = 0.075 mm)
Last but not least, actual experiments were conducted to move the comparison beyond simply the use of synthetic particle images. The experimental setup used to experimentally validate LF-PIV earlier was used and hence its physical details will not be described here again. Instead, Fig. 4.25 shows the physical camera arrangements for LF-PIV and Tomo-PIV configurations. Particle densities used for Tomo-PIV and LF-PIV tests were set at 0.062PPP and 0.06PPM respectively. The light-field camera was the one described earlier in the chapter, whilst four 4-megapixel Imperx B2014 PIV cameras coupled with Micro-Nikkor 85 mm Scheimpflug lenses were used for Tomo-PIV. Effective resolutions for LF-PIV and Tomo-PIV were determined to be 6600 × 4400 pixels and 480 × 320 pixels respectively, which represents a LTPR = 47.27 scenario. General reconstruction methodologies for LF-PIV and Tomo-PIV were similar to the ones used during synthetic particle image analysis, though 400 and 40 iterations were used for the former and latter approaches respectively. Reconstruction domains for LF-PIV and Tomo-PIV were 3300 × 2200 × 182 voxels and 480 × 320 × 130 voxels respectively as well. Velocity fields were obtained by subjecting the reconstructed 3D particle images to multi-grid correlations with 75% overlapping ratio. Initial and final interrogation windows were 320 × 320 × 64 voxels and 160 × 160 × 32 voxels for LF-PIV, whilst they were 64 × 64 × 64 voxels and 32 × 32 × 32 voxels for Tomo-PIV. Details of these post-processing parameters are presented in Table 2 of Shi et al. (2018). Similar to the earlier validation exercise, the goal here was to capture the vortex roll-ups along the jet shear layer, and a side-by-side comparison of how well both approaches capture the same instantaneous vortex roll-up flow field can be seen in Fig. 4.26. It can be deduced that the vortex roll-up captured by the two different approaches are similar and with a correlation level of 0.94 between the two velocity fields, one can appreciate that the outcome of LF-PIV approach is very comparable with Tomo-PIV, at least for the present jet flow experiments.

Schematics of the experimental setup and physical camera arrangements used for LF-PIV and Tomo-PIV approaches

Side-by-side comparison of the instantaneous velocity and vorticity fields obtained by a LF-PIV and b Tomo-PIV
Dual-Camera LF-PIV
One of the issues encountered when developing a single-camera LF-PIV technique is the higher uncertainties in the depth direction when small viewing angles are used, as what we had seen previously. Using synthetic light-field images of one single PIV particle as an example, the reconstruction result for a single light-field camera can be appreciated in Fig. 4.27a, where the reconstruction result shows a reconstructed particle that is stretched in the depth direction. Whilst the centroid of the reconstructed particle can still be successfully identified by the in-house post-processing algorithm, note that an idealised round seeding particle was assumed in generating the synthetic light-field particle images. In most actual PIV measurements, such an assumption is very unlikely to be realised, on top of other considerations such as size variations, particle rotations and other factors. As such, a study was conducted by Mei et al. (2019) to see how much benefit will be by adding one more light-field camera be when it comes down to the accuracy levels of particle reconstruction and tracking for PIV purposes.

Reconstruction results for a PIV particle generated from a synthetic image based on a single light-field camera approach and b dual light-field camera approach
In the study, using the same synthetic light-field images for one single idealised PIV particle but reconstructed with two light-field cameras instead of just one, the reconstructed particle is now much closer to its idealised geometry, as can be seen in Fig. 4.27b. More importantly, the centroid of the reconstructed particle can now be ascertained with greater accuracy, which would in turn translate to higher accuracy levels for LF-PIV measurements. These initial results gave confidence to the possibility of achieving a significant increase in LF-PIV accuracy levels by simply using another light-field camera for flow scenarios. Hence, additional tests were carried out to further quantify the impact of using dual light-field camera approach, as compared to single light-field camera. In principle, implementation of two light-field cameras for dual LF-PIV 3D measurements of a flow scenario will be relatively straight forward and resemble the procedures shown in Fig. 4.28. Briefly speaking, two light-field cameras will be viewing the flow scenario from two different perspectives, with each camera recording its own light-field particle images and synchronised with the other camera. The reconstruction process will take into account the separation angle between the two light-field cameras, before processing the two image sets and arriving at the final combined locations of the 3D particle images. With an additional light-field camera incorporated, the reconstruction process of a dual LF-PIV setup is schematically represented using ray-tracing in Fig. 4.29, from the voxels to the main lens, MLA and eventually the imaging sensor (CCD/CMOS). The volumetric calibration and reconstruction process can be summarised via the flowchart presented in Fig. 4.30 and interested readers can refer to Mei et al. (2019) for more details in the reconstruction algorithms and other details.

General schematics of procedures associated with dual LF-PIV measurements of a flow scenario

Schematics of ray-tracing from the voxels in the measurement volume to the imaging sensor via the main lens and MLA for the two light-field cameras, which will be used for the two-camera reconstruction approach

Flowchart that outlines the volumetric calibration and particle reconstruction processes for dual camera LF-PIV
Before a dual camera LF-PIV approach can be implemented however, the basic principles will need to be validated even if things seem straight forward. And just with the case of a single camera LF-PIV, the effects of experimental parameters such as camera separation angle, particle density and others will have to be understood first, before dual camera LF-PIV can be used for actual experimental flow validations. This will be elaborated in greater detail in the next section.
Initial Validation of Dual Camera Principles
To begin with, initial validations using real-world images of multiple tiny spherical glass beads held up by very slender syringe needles and located at various 3D locations were taken by a single light-field camera, as shown schematically in Fig. 4.31a. To simulate the use of two light-field cameras, a rotating platform was used to rotate the glass bead setup through discrete angular locations during the image capturing process, as shown in Fig. 4.31b. Samples of the light-field images captured by the light-field camera at 0° and 90° are shown in Fig. 4.31c and d to better show the differences in the images between the two orientations. Through this way, the locations and geometries of the glass beads can be reconstructed by considering a single camera approach or dual camera approach with different angular differences between them. This allowed better understanding of the impact of and optimal angular locations in a dual light-field camera approach, even before an actual second light-field camera is used.

a Schematics of the glass bead 3D positioning setup; b photo of the light-field camera and glass bead setup; c and d raw light-field images captured by the camera at 0° and 90° angular locations
To understand how the implementation of a second light-field camera could lead to better reconstruction of the imaged glass beads in the 3D space, an example based on light-field images taken at 0° and 90° angular locations will be briefly described here. Figure 4.32a and b shows the reconstructed results for each of the light-field images taken at these two angular locations. Note that both of them exhibit elongated geometries in the reconstructed results—the one at 0° angular location shows elongations along the Z-direction, whilst the one at 90° angular location shows elongations along the X-direction. Taken individually, each result demonstrates the higher uncertainty levels expected from the use of a single light-field camera. However, if the results from both angular locations are combined, significantly better reconstruction results without discernible elongations in any direction can be achieved, as shown in Fig. 4.32c. With this successful demonstration, dual camera LF-PIV approach will now be studied for the effects of particle density and separate angle based on synthetic light-field particle images.

Reconstructed results for light-field images taken at a 0° and b 90°, as well as based on both orientations for dual light-field camera approach
Effects of Particle Density and Separation Angle
It has been established in earlier studies by the authors that a particle density of 0.5PPM strikes a good balance between reconstruction quality and sample window size. However, this is unclear for a dual camera LF-PIV setup, so a series of tests were conducted to evaluate the impact of particle density on dual camera LF-PIV approach more thoroughly. In this case, 0.1, 0.5 and 1.0PPM will be used. Synthetic light-field images with these particle densities were generated and reconstructed, before the reconstructed particle intensities in the volume were compared with the original one that was used to generate the synthetic light-field images. This was done by using reconstruction quality \(Q_{{\text{Recon}}}\), that was described and used for single camera LF-PIV earlier. Figure 4.33 shows the variations in the reconstruction quality with iteration number under different particle density and light-field camera configurations, where several interesting observations can be made. Firstly, the reconstruction quality is significantly better when a dual camera setup is used for the same iteration number. Secondly, a lower particle density level produces a higher reconstruction quality, similar to what had been observed previously for single camera LF-PIV. Thirdly, the convergence of the reconstruction quality is more rapid for the dual camera setup. And lastly, a dual camera setup is able to handle higher particle density levels much better than a single camera setup. This can be attributed to the fact that two light-field cameras provide wider perspectives of the particles than a single light-field camera, which leads to less elongated reconstructed particles and improve reconstruction quality.

Variations in the reconstruction quality with iteration number under different particle density and light-field camera configurations
Next, synthetic light-field particle images based on different viewing orientations of two different light-field cameras of the same volume were constructed at particle densities of 0.5 and 1PPM. Note that the two different viewing orientations were characterised as the separation angle between them, where 0° and 180° refers to the two cameras having the same and directly opposing viewing orientations. The former configuration would have reverted back to a single-camera-based LF-PIV approach. Figure 4.34 shows how the reconstruction quality varies between 0° and 180° at 10° intervals, where it reaches a peak level at 90° separation angle. Hence, it is expected that this separation angle would be optimal for subsequent experimental validations. Additionally, halving the particle density from 1PPM to 0.5PPM leads to a small increase in reconstruction quality as well. An optimal separation angle of 90° can be understood if one considers the effects upon the spatial resolution distribution along the out-of-plane direction (i.e. z direction for each camera) as the separation angle varies. Two light points are considered to be distinguishable when their light rays reach two separate groups of microlenses, whereas they will be less distinguishable if these light rays are recorded by the same group of microlenses. Hence, a 90° separation angle leads to the most optimal configuration that will allow the best differentiation between the two different light points.

Comparison of reconstruction quality due to variations in the angular perspective or separation angle between the cameras in a dual camera setup
Recall that the objective of having a dual camera LF-PIV approach is to mitigate particle elongations caused by a lower resolution in the depth direction if only a single camera were to be used. Now, the resolution in the depth direction for a dual camera setup will be examined for various separation angles and Fig. 4.35 shows the results for 0° to 90° separation angles at 30° intervals. In the plots, z direction is the depth direction, where in this case for two cameras will be the angular bisector. The origin will also be located where the two optical axes intersect. Note also that the legend is the depth resolution in millimetres. For 0° separation angle, where the optical axes of the two cameras are aligned, the situation resembles that of a single camera configuration and is not expected to demonstrate better improvement beyond that. This can be seen in Fig. 4.35a where resolution is about 0.55 mm along a strip along the x–z plane and \(y = 0\) direction. As the separation angle increases gradually to 90°, two effects can be observed. Firstly, the region with poorer resolution reduces in size and secondly, the resolution improves to about 0.1 mm by the time the separation angle reaches 90°. These findings agree well with the earlier notion that 90° is the optimal separation angle.

Resolution in the depth direction for dual camera separation angles of a 0°, b 30°, c 60° and 90°
Validations with Simulation and Experiment
Just as with the case for single camera LF-PIV, validations with increasingly more realistic flow scenarios were carried out and here, dual camera LF-PIV approach will be tested against DNS results of a \({\text{Re}} = 2500\) incompressible jet flow. Data from the simulation results were used to create corresponding synthetic light-field images for a volume that was located at one jet diameter (D) above the nozzle exit, where the volume has a size of 0.66D × 0.66D × 0.66D. Particle density used for the synthetic light-field images was 1PPM and these particles were randomly dispersed within the first frame. Subsequently, the particles will undergo displacements based on the DNS 3D velocity results and 2 ms time intervals, before they were used to generate the synthetic light-field images. Both single and dual camera LF-PIV approaches were then used to process for the final 3D velocity fields and compare with the DNS results. For the former, the reconstruction volume comprised of 800 × 800 × 267 voxels, whilst the pixel-to-voxel ratio is 3:1 in the x and y directions but 10:1 in the z direction. As for the latter, the reconstruction volume was 800 × 800 × 800 voxels, whilst a pixel-to-voxel ratio of 3:1 was used for all three directions. The voxel number and pixel-to-voxel ratio was different for the dual camera LF-PIV approach, since the computational time was essentially double that of a single camera LF-PIV. It should also be mentioned that GPU acceleration through the use of Nvidia CUDA codes was adopted to reduce computational times. To obtain the final velocity fields, multi-grid cross-correlation and filters similar to those used earlier on were used here as well.
Figure 4.36 shows a comparison between the velocity fields taken along different planes from the DNS, single camera and dual camera LF-PIV results. At first glance, the agreement between the LF-PIV results and DNS data appeared to be excellent, where jet ring vortices were captured regardless of whether a single or dual camera approach was used. Whilst little visual differences can be observed in the plots presented in Fig. 4.36, a more systematic comparison between the cumulative distribution functions of the measurement errors along the x, y and z directions will paint a better picture. Note that x–y plane is normal to the first camera optical axis, whilst z direction is the optical axis direction. Based on the results shown in Fig. 4.37, it can be discerned that the accuracy levels along the x–y plane do not really depend upon whether single or dual camera LF-PIV approach was used. In contrast, the accuracy level in the \(z\) direction clearly benefits from dual camera LF-PIV approach and in fact approaching to that of the \(x - y\) plane. As such, this analysis demonstrates the capability of dual camera LF-PIV approach to achieve more accurate measurement results in the \(z\) direction (i.e. depth direction) over a single camera based approach. After testing out single and dual camera LF-PIV approaches against simulated DNS data, the next logical step would involve the use of dual camera setup on actual experiments to confirm what had been learned thus far. For this experimental test, a canonical and reproducible flow scenario would be preferred and, in this case, well-understood laminar circular vortex rings were used to test out an actual dual camera LF-PIV setup, workflow and analysis outcomes.

Flow fields plotted from the a original DNS data, b single camera LF-PIV post-processed results and c dual camera LF-PIV post-processed results

Comparisons between the cumulative distribution functions of velocity measurement errors in \(x\), \(y\) and \(z\) directions
Figure 4.38 shows the water-based experimental setup used to generate the discrete vortex-rings, where a “cylindrical slug” approach was utilised. Similar setups had been used in earlier vortex-ring studies (New et al. 2016, 2020; New and Zang 2017) and hence, they will be briefly described here. A high-torque stepper motor programmed on a workstation was used to drive a piston impulsively through a stainless-steel tube and push water out of a \(D = 20\,{\text{mm}}\) circular nozzle into a quiescent environment. A stroke length of \(L/D = 1.5\) was used such that it was shorter than the formation length and prevented any trailing jet to be formed aft of the vortex-rings. Trapezoidal velocity profiles with sharp acceleration and deceleration stages were used and the resulting vortex-rings have an approximate Reynolds number of 2000. Two light-field cameras with specifications similar to those used in earlier studies were positioned outside of the water tank, such that they were orthogonal to each other as shown in figure. 200 mm Micro-Nikkor lenses were mounted onto both light-field cameras and set to a consistent f-number of 4.0, with the time interval between the image-pairs set to 2 ms. Volumetric calibration was carried out prior to the experiments using a matt black board with white dots spaced at 3 mm intervals in both vertical and horizontal directions. The calibration board was translated within the intended measurement volume through the use of a high-precision, motorised translation stage with a 0.1 μm resolution. As the calibration effectiveness increases with the number of calibration planes used, a total of 51 calibration images were taken by both light-field cameras at 0.5 mm intervals. 50 μm polyamide seeding particles were uniformly distributed in the water within the entire water tank and vortex-ring producing tube/nozzle and particle density was estimated to be approximated 0.431PPM, which was close to the optimal 0.5PPM mentioned earlier. These seeding particles were subsequently illuminated by a 500 mJ/pulse, double-pulsed Nd:YAG laser during the experiments.

Schematics of the vortex-ring experimental setup used for the testing of dual camera LF-PIV approach, where a shows the side-view and placement of the first light-field camera by the side of the water tank, whilst b shows that the second light-field camera is below the water tank. These camera placements ensured that an optimal separation angle of 90° was used
To maximise the measurement resolution, the measurement volume was set to a relatively small 32 mm × 24 mm × 32 mm physical size, which was just about sufficiently large to contain the entire vortex-ring. On the other hand, the computational load associated with post-processing for high-resolution results had to be taken into consideration and a pixel-to-voxel ratio of 3:1 was used, instead of 2:1 ratio. This resulted in a more manageable 1904 × 1404 × 1904 voxels, as opposed to 2856 × 2106 × 2856 voxels if 2:1 ratio was to be used. The latter voxel density would see each reconstructed volume ballooning to more than 64 GB in size and hence, not feasible at this point. Last but not least, in-house DRT-MART-based post-processing was used to arrive at the final single and dual camera LF-PIV results that are shown in Fig. 4.39. From the figure, it can be observed from the comparison (especially between Fig. 4.39a(i) and b(i)) that the dual camera approach was able to capture the vortex-core and its swirling nature much better than its single camera counterpart. Essentially, this means that a dual camera LF-PIV approach leads to significantly lower measurement errors, which agrees well with the earlier analysis. More accurate velocity field measurements as demonstrated in Fig. 4.39b(i) also means that the isosurfaces of the vortex-ring as based on vorticity magnitudes, whilst not quite perfect, are better mapped out under a dual camera approach as well, when one compares between Fig. 4.39a(ii) and b(ii), as well as between Fig. 4.39a(iii) and b(iii). To further quantify the measurement accuracy levels, probability density functions of the divergence error for the measured velocity vectors between single and dual camera LF-PIV approaches here with and without reconstruction post-processing were determined and presented in Fig. 4.40. The idea of using divergence error as a measure of accuracy stemmed from the consideration of the continuity equation associated with incompressible fluids, with the divergence error defined here as

Comparisons between instantaneous flow fields resulting from a single camera and b dual camera LF-PIV approaches

Comparison of probability density functions (PDF) of the measured velocity vectors between single and dual camera LF-PIV approaches with and without reconstruction post-processing
From the results depicted in Fig. 4.40, it can be discerned that most of the results associated with no reconstruction post-processing have divergence errors of no more than 0.04 \({\text{s}}^{ - 1}\), whilst those with reconstruction post-processing have divergence errors of typically less than 0.02 \({\text{s}}^{ - 1}\). This represents a significant drop in the error level and further reinforces the notion that a dual camera setup goes a long way towards more accurate measurement results than what a single camera setup is able to provide.
References
Adelson EH, Wang JYA (1992) Single lens stereo with a plenoptic camera. IEEE Trans Pattern Anal Mach Intell 14:99–106
Atkinson C, Soria J (2009) An efficient simultaneous reconstruction technique for tomographic particle image velocimetry. Exp Fluids 47:553–568
Deem EA, Zhang Y, Cattafesta LN et al (2016) On the resolution of plenoptic PIV. Meas Sci Technol 27:84003
Elsinga GE, Scarano F, Wieneke B, Van Oudheusden BW (2006) Tomographic particle image velocimetry. Exp Fluids 41:933–947. https://doi.org/10.1007/s00348-006-0212-z
Fahringer TW, Lynch KP, Thurow BS (2015) Volumetric particle image velocimetry with a single plenoptic camera. Meas Sci Technol. https://doi.org/10.1088/0957-0233/26/11/115201
Fahringer TW, Thurow BS (2012) Tomographic reconstruction of a 3-D flow field using a plenoptic camera. In: 42nd AIAA fluid dynamics conference and exhibit 2012
Fahringer TW, Thurow BS (2013) The effect of grid resolution on the accuracy of tomographic reconstruction using a plenoptic camera. In: 51st AIAA aerospace sciences meeting including the new horizons forum and aerospace exposition 2013
Fahringer TW, Thurow BS (2015) Comparing volumetric reconstruction algorithms for plenoptic-PIV. In: 53rd AIAA aerospace sciences meeting
Fahringer TW, Thurow BS (2014) 3d particle position reconstruction accuracy in plenoptic piv. In: 52nd aerospace sciences meeting, p 398
Georgiev T, Intwala C (2006) Light field camera design for integral view photography. Adobe Tech Rep 1:13
Hall EM, Fahringer TW, Guildenbecher DR, Thurow BS (2018) Volumetric calibration of a plenoptic camera. Appl Opt 57:914–923
Hall EM, Guildenbecher DR, Thurow BS (2019) Development and uncertainty characterization of 3D particle location from perspective shifted plenoptic images. Opt Express 27:7997–8010
Klemkowsky JN, Fahringer TW, Clifford CJ et al (2017) Plenoptic background oriented Schlieren imaging. Meas Sci Technol 28:95404
Long J, New TH (2015) A DPIV study on the effects of separation distance upon the vortical behaviour of jet–cylinder impingements. Exp Fluids 56:1–21
Long J, New TH (2016) Vortex dynamics and wall shear stress behaviour associated with an elliptic jet impinging upon a flat plate. Exp Fluids 57:1–18
Long J, New TH (2019) Vortical structures and behaviour of an elliptic jet impinging upon a convex cylinder. Exp Therm Fluid Sci 100:292–310
Lumsdaine A, Georgiev T (2009) The focused plenoptic camera. In: 2009 IEEE international conference on computational photography (ICCP). IEEE, pp 1–8
Lynch K, Fahringer T, Thurow B (2012) Three-dimensional particle image velocimetry using a plenoptic camera. In: 50th AIAA aerospace sciences meeting including the new horizons forum and aerospace exposition
Lynch KP, Thurowy BS (2011) Preliminary development of a 3-D, 3-C PIV technique using light field imaging. In: 41st AIAA fluid dynamics conference and exhibit
Mei D, Ding J, Shi S et al (2019) High resolution volumetric dual-camera light-field PIV. Exp Fluids. https://doi.org/10.1007/s00348-019-2781-7
New TH, Long J, Zang B, Shi S (2020) Collision of vortex rings upon V-walls. J Fluid Mech 899
New TH, Shi S, Zang B (2016) Some observations on vortex-ring collisions upon inclined surfaces. Exp Fluids 57:1–18
New TH, Tsai HM (2007) Experimental investigations on indeterminate-origin V- and A-notched jets. AIAA J 45:828–839
New TH, Tsovolos D (2012) On the flow characteristics of minor-plane inclined elliptic jets. Exp Therm Fluid Sci 38:94–106
New TH, Zang B (2017) Head-on collisions of vortex rings upon round cylinders. J Fluid Mech 833:648–676
Ng R (2006) Digital light field photography. Stanford University
Roberts WA, Thurow BS (2017) Correlation-based depth estimation with a plenoptic camera. AIAA J 55:435–445
Scarano F (2013) Tomographic PIV: principles and practice. Meas Sci Technol 24. https://doi.org/10.1088/0957-0233/24/1/012001
Shi S, Ding J, Atkinson C et al (2018) A detailed comparison of single-camera light-field PIV and tomographic PIV. Exp Fluids. https://doi.org/10.1007/s00348-018-2500-9
Shi S, Ding J, New TH, Soria J (2017) Light-field camera-based 3D volumetric particle image velocimetry with dense ray tracing reconstruction technique. Exp Fluids. https://doi.org/10.1007/s00348-017-2365-3
Shi S, New TH (2013) Some observations in the vortex-turning behaviour of noncircular inclined jets. Exp Fluids 54:1–11
Shi S, Wang J, Ding J et al (2016) Parametric study on light field volumetric particle image velocimetry. Flow Meas Instrum 49:70–88
Soria J (1996) An investigation of the near wake of a circular cylinder using a video-based digital cross-correlation particle image velocimetry technique. Exp Therm Fluid Sci 12:221–233
Soria J, Atkinson C (2008) Towards 3C–3D digital holographic fluid velocity vector field measurement—tomographic digital holographic PIV (Tomo-HPIV). Meas Sci Technol 19:74002
Thomason CM, Thurow BS, Fahringer TW (2014) Calibration of a microlens array for a plenoptic camera. In: 52nd aerospace sciences meeting, p 396
Thurow BS, Fahringer T (2013) Recent development of volumetric PIV with a plenoptic camera
Tsai RY (1986) An efficient and accurate camera calibration technique fro 3D machine vision. In: CVPR’86
Wieneke B (2008) Volume self-calibration for 3D particle image velocimetry. Exp Fluids 45:549–556
Wieneke B (2018) Improvements for volume self-calibration. Meas Sci Technol 29:84002
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Shi, S., New, T.H., Soria, J. (2023). Light-field Particle Image Velocimetry. In: Shi, S., New, T.H. (eds) Development and Application of Light-Field Cameras in Fluid Measurements. Springer, Cham. https://doi.org/10.1007/978-3-031-01779-7_4
Download citation
DOI: https://doi.org/10.1007/978-3-031-01779-7_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-01778-0
Online ISBN: 978-3-031-01779-7
eBook Packages: EngineeringEngineering (R0)