
Abstract
This paper presents a dense ray tracing reconstruction technique for a single light-field camera-based particle image velocimetry. The new approach pre-determines the location of a particle through inverse dense ray tracing and reconstructs the voxel value using multiplicative algebraic reconstruction technique (MART). Simulation studies were undertaken to identify the effects of iteration number, relaxation factor, particle density, voxel–pixel ratio and the effect of the velocity gradient on the performance of the proposed dense ray tracing-based MART method (DRT-MART). The results demonstrate that the DRT-MART method achieves higher reconstruction resolution at significantly better computational efficiency than the MART method (4–50 times faster). Both DRT-MART and MART approaches were applied to measure the velocity field of a low speed jet flow which revealed that for the same computational cost, the DRT-MART method accurately resolves the jet velocity field with improved precision, especially for the velocity component along the depth direction.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Particle image velocimetry (PIV) has become a powerful diagnostic tool for fluid mechanics studies. The necessity to examine complex and three-dimensional flows for scientific research and engineering application has seen PIV technique progress from planar 2-component 2-dimensional (2C-2D) measurements to fully volumetric 3-component 3-dimensional (3C-3D) velocity measurements (Adrian and Westerweel 2011). One of the first efforts was Stereo-PIV, which measures the third velocity component (3C-2D) by including one additional camera to the traditional two dimensional PIV (2C-2D-PIV) system (Prasad and Adrian 1993; Arroyo and Greated 1991). Scanning PIV extends such single slice 3C-2D measurements to multiple planes through the combination of a scanning laser sheet and a high-speed camera. However, in this case the maximum measurable velocity associated with Scanning PIV is limited by the camera frame rate and laser repetition rate/scanning mirror speed (Brucker 1996; Hori and Sakakibara 2004). Instead of measuring the third velocity component via dual-view geometry, Defocusing Digital PIV (DDPIV) recovers depth information from defocused particle images and normally employs a triple-camera arrangement to resolve the flow fields with sufficient accuracy. The limitations of DDPIV primarily lie in its small measurement volume and very low seeding density allowable with this technique (Willert and Gharib 1992; Pereira et al. 2000). On the other hand, Holographic PIV (HPIV) is regarded as one of the first truly three-dimensional flow measurement techniques, which resolves a volumetric velocity field from particle holograms that are recorded using in-line or off-axis holography (Arroyo and Hinsch 2008; Katz and Sheng 2010). The application of this technique, however, is limited by its complex experimental setup. One of the most recent three-dimensional velocity measurement techniques that has seen increasing adoption is Tomographic PIV (Tomo-PIV), which employs multiple view geometries (typically 4–8 views) to capture particle images and calculate three-dimensional velocity fields using multiplicative reconstruction technique (MART) and three-dimensional cross-correlation (Elsinga et al. 2006; Scarano 2012). Tomo-PIV possesses advantages in terms of being able to measure the flow field within a relative large flow volume. Nevertheless, the requirement of multiple optical accesses can be problematic for applications where optical access is limited.
Apart from recording the three-dimensional position of tracer particles through a more traditional multiple view geometry, there are other techniques that record their light-field information instead. One such technique is synthetic aperture PIV (SAPIV), which uses a large camera array (normally 8–15 cameras) to capture the light-field images for seeding particles and reconstructs 3D particle images through a synthetic aperture refocusing method (Belden et al. 2010). SAPIV can tolerate much higher particle density than Tomo-PIV and its dynamic velocity measurement range along the optical axis can be of the same order as the lateral directions. Instead of using a possibly cumbersome camera array system, light-field imaging-based PIV (shorted as LF-PIV hereafter) records particle light-field image through a single plenoptic camera, which consists of a closely encapsulated micro-lens array (MLA) and a CCD/CMOS sensor. LF-PIV eliminates the cumbersome camera spatial calibration process, which is essential in Tomo-PIV. With a compact hardware setup similar as 2D-PIV, LF-PIV is capable of measuring full volumetric velocity fields, which not just greatly simplifies the experimental procedure, but most importantly it allows the accurate measurement of three-dimensional velocity fields for applications that have limited optical access (Ding et al. 2015; Fahringer et al. 2015).
However, the significant processing time and low spatial resolution reconstruction currently limit the present capability of LF-PIV. One of the bottlenecks is the relatively low computational efficiency of the MART method when it comes to the processing of light-field images. Due to the nature of light-field imaging, one voxel will be captured by tens of pixels, which greatly complicate the calculation of the weighting coefficient and increases the iterations required for a given reconstruction precision. For example, the weighting matrix for a 300 × 200 × 200 voxel volume requires 350 GB of storage, even if only non-zero voxel values were to be stored. The reconstruction of such a small volume using the standard MART method takes approximately 1.5 h on a 12-core workstation (Fahringer and Thurow 2015). Another difficulty is the low reconstruction resolution experienced by the current MART and filtered refocusing reconstruction methods, both of which result in severe elongation in the x-, y- and z-directions for reconstructed particles (Fahringer et al. 2015). To overcome these shortcomings, we propose the DRT-MART technique by exploiting the benefits of the multi-perspective associated with light-field imaging and sparse seeding nature of PIV, so as to achieve higher accuracy for weighting coefficient calculation and better computational efficiency for particle reconstruction. The performance and efficiency of the DRT-MART technique compared to the MART method are systematically evaluated in current study.
The structure of this paper is as follows; the principle underpinning the DRT-MART method is introduced in Sect. 2. Systematic studies investigating how the key parameters (i.e., iteration number, relaxation factor, particle density and pixel–voxel ratio) affect the performance of DRT-MART and MART methods are presented in Sect. 3. Section 4 examines the capability of the DRT-MART method in measuring flow fields with different levels of velocity gradients by using synthetic light-field particle images, and Sect. 5 applies the new technique with particle images obtained from an experimental jet flow study. Finally, Sect. 6 concludes the main findings of the current study.
2 Dense ray tracing-based MART reconstruction technique
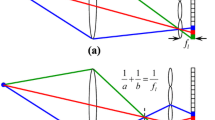
For most volumetric PIV applications, seeding particles tend to be sparsely distributed within the measurement volume. This characteristic can be used to facilitate the particle reconstruction process, which has been proven to be an efficient method in Tomo-PIV as demonstrated by Atkinson and Soria (2009). These authors showed that the non-zero voxels can be pre-determined through a multiplicative line-of-sight (MLOS) approach, resulting in a speed-up of the Tomo-PIV reconstruction which is 5.5 times faster than the standard approach. A similar concept can also be applied to LF-PIV, although the determination of non-zero voxels for LF-PIV is fundamentally different from MLOS. In Tomo-PIV, the line-of-sight of a pixel can be determined using the camera calibration in a straight forward manner, and the non-zero voxels are subsequently identified by multiplying the corresponding pixels. However, this is not possible for LF-PIV as shown in Fig. 1. A line-of-sight of a pixel varies with the spatial location of the tracer particle. To select the non-zero voxels, inverse ray tracing must be performed for each voxel to locate the affected pixels. This can be performed by tracing one central light ray for each discretized section of the main lens. Figure 2 demonstrates the principle of the proposed method, which shows only five pixels for simplicity beneath every lenslet. The analysis of Georgiev et al. (2006) shows that the angular resolution of a standard plenoptic camera is determined by the number of pixels under each lenslet and as such, only five discretized main lens sections are depicted in Fig. 2. Note that this is simply for illustration purposes and the light-field camera used in the present study has 14 × 14 pixel2 beneath each lenslet (Shi et al. 2016). Using the proposed ray tracing method, the affected pixels can be determined for each voxel (i.e., the red voxel shown in Fig. 2), and a simple multiplication of their values analogous to MLOS selects the non-zero voxels, i.e., when the product exceeds a pre-set threshold.

Line-of-sight of a pixel of a light-field camera for a point light source located in the focal plane; b point light source located at dz away from the focal plane; c point light source located at dy away from the optical axis (Shi et al. 2016)

Schematics of the DRT-MART reconstruction method (only the centre light ray of each portion was used for inverse ray tracing)
With the non-zero voxels identified, the voxel intensity can then be iteratively calculated using the MART method according to Eq. 1:
where \(E(X_{j} ,Y_{j} ,Z_{j} )\) is the intensity of the j-th voxel; \(I(x_{i} ,y_{i} )\) is the intensity of the i-th pixel, which is known from the captured light-field image; and \(w_{i,j}\) is the weighting coefficient, which is the contribution of light intensity from the j-th voxel to the i-th pixel value. As stated above, the line-of-sight of a pixel from a light-field camera is very different from Tomo-PIV camera arrangement. Hence, the sphere–cylinder intersection algorithm employed in Tomo-PIV reconstruction (Elsinga et al. 2006) cannot be applied in calculating the weighting coefficient for light-field reconstruction. Based on these considerations, we proposed a ray tracing-based weighting coefficient method (Shi et al. 2016). While detailed information about the ray tracing-based weighting coefficient method can be found in our previous paper, its principle is briefly introduced here, for the sake of completeness. As shown in Fig. 3a, the relation between the voxel, microlens and pixels is established through ray tracings to locate the affected lenslet and pixels more precisely. The weighting coefficient is calculated in two parts, where the first part \(w_{1}\) is calculated as the overlapping area between the light beam and lenslet (Fig. 3b) and the second part \(w_{2}\) is calculated as the overlapping area between the light beam and the pixels (Fig. 3c), and the final weighting coefficient is determined as their product \(w = w_{1} \times w_{ 2}\).

Principle of the ray tracing-based weighting coefficient method a ray tracing to locate the affected lenslet and pixels; b overlapping area between light ray and lenslet; c overlapping area between light ray and pixel; d synthetic light-field image of a point light source (dx = 0 mm, dy = 0 mm, dz = 0.385 mm); e weighting coefficient calculated by ray tracing method; f weighting coefficient calculated by sphere–cylinder intersection algorithm (Shi et al. 2016)
More specifically, the calculation of the weighting coefficient for a simplified light-field camera shown in Fig. 3a is as follows. The main lens area will firstly be discretized into five parts as there are 5 × 5 pixels beneath each lenslet in this example. To determine the weighting coefficient for a voxel, discretized light bundles are traced from the voxel to the microlens plane. Taking the yellow light bundle in Fig. 3a as an example, its location is precisely calculated by ray tracing, and its overlap area with three adjacent lenslet (\(w_{1}\)) can then be estimated (Fig. 3b). Note that the projection of the light bundle on the microlens plane is modeled as a square since the geometry of pixels is typically square. Further tracing this light bundle through the microlens to the CCD/CMOS sensor plane yields the location of its centre light ray, and \(w_{2}\) can be calculated as the overlap area between the affected pixels and the projected sub-light buddle (same size as a pixel). This new method calculates the weighting coefficient more precisely than the sphere–cylinder intersection algorithm. As shown in Fig. 3d, e, the calculated weighting coefficient (plotted in a gray scale image) for a voxel located at dx = 0 mm, dy = 0 mm and dz = 0.385 mm matches well with the original synthetic light-field image (interested readers are referred to Shi et al. 2016 for details of the generation of the synthetic light-field image), whereas the weighting coefficient calculated by the sphere–cylinder intersection algorithm (Fig. 3f) shows distinct disparities from the original light-field image (Fig. 3d). This is because the sphere–cylinder intersection algorithm can only approximate the location of the affected lenslet. To illustrate consider the green ray in Fig. 3a, the sphere–cylinder intersection algorithm will take the surrounding lenslet into consideration which results in an overestimated weighting coefficient. Therefore, the ray tracing-based weighting coefficient method was used for both MART and DRT-MART algorithms throughout the current study.
3 Parametric analysis
In this section, the performance of DRT-MART method is extensively evaluated in terms of elongation of reconstructed particles, effects of iteration number, relaxation factor and particle density, as well as computational efficiency. These studies are facilitated with the use of synthetic light-field particle images, which are generated by massive ray tracing method, as detailed in Shi et al. (2016). The key simulation parameters used in the present study are listed in Table 1. Note that all the results of the calculations presented in the current paper, including DRT-MART and MART reconstructions as well as the three-dimensional direct cross-correlations, were performed via GPU parallel processing using an NVIDIA TITAN X card (Pascal architecture, 12 GB memory, 3584 CUDA cores).
3.1 Elongation effects
Elongation of particle images along the optical axis is a known problem for Tomo-PIV reconstructions, even when multiple cameras are used to view the domain of interest from different directions (Soria and Atkinson 2008; Scarano 2012). Similar effects are expected in LF-PIV imaging since only one camera is used to capture the particle images. To systematically evaluate this effect, synthetic light-field particle images were reconstructed using both the conventional MART and the proposed DRT-MART methods.
Previous studies had already shown that the spatial resolution of light-field camera is non-uniform (Shi et al. 2016; Deem et al. 2016). To prevent the present results being affected by this effect, a large number of synthetic images were generated by randomly seeding particle in the reconstruction volume (with parameters listed in Table 1, fourth column). To begin with, different numbers of synthetic images was tested (5000, 20,000 and 50,000 images) and it was found that 20,000 random synthetic images were sufficient to determine the elongation effects. After the light-field particle images were reconstructed by the DRT-MART and MART methods, the diameters of reconstructed particles were determined at locations where voxel intensity was less than two standard deviations away from the maximum voxel values, which defines a diameter of 3 voxels for an ideal particle image. Note that the number of iterations used for DRT-MART and MART methods was 400 and 23, respectively, which was based on the consideration that the computational cost of the two methods is the same for these iteration numbers. Furthermore, using excessive iteration number for the MART method is found to be practically infeasible. For example, reconstructing 20,000 synthetic images by MART with 400 iterations would require 2016 h on the authors’ current work station. In addition, the DRT-MART method still outperforms MART even if the same 400 iterations are applied to MART. To better illustrate the differences in the elongation effects associated with the DRT-MART and MART methods, an example of the reconstructed particles is shown in Fig. 4. These differences can mostly be attributed to the pre-elimination of zero voxels by the dense ray tracing method. Without such a pre-processing stage, the MART method will reconstruct non-zero voxels together with their zero neighbour voxels because the weighting coefficient method cannot pin-point the exact affected lenslet and pixels (e.g., Fig. 1b, c).

Example of three-dimensional particle image reconstructed by a DRT-MART method with 400 iterations, b MART method with 400 iterations, c MART method with 23 iterations
After reconstructing 20,000 random synthetic images by DRT-MART (400 iterations) and MART (23 iterations), probability density functions (PDF) of the reconstructed particles’ diameter in x-, y- and z-directions were calculated and are shown in Fig. 5. In x- and y-directions, elongation effects are not very significant. For example, most of the reconstructed particles have diameters of 2–4 pixels and 5–7 pixels for the DRT-MART and MART methods, respectively (Fig. 5a, b). In the z-direction, however, the elongation effects of the MART method are much more severe as most of the particle diameters are in the range of 35–45 pixels (Fig. 5c), while the elongation effects of the DRT-MART method are less significant with most of the particle diameters in the depth direction being in the range of 10–25 pixels (Fig. 5c).

Probability density function of reconstructed particle diameter a x-direction, b y-direction, c z-direction
3.2 Effects of iteration number and relaxation factor on reconstruction quality
It has been observed earlier that the iteration number and relaxation factor greatly affect the reconstruction quality for Tomo-PIV (Elsinga et al. 2006; Atkinson and Soria 2009). Since the current reconstruction method is based on the MART method, similar effects are expected in LF-PIV. To illustrate this aspect, a small test volume (i.e., parameters listed in Table 1, 5th column) with low particle density (i.e., 0.1 particle per microlens, ppm) was simulated. The synthetic light-field particle images were reconstructed using the DRT-MART and MART methods, respectively, with different number of iterations and relaxation factors. According to the results from Sect. 3.1, the reconstruction volume was discretized with a pixel–voxel ratio of 1:1 in both x- and y-directions and 10:1 in the z-direction. Note that a detailed analysis on the effect of pixel–voxel ratio will be performed in Sect. 4.1. The reconstruction quality is evaluated by the Q factor, which is defined by the following equation (Elsinga et al. 2006):
where \(E_{0} (x,y,z)\) is the exact voxel intensity approximated by a Gaussian distribution with three voxel diameter, and \(E_{1} (x,y,z)\) is the voxel intensity of the reconstructed particle image.
The relationships between the number of iterations, relaxation factor and reconstruction quality are shown in Fig. 6 for both the DRT-MART and MART methods. Firstly, the reconstruction quality of the DRT-MART method is clearly better than the MART method, which can primarily be attributed to the fact that the three-dimensional particle images reconstructed by the DRT-MART method is less elongated and their voxel intensities have Gaussian-like distributions. Such conclusion coincides with the results shown in Figs. 4 and 5 earlier. A second observation from Fig. 6 is that both the DRT-MART and MART methods need a larger relaxation factor and more iterations than Tomo-PIV reconstructions in order to reach a similar reconstruction quality. Compared to Tomo-PIV where a single voxel only affects a few pixels, every voxel in LF-PIV affects tens of pixels, as has been shown schematically in Fig. 1. For voxels further away from the focal plane, their light rays will spread over even more pixels (i.e., Fig. 1b, c), and the corresponding weighting coefficient value for each affected pixel will subsequently be relatively small.

Effects of iteration number and relaxation factor on reconstruction quality for a DRT-MART and b MART methods
Such a scenario is clearly demonstrated by Fig. 7, which shows the variations in maximum voxel intensity at different depths-of-field with the increase in iteration number. Clearly, there are very small variations in the intensity of reconstructed voxels near the focal plane (i.e., z_slice around 80–110) for both the DRT-MART and MART algorithms. In other words, calculations after the 20th iteration are mainly used to reconstruct voxels further away from the focal plane. As a result, multiple pixels need to be considered during the calculations and their individual contributions (i.e., weighting coefficients) to the final voxel intensity will be limited during the reconstruction of a voxel. Therefore, LF-PIV reconstruction requires more iterations and larger relaxation factors (i.e., 2.0–2.5) to achieve high reconstruction qualities.

Variation of peak voxel intensity at different focal depth with iteration number a DRT-MART method with 20 iterations, b DRT-MART method with 400 iterations, c MART method with 20 iterations, and d MART method with 200 iterations
3.3 Effects of particle density on reconstruction quality and computational efficiency
High seeding densities are always desired for volumetric PIV measurements, as this allows smaller interrogation volumes during cross-correlations and better spatial resolutions can be achieved. However, high seeding density is one of the biggest challenges in Tomo-PIV even with multi-camera configurations, since a higher seeding density will result in more ghost particles (Elsinga et al. 2006; Scarano 2012). Similar challenges are faced by LF-PIV considering the fact that it uses only one camera to record volumetric information. To provide some guidance for LF-PIV experiments, this section considers the influence of particle density on the reconstruction quality for both the DRT-MART and MART method. A series of synthetic light-field images with different seeding densities were generated using simulation parameters listed in Table 1. Synthetic light-field particle images were reconstructed using DRT-MART and MART with 400 and 200, iterations, respectively. The relaxation factor was 2.5 for both approaches, and the pixel–voxel ratio used to discretize the reconstruction volume was 1:1 in the x- and y-directions and 10:1 in the z-direction.
The results from the simulation are shown in Fig. 8, indicating as expected that the reconstruction quality decrease with increasing particle density. However, unlike Tomo-PIV, “ghost particles” are not observed. This can be attributed to the fact that multiple perspectives can be obtained by synthesizing sub-images beneath the micro-lens array for light-field imaging (Ng 2006). As such, LF-PIV offers a unique advantage that voxel reconstruction can exploit the multi-perspective information (e.g., 14 × 14 perspectives for our in-house plenoptic camera), which is beneficial in minimizing the generation of “ghost particles”. To further demonstrate this result, the reconstruction volume was extent in the depth direction so that the region outside the “seeding” area was included. Furthermore, to exclude any unambiguity, which may results from one single calculation, reconstruction results for 30 synthetic light-field particle images were added together and the voxel intensities were accumulated along the y-direction. Figure 9 shows the intensity profile for the final result in the x–z plane, from which it can be seen that the intensity of the reconstructed voxels outside the “seeding” region are zero. Similar calculations were performed for experimental light-field particle images, and the results will be presented in Sect. 5. It is notable that voxel intensity near the focal plane is slightly lower than other areas, e.g., the green strip near z = 0 in Fig. 9a. This a result of lower depth resolution near the focal plane, due to which, the reconstructed particles at this region will occupy more voxels and hence their intensity will be spread more widely. Such findings coincide with conclusions from studies made by Shi et al. (2016) and Deem et al. (2016).

Variation of reconstruction quality with particle density

a Cross section (x–z plane) of the reconstructed synthetic light-field particle images (summation from 30 tests), b voxel intensity along z direction averaged from the x–z plane intensity distribution
To further assess the computational efficiency of the DRT-MART method, synthetic light-field particle images were generated and reconstructed in a similar fashion. In this case, the computational time incurred by the DRT-MART method with 400 iterations was compared with that by the MART method with 200 iterations. Naturally, a higher particle density is expected to increase the number of non-zero voxels and hence computational burden. Therefore, it is unsurprising that Fig. 10 shows a reduction in the computation speed as the particle density increases. Even in this case the DRT-MART method is still four times faster than the MART method at 1 PPM, which is considered as an upper particle density limit for the current reconstruction techniques.

Computational efficiency of the DRT-MART method
4 Simulation tests with oscillatory velocity fields
After investigating the effects of reconstruction parameters on the performance of the DRT-MART method, a set of synthetic light-field images associated with oscillatory velocity fields were generated to test the effects of pixel–voxel ratio, iteration number and velocity gradient on the overall measurement accuracy of LF-PIV. Two types of velocity fields generated for a total of eight velocity fields, where each type represents different levels of velocity fluctuation in x- and z-directions, respectively, were investigated. These flow fields are defined as follows:
-
Type A: \(u\)-component velocity only \(u(x,y,z) = 25e^{{i(k_{x} x + k_{y} y + k_{z} z)}} \begin{array}{*{20}c} {} & {v(x,y,z) = 0\begin{array}{*{20}c} {} & {w(x,y,z) = 0} \\ \end{array} } \\ \end{array}\)
-
Case A1: \(k_{x} = {\raise0.7ex\hbox{${2\pi }$} \!\mathord{\left/ {\vphantom {{2\pi } {\omega L_{x} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\omega L_{x} }$}}\); \(k_{y} = k_{z} = 0\); \(L_{x} = 1820\) pixel
-
Case A2: \(k_{x} = k_{y} = {\raise0.7ex\hbox{${2\pi }$} \!\mathord{\left/ {\vphantom {{2\pi } {\sqrt 2 \omega L_{xy} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\sqrt 2 \omega L_{xy} }$}}\); \(k_{z} = 0\); \(L_{xy} = \sqrt 2 \times 1820\) pixel
-
Case A3: \(k_{x} = k_{z} = {\raise0.7ex\hbox{${2\pi }$} \!\mathord{\left/ {\vphantom {{2\pi } {\sqrt 2 \omega L_{xz} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\sqrt 2 \omega L_{xz} }$}}\); \(k_{y} = 0\); \(L_{xz} = \sqrt 2 \times 1820\) pixel
-
Case A4: \(k_{z} = {\raise0.7ex\hbox{${2\pi }$} \!\mathord{\left/ {\vphantom {{2\pi } {\omega L_{z} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\omega L_{z} }$}}\); \(k_{x} = k_{y} = 0\); \(L_{z} = 1820\) pixel
-
Type B: \(w\)-component velocity only
$$u(x,y,z) = 0\begin{array}{*{20}c} {} & {v(x,y,z) = 0\begin{array}{*{20}c} {} & {w(x,y,z) = 25e^{{i(k_{x} x + k_{y} y + k_{z} z)}} } \\ \end{array} } \\ \end{array}$$ -
Case B1: \(k_{x} = {\raise0.7ex\hbox{${2\pi }$} \!\mathord{\left/ {\vphantom {{2\pi } {\omega L_{x} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\omega L_{x} }$}}\); \(k_{y} = k_{z} = 0\); \(L_{x} = 1820\) pixel
-
Case B2: \(k_{x} = k_{y} = {\raise0.7ex\hbox{${2\pi }$} \!\mathord{\left/ {\vphantom {{2\pi } {\sqrt 2 \omega L_{xy} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\sqrt 2 \omega L_{xy} }$}}\); \(k_{z} = 0\); \(L_{xy} = \sqrt 2 \times 1820\) pixel
-
Case B3: \(k_{x} = k_{z} = {\raise0.7ex\hbox{${2\pi }$} \!\mathord{\left/ {\vphantom {{2\pi } {\sqrt 2 \omega L_{xz} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\sqrt 2 \omega L_{xz} }$}}\); \(k_{y} = 0\); \(L_{xz} = \sqrt 2 \times 1820\) pixel
-
Case B4: \(k_{z} = {\raise0.7ex\hbox{${2\pi }$} \!\mathord{\left/ {\vphantom {{2\pi } {\omega L_{z} }}}\right.\kern-0pt} \!\lower0.7ex\hbox{${\omega L_{z} }$}}\); \(k_{x} = k_{y} = 0\); \(L_{z} = 1820\) pixel
-
For all cases, \(\omega =\) 0.25, 0.5, 1.0 and 2.0.
Synthetic light-field image pairs were generated in such way that several particles were randomly seeded in a predefined measurement volume and the first light-field image was generated using the ray tracing method. These particles were then displaced based on a given time interval \(\Delta t\) and one of the velocity fields defined above, and the second light-field image was subsequently generated.
4.1 Effects of pixel–voxel ratio and number of iterations on measurement accuracy
The results in Sect. 3.1 show that the reconstructed particles are elongated in x-, y- and z-directions for both the DRT-MART and MART methods. It is worthwhile to investigate different pixel–voxel ratios to discretize the reconstruction volume, as the computational load will be further reduced if fewer voxels are reconstructed.
In the first instance, pixel–voxel ratios (PVR) of 1:1, 2:1 and 3:1 were investigated for x- and y-directions, where synthetic light-field particle images were generated according to flow field Case A1 (i.e., \(\omega = 0.25\)). The seeding density was 0.5 PPM and the particles were reconstructed through DRT-MART and MART methods with a relaxation factor of 2.5 and number of iterations of 400 and 200, respectively. Particle images were processed using a multigrid three-dimensional direct cross-correlations (Soria 1996; Atkinson and Soria 2009) with an overlapping ratio of 0.75 and initial and final interrogation volumes of 320 × 320 × 32 voxel and 160 × 160 × 16 voxel, respectively. This ensured that there were approximately 8–10 particles within each interrogation volumes. Unless otherwise stated, the above reconstruction and cross-correlation parameters will be used for the following simulation studies.
The measured data were compared with the known velocity field and the resulting displacement errors are shown in Fig. 11. Firstly, it can be seen that the PVR = 1 and 2 test cases have similar measurement accuracy levels for the DRT-MART method, which performs better than the MART method at either the PVR = 1 or 2 test case. Theoretically speaking, the PVR = 1 test case would offer better reconstruction resolution than the PVR = 2 test case, if a relatively small interrogation volume could be used. However, even with the currently highest possible seeding density (i.e., 1 PPM), the final interrogation window cannot be reduced to one-fourth of the current one or else there will be less than 4 particles in the interrogation area. As such, if the PVR = 2 was to be used to process actual experimental images, this will further speed up the DRT-MART reconstruction process by four times.

PDF of the displacement error for various pixel–voxel ratio tests (x-, y-directions)
Secondly, the pixel binning effects in the z-direction were investigated with the PVR = 5, 10 and 20, while maintaining the PVR in both x- and y-direction at 1. Synthetic light-field particle images were generated according to flow field Case B1 (i.e., \(\omega = 0.25\)). Figure 12 shows the measurement results, which indicates that DRT-MART method achieves the best performance with the PVR = 10. In conjunction to the reconstruction particle size analysis made in Sect. 3.1 earlier (i.e., Fig. 5), the PVR = 10 would result in a final particle diameter of around 2 voxels, which is close to the ideal 3D Gaussian-type blob. Again, this result is in line with our previous study that demonstrated that the depth resolution of our plenoptic camera is around one-tenth of the planar resolution (Shi et al. 2016). In contrast, as the reconstructed particle sizes obtained through MART method are excessively larger than those obtained through DRT-MART method (i.e., Fig. 5c), its measurement accuracy in the present study is lower than the DRT-MART method, regardless of the variation in PVR.

PDF of the displacement error for various pixel–voxel ratio tests (z-direction)
The excessive computational load incurred by LF-PIV reconstructions is mainly due to the large number of iterations needed for a high reconstruction quality, as demonstrated in Fig. 6 previously. To determine how the iteration number will eventually affect the measurement accuracy of the DRT-MART method, two sets of synthetic light-field images were generated according to flow fields Case A1 (i.e., \(\omega = 0.25\)) and Case B1 (i.e., \(\omega = 0.25\)). These two image sets represent velocity variation in the \(u\)- and \(w\)-components, respectively, which are ideal for testing the effects of iteration number on the measurement accuracy along x-, y- and z-directions. Based on the preceding pixel–voxel ratio analysis, the light-field particle images were reconstructed with PVR = 1 in the x and y-directions, and 10 in the z-direction.
Figure 13a plots the measurement errors for Case A1 test and shows that around 50 iterations would be sufficient for a low measurement error in the x- and y-directions. On the other hand, Fig. 13b shows that a minimum of 200 iterations are necessary to achieve the lowest RMS error in the z-direction. This result is consistent with the results shown in Fig. 7 earlier, which indicate that more iterations are required for convergence in the reconstruction of particles further away from the focal plane.

Variation of RMS error with iteration number for DRT-MART method a velocity varies along x-direction, b velocity varies along z-direction
4.2 Effects of velocity gradient on measurement accuracy
After understanding the influences of voxel–pixel ratio and iteration number upon the measurement accuracy, we can now turn our attention towards the capability of LF-PIV (with either DRT-MART or MART method) in terms of resolving flow fields with different velocity gradients. Eight sets of synthetic light-field particle images were generated based on flow fields associated with Case A1–A4 and Case B1–B4, where the particle density was fixed at 0.5 PPM. Light-field particle images were reconstructed using a relaxation factor of 2.5 and PVR = 1 in both x- and y-directions and 10 in the z-direction. The reconstruction volume in this section was much larger than the above simulations (see Table 1, last column). For example, it took more than 400 min for each case if 200 iterations were still used for MART method. Since DRT-MART method has proved to be superior to MART method, only 23 iterations were used for MART method for a more efficient analysis. As noted previously, this incurred similar computational time as DRT-MART method with 400 iterations. After the particles were reconstructed, multigrid three-dimensional direct cross-correlations with an overlapping ratio of 0.75 were implemented. The initial and final interrogation volumes were 320 × 320 × 32 voxel and 160 × 160 × 16 voxel, respectively.
Figure 14 shows the measurement error PDF for the four Case A flow fields, where Fig. 14a plots the measurement error for case A1 (\(u\) varies only along x-direction), Fig. 14b plots the measurement error for case A2 (\(u\) varies along both x- and y-direction), Fig. 14c plots the measurement error for case A3 (\(u\) varies along both x- and z-direction), and Fig. 14d plots the measurement error for case A4 (\(u\) varies only along z-direction). The velocity gradient was controlled by varying the parameter \(\omega\), where \(\omega =\) 0.25, 0.5, 1.0 and 2.0 indicate that there are one-fourth, half, one and two cycles of velocity variations within the measurement volume. The results show that the DRT-MART method performs reasonably well for relatively low velocity gradients (i.e., Fig. 14a–c, where \(\omega =\) 0.25 and 0.5). Note that the wavelengths for Cases A2 and A3 are \(\sqrt 2\) times larger than Case A1, so as to accommodate similar velocity variation cycles for both xy-directions and xz-directions (i.e., Fig. 14b, c). Therefore, when a same \(\omega\) was used, the effective velocity gradients in Cases A2 and A3 were slightly lower than that in Case A1, which is why the measurement errors in Cases A2 and A3 are lower than that in Case A1 for the same \(\omega\). When \(u\) varies only along z-direction (i.e., Case A4, Fig. 14d), the measurement error is much larger than the other three cases due to a lower resolution in the z-direction.

Variation of RMS error with the velocity gradient in \(u\) component for DRT-MART and MART methods. a Case A1, b Case A2, c Case A3 and d Case A4
Figure 15 shows the PDF of measurement error for type B tests, where Fig. 15a plots the measurement error for case B1 (\(w\) varies only along x-direction), Fig. 15b plots the measurement error for case B2 (\(w\) varies along both x- and y-direction), Fig. 15c plots the measurement error for case B3 (\(w\) varies along both x- and z-directions), and Fig. 15d plots the measurement error for case B4 (\(w\) varies only along z-direction). The effects of a lower z-direction resolution on measurement accuracy can be clearly seen from the results. The measurement errors are higher than Case A tests (i.e., Fig. 14a–c), when \(w\) varies along the x-, xy- and xz-directions (i.e., Fig. 15a–c). The worst scenario is when \(w\) varies only in the z-direction (i.e., Fig. 15d) where DRT-MART method can barely resolve the velocity gradient. Such a test indicates that the plenoptic camera should not be located along the dominant velocity component direction for LF-PIV applications.

Variation of RMS error with the velocity gradient in \(w\) component for DRT-MART and MART methods. a Case B1, b Case B2, c Case B3 and d Case B4
5 Experiment application
Through the use of synthetic light-field particle images, the performance of DRT-MART method and effects of key parameters have been systematically examined in the preceding sections. However, it is necessary to further evaluate the new method with actual experimental images that include the presence of background noise and lens distortions. To address these issues, a low speed jet flow experiment was conducted using the test rig shown in Fig. 16. A recirculating pump was used to channel water from a reservoir into a jet apparatus equipped with a diffuser, honeycomb section, three layers of fine screens and a circular-to-circular contraction with a contraction ratio of 20, before the water finally exit into a quiescent octagonal water tank via a D = 20 mm circular nozzle. The water tank was constructed from 20 mm thick Perspex panels with a mean internal diameter of 360 mm and a height of 800 mm. Two pipes installed at top of the tank redirected excess water back to the reservoir to maintain a constant pressure head. The flow speed was controlled via a needle valve and an electromagnetic flow meter. Relatively, similar setups had been successfully used in various jet flow studies previously (New and Tsai 2007; New and Tsovolos 2009, 2011). The Reynolds number was \({Re}_{D} = 2000\) and the measurement volume was approximately 1.9 D × 1.3 D × 0.5 D along the x-, y-, z-directions and located at about 2.25 D above the nozzle exit. The flow was seeded with Dantec Dynamics \(20\,\upmu {\text{m}}\), ρ = 1.03 g/cm3 polyamide seeding particles, with a resulting particle density of around 0.4 PPM. They were illuminated by a 10 mm thick laser sheet produced from a Beamtech 200 mJ/pulse, 532 nm double-pulse Nd:YAG laser and their reflected light were recorded by our in-house plenoptic camera with a Micro-NIKKOR 200 mm lens. The in-house plenoptic camera was modified from an Imperx B6640 PIV camera, readers are referred to Shi et al. (2016) for more details. To achieve the best spatial resolution, the main lens f number was set at 4 and magnification factor was carefully adjusted to −0.95 (Shi et al. 2016). The time interval between two image frames was 2 ms, which was selected to ensure a maximum particle displacement of 60 pixels so as to comply the one-quarter rule for cross-correlation.

Schematics of the experimental system
The captured light-field particle images were pre-processed by subtracting a global background, before they were reconstructed using 400 and 23 iterations of the DRT-MART and MART methods, respectively. The background image was calculated from 200 frames by taking the minimum intensity value for each pixel. Note that the choice of background image should vary with different experiment conditions and it may affect the performance of zero-voxel filtering. Using the current hardware, reconstructing each image frame took 4.5 and 9 h for the DRT-MART and MART methods, respectively. The measurement volume was reconstructed into 3300 × 2200 × 182 voxel by using a relaxation factor of 2.5 and the PVR of 2 (i.e., xy-directions) and 10 (i.e., z-direction). To determine if there are any “ghost particles” reconstructed by the DRT-MART method, the reconstruction volume was made larger than the laser sheet thickness. 30 reconstructed particles images were added together and the voxel intensities were accumulated along y-direction. As the voxel intensity profile shown in Fig. 17, no “ghost particles” were found in the regions outside the laser illumination area. Note that the intensity profile has a peak in the centre region of laser sheet, this is partly due to the non-uniform illumination provided by the laser. But more importantly, this is exaggerated by a much lower intensity level in the region away from the focal plane, which is caused by the microlens calibration error and optics aberration. As Fig. 3 demonstrates, DRT-MART relies on accurate ray tracing to determine the relation between voxel and its affected pixels. During real experiments, the main lens distortion and any misalignment between MLA and CCD sensor will cause the light ray be deflected slightly away from its theoretical path. Such deflection becomes severe in regions away from the focal plane, which results in errors in calculating the weighting coefficient, and ultimately reduces the accuracy of reconstructed voxel intensity during the MART iteration.

a Cross section (x–z plane) of the reconstructed experimental light-field particle images (summation from 30 tests), b voxel intensity along z direction averaged from the x–z plane intensity distribution
Instantaneous velocity fields were calculated using multigrid cross-correlation with 0.75 overlapping-ratio, the initial and final interrogation volume were 320 × 320 × 64 voxel and 160 × 160 × 32 voxel, respectively. Any outliers were detected by a 3 × 3 median filter and replaced through linear interpolations. Instantaneous velocity fields determined by the DRT-MART and MART method are shown in Fig. 18, where velocity vectors along a single plane were plotted together with the vorticity iso-surface. At first glance, both the DRT-MART and MART methods seem to correctly resolve and reconstruct segments of a jet shear layer vortex roll-up. However, if we change the perspective to that of the top view as shown in Fig. 19, clear differences between two methods can be easily observed. As shown in Fig. 19b, the MART method produces incorrect \(w\) velocity component, especially along the lower edges. Recalling the analysis of the effects of number of iterations on the reconstruction quality (i.e., Figs. 6, 7), it was found that particle images further away from the focal plane have much lower voxel intensity than particles on or near the focal plane when an insufficient iteration number was applied (which is the case for MART method here). As a result of this effect, when cross-correlations are applied to the particle images reconstructed through the MART method, the coefficient peak will be biased towards the focal plane, which results in “ghost” \(w\) velocity components pointing towards the focal plane.

Instantaneous velocity fields determined by a DRT-MART and b MART methods

Instantaneous velocity field determined by a DRT-MART and b MART methods (top view)
6 Conclusions
We propose a new reconstruction approach known as DRT-MART method for light-field camera-based volumetric particle image velocimetry, which has been extensively investigated using both synthetic and experimental light-field particle images. Compared to the conventional MART method, the new DRT-MART method mitigates particle elongation effects, improves reconstruction quality and tolerates higher velocity gradients, while requiring less computational time than the MART method. To further improve its reconstruction accuracy, a self-calibration algorithm will be needed to compensate microlens calibration error caused by lens distortion and misalignment between MLA and image sensor.
As a novel volumetric flow measurement technique, single-camera light-field particle image velocimetry possesses many attractive advantages. It eliminates the need for significant fine-tuning for multi-camera configurations, which are normally required by the traditional three-dimensional PIV techniques such as TomoPIV and Stereo-PIV. In addition, it achieves volumetric flow measurement through a single optical window, which is ideal for space-confined applications.
References
Adrian R, Westerweel J (2011) Particle image velocimetry. Cambridge University Press, Cambridge
Arroyo M, Greated C (1991) Stereoscopic particle image velocimetry. Meas Sci Technol 2:1181–1186
Arroyo M, Hinsch K (2008) Recent developments of PIV towards 3D measurements. In: Particle image velocimetry: new developments and recent applications. Springer, New York
Atkinson C, Soria J (2009) An efficient simultaneous reconstruction technique for tomographic particle image velocimetry. Exp Fluid 47:553–568
Belden J, Truscott T, Axiak M, Techet A (2010) Three-dimensional synthetic aperture particle image velocimetry. Meas Sci Technol 21:1–21
Brucker C (1996) 3-D scanning-particle-image-velocimetry: technique and application to a spherical cap wake flow. Appl Sci Res 56:157–179
Deem E, Zhang Y, Cattafesta L, Fahringer T, Thurow B (2016) On the resolution of plenoptic PIV. Meas Sci Technol 27:084003
Ding J, Wang J, Liu Y, Shi S (2015) Dense ray tracing based reconstruction algorithm for light-field volumetric particle image velocimetry. In: 7th Australian Conference on Laser Diagnostics in Fluid Mechanics and Combustion. Melbourne, Australia
Elsinga G, Scarano F, Wieneke B, van Oudheusden B (2006) Tomographic particle image velocimetry. Exp Fluid 41:933–947
Fahringer T, Thurow B (2015) On the development of filtered refocusing: a volumetric reconstruction algorithm for plenoptic-PIV. In: 11th International Symposium on Particle Image Velocimetry–PIV15, Santa Barbara, California
Fahringer T, Lynch K, Thurow B (2015) Volumetric particle image velocimetry with a single plenoptic camera. Meas Sci Technol 26:115201, 25
Georgiev T, Zheng K, Curless B, Salesin D, Nayar S, Intwala C (2006) Spatio-angular resolution tradeoff in integral photography. In: Eurographics Symposium on rendering
Hori T, Sakakibara J (2004) High-speed scanning stereoscopic PIV for 3D vorticity measurement in liquids. Meas Sci Technol 15:1067–1078
Katz J, Sheng J (2010) Applications of holography in fluid mechanics and particle dynamics. Annu Rev Fluid Mech 42:531–555
New TH, Tsai HM (2007) Experimental investigations on indeterminate-origin V-and A-notched jets. AIAA J 45:828–839
New TH, Tsovolos D (2009) Influence of nozzle sharpness on the flow fields of V-notched nozzle jets. Phys Fluids 21:084107
New TH, Tsovolos D (2011) On the vortical structures and behaviour of inclined elliptic jets. Eur J Mech-B/Fluids 30:437–450
Ng R (2006) Digital light-field photography. PhD thesis, Stanford, CA, USA
Pereira F, Gharib M, Dabiri D, Modarress M (2000) Defocusing PIV: a three-component 3-D PIV measurement technique application to bubbly flows. Exp Fluid 29:S78–S84
Prasad A, Adrian R (1993) Stereoscopic particle image velocimetry applied to liquid flows. Exp Fluid 15:49–60
Scarano F (2012) Tomographic PIV: principles and practice. Meas Sci Technol 26:1–28
Shi S, Wang J, Ding J, Zhao Z, New TH (2016) Parametric study on light-field volumetric particle image velocimetry. Flow Meas Instrum 49:70–88
Soria J (1996) An investigation of the near wake of a circular cylinder using a video-based digital cross-correlation particle image velocimetry technique. Exp Therm Fluid Sci 12(2):221–233
Soria J, Atkinson C (2008) Towards 3C–3D digital holographic fluid velocity vector field measurement—tomographic digital holographic PIV (Tomo-HPIV). Meas Sci Technol 19:074002
Willert C, Gharib M (1992) Three-dimensional particle imaging with a single camera. Exp Fluid 12:353–358
Acknowledgements
Financial support provided by National Natural Science Foundation of China (Grant No. 11472175), Shanghai Raising Star Program (Grant No. 15QA1402400) and Singapore Ministry of Education AcRF Tier-2 Grant (Grant No. MOE2014-T2-1-002) are gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Shi, S., Ding, J., New, T.H. et al. Light-field camera-based 3D volumetric particle image velocimetry with dense ray tracing reconstruction technique. Exp Fluids 58, 78 (2017). https://doi.org/10.1007/s00348-017-2365-3
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00348-017-2365-3