
Abstract
The theory of mean field games aims at studying deterministic or stochastic differential games (Nash equilibria) as the number of agents tends to infinity. Since very few mean field games have explicit or semi-explicit solutions, numerical simulations play a crucial role in obtaining quantitative information from this class of models. They may lead to systems of evolutive partial differential equations coupling a backward Bellman equation and a forward Fokker–Planck equation. In the present survey, we focus on such systems. The forward-backward structure is an important feature of this system, which makes it necessary to design unusual strategies for mathematical analysis and numerical approximation. In this survey, several aspects of a finite difference method used to approximate the previously mentioned system of PDEs are discussed, including convergence, variational aspects and algorithms for solving the resulting systems of nonlinear equations. Finally, we discuss in details two applications of mean field games to the study of crowd motion and to macroeconomics, a comparison with mean field type control, and present numerical simulations.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


4.1 Introduction
The theory of mean field games (MFGs for short), has been introduced in the pioneering works of J.-M. Lasry and P.-L. Lions [1,2,3], and aims at studying deterministic or stochastic differential games (Nash equilibria) as the number of agents tends to infinity. It supposes that the rational agents are indistinguishable and individually have a negligible influence on the game, and that each individual strategy is influenced by some averages of quantities depending on the states (or the controls) of the other agents. The applications of MFGs are numerous, from economics to the study of crowd motion. On the other hand, very few MFG problems have explicit or semi-explicit solutions. Therefore, numerical simulations of MFGs play a crucial role in obtaining quantitative information from this class of models.
The paper is organized as follows: in Sect. 4.2, we discuss finite difference schemes for the system of forward-backward PDEs. In Sect. 4.3, we focus on the case when the latter system can be interpreted as the system of optimality of a convex control problem driven by a linear PDE (in this case, the terminology variational MFG is often used), and put the stress on primal-dual optimization methods that may be used in this case. Section 4.4 is devoted to multigrid preconditioners that prove to be very important in particular as ingredients of the latter primal-dual methods for stochastic variational MFGs (when the volatility is positive). In Sect. 4.5, we address numerical algorithms that may be used also for non-variational MFGs. Sections 4.6, 4.7, and 4.8 are devoted to examples of applications of mean field games and their numerical simulations. Successively, we consider a model for a pedestrian flow with two populations, a comparison between mean field games and mean field control still for a model of pedestrian flow, and applications of MFGs to the field of macroeconomics.
In what follows, we suppose for simplicity that the state space is the d-dimensional torus \(\mathbb {T}^d\), and we fix a finite time horizon T > 0. The periodic setting makes it possible to avoid the discussion on non periodic boundary conditions which always bring additional difficulties. The results stated below may be generalized to other boundary conditions, but this would lead us too far. Yet, Sects. 4.6, 4.7, and 4.8 below, which are devoted to some applications of MFGs and to numerical simulations, deal with realistic boundary conditions. In particular, boundary conditions linked to state constraints play a key role in Sect. 4.8.
We will use the notation \(Q_T = [0,T] \times \mathbb {T}^d\), and 〈⋅, ⋅〉 for the inner product of two vectors (of compatible sizes).
Let \(f: \mathbb {T}^d \times \mathbb {R} \times \mathbb {R}^d \to \mathbb {R}, (x,m,\gamma ) \mapsto f(x,m,\gamma )\) and \(\phi : \mathbb {T}^d \times \mathbb {R} \to \mathbb {R}, (x,m) \mapsto \phi (x,m)\) be respectively a running cost and a terminal cost, on which assumptions will be made later on. Let ν > 0 be a constant parameter linked to the volatility. Let \(b: \mathbb {T}^d \times \mathbb {R} \times \mathbb {R}^d \to \mathbb {R}^d, (x,m,\gamma ) \mapsto b(x,m,\gamma )\) be a drift function.
We consider the following MFG: find a flow of probability densities \(\hat m: Q_T \to \mathbb {R}\) and a feedback control \(\hat v: Q_T\to \mathbb {R}^d\) satisfying the following two conditions:
-
1.
\(\hat v\) minimizes
$$\displaystyle \begin{aligned} J_{\hat m}: v \mapsto J_{\hat m}(v) = \mathbb{E} \left[\int_0^T f(X_t^v, \hat m(t,X_t^v), v(t,X_t^v) ) dt + \phi(X_T^v, \hat m(T,X_T^v)) \right] \end{aligned} $$under the constraint that the process \(X^v = (X_t^v)_{t \ge 0}\) solves the stochastic differential equation (SDE)
$$\displaystyle \begin{aligned} d X_t^v = b(X_t^v, \hat m(t,X_t^v), v(t, X_t^v)) dt + \sqrt{2 \nu} d W_t, \qquad t \ge 0, \end{aligned} $$(4.1)and \(X_0^v\) has distribution with density m 0;
-
2.
For all t ∈ [0, T], \(\hat m(t,\cdot )\) is the law of \(X_t^{\hat v}\).
It is useful to note that for a given feedback control v, the density \(m^v_t\) of the law of \(X^v_t\) following (4.1) solves the Kolmogorov–Fokker–Planck (KFP) equation:
Let \(H: \mathbb {T}^d \times \mathbb {R} \times \mathbb {R}^d \ni (x,m,p) \mapsto H(x,m,p) \in \mathbb {R}\) be the Hamiltonian of the control problem faced by an infinitesimal agent in the first point above, which is defined by
where L is the Lagrangian, defined by
In the sequel, we will assume that the running cost f and the drift b are such that H is well-defined, \(\mathcal {C}^1\) with respect to (x, p), and strictly convex with respect to p.
From standard optimal control theory, one can characterize the best strategy through the value function u of the above optimal control problem for a typical agent, which satisfies a Hamilton–Jacobi–Bellman (HJB) equation. Together with the equilibrium condition on the distribution, we obtain that the equilibrium best response \(\hat v\) is characterized by
where (u, m) solves the following forward-backward PDE system:

Example 1 (f Depends Separately on γ and m)
Consider the case where the drift is the control, i.e. b(x, m, γ) = γ, and the running cost is of the form f(x, m, γ) = L 0(x, γ) + f 0(x, m) where \(L_0(x,\cdot ): \mathbb {R}^d \ni \gamma \mapsto L_0(x,\gamma ) \in \mathbb {R}\) is strictly convex and such that \(\lim _{|\gamma |\to \infty } \min _{x\in \mathbb {T}^d} \frac {L_0(x,\gamma )} {|\gamma |}=+\infty \). We set \(H_0(x,p)= \max _{\gamma \in \mathbb {R}^d} \langle -p,\gamma \rangle - L_0(x,\gamma )\), which is convex with respect to p. Then
In particular, if \(H_0(x,\cdot ) = H^*_0(x,\cdot ) = \tfrac {1}{2}|\cdot |{ }^2\), then the maximizer in the above expression is \( \hat \gamma (p) = - p\), the Hamiltonian reads \(H(x,m,p) = \tfrac {1}{2} |p|{ }^2 -f_0(x,m)\) and the equilibrium best response is \(\hat v(t,x) = - \nabla u(t,x)\) where (u, m) solves the PDE system
Remark 1
The setting presented above is somewhat restrictive and does not cover the case when the Hamiltonian depends non locally on m. Nevertheless, the latter situation makes a lot of sense from the modeling viewpoint. The case when the Hamiltonian depends in a separate manner on ∇u and m and when the coupling cost continuously maps probability measures on \(\mathbb {T}^d\) to smooth functions plays an important role in the theory of mean field games, because it permits to obtain the most elementary existence results of strong solutions of the system of PDEs, see [3]. Concerning the numerical aspects, all what follows may be easily adapted to the latter case, see the numerical simulations at the end of Sect. 4.2. Similarly, the case when the volatility \(\sqrt {2\nu }\) is a function of the state variable x can also be dealt with by finite difference schemes.
Remark 2
Deterministic mean field games (i.e. for ν = 0) are also quite meaningful. One may also consider volatilities as functions of the state variable that may vanish. When the Hamiltonian depends separately on ∇u and m and the coupling cost is a smoothing map, see Remark 1, the Hamilton–Jacobi equation (respectively the Fokker–Planck equation) should be understood in viscosity sense (respectively in the sense of distributions), see the notes of P. Cardaliaguet [4]. When the coupling costs depends locally on m, then under some assumptions on the growth at infinity of the coupling cost as a function of m, it is possible to propose a notion of weak solutions to the system of PDEs, see [3, 5, 6]. The numerical schemes discussed below can also be applied to these situations, even if the convergence results in the available literature are obtained under the hypothesis that ν is bounded from below by a positive constant. The results and methods presented in Sect. 4.3 below for variational MFGs, i.e. when the system of PDEs can be seen as the optimality conditions of an optimal control problem driven by a PDE, hold if ν vanishes. In Sect. 4.8 below, we present some applications and numerical simulations for which the viscosity is zero.
Remark 3
The study of the so-called master equation plays a key role in the theory of MFGs, see [7, 8]: the mean field game is described by a single first or second order time dependent partial differential equation in the set of probability measures, thus in an infinite dimensional space in general. When the state space is finite (with say N admissible states), the distribution of states is a linear combination of N Dirac masses, and the master equation is posed in \(\mathbb {R}^N\); numerical simulations are then possible, at least if N is not too large. We will not discuss this aspect in the present notes.
4.2 Finite Difference Schemes
In this section, we present a finite-difference scheme first introduced in [9]. We consider the special case described in Example 1, with H(x, m, p) = H 0(x, p) − f 0(x, m), although similar methods have been proposed, applied and at least partially analyzed in situations when the Hamiltonian does not depend separately on m and p, for example models addressing congestion, see for example [10].
To alleviate the notation, we present the scheme in the one-dimensional setting, i.e. d = 1 and the domain is \(\mathbb {T}\).
Remark 4
Although we focus on the time dependent problem, a similar scheme has also been studied for the ergodic MFG system, see [9].
Discretization
Let N T and N h be two positive integers. We consider (N T + 1) and (N h + 1) points in time and space respectively. Let Δt = T∕N T and h = 1∕N h, and t n = n × Δt, x i = i × h for (n, i) ∈{0, …, N T}×{0, …, N h}.
We approximate u and m respectively by vectors U and \(M \in \mathbb {R}^{(N_T+1)\times (N_h+1)}\), that is, \(u(t_n,x_i) \approx U^{n}_{i}\) and \(m(t_n,x_i) \approx M^{n}_{i}\) for each (n, i) ∈{0, …, N T}×{0, …, N h}. We use a superscript and a subscript respectively for the time and space indices. Since we consider periodic boundary conditions, we slightly abuse notation and for \(W \in \mathbb {R}^{N_h+1}\), we identify \(W_{N_h+1}\) with W 1, and W −1 with \(W_{N_h-1}\).
We introduce the finite difference operators
Discrete Hamiltonian
Let \(\tilde H: \mathbb {T} \times \mathbb {R} \times \mathbb {R} \to \mathbb {R}, (x,p_1,p_2) \mapsto \tilde H(x,p_1,p_2)\) be a discrete Hamiltonian, assumed to satisfy the following properties:
-
1.
(\({\tilde {\boldsymbol {\mathrm {H}}}}_{\boldsymbol {1}}\)) Monotonicity: for every \(x \in \mathbb {T}\), \(\tilde H\) is nonincreasing in p 1 and nondecreasing in p 2.
-
2.
(\({\tilde {\boldsymbol {\mathrm {H}}}}_{\boldsymbol {2}}\)) Consistency: for every \(x \in \mathbb {T}, p \in \mathbb {R}\), \(\tilde H(x,p,p) = H_0(x,p)\).
-
3.
(\({\tilde {\boldsymbol {\mathrm {H}}}}_{\boldsymbol {3}}\)) Differentiability: for every \(x \in \mathbb {T}\), \(\tilde H\) is of class \(\mathcal {C}^1\) in p 1, p 2
-
4.
(\({\tilde {\boldsymbol {\mathrm {H}}}}_{\boldsymbol {4}}\)) Convexity: for every \(x \in \mathbb {T}\), \((p_1,p_2) \mapsto \tilde H(x,p_1,p_2)\) is convex.
Example 2
For instance, if \(H_0(x,p) = \frac {1}{2} |p|{ }^2\), then one can take \(\tilde H(x, p_1, p_2) = \frac {1}{2}|P_K(p_1,p_2)|{ }^2\) where P K denotes the projection on \(K = \mathbb {R}_- \times \mathbb {R}_+\).
Remark 5
Similarly, for d-dimensional problems, the discrete Hamiltonians that we consider are real valued functions defined on \(\mathbb {T}^d \times (\mathbb {R}^2)^d \).
Discrete HJB Equation
We consider the following discrete version of the HJB equation (4.3a):

Note that it is an implicit scheme since the equation is backward in time.
Discrete KFP Equation
To define an appropriate discretization of the KFP equation (4.3b), we consider the weak form. For a smooth test function \(w \in \mathcal {C}^{\infty }([0,T] \times \mathbb {T})\), it involves, among other terms, the expression
where we used an integration by parts and the periodic boundary conditions. In view of what precedes, it is quite natural to propose the following discrete version of the right hand side of (4.5):
and performing a discrete integration by parts, we obtain the discrete counterpart of the left hand side of (4.5) as follows: \( -\displaystyle h \sum _{i=0}^{N_h-1} \mathcal {T}_i(U^n , M^{n+1}) W_i^n\), where \(\mathcal {T}_i\) is the following discrete transport operator:
Then, for the discrete version of (4.3b), we consider

where, for example,
Here again, the scheme is implicit since the equation is forward in time.
Remark 6 (Structure of the Discrete System)
The finite difference system (4.4)–(4.6) preserves the structure of the PDE system (4.3) in the following sense: The operator \(M \mapsto - \nu (\Delta _h M)_{i} - \mathcal {T}_i(U, M)\) is the adjoint of the linearization of the operator \(U \mapsto - \nu (\Delta _h U)_{i} + \tilde H(x_i, [\nabla _h U]_i)\) since
Convergence Results
Existence and uniqueness for the discrete system has been proved in [9, Theorems 6 and 7]. The monotonicity properties ensure that the grid function M is nonnegative. By construction of \(\mathcal {T}\), the scheme preserves the total mass \(h \sum _{i=0}^{N_h-1} M_i^n\). Note that there is no restriction on the time step since the scheme is implicit. Thus, this method may be used for long horizons and the scheme can be very naturally adapted to ergodic MFGs, see [9].
Furthermore, convergence results are available. A first type of convergence theorems see [9, 11, 12] (in particular [9, Theorem 8] for finite horizon problems) make the assumption that the MFG system of PDEs has a unique classical solution and strong versions of Lasry-Lions monotonicity assumptions, see [1,2,3]. Under such assumptions, the solution to the discrete system converges towards the classical solution as the grid parameters tend to zero.
In what follows, we discuss a second type of results that were obtained in [13], namely, the convergence of the solution of the discrete problem to weak solutions of the system of forward-backward PDEs.
Theorem 1 ([13, Theorem 3.1])
We make the following assumptions:
-
ν > 0;
-
ϕ(x, m) = u T(x) where u T is a continuous function on \(\mathbb {T}^d\);
-
m 0 is a nonnegative function in \(L^\infty (\mathbb {T}^d)\) such that \(\int _{\mathbb {T}^d} m_0(x)dx=1\);
-
f 0 is a continuous function on \(\mathbb {T}^d\times \mathbb {R}^+\) , which is bounded from below;
-
The Hamiltonian (x, p)↦H 0(x, p) is assumed to be continuous, convex and \(\mathcal {C}^1\) regular w.r.t. p;
-
The discrete Hamiltonian \(\tilde H\) satisfies ( \(\tilde {\boldsymbol {\mathrm {H}}}_{\boldsymbol {1}}\) )–( \(\tilde {\boldsymbol {\mathrm {H}}}_{\boldsymbol {4}}\) ) and the following further assumption:
-
( \(\tilde {\boldsymbol {\mathrm {H}}}_{\boldsymbol {5}}\) ) growth conditions : there exist positive constants c 1, c 2, c 3, c 4 such that
$$\displaystyle \begin{aligned} \begin{array}{rcl} {} \langle \tilde H_q(x,q), q \rangle -\tilde H(x,q)&\displaystyle \ge&\displaystyle c_1 |\tilde H_q(x,q)|{}^2 - c_2, \end{array} \end{aligned} $$(4.8)$$\displaystyle \begin{aligned} \begin{array}{rcl} {} |\tilde H_q(x,q)|&\displaystyle \le &\displaystyle c_3 |q| + c_4. \end{array} \end{aligned} $$(4.9)
-
Let (U n), (M n) be a solution of the discrete system (4.6a)–(4.6c) (more precisely of its d-dimensional counterpart). Let u h,Δt , m h,Δt be the piecewise constant functions which take the values \(U_{I}^{n+1} \) and \(M_{I}^{n}\) , respectively, in (t n, t n+1) × ω I , where ω I is the d-dimensional cube centered at x I of side h and I is any multi-index in {0, …, N h − 1}d.
Under the assumptions above, there exists a subsequence of h and Δt (not relabeled) and functions \(\tilde u\), \(\tilde m\) , which belong to \(L^\alpha (0,T;W^{1,\alpha }(\mathbb {T}^d))\) for any \(\alpha \in [1,\frac {d+2} {d+1})\) , such that \(u_{h,\Delta t} \to \tilde u\) and \(m_{h,\Delta t} \to \tilde m\) in L β(Q T) for all \(\beta \in [1,\frac {d+2} d )\) , and \((\tilde u, \tilde m)\) is a weak solution to the system

in the following sense:
-
(i)
\(H_0(\cdot , \nabla \tilde u) \in L^1(Q_T)\), \(\tilde mf_0(\cdot ,\tilde m)\in L^1(Q_T)\), \(\tilde m[D_pH_0(\cdot ,\nabla \tilde u)\cdot \nabla \tilde u-H_0(\cdot ,\nabla \tilde u)]\in L^1(Q_T)\)
-
(ii)
\((\tilde u, \tilde m)\) satisfies (4.10a)–(4.10b) in the sense of distributions
-
(iii)
\(\;\tilde u, \tilde m \in C^0([0,T]; L^1(\mathbb {T}^d))\) and \(\tilde u|{ }_{t=T}= u_T\), \(\tilde m|{ }_{t=0}=m_0\) .
Remark 7
-
Theorem 1 does not suppose the existence of a (weak) solution to (4.10a)–(4.10c), nor Lasry-Lions monotonicity assumptions, see [1,2,3]. It can thus be seen as an alternative proof of existence of weak solutions of (4.10a)–(4.10c).
-
The assumption made on the coupling cost f 0 is very general.
-
If uniqueness holds for the weak solutions of (4.10a)–(4.10c), which is the case if Lasry-Lions monotonicity assumptions hold, then the whole sequence of discrete solutions converges.
-
It would not be difficult to generalize Theorem 1 to the case when the terminal condition at T is of the form (4.3c).
-
Similarly, non-local coupling cost of the type F[m](x) could be addressed, where for instance, F maps bounded measures on \(\mathbb {T}^d\) to functions in \(C^0(\mathbb {T}^d)\).
An Example Illustrating the Robustness of the Scheme in the Deterministic Limit
To illustrate the robustness of the finite difference scheme described above, let us consider the following ergodic problem
where the ergodic constant \(\rho \in \mathbb {R}\) is also an unknown of the problem, and
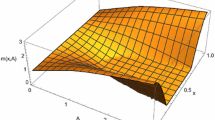
Note the very small value of the viscosity parameter ν. Since the coupling term is a smoothing nonlocal operator, nothing prevents m from becoming singular in the deterministic limit when ν → 0. In Fig. 4.1, we display the solution. We see that the value function tends to be singular (only Lipschitz continuous) and that the density of the distribution of states tends to be the sum of two Dirac masses located at the minima of the value function. The monotonicity of the scheme has made it possible to capture the singularities of the solution.

Left: the value function. Right: the distribution of states
4.3 Variational Aspects of Some MFGs and Numerical Applications
In this section, we restrict our attention to the setting described in the Example 1. We assume that L 0 is smooth, strictly convex in the variable γ and such that there exists positive constants c and C, and r > 1 such that
and that H 0 is smooth and has a superlinear growth in the gradient variable. We also assume that the function f 0 is smooth and non-decreasing with respect to m. We make the same assumption on ϕ.
4.3.1 An Optimal Control Problem Driven by a PDE
Let us consider the functions
and
Let us also introduce
Note that since f 0(x, ⋅) is non-decreasing, F(x, ⋅) is convex and l.s.c. with respect to m. Likewise, since ϕ(x, ⋅) is non-decreasing, then Φ(x, ⋅) is convex and l.s.c. with respect to m. Moreover, it can be checked that the assumptions made on L 0 imply that L(x, ⋅, ⋅) is convex and l.s.c. with respect to (m, w).
We now consider the following minimization problem expressed in a formal way: Minimize, when it is possible, \(\mathcal {J}\) defined by
on pairs (m, w) such that m ≥ 0 and
holds in the sense of distributions.
Note that, thanks to our assumptions and to the structure in terms of the variables (m, w), this problem is the minimization of a convex functional under a linear constraint. The key insight is that the optimality conditions of this minimization problem yield a weak version of the MFG system of PDEs (4.3).
Remark 8
If \((m,w)\in L^1(Q_T)\times L^1(Q_T; \mathbb {R}^d)\) is such that \(\int _0^T \int _{\mathbb {T}^d} L (x,m(t,x), w(t,x)) dx dt <+\infty \), then it is possible to write that w = mγ with \(\int _0^T \int _{\mathbb {T}^d} m(t,x)|\gamma (t,x)|{ }^r dx dt <+\infty \) thanks to the assumptions on L 0. From this piece of information and (4.16), we deduce that t↦m(t) for t < 0 is Hölder continuous a.e. for the weak∗ topology of \(\mathcal {P}(\mathbb {T}^d)\), see [5, Lemma 3.1]. This gives a meaning to \(\int _{\mathbb {T}^d} \Phi (x, m(T,x)) dx\) in the case when Φ(x, m(T, x)) = u T(x)m(T, x) for a smooth function u T(x). Therefore, at least in this case, the minimization problem is defined rigorously in \(L^1(Q_T)\times L^1(Q_T; \mathbb {R}^d)\).
Remark 9
Although we consider here the case of a non-degenerate diffusion, similar problems have been considered in the first-order case or with degenerate diffusion in [5, 14].
Remark 10
Note that, in general, the system of forward-backward PDEs cannot be seen as the optimality conditions of a minimization problem. This is never the case if the Hamiltonian does not depend separately on m and ∇u.
4.3.2 Discrete Version of the PDE Driven Optimal Control Problem
We turn our attention to a discrete version of the minimization problem introduced above. To alleviate notation, we restrict our attention to the one dimensional case, i.e., d = 1. Let us introduce the following spaces, respectively for the discrete counterpart of m, w, and u:
Note that at each space-time grid point, we will have two variables for the value of w, which will be useful to define an upwind scheme.
We consider a discrete Hamiltonian \(\tilde H\) satisfying the assumptions (\(\tilde {\boldsymbol {\mathrm {H}}}_{\boldsymbol {1}}\))–(\(\tilde {\boldsymbol {\mathrm {H}}}_{\boldsymbol {4}}\)), and introduce its convex conjugate w.r.t. the p variable:
Example 3
If \(\tilde H(x, p_1, p_2) = \tfrac {1}{2} |P_K(p_1,p_2)|{ }^2\) with \(K = \mathbb {R}_- \times \mathbb {R}_+\), then
A discrete counterpart Θ to the functional \(\mathcal {J}\) introduced in (4.15) can be defined as
where \(\tilde L\) is a discrete version of L introduced in (4.14) defined as
Furthermore, a discrete version of the linear constraint (4.16) can be written as
where \(0_{\mathcal {U}} \in \mathcal {U}\) is the vector with 0 on all coordinates, \(\bar M^0 = (\bar m_0(x_0), \dots , \bar m_0 (x_{N_h-1})) \in \mathbb {R}^{N_h}\), see (4.7) for the definition of \(\bar m_0\), and
with Λ(M, W) = AM + BW, A and B being discrete versions of respectively the heat operator and the divergence operator, defined as follows:
and
We define the transposed operators \(A^*: \mathcal {U} \to \mathcal {M}\) and \(B^*: \mathcal {U} \to \mathcal {W}\), i.e. such that
This yields
and
This implies that
The discrete counterpart of the variational problem (4.15)–(4.16) is therefore
The following results provide a constraint qualification property and the existence of a minimizer. See e.g. [15, Theorem 3.1] for more details on a special case (see also [16, Section 6] and [17, Theorem 2.1] for similar results respectively in the context of the planning problem and in the context of an ergodic MFG).
Proposition 1 (Constraint Qualification)
There exists a pair \((\tilde M, \tilde W) \in \mathcal {M} \times \mathcal {W}\) such that
Theorem 2
There exists a minimizer \((M,W) \in \mathcal {M} \times \mathcal {W}\) of (4.27). Moreover, if ν > 0, \(M^n_i >0\) for all i ∈{0, …, N h} and all n > 0.
4.3.3 Recovery of the Finite Difference Scheme by Convex Duality
We will now show that the finite difference scheme introduced in the previous section corresponds to the optimality conditions of the discrete minimization problem (4.27) introduced above. To this end, we first rewrite the discrete problem by embedding the constraint in the cost functional as follows:
where \( \chi _0: \mathcal {U} \times \mathbb {R}^{N_h} \to \mathbb {R} \cup \{+\infty \} \) is the characteristic function (in the convex analytical sense) of the singleton \(\{(0_{\mathcal {U}}, \bar M^0)\}\), i.e., χ 0(U, φ) vanishes if \((U, \varphi ) = (0_{\mathcal {U}}, \bar M^0)\) and otherwise it takes the value + ∞.
By Fenchel-Rockafellar duality theorem, see [18], we obtain that
where Σ∗ is the adjoint operator of Σ, and \(\chi _0^*\) and Θ∗ are the convex conjugates of χ 0 and Θ respectively, to wit,
and
Therefore
We use the fact that
We deduce the following:
where for every \(x \in \mathbb {T}\), F ∗(x, ⋅) and \(\left (F+\frac 1 {\Delta t} \Phi \right )^*(x, \cdot )\) are the convex conjugate of F(x, ⋅) and \(F(x,\cdot )+\frac 1 {\Delta t}\Phi (x, \cdot )\) respectively. Note that from the definition of F, it has not been not necessary to impose the constraint M n ≥ 0 for all n ≥ 1 in (4.32). Note also that the last term in (4.32) can be written \(\max _{ M\in \mathcal {M}} M^0_i \left ( -\frac 1 {\Delta t} U^0 _i +\varphi _i \right ) \). Using (4.32), in the dual minimization problem given in the right hand side of (4.29), we see that the minimization with respect to φ yields that \(M_i^0=\tilde M_i^0\). Therefore, the the dual problem can be rewritten as
which is the discrete version of
The arguments above lead to the following:
Theorem 3
The solutions \((M,W) \in \mathcal {M} \times \mathcal {W}\) and \(U \in \mathcal {U}\) of the primal/dual problems are such that:
-
if ν > 0, \(M^n_i>0\) for all 0 ≤ i ≤ N h − 1 and 0 < n ≤ N T;
-
\(W^n_i = M^{n+1}_i P_K([\nabla _h U^n]_i)\) for all 0 ≤ i ≤ N h − 1 and 0 ≤ n < N T;
-
(U, M) satisfies the discrete MFG system (4.4)–(4.6) obtained by the finite difference scheme.
Furthermore, the solution is unique if f 0 and ϕ are strictly increasing.
Proof
The proof follows naturally for the arguments given above. See e.g. [11] in the case of planning problems, [15, Theorem 3.1], or [17, Theorem 2.1] in the stationary case. □
In the rest of this section, we describe two numerical methods to solve the discrete optimization problem.
4.3.4 Alternating Direction Method of Multipliers
Here we describe the Alternating Direction Method of Multipliers (ADMM) based on an Augmented Lagrangian approach for the dual problem. The interested reader is referred to e.g. the monograph [19] by Fortin and Glowinski and the references therein for more details. This idea was made popular by Benamou and Brenier for optimal transport, see [20], and first used in the context of MFGs by Benamou and Carlier in [21]; see also [22] for an application to second order MFG using multilevel preconditioners and [23] for an application to mean field type control.
The dual problem (4.33) can be rewritten as
where
and
Note that Ψ is convex and l.s.c., and Γ is linear. Moreover, Ψ depend in a separate manner on the pairs \((M^n_i ,W^{n-1}_i )_{n,i}\), and a similar observation can be made for Λ.
We can artificially introduce an extra variable \(Q \in \mathcal {M} \times \mathcal {W}\) playing the role of Λ∗ U. Introducing a Lagrange multiplier σ = (M, W) for the constraint Q = Λ∗ U, we obtain the following equivalent problem:
where the Lagrangian \(\mathcal {L}: \mathcal {U} \times \mathcal {M} \times \mathcal {W} \times \mathcal {M} \times \mathcal {W} \to \mathbb {R}\) is defined as
Given a parameter r > 0, it is convenient to introduce an equivalent problem involving the augmented Lagrangian \(\mathcal {L}_r\) obtained by adding to \(\mathcal {L}\) a quadratic penalty term in order to obtain strong convexity:
Since the saddle-points of \(\mathcal {L}\) and \(\mathcal {L}_r\) coincide, equivalently to (4.34), we will seek to solve
In this context, the Alternating Direction Method of Multipliers (see e.g. the method called ALG2 in [19]) is described in Algorithm 1 below. We use ∂ Γ and ∂ Ψ to denote the subgradients of Γ and Ψ respectively.
Algorithm 1 Alternating Direction Method of Multipliers

Remark 11 (Preservation of the Sign)
An important consequence of this method is that, thanks to the second and third steps above, the non-negativity of the discrete approximations to the density is preserved. Indeed, \(\sigma ^{(k+1)} \in \partial \Psi \left ( Q^{(k+1)} \right )\) and \( \Psi \left ( Q^{(k+1)} \right )< +\infty \), hence \(\Psi ^*\left ( \sigma ^{(k+1)} \right ) = \langle \sigma ^{(k+1)}, Q^{(k+1)} \rangle - \Psi \left ( Q^{(k+1)} \right )\), which yields \(\Psi ^*\left ( \sigma ^{(k+1)} \right ) < +\infty \). In particular, denoting \((M^{(k+1)},W^{(k+1)}) = \sigma ^{(k+1)} \in \mathcal {M} \times \mathcal {W}\), this implies that we have \((M^{(k+1)})^n_i \ge 0 \) for every 0 ≤ i < N h, 0 ≤ n ≤ N T, and \((W^{(k+1)})^n_i \in K\) vanishes if \((M^{(k+1)})^{n+1}_i = 0\) for every 0 ≤ i < N h, 0 ≤ n < N T.
Let us provide more details on the numerical solution of the first and second steps in the above method. For the first step, since Γ only acts on U 0, the first order optimality condition amounts to solving the discrete version of a boundary value problem on \((0,T) \times \mathbb {T}\) or more generally \((0,T) \times \mathbb {T}^d\) when the state is in dimension d, with a degenerate fourth order linear elliptic operator (of order four in the state variable if ν is positive and two in time), and with a Dirichlet condition at t = T and a Neumann like condition at t = 0. If d > 1, it is generally not possible to use direct solvers; instead, one has to use iterative methods such as the conjugate gradient algorithm. An important difficulty is that, since the equation is fourth order with respect to the state variable if ν > 0, the condition number grows like h −4, and a careful preconditionning is mandatory (we will come back to this point in the next section). In the deterministic case, i.e. if ν = 0, the first step consists of solving the discrete version of a second order d + 1 dimensional elliptic equation and preconditioning is also useful for reducing the computational complexity.
As for the second step, the first order optimality condition amounts to solving, at each space-time grid node (i, n), a non-linear minimization problem in \(\mathbb {R}^{1+2d}\) of the form
where (a, b) plays the role of \((M^n_i, W^{n-1}_i)\), whereas \((\bar a, \bar b)\) plays the role of \((\Lambda ^* U)^n_i\).
Note that the quadratic term, which comes from the fact that we consider the augmented Lagrangian \(\mathcal {L}_r\) instead of the original Lagrangian \(\mathcal {L}\), provides coercivity and strict convexity. The two main difficulties in this step are the following. First, in general, F ∗ does not admit an explicit formula and is itself obtained by solving a maximization problem. Second, for general F and \(\tilde H\), computing the minimizer explicitly may be impossible. In the latter case, Newton iterations may be used, see e.g. [23].
The following result ensures convergence of the numerical method; see [24, Theorem 8] for more details.
Theorem 4 (Eckstein and Bertsekas [24])
Assume that r > 0, that Λ Λ ∗ is symmetric and positive definite and that there exists a solution to the primal-dual extremality. Then the sequence (U (k), Q (k), σ (k)) converges as k →∞ and
where \(\bar U\) solves the dual problem and \(\bar \sigma \) solves the primal problem.
4.3.5 Chambolle and Pock’s Algorithm
We now consider a primal-dual algorithm introduced by Chambolle and Pock in [25]. The application to stationary MFGs was first investigated by Briceño-Arias, Kalise and Silva in [17]; see also [15] for an extension to the dynamic setting.
Introducing the notation \(\Pi = \chi _0 \circ \Sigma : \mathcal {M} \times \mathcal {W} \ni (M,W) \mapsto \chi _0(\Sigma (M,W)) \in \mathbb {R} \cup \{+\infty \}\), the primal problem (4.28) can be written as
and the dual problem can be written as
For r, s > 0, the first order optimality conditions at \(\hat \sigma \) and \(\hat Q\) can be equivalently written as
Given some parameters r > 0, s > 0, τ ∈ [0, 1], the Chambolle-Pock method is described in Algorithm 2. The algorithm has been proved to converge if rs < 1.
Algorithm 2 Chambolle-Pock Method

Note that the first step is similar to the first step in the ADMM method described in Sect. 4.3.4 and amounts to solving a linear fourth order PDE. The second step is easier than in ADMM because Θ admits an explicit formula.
4.4 Multigrid Preconditioners
4.4.1 General Considerations on Multigrid Methods
Before explaining how multigrid methods can be applied in the context of numerical solutions for MFG, let us recall the main ideas. We refer to [26] for an introduction to multigrid methods and more details. In order to solve a linear system which corresponds to the discretisation of an equation on a given grid, we can use coarser grids in order to get approximate solutions. Intuitively, a multigrid scheme should be efficient because solving the system on a coarser grid is computationally easier and the solution on this coarser grid should provide a good approximation of the solution on the original grid. Indeed, using a coarser grid should help capturing quickly the low frequency modes (i.e., the modes corresponding to the smallest eigenvalues of the differential operator from which the linear system comes), which takes more iterations on a finer grid.
When the linear system stems from a well behaved second order elliptic operator for example, one can find simple iterative methods (e.g. Jacobi or Gauss–Seidel algorithms) such that a few iterations of these methods are enough to damp the higher frequency components of the residual, i.e. to make the error smooth. Typically, these iterative methods have bad convergence properties, but they have good smoothing properties and are hence called smoothers. The produced residual is smooth on the grid under consideration (i.e., it has small fast Fourier components on the given grid), so it is well represented on the next coarser grid. This suggests to transfer the residual to the next coarser grid (in doing so, half of the low frequency components on the finer grid become high frequency components on the coarser one, so they will be damped by the smoother on the coarser grid). These principles are the basis for a recursive algorithm. Note that in such an algorithm, using a direct method for solving systems of linear equations is required only on the coarsest grid, which contains much fewer nodes than the initial grid. On the grids of intermediate sizes, one only needs to perform matrix multiplications.
To be more precise, let us consider a sequence of nested grids \((\mathcal {G}_\ell )_{\ell = 0,\dots ,L}\), i.e. such that \(\mathcal {G}_\ell \subseteq \mathcal {G}_{\ell +1}, \ell =0,\dots ,L-1\). Denote the corresponding number of points by \(\tilde N_\ell = \tilde N 2^{d\ell }\), ℓ = 0, …, L, where \(\tilde N\) is a positive integer representing the number of points in the coarsest grid. Assume that the linear system to be solved is
where the unknown is \(x_L \in \mathbb {R}^{\tilde N_L}\) and with \(b_L \in \mathbb {R}^{\tilde N_L}\), \(M_L \in \mathbb {R}^{\tilde N_L \times \tilde N_L}\). In order to perform intergrid communications, we introduce
-
Prolongation operators, which represent a grid function on the next finer grid: \(P_\ell ^{\ell +1}: \mathcal {G}_\ell \to \mathcal {G}_{\ell +1}\).
-
Restriction operators, which interpolate a grid function on the next coarser grid: \(R_\ell ^{\ell -1}: \mathcal {G}_\ell \to \mathcal {G}_{\ell -1}\).
Using these operators, we can define on each grid \(\mathcal {G}_\ell \) a matrix corresponding to an approximate version of the linear system to be solved:
Then, in order to solve M ℓ x ℓ = b ℓ, the method is decomposed into three main steps. First, a pre-smoothing step is performed: starting from an initial guess \(\tilde x_\ell ^{(0)}\), a few smoothing iterations, say η 1, i.e. Jacobi or Gauss–Seidel iterations for example. This produces an estimate \(\tilde x_\ell = \tilde x_\ell ^{(\eta _1)}\). Second, an (approximate) solution x ℓ−1 on the next coarser grid is computed for the equation \(M_{\ell -1} x_{\ell -1} = R_\ell ^{\ell -1}(b_\ell - M_\ell \tilde x_\ell )\). This is performed either by calling recursively the same function, or by means of a direct solver (using Gaussian elimination) if it is on the coarsest grid. Third, a post-smoothing step is performed: \(\tilde x_\ell + P_{\ell -1}^{\ell } x_{\ell -1}\) is used as an initial guess, from which η 2 iterations of the smoother are applied, for the problem with right-hand side b ℓ. To understand the rationale behind this method, it is important to note that
In words, the initial guess (namely, \(\tilde x_\ell + P_{\ell -1}^{\ell } x_{\ell -1}\)) for the third step above is a good candidate for a solution to the equation M ℓ x ℓ = b ℓ, at least on the coarser grid \(\mathcal {G}_{\ell -1}\).
Algorithm 3 provides a pseudo-code for the method described above. Here, S ℓ(x, b, η) can be implemented by performing η steps of Gauss–Seidel algorithm starting with x and with b as right-hand side. The method as presented uses once the multigrid scheme on the coarser grid, which is called a V-cycle. Other approaches are possible, such as W-cycle (in which the multigrid scheme is called twice) or F-cycle (which is intermediate between the V-cycle and the W-cycle). See e.g. [26] for more details.
Algorithm 3 Multigrid Method for M L x L = b L with V-cycle

4.4.2 Applications in the Context of Mean Field Games
Multigrid methods can be used for a linearized version of the MFG PDE system, see [27], or as a key ingredient of the ADDM or the primal-dual algorithms, see [17, 22]. In the latter case, it corresponds to taking M L = Λ Λ∗ in (4.37). A straightforward application of the multigrid scheme described above leads to coarsening the space-time grid which does not distinguish between the space and time dimensions. This is called full coarsening. However, in the context of second-order MFG, this approach leads to poor performance. See e.g. [27]. We reproduce here one table contained in [27]: the multigrid method is used as a preconditioner in a preconditioned BiCGStab iterative method, see [28], in order to solve a linearized version of the MFG system of PDEs. In Table 4.1, we display the number of iterations of the preconditioned BiCGStab method: we see that the number of iterations grows significantly as the number of nodes is increased.
The reason for this poor behavior can be explained by the fact that the usual smoothers actually make the error smooth in the hyperplanes t = n Δt, i.e. with respect to the variable x, but not with respect to the variable t. Indeed, the unknowns are more strongly coupled in the hyperplanes {(t, x) : t = n Δt}, n = 0, …, N T (fourth order operator w.r.t. x) than on the lines {(t, x) : x = i h}, i = 0, …, N h (second order operator w.r.t. t). This leads to the idea of using semi-coarsening: the hierarchy of nested grids should be obtained by coarsening the grids in the x directions only, but not in the t direction. We refer the reader to [26] for semi-coarsening multigrid methods in the context of anisotropic operators.
In the context of the primal-dual method discussed in Sect. 4.3.5, the first step (4.35) amounts to solving a discrete version of the PDE with operator \(-\partial _{tt}^2 + \nu ^2 \Delta ^2- \Delta \) where Δ2 denotes the bi-Laplacian operator. In other words, one needs to solve a system of the form (4.37) where M L corresponds to the discretization of this operator on the (finest) grid under consideration. One can thus use one cycle of the multigrid algorithm, which is a linear operator as a function of the residual on the finest grid, as a preconditioner for solving (4.37) with the BiCGStab method.
We now give details on the restriction and prolongation operators when d = 1. Using the notations introduced above, we consider that N h is of the form N h = n 02L for some integer n 0. Remember that Δt = T∕N T and h = 1∕N h since we are using the one-dimensional torus as the spatial domain. The number of points on the coarsest grid \(\mathcal {G}_0\) is \(\tilde N = (N_T+1) \times n_0\) while on the ℓ-th grid \(\mathcal {G}_\ell \), it is \(\tilde N_\ell = (N_T+1) \times n_0 \times 2^{\ell }\).
For the restriction operator \(R_\ell ^{\ell -1}: \mathcal {G}_\ell \to \mathcal {G}_{\ell -1}\), following [27], we can use the second-order full-weighting operator defined by
for n = 0, …, N T, i = 1, …, 2ℓ−1 n 0.
As for the prolongation operator \(P_\ell ^{\ell +1}: \mathcal {G}_\ell \to \mathcal {G}_{\ell +1}\), one can take the standard linear interpolation which is second order accurate. An important aspect in the analysis of multigrid methods is that the sum of the accuracy orders of the two intergrid transfer operators should be not smaller than the order of the partial differential operator. Here, both are 4. In this case, multigrid theory states that convergence holds even with a single smoothing step, i.e. it suffices to take η 1, η 2 such that η 1 + η 2 = 1.
4.4.3 Numerical Illustration
In this paragraph, we borrow a numerical example from [15]. We assume that d = 2 and that given q > 1, with conjugate exponent denoted by q′ = q∕(q − 1), the Hamiltonian \(H_0: \mathbb {T}^2 \times \mathbb {R}^2 \to \mathbb {R}\) has the form
In this case the function L defined in (4.14) takes the form
Furthermore, recalling the notation (4.12)–(4.13), we consider ϕ ≡ 0 and
for all \(x = (x_1, x_2) \in \mathbb {T}^2\) and \(m \in \mathbb {R}_+\). This means that in the underlying differential game, a typical agent aims to get closer to the maxima of \(\bar {H}\) and, at the same time, she is adverse to crowded regions (because of the presence of the m 2 term in f).
Figure 4.2 shows the evolution of the mass at four different time steps. Starting from a constant initial density, the mass converges to a steady state, and then, when t gets close to the final time T, the mass is influenced by the final cost and converges to a final state. This behavior is referred to as turnpike phenomenon in the literature on optimal control [29]. Theoretical results on the long time behavior of MFGs can be found in [30, 31]. It is illustrated by Fig. 4.3, which displays as a function of time t the distance of the mass at time t to the stationary state computed as in [17]. In other words, denoting by \(M^\infty \in \mathbb {R}^{N_h\times N_h}\) the solution to the discrete stationary problem and by \(M \in \mathcal {M}\) the solution to the discrete evolutive problem, Fig. 4.3 displays the graph of \(n \mapsto \|M^\infty - M^n\|{ }_{\ell _2} = \left (h^2 \sum _{i,j} (M^\infty _{i,j} - M^n_{i,j})^2 \right )^{1/2}\), n ∈{0, …, N T}.

Evolution of the density m obtained with the multi-grid preconditioner for ν = 0.5, T = 1, N T = 200 and N h = 128. At t = 0.12 the solution is close to the solution of the associated stationary MFG. (a) t = 0. (b) t = 0.1. (c) t = 0.5. (d) t = 1

Distance to the stationary solution at each time t ∈ [0, T], for ν = 0.5, T = 2, N T = 200 and N h = 128. The distance is computed using the ℓ 2 norm as explained in the text. The turnpike phenomenon is observed as for a long time frame the time-dependent mass approaches the solution of the stationary MFG
For the multigrid preconditioner, Table 4.2 shows the computation times for different discretizations (i.e. different values of N h and N T in the coarsest grid). It has been observed in [15, 17] that finer meshes with 1283 degrees of freedom are solvable within CPU times which outperfom several other methods such as Conjugate Gradient or BiCGStab unpreconditioned or preconditioned with modified incomplete Cholesky factorization. Furthermore, the method is robust with respect to different viscosities.
From Table 4.2 we observe that most of the computational time is used for solving (4.36), which does not use a multigrid strategy but which is a pointwise operator (see [17, Proposition 3.1]) and thus could be fully parallelizable.
Table 4.3 shows that the method is robust with respect to the viscosity since the average number of iterations of BiCGStab does not increase much as the viscosity decreases. For instance, as shown in Table 4.3b for a grid of size 128 × 128 × 128, the average number of iterations increases from 3.38 to 4.67 when ν is decreased from 0.6 to 0.046. On the other hand, Table 4.2 shows that the average number of Chambolle-Pock iterations depends on the viscosity parameter, but this is not related to the use of the multigrid preconditioner.
4.5 Algorithms for Solving the System of Non-Linear Equations
4.5.1 Combining Continuation Methods with Newton Iterations
Following previous works of the first author, see e.g. [16], one may use a continuation method (for example with respect to the viscosity parameter ν) in which every system of nonlinear equations (given the parameter of the continuation method) is solved by means of Newton iterations. With Newton algorithm, it is important to have a good initial guess of the solution; for that, it is possible to take advantage of the continuation method by choosing the initial guess as the solution obtained with the previous value of the parameter. Alternatively, the initial guess can be obtained from the simulation of the same problem on a coarser grid, using interpolation. It is also important to implement the Newton algorithm on a “well conditioned” system. Consider for example the system (4.4)–(4.6): in this case, it proves more convenient to introduce auxiliary unknowns, namely \(\Bigl ((f_i^n,)_{i,n}, (\Phi )_i\Bigr )\), and see (4.4)–(4.6) as a fixed point problem for the map \(\Xi : \Bigl ((f_i^n,)_{i,n}, (\Phi )_i\Bigr )\mapsto \Bigl ((g_i^n,)_{i,n}, (\Psi )_i\Bigr ) \) defined as follows: one solves first the discrete Bellman equation with data \(\Bigl ((f_i^n,)_{i,n}, (\Phi )_i\Bigr )\):
then the discrete Fokker–Planck equation
and finally sets
The Newton iterations are applied to the fixed point problem \((I_d- \Xi ) \Bigl ((f_i^n,)_{i,n}, (\Phi )_i\Bigr )=0\). Solving the discrete Fokker–Planck guarantees that at each Newton iteration, the grid functions M n are non negative and have the same mass, which is not be the case if the Newton iterations are applied directly to (4.4)–(4.6). Note also that Newton iterations consist of solving systems of linear equations involving the Jacobian of Ξ: for that, we use a nested iterative method (BiCGStab for example), which only requires a function that returns the matrix-vector product by the Jacobian, and not the construction of the Jacobian, which is a huge and dense matrix.
The strategy consisting in combining the continuation method with Newton iterations has the advantage to be very general: it requires neither a variational structure nor monotonicity: it has been successfully applied in many simulations, for example for MFGs including congestion models, MFGs with two populations, see paragraph Sect. 4.6 or MFGs in which the coupling is through the control. It is generally much faster than the methods presented in paragraph Sect. 4.3, when the latter can be used.
On the other hand, to the best of our knowledge, there is no general proof of convergence. Having these methods work efficiently is part of the know-how of the numerical analyst.
Since the strategy has been described in several articles of the first author, and since it is discussed thoroughly in the paragraph Sect. 4.6 devoted to pedestrian flows, we shall not give any further detail here.
4.5.2 A Recursive Algorithm Based on Elementary Solvers on Small Time Intervals
In this paragraph, we consider a recursive method introduced by Chassagneux, Crisan and Delarue in [32] and further studied in [33]. It is based on the following idea. When the time horizon is small enough, mild assumptions allow one to apply Banach fixed point theorem and give a constructive proof of existence and uniqueness for system (4.3). The unique solution can be obtained by Picard iterations, i.e., by updating iteratively the flow of distributions and the value function. Then, when the time horizon T is large, one can partition the time interval into intervals of duration τ, with τ small enough. Let us consider the two adjacent intervals [0, T − τ] and [T − τ, T]. The solutions in \([0,T-\tau ]\times \mathbb {T}^d\) and in \([T-\tau , T]\times \mathbb {T}^d\) are coupled through their initial or terminal conditions: for the former interval [0, T − τ], the initial condition for the distribution of states is given, but the terminal condition on the value function will come from the solution in [T − τ, T]. The principle of the global solver is to use the elementary solver on [T − τ, T] (because τ is small enough) and recursive calls of the global solver on [0, T − τ], (which will in turn call the elementary solver on [T − 2τ, T − τ] and recursively the global solver on [0, T − 2τ], and so on so forth).
We present a version of this algorithm based on PDEs (the original version in [32] is based on forward-backward stochastic differential equations (FBSDEs for short) but the principle is the same). Recall that T > 0 is the time horizon, m 0 is the initial density, ϕ is the terminal condition, and that we want to solve system (4.3).
Let K be a positive integer such that τ = T∕K is small enough. Let
be an elementary solver which, given τ, an initial probability density \(\tilde m\) defined on \(\mathbb {T}^d\) and a terminal condition \(\tilde \phi : \mathbb {T}^d \to \mathbb {R}\), returns the solution (u(t), m(t))t ∈ [0,τ] to the MFG system of forward-backward PDEs corresponding to these data, i.e.,
The solver ESolver may for instance consist of Picard or Newton iterations.
We then define the following recursive function, which takes as inputs the level of recursion k, the maximum recursion depth K, and an initial distribution \(\tilde m: \mathbb {T}^d \to \mathbb {R}\), and returns an approximate solution of the system of PDEs in \([kT/K, T]\times \mathbb {T}^d\) with initial condition \(m(t,x)=\tilde m (x)\) and terminal condition u(T, x) = ϕ(m(T, x), x). Calling RSolver(0, K, m 0) then returns an approximate solution (u(t), m(t))t ∈ [0,T] to system (4.3) in \([0,T]\times \mathbb {T}^d\), as desired.
To compute the approximate solution on \([kT/K, T]\times \mathbb {T}^d\), the following is repeated J times, say from j = 0 to J − 1, after some initialization step (see Algorithm 4 for a pseudo code):
-
1.
Compute the approximate solution on \([(k+1)T/K, T]\times \mathbb {T}^d\) by a recursive call of the algorithm, given the current approximation of m((k + 1)T∕K, ⋅) (it will come from the next point if j > 0).
-
2.
Call the elementary solver on \([kT/K,(k+1)T/K]\times \mathbb {T}^d\) given u((k + 1)T∕K, ⋅) coming from the previous point.
Algorithm 4 Recursive Solver for the system of forward-backward PDEs

In [32], Chassagneux et al. introduced a version based on FBSDEs and proved, under suitable regularity assumptions on the decoupling field, the convergence of the algorithm, with a complexity that is exponential in K. The method has been further tested in [33] with implementations relying on trees and grids to discretize the evolution of the state process.
4.6 An Application to Pedestrian Flows
4.6.1 An Example with Two Populations, Congestion Effects and Various Boundary Conditions
The numerical simulations discussed in this paragraphs somehow stand at the state of the art because they combine the following difficulties:
-
The MFG models includes congestion effects. Hence the Hamiltonian does not depend separately on Du and m. In such cases, the MFG can never be interpreted as an optimal control problem driven by a PDE; in other words, there is no variational interpretation, which makes it impossible to apply the methods discussed in Sect. 4.3.
-
There are two populations of agents which interact with each other, which adds a further layer of complexity. The now well known arguments due to Lasry and Lions and leading to uniqueness do not apply
-
The model will include different kinds of boundary conditions corresponding to walls, entrances and exits, which need careful discretizations.
-
We are going to look for stationary equilibria, despite the fact that there is no underlying ergodicity: there should be a balance between exit and entry fluxes. A special numerical algorithm is necessary in order to capture such situations
We consider a two-population mean field game in a complex geometry. It models situations in which two crowds of pedestrians have to share a confined area. In this case, the state space is a domain of \(\mathbb {R}^2\). The agents belonging to a given population are all identical, and differ from the agents belonging to the other population because they have for instance different objectives, and also because they feel uncomfortable in the regions where their own population is in minority (xenophobia). In the present example, there are several exit doors and the agents aim at reaching some of these doors, depending on which population they belong to. To reach their targets, the agents may have to cross regions in which their own population is in minority. More precisely, the running cost of each individual is made of different terms:
-
a first term only depends of the state variable: it models the fact that a given agent more or less wishes to reach one or several exit doors. There is an exit cost or reward at each doors, which depends on which population the agents belong to. This translates the fact that the agents belonging to different populations have different objectives
-
the second term is a cost of motion. In order to model congestion effects, it depends on the velocity and on the distributions of states for both populations
-
the third term models xenophobia and aversion to highly crowded regions.
4.6.1.1 The System of Partial Differential Equations
Labelling the two populations with the indexes 0 and 1, the model leads to a system of four forward-backward partial differential equations as follows:
In the numerical simulations discussed below, we have chosen
and
where 𝜖 is a small parameter and j = 1 − i. Note that we may replace (4.43) by a smooth function obtained by a regularization involving another small parameter 𝜖 2.
-
The choice of H i aims at modelling the fact that motion gets costly in the highly populated regions of the state space. The different factors in front of m i and m j in (4.42) aim at modelling the fact that the cost of motion of an agent of a given type, say i, is more sensitive to the density of agents of the different type, say j; indeed, since the agents of different types have different objectives, their optimal controls are unlikely to be aligned, which makes motion even more difficult.
-
The coupling cost in (4.43) is made of three terms: the first term, namely 0.5, is the instantaneous cost for staying in the domain; the term \(0.5 \left ( \frac {m_i}{ m_i+m_j+\epsilon } -0.5 \right )_- \) translates the fact that an agent in population i feels uncomfortable if its population is locally in minority. The last term, namely (m i + m j − 4)+, models aversion to highly crowded regions.
4.6.1.2 The Domain and the Boundary Conditions
The domain Ω is displayed in Fig. 4.4. The solid lines stand for walls, i.e. parts of the boundaries that cannot be crossed by the agents. The colored arrows indicate entries or exits depending if they are pointing inward or outward. The two different colors correspond to the two different populations, green for population 0 and orange for population 1. The length of the northern wall is 5, and the north-south diameter is 2.5. The width of the southern exit is 1. The widths of the other exits and entrances are 0.33. The width of the outward arrows stands for the reward for exiting.

The domain Ω. The colored arrows indicate entries or exits depending if they are pointing inward or outward. The two different colors correspond to the two different populations. The width of the outward arrows stands for the reward for exiting
-
The boundary conditions at walls are as follows:
$$\displaystyle \begin{aligned} \frac{\partial u_i}{\partial n}(x)= 0, \quad \mbox{and }\quad \frac{\partial m_i}{\partial n}(x)= 0. \end{aligned} $$(4.44)The first condition in (4.44) comes from the fact that the stochastic process describing the state of a given agent in population i is reflected on walls. The second condition in (4.44) is in fact \(-\nu \frac {\partial m_i}{\partial n} - m_i\; n\cdot \frac {\partial H_i} {\partial p} (\nabla u_i; m_i,m_j) = 0\), where we have taken into account the Neumann condition on u i.
-
At an exit door for population i, the boundary conditions are as follow
$$\displaystyle \begin{aligned} u_i =\mbox{ exit cost},\quad \mbox{and }\quad m_i=0. \end{aligned} $$(4.45)A negative exit cost means that the agents are rewarded for exiting the domain through this door. The homogeneous Dirichlet condition on m i in (4.45) can be explained by saying that the agents stop taking part to the game as soon as they reach the exit.
-
At an entrance for population i, the boundary conditions are as follows:
$$\displaystyle \begin{aligned} u_i =\mbox{ exit cost},\quad \mbox{ and }\quad \nu \frac{\partial m_i}{\partial n} + m_i\;n\cdot \frac {\partial H_i} {\partial p} (\nabla u_i; m_i,m_j) =\mbox{ entry flux}. \end{aligned} $$(4.46)Setting a high exit cost prevents the agents from exiting though the entrance doors.
In our simulations, the exit costs of population 0 are as follows:
-
1.
North-West entrance : 0
-
2.
South-West exit : − 8.5
-
3.
North-East exit : − 4
-
4.
South-East exit : 0
-
5.
South exit : − 7
and the exit costs of population 1 are
-
1.
North-West exit : 0
-
2.
South-West exit : − 7
-
3.
North-East exit : − 4
-
4.
South-East entrance : 0
-
5.
South exit: − 4.
The entry fluxes are as follows:
-
1.
Population 0: at the North-West entrance, the entry flux is 1
-
2.
Population 1: at the South-East entrance, the entry flux is 1.
For equilibria in finite horizon T, the system should be supplemented with an initial Dirichlet condition for m 0, m 1 since the laws of the initial distributions are known, and a terminal Dirichlet-like condition for u 0, u 1 accounting for the terminal costs.
4.6.2 Stationary Equilibria
We look for a stationary equilibrium. For that, we solve numerically (4.38)–(4.41) with a finite horizon T, and with the boundary conditions described in paragraph Sect. 4.6.1.2, see paragraph Sect. 4.6.5 below and use an iterative method in order to progressively diminish the effects of the initial and terminal conditions: starting from \((u_i^0, m_i^0)_{i=0,1}\), the numerical solution of the finite horizon problem described above, we construct a sequence of approximate solutions \((u_i^\ell , m_i^\ell )_{\ell \ge 1}\) by the following induction: \((u_i^{\ell +1}, m_i^{\ell +1})\) is the solution of the finite horizon problem with the same system of PDEs in (0, T) × Ω, the same boundary conditions on (0, T) × ∂ Ω, and the new initial and terminal conditions as follows:
As ℓ tends to + ∞, we observe that \((u_i^\ell , m_i^\ell )\) converge to time-independent functions. At the limit, we obtain a steady solution of
with the boundary conditions on ∂ Ω described in paragraph Sect. 4.6.1.2.
4.6.3 A Stationary Equilibrium with ν = 0.30
We first take a relatively large viscosity coefficient namely ν = 0.30. In Fig. 4.5, we display the distributions of states for the two populations, see Fig. 4.5a, the value functions for both populations, see Fig. 4.5b, and the optimal feedback controls of population 0 (respectively 1) in Fig. 4.5c (respectively Fig. 4.5d). We see that population 0 enters the domain via the north-west entrance, and most probably exits by the south-west exit door. Population 1 enters the domain via the south-east entrance, and exits by two doors, the south-west and the southern ones. The effect of viscosity is large enough to prevent complete segregation of the two populations.

Numerical Solution to Stationary Equilibrium with ν ∼ 0.3. (a) Distributions of the two populations. (b) Value functions of the two populations. (c) Optimal feedback for population 0. (d) Optimal feedback for population 1
4.6.4 A Stationary Equilibrium with ν = 0.16
We decrease the viscosity coefficient to the value ν = 0.16. We are going to see that the solution is quite different from the one obtained for ν = 0.3, because the populations now occupy separate regions. In Fig. 4.6, we display the distributions of states for the two populations, see Fig. 4.6a, the value functions for both populations, see Fig. 4.6b, and the optimal feedback controls of population 0 (respectively 1) in Fig. 4.6c (respectively Fig. 4.6d). We see that population 0 enters the domain via the north-west entrance, and most probably exits by the south-west exit door. Population 1 enters the domain via the south-east entrance, and most probably exits the domain by the southern door. The populations occupy almost separate regions. We have made simulations with smaller viscosities, up to ν = 10−3, and we have observed that the results are qualitatively similar to the ones displayed on Fig. 4.6, i.e. the distribution of the populations overlap less and less and the optimal strategies are similar. As ν is decreased, the gradients of the distributions of states increase in the transition regions between the two populations.

Numerical Solution to Stationary Equilibrium with ν ∼ 0.16. (a) Distributions of the two populations. (b) Value functions of the two populations. (c) Optimal feedback for population 0. (d) Optimal feedback for population 1
4.6.5 Algorithm for Solving the System of Nonlinear Equations
We briefly describe the iterative method used in order to solve the system of nonlinear equations arising from the discretization of the finite horizon problem. Since the latter system couples forward and backward (nonlinear) equations, it cannot be solved by merely marching in time. Assuming that the discrete Hamiltonians are C 2 and the coupling functions are C 1 (this is true after a regularization procedure involving a small regularization parameter) allows us to use a Newton–Raphson method for the whole system of nonlinear equations (which can be huge if d ≥ 2).
Disregarding the boundary conditions for simplicity, the discrete version of the MFG system reads
for k = 0, 1. The system above is satisfied for internal points of the grid, i.e. 2 ≤ i, j ≤ N h − 1, and is supplemented with suitable boundary conditions. The ingredients in (4.53)–(4.56) are as follows:
and the Godunov discrete Hamiltonian is
The transport operator in the discrete Fokker–Planck equation is given by
We define the map Θ :
by solving first the discrete HJB equation (4.53) (supplemented with boundary conditions) then the discrete Fokker–Planck equation (4.54) (supplemented with boundary conditions). We then summarize (4.55) and (4.56) by writing
Here n takes its values in {1…, N} and i, j take their values in {1…, N h}. We then see the full system (4.53)–(4.56) (supplemented with boundary conditions) as a fixed point problem for the map Ξ = Ψ ∘ Θ.
Note that in (4.53) the two discrete Bellman equations are decoupled and do not involve M k, n+1. Therefore, one can first obtain U k, n 0 ≤ n ≤ N, k = 0, 1 by marching backward in time (i.e. performing a backward loop with respect to the index n). For every time index n, the two systems of nonlinear equations for U k, n, k = 0, 1 are themselves solved by means of a nested Newton–Raphson method. Once an approximate solution of (4.53) has been found, one can solve the (linear) Fokker–Planck equations (4.54) for M k, n 0 ≤ n ≤ N, k = 0, 1, by marching forward in time (i.e. performing a forward loop with respect to the index n). The solutions of (4.53)–(4.54) are such that M k, n are nonnegative.
The fixed point equation for Ξ is solved numerically by using a Newton–Raphson method. This requires the differentiation of both the Bellman and Kolmogorov equations in (4.53)–(4.54), which may be done either analytically (as in the present simulations) or via automatic differentiation of computer codes (to the best of our knowledge, no computer code for MFGs based on automatic differentiation is available yet, but developing such codes seems doable and interesting).
A good choice of an initial guess is important, as always for Newton methods. To address this matter, we first observe that the above mentioned iterative method generally quickly converges to a solution when the value of ν is large. This leads us to use a continuation method in the variable ν: we start solving (4.53)–(4.56) with a rather high value of the parameter ν (of the order of 1), then gradually decrease ν down to the desired value, the solution found for a value of ν being used as an initial guess for the iterative solution with the next and smaller value of ν.
4.7 Mean Field Type Control
As mentioned in the introduction, the theory of mean field games allows one to study Nash equilibria in games with a number of players tending to infinity. In such models, the players are selfish and try to minimize their own individual cost. Another kind of asymptotic regime is obtained by assuming that all the agents use the same distributed feedback strategy and by passing to the limit as N →∞ before optimizing the common feedback. For a fixed common feedback strategy, the asymptotic behavior is given by the McKean-Vlasov theory, [34, 35]: the dynamics of a representative agent is found by solving a stochastic differential equation with coefficients depending on a mean field, namely the statistical distribution of the states, which may also affect the objective function. Since the feedback strategy is common to all agents, perturbations of the latter affect the mean field (whereas in a mean field game, the other players’ strategies are fixed when a given player optimizes). Then, having each agent optimize her objective function amounts to solving a control problem driven by the McKean-Vlasov dynamics. The latter is named control of McKean-Vlasov dynamics by R. Carmona and F. Delarue [36,37,38] and mean field type control by A. Bensoussan et al. [39, 40]. Besides the aforementioned interpretation as a social optima in collaborative games with a number of agents growing to infinity, mean field type control problems have also found applications in finance and risk management for problems in which the distribution of states is naturally involved in the dynamics or the cost function. Mean field type control problems lead to a system of forward-backward PDEs which has some features similar to the MFG system, but which can always be seen as the optimality conditions of a minimization problem. These problems can be tackled using the methods presented in this survey, see e.g. [23, 41]. For the sake of comparison with mean field games, we provide in this section an example of crowd motion (with a single population) taking into account congestion effects. The material of this section is taken from [42].
4.7.1 Definition of the Problem
Before focusing a specific example, let us present the generic form of a mean field type control problem. To be consistent with the notation used in the MFG setting, we consider the same form of dynamics and the same running and terminal costs functions f and ϕ. However, we focus on a different notion of solution: Instead of looking for a fixed point, we look for a minimizer when the control directly influences the evolution of the population distribution. More precisely, the goal is to find a feedback control \(v^*: Q_T\to \mathbb {R}^d\) minimizing the following functional:
under the constraint that the process \(X^v = (X_t^v)_{t \ge 0}\) solves the stochastic differential equation (SDE)
and \(X_0^v\) has distribution with density m 0. Here \(m^v_t\) is the probability density of the law of \(X_t^v\), so the dynamics of the stochastic process is of McKean-Vlasov type.
For a given feedback control v, \(m^v_t\) solves the same Kolmogorov–Fokker–Planck (KFP) equation (4.2) as in the MFG, but the key difference between the two problems lies in the optimality condition. For the mean field type control problem, one cannot rely on standard optimal control theory because the distribution of the controlled process is involved in a potentially non-linear way.
In [40], A. Bensoussan, J. Frehse and P. Yam have proved that a necessary condition for the existence of a smooth feedback function v ∗ achieving \(J( v^*)= \min J(v)\) is that
where (m, u) solve the following system of partial differential equations
Here, \(\frac {\partial }{\partial m}\) denotes a derivative with respect to the argument m, which is a real number because the dependence on the distribution is purely local in the setting considered here. When the Hamiltonian depends on the distribution m in a non-local way, one needs to use a suitable notion of derivative with respect to a probability density or a probability measure, see e.g. [4, 38, 40] for detailed explanations.
4.7.2 Numerical Simulations
Here we model a situation in which a crowd of pedestrians is driven to leave a given square hall (whose side is 50 m long) containing rectangular obstacles: one can imagine for example a situation of panic in a closed building, in which the population tries to reach the exit doors. The chosen geometry is represented on Fig. 4.7.

Left: the geometry (obstacles are in red). Right: the density at t = 0
The aim is to compare the evolution of the density in two models:
-
1.
Mean field games: we choose ν = 0.05 and the Hamiltonian takes congestion effects into account and depends locally on m; more precisely:
$$\displaystyle \begin{aligned} H(x, m, p)= -\frac {8 |p|{}^2} {(1+m)^{\frac 3 4}} + \frac 1 {3200} \,. \end{aligned}$$The MFG system of PDEs (4.3) becomes

The horizon T is T = 50 min. There is no terminal cost, i.e. ϕ ≡ 0.
There are two exit doors, see Fig. 4.7. The part of the boundary corresponding to the doors is called ΓD. The boundary conditions at the exit doors are chosen as follows: there is a Dirichlet condition for u on ΓD, corresponding to an exit cost; in our simulations, we have chosen u = 0 on ΓD. For m, we may assume that m = 0 outside the domain, so we also get the Dirichlet condition m = 0 on ΓD.
The boundary ΓN corresponds to the solid walls of the hall and of the obstacles. A natural boundary condition for u on ΓN is a homogeneous Neumann boundary condition, i.e. \( \frac {\partial u}{\partial n}=0\) which says that the velocity of the pedestrians is tangential to the walls. The natural condition for the density m is that \(\nu \frac {\partial m}{\partial n}+m \frac {\partial \tilde H} {\partial p} (\cdot , m, \nabla u )\cdot n=0\), therefore \( \frac {\partial m}{\partial n}=0\) on ΓN.
-
2.
Mean field type control: this is the situation where pedestrians or robots use the same feedback law (we may imagine that they follow the strategy decided by a leader); we keep the same Hamiltonian, and the HJB equation becomes
$$\displaystyle \begin{aligned} \frac {\partial u}{\partial t} + 0.05 \; \Delta u - \left( \frac {2} {(1+m)^{\frac 3 4}} + \frac {6} {(1+m)^{\frac 7 4}}\right) \; |\nabla u|{}^2= - \frac 1 {3200}. \end{aligned} $$(4.60)while (4.59a) and the boundary conditions are unchanged.

The initial density m 0 is piecewise constant and takes two values 0 and 4 people/m2, see Fig. 4.7. At t = 0, there are 3300 people in the hall.
We use the method described in Sect. 4.5.1, i.e., Newton iterations with the finite difference scheme originally proposed in [9], see [16] for some details on the implementation.
On Fig. 4.8, we plot the density m obtained by the simulations for the two models, at t = 1, 2, 5, and 15 min. With both models, we see that the pedestrians rush towards the narrow corridors leading to the exits, at the left and right sides of the hall, and that the density reaches high values at the intersections of corridors; then congestion effects explain why the velocity is low (the gradient of u) in the regions where the density is high, see Fig. 4.9. We see on Fig. 4.8 that the mean field type control leads to lower peaks of density, and on Fig. 4.10 that it leads to a faster exit of the room. We can hence infer that the mean field type control performs better than the mean field game, leading to a positive price of anarchy.

The density computed with the two models at different dates, t = 1, 5 and 15 min. (from top to bottom). Left: Mean field game. Right: Mean field type control

The velocity (v(t, x) = −16∇u(t, x)(1 + m(t, x))−3∕4) computed with the two models at different dates, t = 1, 2, 5 and t = 15 min. (from top-left to bottom-right). Red: Mean field game. Blue: Mean field type control

Evolution of the total remaining number of people in the room for the mean field game (red line) and the mean field type control (dashed blue line)
4.8 MFGs in Macroeconomics
The material of this section is taken from a work of the first author with Jiequn Han, Jean-Michel Lasry, Pierre-Louis Lions, and Benjamin Moll, see [43], see also [44]. In economics, the ideas underlying MFGs have been investigated in the so-called heterogeneous agents models, see for example [45,46,47,48], for a long time before the mathematical formalization of Lasry and Lions. The latter models mostly involve discrete in time optimal control problems, because the economists who proposed them felt more comfortable with the related mathematics. The connection between heterogeneous agents models and MFGs is discussed in [44].
We will first describe the simple yet prototypical Huggett model, see [45, 46], in which the constraints on the state variable play a key role. We will then discuss the finite difference scheme for the related system of differential equations, putting the stress on the boundary conditions. Finally, we will present numerical simulations of the richer Aiyagari model, see [47].
Concerning HJB equations, state constraints and related numerical schemes have been much studied in the literature since the pioneering works of Soner and Capuzzo Dolcetta-Lions, see [49,50,51]. On the contrary, the boundary conditions for the related invariant measure had not been addressed before [43, 44]. The recent references [52, 53] contain a rigorous study of MFGs with state constraints in a different setting from the economic models considered below.
4.8.1 A Prototypical Model with Heterogeneous Agents: The Huggett Model
4.8.1.1 The Optimal Control Problem Solved by an Agent
We consider households which are heterogeneous in wealth x and income y. The dynamics of the wealth of a household is given by
where r is an interest rate and c t is the consumption (the control variable). The income y t is a two-state Poisson process with intensities λ 1 and λ 2, i.e. y t ∈{y 1, y 2} with y 1 < y 2, and
Recall that a negative wealth means debts; there is a borrowing constraint: the wealth of a given household cannot be less than a given borrowing limit \( \underline {x}\). In the terminology of control theory, \( x_t\ge \underline {x}\) is a constraint on the state variable.
A household solves the optimal control problem
where
-
ρ is a positive discount factor
-
u is a utility function, strictly increasing and strictly concave, e.g. the CRRA (constant relative risk aversion) utility:
$$\displaystyle \begin{aligned} u(c)=c^{1-\gamma}/(1-\gamma),\qquad \gamma>0.\end{aligned}$$
For i = 1, 2, let v i(x) be the value of the optimal control problem solved by an agent when her wealth is x and her income y i. The value functions (v 1(x), v 2(x)) satisfy the system of differential equations:
where the Hamiltonian H is given by
The system of differential equations (4.61)–(4.62) must be supplemented with boundary conditions connected to the state constraints \(x\ge \underline {x}\). Viscosity solutions of Hamilton–Jacobi equations with such boundary conditions have been studied in [49,50,51]. It is convenient to introduce the non-decreasing and non-increasing envelopes H ↑ and H ↓ of H:
It can be seen that
The boundary conditions associated to the state constraint can be written
Consider for example the prototypical case when \(u(c)=\frac 1 {1-\gamma } c^{1-\gamma }\) with γ > 0. Then
In Fig. 4.11, we plot the graphs of the functions p↦H(x, y, p), p↦H ↑(x, y, p) and p↦H ↓(x, y, p) for γ = 2.

The bold line is the graph of the function p↦H(x, y, p). The dashed and bold blue lines form the graph of p↦H ↓(x, y, p). The dashed and bold red lines form the graph of p↦H ↑(x, y, p)
4.8.1.2 The Ergodic Measure and the Coupling Condition
In Huggett model, the interest rate r is an unknown which is found from the fact that the considered economy neither creates nor destroys wealth: the aggregate wealth ! can be fixed to 0.
On the other hand, the latter quantity can be deduced from the ergodic measure of the process, i.e. m 1 and m 2, the wealth distributions of households with respective income y 1 and y 2, defined by
The measures m 1 and m 2 are defined on \([ \underline {x},+\infty )\) and obviously satisfy the following property:
Prescribing the aggregate wealth amounts to writing that
In fact (4.66) plays the role of the coupling condition in MFGs. We will discuss this point after having characterized the measures m 1 and m 2: it is well known that they satisfy the Fokker–Planck equations
in the sense of distributions in \(( \underline {x},+\infty )\).
Note that even if m 1 and m 2 are regular in the open interval \(( \underline {x},+\infty )\), it may happen that the optimal strategy of a representative agent (with income y 1 or y 2) consists of reaching the borrowing limit \(x= \underline {x}\) in finite time and staying there; in such a case, the ergodic measure has a singular part supported on \(\{x= \underline {x}\}\), and its absolutely continuous part (with respect to Lebesgue measure) may blow up near the boundary.
For this reason, we decompose m i as the sum of a measure absolutely continuous with respect to Lebesgue measure on \(( \underline x,+\infty )\) with density g i and possibly of a Dirac mass at \(x= \underline x\): for each Borel set \(A\subset [ \underline {x},+\infty )\),
Here, g i is a measurable and nonnegative function.
Assuming that ∂ x v i(x) have limits when \(x\to \underline {x}_+\) (this can be justified rigorously for suitable choices of u), we see by definition of the ergodic measure, that for all test-functions \((\phi _1,\phi _2)\in \left (C^1_c([ \underline x, +\infty ))\right )^2\),
It is also possible to use ϕ 1 = 1 and ϕ 2 = 0 as test-functions in the equation above. This yields
Hence
4.8.1.3 Summary
To summarize, finding an equilibrium in the Huggett model given that the aggregate wealth is 0 consists in looking for (r, v 1, v 2, m 1, m 2) such that
-
the functions v 1 and v 2 are viscosity solutions to (4.61), (4.62), (4.63), and (4.64)
-
the measures m 1 and m 2 satisfy (4.68), \(m_i=g_i L+\mu _i \delta _{x= \underline x}\), where L is the Lebesgue measure on \(( \underline {x}, +\infty )\), g i is a measurable nonnegative function \(( \underline {x}, +\infty )\) and for all i = 1, 2, for all test function ϕ:
$$\displaystyle \begin{aligned} \left. \begin{array}[c]{r} \displaystyle \displaystyle \int_{x> \underline x} \left( \lambda_j g_j(x)-\lambda_i g_i(x) \right) \phi(x) dx + \int_{x> \underline x} H_p(x ,y_i,\partial_x v_i(x)) \partial_x \phi(x) dx \\ + \displaystyle \mu_i\Bigl( -\lambda_i \phi(\underline{x}) + H_p^\uparrow (\underline{x}, y_i , \partial_x v_i(\underline{x}_+)) \partial_x \phi (\underline{x}) \Bigr) +\mu_j \lambda_j \phi(\underline{x}) \end{array} \right\}=0, \end{aligned} $$(4.69)where j = 2 if i = 1 and j = 1 if i = 2.
-
the aggregate wealth is fixed, i.e. (4.66). By contrast with the previously considered MFG models, the coupling in the Bellman equation does not come from a coupling cost, but from the implicit relation (4.66) which can be seen as an equation for r. Since the latter coupling is only through the constant value r, it can be said to be weak.
4.8.1.4 Theoretical Results
The following theorem, proved in [43], gives quite accurate information on the equilibria for which r < ρ:
Theorem 5
Let \(c_i^*(x)\) be the optimal consumption of an agent with income y i and wealth x.
-
1.
If r < ρ, then the optimal drift (whose economical interpretation is the optimal saving policy) corresponding to income y 1 , namely \(rx+y_1-c_1^*(x)\) , is negative for all \(x> \underline {x}\).
-
2.
If r < ρ and \(-\frac {u''(y_1+r \underline x)}{u'(y_1+r \underline x)}<+\infty \) , then there exists a positive number ν 1 (that can be written explicitly) such that for x close to \( \underline {x}\),
$$\displaystyle \begin{aligned} \begin{array}{rcl} rx+y_1-c_1^*(x) \sim -\sqrt{2\nu_1} \sqrt{x-\underline x}<0, \end{array} \end{aligned} $$so the agents for which the income stays at the lower value y 1 hit the borrowing limit in finite time, and
$$\displaystyle \begin{aligned} \mu_1>0, \qquad g_1(x)\sim \frac {\gamma_1 }{\sqrt{x-\underline{x}}} , \end{aligned}$$for some positive value γ 1 (that can be written explicitly).
-
3.
If r < ρ and \(\sup _{c} \left (-\frac {cu''(c)}{u'(c)}\right )<+\infty \) , then there exists \( \underline x \le \overline {x}<+\infty \) such that
$$\displaystyle \begin{aligned} \begin{array}{rcl} rx+y_2-c_2^*(x)<0, &\displaystyle \quad &\displaystyle \mathit{\mbox{ for all }} x>\overline{x},\\ rx+y_2-c_2^*(x)>0, &\displaystyle \quad &\displaystyle \mathit{\mbox{ for all }} \underline x < x<\overline{x}. \end{array} \end{aligned} $$Moreover μ 2 = 0 and if \(\overline {x}> \underline {x}\) , then for some positive constant ζ 2, \(rx+y_2-c_2^*(x) \sim \zeta _2 (\overline {x}-x)\) for x close to \(\overline {x}\).
From Theorem 5, we see in particular that agents whose income remains at the lower value are drifted toward the borrowing limit and get stuck there, while agents whose income remains at the higher value get richer if their wealth is small enough. In other words, the only way for an agent in the low income state to avoid being drifted to the borrowing limit is to draw the high income state. Reference [43] also contains existence and uniqueness results.
4.8.2 A Finite Difference Method for the Huggett Model
4.8.2.1 The numerical scheme
We wish to simulate the Huggett model in the interval \([ \underline x, \tilde x]\). Consider a uniform grid on \([ \underline x, \tilde x]\) with step \(h= \frac {\tilde x- \underline x}{N_h} \): we set \(x_i= \underline x+ ih\), i = 0, …, N h. The discrete approximation of v j(x i) is named v i,j. The discrete version of the Hamiltonian H involves the function \(\mathcal {H}: \mathbb {R}^4\to \mathbb {R}\),
We do not discuss the boundary conditions at \(x=\tilde {x}\) in order to focus on the difficulties coming from the state constraint \(x_t\ge \underline x\). In fact, if \(\tilde x\) is large enough, state constraint boundary conditions can also be chosen at \(x=\tilde x\). The numerical monotone scheme for (4.61), (4.62), (4.63), and (4.64) is
where k = 2 if j = 1 and k = 1 if j = 2. In order to find the discrete version of the Fokker–Planck equation, we start by writing (4.70)–(4.71) in the following compact form:
with self-explanatory notations. The differential of \(\mathcal {F}\) at V maps W to the grid functions whose (i, j)-th components is:
-
if 0 < i < N h:
$$\displaystyle \begin{aligned} H_p^\uparrow \left( x_i,y_j,\frac { v_{i+1,j}-v_{i,j} } h \right)\frac { w_{i+1,j}-w_{i,j} } h + H_p^\downarrow \left( x_i,y_j,\frac { v_{i,j}-v_{i-1,j} } h \right)\frac { w_{i,j}-w_{i-1,j} } h +\lambda_i \left( w_{i,k}- w_{i,j} \right), \end{aligned} $$(4.73) -
If i = 0:
$$\displaystyle \begin{aligned} H_p^\uparrow \left( \underline x,y_j,\frac { v_{1,j}-v_{0,j} } h \right)\frac { w_{1,j}-w_{0,j} } h +\lambda_i \left( w_{0,k}- w_{0,j} \right). \end{aligned} $$(4.74)
We get the discrete Fokker–Planck equation by requiring that \( \langle D\mathcal {F}(V)W, M\rangle =0\) for all W, where \(M=(m_{i,j})_{0\le i\le N_h, j=1,2}\); more explicitly, we obtain:
for 0 < i < N h, and
Assuming for simplicity that in (4.67), (g j)j=1,2 are absolutely continuous with respect to the Lebesgue measure, equations (4.75) and (4.76) provide a consistent discrete scheme for (4.69) if hm 0,j is seen as the discrete version of μ j and if m i,j is the discrete version of g j(x i). If we do not suppose that g j is absolutely continuous with respect to the Lebesgue measure, then m i,j may be seen as a discrete version of \(\frac 1 h \int _{x_i -h /2 } ^{x_i +h/2 } dg_j(x)\).
The consistency of (4.75) for i > 0 is obtained as usual. Let us focus on (4.76): assume that the following convergence holds:
Assume that \(H_p( \underline x, \partial _x v_j( \underline x))>\varepsilon \) for a fixed positive number ε > 0. Then for h small enough,
for i = 0, 1. Plugging this information in (4.76) yields that m 0,j is of the same order as hm 0,k, in agreement with the fact that since the optimal drift is positive, there is no Dirac mass at \(x= \underline x\). In the opposite case, we see that (4.76) is consistent with the asymptotic expansions found in Theorem 5.
4.8.2.2 Numerical Simulations
On Fig. 4.12, we plot the densities g 1 and g 2 and the cumulative distributions \(\int _{ \underline {x}}^{x} dm_1\) and \(\int _{ \underline {x}}^{x} dm_2\), computed by two methods: the first one is the finite difference descrived above. The second one consists of coupling the finite difference scheme described above for the HJB equation and a closed formula for the Fokker–Planck equation. Two different grids are used with N h = 500 and N h = 30. We see that for N h = 500, it is not possible to distinguish the graphs obtained by the two methods. The density g 1 blows up at \(x= \underline {x}\) while g 2 remains bounded. From the graphs of the cumulative distributions, we also see that μ 1 > 0 while μ 2 = 0.

Huggett model: Left: the measures g i obtained by an explicit formula and by the finite difference method for two grid resolutions with 500 nodes (Top) and 30 nodes (Bottom). Right: the cumulative distributions \( \int _{ \underline {x}}^{x} dm_i\). Top: (a) Densities. (b) Cumulative Distribution. Bottom: (a) Densities. (b) Cumulative Distribution
4.8.3 The Model of Aiyagari
There is a continuum of agents which are heterogeneous in wealth x and productivity y. The dynamics of the wealth of a household is given by
where r is the interest rate, w is the level of wages, and c t is the consumption (the control variable). The dynamics of the productivity y t is given by the stochastic differential equation in \(\mathbb {R}_+\):
where W t is a standard one dimensional Brownian motion. Note that this models situations in which the noises in the productivity of the agents are all independent (idiosyncratic noise). Common noise will be briefly discussed below.
As for the Huggett model, there is a borrowing constraint \(x_t\ge \underline {x}\), a household tries to maximize the utility \( \mathbb {E}\int _0^\infty e^{-\rho t} u(c_t)dt\). To determine the interest rate r and the level of wages w, Aiyagari considers that the production of the economy is given by the following Cobb-Douglas law:
for some α ∈ (0, 1), where, if m(⋅, ⋅) is the ergodic measure,
-
A is a productivity factor
-
\(X= \int _{x\ge \underline x} \int _{y\in \mathbb {R}_+} x dm (x,y) \) is the aggregate capital
-
\(Y= \int _{x\ge \underline x} \int _{y\in \mathbb {R}_+} y dm (x,y)\) is the aggregate labor.
The level of wages w and interest rate r are obtained by the equilibrium relation
where δ is the rate of depreciation of the capital. This implies that
Remark 12
Tackling a common noise is possible in the non-stationary version of the model, by letting the productivity factor become a random process A t (for example A t may be a piecewise constant process with random shocks): this leads to a more complex setting which is the continuous-time version of the famous Krusell-Smith model, see [48]. Numerical simulations of Krusell-Smith models have been carried out by the authors of [43], but, in order to keep the survey reasonnably short, we will not discuss this topic.
The Hamiltonian of the problem is \( H( x, y , p)=\max _c \Bigl ( u(c) + p ( w y + r x -c) \Bigr )\) and the mean field equilibrium is found by solving the system of partial differential equations:
in \(( \underline {x},+\infty )\times \mathbb {R}_+\) with suitable boundary conditions on the line \(\{x= \underline x\}\) linked to the state constraints, \( \int _{x\ge \underline x} \int _{y\in \mathbb {R}_+} dm(x,y)=1\), and the equilibrium condition
The boundary condition for the value function can be written
where p↦H ↑(x, y, p) is the non-decreasing envelope of p↦H(x, y, p).
We are going to look for m as the sum of a measure which is absolutely continuous with respect to the two dimensional Lebesgue measure on \(( \underline x,+\infty )\times \mathbb {R}_+\) with density g and of a measure η supported in the line \(\{x= \underline x\}\):
and for all test function ϕ:
Note that it is not possible to find a partial differential equation for η on the line \(x= \underline {x}\), nor a local boundary condition for g, because it is not possible to express the term \(\displaystyle \int _{y\in \mathbb {R}_+} H_p^\uparrow ( \underline {x} ,y,\partial _x v( \underline {x}_+,y)) \partial _x \phi ( \underline {x},y) d\eta ( \underline x,y)\) as a distribution acting on \(\phi ( \underline x,\cdot )\).
The finite difference scheme for (4.77), (4.80), (4.81), (4.82), and (4.79) is found exactly in the same spirit as for Huggett model and we omit the details. In Fig. 4.13, we display the optimal saving policy (x, y)↦wy + rx − c ∗(x, y) and the ergodic measure obtained by the above-mentioned finite difference scheme for Aiyagari model with u(c) = −c −1. We see that the ergodic measure m (right part of Fig. 4.13) has a singularity on the line \(x= \underline {x}\) for small values of the productivity y, and for the same values of y, the density of the absolutely continuous part of m with respect to the two-dimensional Lebesgue measure blows up when \(x\to \underline x\). The economic interpretation is that the agents with low productivity are drifted to the borrowing limit. The singular part of the ergodic measure is of the same nature as the Dirac mass that was obtained for y = y 1 in the Huggett model. It corresponds to the zone where the optimal drift is negative near the borrowing limit (see the left part of Fig. 4.13).

Numerical simulations of Aiyagari model with u(c) = −c −1. Left: the optimal drift (optimal saving policy) wy + rx − c ∗(x, y). Right: the part of the ergodic measure which is absolutely continuous with respect to Lebesgue measure
4.9 Conclusion
In this survey, we have put stress on finite difference schemes for the systems of forward-backward PDEs that may stem from the theory of mean field games, and have discussed in particular some variational aspects and numerical algorithms that may be used for solving the related systems of nonlinear equations. We have also addressed in details two applications of MFGs to crowd motion and macroeconomics, and a comparison of MFGs with mean field control: we hope that these examples show well on the one hand, that the theory of MFGs is quite relevant for modeling the behavior of a large number of rational agents, and on the other hand, that several difficulties must be addressed in order to tackle realistic problems.
To keep the survey short, we have not addressed the following interesting aspects:
-
Semi-Lagrangian schemes for the system of forward-backward PDEs. While semi-Lagrangian schemes for optimal control problems have been extensively studied, much less has been done regarding the Fokker–Planck equation. In the context of MFGs, semi-Lagrangian schemes have been investigated by F. Camilli and F. Silva, E. Carlini and F. Silva, see the references [54,55,56,57]. Arguably, the advantage of such methods is their direct connection to the underlying optimal control problems, and a possible drawback may be the difficulty to address realistic boundary conditions.
-
An efficient algorithm for ergodic MFGs has been proposed by in [58, 59]. The approach relies on a finite difference scheme and a least squares formulation, which is then solved using Gauss-Newton iterations.
-
D. Gomes and his coauthors have proposed gradient flow methods for solving deterministic mean field games in infinite horizon, see [60, 61], under a monotonicity assumption. Their main idea is that the solution to the system of PDEs can be recast as a zero of a monotone operator, an can thus be found by following the related gradient flow. They focus on the following example:

where the ergodic constant λ is an unknown. They consider the following monotone map :
$$\displaystyle \begin{aligned} A \begin{pmatrix} u \\ m \end{pmatrix} = \begin{pmatrix} -\mathrm{div}\left( m(\cdot) \partial_p H_0 (\cdot, m(\cdot), \nabla u(\cdot)) \right) \\ - H_0(\cdot, \nabla u) + \log(m) \end{pmatrix}. \end{aligned}$$Thanks to the special choice of the coupling cost \(\log (m)\), a gradient flow method applied to A, i.e.
$$\displaystyle \begin{aligned} \frac{d}{d \tau} \begin{pmatrix} u_\tau \\ m_\tau \end{pmatrix} = - A \begin{pmatrix} u_\tau \\ m_\tau \end{pmatrix} - \begin{pmatrix} 0 \\ \lambda_\tau \end{pmatrix} , \end{aligned}$$preserves the positivity of m (this may not be true with other coupling costs, in which case additional projections may be needed). The real number λ τ is used to enforce the constraint \(\int _{\mathbb {T}} m_\tau =1\).
This idea has been studied on the aforementioned example and some variants but needs to be tested in the stochastic case (i.e., second order MFGs) and with general boundary conditions. The generalization to finite horizon is not obvious.
-
Mean field games related to impulse control and optimal exit time have been studied by C. Bertucci, both from a theoretical and a numerical viewpoint, see [62]. In particular for MFGs related to impulse control problems, there remains a lot of difficult open issues.
-
High dimensional problems. Finite difference schemes can only be used if the dimension d of the state space is not too large, say d ≤ 4. Very recently, there have been attempts to use machine learning methods in order to solve problems in higher dimension or with common noise, see e.g. [63,64,65,66]. The main difference with the methods discussed in the present survey is that these methods do not rely on a finite-difference scheme but instead use neural networks to approximate functions with a relatively small number of parameters. Further studies remain necessary before it is possible to really evaluate these methods.
-
Numerical methods for the master equation when the state space is finite, see works in progress by the first author and co-workers.

To conclude, acknowledging the fact that the theory of mean field games have attracted a lot of interest in the past decade, the authors think that some of the most interesting open problems arise in the actual applications of this theory. Amongst the most fascinating aspects of mean field games are their interactions with social sciences and economics. A few examples of such interactions have been discussed in the present survey, and many more applications remain to be investigated.
References
J.M. Lasry, P.-L. Lions, Jeux à champ moyen. I. Le cas stationnaire. C. R. Math. Acad. Sci. Paris 343(9), 619–625 (2006)
J.-M. Lasry, P.-L. Lions, Jeux à champ moyen. II. Horizon fini et contrôle optimal. C. R. Math. Acad. Sci. Paris 343(10), 679–684 (2006)
J.-M. Lasry, P.-L. Lions, Mean field games. Jpn. J. Math. 2(1), 229–260 (2007)
P. Cardaliaguet, Notes on Mean Field Games (2011), preprint
P. Cardaliaguet, P. Jameson Graber, A. Porretta, D. Tonon, Second order mean field games with degenerate diffusion and local coupling. NoDEA Nonlinear Differential Equations Appl. 22(5), 1287–1317 (2015)
A. Porretta, Weak Solutions to Fokker–Planck Equations and Mean Field Games. Arch. Ration. Mech. Anal. 216(1), 1–62 (2015)
P.-L. Lions, Cours du Collège de France (2007–2011). https://www.college-de-france.fr/site/en-pierre-louis-lions/_course.htm
P. Cardaliaguet, F. Delarue, J.-M. Lasry, P.-L. Lions, The Master Equation and the Convergence Problem in Mean Field Games. Annals of Mathematics Studies, vol. 201 (Princeton University, Princeton, 2019)
Y. Achdou, I. Capuzzo-Dolcetta, Mean field games: numerical methods. SIAM J. Numer. Anal. 48(3), 1136–1162 (2010)
Y. Achdou, J.-M. Lasry, Mean field games for modeling crowd motion, in Contributions to Partial Differential Equations and Applications, chapter 4 (Springer, Berlin, 2019), pp. 17–42
Y. Achdou, F. Camilli, I. Capuzzo-Dolcetta, Mean field games: numerical methods for the planning problem. SIAM J. Control Optim. 50(1), 77–109 (2012)
Y. Achdou, F. Camilli, I. Capuzzo-Dolcetta, Mean field games: convergence of a finite difference method. SIAM J. Numer. Anal. 51(5), 2585–2612 (2013)
Y. Achdou, A. Porretta, Convergence of a finite difference scheme to weak solutions of the system of partial differential equations arising in mean field games. SIAM J. Numer. Anal. 54(1), 161–186 (2016)
P. Cardaliaguet, P. Jameson Graber, Mean field games systems of first order. ESAIM Control Optim. Calc. Var. 21(3), 690–722 (2015)
L.M. Briceño Arias, D. Kalise, Z. Kobeissi, M. Laurière, Á.M. González, F.J. Silva, On the implementation of a primal-dual algorithm for second order time-dependent mean field games with local couplings. ESAIM: ProcS 65, 330–348 (2019)
Y. Achdou, Finite difference methods for mean field games, in Hamilton-Jacobi Equations: Approximations, Numerical Analysis and Applications. Lecture Notes in Mathematical, vol. 2074 (Springer, Heidelberg, 2013), pp. 1–47
L.M. Briceño Arias, D. Kalise, F.J. Silva, Proximal methods for stationary mean field games with local couplings. SIAM J. Control Optim. 56(2), 801–836 (2018)
R.T. Rockafellar, Convex Analysis. Princeton Landmarks in Mathematics (Princeton University, Princeton, 1997). Reprint of the 1970 original, Princeton Paperbacks
M. Fortin, R. Glowinski, Augmented Lagrangian methods. Studies in Mathematics and its Applications, vol. 15 (North-Holland, Amsterdam, 1983). Applications to the numerical solution of boundary value problems, Translated from the French by B. Hunt and D.C. Spicer
J.-D. Benamou, Y. Brenier, A computational fluid mechanics solution to the Monge-Kantorovich mass transfer problem. Numer. Math. 84(3), 375–393 (2000)
J.-D. Benamou, G. Carlier, Augmented Lagrangian methods for transport optimization, mean field games and degenerate elliptic equations. J. Optim. Theory Appl. 167(1), 1–26 (2015)
R. Andreev, Preconditioning the augmented Lagrangian method for instationary mean field games with diffusion. SIAM J. Sci. Comput. 39(6), A2763–A2783 (2017)
Y. Achdou, M. Laurière, Mean field type control with congestion (II): an augmented Lagrangian method. Appl. Math. Optim. 74(3), 535–578 (2016)
J. Eckstein, D.P. Bertsekas, On the Douglas-Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math. Program. 55(3, Ser. A), 293–318 (1992)
A. Chambolle, T. Pock, A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vision 40(1), 120–145 (2011)
U. Trottenberg, C.W. Oosterlee, A. Schüller, Multigrid (Academic Press, San Diego, 2001). With contributions by A. Brandt, P. Oswald, K. Stüben
Y. Achdou, V. Perez, Iterative strategies for solving linearized discrete mean field games systems. Netw. Heterog. Media 7(2), 197–217 (2012)
H.A. van der Vorst, Bi-CGSTAB: a fast and smoothly converging variant of Bi-CG for the solution of nonsymmetric linear systems. SIAM J. Sci. Statist. Comput. 13(2), 631–644 (1992)
A. Porretta, E. Zuazua, Long time versus steady state optimal control. SIAM J. Control Optim. 51(6), 4242–4273 (2013)
P. Cardaliaguet, J.-M. Lasry, P.-L. Lions, A. Porretta, Long time average of mean field games. Netw. Heterog. Media 7(2), 279–301 (2012)
P. Cardaliaguet, J.-M. Lasry, P.-L. Lions, A. Porretta, Long time average of mean field games with a nonlocal coupling. SIAM J. Control Optim. 51(5), 3558–3591 (2013)
J.-F. Chassagneux, D. Crisan, F. Delarue, Numerical method for FBSDEs of McKean-Vlasov type. Ann. Appl. Probab. 29(3), 1640–1684 (2019)
A. Angiuli, C.V. Graves, H. Li, J.-F. Chassagneux, F. Delarue, R. Carmona, Cemracs 2017: numerical probabilistic approach to MFG. ESAIM: ProcS 65, 84–113 (2019)
H.P. McKean, Jr. A class of Markov processes associated with nonlinear parabolic equations. Proc. Nat. Acad. Sci. USA 56, 1907–1911 (1966)
A.-S. Sznitman, Topics in propagation of chaos, in École d’Été de Probabilités de Saint-Flour XIX—1989. Lecture Notes in Mathematical, vol. 1464 (Springer, Berlin, 1991), pp. 165–251
R. Carmona, F. Delarue, A. Lachapelle, Control of McKean-Vlasov dynamics versus mean field games. Math. Financ. Econ. 7(2), 131–166 (2013)
R. Carmona, F. Delarue, Mean field forward-backward stochastic differential equations. Electron. Commun. Probab. 18(68), 15 (2013)
R. Carmona, F. Delarue, Probabilistic Theory of Mean Field Games with Applications. I. Probability Theory and Stochastic Modelling, vol. 83 (Springer, Cham, 2018). Mean field FBSDEs, control, and games
A. Bensoussan, J. Frehse, Control and Nash games with mean field effect. Chin. Ann. Math. Ser. B 34(2), 161–192 (2013)
A. Bensoussan, J. Frehse, S.C.P. Yam, Mean Field Games and Mean Field Type Control Theory. Springer Briefs in Mathematics (Springer, New York, 2013)
Y. Achdou, M. Laurière, Mean Field Type Control with Congestion. Appl. Math. Optim. 73(3), 393–418 (2016)
Y. Achdou, M. Laurière, On the system of partial differential equations arising in mean field type control. Discrete Contin. Dyn. Syst. 35(9), 3879–3900 (2015)
Y. Achdou, J. Han, J.-M. Lasry, P.-L. Lions, B. Moll, Income and Wealth Distribution in Macroeconomics: A Continuous-time Approach. Technical report, National Bureau of Economic Research (2017)
Y. Achdou, F.J. Buera, J.-M. Lasry, P.-L. Lions, B. Moll, Partial differential equation models in macroeconomics. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 372(2028), 20130397, 19 (2014)
T. Bewley, Stationary monetary equilibrium with a continuum of independently fluctuating consumers, in Contributions to Mathematical Economics in Honor of Gerard Debreu, ed. by W. Hildenbrand, A. Mas-Collel (North-Holland, Amsterdam, 1986)
M. Huggett, The risk-free rate in heterogeneous-agent incomplete-insurance economies. J. Econ. Dyn. Control. 17(5–6), 953–969 (1993)
S.R. Aiyagari, Uninsured idiosyncratic risk and aggregate saving. Q. J. Econ. 109(3), 659–84 (1994)
P. Krusell, A.A. Smith, Income and wealth heterogeneity in the macroeconomy. J. Polit. Econ. 106(5), 867–896 (1998)
H.M. Soner, Optimal control with state-space constraint. I. SIAM J. Control Optim. 24(3), 552–561 (1986)
H.M. Soner, Optimal control with state-space constraint. II. SIAM J. Control Optim. 24(6), 1110–1122 (1986)
I. Capuzzo-Dolcetta, P.-L. Lions, Hamilton-Jacobi equations with state constraints. Trans. Am. Math. Soc. 318(2), 643–683 (1990)
P. Cannarsa, R. Capuani, Existence and Uniqueness for Mean Field Games with State Constraints (2017)
P. Cannarsa, R. Capuani, P. Cardaliaguet, Mean Field Games with State Constraints: From Mild to Pointwise Solutions of the PDE System (2018)
F. Camilli, F. Silva, A semi-discrete approximation for a first order mean field game problem. Netw. Heterog. Media 7(2), 263–277 (2012)
E. Carlini, F.J. Silva, A fully discrete semi-Lagrangian scheme for a first order mean field game problem. SIAM J. Numer. Anal. 52(1), 45–67 (2014)
E. Carlini, F.J. Silva, A semi-Lagrangian scheme for a degenerate second order mean field game system. Discrete Contin. Dyn. Syst. 35(9), 4269–4292 (2015)
E. Carlini, F.J. Silva, On the discretization of some nonlinear Fokker-Planck-Kolmogorov equations and applications. SIAM J. Numer. Anal. 56(4), 2148–2177 (2018)
S. Cacace, F. Camilli, C. Marchi, A numerical method for mean field games on networks. ESAIM Math. Model. Numer. Anal. 51(1), 63–88 (2017)
S. Cacace, F. Camilli, A. Cesaroni, C. Marchi, An ergodic problem for mean field games: qualitative properties and numerical simulations. Minimax Theory Appl. 3(2), 211–226 (2018)
N. Almulla, R. Ferreira, D. Gomes, Two numerical approaches to stationary mean-field games. Dyn. Games Appl. 7(4), 657–682 (2017)
D.A. Gomes, J. Saúde, Numerical methods for finite-state mean-field games satisfying a monotonicity condition. Appl. Math. Optim. 1, 1–32 (2018)
C. Bertucci, A remark on uzawa’s algorithm and an application to mean field games systems (2018). arXiv preprint: 1810.01181
R. Carmona, M. Laurière, Convergence analysis of machine learning algorithms for the numerical solution of mean field control and games: I–the ergodic case (2019). arXiv preprint:1907.05980
R. Carmona, M. Laurière, Convergence analysis of machine learning algorithms for the numerical solution of mean field control and games: Ii–the finite horizon case (2019). arXiv preprint:1908.01613
R. Carmona, M. Laurière, Z. Tan, Model-free mean-field reinforcement learning: mean-field MDP and mean-field Q-learning (2019). arXiv preprint:1910.12802
L. Ruthotto, S. Osher, W. Li, L. Nurbekyan, S.W. Fung, A machine learning framework for solving high-dimensional mean field game and mean field control problems (2019). arXiv preprint:1912.01825
Acknowledgements
The research of the first author was partially supported by the ANR (Agence Nationale de la Recherche) through MFG project ANR-16-CE40-0015-01.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Achdou, Y., Laurière, M. (2020). Mean Field Games and Applications: Numerical Aspects. In: Cardaliaguet, P., Porretta, A. (eds) Mean Field Games. Lecture Notes in Mathematics(), vol 2281. Springer, Cham. https://doi.org/10.1007/978-3-030-59837-2_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-59837-2_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-59836-5
Online ISBN: 978-3-030-59837-2
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)