
Abstract
Developing a robust bone fracture segmentation technique using deep learning is an important step in the medical imaging system. Bone fracture segmentation is the technique to separate out the various fracture and Non-fracture tissues. The fracture can occur in upper extremity parts of the human body like elbow, shoulder, finger, wrist, hand, humerus and forearm etc. X-ray is one of the widely used imaging modality for visualizing and assessing bone anatomy of the upper extremity. X-ray is used in the diagnosis and planning of the treatment for the bone fracture. The problem of computational bone fracture segmentation has gained researchers attention over a decade because of high variation in fracture size, shape, location, variation in intensities and variation textures. Many semi-automatic and fully automatic methods have been proposed and they are becoming more and more mature. A recent technique that is CNN based deep learning gives the promising result of the segmentation. In this Method, MURA (Musculoskeletal Radiographs) database is used. The CNN based U-Net model is trained using the MURA Database. After the training, the Model is tested on the test images. The Evaluation parameters Like Dice Coefficient and Validation Dice coefficient are found out to check the robustness of the technique. The CNN based U-Net architecture gives the training dice coefficient of 95.95% and validation dice coefficient of 90.29% for whole bone fracture segmentation.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Medical image processing is the technique for visualization of interior parts and posterior parts of the body for clinical analysis. Medical image processing helps to represent interior structures of the bone, muscle and is useful for diagnosis.
Musculoskeletal disorders are commonly due to an injury to the bones, joints, muscles, tendons, ligaments or nerves. There are different reasons behind this cause like by jerk in muscles or bone, car accidents, falls, fractures, sprains, dislocations, overuse and direct damage to muscle [1]. The locomotor or human musculoskeletal system provides the ability for movement of muscles, form, stability, and support. The purpose of a skeletal X-ray is to identify and evaluate bone density and structure.
Radiography shows the internal form of an object; it uses imaging techniques such as X-ray, gamma rays or similar ionizing radiation and non-ionizing radiation. As the human body made up of different bone densities, therefore ionizing and non-ionizing radiations help for viewing the internal structure of the bone. Radiography is also used in the field of security, such as airport and industrial area [2]. Wilhelm Roentgen discovered the X-ray in 1895, which is the main diagnostic tool used in the medical field. There is approximately 650 medical and dental examination per thousand patient per year.
X-ray is the high energy electromagnetic radiation which is ranging between 0.01 and 10 nm. It uses the small amount of radiation which is passed through our body to capture the injury or crack in the bone, diseases like infections, degeneration of bones and tumors.
X-ray image shows the different shades for the various part of our body because various tissues absorb the different amount of radiation. Bones look white in the image because they absorb more radiation whereas fat, tissues absorb less due to its which it looks gray. Air absorbs the least radiation. These are the four densities of the X-ray [3].
Bone is a rigid organ which comprises part of the vertebral skeletal. Bone is to Protects and supports the different organs of the body. There are various types of bones present in the human body like long, short, fat, irregular, and sesamoid bones.
There are about 206 bones that are present in our body with different structure, size, and shape. It is composed of around 300 bones at birth [4]. Fracture in the bone is a very common problem in the humans and is classified as follows,
-
Traumatic fracture.
-
Pathologic fracture.
-
Periprosthetic fracture.
Fracture (Crack) can also be classified based on soft tissue involvement as:
-
Closed fracture.
-
Open fracture/compound fracture.
Other than these fractures or crack can also be classified using other categories, i.e. displacement, fracture pattern, fragments, etc. Today, there are numerous types of tools such as CT (computed tomography), MRI (magnetic resonance imaging), Ultrasound, etc. are available for detecting the abnormalities present in the X-ray body is most commonly used in the detection of the fracture because it has some advantages like it is faster and easier for the doctors to studying about the bones and joints. Doctors generally prefer the X-ray technique to detect whether the crack exists or not and for the exact location of the crack.
This study gives details about the different methods for fracture or crack detection based on X-ray images. For that purpose, we have been studied frequently used techniques of previous papers. For this paper, we used the MURA (musculoskeletal radiographs) dataset, which contains seven different classes such as hand, wrist, finger, shoulder, hummus, elbow, forearm. These images are classified as normal and abnormal in the classification task [5].
The final goal of the paper is to segment out the lesion from the remaining bone tissue that the temporal changes can be examined. The use of a deep learning approach based on the U-Net model in if to avoid the human interventions and it can be seen as automatic and accurate combine bone and fracture segmentation. This could permit doctors to find a similar lesion in the bone X-ray images.
2 Anatomy of Upper Extremity
In this paper, MURA dataset is used only upper extremity part of the human body in shown Fig. 1.

Basic diagram upper extremity part of human body [6]
In MURA dataset, seven different upper extremity part of the human body are present such as elbow, humerus, shoulder, finger, forearm, hand and wrist showed in Fig. 2. The shoulder is an upper part of the back and arms. Long bone in the arm that runs from the shoulder and elbows is known as the humerus. Elbow is the visible joint between the upper and lower part of the arm. The forearm is part of the arm between the elbow and wrist. The wrist is the joint connecting the hand with the forearm. The finger is a basic part of the hand. In the above study, different views are present in Fig. 3.

Upper extremity part included shoulder, wrist, elbow, forearm, humerus, hand [7]

Different view of shoulder, elbow, wrist, hand and finger [7]
The shoulder (radiography) different views are present such as shoulder Rx Anteroposterior (AP), shoulder internal rotation, shoulder external rotation, shoulder Axial, shoulder Outlet, scapula Lateral, scapula Axial Acromioclavicular joint (AC) comparative Clavicle. Anteroposterior (AP), Lateral (LAT) internal rotation, Lateral (LAT) external rotation, Oblique (OBL) this is the view of the humerus (radiography). Anteroposterior (AP), Lateral (LAT), Oblique (OBL), Greenspan projection is the view of the elbow (radiography).
Only two views are present in the forearm (radiography) such as Anteroposterior (AP), Lateral (LAT). Wrist (radiography) six different view is present Anteroposterior (AP), Lateral (LAT), Internal rotation, External rotation, Carpal tunnel. Three views are present in hand (radiography) Antero- posterior (AP), Lateral (LAT), Oblique (OBL).
3 Mura
MURA means Musculoskeletal radiographs. Mura is a big database [8] of bone X-rays are shown in Fig. 4. The X-ray study is normal or abnormal, algorithms are tasked determining the 1.7 billion people worldwide affect Musculoskeletal conditions, and they are the most common cause of long-term pain and disability, the 30 million emergency department visits annually. Our dataset provides accurate localization of the fracture in the bone due to which experts can diagnose at an early stage.

Sample images from dataset [7]
MURA is a big dataset of the upper extremity part of bone X-rays. This dataset is publicly available for research. The total number of patient and images in mura dataset is 14,656 and 40,561. Dataset consists of 36,808 train images and 3753 validation images. Each consists of upper extremity study training and validation types such as Elbow, Finger, Forearm, Hand, Humerus, Shoulder and Wrist. The labels are manually created as fractures or non-fracture by the experts. The total size of the MURA dataset is 3.5 GB. Images format in the MURA dataset is’.png’. But we have 2000 images use for bone fracture segmentation. 2000 images for training images and 2000 for the mask. Training and masks images are splinted in training and testing images. 25% images for testing.
4 Related Work
Chokkalingam et al. [9] developed a scheme to diagnose rheumatoid arthritis by a sequence of image processing techniques. The system can be enhanced by the improvement of the edge detection and find better segmentation technique. Mean, Median, Energy, Correlation, Bone Mineral Density (BMD) etc. are Gray level co-occurrence matrix (GLCM) features. After getting each and every feature, it can be stored in the dataset. The training dataset is trained with non-inflamed and inflamed values and with the help of classifier (neural network).
Swathika et al. [10] developed an algorithm for bone fracture detection in X-ray images. First, they applied morphological gradient technique to remove the noise and, i.e. enhances the image details fracture region is highlighted. After that, they detected the edges using Canny edge detection technique. As compared to other edge detection methods, the proposed technique shows give efficient results for fracture detection.
Aishwariya et al. [11] discussed the technique to detect the boundaries of objects of X-ray images in which fracture is detected. They have used a canny edge detector to locate edges in X-ray images and to use boundary detection, the system which detects the fracture automatically. Active Contour Model, Geodesic Active Contour Model uses the boundary detection technique.
Lindseya et al. [12] proposed the fracture detection of bone using the Deep Convolution Neural Network (DCNN). In this paper, used wrist X-ray images to detect crack and input radiograph are first preprocessed by rotating, cropping, and applied an aspect ratio to yield a fixed resolution of 1024 × 512. DCNN is an extension of the U-Net architecture and achieved the fracture probability of 0.98.
Dong et al. [13] developed a brain tumor segmentation using U-Net based deep convolutional networks. Proposed Model is trained using Multimodal Brain Tumor Image Segmentation (BRATS 2015) dataset, which consist of 220 high-grade brain tumor and 54 low-grade tumor cases. Cross-validation has shown that this method can obtain promising segmentation efficiently.
Ng et al. [14], proposed a method for the classification using DenseNet169 architecture based deep convolutional network. MURA dataset is used Hight classification accuracy of 0.93% including seven different classes.
5 Deep Learning
Deep structured learning; hierarchical learning which is part of machine learning is called deep learning is shown in Fig. 5. It is based on the data representation. It requires the learned features rather than manually designed because they are incomplete, over-specified, and it takes a long time to validate. DL is a flexible, universal and learnable framework for the representation of the world, visual information. DL supports both supervised and unsupervised learning. High levels feature from the data can also be learned by using the DL. It requires a large amount of data, and performance can be reduced if data is small. Performance is increased with an increase in data. DL acts like a brain, learns from the ANN and allows a machine for analyzing the data like a human.

Representation of deep learning [15]
6 Methodology
The while images which are required for this project are collected from Stanford radiologists the images are in the size of 512 × 512 after resizing. we have used 2000 images in the MURA database including elbow, forearm, hand, finger, humerus, wrist, shoulder.
-
A.
Input Image: Input image is taken from the Database. The size of the image is 512 × 512 in ‘.png’ format (Fig. 6).
-
B.
Conversion: In this stage, the input image is converted into the Gray in shown in Fig. 7.
-
C.
Creating Mask: For the segmentation stage, the mask of the input image is needed. Mask is nothing but the region of interest. We can create the region of interest of various shapes like circle, polygon, rectangle, and ellipses, but here we used freehand shape because bones do not have any fixed shape.
Mask for bone fracture segmentation:
In the deep learning approach, we need ground truth data to compare network generated masks with the annotated masks. Some datasets are provided with their ground truth masks. But this dataset does not have annotated masks with them. So, the masks are manually created, and they binarized to get the masks as shown in the Fig. 6. The ground truth marked on MURE data is verified by the expert radiologist.
Fig. 6 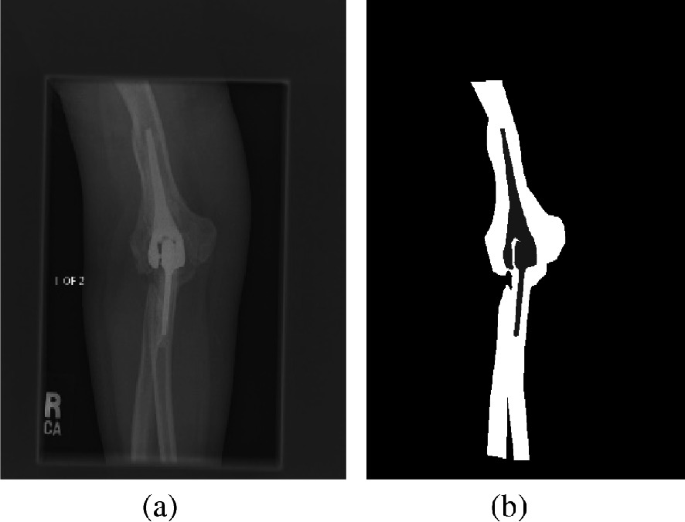
a Input from the database. b Mask of the input image
Fig. 7 
Overview of the proposed system
-
D.
Data Augmentation: Augmenting the data is nothing but increasing the number of images in the database to get better generalization in the Model used where more amount of the data, as well as variation, is needed so, for getting enough variation, we must generate more data from the dataset with limited images. This is what data augmentation is. The augmentation process increases the training images based on the operations which are used when a neural network is developed, which improves the overall network performance whenever the training images in the database are relatively smaller in number. Augmentation includes horizontal, vertical flipping and adding random Noise, zooming and blurring.
-
E.
Model: U-Net architecture is proposed by Ranneberger et al. [16]. U-Net model is developed for the Biomedical image segmentation, which is basically a CNN (convolutional neural network) is shown in Fig. 8. The architecture of this fully convolutional network is modified and extended for less training images to gives more precise segmentation. It follows the encoder and decoder approach. Its architecture consists of three parts 1. contracting or downsampling part; 2. Bottleneck layer; 3. Expansive or upsampling part this is the u-shaped architecture.
Fig. 8 
Architecture of U-net
-
a.
Downsampling Path: It is also called a contracting path. It has two 3 × 3 convolutions followed by the ReLU and 2 × 2 max-pooling for the Downsampling. At each stage of the downsampling and the Number of features, the channel is doubled.
-
b.
Upsampling Path: It is also known as expansive path. It performs the Upsampling of the feature map by using the 2 × 2 convolutions, concatenation between feature map from the downsampling and 3 × 3 convolution followed by the rectified linear unit.
-
c.
Skip Connection: Skip connections from the down- sampling path are concatenated with a feature map during the upsampling path. The skip connection provides local information to global information while upsampling.
-
d.
Final Layer: Finally, the 1 × 1 convolution is used at the final layer of mapping the feature vector to the number of classes. each feature vector to the desired no. of classes.
-
e.
Advantages of U-net: This U-net follows the encoder and the decoder approach. The three parts of this architecture give it U shape; therefore, it is known as the U-net model.
-
a.



7 Results
The proposed bone fracture segmentation method is implemented on Python version 3.6. We used the test and train images for the U-Net segmentation, test images are the input image, and train images are the mask images.
The images are of size 512 × 512; however, they are converted into grayscale images. The system has been tested on more than 2000 images. The proposed method shows the efficient and successful results for the segmentation of the Fracture regions in an affected bone X-ray image.
Consider, S and G are segmentation results and the ground truth. Then, the Dice coefficient is defined as for Eq. 1,
The total number parameter: 31,030,593 in U-Net Model.
The training and validation Dice coefficient of the dataset is given in the Table 1:
Thus, Fig. 9 shows the result for bone fracture segmentation where the similarity between the segmentation performance by network and the segmentation masks which are manually create is shown. The first image in each row represents input images, the second image is of the manually create masks, and the third image in each row represents the masks generated by our network.

Result for bone fracture segmentation
8 Dependencies
For the deep learning approach, there are some libraries, and high computation systems are required. Following some dependencies used for the training model, Keras with a TensorFlow backend Next to this We used scikit-learn, simpleitk, beautiful soup, OpenCV.
9 Conclusion
The paper presented bone fracture Segmentation Using Deep learning. This method required to test and train images that contains the original input image and mask images, respectively. The system has been tested on images obtained from Miles Research. The proposed method gives approximately 95.95% for training accuracy and 90.29% for testing accuracy, including bone fracture segmentation. The proposed system is very effective and can be implemented in real-time applications. We can also classify the bone X-ray images, whether it is either normal or abnormal. The main advantage of the approach, which is presented in this paper is its uniform nature and can be applied to different medical image segmentation tasks. The proposed Model achieved an acceptable performance with the MURA dataset images.
References
Khatik I (2017) A study of various bone fracture detection techniques. Int J Eng Comput Sci 6(5)
Johari N, Goyal S, Singh N, Pal A (2016) Bone fracture detection algorithms based on image processing- a survey. Int J Eng Manag Res 36, 2
Kaur T, Garg A et al. (2016) Bone fraction detection using image segmentation. In: Int J Eng Trends Technology (IJETT), 36(2)
Rajpurkar P, Bagul A, Ding D, Ball RL, Langlotz C, Ng A et al (2017) MURA ataset: towards radiologist-level abnormality detection in musculoskeletal radiographs, arXiv preprint arXiv:1712.06957v2
Artificial intelligence in medicine and imagin (2017) Available labeled medical datasets. https://aimi.stanford.edu/available-labeled-medical-datasets, [Online; Accessed -2 Dec 2017]
Chokkalingam SP, Komathy K et al (2014) Intelligent assistive methods for diagnosis of rheumatoid arthritis using histogram smoothing and feature extraction of bone images. World Acad Sci Eng Technol Int J Comput Inf Syst Control Eng 8(5):834–843
Swastika B, Anandhanarayanan K, Baskaran B, Govindaraj R (2015) Radius bone fracture detection using morphological gradient based image segmentation technique. Int J Comput Sci Inf Technol 6(2):1616–1619
Aishwarya R, Kalaiselvi GM, Archana M et al (2013) Computer- aided fracture detection of X-ray images. IOSR J Comput Eng 44–51
Lindsey R, Daluiski A, Chopra S, Chapelle ALA et al (2018) Deep neural network improves fracture detection by clinicians. In: PNAS
Dong H et al (2017) Automatic brain tumor detection and segmentation using U-net based fully convolutional networks. In: MIUA 2017, 069, v3: ’Automatic Brain Tumor Detection and Segmentation Using U-Net
Rajpurkar P, Irvin J, Bagul A, Ding D, Duan T, Mehta H, Yang B, Zhu K, Laird D, Ball RL, Langlotz C, Shpanskaya K, Lungren MP, Ng A et al (2018) MURA, 22 May 2018, “Large dataset for abnormality detection in musculoskeletal radiograph.” arXiv preprint arXiv:1712.06957v4.
Ronneberger O, Fischer P, Brox T (2015) 18 May 2015, U-Net: Convolutional networks for biomedical image segmentation. arXiv:1505.04597v1
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Ghoti, K., Baid, U., Talbar, S. (2021). MURA: Bone Fracture Segmentation Using a U-net Deep Learning in X-ray Images. In: Pawar, P.M., Balasubramaniam, R., Ronge, B.P., Salunkhe, S.B., Vibhute, A.S., Melinamath, B. (eds) Techno-Societal 2020. Springer, Cham. https://doi.org/10.1007/978-3-030-69921-5_52
Download citation
DOI: https://doi.org/10.1007/978-3-030-69921-5_52
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-69920-8
Online ISBN: 978-3-030-69921-5
eBook Packages: EngineeringEngineering (R0)